Недавно меня попросили помочь с получением данных из интернета по стоимости ЕТФ фондов.
Первое, что пришло в голову — конечно же googlefinance()
Однако ТКСных ЕТФок там не оказалось. Данную проблему можно решить двумя способами — через регулярные выражения (и о них я поговорю в следующей статье) и стандартным способом — через встроенную гугл функцию importxml(). Взвесив все за и против, я решил пойти путём наименьшего сопротивления.
Почему так? Очень просто — кастом-функция по regExp через фетч, воспринимается как скрипт и, как следствие, подлежит квотированию со стороны гугла. Вообще тема квотирования, как и кэширования, для меня (и гугла) — больная и о ней я тоже как-нибудь напишу отдельно большой «возмущения пост» 🙂
Importxml принимает в себя два текстовых аргумента:
IMPORTXML(ссылка; запрос_xpath)
- ссылка – адрес веб-страницы с указанием протокола (например, http://).
- запрос_xpath – запрос XPath для поиска данных.
И если с ссылкой все понятно, то с запросом XPath может возникнуть сложность.
Вообще, если глубоко погружаться в XPath, то рекомендую почитать здесь: https://msiter.ru/tutorials/xpath.
Однако, есть более простой способ решить проблему понимания дерева xpath для тех, кому надо всё, сразу, здесь и сейчас.
XPath в хроме
Вернёмся к задаче, потому что на практическом примере это понять намного проще
У меня был список требуемых ЕТФ:

И, как писал ранее, таких тикеров в googlefinance нет.
Хорошо, перехожу на сайт — https://www.tinkoff.ru/invest/etfs/TSPX/ — и вижу стоимость:

Мне нужно получить в гугл таблицу 0,1199$
Для этого подвожу мышь к цене 0,1199 и перехожу в «Просмотреть код«

Стоимость находится тут:

Уже здесь можно скопировать путь Xpath:

и дальше просто вставить его в пустую ячейку таблицы.
Итого: у меня есть url и есть Xpath

Самое время посмотреть что получу через importxml:

Цена есть, правда знак доллара уехал.
Те, кто был чуть повнимательнее, заметили выше   — неразрывный пробел ( в данном случае их два) который как раз и разносит содержимое.
Что делать?
Подняться на уровень (а в случае сайта тинькофф — на два уровня) выше и импортировать все содержимое span класса со всеми переносами, пробелами, спец символами и так далее и тому подобное:

Получив в результате:

Победа? Ну… почти.
Все дело в том, что результат импорта «0,1199 $» — это текст и для дальнейших вычислений он не пригоден.
Из текста в цифру
Через стандартные функции:
- Удаляю пробелы (если они там есть) — Trim:
=TRIM(A4)

2. Заменяю спецсимволы на пустоту — Subsitute: =SUBSTITUTE(B4;" ";"")

3. Заменяю знак доллара на пустоту — Subsitute: =SUBSTITUTE(C4;"$";"")

4. Привожу результат к числовому значению — Value: =VALUE(D4)

Так как тикеры из списка не только долларовые, но и рублёвые, необходимо так же через substitute сделать замену «₽» на пустоту. Если в итоге объединить всё в одну формулу в рамках одной ячейки, получится примерно следующий «вложенный монстр»:
=VALUE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(TRIM(K2);" ";"");"$";"");"₽";""))Далее, дело за малым — распространить importxml и формулу выше на все тикеры.

Что же, первую часть задачи я решил. У меня есть цена на каждый указанный тикер.
Но это только пол дела. Цену надо ещё и обновлять.
И вот тут в дело вступают google apps scripts.
Переключатель ссылки (или просто Switcher)
Все дело в том, что гугл кэширует результаты выполнения importxml и обновляет их по одним гуглу известным алгоритмам. Я перерыл тонны вариантов решения этой проблемы где только можно и нельзя и самым «изящным» и приемлемым стал следующий: при обновлении ссылки (как аргумента importxml) гугл воспринимает ее как новую и заново перевыполняет функцию importxml.
То есть мне надо обновлять первый аргумент функции, при неизменном втором — xpath. Вот тут в действие и вступает так называемый «свитчер».

Это «условный» переключатель, который будет меняться с 1 на 0 скриптом.

Что все это значит? Написанный далее скрипт будет менять значение ячейки B1 c единицы на ноль (и обратно) и далее в зависимости от значения ячейки «свитчера» (1 или 0), будет меняться ссылка в importxml.
Чтобы она менялась на новую, но вела на тот же сайт за теми же значениями, я добавляю несуществующий параметр сайта ?Param=1
Скрипт
Перехожу в Apps script

и пишу следующий скрипт:

const ss = SpreadsheetApp.getActiveSpreadsheet()
const paramsWs = ss.getSheetByName("Params")
const SWITCHER_CELL = "B1"
function switcher() {
const switcherCell = paramsWs.getRange(SWITCHER_CELL)
const switcherValue = switcherCell.getValue()
if(switcherValue == 1){
switcherCell.setValue(0)
} else {
switcherCell.setValue(1)
}
}
const ss = SpreadsheetApp.getActiveSpreadsheet() // обращаюсь к книге
const paramsWs = ss.getSheetByName("Params")
const SWITCHER_CELL = "B1"
const switcherCell = paramsWs.getRange(SWITCHER_CELL)
const switcherValue = switcherCell.getValue()
if(switcherValue == 1){
switcherCell.setValue(0)
} else {
switcherCell.setValue(1)
}
}
Ну и под конец….
Триггер — запуск по таймеру
Перехожу в «Триггеры«

В правом нижнем углу нажимаю

Выбираю свитчер (он у меня один)

Выбираю «триггер по времени»

Тип триггера — по минутам и далее — интервал

Сохраняю 🙂

Теперь гугл по триггеру будет сам включать свитчер. Свитчер будет менять свое значение (0 или 1) и, как следствие, вызывать пересчет importxml.
Небольшой комментарий. Как показала практика, при списках — т.е. где надо импортировать не одну запись, а целую таблицу записей, промежуток времени лучше ставить либо 15, либо 30 минут.
Послесловие к этому посту, спустя больше года публикации
Уважаемые читатели! Ведение этого сайта — хобби вне основной работы, нацеленное на поднятие уровня образованности в использовании гугл таблиц.
За весь срок мне поступило (и продолжает поступать) достаточно много вопросов, как сюда, так и в почту по поводу парсинга:
- других ресурсов;
- изменения кода расписанных здесь вариантов;
- нерабочего своего кода;
- нерабочих своих формул в книгах.
Суть таких вопросов примерно одна и та же — дать конкретный совет (с формулами и кодами) как сделать так чтобы все работало у конкретного читателя под конкретную задачу, либо вообще написать отлаженный и работающий код за читателя. То есть мне надо потратить свое время, чтобы решить вашу проблему — в обычном мире это платная услуга: консультация или разработка.
В связи с этим прошу посмотреть в интернете примерные расценки часа работы программиста с опытом от года и иметь это в виду, прежде чем описывать конкретные задачи, присылать ссылки не неработающие скрипты или таблицы с просьбой совета или помощи.
Спасибо и надеюсь на понимание!
Google Docs Editors Help
Sign in
Google Help
- Help Center
- Community
- Google Docs Editors
- Privacy Policy
- Terms of Service
- Submit feedback
Send feedback on…
This help content & information
General Help Center experience
- Help Center
- Community
Google Docs Editors
I’m trying to get the value of the link of the first youtube video that appears after a youtube search and write it into my google spreadsheet. In order to do this, I am using the in-built IMPORTXML(url, xml_query) function. I have copied the full XPath using google chrome and received the following:
/html/body/ytd-app/div/ytd-page-manager/ytd-search/div[1]/ytd-two-column-search-results-renderer/div/ytd-section-list-renderer/div[2]/ytd-item-section-renderer/div[3]/ytd-video-renderer[1]/div[1]/ytd-thumbnail/a/@href
I have placed the following code in a spreadsheet cell:
=IMPORTXML("https://www.youtube.com/results?search_query=ajfdkla+trailer", "/html/body/ytd-app/div/ytd-page-manager/ytd-search/div[1]/ytd-two-column-search-results-renderer/div/ytd-section-list-renderer/div[2]/ytd-item-section-renderer/div[3]/ytd-video-renderer[1]/div[1]/ytd-thumbnail/a/@href")
and received the following error:
Imported content is empty.
How can I write the URL of the first youtube video following a youtube search into my spreadsheet cell.
I want to scrape a text within this website in google sheets with the IMPORTXML function. Through dev tools by inspecting the text in question, I get the corresponding HTML:
<li _ngcontent-udl-c4="">The outbound route is available for sale until 28/03/2020 and these are the last available dates.</li>
If I right-click > copy full XPath, I get /html/body/main/nas-fare-calendar/nas-info/div/div/ul/li[1]. If I input that in my sheet, as in (A1 has the URL linked to above):
=IMPORTXML(A1,"/html/body/main/nas-fare-calendar/nas-info/div/div/ul/li[1]")
I get an error ‘Imported content is empty.’. What gives?
I’ve also tried Web Scrapper extension and the way that selects the text in question is with ‘.list—spaceless li:nth-of-type(1)’. Any way I could use that as inspiration for an XPath? Just putting that as input for IMPORTXML doesn’t work.
What is the easiest way to select for the innerHTML of that HTML snippet above? Just trying with ‘//li’ just won’t include the li above. I don’t know how to include _ngcontent-udl-c4 or li that has _ngcontent-udl-c4 as a style.

Задача такая: спарсить 5 url ссылок фотографий отсюда в гугл таблицы с последующей загрузкой в Вк. https://item.taobao.com/item.htm?spm=a1z10.3-c-s.w…
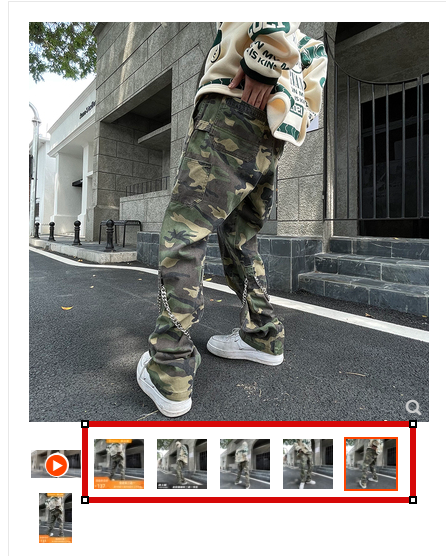
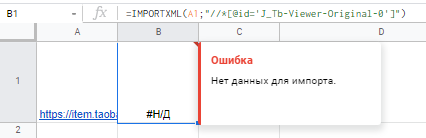
Пытаюсь спарсить url на самую первую картинку с помощью =IMPORTXML(A1;»//*[@id=’J_Tb-Viewer-Original-0′]») — где A1 это ссылка на страницу, но всегда получаю ошибку об отсутствии данных для импорта.
Таких страниц у меня около полутысячи, вручную это делать слишком долго. Вроде ничего сложного, но чувство что бьюсь в закрытую дверь, информации в интернете на эту тему крайне мало.
-
Вопрос задан
-
1146 просмотров
Xpath в гуглотаблицах это не про динамически добавляемый html. Это про то, что отдаёт сервер при запросе.
=IMPORTXML(A1;"//ul[@class = 'tb-thumb tb-clearfix']/li[position() = 1]/div/a/img/@data-src")=REGEXREPLACE(B1; "_50x50\.jpg$"; "")
Пригласить эксперта
-
Показать ещё
Загружается…
21 сент. 2023, в 14:51
30000 руб./за проект
21 сент. 2023, в 14:49
25000 руб./за проект
21 сент. 2023, в 14:33
5000 руб./за проект