Вглядываясь в зеркала или еще раз о проблеме гетероскедастичности
Время на прочтение
2 мин
Количество просмотров 1.5K
Секунда теории
Гетероскедастичность – это ситуация, когда ошибка регрессии не удовлетворяет условию гомоскедастичности, т.е. дисперсия этой самой ошибки непостоянно. Это приводит при использовании метода наименьших квадратов к разным неприятным эффектам смещения значений оценок, что ставит под сомнение смысл всей проделанной на основании данного уравнения регрессии работы.
В странствиях по CRAN-у попался пакет skedastic, в котором реализованы 25 разных тестов гомоскедастичности – о нем и поговорим.
О тестах
Вдумчивый разбор математического основания всех реализованных тестов – это дело статьи в специализированном журнале, дело данной заметки – посмотреть, как они работают.
Возьмем из пакета UsingR данные о бриллиантах diamond и посмотрим уравнение регрессии (цена зависит от веса)
library(tidyverse)
library(ggplot2)
library(skedastic)
library(AER)
library(gvlma)
library(UsingR)
data(diamond)
ggplot(data = diamond, aes(x=carat, y=price)) + geom_point()
model_1 <- lm(price~carat, data=diamond)
summary(model_1)
gvlma(model_1)
ggplot(data = diamond, aes(x=carat, y=model_1$residuals)) + geom_point() + ylab("Error of model")
На графике видна классическая линейная зависимость. Соответствующая модель значима и даже (по версии пакета gvlma) все условия Гаусса-Маркова выполняются

График ошибок говорит о том же самом:

Есть значительные основания полагать, что гетероскедастичности тут нет. Теперь посмотрим на результаты применения пакета skedastic (во всех тестах нулевая гипотеза: есть гомоскедастичность; при уровне значимости меньше заданного, допустим, 0.05, она будет отвергнута):

Собственно, тесты почти единодушны: 24 из 25 (кроме теста Хонды) указали, что нулевая гипотеза не может быть отвергнута, значит, можно смело говорить про гомоскедастичность.
Эксперимент
Самое интересное, правда, другое – вопрос о том, насколько эти тесты определяют гетероскедастичность, когда у нас она есть. Создадим искусственный датафрейм по формуле y = ax+b+e(1+s|x|) при разных значениях s. При s=0 у нас классическая гомоскедастичность (ошибки происходят из нормального распределения), при s=1 – классическая гетероскедастичность (когда дисперсия ошибок растет при увеличении х по модулю). Логично предположить, что нормальное поведение теста в этих случаях – обратная пропорциональность p-значения от значения s. Каждый тест проводился 100 раз на разных значениях a и b, его результаты потом усреднялись. Соответствующие графики представлены ниже:

























Собственно, тестов, определяющий данный вид гетероскедастичности, всего 4 (из 25): Диблази-Боуманна, Уайта, Юса и Чжоу. Это говорит о том, что даже если вам тесты показали, что у вас все хорошо, это не значит, что оно так и есть. И это также повод внимательно посмотреть и определить области эффективности этих тестов.
Все материалы, в т.ч. статьи авторов-изобретателей тестов, есть на https://github.com/acheremuhin/Heteroscedacity
Prerequisite: Linear Regression
In Simple Linear Regression or Multiple Linear Regression we make some basic assumptions on the error term .
Simple Linear Regression:
(1)
Multiple Linear Regression:
(2)
Assumptions:
1. Error has zero mean 2. Error has constant variance 3. Errors are uncorrelated 4. Errors are normally distributed
The second assumption is known as Homoscedasticity and therefore, the violation of this assumption is known as Heteroscedasticity.
Homoscedasticity vs Heteroscedasticity:
Therefore, in simple terms, we can define heteroscedasticity as the condition in which the variance of error term or the residual term in a regression model varies. As you can see in the above diagram, in case of homoscedasticity, the data points are equally scattered while in case of heteroscedasticity the data points are not equally scattered.
Possible reasons of arising Heteroscedasticity:
- Often occurs in those data sets which have a large range between the largest and the smallest observed values i.e. when there are outliers.
- When model is not correctly specified.
- If observations are mixed with different measures of scale.
- When incorrect transformation of data is used to perform the regression.
- Skewness in the distribution of a regressor, and may be some other sources.
Effects of Heteroscedasticity:
- As mentioned above that one of the assumption (assumption number 2) of linear regression is that there is no heteroscedasticity. Breaking this assumption means that OLS (Ordinary Least Square) estimators are not the Best Linear Unbiased Estimator(BLUE) and their variance is not the lowest of all other unbiased estimators.
- Estimators are no longer best/efficient.
- The tests of hypothesis (like t-test, F-test) are no longer valid due to the inconsistency in the co-variance matrix of the estimated regression coefficients.
Identifying Heteroscedasticity with residual plots:
As shown in the above figure, heteroscedasticity produces either outward opening funnel or outward closing funnel shape in residual plots.
Identifying Heteroscedasticity Through Statistical Tests:
The presence of heteroscedasticity can also be quantified using the algorithmic approach. There are some statistical tests or methods through which the presence or absence of heteroscedasticity can be established.
- The Breush – Pegan Test: It tests whether the variance of the errors from regression is dependent on the values of the independent variables. In that case, heteroskedasticity is present.
- White test: White test establishes whether the variance of the errors in a regression model is constant. To test for constant variance one undertakes an auxiliary regression analysis: this regresses the squared residuals from the original regression model onto a set of regressors that contain the original regressors along with their squares and cross-products.
Corrections for heteroscedasticity:
- We can use different specification for the model.
- Weighted Least Squares method is one of the common statistical method. This is the generalization of ordinary least square and linear regression in which the errors co-variance matrix is allowed to be different from an identity matrix.
- Use MINQUE: The theory of Minimum Norm Quadratic Unbiased Estimation (MINQUE) involves three stages. First, defining a general class of potential estimators as quadratic functions of the observed data, where the estimators relate to a vector of model parameters. Secondly, specifying certain constraints on the desired properties of the estimators, such as unbiasedness and third, choosing the optimal estimator by minimizing a “norm” which measures the size of the covariance matrix of the estimators.
Reference: https://en.wikipedia.org/wiki/Heteroscedasticity
Понимание гетероскедастичности в регрессионном анализе
читать 3 мин
В регрессионном анализе гетероскедастичность (иногда пишется как гетероскедастичность) относится к неравномерному разбросу остатков или ошибок. В частности, это относится к случаю, когда имеет место систематическое изменение разброса невязок по диапазону измеренных значений.
Гетероскедастичность является проблемой, потому что обычная регрессия методом наименьших квадратов (OLS) предполагает, что остатки поступают из совокупности с гомоскедастичностью , что означает постоянную дисперсию.
Когда в регрессионном анализе присутствует гетероскедастичность, его результатам становится трудно доверять. В частности, гетероскедастичность увеличивает дисперсию оценок коэффициента регрессии, но регрессионная модель этого не учитывает.
Это повышает вероятность того, что регрессионная модель объявит термин в модели статистически значимым, хотя на самом деле это не так.
В этом руководстве объясняется, как обнаружить гетероскедастичность, причины гетероскедастичности и потенциальные способы решения проблемы гетероскедастичности.
Как обнаружить гетероскедастичность
Самый простой способ обнаружить гетероскедастичность — использовать график сопоставления значения и остатка .
После того, как вы подгоните линию регрессии к набору данных, вы можете создать диаграмму рассеяния, которая показывает подобранные значения модели в сравнении с остатками этих подобранных значений.
На приведенной ниже диаграмме рассеяния показано типичное подобранное значение по сравнению с остаточным графиком , на котором присутствует гетероскедастичность.

Обратите внимание, как остатки становятся намного более разбросанными по мере того, как подобранные значения становятся больше. Эта форма «конуса» является явным признаком гетероскедастичности.

Что вызывает гетероскедастичность?
Гетероскедастичность возникает естественным образом в наборах данных с большим диапазоном наблюдаемых значений данных. Например:
- Рассмотрим набор данных, который включает годовой доход и расходы 100 000 человек в Соединенных Штатах. Для лиц с более низкими доходами изменчивость соответствующих расходов будет ниже, поскольку у этих людей, вероятно, достаточно денег только для оплаты самого необходимого. Для людей с более высокими доходами будет более высокая изменчивость соответствующих расходов, поскольку у этих людей есть больше денег, которые они могут потратить, если захотят. Некоторые люди с более высоким доходом предпочтут тратить большую часть своего дохода, в то время как некоторые могут предпочесть быть бережливыми и тратить только часть своего дохода, поэтому изменчивость расходов среди этих людей с более высоким доходом по своей сути будет выше.
- Рассмотрим набор данных, включающий население и количество цветочных магазинов в 1000 различных городах США. Для городов с небольшим населением может быть обычным наличие только одного или двух цветочных магазинов. Но в городах с большим населением будет гораздо большая вариабельность количества цветочных магазинов. В этих городах может быть от 10 до 100 магазинов. Это означает, что когда мы создаем регрессионный анализ и используем население для прогнозирования количества цветочных магазинов, по своей сути будет большая изменчивость остатков для городов с более высоким населением.
Некоторые наборы данных просто более склонны к гетероскедастичности, чем другие.
Как исправить гетероскедастичность
Существует три распространенных способа исправить гетероскедастичность:
1. Преобразуйте зависимую переменную
Один из способов исправить гетероскедастичность — каким-то образом преобразовать зависимую переменную. Одним из распространенных преобразований является просто получение журнала зависимой переменной.
Например, если мы используем численность населения (независимая переменная) для прогнозирования количества цветочных магазинов в городе (зависимая переменная), вместо этого мы можем попытаться использовать численность населения для прогнозирования логарифма количества цветочных магазинов в городе.
Использование журнала зависимой переменной, а не исходной зависимой переменной, часто приводит к исчезновению гетероскедастичности.
2. Переопределите зависимую переменную
Другой способ исправить гетероскедастичность — переопределить зависимую переменную. Один из распространенных способов сделать это — использовать скорость для зависимой переменной, а не необработанное значение.
Например, вместо использования численности населения для прогнозирования количества цветочных магазинов в городе мы можем вместо этого использовать численность населения для прогнозирования количества цветочных магазинов на душу населения.
В большинстве случаев это снижает изменчивость, которая естественным образом возникает среди больших групп населения, поскольку мы измеряем количество цветочных магазинов на человека, а не простое количество цветочных магазинов.
3. Используйте взвешенную регрессию
Другой способ исправить гетероскедастичность — использовать взвешенную регрессию. Этот тип регрессии присваивает вес каждой точке данных на основе дисперсии ее подобранного значения.
По сути, это дает небольшие веса точкам данных с более высокой дисперсией, что уменьшает их квадраты невязок. Когда используются правильные веса, это может устранить проблему гетероскедастичности.
Вывод
Гетероскедастичность — довольно распространенная проблема, когда дело доходит до регрессионного анализа, потому что многие наборы данных по своей природе склонны к непостоянной дисперсии.
Однако, используя график сравнения подобранного значения с остатком , можно довольно легко обнаружить гетероскедастичность.
А путем преобразования зависимой переменной, переопределения зависимой переменной или использования взвешенной регрессии проблему гетероскедастичности часто можно устранить.
Термин гетероскедастичность в широком
смысле означает предположение о дисперсии
случайных ошибок регрессионной модели.
Случайная ошибка – отклонение в модели
линейной множественной регрессии:
![]()
Величина случайной регрессионной ошибки
является неизвестной, поэтому вычисляется
выборочная оценка случайной ошибки
регрессионной модели по формуле:
![]()
,
где
![]()
— остатки регрессионной модели.
Нормальная линейная регрессионная
модель строится на основании следующих
предположения о случайной ошибке:
Матожидание случайной ошибки уравнения
регрессии равно 0 во всех наблюдениях:
![]()
,
где
![]()
Дисперсия случайной ошибки уравнения
регрессии является постоянной для всех
наблюдений:
![]()
Случайные ошибки уравнения регрессии
не коррелированны между собой, то есть
ковариация случайных ошибок любых двух
разных наблюдений равна 0:
![]()
,
где
![]()
Условие
трактуется как гомоскедастичность
(однородный разброс) дисперсий случайных
ошибок регрессионной модели.
Гомоскедастичность – это предположение
от том, что дисперсии случайной ошибки
![]()
является известной постоянной величиной
для всех
![]()
наблюдений регрессионной модели. На
практике предположение о гомоскедатичности
случайной ошибки
или остатков регрессионной модели
далеко не всегда оказывается верным.
Предположение о том, что дисперсии
случайных ошибок являются разными
величинами для всех наблюдений, называется
гетероскедастичностью (неоднородный
разброс).
![]()
,
где
.
Условие гетероскедастичности можно
записать через ковариационную матрицу
случайных ошибок регрессионной модели.
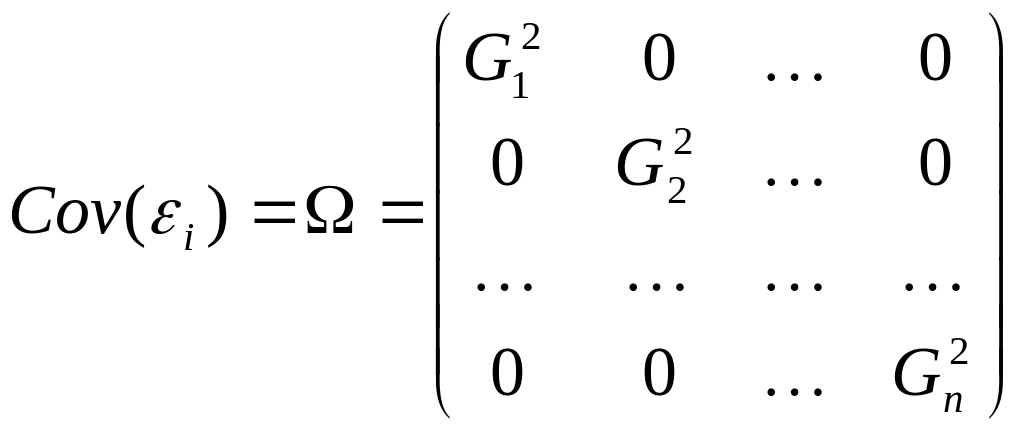
,
где
![]()
Тогда
подчиняется нормальному закону
распределения с параметрами:
![]()
,
где
![]()
— матрица ковариации случайной ошибки.
Если дисперсии случайных ошибок
регрессионной модели
![]()
известны заранее, то от проблемы
гетероскедастичности можно было бы
легко избавиться. Но на практике, как
правило, неизвестна даже точная функция
зависимости
![]()
между изучаемыми переменными, которую
предстоит построить и оценить. Чтобы в
подобранной регрессионной модели
обнаружить гетероскедастичность,
необходимо провести анализ остатков
регрессионной модели. Проверяются
следующие гипотезы:
Основная гипотеза
![]()
,
утверждающая о постоянстве дисперсий
случайных ошибок регрессии, то есть о
присутствии в модели условия
гомоскедастичности:
![]()
Альтернативной гипотезой
![]()
является предположение о неодинаковых
дисперсиях случайных ошибок в различных
наблюдениях, то есть о присутствии в
модели условия гетероскедастичности:
![]()
Обнаружение гетероскедастичности.
Существует несколько тестов на обнаружение
гетероскедастичности в регрессионной
модели.
Тест Глейзера.
На первом этапе строится обычная
регрессионная модель:
![]()
Методом наименьших квадратов вычисляются
оценки коэффициентов построенной
модели:
![]()
На следующем этапе вычисляются остатки
регрессионной модели:
![]()
.
Полученные регрессионные остатки
возводятся в квадрат
![]()
.
С целью обнаружение гетероскедастичности
определяется коэффициент Спирмена.
Коэффициент Спирмена является аналогом
парного коэффициента корреляции, но
позволяет выявить взаимосвязь между
качественным и количественным признаками.
Зависимой переменной является
,
в качестве независимой выступает
![]()
.
Переменная
ранжируется и располагается оп
возрастанию. Ранги обозначаются как
![]()
.
Далее проставляются ранги переменной
,
обозначаемые как
![]()
.
Коэффициент Спирмена рассчитывается
по формуле:
![]()
,
где d – ранговая разность (
—
);
n – количество пар вариантов.
Значимость коэффициента Сирмена
проверяется с помощью t-критерия
Стьюдента.
![]()
Критическое значение определяется по
таблице распределения Стьюдента:
![]()
.
Если
![]()
,
то основная гипотеза отвергается, и
между переменной
и остатками регрессионной модели
существует взаимосвязь, то есть в модели
присутствует гетероскедастичность.
Если
![]()
,
то основная гипотеза принимается, и в
модели парной регрессии гетероскедастичность
отсутсвует. Для модели множественной
регрессии вывод может быть следующий:
гетероскедастичность не зависит от
выбранной переменной
.
Устранение гетероскедастичности.
Наиболее простым методом устранение
гетероскедастичности является взвешивание
параметров регрессионной модели. Суть
метода состоит в том, что отдельным
наблюдениям независимой переменной с
максимальным среднеквадратическим
отклонением случайной ошибки придается
больший вес, а остальным наблюдениям с
минимальным среднеквадратическим
отклонением случайной ошибки придается
меньший вес. Благодаря этому оценки
коэффициентов уравнения остаются
эффективными. Модель регрессии при
таком подходе называется взвешенной
регрессией с весами
![]()
.
Рассмотрим процесс взвешивания для
линейной модели парной регрессии, в
которой доказано наличие гетероскедастичности:
![]()
,
где
![]()
.
Разделим регрессионное уравнение на
среднеквадратическое отклонение
случайной ошибки
![]()
:
![]()
Данное уравнение записывают в линейном
виде с помощью метода замен. Введем
обозначения:
![]()
Уравнение регрессии записывают в
преобразованном виде:
![]()
Эта регрессионная модель является
моделью с двумя факторными переменными
![]()
и
![]()
.
Дисперсия случайной ошибки взвешенной
регрессионной модели:
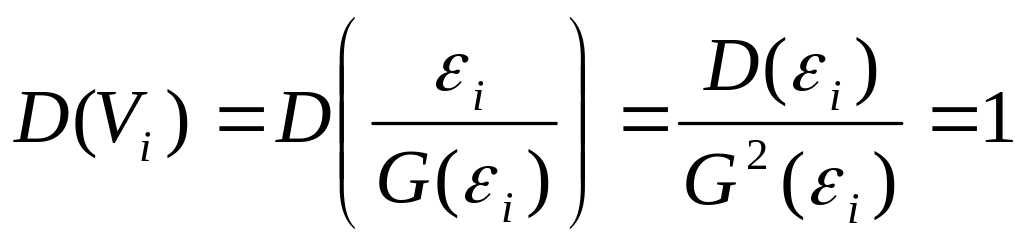
Основной проблемой рассмотренного
подхода к устранению гетероскедастичности
является необходимость априорного
знания среднеквадратических отклонений
случайных ошибок регрессионной модели.
Такое условие в реальности практически
невыполнимо, приходится прибегать к
другим методам устранения
гетероскедастичности.
Методы коррекции гетероскедастичности
сводятся к нахождению ковариационной
матрицы случайных ошибок регрессионной
модели.
,
где
Оценки
![]()
находятся с помощью метода Бреуше-Пайана:
На основании уравнения регрессии
находятся остатки
и сумма квадратов остатков
![]()
Оценкой дисперсии остатков регрессионной
модели будет величина:
![]()
Строится взвешенная регрессия, где
весами является оценка дисперсии
остатков регрессионной модели
![]()
Если взвешенное уравнение получается
незначимым, то и оценки матрицы ковариаций
![]()
являются неточными.
После нахождения оценок дисперсий
остатков можно воспользоваться доступным
обобщенным или взвешенным методом
наименьших квадратов для вычисления
оценок коэффициентов уравнения регрессии,
которые различаются лишь оценкой
.
Если нельзя выполнить коррекцию
гетероскедастичности, то вполне возможно
вычислить оценки коэффициентов уравнения
регрессии по обычному МНК, но корректировать
ковариационную матрицу оценок
коэффициентов
![]()
,
так как условие гетероскедастичности
приводит к увеличению данной матрицы.
содержание
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Определение гетероскедастичности
Тест гетероскедастичности относится к неравномерной дисперсии в последовательности переменных. Его также называют ошибкой. В идеале исследователям нужна гомоскедастичность или однородность дисперсии. Однородная дисперсия объясняет предположение исследователя.
Конусообразная форма видна, когда гетероскедастическая дисперсия нанесена на график. Это изображает ошибки в дисперсии. Большинство реальных данных демонстрируют гетероскедастичность. Более вероятен неравный разброс — это становится проблемой для допущений регрессии. Исследователи изменяют статистическую модель, пытаясь найти лучшие результаты.
Оглавление
- Определение гетероскедастичности
- Объяснение гетероскедастичности
- Методы
- Причины
- Примеры
- Гомоскедастичность против гетероскедастичности
- Часто задаваемые вопросы (FAQ)
- Рекомендуемые статьи
- Гетероскедастичность обычно относится к неравному рассеянию точек данных. В результате наблюдаемые значения отклоняются от предсказанных значений неравномерно.
- Существует два подтипа: чистая и нечистая гетероскедастическая дисперсия. Такие статистические ошибки характерны для больших диапазонов и перекрестных исследований.
- Гетероскедастическая дисперсия снижает точность коэффициента вариации — аналитики должны переработать или улучшить свою модель, чтобы определить большую точность.
- Некоторые регрессионные модели склонны к гетероскедастической дисперсии. Аналитики пытаются решить такие ошибки, изменяя зависимую переменную.
Объяснение гетероскедастичности
Гетероскедастичность в переводе с греческого означает данные с различной дисперсией. Например, в статистике, если последовательность случайных величин имеет одинаковую конечную дисперсию, это называется гомоскедастической дисперсией; если последовательность не имеет одинаковой дисперсии, она известна как гетероскедастическая дисперсия.
Дисперсия — это средство описания степени распределения данных вокруг центрального значения или точки. Более низкая дисперсия указывает на более высокую точность измерения данных, тогда как более высокая дисперсия означает более низкую точность.
Остаточный разброс отображается на графике для визуализации корреляции между данными и конкретной статистической моделью. Если дисперсия гетероскедастична, это рассматривается как проблема. Исследователи ищут гомоскедастичность. Точки данных должны иметь постоянную дисперсию, чтобы удовлетворить предположение исследователя.
На остаточных графиках гетероскедастичность регрессии имеет конусообразную форму. На точечных диаграммах дисперсия увеличивается с увеличением подобранного значения. Для перекрестных исследований, таких как доход, диапазон варьируется от бедности до граждан с высоким доходом; при нанесении на график данные гетероскедастичны.
Гетероскедастичность подразделяется на два типа.
- Чистая гетероскедастичность
- Нечистая гетероскедастичность
В чистой гетероскедастической дисперсии выбранная статистическая модель верна. Но при этом наблюдаются нечистые (остаточные) гетероскедастические дисперсионные ошибки — в результате статистическая модель для заданных данных неверна. Эти ошибки вызывают дисперсию.
Методы
Существует три метода исправления гетероскедастичности и улучшения модели:
- Переопределение переменных
- Взвешенная регрессия
- Преобразование зависимой переменной
В первом методе аналитик может переопределить переменные, чтобы улучшить модель и получить желаемые результаты с большей точностью. Во втором методе регрессионный анализ соответствующим образом взвешивается. Наконец, третий подход заключается в замене работы в каждой модели. Например, есть зависимая переменная и предикторная переменная; при изменении зависимой переменной вся модель обновляется. Таким образом, это важный подход к продвижению вперед.
Независимые переменные, используемые в регрессионном анализе, называются переменными-предикторами. Переменная-предиктор предоставляет информацию о связанной зависимой переменной относительно конкретного результата.
Крайне важно определить, демонстрируют ли данные чистую гетероскедастическую дисперсию или нечистую гетероскедастическую дисперсию — подход различается для каждого подтипа. Кроме того, важно улучшить переменные, используемые в нечистой форме. Если их игнорировать, эти переменные вызывают смещение в точности коэффициентов, и p-значения становятся меньше, чем должны быть.
Причины
Гетероскедастическая дисперсия обусловлена следующими причинами.
- Это происходит в наборах данных с большими диапазонами и колеблется между наибольшими и наименьшими значениями.
- Это происходит из-за изменения пропорциональности факторов.
- Среди других причин характер переменной может быть основной причиной.
- В основном это происходит в перекрестных исследованиях.
- Некоторые регрессионные модели склонны к гетероскедастической дисперсии.
- Это может быть вызвано неправильным выбором регрессионных моделей.
- Это также может быть вызвано формированием набора данных и неэффективностью вычислений.
Примеры
Пример №1
Самый простой гетероскедастический пример — потребление домохозяйств. Разница в потреблении увеличивается с ростом дохода — прямо пропорционально. Потому что, когда доход низок, дисперсия в потреблении также низка. Люди с низким доходом тратят преимущественно на предметы первой необходимости и счета — меньше дисперсии. Напротив, с увеличением дохода люди склонны покупать предметы роскоши и приобретают множество привычек, менее предсказуемых.
Пример #2
Примером гомоскедастичности является тренер, сопоставляющий количество пробежек, набранных каждым игроком, со временем, проведенным на тренировках. В этом случае баллы станут зависимой переменной, а время обучения — переменной-предиктором.
Пример №3
В основном гетероскедастичность применяется на фондовом рынке — сравнивается дисперсия запасов на разные даты. Кроме того, инвесторы используют гетероскедастическую дисперсию в регрессионных моделях для отслеживания ценных бумаг и портфелей. Гетероскедастическая дисперсия может или не может быть предсказана в зависимости от конкретной ситуации, рассматриваемой в исследовании.
Например, когда цены на продукт изучаются при запуске новой модели, гетероскедастичность предсказуема. Но для сравнения осадков или доходов характер дисперсии нельзя предсказать.
Гомоскедастичность против гетероскедастичностигород
- Гомокедастичность относится к равной дисперсии остатков. С другой стороны, неравная дисперсия остатков вызывает гетероскедастическую дисперсию. В регрессионном анализе термин «остаток» относится к разнице между наблюдаемыми и прогнозируемыми данными.
- При использовании регрессионных моделей исследователи обращают внимание на гомоскедастическую дисперсию. Таким образом, гетероскедастическая дисперсия рассматривается как проблема, требующая решения.
- Гомоскедастичность встречается редко, тогда как гетероскедастическая дисперсия обычно наблюдается в реальных примерах.
- Гомоскедастичность также называют однородностью дисперсии. С другой стороны, гетероскедастичность часто называют «ошибкой».
- Гомоскедастичность не классифицируется, но гетероскедастическая дисперсия имеет подтипы — чистый и нечистый.
Часто задаваемые вопросы (FAQ)
1. Что такое гетероскедастичность простыми словами?
Это неравное отклонение наблюдаемых данных от прогнозируемых данных. На графике видна конусообразная форма, показывающая неравную дисперсию остатка. Гетероскедастическая дисперсия может быть предсказана в определенных сценариях — в зависимости от приложения.
2. Что такое гетероскедастичность в регрессии?
В регрессионном анализе невязка показывает неравномерный разброс дисперсии вокруг измеренных значений и поэтому считается ошибкой. Гетероскедастическая дисперсия очень часто наблюдается в данных регрессии, включающих большие диапазоны. Выбор модели регрессии играет ключевую роль в дисперсии. Некоторые статистические модели подвержены ошибкам. Данные и выбранная статистическая модель должны подходить друг другу.
3. Что вызывает гетероскедастичность?
Это вызвано большим количеством наборов данных и перекрестных исследований. Это также может быть вызвано неправильным выбором — некоторые регрессионные модели склонны к гетероскедастической дисперсии. Кроме того, это может быть вызвано характером выбранных переменных.
Рекомендуемые статьи
Это руководство по гетероскедастичности и ее определению. Мы объясним это в регрессии на примерах и сравним с гомоскедастичностью. Подробнее об этом вы можете узнать из следующих статей —
- Лучшие книги по эконометрике
- Выведенный статистика
- Описательная статистика