Интеграл вероятностей
Интегральная
функция нормального распределения
результатов измерения F
(X) или ошибок F(Δx)
в новых переменных будет иметь один и
тот же вид:
![]() (26)
(26)
Вероятность
того, что возможный результат измерения
Х окажется внутри заданного интервала
(Х1,
Х2)
согласно (26) может быть вычислен по
уравнению:
![]()
где
![]()
![]()
В
частности, для симметричного относительно
истинного значения Х0
интервала (![]() )
)
получим:
![]() (27)
(27)
Здесь
учитывается, что функция
![]() является нечетной.
является нечетной.
Функция
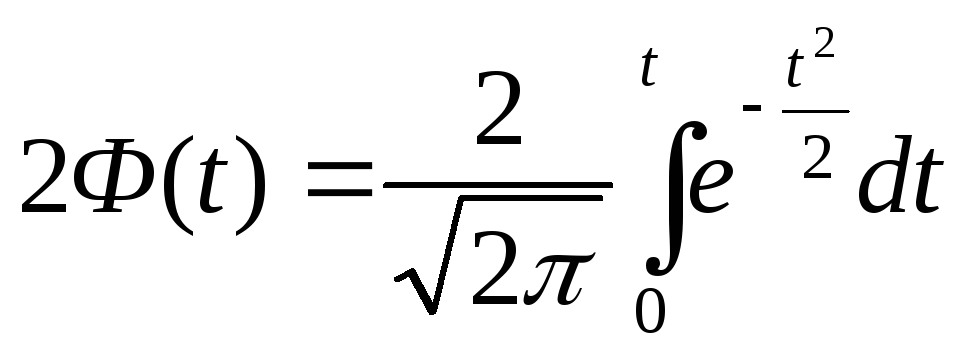 (28)
(28)
называется
функцией Лапласа или интегралом
вероятностей (табл.1).
Таблица
1
Функция
Лапласа
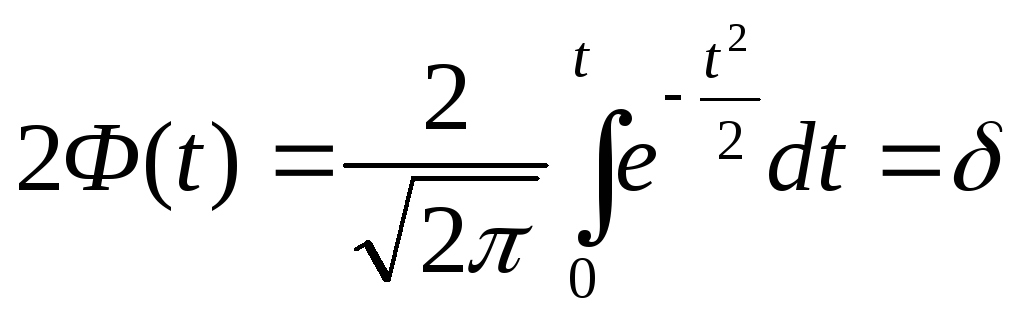
|
t |
2Ф(t) |
t |
2Ф(t) |
t |
2Ф(t) |
t |
2Ф(t) |
|
0, |
0,0000 |
1,0 |
0,6827 |
2 |
0,9545 |
3 |
0,9973 |
|
0,5 |
0,3829 |
1,5 |
0,8664 |
2,5 |
0,9876 |
3,5 |
0,9995 |
Интеграл
вероятностей (28) по уравнению (27) позволяет
вычислять вероятность нахождения
результата измерения Х или его ошибки
ΔХ в заданном симметричном относительно
центра распределения интервала (-σt,
σt
). Для этого нужно величину![]() заданного интервале (
заданного интервале (![]() )
)
или (![]() )
)
выразить в долях σ .т.е. найти![]() и по табл1 определить искомую вероятность
и по табл1 определить искомую вероятность![]() .
.
Решается
и обратная задача. Для заданной вероятности
δ (по табл.1) определяют t
и по известному σ находят искомый
интервал (![]() ).
).
Найдем
значения вероятностей δ для интервалов
(![]() )
)
приt=
I. 2. 3 :
![]()
![]()
![]() Из
Из
последнего равенства следует, что 99,73%
всех результатов измерений находятся
в пределах интервала
(![]() )
)
и лишь 0,27% — за его пределами.
На
рис.4 искомые вероятности δ изображены
заштрихованными площадями под кривыми
Гаусса f(t).
Вся площадь код кривой равна единице
(на рис. 4а
-t=1,
δ=0,68; 4б –t=2,
δ=0,95;
4в –t=3,
δ=0,997).
Те
результаты измерений, ошибки которых
вышли за пределы ± 3 σ , имеют очень малую
вероятность и такие измерения практически
невозможны («правило трех сигм»).
При большом числе отсчетов “правило
трех сигм” применяют для выявления
грубых ошибок — промахов.

Ошибка среднего арифметического
На
практике обычно вы-полняется некоторый
ряд из n
измерений
x1,
x2,
x3,…
xn.
(29)
Этот
ряд можно рассматривать как случайную
выборку из нормальной генеральной
совокупности возможных ре-зультатов с
математическим ожиданием М(Х)=Х0
и диспер- сией :D(х)=σ2.
В
качестве приближенного значения Х0
целесообразно принять среднее
арифмети-ческое из результатов изме-рений:
![]() (30)
(30)
Основной
задачей теории ошибок является оценка
точности приближенного равенства (30).
Среднее
арифметическое
![]() случайных величин является также
случайных величин является также
случайной величиной, имеющей нормальное
распределение с тем же центром М(Х)=Х0,
но с дисперсией
![]() (31)
(31)
Величину
![]() называют средней квадратичной ошибкой
называют средней квадратичной ошибкой
среднего арифметического. Следовательно,
средняя квадратичная ошибка среднего
арифметического изn
измерений в
![]() раз меньше средней квадратичной ошибки
раз меньше средней квадратичной ошибки
отдельного измерения.
Следует
помнить, что σ
зависит от обстоятельств измерений
изучаемого объекта, инструмента,
обстановки измерений и наблюдателя.
Поэтому когда характеризуют точность
применяемого способа измерения или же
сравнивают качество отдельных результатов
(выделение промахов), пользуются величиной
σ. Когда же оценивают точность
окончательного результата измерений
(среднего арифметического), применяют
![]() .
.
Остается
выяснить, как можно вычислить
![]() из опытных данных (29).
из опытных данных (29).
Согласно
определению (12) дисперсия
![]() можно было бы вычислить следующим
можно было бы вычислить следующим
образом:
![]()
однако
нам неизвестно истинное значение х0.
Если
Х0
заменить его приближенным значением
![]() ,
,
то, как показывает теория, для вычисления
дисперсии получится приближенная
формула:
![]() (32)
(32)
Дисперсию
![]() называют выборочной дисперсией, а
называют выборочной дисперсией, а
разность
![]() (33)
(33)
остаточной
ошибкой отдельного измерения. Извлекая
квадратный корень из (32), получим
 (34)
(34)
Эта
формула, определяющая среднюю квадратичную
ошибку по данным случайной выборки,
называется формулой Бесселя.
Из
выражения (31) аналогично найдем
приближенную оценку средней квадратичной
ошибки среднего арифметического
 (35)
(35)
Соседние файлы в папке МЕХАНИКА
- #
12.03.20151.05 Mб290BAZA.XLS
- #
- #
- #
- #
- #
- #
- #
Результат любого измерения не определён однозначно и имеет случайную составляющую.
Поэтому адекватным языком для описания погрешностей является язык вероятностей.
Тот факт, что значение некоторой величины «случайно», не означает, что
она может принимать совершенно произвольные значения. Ясно, что частоты, с которыми
возникает те или иные значения, различны. Вероятностные законы, которым
подчиняются случайные величины, называют распределениями.
2.1 Случайная величина
Случайной будем называть величину, значение которой не может быть достоверно определено экспериментатором. Чаще всего подразумевается, что случайная величина будет изменяться при многократном повторении одного и того же эксперимента. При интерпретации результатов измерений в физических экспериментах, обычно случайными также считаются величины, значение которых является фиксированным, но не известно экспериментатору. Например смещение нуля шкалы прибора. Для формализации работы со случайными величинами используют понятие вероятности. Численное значение вероятности того, что какая-то величина примет то или иное значение определяется либо как относительная частота наблюдения того или иного значения при повторении опыта большое количество раз, либо как оценка на основе данных других экспериментов.
Замечание.
Хотя понятия вероятности и случайной величины являются основополагающими, в литературе нет единства в их определении. Обсуждение формальных тонкостей или построение строгой теории лежит за пределами данного пособия. Поэтому на начальном этапе лучше использовать «интуитивное» понимание этих сущностей. Заинтересованным читателям рекомендуем обратиться к специальной литературе: [5].
Рассмотрим случайную физическую величину x, которая при измерениях может
принимать непрерывный набор значений. Пусть
P[x0,x0+δx] — вероятность того, что результат окажется вблизи
некоторой точки x0 в пределах интервала δx: x∈[x0,x0+δx].
Устремим интервал
δx к нулю. Нетрудно понять, что вероятность попасть в этот интервал
также будет стремиться к нулю. Однако отношение
w(x0)=P[x0,x0+δx]δx будет оставаться конечным.
Функцию w(x) называют плотностью распределения вероятности или кратко
распределением непрерывной случайной величины x.
Замечание. В математической литературе распределением часто называют не функцию
w(x), а её интеграл W(x)=∫w(x)𝑑x. Такую функцию в физике принято
называть интегральным или кумулятивным распределением. В англоязычной литературе
для этих функций принято использовать сокращения:
pdf (probability distribution function) и
cdf (cumulative distribution function)
соответственно.
Гистограммы.
Проиллюстрируем наглядно понятие плотности распределения. Результат
большого числа измерений случайной величины удобно представить с помощью
специального типа графика — гистограммы.
Для этого область значений x, размещённую на оси абсцисс, разобьём на
равные малые интервалы — «корзины» или «бины» (англ. bins)
некоторого размера h. По оси ординат будем откладывать долю измерений w,
результаты которых попадают в соответствующую корзину. А именно,
пусть k — номер корзины; nk — число измерений, попавших
в диапазон x∈[kh,(k+1)h]. Тогда на графике изобразим «столбик»
шириной h и высотой wk=nk/n.
В результате получим картину, подобную изображённой на рис. 2.1.
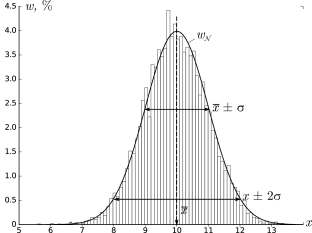
σ=1,0, h=0,1, n=104)
Высоты построенных столбиков будут приближённо соответствовать значению
плотности распределения w(x) вблизи соответствующей точки x.
Если устремить число измерений к бесконечности (n→∞), а ширину корзин
к нулю (h→0), то огибающая гистограммы будет стремиться к некоторой
непрерывной функции w(x).
Самые высокие столбики гистограммы будут группироваться вблизи максимума
функции w(x) — это наиболее вероятное значение случайной величины.
Если отклонения в положительную и отрицательную стороны равновероятны,
то гистограмма будет симметрична — в таком случае среднее значение ⟨x⟩
также будет лежать вблизи этого максимума. Ширина гистограммы будет характеризовать разброс
значений случайной величины — по порядку величины
она, как правило, близка к среднеквадратичному отклонению sx.
Свойства распределений.
Из определения функции w(x) следует, что вероятность получить в результате
эксперимента величину x в диапазоне от a до b
можно найти, вычислив интеграл:
| Px∈[a,b]=∫abw(x)𝑑x. | (2.1) |
Согласно определению вероятности, сумма вероятностей для всех возможных случаев
всегда равна единице. Поэтому интеграл распределения w(x) по всей области
значений x (то есть суммарная площадь под графиком w(x)) равен единице:
Это соотношение называют условием нормировки.
Среднее и дисперсия.
Вычислим среднее по построенной гистограмме. Если размер корзин
h достаточно мал, все измерения в пределах одной корзины можно считать примерно
одинаковыми. Тогда среднее арифметическое всех результатов можно вычислить как
Переходя к пределу, получим следующее определение среднего значения
случайной величины:
где интегрирование ведётся по всей области значений x.
В теории вероятностей x¯ также называют математическим ожиданием
распределения.
Величину
| σ2=(x-x¯)2¯=∫(x-x¯)2w𝑑x | (2.3) |
называют дисперсией распределения. Значение σ есть
срекднеквадратичное отклонение в пределе n→∞. Оно имеет ту
же размерность, что и сама величина x и характеризует разброс распределения.
Именно эту величину, как правило, приводят как характеристику погрешности
измерения x.
Доверительный интервал.
Обозначим как P|Δx|<δ вероятность
того, что отклонение от среднего Δx=x-x¯ составит величину,
не превосходящую по модулю значение δ:
| P|Δx|<δ=∫x¯-δx¯+δw(x)𝑑x. | (2.4) |
Эту величину называют доверительной вероятностью для
доверительного интервала |x-x¯|≤δ.
2.2 Нормальное распределение
Одним из наиболее примечательных результатов теории вероятностей является
так называемая центральная предельная теорема. Она утверждает,
что сумма большого количества независимых случайных слагаемых, каждое
из которых вносит в эту сумму относительно малый вклад, подчиняется
универсальному закону, не зависимо от того, каким вероятностным законам
подчиняются её составляющие, — так называемому нормальному
распределению (или распределению Гаусса).
Доказательство теоремы довольно громоздко и мы его не приводим (его можно найти
в любом учебнике по теории вероятностей). Остановимся
кратко на том, что такое нормальное распределение и его основных свойствах.
Плотность нормального распределения выражается следующей формулой:
| w𝒩(x)=12πσe-(x-x¯)22σ2. | (2.5) |
Здесь x¯ и σ
— параметры нормального распределения: x¯ равно
среднему значению x, a σ —
среднеквадратичному отклонению, вычисленным в пределе n→∞.
Как видно из рис. 2.1, распределение представляет собой
симметричный
«колокол», положение вершины которого
соответствует x¯ (ввиду симметрии оно же
совпадает с наиболее вероятным значением — максимумом
функции w𝒩(x)).
При значительном отклонении x от среднего величина
w𝒩(x)
очень быстро убывает. Это означает, что вероятность встретить отклонения,
существенно большие, чем σ, оказывается пренебрежимо
мала. Ширина «колокола» по порядку величины
равна σ — она характеризует «разброс»
экспериментальных данных относительно среднего значения.
Замечание. Точки x=x¯±σ являются точками
перегиба графика w(x) (в них вторая производная по x
обращается в нуль, w′′=0), а их положение по высоте составляет
w(x¯±σ)/w(x¯)=e-1/2≈0,61
от высоты вершины.
Универсальный характер центральной предельной теоремы позволяет широко
применять на практике нормальное (гауссово) распределение для обработки
результатов измерений, поскольку часто случайные погрешности складываются из
множества случайных независимых факторов. Заметим, что на практике
для приближённой оценки параметров нормального распределения
случайной величины используются выборочные значения среднего
и дисперсии: x¯≈⟨x⟩, sx≈σx.
Вычислим некоторые доверительные вероятности (2.4) для нормально Замечание. Значение интеграла вида ∫e-x2/2𝑑x Вероятность того, что результат отдельного измерения x окажется Вероятность отклонения в пределах x¯±2σ: а в пределах x¯±3σ: Иными словами, при большом числе измерений нормально распределённой Пример. В сообщениях об открытии бозона Хиггса на Большом адронном коллайдере Полученные значения доверительных вероятностей используются при означает, что измеренное значение лежит в диапазоне (доверительном Замечание. Хотя нормальный закон распределения встречается на практике довольно Теперь мы можем дать количественный критерий для сравнения двух измеренных Пусть x1 и x2 (x1≠x2) измерены с Допустим, одна из величин известна с существенно большей точностью: Пусть погрешности измерений сравнимы по порядку величины: Замечание. Изложенные здесь соображения применимы, только если x¯ и x-x0σ2=2w(x)σ1=1
x-x0σ2=2w(x)σ1=1Доверительные вероятности.
распределённых случайных величин.
(его называют интегралом ошибок) в элементарных функциях не выражается,
но легко находится численно.
в пределах x¯±σ оказывается равна
P|Δx|<σ=∫x¯-σx¯+σw𝒩𝑑x≈0,68.
величины можно ожидать, что лишь треть измерений выпадут за пределы интервала
[x¯-σ,x¯+σ]. При этом около 5%
измерений выпадут за пределы [x¯-2σ;x¯+2σ],
и лишь 0,27% окажутся за пределами
[x¯-3σ;x¯+3σ].
говорилось о том, что исследователи ждали подтверждение результатов
с точностью «5 сигма». Используя нормальное распределение (2.5)
нетрудно посчитать, что они использовали доверительную вероятность
P≈1-5,7⋅10-7=0,99999943. Такую точность можно назвать фантастической.
стандартной записи результатов измерений. В физических измерениях
(в частности, в учебной лаборатории), как правило, используется P=0,68,
то есть, запись
интервале) x∈[x¯-δx;x¯+δx] с
вероятностью 68%. Таким образом погрешность ±δx считается
равной одному среднеквадратичному отклонению: δx=σ.
В технических измерениях чаще используется P=0,95, то есть под
абсолютной погрешностью имеется в виду удвоенное среднеквадратичное
отклонение, δx=2σ. Во избежание разночтений доверительную
вероятность следует указывать отдельно.
часто, стоит помнить, что он реализуется далеко не всегда.
Полученные выше соотношения для вероятностей попадания значений в
доверительные интервалы можно использовать в качестве простейшего
признака нормальности распределения: в частности, если количество попадающих
в интервал ±σ результатов существенно отличается от 2/3 — это повод
для более детального исследования закона распределения ошибок.Сравнение результатов измерений.
величин или двух результатов измерения одной и той же величины.
погрешностями σ1 и σ2 соответственно.
Ясно, что если различие результатов |x2-x1| невелико,
его можно объяснить просто случайными отклонениями.
Если же теория предсказывает, что вероятность обнаружить такое отклонение
слишком мала, различие результатов следует признать значимым.
Предварительно необходимо договориться о соответствующем граничном значении
вероятности. Универсального значения здесь быть не может,
поэтому приходится полагаться на субъективный выбор исследователя. Часто
в качестве «разумной» границы выбирают вероятность 5%,
что, как видно из изложенного выше, для нормального распределения
соответствует отклонению более, чем на 2σ.
σ2≪σ1 (например, x1 — результат, полученный
студентом в лаборатории, x2 — справочное значение).
Поскольку σ2 мало, x2 можно принять за «истинное»:
x2≈x¯. Предполагая, что погрешность измерения
x1 подчиняется нормальному закону с и дисперсией σ12,
можно утверждать, что
различие считают будет значимы, если
σ1∼σ2. В теории вероятностей показывается, что
линейная комбинация нормально распределённых величин также имеет нормальное
распределение с дисперсией σ2=σ12+σ22
(см. также правила сложения погрешностей (2.7)). Тогда
для проверки гипотезы о том, что x1 и x2 являются измерениями
одной и той же величины, нужно вычислить, является ли значимым отклонение
|x1-x2| от нуля при σ=σ12+σ22.
Пример. Два студента получили следующие значения для теплоты испарения
некоторой жидкости: x1=40,3±0,2 кДж/моль и
x2=41,0±0,3 кДж/моль, где погрешность соответствует
одному стандартному отклонению. Можно ли утверждать, что они исследовали
одну и ту же жидкость?
Имеем наблюдаемую разность |x1-x2|=0,7 кДж/моль,
среднеквадратичное отклонение для разности
σ=0,22+0,32=0,36 кДж/моль.
Их отношение |x2-x1|σ≈2. Из
свойств нормального распределения находим вероятность того, что измерялась
одна и та же величина, а различия в ответах возникли из-за случайных
ошибок: P≈5%. Ответ на вопрос, «достаточно»
ли мала или велика эта вероятность, остаётся на усмотрение исследователя.
его стандартное отклонение σ получены на основании достаточно
большой выборки n≫1 (или заданы точно). При небольшом числе измерений
(n≲10) выборочные средние ⟨x⟩ и среднеквадратичное отклонение
sx сами имеют довольно большую ошибку, а
их распределение будет описываться не нормальным законом, а так
называемым t-распределением Стъюдента. В частности, в зависимости от
значения n интервал ⟨x⟩±sx будет соответствовать несколько
меньшей доверительной вероятности, чем P=0,68. Особенно резко различия
проявляются при высоких уровнях доверительных вероятностей P→1.
2.3 Независимые величины
Величины x и y называют независимыми если результат измерения одной
из них никак не влияет на результат измерения другой. Для таких величин вероятность того, что x окажется в некоторой области X, и одновременно y — в области Y,
равна произведению соответствующих вероятностей:
Обозначим отклонения величин от их средних как Δx=x-x¯ и
Δy=y-y¯.
Средние значения этих отклонений равны, очевидно, нулю: Δx¯=x¯-x¯=0,
Δy¯=0. Из независимости величин x и y следует,
что среднее значение от произведения Δx⋅Δy¯
равно произведению средних Δx¯⋅Δy¯
и, следовательно, равно нулю:
| Δx⋅Δy¯=Δx¯⋅Δy¯=0. | (2.6) |
Пусть измеряемая величина z=x+y складывается из двух независимых
случайных слагаемых x и y, для которых известны средние
x¯ и y¯, и их среднеквадратичные погрешности
σx и σy. Непосредственно из определения (1.1)
следует, что среднее суммы равно сумме средних:
Найдём дисперсию σz2. В силу независимости имеем
| Δz2¯=Δx2¯+Δy2¯+2Δx⋅Δy¯≈Δx2¯+Δy2¯, |
то есть:
Таким образом, при сложении независимых величин их погрешности
складываются среднеквадратичным образом.
Подчеркнём, что для справедливости соотношения (2.7)
величины x и y не обязаны быть нормально распределёнными —
достаточно существования конечных значений их дисперсий. Однако можно
показать, что если x и y распределены нормально, нормальным
будет и распределение их суммы.
Замечание. Требование независимости
слагаемых является принципиальным. Например, положим y=x. Тогда
z=2x. Здесь y и x, очевидно, зависят друг от друга. Используя
(2.7), находим σ2x=2σx,
что, конечно, неверно — непосредственно из определения
следует, что σ2x=2σx.
Отдельно стоит обсудить математическую структуру формулы (2.7).
Если одна из погрешностей много больше другой, например,
σx≫σy,
то меньшей погрешностью можно пренебречь, σx+y≈σx.
С другой стороны, если два источника погрешностей имеют один порядок
σx∼σy, то и σx+y∼σx∼σy.
Эти обстоятельства важны при планирования эксперимента: как правило,
величина, измеренная наименее точно, вносит наибольший вклад в погрешность
конечного результата. При этом, пока не устранены наиболее существенные
ошибки, бессмысленно гнаться за повышением точности измерения остальных
величин.
Пример. Пусть σy=σx/3,
тогда σz=σx1+19≈1,05σx,
то есть при различии двух погрешностей более, чем в 3 раза, поправка
к погрешности составляет менее 5%, и уже нет особого смысла в учёте
меньшей погрешности: σz≈σx. Это утверждение
касается сложения любых независимых источников погрешностей в эксперименте.
2.4 Погрешность среднего
Выборочное среднее арифметическое значение ⟨x⟩, найденное
по результатам n измерений, само является случайной величиной.
Действительно, если поставить серию одинаковых опытов по n измерений,
то в каждом опыте получится своё среднее значение, отличающееся от
предельного среднего x¯.
Вычислим среднеквадратичную погрешность среднего арифметического
σ⟨x⟩.
Рассмотрим вспомогательную сумму n слагаемых
Если {xi} есть набор независимых измерений
одной и той же физической величины, то мы можем, применяя результат
(2.7) предыдущего параграфа, записать
| σZ=σx12+σx22+…+σxn2=nσx, |
поскольку под корнем находится n одинаковых слагаемых. Отсюда с
учётом ⟨x⟩=Z/n получаем
Таким образом, погрешность среднего значения x по результатам
n независимых измерений оказывается в n раз меньше погрешности
отдельного измерения. Это один из важнейших результатов, позволяющий
уменьшать случайные погрешности эксперимента за счёт многократного
повторения измерений.
Подчеркнём отличия между σx и σ⟨x⟩:
величина σx — погрешность отдельного
измерения — является характеристикой разброса значений
в совокупности измерений {xi}, i=1..n. При
нормальном законе распределения примерно 68% измерений попадают в
интервал ⟨x⟩±σx;
величина σ⟨x⟩ — погрешность
среднего — характеризует точность, с которой определено
среднее значение измеряемой физической величины ⟨x⟩ относительно
предельного («истинного») среднего x¯;
при этом с доверительной вероятностью P=68% искомая величина x¯
лежит в интервале
⟨x⟩-σ⟨x⟩<x¯<⟨x⟩+σ⟨x⟩.
2.5 Результирующая погрешность опыта
Пусть для некоторого результата измерения известна оценка его максимальной
систематической погрешности Δсист и случайная
среднеквадратичная
погрешность σслуч. Какова «полная»
погрешность измерения?
Предположим для простоты, что измеряемая величина в принципе
может быть определена сколь угодно точно, так что можно говорить о
некотором её «истинном» значении xист
(иными словами, погрешность результата связана в основном именно с
процессом измерения). Назовём полной погрешностью измерения
среднеквадратичное значения отклонения от результата измерения от
«истинного»:
Отклонение x-xист можно представить как сумму случайного
отклонения от среднего δxслуч=x-x¯
и постоянной (но, вообще говоря, неизвестной) систематической составляющей
δxсист=x¯-xист=const:
Причём случайную составляющую можно считать независимой от систематической.
В таком случае из (2.7) находим:
| σполн2=⟨δxсист2⟩+⟨δxслуч2⟩≤Δсист2+σслуч2. | (2.9) |
Таким образом, для получения максимального значения полной
погрешности некоторого измерения нужно квадратично сложить максимальную
систематическую и случайную погрешности.
Если измерения проводятся многократно, то согласно (2.8)
случайная составляющая погрешности может быть уменьшена, а систематическая
составляющая при этом остаётся неизменной:
Отсюда следует важное практическое правило
(см. также обсуждение в п. 2.3): если случайная погрешность измерений
в 2–3 раза меньше предполагаемой систематической, то
нет смысла проводить многократные измерения в попытке уменьшить погрешность
всего эксперимента. В такой ситуации измерения достаточно повторить
2–3 раза — чтобы убедиться в повторяемости результата, исключить промахи
и проверить, что случайная ошибка действительно мала.
В противном случае повторение измерений может иметь смысл до
тех пор, пока погрешность среднего
σ⟨x⟩=σxn
не станет меньше систематической.
Замечание. Поскольку конкретная
величина систематической погрешности, как правило, не известна, её
можно в некотором смысле рассматривать наравне со случайной —
предположить, что её величина была определена по некоторому случайному
закону перед началом измерений (например, при изготовлении линейки
на заводе произошло некоторое случайное искажение шкалы). При такой
трактовке формулу (2.9) можно рассматривать просто
как частный случай формулы сложения погрешностей независимых величин
(2.7).
Подчеркнем, что вероятностный закон, которому подчиняется
систематическая ошибка, зачастую неизвестен. Поэтому неизвестно и
распределение итогового результата. Из этого, в частности, следует,
что мы не можем приписать интервалу x±Δсист какую-либо
определённую доверительную вероятность — она равна 0,68
только если систематическая ошибка имеет нормальное распределение.
Можно, конечно, предположить,
— и так часто делают — что, к примеру, ошибки
при изготовлении линеек на заводе имеют гауссов характер. Также часто
предполагают, что систематическая ошибка имеет равномерное
распределение (то есть «истинное» значение может с равной вероятностью
принять любое значение в пределах интервала ±Δсист).
Строго говоря, для этих предположений нет достаточных оснований.
Пример. В результате измерения диаметра проволоки микрометрическим винтом,
имеющим цену деления h=0,01 мм, получен следующий набор из n=8 значений:
Вычисляем среднее значение: ⟨d⟩≈386,3 мкм.
Среднеквадратичное отклонение:
σd≈9,2 мкм. Случайная погрешность среднего согласно
(2.8):
σ⟨d⟩=σd8≈3,2
мкм. Все результаты лежат в пределах ±2σd, поэтому нет
причин сомневаться в нормальности распределения. Максимальную погрешность
микрометра оценим как половину цены деления, Δ=h2=5 мкм.
Результирующая полная погрешность
σ≤Δ2+σd28≈6,0 мкм.
Видно, что σслуч≈Δсист и проводить дополнительные измерения
особого смысла нет. Окончательно результат измерений может быть представлен
в виде (см. также правила округления
результатов измерений в п. 4.3.2)
d=386±6мкм,εd=1,5%.
Заметим, что поскольку случайная погрешность и погрешность
прибора здесь имеют один порядок величины, наблюдаемый случайный разброс
данных может быть связан как с неоднородностью сечения проволоки,
так и с дефектами микрометра (например, с неровностями зажимов, люфтом
винта, сухим трением, деформацией проволоки под действием микрометра
и т. п.). Для ответа на вопрос, что именно вызвало разброс, требуются
дополнительные исследования, желательно с использованием более точных
приборов.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=±1 м/c.
Результаты измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=162,0м/с,
среднеквадратичное отклонение σv=13,8м/c, случайная
ошибка для средней скорости
σv¯=σv/6=5,6м/с.
Поскольку разброс экспериментальных данных существенно превышает погрешность
каждого измерения, σv≫δv, он почти наверняка связан
с реальным различием скоростей пули в разных выстрелах, а не с ошибками
измерений. В качестве результата эксперимента представляют интерес
как среднее значение скоростей ⟨v⟩=162±6м/с
(ε≈4%), так и значение σv≈14м/с,
характеризующее разброс значений скоростей от выстрела к выстрелу.
Малая инструментальная погрешность в принципе позволяет более точно
измерить среднее и дисперсию, и исследовать закон распределения выстрелов
по скоростям более детально — для этого требуется набрать
бо́льшую статистику по выстрелам.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=10 м/c. Результаты
измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=163,3м/с,
σv=12,1м/c, σ⟨v⟩=5м/с,
σполн≈11,2м/с. Инструментальная
погрешность каждого измерения превышает разброс данных, поэтому в
этом опыте затруднительно сделать вывод о различии скоростей от выстрела
к выстрелу. Результат измерений скорости пули:
⟨v⟩=163±11м/с,
ε≈7%. Проводить дополнительные выстрелы при такой
большой инструментальной погрешности особого смысла нет —
лучше поработать над точностью приборов и методикой измерений.
2.6 Обработка косвенных измерений
Косвенными называют измерения, полученные в результате расчётов,
использующих результаты прямых (то есть «непосредственных»)
измерений физических величин. Сформулируем основные правила пересчёта
погрешностей при косвенных измерениях.
2.6.1 Случай одной переменной
Пусть в эксперименте измеряется величина x, а её «наилучшее»
(в некотором смысле) значение равно x⋆ и оно известно с
погрешностью σx. После чего с помощью известной функции
вычисляется величина y=f(x).
В качестве «наилучшего» приближения для y используем значение функции
при «наилучшем» x:
Найдём величину погрешности σy. Обозначая отклонение измеряемой
величины как Δx=x-x⋆, и пользуясь определением производной,
при условии, что функция y(x) — гладкая
вблизи x≈x⋆, запишем
где f′≡dydx — производная фукнции f(x), взятая в точке
x⋆. Возведём полученное в квадрат, проведём усреднение
(σy2=⟨Δy2⟩,
σx2=⟨Δx2⟩), и затем снова извлечём
корень. В результате получим
Пример. Для степенной функции
y=Axn имеем σy=nAxn-1σx, откуда
σyy=nσxx,или εy=nεx,
то есть относительная погрешность степенной функции возрастает пропорционально
показателю степени n.
Пример. Для y=1/x имеем ε1/x=εx
— при обращении величины сохраняется её относительная
погрешность.
Упражнение. Найдите погрешность логарифма y=lnx, если известны x
и σx.
Упражнение. Найдите погрешность показательной функции y=ax,
если известны x и σx. Коэффициент a задан точно.
2.6.2 Случай многих переменных
Пусть величина u вычисляется по измеренным значениям нескольких
различных независимых физических величин x, y, …
на основе известного закона u=f(x,y,…). В качестве
наилучшего значения можно по-прежнему взять значение функции f
при наилучших значениях измеряемых параметров:
Для нахождения погрешности σu воспользуемся свойством,
известным из математического анализа, — малые приращения гладких
функции многих переменных складываются линейно, то есть справедлив
принцип суперпозиции малых приращений:
где символом fx′≡∂f∂x обозначена
частная производная функции f по переменной x —
то есть обычная производная f по x, взятая при условии, что
все остальные аргументы (кроме x) считаются постоянными параметрами.
Тогда пользуясь формулой для нахождения дисперсии суммы независимых
величин (2.7), получим соотношение, позволяющее вычислять
погрешности косвенных измерений для произвольной функции
u=f(x,y,…):
| σu2=fx′2σx2+fy′2σy2+… | (2.11) |
Это и есть искомая общая формула пересчёта погрешностей при косвенных
измерениях.
Отметим, что формулы (2.10) и (2.11) применимы
только если относительные отклонения всех величин малы
(εx,εy,…≪1),
а измерения проводятся вдали от особых точек функции f (производные
fx′, fy′ … не должны обращаться в бесконечность).
Также подчеркнём, что все полученные здесь формулы справедливы только
для независимых переменных x, y, …
Остановимся на некоторых важных частных случаях формулы
(2.11).
Пример. Для суммы (или разности) u=∑i=1naixi имеем
σu2=∑i=1nai2σxi2.
(2.12)
Пример. Найдём погрешность степенной функции:
u=xα⋅yβ⋅…. Тогда нетрудно получить,
что
σu2u2=α2σx2x2+β2σy2y2+…
или через относительные погрешности
εu2=α2εx2+β2εy2+…
(2.13)
Пример. Вычислим погрешность произведения и частного: u=xy или u=x/y.
Тогда в обоих случаях имеем
εu2=εx2+εy2,
(2.14)
то есть при умножении или делении относительные погрешности складываются
квадратично.
Пример. Рассмотрим несколько более сложный случай: нахождение угла по его тангенсу
u=arctgyx.
В таком случае, пользуясь тем, что (arctgz)′=11+z2,
где z=y/x, и используя производную сложной функции, находим
ux′=uz′zx′=-yx2+y2,
uy′=uz′zy′=xx2+y2, и наконец
σu2=y2σx2+x2σy2(x2+y2)2.
Упражнение. Найти погрешность вычисления гипотенузы z=x2+y2
прямоугольного треугольника по измеренным катетам x и y.
По итогам данного раздела можно дать следующие практические рекомендации.
-
•
Как правило, нет смысла увеличивать точность измерения какой-то одной
величины, если другие величины, используемые в расчётах, остаются
измеренными относительно грубо — всё равно итоговая погрешность
скорее всего будет определяться самым неточным измерением. Поэтому
все измерения имеет смысл проводить примерно с одной и той же
относительной погрешностью. -
•
При этом, как следует из (2.13), особое внимание
следует уделять измерению величин, возводимых при расчётах в степени
с большими показателями. А при сложных функциональных зависимостях
имеет смысл детально проанализировать структуру формулы
(2.11):
если вклад от некоторой величины в общую погрешность мал, нет смысла
гнаться за высокой точностью её измерения, и наоборот, точность некоторых
измерений может оказаться критически важной. -
•
Следует избегать измерения малых величин как разности двух близких
значений (например, толщины стенки цилиндра как разности внутреннего
и внешнего радиусов): если u=x-y, то абсолютная погрешность
σu=σx2+σy2
меняется мало, однако относительная погрешность
εu=σux-y
может оказаться неприемлемо большой, если x≈y.
| Error function | |
|---|---|

Plot of the error function |
|
| General information | |
| General definition |  |
| Fields of application | Probability, thermodynamics |
| Domain, Codomain and Image | |
| Domain |  |
| Image |  |
| Basic features | |
| Parity | Odd |
| Specific features | |
| Root | 0 |
| Derivative |  |
| Antiderivative |  |
| Series definition | |
| Taylor series |  |
In mathematics, the error function (also called the Gauss error function), often denoted by erf, is a complex function of a complex variable defined as:[1]

Some authors define  without the factor of
without the factor of  .[2]
.[2]
This nonelementary integral is a sigmoid function that occurs often in probability, statistics, and partial differential equations. In many of these applications, the function argument is a real number. If the function argument is real, then the function value is also real.
In statistics, for non-negative values of x, the error function has the following interpretation: for a random variable Y that is normally distributed with mean 0 and standard deviation 1/√2, erf x is the probability that Y falls in the range [−x, x].
Two closely related functions are the complementary error function (erfc) defined as

and the imaginary error function (erfi) defined as

where i is the imaginary unit.
Name[edit]
The name «error function» and its abbreviation erf were proposed by J. W. L. Glaisher in 1871 on account of its connection with «the theory of Probability, and notably the theory of Errors.»[3] The error function complement was also discussed by Glaisher in a separate publication in the same year.[4]
For the «law of facility» of errors whose density is given by

(the normal distribution), Glaisher calculates the probability of an error lying between p and q as:

Plot of the error function Erf(z) in the complex plane from -2-2i to 2+2i with colors created with Mathematica 13.1 function ComplexPlot3D

Applications[edit]
When the results of a series of measurements are described by a normal distribution with standard deviation σ and expected value 0, then erf (a/σ √2) is the probability that the error of a single measurement lies between −a and +a, for positive a. This is useful, for example, in determining the bit error rate of a digital communication system.
The error and complementary error functions occur, for example, in solutions of the heat equation when boundary conditions are given by the Heaviside step function.
The error function and its approximations can be used to estimate results that hold with high probability or with low probability. Given a random variable X ~ Norm[μ,σ] (a normal distribution with mean μ and standard deviation σ) and a constant L < μ:
![{\displaystyle {\begin{aligned}\Pr[X\leq L]&={\frac {1}{2}}+{\frac {1}{2}}\operatorname {erf} {\frac {L-\mu }{{\sqrt {2}}\sigma }}\\&\approx A\exp \left(-B\left({\frac {L-\mu }{\sigma }}\right)^{2}\right)\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f3cb760eaf336393db9fd0bb12c4465655a27de8)
where A and B are certain numeric constants. If L is sufficiently far from the mean, specifically μ − L ≥ σ√ln k, then:
![{\displaystyle \Pr[X\leq L]\leq A\exp(-B\ln {k})={\frac {A}{k^{B}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2baadea015e20a45d1034fd88eed861e7fcce178)
so the probability goes to 0 as k → ∞.
The probability for X being in the interval [La, Lb] can be derived as
![{\displaystyle {\begin{aligned}\Pr[L_{a}\leq X\leq L_{b}]&=\int _{L_{a}}^{L_{b}}{\frac {1}{{\sqrt {2\pi }}\sigma }}\exp \left(-{\frac {(x-\mu )^{2}}{2\sigma ^{2}}}\right)\,\mathrm {d} x\\&={\frac {1}{2}}\left(\operatorname {erf} {\frac {L_{b}-\mu }{{\sqrt {2}}\sigma }}-\operatorname {erf} {\frac {L_{a}-\mu }{{\sqrt {2}}\sigma }}\right).\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cd2214f0db2c1d36075815825b616501175c6283)
Properties[edit]
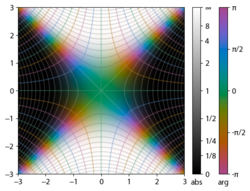
Integrand exp(−z2)

erf z
The property erf (−z) = −erf z means that the error function is an odd function. This directly results from the fact that the integrand e−t2 is an even function (the antiderivative of an even function which is zero at the origin is an odd function and vice versa).
Since the error function is an entire function which takes real numbers to real numbers, for any complex number z:

where z is the complex conjugate of z.
The integrand f = exp(−z2) and f = erf z are shown in the complex z-plane in the figures at right with domain coloring.
The error function at +∞ is exactly 1 (see Gaussian integral). At the real axis, erf z approaches unity at z → +∞ and −1 at z → −∞. At the imaginary axis, it tends to ±i∞.
Taylor series[edit]
The error function is an entire function; it has no singularities (except that at infinity) and its Taylor expansion always converges, but is famously known «[…] for its bad convergence if x > 1.»[5]
The defining integral cannot be evaluated in closed form in terms of elementary functions (see Liouville’s theorem), but by expanding the integrand e−z2 into its Maclaurin series and integrating term by term, one obtains the error function’s Maclaurin series as:
![{\displaystyle {\begin{aligned}\operatorname {erf} z&={\frac {2}{\sqrt {\pi }}}\sum _{n=0}^{\infty }{\frac {(-1)^{n}z^{2n+1}}{n!(2n+1)}}\\[6pt]&={\frac {2}{\sqrt {\pi }}}\left(z-{\frac {z^{3}}{3}}+{\frac {z^{5}}{10}}-{\frac {z^{7}}{42}}+{\frac {z^{9}}{216}}-\cdots \right)\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c80541f305af070bb0510625c584fe1559a0cd2c)
which holds for every complex number z. The denominator terms are sequence A007680 in the OEIS.
For iterative calculation of the above series, the following alternative formulation may be useful:
![{\displaystyle {\begin{aligned}\operatorname {erf} z&={\frac {2}{\sqrt {\pi }}}\sum _{n=0}^{\infty }\left(z\prod _{k=1}^{n}{\frac {-(2k-1)z^{2}}{k(2k+1)}}\right)\\[6pt]&={\frac {2}{\sqrt {\pi }}}\sum _{n=0}^{\infty }{\frac {z}{2n+1}}\prod _{k=1}^{n}{\frac {-z^{2}}{k}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dca22e8e7dee0297e87a455249c282c6b92fedcb)
because −(2k − 1)z2/k(2k + 1) expresses the multiplier to turn the kth term into the (k + 1)th term (considering z as the first term).
The imaginary error function has a very similar Maclaurin series, which is:
![{\displaystyle {\begin{aligned}\operatorname {erfi} z&={\frac {2}{\sqrt {\pi }}}\sum _{n=0}^{\infty }{\frac {z^{2n+1}}{n!(2n+1)}}\\[6pt]&={\frac {2}{\sqrt {\pi }}}\left(z+{\frac {z^{3}}{3}}+{\frac {z^{5}}{10}}+{\frac {z^{7}}{42}}+{\frac {z^{9}}{216}}+\cdots \right)\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ff91095cd6825137cc951ec0a786db0b7f68fac)
which holds for every complex number z.
Derivative and integral[edit]
The derivative of the error function follows immediately from its definition:

From this, the derivative of the imaginary error function is also immediate:

An antiderivative of the error function, obtainable by integration by parts, is

An antiderivative of the imaginary error function, also obtainable by integration by parts, is

Higher order derivatives are given by

where H are the physicists’ Hermite polynomials.[6]
Bürmann series[edit]
An expansion,[7] which converges more rapidly for all real values of x than a Taylor expansion, is obtained by using Hans Heinrich Bürmann’s theorem:[8]
![{\displaystyle {\begin{aligned}\operatorname {erf} x&={\frac {2}{\sqrt {\pi }}}\operatorname {sgn} x\cdot {\sqrt {1-e^{-x^{2}}}}\left(1-{\frac {1}{12}}\left(1-e^{-x^{2}}\right)-{\frac {7}{480}}\left(1-e^{-x^{2}}\right)^{2}-{\frac {5}{896}}\left(1-e^{-x^{2}}\right)^{3}-{\frac {787}{276480}}\left(1-e^{-x^{2}}\right)^{4}-\cdots \right)\\[10pt]&={\frac {2}{\sqrt {\pi }}}\operatorname {sgn} x\cdot {\sqrt {1-e^{-x^{2}}}}\left({\frac {\sqrt {\pi }}{2}}+\sum _{k=1}^{\infty }c_{k}e^{-kx^{2}}\right).\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/164e7f029977edb47c83845b04abfe5b2d28b837)
where sgn is the sign function. By keeping only the first two coefficients and choosing c1 = 31/200 and c2 = −341/8000, the resulting approximation shows its largest relative error at x = ±1.3796, where it is less than 0.0036127:

Inverse functions[edit]
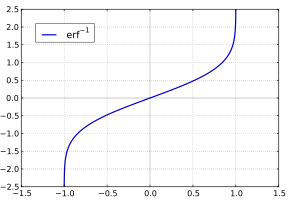
Given a complex number z, there is not a unique complex number w satisfying erf w = z, so a true inverse function would be multivalued. However, for −1 < x < 1, there is a unique real number denoted erf−1 x satisfying

The inverse error function is usually defined with domain (−1,1), and it is restricted to this domain in many computer algebra systems. However, it can be extended to the disk |z| < 1 of the complex plane, using the Maclaurin series[9]

where c0 = 1 and

So we have the series expansion (common factors have been canceled from numerators and denominators):

(After cancellation the numerator/denominator fractions are entries OEIS: A092676/OEIS: A092677 in the OEIS; without cancellation the numerator terms are given in entry OEIS: A002067.) The error function’s value at ±∞ is equal to ±1.
For |z| < 1, we have erf(erf−1 z) = z.
The inverse complementary error function is defined as

For real x, there is a unique real number erfi−1 x satisfying erfi(erfi−1 x) = x. The inverse imaginary error function is defined as erfi−1 x.[10]
For any real x, Newton’s method can be used to compute erfi−1 x, and for −1 ≤ x ≤ 1, the following Maclaurin series converges:

where ck is defined as above.
Asymptotic expansion[edit]
A useful asymptotic expansion of the complementary error function (and therefore also of the error function) for large real x is
![{\displaystyle {\begin{aligned}\operatorname {erfc} x&={\frac {e^{-x^{2}}}{x{\sqrt {\pi }}}}\left(1+\sum _{n=1}^{\infty }(-1)^{n}{\frac {1\cdot 3\cdot 5\cdots (2n-1)}{\left(2x^{2}\right)^{n}}}\right)\\[6pt]&={\frac {e^{-x^{2}}}{x{\sqrt {\pi }}}}\sum _{n=0}^{\infty }(-1)^{n}{\frac {(2n-1)!!}{\left(2x^{2}\right)^{n}}},\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/35a11e2e5b22ca898c74f2e913d276c9ac11124a)
where (2n − 1)!! is the double factorial of (2n − 1), which is the product of all odd numbers up to (2n − 1). This series diverges for every finite x, and its meaning as asymptotic expansion is that for any integer N ≥ 1 one has

where the remainder is

which follows easily by induction, writing

and integrating by parts.
The asymptotic behavior of the remainder term, in Landau notation, is

as x → ∞. This can be found by

For large enough values of x, only the first few terms of this asymptotic expansion are needed to obtain a good approximation of erfc x (while for not too large values of x, the above Taylor expansion at 0 provides a very fast convergence).
Continued fraction expansion[edit]
A continued fraction expansion of the complementary error function is:[11]

Integral of error function with Gaussian density function[edit]

which appears related to Ng and Geller, formula 13 in section 4.3[12] with a change of variables.
Factorial series[edit]
The inverse factorial series:

converges for Re(z2) > 0. Here

zn denotes the rising factorial, and s(n,k) denotes a signed Stirling number of the first kind.[13][14]
There also exists a representation by an infinite sum containing the double factorial:

Numerical approximations[edit]
Approximation with elementary functions[edit]
- Abramowitz and Stegun give several approximations of varying accuracy (equations 7.1.25–28). This allows one to choose the fastest approximation suitable for a given application. In order of increasing accuracy, they are:
(maximum error: 5×10−4)
where a1 = 0.278393, a2 = 0.230389, a3 = 0.000972, a4 = 0.078108
(maximum error: 2.5×10−5)
where p = 0.47047, a1 = 0.3480242, a2 = −0.0958798, a3 = 0.7478556
(maximum error: 3×10−7)
where a1 = 0.0705230784, a2 = 0.0422820123, a3 = 0.0092705272, a4 = 0.0001520143, a5 = 0.0002765672, a6 = 0.0000430638
(maximum error: 1.5×10−7)
where p = 0.3275911, a1 = 0.254829592, a2 = −0.284496736, a3 = 1.421413741, a4 = −1.453152027, a5 = 1.061405429
All of these approximations are valid for x ≥ 0. To use these approximations for negative x, use the fact that erf x is an odd function, so erf x = −erf(−x).
- Exponential bounds and a pure exponential approximation for the complementary error function are given by[15]
- The above have been generalized to sums of N exponentials[16] with increasing accuracy in terms of N so that erfc x can be accurately approximated or bounded by 2Q̃(√2x), where
In particular, there is a systematic methodology to solve the numerical coefficients {(an,bn)}N
n = 1 that yield a minimax approximation or bound for the closely related Q-function: Q(x) ≈ Q̃(x), Q(x) ≤ Q̃(x), or Q(x) ≥ Q̃(x) for x ≥ 0. The coefficients {(an,bn)}N
n = 1 for many variations of the exponential approximations and bounds up to N = 25 have been released to open access as a comprehensive dataset.[17] - A tight approximation of the complementary error function for x ∈ [0,∞) is given by Karagiannidis & Lioumpas (2007)[18] who showed for the appropriate choice of parameters {A,B} that
They determined {A,B} = {1.98,1.135}, which gave a good approximation for all x ≥ 0. Alternative coefficients are also available for tailoring accuracy for a specific application or transforming the expression into a tight bound.[19]
- A single-term lower bound is[20]
where the parameter β can be picked to minimize error on the desired interval of approximation.
-
- Another approximation is given by Sergei Winitzki using his «global Padé approximations»:[21][22]: 2–3
where
This is designed to be very accurate in a neighborhood of 0 and a neighborhood of infinity, and the relative error is less than 0.00035 for all real x. Using the alternate value a ≈ 0.147 reduces the maximum relative error to about 0.00013.[23]
This approximation can be inverted to obtain an approximation for the inverse error function:
- An approximation with a maximal error of 1.2×10−7 for any real argument is:[24]
with
and
- An approximation of with a maximum relative error less than in absolute value is:[25]
for
,and for





















Table of values[edit]
| x | erf x | 1 − erf x |
|---|---|---|
| 0 | 0 | 1 |
| 0.02 | 0.022564575 | 0.977435425 |
| 0.04 | 0.045111106 | 0.954888894 |
| 0.06 | 0.067621594 | 0.932378406 |
| 0.08 | 0.090078126 | 0.909921874 |
| 0.1 | 0.112462916 | 0.887537084 |
| 0.2 | 0.222702589 | 0.777297411 |
| 0.3 | 0.328626759 | 0.671373241 |
| 0.4 | 0.428392355 | 0.571607645 |
| 0.5 | 0.520499878 | 0.479500122 |
| 0.6 | 0.603856091 | 0.396143909 |
| 0.7 | 0.677801194 | 0.322198806 |
| 0.8 | 0.742100965 | 0.257899035 |
| 0.9 | 0.796908212 | 0.203091788 |
| 1 | 0.842700793 | 0.157299207 |
| 1.1 | 0.880205070 | 0.119794930 |
| 1.2 | 0.910313978 | 0.089686022 |
| 1.3 | 0.934007945 | 0.065992055 |
| 1.4 | 0.952285120 | 0.047714880 |
| 1.5 | 0.966105146 | 0.033894854 |
| 1.6 | 0.976348383 | 0.023651617 |
| 1.7 | 0.983790459 | 0.016209541 |
| 1.8 | 0.989090502 | 0.010909498 |
| 1.9 | 0.992790429 | 0.007209571 |
| 2 | 0.995322265 | 0.004677735 |
| 2.1 | 0.997020533 | 0.002979467 |
| 2.2 | 0.998137154 | 0.001862846 |
| 2.3 | 0.998856823 | 0.001143177 |
| 2.4 | 0.999311486 | 0.000688514 |
| 2.5 | 0.999593048 | 0.000406952 |
| 3 | 0.999977910 | 0.000022090 |
| 3.5 | 0.999999257 | 0.000000743 |
[edit]
Complementary error function[edit]
The complementary error function, denoted erfc, is defined as
Plot of the complementary error function Erfc(z) in the complex plane from -2-2i to 2+2i with colors created with Mathematica 13.1 function ComplexPlot3D
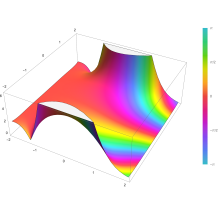
![{\displaystyle {\begin{aligned}\operatorname {erfc} x&=1-\operatorname {erf} x\\[5pt]&={\frac {2}{\sqrt {\pi }}}\int _{x}^{\infty }e^{-t^{2}}\,\mathrm {d} t\\[5pt]&=e^{-x^{2}}\operatorname {erfcx} x,\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4acd0062271e2a19c209a02c8cc33d44a28af7cc)
which also defines erfcx, the scaled complementary error function[26] (which can be used instead of erfc to avoid arithmetic underflow[26][27]). Another form of erfc x for x ≥ 0 is known as Craig’s formula, after its discoverer:[28]

This expression is valid only for positive values of x, but it can be used in conjunction with erfc x = 2 − erfc(−x) to obtain erfc(x) for negative values. This form is advantageous in that the range of integration is fixed and finite. An extension of this expression for the erfc of the sum of two non-negative variables is as follows:[29]

Imaginary error function[edit]
The imaginary error function, denoted erfi, is defined as

![{\displaystyle {\begin{aligned}\operatorname {erfi} x&=-i\operatorname {erf} ix\\[5pt]&={\frac {2}{\sqrt {\pi }}}\int _{0}^{x}e^{t^{2}}\,\mathrm {d} t\\[5pt]&={\frac {2}{\sqrt {\pi }}}e^{x^{2}}D(x),\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bfd2dd94cd6d0325224d412f6b5e5ed63ca81d4a)
where D(x) is the Dawson function (which can be used instead of erfi to avoid arithmetic overflow[26]).
Despite the name «imaginary error function», erfi x is real when x is real.
When the error function is evaluated for arbitrary complex arguments z, the resulting complex error function is usually discussed in scaled form as the Faddeeva function:

Cumulative distribution function[edit]
The error function is essentially identical to the standard normal cumulative distribution function, denoted Φ, also named norm(x) by some software languages[citation needed], as they differ only by scaling and translation. Indeed,

the normal cumulative distribution function plotted in the complex plane
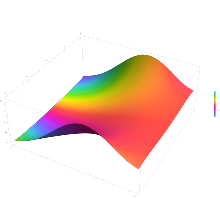
![{\displaystyle {\begin{aligned}\Phi (x)&={\frac {1}{\sqrt {2\pi }}}\int _{-\infty }^{x}e^{\tfrac {-t^{2}}{2}}\,\mathrm {d} t\\[6pt]&={\frac {1}{2}}\left(1+\operatorname {erf} {\frac {x}{\sqrt {2}}}\right)\\[6pt]&={\frac {1}{2}}\operatorname {erfc} \left(-{\frac {x}{\sqrt {2}}}\right)\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/89a9e9eaaddcd7a91ade15a41b8d1e272d437559)
or rearranged for erf and erfc:
![{\displaystyle {\begin{aligned}\operatorname {erf} (x)&=2\Phi \left(x{\sqrt {2}}\right)-1\\[6pt]\operatorname {erfc} (x)&=2\Phi \left(-x{\sqrt {2}}\right)\\&=2\left(1-\Phi \left(x{\sqrt {2}}\right)\right).\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/86c84a4d2d79631fe9996e30f1d6c0da3089bfe2)
Consequently, the error function is also closely related to the Q-function, which is the tail probability of the standard normal distribution. The Q-function can be expressed in terms of the error function as

The inverse of Φ is known as the normal quantile function, or probit function and may be expressed in terms of the inverse error function as

The standard normal cdf is used more often in probability and statistics, and the error function is used more often in other branches of mathematics.
The error function is a special case of the Mittag-Leffler function, and can also be expressed as a confluent hypergeometric function (Kummer’s function):

It has a simple expression in terms of the Fresnel integral.[further explanation needed]
In terms of the regularized gamma function P and the incomplete gamma function,

sgn x is the sign function.
Generalized error functions[edit]

grey curve: E1(x) = 1 − e−x/√π
red curve: E2(x) = erf(x)
green curve: E3(x)
blue curve: E4(x)
gold curve: E5(x).
Some authors discuss the more general functions:[citation needed]

Notable cases are:
- E0(x) is a straight line through the origin: E0(x) = x/e√π
- E2(x) is the error function, erf x.
After division by n!, all the En for odd n look similar (but not identical) to each other. Similarly, the En for even n look similar (but not identical) to each other after a simple division by n!. All generalised error functions for n > 0 look similar on the positive x side of the graph.
These generalised functions can equivalently be expressed for x > 0 using the gamma function and incomplete gamma function:

Therefore, we can define the error function in terms of the incomplete gamma function:

Iterated integrals of the complementary error function[edit]
The iterated integrals of the complementary error function are defined by[30]
![{\displaystyle {\begin{aligned}\operatorname {i} ^{n}\!\operatorname {erfc} z&=\int _{z}^{\infty }\operatorname {i} ^{n-1}\!\operatorname {erfc} \zeta \,\mathrm {d} \zeta \\[6pt]\operatorname {i} ^{0}\!\operatorname {erfc} z&=\operatorname {erfc} z\\\operatorname {i} ^{1}\!\operatorname {erfc} z&=\operatorname {ierfc} z={\frac {1}{\sqrt {\pi }}}e^{-z^{2}}-z\operatorname {erfc} z\\\operatorname {i} ^{2}\!\operatorname {erfc} z&={\tfrac {1}{4}}\left(\operatorname {erfc} z-2z\operatorname {ierfc} z\right)\\\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c3e7b953efaa4d730a5479bd61a2c378c8f761dc)
The general recurrence formula is

They have the power series

from which follow the symmetry properties

and

Implementations[edit]
As real function of a real argument[edit]
- In POSIX-compliant operating systems, the header
math.hshall declare and the mathematical librarylibmshall provide the functionserfanderfc(double precision) as well as their single precision and extended precision counterpartserff,erflanderfcf,erfcl.[31]
- The GNU Scientific Library provides
erf,erfc,log(erf), and scaled error functions.[32]
As complex function of a complex argument[edit]
libcerf, numeric C library for complex error functions, provides the complex functionscerf,cerfc,cerfcxand the real functionserfi,erfcxwith approximately 13–14 digits precision, based on the Faddeeva function as implemented in the MIT Faddeeva Package
See also[edit]
[edit]
- Gaussian integral, over the whole real line
- Gaussian function, derivative
- Dawson function, renormalized imaginary error function
- Goodwin–Staton integral
In probability[edit]
- Normal distribution
- Normal cumulative distribution function, a scaled and shifted form of error function
- Probit, the inverse or quantile function of the normal CDF
- Q-function, the tail probability of the normal distribution
- Standard score
References[edit]
- ^ Andrews, Larry C. (1998). Special functions of mathematics for engineers. SPIE Press. p. 110. ISBN 9780819426161.
- ^ Whittaker, E. T.; Watson, G. N. (1927). A Course of Modern Analysis. Cambridge University Press. p. 341. ISBN 978-0-521-58807-2.
- ^ Glaisher, James Whitbread Lee (July 1871). «On a class of definite integrals». London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science. 4. 42 (277): 294–302. doi:10.1080/14786447108640568. Retrieved 6 December 2017.
- ^ Glaisher, James Whitbread Lee (September 1871). «On a class of definite integrals. Part II». London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science. 4. 42 (279): 421–436. doi:10.1080/14786447108640600. Retrieved 6 December 2017.
- ^ «A007680 – OEIS». oeis.org. Retrieved 2 April 2020.
- ^ Weisstein, Eric W. «Erf». MathWorld.
- ^ Schöpf, H. M.; Supancic, P. H. (2014). «On Bürmann’s Theorem and Its Application to Problems of Linear and Nonlinear Heat Transfer and Diffusion». The Mathematica Journal. 16. doi:10.3888/tmj.16-11.
- ^ Weisstein, Eric W. «Bürmann’s Theorem». MathWorld.
- ^ Dominici, Diego (2006). «Asymptotic analysis of the derivatives of the inverse error function». arXiv:math/0607230.
- ^ Bergsma, Wicher (2006). «On a new correlation coefficient, its orthogonal decomposition and associated tests of independence». arXiv:math/0604627.
- ^ Cuyt, Annie A. M.; Petersen, Vigdis B.; Verdonk, Brigitte; Waadeland, Haakon; Jones, William B. (2008). Handbook of Continued Fractions for Special Functions. Springer-Verlag. ISBN 978-1-4020-6948-2.
- ^ Ng, Edward W.; Geller, Murray (January 1969). «A table of integrals of the Error functions». Journal of Research of the National Bureau of Standards Section B. 73B (1): 1. doi:10.6028/jres.073B.001.
- ^ Schlömilch, Oskar Xavier (1859). «Ueber facultätenreihen». Zeitschrift für Mathematik und Physik (in German). 4: 390–415.
- ^ Nielson, Niels (1906). Handbuch der Theorie der Gammafunktion (in German). Leipzig: B. G. Teubner. p. 283 Eq. 3. Retrieved 4 December 2017.
- ^ Chiani, M.; Dardari, D.; Simon, M.K. (2003). «New Exponential Bounds and Approximations for the Computation of Error Probability in Fading Channels» (PDF). IEEE Transactions on Wireless Communications. 2 (4): 840–845. CiteSeerX 10.1.1.190.6761. doi:10.1109/TWC.2003.814350.
- ^ Tanash, I.M.; Riihonen, T. (2020). «Global minimax approximations and bounds for the Gaussian Q-function by sums of exponentials». IEEE Transactions on Communications. 68 (10): 6514–6524. arXiv:2007.06939. doi:10.1109/TCOMM.2020.3006902. S2CID 220514754.
- ^ Tanash, I.M.; Riihonen, T. (2020). «Coefficients for Global Minimax Approximations and Bounds for the Gaussian Q-Function by Sums of Exponentials [Data set]». Zenodo. doi:10.5281/zenodo.4112978.
- ^ Karagiannidis, G. K.; Lioumpas, A. S. (2007). «An improved approximation for the Gaussian Q-function» (PDF). IEEE Communications Letters. 11 (8): 644–646. doi:10.1109/LCOMM.2007.070470. S2CID 4043576.
- ^ Tanash, I.M.; Riihonen, T. (2021). «Improved coefficients for the Karagiannidis–Lioumpas approximations and bounds to the Gaussian Q-function». IEEE Communications Letters. 25 (5): 1468–1471. arXiv:2101.07631. doi:10.1109/LCOMM.2021.3052257. S2CID 231639206.
- ^ Chang, Seok-Ho; Cosman, Pamela C.; Milstein, Laurence B. (November 2011). «Chernoff-Type Bounds for the Gaussian Error Function». IEEE Transactions on Communications. 59 (11): 2939–2944. doi:10.1109/TCOMM.2011.072011.100049. S2CID 13636638.
- ^ Winitzki, Sergei (2003). «Uniform approximations for transcendental functions». Computational Science and Its Applications – ICCSA 2003. Lecture Notes in Computer Science. Vol. 2667. Springer, Berlin. pp. 780–789. doi:10.1007/3-540-44839-X_82. ISBN 978-3-540-40155-1.
- ^ Zeng, Caibin; Chen, Yang Cuan (2015). «Global Padé approximations of the generalized Mittag-Leffler function and its inverse». Fractional Calculus and Applied Analysis. 18 (6): 1492–1506. arXiv:1310.5592. doi:10.1515/fca-2015-0086. S2CID 118148950.
Indeed, Winitzki [32] provided the so-called global Padé approximation
- ^ Winitzki, Sergei (6 February 2008). «A handy approximation for the error function and its inverse» (Document).
- ^ Numerical Recipes in Fortran 77: The Art of Scientific Computing (ISBN 0-521-43064-X), 1992, page 214, Cambridge University Press.
- ^ Dia, Yaya D. (2023). Approximate Incomplete Integrals, Application to Complementary Error Function. Available at SSRN: https://ssrn.com/abstract=4487559 or http://dx.doi.org/10.2139/ssrn.4487559, 2023
- ^ a b c Cody, W. J. (March 1993), «Algorithm 715: SPECFUN—A portable FORTRAN package of special function routines and test drivers» (PDF), ACM Trans. Math. Softw., 19 (1): 22–32, CiteSeerX 10.1.1.643.4394, doi:10.1145/151271.151273, S2CID 5621105
- ^ Zaghloul, M. R. (1 March 2007), «On the calculation of the Voigt line profile: a single proper integral with a damped sine integrand», Monthly Notices of the Royal Astronomical Society, 375 (3): 1043–1048, Bibcode:2007MNRAS.375.1043Z, doi:10.1111/j.1365-2966.2006.11377.x
- ^ John W. Craig, A new, simple and exact result for calculating the probability of error for two-dimensional signal constellations Archived 3 April 2012 at the Wayback Machine, Proceedings of the 1991 IEEE Military Communication Conference, vol. 2, pp. 571–575.
- ^ Behnad, Aydin (2020). «A Novel Extension to Craig’s Q-Function Formula and Its Application in Dual-Branch EGC Performance Analysis». IEEE Transactions on Communications. 68 (7): 4117–4125. doi:10.1109/TCOMM.2020.2986209. S2CID 216500014.
- ^ Carslaw, H. S.; Jaeger, J. C. (1959), Conduction of Heat in Solids (2nd ed.), Oxford University Press, ISBN 978-0-19-853368-9, p 484
- ^ «math.h — mathematical declarations». opengroup.org. 2018. Retrieved 21 April 2023.
- ^ «Special Functions – GSL 2.7 documentation».
Further reading[edit]
- Abramowitz, Milton; Stegun, Irene Ann, eds. (1983) [June 1964]. «Chapter 7». Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables. Applied Mathematics Series. Vol. 55 (Ninth reprint with additional corrections of tenth original printing with corrections (December 1972); first ed.). Washington D.C.; New York: United States Department of Commerce, National Bureau of Standards; Dover Publications. p. 297. ISBN 978-0-486-61272-0. LCCN 64-60036. MR 0167642. LCCN 65-12253.
- Press, William H.; Teukolsky, Saul A.; Vetterling, William T.; Flannery, Brian P. (2007), «Section 6.2. Incomplete Gamma Function and Error Function», Numerical Recipes: The Art of Scientific Computing (3rd ed.), New York: Cambridge University Press, ISBN 978-0-521-88068-8
- Temme, Nico M. (2010), «Error Functions, Dawson’s and Fresnel Integrals», in Olver, Frank W. J.; Lozier, Daniel M.; Boisvert, Ronald F.; Clark, Charles W. (eds.), NIST Handbook of Mathematical Functions, Cambridge University Press, ISBN 978-0-521-19225-5, MR 2723248.
External links[edit]
- A Table of Integrals of the Error Functions
Статистические гипотезы
Определение статистической гипотезы. Нулевая и альтернативная, простая и сложная гипотезы. Ошибки первого и второго рода. Статистический критерий, наблюдаемое значение критерия. Критическая область. Область принятия нулевой гипотезы; критическая точка. Общая методика построения право-, лево- и двухсторонней критических областей
Понятие и определение статистической гипотезы
Проверка статистических гипотез тесно связана с теорией оценивания параметров. В естествознании, технике, экономике для выяснения того или иного случайного факта часто прибегают к высказыванию гипотез, которые можно проверить статистически, т. е. опираясь на результаты наблюдений в случайной выборке. Под статистическими подразумеваются такие гипотезы, которые относятся или к виду, или к отдельным параметрам распределения случайной величины. Например, статистической является гипотеза о том, что распределение производительности труда рабочих, выполняющих одинаковую работу в одинаковых условиях, имеет нормальный закон распределения. Статистической будет также гипотеза о том, что средние размеры деталей, производимые на однотипных, параллельно работающих станках, не различаются.
Статистическая гипотеза называется простой, если она однозначно определяет распределение случайной величины , в противном случае гипотеза называется сложной. Например, простой гипотезой является предположение о том, что случайная величина
распределена по нормальному закону с математическим ожиданием, равным нулю, и дисперсией, равной единице. Если высказывается предположение, что случайная величина
имеет нормальное распределение с дисперсией, равной единице, а математическое ожидание — число из отрезка
, то это сложная гипотеза. Другим примером сложной гипотезы является предположение о том, что непрерывная случайная величина
с вероятностью
принимает значение из интервала
, в этом случае распределение случайной величины
может быть любым из класса непрерывных распределений.
Часто распределение величины известно, и по выборке наблюдений необходимо проверить предположения о значении параметров этого распределения. Такие гипотезы называются параметрическими.
Проверяемая гипотеза называется нулевой и обозначается . Наряду с гипотезой
рассматривают одну из альтернативных (конкурирующих) гипотез
. Например, если проверяется гипотеза о равенстве параметра
некоторому заданному значению
, то есть
, то в качестве альтернативной гипотезы можно рассмотреть одну из следующих гипотез:
где
— заданное значение,
. Выбор альтернативной гипотезы определяется конкретной формулировкой задачи.
Правило, по которому принимается решение принять или отклонить гипотезу , называется критерием
. Так как решение принимается на основе выборки наблюдений случайной величины
, необходимо выбрать подходящую статистику, называемую в этом случае статистикой
критерия
. При проверке простой параметрической гипотезы
в качестве статистики критерия выбирают ту же статистику, что и для оценки параметра
.
Проверка статистической гипотезы основывается на принципе, в соответствии с которым маловероятные события считаются невозможными, а события, имеющие большую вероятность, — достоверными; Этот принцип можно реализовать следующим образом. Перед анализом выборки фиксируется некоторая малая вероятность , называемая уровнем значимости. Пусть
— множество значений статистики
, а
— такое подмножество, что при условии истинности гипотезы
вероятность попадания статистики критерия в
равна
, то есть
.
Обозначим выборочное значение статистики
, вычисленное по выборке наблюдений. Критерий формулируется так: отклонить гипотезу
, если
; принять гипотезу
, если
. Критерий, основанный на использовании заранее заданного уровня значимости, называют критерием значимости. Множество
всех значений статистики критерия
, при которых принимается решение отклонить гипотезу
, называется критической областью; область
называется областью принятия гипотезы
.
Уровень значимости определяет размер критической области
. Положение критической области на множестве значений статистики
зависит от формулировки альтернативной гипотезы
. Например, если проверяется гипотеза
, а альтернативная гипотеза формулируется как
, то критическая область размещается на правом (левом) «хвосте» распределения статистики
, т. е. имеет вид неравенства
, где
— значения статистики
, которые принимаются с вероятностями соответственно
и
при условии, что верна гипотеза
. В этом случае критерий называется односторонним (соответственно правосторонним и левосторонним). Если альтернативная гипотеза формулируется как
, то критическая область размещается на обоих «хвостах» распределения
, то есть определяется совокупностью неравенств
и
в этом случае критерий называется двухсторонним.
Расположение критической области для различных альтернативных гипотез показано на рис. 30, где
— плотность распределения статистики
критерия при условии, что верна гипотеза
,
— область принятия гипотезы,
.
Проверку параметрической статистической гипотезы с помощью критерия значимости можно разбить на этапы:
1) сформулировать проверяемую и альтернативную
гипотезы;
2) назначить уровень значимости ;
3) выбрать статистику критерия для проверки гипотезы
;
4) определить выборочное распределение статистики при условии, что верна гипотеза
;
5) в зависимости от формулировки альтернативной гипотезы определить критическую область одним из неравенств
или совокупностью неравенств
и
;
6) получить выборку наблюдений и вычислить выборочные значения статистики критерия;
7) принять статистическое решение: если , то отклонить гипотезу
как не согласующуюся с результатами наблюдений; если
, то принять гипотезу
, т. е. считать, что гипотеза
не противоречит результатам наблюдений.
Обычно при выполнении пп. 4-7 используют статистику с нормальным распределением, статистику Стьюдента, Фишера.
Пример 3. По паспортным данным автомобильного двигателя расход топлива на 100 км пробега составляет 10 л. В результате изменения конструкции двигателя ожидается, что расход топлива уменьшится. Для проверки проводятся испытания 25 случайно отобранных автомобилей с модернизированным двигателем, причем выборочное среднее расходов топлива на 100 км пробега по результатам испытаний составило 9,3 л. Предположим, что выборка расходов топлива получена из нормально распределенной генеральной совокупности со средним и дисперсией
л². Используя критерий значимости, проверить гипотезу, утверждающую, что изменение конструкции двигателя не повлияло на расход топлива.
Решение. Проверим гипотезу о среднем нормально распределенной генеральной совокупности. Проверку проведем по этапам:
1) проверяемая гипотеза ; альтернативная гипотеза
;
2) уровень значимости ;
3) в качестве статистики критерия используем статистику математического ожидания — выборочное среднее;
4) так как выборка получена из нормально распределенной генеральной совокупности, выборочное среднее также имеет нормальное распределение с дисперсией . При условии, что верна гипотеза
, математическое ожидание этого распределения равно 10. Нормированная статистика
имеет нормальное распределение;
5) альтернативная гипотеза предполагает уменьшение расхода топлива, следовательно, нужно использовать односторонний критерий. Критическая область определяется неравенством
. По прил. 5 находим
;
б) выборочное значение нормированной статистики критерия
7) статистическое решение: так как выборочное значение статистики критерия принадлежит критической области, гипотеза отклоняется: следует считать, что изменение конструкции двигателя привело к уменьшению расхода топлива. Границу
критической области для исходной статистики
критерия можно получить из соотношения
, откуда
, т. е. критическая область для статистики
определяется неравенством
.
Ошибки первого и второго рода
Решение, принимаемое на основе критерия значимости, может быть ошибочным. Пусть выборочное значение статистики критерия попадает в критическую область, и гипотеза , отклоняется в соответствии с критерием. Если, тем не менее, гипотеза
верна, то принимаемое решение неверно. Ошибка, совершаемая при отклонении правильной гипотезы if о, называется ошибкой первого рода. Вероятность ошибки первого рода равна вероятности попадания статистики критерия в критическую область при условии, что верна гипотеза
, т. е. равна уровню значимости
Ошибка второго рода происходит тогда, когда гипотеза принимается, но в действительности верна гипотеза
. Вероятность
ошибки второго рода вычисляется по формуле
Пример 4. В условиях примера 3 предположим, что наряду с гипотезой л рассматривается альтернативная гипотеза
л. В качестве статистики критерия снова возьмем выборочное среднее
. Предположим, что критическая область задана неравенством
л. Найти вероятности ошибок первого и второго рода для критерия с такой критической областью.
Решение. Найдем вероятность ошибки первого рода. Статистика критерия при условии, что верна гипотеза
л, имеет нормальное распределение с математическим ожиданием, равным 10, и дисперсией, равной
. Используя прил. 5, по формуле (11.1) находим
Это означает, что принятый критерий классифицирует примерно 8% автомобилей, имеющих расход 10 л на 100 км пробега, как автомобили, имеющие меньший расход топлива. При условии, что верна гипотеза л, статистика
имеет нормальное распределение с математическим ожиданием, равным 9, и дисперсией, равной
. Вероятность ошибки второго рода найдем по формуле (11.2):
Следовательно, в соответствии с принятым критерием 13,6% автомобилей, имеющих расход топлива 9 л на 100 км пробега, классифицируются как автомобили, имеющие расход топлива 10 л.
Математический форум (помощь с решением задач, обсуждение вопросов по математике).
Если заметили ошибку, опечатку или есть предложения, напишите в комментариях.
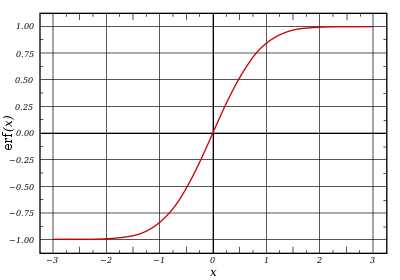
График функции ошибок
В математике функция ошибок — это неэлементарная функция, возникающая в теории вероятностей, статистике и теории дифференциальных уравнений в частных производных. Она определяется как
- .
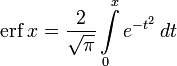 .
.Дополнительная функция ошибок, обозначаемая 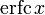 (иногда применяется обозначение
(иногда применяется обозначение 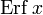 , определяется через функцию ошибок:
, определяется через функцию ошибок:
- .
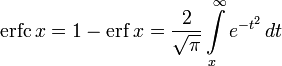 .
.Комплексная функция ошибок, обозначаемая w(x), также определяется через функцию ошибок:
- .
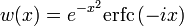 .
.Содержание
- 1 Свойства
- 2 Применение
- 3 Асимптотическое разложение
- 4 Родственные функции
- 4.1 Обобщённые функции ошибок
- 4.2 Итерированные интегралы дополнительной функции ошибок
- 5 Реализация
- 6 См. также
- 7 Литература
- 8 Внешние ссылки
Свойства
- Функция ошибок нечётна:
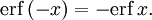
- Для любого комплексного x выполняется
где черта обозначает комплексное сопряжение числа x.
- Функция ошибок не может быть представлена через элементарные функции, но, разлагая интегрируемое выражение в ряд Тейлора и интегрируя почленно, мы можем получить её представление в виде ряда:
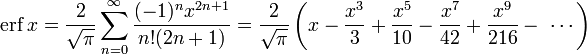
Это равенство выполняется (и ряд сходится) как для любого вещественного x, так и на всей комплексной плоскости. Последовательность знаменателей образует последовательность A007680 в OEIS.
- Для итеративного вычисления элементов ряда полезно представить его в альтернативном виде:
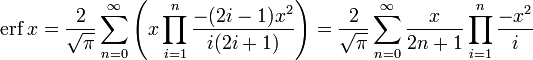
поскольку 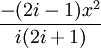 — сомножитель, превращающий i-й член ряда в (i + 1)-й, считая первым членом x.
— сомножитель, превращающий i-й член ряда в (i + 1)-й, считая первым членом x.
- Функция ошибок на бесконечности равна единице; однако это справедливо только при приближении к бесконечности по вещественной оси, так как:
- При рассмотрении функции ошибок в комплексной плоскости точка будет для неё существенно особой.
 будет для неё существенно особой.
будет для неё существенно особой.- Производная функции ошибок выводится непосредственно из определения функции:
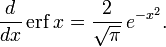
- Обратная функция ошибок представляет собой ряд
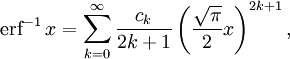
где c0 = 1 и
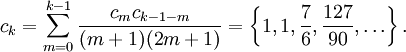
Поэтому ряд можно представить в следующем виде (заметим, что дроби сокращены):
- [1]
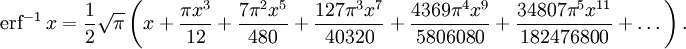 [1]
[1]Последовательности числителей и знаменателей после сокращения — A092676 и A132467 в OEIS; последовательность числителей до сокращения — A002067 в OEIS.
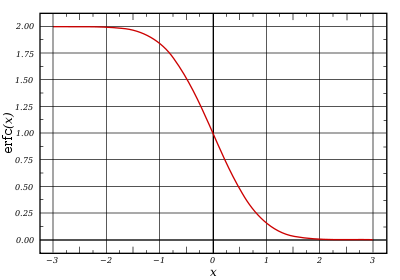
Дополнительная функция ошибок
Применение
Если набор случайных чисел подчиняется нормальному распределению со стандартным отклонением σ, то вероятность, что число отклонится от среднего не более чем на a, равна 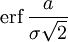 .
.
Функция ошибок и дополнительная функция ошибок встречаются в решении некоторых дифференциальных уравнений, например, уравнения теплопроводности с граничными условиями описываемыми функцией Хевисайда («ступенькой»).
В системах цифровой оптической коммуникации, вероятность ошибки на бит также выражается формулой, использующей функцию ошибок.
Асимптотическое разложение
При больших x полезно асимптотическое разложение для дополнительной функции ошибок:
![\operatorname{erfc}\,x = \frac{e^{-x^2}}{x\sqrt{\pi}}\left [1+\sum_{n=1}^\infty (-1)^n \frac{1\cdot3\cdot5\cdots(2n-1)}{(2x^2)^n}\right ]=\frac{e^{-x^2}}{x\sqrt{\pi}}\sum_{n=0}^\infty (-1)^n \frac{(2n)!}{n!(2x)^{2n}}.\,](https://dic.academic.ru/pictures/wiki/files/50/2d5fe0b0f05b66753a4dc4d68612c2e1.png)
Хотя для любого конечного x этот ряд расходится, на практике первых нескольких членов достаточно для вычисления с хорошей точностью, в то время как ряд Тейлора сходится очень медленно.
Другое приближение даётся формулой
где
Родственные функции
С точностью до масштаба и сдвига, функция ошибок совпадает с нормальным интегральным распределением, обозначаемым Φ(x)
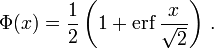
Обратная функция к Φ, известная как нормальная квантильная функция, иногда обозначается  и выражается через нормальную функцию ошибок как
и выражается через нормальную функцию ошибок как
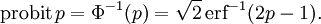
Нормальное интегральное распределение чаще применяется в теории вероятностей и математической статистике, в то время как функция ошибок чаще применяется в других разделах математики.
Функция ошибок является частным случаем функции Миттаг-Леффлера, а также может быть представлена как вырожденная гипергеометрическая функция (функция Куммера):
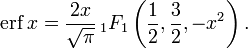
Функция ошибок выражается также через интеграл Френеля. В терминах регуляризованной неполной гамма-функции P и неполной гамма-функции,
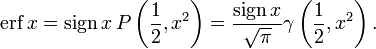
Обобщённые функции ошибок
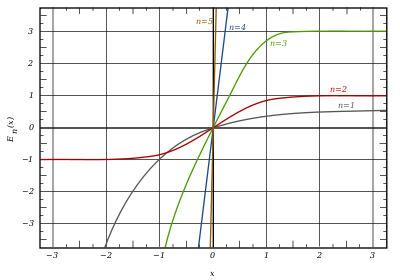
График обобщённых функций ошибок En(x):
серая линия: 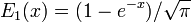
красная линия: 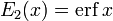
зелёная линия: E3(x)
синяя линия: E4(x)
жёлтая линия: E5(x).
Некоторые авторы обсуждают более общие функции
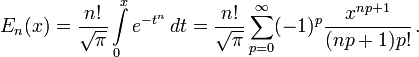
Примечательными частными случаями являются:
После деления на n! все En с нечётными n выглядят похоже (но не идентично). Все En с чётными n тоже выглядят похоже, но не идентично, после деления на n!. Все обощённые функции ошибок с n > 0 выглядят похоже на полуоси x > 0.
На полуоси x > 0 все обобщённые функции могут быть выражены через гамма-функцию:
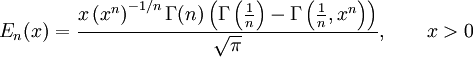
Следовательно, мы можем выразить функцию ошибок через гамма-функцию:
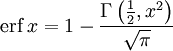
Итерированные интегралы дополнительной функции ошибок
Итерированные интегралы дополнительной функции ошибок определяются как
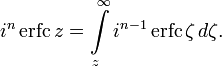
Их можно разложить в ряд:
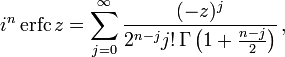
откуда следуют свойства симметрии
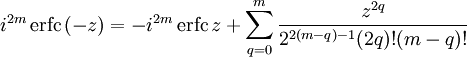
и
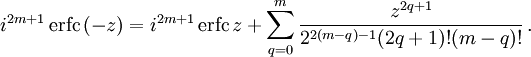
Реализация
В стандартах языков Си и C++ функция ошибок 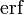 и дополнительная функция ошибок
и дополнительная функция ошибок 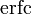 отсутствуют в стандартной библиотеке. Однако в GCC (GNU Compilier Collection) эти функции реализованы как
отсутствуют в стандартной библиотеке. Однако в GCC (GNU Compilier Collection) эти функции реализованы как double erf(double x) и double erfc(double x). Функции находятся в заголовочных файлах math.h или cmath. Там же есть пары функций erff(),erfcf() и erfl(),erfcl(). Первая пара получает и возвращает значения типа float, а вторая — значения типа long double. Соответствующие функции также содержатся в библиотеке Math проекта Boost.
В языке [2]. Класс Erf есть в пакете org.apache.commons.math.special от [3]. Однако эта библиотека не является одной из стандартных библиотек Java 6.
Matlab[4] и
В языке Special проекта scipy [5].
См. также
- Функция Гаусса
Литература
- Milton Abramowitz and Irene A. Stegun, eds. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables. New York: Dover, 1972. (См. часть 7)
Внешние ссылки
- MathWorld — Erf
- Онлайновый калькулятор Erf и много других специальных функций (до 6 знаков)
- Онлайновый калькулятор, вычисляющий в том числе Erf
Wikimedia Foundation.
2010.