
Добро пожаловать во вторую часть руководства по нейронным сетям. Сразу хочу принести извинения всем кто ждал вторую часть намного раньше. По определенным причинам мне пришлось отложить ее написание. На самом деле я не ожидал, что у первой статьи будет такой спрос и что так много людей заинтересует данная тема. Взяв во внимание ваши комментарии, я постараюсь предоставить вам как можно больше информации и в то же время сохранить максимально понятный способ ее изложения. В данной статье, я буду рассказывать о способах обучения/тренировки нейросетей (в частности метод обратного распространения) и если вы, по каким-либо причинам, еще не прочитали первую часть, настоятельно рекомендую начать с нее. В процессе написания этой статьи, я хотел также рассказать о других видах нейросетей и методах тренировки, однако, начав писать про них, я понял что это пойдет вразрез с моим методом изложения. Я понимаю, что вам не терпится получить как можно больше информации, однако эти темы очень обширны и требуют детального анализа, а моей основной задачей является не написать очередную статью с поверхностным объяснением, а донести до вас каждый аспект затронутой темы и сделать статью максимально легкой в освоении. Спешу расстроить любителей “покодить”, так как я все еще не буду прибегать к использованию языка программирования и буду объяснять все “на пальцах”. Достаточно вступления, давайте теперь продолжим изучение нейросетей.
Что такое нейрон смещения?
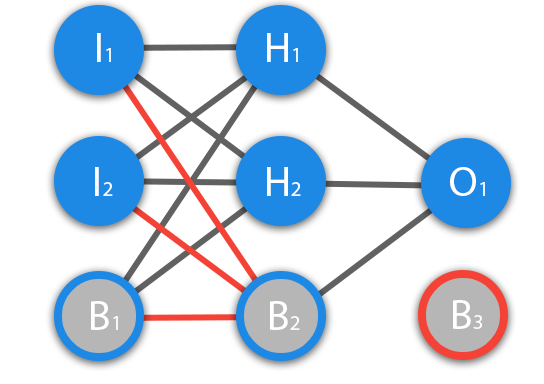
Перед тем как начать нашу основную тему, мы должны ввести понятие еще одного вида нейронов — нейрон смещения. Нейрон смещения или bias нейрон — это третий вид нейронов, используемый в большинстве нейросетей. Особенность этого типа нейронов заключается в том, что его вход и выход всегда равняются 1 и они никогда не имеют входных синапсов. Нейроны смещения могут, либо присутствовать в нейронной сети по одному на слое, либо полностью отсутствовать, 50/50 быть не может (красным на схеме обозначены веса и нейроны которые размещать нельзя). Соединения у нейронов смещения такие же, как у обычных нейронов — со всеми нейронами следующего уровня, за исключением того, что синапсов между двумя bias нейронами быть не может. Следовательно, их можно размещать на входном слое и всех скрытых слоях, но никак не на выходном слое, так как им попросту не с чем будет формировать связь.
Для чего нужен нейрон смещения?
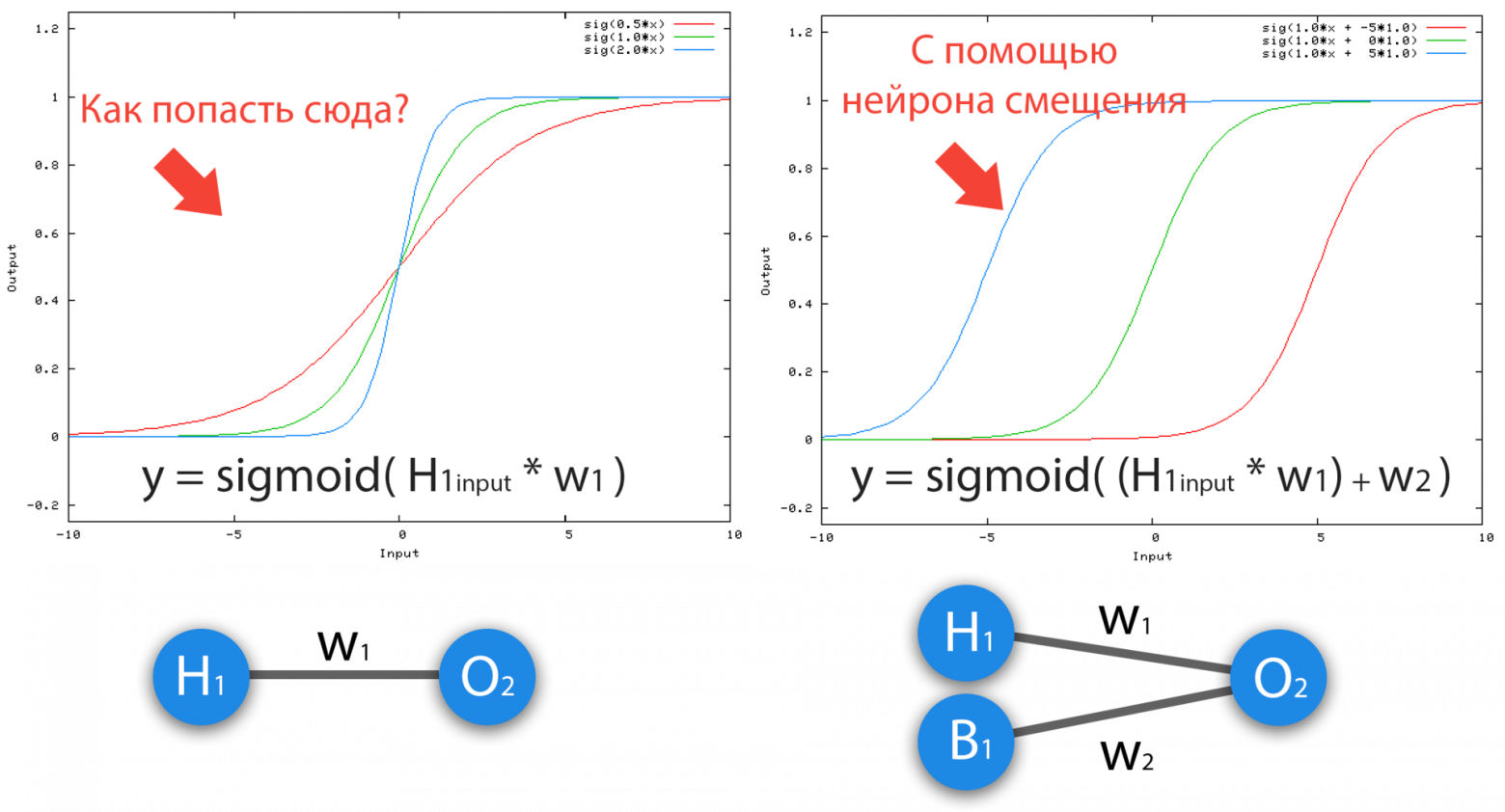
Нейрон смещения нужен для того, чтобы иметь возможность получать выходной результат, путем сдвига графика функции активации вправо или влево. Если это звучит запутанно, давайте рассмотрим простой пример, где есть один входной нейрон и один выходной нейрон. Тогда можно установить, что выход O2 будет равен входу H1, умноженному на его вес, и пропущенному через функцию активации (формула на фото слева). В нашем конкретном случае, будем использовать сигмоид.
Из школьного курса математики, мы знаем, что если взять функцию y = ax+b и менять у нее значения “а”, то будет изменяться наклон функции (цвета линий на графике слева), а если менять “b”, то мы будем смещать функцию вправо или влево (цвета линий на графике справа). Так вот “а” — это вес H1, а “b” — это вес нейрона смещения B1. Это грубый пример, но примерно так все и работает (если вы посмотрите на функцию активации справа на изображении, то заметите очень сильное сходство между формулами). То есть, когда в ходе обучения, мы регулируем веса скрытых и выходных нейронов, мы меняем наклон функции активации. Однако, регулирование веса нейронов смещения может дать нам возможность сдвинуть функцию активации по оси X и захватить новые участки. Иными словами, если точка, отвечающая за ваше решение, будет находиться, как показано на графике слева, то ваша НС никогда не сможет решить задачу без использования нейронов смещения. Поэтому, вы редко встретите нейронные сети без нейронов смещения.
Также нейроны смещения помогают в том случае, когда все входные нейроны получают на вход 0 и независимо от того какие у них веса, они все передадут на следующий слой 0, но не в случае присутствия нейрона смещения. Наличие или отсутствие нейронов смещения — это гиперпараметр (об этом чуть позже). Одним словом, вы сами должны решить, нужно ли вам использовать нейроны смещения или нет, прогнав НС с нейронами смешения и без них и сравнив результаты.
ВАЖНО знать, что иногда на схемах не обозначают нейроны смещения, а просто учитывают их веса при вычислении входного значения например:
input = H1*w1+H2*w2+b3
b3 = bias*w3
Так как его выход всегда равен 1, то можно просто представить что у нас есть дополнительный синапс с весом и прибавить к сумме этот вес без упоминания самого нейрона.
Как сделать чтобы НС давала правильные ответы?
Ответ прост — нужно ее обучать. Однако, насколько бы прост не был ответ, его реализация в плане простоты, оставляет желать лучшего. Существует несколько методов обучения НС и я выделю 3, на мой взгляд, самых интересных:
- Метод обратного распространения (Backpropagation)
- Метод упругого распространения (Resilient propagation или Rprop)
- Генетический Алгоритм (Genetic Algorithm)
Об Rprop и ГА речь пойдет в других статьях, а сейчас мы с вами посмотрим на основу основ — метод обратного распространения, который использует алгоритм градиентного спуска.
Что такое градиентный спуск?
Это способ нахождения локального минимума или максимума функции с помощью движения вдоль градиента. Если вы поймете суть градиентного спуска, то у вас не должно возникнуть никаких вопросов во время использования метода обратного распространения. Для начала, давайте разберемся, что такое градиент и где он присутствует в нашей НС. Давайте построим график, где по оси х будут значения веса нейрона(w) а по оси у — ошибка соответствующая этому весу(e).
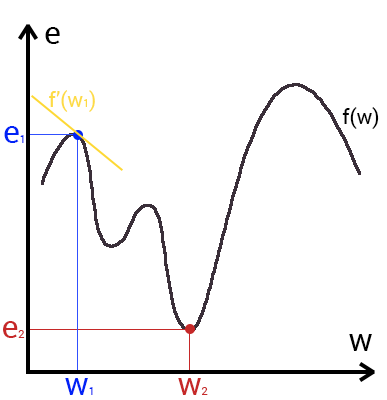
Посмотрев на этот график, мы поймем, что график функция f(w) является зависимостью ошибки от выбранного веса. На этом графике нас интересует глобальный минимум — точка (w2,e2) или, иными словами, то место где график подходит ближе всего к оси х. Эта точка будет означать, что выбрав вес w2 мы получим самую маленькую ошибку — e2 и как следствие, самый лучший результат из всех возможных. Найти же эту точку нам поможет метод градиентного спуска (желтым на графике обозначен градиент). Соответственно у каждого веса в нейросети будет свой график и градиент и у каждого надо найти глобальный минимум.
Так что же такое, этот градиент? Градиент — это вектор который определяет крутизну склона и указывает его направление относительно какой либо из точек на поверхности или графике. Чтобы найти градиент нужно взять производную от графика по данной точке (как это и показано на графике). Двигаясь по направлению этого градиента мы будем плавно скатываться в низину. Теперь представим что ошибка — это лыжник, а график функции — гора. Соответственно, если ошибка равна 100%, то лыжник находиться на самой вершине горы и если ошибка 0% то в низине. Как все лыжники, ошибка стремится как можно быстрее спуститься вниз и уменьшить свое значение. В конечном случае у нас должен получиться следующий результат:

Представьте что лыжника забрасывают, с помощью вертолета, на гору. На сколько высоко или низко зависит от случая (аналогично тому, как в нейронной сети при инициализации веса расставляются в случайном порядке). Допустим ошибка равна 90% и это наша точка отсчета. Теперь лыжнику нужно спуститься вниз, с помощью градиента. На пути вниз, в каждой точке мы будем вычислять градиент, что будет показывать нам направление спуска и при изменении наклона, корректировать его. Если склон будет прямым, то после n-ого количества таких действий мы доберемся до низины. Но в большинстве случаев склон (график функции) будет волнистый и наш лыжник столкнется с очень серьезной проблемой — локальный минимум. Я думаю все знают, что такое локальный и глобальный минимум функции, для освежения памяти вот пример. Попадание в локальный минимум чревато тем, что наш лыжник навсегда останется в этой низине и никогда не скатиться с горы, следовательно мы никогда не сможем получить правильный ответ. Но мы можем избежать этого, снарядив нашего лыжника реактивным ранцем под названием момент (momentum). Вот краткая иллюстрация момента:
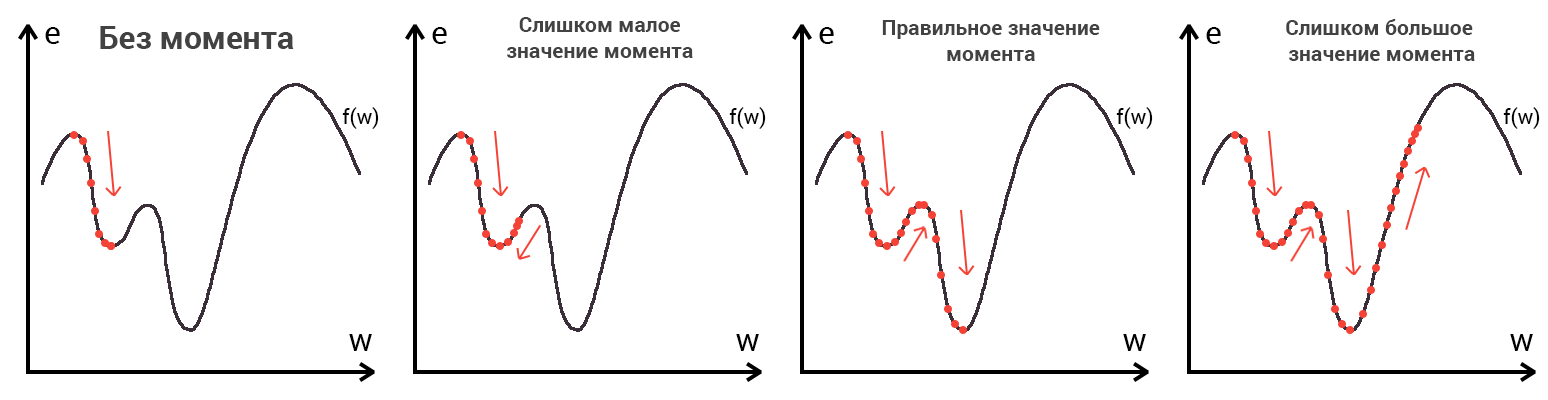
Как вы уже наверное догадались, этот ранец придаст лыжнику необходимое ускорение чтобы преодолеть холм, удерживающий нас в локальном минимуме, однако здесь есть одно НО. Представим что мы установили определенное значение параметру момент и без труда смогли преодолеть все локальные минимумы, и добраться до глобального минимума. Так как мы не можем просто отключить реактивный ранец, то мы можем проскочить глобальный минимум, если рядом с ним есть еще низины. В конечном случае это не так важно, так как рано или поздно мы все равно вернемся обратно в глобальный минимум, но стоит помнить, что чем больше момент, тем больше будет размах с которым лыжник будет кататься по низинам. Вместе с моментом в методе обратного распространения также используется такой параметр как скорость обучения (learning rate). Как наверняка многие подумают, чем больше скорость обучения, тем быстрее мы обучим нейросеть. Нет. Скорость обучения, также как и момент, является гиперпараметром — величина которая подбирается путем проб и ошибок. Скорость обучения можно напрямую связать со скоростью лыжника и можно с уверенностью сказать — тише едешь дальше будешь. Однако здесь тоже есть определенные аспекты, так как если мы совсем не дадим лыжнику скорости то он вообще никуда не поедет, а если дадим маленькую скорость то время пути может растянуться на очень и очень большой период времени. Что же тогда произойдет если мы дадим слишком большую скорость?
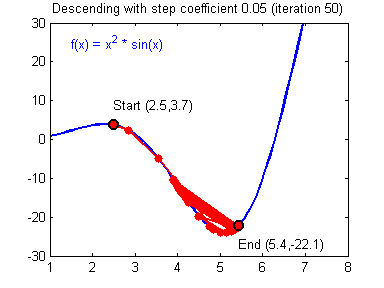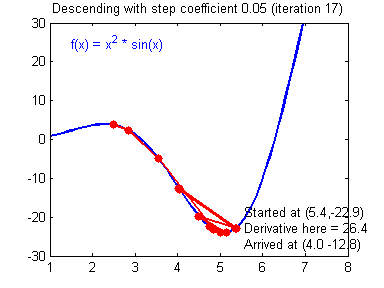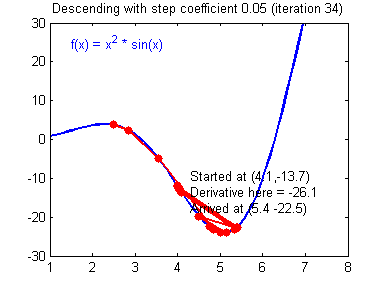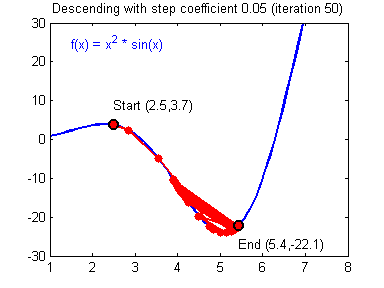
Как видите, ничего хорошего. Лыжник начнет скатываться по неправильному пути и возможно даже в другом направлении, что как вы понимаете только отдалит нас от нахождения правильного ответа. Поэтому во всех этих параметрах нужно находить золотую середину чтобы избежать не сходимости НС (об этом чуть позже).
Что такое Метод Обратного Распространения (МОР)?
Вот мы и дошли до того момента, когда мы можем обсудить, как же все таки сделать так, чтобы ваша НС могла правильно обучаться и давать верные решения. Очень хорошо МОР визуализирован на этой гифке:
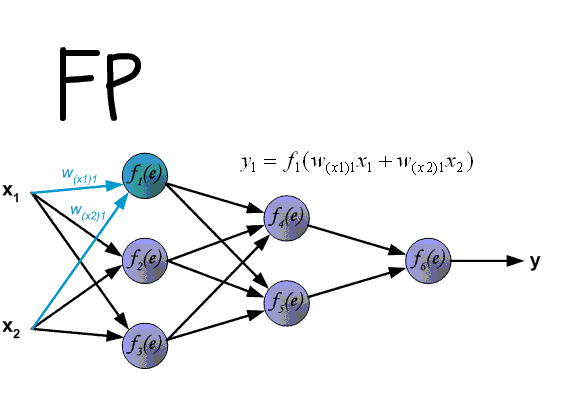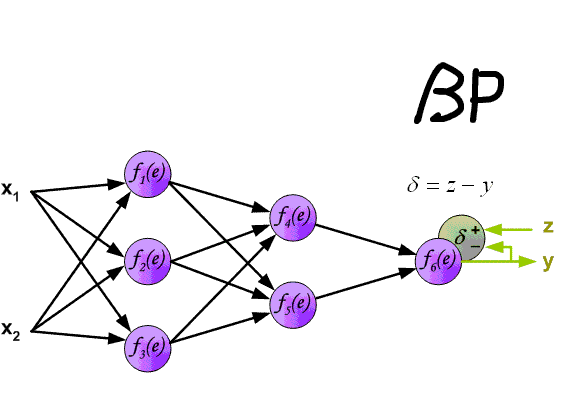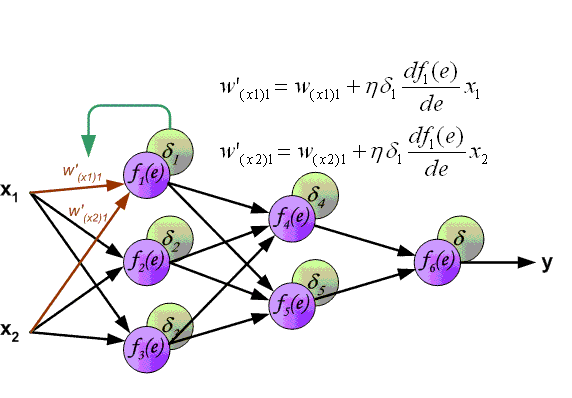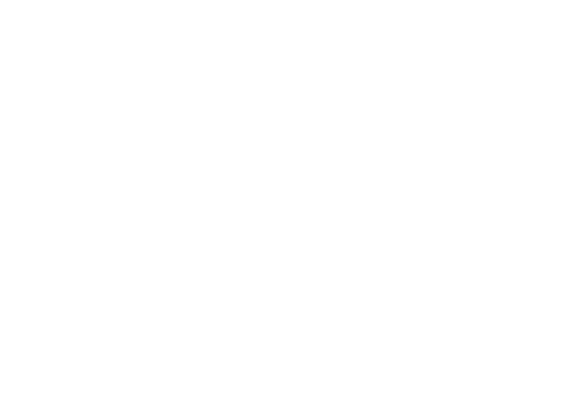
А теперь давайте подробно разберем каждый этап. Если вы помните то в предыдущей статье мы считали выход НС. По другому это называется передача вперед (Forward pass), то есть мы последовательно передаем информацию от входных нейронов к выходным. После чего мы вычисляем ошибку и основываясь на ней делаем обратную передачу, которая заключается в том, чтобы последовательно менять веса нейронной сети, начиная с весов выходного нейрона. Значение весов будут меняться в ту сторону, которая даст нам наилучший результат. В моих вычисления я буду пользоваться методом нахождения дельты, так как это наиболее простой и понятный способ. Также я буду использовать стохастический метод обновления весов (об этом чуть позже).
Теперь давайте продолжим с того места, где мы закончили вычисления в предыдущей статье.
Данные задачи из предыдущей статьи
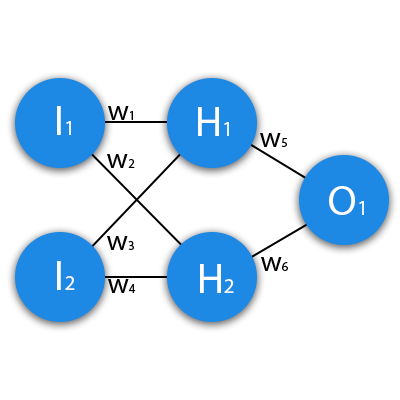
Данные: I1=1, I2=0, w1=0.45, w2=0.78 ,w3=-0.12 ,w4=0.13 ,w5=1.5 ,w6=-2.3.
H1input = 1*0.45+0*-0.12=0.45
H1output = sigmoid(0.45)=0.61
H2input = 1*0.78+0*0.13=0.78
H2output = sigmoid(0.78)=0.69
O1input = 0.61*1.5+0.69*-2.3=-0.672
O1output = sigmoid(-0.672)=0.33
O1ideal = 1 (0xor1=1)
Error = ((1-0.33)^2)/1=0.45
Результат — 0.33, ошибка — 45%.
Так как мы уже подсчитали результат НС и ее ошибку, то мы можем сразу приступить к МОРу. Как я уже упоминал ранее, алгоритм всегда начинается с выходного нейрона. В таком случае давайте посчитаем для него значение δ (дельта) по формуле 1.
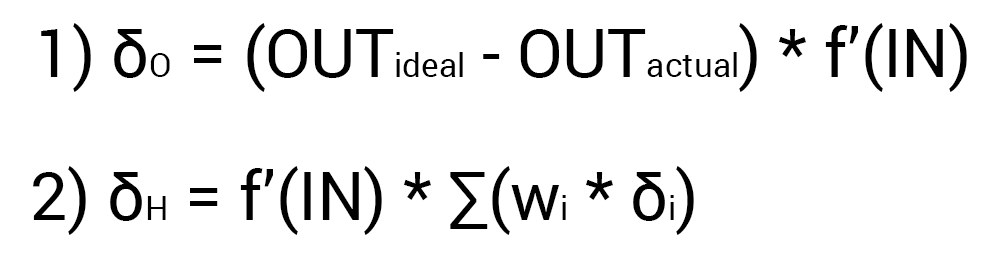 Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (δ output), следственно для скрытых нейронов мы уже будем брать вторую формулу (δ hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (δ output), следственно для скрытых нейронов мы уже будем брать вторую формулу (δ hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
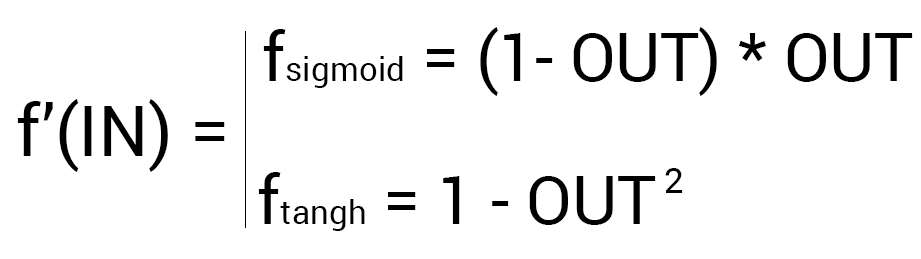
Таким образом наши вычисления для точки O1 будут выглядеть следующим образом.
Решение
O1output = 0.33
O1ideal = 1
Error = 0.45
δO1 = (1 — 0.33) * ( (1 — 0.33) * 0.33 ) = 0.148
На этом вычисления для нейрона O1 закончены. Запомните, что после подсчета дельты нейрона мы обязаны сразу обновить веса всех исходящих синапсов этого нейрона. Так как в случае с O1 их нет, мы переходим к нейронам скрытого уровня и делаем тоже самое за исключение того, что формула подсчета дельты у нас теперь вторая и ее суть заключается в том, чтобы умножить производную функции активации от входного значения на сумму произведений всех исходящих весов и дельты нейрона с которой этот синапс связан. Но почему формулы разные? Дело в том что вся суть МОР заключается в том чтобы распространить ошибку выходных нейронов на все веса НС. Ошибку можно вычислить только на выходном уровне, как мы это уже сделали, также мы вычислили дельту в которой уже есть эта ошибка. Следственно теперь мы будем вместо ошибки использовать дельту которая будет передаваться от нейрона к нейрону. В таком случае давайте найдем дельту для H1:
Решение
H1output = 0.61
w5 = 1.5
δO1 = 0.148
δH1 = ( (1 — 0.61) * 0.61 ) * ( 1.5 * 0.148 ) = 0.053
Теперь нам нужно найти градиент для каждого исходящего синапса. Здесь обычно вставляют 3 этажную дробь с кучей производных и прочим математическим адом, но в этом и вся прелесть использования метода подсчета дельт, потому что в конечном счете ваша формула нахождения градиента будет выглядеть вот так:

Здесь точка A это точка в начале синапса, а точка B на конце синапса. Таким образом мы можем подсчитать градиент w5 следующим образом:
Решение
H1output = 0.61
δO1 = 0.148
GRADw5 = 0.61 * 0.148 = 0.09
Сейчас у нас есть все необходимые данные чтобы обновить вес w5 и мы сделаем это благодаря функции МОР которая рассчитывает величину на которую нужно изменить тот или иной вес и выглядит она следующим образом:

Настоятельно рекомендую вам не игнорировать вторую часть выражения и использовать момент так как это вам позволит избежать проблем с локальным минимумом.
Здесь мы видим 2 константы о которых мы уже говорили, когда рассматривали алгоритм градиентного спуска: E (эпсилон) — скорость обучения, α (альфа) — момент. Переводя формулу в слова получим: изменение веса синапса равно коэффициенту скорости обучения, умноженному на градиент этого веса, прибавить момент умноженный на предыдущее изменение этого веса (на 1-ой итерации равно 0). В таком случае давайте посчитаем изменение веса w5 и обновим его значение прибавив к нему Δw5.
Решение
E = 0.7
Α = 0.3
w5 = 1.5
GRADw5 = 0.09
Δw5(i-1) = 0
Δw5 = 0.7 * 0.09 + 0 * 0.3 = 0.063
w5 = w5 + Δw5 = 1.563
Таким образом после применения алгоритма наш вес увеличился на 0.063. Теперь предлагаю сделать вам тоже самое для H2.
Решение
H2output = 0.69
w6 = -2.3
δO1 = 0.148
E = 0.7
Α = 0.3
Δw6(i-1) = 0
δH2 = ( (1 — 0.69) * 0.69 ) * ( -2.3 * 0.148 ) = -0.07
GRADw6 = 0.69 * 0.148 = 0.1
Δw6 = 0.7 * 0.1 + 0 * 0.3 = 0.07
w6 = w6 + Δw6 = -2.2
И конечно не забываем про I1 и I2, ведь у них тоже есть синапсы веса которых нам тоже нужно обновить. Однако помним, что нам не нужно находить дельты для входных нейронов так как у них нет входных синапсов.
Решение
w1 = 0.45, Δw1(i-1) = 0
w2 = 0.78, Δw2(i-1) = 0
w3 = -0.12, Δw3(i-1) = 0
w4 = 0.13, Δw4(i-1) = 0
δH1 = 0.053
δH2 = -0.07
E = 0.7
Α = 0.3
GRADw1 = 1 * 0.053 = 0.053
GRADw2 = 1 * -0.07 = -0.07
GRADw3 = 0 * 0.053 = 0
GRADw4 = 0 * -0.07 = 0
Δw1 = 0.7 * 0.053 + 0 * 0.3 = 0.04
Δw2 = 0.7 * -0.07 + 0 * 0.3 = -0.05
Δw3 = 0.7 * 0 + 0 * 0.3 = 0
Δw4 = 0.7 * 0 + 0 * 0.3 = 0
w1 = w1 + Δw1 = 0.5
w2 = w2 + Δw2 = 0.73
w3 = w3 + Δw3 = -0.12
w4 = w4 + Δw4 = 0.13
Теперь давайте убедимся в том, что мы все сделали правильно и снова посчитаем выход НС только уже с обновленными весами.
Решение
I1 = 1
I2 = 0
w1 = 0.5
w2 = 0.73
w3 = -0.12
w4 = 0.13
w5 = 1.563
w6 = -2.2
H1input = 1 * 0.5 + 0 * -0.12 = 0.5
H1output = sigmoid(0.5) = 0.62
H2input = 1 * 0.73 + 0 * 0.124 = 0.73
H2output = sigmoid(0.73) = 0.675
O1input = 0.62* 1.563 + 0.675 * -2.2 = -0.51
O1output = sigmoid(-0.51) = 0.37
O1ideal = 1 (0xor1=1)
Error = ((1-0.37)^2)/1=0.39
Результат — 0.37, ошибка — 39%.
Как мы видим после одной итерации МОР, нам удалось уменьшить ошибку на 0.04 (6%). Теперь нужно повторять это снова и снова, пока ваша ошибка не станет достаточно мала.
Что еще нужно знать о процессе обучения?
Нейросеть можно обучать с учителем и без (supervised, unsupervised learning).
Обучение с учителем — это тип тренировок присущий таким проблемам как регрессия и классификация (им мы и воспользовались в примере приведенном выше). Иными словами здесь вы выступаете в роли учителя а НС в роли ученика. Вы предоставляете входные данные и желаемый результат, то есть ученик посмотрев на входные данные поймет, что нужно стремиться к тому результату который вы ему предоставили.
Обучение без учителя — этот тип обучения встречается не так часто. Здесь нет учителя, поэтому сеть не получает желаемый результат или же их количество очень мало. В основном такой вид тренировок присущ НС у которых задача состоит в группировке данных по определенным параметрам. Допустим вы подаете на вход 10000 статей на хабре и после анализа всех этих статей НС сможет распределить их по категориям основываясь, например, на часто встречающихся словах. Статьи в которых упоминаются языки программирования, к программированию, а где такие слова как Photoshop, к дизайну.
Существует еще такой интересный метод, как обучение с подкреплением (reinforcement learning). Этот метод заслуживает отдельной статьи, но я попытаюсь вкратце описать его суть. Такой способ применим тогда, когда мы можем основываясь на результатах полученных от НС, дать ей оценку. Например мы хотим научить НС играть в PAC-MAN, тогда каждый раз когда НС будет набирать много очков мы будем ее поощрять. Иными словами мы предоставляем НС право найти любой способ достижения цели, до тех пор пока он будет давать хороший результат. Таким способом, сеть начнет понимать чего от нее хотят добиться и пытается найти наилучший способ достижения этой цели без постоянного предоставления данных “учителем”.
Также обучение можно производить тремя методами: стохастический метод (stochastic), пакетный метод (batch) и мини-пакетный метод (mini-batch). Существует очень много статей и исследований на тему того, какой из методов лучше и никто не может прийти к общему ответу. Я же сторонник стохастического метода, однако я не отрицаю тот факт, что каждый метод имеет свои плюсы и минусы.
Вкратце о каждом методе:
Стохастический (его еще иногда называют онлайн) метод работает по следующему принципу — нашел Δw, сразу обнови соответствующий вес.
Пакетный метод же работает по другому. Мы суммируем Δw всех весов на текущей итерации и только потом обновляем все веса используя эту сумму. Один из самых важных плюсов такого подхода — это значительная экономия времени на вычисление, точность же в таком случае может сильно пострадать.
Мини-пакетный метод является золотой серединой и пытается совместить в себе плюсы обоих методов. Здесь принцип таков: мы в свободном порядке распределяем веса по группам и меняем их веса на сумму Δw всех весов в той или иной группе.
Что такое гиперпараметры?
Гиперпараметры — это значения, которые нужно подбирать вручную и зачастую методом проб и ошибок. Среди таких значений можно выделить:
- Момент и скорость обучения
- Количество скрытых слоев
- Количество нейронов в каждом слое
- Наличие или отсутствие нейронов смещения
В других типах НС присутствуют дополнительные гиперпараметры, но о них мы говорить не будем. Подбор верных гиперпараметров очень важен и будет напрямую влиять на сходимость вашей НС. Понять стоит ли использовать нейроны смещения или нет достаточно просто. Количество скрытых слоев и нейронов в них можно вычислить перебором основываясь на одном простом правиле — чем больше нейронов, тем точнее результат и тем экспоненциально больше время, которое вы потратите на ее обучение. Однако стоит помнить, что не стоит делать НС с 1000 нейронов для решения простых задач. А вот с выбором момента и скорости обучения все чуточку сложнее. Эти гиперпараметры будут варьироваться, в зависимости от поставленной задачи и архитектуры НС. Например, для решения XOR скорость обучения может быть в пределах 0.3 — 0.7, но в НС которая анализирует и предсказывает цену акций, скорость обучения выше 0.00001 приводит к плохой сходимости НС. Не стоит сейчас заострять свое внимание на гиперпараметрах и пытаться досконально понять, как же их выбирать. Это придет с опытом, а пока что советую просто экспериментировать и искать примеры решения той или иной задачи в сети.
Что такое сходимость?
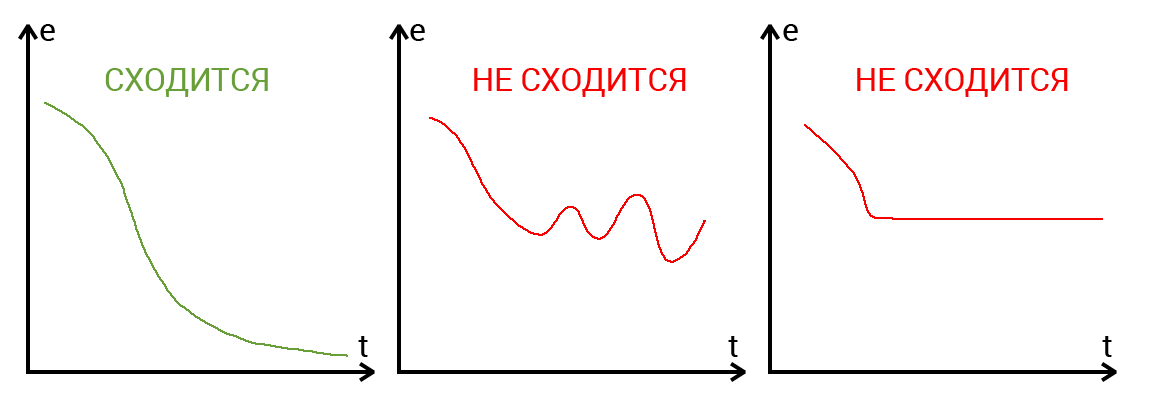
Сходимость говорит о том, правильная ли архитектура НС и правильно ли были подобраны гиперпараметры в соответствии с поставленной задачей. Допустим наша программа выводит ошибку НС на каждой итерации в лог. Если с каждой итерацией ошибка будет уменьшаться, то мы на верном пути и наша НС сходится. Если же ошибка будет прыгать вверх — вниз или застынет на определенном уровне, то НС не сходится. В 99% случаев это решается изменением гиперпараметров. Оставшийся 1% будет означать, что у вас ошибка в архитектуре НС. Также бывает, что на сходимость влияет переобучение НС.
Что такое переобучение?
Переобучение, как следует из названия, это состояние нейросети, когда она перенасыщена данными. Это проблема возникает, если слишком долго обучать сеть на одних и тех же данных. Иными словами, сеть начнет не учиться на данных, а запоминать и “зубрить” их. Соответственно, когда вы уже будете подавать на вход этой НС новые данные, то в полученных данных может появиться шум, который будет влиять на точность результата. Например, если мы будем показывать НС разные фотографии яблок (только красные) и говорить что это яблоко. Тогда, когда НС увидит желтое или зеленое яблоко, оно не сможет определить, что это яблоко, так как она запомнила, что все яблоки должны быть красными. И наоборот, когда НС увидит что-то красное и по форме совпадающее с яблоком, например персик, она скажет, что это яблоко. Это и есть шум. На графике шум будет выглядеть следующим образом.
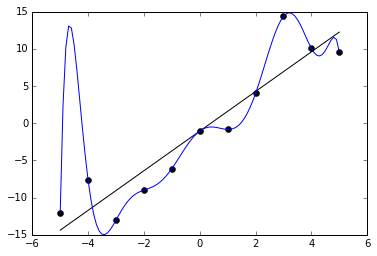
Видно, что график функции сильно колеблется от точки к точке, которые являются выходными данными (результатом) нашей НС. В идеале, этот график должен быть менее волнистый и прямой. Чтобы избежать переобучения, не стоит долго тренировать НС на одних и тех же или очень похожих данных. Также, переобучение может быть вызвано большим количеством параметров, которые вы подаете на вход НС или слишком сложной архитектурой. Таким образом, когда вы замечаете ошибки (шум) в выходных данных после этапа обучения, то вам стоит использовать один из методов регуляризации, но в большинстве случаев это не понадобиться.
Заключение
Надеюсь эта статья смогла прояснить ключевые моменты такого нелегко предмета, как Нейронные сети. Однако я считаю, что сколько бы ты статей не прочел, без практики такую сложную тему освоить невозможно. Поэтому, если вы только в начале пути и хотите изучить эту перспективную и развивающуюся отрасль, то советую начать практиковаться с написания своей НС, а уже после прибегать к помощи различных фреймворков и библиотек. Также, если вам интересен мой метод изложения информации и вы хотите, чтобы я написал статьи на другие темы связанные с Машинным обучением, то проголосуйте в опросе ниже за ту тему которую вам интересна. До встречи в будущих статьях 
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Какая тема вам интересна больше всего?
13.28%
Обзор НС библиотеки для Android, написанной мной на Java c 0
215
53.8%
Другие виды нейросетей: Рекуррентные, Сверточные, LSTM
871
25.08%
Генетический алгоритм
406
7.84%
Методы регуляризации выходных данных
127
Проголосовали 1619 пользователей.
Воздержались 185 пользователей.
Рад снова всех приветствовать, и сегодня продолжим планомерно двигаться в выбранном направлении. Речь, конечно, о масштабном разборе искусственных нейронных сетей для решения широкого спектра задач. Продолжим ровно с того момента, на котором остановились в предыдущей части, и это означает, что героем данного поста будет ключевой процесс — обучение нейронных сетей.
- Градиентный спуск
- Функция ошибки
- Метод обратного распространения ошибки
- Пример расчета
Тема эта крайне важна, поскольку именно процесс обучения позволяет сети начать выполнять задачу, для которой она, собственно, и предназначена. То есть нейронная сеть функционирует не по какому-либо жестко заданному на этапе проектирования алгоритму, она совершенствуется в процессе анализа имеющихся данных. Этот процесс и называется обучением нейронной сети. Математически суть процесса обучения заключается в корректировке значений весов синапсов (связей между имеющимися нейронами). Изначально значения весов задаются случайно, затем производится обучение, результатом которого будут новые значения синаптических весов. Это все мы максимально подробно разберем как раз в этой статье.
На своем сайте я всегда придерживаюсь концепции, при которой теоретические выкладки по максимуму сопровождаются практическими примерами для максимальной наглядности. Так мы поступим и сейчас 👍
Итак, суть заключается в следующем. Пусть у нас есть простейшая нейронная сеть, которую мы хотим обучить (продолжаем рассматривать сети прямого распространения):

То есть на входы нейронов I1 и I2 мы подаем какие-либо числа, а на выходе сети получаем соответственно новое значение. При этом нам необходима некая выборка данных, включающая в себя значения входов и соответствующее им, правильное, значение на выходе:
| \bold{I_1} | \bold{I_2} | \bold{O_{net}} |
|---|---|---|
| x_{11} | x_{12} | y_{1} |
| x_{21} | x_{22} | y_{2} |
| x_{31} | x_{32} | y_{3} |
| … | … | … |
| x_{N1} | x_{N2} | y_{N} |
Допустим, сеть выполняет суммирование значений на входе, тогда данный набор данных может быть таким:
| \bold{I_1} | \bold{I_2} | \bold{O_{net}} |
|---|---|---|
| 1 | 4 | 5 |
| 2 | 7 | 9 |
| 3 | 5 | 8 |
| … | … | … |
| 1000 | 1500 | 2500 |
Эти значения и используются для обучения сети. Как именно — рассмотрим чуть ниже, пока сконцентрируемся на идее процесса в целом. Для того, чтобы иметь возможность тестировать работу сети в процессе обучения, исходную выборку данных делят на две части — обучающую и тестовую. Пусть имеется 1000 образцов, тогда можно 900 использовать для обучения, а оставшиеся 100 — для тестирования. Эти величины взяты исключительно ради наглядности и демонстрации логики выполнения операций, на практике все зависит от задачи, размер обучающей выборки может спокойно достигать и сотен тысяч образцов.
Итак, итог имеем следующий — обучающая выборка прогоняется через сеть, в результате чего происходит настройка значений синаптических весов. Один полный проход по всей выборке называется эпохой. И опять же, обучение нейронной сети — это процесс, требующий многократных экспериментов, анализа результатов и творческого подхода. Все перечисленные параметры (размер выборки, количество эпох обучения) могут иметь абсолютно разные значения для разных задач и сетей. Четкого правила тут просто нет, в этом и кроется дополнительный шарм и изящность )
Возвращаемся к разбору, и в результате прохода обучающей выборки через сеть мы получаем сеть с новыми значениями весов синапсов.
Далее мы через эту, уже обученную в той или иной степени, сеть прогоняем тестовую выборку, которая не участвовала в обучении. При этом сеть выдает нам выходные значения для каждого образца, которые мы сравниваем с теми верными значениями, которые имеем.
Анализируем нашу гипотетическую выборку:

Таким образом, для тестирования подаем на вход сети значения x_{(M+1)1}, x_{(M+1)2} и проверяем, чему равен выход, ожидаем очевидно значение y_{(M+1)}. Аналогично поступаем и для оставшихся тестовых образцов. После чего мы можем сделать вывод, успешно или нет работает сеть. Например, сеть дает правильный ответ для 90% тестовых данных, дальше уже встает вопрос — устраивает ли нас данная точность или процесс обучения необходимо повторить, либо провести заново, изменив какие-либо параметры сети.
В этом и заключается суть обучения нейронных сетей, теперь перейдем к деталям и конкретным действиям, которые необходимо осуществить для выполнения данного процесса. Двигаться снова будем поэтапно, чтобы сформировать максимально четкую и полную картину. Поэтому начнем с понятия градиентного спуска, который используется при обучении по методу обратного распространения ошибки. Обо всем этом далее…
Обучение нейронных сетей. Градиентный спуск.
Рассмотрев идею процесса обучения в целом, на данном этапе мы можем однозначно сформулировать текущую цель — необходимо определить математический алгоритм, который позволит рассчитать значения весовых коэффициентов таким образом, чтобы ошибка сети была минимальна. То есть грубо говоря нам необходима конкретная формула для вычисления:
Здесь \Delta w_{ij} — величина, на которую необходимо изменить вес синапса, связывающего нейроны i и j нашей сети. Соответственно, зная это, необходимо на каждом этапе обучения производить корректировку весов связей между всеми элементами нейронной сети. Задача ясна, переходим к делу.
Пусть функция ошибки от веса имеет следующий вид:
Для удобства рассмотрим зависимость функции ошибки от одного конкретного веса:

В начальный момент мы находимся в некоторой точке кривой, а для минимизации ошибки попасть мы хотим в точку глобального минимума функции:
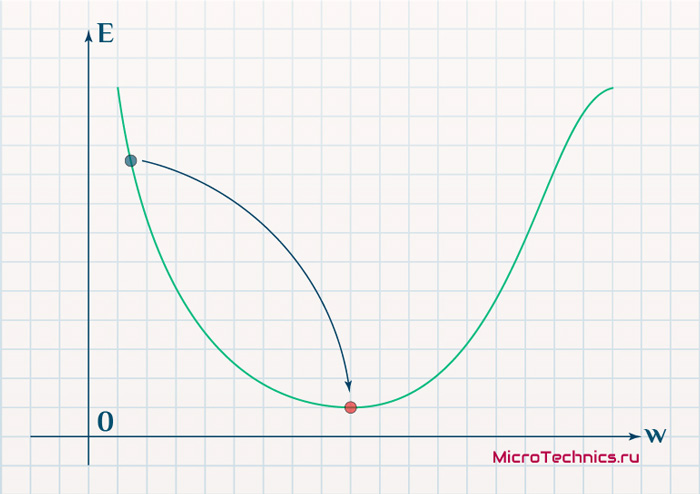
Нанесем на график вектора градиентов в разных точках. Длина векторов численно равна скорости роста функции в данной точке, что в свою очередь соответствует значению производной функции по данной точке. Исходя из этого, делаем вывод, что длина вектора градиента определяется крутизной функции в данной точке:
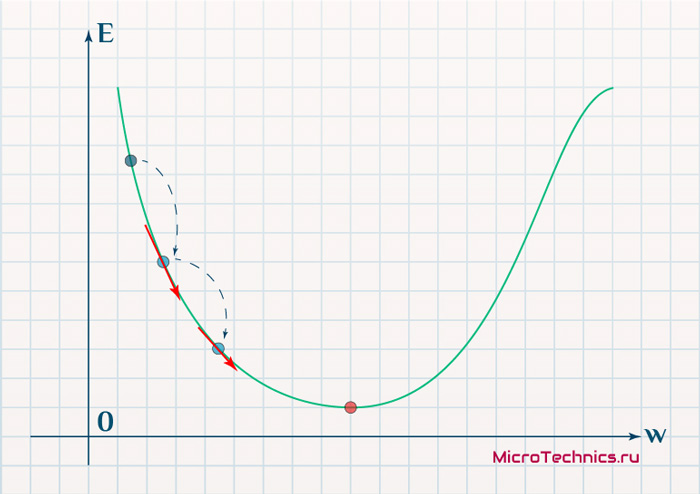
Вывод прост — величина градиента будет уменьшаться по мере приближения к минимуму функции. Это важный вывод, к которому мы еще вернемся. А тем временем разберемся с направлением вектора, для чего рассмотрим еще несколько возможных точек:
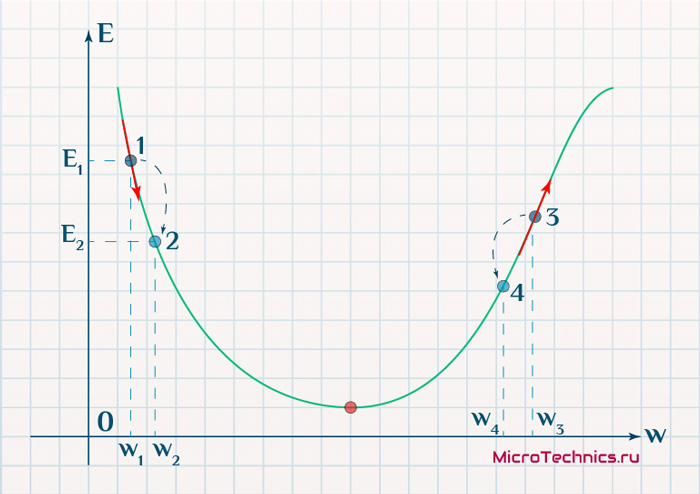
Находясь в точке 1, целью является перейти в точку 2, поскольку в ней значение ошибки меньше (E_2 < E_1), а глобальная задача по-прежнему заключается в ее минимизации. Для этого необходимо изменить величину w на некое значение \Delta w (\Delta w = w_2 — w_1 > 0). При всем при этом в точке 1 градиент отрицательный. Фиксируем данные факты и переходим к точке 3, предположим, что мы находимся именно в ней.
Тогда для уменьшения ошибки наш путь лежит в точку 4, а необходимое изменение значения: \Delta w = w_4 — w_3 < 0. Градиент же в точке 3 положителен. Этот факт также фиксируем.
А теперь соберем воедино эту информацию в виде следующей иллюстрации:
| Переход | \bold{\Delta w} | Знак \bold{\Delta w} | Градиент |
|---|---|---|---|
| 1 \rArr 2 | w_2 — w_1 | + | — |
| 3 \rArr 4 | w_4 — w_3 | — | + |
Вывод напрашивается сам собой — величина, на которую необходимо изменить значение w, в любой точке противоположна по знаку градиенту. И, таким образом, представим эту самую величину в виде:
\Delta w = -\alpha \cdot \frac{dE}{dw}
Имеем в наличии:
- \Delta w — величина, на которую необходимо изменить значение w.
- \frac{dE}{dw} — градиент в этой точке.
- \alpha — скорость обучения.
Собственно, логика метода градиентного спуска и заключается в данном математическом выражении, а именно в том, что для минимизации ошибки необходимо изменять w в направлении противоположном градиенту. В контексте нейронных сетей имеем искомый закон для корректировки весов синаптических связей (для синапса между нейронами i и j):
\Delta w_{ij} = -\alpha \cdot \frac{dE}{dw_{ij}}
Более того, вспомним о важном свойстве, которое мы отдельно пометили. И заключается оно в том, что величина градиента будет уменьшаться по мере приближения к минимуму функции. Что это нам дает? А то, что в том случае, если наша текущая дислокация далека от места назначения, то величина, корректирующая вес связи, будет больше. А это обеспечит скорейшее приближение к цели. При приближении к целевому пункту, величина \frac{dE}{dw_{ij}} будет уменьшаться, что поможет нам точнее попасть в нужную точку, а кроме того, не позволит нам ее проскочить. Визуализируем вышеописанное:
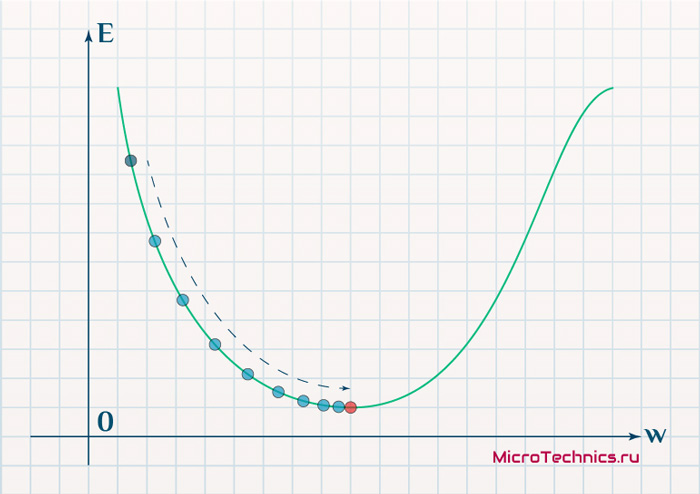
Скорость же обучения несет в себе следующий смысл. Она определяет величину каждого шага при поиске минимума ошибки. Слишком большое значение приводит к тому, что точка может «перепрыгнуть» через нужное значение и оказаться по другую сторону от цели:
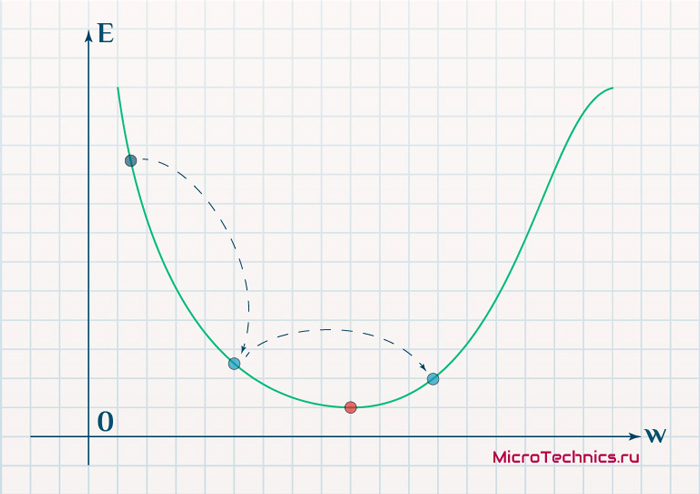
Если же величина будет мала, то это приведет к тому, что спуск будет осуществляться очень медленно, что также является нежелательным эффектом. Поэтому скорость обучения, как и многие другие параметры нейронной сети, является очень важной величиной, для которой нет единственно верного значения. Все снова зависит от конкретного случая и оптимальная величина определяется исключительно исходя из текущих условий.
И даже на этом еще не все, здесь присутствует один важный нюанс, который в большинстве статей опускается, либо вовсе не упоминается. Реальная зависимость может иметь совсем другой вид:
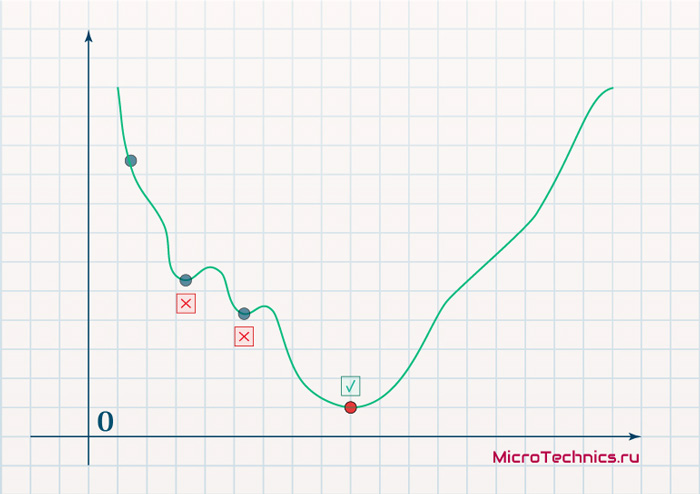
Из чего вытекает потенциальная возможность попадания в локальный минимум, вместо глобального, что является большой проблемой. Для предотвращения данного эффекта вводится понятие момента обучения и формула принимает следующий вид:
\Delta w_{ij} = -\alpha \cdot \frac{dE}{dw_{ij}} + \gamma \cdot \Delta w_{ij}^{t - 1}
То есть добавляется второе слагаемое, которое представляет из себя произведение момента на величину корректировки веса на предыдущем шаге.
Итого, резюмируем продвижение к цели:
- Нашей задачей было найти закон, по которому необходимо изменять величину весов связей между нейронами.
- Наш результат — \Delta w_{ij} = -\alpha \cdot \frac{dE}{dw_{ij}} + \gamma \cdot \Delta w_{ij}^{t — 1} — именно то, что и требовалось 👍
И опять же, полученный результат логичным образом перенаправляет нас на следующий этап, ставя вопросы — что из себя представляет функция ошибки, и как определить ее градиент.
Обучение нейронных сетей. Функция ошибки.
Начнем с того, что определимся с тем, что у нас в наличии, для этого вернемся к конкретной нейронной сети. Пусть вид ее таков:
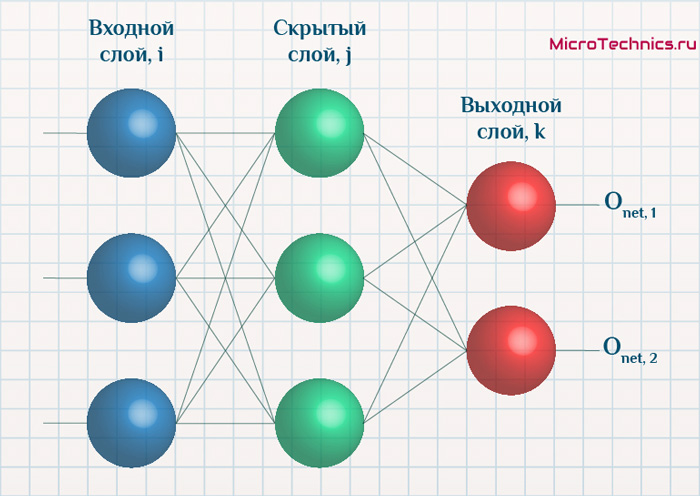
Интересует нас, в первую очередь, часть, относящаяся к нейронам выходного слоя. Подав на вход определенные значения, получаем значения на выходе сети: O_{net, 1} и O_{net, 2}. Кроме того, поскольку мы ведем речь о процессе обучения нейронной сети, то нам известны целевые значения: O_{correct, 1} и O_{correct, 2}. И именно этот набор данных на этом этапе является для нас исходным:
- Известно: O_{net, 1}, O_{net, 2}, O_{correct, 1} и O_{correct, 2}.
- Необходимо определить величины \Delta w_{ij} для корректировки весов, для этого нужно вычислить градиенты (\frac{dE}{dw_{ij}}) для каждого из синапсов.
Полдела сделано — задача четко сформулирована, начинаем деятельность по поиску решения.
В плане того, как определять ошибку, первым и самым очевидным вариантом кажется простая алгебраическая разность. Для каждого из выходных нейронов:
E_k = O_{correct, k} - O_{net, k}
Дополним пример числовыми значениями:
| Нейрон | \bold{O_{net}} | \bold{O_{correct}} | \bold{E} |
|---|---|---|---|
| 1 | 0.9 | 0.5 | -0.4 |
| 2 | 0.2 | 0.6 | 0.4 |
Недостатком данного варианта является то, что в том случае, если мы попытаемся просуммировать ошибки нейронов, то получим:
E_{sum} = e_1 + e_2 = -0.4 + 0.4 = 0
Что не соответствует действительности (нулевая ошибка, говорит об идеальной работе нейронной сети, по факту оба нейрона дали неверный результат). Так что вариант с разностью откидываем за несостоятельностью.
Вторым, традиционно упоминаемым, методом вычисления ошибки является использование модуля разности:
E_k = | O_{correct, k} - O_{net, k} |
Тут в действие вступает уже проблема иного рода:
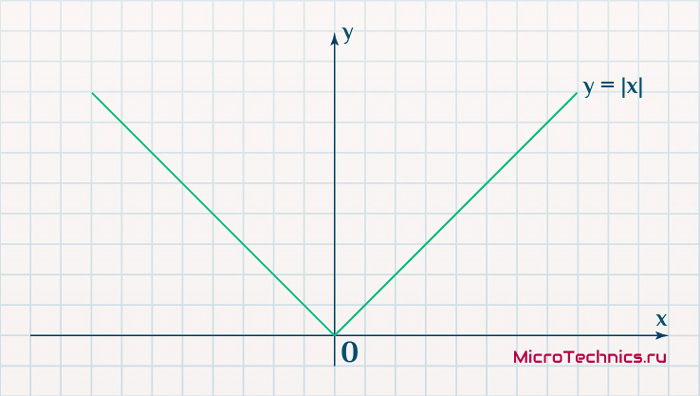
Функция, бесспорно, симпатична, но при приближении к минимуму ее градиент является постоянной величиной, скачкообразно меняясь при переходе через точку минимума. Это нас также не устраивает, поскольку, как мы обсуждали, концепция заключалась в том числе в том, чтобы по мере приближения к минимуму значение градиента уменьшалось.
В итоге хороший результат дает зависимость (для выходного нейрона под номером k):
E_k = (O_{correct, k} - O_{net, k})^2
Функция по многим своим свойствам идеально удовлетворяет нуждам обучения нейронной сети, так что выбор сделан, остановимся на ней. Хотя, как и во многих аспектах, качающихся нейронных сетей, данное решение не является единственно и неоспоримо верным. В каких-то случаях лучше себя могут проявить другие зависимости, возможно, что какой-то вариант даст большую точность, но неоправданно высокие затраты производительности при обучении. В общем, непаханное поле для экспериментов и исследований, это и привлекательно.
Краткий вывод промежуточного шага, на который мы вышли:
- Имеющееся: \frac{dE}{dw_{jk}} = \frac{d}{d w_{jk}}(O_{correct, k} — O_{net, k})^2.
- Искомое по-прежнему: \Delta w_{jk}.
Несложные диффернциально-математические изыскания выводят на следующий результат:
\frac{dE}{d w_{jk}} = -(O_{correct, k} - O_{net, k}) \cdot f{\Large{\prime}}(\sum_{j}w_{jk}O_j) \cdot O_j
Здесь эти самые изыскания я все-таки решил не вставлять, дабы не перегружать статью, которая и так выходит объемной. Но в случае необходимости и интереса, отпишите в комментарии, я добавлю вычисления и закину их под спойлер, как вариант.
Освежим в памяти структуру сети:
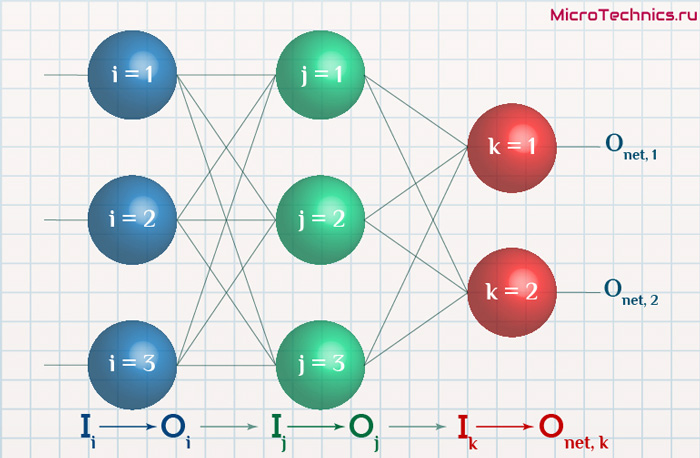
Формулу можно упростить, сгруппировав отдельные ее части:
- (O_{correct, k} — O_{net, k}) \cdot f{\Large{\prime}}(\sum_{j}w_{jk}O_j) — ошибка нейрона k.
- O_j — тут все понятно, выходной сигнал нейрона j.
f{\Large{\prime}}(\sum_{j}w_{jk}O_j) — значение производной функции активации. Причем, обратите внимание, что \sum_{j}w_{jk}O_j — это не что иное, как сигнал на входе нейрона k (I_{k}). Тогда для расчета ошибки выходного нейрона: \delta_k = (O_{correct, k} — O_{net, k}) \cdot f{\Large{\prime}}(I_k).
Итог: \frac{dE}{d w_{jk}} = -\delta_k \cdot O_j.
Одной из причин популярности сигмоидальной функции активности является то, что ее производная очень просто выражается через саму функцию:
f{'}(x) = f(x)\medspace (1\medspace-\medspace f(x))
Данные алгебраические вычисления справедливы для корректировки весов между скрытым и выходным слоем, поскольку для расчета ошибки мы используем просто разность между целевым и полученным результатом, умноженную на производную.
Для других слоев будут незначительные изменения, касающиеся исключительно первого множителя в формуле:
\frac{dE}{d w_{ij}} = -\delta_j \cdot O_i
Который примет следующий вид:
\delta_j = (\sum_{k}{}{\delta_k\medspace w_{jk}}) \cdot f{\Large{\prime}}(I_j)
То есть ошибка для элемента слоя j получается путем взвешенного суммирования ошибок, «приходящих» к нему от нейронов следующего слоя и умножения на производную функции активации. В результате:
\frac{dE}{d w_{ij}} = -(\sum_{k}{}{\delta_k\medspace w_{jk}}) \cdot f{\Large{\prime}}(I_j) \cdot O_i
Снова подводим промежуточный итог, чтобы иметь максимально полную и структурированную картину происходящего. Вот результаты, полученные нами на двух этапах, которые мы успешно миновали:
- Ошибка:
- выходной слой: \delta_k = (O_{correct, k} — O_{net, k}) \cdot f{\Large{\prime}}(I_k)
- скрытые слои: \delta_j = (\sum_{k}{}{\delta_k\medspace w_{jk}}) \cdot f{\Large{\prime}}(I_j)
- Градиент: \frac{dE}{d w_{ij}} = -\delta_j \cdot O_i
- Корректировка весовых коэффициентов: \Delta w_{ij} = -\alpha \cdot \frac{dE}{dw_{ij}} + \gamma \cdot \Delta w_{ij}^{t — 1}
Преобразуем последнюю формулу:
\Delta w_{ij} = \alpha \cdot \delta_j \cdot O_i + \gamma \cdot \Delta w_{ij}^{t - 1}
Из этого мы делаем вывод, что на данный момент у нас есть все, что необходимо для того, чтобы произвести обучение нейронной сети. И героем следующего подраздела будет алгоритм обратного распространения ошибки.
Метод обратного распространения ошибки.
Данный метод является одним из наиболее распространенных и популярных, чем и продиктован его выбор для анализа и разбора. Алгоритм обратного распространения ошибки относится к методам обучение с учителем, что на деле означает необходимость наличия целевых значений в обучающих сетах.
Суть же метода подразумевает наличие двух этапов:
- Прямой проход — входные сигналы двигаются в прямом направлении, в результате чего мы получаем выходной сигнал, из которого в дальнейшем рассчитываем значение ошибки.
- Обратный проход — обратное распространение ошибки — величина ошибки двигается в обратном направлении, в результате происходит корректировка весовых коэффициентов связей сети.
Начальные значения весов (перед обучением) задаются случайными, есть ряд методик для выбора этих значений, я опишу в отдельном материале максимально подробно. Пока вот можно полистать — ссылка.
Вернемся к конкретному примеру для явной демонстрации этих принципов:
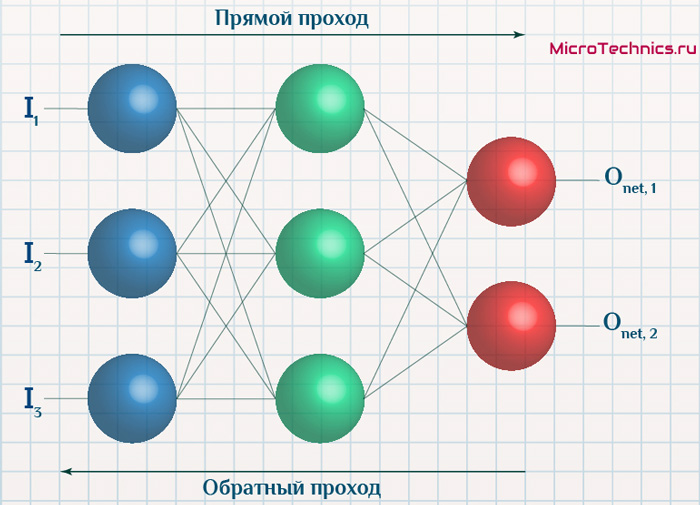
Итак, имеется нейронная сеть, также имеется набор данных обучающей выборки. Как уже обсудили в начале статьи — обучающая выборка представляет из себя набор образцов (сетов), каждый из которых состоит из значений входных сигналов и соответствующих им «правильных» значений выходных величин.
Процесс обучения нейронной сети для алгоритма обратного распространения ошибки будет таким:
- Прямой проход. Подаем на вход значения I_1, I_2, I_3 из обучающей выборки. В результате работы сети получаем выходные значения O_{net, 1}, O_{net, 2}. Этому целиком и полностью был посвящен предыдущий манускрипт.
- Рассчитываем величины ошибок для всех слоев:
- для выходного: \delta_k = (O_{correct, k} — O_{net, k}) \cdot f{\Large{\prime}}(I_k)
- для скрытых: \delta_j = (\sum_{k}{}{\delta_k\medspace w_{jk}}) \cdot f{\Large{\prime}}(I_j)
- Далее используем полученные значения для расчета \Delta w_{ij} = \alpha \cdot \delta_j \cdot O_i + \gamma \cdot \Delta w_{ij}^{t — 1}
- И финишируем, рассчитывая новые значения весов: w_{ij \medspace new} = w_{ij} + \Delta w_{ij}
- На этом один цикл обучения закончен, данные шаги 1 — 4 повторяются для других образцов из обучающей выборки.
Обратный проход завершен, а вместе с ним и одна итерация процесса обучения нейронной сети по данному методу. Собственно, обучение в целом заключается в многократном повторении этих шагов для разных образцов из обучающей выборки. Логику мы полностью разобрали, при повторном проведении операций она остается в точности такой же.
Таким образом, максимально подробно концентрируясь именно на сути и логике процессов, мы в деталях разобрали метод обратного распространения ошибки. Поэтому переходим к завершающей части статьи, в которой разберем практический пример, произведя полностью все вычисления для конкретных числовых величин. Все в рамках продвигаемой мной концепции, что любая теоретическая информация на порядок лучше может быть осознана при применении ее на практике.
Пример расчетов для метода обратного распространения ошибки.
Возьмем нейронную сеть и зададим начальные значения весов:
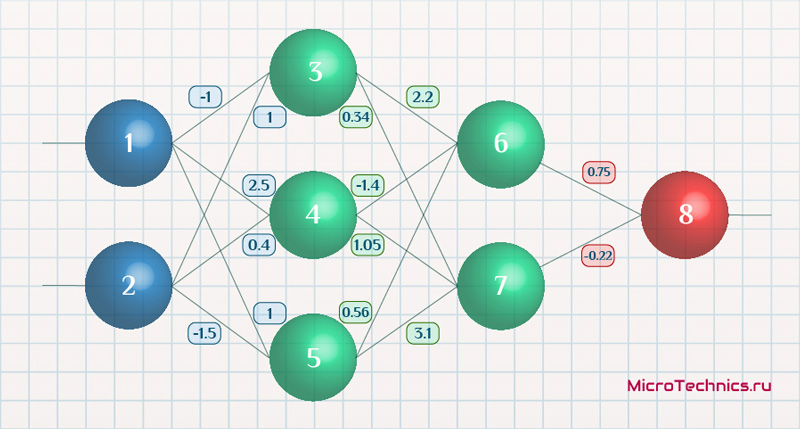
Здесь я задал значения не в соответствии с существующими на сегодняшний день методами, а просто случайным образом для наглядности примера.
В качестве функции активации используем сигмоиду:
f(x) = \frac{1}{1 + e^{-x}}
И ее производная:
f{\Large{\prime}}(x) = f(x)\medspace (1\medspace-\medspace f(x))
Берем один образец из обучающей выборки, пусть будут такие значения:
- Входные: I_1 = 0.6, I_1 = 0.7.
- Выходное: O_{correct} = 0.9.
Скорость обучения \alpha пусть будет равна 0.3, момент — \gamma = 0.1. Все готово, теперь проведем полный цикл для метода обратного распространения ошибки, то есть прямой проход и обратный.
Прямой проход.
Начинаем с выходных значений нейронов 1 и 2, поскольку они являются входными, то:
O_1 = I_1 = 0.6 \\ O_2 = I_2 = 0.7
Значения на входе нейронов 3, 4 и 5:
I_3 = O_1 \cdot w_{13} + O_2 \cdot w_{23} = 0.6 \cdot (-1\medspace) + 0.7 \cdot 1 = 0.1 \\
I_4 = 0.6 \cdot 2.5 + 0.7 \cdot 0.4 = 1.78 \\
I_5 = 0.6 \cdot 1 + 0.7 \cdot (-1.5\medspace) = -0.45
На выходе этих же нейронов первого скрытого слоя:
O_3 = f(I3\medspace) = 0.52 \\ O_4 = 0.86\\ O_5 = 0.39
Продолжаем аналогично для следующего скрытого слоя:
I_6 = O_3 \cdot w_{36} + O_4 \cdot w_{46} + O_5 \cdot w_{56} = 0.52 \cdot 2.2 + 0.86 \cdot (-1.4\medspace) + 0.39 \cdot 0.56 = 0.158 \\
I_7 = 0.52 \cdot 0.34 + 0.86 \cdot 1.05 + 0.39 \cdot 3.1 = 2.288 \\
O_6 = f(I_6) = 0.54 \\
O_7 = 0.908
Добрались до выходного нейрона:
I_8 = O_6 \cdot w_{68} + O_7 \cdot w_{78} = 0.54 \cdot 0.75 + 0.908 \cdot (-0.22\medspace) = 0.205 \\
O_8 = O_{net} = f(I_8) = 0.551
Получили значение на выходе сети, кроме того, у нас есть целевое значение O_{correct} = 0.9. То есть все, что необходимо для обратного прохода, имеется.
Обратный проход.
Как мы и обсуждали, первым этапом будет вычисление ошибок всех нейронов, действуем:
\delta_8 = (O_{correct} - O_{net}) \cdot f{\Large{\prime}}(I_8) = (O_{correct} - O_{net}) \cdot f(I_8) \cdot (1-f(I_8)) = (0.9 - 0.551\medspace) \cdot 0.551 \cdot (1-0.551\medspace) = 0.0863 \\
\delta_7 = (\sum_{k}{}{\delta_k\medspace w_{jk}}) \cdot f{\Large{\prime}}(I_7) = (\delta_8 \cdot w_{78}) \cdot f{\Large{\prime}}(I_7) = 0.0863 \cdot (-0.22\medspace) \cdot 0.908 \cdot (1 - 0.908\medspace) = -0.0016 \\
\delta_6 = 0.086 \cdot 0.75 \cdot 0.54 \cdot (1 - 0.54\medspace) = 0.016 \\
\delta_5 = (\sum_{k}{}{\delta_k\medspace w_{jk}}) \cdot f{\Large{\prime}}(I_5) = (\delta_7 \cdot w_{57} + \delta_6 \cdot w_{56}) \cdot f{\Large{\prime}}(I_7) = (-0.0016 \cdot 3.1 + 0.016 \cdot 0.56) \cdot 0.39 \cdot (1 - 0.39\medspace) = 0.001 \\
\delta_4 = (-0.0016 \cdot 1.05 + 0.016 \cdot (-1.4)) \cdot 0.86 \cdot (1 - 0.86\medspace) = -0.003 \\
\delta_3 = (-0.0016 \cdot 0.34 + 0.016 \cdot 2.2) \cdot 0.52 \cdot (1 - 0.52\medspace) = -0.0087
С расчетом ошибок закончили, следующий этап — расчет корректировочных величин для весов всех связей. Для этого мы вывели формулу:
\Delta w_{ij} = \alpha \cdot \delta_j \cdot O_i + \gamma \cdot \Delta w_{ij}^{t - 1}
Как вы помните, \Delta w_{ij}^{t — 1} — это величина поправки для данного веса на предыдущей итерации. Но поскольку у нас это первый проход, то данное значение будет нулевым, соответственно, в данном случае второе слагаемое отпадает. Но забывать о нем нельзя. Продолжаем калькулировать:
\Delta w_{78} = \alpha \cdot \delta_8 \cdot O_7 = 0.3 \cdot 0.0863 \cdot 0.908 = 0.0235 \\
\Delta w_{68} = 0.3 \cdot 0.0863 \cdot 0.54= 0.014 \\
\Delta w_{57} = \alpha \cdot \delta_7 \cdot O_5 = 0.3 \cdot (−0.0016\medspace) \cdot 0.39= -0.00019 \\
\Delta w_{47} = 0.3 \cdot (−0.0016\medspace) \cdot 0.86= -0.0004 \\
\Delta w_{37} = 0.3 \cdot (−0.0016\medspace) \cdot 0.52= -0.00025 \\
\Delta w_{56} = \alpha \cdot \delta_6 \cdot O_5 = 0.3 \cdot 0.016 \cdot 0.39= 0.0019 \\
\Delta w_{46} = 0.3 \cdot 0.016 \cdot 0.86= 0.0041 \\
\Delta w_{36} = 0.3 \cdot 0.016 \cdot 0.52= 0.0025 \\
\Delta w_{25} = \alpha \cdot \delta_5 \cdot O_2 = 0.3 \cdot 0.001 \cdot 0.7= 0.00021 \\
\Delta w_{15} = 0.3 \cdot 0.001 \cdot 0.6= 0.00018 \\
\Delta w_{24} = \alpha \cdot \delta_4 \cdot O_2 = 0.3 \cdot (-0.003\medspace) \cdot 0.7= -0.00063 \\
\Delta w_{14} = 0.3 \cdot (-0.003\medspace) \cdot 0.6= -0.00054 \\
\Delta w_{23} = \alpha \cdot \delta_3 \cdot O_2 = 0.3 \cdot (−0.0087\medspace) \cdot 0.7= -0.00183 \\
\Delta w_{13} = 0.3 \cdot (−0.0087\medspace) \cdot 0.6= -0.00157
И самый что ни на есть заключительный этап — непосредственно изменение значений весовых коэффициентов:
w_{78 \medspace new} = w_{78} + \Delta w_{78} = -0.22 + 0.0235 = -0.1965 \\
w_{68 \medspace new} = 0.75+ 0.014 = 0.764 \\
w_{57 \medspace new} = 3.1 + (−0.00019\medspace) = 3.0998\\
w_{47 \medspace new} = 1.05 + (−0.0004\medspace) = 1.0496\\
w_{37 \medspace new} = 0.34 + (−0.00025\medspace) = 0.3398\\
w_{56 \medspace new} = 0.56 + 0.0019 = 0.5619 \\
w_{46 \medspace new} = -1.4 + 0.0041 = -1.3959 \\
w_{36 \medspace new} = 2.2 + 0.0025 = 2.2025 \\
w_{25 \medspace new} = -1.5 + 0.00021 = -1.4998 \\
w_{15 \medspace new} = 1 + 0.00018 = 1.00018 \\
w_{24 \medspace new} = 0.4 + (−0.00063\medspace) = 0.39937 \\
w_{14 \medspace new} = 2.5 + (−0.00054\medspace) = 2.49946 \\
w_{23 \medspace new} = 1 + (−0.00183\medspace) = 0.99817 \\
w_{13 \medspace new} = -1 + (−0.00157\medspace) = -1.00157\\
И на этом данную масштабную статью завершаем, конечно же, не завершая на этом деятельность по использованию нейронных сетей. Так что всем спасибо за прочтение, любые вопросы пишите в комментариях и на форуме, ну и обязательно следите за обновлениями и новыми материалами, до встречи!
«Перевариваю» лекцию Дмитрием Романовым по регрессии из курса «Нейронные сети на Python» читаемого в «Университете искуственного интеллекта«.
Задача прогнозирования данных по известным цифровым рядам решалась с помощью различных методов регрессионного анализа. Чтобы сделать качественный прогноз приходилось использовать различные варианты уравнений регрессии, брать преобразование Фурье для выявления сезонной составляющей и использовать другие математические методы. При достаточном упорстве аналитика можно было найти комбинацию матметодов, неплохо предсказывающих поведение анализируемого параметра. Включение в модель категориальных данных было уже непросто, а текстовые — это вообще отдельная сложная тема.
Решение задачи регрессии с помощью нейронных сетей — иной подход. Рассмотрим его подробнее для начала на примере определения стоимости недвижимости из набора данных Boston Housing, включенном в Keras. Это 13 столбцов различных параметров описывающих недвижимость и всего-то 400 записей с информацией. Т.е. речь не идет о тысячах выборок для тренировки нейронки. Мой notebook после анализа лекции Дмитрия с экспериментами.
Подготовка данных
from tensorflow.keras.datasets import boston_housing from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense import matplotlib.pyplot as plt import numpy as np %matplotlib inline (x_train, y_train), (x_test, y_test) = boston_housing.load_data() #загрузка данных
Я буду рассматривать всю подготовительную фазу достаточно подробно, чтобы исключить любые вопросы, которые возникали у меня в ходе изучения кода. Заодно вспомним как работать с Python. 🙂
Итак, для начала нужно сделать нормализацию данных. В некоторых случаях нормализация позволяет существенно улучшить качество предсказания результатов сетью. Но, как говорит Дмитрий, «все гипотезы нужно тестировать». 🙂
Остановлюсь немного подробнее на нормализации в варианте Python. Для начала найдем среднее арифметическое (mean) на тестовом примере, чтобы лучше понять, как работают матричные операции Python.
value = [[x for x in range(0,5)],
[x for x in range(10,15)],
[x for x in range(20,25)]]
value = np.array(value)
print("Numpy array:", value)
sum = value.sum(axis=0)
print("Mean:", sum / value.shape[0])
Сначала суммируем по строкам. Для этого указываем axis=0. Если указать axis = 1, то суммирование будет проходить по столбцам, а это нам не нужно. После того, как просуммировали, делим на общее количество записей, которое получаем через: value.shape[0].
Numpy array: [[ 0 1 2 3 4] [10 11 12 13 14] [20 21 22 23 24]] Mean: [10. 11. 12. 13. 14.]
В numpy array есть стандартный метод для определения среднего арифметического «mean»:
mean = value.mean(axis=0) #Вычисляем среднее по строкам
print("Mean:\r\n", mean)
Mean:
[10. 11. 12. 13. 14.]
При нормировке среднее арифметическое вычитается из исходных данных, чтобы новые значения лежали равномернее относительно оси х.
mean = x_train.mean(axis=0) x_train -= mean
Далее распространено деление полученных данных на стандартное отклонение. Явно выраженного физического смысла в этой процедуре нет. Однако, как указывается в источниках, приближая значения данных к диапазону функций активации, ускоряется корректировка весов и сеть быстрее сходится. Подробное описание можно посмотреть здесь.
std = x_train.std(axis=0) x_train /= std
Поскольку нормализацию нужно проделать и для обучающей x_train и для проверочной x_test выборки, воспользуемся функцией.
def norm(x): return (x - mean) / std x_train = norm(x_train); x_test = norm(x_test);
Поскольку функция активации sigmoid на выходе работает от 0 до 1, то сделаем нормировку для правильных ответов y_train. Для этого опустим минимальные значения к 0, вычтя из данных минимальное значение обучающей выборки.
Чтобы привести величины в выборке к 1, разделим данные на значение амплитуды взятое от новой (смещенной) выборки. Сохраняем минимальные и максимальные значения, поскольку после получения результатов на выходе сети нужно будет выполнить обратную процедуру.
При корректировке данных тестовой выборки воспользуемся полученным максимальным значением амплитуды от обучающей выборки:
# Приводим значения ответов в диапазон от 0 до 1 min_y = y_train.min() y_train = y_train - min_y #смещаем ответы к 0, вычитая минимальное значение max_y = y_train.max() #берем максимум от уже "опущенных" вниз на min_y данных y_train /= max_y #приводим к 1 обучающую выборку #нормируем ответы проверочной выборки, используя статистику min_y и max_y обучающей y_test = y_test - min_y y_test /= max_y
Предыдущий код можно написать по-другому, сместив на min_y и значения выборки, и значение максимума.
# Приводим значения ответов в диапазон от 0 до 1 min_y = y_train.min() max_y = y_train.max() - min_y #"опустим" максимум на min_y y_train = (y_train - min_y) / max_y #отклонение от минимума к амплитуде y_test = (y_test - min_y) / max_y
Остановлюсь чуть подробнее на моменте, что и обучающая, и проверочная выборка нормируется статистикой, полученной по обучающей выборке. Это сделано намеренно. В тексте статьи про регрессию есть небольшое пояснение почему так делается.
Использование статистики обучающей выборки при нормализации тестовой позволяет выявлять ошибки тестовой выборки, если её статистика отличается от обучающей. Скажем, в предыдущей статье по распознаванию автора книги я брал для тренировки сети первый том автора, а в качестве тестовой использовал второй.
После тренировки сети на обучающей выборке её веса будут подобраны таким образом, чтобы минимизировать ошибку. Сеть настроена на статистику обучающей выборки. Затем на сеть подается проверочная выборка, отнормированная статистикой обучающей. Сеть выдаст на выходе некоторый результат, который будет денормализован опять же с использованием статистики обучающей выборки. Если данные в проверочной выборке отличаются, то денормализация статистикой обучающей выборки приведет к росту ошибки.
Особенно явно рост ошибки может проявиться при использовании активационных функций, ограничивающих предельные значения на выходе нейронной сети. Например, в случае сигмоида возможные значения должны быть в коридоре: 0 — 1. Если после денормализации сеть предскажет значение большее 1 или меньшее 0, то оно будет усечено до 1 или 0 соответственно.
Нейронная сеть
Строим простую полносвязную нейронную сеть (feed forward neural network). Выходной слой с одним линейным нейроном — для задачи регрессии. Функция активации — RELU в промежуточном слое и sigmoid в выходном. Конфигурация сети взята из хорошего примера — https://www.tensorflow.org/tutorials/keras/basic_regression
model = Sequential() model.add(Dense(64, activation='relu', input_shape=(x_train.shape[1],))) model.add(Dense(64, activation='relu')) model.add(Dense(1, activation='sigmoid')) # sigmoid, т.к. данные от 0 до 1
Чтобы посмотреть архитектуру нейронной сети:
print(model.summary()) # архитектура нашей модели Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_6 (Dense) (None, 64) 896 _________________________________________________________________ dense_7 (Dense) (None, 64) 4160 _________________________________________________________________ dense_8 (Dense) (None, 1) 65 ================================================================= Total params: 5,121 Trainable params: 5,121 Non-trainable params: 0
Компилируем сеть
# Т.к. задача регрессии, удобнее использовать mean square error(средне-квадратичная ошибка). # В качестве метрики берем mean absolute error (средний модуль ошибки) model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
И обучаем:
history = model.fit(x_train,
y_train,
epochs=100,
validation_split=0.1,
verbose=2)
Делаем прогноз, приведя полученные значения ответов сети к нашим значениям, умножив на max_y (приводим амплитуду к нормальному виду) и «подняв» на min_y:
# Делаем прогноз. Возвращается копия предсказания в виде одномерного массива pred = model.predict(x_test).flatten() # Возвращаем к прежнему размеру pred = pred * max_y + min_y y_test = y_test * max_y + min_y
Проверяем, какая ошибка (средний модуль отклонения) получилась:
# Средний модуль отклонения err = np.mean(abs(pred - y_test)) print(err) 2.678478168038761
И получаем довольно хорошую ошибку при том, что вся процедура подбора модели предсказания прошла без нашего участия. В случае с классической регрессией пришлось бы посидеть немало времени, чтобы сделать необходимые преобразования исходных данных, которые можно было бы использовать для построения функции регрессии. Но в этом случае бонусом было бы то, что мы смогли бы увидеть полученную функцию. В случае нейронки полученная модель — «черный ящик».
# Средняя цена по выборке print(np.mean(y_test)) 23.07843137254902
Если построить результаты предсказания сетью значений, то можно заметить, что без шаманства с архитектурой нейронной сети, очистки входных данных и пр. качество предсказания довольно неплохое:
# Предсказание vs правильный ответ
for i in range(len(pred)):
print("Сеть сказала: ", round(pred[i],2), ", а верный ответ: ", round(y_test[i],2), ", разница: ", round(pred[i] - y_test[i],2))
Сеть сказала: 9.68 , а верный ответ: 7.2 , разница: 2.48
Сеть сказала: 18.21 , а верный ответ: 18.8 , разница: -0.59
Сеть сказала: 21.38 , а верный ответ: 19.0 , разница: 2.38
Сеть сказала: 36.57 , а верный ответ: 27.0 , разница: 9.57
Сеть сказала: 26.3 , а верный ответ: 22.2 , разница: 4.1
Сеть сказала: 24.11 , а верный ответ: 24.5 , разница: -0.39
Естественно, для каких-то входных данных ошибка значительна, но, вполне вероятно, что в данных есть аномалии. Этот момент нужно изучать дополнительно.
Визуализируем полученные данные:
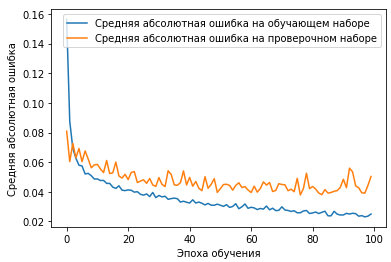
# Считаем графики ошибки
plt.plot(history.history['mean_absolute_error'],
label='Средняя абсолютная ошибка на обучающем наборе')
plt.plot(history.history['val_mean_absolute_error'],
label='Средняя абсолютная ошибка на проверочном наборе')
plt.xlabel('Эпоха обучения')
plt.ylabel('Средняя абсолютная ошибка')
plt.legend()
plt.show()
# Разброс предсказаний может показать перекос, если есть
plt.scatter(y_test, pred)
plt.xlabel('Правильные значение, $1K')
plt.ylabel('Предсказания, $1K')
plt.axis('equal')
plt.xlim(plt.xlim())
plt.ylim(plt.ylim())
plt.plot([-100, 100], [-100, 100])
plt.show()
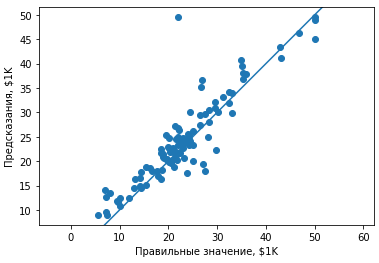
Видно, что результаты предсказания довольно неплохо укладываются относительно верных результатов за исключением одного выброса. Скорее всего в исходных данных для этого значения будут какие-то значительные аномалии, которые позволят сделать вычистку данных.
Гистограмма ошибок следующая:
#Разность предсказанного и правильного ответа
error = pred - y_test
#Построение гистограммы
plt.hist(abs(error), bins = 25)
plt.xlabel("Значение ошибки, $1K")
plt.ylabel("Количество")
plt.show()
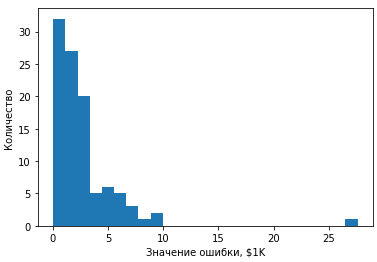
Видно, что большая часть ошибок укладывается в диапазон примерно до 4000$, и единственный аномальный вариант — с ошибкой в районе 27 тыс. $ Понятно, что в реальной жизни при выполнении прогноза сравнивать будет не с чем, поэтому нужно будет выработать критерии для идентификации явно аномальных значений в предсказании.
Полезные ссылки
- Прогнозирование финансовых временных рядов с MLP в Keras — https://webhamster.ru/mytetrashare/index/mtb0/1539612644nodqf6fjw9
- Deep learning: the final frontier for signal processing and time series analysis? — https://medium.com/@alexrachnog/deep-learning-the-final-frontier-for-signal-processing-and-time-series-analysis-734307167ad6
- A Guide For Time Series Prediction Using Recurrent Neural Networks (LSTMs) — https://blog.statsbot.co/time-series-prediction-using-recurrent-neural-networks-lstms-807fa6ca7f
- Forecasting of Forex Time Series Data Based on Deep Learning — https://www.sciencedirect.com/science/article/pii/S1877050919302066
- How to Develop LSTM Models for Time Series Forecasting — https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
- Multivariate Time Series Forecasting with LSTMs in Keras — https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras/
![]()
В предыдущей части мы учились рассчитывать изменения сигнала при проходе по нейросети. Мы познакомились с матрицами, их произведением и вывели простые формулы для расчетов.
В 6 части перевода выкладываю сразу 4 раздела книги. Все они посвящены одной из самых важных тем в области нейросетей — методу обратного распространения ошибки. Вы научитесь рассчитывать погрешность всех нейронов нейросети основываясь только на итоговой погрешности сети и весах связей.
Материал сложный, так что смело задавайте свои вопросы на форуме.
Вы можете скачать PDF версию перевода.
Приятного чтения!
Оглавление
1 Глава. Как они работают.
- 1.1 Легко для меня, тяжело для тебя
- 1.2 Простая предсказательная машина
- 1.3 Классификация это почти что предсказание
- 1.4 Тренировка простого классификатора
- 1.5 Иногда одного классификатора недостаточно
- 1.6 Нейроны — природные вычислительные машины
- 1.7 Проход сигнала через нейросеть
- 1.8 Умножать матрицы полезно… Серьезно!
- 1.9 Трехслойная нейросеть и произведение матриц
- 1.10 Калибровка весов нескольких связей
- 1.11 Обратное распространение ошибки от выходных нейронов
- 1.12 Обратное распространение ошибки на множество слоев
- 1.13 Обратное распространение ошибки и произведение матриц
1.10 Калибровка весов нескольких связей
Ранее мы настраивали линейный классификатор с помощью изменения постоянного коэффициента уравнения прямой. Мы использовали погрешность, разность между полученным и желаемым результатами, для настройки классификатора.
Все те операции были достаточно простые, так как сама связь между погрешностью и величины, на которую надо было изменить коэффициент прямой оказалось очень простой.
Но как нам калибровать веса связей, когда на получаемый результат, а значит и на погрешность, влияют сразу несколько нейронов? Рисунок ниже демонстрирует проблему:

Очень легко работать с погрешностью, когда вход у нейрона всего один. Но сейчас уже два нейрона подают сигналы на два входа рассматриваемого нейрона. Что же делать с погрешностью?
Нет никакого смысла использовать погрешность целиком для корректировки одного веса, потому что в этом случае мы забываем про второй вес. Ведь оба веса задействованы в создании полученного результата, а значит оба веса виновны в итоговой погрешности.
Конечно, существует очень маленькая вероятность того, что только один вес внес погрешность, а второй был идеально откалиброван. Но даже если мы немного поменяем вес, который и так не вносит погрешность, то в процессе дальнейшего обучения сети он все равно придет в норму, так что ничего страшного.
Можно попытаться разделить погрешность одинаково на все нейроны:

Классная идея. Хотя я никогда не пробовал подобный вариант использования погрешности в реальных нейросетях, я уверен, что результаты вышли бы очень достойными.
Другая идея тоже заключается в разделении погрешности, но не поровну между всеми нейронами. Вместо этого мы кладем большую часть ответственности за погрешность на нейроны с большим весом связи. Почему? Потому что за счет своего большего веса они внесли больший вклад в выход нейрона, а значит и в погрешность.

На рисунке изображены два нейрона, которые подают сигналы третьему, выходному нейрону. Веса связей: \( 3 \) и \( 1 \). Согласно нашей идее о переносе погрешности на нейроны мы используем \( \frac{3}{4} \) погрешности на корректировку первого (большего) веса и \( \frac{1}{4} \) на корректировку второго (меньшего) веса.
Идею легко развить до любого количества нейронов. Пусть у нас есть 100 нейронов и все они соединены с результирующим нейроном. В таком случае, мы распределяем погрешность на все 100 связей так, чтобы на каждую связь пришлась часть погрешности, соответствующая ее весу.
Как видно, мы используем веса связей для двух задач. Во-первых, мы используем веса в процессе распространения сигнала от входного до выходного слоя. Мы уже разобрались, как это делается. Во-вторых, мы используем веса для распространения ошибки в обратную сторону: от выходного слоя к входному. Из-за этого данный метод использования погрешности называют методом обратного распространения ошибки.
Если у нашей сети 2 нейрона выходного слоя, то нам пришлось бы использовать этот метод еще раз, но уже для связей, которые повлияли на выход второго нейрона выходного слоя. Рассмотрим эту ситуацию подробнее.
1.11 Обратное распространение ошибки от выходных нейронов
На диаграмме ниже изображена нейросеть с двумя нейронами во входном слое, как и в предыдущем примере. Но теперь у сети имеется два нейрона и в выходном слое.

Оба выхода сети могут иметь погрешность, особенно в тех случаях, когда сеть еще не натренирована. Мы должны использовать полученные погрешности для настройки весов связей. Можно использовать метод, который мы получили в предыдущем разделе — больше изменяем те нейроны, которые сделали больший вклад в выход сети.
То, что сейчас у нас больше одного выходного нейрона по сути ни на что не влияет. Мы просто используем наш метод дважды: для первого и второго нейронов. Почему так просто? Потому что связи с конкретным выходным нейроном никак не влияют на остальные выходные нейроны. Их изменение повлияет только на конкретный выходной нейрон. На диаграмме выше изменение весов \( w_{1,2} \) и \( w_{2,2} \) не повлияет на результат \( o_1 \).
Погрешность первого нейрона выходного слоя мы обозначили за \( e_1 \). Погрешность равна разнице между желаемым выходом нейрона \( t_1 \), который мы имеем в обучающей выборке и полученным реальным результатом \( o_1 \).
\[ e_1 = t_1 — o_1 \]
Погрешность второго нейрона выходного слоя равна \( e_2 \).
На диаграмме выше погрешность \( e_1 \) разделяется на веса \( w_{1,1} \) и \( w_{2,1} \) соответственно их вкладу в эту погрешность. Аналогично, погрешность \( e_2 \) разделяется на веса \( w_{1,2} \) и \( w_{2,2} \).
Теперь надо определить, какой вес оказал большее влияние на выход нейрона. Например, мы можем определить, какая часть ошибки \( e_1 \) пойдет на исправление веса \( w_{1,1} \):
\[ \frac{w_{1,1}}{w_{1,1}+w_{2,1}} \]
А вот так находится часть \( e_1 \), которая пойдет на корректировку веса \( w_{2,1} \):
\[ \frac{w_{2,1}}{w_{1,1} + w_{2,1}} \]
Теперь разберемся, что означают два этих выражения выше. Изначально наша идея заключается в том, что мы хотим сильнее изменить связи с большим весом и слегка изменить связи с меньшим весом.
А как нам понять величину веса относительно всех остальных весов? Для этого мы должны сравнить какой-то конкретный вес (например \( w_{1,1} \)) с абстрактной «общей» суммой всех весов, повлиявших на выход нейрона. На выход нейрона повлияли два веса: \( w_{1,1} \) и \( w_{2,1} \). Мы складываем их и смотрим, какая часть от общего вклада приходится на \( w_{1,1} \) с помощью деления этого веса на полученную ранее общую сумму:
\[ \frac{w_{1,1}}{w_{1,1}+w_{2,1}} \]
Пусть \( w_{1,1} \) в два раза больше, чем \( w_{2,1} \): \( w_{1,1} = 6 \) и \( w_{2,1} = 3 \). Тогда имеем \( 6/(6+3) = 6/9 = 2/3 \), а значит \( 2/3 \) погрешности \( e_1 \) пойдет на корректировку \( w_{1,1} \), а \( 1/3 \) на корректировку \( w_{2,1} \).
В случае, когда оба веса равны, то каждому достанется по половине погрешности. Пусть \( w_{1,1} = 4 \) и \( w_{2,1}=4 \). Тогда имеем \( 4/(4+4)=4/8=1/2 \), а значит на каждый вес пойдет \( 1/2 \) погрешности \( e_1 \).
Прежде чем мы двинемся дальше, давайте на секунду остановимся и посмотрим, чего мы достигли. Нам нужно что-то менять в нейросети для уменьшения получаемой погрешности. Мы решили, что будем менять веса связей между нейронами. Мы также нашли способ, как распределять полученную на выходном слое сети погрешность между весами связей. В этом разделе мы получили формулы для вычисления конкретной части погрешности для каждого веса. Отлично!
Но есть еще одна проблема. Сейчас мы знаем, что делать с весами связей слое, который находится прямо перед выходным слоем сети. А что если наша нейросеть имеет больше 2 слоев? Что делать с весами связей в слоях, которые находятся за предпоследним слоем сети?
1.12 Обратное распространение ошибки на множество слоев
На диаграмме ниже изображена простая трехслойная нейросеть с входным, скрытым и выходным слоями.

Сейчас мы наблюдаем процесс, который обсуждался в разделе выше. Мы используем погрешность выходного слоя для настройки весов связей, которые соединяют предпоследний слой с выходным слоем.
Для простоты обозначения были обобщены. Погрешности нейронов выходного слоя мы в целом назвали \( e_{\text{out}} \), а все веса связей между скрытым и выходным слоем обозначили за \( w_{\text{ho}} \).
Еще раз повторю, что для корректировки весов \( w_{\text{ho}} \) мы распределяем погрешность нейрона выходного слоя по всем весам в зависимости от их вклада в выход нейрона.
Как видно из диаграммы ниже, для корректировки весов связей между входным и скрытым слоем нам надо повторить ту же операцию еще раз. Мы берем погрешности нейронов скрытого слоя \( e_{\text{hi}} \) и распределяем их по весам связей между входным и скрытым слоем \( w_{\text{ih}} \):

Если бы у нас было бы больше слоев, то мы бы и дальше повторяли этот процесс корректировки, распространяющийся от выходного ко входному слою. И снова вы видите, почему этот способ называется методом обратного распространения ошибки.
Для корректировки связей между предпоследним и выходным слоем мы использовали погрешность выходов сети \( e_{\text{out}} \). А чему же равна погрешность выходов нейронов скрытых слоев \( e_{\text{hi}} \)? Это отличный вопрос потому что сходу на этот вопрос ответить трудно. Когда сигнал распространяется по сети от входного к выходному слою мы точно знаем значения выходных нейронов скрытых слоев. Мы получали эти значения с помощью функции активации, у которой в качестве аргумента использовалась сумма взвешенных сигналов, поступивших на вход нейрона. Но как из выходного значения нейрона скрытого слоя получить его погрешность?
У нас нет никаких ожидаемых или заранее подготовленных правильных ответов для выходов нейронов скрытого слоя. У нас есть готовые правильные ответы только для выходов нейронов выходного слоя. Эти выходы мы сравниваем с заранее правильными ответами из обучающей выборки и получаем погрешность. Давайте вновь проанализируем диаграмму выше.
Мы видим, что из первого нейрона скрытого слоя выходят две связи с двумя нейронами выходного слоя. В предыдущем разделе мы научились распределять погрешность на веса связей. Поэтому мы можем получить две погрешности для обоих весов этих связей, сложить их и получить общую погрешность данного нейрона скрытого слоя. Наглядная демонстрация:

Уже из рисунка можно понять, что делать дальше. Но давайте все-таки еще раз пройдемся по всему алгоритму. Нам нужно получить погрешность выхода нейрона скрытого слоя для того, чтобы скорректировать веса связей между текущим и предыдущим слоями. Назовем эту погрешность \( e_{\text{hi}} \). Но мы не можем получить значение погрешности напрямую. Погрешность равна разности между ожидаемым и полученным значениями, но проблема заключается в том, что у нас есть ожидаемые значения только для нейронов выходного слоя нейросети.
В невозможности прямого нахождения погрешности нейронов скрытого слоя и заключается основная сложность.
Но выход есть. Мы умеем распределять погрешность нейронов выходного слоя по весам связей. Значит на каждый вес связи идет часть погрешности. Поэтому мы складываем части погрешностей, которые относятся к весам связей, исходящих из данного скрытого нейрона. Полученная сумма и будем считать за погрешность выхода данного нейрона. На диаграмме выше часть погрешности \( e_{\text{out 1}} \) идет на вес \( w_{1,1} \), а часть погрешности \( e_{\text{out 2}} \) идет на вес \( w_{1,2} \). Оба этих веса относятся к связям, исходящим из первого нейрона скрытого слоя. А значит мы можем найти его погрешность:
\[ e_{\text{hi 1}} = \text{сумма частей погрешностей для весов } w_{1,1} \text{ и } w_{1,2} \]
\[ e_{\text{hi 1}} = \left(e_{\text{out 1}}\cdot\frac{w_{1,1}}{w_{1,1} + w_{2,1}}\right) + \left(e_{\text{out 2}}\cdot\frac{w_{1,2}}{w_{1,2} + w_{2,2}}\right) \]
Рассмотрим алгоритм на реальной трехслойной нейросети с двумя нейронами в каждом слое:

Давайте отследим обратное распространение одной ошибки/погрешности. Погрешность второго выходного нейрона равна \( 0.5 \) и она распределяется на два веса. На вес \( w_{12} \) идет погрешность \( 0.1 \), а на вес \( w_{22} \) идет погрешность \( 0.4 \). Дальше у нас идет второй нейрон скрытого слоя. От него отходят две связи с весами \( w_{21} \) и \( w_{22} \). На эти веса связей также распределяется погрешность как от \( e_1 \), так и от \( e_2 \). На вес \( w_{21} \) идет погрешность \( 0.9 \), а на вес \( w_{22} \) идет погрешность \( 0.4 \). Сумма этих погрешностей и дает нам погрешность выхода второго нейрона скрытого слоя: \( 0.4 + 0.9 = 1.3 \).
Но это еще не конец. Теперь надо распределить погрешность нейронов выходного слоя на веса связей между входным и скрытым слоями. Проиллюстрируем этот процесс дальнейшего распространения ошибки:

Ключевые моменты
- Обучение нейросетей заключается в корректировки весов связей. Корректировка зависит от погрешности — разности между ожидаемым ответом из обучающей выборки и реально полученным результатами.
- Погрешность для нейронов выходного слоя рассчитывается как разница между желаемым и полученным результатами.
- Однако, погрешность скрытых нейронов определить напрямую нельзя. Одно из популярных решений — сначала необходимо распределить известную погрешность на все веса связей, а затем сложить те части погрешностей, которые относятся к связям, исходящим из одного нейрона. Сумма этих частей погрешностей и будет являться общей погрешностью этого нейрона.
1.13 Обратное распространение ошибки и произведение матриц
А можно ли использовать матрицы для упрощения всех этих трудных вычислений? Они ведь помогли нам ранее, когда мы рассчитывали проход сигнала по сети от входного к выходному слою.
Если бы мы могли выразить обратное распространение ошибки через произведение матриц, то все наши вычисления разом бы уменьшились, а компьютер бы сделал всю грязную и повторяющуюся работу за нас.
Начинаем мы с самого конца нейросети — с матрицы погрешностей ее выходов. В примере выше у нас имеется две погрешности сети: \( e_1 \) и \( e_2 \).
\[ \mathbf{E}_{\text{out}} = \left(\begin{matrix}e_1 \\ e_2\end{matrix}\right) \]
Теперь нам надо получить матрицу погрешностей выходов нейронов скрытого слоя. Звучит довольно жутко, поэтому давайте действовать по шагам. Из предыдущего раздела вы помните, что погрешность нейрона скрытого слоя высчитывается как сумма частей погрешностей весов связей, исходящих из этого нейрона.
Сначала рассматриваем первый нейрон скрытого слоя. Как было показано в предыдущем разделе, погрешность этого нейрона высчитывается так:
\[ e_{\text{hi 1}} = \left(e_1\cdot\frac{w_{11}}{w_{11} + w_{21}}\right) + \left(e_2\cdot\frac{w_{12}}{w_{12} + w_{22}}\right) \]
Погрешность второго нейрона скрытого слоя высчитывается так:
\[ e_{\text{hi 2}} = \left(e_1\cdot\frac{w_{21}}{w_{11} + w_{21}}\right) + \left(e_2\cdot\frac{w_{22}}{w_{12} + w_{22}}\right) \]
Получаем матрицу погрешностей скрытого слоя:
\[ \mathbf{E}_{\text{hid}} = \left(\begin{matrix}e_{\text{hid 1}} \\ e_{\text{hid 2}}\end{matrix}\right) = \left(\begin{matrix} e_1\cdot\dfrac{w_{11}}{w_{11} + w_{21}} \hspace{5pt} + \hspace{5pt} e_2\cdot\dfrac{w_{12}}{w_{12} + w_{22}} \\ e_1\cdot\dfrac{w_{21}}{w_{11} + w_{21}} \hspace{5pt} + \hspace{5pt} e_2\cdot\dfrac{w_{22}}{w_{12} + w_{22}} \end{matrix}\right) \]
Многие из вас уже заметили произведение матриц:
\[ \mathbf{E}_{\text{hid}} = \left(\begin{matrix} \dfrac{w_{11}}{w_{11} + w_{21}} & \dfrac{w_{12}}{w_{12} + w_{22}} \\ \dfrac{w_{21}}{w_{11} + w_{21}} & \dfrac{w_{22}}{w_{12} + w_{22}} \end{matrix}\right)\times \left(\begin{matrix} e_1 \\ e_2 \end{matrix}\right) \]
Таким образом, мы смогли выразить вычисление матрицы погрешностей нейронов выходного слоя через произведение матриц. Однако выражение выше получилось немного сложнее, чем мне хотелось бы.
В формуле выше мы используем большую и неудобную матрицу, в которой делим каждый вес связи на сумму весов, приходящих в данный нейрон. Мы самостоятельно сконструировали эту матрицу.
Было бы очень удобно записать произведение из уже имеющихся матриц. А имеются у нас только матрицы весов связей, входных сигналов и погрешностей выходного слоя.
К сожалению, формулу выше никак нельзя записать в мега-простом виде, который мы получили для прохода сигнала в предыдущих разделах. Вся проблема заключается в жутких дробях, с которыми трудно что-то поделать.
Но нам очень нужно получить простую формулу для удобного и быстрого расчета матрицы погрешностей.
Пора немного пошалить!
Вновь обратим взор на формулу выше. Можно заметить, что самым главным является умножение погрешности выходного нейрона \( e_n \) на вес связи \( w_{ij} \), которая к этому выходному нейрону подсоединена. Чем больше вес, тем большую погрешность получит нейрон скрытого слоя. Эту важную деталь мы сохраняем. А вот знаменатели дробей служат лишь нормализующим фактором. Если их убрать, то мы лишимся масштабирования ошибки на предыдущие слои, что не так уж и страшно. Таким образом, мы можем избавиться от знаменателей:
\[ e_1\cdot \frac{w_{11}}{w_{11} + w_{21}} \hspace{5pt} \longrightarrow \hspace{5pt} e_1 \cdot w_{11} \]
Запишем теперь формулу для получения матрицы погрешностей, но без знаменателей в левой матрице:
\[ \mathbf{E}_{\text{hid}} = \left(\begin{matrix} w_{11} & w_{12} \\ w_{21} & w_{22} \end{matrix}\right)\times \left(\begin{matrix} e_1 \\ e_2 \end{matrix}\right) \]
Так гораздо лучше!
В разделе по использованию матриц при расчетах прохода сигнала по сети мы использовали следующую матрицу весов:
\[ \left(\begin{matrix} w_{11} & w_{21} \\ w_{12} & w_{22} \end{matrix}\right) \]
Сейчас, для расчета матрицы погрешностей мы используем такую матрицу:
\[ \left(\begin{matrix} w_{11} & w_{12} \\ w_{21} & w_{22} \end{matrix}\right) \]
Можно заметить, что во второй матрице элементы как бы отражены относительно диагонали матрицы, идущей от левого верхнего до правого нижнего края матрицы: \( w_{21} \) и \( w_{12} \) поменялись местами. Такая операция над матрицами существует и называется она \textbf{транспонированием} матрицы. Ранее мы использовали матрицу весов \( \mathbf{W} \). Транспонированные матрицы имеют специальный значок справа сверху: \( ^\intercal \). В расчете матрицы погрешностей мы используем транспонированную матрицу весов: \( \mathbf{W}^\intercal \).
Вот два примера для иллюстрации транспонирования матриц. Заметьте, что данную операцию можно выполнять даже для матриц, в которых число столбцов и строк различно.
\[ \left(\begin{matrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{matrix}\right)^\intercal = \left(\begin{matrix} 1 & 4 & 7 \\ 2 & 5 & 8 \\ 3 & 6 & 9 \end{matrix}\right) \]
\[ \left(\begin{matrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{matrix}\right)^\intercal = \left(\begin{matrix} 1 & 4 \\ 2 & 5 \\ 3 & 6 \end{matrix}\right) \]
Мы получили то, что хотели — простую формулу для расчета матрицы погрешностей нейронов скрытого слоя:
\[ \mathbf{E}_{\text{hid}} = \mathbf{W}^\intercal \times \mathbf{E}_{\text{out}} \]
Это все конечно отлично, но правильно ли мы поступили, просто проигнорировав знаменатели? Да.
Дело в том, что сеть обучается не мгновенно, а проходит через множество шагов обучения. Таким образом она постепенно калибрует и корректирует собственные веса до приемлемого значения. Поэтому способ, с помощью которого мы находим погрешность не так важен. Я уже упоминал ранее, что мы могли бы разделить всю погрешность просто пополам между всеми весами, вносящими вклад в выход нейрона и даже тогда, по окончанию обучения, сеть выдавала бы неплохие результаты.
Безусловно, игнорирование знаменателей повлияет на процесс обучения сети, но рано или поздно, через сотни и тысячи шагов обучения, она дойдет до правильных результатов что со знаменателями, что без них.
Убрав знаменатели, мы сохранили общую суть обратного распространения ошибки — чем больше вес, тем больше его надо скорректировать. Мы просто убрали смягчающий фактор.
Ключевые моменты
- Обратное распространение ошибки может быть выражено через произведение матриц.
- Это позволяет нам удобно и эффективно производить расчеты вне зависимости от размеров нейросети.
- Получается что и прямой проход сигнала по нейросети и обратно распространение ошибки можно выразить через матрицы с помощью очень похожих формул.
Сделайте перерыв. Вы его заслужили. Следующие несколько разделов будут финальными и очень крутыми. Но их надо проходить на свежую голову.
Анализ ошибок в нейронных сетях
Перевод
Ссылка на автора
Анализ ошибок — это анализ ошибок. Хе хе! Ты не должен говорить мне это. На самом деле весь анализ ошибок столь же интуитивен. Но люди склонны упускать некоторые моменты в реальных проектах. Мы можем рассматривать это как своего рода переподготовку, которую можно проверить — когда разочарование заставляет нас забыть основы.
С такими богатыми библиотеками, как Pytorch и Tensorflow, большинство алгоритмов машинного обучения теперь доступны прямо из коробки — просто создайте экземпляр объекта и обучите его имеющимся данным. Вы готовы к работе!
Это может работать для тривиальных задач учебника, таких как Чтение цифр MNIST, Мы можем просто поиграть с несколькими конфигурациями и вскоре получить почти 100% точность. Но жизнь не так проста. Все становится все сложнее, когда мы пытаемся работать над «реальными» проблемами.

Разработка модели нейронной сети — это гораздо больше, чем просто создание экземпляра объекта Python. Что мне делать, если я понимаю, что моя модель не так точна, как хотелось бы? Должен ли я добавить слои? Должен ли я обрезать модель? Должен ли я изменить некоторые гиперпараметры? Это где анализ ошибок приходит.
Что такое анализ ошибок
Формально, анализ ошибок относится к процессу изучения примеров наборов разработчика, которые ваш алгоритм неверно классифицировал, чтобы мы могли понять основные причины ошибок. Это может помочь нам определить, какая проблема заслуживает внимания и насколько. Это дает нам направление для обработки ошибок.
Анализ ошибок — это не просто окончательная операция по спасению. Это должно быть частью основного развития. Как правило, мы начинаем с небольшой модели, которая должна иметь низкую точность (высокую погрешность). Затем мы можем приступить к оценке этой модели и проанализировать ошибки. Анализируя и исправляя такие ошибки, мы можем расти вместе с моделью.
Распространенные источники ошибок
Мы можем столкнуться с несколькими источниками ошибок. У каждой модели будут свои уникальные ошибки. И нам нужно смотреть на них индивидуально. Но типичные причины:
Неправильно маркированные данные
Большая часть маркировки данных восходит к людям. Мы можем извлекать данные из сети или опросов или из других источников. Основные материалы поступили от людей. И люди подвержены ошибкам. Таким образом, мы должны признать тот факт, что все наши данные по train / dev / test имеют ошибочные записи. Если наша модель хорошо построена и обучена должным образом, то она должна быть в состоянии преодолеть такие ошибки.
Размытая линия разграничения
Алгоритмы классификации работают хорошо, когда положительное и отрицательное четко разделены. Например, если мы пытаемся классифицировать изображения муравья и человека; демаркация довольно хорошая, и это должно помочь ускорить процесс обучения.
Но если мы хотим провести различие между мужской и женской фотографиями, это не так просто. Мы очень хорошо знаем крайности. Но демаркация не так ясна. Такая классификация естественно подвержена ошибкам. В таком случае мы должны работать над лучшим обучением вблизи этой туманной линии разграничения — возможно, предоставляя больше данных, которые находятся рядом с этой линией.
Переоснащение или занижение размера
Давайте рассмотрим тривиальный пример, чтобы понять концепцию. Предположим, мы работаем над классификатором изображений, чтобы различать ворону и попугая. Помимо размера, клюва, хвоста, крыльев … очевидным отличием является цвет. Но возможно как-то модель не узнает эту разницу. Таким образом, классифицирует маленькую ворону как попугая.
Это означает, что модели не удалось узнать измерение на основе доступных данных. Когда мы замечаем это, мы должны попытаться собрать больше данных, которые могут научить сеть классифицировать по цвету больше, чем другие параметры.
Точно так же возможно, что модель соответствует определенному измерению. Предположим, что в классификаторе Cat / Dog мы отмечаем в записях ошибок, что многие темные собаки были классифицированы как кошки, а светлые кошки были классифицированы как собаки. Это означает, что данные обучения не имели достаточного количества записей, которые могли бы обучить модель против такой неправильной классификации.
Многие другие
Это всего лишь несколько видов источников ошибок. Их может быть гораздо больше, которые можно обнаружить, проанализировав набор ошибок. Давайте не будем «переусердствовать» в нашем понимании, чтобы ограничить наш анализ этими типами ошибок.
Каждый анализ ошибок покажет нам новый набор источников проблем. Но правильный подход состоит в том, чтобы выявить любую склонность к недостаточному или избыточному подгонке — в целом или к определенной функции или набору функций или вокруг определенных значений некоторых входных функций.
Набор для глазных яблок
Теперь мы знаем, что в нашей модели есть ошибки и может быть несколько источников ошибок. Но как определить, какой? У нас есть миллионы записей в обучающем наборе и, по крайней мере, несколько тысяч в наборе разработчиков. Тестового набора пока не видно.
Мы не можем оценить каждую запись в тренировочном наборе. Мы также не можем оценить каждую запись в наборе разработчиков Чтобы определить тип ошибок, которые генерирует наша модель, мы разделили набор dev на две части — набор eyeball и blackbox set.
Набор глазного яблока — это набор образцов, который мы на самом деле оцениваем. Мы можем проверить эти записи вручную, чтобы угадать источник ошибок. Поэтому набор глазных яблок должен быть достаточно маленьким, чтобы мы могли работать вручную, и достаточно большим, чтобы получить статистическое представление всего набора разработчиков.
Анализируя ошибки в наборе глазного яблока, мы можем определить различные источники ошибок и вклад каждого из них. Получив эту информацию, мы можем начать работать с основными источниками ошибок. Как только мы сделаем соответствующие исправления, мы сможем продолжить поиск источников ошибок.
Обратите внимание, что анализ должен быть основан только на наборе глазного яблока. Если мы используем весь набор dev для этого анализа, мы в конечном итоге перегоним набор dev. Но если набор разработчиков недостаточно велик, мы должны использовать его целиком. В таком случае, мы просто должны отметить, что у нас есть высокий риск переоснащения набора разработчиков — и планировать остальное соответственно. (Возможно, мы можем использовать вращающийся набор разработчиков — где мы выбираем новый набор разработчиков из тренировочного набора при каждой попытке.)
Предвзятость и дисперсия
Работая над анализом ошибок, мы определяем определенный параметр или область проблем; или мы замечаем, что ошибка довольно равномерная. Как мы пойдем отсюда? Я получу больше данных? Это может звучать логично. Но не всегда так. Дополнительные данные не всегда могут помочь — после определенного момента любые другие данные могут быть просто избыточными. Нужна ли мне более богатая модель? Простое обогащение модели может значительно улучшить цифры — путем переоснащения. Это тоже не правильно! Итак, как мы решаем направление?
Предвзятость и дисперсия дают нам хорошее представление об этом. Проще говоря, если ошибка высока в обучающем наборе, а также в наборе разработчиков, то мы имеем высокий уклон. Хотя, если тренировочный набор хороший, а набор плохой, у нас высокая дисперсия. Смещение по существу подразумевает, что вывод плох для всех данных. Дисперсия подразумевает, что вывод хорош для некоторых данных и плох для остальных.
Если у нас есть модель с точностью 60% на тренировочном наборе. Естественно, мы называем это большим уклоном. С такой точностью мы можем даже не захотеть проверять набор разработчиков. Но, если ошибка обучающего набора намного лучше, чем наша цель, оставляя разработчик позади, мы можем назвать это высокой дисперсией. Это связано с тем, что поведение модели сильно зависит от доступных данных.
Можно интуитивно сказать, что если у нас высокий уклон, это означает, что мы недостаточно приспособлены. Это может быть связано с тем, что конкретная функция не обрабатывается должным образом или сама модель недостаточно богата. Исходя из этого, мы можем обновить решение для повышения производительности — путем улучшения конкретной функции или самой модели.
С другой стороны, высокая дисперсия означает, что мы недостаточно тренируемся. Нам нужно больше данных или нам нужно намного лучше обрабатывать имеющиеся данные. С этим мы могли бы тренировать лучшую модель.
Уменьшение смещения
Модель машинного обучения может учиться только на основе имеющихся данных. Некоторые ошибки неизбежны во входных данных. Это не человеческие ошибки, а истинные ограничения людей, которые классифицируют или тестируют модель. Например, если я не могу различить пару идентичных близнецов, я никак не могу сгенерировать помеченные данные и научить машину это делать!
Такое ограничение называется неизбежным смещением. Остальное можно избежать, и мы должны сосредоточиться на этом. Таким образом, когда мы выполняем анализ ошибок, когда мы пытаемся определить основную причину ошибки, мы должны учитывать смещение, которого можно избежать, а не смещение в целом.
Если наш анализ ошибок говорит нам, что смещение, которое можно избежать, является основным источником ошибок, мы можем попробовать некоторые из следующих шагов
Увеличить размер модели
Высокий уклон означает, что модель не может выучить все, что она может извлечь из доступных ей данных. Это происходит, когда модель недостаточно способна к обучению. Если модель имеет только два параметра, она не может узнать больше, чем могут содержать эти два параметра. Кроме того, любые новые данные обучения будут перезаписывать то, что они узнали из предыдущих записей. Модель должна иметь достаточно параметров для изучения — только тогда она может содержать информацию, необходимую для выполнения требуемой работы.
Следовательно, первичное решение высокого уклона состоит в создании более богатой модели.
Разрешить больше возможностей
Одним из основных шагов в нашей очистке данных является сокращение всех избыточных функций. На самом деле, ни одна функция не является избыточной. Но некоторые менее значимы, чем другие. А сокращение возможностей по существу отбрасывает такие функции с меньшей ценностью — таким образом, отбрасывая некоторую информацию с низким значением.
Это хорошо для начала. Но когда мы замечаем, что функции, которыми мы располагаем, не способны передавать требуемую информацию, мы должны переделать этап сокращения функций и позволить пройти еще некоторым функциям. Это может сделать модель богаче и дать ей больше информации для изучения
Уменьшить регуляризацию модели
Все методы регуляризации по существу держат параметры модели ближе к нулю. То есть он не позволяет каждому параметру «учиться слишком много». Это хорошая техника для обеспечения сбалансированности модели. Но когда мы понимаем, что модель не в состоянии учиться достаточно, мы должны уменьшить уровни регуляризации, чтобы каждый узел в сети мог учиться на основе данных, доступных для обучения.
Избегайте локального минимума
Локальный минимум является еще одним распространенным источником высокого уклона. У нас может быть богатая модель и хороший объем данных. Но если градиентный спуск застрянет на локальном минимуме, смещение не уменьшится. Существуют различные способы избежать локального минимума — случайные запуски (обучайте его снова и снова с разными начальными значениями. Поскольку каждый выбирает разностный путь, локальный минимум избегается). Или мы можем добавить импульс к градиентному спуску — это может снова предотвратить неглубокий минимум вдоль спуска.
Лучшая сетевая архитектура
Простое увеличение нейронов и слоев не обязательно улучшает модель. Использование соответствующей сетевой архитектуры может гарантировать, что новые слои действительно добавят ценность.
Исследователи сталкивались и работали над этими проблемами в прошлом и предоставили нам хорошие модели архитектуры, которые могут быть использованы для лучшего компромисса между смещением и дисперсией — например, AlexNet, RESNET, GoogleNet а также многое другое, Приспособление к такой архитектуре может помочь нам избежать многих наших проблем.
Уменьшение дисперсии
Если анализ ошибок указывает на то, что основной причиной ошибки является высокая дисперсия, мы можем использовать один из этих методов, чтобы уменьшить это.
Добавить больше данных обучения
Это основное решение. Дисперсия возникает, когда у нас недостаточно данных, чтобы обучить сеть наилучшей производительности. Таким образом, основной целью действий должно быть поиск дополнительных данных. Но это имеет свои пределы, так как данные не всегда доступны.
Добавить регуляризацию
Регуляризация L1 или L2 — это проверенные методы, позволяющие уменьшить проблему переоснащения и, таким образом, избежать высокой дисперсии По сути, они держат каждый параметр ближе к 0. Это означает, что ни один параметр не может учиться слишком много. Если один параметр содержит много информации, модель становится несбалансированной и приводит к переобучению и высокой дисперсии.
Методы регуляризации L1 и L2 помогают предотвратить такие проблемы. Регуляризация L1 быстрее и вычислительно проще. Он генерирует разреженные модели. Естественно, L2 намного точнее, поскольку имеет дело с более мелкими деталями.
Ранняя остановка
По мере того, как мы обучаем модель с использованием доступных данных обучения, каждая итерация делает модель немного лучше для доступных данных. Но чрезмерное количество итераций этого может привести к переобучению. Для этого нужно найти золотую середину. Лучший способ — это остановиться рано, а не осознавать, что мы уже перешли границы.
Уменьшить Особенности
Чем меньше функций, тем легче модель и, следовательно, меньше возможностей для переоснащения. У нас есть несколько алгоритмов выбора функций, таких как PCA, которые могут помочь нам определить минимальный и ортогональный набор функций, который может обеспечить более простой способ обучения моделей.
Знание предметной области также может помочь нам сократить количество функций. Мы также можем использовать результаты анализа ошибок, чтобы определить, как следует изменить набор функций, чтобы повысить производительность.
Уменьшить размер модели
Высокая дисперсия или переоснащение обычно означает, что у нас слишком много параметров для обучения. Если у нас недостаточно данных для обучения каждого из этих параметров, случайность значений инициализации остается в параметрах, что приводит к неверным результатам.
Уменьшение размера модели напрямую влияет на это.
Используйте разреженную модель
Иногда мы знаем, что размер модели является обязательным, и уменьшение размера приведет только к снижению функциональности. В таком случае мы можем рассмотреть возможность обучения разреженной модели. Это дает хорошее сочетание лучшей модели с меньшей дисперсией.
Модельная архитектура
Подобно уменьшению смещения, дисперсия также определяется архитектурой модели. Исследователи предоставили нам хорошие модели архитектуры, которые могут быть использованы для лучшего компромисса между смещением и дисперсией. Приспособление к такой архитектуре может помочь нам избежать многих наших проблем.
Резюме
Мы видели, что может быть много причин для ошибки в модели, которую мы обучаем. Каждая модель будет иметь уникальный набор ошибок и источников ошибок. Но, если мы будем придерживаться формального подхода к этому анализу, мы сможем не изобретать велосипед каждый раз.