16. Подсистема ввода данных.
Функции системы ввода заключаются в
записи (кодировании) данных в память
компьютера.
Данные— это пространственные объекты
реального мира, которые можно разделить
на легко идентифицируемые 4 типа: точки,
линии, области, поверхности. На этапе
сбора и первичной обработки геоданных
в ГИС обеспечиваютсясоздание моделей
пространственных данных. Затраты
на информационное обеспечение
геоинформационных проектов достигают
90 % от их общей стоимости.Требования
к подсистеме: 1). Должна быть
спроектирована для переноса графических
и атрибутивных данных в компьютере; 2).
Должна отвечать хотя бы одному из двух
фундаментальных методов представления
графических объектов – растровому или
векторному; 3). Должна напрямую связываться
с подсистемой хранения данных, чтобы
можно было устранить ошибки ввода и
вносить изм-я по мере необходимости.
Источники пространственных данных:
готовые цифровые модели простр-х
дан., аэрокосм материалы, рез-ты съемок,
статистические, литер. источники,
бумажные карты. Чтобы их ввести, нужно
преобразовать формат данных из др.
систем в формат АркГИС, преобр-ть бумаж.
инф-ю в цифровую. Преобр. форм. яв-ся
средством обмена дан. с др. сист. и
позволяет ГИС исп-ть данные, получаемые
в др. технологиях. Пеобр-е осущ-ся с
помощ. спец. прогр. –конвертеров.
Загрузка пространственных данных
осуществляется с помощью ArcCatalog.
Ввод табличных данных (dbf,xls,txtи др.):
1.Добав. табл. к карте. 2.Создать слой
СОБЫТИЯ («Отобразить данные ХУ», если
в табл. есть коорд.). Этот слой сущ-т
виртуально. Если в добавляемой табл.
нет координат, то ее мож. привязать к
уже существующему слою с координатами.
3.Экспорт вирт. слоя События в формат
простран. данных (теперь слой не
виртуальный).
Аналого-цифровое преобразованиеданных – преобр-е данных из бумажной
формы в цифровую с помощ. дигитайзеров
(каж. объект представ-ся в виде наб. коор.
в век. форме) и сканеров (резул.: растровое
изобр. ).
Векторизация– преобразование
растрового изобр-я в векторную форму с
сохранением геометрических связей
растровых аналогов при максимальной
информативности векторного образа.
Основные операции: выделение объектов;
их идентификация; присвоение истинных
координат. Большинство ГИС позволяют
осуществлять векторизацию в графических
редакторах в ручном режиме. Специальные
программы – векторизаторы (R2V, EasyTrace и
др.) осуществляют векторизацию в ручном,
автоматическом и полуавтоматическом
режимах.Векторизация в ArcGIS
осущ-ся с помощ. инструмента СКЕТЧ –
отмечаю объекты на растре. Скетч сохр.
наборы точек в вирт. памяти, пока я сам
не экспортирую. Оцифр. дан. сохр-ся в
коор. например листа карты, т.е. не
привязаны к пов-ти З. Поэт. обяз-но надо
делать пространств-ю привязку с помощ.
трансформации.
17.Ошибки ввода данных и их устранение.
1. Графические ошибки: пропуск
объекта, неправильное положение объекта
и неправильный порядок объектов;2.
Ошибки атрибутов:опечатки, неверные
названия или неверные коды объектов;3.Ошибки согласования графики и
атрибутов: правильно набранные
коды связываются с неправильными
графическими объектами.
1. Графические ошибки векторных
систем:а) Псевдоузлы. Ошибка:
Псевдоузел, в котором соединяются только
две дуги. Исключение: Псевдоузел
изолированного полигона; Псевдоузел,
разделяющий линейный объект на основе
атрибута (например, когда заканчивается
асфальт и начинается грунтовая дорога);
б) Висячие узлы.Ошибки:
1).незамкнутый полигон; 2). «недолет»
(недоведение линии до пересечения);
3). «перелет». Исключения:1).истоки
рек; 2). тупиковые улицы.
в) Ошибки полигонов: 1). Неверные
метки полигонов (метка отсутствует, две
метки в одном полигоне);
2). Осколочные полигоны (возникают при
состыковке двух полигонов, которые не
совсем совпали по границе; незанятое
пространство между ними и создает
осколочные полигоны).
Ошибки векторизации: 1). Потеря
контроля за процессом оцифровки (разрывы
линий, подергивания, образование петель
и пересечений); 2). Образование висячих
узлов; 3). Несовпадение позиционной
точности (плавная кривая становится
ломанной линией).
Ошибки электронных карт: (Первые
семь явл-ся логическими ошибками).
1).Недотягивание объектов до рамки карты;
2).Отсутствие границ у площадных объектов;
3).Оконтуривание полигоном внемасштабных
условных знаков; 4).Подписи части объектов,
зрительно воспринимаемых как единые
(река); 5).Присвоение локализованной
характеристики всему объекту (ширина
реки, скорость течения, породный состав
леса и т.п.); 6).Неоднородность в атрибуте
(абсолютное значение и диапазон в
численности населения); 7).Неверные
надписи объектов; 8).Отсутствие согласования
между слоями карты (кварталы не вписываются
в контуры города; мост «посажен» на
реку, но не согласован с дорогой и т.д.);
9).Ошибки в интерпретации условных знаков
(прерывание автомагистрали, проходящей
через населенный пункт, условным знаком
улицы; оконтуривание полигоном отдельно
стоящих условных знаков – в редко
населенных районах отдельно стоящие
избы оконтуриваются как единый населенный
пункт); 10).Прерывание объекта в месте
подписи или другого условного знака
(напр., ж/д может быть разорвана мостом,
который храниться в другом тематическом
слое; в месте надписи горизонтали
разываются; 11).Отсутствие согласования
объектов на стыке листов.
Как поступать с ошибками?:
1). Игнорировать– это не мешает
использовать данные; 2).Обозначить
ошибку как исключениеиз правила; 3).Исправить ошибку предполагаемыми
методами: а).ошибки нельзя удалить:
только исправить или отнести к исключению;
б). контроль за ошибками можно встроить
в процесс работы: кто и когда контролирует.
17.Типы ошибок ввода данных:графические (пропуск объекта, неправильное
пространствен. полож. объекта), ош.
атрибутов (опечатки, перепутанные
названия), ош. согласов. граф объекта и
его атрибутов (правильно набранные
атрибуты согласуются не с теми объектами
которым принадлежат).
Графические ошибки: псевдоузлы,
висящие узлы, ошибки полигонов (неверные
метки и осколочные полигоны), дерганья
мышью и др. Граф. ош. выяв-ся на ст. ввода
и м.б. выявлены и устранены с помощ.
задания топологии. Ош. атриб. и ош.
согласования графики и атрибутов
обнар-ся позднее на стад. анал. данных.
Класс Топология – кл. базы геоданных,
включает: 1.Перечень классов простран-х
данных, участв-х в тополог. отношениях;
2.Топологические параметры (кластерный
допуск, ранги и правила); 3.Слой простран-х
объектов, к-й содерж измененные обл-ти,
ошибки и исключения.
Кластерный допуск– это минимальное
расстояние меж. 2 вершинами, к-е мож.
рассм-ть как самостоятельные. Т.е. если
раст-е меньше допуска, то они совмещ-ся
в один объект после проверки топологии.
Все кл. объектов дел-ся на ранги
координатной точности(1-50).При проверке
топологии, будут исправляться объекты
меньшего ранга.
Правила топологииустан-т допустимые
простран. отноршения между объектами
и контролируют отношения: между
пространственными объектами внутри
одного класса объектов; между объектами
разных классов; или между подтипами
пространственных объектов (напр. раст-ть
и озеро НЕ ДОЛЖ ПЕРЕСЕК-СЯ (вычесть,
слить, объединить); точки адресов Д.Б.
ПОЛНОСТЬЮ ВНУТРИ (удалить, подвинуть)).
Проверка и исправление ошибок в ArcMap
осуществляется с помощью панели
«Топология». АркГИС находит ош., я выбираю
правила исправления. Ош., не входящ. в
мои правила, отображ-ся на карте и
высвечив-ся в табл. ошибок, я должен
принять меры. Ош нельзя удалить, можно:
игнорировать (так и останутся, карту
мож. строить дальше), обознач. ош. как
исключения (исток реки – висячий объект),
исправить (удлин./укорот. объект).
Результаты проверки топологии: измененные
области, ошибки и исключения – записываются
в специальные вспомогательные
топологические слои и хранятся в классе
Топология. При редактировании объектов
создается измененная область, чтобы
ограничить территорию, в пределах
которой необходимо провести вновь
проверку топологии.
Требования к подсистеме ввода данных:
-
Должна
иметь инструменты для переноса
графических и атрибутивных данных в
компьютер (сканер, дигитайзер и др.). -
Должна
работать хотя бы с одним из типов моделей
простран. данных – растровым или
векторным. -
Должна
иметь связь с подсистемой хранения и
редактирования, чтобы можно было
устранять ошибки и вносить изменения
по мере необходимости.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
1. Понятие Географической Информационной Системы. Подсистемы ГИС.
Геоинформационные системы это инструменты для обработки пространственной информации, обычно явно привязанной к некоторой части земной поверхности и используемые для управления ею. Географическая информационная система (ГИС) — это система для управления географической информацией, ее анализа и отображения.
ГИС представляет собой набор подсистем, ее образующих. В соответствии с этим определением, ГИС имеют следующие подсистемы:
1.Подсистема сбора данных, которая собирает и проводит предварительную обработку данных из различных источников. Эта подсистема также в основном отвечает за преобразования различных типов пространственных данных (например, от изолиний топографической карты к модели рельефа ГИС).
2.Подсистема хранения и выборки данных, организующая пространственные данные с целью их выборки, обновления и редактирования.
3.Подсистема анализа данных, которая выполняет различные задачи на основе этих данных, группирует и разделяет их, устанавливает параметры и ограничения и выполняет моделирующие функции.
4.Подсистема вывода, которая отображает всю базу данных или часть ее в табличной, диаграммной или картографической форме.
2.Современные компьютерные ГИС и традиционные бумажные карты: сходство и различие.
Карты в ГИС во многом схожи со статичными бумажными картами, но к тому же они интерактивны, то есть вы можете взаимодействовать с ними. Интерактивную карту можно уменьшать и увеличивать, причем при определенных масштабах некоторые слои на карте могут появляться или исчезать. Вы можете применять условные знаки для отображения слоев карты на основе любого выбранного набора атрибутов. При указании географического объекта на интерактивной карте можно получить о нем дополнительную информацию, строить пространственные запросы и проводить анализ. Кроме того, многие пользователи ГИС посредством интерактивных карт проводят редактирование данных и создают пространственные представления объектов. Типичным примером некартографического представления являются распечатки таблиц, гистограмм или графиков, анимация объектов. Кроме картографического или графического вывода, современные системы обладают и альтернативными формами вывода.
3. Пространственные элементы.
Пространственные объекты можно разделить на легко идентифицируемые четыре типа: точки, линии, области и поверхности. Точечные объекты – это такие объекты, каждый из которых расположен только в одной точке пространства. В целях моделирования считают, что у таких объектов нет пространственной протяженности, длины или ширины, но каждый из них может быть обозначен координатами своего местоположения. Линейные объекты представляются как одномерные в нашем координатном пространстве. Несмотря на их неосязаемость, их можно, тем не менее, представлять как определенно пространственные объекты, поскольку они разделяют две области географического пространства. Для линейных объектов, в отличие от точечных, мы можем указать пространственный размер простым определением их длины. Объекты, имеющие и длину и ширину, называются областями или площадными объектами или полигонами. При определении местоположения области в пространстве мы обнаруживаем, что ее граница является линией, которая начинается и кончается в одной и той же точке. Для полигонов мы может определить периметр и площадь. Добавление нового измерения, высоты, к площадным объектам позволяет нам наблюдать и фиксировать поверхности. Работая с поверхностями, мы можем определить объем материала в выбранной области пространства, а также периметр и площадь этой области.
4. Шкалы измерений атрибутов.
Шкалы измерения данных — устоявшаяся основа для измерения практически всех видов данных, в том числе и географических. На первом уровне находится номинальная шкала, из названия которой следует, что объекты различаются по именам. Если мы хотим провести более тонкое сравнение объектов, нам следует выбрать более высокую шкалу измерений, например, порядковую. Порядковые шкалы позволяют сравнивать объекты на качественном уровне (больше-меньше, светлее -темнее, лучше – хуже) с произвольным числом градаций. Если мы хотим быть более точными в наших измерениях, нам нужно воспользоваться интервальной шкалой измерения или шкалой отношений, в которых измеряемым величинам приписываются численные значения. В результате перехода от шкалы Цельсия к шкале Кельвина мы оказались на последней и наиболее «количественной» шкале измерений — шкале отношений. Преобразовав температуры в абсолютную шкалу, мы смогли получить осмысленное отношение величин, поскольку мы действовали теперь на шкале отношений.
5. Карта-модель пространственных явлений.
Карта — модель, представляющая реальность. Карта является моделью пространственных явлений, абстракцией. Она не является миниатюрной версией реальности, предназначенной показать все детали изучаемой области. Мы строим карту необходимую для решения конкретной задачи. Детальность карты не может быть высока из-за того, что очень много объектов должны быть размещены на маленьком куске бумаги. Более того, существуют специальные картографические приемы, которые допускают некоторое искажение в изображении действительности. чтобы отображение всех важных для нас объектов на карте было читаемым, в координаты некоторых вносят заведомую ошибку (сдвиг). Главной причиной нашей переоценки возможностей карт в отображении реальности является то, что они — наиболее удачные графические инструменты, созданных для передачи пространственной информации.
6.Картографические проекции. Семейства проекций.
Они предназначены для изображения с приемлемой точностью сферической Земли на плоском носителе. Для проведения измерений сферические координаты приспособлены плохо. Проекция – преобразование трехмерной поверхности в плоское изображение, выполняемое по математическим законам. В зависимости от того, какие пространственные характеристики при проектировании остаются без искажения, различают равноугольные (или — 8-конформные), равновеликие, равнопромежуточные (эквидистантные) проекции и проекции истинных направлений. Равноугольные проекции сохраняют без искажений малые локальные формы. Равновеликие проекции сохраняют площадь изображаемых объектов. Вследствие этого другие свойства: форма, углы, масштаб — искажаются. Карты с равнопромежуточными проекциями сохраняют расстояния между определенными точками. Проекции истинного направления, или азимутальные проекции, используются для сохранения некоторых кривых, описывающих большие окружности, и придают правильные азимутальные направления всем точкам на карте относительно центра. Некоторые проекции этого типа являются также равноугольными, равновеликими или равнопромежуточными.
7. Масштабный коэффициент.
Масштабный коэффициент- безразмерная величина, применяемая для центральной точки или линии проекции. Масштабный коэффициент, называемый также относительным масштабом, определяется как отношение местного масштаба на карте к главному масштабу. По определению масштабный коэффициент на промежуточном сфероиде равен 1. Когда же мы переходим от его сферической поверхности к двумерной карте местный масштаб не будет равен главному, поскольку плоская и сферическая поверхности не совместимы. Следовательно, масштабный коэффициент в общем случае не равен 1 и будет различным в разных частях карты. Чем больше масштабный коэффициент отличен от 1, тем сильнее искажения на карте.
8. Виды искажений, возникающих при проецировании.
Проекции – не абсолютно точные представления географического пространства. Каждая создает свой набор типов и величин искажений на карте. Бывают искажения формы (или углов), площади, расстояния и направления. Для представления различных частей земной поверхности используют разные разновидности картографических проекций. Ни одна из картографических проекций не может сохранять большие территории без искажения формы. Смбилет6
9. Картографические системы координат.
Система координат картографической проекции во многих случаях является прямоугольной. По традиции горизонтальную координату называют Х , вертикальную — Y. Так как обычно, карты ориентированы севером вверх, X – координата называется отсчетом на восток, Y- координата – отсчетом на север. Различают угловые и линейные параметры проекций: Угловые параметры Центральный меридиан — Определяет начало координат по оси x. Широта начала координат— Определяет начало координат по оси x. Стандартная параллель 1 и стандартна параллель 2— для конических проекций.Широта и долгота точек касания и др.Линейные параметры Сдвиг по оси x —линейное значение, применяемое для определения начала координат по оси x. Сдвиг по оси y —линейное значение, применяемое для определения начала координат по оси y. Масштабный коэффициент безразмерная величина, применяемая для центральной точки или линии проекции.
10. UTM.
Наиболее широко распространенной в ГИС системой проекций и координат является Универсальная Поперечная проекция Меркатора (UTM), в России аналогом этой системы является система проекция Гаусса-Крюгера. Эта проекция является поперечно цилиндрической, зональной. UTM делит земную поверхность на 60 пронумерованных зон шириной по 6 градусов долготы, каждая из которых проходит от 80—го градуса южной широты, до 84-го градуса северной широты. Чтобы все координаты были положительными в UTM есть два начала координат – на экваторе (для северного полушария), другое- на 80 -й параллели ю.ш. (для южного полушария). Зоны пронумерованы, начиная от 180- градусного меридиана в восточном направлении. Каждая зона UTM имеет свой центральный меридиан, относительно которого она охватывает 3 градуса к западу и 3 градуса к востоку. Меридианы и параллели представляют собой кривые линии, за исключением осевого (центрального меридиана) меридиана. Как было указано выше, каждая зона представляет особую координатную систему. Система координат прямоугольная. Начало координат каждой зоны находится в точке пересечения экватора с осевым меридианом зоны. Каждая зона имеет свое начало координат. Осевой меридиан и экватор принимают за координатные оси: осевой меридиан за ось абсцисс, а экватор за ось ординат. Единица измерения – метр.
11. Проекция Гаусса-Крюгера, система координат 1942 г.
Наиболее широко распространенной в ГИС системой проекций и координат является Универсальная Поперечная проекция Меркатора (UTM), в России аналогом этой системы является система проекция Гаусса-Крюгера. Эта проекция является поперечно цилиндрической, зональной. UTM делит земную поверхность на 60 пронумерованных зон шириной по 6 градусов долготы, каждая из которых проходит от 80—го градуса южной широты, до 84-го градуса северной широты. Чтобы все координаты были положительными в UTM есть два начала координат – на экваторе (для северного полушария), другое- на 80 -й параллели ю.ш. (для южного полушария). Зоны пронумерованы, начиная от 180- градусного меридиана в восточном направлении. Следующим этапом вляется задание системы геодезических координат на поверхности эллипсоида. В качестве координат используются криволинейные координаты, известные как широта и долгота. Хотя начало координат определяется как точка на пересечении экватора и Гринвичского меридиана, в действительности для задания отсчета координат используется косвенный метод, когда для некоторой точки на реальной поверхности Земли (так называемого начального пункта) фиксируются значения широты и долготы, производится совмещение нормали к поверхности референц-эллипсоида и отвесной линии в данной точке, а плоскость меридиана исходного пункта устанавливается параллельно оси вращения Земли. Эти исходные данные, называемые также геодезическими датами (datum), жестко фиксируют систему геодезических координат относительно тела Земли. Для эллипсоида Красовского такая точка задана в Пулково (центр круглого зала обсерватории), и этим задается основа Системы координат 1942 г. (СК-42).
12. Основные структуры компьютерных файлов. Внешний индекс.
1.Неупорядоченные файлы. Простейшей структурой файла является неупорядоченный массив записей. Вы помещаете записи в файл в последовательности их появления. Единственным преимуществом такой структуры файла является то, что для добавления новой записи нужно просто поместить ее в конец файла, позади всех других записей. Последовательно упорядоченные файлы. Этот метод использует сравнение каждой новой записи с имеющимися для определения того, где ее место. Такие последовательно упорядоченные файлы могут использовать буквы алфавита или числа, которые тоже имеют определенную последовательность. Обычной стратегией поиска здесь является так называемый поиск делением пополам (или дихотомия). 2.Каждому объекту может быть приписано большое количество атрибутов, но мы физически не можем отсортировать записи в файле одновременно более чем одним способом. Решение этой проблемы— внешний индекс. Найдя нужные записи в индексном файле, мы получим адреса записей исходного файла, по которым можем получить все атрибуты объектов. Таким образом, для поиска в основном файле используется дополнительный индексный файл, который называется внешним индексом, а сам исходный файл, таким образом, становиться индексированным. Индекс обычно хранится на том же устройстве, что и сам файл, и состоит из списка элементов, каждый из которых содержит идентификатор записи, за которым следует указание о местоположении данной записи. Для поиска записи вначале происходит обращение к индексу, где находится указатель на нужную запись.
13. Реляционная СУБД.
Они свободны от всех ограничений, присущих иерархическим и сетевым структурам. Эти модели имеют табличную структуру: строки таблицы (записи) соответствуют одной записи сведений об объекте, а столбцы таблицы (поля) — содержат однотипные характеристики всех объектов. Способы индексации данных существенно сокращают время поиска и запроса к данным. Реляционные системы ценны тем, что позволяют нам собирать данные в достаточно простые таблицы, при этом задачи организации данных также просты. Используя механизм реляционных баз данных, вы можете быстро сочетать данные, хранящиеся в отдельных таблицах. Этот связующий механизм называется реляционным соединением. Любое количество таблиц может быть «связано». Вы можете скомбинировать две таблицы по общему полю. Общие поля дифференцируются терминами первичный ключ и внешний ключ. Первичный ключ — это ключевое поле в таблице данных. Внешний ключ является общим полем в другой таблице. Соединение происходит по равенству значений записей первичного ключа одной таблицы с записями внешнего ключа второй таблицы. Записи с одинаковыми значениями полей первичного и внешнего ключей называются совпадающими.
14. Растровая модель пространственных данных. Ее преимущества и недостатки.
Растровая модель данных использует разбиение пространства на множество элементов, каждый из которых представляет малую, но вполне определенную часть земной поверхности.Растровый набор данных состоит из ячеек. Каждая ячейка, или пиксель, — это квадрат, представляющий определенную часть территории. Все ячейки растра должны быть одного размера. Ячейки организованы в виде строк и столбцов, составляя двумерную матрицу. Для каждой ячейки существует уникальный адрес, состоящий из номера строки и номера столбца. Все точки исследуемой области покрываются ячейками растра. Значения ячеек могут быть как целые, так и с плавающей запятой. Целочисленные значения удобны для представления значений дискретных данных, а значения с плавающей запятой — для представления непрерывных поверхностей. Зоны. Любые две или более ячейки с одинаковым значением принадлежат к одной зоне. Регионы. Каждая группа соединенных ячеек в зоне называется регионом. Зона, состоящая из одной группы соединенных ячеек, включает один регион. Преимущества. 1. Несмотря на то, что все объекты представлены набором точек (пикселов), на растрах они хорошо распознаются. Вы всегда узнаете своего друга даже на очень плохой фотографии.2. Растровая структура данных организована точно также как и данные дистанционного зондирования (ДДЗ), что обеспечивает легкий перенос и использование спутниковых изображений в ГИС.3. Прямоугольная сетка данных легко привязывается к прямоугольной системе координат (системе координат проекций). 4. Многие функции, особенно связанные с операциями с поверхностями и наложением (overlay), легко выполняются на этом типе структур данных. Недостатки. Среди главных недостатков растровой структуры данных – уже упоминавшаяся проблема низкой пространственной точности, которая уменьшает достоверность измерения площадей и расстояний. Другой недостаток — необходимость большого объема памяти, обусловленная тем, что каждая ячейка растра хранится как отдельная числовая величина. Последняя проблема сегодня не так серьезна, как прежде, благодаря огромному росту емкости внешних запоминающих устройств компьютеров. Кроме того, в настоящее время существуют развитые методы сжатия растровых данных, позволяющие значительно сокращать объем растров без существенной потери их качества.
15. Векторная модель пространственных данных. Ее преимущества и недостатки.
Векторная модель данных основана на векторах (направленных отрезках прямых). Базовым примитивом является точка, а основными базовыми элементами являются дуга (arc) и узел (node). Векторные линейные объекты создаются путем соединения точек прямыми линиями или дугами. Для того, чтобы определить дугу нужно указать, по меньшей мере, 2 точки — начальную и конечную — для описания местоположения линейного объекта в пространстве. Если линия является кривой или ломаной, то необходимы дополнительные точки – формообразующие (вертексы). Векторный метод позволяет задавать точные пространственные координаты явным образом. Это достигается приписыванием точкам пары координат (Х и Y), линиям – связной последовательности пар координат их вершин, областям – замкнутой последовательности соединенных линий, начальная и конечная точки которой совпадают. Векторная структура данных показывает только геометрию картографических объектов. Чтобы придать ей полезность карты, геометрию необходимо связать с атрибутивной информацией. В векторном представлении используется совсем другой подход: в явном виде хранятся графические примитивы без атрибутов, а атрибуты векторных объектов хранятся в специальных таблицах и связываются с графическими элементами с помощью служебных идентификаторов. Идентификаторы в большинстве случаев недоступны для пользователей и являются одними из наиболее важных, можно сказать, ключевых элементов в различных форматах пространственных данных.
16. Нетопологические модели векторных данных.
Простейшей векторной структурой данных является спагетти-модель [Dangermond, 1982], которая, по сути, переводит «один в один» графическое изображение бумажной карты. Если представить себе каждый графический объект нашей бумажной карты кусочком (одним или несколькими) макарон, то вы получите достаточно точное изображение того, как эта модель работает. Каждый кусочек действует как один примитив: очень короткие — для точек, более длинные — для отрезков прямых, наборы отрезков, соединенных концами, — для границ областей. Каждый примитив — одна логическая запись в компьютере, записанная как строки переменной длины пар координат (X,Y). В этой модели соседние области должны иметь разные цепочки спагетти для общих сторон. То есть, не существует областей, для которых какая-либо цепочка спагетти была бы общей. Каждая сторона каждой области имеет свой уникальный набор линий и пар координат. Пространственные отношения между объектами и все отношения между всеми объектами должны вычисляться независимо. Результатом отсутствия такого явного описания отношений между объектами является огромная дополнительная вычислительная нагрузка, которая затрудняет измерения и анализ. Но так как спагетти-модель очень сильно напоминает бумажную карту, она является эффективным методом картографического отображения и все еще часто используется в компьютеризованной картографии, где анализ не является главной целью. Нетопологическая модель данных хранит каждый примитив.
17. Топологические модели векторных данных.
В отличие от спагетти-модели, топологические модели [Dangermond, 1982], как это следует из названия, содержат топологическую информацию в явном виде. Топологическая информация описывается набором узлов и дуг. Узел (node) — больше, чем просто точка, обычно это пересечение двух или более дуг, и его номер используется для ссылки на любую дугу, которой он принадлежит. Каждая дуга (аrс) начинается и заканчивается либо в точке пересечения с другой дугой, либо в узле, не принадлежащем другим дугам. Топология представляет математическую процедуру, которая определяет пространственные свойства и взаимосвязи, включающие: связность и длины дуг, направление дуг, смежность и площади полигонов. Линейно-узловая топология (дуга-узел) выражает пространственные взаимосвязи между дугами и узлами: она определяет длину, направление, связность. Географический анализ опирается на эти свойства. Полигонально-линейная топология представляет пространственные взаимосвязи между дугами и полигонами, которые ограничиваются дугами; она определяет площадь и соседство. Топологическая модель обеспечивает эффективное хранение данных и возможность дальнейшего географического анализа. Топологическая модель данных объединяет решения некоторых из наиболее часто используемых в географическом анализе функций. Они способны выявить и исправить графические ошибки при вводе и редактировании данных.
18. Устройства ввода пространственной информации.
Для ручного ввода пространственных данных стандартом является дигитайзер (digitizer). Дигитайзер — устройство для преобразования готовых (бумажных) изображений в цифровую форму. Дигитайзеры создают векторные типы данных. Механизм регистрации позволяет получить шаг считывания информации намного меньше шага сетки (до 100 линий на мм). Этот шаг называется разрешением (resolution) дигитайзера. Автоматизированные дигитайзеры, или дигитайзеры с отслеживанием линий, имеют устройство, подобное головке оптического считывания проигрывателя компакт-дисков. Сканер представляет собой устройство для преобразования бумажных изображений в цифровую форму. Сканеры создают растровые типы данных. Сканеры делятся на планшетные, роликовые (с протяжкой листа) и барабанные. Планшетные сканеры представляют собой прозрачное стекло, на которое кладется оригинал, и под которым перемещается лампа и устройство оптического считывания. Сканеры с протяжкой листа действуют подобно факсовому аппарату и позволяют сканировать очень длинные оригиналы. В барабанных сканерах оригинал закрепляется на круглом барабане, вдоль которого перемещается головка считывания. Эти устройства могут обеспечить высокую точность сканирования очень больших оригиналов.
19. Типы ошибок.
Ошибки разделяют на три типа. Первый относится главным образом к векторным системам и называется графической ошибкой. Такие ошибки встречаются трех видов: пропуск объекта, неправильное положение объекта (ошибка положения) и неправильный порядок объектов. Второй тип ошибок — это ошибки атрибутов. Они встречаются и в векторных, и в растровых системах с одинаковой частотой. Чаще всего они являются опечатками, а огромный объем работы, требующийся для больших БД, часто оказывается главным источником ошибок. В векторных системах ошибки атрибутов включают использование неправильного кода для атрибута, ошибки записи одинаковых по произношению, но разных по написанию слов, и т.д. Третий тип ошибок — ошибки согласования графики и атрибутов, которые случаются и в векторных, и в растровых системах, когда правильно набранные коды атрибутов связываются с неправильными графическими объектами.
20. Графические ошибки в векторных системах.
Первая распространенная ошибка –псевдоузел. Псевдоузлом называют узел, в котором линия соединяется сама с собой или когда в узле соединяются только две линии. Псевдоузел является ошибкой, когда мы не трактуем линию как две самостоятельные дуги. Бывают ситуации, когда создание псевдоузла необходимо. Другая обычная ошибка, называемая висящим узлом, может быть определена как узел на ни с чем не соединенном конце линии. Возможны три вида ошибок, создающих висящие узлы: незамыкание границы полигона; «недолет», т.е. неприсоединение дуги к объекту, к которому она должна быть присоединена; «перелет», при заходе дуги за объект, к которому она должна быть присоединена. При оцифровке полигонов вы должны указывать метку — точку внутри каждого из них, которая служит для связи с атрибутами и выбора места отображения текстовой информации об этом полигоне. В связи с этим возможны ошибки двух типов: отсутствующие метки и лишние метки. И те, и другие чаще всего обязаны потере контроля в процессе оцифровки. Другой тип ошибок чаще всего встречается, когда программа использует векторную модель, в которой каждый полигон имеет свою отдельную границу. В таких случаях вы должны оцифровывать общие линии границ полигонов более одного раза. Среди ошибок цифрования наиболее распространены: 1 Несоблюдение позиционной точности («съезд» с растра) 2 Пропуски объектов 3 Висящие узлы 4 Разрывы, передергивания, петли и самопересечения линий.
21. Точечные объекты высокого уровня.
Существует два основных типа точечных объектов высокого уровня: центроиды и узлы. Узел – это особая точка, в которой соединяются 2 или более дуг. Узел — один из основных элементов топологических моделей векторных данных. Центроид (centroid) обычно определяется как точка, находящаяся в точном географическом центре области или полигона. Географические центроиды в векторном случае вычисляются по правилу четырехугольников (trapezoidal rule), которое делит многоугольник на некоторое число перекрывающихся четырехугольников. Затем вычисляются центроиды, или центральные координаты, каждого четырехугольника, затем — их взвешенное среднее. Каноническим для ГИС центроидом является центр эллипса, наиболее близкого по форме к контуру полигона. Центроид выполняет функцию точечного объекта, к которому при известных обстоятельствах можно отнести данные полигона.
22. Линейные объекты высокого уровня.
Два типа линий особенно важны и оправдывают свое название объектов высокого уровня: границы и сети. Линии называются границами, если при их пересечении происходит существенное изменение одного или многих атрибутов местности. Линии могут также становиться объектами высокого уровня, когда они связаны друг с другом некоторыми отношениями. В таких случаях это не просто изображения линейных объектов или границ между полигонами, а особые структуры, которые вместе с узлами образуют сети (networks). Сети могут быть определены как набор соединенных линейных объектов, вдоль которых возможно движение от одного узла к другому. Сети состоят из двух основных компонентов: ребер и соединений.
23. Площадные объекты высокого уровня.
Полигоны высокого уровня называются регионами. Регионы создаются на основе атрибутов: в один регион объединяются полигоны с одинаковым значением какого-либо атрибута. Имеются три основных вида регионов: сплошные, фрагментированные и перфорированные. Сплошной регион образуется из смежных полигонов. Фрагментированный регион составлен из двух или более полигональных фигур, разделенных пространством, которое не относится к этому региону. Перфорированный регион, в отличие от фрагментированного, не состоит из отдельных полигонов, а исключает их. То есть, такой регион представляет собой связную область, из которой исключены некоторые внутренние полигоны, называемые отверстиями или островами. Если полигоны, содержащиеся внутри перфорированного региона, имеют общие между собой атрибуты, то они могут образовывать фрагментированный регион.
24. Измерение длин линейных объектов и периметров.
Измерения длин линейных объектов различно при использовании растровых и векторных моделей данных. Определение длины вертикальных или горизонтальных линий в растре проводится подсчетом числа ячеек, через которые линия проходит, и умножением его на линейный размер одной ячейки (разрешение) растра. Но если линия ориентирована не точно по горизонтали или вертикали, метод будет неточным. В зависимости от разрешения растра и извилистости линии, вполне возможно, что целые петли могут быть представлены лишь одной ячейкой растра; в таком случае длина будет преуменьшена независимо от метода ее определения. В векторной системе для каждого прямого отрезка из образующих линию система хранит координаты крайних точек, из которых может быть получена по теореме Пифагора длина этого отрезка. Просто сложив длины всех отрезков линии, мы получим точное значение ее общей длины. Измерение периметра полигонов производится таким же образом, что и измерение длин линий.
25. Определение площадей.
Вычисление площадей для растрового и векторного способов представления данных также различно. В растре площадь подсчитывается простым умножением площади ячейки (а это есть разрешение в квадрате) на количество ячеек, занимаемых областью. Для векторного представления данных наиболее простое решение состоит в делении сложного полигона на несколько простых фигур, площади которых легко определяются по формулам, после чего эти числа суммируются. Во многих векторных ГИС площади полигонов подсчитываются при их вводе и заносятся в таблицы атрибутов, так что в дальнейшем определение площади требует только выборки соответствующего значения из БД.
26. Измерение извилистости.
Существуют две простые меры извилистости, которые могут использоваться для характеристики линий. Первая- это отношение суммарной длины отрезков, составляющих линию, к расстоянию между ее крайними точками. Чем ближе это значение к единице, тем менее извилиста линия, для прямой линии это отношение составляет ровно единицу. Извилистость = L/L0. Вторая – радиус кривизны, который представляет собой радиус вписанной окружности в изгиб линейного объекта. Если объект представлен полигоном, то появляется возможность измерить еще и отношение радиуса к ширине объекта, которое дает еще одну полезную характеристику формы.
27. Меры формы полигонов.
Существует несколько подходов для измерения формы полигона. Одни из них основаны на изучение пространственной целостности полигонов, другие используют меры выпуклости или отношение периметр/площадь, третьи изучают форму границ. Первый подход основан на идеи перфорированных и фрагментированных регионов и имеет общее название пространственной целостности. Наиболее распространенной мерой пространственной целостности является функция Эйлера. Функция Эйлера представляет численное выражение степени фрагментированности и перфорированности. На слайде изображены три возможные конфигурации полигонов. Функция Эйлера сопоставляет с каждой из них одно число, называемое числом Эйлера, которое определяется так:
E = H-(F- 1), где Е — число Эйлера, Н — суммарное количество отверстий во всех полигонах региона, F -количество полигонов во фрагментированном регионе. Отношение периметра к площади является наиболее сжатой характеристикой формы, мерой сложности полигона. Наименьшее такое отношение из всех фигур имеет круг, в то время как вытянутые узкие полигоны имеют большее значение этого отношения. CI=kP/S –индекс выпуклости, где P –периметр полигона, S –площадь полигона, k=1÷99. Приk=100 полигон имеет форму круга. Имеется еще одна мера конфигурации границ полигонов, называемая развитостью границ. Для расчета этой меры используется оконная функция. Возьмем окно разм
Слайд 1ГЕОФИЗИЧЕСКИЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ

Слайд 2Функциональные возможности ГИС

Слайд 3Структура ГИС
ГЕОИНФОРМАЦИОННАЯ СИСТЕМА
Подсистема сбора данных
Подсистема хранения и
выборки данных
Подсистема анализа
данных
Подсистема вывода данных

Слайд 5 Источники пространственных данных
цифровые модели пространственных данных;
аэрокосмические материалы;
данные специально проводимых полевых исследований и съемок (геофизических, геологических, геохимических и т.д.);
статистические;
литературные (текстовые) источники;
бумажные карты:
общегеографические;
тематические.

Слайд 6 Подсистема сбора данных осуществляет
ввод и предварительную обработку данных из различных источников. Эта подсистема также в основном отвечает за преобразования различных типов пространственных данных (например, от изолиний топографической карты к модели рельефа ГИС).
На этапе сбора и первичной обработки данных в ГИС обеспечивается создание моделей пространственных данных.
Затраты на информационное обеспечение геоинформационных проектов достигают 90 % от их общей стоимости.

Слайд 7
Подсистема ввода данных обеспечивает:
преобразование
(конвертацию) форматов пространственных данных;
аналого-цифровое преобразование данных.
Операции преобразования форматов является средством обмена данными с другими системами и позволяет ГИС использовать данные, получаемые в других технологиях.
Преобразование форматов осуществляется с помощью специальных программ – конвертеров.
 форматов пространственных")
Слайд 8 ArcGIS позволяет использовать при работе таблицы различных форматов [.DBF], [.XLS], [.TXT]
и др.
Ввод табличных данных
1. Загрузка таблиц
![ArcGIS позволяет использовать при работе таблицы различных форматов [.DBF], [.XLS], [.TXT] и др. Ввод табличных данных](https://thepresentation.ru/img/tmb/1/89357/a83828db3e0ec485e076137a2d036861-800x.jpg "Функциональные возможности ГИС ArcGIS позволяет использовать при работе таблицы различных форматов [.DBF], [.XLS], [.TXT]")
Слайд 103. Экспорт в формат пространственных данных

Слайд 113D дигитайзер
Устройства ввода: дигитайзеры
Планшетный дигитайзер
Графический планшет и перо
Аналого-цифровое преобразование данных

Слайд 12роликовые
(с протяжкой листа)
Устройства ввода: сканеры
планшетные
барабанные
 Устройства ввода: сканерыпланшетныебарабанные")
Слайд 13Создание новых данных
Сканирование данных:
На выходе – растр;
Пространственная привязка после сканирования.
Оцифровка
на планшетном дигитайзере:
Векторные данные;
Привязка во время или после оцифровки.

Слайд 14Трансформация
Опорная
точка
Трансформация — геометрическое преобразование координат.
Трансформация изменяет положение объектов
в двумерном координатном пространстве:
конвертирует данные из единиц дигитайзера или сканера в реальные координаты;
сдвигает данные в пределах координатной системы, например из футов в метры.

Слайд 15Преобразование координат
Дифференцированное масштабирование
Скос
Поворот
Перенос

Слайд 16Среднеквадратичная ошибка (RMS error)
Трансформированное местоположения могут не совпадать с опорными точками;
Среднеквадратичная
ошибка характеризует расхождение;
Просмотр ошибки в таблице связей, удаление связи со значительной ошибкой
Трансформированное местоположения могут не совпадать с опорными точками;Среднеквадратичная")
Слайд 17Инструменты векторной трансформации в ArcGIS
Векторная трансформация
1. Аффинное преобразование требует задания, как
минимум, 3 связи смещения. Позволяет дифференцированно масштабировать, задавать скос, поворачивать, переносить данные.
2. При преобразовании подобия данные масштабируются, поворачиваются и сдвигаются. Требует задания 2 и более связей смещения.
3. Проективное преобразование основано на принципах фотограмметрии и требует, по крайней мере, четырех связей смещения

Слайд 18 Метод резинового листа
Корректировка исходного слоя для совпадения с более точным
слоем;
объекты растягиваются, прямые линии сохраняются;
связи идентичности удерживают объекты на месте;
корректировка всех объектов только в указанной области.
Реализуется линейно-кусочная трасформация
Связи идентичности

Слайд 19 Подгонка границ
Корректировка объектов в соседних слоях;
инструмент Подгонки добавляет связь;
методы:
сглаженный или линейный;
дополнительные возможности:
сдвиг к центру связи,
использование атрибутов для определения подгонки.
Связи смещения
Сшивка листов карты

Слайд 20
Трансформация растровых данных
Растр сдвигается в новое местоположение по опорным точкам
Исходное изображение
Линейные
преобразования:
Скос по Х Скос по Y Поворот
Нелинейные преобразования
Связи смещения

Слайд 21Пространственная привязка в ArcGIS

Слайд 22 Задачей векторизации является
перевод пространственных данных из растрового формата в векторный.
Векторизация
Векторизация осуществляется с помощью цифрованию по растру на экране компьютера и включает следующие основные операции:
выделение объектов;
их идентификация;
позицирование (присвоение истинных координат).

Слайд 23
Большинство ГИС ( в том числе ArcGIS) позволяют осуществлять векторизацию в
графических редакторах в ручном режиме.
Специальные программы – векторизаторы (R2V, EasyTrace и др.) осуществляют векторизацию в ручном, автоматическом и полуавтоматическом режимах.
Программы векторизации
 позволяют осуществлять векторизацию в")
Слайд 24Программа – векторизатор Easy Trace Pro

Слайд 26Ошибки ввода данных и их устранение
Графические ошибки: пропуск объекта,
неправильное положение объекта и неправильный порядок объектов.
Ошибки атрибутов: опечатки, неверные названия или неверные коды объектов.
Ошибки согласования графики и атрибутов: правильно набранные коды атрибутов связываются с неправильными графическими объектами.

Слайд 27Графические ошибки векторных систем: псевдоузлы
Псевдоузел изолированного полигона
Ошибки
Исключения
Псевдоузел, разделяющий линейный
объект на основе атрибута
Асфальтовая дорога
Грунтовая дорога

Слайд 28Графические ошибки векторных систем:
висящие узлы

Слайд 29Графические ошибки векторных систем:
ошибки полигонов
Осколочные полигоны
Неверные метки полигонов

Слайд 30Ошибки векторизации
Несовпадение позиционной точности
Висящие узлы
Потеря контроля за процессом оцифровки

Слайд 31 Логические ошибки электронных карт
Недотягивание объектов до рамки карты.
Отсутствие границ у
площадных объектов.
Оконтуривание полигоном внемасштабных условных знаков.
Подписи части объектов, зрительно воспринимаемых как единые (река).
Присвоение локализованной характеристики всему объекту (ширина реки, скорость течения, породный состав леса и т.п.).
Неоднородность в атрибуте (абсолютное значение и диапазон в численности населения).
Неверные надписи объектов.

Слайд 32Ошибки электронных карт: отсутствие согласования между слоями карты
Болота не согласованы с
растительностью
Мост «посажен» на реку,
но не согласован с дорогой
Кварталы не вписываются в контур города

Слайд 33Ошибки электронных карт:
ошибки в интерпретации условных знаков
Прерывание автомагистрали, проходящей
через населенный пункт, условным знаком улицы

Слайд 34Ошибки в интерпретации условных знаков: оконтуривание полигоном отдельно стоящих условных знаков
В редко заселенных районах отдельно стоящие избы оконтуриваются как единый населенный пункт
На одних листах один и тот же условный знак снимается как полигон, на других — как точка

Слайд 35Ошибки электронных карт: прерывание объекта в месте подписи или другого условного
знака
Железная дорога оказалась разорванной мостом, который хранится в другом тематическом слое.
Красным отмечены изолинии, касающиеся или пересекающие другие горизонтали.
Горизонталь в месте надписи разорвана.
200

Слайд 36Ошибки электронных карт:
отсутствие согласования объектов на стыке листов
Объекты одного листа не стыкуются с рамкой и не стыкуются с объектами смежного листа
Не стыкованы линейные объекты

Слайд 37Устранение ошибок ввода данных
Графические ошибки выявляются, как правило, на стадии
ввода и могут быть выявлены и устранены с помощью задания топологии.
Ошибки атрибутов и согласования графики и атрибутов обнаруживаются позднее на стадии анализа данных.

Слайд 38 Подсистема ввода данных должна быть спроектирована для переноса графических и
атрибутивных данных в компьютер.
Подсистема ввода данных должна отвечать хотя бы одному из двух фундаментальных методов представления графических объектов — растровому или векторному.
Подсистема ввода данных должна иметь связь с подсистемой хранения и редактирования, чтобы можно было устранять ошибки и вносить изменения по мере необходимости.
Требования к подсистеме ввода данных:

Скачать материал

Скачать материал




- Сейчас обучается 424 человека из 64 регионов




Описание презентации по отдельным слайдам:
-

1 слайд
ЗАЩИТА ДАННЫХ ОТ ОШИБОК ВВОДА
-
2 слайд
ЗАЩИТА ДАННЫХ ОТ ОШИБОК ВВОДА
Число ошибок, которые нельзя обнаружить, бесконечно, в противовес
числу ошибок, которые можно обнаружить, — оно конечно по определению.
(А. Блох. Закон Мэрфи)
Ошибки ввода данных, как мины замедленного действия, опасны срабатыванием в самое неподходящее время с непредсказуемыми последствиями. В приложениях MS Office предусмотрены различные средства защиты от таких ошибок. В частности, весьма развиты профилактические средства автоматизации ввода, которые помимо стандартизации и ускорения ввода данных в той или иной мере способствуют обнаружению и предотвращению ошибок ввода. Это технологии шаблонов (включая использование списковых полей и флажков), сканирование и копирование однотипных данных, использование автозамены, автоформата, автотекста и масок ввода, подсказки (тексты по умолчанию, справки, сноски, примечания). Одни средства напоминают пользователю о допустимых форматах ввода данных, другие контролируют эти форматы (типы)22, третьи, не доверяя ручной ввод пользователю, заставляют его выбирать данные из заранее созданных списков или сами вводят данные с бумажных и машинных носителей и т.д. Существует также группа средств, основное назначение которых – выполнение непосредственных защитных функций, связанных с обнаружением и предотвращением ошибок ввода данных. -
3 слайд
Обнаружение ошибок ввода
Условное форматирование в Excel
Смысл условного форматирования в том, что на форму представления вводимых данных налагаются одно или больше условий, соответствующих правильным и/или ошибочным данным. В зависимости от выполнения этих условий формат данных (шрифт, цвет и др.) и, соответственно, их вид на экране монитора меняются. В результате пользователь может сразу после ввода или потом – при проверке данных – легко обнаружить ошибки. Условное форматирование реализовано в Excel и Access. В Excel условное форматирование начинается с выделения проверяемых ячеек ввода данных (переменная часть шаблона) и вызова команды
Формат/Условное форматирование. -
4 слайд
Условное форматирование в Excel
В появившемся окне (рис. 1) с помощью диалоговых средств, входящих в блок «Условие 1», вписываются
значения или формулы, регламентирующие
допустимые значения данных
Это, кстати, делают и стандартные форматы ячеек в Excel, типы полей данных в Access, типы текста в текстовых полях шаблонов Word.
В выделенном блоке ячеек, и с помощью кнопки Формат устанавливается формат отображения данных ячеек при выполнении регламентирующего
условия (рис. 1а). С помощью кнопки А также >> (рис. 1) можно сформировать «Условие 2» по той же технологии, что и «Условие 1», и, наконец, «Условие 3» – не более трех условий форматирования (рис. 1б).
Рис. 1. Первичное окно условного форматирования в Excel
1а) формирование -
5 слайд
Условное форматирование в Excel
1б) формирование трех условий
1в) условное форматирование после ввода правильных и ошибочных данных
Подготовка и реализация условного форматирования в Excel
Кнопка А также>> после третьего условия неактивна. -
6 слайд
Условное форматирование в Access
В Access условное форматирование полей производится при активизации формы (войти в форматируемое поле и выполнить команду Формат/Условное форматирование в статическом меню – рис. 46а) или в режиме конструктора формы (выделить форматируемое поле и выполнить команду Условное форматирование в динамическом меню). В отличие от Excel, в Access предусмотрены 1 – 3 условных формата при выполнении условий и один формат – при невыполнении условий. Кнопка Добавить (рис. 2) – аналог кнопки А также >> (см. рис. 1).2а) условное форматирование поля формы
-
7 слайд
Условное форматирование в Access
2б) вид формы при вводе правильных
2в) вид таблицыи ошибочных значений с ошибочными значениямиПри вводе данных в форму срабатывают условные форматы для правильных и ошибочных значений (рис. 2б), что должно привлекать внимание пользователя (по замыслу условного форматирования). Если пользователь не реагирует на ошибки ввода из-за невнимательности или незнания, Access без дополнительных мер не спасает таблицу от ошибочных данных (рис. 2в).
Но в Excel и Access есть более радикальные средства для защиты от ошибок ввода. Эти средства регламентируют допустимые значения вводимых данных, сообщают об ошибках ввода и не позволяют сохранять ошибочные данные. -
8 слайд
Обнаружение и предотвращение ошибок ввода
Текущий контроль данных в Excel включается по команде Данные/Проверка. Действие команды распространяется на выделенный блок ячеек (минимальный блок – одна ячейка, максимальный – вся таблица, реальный – поля (столбцы) базы данных). Поэтому прежде чем устанавливать параметры проверки, надо определиться с проверяемыми полями базы данных, имея при этом в виду, что могут быть поля как с одинаковыми, так и разными параметрами проверки. Затем надо выделить одно или несколько полей с одинаковыми параметрами и вызвать диалоговое окно проверки(рис. 3а).3а) вход в проверку, выбор типа данных
-
9 слайд
Обнаружение и предотвращение ошибок ввода
Вкладка Параметры позволяет установить тип контролируемых данных (рис. 3а) и условие проверки на значение, по списку или формуле (тип Другой) (рис. 3б, 3а). Здесь же принимается решение игнорировать пустые ячейки или считать их ошибочными, если пользователь активизировал (выделил) ячейку и не ввел в нее значение. Если решено игнорировать, соответствующий флажок следует установить, иначе – снять. На рис. 3а, 3б флажок снят – следовательно, пустые ячейки не игнорируются и считаются ошибочными (с соответствующей системной диагностикой).3б) установка условия на значения
-
10 слайд
Обнаружение и предотвращение ошибок ввода
Вкладки Сообщение для ввода и Сообщение об ошибке позволяют установить подсказку ввода (рис. 3в) и сообщение об ошибке (рис. 3г).Если выбран режим «Останов» (рис. 3г) при вводе данных возле каждой ячейки выделенного блока появляется подсказка, а возникновение ошибок вызывает соответствующую диагностику (рис. 4). Кнопка Отмена стирает ошибочное значение в ячейке, а кнопка Повторить позволяет возобновить ввод в ячейку. Таким образом, в ячейку можно ввести только допустимое значение (рис. 4а, 4б).
3в) установка подсказки ввода
3г) установка сообщения об ошибке -
11 слайд
Обнаружение и предотвращение ошибок ввода
В режимах Предупреждение и Сообщение ошибки не устраняются, а только обнаруживаются соответственно с сообщениями или предупреждениями, как в условном форматировании или справке. В режиме Предупреждение в диалоговом окне появляется вопрос Продолжить? Нажатие на кнопку Да позволяет оставить ошибочное значение в ячейке, а нажатие на кнопки Нет или Отмена стирает ошибочное значение, переводя курсор в другую ячейку или оставляя его в текущей (рис. 4в). В режиме Сообщение появляется только окно с сообщением об ошибке. Нажатие кнопки Да переводит курсор в другую ячейку, нажатие кнопки Отмена оставляет курсор в текущей ячейке. Но ошибочное значение все равно может остаться в ячейке (рис. 4г).4а) невыполнение условия на значение
4б) ячейка не содержит значения -
12 слайд
Обнаружение и предотвращение ошибок ввода
4в) предупреждение о вводе ошибочного значения
4г) сообщение о вводе ошибочного значения -
13 слайд
Обнаружение и предотвращение ошибок ввода
Текущий контроль данных в Access производится установкой Условия на значение в одноименном свойстве поля, защищаемого от ошибок ввода.В режиме конструктора таблицы формулируется выражение, регламентирующее допустимые значения данного поля (рис. 5а). Это выражение можно ввести вручную или, если оно слишком сложное, то с помощью Построителя выражений, который включается кнопкой рядом со свойством. Ниже в свойстве Сообщение об ошибке пользователь может ввести свою текстовую реакцию на ошибку ввода. После сохранения структуры таблицы при вводе ошибочных данных появляется пользовательское сообщение об ошибке (рис. 5б). При отсутствии пользовательского сообщения Access выдает системное сообщение (рис. 5в). Попытка сохранить запись с ошибочными данными категорически пресекается (рис. 5г).5а) свойства Условие на значение и Сообщение об ошибке
5б) пользовательское сообщение об ошибке -
14 слайд
Обнаружение и предотвращение ошибок ввода
5в) системное сообщение об ошибке
5г) системный отказ от сохранения ошибочной записи -
15 слайд
Обнаружение и предотвращение ошибок ввода
Рис. 6. Защита от ошибочной потери значения в обязательном поле (Access) -
16 слайд
Спасибо за внимание!


 с помощью диалогов...")
 формирование трех условий1в) условное форм...")

 вид формы при вводе правильных 2в) вид та...")




 предупреждение о вводе ошибочног...")

 системное сообщение об ошибке5г)...")


Найдите материал к любому уроку, указав свой предмет (категорию), класс, учебник и тему:
6 092 734 материала в базе
- Выберите категорию:
- Выберите учебник и тему
- Выберите класс:
-
Тип материала:
-
Все материалы
-
Статьи
-
Научные работы
-
Видеоуроки
-
Презентации
-
Конспекты
-
Тесты
-
Рабочие программы
-
Другие методич. материалы
-
Найти материалы
Другие материалы
- 27.12.2020
- 3309
- 1
- 27.12.2020
- 4659
- 2
- 27.12.2020
- 4878
- 11
- 27.12.2020
- 5660
- 13
- 27.12.2020
- 4954
- 8
- 27.12.2020
- 4016
- 1
- 27.12.2020
- 3842
- 0
- 27.12.2020
- 3885
- 1
Вам будут интересны эти курсы:
-
Курс повышения квалификации «Основы управления проектами в условиях реализации ФГОС»
-
Курс профессиональной переподготовки «Экскурсоведение: основы организации экскурсионной деятельности»
-
Курс повышения квалификации «Экономика и право: налоги и налогообложение»
-
Курс повышения квалификации «Организация практики студентов в соответствии с требованиями ФГОС педагогических направлений подготовки»
-
Курс повышения квалификации «Организация практики студентов в соответствии с требованиями ФГОС юридических направлений подготовки»
-
Курс профессиональной переподготовки «Логистика: теория и методика преподавания в образовательной организации»
-
Курс повышения квалификации «Маркетинг в организации как средство привлечения новых клиентов»
-
Курс повышения квалификации «Источники финансов»
-
Курс профессиональной переподготовки «Организация технической поддержки клиентов при установке и эксплуатации информационно-коммуникационных систем»
-
Курс повышения квалификации «Мировая экономика и международные экономические отношения»
-
Курс профессиональной переподготовки «Управление информационной средой на основе инноваций»
-
Курс профессиональной переподготовки «Политология: взаимодействие с органами государственной власти и управления, негосударственными и международными организациями»
-
Курс профессиональной переподготовки «Техническая диагностика и контроль технического состояния автотранспортных средств»
-
Курс повышения квалификации «Международные валютно-кредитные отношения»
Автозамена как средство предотвращения ошибок при вводе
Автозамена как средство предотвращения ошибок при вводе
В данном разделе мы рассмотрим механизм автозамены, использование которого позволяет избежать случайных ошибок, возникающих при вводе тех либо иных данных (текстовых, в формате даты и др.). Его смысл заключается в том, что ошибочно введенные данные Excel 2007 будет автоматически исправлять сразу после нажатия клавиш «пробел» или Enter.
Для перехода в режим настройки автозамены войдите в режим настройки Excel 2007 и в разделе Правописание нажмите кнопку Параметры автозамены. В результате откроется окно (рис. 3.12), в котором можно настроить параметры автозамены. Все основные параметры находятся на вкладке Автозамена.
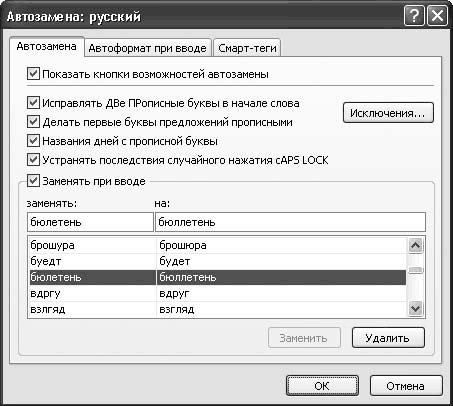
Рис. 3.12. Настройка параметров автозамены
Если установлен флажок Исправлять ДВе ПРописные буквы в начале слова, то при вводе слов с двумя прописными буквами вторая буква слова автоматически будет преобразована в строчную.
Если установлен флажок Делать первые буквы предложений прописными, то после каждой точки следующее слово будет начинаться с прописной буквы.
При установленном флажке Названия дней с прописной буквы первая буква в названии дней недели будет автоматически преобразовываться в прописную.
Устранять последствия случайного нажатия Caps Lock – установку данного флажка используют для автоматического изменения ошибок, связанных со случайным включением режима Caps Lock. Например, если введено слово рОССИЯ, то оно автоматически будет преобразовано в слово Россия.
Вы сами можете создать перечень возможных ошибок и указать вариант устранения каждой из них. Например, если пользователю в процессе работы часто приходится набирать слово «аккумулятор», и он часто ошибается, вводя его как «акумулятор», то можно в список автозамены включить ошибочное написание этого слова и вариант его исправления. Подобные настройки выполняют в нижней части вкладки, и в первую очередь для этого нужно установить флажок Заменять при вводе (при снятом флажке механизм автоматической замены в соответствии с пользовательским списком будет отключен).
Чтобы добавить в список новую позицию, введите в поле заменять слово либо иное значение (число, дату и др.) в том виде, который является ошибочным и который должен быть автоматически исправлен после ввода, а в поле на – вариант исправления этого значения. Например, в поле заменять можно ввести слово «акумулятор», а в поле на – «аккумулятор». Для добавления в список введенной позиции нажмите кнопку Добавить, которая расположена справа под списком.
Чтобы удалить из списка ненужную позицию, выделите ее щелчком кнопкой мыши и нажмите кнопку Удалить. Помните, что Excel 2007 не выдает дополнительный запрос на подтверждение операции удаления, поэтому будьте внимательны.
Однако в процессе работы могут возникать ситуации, когда не нужно, например, исправлять две прописные буквы в слове либо после точки писать слово с большой буквы. Для таких случаев механизм автозамены предусматривает введение списка исключений. Чтобы перейти в режим работы с этим списком, на вкладке Автозамена нажмите кнопку Исключения. В результате откроется окно, которое включает в себя две вкладки: Первая буква и ДВе ПРописные (рис. 3.13).
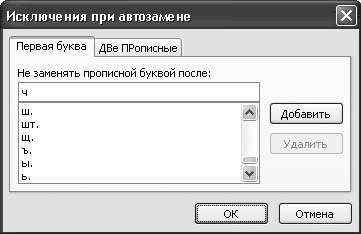
Рис. 3.13. Формирование перечня исключений
МУЛЬТИМЕДИЙНЫЙ КУРС
По умолчанию пользовательский список уже включает в себя немалое количество возможных ошибок и вариантов их исправления, но при необходимости в этот список можно и добавлять новые данные, и удалять введенные ранее.
Вкладка Первая буква предназначена для формирования и ведения перечня исключений при исправлении первой буквы слова на прописную в начале предложения (после точки). Чтобы добавить новое исключение, введите слово либо его фрагмент (поставив после него точку) в поле Не заменять прописной буквой после и нажмите кнопку Добавить. Самые характерные примеры подобных исключений – «т. д.», «водит.», «доп.», «повыш.», «нач.», «обл.» и др. Чтобы убрать исключение из перечня, щелкните на нем кнопкой мыши и нажмите кнопку Удалить.
На вкладке ДВе ПРописные подобным образом составляют перечень исключений при исправлении двух прописных букв в начале слова. В поле Не заменять введите текст исключения и нажмите кнопку Добавить. Чтобы удалить исключение из списка, выделите его и нажмите Удалить.
На вкладке Автоформат при вводе (см. рис. 3.12) есть флажок Заменять при вводе адреса Интернета и сетевые пути гиперссылками. Если он установлен, то при вводе в документ адресов Интернета либо сетевых путей они автоматически будут преобразованы в гиперссылки.
Выполненные настройки автозамены вступают в силу только после нажатия в окне Автозамена кнопки ОК. Нажав кнопку Отмена, вы выйдете из данного режима без сохранения изменений.
Данный текст является ознакомительным фрагментом.
Читайте также
Автозамена
Автозамена
Команда Автозамена служит для исправления ошибок, которые часто возникают при наборе (опечаток). В словарь автозамены вносятся правильные и ошибочные написания слов. При вводе ошибочного написания Microsoft Word автоматически исправляет его на правильное. Это
Совет 29. Рассмотрите возможность использования istreambuf_iterator при посимвольном вводе
Совет 29. Рассмотрите возможность использования istreambuf_iterator при посимвольном вводе
Предположим, вы хотите скопировать текстовый файл в объект string. На первый взгляд следующее решение выглядит вполне разумно:ifstream inputFile(«interestringData.txt»);string fileData(istream_iterator<char>(inputFile)), //
Орфография, стиль, автозамена
Орфография, стиль, автозамена
Правильность письменной речи важна в любом документе. Дело здесь не только в грамотности: даже если вы в совершенстве знаете язык, на котором создаете документ, вы не застрахованы от опечаток. Word и в этом случае незаменимый помощник и даже
Поиск величины при вводе
Поиск величины при вводе
Каким способом можно производить поиск подходящих величин в момент ввода? Табличный курсор (визуально) должен перемещаться к наиболее подходящему значению при добавлении пользователем новых символов водимой величины.Первоначально код писался
Предупреждение дублирования записей при вводе их из формы
Предупреждение дублирования записей при вводе их из формы
В главе 11 мы обсуждали вопрос об очистке базы данных от повторяющихся записей, которые попали в таблицы, и выяснили, что этот механизм может работать и в профилактическом режиме, предотвращая попадание дубликатов
18.7.2. Применение цикла while при вводе с клавиатуры
18.7.2. Применение цикла while при вводе с клавиатуры
Цикл while может применяться для ввода информации с клавиатуры. В следующем примере введенная информация присваивается переменной film. Если нажать клавиши [Ctrl+D], цикл завершает выполнение.$ pg whileread#!/bin/sh# whilereadecho » type <CTRL?D> to
Высотное строительство как способ предотвращения бунтов и революций Василий Щепетнёв
Высотное строительство как способ предотвращения бунтов и революций
Василий Щепетнёв
Опубликовано 03 июня 2013
Есть в русском языке изречения, затёртые до блеска. Употребляемые постоянно, они постоянно же оказываются к месту, не теряя ни
5.8. Сервис. Автозамена. Колонтитулы
5.8. Сервис. Автозамена. Колонтитулы
Если в тексте приходится печатать часто повторяющиеся слова или выражения, то с помощью автозамены можно задать начальную букву или сочетание букв, при котором оно автоматически будет заменяться нужным текстом. Данная команда
13.3.5. Автозамена
13.3.5. Автозамена
Word настолько умен, что может исправлять ваши опечатки при вводе. Конечно, не все, но очень многие. Например, ДВе ПРописные буквы в начале слова, устранять последствия случайного нажатия Caps Lock, а также производить ряд автоматических замен текста, которые
Поломки при вводе
Поломки при вводе
Предположим, что в интерактивной системе необходимо выдать подсказку пользователю, от которого требуется ввести целое. Пусть только одна процедура занимается вводом целых — read_one_integer, которая результат ввода присваивает атрибуту last_integer_read. Эта
4.5. Исправление ошибок и автозамена
4.5. Исправление ошибок и автозамена
Как я упоминал ранее, Word может исправлять ошибки в тексте. Слова, в которых допущены орфографические ошибки, подчеркиваются красной линией; слова и словосочетания, в которых имеются грамматические ошибки, — зеленой линией. Чтобы
6 О вводе
6
О вводе
ОДНО ИЗ ГЛАВНЫХ ПРЕИМУЩЕСТВ Интернета заключается в том, что он позволяет человеку не только изучать и использовать контент, но и участвовать в его создании. В мобильных технологиях правильная организация ввода данных — вопрос не менее важный, чем их
Автозамена
Автозамена
Автозамена – это возможность программы автоматически заменять в процессе ввода текста определенные сочетания символов на другие. Чаще всего она используется либо для исправления часто встречающихся ошибок при вводе (например, заменить «хороош» на
Автозамена и автоформат
Автозамена и автоформат
Автозамена позволяет автоматически исправлять типичные ошибки при вводе текста, например делать первую букву предложения прописной или исправить опечатку, в виде случайной перестановки букв в некоторых словах.Чтобы узнать, какие именно ошибки
Юзабилити: как сделать сайт удобным
Ошибки ввода данных и их предотвращение
Когда я работал тестировщиком программного обеспечения, моим излюбленным способом поставить систему «на колени» был ввод заведомо неверных и так называемых граничных данных. Например, нескольких букв в поле для ввода даты, запрос на поиск в базе и вывод на экран списка из 10 ООО документов, ввод длинной беспробельной строки или символов «<» в HTML-форме. Все эти действия относятся к ошибкам ввода данных и являются далеко не самыми безобидными для деятельности системы. Некоторые из них могли ввести систему в такой «клинч», что приходилось едва ли не перезагружать сервер. Этот же способ можно использовать для анализа ошибок ввода данных. Позже подобные ошибки стали обрабатываться и предотвращаться самой системой. Так, при нахождении 10 000 документов мне предлагалось либо уточнить поисковый запрос для лучшего результата, либо автоматически включался механизм работы с порциями по 100 (50, 20) документов. Символы «<» и «>» просто «проглатывались» и обрабатывались специальным нормализатором ввода, а беспробельные строки разрезались на куски по сто символов. Пользователи, не став более внимательными, совершали меньше ошибок и работали быстрее.
Ошибки ввода данных могут быть предотвращены такими способами:
• уменьшение самостоятельности пользователя при выборе данных (если команда выбирается из предоставляемого системой списка, ошибку допустить намного сложнее, чем в командной строке);
• ограничения в способе ввода данных (предоставление выбора численных значений только из выпадающего списка);
• валидация (проверка корректности) и нормализация (приведение к «безопасному» виду) системой данных перед тем, как принимать их от пользователя (например, проверка наличия знака «@» в адресе электронной почты или проверка длины пароля).
Валидация бывает двух видов: прикладная и системная. Системная валидация — проверка корректности информации на уровне типа данных, являются ли введенные данные строкой, числом, временем, адресом электронной почты и т. п. Прикладная валидация — проверка диапазона данных конкретного типа (равно, не равно, больше, меньше, от и до). Типы не сильно отличаются: прикладная валидация скорее частный случай системной. Если пользователь должен ввести год своего рождения, то при системной валидации мы проверяем, все ли введенные символы есть цифры, а при прикладной мы предполагаем, что человек не живет больше 150 лет, и ограничиваем ввод данных числом в промежутке от 1854 до 2004.
Простейшими примерами предотвращения ошибок ввода данных могут служить элементы Календарь и Выбор из списка, используемые вместо простых полей для ввода даты. Рассмотрим несколько вариантов На примере ввода в форме даты рождения.
1. Составной компонент из трех простых полей ввода (рис. 10.1).
Введите дату Вашего рождения (дц мм гггг)
год |
Рис. 10.1. Компонент ввода даты рождения реализован при помощи трех простых полей ввода
Минусы этого варианта:
• компонент выглядит несколько громоздко и занимает много места;
• пользователь может ввести данные, не соответствующие формату;
• пользователь может ошибиться при выборе формата ввода месяца («апрель»);
• ввод данных осуществляется с клавиатуры, поэтому необходимо отвлечься, чтобы совершить это действие, кроме того, возможны опечатки.
Плюс у такого варианта только один: реализация подобного
компонента требует минимальных знаний и усилий.
/
2. Составной компонент из трех полей «выпадающии список» (рис. 10.2).
Введите дату своего рождения
День [ОТ 3 Месяц j сентября З Год 11967 3
Рис. 10.2. Компонент ввода даты рождения реализован при помощи
трех полей «выпадающий список Минусы этого варианта: 
• компонент также выглядит несколько громоздко и занижает много места; 
• листать и просматривать список может быть неудобно из-за большого количества элементов;
• возможно непроизвольное изменение пользователе^ введен-
ных данных при использовании колеса прокрутки в то время, как фокус установлен в каком-либо поле «выбор из списка».
Плюсы этого варианта:
• пользователь не может ввести данные, не соответствующие формату (если предусмотреть проверку соответствия месяца и количества дней);
• реализация подобного компонента не требует глубоких знаний.
3. Компонент ввода при помощи выбора даты из календаря (рис. 10.3).
ЯВНЯЯИИПшЗ’ 1 ‘угЇпа.-iij
![]()
12 3 4
5 б Б 8 9 10 11
12 ІЗ И 15 16 17 18
19 20 21 22 23 24 25
Рис. 10.3. Компонент ввода даты рождения реализован как выбор даты из календаря
Введите дату Вашего рождения j2004.04.07 іїр”У^в
Минусы этого варианта:
• листать и просматривать список может быть неудобно из-за большого количества элементов;
• маловероятно, но все же возможно непроизвольное изменение введенных данных;
• необходимо догадаться, что пиктограмма с листком календаря не просто украшение;
• некоторые пользователи попытаются ввести /іату в недоступное для редактирования поле (при этом установленная по умолчанию дата в поле ввода может вообще поставить пользователя в тупик);
• реализация компонента требует серьезных знаний и дизайнерских навыков. і
Плюсы этого варианта:
• компонент в пассивном состоянии занимает мало места;
• пользователь не может ввести данные, не соответствующие формату (если предусмотрена проверка соответствия месяца и количества дней).
Проанализировав эти варианты, получаем, что худший — первый, а оптимальный — второй. Если рассматривать возможные способы ввода даты рождения только с позиции предотвращения ошибок, то пользователь не совершит ошибку при вводе данных во втором и третьем вариантах. Кроме того, сложные программы наиболее подвержены ошибкам программистов. Скорее всего программист напишет календарь на JavaScript, а какой-либо из браузеров наверняка откажется его корректно отобразить. Наряду с требованиями по предотвращению ошибок необходимо учитывать и юзабилити. С этой точки зрения оптимальным кажется составной компонент из трёх полей «выпадающий спиеок».
Я сократил количество вариантов, устранив те, что явно будут неудобны пользователю. В варианте с календарем я рассматриваю сам принцип, а не способы организации календаря, ведь его трже можно исполнить по-разному.
Раньше меня раздражали стандартные в MS Windows закладки, расположенные в два уровйя (рис. 11.19). Вернее, раздражали не сами закладки, а то, что при переключении с нижнего ряда на верхний они …
Путешествуя по интернету, я встречал самые разные варианты оформления текстового материала. Недавно я попал На страницу с результатами поиска по запросу «Установка унитаза» по адресу http://otdelka. hl. ru/(я делаю дома …
Ярчайший пример того, как делать нельзя, на pashen. kiev. ua — (рис. 11.16). Форма поиска без кнопки! Вы где-нибудь еще такое видели? Мало того, что нужно догадываться о ее использовагіии, …
Добавлено 31 мая 2021 в 22:08
Большинство программ, имеющих какой-либо пользовательский интерфейс, должны обрабатывать вводимые пользователем данные. В программах, которые мы писали, мы использовали std::cin, чтобы попросить пользователя ввести текст. Поскольку ввод текста имеет произвольную форму (пользователь может вводить что угодно), пользователю очень легко ввести данные, которые не ожидаются.
При написании программ вы всегда должны учитывать, как пользователи (непреднамеренно или наоборот) будут использовать ваши программы некорректно. Хорошо написанная программа будет предвидеть, как пользователи будут использовать ее неправильно, и либо аккуратно обработает эти случаи, либо вообще предотвратит их появление (если это возможно). Программа, которая хорошо обрабатывает случаи ошибок, называется надежной.
В этом уроке мы подробно рассмотрим способы, которыми пользователь может вводить недопустимые текстовые данные через std::cin, и покажем вам несколько разных способов обработки таких случаев.
std::cin, буферы и извлечение
Чтобы обсудить, как std::cin и operator>> могут давать сбой, сначала полезно немного узнать, как они работают.
Когда мы используем operator>> для получения пользовательского ввода и помещения его в переменную, это называется «извлечением». Соответственно, в этом контексте оператор >> называется оператором извлечения.
Когда пользователь вводит данные в ответ на операцию извлечения, эти данные помещаются в буфер внутри std::cin. Буфер (также называемый буфером данных) – это просто часть памяти, отведенная для временного хранения данных, пока они перемещаются из одного места в другое. В этом случае буфер используется для хранения пользовательских входных данных, пока они ожидают извлечения в переменные.
При использовании оператора извлечения происходит следующая процедура:
- Если во входном буфере уже есть данные, то для извлечения используются они.
- Если входной буфер не содержит данных, пользователя просят ввести данные для извлечения (так бывает в большинстве случаев). Когда пользователь нажимает Enter, во входной буфер помещается символ ‘n’.
operator>>извлекает столько данных из входного буфера, сколько может, в переменную (игнорируя любые начальные пробельные символы, такие как пробелы, табуляции или ‘n’).- Любые данные, которые не могут быть извлечены, остаются во входном буфере для следующего извлечения.
Извлечение завершается успешно, если из входного буфера извлечен хотя бы один символ. Любые неизвлеченные входные данные остаются во входном буфере для дальнейшего извлечения. Например:
int x{};
std::cin >> x;Если пользователь вводит «5a», 5 будет извлечено, преобразовано в целое число и присвоено переменной x. А «an» останется во входном потоке для следующего извлечения.
Извлечение не выполняется, если входные данные не соответствуют типу переменной, в которую они извлекаются. Например:
int x{};
std::cin >> x;Если бы пользователь ввел ‘b’, извлечение не удалось бы, потому что ‘b’ не может быть извлечено в переменную типа int.
Проверка ввода
Процесс проверки того, соответствуют ли пользовательские входные данные тому, что ожидает программа, называется проверкой ввода.
Есть три основных способа проверки ввода:
- встроенный (по мере печати пользователя):
- прежде всего, не позволить пользователю вводить недопустимые данные;
- пост-запись (после печати пользователя):
- позволить пользователю ввести в строку всё, что он хочет, затем проверить правильность строки и, если она корректна, преобразовать строку в окончательный формат переменной;
- позволить пользователю вводить всё, что он хочет, позволить
std::cinиoperator>>попытаться извлечь данные и обработать случаи ошибок.
Некоторые графические пользовательские интерфейсы и расширенные текстовые интерфейсы позволяют проверять входные данные, когда пользователь их вводит (символ за символом). В общем случае, программист предоставляет функцию проверки, которая принимает входные данные, введенные пользователем, и возвращает true, если входные данные корректны, и false в противном случае. Эта функция вызывается каждый раз, когда пользователь нажимает клавишу. Если функция проверки возвращает истину, клавиша, которую только что нажал пользователь, принимается. Если функция проверки возвращает false, введенный пользователем символ отбрасывается (и не отображается на экране). Используя этот метод, вы можете гарантировать, что любые входные данные, вводимые пользователем, гарантированно будут корректными, потому что любые недопустимые нажатия клавиш обнаруживаются и немедленно отбрасываются. Но, к сожалению, std::cin не поддерживает этот стиль проверки.
Поскольку строки не имеют никаких ограничений на ввод символов, извлечение гарантированно завершится успешно (хотя помните, что std::cin прекращает извлечение на первом неведущем пробельном символе). После того, как строка введена, программа может проанализировать эту строку, чтобы узнать, корректна она или нет. Однако анализ строк и преобразование вводимых строк в другие типы (например, числа) может быть сложной задачей, поэтому это делается только в редких случаях.
Чаще всего мы позволяем std::cin и оператору извлечения выполнять эту тяжелую работу. В этом методе мы позволяем пользователю вводить всё, что он хочет, заставляем std::cin и operator>> попытаться извлечь данные и справиться с последствиями, если это не удастся. Это самый простой способ, о котором мы поговорим ниже.
Пример программы
Рассмотрим следующую программу-калькулятор, в которой нет обработки ошибок:
#include <iostream>
double getDouble()
{
std::cout << "Enter a double value: ";
double x{};
std::cin >> x;
return x;
}
char getOperator()
{
std::cout << "Enter one of the following: +, -, *, or /: ";
char op{};
std::cin >> op;
return op;
}
void printResult(double x, char operation, double y)
{
switch (operation)
{
case '+':
std::cout << x << " + " << y << " is " << x + y << 'n';
break;
case '-':
std::cout << x << " - " << y << " is " << x - y << 'n';
break;
case '*':
std::cout << x << " * " << y << " is " << x * y << 'n';
break;
case '/':
std::cout << x << " / " << y << " is " << x / y << 'n';
break;
}
}
int main()
{
double x{ getDouble() };
char operation{ getOperator() };
double y{ getDouble() };
printResult(x, operation, y);
return 0;
}Эта простая программа просит пользователя ввести два числа и математический оператор.
Enter a double value: 5
Enter one of the following: +, -, *, or /: *
Enter a double value: 7
5 * 7 is 35Теперь подумайте, где неверный ввод пользователя может нарушить работу этой программы.
Сначала мы просим пользователя ввести несколько чисел. Что, если он введет что-то, отличающееся от числа (например, ‘q’)? В этом случае извлечение не удастся.
Во-вторых, мы просим пользователя ввести один из четырех возможных символов. Что, если он введет символ, отличный от ожидаемых? Мы сможем извлечь входные данные, но пока не обрабатываем то, что происходит после.
В-третьих, что, если мы попросим пользователя ввести символ, а он введет строку типа «*q hello». Хотя мы можем извлечь нужный нам символ ‘*’, в буфере останутся дополнительные входные данные, которые могут вызвать проблемы в будущем.
Типы недопустимых входных текстовых данных
Обычно мы можем разделить ошибки ввода текста на четыре типа:
- извлечение входных данных выполняется успешно, но входные данные не имеют смысла для программы (например, ввод ‘k’ в качестве математического оператора);
- извлечение входных данных выполняется успешно, но пользователь вводит дополнительные данные (например, вводя «*q hello» в качестве математического оператора);
- ошибка извлечения входных данных (например, попытка ввести ‘q’ при запросе ввода числа);
- извлечение входных данных выполнено успешно, но пользователь выходит за пределы значения числа.
Таким образом, чтобы сделать наши программы устойчивыми, всякий раз, когда мы запрашиваем у пользователя ввод, мы в идеале должны определить, может ли произойти каждый из вышеперечисленных возможных вариантов, и если да, написать код для обработки этих случаев.
Давайте разберемся в каждом из этих случаев и в том, как их обрабатывать с помощью std::cin.
Случай ошибки 1: извлечение успешно, но входные данные не имеют смысла
Это самый простой случай. Рассмотрим следующий вариант выполнения приведенной выше программы:
Enter a double value: 5
Enter one of the following: +, -, *, or /: k
Enter a double value: 7В этом случае мы попросили пользователя ввести один из четырех символов, но вместо этого он ввел ‘k’. ‘k’ – допустимый символ, поэтому std::cin успешно извлекает его в переменную op, и она возвращается в main. Но наша программа не ожидала этого, поэтому она не обрабатывает этот случай правильно (и, таким образом, ничего не выводит).
Решение здесь простое: выполните проверку ввода. Обычно она состоит из 3 шагов:
- убедитесь, что пользовательский ввод соответствует вашим ожиданиям;
- если да, верните значение вызывающей функции;
- если нет, сообщите пользователю, что что-то пошло не так, и попросите его повторить попытку.
Вот обновленная функция getOperator(), которая выполняет проверку ввода.
char getOperator()
{
while (true) // Цикл, пока пользователь не введет допустимые данные
{
std::cout << "Enter one of the following: +, -, *, or /: ";
char operation{};
std::cin >> operation;
// Проверяем, ввел ли пользователь подходящие данные
switch (operation)
{
case '+':
case '-':
case '*':
case '/':
return operation; // возвращаем символ вызывающей функции
default: // в противном случае сообщаем пользователю, что пошло не так
std::cout << "Oops, that input is invalid. Please try again.n";
}
} // и попробуем еще раз
}Как видите, мы используем цикл while для бесконечного цикла до тех пор, пока пользователь не предоставит допустимые данные. Если он этого не делает, мы просим его повторить попытку, пока он не даст нам правильные данные, не закроет программу или не уничтожит свой компьютер.
Случай ошибки 2: извлечение успешно, но с посторонними входными данными
Рассмотрим следующий вариант выполнения приведенной выше программы:
Enter a double value: 5*7Как думаете, что будет дальше?
Enter a double value: 5*7
Enter one of the following: +, -, *, or /: Enter a double value: 5 * 7 is 35Программа выводит правильный ответ, но форматирование испорчено. Давайте подробнее разберемся, почему.
Когда пользователь вводит «5*7» в качестве вводных данных, эти данные попадают в буфер. Затем оператор >> извлекает 5 в переменную x, оставляя в буфере «*7n». Затем программа напечатает «Enter one of the following: +, -, *, or /:». Однако когда был вызван оператор извлечения, он видит символы «*7n», ожидающие извлечения в буфере, поэтому он использует их вместо того, чтобы запрашивать у пользователя дополнительные данные. Следовательно, он извлекает символ ‘*’, оставляя в буфере «7n».
После запроса пользователя ввести другое значение double, из буфера извлекается 7 без ожидания ввода пользователя. Поскольку у пользователя не было возможности ввести дополнительные данные и нажать Enter (добавляя символ новой строки), все запросы в выводе идут вместе в одной строке, даже если вывод правильный.
Хотя программа работает, выполнение запутано. Было бы лучше, если бы любые введенные посторонние символы просто игнорировались. К счастью, символы игнорировать легко:
// очищаем до 100 символов из буфера или пока не будет удален символ 'n'
std::cin.ignore(100, 'n');Этот вызов удалит до 100 символов, но если пользователь ввел более 100 символов, мы снова получим беспорядочный вывод. Чтобы игнорировать все символы до следующего символа ‘n’, мы можем передать std::numeric_limits<std::streamsize>::max() в std::cin.ignore(). std::numeric_limits<std::streamsize>::max() возвращает наибольшее значение, которое может быть сохранено в переменной типа std::streamsize. Передача этого значения в std::cin.ignore() приводит к отключению проверки счетчика.
Чтобы игнорировать всё, вплоть до следующего символа ‘n’, мы вызываем
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), 'n');Поскольку эта строка довольно длинная для того, что она делает, будет удобнее обернуть ее в функцию, которую можно вызвать вместо std::cin.ignore().
#include <limits> // для std::numeric_limits
void ignoreLine()
{
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), 'n');
}Поскольку последний введенный пользователем символ должен быть ‘n’, мы можем указать std::cin игнорировать символы в буфере, пока не найдет символ новой строки (который также будет удален).
Давайте обновим нашу функцию getDouble(), чтобы игнорировать любой посторонний ввод:
double getDouble()
{
std::cout << "Enter a double value: ";
double x{};
std::cin >> x;
ignoreLine();
return x;
}Теперь наша программа будет работать, как ожидалось, даже если мы введем «5*7» при первом запросе ввода – 5 будет извлечено, а остальные символы из входного буфера будут удалены. Поскольку входной буфер теперь пуст, при следующем выполнении операции извлечения данные у пользователя будут запрашиваться правильно!
Случай ошибки 3: сбой при извлечении
Теперь рассмотрим следующий вариант выполнения нашей программы калькулятора:
Enter a double value: aНеудивительно, что программа работает не так, как ожидалось, но интересно, как она дает сбой:
Enter a double value: a
Enter one of the following: +, -, *, or /: Enter a double value: и программа внезапно завершается.
Это очень похоже на случай ввода посторонних символов, но немного отличается. Давайте посмотрим подробнее.
Когда пользователь вводит ‘a’, этот символ помещается в буфер. Затем оператор >> пытается извлечь ‘a’ в переменную x, которая имеет тип double. Поскольку ‘a’ нельзя преобразовать в double, оператор >> не может выполнить извлечение. В этот момент происходят две вещи: ‘a’ остается в буфере, а std::cin переходит в «режим отказа».
Находясь в «режиме отказа», будущие запросы на извлечение входных данных будут автоматически завершаться ошибкой. Таким образом, в нашей программе калькулятора вывод запросов всё еще печатается, но любые запросы на дальнейшее извлечение игнорируются. Программа просто выполняется до конца, а затем завершается (без вывода результата потому, что мы не прочитали допустимую математическую операцию).
К счастью, мы можем определить, завершилось ли извлечение сбоем, и исправить это:
if (std::cin.fail()) // предыдущее извлечение не удалось?
{
// да, давайте разберемся с ошибкой
std::cin.clear(); // возвращаем нас в "нормальный" режим работы
ignoreLine(); // и удаляем неверные входные данные
}Вот и всё!
Давайте, интегрируем это в нашу функцию getDouble():
double getDouble()
{
while (true) // Цикл, пока пользователь не введет допустимые данные
{
std::cout << "Enter a double value: ";
double x{};
std::cin >> x;
if (std::cin.fail()) // предыдущее извлечение не удалось?
{
// да, давайте разберемся с ошибкой
std::cin.clear(); // возвращаем нас в "нормальный" режим работы
ignoreLine(); // и удаляем неверные входные данные
}
else // иначе наше извлечение прошло успешно
{
ignoreLine();
return x; // поэтому возвращаем извлеченное нами значение
}
}
}Примечание. До C++11 неудачное извлечение не приводило к изменению извлекаемой переменной. Это означает, что если переменная была неинициализирована, она останется неинициализированной в случае неудачного извлечения. Однако, начиная с C++11, неудачное извлечение из-за недопустимого ввода приведет к тому, что переменная будет инициализирована нулем. Инициализация нулем означает, что для переменной установлено значение 0, 0.0, «» или любое другое значение, в которое 0 преобразуется для этого типа.
Случай ошибки 4: извлечение успешно, но пользователь выходит за пределы значения числа
Рассмотрим следующий простой пример:
#include <cstdint>
#include <iostream>
int main()
{
std::int16_t x{}; // x - 16 бит, может быть от -32768 до 32767
std::cout << "Enter a number between -32768 and 32767: ";
std::cin >> x;
std::int16_t y{}; // y - 16 бит, может быть от -32768 до 32767
std::cout << "Enter another number between -32768 and 32767: ";
std::cin >> y;
std::cout << "The sum is: " << x + y << 'n';
return 0;
}Что произойдет, если пользователь введет слишком большое число (например, 40000)?
Enter a number between -32768 and 32767: 40000
Enter another number between -32768 and 32767: The sum is: 32767В приведенном выше случае std::cin немедленно переходит в «режим отказа», но также присваивает переменной ближайшее значение в диапазоне. Следовательно, x остается с присвоенным значением 32767. Дополнительные входные данные пропускаются, оставляя y с инициализированным значением 0. Мы можем обрабатывать этот вид ошибки так же, как и неудачное извлечение.
Примечание. До C++11 неудачное извлечение не приводило к изменению извлекаемой переменной. Это означает, что если переменная была неинициализирована, в случае неудачного извлечения она останется неинициализированной. Однако, начиная с C++11, неудачное извлечение вне диапазона приведет к тому, что переменной будет присвоено ближайшее значение в диапазоне.
Собираем всё вместе
Вот наш пример калькулятора с полной проверкой ошибок:
#include <iostream>
#include <limits>
void ignoreLine()
{
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), 'n');
}
double getDouble()
{
while (true) // Цикл, пока пользователь не введет допустимые данные
{
std::cout << "Enter a double value: ";
double x{};
std::cin >> x;
// Проверяем на неудачное извлечение
if (std::cin.fail()) // предыдущее извлечение не удалось?
{
// да, давайте разберемся с ошибкой
std::cin.clear(); // возвращаем нас в "нормальный" режим работы
ignoreLine(); // и удаляем неверные входные данные
std::cout << "Oops, that input is invalid. Please try again.n";
}
else
{
ignoreLine(); // удаляем любые посторонние входные данные
// пользователь не может ввести бессмысленное значение double,
// поэтому нам не нужно беспокоиться о его проверке
return x;
}
}
}
char getOperator()
{
while (true) // Цикл, пока пользователь не введет допустимые данные
{
std::cout << "Enter one of the following: +, -, *, or /: ";
char operation{};
std::cin >> operation;
ignoreLine();
// Проверяем, ввел ли пользователь осмысленные данные
switch (operation)
{
case '+':
case '-':
case '*':
case '/':
return operation; // возвращаем символ вызывающей функции
default: // в противном случае сообщаем пользователю, что пошло не так
std::cout << "Oops, that input is invalid. Please try again.n";
}
} // и попробуем еще раз
}
void printResult(double x, char operation, double y)
{
switch (operation)
{
case '+':
std::cout << x << " + " << y << " is " << x + y << 'n';
break;
case '-':
std::cout << x << " - " << y << " is " << x - y << 'n';
break;
case '*':
std::cout << x << " * " << y << " is " << x * y << 'n';
break;
case '/':
std::cout << x << " / " << y << " is " << x / y << 'n';
break;
default: // Надежность означает также обработку неожиданных параметров,
// даже если getOperator() гарантирует, что op в этой
// конкретной программе корректен
std::cerr << "Something went wrong: printResult() got an invalid operator.n";
}
}
int main()
{
double x{ getDouble() };
char operation{ getOperator() };
double y{ getDouble() };
printResult(x, operation, y);
return 0;
}Заключение
При написании программы подумайте о том, как пользователи будут неправильно использовать вашу программу, особенно при вводе текста. Для каждой точки ввода текста учтите:
- Могло ли извлечение закончиться неудачей?
- Может ли пользователь ввести больше, чем ожидалось?
- Может ли пользователь ввести бессмысленные входные данные?
- Может ли пользователь переполнить входные данные?
Вы можете использовать операторы if и булеву логику, чтобы проверить, являются ли входные данные ожидаемыми и осмысленными.
Следующий код очистит любые посторонние входные данные:
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), 'n');Следующий код будет проверять и исправлять неудачные извлечения или переполнение:
if (std::cin.fail()) // предыдущее извлечение не удалось или закончилось переполнением?
{
// да, давайте разберемся с ошибкой
std::cin.clear(); // возвращаем нас в "нормальный" режим работы
ignoreLine(); // и удаляем неверные входные данные
}Наконец, используйте циклы, чтобы попросить пользователя повторно ввести данные, если исходные входные данные были недопустимыми.
Примечание автора
Проверка ввода важна и полезна, но она также делает примеры более сложными и трудными для понимания. Соответственно, на будущих уроках мы, как правило, не будем проводить никакой проверки вводимых данных, если они не имеют отношения к чему-то, чему мы пытаемся научить.
Теги
C++ / CppLearnCppstd::cinДля начинающихОбнаружение ошибокОбработка ошибокОбучениеПрограммирование
|
8 4 |
Глава 2. Представление и организация географической информации |
поступающим с серии ИСЗ: Глобальной навигационной спутниковой системы (ГЛОНАСС, Россия) и Global Positioning Systeir. (GPS, США) — Глобальной спутниковой системы (ГПС) — с точностью от метров до нескольких сантиметров [Серапинас, 2002]. Она сопоставима с точностью самых крупномасштабных карт Основное достоинство спутниковых систем — их глобальность оперативность, оптимальная точность; в отличие от традиционных геодезических измерений видимость между определяемыми пунктами не нужна. ГЛОНАСС работает в системе координат ПЗ-90,
аГПС — в WGS-84.
2.6.1. Типы ошибок в данных и их источники
Вполне резонно предположить, что множество пространственных данных содержит ошибки разного рода. Они могут вытекать из-за неточностей в источниках данных, лимитированной точности устройств цифрования или используемых компьютерных систем.
На весь набор данных влияют: ошибки регистрации и определения контрольных точек, преобразования координат, особенно когда неизвестна проекция исходного документа; ошибки обработки данных, неправильный логический подход, генерализация и интерпретация; математические погрешности; потеря точности представления из-за невысокой точности вычислений; перевод векторных данных в растровый формат и наоборот.
Основную информацию для ГИС поставляют разные карты, существенное значение имеет использование тематических карт созданных по данным дистанционного зондирования. Однако при использовании карт в ГИС нужно постоянно помнить их важные особенности:
•изображение на картах абстрактно и генерализовано, что требует весьма осторожной его интерпретации;
•карты показывают статичную картину, некий временной срез и часто устаревают;
•от масштаба карты зависит не только «как», но и «какие* объекты изображены, а большая часть ГИС не учитывает
|
2.6. Качество данных и контроль ошибок |
85 |
различий между наборами данных, полученных с разномасштабных карт;
•при показе сферической поверхности Земли на карте неизбежны искажения.
Почти каждый этап создания БД чреват внесением ошибок. Свойства карт, заложенные при их создании, при цифровании автоматически переносятся в базу данных: из-за генерализации они не всегда точно фиксируют информацию о местоположении объекта, а несоответствия на границах листов могут обусловить несоответствия в базе данных, которые обнаруживаются часто лишь при последующей обработке.
Ошибки характерны для данных, взятых из некартографических источников. Они могут появиться и при проведении инвентаризации по аэрофотоснимкам, если изображения дешифрированы неверно, или потому, что слишком велико доверие к базовым картам. Другие ошибки связаны с проблемой границ и погрешностями классификации. Многие ошибки обусловлены особенностями сбора данных. Ручной ввод цифровых данных весьма утомителен и трудно сохранять качество работы на протяжении долгого времени.
Представления о качестве данных, их точности и оценке погрешности становятся чрезвычайно важными при создании баз и банков данных ГИС. Существует практически всеобщая тенденция забывать об ошибках в данных, если последние представлены в цифровой форме. Все пространственные данные до некоторой степени неточны, но в цифровой форме они обычно представляются с высокой точностью, определяемой параметрами памяти компьютера. Поэтому вопросы анализа и оценки качества данных приобретают еще большую актуальность, чем в традиционной картометрии. Необходимо каждый раз рассматривать два вопроса:
•насколько правильно представляемые в БД цифровые структуры отражают реальный мир;
•насколько точно алгоритмы позволяют рассчитать истинное значение результата.
Важно выявить и оценить следующие показатели качества данных: полнота материалов, их актуальность, происхождение, достоверность, геометрическая точность, составляющие математической
8 6 Глава 2. Представление и организация географической информации
основы, влияние деформации бумаги и искажений при цифровании и сканировании, влияние генерализации.
Основные из этих показателей — позиционная точность и точность атрибутов объектов, а также логическая непротиворечивость, полнота, происхождение — относятся к базе данных в целом.
Методы расчета точности определений по картам рассматриваются в курсе картографии, показатели качества данных определяются стандартами [ГОСТ, 1995]. Актуальны вопросы контроля измерений данных. Их желательно выполнять разными способами по разным источникам.
Определенные типы ошибок, возникающие, например, вследствие неточности оригинальной съемки данных, картографических источников, ошибочных действий оператора при ручном цифровании графических объектов, не могут быть исправлены без привлечения других источников. Ошибки позиционирования часто даже не обнаруживаются без комбинирования данных разных источников. Большинство ошибок цифрования устраняется на основе визуального контроля и интерактивных действий оператора.
Успех применения ГИС для выделения и изучения геосистем разных рангов в большой степени зависит также от качества информационной взаимоувязки слоев базы данных. Разнотипные цифровые данные — их позиционная и семантическая составляющие — должны быть согласованы на основе учета взаимосвязей объектов и явлений. Эти вопросы рассматриваются в параграфе 5.1.6.
2.6.2. Позиционная точность данных
Позиционная точность определяется как величина отклонения измерения данных о местоположении (обычно координат) от истинного значения.
При ее определении, как правило, исходят из масштаба исследования или первичного материала, например, в данных о природных ресурсах стремятся достичь точности карты заданного масштаба. Обеспечение большей точности требует более качественных исходных материалов, но всегда следует задаться вопросом, оправданы ли дополнительные затраты задачами исследования.
Точность координат определяется по-разному в векторном и растровом представлении, а ее компьютерное представление зависит от выбранной точности вычислений.
|
2.6. Качество данных и контроль ошибок |
87 |
Координаты в векторном формате могут кодироваться с любой мыслимой степенью точности; она ограничивается возможностями внутреннего представления координат в памяти компьютера. Обычно для представления используется 8 или 16 десятичных знаков (одинарная или двойная точность), что соответствует ограничению по точности соответственно до 1/108 и 1/1016 измерения на местности. Таким образом, математическая точность представления координаты основывается на возможном числе значащих цифр, которые могут храниться для каждой координаты. При одинарной точности сохраняется до семи значащих цифр, при двойной — до 15 цифр, что позволяет сохранять математическую точность значений координат, намного меньших 1 м. Этого достаточно, чтобы закодировать любую точку земной поверхности с точностью, превышающей 1 мм. Поскольку компьютер в зависимости от установленной точности может различать только ограниченное число десятичных позиций, то для координат одинарной точности значения 1.2345678 и 1.23456789 эквивалентны, т. е. представляют одно и то же местоположение, так как цифры, выходящие за пределы седьмой позиции, игнорируются.
Математическая точность сама по себе не может обеспечить картографическую точность, однако она является главным фактором в определении разрешающей способности пространственных данных.
Точность вычислений описывается числом знаков, используемых для представления одной единицы измерения, и определяет степень детальности, поддерживаемой при хранении значений данных в базе данных. Так, при точности пространственной привязки, равной 1, координаты будут храниться в целых числах, в то время как точность 1,000 требует хранения трех десятичных знаков. Если координаты в базе данных хранятся как 4-байтовые целые числа, то они могут принимать максимальное значение 2 147 483 648 (231). Тогда при вычислениях с метровой точностью такое представление дает возможность работать с числами, не превышающими 2,1 млрдм. Соответственно при единицах измерения в сантиметрах диапазон чисел ограничен 2,1 млрд см. Эти единицы называют единицами хранения,
иустанавливают их на основе задаваемой точности всей БД.
ВГИС-пакетах вводится еще показатель «единицы карты», но он не имеет никакого отношения к точности. Эти единицы представляют
88 Глава 2. Представление и организациягеографическойинформации
размеры или измерения по карте. Например, метр — стандартная единица для карт в проекциях Гаусса-Крюгера, UTM, а фут — стандартная единица для плановой государственной системы координат США.
В некоторых картографических проекциях используются большие значения координат, например, в проекции UTM координаты принимают значения в диапазоне от 2 до 6 млн. Для того чтобы поддержать картографическую точность, составляющую менее одной единицы измерения и выражающуюся разрядами, расположенными за десятичной запятой, нужно использовать двойную точность. Двойная точность требует дополнительного дискового пространства для хранения координат.
Точность растра зависит от размера ячеек сетки. Для избежания потери информации можно использовать ячейки меньшего размера с тем, например, чтобы показать искусственные объекты, но следует оценить, что будет представлять выбранная ячейка в заданном масштабе. В большинстве случаев неясно, относятся ли координаты, представленные в растровом формате, к центральной точке ячейки или к одному из ее углов; точность привязки, таким образом, составляет 1/2 ширины и высоты ячейки.
Для получения точности растра, аналогичной математической точности представления данных в компьютере, необходимо, соответственно, 108х 108 или 1016х1016 ячеек, что невозможно даже при специальном сжатии данных. Однако и в векторном представлении только некоторые классы данных соответствуют такой точности: данные, полученные точной съемкой, карты небольших участков, составленные на основе крупномасштабных топографических карт лишь для немногих природных явлений характерны четкие границы которые можно представить в виде математически определенных линий. Поэтому можно утверждать, что тонкие линии в векторном формате дают ложное ощущение точности. Обычно на карте толщина линии отражает неопределенность положения объекта. Поэтом} в векторной системе фиксируется неопределенность положений векторного объекта, а не точность координат. В растровой системе эта неопределенность автоматически выражается размером ячейки который и дает действительное представление о точности.
Помимо ошибок в указании местоположения ошибки проявляются в нарушении топологических отношений объектов. Существуют
|
2.6. Качество данных и контроль ошибок |
89 |
объекты, для которых на карте некоторые типы отношений недопустимы, например, наложение, пересечение и т. д. Так, не могут пересекаться горизонтали, дом не может попасть в пределы водоема.
Большая часть данных о местоположении берется с аэроснимков, при этом точность зависит от правильного размещения контрольных точек. Данные космической съемки труднее расположить с большой точностью — не позволяет разрешение снимка.
Часто возникают искусственные признаки ошибок (артефакты) — это нежелательные последствия применения высокоточных процедур для обработки пространственных данных, имеющих небольшую точность. Использование растровых данных позволяет застраховаться от артефактов до тех пор, пока размер элемента растра больше или равен позиционной точности данных. При работе с векторными данными артефакты возникают при кодировании (цифровании) и наложении полигонов.
Чтобы проверить позиционную точность, нужно использовать:
•независимый, более точный источник, например, карту более крупного масштаба;
•данные спутникового позиционирования;
•первичные («сырые») данные съемки.
Для контроля используют и внутренние признаки: незамкнутые полигоны, линии, проходящие выше или ниже узловых точек, и т. п. Величина этих погрешностей может служить мерой позиционной точности.
2.6.3 .Точность атрибутивных данных
Точность атрибутов определяется как близость их к истинным показателям (на данный момент времени).
В зависимости от природы данных точность атрибутов может быть проанализирована разными способами.
Для непрерывных атрибутов, представляющих модель поверхности, например, ЦМР, точность определяется как погрешность измерений по этой модели.
Атрибуты представляют семантическую составляющую данных, и ее проверка в большинстве случаев возможна только путем визуального просмотра цифровой карты. Проверка правильности интерпретации условных знаков проводится путем сравнения исходного
9 0 Глава2. Представление и организация географической информации
оригинала и цифровой карты. Синтаксический контроль включает проверку на синтаксические ошибки, описки, лишние пробелы в текстовых атрибутах, соответствие кодов характеристик или их расшифровок классификатору или тексту легенды и т. п. Иногда существенную помощь в поиске ошибок и редактировании оказывают правильно построенные SQL запросы с операциями группировки по контролируемому полю.
Для атрибутов объектов, выделяемых в результате классификации, точность выражается в оценках соответствия, опреде-
|
ленности или правдоподобия. В случае двух объектов |
ситуация, |
|
в которой они представлены сочетанием 70 % атрибута |
объекта А |
и 30 % атрибута В, лучше, чем когда объекты Ли В недостаточно определены, что не позволяет четко разграничить их. В общем случае для оценки точности атрибутов полезно составить матрицу ошибок классификации. Для этого нужно взять несколько случайных точек, определить их категорию по базе данных, затем на местности определить истинный класс и заполнить матрицу классификации (соответствия). В приведенном примере число классов 4, а число обследованных точек 100, из них на местности определено 25 точек класса Л, 18 точек — Я, 24 — С и 33 — D (табл. 2.3).
Таблица 2.3. Матрица ошибок классификации
|
Класс на местности |
Класс в БД |
|||
|
А |
В |
С |
D |
|
|
А |
12 |
7 |
3 |
3 |
|
В |
3 |
10 |
3 |
2 |
|
С |
3 |
5 |
15 |
1 |
|
D |
4 |
4 |
4 |
21 |
|
Всего |
22 |
26 |
25 |
27 |
В идеале все точки должны располагаться по диагонали матрицы; это показывает, что на местности и в базе данных зафиксирован один и тот же класс. Ошибка пропуска возникает тогда, когда точки класса на местности неправильно зафиксированы в базе
|
2.6. Качество данных и контроль ошибок |
91 |
данных. В матрице число ошибочных точек класса В равно сумме записей в столбцах Л, CwD строки В (числу точек, относящихся на местности к классу В, а в базе данных — к другим классам). Ошибка добавления (ложного класса) имеет место в случаях, когда в базе данных зафиксирован класс, которого нет на местности, например, для класса А — это сумма записей в строках В, С и D столбца Л (соответствует числу точек, неправильно отнесенных к классу Л в базе данных).
Для обобщения матрицы соответствия используют такой показатель достоверности классификации, как количество правильно классифицированных точек, расположенных по диагонали матрицы (в %). На самом деле это число может быть случайным. Чтобы учесть этот факт, часто при обобщении результатов используют так называемый индекс к каппа Коэна, вносящий поправку на случайность.
|
Он вычисляется по формуле |
|
|
к = (d-q)/(N-q), |
(2.1) |
где rf— число случаев правильного получения результата (сумма значений, стоящих на диагонали матрицы соответствия); q — число случайных результатов, вычисляемое через число случайных результатов в столбцах пс и истинных в строках пг матрицы соответствия как q = X n r i J N , N — общее число точек. Для абсолютно точных результатов (все N точек на диагонали) каппа равна 1, а при чисто случайном попадании — 0. В приведенном примере
q — (22×25/100 + 26×18/100 + 25×24/100 + 27×33/100) = 25,09;
к = (58—25)/( 100—25) = 0,44;
показатель достоверности классификации равен 44 %, что меньше значения, полученного по диагональным элементам (58 %).
Неопределенность атрибутов каждого элемента растра постоянна для каждого из представленных классов объектов, а позиционная неопределенность постоянна для всего растра — фиксируется один раз для всей карты.
Для социальных данных основной источник неточности в атрибутах — недоучет данных. Например, при проведении переписи в некоторых районах и по некоторым социальным группам недоучет может быть очень высоким (>10 %).
|
9 2 |
Глава2. Представление и организация географической информации |
|
|
2.6.4. Логическая непротиворечивость, полнота, |
||
|
происхождение |
||
|
Эти элементы качества данных относятся к базе данных в целом |
||
|
а не к объектам, атрибутам или координатам. |
||
|
Логическая непротиворечивость |
связана с внутренней |
непротиворечивостью структуры данных, с топологическим представлением данных, что означает наличие исчерпывающего списка взаимоотношений между связными геометрическими представлениями данных без измерения хранимых координат пространственных объектов. Она обычно заключается в ответах на вопросы замкнуты ли полигоны, нет ли полигонов без меток или с несколькими метками, есть ли узлы на всех пересечениях дуг. Логические противоречия могут быть связаны с проблемами согласования информации и географических границ при совмещении данных из разных источников.
Полнота связана со степенью охвата данными множества объектов, необходимых для представления реальности или отображения на результирующей карте (все ли соответствующие объекты включены в базу данных?). Она зависит от правил отбора объектов или явлений, генерализации и масштаба.
Происхождение включает сведения об источниках данных, времени сбора данных, точности источников и цифровых данных, организации, которая их собирала, об операциях по созданию базы данных (как кодировались данные и с какого исходного материала, как происходила их обработка). Обычно эта информация содержится
вспециальных файлах метаданных.
2.7.Особенности интеграции разнотипных
данных
Интеграционные свойства ГИС проявляются в использовании разных видов и типов цифровых данных, полученных из разньп источников, возможно с разной точностью. Такие данные требуют разработки методов их совместного применения, оценки пригодности для пространственно-временного анализа в ГИС.
Проблемы интеграции данных особенно остро встали в связг с широким использованием уже существующих цифровых карт содержащихся в разнообразных базах пространственных ланньп
|
2.7. Особенности интеграции разнотипных данных |
93 |
и распространяемых по телекоммуникационным сетям. Они могут быть слоями проблемно-ориентированных ГИС, представлять результаты компьютерного дешифрирования аэро- и космических снимков, цифрового моделирования объектов или явлений. Информация относительно их происхождения, методов создания, точности и достоверности часто отсутствует или недоступна.
Современное техническое и программное обеспечение позволяет на основе любых доступных данных создавать сколь угодно сложные по содержанию карты и делать их легко доступными для использования и модификаций. Но часто это делается без учета картографических традиций, в то время как доверие к цифровым картам велико.
Технология создания цифровых карт часто определяется временными, не устоявшимися, разрозненными и не всегда профессионально составленными инструкциями и техническими заданиями производителя или заказчика работ, ведомственными инструкциями. Все чаще появляются в публикациях сообщения об ошибках цифровых карт, а иногда об их полной непригодности или недостоверности как источников данных.
Совокупность цифровых данных о пространственных объектах, составляющих содержание баз географических данных ГИС, по существу, еще не является цифровой картой. На картах, созданных на основе данных дистанционного зондирования, «пиксельные» разрешение и генерализация могут не соответствовать показателям картографической точности и генерализации для выбранных масштаба и проекции. Особенно сложна интеграция данных, представляемых на карте условными знаками, из-за их внемасштабности и уникальности.
В БД обычно используются данные из разных источников с разной степенью точности. При наложении множества карт точность результирующего материала может оказаться очень низкой. Однако больший интерес представляет показатель пригодности полученной карты. Для некоторых типов операций степень пригодности карт определяется точностью наименее точного слоя БД. Показатель пригодности можно оценить также по его устойчивости при смене порядка ввода данных или изменении веса атрибута.
Преимущество геоинформационных методов заключается в возможности оценить пригодность данных для совместного
|
9 4 |
Глава 2. Представление и организация географической информации |
использования и осуществить их интеграцию на основе выполнения пространственного анализа с помощью ГИС-технологий (см. раздел 4.5). Однако основное правило при интеграции информации таково: качество данных должно быть определено скорее вс время получения данных, чем при попытке применить эти данные Тогда указанные технологии могут существенно облегчить их корректировку для поставленной задачи.
Основные проблемы, возникающие при совместном использовании разнотипных данных: отображение положения границ в разных цифровых источниках, временные параметры данных и способ отражения структуры геосистем, а при интеграции данных о природных компонентах и окружающей среде — разные принципы классификации объектов на снимках и картах, не очень частое обновление, а также различия генерализации и согласования.
Разные принципы представления пространственной информации в БД, применение разных моделей и форматов данных, разных типов СУБД требует наличия различных технических и программных средств манипулирования совмещаемыми данными. Этим объясняется расширение наборов обменных форматов и процедур импорта-экспорта данных, которыми сейчас снабжаются наиболее распространенные ГИС-пакеты, и стремление к открытости ГИС.
Использование систем, в которых растровый и векторный анализ могут выполняться параллельно, позволяет осуществлять наложение векторной карты на растровую или на космический снимок. Интеграция векторных и растровых данных не приводит к конфликтным ситуациям, если разрешение растра (параметров съемки или сканирования) согласовано с точностью картографи- рования в данном масштабе. Неправильный выбор разрешения при сканировании космических снимков может привести к потер*» информации. С другой стороны, уменьшение размера пиксела (увеличение разрешения при сканировании) не всегда повышает точность и информативность данных, зачастую только значительно увеличивая объемы хранимой информации. Знание этих параметров особенно важно при совместном использовании растровых и векторных карт, поскольку большинство операций с растровыми данными осуществляется с точностью до пиксела. Это относится
|
2.7. Особенности интеграции разнотипных данных |
95 |
и к совмещению разнотипных дискретных данных для построения математико-картографической модели и ее использования в качестве источника непрерывно распределенной цифровой информации. Как правило, модели строятся с использованием различного типа сеток. Совмещение данных с разным размером сеток, характеризующим уровень дискретизации и, следовательно, обобщения информации, искажает передачу взаимосвязей объектов и явлений, имеющих пространственное распространение. Подобные искажения могут возникнуть при попытке создания моделей динамики объектов на основе использования оригинальных космических снимков и цифровых снимков, называемых Quicklook, распространенных в Интернете.
Разные принципы генерализации изображений на картах и снимках, в автоматизированном режиме зачастую реализуемые в интерактивном режиме отдельно для позиционных и атрибутивных данных, создают особую проблему совместного использования данных. Без знания методов и уровня генерализации совмещаемых данных их применение становится невозможным, необходимы также сведения, в каком диапазоне масштабов следует использовать тематические слои БД.
Разнотипные цифровые данные должны быть согласованы на основе учета взаимосвязей исследуемых явлений. Методы обеспечения единства карт — их согласования — один из главных принципов комплексного картографирования, а соответственно и ГИС. Поэтому выбор ГИС-технологий интеграции определяется также типом самих природных, социально-экономических, экологических данных, а также данными географической привязки.
К данным географической привязки предъявляют особенно высокие требования по точности и достоверности еще на этапе сбора исходной информации. Их применение в качестве основы для интеграции данных в известных оригинальных масштабах и проекциях не вызывает затруднений. Во всех других случаях требуется преобразование информации, которое должно выполняться по правилам картографической генерализации и согласования.
Создание проблемно-ориентированных банков географических
икартографических данных и знаний способствует не только накоплению и обмену информацией, но и повышению качества
идостоверности ГИС-анализа и картографирования. Особенно
9 6 Глава2. Представление и организация географической информации
возрастает роль таких банков для интеграции, пространственного и тематического согласования информации при использовании карт в ГИС, создании цифровых карт, комплексных электронных атласов.
Решение проблем интеграции данных при создании и использовании цифровых карт заключается в разработке инфраструктуры пространственных данных (на национальном, межгосударственном уровнях), четкой структуры метаданных и картографически обоснованного применения ГИС-технологий при работе с разнотипными
|
данными. |
||
|
Инфраструктура |
пространственных |
данных (ИПД) — |
«информационно-коммуникационная система, обеспечивающая доступ пользователей (граждан, хозяйствующих субъектов, органов государственной и муниципальной власти) к национальным распределенным ресурсам пространственных данных, а также распространение и обмен ими в сети Интернет или иной общедоступной глобальной сети в целях повышения эффективности их производства и использования. ИПД включает четыре необходимых компонента: базовые пространственные данные, стандартизацию, базы метаданных и механизм обмена данными, а также институциональную основу их реализации» [Геоинформатика, 2005].
Под формированием инфраструктуры пространственных данных подразумевается разработка механизма их обмена и накопления (доступность, стоимость, система стандартов), а также определение единой — базовой — пространственной информации; этой составляющей ИПД уделяется особое внимание.
Базовые пространственные данные — общедоступная часть ресурсов пространственных данных, включающая информацию об их геодезической основе, избранных пространственных объектах и их наборах, необходимых для позиционирования любых иных данных. Критериями для отнесения данных к базовым служат: их всеобщая востребованность, возможность многократного и многоцелевого использования, наличие готовых цифровых наборов пространственных данных и технологий их массового производства, обеспечивающих повышенные требования к качеству, включая позиционную точность и актуальность.
Базовый пространственный объект — пространственный объект в составе базовых пространственных данных, идентифи-
|
2.7. Особенности интеграции разнотипных данных |
97 |
цируемый в соответствии с установленными правилами, отличающийся устойчивостью пространственного положения во времени и служащий основой позиционирования других пространственных объектов.
В Руководстве по созданию ИПД, изданном Ассоциацией глобальной инфраструктуры пространственных данных (GSDI), к набору элементов базовых данных отнесены: геодезические сети, ортоизображения, рельеф в виде ЦМР, транспортные сети, гидрография, границы административных единиц, кадастровая информация и национальные газеттиры (особые БД, позволяющие соотносить топонимы с местоположением на базовой карте). Этот набор рекомендован и для Российской ИПД [ГОСТ, 2006].
Классическим источником базовой пространственной информации служат топографические карты. Во многих странах данные этого типа представлены и в цифровой форме, обычно в разных масштабах. Но составляются они, как правило, с соблюдением национальных стандартов. В России, часто в силу высокой стоимости цифровых карт или отсутствия карты нужного масштаба, появились цифровые топографические основы, полученные «пользовательским» цифрованием топографических карт на различные районы или регионы. Это ведет к появлению многочисленных цифровых дублей неопределенного качества, широкое использование которых, несмотря даже на их доступность, проблематично.
Наиболее надежным путем создания качественной БД, особенно для ее многократного и многопользовательского применения, является хранение информации о точности в самой БД в виде атрибутов или метаданных, что требует стандартизации их описания.
Метаданные должны содержать информацию о проекции, географической основе и базовой карте, уровне генерализации, цензе и норме отбора объектов картографирования, дизайне, времени создания или переиздания карты и давать дополнительную информацию о процедурах сбора и компиляции данных, системах кодирования и точности приборов и др. Например, общий список характеристик метаданных стандарта CSDGM (Content Standarts for Digital Geospatial Metadata), США, насчитывает более 300 позиций. В метаданных необходимо указывать все примененные способы преобразования данных и их точности. Наличие метаданных
|
9 8 |
Глава2. Представление и организация географической информации |
позволяет пользователю получить представление о достоверности информации, а их отсутствие часто ведет к неправильной трактовке и ложным представлениям о точности самих данных. Заполнение файлов метаданных обеспечивает контроль качества БД при ее обновлении.
Механизм обмена данными включает не только стандарты на пространственные данные и метаданные, но и правила доступа к ним через национальные информационные центры, поиск на основе каталогов метаданных через Интернет.
Для обеспечения поиска пространственных данных, в том числе базовых, в сети Интернет создаются различные поисковые системы (например, Googl Earth, Geography Network) и каталоги на Web-cepeepax.
Библиографическое описание:
Панфиленкова, О. В. Анализ и устранение ошибок при подготовке БД к подсчету запасов ПИ / О. В. Панфиленкова. — Текст : непосредственный // Молодой ученый. — 2012. — № 11 (46). — С. 70-73. — URL: https://moluch.ru/archive/46/5619/ (дата обращения: 22.09.2023).
Основой
для современного подсчета запасов полезных ископаемых (ПИ) является
цифровая база данных (БД), создаваемая на основе результатов
геологоразведочных работах в период оценочных работ или разведки
месторождений, а также на стадии эксплуатации. Осуществляется подсчет
запасов в соответствии с требованиями и правилами оформления
материалов для подсчета запасов месторождений полезных ископаемых,
представляемых на государственную экспертизу. При этом рекомендуется
использовать программные комплексы, обеспечивающие возможность
просмотра, проверки и корректировки исходных данных, результатов
промежуточных расчетов, построений, сводных результатов. Графические
материалы и модели представляются в виде форматов, выполненных с
помощью геоинформационных систем (ГИС) и горно-геологических
информационных систем (ГГИС).
Цифровая база данных может
быть представлена в формате таблиц MS
Excel
или MS
Access.
Включает в себя несколько структурных элементов (таблиц):
-
Результатов опробования
(ASSAY).
Формируется из данных химических, пробирных или иных результатов
лабораторных исследований, отобранных из керна скважин или иных
горных выработок (шурфов, штреков и т.д.); -
Координат выработок
(HEADER).
Содержит координаты устьев скважин и т.д.; -
Отметки
литолого-стратиграфических границ или контактов (LITHOLOGY); -
Данные инклинометрии
(SURVEY).
Однако
первичная документация до недавнего времени велась, да и отчасти
ведется на аналоговых (бумажных) носителях в виде полевых дневников,
журналов и планов опробования. Поэтому на начальном этапе создания БД
стоит задача перевода этой информации в формат цифровых таблиц.
Осуществляется перевод первичной документации посредством
сканирования с последующей оцифровкой и вводом полученной при
геологоразведочных работах информации. При этом возможны ошибки, а БД
с ошибками не может быть использована при подсчете запасов, в
частности с применением геоинформационных систем.
В настоящее время
применение специализированного ПО позволяет выявить ошибки в
инклинометрии, наличие пересекающихся интервалов, соответствие полей
в БД, но не способны устранить ошибки при наборе результатов
опробования (опечатки, повторения, пропуски и т.д.). Кроме того,
такого рода специализированное ПО существует не на всех предприятиях,
а с учетом необходимости привлечения специалистов, знающих данные
системы, встает необходимость проверки цифровой БД при помощи
доступных средств, к примеру, MS
Excel.
Проверка БД на пригодность
для использования в геоинформационных системах может производиться
двумя методами статистическим (1) или перекрестным (2):
-
После ввода части
информации сверяется 10% введенных данных с первоисточниками. Если
ошибки встречаются более чем в 10% записей, то снова проверяется уже
50% введенной информации. Если и в этом случае уровень ошибок
превышает допустимый, то перепроверяется уже вся введенная
информация, а выявленные ошибки тщательно исправляются. -
Данные
вводятся двумя операторами, независимо друг от друга. Полученные
таблицы сортируются и сравниваются. Отличающиеся строки
отбраковываются и снова вводятся одновременно двумя операторами, а
затем снова сравниваются. Как правило, количество таких операций
достигает трех-четырех. Только после достижения полного соответствия
информации, она считается принятой, и может использоваться в
дальнейшей работе [1, c.
29].
Мы
остановимся на рассмотрении перекрестного метода проверки ошибок, так
как считаем его наиболее достоверным и позволяющим достичь
максимальной сходимости с исходной информацией.
Возможные ошибки при вводе
в цифровые таблицы информации, полученной при геологоразведочных
работах, можно разделить на две групп:
-
ошибки, возникающие при
ведении документации, в том числе и первичной; -
ошибки, возникающие на
этапе ввода данных в цифровые табличные формы.
Первая
группа ошибок появляется в процессе работы геологической службы на
горнодобывающих предприятиях (месторождениях), выявление которых в
процессе создания цифровой базы данных зачастую невозможно.
Устранение или существенное их сокращение связано с
совершенствованием геологической службы, ее материально технической
базы и повышением квалификации специалистов.
Вторая группа ошибок во
многом связана с человеческим фактором, в процессе формирования
цифровой базы данных, при этом выявленные ошибки могут быть устранены
в процессе проверки.
Наиболее типичные ошибки
при вводе данных, это:
-
опечатки (изменение
порядка или пропуск цифр); -
пропуск отдельных значений
или строк; -
повторные значения или
строки.
Для
устранения ошибок можно использовать методику, состоящую из
нескольких этапов проверки с использованием программного продукта MS
Excel,
которая позволяет сократить их объем и обеспечить практически 100%
сходимость с первоисточником. Рассмотрим методику на примере ввода
данных опробования (ASSAY).
1 этап. Ввод результатов
опробования производится в две руки независимыми друг от друга
операторами в таблицы, структура которых заблаговременно подготовлена
и однотипна. Вводятся следующие данные: номер скважины (HOLEID),
номер пробы (SAMPLE),
интервалы опробования — от (FROM)
и до (TO),
выход керна в метрах (CORE_M)
и результаты анализов. Столбцы — длина интервалов опробования
(LENGTH),
выход керна в процентах (CORE_%)
рассчитываются по формулам 1.1 и 1.2.
[TO]-[FROM]
= [LENGTH] 1.1
[CORE_M]*100/[LENGTH]
= [CORE_%] 1.2
Использование формул
позволяет уже на стадии ввода, выявлять возможные ошибки и
своевременно их устранять. Так, к примеру, ошибка в интервале
опробования, при вычислении формулы 1.1, может привести к появлению в
столбце (LENGTH)
значений, резко отличающихся от принятой на месторождении длины
интервала опробования; при вычислении формулы 1.2, приведет к
появлению выхода керна более 100%.
Кроме того, при вводе
данных рекомендуется структурировать исходную информацию, что
значительно облегчит и, что важно, уменьшить затраты времени на
проверку в процессе 2-го этапа.
2 этап. Введенные данные
проверяются путем перекрёстного сопоставления двух полученных таблиц
с использованием идентификатора (ID).
ID
может формироваться из номера выработки (HOLEID)
и начала интервала опробования (FROM)
(1.3).
[HOLEID]
& «_» & [FROM]
1.3
Для избегания случаев
путаницы в случаи присутствия в исходной информации повторных номеров
скважин следует дополнить ID,
к примеру, номером страницы журнала опробования с которого
производился ввод.
Таблицы копируются в один
документ MS
Excel
на отдельные листы (рис. 1). Сопоставление производится с помощью
функции ВПР, в схожих по ID
строках рассчитывается разница значений одной и второй таблиц. В
случае если разница не равна 0, при помощи логической функции, ЕСЛИ в
ячейке выводится слово ОШИБКА. В этом случае проверяющий, используя
исходную информацию, сравнивает данные цифровых таблиц с оригиналами
и исправляет ошибки (рис. 2). Таким образом, можно исправить
повторные пробы, пропущенные данные, опечатки и т.д.

Рис. 1. Таблицы данных
опробования, полученные при вводе двумя операторами
Рис. 2. Проверка на наличие
ошибок в таблице 1 и таблице 2 (см. рис. 1)
В
завершении проверки производится анализ на присутствие скважин с
одинаковыми номерами и в случае их обнаружения, такие данные
бракуются, а информация о них высылается или сообщается геологической
службе горнодобывающего предприятия.
3 этап.
После проверки итоговая таблица сортируется по полям (HOLEID)
и (FROM),
а данные анализируются на присутствие в опробовании перекрывающихся
интервалов или их отсутствие.
Для полной проверки БД в MS
Excel
проводится сопоставление данных инклинометрии с опробованием и
глубиной скважины, выявляются расхождения в глубинах трех таблиц,
вносятся соответствующие поправки.
Данная методика проверки
подходит для маленьких предприятий, у которых нет возможности
приобретения дорогостоящего ПО, позволяющего в автоматической режиме
сообщать о имеющихся ошибках, например ГГИС.
Проверенная БД может
использоваться для создания блочной модели или для традиционного
метода подсчета запасов МПИ.
Литература:
-
Требования к составу и
правила оформления материалов технико-экономических обоснований
(ТЭО) кондиций для подсчета запасов месторождений полезных
ископаемых, представляемых на государственную экспертизу. М.,2005,
с. (Государственная комиссия по запасам полезных ископаемых (ГКЗ)
Министерства природных ресурсов Российской Федерации) -
Подсчет запасов и
геолого-промышленная оценка рудных месторождений. Коган И.Д. М.,
«Недра», 1971, 296 стр.
Основные термины (генерируются автоматически): FROM, HOLEID, LENGTH, ошибка, ASSAY, CORE, данные, интервал опробования, исходная информация, цифровая база данных.
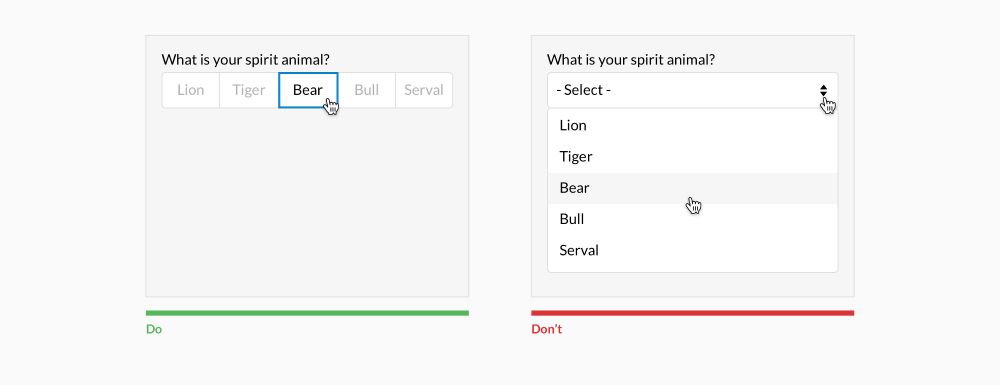
![]()
Редакція
Опубліковано
• Оновлено
![]()
![]()
![]()
![]()
![]()
Ошибки в дизайне форм и способы их исправления
Форма регистрации, многошаговая форма или интерфейс заполнения данных — формы являются одним из самых важных компонентов продакт дизайна. Эта статья посвящена наиболее общим “за” и “против” дизайна форм. Помните, что это общие предложения и у всех правил есть исключения.
…
Формы должны быть в виде одной колонки
 Множество колонок являются сложными для восприятия
Множество колонок являются сложными для восприятия
Надписи сверху
 Пользователи заполняют формы с надписями сверху намного охотнее, чем с надписями слева. Также, надписи сверху легко адаптируются под мобильное устройство. Однако стоит задуматься об использовании надписей слева в случае форм с большим количеством данных потому, что их проще читать, они экономят место по высоте и лучше воспринимаются чем надписи сверху.
Пользователи заполняют формы с надписями сверху намного охотнее, чем с надписями слева. Также, надписи сверху легко адаптируются под мобильное устройство. Однако стоит задуматься об использовании надписей слева в случае форм с большим количеством данных потому, что их проще читать, они экономят место по высоте и лучше воспринимаются чем надписи сверху.
Группируйте надписи со строками ввода
 Презентуйте надпись ближе к строке ввода данных и оставьте достаточно места между полями для удобства пользователя.
Презентуйте надпись ближе к строке ввода данных и оставьте достаточно места между полями для удобства пользователя.
Избегайте заглавных букв
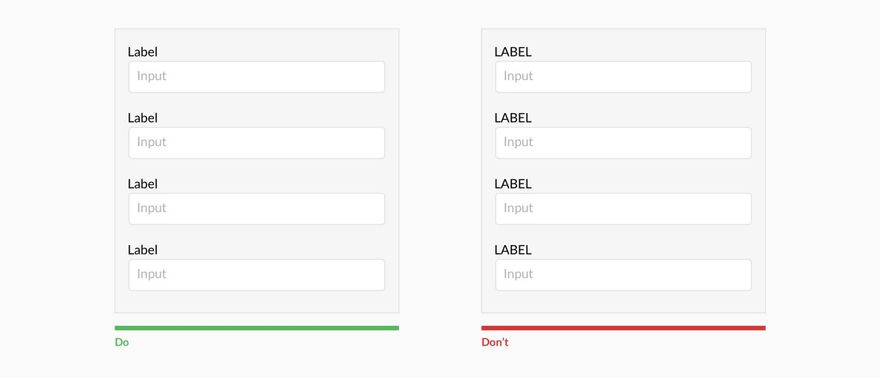 Используя только заглавные буквы в надписях, вы усложняете читабельность формы
Используя только заглавные буквы в надписях, вы усложняете читабельность формы
Отображайте все поля выбора, если их меньше 5ти
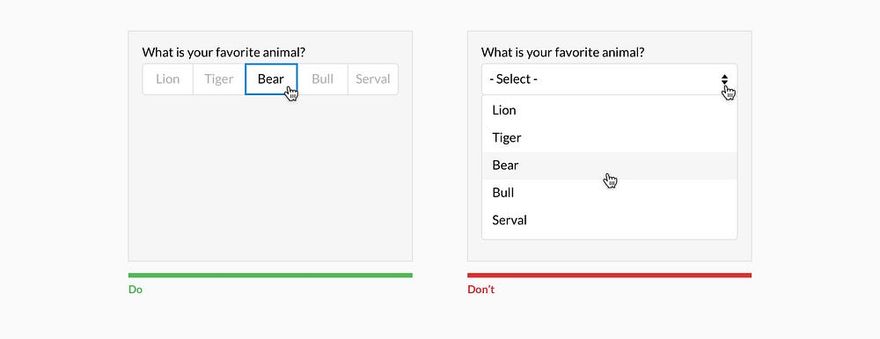 Использование поля выбора в “выпадающем окне”, требует от пользователя кликать дважды. Используйте обычный ввод для элементов более 5ти. Выпадающий список лучше использовать при наличии более 25ти элементов.
Использование поля выбора в “выпадающем окне”, требует от пользователя кликать дважды. Используйте обычный ввод для элементов более 5ти. Выпадающий список лучше использовать при наличии более 25ти элементов.
Не используйте плейсхолдеры в качестве надписей
 Частая ошибка связанная с экономией места в использовании заголовков в плейсхолдерах. Это служит причиной проблем юзабилити описанных Кэти Шервин из Nielsen Norman Group.
Частая ошибка связанная с экономией места в использовании заголовков в плейсхолдерах. Это служит причиной проблем юзабилити описанных Кэти Шервин из Nielsen Norman Group.
Размещайте чекбоксы (radio buttons) напротив выбора
 Размещая чекбоксы напротив элементов выбора упрощает читабельность
Размещая чекбоксы напротив элементов выбора упрощает читабельность
Делайте призыв к действию более понятным
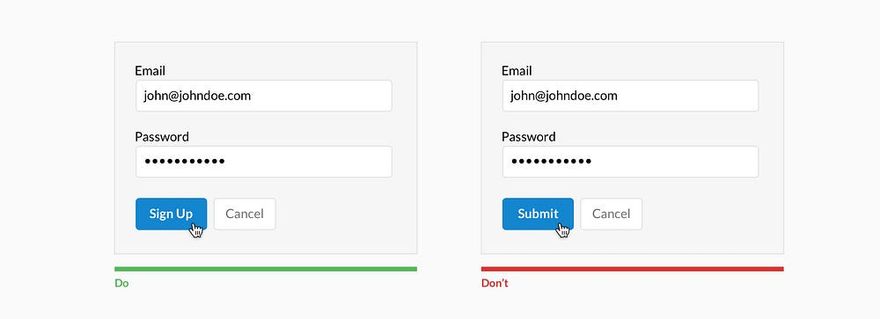 Призыв к действию должен показывать намерение.
Призыв к действию должен показывать намерение.
Уточняйте причину ошибки ввода
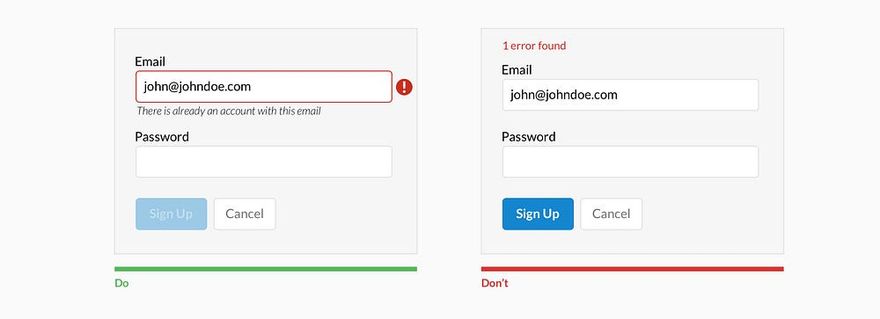 Укажите, где пользователь ошибся и покажите причину
Укажите, где пользователь ошибся и покажите причину
Используйте валидационное сообщение после заполнения поля (если только это не поможет пользователю в процессе)
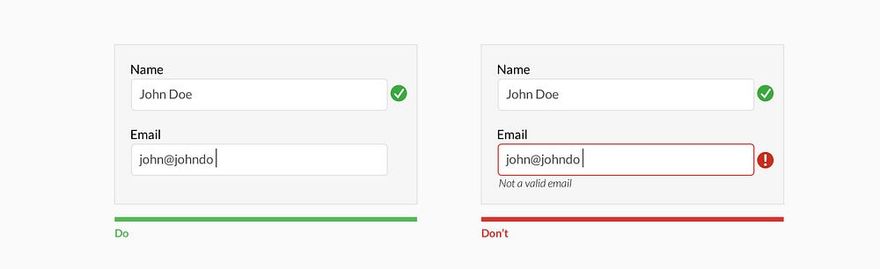 Не используйте валидационные сообщения на моменте ввода данных, если это не помогает пользователю, как в случае создания пароля, имени на сайте или сообщения со счетчиком символов.
Не используйте валидационные сообщения на моменте ввода данных, если это не помогает пользователю, как в случае создания пароля, имени на сайте или сообщения со счетчиком символов.
Не прячьте короткий вспомогательный текст
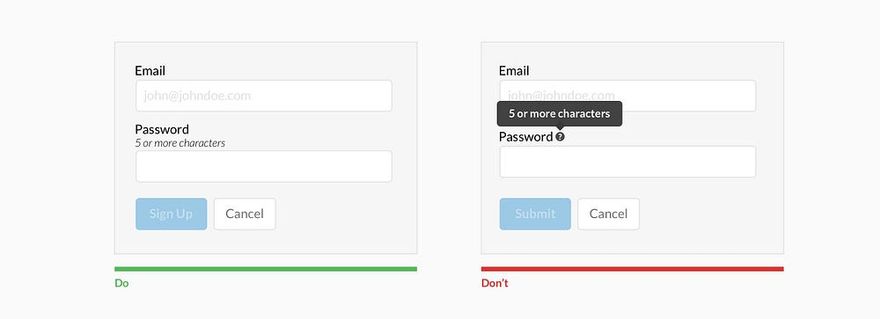 Используйте короткий вспомогательный текст, где это уместно. Для более длинного текста продумайте место рядом с местом ввода, чтобы не отвлекать пользователя.
Используйте короткий вспомогательный текст, где это уместно. Для более длинного текста продумайте место рядом с местом ввода, чтобы не отвлекать пользователя.
Отделите первостепенные действия от второстепенных
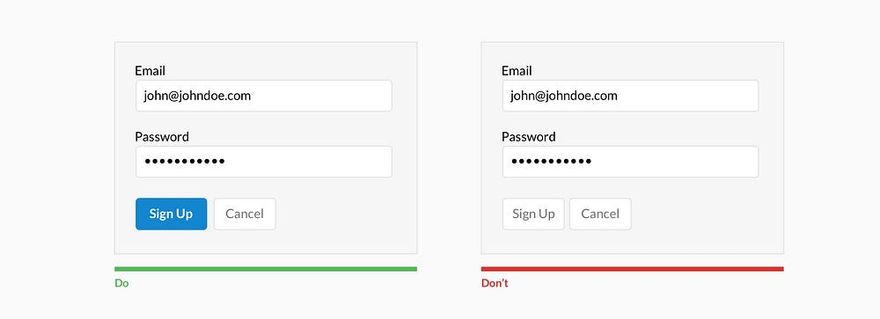 Ведется множество споров о том, включать ли вообще второстепенные действия.
Ведется множество споров о том, включать ли вообще второстепенные действия.
Используйте длину поля по мере заполнения
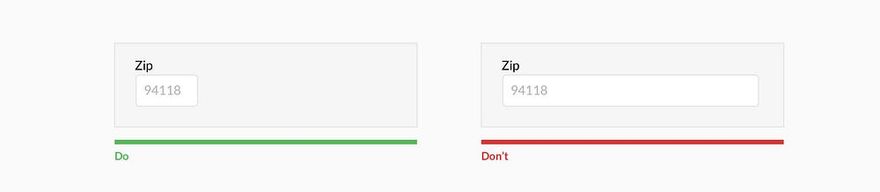 Длина поля должна меняться по мере заполнения. Возьмите это на вооружение при создание полей с определенным количеством символов, таких как номер телефона, почтовый индекс, и т. д.
Длина поля должна меняться по мере заполнения. Возьмите это на вооружение при создание полей с определенным количеством символов, таких как номер телефона, почтовый индекс, и т. д.
Отбросьте идею использовать * и просто укажите необязательные поля
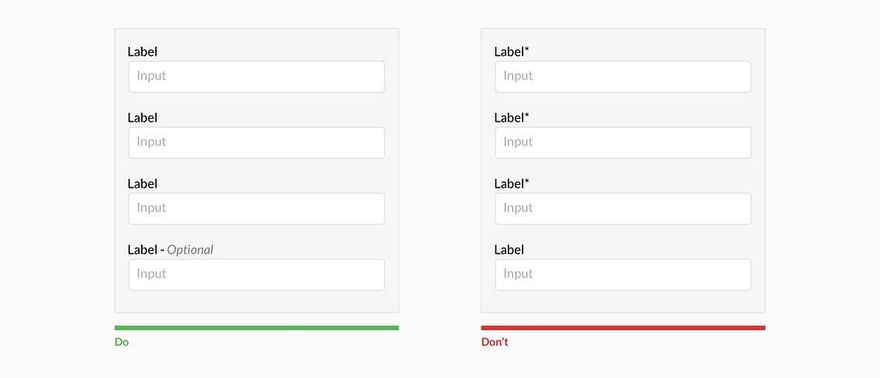 Пользователи не всегда понимают, зачем поле помечено (*). Вместо этого, лучше, укажите какие поля являются необязательными к заполнению.
Пользователи не всегда понимают, зачем поле помечено (*). Вместо этого, лучше, укажите какие поля являются необязательными к заполнению.
Группируйте соответствующую информацию
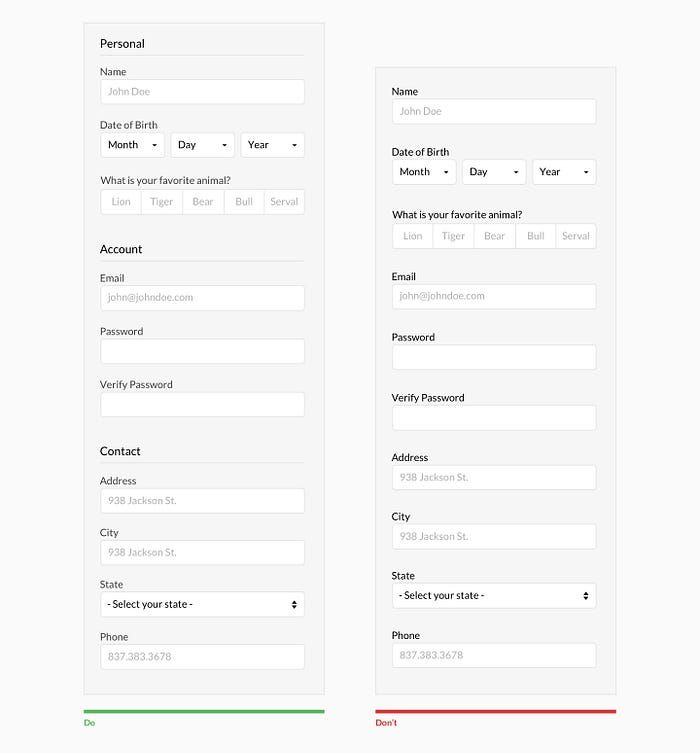 Пользователи мыслят обобщенными понятиями и длинные формы выглядят перегружено. Форма с логическими группами полей будет заполнена быстрее.
Пользователи мыслят обобщенными понятиями и длинные формы выглядят перегружено. Форма с логическими группами полей будет заполнена быстрее.
В чем вопрос?
Исключите необязательные поля и продумайте другие способы сбора информации о пользователе. Всегда спрашивайте себя, можно ли додумать, отложить или вообще исключить тот, или иной вопрос.
Ввод данных постоянно автоматизируется. Например, мобильные и другие “карманные” устройства собираю массу данных без ведома пользователей. Подумайте о методах использования социальных, интерактивных UI, СМС, имейл, голоса, оптического распознавания символов, локации, отпечатков пальцев, биометрии, и т. д.
Сделайте это интересным.
Жизнь коротка. Никто не хочет тратить время на заполнение форм. Общайтесь с пользователем. Развеселите его. Вдохновите. Привнесите эффект неожиданности. Задача дизайнера вызвать эмоции по отношению к бренду компании. Если сделать это правильно, конкурентоспособность вырастет. Не пренебрегайте правилами, которые описаны выше.
Перевод статьи Andrew Coyle
Время на прочтение
6 мин
Количество просмотров 8.2K

Многие компании считают, что работают и принимают решения на основе данных, но часто это не так. Ведь для того чтобы управление велось на основе данных, их, эти самые данные, недостаточно только собрать и свести в статистику.
Намного важнее провести правильный анализ, а для этого они должны быть «чисты».
Разбираться в чистоте данных и в основных качественных параметрах я начну с этой статьи.
Для достоверной аналитики должны быть соблюдены все «П» данных: правильные, правильно собранные, собранные в правильной форме, в правильном месте и в правильное время.
Если один из параметров нарушен, это может сказаться на достоверности всей аналитики, а значит нужно понимать, на что важно обращать внимание при работе с данными.
Главные аспекты качества данных
Доступность
У аналитиков должен быть доступ к необходимым данным, но, кроме этого, доступ должен быть и к инструментам, используемым в аналитике.
Точность
Все данные должны быть достоверны, а также указаны допустимые погрешности.
Точная температура — хорошие данные, а устаревший адрес, телефон или e-mail — нехорошие данные.
Взаимосвязанность
Всегда должна быть возможность связать одни данные с другими. Например, к номеру заказа должна быть привязана информация о клиенте, его адрес, контактная и платежная информации.
Полнота
Данные должны быть «жирными» и со всеми частями. «Инвалиды» с отсутствующей частью информации могут помешать получить качественную аналитику.
Непротиворечивость
Если данные не согласованы и противоречат друг другу, значит где-то закралась ошибка.
Так если адрес клиента присутствует в двух базах, то он должен совпадать. В противном случае необходимо выбрать один источник достоверным и игнорировать остальные до исправления ошибок.
Однозначность
Каждое поле с информацией должно иметь полноценное описание, не допускающее двусмысленных значений.
Релевантность
Данные должны соответствовать характеру анализа.
Например, статистика сезонных миграций леммингов слабо относится к сезонным колебаниям биржевых курсов.

Тот самый лемминг, не влияющий на биржевые курсы.
Надежность
Надежные данные — это одновременно полная и точная информация.
Своевременность
Бич российского бизнеса — несвоевременные данные.
Часто случается, что данные еще не успели обработать и проанализировать, а они уже устарели.
С устаревшими данными нельзя работать в построении кратковременной стратегии, их можно использовать только как основу для долгосрочного стратегического планирования и прогнозирования.
Еще один недостаток устаревших данных — они стали уже почти бесполезны, а компания несет издержки по их хранению и обработке.
Ошибка в любом из пунктов может привести к частичной или полной непригодности данных для использования, или, что хуже, к неправильным выводам, сделанным на основе ошибочных данных.
Данные с ошибками

Василиск — в его описании явно закралась ошибка.
Ошибки появляются на любом этапе работы с данными, и зачастую аналитики уже не могут повлиять на их исправление, так как данные специалисты являются заключительным звеном в работе с материалом и не могут контролировать сбор и обработку информации.
Давайте разберем основные причины возникновения ошибок и способы, которые помогут их избежать.
Генерация данных
Самая частая и очевидная причина ошибок: тут могут быть как технические причины, так и влияние человеческого фактора.
В случае технических причин и сбоев все решается калибровкой и правильной настройкой инструментов сбора информации.
Когда ремонт и калибровка не помогают в решении вопроса и данные продолжают поступать недостоверными, тогда одна из возможных причин — ненадежность приборов.
Так ИК-датчики, измеряющие расстояние до ближайшей стены при картографировании местности, могут давать погрешность метр и более или сбрасывать собранные данные. Доверять показаниям настолько ненадежных датчиков нельзя.
Человеческий фактор также может проявляться по-разному. Например, сотрудники могут не знать как правильно собирать данные или не уметь работать с инструментом, могут быть невнимательными или уставшими, не знать инструкции или неправильно их понимать.
▍Самое надежное и простое решение — стандартизировать как можно больше этапов процесса сбора данных.
Ввод данных
При ручной генерации данных необходимо их зафиксировать, на этом этапе возникает множество ошибок.
Как бы не расширялся электронный документооборот, многие данные до попадания в компьютер проходят через бумажные носители.
Ошибки часто случаются при расшифровке рукописных данных. Большинство исследований по решению ошибок расшифровки проводится в медицинской сфере, так как из-за малейших неточностей под угрозу ставится здоровье и жизнь пациента.
Так исследование показало, что 46% медицинских ошибок обусловлено неточностью при расшифровке рукописных данных. А уровень ошибок в медицинских базах данных достигал 26%, есть предположение, что это связано с тем, что персонал неправильно понял или не смог разобрать написанное от руки.
Так, например, некоторые результаты медицинских опросов населения показывают, что рост взрослого человека может быть 53 см или 112 см. И если в первом случае понятно, что закралась ошибка, и скорее всего рост реципиента был 153 см, то во втором случае рост может быть как правильным, так и ошибочным. При опросах часто встречаются ошибки-очепятки, такие как «аллергия на окошек» или вес 156 кг вместо 56 кг.
В среднем ошибки делятся на четыре типа:
- Запись
Ошибка, при которой данные были изначально записаны неверно. - Вставка
Появление дополнительного символа.
Например: 53,247 ► 523,247. - Удаление
Потеря одного или нескольких символов.
Например: 53,247 ► 53,27. - Перемена мест
Просто берем и меняем два или более символов местами.
Например: 53,247 ► 52,437.
Отдельно стоит рассмотреть диттографию (случайное повторение символа) и гаплографию (пропуск повторяющихся символов). С этими ошибками часто сталкиваются ученые, занимающиеся восстановлением поврежденных или переписанных от руки древних текстов. И это еще одна проблема, связанная с некачественными данными.
Часто ошибки встречаются в написании дат, а еще чаще при столкновении разных стандартов, таких как американский (месяц/день/год) и европейский (день/месяц/год).
И если иногда ясно, что это ошибка (23 марта — 3/25), то в других случаях она может быть не замечена (3 апреля — 3 / 5 или 5/3?).
Как снизить количество ошибок

Гиппогриф — гордое и величественное мифическое животное, разновидность грифонов. Да, на гравюре тоже он, но с ошибками в описании.
Первым действием нужно сократить количество этапов генерации данных до ввода. Если вы можете избежать участия бумажного носителя, как передаточного звена, исключайте его.
В электронных формах следует ввести проверку значений, особенно это важно при введении структурированных данных: индекс, номер телефона и код города, БИК, СНИЛС и р/с.
Во многих данных есть четкая структура, которая помогает снизить ошибки — это может быть и количество символов, и их разбивка по группам, и иные виды форматов.
▍При возможности исключайте ручной ввод данных и предлагайте оператору или пользователю выбрать значение из выпадающего списка.
Если же количество вариантов велико, то можно использовать форму вопрос-ответ с заключительным подтверждением правильности введенных данных.
Идеально — исключить человеческий фактор при вводе данных и автоматизировать процесс.
При расшифровке данных хорошо себя зарекомендовал «принцип двойной записи».
При использовании этого метода два сотрудника независимо друг от друга занимаются расшифровкой, а после результаты сравниваются и перепроверяются данные, в которых обнаружены расхождения.
Интересный метод проверки данных используется при передаче данных в цифровом формате.
Так, например, в номерах банковских счетов используется контрольное число (сумма).
Контрольное число — это когда после передаваемого номера добавляется число, используемое для проверки данных и обнаружения ошибок.
Так для числа 94121 контрольным числом будет 8, при последовательном складывании цифр получается сумма 17, продолжаем складывание и получаем 17=1+7=8.
Передаем 941218, а при получении система проводит обратные расчеты и, если сумма не совпадает, то число будет отмечено как ошибочное.
Контрольных чисел может быть несколько, по одному на каждый блок цифр.
У этого метода есть недостатки, связанные с ошибкой перестановки символов, но это лучше чем ничего.
На этом я закончу вводную статью по сбору данных и контролю их качества. Если информация была для вас полезна, то я буду рад обратной связи.
Возможно, вы с чем-то не согласны или хотите поделиться своими методами и наработками — приглашаю в комментарии и надеюсь на увлекательное и полезное обсуждение.
Всем спасибо за внимание и хорошего дня!
Источник информации
 Автор: Карл Андерсон
Автор: Карл Андерсон
Аналитическая культура. От сбора данных до бизнес-результатов
Creating a Data-Driven Organization
ISBN: 978-5-00100-781-4
Издательство: Манн, Иванов и Фербер