-
Гетероскедастичность и автокорреляция
-
Гетероскедастичность и ее последствия
-
Предположим, что
мы оцениваем парную регрессию, и истинное
регрессионное уравнение имеет следующий
вид:
|
, |
(1) |
Напомним еще раз
условия Гаусса-Маркова:
-
для всех наблюдений.
-
постоянна для
всех наблюдений. -
.
-
для всех наблюдений.
Во втором условии
Гаусса-Маркова утверждается, что
дисперсия случайного члена в каждом
наблюдении должна быть постоянной.
Такое утверждение может показаться
странным, и здесь требуется пояснение.
Случайный член в каждом наблюдении
имеет только одно значение, и может
возникнуть вопрос о том, что означает
его «дисперсия».
Имеется в виду его
возможное поведение до того, как сделана
выборка. Когда мы записываем модель
(1), первые два условия Гаусса-Маркова
указывают, что случайные члены
![]()
в
наблюдениях появляются на основе
вероятностных распределений, имеющих
нулевое математическое ожидание и одну
и ту же дисперсию. Их фактические значения
в выборке иногда будут положительными,
иногда – отрицательными, иногда –
относительно далекими от нуля, иногда
– относительно близкими к нулю, но у
нас нет причин a priori ожидать появления
особенно больших отклонений в любом
данном наблюдении. Другими словами,
вероятность того, что величина и примет
какое-то данное положительное (или
отрицательное) значение, будет одинаковой
для всех наблюдений. Это условие известно
как гомоскедастичностъ, что означает
«одинаковый разброс». Оно проиллюстрировано
в левой части рис. 1.
Вместе с тем для
некоторых выборок, возможно, более
целесообразно предположить, что
теоретическое распределение случайного
члена является разным для различных
наблюдений в выборке. В правой части
рис. 1 дисперсия величины
![]()
увеличивается по мере продолжения
выборочных наблюдений. Это не означает,
что случайный член обязательно будет
иметь особенно большие (положительные
или отрицательные) значения в конце
выборки, но это значит, что априорная
вероятность получения сильно отклоненных
величин будет относительно высока. Это
пример гетероскедастичности, что
означает «неодинаковый разброс».
Математически
гомоскедастичность и гетероскедастичность
могут определяться следующим образом:
-
гомоскедастичность:

и постоянна для всех наблюдений;
-
гетероскедастичностъ:

,
она не обязательно одинакова для всех
наблюдений.
На рис. 2 показано,
как будет выглядеть характерная диаграмма
рассеяния, если
– возрастающая функция от
и имеется гетероскедастичность типа,
показанного на рис. 1. Можно видеть, что,
хотя наблюдения не обязательно все
дальше отстоят от основной нестохастической
составляющей линии регрессии, по мере
роста
все же имеется тенденция к увеличению
их разброса.
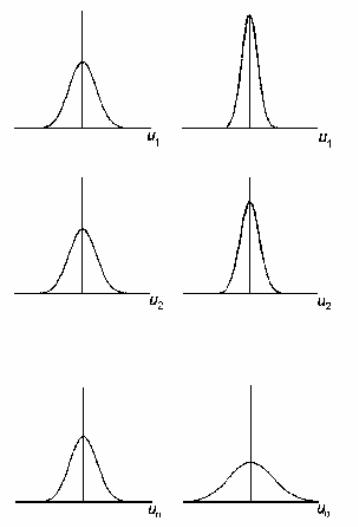
Рис. 6. 1.
Гомоскедастичность (слева) и
гетероскедастичность (справа)
Следует иметь в
виду, что гетероскедастичность не
обязательно относится к типу, показанному
на рис. 6. 1. Данное понятие относится к
любому случаю, в котором дисперсия
вероятностного распределения случайного
члена различна для разных наблюдений.
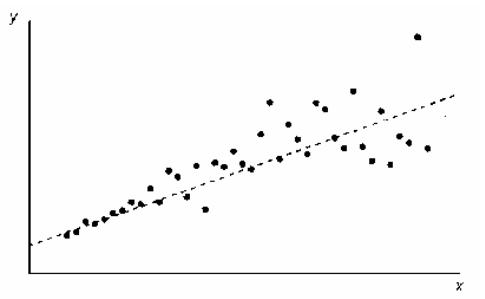
Рис. 6. 2.
Гетероскедастичный случайный член
Возникает вопрос,
почему гетероскедастичность имеет
существенное значение. В самом деле,
соответствующее условие Гаусса-Маркова
пока не использовалось в проводимом
анализе, и оно может показаться практически
не нужным. В частности, при рассмотрении
простой модели (1) и оцененного уравнения
|
, |
(2) |
в
доказательстве того, что
является несмещенной оценкой
и
— несмещенной оценкой
,
это условие не использовалось.
Это объясняется
двумя причинами. Первая касается
дисперсии оценок
и
.
Желательно, чтобы она была как можно
меньше, т.е. (в вероятностном смысле)
обеспечивала максимальную точность.
При отсутствии гетероскедастичности
обычные коэффициенты регрессии имеют
наиболее низкую дисперсию среди всех
несмещенных оценок, являющихся линейными
функциями от наблюдений у. Если имеет
место гетероскедастичность, то оценки
МНК, которые мы до сих пор использовали,
неэффективны. Можно, по меньшей мере в
принципе, найти другие оценки, которые
имеют меньшую дисперсию и, тем не менее,
являются несмещенными.
Вторая, не менее
важная причина заключается в том, что
сделанные оценки стандартных ошибок
коэффициентов регрессии будут неверны.
Они вычисляются на основе предположения
о том, что распределение случайного
члена гомоскедастично; если это не так,
то они неверны. Вполне вероятно, что
стандартные ошибки будут занижены, а
следовательно,
-статистика
– завышена, и будет получено неправильное
представление о точности оценки уравнения
регрессии.
Свойство
неэффективности можно легко объяснить
интуитивно. Предположим, что имеется
гетероскедастичность типа, показанного
на рис. 6.1 и рис. 6.2. Наблюдение, для
которого теоретическое распределение
случайного члена имеет малое стандартное
отклонение (как в наблюдении 1 на рис.
6.1), будет обычно находиться близко к
линии регрессии и, следовательно, может
стать хорошим направляющим ориентиром,
указывающим место этой линии. В
противоположность этому наблюдение,
где теоретическое распределение имеет
большое стандартное отклонение (как в
наблюдении
на рис. 6.1), не сможет существенно помочь
в определении местоположения линии
регрессии. Обычный МНК не делает различия
между качеством наблюдений, придавая
одинаковые «веса» каждому из них
независимо от того, является ли наблюдение
хорошим или плохим для определения
местоположения этой линии. Из этого
следует, что, если мы сможем найти способ
придания большего «веса» наблюдениям
высокого качества и меньшего – наблюдениям
низкого качества, мы, вероятно, получим
более точные оценки. Другими словами,
оценки для
и
будут более эффективными.
Гетероскедастичность
становится проблемой, когда значения
переменных в уравнении регрессии
значительно различаются в разных
наблюдениях. Если истинная зависимость
описывается уравнением (1) и изменения
значений невключенных переменных, и
ошибки измерения, влияя на случайный
член, делают его сравнительно малым при
малых
и
и сравнительно большим — при больших
и
,
то экономические переменные часто
совместно меняют свой масштаб.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Все курсы > Оптимизация > Занятие 4 (часть 1)
Прежде чем обратиться к теме множественной линейной регрессии, давайте вспомним, что было сделано до сих пор. Возможно, будет полезно посмотреть эти уроки, чтобы освежить знания.
- В рамках вводного курса мы узнали про моделирование взаимосвязи переменных и минимизацию ошибки при обучении алгоритма, а также научились строить несложные модели линейной регрессии с помощью библиотеки sklearn.
- При изучении объектно-ориентированного программирования мы создали класс простой линейной регрессии. Сегодня эти знания пригодятся при создании классов более сложных моделей.
- Также рекомендую вспомнить умножение векторов и матриц.
- Кроме того, в рамках текущего курса по оптимизации мы познакомились с понятием производной и методом градиентного спуска, а также построили модель простой линейной регрессии (использовав метод наименьших квадратов и градиент).
- Наконец, на прошлом занятии мы вновь поговорили про взаимосвязь переменных.
В рамках сегодняшнего занятия мы с нуля построим несколько алгоритмов множественной линейной регрессии.
Регрессионный анализ
Прежде чем обратиться к практике, обсудим некоторые теоретические вопросы регрессионного анализа.
Генеральная совокупность и выборка
Как мы уже знаем, множество всех имеющихся наблюдений принято считать генеральной совокупностью (population). И эти наблюдения, если в них есть взаимосвязи, можно теоретически аппроксимировать, например, линией регрессии. При этом важно понимать, что это некоторая идеальная модель, которую мы никогда не сможем построить.
Единственное, что мы можем сделать, взять выборку (sample) и на ней построить нашу модель, предполагая, что если выборка достаточно велика, она сможет достоверно описать генсовокупность.

Отклонение прогнозного значения от фактического для «идеальной» линии принято называть ошибкой (error или true error).
$$ \varepsilon = y-\hat{y} $$
Отклонение прогноза от факта для выборочной модели (которую мы и строим) называют остатками (residuals или residual error).
$$ \varepsilon = y-f(x) $$
В этом смысле среднеквадратическую ошибку (mean squared error, MSE) корректнее называть средними квадратичными остатками (mean squared residuals).
На практике ошибку и остатки нередко используют как взаимозаменяемые термины.
Уравнение множественной линейной регрессии
Посмотрим на уравнение множественной линейной регрессии.
$$ y = \theta_0 + \theta_1x_1 + \theta_2x_2 + … + \theta_jx_j + \varepsilon $$
В отличие от простой линейной регрессии в данном случае у нас несколько признаков x (независимых переменных) и несколько коэффициентов $ \theta $ («тета»).
Интерпретация результатов модели
Коэффициент $ \theta_0 $ задает некоторый базовый уровень (baseline) при условии, что остальные коэффициенты равны нулю и зачастую не имеет смысла с точки зрения интерпретации модели (нужен лишь для того, что поднять линию на нужный уровень).
Параметры $ \theta_1, \theta_2, …, \theta_n $ показывают изменение зависимой переменной при условии «неподвижности» остальных коэффициентов. Например, каждая дополнительная комната может увеличивать цену дома в 1.3 раза.
Переменная $ \varepsilon $ (ошибка) представляет собой отклонение фактических данных от прогнозных. В этой переменной могут быть заложены две составляющие. Во-первых, она может включать вариативность целевой переменной, описанную другими (не включенными в нашу модель) признаками. Во-вторых, «улавливать» случайный шум, случайные колебания.
Категориальные признаки
Модель линейной регрессии может включать категориальные признаки. Продолжая пример с квартирой, предположим, что мы строим модель, в которой цена зависит от того, находится ли квартира в центре города или в спальном районе.
Перед этим переменную необходимо закодировать, создав, например, через Label Encoder признак «центр», который примет значение 1, если квартира в центре, и 0, если она находится в спальном районе.
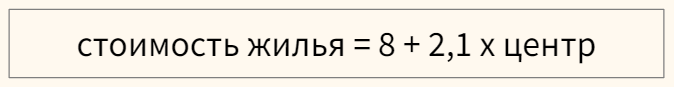
В модели, представленной выше, если квартира находится в центре (переменная «центр» равна единице), ее стоимость составит 10,1 миллиона рублей, если на окраине (переменная «центр» равна нулю) — лишь восемь.
Для категориального признака с множеством классов можно использовать one-hot encoding, если между классами признака отсутствует иерархия,
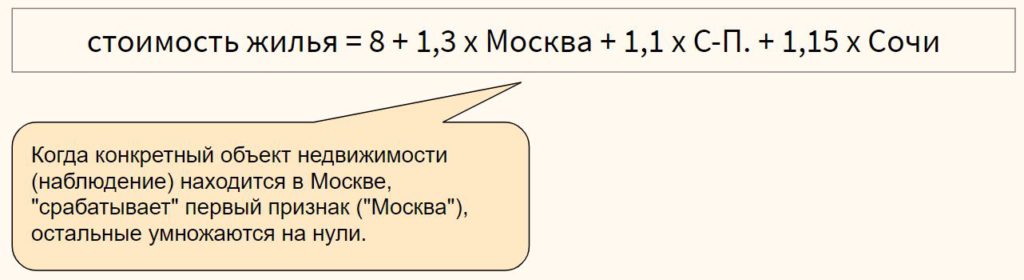
или, например, ordinal encoding в случае наличия иерархии классов в признаке

Выбросы в линейной регрессии
Как и коэффициент корреляции Пирсона, модель линейной регрессии чувствительна к выбросам (outliers), то есть наблюдениям, серьезно выпадающим из общей совокупности. Сравните рисунки ниже.

При наличии выброса (слева), линия регрессии имеет наклон и может использоваться для построения прогноза. Удалив это наблюдение (справа), линия регрессии становится горизонтальной и построение прогноза теряет смысл.
При этом различают два типа выбросов:
- горизонтальные выбросы или влиятельные точки (leverage points) — они сильно отклоняются от среднего по оси x; и
- вертикальные выбросы или просто выбросы (influential points) — отклоняются от среднего по оси y
Ключевое отличие заключается в том, что вертикальные выбросы влияют на наклон модели (изменяют ее коэффициенты), а горизонтальные — нет.
Сравним два графика.

На левом графике черная точка (leverage point) сильно отличается от остальных наблюдений, но наклон прямой линии регрессии с ее появлением не изменился. На правом графике, напротив, появление выброса (influential point) существенно изменяет наклон прямой.
На практике нас конечно больше интересуют influential points, потому что именно они существенно влияют на качество модели.
Если в простой линейной регрессии мы можем оценить leverage и influence наблюдения графически⧉, в многомерной модели это сделать сложнее. Можно использовать график остатков (об этом ниже) или применить один из уже известных нам методов выявления выбросов.
Про выявление leverage и infuential points можно почитать здесь⧉.
Допущения модели регрессии
Применение алгоритма линейной регрессии предполагает несколько допущений (assumptions) или условий, при выполнении которых мы можем говорить о качественно построенной модели.
1. Правильный выбор модели
Вначале важно убедиться, что данные можно аппроксимировать с помощью линейной модели (correct model specification).
Оценить распределение данных можно через график остатков (residuals plot), где по оси x отложен прогноз модели, а на оси y — сами остатки.

В отличие от простой линейной регрессии мы не используем точечную диаграмму X vs. y, потому что хотим оценить зависимость целевой переменной от всех признаков сразу.
Остатки модели относительно ее прогнозных значений должны быть распределены случайным образом без систематической составляющей (residuals do not follow a pattern).
- Если вы попробовали применить линейную модель с коэффициентами первой степени ($x_n^1$) и выявили некоторый паттерн в данных, можно попробовать полиномиальную или какую-либо еще функцию (об этом ниже).
- Кроме того, количественные признаки можно попробовать преобразовать таким образом, чтобы их можно было аппроксимировать прямой линией.
- Если ни то, ни другое не помогло, вероятно данные не стоит моделировать линейной регрессией.
Также замечу, что график остатков показывает выбросы в данных.

2. Нормальность распределения остатков
Среднее значение остатков должно быть равно нулю. Если это не так, и среднее значение меньше нуля (скажем –5), то это значит, что модель регулярно недооценивает (underestimates) фактические значения. В противном случае, если среднее больше нуля, переоценивает (overestimated).

Кроме того, предполагается, что остатки следуют нормальному распределению.
$$ \varepsilon \sim N(0, \sigma) $$
Проверить нормальность остатков можно визуально с помощью гистограммы или рассмотренных ранее критериев нормальности распределения.
Если остатки не распределены нормально, мы не сможем провести статистические тесты на значимость коэффициентов или построить доверительные интервалы. Иначе говоря, мы не сможем сделать статистически значимый вывод о надежности нашей модели.
Причинами могут быть (1) выбросы в данных или (2) неверный выбор модели. Решением может быть, соответственно, исследование выбросов, выбор новой модели и преобразование как признаков, так и целевой переменной.
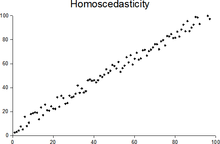
3. Гомоскедастичность остатков
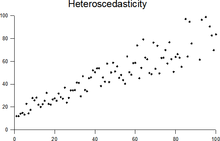
Гомоскедастичность (homoscedasticity) или одинаковая изменчивость остатков предполагают, что дисперсия остатков не изменяется для различных наблюдений. Противоположное и нежелательное явление называется гетероскедастичностью (heteroscedasticity) или разной изменчивостью.

Гетероскедастичность остатков показывает, что модель ошибается сильнее при более высоких или более низких значениях признаков. Как следствие, если для разных прогнозов у нас разная погрешность, модель нельзя назвать надежной (robust).
Как правило, гетероскедастичность бывает изначально заложена в данные. Ее можно попробовать исправить через преобразование целевой переменной (например, логарифмирование)
4. Отсутствие мультиколлинеарности
Еще одним важным допущением является отсутствие мультиколлинеарности. Мультиколлинеарность (multicollinearity) — это корреляция между зависимыми переменными. Например, если мы предсказываем стоимость жилья по квадратным метрам и количеству комнат, то метры и комнаты логичным образом также будут коррелировать между собой.
Почему плохо, если такая корреляция существует? Базовое предположение линейной регрессии — каждый коэффициент $\theta$ оказывает влияние на конечный результат при условии, что остальные коэффициенты постоянны. При мультиколлинеарности на целевую переменную оказывают эффект сразу несколько признаков, и мы не можем с точностью интерпретировать каждый из них.
Также говорят о том, что нужно стремиться к экономной (parsimonious) модели то есть такой модели, которая при наименьшем количестве признаков в наибольшей степени объясняет поведение целевой переменной.
Variance inflation factor
Расчет коэффициента
Variance inflation factor (VIF) или коэффициент увеличения дисперсии позволяет выявить корреляцию между признаками модели.
Принцип расчета VIF заключается в том, чтобы поочередно делать каждый из признаков целевой переменной и строить модель линейной регрессии на основе оставшихся независимых переменных. Например, если у нас есть три признака $x_1, x_2, x_3$, мы поочередно построим три модели линейной регрессии: $x_1 \sim x_2 + x_3, x_2 \sim x_1 + x_3$ и $x_3 \sim x_1 + x_3$.
Обратите внимание на новый для нас формат записи целевой и зависимых переменных модели через символ $\sim$.
Затем для каждой модели (то есть для каждого признака $x_1, x_2, x_3$) мы рассчитаем коэффициент детерминации $R^2$. Если он велик, значит данный признак можно объяснить с помощью других независимых переменных и имеется мультиколлинеарность. Если $R^2$ мал, то нельзя и мультиколлинеарность отсутствует.
Теперь рассчитаем VIF на основе $R^2$:
$$ VIF = \frac{1}{1-R^2} $$
При таком способе расчета большой (близкий к единице) $R^2$ уменьшит знаменатель и существенно увеличит VIF, при небольшом коэффициенте детерминации коэффициент увеличения дисперсии наоборот уменьшится.
Замечу, что $1-R^2$ принято называть tolerance.
Другие способы выявления мультиколлинеарности
Для выявления корреляции между независимыми переменными можно использовать точечные диаграммы или корреляционные матрицы. При этом важно понимать, что в данном случае мы выявляем зависимость лишь между двумя признаками. Корреляцию множества признаков выявляет только коэффициент увеличения дисперсии.
Интерпретация VIF
VIF находится в диапазон от единицы до плюс бесконечности. Как правило, при интерпретации показателей variance inflation factor придерживаются следующих принципов:
- VIF = 1, между признаками отсутствует корреляция
- 1 < VIF $\leq$ 5 — умеренная корреляция
- 5 < VIF $\leq$ 10 — высокая корреляция
- Более 10 — очень высокая
После расчета VIF можно по одному удалять признаки с наибольшей корреляцией и смотреть как изменится этот показатель для оставшихся независимых переменных.
5. Отсутствие автокорреляции остатков
На занятии по временным рядам (time series), мы сказали, что автокорреляция (autocorrelation) — это корреляция между значениями одной и той же переменной в разные моменты времени.
Применительно к модели линейной регрессии автокорреляция целевой переменной (для простой линейной регрессии) и автокорреляция остатков, residuals autocorrelation (для модели множественной регрессии) означает, что результат или прогноз зависят не от признаков, а от самой этой целевой переменной. В такой ситуации признаки теряют свою значимость и применение модели регрессии становится нецелесообразным.
Причины автокорреляции остатков
Существует несколько возможных причин:
- Прогнозирование целевой переменной с высокой автокорреляцией (например, если мы моделируем цену акций с помощью других переменных, то можем ожидать высокую автокорреляцию остатков, поскольку цена акций как правило сильно зависит от времени)
- Удаление значимых признаков
- Другие причины
Автокорреляция первого порядка
Дадим формальное определение автокорреляции первого порядка (first order correlation), то есть автокорреляции с лагом 1.
$$ \varepsilon_t = p\varepsilon_{t-1} + u_t $$
где $u_t$ — некоррелированная при различных t одинаково распределенная случайная величина (independent and identically distributed (i.i.d.) random variable), а $p$ — коэффициент автокорреляции, который находится в диапазоне $-1 < p < 1$. Чем он ближе к нулю, тем меньше зависимость остатка $\varepsilon_t$ от остатка предыдущего периода $\varepsilon_{t-1}$.
Такое уравнение также называется схемой Маркова первого порядка (Markov first-order scheme).
Обратите внимание, что для модели автокорреляции первого порядка коэффициент автокорреляции $p$ совпадает с коэффициентом авторегрессии AR(1) $\varphi$.
$$ y_t = c + \varphi \cdot y_{t-1} $$
Разумеется, мы можем построить модель автокорреляции, например, третьего порядка.
$$ \varepsilon_t = p_1\varepsilon_{t-1} + p_2\varepsilon_{t-2} + p_3\varepsilon_{t-3} + u_t $$
Выявление автокорреляции остатков
Для выявления автокорреляции остатков можно использовать график последовательности и график остатков с лагом 1, график автокорреляционной функции или критерий Дарбина-Уотсона.
График последовательности и график остатков с лагом 1
На графике последовательности (sequence plot) по оси x откладывается время (или порядковый номер наблюдения), а по оси y — остатки модели. Кроме того, на графике остатков с лагом 1 (lag-1 plot) остатки (ось y) можно сравнить с этими же значениями, взятыми с лагом 1 (ось x).
Рассмотрим вариант положительной автокорреляции (positive autocorrelation) на графиках остатков типа (а) и (б).
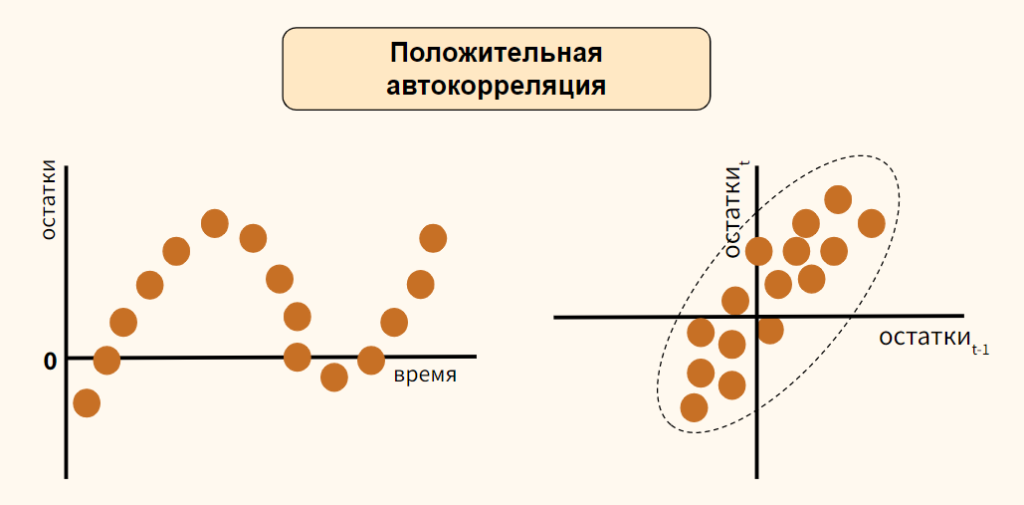
Как вы видите, при положительной автокорреляции в большинстве случаев, если одно наблюдение демонстрирует рост по отношению к предыдущему значению, то и последующее будет демонстрировать рост, и наоборот.
Теперь обратимся к отрицательной автокорреляции (negative autocorrelation).
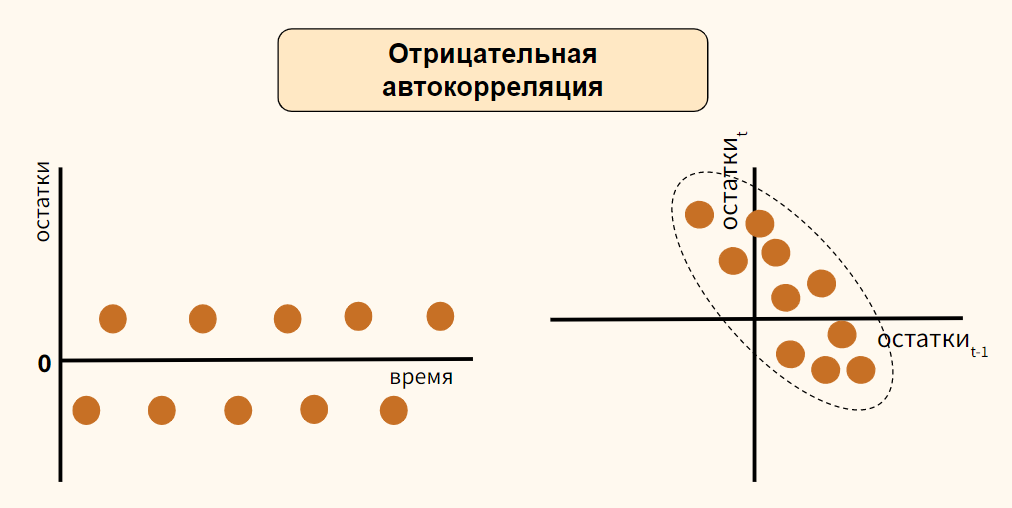
Здесь наоборот, если одно наблюдение демонстрирует рост показателя по отношению к предыдущему значению, то последующее наблюдение будет наоборот снижением. Опять же справедливо и обратное утверждение.
В случае отсутствия автокорреляции мы не должны увидеть на графиках какого-либо паттерна.

График автокорреляционной функции
Еще один способ выявить автокорреляцию — построить график автокорреляционной функции (autocorrelation function, ACF).

Напомню, такой график показывает автокорреляцию данных с этими же данными, взятыми с первым, вторым и последующими лагами.
Критерий Дарбина-Уотсона
Количественным выражением автокорреляции является критерий Дарбина-Уотсона (Durbin-Watson test). Этот критерий выявляет только автокорреляцию первого порядка.
- Нулевая гипотеза утверждает, что такая автокорреляция отсутствует ($p=0$),
- Альтернативная гипотеза соответственно утверждает, что присутствует
- Положительная ($p \approx -1$) или
- Отрицательная ($p \approx 1$) автокорреляция
Значение теста находится в диапазоне от 0 до 4.
- При показателе близком к двум можно говорить об отсутствии автокорреляции
- Приближение к четырем говорит о положительной автокорреляции
- К нулю, об отрицательной
Как избавиться от автокорреляции
Автокорреляцию можно преодолеть, добавив значимый признак в модель, выбрав иной тип модели (например, полиномиальную регрессию) или в целом перейдя к моделированию и прогнозированию временного ряда.
Рассмотрение этих методов находится за рамками сегодняшнего занятия. Перейдем к практике.
From Wikipedia, the free encyclopedia
In statistics, a sequence (or a vector) of random variables is homoscedastic () if all its random variables have the same finite variance; this is also known as homogeneity of variance. The complementary notion is called heteroscedasticity, also known as heterogeneity of variance. The spellings homoskedasticity and heteroskedasticity are also frequently used.[1][2][3]
Assuming a variable is homoscedastic when in reality it is heteroscedastic () results in unbiased but inefficient point estimates and in biased estimates of standard errors, and may result in overestimating the goodness of fit as measured by the Pearson coefficient.
The existence of heteroscedasticity is a major concern in regression analysis and the analysis of variance, as it invalidates statistical tests of significance that assume that the modelling errors all have the same variance. While the ordinary least squares estimator is still unbiased in the presence of heteroscedasticity, it is inefficient and inference based on the assumption of homoskedasticity is misleading. In that case, generalized least squares (GLS) was frequently used in the past.[4][5] Nowadays, standard practice in econometrics is to include Heteroskedasticity-consistent standard errors instead of using GLS, as GLS can exhibit strong bias in small samples if the actual Skedastic function is unknown.[6]
Because heteroscedasticity concerns expectations of the second moment of the errors, its presence is referred to as misspecification of the second order.[7]
The econometrician Robert Engle was awarded the 2003 Nobel Memorial Prize for Economics for his studies on regression analysis in the presence of heteroscedasticity, which led to his formulation of the autoregressive conditional heteroscedasticity (ARCH) modeling technique.[8]
Definition[edit]
Consider the linear regression equation  where the dependent random variable
where the dependent random variable  equals the deterministic variable
equals the deterministic variable  times coefficient
times coefficient  plus a random disturbance term
plus a random disturbance term  that has mean zero. The disturbances are homoscedastic if the variance of is a constant
that has mean zero. The disturbances are homoscedastic if the variance of is a constant  ; otherwise, they are heteroscedastic. In particular, the disturbances are heteroscedastic if the variance of depends on
; otherwise, they are heteroscedastic. In particular, the disturbances are heteroscedastic if the variance of depends on  or on the value of . One way they might be heteroscedastic is if
or on the value of . One way they might be heteroscedastic is if  (an example of a scedastic function), so the variance is proportional to the value of
(an example of a scedastic function), so the variance is proportional to the value of  .
.
More generally, if the variance-covariance matrix of disturbance across has a nonconstant diagonal, the disturbance is heteroscedastic.[9] The matrices below are covariances when there are just three observations across time. The disturbance in matrix A is homoscedastic; this is the simple case where OLS is the best linear unbiased estimator. The disturbances in matrices B and C are heteroscedastic. In matrix B, the variance is time-varying, increasing steadily across time; in matrix C, the variance depends on the value of . The disturbance in matrix D is homoscedastic because the diagonal variances are constant, even though the off-diagonal covariances are non-zero and ordinary least squares is inefficient for a different reason: serial correlation.

Examples[edit]
Heteroscedasticity often occurs when there is a large difference among the sizes of the observations.
A classic example of heteroscedasticity is that of income versus expenditure on meals. A wealthy person may eat inexpensive food sometimes and expensive food at other times. A poor person will almost always eat inexpensive food. Therefore, people with higher incomes exhibit greater variability in expenditures on food.
At a rocket launch, an observer measures the distance traveled by the rocket once per second. In the first couple of seconds, the measurements may be accurate to the nearest centimeter. After five minutes, the accuracy of the measurements may be good only to 100 m, because of the increased distance, atmospheric distortion, and a variety of other factors. So the measurements of distance may exhibit heteroscedasticity.
Consequences[edit]
One of the assumptions of the classical linear regression model is that there is no heteroscedasticity. Breaking this assumption means that the Gauss–Markov theorem does not apply, meaning that OLS estimators are not the Best Linear Unbiased Estimators (BLUE) and their variance is not the lowest of all other unbiased estimators.
Heteroscedasticity does not cause ordinary least squares coefficient estimates to be biased, although it can cause ordinary least squares estimates of the variance (and, thus, standard errors) of the coefficients to be biased, possibly above or below the true of population variance. Thus, regression analysis using heteroscedastic data will still provide an unbiased estimate for the relationship between the predictor variable and the outcome, but standard errors and therefore inferences obtained from data analysis are suspect. Biased standard errors lead to biased inference, so results of hypothesis tests are possibly wrong. For example, if OLS is performed on a heteroscedastic data set, yielding biased standard error estimation, a researcher might fail to reject a null hypothesis at a given significance level, when that null hypothesis was actually uncharacteristic of the actual population (making a type II error).
Under certain assumptions, the OLS estimator has a normal asymptotic distribution when properly normalized and centered (even when the data does not come from a normal distribution). This result is used to justify using a normal distribution, or a chi square distribution (depending on how the test statistic is calculated), when conducting a hypothesis test. This holds even under heteroscedasticity. More precisely, the OLS estimator in the presence of heteroscedasticity is asymptotically normal, when properly normalized and centered, with a variance-covariance matrix that differs from the case of homoscedasticity. In 1980, White proposed a consistent estimator for the variance-covariance matrix of the asymptotic distribution of the OLS estimator.[2] This validates the use of hypothesis testing using OLS estimators and White’s variance-covariance estimator under heteroscedasticity.
Heteroscedasticity is also a major practical issue encountered in ANOVA problems.[10]
The F test can still be used in some circumstances.[11]
However, it has been said that students in econometrics should not overreact to heteroscedasticity.[3] One author wrote, «unequal error variance is worth correcting only when the problem is severe.»[12] In addition, another word of caution was in the form, «heteroscedasticity has never been a reason to throw out an otherwise good model.»[3][13] With the advent of heteroscedasticity-consistent standard errors allowing for inference without specifying the conditional second moment of error term, testing conditional homoscedasticity is not as important as in the past.[6]
For any non-linear model (for instance Logit and Probit models), however, heteroscedasticity has more severe consequences: the maximum likelihood estimates (MLE) of the parameters will usually be biased, as well as inconsistent (unless the likelihood function is modified to correctly take into account the precise form of heteroscedasticity or the distribution is a member of the linear exponential family and the conditional expectation function is correctly specified).[14][15] Yet, in the context of binary choice models (Logit or Probit), heteroscedasticity will only result in a positive scaling effect on the asymptotic mean of the misspecified MLE (i.e. the model that ignores heteroscedasticity).[16] As a result, the predictions which are based on the misspecified MLE will remain correct. In addition, the misspecified Probit and Logit MLE will be asymptotically normally distributed which allows performing the usual significance tests (with the appropriate variance-covariance matrix). However, regarding the general hypothesis testing, as pointed out by Greene, “simply computing a robust covariance matrix for an otherwise inconsistent estimator does not give it redemption. Consequently, the virtue of a robust covariance matrix in this setting is unclear.”[17]
Correction[edit]
There are several common corrections for heteroscedasticity. They are:
- A stabilizing transformation of the data, e.g. logarithmized data. Non-logarithmized series that are growing exponentially often appear to have increasing variability as the series rises over time. The variability in percentage terms may, however, be rather stable.
- Use a different specification for the model (different X variables, or perhaps non-linear transformations of the X variables).
- Apply a weighted least squares estimation method, in which OLS is applied to transformed or weighted values of X and Y. The weights vary over observations, usually depending on the changing error variances. In one variation the weights are directly related to the magnitude of the dependent variable, and this corresponds to least squares percentage regression.[18]
- Heteroscedasticity-consistent standard errors (HCSE), while still biased, improve upon OLS estimates.[2] HCSE is a consistent estimator of standard errors in regression models with heteroscedasticity. This method corrects for heteroscedasticity without altering the values of the coefficients. This method may be superior to regular OLS because if heteroscedasticity is present it corrects for it, however, if the data is homoscedastic, the standard errors are equivalent to conventional standard errors estimated by OLS. Several modifications of the White method of computing heteroscedasticity-consistent standard errors have been proposed as corrections with superior finite sample properties.
- Wild bootstrapping can be used as a Resampling method that respects the differences in the conditional variance of the error term. An alternative is resampling observations instead of errors. Note resampling errors without respect for the affiliated values of the observation enforces homoskedasticity and thus yields incorrect inference.
- Use MINQUE or even the customary estimators
 (for independent samples with observations each), whose efficiency losses are not substantial when the number of observations per sample is large (), especially for small number of independent samples.[19]
(for independent samples with observations each), whose efficiency losses are not substantial when the number of observations per sample is large (), especially for small number of independent samples.[19]




Testing[edit]

Residuals can be tested for homoscedasticity using the Breusch–Pagan test,[20] which performs an auxiliary regression of the squared residuals on the independent variables. From this auxiliary regression, the explained sum of squares is retained, divided by two, and then becomes the test statistic for a chi-squared distribution with the degrees of freedom equal to the number of independent variables.[21] The null hypothesis of this chi-squared test is homoscedasticity, and the alternative hypothesis would indicate heteroscedasticity. Since the Breusch–Pagan test is sensitive to departures from normality or small sample sizes, the Koenker–Bassett or ‘generalized Breusch–Pagan’ test is commonly used instead.[22][additional citation(s) needed] From the auxiliary regression, it retains the R-squared value which is then multiplied by the sample size, and then becomes the test statistic for a chi-squared distribution (and uses the same degrees of freedom). Although it is not necessary for the Koenker–Bassett test, the Breusch–Pagan test requires that the squared residuals also be divided by the residual sum of squares divided by the sample size.[22] Testing for groupwise heteroscedasticity can be done with the Goldfeld–Quandt test.[23]
Due to the standard use of heteroskedasticity-consistent Standard Errors and the problem of Pre-test, econometricians nowadays rarely use tests for conditional heteroskedasticity.[6]
List of tests[edit]
Although tests for heteroscedasticity between groups can formally be considered as a special case of testing within regression models, some tests have structures specific to this case.
Generalisations[edit]
Homoscedastic distributions[edit]
Two or more normal distributions,  are both homoscedastic and lack Serial correlation if they share the same diagonals in their covariance matrix,
are both homoscedastic and lack Serial correlation if they share the same diagonals in their covariance matrix,  and their non-diagonal entries are zero. Homoscedastic distributions are especially useful to derive statistical pattern recognition and machine learning algorithms. One popular example of an algorithm that assumes homoscedasticity is Fisher’s linear discriminant analysis.
and their non-diagonal entries are zero. Homoscedastic distributions are especially useful to derive statistical pattern recognition and machine learning algorithms. One popular example of an algorithm that assumes homoscedasticity is Fisher’s linear discriminant analysis.
The concept of homoscedasticity can be applied to distributions on spheres.[27]
Multivariate data[edit]
The study of homescedasticity and heteroscedasticity has been generalized to the multivariate case, which deals with the covariances of vector observations instead of the variance of scalar observations. One version of this is to use covariance matrices as the multivariate measure of dispersion. Several authors have considered tests in this context, for both regression and grouped-data situations.[28][29] Bartlett’s test for heteroscedasticity between grouped data, used most commonly in the univariate case, has also been extended for the multivariate case, but a tractable solution only exists for 2 groups.[30] Approximations exist for more than two groups, and they are both called Box’s M test.
See also[edit]
- Heterogeneity
- Spherical error
- Heteroskedasticity-consistent standard errors
References[edit]
- ^ For the Greek etymology of the term, see McCulloch, J. Huston (1985). «On Heteros*edasticity». Econometrica. 53 (2): 483. JSTOR 1911250.
- ^ a b c d
White, Halbert (1980). «A heteroskedasticity-consistent covariance matrix estimator and a direct test for heteroskedasticity». Econometrica. 48 (4): 817–838. CiteSeerX 10.1.1.11.7646. doi:10.2307/1912934. JSTOR 1912934. - ^ a b c
Gujarati, D. N.; Porter, D. C. (2009). Basic Econometrics (Fifth ed.). Boston: McGraw-Hill Irwin. p. 400. ISBN 9780073375779. - ^ Goldberger, Arthur S. (1964). Econometric Theory. New York: John Wiley & Sons. pp. 238–243. ISBN 9780471311010.
- ^ Johnston, J. (1972). Econometric Methods. New York: McGraw-Hill. pp. 214–221.
- ^ a b c Angrist, Joshua D.; Pischke, Jörn-Steffen (2009-12-31). Mostly Harmless Econometrics: An Empiricist’s Companion. Princeton University Press. doi:10.1515/9781400829828. ISBN 978-1-4008-2982-8.
- ^ Long, J. Scott; Trivedi, Pravin K. (1993). «Some Specification Tests for the Linear Regression Model». In Bollen, Kenneth A.; Long, J. Scott (eds.). Testing Structural Equation Models. London: Sage. pp. 66–110. ISBN 978-0-8039-4506-7.
- ^ Engle, Robert F. (July 1982). «Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation». Econometrica. 50 (4): 987–1007. doi:10.2307/1912773. ISSN 0012-9682. JSTOR 1912773.
- ^ Peter Kennedy, A Guide to Econometrics, 5th edition, p. 137.
- ^ Jinadasa, Gamage; Weerahandi, Sam (1998). «Size performance of some tests in one-way anova». Communications in Statistics — Simulation and Computation. 27 (3): 625. doi:10.1080/03610919808813500.
- ^ Bathke, A (2004). «The ANOVA F test can still be used in some balanced designs with unequal variances and nonnormal data». Journal of Statistical Planning and Inference. 126 (2): 413–422. doi:10.1016/j.jspi.2003.09.010.
- ^ Fox, J. (1997). Applied Regression Analysis, Linear Models, and Related Methods. California: Sage Publications. p. 306. (Cited in Gujarati et al. 2009, p. 400)
- ^ Mankiw, N. G. (1990). «A Quick Refresher Course in Macroeconomics». Journal of Economic Literature. 28 (4): 1645–1660 [p. 1648]. doi:10.3386/w3256. JSTOR 2727441.
- ^ Giles, Dave (May 8, 2013). «Robust Standard Errors for Nonlinear Models». Econometrics Beat.
- ^ Gourieroux, C.; Monfort, A.; Trognon, A. (1984). «Pseudo Maximum Likelihood Methods: Theory». Econometrica. 52 (3): 681–700. doi:10.2307/1913471. ISSN 0012-9682.
- ^ Ginker, T.; Lieberman, O. (2017). «Robustness of binary choice models to conditional heteroscedasticity». Economics Letters. 150: 130–134. doi:10.1016/j.econlet.2016.11.024.
- ^ Greene, William H. (2012). «Estimation and Inference in Binary Choice Models». Econometric Analysis (Seventh ed.). Boston: Pearson Education. pp. 730–755 [p. 733]. ISBN 978-0-273-75356-8.
- ^ Tofallis, C (2008). «Least Squares Percentage Regression». Journal of Modern Applied Statistical Methods. 7: 526–534. doi:10.2139/ssrn.1406472. SSRN 1406472.
- ^ J. N. K. Rao (March 1973). «On the Estimation of Heteroscedastic Variances». Biometrics. 29 (1): 11–24. doi:10.2307/2529672. JSTOR 2529672.
- ^ Breusch, T. S.; Pagan, A. R. (1979). «A Simple Test for Heteroscedasticity and Random Coefficient Variation». Econometrica. 47 (5): 1287–1294. doi:10.2307/1911963. ISSN 0012-9682. JSTOR 1911963.
- ^ Ullah, Muhammad Imdad (2012-07-26). «Breusch Pagan Test for Heteroscedasticity». Basic Statistics and Data Analysis. Retrieved 2020-11-28.
- ^ a b Pryce, Gwilym. «Heteroscedasticity: Testing and Correcting in SPSS» (PDF). pp. 12–18. Archived (PDF) from the original on 2017-03-27. Retrieved 26 March 2017.
- ^ Baum, Christopher F. (2006). «Stata Tip 38: Testing for Groupwise Heteroskedasticity». The Stata Journal: Promoting Communications on Statistics and Stata. 6 (4): 590–592. doi:10.1177/1536867X0600600412. ISSN 1536-867X. S2CID 117349246.
- ^ R. E. Park (1966). «Estimation with Heteroscedastic Error Terms». Econometrica. 34 (4): 888. doi:10.2307/1910108. JSTOR 1910108.
- ^ Glejser, H. (1969). «A new test for heteroscedasticity». Journal of the American Statistical Association. 64 (325): 316–323. doi:10.1080/01621459.1969.10500976.
- ^ Machado, José A. F.; Silva, J. M. C. Santos (2000). «Glejser’s test revisited». Journal of Econometrics. 97 (1): 189–202. doi:10.1016/S0304-4076(00)00016-6.
- ^ Hamsici, Onur C.; Martinez, Aleix M. (2007) «Spherical-Homoscedastic Distributions: The Equivalency of Spherical and Normal Distributions in Classification», Journal of Machine Learning Research, 8, 1583-1623
- ^
- ^ Gupta, A. K.; Tang, J. (1984). «Distribution of likelihood ratio statistic for testing equality of covariance matrices of multivariate Gaussian models». Biometrika. 71 (3): 555–559. doi:10.1093/biomet/71.3.555. JSTOR 2336564.
- ^ d’Agostino, R. B.; Russell, H. K. (2005). «Multivariate Bartlett Test». Encyclopedia of Biostatistics. doi:10.1002/0470011815.b2a13048. ISBN 978-0470849071.
Further reading[edit]
Most statistics textbooks will include at least some material on homoscedasticity and heteroscedasticity. Some examples are:
- Asteriou, Dimitros; Hall, Stephen G. (2011). Applied Econometrics (Second ed.). Palgrave MacMillan. pp. 109–147. ISBN 978-0-230-27182-1.
- Davidson, Russell; MacKinnon, James G. (1993). Estimation and Inference in Econometrics. New York: Oxford University Press. pp. 547–582. ISBN 978-0-19-506011-9.
- Dougherty, Christopher (2011). Introduction to Econometrics. New York: Oxford University Press. pp. 280–299. ISBN 978-0-19-956708-9.
- Gujarati, Damodar N.; Porter, Dawn C. (2009). Basic Econometrics (Fifth ed.). New York: McGraw-Hill Irwin. pp. 365–411. ISBN 978-0-07-337577-9.
- Kmenta, Jan (1986). Elements of Econometrics (Second ed.). New York: Macmillan. pp. 269–298. ISBN 978-0-02-365070-3.
- Maddala, G. S.; Lahiri, Kajal (2009). Introduction to Econometrics (Fourth ed.). New York: Wiley. pp. 211–238. ISBN 978-0-470-01512-4.
External links[edit]
- Econometrics lecture (topic: heteroscedasticity) on YouTube by Mark Thoma
Гомоскедастичность – допущение линейной регрессии об «одинаковости» Дисперсии (Variance). Иными словами, разность между реальным Ypred и предсказанным Yactual значениями, скажем, Линейной регрессии (Linear Regresion) остается в определенном известном диапазоне, что позволяет в принципе использовать такую Модель (Model). В случае такого единообразия ошибок Наблюдения (Observation) с большими значениями будут иметь то же влияние на предсказывающий Алгоритм (Algorithm), что и наблюдения с меньшими значениями:

Линейная регрессия базируется на предположении, что для всех случаев ошибки будут одинаковыми и с очень малой дисперсией.
Пример. У нас есть две переменные – высота дерева навскидку и реальный его рост. Естественно, по мере увеличения оценочной высоты реальные тоже растут. Итак, мы подбираем модель линейной регрессии и видим, что ошибки имеют одинаковую дисперсию:

Прогнозы почти совпадают с линейной регрессией и имеют одинаковую известную дисперсию повсюду. Кроме того, если мы нанесем эти остатки на ось X, мы увидим их вдоль прямой линии, параллельной оси X. Это явный признак гомоскедастичности.

Когда это условие нарушается, в модели присутствует Гетероскедастичность (Heteroscedasticity). Предположим, что для деревьев с меньшей приблизительной высотой разность между прогнозируемым и реальным значением меньше, чем для высоких представителей флоры. По мере увеличения высоты дисперсия в прогнозах увеличивается, что приводит к увеличению значения ошибки или Остатка (Residual). Когда мы снова построим график остатков, то увидим типичную коническую кривую, которая четко указывает на наличие гетероскедастичности в модели:

Гетероскедастичность – это систематическое увеличение или уменьшение дисперсии остатков в диапазоне независимых переменных. Это проблема, потому нарушается базовое предположение о линейной регрессии: все ошибки должны иметь одинаковую дисперсию.
Как узнать, присутствует ли гетероскедастичность?
Проще говоря, самый простой способ узнать, присутствует ли гетероскедастичность, – построить график остатков. Если вы видите какую-либо закономерность, значит, есть гетероскедастичность. Обычно значения увеличиваются, образуя конусообразную кривую.
Причины гетероскедастичности
- Есть большая разница в переменной. Другими словами, когда наименьшее и наибольшее значения переменной слишком экстремальны. Это также могут быть Выбросы (Outlier).
- Мы выбираем неправильную модель. Если вы подгоните модель линейной регрессии к нелинейным данным, это приведет к гетероскедастичности.
- Когда масштаб значений в переменной некорректен (например, стоит рассматривать данные по сезонам, а не по дням).
- Когда для регрессии используется неправильное преобразование данных.
- Когда в данных присутствует Скошенность (Skewness).
Чистая и нечистая гетероскедастичности
Когда мы подбираем правильную модель (линейную или нелинейную) и все же есть видимый образец в остатках, это называется чистой гетероскедастичностью.
Однако, если мы подбираем неправильную модель, а затем наблюдаем закономерность в остатках, то это случай нечистой гетероскедастичности. В зависимости от типа гетероскедастичности необходимо принять меры для ее преодоления. Это зависит и от сферы, в которой мы работаем.
Эффекты гетероскедастичности в Машинном обучении
Как мы обсуждали ранее, модель линейной регрессии делает предположение о наличии гомоскедастичности в данных. Если это предположение неверно, мы не сможем доверять полученным результатам.
Наличие гетероскедастичности делает коэффициенты менее точными, и, следовательно, правильные находятся дальше от значения Генеральной совокупности (Population).
Как лечить гетероскедастичность?
Если мы обнаружили гетероскедастичность, есть несколько способов справиться с ней. Во-первых, давайте рассмотрим пример, в котором у нас есть две переменные: население города и количество заражений COVID-19.
В этом примере будет огромная разница в количестве заражений в крупных мегаполисах по сравнению с небольшими городами. Переменная «Количество инфекций» будет Целевой переменной (Target Variable), а «Население города» – Предиктором (Predictor Variable). Мы знаем, что в модели присутствует гетероскедастичность, и ее необходимо исправить.
В нашем случае, источник проблемы – это переменная с большой дисперсией (Население). Есть несколько способов справиться с подобным неоднообразием остатков, мы же рассмотрим три таких метода.
Управление переменными
Мы можем внести некоторые изменения в имеющиеся переменные, чтобы уменьшить влияние этой большой дисперсии на прогнозы модели. Один из способов сделать это – осуществить Нормализацию (Normalization), то есть привести значения Признака (Feature) к диапазону от 0 до 1. Это заставит признаки передавать немного другую информацию. От проблемы и данных будет зависеть, можно ли реализовать такой подход.
Этот метод требует минимальных модификаций и часто помогает решить проблему, а в некоторых случаях даже повысить производительность модели.
В нашем случае, мы изменим параметр «Количество инфекций» на «Скорость заражения». Это поможет уменьшить дисперсию, поскольку совершенно очевидно, что число инфекций в городах с большой численностью населения будет большим.
Взвешенная регрессия
Взвешенная регрессия – это модификация нормальной регрессии, при которой точкам данных присваиваются определенные Веса (Weights) в соответствии с их дисперсией. Те, у которых есть бо́льшая дисперсия, получают небольшой вес, а те, у которых меньшая дисперсия, получают бо́льший вес.
Таким образом, когда веса возведены в квадрат, это позволяет снизить влияние остатков с большой дисперсией.
Когда используются правильные веса, гетероскедастичность заменяется гомоскедастичностью. Но как найти правильный вес? Один из быстрых способов – использовать инверсию этой переменной в качестве веса (население города превратится в дробь 1/n, где n – число жителей).
Трансформация
Преобразование данных – последнее средство, поскольку при этом вы теряете интерпретируемость функции. Это означает, что вы больше не сможете легко объяснить, что показывает признак. Один из способов – взятие логарифма. Воспринять новые значения высоты дерева (например, 16 метров превратятся в ≈2.772) будет сложнее.
Фото: @sorasagano
Автор оригинальной статьи: Pavan Vadapalli