«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
Method[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complicated function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]

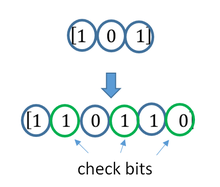
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[6]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[7][8] NOR Flash typically does not use any error correction.[7]
Classical block codes are usually decoded using hard-decision algorithms,[9] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[10]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[11] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[12] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[13]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[14] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.

Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[15] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[16] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[17]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[15][18] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[19]
- a contention-free quadratic permutation polynomial (QPP).[20] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[21]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[22]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[23] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[24] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- Algebraic geometry code
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[25]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[26]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most
 bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters
bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters


See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
- Linear code
- Quantum error correction
References[edit]
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work]
- ^ a b Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
Время на прочтение
4 мин
Количество просмотров 27K
Код исправления ошибок (Error Correction Code или ECC) добавляется к передаваемому сигналу и позволяет не только выявить ошибки при передаче, но и при необходимости исправить их (что в общем-то очевидно из названия), без повторного запроса данных у передатчика. Такой алгоритм работы позволяет передавать данные с постоянной скоростью, что может быть важно во многих случаях. Например, когда вы смотрите цифровое телевидение — смотреть на застывшую картинку, ожидая, пока осуществляются многократные повторные запросы данных, было бы весьма неинтересно.

В 1948 году Клод Шеннон опубликовал свою знаменитую работу о передаче информации, в которой, помимо прочего, была сформулирована теорема о передаче информации по каналу с помехами. После публикации, было разработано немало алгоритмов исправления ошибок с помощью некоторого увеличения объема передаваемых данных, но одним из часто встречающихся семейств алгоритмов, являются алгоритмы, основанные на коде с малой плотностью проверок на четность (Low-density parity-check code, LDPC-code, низкоплотностный код), получившие сейчас распространение за счет простоты реализации.

Клод Шеннон
LDPC был впервые представлен миру в стенах MIT Робертом Греем Галлагером (Robert Gray Gallager), выдающимся специалистом в области коммуникационных сетей. Произошло это в 1960 году, и LDPC опередил свое время. Компьютеры на вакуумных лампах, распространенные в то время, редко обладали мощностью достаточной, для эффективной работы с LDPC. Компьютер, способный обрабатывать такие данные в реальном времени, в те годы занимал площадь почти в 200 квадратных метров, и это автоматически делало все алгоритмы, основанные на LDPC экономически невыгодными. Поэтому, на протяжении почти 40 лет использовались более простые коды, а LDPC оставался скорее изящным теоретическим построением.

Роберт Галлагер
В середине 90-х, инженеры, работающие над алгоритмами спутниковой передачи цифрового телевидения, «стряхнули пыль» с LDPC и стали его использовать, поскольку компьютеры к тому времени стали и мощней, и меньше. К началу 2000-х годов, LDPC получает повсеместное распространение, поскольку он позволяет с большой эффективностью исправлять ошибки при высокоскоростной передаче данных в условиях высоких помех (например при сильных электромагнитных наводках). Так же распространению способствовало появление специализированных систем на чипах, использующихся в WiFi технике, жестких дисках, контроллерах SCSI и т.д., такие SoC оптимизируются под задачи, и для них вычисления, связанные с LDPC вообще не представляют проблемы. В 2003 году LDPC-код, вытеснил технологию турбо-кода, и стал частью стандарта спутниковой передачи данных для цифрового телевидения DVB-S2. Аналогичная замена произошла и в стандарте DVB-T2 для цифрового «эфирного» телевидения.
Стоит сказать, что на базе LDPC строятся очень разные решения, нет «единственно правильной» эталонной реализации. Часто решения, основанные на LDPC несовместимы между собой и код, разработанный, например, для спутникового телевидения, не может быть портирован и использован в жестких дисках. Хотя чаще всего, объединение усилий инженеров разных областей дает массу преимуществ, и LDPC «в целом» является технологией не запатентованной, разные ноу-хау и проприетарные технологии вместе с корпоративными интересами встают на пути. Чаще всего, подобное сотрудничество возможно только в пределах одной компании. В качестве примера можно привести решение для канала чтения HDD от LSI под названием TrueStore®, которое компания предлагает на протяжении уже 3 лет. После приобретения компании SandForce, инженеры LSI стали работать над алгоритмами исправления ошибок SHIELD™ для SSD контроллеров (основанными на LDPC), не существовало портов алгоритмов для работы с SSD, но знания инженерной команды, работавшей над решениями для HDD очень помогли в разработке новых алгоритмов.
Тут, разумеется, у большинства читателей возникнет вопрос: чем алгоритмы, каждый алгоритм LDPC отличается от остальных? Большинство решений LDPC начинаются как декодеры с жестким решением, то есть такой декодер работает с жестко ограниченным набором данных (чаще всего 0 и 1) и использует код коррекции ошибок при малейших отклонениях от нормы. Такое решение, конечно, позволяет эффективно обнаруживать ошибки в передаваемых данных и исправлять их, но в случае высокого уровня ошибок, что иногда случается при работе с SSD, такие алгоритмы перестают справляться с ними. Как вы помните из наших предыдущих статей, любая флеш-память подвержена росту количества ошибок в процессе эксплуатации. Этот неизбежный процесс стоит учитыавть при разработке алгоритмов корреции ошибок для SSD накопителей. Что же делать в случае роста числа ошибок?
Тут на помощь приходят LDPC с мягким решением, являющиеся по сути «более аналоговыми». Подобные алгоритмы «смотрят» глубже, чем «жесткие», и, обладают большим набором возможностей. Примером самого простого такого решения может быть попытка прочитать данные снова, используя другое напряжение, так же как мы часто просим собеседника повторить фразу погромче. Продолжая метафоры с общением людей, можно привести пример более сложных алгоритмов коррекции. Представьте, что вы общаетесь на английском с человеком, говорящим с сильнейшим акцентом. В данном случае сильный акцент выступает в роли помехи. Ваш собеседник произнес некую длинную фразу, которую вы не поняли. В роли LDPC с мягким решением в данном случае будут выступать несколько коротких наводящих вопросов, которые вы можете задать и прояснить весь смысл фразы, которую вы изначально не поняли. Подобные мягкие решения часто используют так же сложные статистические алгоритмы, позволяющие исключить ложнопозитивные срабатывания. В общем, как вы уже поняли, такие решения заметно сложней в реализации, но они чаще всего показывают куда лучшие результаты по сравнению с «жексткими».
В 2013 году, на саммите, посвященном флэш-памяти, проходившем в Санта-Кларе, Калифорния, LSI представили свою технологию расширенной коррекции ошибок SHIELD. Комбинируя подходы с мягким и жестким решением, DSP SHIELD предлагает ряд уникальных оптимизаций для будущих технологий Flash-памяти. Например, технология Adaptive Code Rate, позволяет менять объем, отведенный под ECC так, чтоб он занимал как можно меньше места изначально, и динамически увеличивался по мере неизбежного роста количества ошибок, характерных для SSD.
Как видите, различные решения LDPC работают очень по-разному, и предлагают разные фунции и возможности, от которых во многом будет зависеть и качество работы финального продукта.
Модули оперативной памяти. Технология исправления ошибок Chipkill.
На работу модулей оперативной памяти оказывают влияние множество негативных факторов, которые могут вызвать появление ошибок в считанной информации. Ошибки памяти можно подразделить на аппаратные и случайные. Аппаратные ошибки обычно обусловлены неустранимыми дефектами кремниевого кристалла или монтажных соединений микросхем DRAM. Случайные ошибки (сбои) обычно вызываются заряженными частицами или излучением. Такие ошибки непостоянны и действуют кратковременно. Ранее основной причиной случайных ошибок были альфа-частицы, но более строгий контроль качества материала, из которого делаются корпуса микросхем DRAM, позволил производителям практически ликвидировать эту причину сбоев. В настоящее время основной источник случайных ошибок в микросхемах DRAM — электрические возмущения, вызванные космическими лучами — потоками высокоэнергетических элементарных частиц, приходящими из космоса. Для повышения надежности функционирования компьютерной техники, применяется метод контроля четности памяти, но этот метод позволяет лишь обнаруживать ошибки, а не исправлять их.
Но для наиболее ответственных приложений, где цена ошибки очень высока, используют модули памяти с коррекцией ошибок ECC (Error Checking and Correcting — обнаружение и исправление ошибок).
Идея, лежащая в основе метода ECC, довольно проста — каждый разряд памяти входит более чем в одну контрольную сумму. Это увеличивает число контрольных разрядов, но дает возможность восстанавливать значение сбойного бита по несовпадающим контрольным суммам. Основной недостаток при использования ECC — снижение общей производительности системы, на которую возлагаются дополнительные вычисления.
Другой способ реализации ECC — размещение логики контроля не в контроллере памяти на системной плате, а на самом модуле. Это позволяет избежать снижения производительности, но стоимость таких модулей выше, чем обычных. Поскольку ошибки в большем числе разрядов случались чрезвычайно редко, метод ECC позволил существенно повысить надежность систем. Сегодня технология ECC стала стандартом и применяется практически во всех серверах.
Еще одним механизмом исправления ошибок, который был предложен как одна из составных частей инициативы X-Architecture корпорации IBM, стала технология исправления ошибок Chipkill. Эта технология обеспечивает защиту серверов от отказов отдельных микросхем и многоразрядных ошибок в модулях памяти. Технология Chipkill, перенесенная IBM с больших систем, существенно сокращает среднее время простоя серверов и обеспечивает более надежную платформу для клиент-серверных вычислений на базе микропроцессоров Intel. Она призвана повысить надежность систем, доступность и удобство в эксплуатации, что является ключевыми характеристиками серверов масштаба предприятия, обслуживающих критически важные приложения.
Архитектура Chipkill позволяет системе безболезненно воспринимать ошибки, которые в обычных условиях приводят к неустранимым сбоям, тем самым обеспечивая сохранность данных и высокую доступность системы. В системах высокой доступности, таких как серверы масштаба предприятия IBM S/390, проблема многоразрядных ошибок памяти DRAM отсутствует благодаря особой архитектуре оперативной памяти. Подсистема памяти сконструирована так, что отказ отдельной микросхемы, независимо от ее разрядности, не затронет более одного разряда в каком-либо из нескольких слов ECC. Например, в 4-разрядной микросхеме DRAM отдельные биты из всей четверки попадают в разные слова ECC, т. е. в разные адресные пространства памяти. Поэтому даже в случае полного отказа микросхемы количество ошибочных разрядов в словах ECC не превысит единицу, а такую ошибку механизм ECC устраняет автоматически. Данная архитектура обеспечивает отказоустойчивость всей подсистемы памяти.
Тщательно продуманная конструкция мэйнфреймов защищает их и от сбоев микросхем памяти. В каждом модуле памяти разрядность микросхем равна числу разрядов, защищенных механизмом ECC. Нынешние серверы на базе микропроцессоров Intel такого механизма не поддерживают так как рынок требует дешевой памяти, вынуждая проектировщиков создавать очень плотные микросхемы памяти, поддерживающие отраслевой стандарт (исключительно ECC).
Предлагаемая технология Chipkill является механизмом, позволяющим памяти противостоять многоразрядным ошибкам на отдельных микросхемах DRAM, в том числе и сбою всех разрядов данных. В механизме Chipkill есть два основных метода исправления ошибок, причем они могут применяться совместно. Эти методы базируются на определенном наборе микросхем и особой аппаратной архитектуре системы, поэтому их поддержку невозможно обеспечить простым обновлением ПО.
В первом методе каждый бит данных модуля памяти размещается в отдельном «слове ECC», которое представляет собой набор разрядов данных и контрольных разрядов, в котором обнаружение и исправление ошибок обеспечивается алгоритмом ECC.) Предположим, что разрядность системы памяти составляет 32 байт (или 256 разрядов). Биты ECC добавляются так, чтобы общая ширина блока (и контрольные, и биты данных) составляла 288 разрядов. Четыре слова ECC, каждое из которых состоит из 64 разрядов данных и 8 контрольных разрядов ECC, поддерживают механизм SEC/DED. Эти четыре слова ECC распределяются по DRAM-модулям. Например, если DIMM содержит модули х4 DRAM, четыре бита каждого устройства распределяются по разным словам ECC (рис. 1). Сбой всех четырех битов — это всего лишь четыре единичные ошибки в четырех словах ECC, и они устраняются автоматически. В этом примере механизм Chipkill поддерживается только на DIMM-модулях, состоящих из микросхем х4 DRAM.
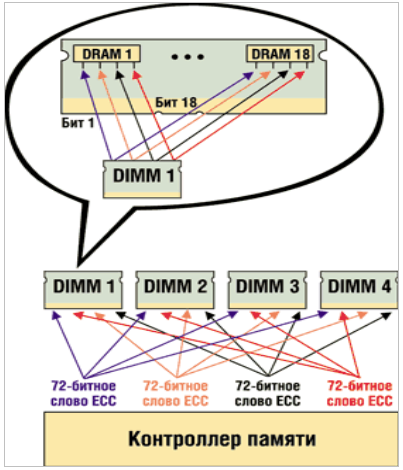
Рис. 1. Пример технологии Chipkill.
Второй метод заключается в предоставлении механизму ECC большего числа разрядов для хранения контрольных кодов, чтобы обеспечить исправление не одного, а нескольких разрядов. При этом используются соответствующие математические алгоритмы устранения многоразрядных ошибок при определенном количестве контрольных битов ECC и битов данных. Например, 144-разрядное слово ECC, состоящее из 128 разрядов данных и 16 битов ECC, позволяет исправлять ошибки, охватывающие до 4 разрядов данных. Для исправления сбоя четырех бит необходимо, чтобы они были смежными, а не располагались случайно. Соотношение разрядов ECC и разрядов данных такое же, как и в предыдущем примере (16/128 и 8/64), однако более длинное слово ECC позволяет применить более эффективный алгоритм обнаружения и исправления ошибок.
Совместное использование этих двух методов обеспечивает коррекцию по механизму Chipkill на DIMM-модулях с микросхемами х8 DRAM. Два 144-разрядных слова ECC распределяются так, чтобы на каждом DRAM в первом и втором словах ECC исправлялись по 4 разряда. Этот метод обеспечивает поддержку механизма Chipkill при использовании DIMM-модулей, состоящих как из микросхем х4 DRAM, так и из х8 DRAM. Инженеры IBM решили эту проблему, разместив избыточный массив недорогих микросхем DRAM (Redundant Array of Inexpensive DRAM, RAID) непосредственно на DIMM-модулях. При каждом доступе к памяти RAID-микросхема вычисляет контрольный код ECC для всего набора микросхем и сохраняет результат в резервной памяти на защищаемом DIMM-модуле. В случае отказа одной микросхемы DIMM-модуля сохраненная на RAID-массиве информация применяется для восстановления потерянных данных, обеспечивая бесперебойную работу всего сервера Netfinity. Такая RAID-технология напоминает RAID-механизмы, применяемые для защиты данных в дисковых массивах, и называется Chipkill DRAM.
Специалисты компании IBM разработали заказную специализированную микросхему для Chipkill, которая называется ECC ASIC (Application-Specific Integrated Circuit) и выполняет исправление ошибок без замедления доступа к высокопроизводительной EDO-памяти со временем доступа 50 нс. Таким образом, при установке DIMM-модулей IBM Chipkill на серверы Netfinity, оборудованные процессором Intel Xeon, модификация плат памяти не нужна, а новые модули не вызывают снижения производительности.
Технология IBM Chipkill Memory позволила снизить число отказов серверов Netfinity по причине сбоев подсистемы памяти до невероятно низкого уровня. Основной задачей механизма Chipkill является исправление ошибок памяти, в нем применяются такие же способы обнаружения и оповещения, что и в ECC. Обнаружение и оповещение Chipkill никак не сказывается на производительности оборудования или ПО (потери те же, что и для стандартных механизмов ECC). Обнаружение постоянных и случайных ошибок, исправление ошибок памяти и оповещение о них в серверных архитектурах с применением обоих механизмов — ECC и Chipkill выполняется в системном наборе микросхем. Для обнаружения, код исправления ошибок (ECC) генерируется при записи и проверяется при чтении во всех системных операциях с памятью «прозрачно» для прикладных программ. Обнаруженная ошибка автоматически исправляется до передачи данных получателю. При этом событие ошибки регистрируется оборудованием, а системная BIOS уведомляется об исправлении ошибки и о месте, где она произошла. Набор микросхем также ведет учет исправленных ошибок, что позволяет BIOS выявлять DIMM-модули, в которых ошибки возникают и исправляются постоянно. Получив уведомление, система BIOS опрашивает регистры набора микросхем, чтобы определить, где произошла ошибка памяти (порядок такого опроса сильно зависит от конструкции конкретной системы, поэтому он и выполняется на уровне BIOS). Обнаружив модуль DIMM, вызвавший ошибку, BIOS регистрирует эту информацию в системном журнале, который является, например, частью встроенной системы управления сервером (Embedded Server Management).
Дефектные DIMM-модули легко заменить в процессе эксплуатации, для них требуется лишь предсказательное оповещение об ошибках и замене, поэтому нет необходимости локализовать ошибки с точностью до отдельной микросхемы на плате DIMM-модуля. Получая за сравнительно короткое время повторяющиеся сообщения об исправленных ошибках от одного и того же DIMM-модуля, BIOS отключает соответствующий механизм оповещения и регистрирует этот факт в журнале системы управления сервером. Это избавляет систему от дополнительной нагрузки, обусловленной обработкой всех ошибок памяти.
Программное обеспечение управления системой, поставляемое в составе многих серверов, анализирует системный журнал при каждом внесении записи системой BIOS. Ошибки единичных разрядов инициируют уведомления одного из трех возможных уровней: warning («предупреждение»), critical («критическая»), nonrecoverable («неустранимая»). По-настоящему случайная ошибка вряд ли инициирует уведомление в стеке программы управления системой. Однако в случае постоянных неполадок в работе DIMM-модуля инициируется уведомление программе управления системой, после чего та назначает службе технической поддержки задание на замену неисправного DIMM-модуля. А постоянная ошибка, вызвавшая отключение механизма регистрации исправлений, в любом случае инициирует уведомление. Конечно постоянные ошибки в одном разряде или ошибки, устраняемые средствами Chipkill, не вызывают отказа системы, но тем не менее они увеличивают вероятность того, что очередная случайная ошибка приведет к критическому, неустранимому сбою, поэтому администраторы системы внимательно следят за уведомлениями о дефектных DIMM-модулях и своевременно выдают ремонтной службе задания на их замену.
Технология Chipkill поддерживается и в новом универсальном наборе микросхем IBM Summit, который хорошо подходит как для 64-разрядных микропроцессоров семейства Itanium, так и для 32-64 разрядных процессоров Xeon. Чипсет сможет поддерживать до четырех процессоров, позволяя им разделять такие ресурсы, как шины ввода-вывода и шины памяти. Четыре набора могут связываться воедино, что даст серверам на базе Summit возможность поддерживать до 16 полностью автономных микропроцессоров (например, в четырехпроцессорном сервере можно будет выделить три кристалла под Windows, а один — под Linux, а если все процессоры работают в одной среде, можно будет проводить их «горячую» замену).
По мнению ряда экспертов, присущая мэйнфреймам надежность и отказоустойчивость скоро потребуется и в небольших серверах, оборудованных микропроцессорами Intel.
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code, (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complicated function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]
A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[6]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[7][8] NOR Flash typically does not use any error correction.[7]
Classical block codes are usually decoded using hard-decision algorithms,[9] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[10]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[11] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[12] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[13]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[14] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[15] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[16] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[17]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[15][18] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[19]
- a contention-free quadratic permutation polynomial (QPP).[20] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[21]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[22]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[23] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[24] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- Algebraic geometry code
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[25]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[26]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters
See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
- Linear code
- Quantum error correction
References[edit]
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work]
- ^ a b Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
Время на прочтение
4 мин
Количество просмотров 27K
Код исправления ошибок (Error Correction Code или ECC) добавляется к передаваемому сигналу и позволяет не только выявить ошибки при передаче, но и при необходимости исправить их (что в общем-то очевидно из названия), без повторного запроса данных у передатчика. Такой алгоритм работы позволяет передавать данные с постоянной скоростью, что может быть важно во многих случаях. Например, когда вы смотрите цифровое телевидение — смотреть на застывшую картинку, ожидая, пока осуществляются многократные повторные запросы данных, было бы весьма неинтересно.
В 1948 году Клод Шеннон опубликовал свою знаменитую работу о передаче информации, в которой, помимо прочего, была сформулирована теорема о передаче информации по каналу с помехами. После публикации, было разработано немало алгоритмов исправления ошибок с помощью некоторого увеличения объема передаваемых данных, но одним из часто встречающихся семейств алгоритмов, являются алгоритмы, основанные на коде с малой плотностью проверок на четность (Low-density parity-check code, LDPC-code, низкоплотностный код), получившие сейчас распространение за счет простоты реализации.
Клод Шеннон
LDPC был впервые представлен миру в стенах MIT Робертом Греем Галлагером (Robert Gray Gallager), выдающимся специалистом в области коммуникационных сетей. Произошло это в 1960 году, и LDPC опередил свое время. Компьютеры на вакуумных лампах, распространенные в то время, редко обладали мощностью достаточной, для эффективной работы с LDPC. Компьютер, способный обрабатывать такие данные в реальном времени, в те годы занимал площадь почти в 200 квадратных метров, и это автоматически делало все алгоритмы, основанные на LDPC экономически невыгодными. Поэтому, на протяжении почти 40 лет использовались более простые коды, а LDPC оставался скорее изящным теоретическим построением.
Роберт Галлагер
В середине 90-х, инженеры, работающие над алгоритмами спутниковой передачи цифрового телевидения, «стряхнули пыль» с LDPC и стали его использовать, поскольку компьютеры к тому времени стали и мощней, и меньше. К началу 2000-х годов, LDPC получает повсеместное распространение, поскольку он позволяет с большой эффективностью исправлять ошибки при высокоскоростной передаче данных в условиях высоких помех (например при сильных электромагнитных наводках). Так же распространению способствовало появление специализированных систем на чипах, использующихся в WiFi технике, жестких дисках, контроллерах SCSI и т.д., такие SoC оптимизируются под задачи, и для них вычисления, связанные с LDPC вообще не представляют проблемы. В 2003 году LDPC-код, вытеснил технологию турбо-кода, и стал частью стандарта спутниковой передачи данных для цифрового телевидения DVB-S2. Аналогичная замена произошла и в стандарте DVB-T2 для цифрового «эфирного» телевидения.
Стоит сказать, что на базе LDPC строятся очень разные решения, нет «единственно правильной» эталонной реализации. Часто решения, основанные на LDPC несовместимы между собой и код, разработанный, например, для спутникового телевидения, не может быть портирован и использован в жестких дисках. Хотя чаще всего, объединение усилий инженеров разных областей дает массу преимуществ, и LDPC «в целом» является технологией не запатентованной, разные ноу-хау и проприетарные технологии вместе с корпоративными интересами встают на пути. Чаще всего, подобное сотрудничество возможно только в пределах одной компании. В качестве примера можно привести решение для канала чтения HDD от LSI под названием TrueStore®, которое компания предлагает на протяжении уже 3 лет. После приобретения компании SandForce, инженеры LSI стали работать над алгоритмами исправления ошибок SHIELD™ для SSD контроллеров (основанными на LDPC), не существовало портов алгоритмов для работы с SSD, но знания инженерной команды, работавшей над решениями для HDD очень помогли в разработке новых алгоритмов.
Тут, разумеется, у большинства читателей возникнет вопрос: чем алгоритмы, каждый алгоритм LDPC отличается от остальных? Большинство решений LDPC начинаются как декодеры с жестким решением, то есть такой декодер работает с жестко ограниченным набором данных (чаще всего 0 и 1) и использует код коррекции ошибок при малейших отклонениях от нормы. Такое решение, конечно, позволяет эффективно обнаруживать ошибки в передаваемых данных и исправлять их, но в случае высокого уровня ошибок, что иногда случается при работе с SSD, такие алгоритмы перестают справляться с ними. Как вы помните из наших предыдущих статей, любая флеш-память подвержена росту количества ошибок в процессе эксплуатации. Этот неизбежный процесс стоит учитыавть при разработке алгоритмов корреции ошибок для SSD накопителей. Что же делать в случае роста числа ошибок?
Тут на помощь приходят LDPC с мягким решением, являющиеся по сути «более аналоговыми». Подобные алгоритмы «смотрят» глубже, чем «жесткие», и, обладают большим набором возможностей. Примером самого простого такого решения может быть попытка прочитать данные снова, используя другое напряжение, так же как мы часто просим собеседника повторить фразу погромче. Продолжая метафоры с общением людей, можно привести пример более сложных алгоритмов коррекции. Представьте, что вы общаетесь на английском с человеком, говорящим с сильнейшим акцентом. В данном случае сильный акцент выступает в роли помехи. Ваш собеседник произнес некую длинную фразу, которую вы не поняли. В роли LDPC с мягким решением в данном случае будут выступать несколько коротких наводящих вопросов, которые вы можете задать и прояснить весь смысл фразы, которую вы изначально не поняли. Подобные мягкие решения часто используют так же сложные статистические алгоритмы, позволяющие исключить ложнопозитивные срабатывания. В общем, как вы уже поняли, такие решения заметно сложней в реализации, но они чаще всего показывают куда лучшие результаты по сравнению с «жексткими».
В 2013 году, на саммите, посвященном флэш-памяти, проходившем в Санта-Кларе, Калифорния, LSI представили свою технологию расширенной коррекции ошибок SHIELD. Комбинируя подходы с мягким и жестким решением, DSP SHIELD предлагает ряд уникальных оптимизаций для будущих технологий Flash-памяти. Например, технология Adaptive Code Rate, позволяет менять объем, отведенный под ECC так, чтоб он занимал как можно меньше места изначально, и динамически увеличивался по мере неизбежного роста количества ошибок, характерных для SSD.
Как видите, различные решения LDPC работают очень по-разному, и предлагают разные фунции и возможности, от которых во многом будет зависеть и качество работы финального продукта.
схема управления ошибками в данных по зашумленным каналам связи
В вычислениях, телекоммуникации, теория информации и теория кодирования, код исправления ошибок, иногда код исправления ошибок, (ECC ) используется для контроля ошибок в данных по ненадежным или зашумленным каналам связи. Основная идея заключается в том, что отправитель кодирует сообщение с помощью избыточной информации в форме ECC. Избыточность позволяет получателю обнаруживать ограниченное количество ошибок, которые могут возникать в любом месте сообщения, и часто исправлять эти ошибки без повторной передачи. Американский математик Ричард Хэмминг был пионером в этой области в 1940-х годах и изобрел первый исправляющий ошибки код в 1950 году: код Хэмминга (7,4).
ECC контрастирует с обнаружением ошибок. в том, что обнаруженные ошибки можно исправить, а не просто обнаружить. Преимущество состоит в том, что системе, использующей ECC, не требуется обратный канал для запроса повторной передачи данных при возникновении ошибки. Обратной стороной является то, что к сообщению добавляются фиксированные накладные расходы, что требует более высокой полосы пропускания прямого канала. Таким образом, ECC применяется в ситуациях, когда повторные передачи являются дорогостоящими или невозможными, например, при односторонних каналах связи и при передаче на несколько приемников в многоадресной передаче. Соединения с длительной задержкой также выигрывают; в случае спутника, вращающегося вокруг Урана, повторная передача из-за ошибок может вызвать задержку в пять часов. Информация ECC обычно добавляется к запоминающим устройствам для восстановления поврежденных данных, широко используется в модемах и используется в системах, где основной памятью является память ECC.
Обработка ЕСС в приемнике может применяться к цифровому потоку битов или к демодуляции несущей с цифровой модуляцией. В последнем случае ECC является неотъемлемой частью начального аналого-цифрового преобразования в приемнике. Декодер Витерби реализует алгоритм мягкого решения для демодуляции цифровых данных из аналогового сигнала, искаженного шумом. Многие кодеры / декодеры ECC также могут генерировать сигнал с коэффициентом ошибок по битам (BER), который можно использовать в качестве обратной связи для точной настройки аналоговой приемной электроники.
Максимальная доля ошибок или отсутствующих битов, которые могут быть исправлены, определяется конструкцией кода ECC, поэтому разные коды исправления ошибок подходят для разных условий. Как правило, более сильный код вызывает большую избыточность, которую необходимо передавать с использованием доступной полосы пропускания, что снижает эффективную скорость передачи данных при одновременном улучшении принимаемого эффективного отношения сигнал / шум. Теорема кодирования с шумом канала из Клод Шеннон отвечает на вопрос о том, какая полоса пропускания остается для передачи данных при использовании наиболее эффективного кода, который сводит вероятность ошибки декодирования к нулю. Это устанавливает границы теоретической максимальной скорости передачи информации канала с некоторым заданным базовым уровнем шума. Однако это доказательство неконструктивно и, следовательно, не дает представления о том, как создать код, обеспечивающий производительность. После многих лет исследований некоторые современные системы ECC сегодня очень близки к теоретическому максимуму.
Содержание
- 1 Прямое исправление ошибок
- 2 Как это работает
- 3 Усреднение шума для уменьшения количества ошибок
- 4 Типы ECC
- 5 Кодовая скорость и компромисс между надежностью и скоростью передачи данных
- 6 Составные коды ECC для повышения производительности
- 7 Проверка четности с низкой плотностью (LDPC)
- 8 Турбо-коды
- 9 Локальное декодирование и тестирование кодов
- 10 Чередование
- 10.1 Пример
- 10.2 Недостатки чередования
- 11 Программное обеспечение для кодов исправления ошибок
- 12 Список кодов исправления ошибок
- 13 См. Также
- 14 Ссылки
- 15 Дополнительная литература
- 16 Внешние ссылки
Прямое исправление ошибок
В электросвязи, теории информации и теории кодирования, прямое исправление ошибок (FEC ) или канальное кодирование — это метод, используемый для контроля ошибок в передаче данных по ненадежным или зашумленным каналам связи. Основная идея заключается в том, что отправитель кодирует сообщение с помощью избыточного способа, чаще всего с помощью ECC.
Избыточность позволяет получателю обнаруживать ограниченное количество ошибок, которые могут возникнуть в любом месте сообщения, и часто исправлять эти ошибки без повторной передачи. FEC дает приемнику возможность исправлять ошибки без необходимости использования обратного канала для запроса повторной передачи данных, но за счет фиксированной более высокой полосы пропускания прямого канала. Поэтому FEC применяется в ситуациях, когда повторные передачи являются дорогостоящими или невозможными, например, при односторонних каналах связи и при передаче на несколько приемников в многоадресной передаче. Информация FEC обычно добавляется к запоминающим устройствам (магнитным, оптическим и твердотельным / флэш-накопителям) для восстановления поврежденных данных, широко используется в модемах, используется в системах, где первичной памятью является память ECC, и в ситуациях широковещательной передачи, когда приемник не имеет возможности запрашивать повторную передачу или это может вызвать значительную задержку. Например, в случае спутника, вращающегося вокруг Урана, повторная передача из-за ошибок декодирования может вызвать задержку не менее 5 часов.
Обработка FEC в приемнике может применяться к цифровому битовому потоку или при демодуляции несущей с цифровой модуляцией. Для последнего FEC является неотъемлемой частью начального аналого-цифрового преобразования в приемнике. Декодер Витерби реализует алгоритм мягкого решения для демодуляции цифровых данных из аналогового сигнала, искаженного шумом. Многие кодеры FEC могут также генерировать сигнал с коэффициентом ошибок по битам (BER), который можно использовать в качестве обратной связи для точной настройки аналоговой приемной электроники.
Максимальная доля ошибок или недостающих битов, которые могут быть исправлены, определяется конструкцией ECC, поэтому разные коды прямого исправления ошибок подходят для разных условий. Как правило, более сильный код вызывает большую избыточность, которую необходимо передавать с использованием доступной полосы пропускания, что снижает эффективную скорость передачи данных при одновременном улучшении принимаемого эффективного отношения сигнал / шум. Теорема кодирования канала с шумом Клода Шеннона отвечает на вопрос о том, какая полоса пропускания остается для передачи данных при использовании наиболее эффективного кода, который обращает вероятность ошибки декодирования в ноль. Это устанавливает границы теоретической максимальной скорости передачи информации канала с некоторым заданным базовым уровнем шума. Его доказательство неконструктивно и, следовательно, не дает понимания того, как создать код, обеспечивающий производительность. Однако после многих лет исследований некоторые передовые системы FEC, такие как полярный код, достигают пропускной способности канала Шеннона при гипотезе кадра бесконечной длины.
Как это работает
ECC достигается путем добавления избыточности к передаваемой информации с использованием алгоритма. Избыточный бит может быть сложной функцией многих исходных информационных битов. Исходная информация может появляться или не появляться буквально в закодированном выводе; коды, которые включают немодифицированный ввод в вывод, являются систематическими, тогда как те, которые не включают, являются несистематическими .
Упрощенный пример ECC — передача каждого бита данных 3 раза, что известно как код повторения (3,1) . Через шумный канал приемник может видеть 8 вариантов вывода, см. Таблицу ниже.
| Получен триплет | Интерпретируется как |
|---|---|
| 000 | 0 (без ошибок) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (без ошибок) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
Это позволяет исправить ошибку в любой из трех выборок «большинством голосов» или «демократическим голосованием». Корректирующая способность этого ECC:
- До 1 бита триплета с ошибкой или
- до 2 битов триплета пропущены (случаи не показаны в таблице).
Хотя прост в реализации и Это широко используемое тройное модульное резервирование является относительно неэффективным ECC. Более совершенные коды ECC обычно проверяют несколько последних десятков или даже несколько последних сотен ранее принятых битов, чтобы определить, как декодировать текущую небольшую группу битов (обычно в группах от 2 до 8 бит).
Усреднение шума для уменьшения ошибок
Можно сказать, что ECC работает посредством «усреднения шума»; поскольку каждый бит данных влияет на многие передаваемые символы, искажение одних символов шумом обычно позволяет извлекать исходные пользовательские данные из других неповрежденных принятых символов, которые также зависят от тех же пользовательских данных.
- Из-за этого эффекта «объединения рисков» цифровые системы связи, использующие ECC, как правило, работают значительно выше определенного минимального отношения сигнал / шум, а не ниже него.
- Эта тенденция «все или ничего» — эффект обрыва — становится более выраженной по мере использования более сильных кодов, которые более близко подходят к теоретическому пределу Шеннона.
- Чередование данных, закодированных с помощью ECC, может уменьшить все или ничего свойства переданных кодов ECC, когда ошибки канала имеют тенденцию возникать в пакетах. Однако у этого метода есть ограничения; его лучше всего использовать для узкополосных данных.
Большинство телекоммуникационных систем используют фиксированный канальный код, рассчитанный на ожидаемый наихудший случай частоты ошибок по битам, а затем вообще не работают если частота ошибок по битам станет еще хуже. Однако некоторые системы адаптируются к данным условиям ошибки канала: некоторые экземпляры гибридного автоматического запроса на повторение используют фиксированный метод ECC, пока ECC может обрабатывать частоту ошибок, затем переключаются на ARQ когда частота ошибок становится слишком высокой; адаптивная модуляция и кодирование использует различные скорости ECC, добавляя больше битов исправления ошибок на пакет, когда в канале более высокие частоты ошибок, или удаляя их, когда они не нужны.
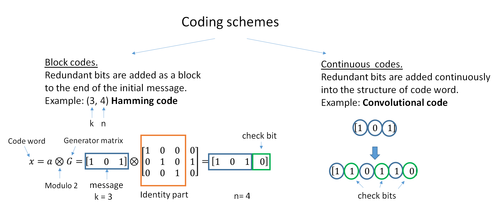 Краткая классификация кодов коррекции ошибок.
Краткая классификация кодов коррекции ошибок.
Двумя основными категориями кодов ECC являются блочные коды и сверточные коды.
- Блочные коды работают с блоками фиксированного размера (пакетами) битов или символов заранее определенного размера. Практические блочные коды обычно могут быть жестко декодированы за полиномиальное время до их длины блока.
- Сверточные коды работают с битовыми или символьными потоками произвольной длины. Чаще всего они программно декодируются с помощью алгоритма Витерби, хотя иногда используются и другие алгоритмы. Декодирование Витерби обеспечивает асимптотически оптимальную эффективность декодирования с увеличением длины ограничения сверточного кода, но за счет экспоненциально возрастающей сложности. Завершенный сверточный код также является «блочным кодом» в том смысле, что он кодирует блок входных данных, но размер блока сверточного кода, как правило, произвольный, в то время как блочные коды имеют фиксированный размер, определяемый их алгебраическими характеристиками. Типы завершения для сверточных кодов включают в себя «бит в конце» и «сброс битов».
Существует много типов блочных кодов; Кодирование Рида-Соломона примечательно тем, что оно широко используется в компакт-дисках, DVD и жестких дисках. Другие примеры классических блочных кодов включают Голея, BCH, многомерную четность и коды Хэмминга.
ECC Хэмминга обычно используются для исправления NAND flash ошибки памяти. Это обеспечивает исправление однобитовых ошибок и обнаружение двухбитовых ошибок. Коды Хэмминга подходят только для более надежной одноуровневой ячейки (SLC) NAND. Более плотная многоуровневая ячейка (MLC) NAND может использовать многобитовый корректирующий ECC, такой как BCH или Reed-Solomon. NOR Flash обычно не использует никакого исправления ошибок.
Классические блочные коды обычно декодируются с использованием алгоритмов жесткого решения, что означает, что для каждого входного и выходного сигнала принимается жесткое решение, будет ли он соответствует единице или нулю бит. Напротив, сверточные коды обычно декодируются с использованием алгоритмов мягкого решения, таких как алгоритмы Витерби, MAP или BCJR, которые обрабатывают (дискретизированные) аналоговые сигналы и которые допускают гораздо более высокие ошибки — производительность коррекции, чем декодирование с жестким решением.
Почти все классические блочные коды применяют алгебраические свойства конечных полей. Поэтому классические блочные коды часто называют алгебраическими кодами.
В отличие от классических блочных кодов, которые часто определяют способность обнаружения или исправления ошибок, многие современные блочные коды, такие как коды LDPC, не имеют таких гарантий. Вместо этого современные коды оцениваются с точки зрения их частоты ошибок по битам.
Большинство кодов прямого исправления ошибок исправляют только перевороты битов, но не вставки или удаления битов. В этой настройке расстояние Хэмминга является подходящим способом измерения коэффициента битовых ошибок. Несколько кодов прямого исправления ошибок предназначены для исправления вставки и удаления битов, например, коды маркеров и коды водяных знаков. Расстояние Левенштейна является более подходящим способом измерения частоты ошибок по битам при использовании таких кодов.
Кодовая скорость и компромисс между надежностью и скоростью передачи данных
Фундаментальный принцип ECC состоит в добавлении избыточных битов, чтобы помочь декодеру узнать истинное сообщение, которое было закодировано передатчик. Кодовая скорость данной системы ЕСС определяется как соотношение между количеством информационных битов и общим количеством битов (то есть информацией плюс биты избыточности) в данном коммуникационном пакете. Кодовая скорость, следовательно, является действительным числом. Низкая кодовая скорость, близкая к нулю, подразумевает сильный код, который использует много избыточных битов для достижения хорошей производительности, в то время как большая кодовая скорость, близкая к 1, подразумевает слабый код.
Избыточные биты, защищающие информацию, должны передаваться с использованием тех же коммуникационных ресурсов, которые они пытаются защитить. Это вызывает фундаментальный компромисс между надежностью и скоростью передачи данных. В одном крайнем случае сильный код (с низкой кодовой скоростью) может вызвать значительное увеличение SNR приемника (отношение сигнал / шум), уменьшая частоту ошибок по битам, за счет снижения эффективной скорости передачи данных. С другой стороны, без использования какого-либо ECC (то есть кодовой скорости, равной 1) используется полный канал для целей передачи информации за счет того, что биты остаются без какой-либо дополнительной защиты.
Один интересный вопрос заключается в следующем: насколько эффективным с точки зрения передачи информации может быть ECC, имеющий незначительную частоту ошибок декодирования? На этот вопрос ответил Клод Шеннон с его второй теоремой, которая гласит, что пропускная способность канала — это максимальная скорость передачи данных, достижимая для любого ECC, частота ошибок которого стремится к нулю: его доказательство основано на гауссовском случайном кодировании, которое не подходит для реального мира. Приложения. Верхняя граница, заданная работой Шеннона, вдохновила на долгий путь к разработке ECC, которые могут приблизиться к пределу конечных характеристик. Различные коды сегодня могут достигать почти предела Шеннона. Однако ECC, обеспечивающие пропускную способность, обычно чрезвычайно сложно реализовать.
Наиболее популярные ECC имеют компромисс между производительностью и вычислительной сложностью. Обычно их параметры дают диапазон возможных кодовых скоростей, которые можно оптимизировать в зависимости от сценария. Обычно эта оптимизация выполняется для достижения низкой вероятности ошибки декодирования при минимальном влиянии на скорость передачи данных. Другим критерием оптимизации кодовой скорости является уравновешивание низкой частоты ошибок и количества повторных передач с учетом энергетических затрат на связь.
Составные коды ECC для повышения производительности
Классические (алгебраические) блочные коды а сверточные коды часто комбинируются в схемах конкатенированного кодирования, в которых сверточный код, декодированный по Витерби с короткой ограниченной длиной, выполняет большую часть работы, а блочный код (обычно Рида-Соломона) с большим размером символа и длиной блока «стирает» любые ошибки, сделанные сверточным декодером. Однопроходное декодирование с использованием этого семейства кодов с исправлением ошибок может дать очень низкий уровень ошибок, но для условий передачи на большие расстояния (например, в глубоком космосе) рекомендуется итеративное декодирование.
Составные коды были стандартной практикой в спутниковой связи и связи в дальнем космосе с тех пор, как «Вояджер-2 » впервые применил эту технику во время встречи с Ураном в 1986 году. Аппарат Galileo использовал итеративные конкатенированные коды для компенсации условий очень высокой частоты ошибок, вызванных отказом антенны.
Проверка на четность с низкой плотностью (LDPC)
Коды с проверкой на четность с низкой плотностью (LDPC) — это класс высокоэффективных линейных блочных кодов, созданных из множества кодов одиночной проверки на четность (SPC). Они могут обеспечить производительность, очень близкую к пропускной способности канала (теоретический максимум), используя подход итеративного декодирования с мягким решением, при линейной временной сложности с точки зрения длины их блока. Практические реализации в значительной степени полагаются на параллельное декодирование составляющих кодов SPC.
Коды LDPC были впервые введены Робертом Г. Галлагером в его докторской диссертации в 1960 году, но из-за вычислительных усилий при реализации кодера и декодера и введения Рида-Соломона коды, они в основном игнорировались до 1990-х годов.
Коды LDPC теперь используются во многих недавних стандартах высокоскоростной связи, таких как DVB-S2 (цифровое видеовещание — спутниковое — второе поколение), WiMAX ( стандарт IEEE 802.16e для микроволновой связи), высокоскоростная беспроводная локальная сеть (IEEE 802.11n ), 10GBase-T Ethernet (802.3an) и G.hn/G.9960 (Стандарт ITU-T для организации сетей по линиям электропередач, телефонным линиям и коаксиальному кабелю). Другие коды LDPC стандартизированы для стандартов беспроводной связи в пределах 3GPP MBMS (см. исходные коды ).
Турбокоды
Турбокодирование — это схема повторяющегося мягкого декодирования, которая объединяет два или более относительно простых сверточных кода и перемежитель для создания блочного кода, который может работать с точностью до долей децибела. предела Шеннона. Предшествующие LDPC-коды с точки зрения практического применения, теперь они обеспечивают аналогичную производительность.
Одним из первых коммерческих приложений турбо-кодирования была технология цифровой сотовой связи CDMA2000 1x (TIA IS-2000), разработанная Qualcomm и продаваемая Verizon Беспроводная связь, Sprint и другие операторы связи. Он также используется для развития CDMA2000 1x специально для доступа в Интернет, 1xEV-DO (TIA IS-856). Как и 1x, EV-DO был разработан Qualcomm и продается Verizon Wireless, Sprint и другими операторами (маркетинговое название Verizon для 1xEV-DO — Широкополосный доступ, потребительские и бизнес-маркетинговые названия компании Sprint для 1xEV-DO — Power Vision и Mobile Broadband соответственно).
Локальное декодирование и тестирование кодов
Иногда необходимо декодировать только отдельные биты сообщения или проверить, является ли данный сигнал кодовым словом, и делать это, не глядя на все сигнал. Это может иметь смысл в настройке потоковой передачи, где кодовые слова слишком велики для того, чтобы их можно было классически декодировать достаточно быстро, и где на данный момент интересны только несколько битов сообщения. Также такие коды стали важным инструментом в теории сложности вычислений, например, для разработки вероятностно проверяемых доказательств.
Локально декодируемые коды являются кодами с исправлением ошибок, для которых отдельные биты сообщение может быть восстановлено вероятностно, если посмотреть только на небольшое (скажем, постоянное) количество позиций кодового слова, даже после того, как кодовое слово было искажено на некоторой постоянной доле позиций. Локально тестируемые коды — это коды с исправлением ошибок, для которых можно вероятностно проверить, близок ли сигнал к кодовому слову, посмотрев только на небольшое количество позиций сигнала.
Чередование
Краткая иллюстрация идеи чередования.
Чередование часто используется в системах цифровой связи и хранения для повышения производительности кодов прямого исправления ошибок. Многие каналы связи не лишены памяти: ошибки обычно возникают в пакетах, а не независимо друг от друга. Если количество ошибок в кодовом слове превышает возможности кода исправления ошибок, ему не удается восстановить исходное кодовое слово. Чередование облегчает эту проблему путем перетасовки исходных символов по нескольким кодовым словам, тем самым создавая более равномерное распределение ошибок. Поэтому перемежение широко используется для пакетной коррекции ошибок.
. Анализ современных повторяющихся кодов, таких как турбокоды и коды LDPC, обычно предполагает независимое распределение ошибок.. Поэтому системы, использующие коды LDPC, обычно используют дополнительное перемежение символов в кодовом слове.
Для турбокодов перемежитель является неотъемлемым компонентом, и его правильная конструкция имеет решающее значение для хорошей производительности. Алгоритм итеративного декодирования работает лучше всего, когда нет коротких циклов в графе коэффициентов, который представляет декодер; перемежитель выбран, чтобы избежать коротких циклов.
Конструкции перемежителя включают:
- прямоугольные (или однородные) перемежители (аналогично методу с использованием коэффициентов пропуска, описанному выше)
- сверточные перемежители
- случайные перемежители (где перемежитель — известная случайная перестановка)
- S-случайный перемежитель (где перемежитель — это известная случайная перестановка с ограничением, что никакие входные символы на расстоянии S не появляются на расстоянии S на выходе).
- бесконфликтный квадратичный многочлен с перестановками (QPP). Пример использования — в стандарте мобильной связи 3GPP Long Term Evolution.
В системах связи с несколькими несущими может использоваться перемежение по несущим для обеспечения частотного разнесения., например, для уменьшения частотно-избирательного замирания или узкополосных помех.
Пример
Передача без перемежения :
Сообщение без ошибок: aaaabbbbccccddddeeeeffffgggg Передача с пакетной ошибкой: aaaabbbbccc____deeeeffffgggg
Здесь каждая группа одинаковых букв представляет 4-битное однобитовое кодовое слово с исправлением ошибок. Кодовое слово cccc изменяется в один бит и может быть исправлено, но кодовое слово dddd изменяется в трех битах, поэтому либо оно не может быть декодировано вообще, либо может быть декодировано неправильно.
С чередованием :
Ошибка- свободные кодовые слова: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Передача с ошибкой пакета: abcdefgabcd____bcdefgabcdefg Полученные кодовые слова после деинтерлейвинга: "aa_abbb_gg2ccd_dd>,", ",", ",", ","Передача без чередования :
Исходное переданное предложение: ThisIsAnExampleOfInterleaving Полученное предложение с пакетной ошибкой: ThisIs______pleOfInterleavingТермин «AnExample» оказывается в основном неразборчивым и трудным для исправления.
С чередованием :
Переданное предложение: ThisIsAnExampleOfInterleaving... Безошибочная передача: TIEpfeaghsxlIrv.iAaenli.snmOten. Получено предложение с пакетной ошибкой: TIEpfe ______ Irv.iAaenli.snmOten. Полученное предложение после деинтерлейвинга: T_isI_AnE_amp_eOfInterle_vin _...Ни одно слово не потеряно полностью, а недостающие буквы можно восстановить с минимальными догадками.
Недостатки чередования
Использование методов чередования увеличивает общую задержку. Это связано с тем, что весь чередующийся блок должен быть принят до того, как пакеты могут быть декодированы. Также перемежители скрывают структуру ошибок; Без перемежителя более совершенные алгоритмы декодирования могут использовать структуру ошибок и обеспечивать более надежную связь, чем более простой декодер, объединенный с перемежителем. Пример такого алгоритма основан на структурах нейронной сети .
Программное обеспечение для кодов с исправлением ошибок
Моделирование поведения кодов с исправлением ошибок (ECC) в программном обеспечении является обычной практикой для разработки, проверки и улучшения кодов ECC. Предстоящий стандарт беспроводной связи 5G поднимает новый диапазон приложений для программных ECC: Облачные сети радиодоступа (C-RAN) в контексте Программно-определяемого радио (SDR). Идея состоит в том, чтобы напрямую использовать программные ECC в коммуникациях. Например, в 5G программные ECC могут быть расположены в облаке, а антенны могут быть подключены к этим вычислительным ресурсам: таким образом повышается гибкость сети связи и, в конечном итоге, повышается энергоэффективность системы.
В этом контексте существует различное доступное программное обеспечение с открытым исходным кодом, перечисленное ниже (не является исчерпывающим).
- AFF3CT (Панель инструментов быстрого исправления ошибок): полная цепочка связи на C ++ (многие поддерживаемые коды, такие как Turbo, LDPC, полярные коды и т. Д.), Очень быстрая и специализированная на канальном кодировании (может использоваться как программа для моделирования или как библиотека для SDR).
- IT ++ : библиотека классов и функций C ++ для линейной алгебры, числовой оптимизации, обработки сигналов, связи и статистики.
- OpenAir : реализация (на языке C) спецификаций 3GPP, касающихся Evolved Packet Core Networks.
Список кодов исправления ошибок
| Расстояние | Код |
|---|---|
| 2 (обнаружение единичной ошибки) | Четность |
| 3 (исправление одиночной ошибки) | Тройное модульное резервирование |
| 3 (исправление одиночной ошибки) | совершенное Хэмминга, такое как Хэмминга (7,4) |
| 4 (SECDED ) | Расширенный Хэмминга |
| 5 (исправление двойной ошибки) | |
| 6 (исправление двойной ошибки / обнаружение тройной ошибки) | |
| 7 (исправление трех ошибок) | совершенный двоичный код Голея |
| 8 (TECFED) | расширенный двоичный код Голея |
- коды AN
- код BCH, который может быть разработан для исправления любого произвольного количества ошибок в кодовом блоке.
- код Бергера
- код постоянного веса
- сверточный код
- Расширительные коды
- Групповые коды
- коды Голея, из которых двоичный код Голея представляет практический интерес
- код Гоппа, используемый в Криптосистема Мак-Элиса
- Код Адамара
- Код Хагельбаргера
- Код Хэмминга
- Код на основе латинского квадрата для небелого шума (преобладающий, например, в широкополосной связи по сравнению с линиями электропередач)
- Лексикографический код
- Линейное сетевое кодирование, тип кода с исправлением стирания в сетях вместо двухточечных ссылок
- Длинный код
- Код проверки четности с низкой плотностью, также известный как код Галлагера, как архетип для кодов разреженного графа
- LT-кода, который является почти оптимальным бесскоростным кодом коррекции стирания (код Фонтана)
- m из n кодов
- Онлайн-код, почти оптимальный код бесскоростной коррекции стирания
- Полярный код (codi ng теория)
- Код Raptor, почти оптимальный код с бесскоростной коррекцией стирания
- Исправление ошибок Рида – Соломона
- Код Рида – Маллера
- Код повторения-накопления
- Коды повторения, например, Тройная модульная избыточность
- Спинальный код, бесскоростной нелинейный код, основанный на псевдослучайных хэш-функциях
- Код Торнадо, почти оптимальный код коррекции стирания, и предшественник кодов Фонтана
- Турбо-код
- код Уолша – Адамара
- Циклические проверки избыточности (CRC) могут исправлять 1-битные ошибки для сообщений не более 2 n - 1 - 1 { displaystyle 2 ^ {n-1} -1}бит длиной для оптимальных порождающих полиномов степени n { displaystyle n}, см. Математика циклических проверок избыточности # Битовые фильтры
См. Также
Ссылки
Дополнительная литература
- Clark, Jr., George C.; Каин, Дж. Бибб (1981). Кодирование с коррекцией ошибок для цифровой связи. Нью-Йорк, США: Plenum Press. ISBN 0-306-40615-2. ISBN 978-0-306-40615-7.
- Уикер, Стивен Б. (1995). Системы контроля ошибок для цифровой связи и хранения. Энглвуд Клиффс, Нью-Джерси, США: Прентис-Холл. ISBN 0-13-200809-2. ISBN 978-0-13-200809-9.
- Уилсон, Стивен Г. (1996). Цифровая модуляция и кодирование. Энглвуд Клиффс, Нью-Джерси, США: Прентис-Холл. ISBN 0-13-210071-1. ISBN 978-0-13-210071-7.
- "Код коррекции ошибок в одноуровневой ячейке NAND флэш-памяти « 16 февраля 2007 г.
- « Код исправления ошибок во флэш-памяти NAND » 29 ноября 2004 г.
- Наблюдения за ошибками, исправлениями и доверием зависимых систем, Джеймс Гамильтон, 26 февраля 2012 г.
- Сферические упаковки, решетки и группы, Дж. Х. Конвей, NJA Sloane, Springer Science Business Media, 9 марта 2013 г. - Математика - 682 страницы.
Внешние ссылки
Каждому устройству, использующему флэш-память NAND, необходим код с исправлением случайных битов (известный как «мягкая» ошибка). Это потому что много электрический шум производится внутри чипа NAND, а уровни сигналов битов, проходящих через цепочку чипов NAND, очень слабые.

Один из способов, которым NAND память стали самый дешевый всего, потому что это требует, чтобы исправление ошибок было выполнено от элемента вне самого чипа NAND; В случае SSD, ECC выполняется на контроллере .
Такое же исправление ошибок также помогает исправить битовые ошибки из-за носить на Память сами клетки , Истощение может вызвать «застревание» битов в том или ином состоянии (известное как «жесткая» ошибка или жесткая ошибка) и может увеличить частоту «мягких» ошибок.
Хотя это понятие не является слишком широким, сопротивление флэш-памяти является мерой того, сколько циклов стирания / записи может выдержать блок флэш-памяти, прежде чем начнут появляться «серьезные» ошибки. Очень часто эти сбои происходят только в отдельных битах, и очень редко происходит сбой всего блока. При достаточно высоком числе стирания / записи «мягкая» частота ошибок также увеличивается из-за ряда других механизмов в самом SSD.
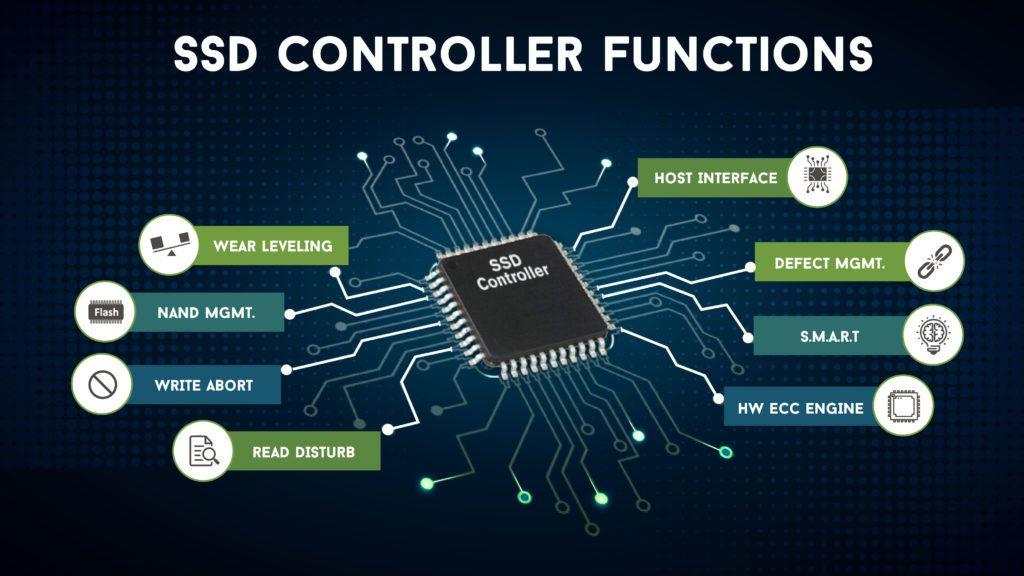
If ECC может быть используемый чтобы исправить эти «жесткие» ошибки, а «мягкие» ошибки не увеличиваются, срок службы всего блока значительно удлиняется, что значительно превышает сопротивление, указанное производителем.
Давайте рассмотрим пример: допустим, что неиспользуемый чип NAND имеет достаточно «мягких» ошибок, чтобы требовать 8 бит ECC, то есть при каждом считывании страницы может быть до 8 бит, которые были случайно повреждены (обычно из-за электрических помех, которые мы говорили о). вначале). ECC, используемый в этом чипе, может исправлять 12-битные ошибки, так что ECC не может решить эту проблему мы должны найти 8 «мягких» ошибок, связанных с электрическим шумом, плюс еще 5 «мягких» из-за износа.
Теперь производители флэш-памяти гарантируют, что первый из этих 5 сбоев произойдет через некоторое время после спецификации прочности SSD. Это означает, что ни один бит не выйдет из строя из-за износа, пока не будут превышены циклы стирания / записи, указанные производителем. Теперь имейте в виду, что спецификации не достаточно точны, чтобы предсказать, когда следующий бит выйдет из строя, и на самом деле это может занять несколько тысяч циклов стирания / записи выше спецификации, чтобы это произошло; помните, что производитель гарантирует, что это не произойдет до X циклов, но не тогда, когда это произойдет после их превышения.

Это означает, что это может занять много времени, прежде чем блок становится настолько коррумпированным что его необходимо удалить из службы (а также для этого на SSD обычно есть «дополнительные» блоки для замены поврежденных), что, в свою очередь, означает, что сопротивление исправлен от ошибок блок может быть во много раз больше указанного сопротивления, в зависимости от количества избыточных ошибок, которые ECC предназначен для исправления.
Какое влияние оказывает код исправления ошибок на SSD?
Как мы объясняли ранее, флэш-память настолько дешева, потому что она не включает в себя ECC в самих чипах, но интегрирована в другое внешнее оборудование, и, как вы предположите, это имеет свою цену. Более сложный ECC требует большей вычислительной мощности на контроллере и может быть медленнее, если алгоритмы не очень современные. Кроме того, количество ошибок, которые могут быть исправлены, будет зависеть от того, насколько большой сектор памяти исправляется, поэтому контроллер SSD со сложным алгоритмом ECC, вероятно, будет использовать много ресурсов, снижение общий SSD производительность , Эти улучшения также делают контроллер дороже .

Алгоритмы ECC имеют свое собственное математическое состояние в зависимости от контроллера (другими словами, нет никакого стандарта), и даже самые базовые кодировки ECC (Рида-Соломона и LDPC) довольно сложны для понимания. Когда кто-то говорит о пределе Шеннона (максимальное количество битов, которое может быть исправлено), это величина, которую, как вы не знаете от производителя в технических характеристиках, чрезвычайно сложно вычислить.
Просто придерживайтесь этого: большее количество корректирующих битов увеличивает срок службы SSD, но также оказывает некоторое влияние на производительность или даже цену продукта, так как требует более мощный контроллер.
Оглавление
- Вступление
- Коррекция ошибок
- Финансовая сторона
- Тестовый стенд
- Методика тестирования
- Результаты тестирования
- Тест памяти
- 3DMark
- 7Zip
- Cinebench
- CrystalMark
- Fritz
- LinX
- wPrime
- AIDA64 Extreme
- Заключение
Вступление
На сегодняшний день на просторах Рунета можно встретить открытые темы на форумах с вопросами – стоит ли брать рабочую станцию с ECC-памятью или можно обойтись обычной? В данных ветках можно прочесть множество противоречивых утверждений, и часть из них говорит о том, что коррекция ошибок сильно замедляет память, а следовательно и ЦП. Но мало кто это проверял на деле на современных процессорах.
Сегодня мы разберемся в этом вопросе и сравним производительность серверного процессора с обоими типами памяти. Но для начала небольшой экскурс.
Коррекция ошибок
Для чего необходима коррекция? И почему в работе памяти возникают ошибки? Перед ответом на эти вопросы следует разделить ошибки на два типа:
- Аппаратные ошибки;
- Случайные ошибки.
Причиной появления аппаратных ошибок является дефектная микросхема DRAM, а случайные ошибки возникают под воздействием излучения, альфа-частиц, элементарных частиц и прочего. Соответственно, первые в принципе неисправимы – если чип дефектный, то поможет только его замена; а вот вторые могут быть исправлены.
Почему же так необходима коррекция ошибок в рабочих станциях и серверах? Однобитовая ошибка в 64-битном слове меняет содержимое ячейки памяти, а в конечном итоге на жесткий диск может быть записано другое число, другие данные, при этом компьютер не зафиксирует эту подмену. А изменение бита в оперативной памяти может вызвать сбой программы, что для рабочей станции и сервера недопустимо.
рекомендации
3060 дешевле 30тр в Ситилинке
3070 Gigabyte Gaming за 50 тр с началом
<b>13900K</b> в Регарде по СТАРОМУ курсу 62
3070 Gainward Phantom дешевле 50 тр
10 видов <b>4070 Ti</b> в Ситилинке — все до 100 тр
13700K дешевле 40 тр в Регарде
MSI 3050 за 25 тр в Ситилинке
13600K дешевле 30 тр в Регарде
4080 почти за 100тр — дешевле чем по курсу 60
12900K за 40тр с началом в Ситилинке
RTX 4090 за 140 тр в Регарде
Компьютеры от 10 тр в Ситилинке
3060 Ti Gigabyte дешевле 40 тр в Регарде
3070 дешевле 50 тр в Ситилинке
-7% на 4080 Gigabyte Gaming
Для обнаружения изменения битов памяти можно использовать метод подсчета контрольной суммы, но он позволяет лишь обнаруживать ошибки без их исправления.
В свое время было предложено много различных способов решения данной проблемы, но на сегодняшний день наибольшее распространение получил метод коррекции ошибок или ECC (Error-Correcting Code). Данный метод позволяет автоматически исправлять однобитовые ошибки в 64-битном слове – SEC (Single Error Correction) и детектировать двухбитовые – DED (Double Error Detection).
Физическая реализация ECC заключается в размещении дополнительной микросхемы памяти на модуле ОЗУ – соответственно, при одностороннем дизайне модуля памяти вместо восьми чипов располагается девять, а при двустороннем вместо шестнадцати – восемнадцать. Таким образом, ширина модуля становится не 64 бита, а 72 бита.
Метод коррекции ошибок работает следующим образом: при записи 64 бит данных в ячейку памяти происходит подсчет контрольной суммы, составляющей 8 бит. Когда процессор обращается к этим данным и производит считывание, проводится повторный подсчет контрольной суммы и сравнение с исходной. Если суммы не совпадают – произошла ошибка. Если она однобитовая, то неправильный бит исправляется автоматически, если двухбитовая – детектируется и сообщается ОС.
Финансовая сторона
Прежде чем приступить к тестированию, необходимо затронуть финансовый вопрос.
Стоимость обычного модуля памяти DDR3-1600 с напряжением 1.35 В и объемом 8 Гбайт составляет около 3600 рублей, а с коррекцией ошибок – 4800 рублей. На первый взгляд ECC-память выходит на 30-35% дороже, что, в целом, не позволяет их сравнивать в силу существенно большей стоимости последней. Но почему же тогда такой вопрос возникает при сборке рабочей станции? Все просто – необходимо смотреть на данный вопрос шире, а именно – смотреть на общую стоимость рабочей станции.
Ценник однопроцессорной станции на базе четырехъядерного восьмипоточного Xeon (настольные процессоры серий i5 и i7 не поддерживают ECC-память) с 32 Гбайтами памяти, материнской платы с чипсетом C222/С224/С226 (десктопные наборы логики Z87/Z97 и другие также не поддерживают память с коррекцией ошибок) будет превышать 70 000 рублей (при условии, что устанавливаются серверные SSD с повышенным ресурсом). А если включить в эту стоимость и дискретную видеокарту, и прочие сопутствующие компоненты, например, ИБП, то ценник из пятизначного превратится в шестиизначный, перевалив планку в 100 000 рублей.
Покупка 32 Гбайт памяти с коррекцией ошибок потребует дополнительных 4-6 тысяч рублей, что по отношению к общей стоимости рабочей станции не превышает 5%, то есть не является критичным. Также переход от десктопного к серверному железу предоставит и другие преимущества, например: интегрированные графические карты P4600 в процессорах Intel Xeon E3-1200 третьего поколения получили оптимизированные драйверы, которые должны повышать производительность в профессиональных приложениях, например, в CAD; поддержка технологии Intel VT-d, которая позволяет пробрасывать устройства в виртуальную среду, например, видеокарты; прочие серверные технологии – Intel AMT или IPMI, WatchDog и другие, которые также могут оказаться полезными.
Таким образом, хоть и сама ECC-память стоит заметно дороже обычной, в общей стоимости рабочей станции данная статья затрат является несущественной, и переплата не превышает 5%.
Тестовый стенд
Для данного обзора использовалась следующая конфигурация:
- Материнская плата: Supermicro X10SAE (Intel C226, LGA 1150);
- Процессор: Xeon E3-1245V3 (Turbo Boost – off, EIST – off, HT – on);
- Оперативная память:
- 2x Kingston DDR3-1600 ECC 8 Гбайт (KVR16LE11/8 CL11, 1.35 В);
- 2x Kingston DDR3-1600 8 Гбайт (KVR16LN11/8 CL11, 1.35 В);
- ОС: Windows 8.1 Pro 64-bit.
Методика тестирования
В рамках тестирования были произведены замеры производительности как при одноканальном режиме работы ИКП, так и при двухканальном. Суммарный объем ОЗУ составил 8 (один модуль) и 16 Гбайт (два модуля) соответственно.
Программное обеспечение:
- 3DMark 2006 1.2;
- 7Zip 9.20;
- AIDA64 Extreme 5.20.3400;
- Cinebench R15;
- CrystalMark 2004R3;
- Fritz 4.20;
- LinX 0.6.5;
- wPrime 2.10.
Результаты тестирования
Тест памяти
Перед тем, как приступить к тестированию, проведем замер пропускной способности памяти и латентности.

При изучении результатов можно заключить, что производительность ECC- и non-ECC- памяти находится на одном и том же уровне в рамках погрешности.

Если в предыдущем тесте от замера к замеру выигрывал то один, то другой тип памяти, то при замере латентности ECC-память постоянно показывает большие задержки. Но разница несущественна – всего лишь 1 нс.
Таким образом, замер ПС и латентности памяти не показал особых различий между ECC- и non-ECC-памятью. Посмотрим, повторится ли это в последующих тестах.
3DMark
Тестовый пакет 3DMark содержит подтесты как для процессора, так и для графической карты. Здесь и кроется самое интересное – давно известно, что встроенному видеоядру не хватает существующей ПСП в 25.6 Гбайт/с, поэтому именно в графических подтестах можно выявить негативное влияние коррекции ошибок, если оно вообще есть,…

… но разницы нет – что ECC, что non-ECC. Ни процессор, ни интегрированное ядро никак не реагируют на замену обычной памяти на DDR с коррекцией ошибок – результаты одинаковы в рамках погрешности. Среднеарифметическая разница составила 0.02% в пользу ECC-памяти для одноканального режима и 1.6% для двухканального режима.
При этом нельзя сказать, что встроенная видеокарта P4600 не зависит от скорости ОЗУ – при одноканальном доступе общий результат почти на 30% ниже, чем при двухканальном. Другими словами, скорость ОЗУ критична для графического ядра, но сами по себе «ECC-версии» не влияют ни на скорость ОЗУ, ни на видеокарту.
7Zip
Архиваторы, как известно, чувствительны к памяти, поэтому, возможно, здесь получится зафиксировать влияние типа памяти на производительность.

Ситуация с архивацией неоднозначная: с одной стороны – в одноканальном режиме (как при распаковке, так и при сжатии) ECC-память уверенно оказывается медленнее на 2%; с другой – в двухканальном режиме при сжатии ECC-память уверенно быстрее, а при распаковке – медленнее, а среднее арифметическое – быстрее на 0.65%.
Скорее всего, причина в следующем – пропускной способности памяти при одноканальном доступе процессору явно недостаточно, и поэтому чуть большая латентность ECC-памяти сказывается на производительности; а при двухканальном доступе ПСП полностью покрывает нужды CPU и поэтому чуть большая латентность памяти с коррекцией ошибок не сказывается на производительности. В любом случае зафиксировать существенного влияния на скорость архивации не получилось.
Cinebench
Тестовый пакет Cinebench содержит подтест как процессора, так и видеокарты.

Но ни первый, ни вторая никак не отреагировали на ECC-память.
Зато налицо явная зависимость видеокарты от ПСП – при одноканальном доступе результат в OpenGL оказался на 25% ниже, чем при двухканальном. Вспоминая результаты 3DMark и смотря на нынешние, можно заключить, что производительность интегрированной видеокарты хоть и зависит от ПСП, но ECC-память не оказывает на нее негативного влияния.
Ошибки при хранении
информации в памяти неизбежны. Они
обычно классифицируются как отказы и
нерегулярные ошибки (сбои). Если нормально
функционирующая микросхема вследствие,
например, физического повреждения
начинает работать неправильно, то все
происходящее и называется постоянным
отказом. Чтобы устранить этот тип отказа,
обычно требуется заменить некоторую
часть аппаратных средств памяти, например
неисправную микросхему SIMM или DIMM.
Другой, более
коварный тип отказа
нерегулярная ошибка (сбой). Это непостоянный
отказ, который не происходит при
повторении условий функционирования
или через регулярные интервалы.
Приблизительно
20 лет назад сотрудники Intel
установили, что причиной сбоев являются
альфа-частицы. Поскольку альфа-частицы
не могут проникнуть даже через тонкий
лист бумаги, выяснилось, что их источником
служит вещество, используемое в
полупроводниках. При исследовании были
обнаружены частицы тория и урана в
пластмассовых и керамических корпусах
микросхем, применявшихся в те годы.
Изменив технологический процесс,
производители памяти избавились от
этих примесей.
В настоящее время
производители памяти почти полностью
устранили источники альфа-частиц. И
многие стали думать, что проверка
четности не нужна вовсе. Например, сбои
в памяти емкостью 16 Мбайт из-за альфа-частиц
случаются в среднем только один раз за
16 лет! Однако сбои памяти происходят
значительно чаще.
Сегодня самая
главная причина нерегулярных ошибок
космические лучи. Поскольку они имеют
очень большую проникающую способность,
от них практически нельзя защититься
с помощью экранирования.
К сожалению,
производители персональных компьютеров
не признали это причиной погрешностей
памяти; случайную природу сбоя намного
легче оправдать разрядом электростатического
электричества, большими выбросами
мощности или неустойчивой работой
программного обеспечения (например,
использованием новой версии операционной
системы или большой прикладной программы).
Хотя космические
лучи и радиация являются причиной
большинства программных ошибок памяти,
существуют и другие факторы.
-
Скачки в
энергопотреблении или шум на линии.
Причиной может быть неисправный блок
питания или настенная розетка. -
Использование
неверного типа или параметра быстродействия
памяти. Тип
памяти должен поддерживаться конкретным
набором микросхем и обладать определенной
этим набором скоростью доступа. -
Радиочастотная
интерференция.
Связана с расположением радиопередатчиков
рядом с компьютером, что иногда приводит
к генерированию паразитных электрических
сигналов в монтажных соединениях и
схемах компьютера. Беспроводные сети,
мыши и клавиатуры увеличивают риск
появления радиочастотной интерференции. -
Статические
разряды.
Вызывают моментальные скачки в
энергоснабжении, что может повлиять
на целостность данных. -
Ошибки
синхронизации. Не
поступившие своевременно данные могут
стать причиной появления программных
ошибок. Зачастую причина заключается
в неверных параметрах BIOS,
оперативной памяти, быстродействие
которой ниже, чем требуется системой,
«разогнанных» процессорах и прочих
ситемных компонентах.
Большинство
системных проблем не приводят к
прекращению работы микросхем памяти,
однако могут повлиять на хранимые
данные.
Игнорирование
сбоев, конечно, не лучший способ борьбы
с ними. К сожалению, именно этот способ
сегодня выбрали многие производители
компьютеров. Лучше было бы увеличить
отказоустойчивость систем. Для этого
необходимы механизмы обнаружения и,
возможно, исправления ошибок в памяти
персонального компьютера. В основном
для повышения отказоустойчивости в
современных компьютерах применяются
следующие методы:
-
контроль четности;
-
коды коррекции
ошибок (ECC).
Соседние файлы в папке Сватов лабы
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Контроль четности и коды коррекции ошибок (ECC).
Ошибки при хранении информации в памяти неизбежны. Они обычно классифицируются как отказы и нерегулярные ошибки (сбои). Если нормально функционирующая микросхема вследствие, например, физического повреждения начинает работать неправильно, то все происходящее и называется постоянным отказом. Чтобы устранить этот тип отказа, обычно требуется заменить некоторую часть аппаратных средств памяти, например неисправную микросхему памяти.
Другой, более коварный тип отказа — нерегулярная ошибка (сбой). Это непостоянный отказ, который не происходит при повторении условий функционирования или через регулярные интервалы.
Приблизительно 20 лет назад сотрудники Intel установили, что причиной сбоев являются альфа-частицы. Поскольку альфа-частицы не могут проникнуть даже через тонкий лист бумаги, выяснилось, что их источником служит вещество, используемое в полупроводниках. При исследовании были обнаружены частицы тория и урана в пластмассовых и керамических корпусах микросхем, применявшихся в те годы. Изменив технологический процесс, производители памяти избавились от этих примесей.
В настоящее время производители памяти почти полностью устранили источники альфачастиц. И многие стали думать, что проверка четности не нужна вовсе. Например, сбои в памяти емкостью 16 Мбайт из-за альфа-частиц случаются в среднем только один раз за 16 лет! Однако сбои памяти происходят значительно чаще.
Сегодня самая главная причина нерегулярных ошибок — космические лучи. Поскольку они имеют очень большую проникающую способность, от них практически нельзя защититься с помощью экранирования.
Эксперимент, проверяющий степень влияния космических лучей на появление ошибок в работе микросхем, показал, что соотношение “сигнал–ошибка” (signal-to-error ratio — SER) для некоторых модулей DRAM составило 5950 единиц интенсивности отказов (failure units — FU) на миллиард часов наработки для каждой микросхемы. Измерения проводились в условиях, приближенных к реальной жизни, с учетом длительности в несколько миллионов машиночасов. В среднестатистическом компьютере это означало бы появление программной ошибки памяти примерно каждые шесть месяцев. В серверных системах или мощных рабочих станциях с большим объемом установленной оперативной памяти подобная статистика указывает на одну ошибку (или даже более) в работе памяти каждый месяц! Когда тестовая система с теми же модулями DIMM была размещена в надежном убежище на глубине более 15 метров каменной породы, что полностью устраняет влияние космических лучей, программные ошибки в работе памяти вообще не были зафиксированы. Эксперимент продемонстрировал не только опасность влияния космических лучей, но и доказал, насколько эффективно устранять влияние альфалучей и радиоактивных примесей в оболочках модулей памяти.
К сожалению, производители ПК не признали это причиной погрешностей памяти; случайную природу сбоя намного легче оправдать разрядом электростатического электричества, большими выбросами мощности или неустойчивой работой программного обеспечения (например, использованием новой версии операционной системы или большой прикладной программы). Исследования показали, что для систем ECC доля программных ошибок в 30 раз больше, чем аппаратных. Это неудивительно, учитывая вредное влияние космических лучей. Количество ошибок зависит от числа установленных модулей памяти и их объема. Программные ошибки могут случаться и раз в месяц, и несколько раз в неделю, и даже чаще!
Хотя космические лучи и радиация являются причиной большинства программных ошибок памяти, существуют и другие факторы:
1. Скачки в энергопотреблении или шум на линии. Причиной может быть неисправный блок питания или настенная розетка.
2. Использование неверного типа или параметра быстродействия памяти. Тип памяти
должен поддерживаться конкретным набором микросхем и обладать определенной
этим набором скоростью доступа.
3. Электромагнитные помехи. Возникают при расположении радиопередатчиков рядом с
компьютером, что иногда приводит к генерированию паразитных электрических сигна-
лов в монтажных соединениях и схемах компьютера. Имейте в виду, что беспроводные
сети, мыши и клавиатуры увеличивают риск появления электромагнитных помех.
4. Статические разряды. Вызывают моментальные скачки в энергоснабжении, что может
повлиять на целостность данных.
5. Ошибки синхронизации. Не поступившие своевременно данные могут стать причиной
появления программных ошибок. Зачастую причина заключается в неверных парамет-
рах BIOS, оперативной памяти, быстродействие которой ниже, чем требуется систе-
мой, “разогнанных” процессорах и прочих системных компонентах.
Большинство описанных проблем не приводят к прекращению работы микросхем памяти (хотя некачественное энергоснабжение или статическое электричество могут физически повредить микросхемы), однако могут повлиять на хранимые данные.
Игнорирование сбоев, конечно, не лучший способ борьбы с ними. К сожалению, именно этот способ сегодня выбрали многие производители компьютеров. Лучше было бы повысить отказоустойчивость систем. Для этого необходимы механизмы определения и, возможно, исправления ошибок в памяти ПК. В основном для повышения отказоустойчивости в современных компьютерах применяются следующие методы:
— контроль четности;
— коды коррекции ошибок (ECC).
Системы без контроля четности вообще не обеспечивают отказоустойчивости данных. Единственная причина, по которой они используются, — их минимальная базовая стоимость. При этом, в отличие от других технологий (ECC и контроль четности), не требуется дополнительная оперативная память.
Байт данных с контролем четности включает в себя 9, а не 8 бит, поэтому стоимость памяти с контролем четности выше примерно на 12,5%. Кроме того, контроллеры памяти, не требующие логических мостов для подсчета данных четности или ECC, обладают упрощенной внутренней архитектурой. Портативные системы, для которых вопрос минимального энергопотребления особенно важен, выигрывают от уменьшенного энергопотребления памяти благодаря использованию меньшего количества микросхем DRAM. И наконец, шина данных памяти без контроля четности имеет меньшую разрядность, что выражается в сокращении количества буферов данных. Статистическая вероятность возникновения ошибок памяти в современных настольных компьютерах составляет примерно одну ошибку в несколько месяцев. При этом количество ошибок зависит от объема и типа используемой памяти. Подобный уровень ошибок может быть приемлемым для обычных компьютеров, не используемых для работы с важными приложениями. В этом случае цена играет основную роль, а дополнительная стоимость модулей памяти с поддержкой контроля четности и кода ECC себя не оправдывает.
Применение не отказоустойчивых к ошибкам компьютеров рискованно и предполагает отсутствие ошибок памяти при эксплуатации систем. При этом также учитывается, что совокупная стоимость потерь, вызванная ошибками в работе памяти, будет меньше, чем затраты на приобретение дополнительных аппаратных устройств для определения таковых ошибок.
Тем не менее ошибки памяти вполне могут стать причиной серьезных проблем: например, представьте себе указание неверного значения суммы в банковском чеке. Ошибки в работе оперативной памяти серверных систем зачастую приводят к “зависанию” последних и отключению всех клиентских компьютеров, соединенных с серверами по локальной сети. Наконец, отследить причину возникновения проблем в компьютерах, не поддерживающих контроль четности или код ECC, крайне сложно. Последние технологии по крайней мере однозначно укажут на оперативную память как на источник проблемы, тем самым экономя время и усилия системных администраторов.
Контроль четности
Это один из стандартов, введенных IBM, в соответствии с которым информация в банках памяти хранится фрагментами по девять битов, причем восемь из них (составляющих один байт) предназначены собственно для данных, а девятый является битом четности (parity). Использование девятого бита позволяет схемам управления памятью на аппаратном уровне контролировать целостность каждого байта данных. Если обнаруживается ошибка, работа компьютера останавливается и на экран выводится сообщение о неисправности.
Технология контроля четности не позволяет исправлять системные ошибки, однако дает возможность их обнаружить пользователю компьютера, что имеет следующие преимущества:
— контроль четности оберегает от последствий проведения неверных вычислений на базе некорректных данных;
— контроль четности точно указывает на источник возникновения ошибок, помогая разобраться с проблемой и улучшая степень эксплутационной надежности компьютера.
Для реализации поддержки памяти с контролем четности или без него не требуется особых усилий. В частности, внедрить поддержку контроля четности для системной платы не составит никакого труда. Основная стоимость внедрения относится к цене самих модулей памяти с контролем четности. Если покупатели нуждаются в контроле четности для работы с определенными приложениями, поставщики компьютеров могут без проблем предложить соответствующие системы.
Компания Intel и прочие производители наборов микросхем системной логики внедрили поддержку контроля четности и кода ECC в большинстве своих продуктов (особенно в наборах микросхем, ориентированных на рынок высокопроизводительных серверов). В то же время наборы микросхем низшей ценовой категории, как правило, не поддерживают эти технологии. Пользователям, требовательным к надежности выполняемых приложений, следует обращать особое внимание на поддержку контроля четности и ECC.
Код коррекции ошибок
Коды коррекции ошибок (Error Correcting Code — ECC) позволяют не только обнаружить ошибку, но и исправить ее в одном разряде. Поэтому компьютер, в котором используются подобные коды, в случае ошибки в одном разряде может работать без прерывания, причем данные не будут искажены. Коды коррекции ошибок в большинстве ПК позволяют только обнаруживать, но не исправлять ошибки в двух разрядах. Но приблизительно 98% сбоев памяти вызвано именно ошибкой в одном разряде, т.е. она успешно исправляется с помощью данного типа кодов. Данный тип ECC получил название SEC)DED (single-bit error-correction double-bit error detection — одноразрядная коррекция, двухразрядное обнаружение ошибок). В кодах коррекции ошибок этого типа для каждых 32 бит требуется дополнительно семь контрольных разрядов при 4-байтовой и восемь — при 8-байтовой организации (64-разрядные процессоры Athlon/Pentium). Реализация кода коррекции ошибок при 4-байтовой организации, очевидно, дороже реализации проверки нечетности или четности, но при 8-байтовой организации стоимость реализации кода коррекции ошибок не превышает стоимости реализации проверки четности.
Для использования кодов коррекции ошибок необходим контроллер памяти, вычисляющий контрольные разряды при операции записи в память. При чтении из памяти такой контроллер сравнивает прочитанные и вычисленные значения контрольных разрядов и при необходимости исправляет испорченный бит (или биты). Стоимость дополнительных логических схем для реализации кода коррекции ошибок в контроллере памяти не очень высока, но это может значительно снизить быстродействие памяти при операциях записи. Это происходит потому, что при операциях записи и чтения необходимо ждать, когда завершится вычисление контрольных разрядов. При записи части слова вначале следует прочитать полное слово, затем перезаписать изменяемые байты и только после этого — новые вычисленные контрольные разряды.
В большинстве случаев сбой памяти происходит в одном разряде, и потому такие ошибки успешно исправляются кодом коррекции ошибок. Использование отказоустойчивой памяти обеспечивает высокую надежность компьютера. Память с кодом ECC предназначена для серверов, рабочих станций или приложений, для которых последствия потенциальных ошибок памяти менее желательны, чем дополнительные затраты на приобретение добавочных модулей памяти и вычислительные затраты на коррекцию ошибок. Если данные имеют особое значение и компьютеры применяются для решения важных задач, без памяти ECC не обойтись. По сути, ни один уважающий себя системный инженер не будет использовать сервер, даже самый неприхотливый, без памяти ECC.
Пользователи имеют выбор между системами без контроля четности, с контролем четности и с ECC, т.е. между желательным уровнем отказоустойчивости компьютера и степенью ценности используемых данных.
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, an error correction code, sometimes error correcting code, (ECC) is used for controlling errors in data over unreliable or noisy communication channels.[1][2] The central idea is the sender encodes the message with redundant information in the form of an ECC. The redundancy allows the receiver to detect a limited number of errors that may occur anywhere in the message, and often to correct these errors without retransmission. The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[2]
ECC contrasts with error detection in that errors that are encountered can be corrected, not simply detected. The advantage is that a system using ECC does not require a reverse channel to request retransmission of data when an error occurs. The downside is that there is a fixed overhead that is added to the message, thereby requiring a higher forward-channel bandwidth. ECC is therefore applied in situations where retransmissions are costly or impossible, such as one-way communication links and when transmitting to multiple receivers in multicast. Long-latency connections also benefit; in the case of a satellite orbiting around Uranus, retransmission due to errors can create a delay of five hours. ECC information is usually added to mass storage devices to enable recovery of corrupted data, is widely used in modems, and is used on systems where the primary memory is ECC memory.
ECC processing in a receiver may be applied to a digital bitstream or in the demodulation of a digitally modulated carrier. For the latter, ECC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many ECC encoders/decoders can also generate a bit-error rate (BER) signal, which can be used as feedback to fine-tune the analog receiving electronics.
The maximum fractions of errors or of missing bits that can be corrected are determined by the design of the ECC code, so different error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced ECC systems as of 2016[3] come very close to the theoretical maximum.
Forward error correction[edit]
In telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[4][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels. The central idea is that the sender encodes the message in a redundant way, most often by using an ECC.
The redundancy allows the receiver to detect a limited number of errors that may occur anywhere in the message, and often to correct these errors without re-transmission. FEC gives the receiver the ability to correct errors without needing a reverse channel to request re-transmission of data, but at the cost of a fixed, higher forward channel bandwidth. FEC is therefore applied in situations where re-transmissions are costly or impossible, such as one-way communication links and when transmitting to multiple receivers in multicast. FEC information is usually added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, is widely used in modems, is used on systems where the primary memory is ECC memory and in broadcast situations, where the receiver does not have capabilities to request re-transmission or doing so would induce significant latency. For example, in the case of a satellite orbiting Uranus, a re-transmission because of decoding errors would create a delay of at least 5 hours.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC coders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon answers the question of how much bandwidth is left for data communication while using the most efficient code that turns the decoding error probability to zero. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. His proof is not constructive, and hence gives no insight of how to build a capacity achieving code. However, after years of research, some advanced FEC systems like polar code[3] achieve the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complex function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]
A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[5]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[6][7] NOR Flash typically does not use any error correction.[6]
Classical block codes are usually decoded using hard-decision algorithms,[8] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[9]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[10] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[11] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[12]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[13] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[14] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[15] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[16]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[14][17] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[18]
- a contention-free quadratic permutation polynomial (QPP).[19] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[20]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[21]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[22] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[23] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[24]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[25]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters
See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
References[edit]
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ a b c Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
Каждому устройству, использующему флэш-память NAND, необходим код с исправлением случайных битов (известный как «мягкая» ошибка). Это потому что много электрический шум производится внутри чипа NAND, а уровни сигналов битов, проходящих через цепочку чипов NAND, очень слабые.

Один из способов, которым NAND память стали самый дешевый всего, потому что это требует, чтобы исправление ошибок было выполнено от элемента вне самого чипа NAND; В случае SSD, ECC выполняется на контроллере .
Такое же исправление ошибок также помогает исправить битовые ошибки из-за носить на Память сами клетки , Истощение может вызвать «застревание» битов в том или ином состоянии (известное как «жесткая» ошибка или жесткая ошибка) и может увеличить частоту «мягких» ошибок.
Хотя это понятие не является слишком широким, сопротивление флэш-памяти является мерой того, сколько циклов стирания / записи может выдержать блок флэш-памяти, прежде чем начнут появляться «серьезные» ошибки. Очень часто эти сбои происходят только в отдельных битах, и очень редко происходит сбой всего блока. При достаточно высоком числе стирания / записи «мягкая» частота ошибок также увеличивается из-за ряда других механизмов в самом SSD.
If ECC может быть используемый чтобы исправить эти «жесткие» ошибки, а «мягкие» ошибки не увеличиваются, срок службы всего блока значительно удлиняется, что значительно превышает сопротивление, указанное производителем.
Давайте рассмотрим пример: допустим, что неиспользуемый чип NAND имеет достаточно «мягких» ошибок, чтобы требовать 8 бит ECC, то есть при каждом считывании страницы может быть до 8 бит, которые были случайно повреждены (обычно из-за электрических помех, которые мы говорили о). вначале). ECC, используемый в этом чипе, может исправлять 12-битные ошибки, так что ECC не может решить эту проблему мы должны найти 8 «мягких» ошибок, связанных с электрическим шумом, плюс еще 5 «мягких» из-за износа.
Теперь производители флэш-памяти гарантируют, что первый из этих 5 сбоев произойдет через некоторое время после спецификации прочности SSD. Это означает, что ни один бит не выйдет из строя из-за износа, пока не будут превышены циклы стирания / записи, указанные производителем. Теперь имейте в виду, что спецификации не достаточно точны, чтобы предсказать, когда следующий бит выйдет из строя, и на самом деле это может занять несколько тысяч циклов стирания / записи выше спецификации, чтобы это произошло; помните, что производитель гарантирует, что это не произойдет до X циклов, но не тогда, когда это произойдет после их превышения.
Это означает, что это может занять много времени, прежде чем блок становится настолько коррумпированным что его необходимо удалить из службы (а также для этого на SSD обычно есть «дополнительные» блоки для замены поврежденных), что, в свою очередь, означает, что сопротивление исправлен от ошибок блок может быть во много раз больше указанного сопротивления, в зависимости от количества избыточных ошибок, которые ECC предназначен для исправления.
Какое влияние оказывает код исправления ошибок на SSD?
Как мы объясняли ранее, флэш-память настолько дешева, потому что она не включает в себя ECC в самих чипах, но интегрирована в другое внешнее оборудование, и, как вы предположите, это имеет свою цену. Более сложный ECC требует большей вычислительной мощности на контроллере и может быть медленнее, если алгоритмы не очень современные. Кроме того, количество ошибок, которые могут быть исправлены, будет зависеть от того, насколько большой сектор памяти исправляется, поэтому контроллер SSD со сложным алгоритмом ECC, вероятно, будет использовать много ресурсов, снижение общий SSD производительность , Эти улучшения также делают контроллер дороже .
Алгоритмы ECC имеют свое собственное математическое состояние в зависимости от контроллера (другими словами, нет никакого стандарта), и даже самые базовые кодировки ECC (Рида-Соломона и LDPC) довольно сложны для понимания. Когда кто-то говорит о пределе Шеннона (максимальное количество битов, которое может быть исправлено), это величина, которую, как вы не знаете от производителя в технических характеристиках, чрезвычайно сложно вычислить.
Просто придерживайтесь этого: большее количество корректирующих битов увеличивает срок службы SSD, но также оказывает некоторое влияние на производительность или даже цену продукта, так как требует более мощный контроллер.
Олег Спиряев
Серверы стандартной архитектуры все чаще используются для выполнения критически
важных приложений и приложений с повышенными требованиями к оперативной памяти.
Известно, что компоненты оперативной памяти за последние годы становятся все
более надежными, причем не только за счет усовершенствования процесса производства
микросхем, но и благодаря новым технологиям защиты памяти, например, обнаружения
и коррекции ошибок (Error Correction Code, ECC). Кстати, эта защита впервые
была применена именно в серверах стандартной архитектуры корпорации HP (http://www.hp.com).
Однако по мере увеличения плотности этих компонентов и максимального объема оперативной памяти серверов возрастает и риск возникновения ошибок памяти. Такие ошибки могут привести к порче данных и сбою в работе сервера, что будет означать безвозвратную потерю необходимой для бизнеса информации и потери прибыли из-за простоев системы.
Для решения проблем надежности оперативной памяти HP предлагает технологию трехуровневой защиты Advanced Memory Protection, улучшающую отказоустойчивость приложений с повышенными требованиями к доступности. Клиенты HP могут выбрать систему с оптимальным для них уровнем защиты оперативной памяти – Online Spare Memory, Hot Plug Mirrored Memory и Hot Plug RAID Memory.
Ошибки памяти
Поскольку используемые в серверах модули памяти представляют собой обычные электронные запоминающие устройства, неизбежен риск возникновения различных ошибок. Как известно, в компьютерных системах обычно используется два типа устройств памяти с произвольным доступом – статическим (Static RAM) и динамическим RAM (Dynamic RAM). Микросхемы SRAM используются обычно для организации кэш-памяти, поскольку они работают очень быстро и сохраняют данные до отключения питания. Микросхемы DRAM устанавливаются как 168-контактные модули типа DIMM (Dual Inline Memory Modules). Каждый кристалл DRAM хранит данные в так называемых ячейках памяти, которые представляют собой конденсаторы, выполненные в полупроводниковой структуре кристалла. Для сохранения заряда (или обновления сохраненных данных) такие конденсаторы должны непрерывно перезаряжаться. Наличие заряда в конденсаторе интерпретируется как бит данных «1», а отсутствие заряда – как бит данных «0». Уровень электрического заряда определяется рабочим напряжением запоминающего устройства.
Если обращение к ячейке памяти происходит при операции считывания, то наличие заряда в ней определяет, будет считана «1» или «0». Например, если в системе с рабочим напряжением 5 В считанный заряд конденсатора равен 5 В, предполагается, что в нем записана единица, а если 0 В – ноль. Если напряжение конденсатора составляет немного меньше +5 В, то значение будет считываться правильно, но если заряд конденсатора изменится из-за некоторых внешних событий, то при считывании может возникнуть ошибка. Например, в серверах, выполняющих критически важные приложения, из-за таких ошибок может произойти потеря информации.
Ошибки памяти классифицируются по числу битов, которые они затрагивают (одно- и многобитовые) и по причине ошибки. Шина памяти обычно состоит из двух частей – шины данных и шины адресов. Шина данных – это дорожки, по которым реальные данные передаются к DRAM и от нее. Каждая дорожка в определенный момент времени передает только один бит данных. У современных компьютеров ширина шины данных равна 64 разрядам, т. е. за один такт шина может передавать 64 бита. Эти 64 разряда составляют слово данных ECC. Ошибка в одном разряде слова данных называется однобитовой, а в нескольких разрядах – многобитовой.
В зависимости от их природы ошибки памяти делятся на так называемые «жесткие» (аппаратные) и «мягкие». «Жесткие» ошибки связаны с неисправностью или дефектом оборудования, из-за чего устройство постоянно выдает неправильные результаты. Например, из-за дефекта ячейки памяти может случиться, что она все время будет возвращать «0», даже если в нее записано «1». Подобные аппаратные ошибки бывают вызваны дефектами кристаллов DRAM, низким качеством спайки, проблемами соединителей, разъемов и т. п. Чаще встречаются «мягкие» ошибки, возникающие случайным образом; обычно они вызываются заряженными частицами или излучением. Данные ошибки непостоянны и со временем пропадают. Ранее основной причиной случайных ошибок были альфа-частицы, но более строгий контроль качества материала, из которого делаются корпуса микросхем DRAM, позволил производителям практически ликвидировать эту причину сбоев. В настоящее время основной источник случайных ошибок в микросхемах DRAM – электрические возмущения, вызванные космическими лучами – потоками элементарных частиц высокой энергии, приходящими из космоса. Следовательно, такие ошибки не связаны с проблемами запоминающего устройства, поскольку после исправления хранящихся данных (например, путем записи в ячейку памяти) ошибки не повторяются.
Вероятность ошибок памяти увеличивается по двум причинам – роста плотности хранения в компонентах памяти и объема памяти, устанавливаемой в серверах. Дело в том, что себестоимость памяти обычно снижают путем максимального повышения разрядности микросхем. Плотная упаковка (т. е. повышение разрядности) микросхем памяти позволила резко снизить соотношение цена/емкость. Такие микросхемы, как правило, передают и получают четыре или восемь разрядов данных в каждой операции доступа.
Два параметра DRAM тесно связаны между собой – плотность хранения микросхем DRAM и рабочее напряжение системы памяти. По мере роста емкости ячеек памяти растет и плотность хранения DRAM, и чувствительность ячеек к изменению напряжения. До недавнего времени стандартные DIMM использовали напряжение 5 В, но после повышения плотности хранения DRAM рабочее напряжение уменьшили до 3,3 В, а затем и до 2,5 В – для того, чтобы память работа быстрее и потребляла меньше энергии. Но из-за увеличения плотности хранения и уменьшения рабочего напряжения возросла вероятность ошибок. А если бит данных неправильно считан и ошибка не исправлена, это приведет к сбою в работе приложения.
Поставщики ПО разрабатывают все более сложные и интенсивно использующие память приложения, которые необходимы в сфере финансов, телекоммуникаций и индустрии развлечений. В результате расширяется адресное пространство операционных систем и производители серверов увеличивают поддерживаемый объем запоминающих устройств.
Вообще говоря, существует два способа защиты от ошибок памяти – тестирование и использование технологий обнаружения/исправления ошибок. Качество процедуры тестирования зависит от источника модулей памяти. Поскольку микросхемы памяти работают быстрее и становятся все сложнее, их тестирование – это крайне трудная и дорогостоящая процедура. Производители микросхем памяти вкладывают значительные средства в системы тестирования и непрерывно совершенствуют эту процедуру, чтобы поддерживать высокое качество продукции.
Поскольку процесс производства памяти постоянно изменяется, компания HP проводит сертификацию каждой новой модели модулей памяти и его производства для устранения риска «жестких» ошибок. Корпорация также проводит тестирование каждого модуля памяти для каждой модели сервера, в которой он будет устанавливаться, включая серверы, поставляемые в настоящее время, и повторную сертификацию и тестирование модулей при переводе серверов на процессоры с увеличенной тактовой частотой. Такое тщательное тестирование позволяет HP предоставлять трехлетнюю гарантию на модули памяти с предупреждающей заменой.
Обнаружение и исправление ошибок
Конечно, проводя сертификацию фирм-производителей памяти и непрерывно тестируя их продукты, можно свести к минимуму риск возникновения большинства ошибок, связанных с процессом производства, однако эти меры никак не защищают от «мягких» ошибок. По мере увеличения емкости модулей памяти растет и вероятность возникновения «мягких» ошибок, поэтому технологии обнаружения и исправления ошибок применять просто необходимо. Ведь без этих технологий в работе критически важных приложений будут периодически происходить непредсказуемые сбои. Несмотря на средства защиты от аппаратных ошибок, сбои в запоминающем устройстве могут происходить по причинам, непосредственно не связанным с памятью. Единственная надежная защита от ошибок памяти – это использование специальных протоколов обнаружения и исправления. Некоторые из них способны только обнаруживать ошибки, а другие – идентифицировать и сразу же исправлять проблемы памяти.
Технология ECC
В 1993 г. HP первой среди фирм-производителей серверов стандартной архитектуры применила память ECC, которая значительно сокращает вероятность ошибок памяти. В настоящее время память с функцией ECC стала стандартной функцией серверов HP ProLiant. ECC работает надежнее, чем обычная проверка четности, которая обеспечивает обнаружение однобитовых ошибок, но неспособна исправлять ошибки памяти или обрабатывать многобитовые ошибки. Память ECC может обнаружить как одно-, так и многобитовые ошибки в 64-разрядном слове данных и исправить однобитовые ошибки. Обычно этот механизм называют SEC/DED (Single Error Correction/Double Error Detection – коррекция единичных и обнаружение двойных ошибок). Рассмотрим механизм работы ECC (рис. 1).
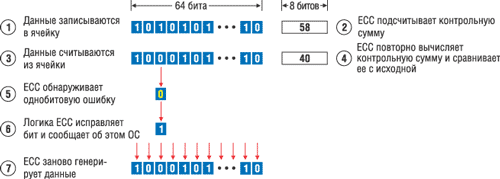 |
| Рис. 1. Схема обнаружения и исправления однобитовой ошибки.
|
Итак, ECC кодирует информацию в восьмиразрядные блоки, что позволяет исправлять однобитовые ошибки. При каждой записи данных в память ECC с помощью специального алгоритма вычисляет контрольные биты. Алгоритм суммирует контрольные биты, и получается контрольная сумма, которая и хранится вместе с данными. Когда данные считываются из памяти, алгоритм заново вычисляет контрольную сумму и сравнивает ее с тем значением, которое хранится вместе с данными. Если контрольные суммы одинаковы, то данные рассматриваются как правильные и операции с ними продолжаются, но если контрольные суммы различаются, это означает, что данные содержат ошибку. Тогда логика памяти ECC изолирует ошибку и сообщает о ней системе. В случае однобитовой ошибки логика памяти ECC может исправить ее и записать правильные данные, так что система продолжит работу.
Кроме обнаружения и исправления однобитовых ошибок, ECC обнаруживает (но не исправляет) ошибки в двух не идущих подряд разрядах и в четырех разрядах в одном кристалле DRAM. ECC обрабатывает такие многобитовые ошибки, генерируя немаскируемое прерывание NMI (Non-Maskable Interrupt), при получении которого система останавливает операции для того, чтобы не испортить данные. Механизм SEC/DED не позволяет обнаруживать ошибки в более чем двух разрядах; в этом случае целостность информации нарушается. В архитектуре этого типа ошибки в нескольких разрядах неустранимы и приводят к отказу системы, а сбои единичных разрядов исправляются автоматически, незаметно (прозрачно) для операционной системы и приложений.
Технология ECC обеспечивает достаточный для многих приложений уровень защиты. Стоит отметить, что эффективность подобной защиты ухудшается (частота сбоев в работе сервера может вырасти с 3 до 48%) при увеличении емкости памяти в серверах стандартной архитектуры, которое связано с расширением максимального объема оперативной памяти, поддерживаемого ОС, и доступностью относительно дешевых модулей памяти повышенной емкости.
Что такое Chipkill
Один из базовых механизмов защиты памяти – механизм Chipkill, позволяющий
памяти противостоять многоразрядным ошибкам на отдельных микросхемах DRAM,
в том числе сбою всех разрядов данных. В механизме Chipkill существуют
два основных метода исправления ошибок, причем они могут применяться совместно.
Эти методы базируются на определенном наборе микросхем и особой аппаратной
архитектуре системы – их поддержка не обеспечивается простым обновлением
ПО.
В первом методе каждый бит данных модуля памяти размещается в отдельном
«слове ECC». Иными словами, это набор разрядов данных и контрольных разрядов,
в котором обнаружение и исправление ошибок обеспечивается алгоритмом ECC.
Допустим, что разрядность системы памяти составляет 32 байта (или 256
разрядов). Биты ECC добавляются так, чтобы общая ширина блока (и контрольные,
и биты данных) составляла 288 разрядов. Четыре слова ECC, каждое из которых
состоит из 64 разрядов данных и 8 контрольных разрядов ECC, поддерживают
механизм SEC/DED. Эти четыре слова ECC распределяются по DRAM-модулям.
Например, если DIMM содержит модули х4 DRAM, четыре бита каждого устройства
распределяются по разным словам ECC. Сбой всех четырех битов – это всего
лишь четыре единичные ошибки в четырех словах ECC, и они устраняются автоматически.
В данном примере механизм Chipkill поддерживается только на DIMM-модулях,
состоящих из микросхем х4 DRAM.
Второй метод заключается в том, что механизму ECC предоставляется больше
разрядов для хранения контрольных кодов, чтобы обеспечить исправление
не одного, а нескольких разрядов. При этом используются соответствующие
математические алгоритмы устранения многоразрядных ошибок при определенном
количестве контрольных битов ECC и битов данных. Например, 144-разрядное
слово ECC, состоящее из 128 разрядов данных и 16 битов ECC, позволяет
исправлять ошибки, охватывающие до 4 разрядов данных. Для исправления
сбоя четырех битов необходимо, чтобы они располагались смежно, а не случайно.
Соотношение разрядов ECC и разрядов данных в этом случае такое же, как
и в предыдущем примере (16/128 и 8/64), однако более длинное слово ECC
позволяет применить более эффективный алгоритм обнаружения и исправления
ошибок.
Совместное использование этих двух методов обеспечивает коррекцию по
механизму Chipkill на DIMM-модулях с микросхемами х8 DRAM. Два 144-разрядных
слова ECC распределяются так, чтобы на каждом DRAM в первом и втором словах
ECC исправлялись по четыре разряда. Этот метод обеспечивает поддержку
механизма Chipkill при использовании DIMM-модулей, состоящих из микросхем
х4 DRAM и х8 DRAM.
Технология Advanced ECC
Для совершенствования защиты памяти в 1993 г. HP разработала технологию Advanced ECC, которая защищена патентом Error Correction System for N Bits Using Error Correcting Code Designed for Fewer than N Bits. Сегодня не только HP, но и другие фирмы-производители серверов используют это решение в своих системах. Если стандартные устройства ECC могут исправлять однобитовые ошибки при чтении из DIMM, то технология Advanced ECC способна исправлять многобитовые ошибки в одной микросхеме DRAM (табл. 1). Именно поэтому теперь возможно восстановление данных в случае отказа всей микросхемы DRAM. При использовании Advanced ECC с четырехбитовыми (х4) устройствами слово данных состоит из комбинации четырех разрядов от каждой микросхемы (рис. 2). Четыре разряда от каждой микросхемы распределяются по четырем устройствам ECC (по одному разряду для каждого устройства ECC), поэтому при ошибке в одной микросхеме возникают до четырех однобитовых ошибок.
| Рис. 2. Схема работы технологии Advanced ECC.
|
Поскольку алгоритм ECC предназначен как раз для исправления однобитовых ошибок, технология Advanced ECC способна исправлять многобитовые ошибки, которые произошли в одной схеме DRAM. Таким образом, Advanced ECC обеспечивает защиту от сбоя всего устройства.
Таблица 1. Сравнение технологий защиты от ошибок ECC и Advanced ECC
| Тип ошибки | ECC | Advanced ECC |
| Однобитовая | Исправляет | Исправляет |
| Двухбитовая | Обнаруживает | Исправляет или обнаруживает |
| Сбой DRAM | Обнаруживает | Исправляет |
| Сбой обнаружения ECC | – | – |
Хотя Advanced ECC обеспечивает защиту от сбоя, она исправляет многобитовые
ошибки только в том случае, если они произошли в одной микросхеме DRAM. Здесь
не поддерживаются такие функции, как переключение при отказе или горячая замена,
которые сейчас стали обязательными для критически важных приложений, работающих
круглые сутки. В результате при сбое памяти для ее замены необходимо остановить
систему.
Технологии HP Advanced Memory Protection
HP стремится использовать в серверах ProLiant различные технологии, улучшающие отказоустойчивость для приложений, которым необходима высокая доступность. Например, в серверах HP ProLiant 300, 500 и 700 Series применяются одна или несколько технологий Advanced Memory Protection: Online Spare Memory, Hot Plug Mirrored Memory и Hot Plug RAID Memory. Все эти технологии оптимизированы для функциональности и приложений каждой серии серверов. Изначально технологии Advanced Memory Protection поддерживали стандартные модули DDR DIMM емкостью 256 и 512 Мбайт, 1 и 2 Гбайт.
Например, в серверах HP ProLiant ML370 G2 и G3 и DL380 G2 и G3 на системной плате размещены шесть разъемов DIMM. Эти разъемы объединены для создания трех банков памяти (A, B и C). В обычном режиме работы памяти все банки используются как доступная системная память общей емкостью 6 Гбайт (в случае 1-Гбайт модулей DIMM). Поскольку система использует чередование, DIMM-модули должны устанавливаться парами в один банк за один раз. DIMM в одном банке должны быть одинаковы по типу и емкости, иначе производительность подсистемы памяти ухудшается. Например, банк A может содержать два 512-Мбайт DIMM, а B – два 1-Гбайт DIMM.
Чередование памяти
Чередование улучшает производительность памяти за счет ее разделения
на несколько блоков (два, четыре и т.д.), к которым можно обращаться одновременно.
В результате последовательные данные равномерно распределяются по блокам,
и от системы не требуется сначала заполнить один блок, а затем – другой.
Режим Online Spare Memory обеспечивает более надежную защиту памяти, чем режим
Standard Memory. Подобный режим выгоден компаниям, у которых не хватает ИТ-персонала,
способного вручную устранить сбой, не всегда имеются запасные модули памяти
и т. п. Чтобы задействовать режим Online Spare Memory, пользователь при запуске
системы с помощью записанной в ПЗУ утилиты Setup Utility назначает банк C на
роль Online Spare Memory (возможно также, что Online Spare Memory не будет использовать
выделенный банк памяти, вместо этого банком для Online Spare Memory будет последний
заполненный банк). Например, если заполнены банки A и B, то DIMM-модули в банке
B будут использоваться как Online Spare Memory. Например, в серверах ProLiant
ML370 G2 и DL380 G2 банк C должен быть заполнен до того, как сервер сконфигурирован
для режима Online Spare Memory. Банки A и B считаются оперативной памятью общим
объемом 4 Гбайт, если используются 1-Гбайт DIMM-модули. DIMM-модули в банке
C должны иметь не меньшую емкость, чем модули в остальных банках. Например,
если в банке A используются 512-Мбайт DIMM, а в банке B – 1-Гбайт DIMM, то в
банке C нельзя установить DIMM емкостью меньше 1 Гбайт.
Если в режиме Online Spare Mode DIMM в банке A или B превысит заранее установленное пороговое значение ошибок, то загорится сигнальный светодиод перед неисправным DIMM. Ошибка будет исправлена, а данные из всего банка, который содержал неисправный DIMM, будут скопированы в банк памяти Online Spare. Банк, в котором произошел сбой, будет отключен, но сервер продолжит работу до тех пор, пока пользователь не заменит сбойный DIMM-модуль при запланированном отключении. Стоит отметить, что реализация режима Online Spare Memory в серверах ProLiant ML370 G3 и DL380 G3 не требует заполнения банка C. Здесь Online Spare Bank – это всегда последний заполненный банк.
Режимы для серверов HP ProLiant 500
Серверы HP ProLiant 500 стандартно поставляются с основной платой памяти, которая имеет восемь разъемов для DIMM-модулей общим объемом до 8 Гбайт (если в режиме Standard Memory используются 1-Гбайт DIMM). В серверах HP ProLiant ML570 G2 и ML530 G2 применяется двухуровневое чередование, а в ProLiant DL580 G2 – четырехуровневое. Если в системе используется двунаправленное чередование, то разъемы для модулей памяти организованы в четыре банка (A, B, C и D) – по два соединителя в банке. DIMM-модули устанавливаются парами в один банк за один раз, причем модули в каждом банке должны быть идентичны (одного типа и емкости), чтобы система работала правильно. Например, банк A может содержать два 1-Гбайт DIMM, а банк B – два DIMM по 512 Мбайт.
Системы с четырехуровневым чередованием организованы в два банка с четырьмя разъемами в каждом. DIMM-модули должны устанавливаться по четыре в банк. В этом случае так же обязательно, чтобы модули из одного банка были идентичными (одного типа и емкости). Стоит отметить, что для этой опции не требуется поддержка ОС – все ПО и драйверы записаны в системной BIOS.
При запуске системы с одной платой памяти с помощью записанной в ROM утилиты Setup Utility банк D указывается как Online Spare Memory, а остальные банки (A, B и C) – как системная память. Банк D на основной плате памяти всегда остается банком Online Spare, даже если установлена дополнительная плата памяти. Банк D должен быть заполнен до того, как сервер сконфигурирован для режима Online Spare Memory. В режиме Online Spare Memory сервер может поддерживать до 6 Гбайт системной памяти в банках A, B и C и 2 Гбайт Online Spare Memory в банке D. Как и в предыдущем случае, DIMM-модули в банке D должны иметь не меньшую емкость, чем модули в остальных банках. Например, если в одном банке используются 512-Мбайт DIMM, а в другом – 1-Гбайт DIMM, то в банке D нельзя установить DIMM емкостью меньше 1 Гбайт, иначе в банке Online Spare не хватит емкости для хранения всей оперативной памяти.
Если DIMM в банке A, B или C превысит заранее установленное пороговое значение ошибок, то система скопирует все данные из банка памяти, где находится сбойный DIMM-модуль, в банк памяти Online Spare. Банк, в котором произошел сбой, будет отключен, и рядом с неисправным DIMM-модулем загорится сигнальный светодиод платы памяти.
ПО HP Insight Manager может выдавать предупреждение системы на монитор или другим способом, например, на пейджер. Эта операция обеспечивает доступность сервера и надежность памяти без вмешательства, связанного с обслуживанием. Пользователь может заменить DIMM-модуль, который превысил пороговое значение ошибок, когда ему будет удобно, например, при запланированном отключении.
Серверы ProLiant ML570 G2 и DL580 G2 поддерживают две платы памяти. Это позволяет в режиме Online Spare Memory увеличить оперативную память до 16 Гбайт и обеспечить более надежную защиту по сравнению с режимом Standard Memory. Если дополнительная плата памяти установлена до загрузки сервера, то банк D на основной плате памяти можно назначить банком Online Spare с помощью записанной в ПЗУ утилиты Setup Utility.
В конфигурации с двухуровневым чередованием в режиме Online Spare Memory сервер поддерживает до 2 Гбайт памяти Online Spare в банке D основной платы и до 14 Гбайт системной памяти в остальных банках (при использовании 1-Гбайт DIMM). DIMM-модули в банке D также должны иметь не меньшую емкость, чем модули в остальных банках.
Если DIMM в одном из банков системы C превысит заранее установленное пороговое значение ошибок, система скопирует все данные из банка памяти, где находится сбойный DIMM-модуль, в банк памяти Online Spare. Банк, в котором произошел сбой, будет отключен, и рядом с неисправным модулем загорится соответствующий светодиод.
Системы с четырехуровневым чередованием имеют только по два банка памяти на плату (по четыре разъема на банк) и потому могут поддерживать переключение на банк Online Spare Memory при отказе максимум трех банков.
Режим Mirrored Memory
Mirrored Memory – это опция отказоустойчивой памяти, обеспечивающая более надежную защиту, чем Online Spare Memory, который защищает от однобитовых ошибок и выхода из строя всего модуля DRAM. А вот режим Mirrored Memory обеспечивает полную защиту от однобитовых и многобитовых ошибок при использовании одной платы памяти, поэтому он оптимален для компаний, у которых не должно быть простоев или которые не могут рисковать, ожидая запланированного простоя для замены сбойного модуля памяти.
Заказчики могут активизировать режим Mirrored Memory, используя стандартно поставляемую с сервером основную плату памяти. До двух банков памяти (С и D) можно назначить в качестве так называемой зеркалированной памяти. Серверы, работающие в режиме Mirrored Memory с одной платой памяти, поддерживают до 4 Гбайт системной памяти (и эквивалентный объем резервированной памяти) при использовании 1-Гбайт DIMM. Для активизации режима Mirrored Memory в сервере с двухуровневым чередованием банки A и B должны быть сконфигурированы идентично банкам C и D соответственно. Для активизации режима Mirrored Memory в сервере с четырехуровневым чередованием банк A должен быть сконфигурирован идентично банку B.
Одни и те же данные записываются в банки системной памяти и зеркалированной памяти, но считываются они из банков системной памяти. Если в одном из DIMM-модулей банков системной памяти произошла многобитовая ошибка или достигнут заранее определенный порог однобитовых ошибок, банки C и D автоматически назначаются системной памятью, а банки A и B – зеркалированной. Данные по-прежнему записываются в банки системной и зеркалированной памяти, но считываются только из банков системной памяти. Это обеспечивает непрерывность операций и поддерживает доступность сервера за исключением тех случаев, когда ошибка одновременно происходит в одном и том же месте в системном и зеркалированном DIMM (вероятность таких совпадений, впрочем, крайне мала). Система включает светодиод на плате памяти для DIMM, в котором произошла многобитовая ошибка.
В режиме Hot Plug Mirrored Memory дополнительная плата памяти обеспечивает полное резервирование и более надежную защиту по сравнению с режимом Online Spare Memory. Hot Plug Mirrored Memory также поддерживает горячее добавление и замену модулей для повышения доступности сервера. Горячее добавление позволяет нарастить объем памяти путем добавления DIMM-модуля в свободные разъемы, а горячая замена – заменять сбойный модуль без остановки системы. Этот режим также предназначен для тех компаний, у которых не должно быть простоев или нет возможности подождать запланированного простоя для замены сбойного модуля.
Серверы, работающие в режиме Mirrored Memory с одной платой памяти, поддерживают до 8 Гбайт системной памяти (и эквивалентный объем резервированной памяти) при использовании 1-Гбайт DIMM. Для активизации режима Mirrored Memory в сервере с двухуровневым чередованием банки A и B должны быть сконфигурированы идентично банкам C и D соответственно. Для активизации режима Hot Plug Mirrored Memory две платы должны быть сконфигурированы идентично. Одни и те же данные записываются на обе платы, но считываются только с основной.
Требования к конфигурации Hot Plug Memory
Для поддержки данного режима вторая плата памяти должна отвечать следующим
требованиям:
- задействовать то же число заполненных банков памяти, что и первая;
- иметь тот же объем (суммарную емкость) каждого банка, что и первая;
- использовать тот же тип памяти в каждом банке (одно- или двухсторонняя),
что и первая плата.
Если в DIMM-модуле основной платы произошла многобитовая ошибка или превышен
порог однобитовых ошибок, то данные считываются с дополнительной платы. Благодаря
этому пользователь может в горячем режиме заменять сбойные DIMM-модули основной
платы без остановки сервера.
В том случае, если соответствующий светодиод (Ready to Hot Plug) платы памяти светится зеленым светом, можно безопасно удалить одну из плат памяти, соблюдая следующие ограничения:
- если не было ошибок, то можно снять любую плату;
- если в одном из банков памяти произошел сбой, то можно снять только ту плату, где находится сбойный банк;
- если в обеих платах есть сбойные банки, то платы заменять нельзя.
Хотя вероятность последнего случая крайне мала, соблюдение данного ограничения защищает от такой рискованной ситуации, когда в сервере есть только одна плата, в которой происходили многобитовые ошибки. В таком случае сервер надо выключить и устранить сбои.
Хотя в серверах ProLiant 500 поддерживается функция горячего добавления DIMM-модулей в свободные разъемы для расширения объема памяти, для ее реального использования требуется, чтобы и операционная система могла обнаруживать установку дополнительной памяти.
Особенности защиты в серверах ProLiant 700
Серверы ProLiant 700 стали первыми в индустрии компьютерами, оперативная память которых имеет функциональность Hot Plug RAID Memory. Именно она обеспечивает непрерывную работу подсистемы памяти даже в случае полного выхода из строя запоминающего устройства. В данном случае RAID расшифровывается как Redundant Array of Industry-standard DIMMs (резервированный массив стандартных DIMM-модулей). Не стоит путать эту аббревиатуру с резервированным массивом независимых дисков (Redundant Array of Independent Disks, RAID), используемых в системах хранения. Тем не менее концепция HP Hot Plug RAID чем-то схожа с технологией RAID Level 4 для дисковых систем хранения, хотя имеются и некоторые существенные отличия.
Общность концепции Hot Plug RAID Memory с RAID Level 4 заключается в том, что при записи данных вычисляется контрольная сумма четности для всей строки данных кэш-памяти и эта сумма записывается в специальный картридж четности (рис. 3). Далее указанная контрольная сумма четности проверяется при операции чтения. Вообще говоря, на этом сходство HP Hot Plug RAID Memory и дисковых массивов RAID заканчивается. В Hot Plug RAID Memory отсутствует механическое запаздывание поиска и запаздывание из-за вращения диска, которые остаются недостатком дисковых массивов. Дисковые массивы используют одну шину для последовательной записи расщепленных данных на несколько массивов, а Hot Plug RAID Memory использует параллельные соединения типа «точка-точка» для одновременной записи данных на несколько картриджей памяти. Кроме того, в Hot Plug RAID Memory нет узкого места записи, которое обычно снижает производительность дисковых массивов RAID. RAID-контроллер дискового массива перед завершением записи обычно считывает существующее значение четности. Если четность хранится на выделенном диске, то он становится узким местом системы. Поскольку обычно Hot Plug RAID Memory работает со всей строкой данных из кэш-памяти, то не нужно перед записью считывать существующее значение четности.
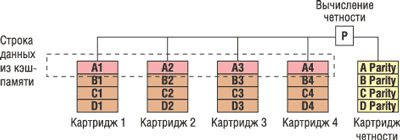 |
Рис. 3. Механизм HP Hot Plug RAID Memory.
|
Рассмотрим принципы работы HP Hot Plug RAID Memory. Серверы с HP Hot Plug RAID Memory используют пять контроллеров памяти для управления пятью картриджами памяти, каждый из которых вмещает до восьми стандартных DIMM-модулей (рис. 4). Когда контроллерам памяти нужно записать данные в память, они разбивают данные на четыре блока и записывают их в четыре из пяти картриджей памяти. Механизм RAID вычисляет контрольную сумму четности, которая записывается в пятом картридже. С четырьмя картриджами данных и одним картриджем четности обеспечивается полная отказоустойчивость подсистемы данных. Если данные из любого DIMM-модуля неправильные или один из картриджей удален, то данные можно восстановить по остальным четырем картриджам.
| Рис. 4. Процесс записи в Hot Plug RAID Memory.
|
Резервирование HP Hot Plug RAID Memory позволяет в горячем режиме заменять, добавлять и обновлять модули памяти без отключения сервера. Горячая замена отказавшего модуля выполняется без прерывания работы системы. Для замены в горячем режиме не требуется специальный драйвер или поддержка этой операции в ОС (серверы стандартно поддерживают горячую замену независимо от ОС). Горячее добавление и обновление позволяют наращивать доступную память сервера: при горячем добавлении в свободные разъемы устанавливаются дополнительные DIMM-модули, а при горячем обновлении «старые» модули заменяются на модули большей емкости.
Для использования горячего добавления и обновления требуется, чтобы ОС могла обнаружить увеличение памяти. Современные версии Microsoft Windows Advanced Server, Windows Data Center, Novell NetWare и SCO UnixWare поддерживают эти функции в серверах HP ProLiant 700, при этом HP совместно с разработчиками ОС работает над введением поддержки этих функций в других релизах ОС.
Когда операция завершена, HP Hot Plug RAID Memory автоматически перераспределяет данные по всем картриджам памяти. По данным HP, перераспределение 4 Гбайт памяти выполняется менее чем за полминуты – это совсем небольшая плата за повышение отказоустойчивости и защиту от сбоев памяти.
В табл. 2 приведены сравнительные характеристики и конкурентные преимущества технологий HP Advanced Memory Protection.
Таблица 2. Сравнение механизмов защиты Advanced Memory Protection
| HP Advanced Memory | HP Online Spare Memory | HP Hot Plug Mirrored Memory | HP Hot Plug RAID Memory | |
| Защита от сбоев устройств | Да | Да | Да | Да |
| Стандартные DIMM | Да | Да | Да | Да |
| Hot Plug | Нет | Нет | Да | Да |
| Замена сбойных DIMM | Offline | Offline | Online | Online |
| Расширение памяти | Offline | Offline | Online | Online |
Можно отметить, что совокупность технологий, предлагаемых HP для защиты памяти,
позволяет покупателям выбрать системы с оптимальным для них уровнем доступности
для повышения надежности всего решения. Тем не менее технология HP Hot Plug
RAID Memory обеспечивает максимальную доступность и оптимальна для компаний,
которые используют серверы стандартной архитектуры с большой памятью для выполнения
приложений в круглосуточном режиме. Эта технология позволяет подсистеме памяти
работать непрерывно даже в случае полного выхода из строя устройства памяти
и выполнять в горячем режиме замену, добавление и обновление DIMM-модулей.