An experiment is the only research method that enables a scientist to establish a causal relationship between an independent and a dependent variable, but there is still much that can be learned about human behavior from naturalistic observation. Indeed, it is in the real world that a person often observes a phenomenon that intrigues and captivates that individual, leading her or him to generate a hypothesis about that phenomenon, and then to test that hypothesis (often with an experiment). Given the important role that naturalistic observation plays in the scientific method, we developed a freely-available tool accessible via the Internet to encourage expert-scientists, scientists-in-training, and science-enthusiasts to engage in the naturalistic observation of spoken language, focusing on various types of speech errors. This website amasses those observations, and makes the archive of observations available to others for further analysis.
The thorough history of the field of psycholinguistics reported in Levelt (2013) shows that the use of diaries to record naturally occurring observations has a long history in the study of language development. In the production of words and sounds, the use of diaries, especially collections of speech errors such as malapropisms and slips of the tongue, has waxed and waned over time, starting with the ground-breaking work of Meringer and Meyer (1895), with periodic resurgences in the use of diaries/collections of errors appearing in the work of Boomer and Laver, Cutler, Hockett, Fromkin, Fry, MacKay, Nooteboom, Shattuck-Hufnagel, Stemberger, and others. In contrast, diaries and collections of misperceptions, known as slips of the ear, have been used much less often in the study of speech perception; the work of Bond (1999) stands out as one of the few examples of this approach being used for several decades to study speech perception.
Despite the important role that analysis of errors can play in theories of language processing the area of speech production has one class of models that tends to focus on chronometric aspects of speech production, rather than speech errors (e.g., Levelt et al., 1999; but see Section 10 of Levelt et al., 1999), and another class of models that tends to focus on speech production errors, rather than chronometric aspects of speech production (e.g., Dell, 1986, 1988; but see Oppenheim et al., 2010). In the case of models of spoken word recognition, none of the widely-accepted models have been used to account for perception errors/slips of the ear even though many of these models have been around for several decades, and some have undergone significant revision in that time (NAM: Luce and Pisoni, 1998; PARSYN: Luce et al., 2000; Shortlist: Norris, 1994; Norris and McQueen, 2008; Cohort: Marslen-Wilson, 1987; Gaskell and Marslen-Wilson, 1997; TRACE: McClelland and Elman, 1986). We hope that the use of the on-line diary described in this report will lead to significant changes in the widely-accepted models of language processing with regards to accounting for various types of speech errors.
Perceptual limitations of or biases in the observer are often raised as concerns about the conclusions drawn from collections of naturally occurring speech errors. However, several studies have compared naturally occurring errors and errors that have been elicited using various techniques in controlled-laboratory settings, and found close correspondence in the types of errors observed in the two settings (e.g., Stemberger, 1985). Thus, analyses of speech errors of various types can provide ecological validity to our theories of language processing [e.g., Fay and Cutler, 1977; Vitevitch, 2002; Vitevitch et al., 2014a; see Lambert et al. (2010) for another way to provide ecological validity to theories of language processing], or as Norman (1981, p. 13) reminds us: “By examining errors, we are forced to demonstrate that our theoretical ideas can have some relevance to real behavior.”
The more significant challenges to the use of diaries to accumulate various types of naturally occurring speech errors are instead of a practical nature. First, speech errors occur “in the wild” infrequently. Wijnen (1992) estimated that adults may commit a speech error once every 1000 words produced, whereas young children may make from 4 to 8 speech errors per every 1000 words produced. Using laboratory-based techniques to elicit speech—such as tongue twisters (Shattuck-Hufnagel, 1992), Spoonerisms of Laboratory Induced Predisposition (SLIPs; Baars, 1992), or tip of the tongue (ToT) elicitation tasks (Brown and McNeill, 1966)—also tends to yield low rates of speech errors.
The low rate of naturally occurring speech errors means that an individual researcher must expend a significant amount of time and effort to collect a large enough sample of speech errors to enable the use of statistical analyses. For example, Jaeger (2005) documented over 4 years the speech errors made by her three children. In contrast, some laboratory-based experiments examining other phenomena in college-aged adults can be completed in less than 4 days. The amount of time and effort expended does not decrease very much if several participants instead of an individual researcher maintain a diary of the speech errors that they experience, as has been done to examine ToT states (Burke et al., 1991). Clearly, accumulating various types of speech errors requires much time and effort (sometimes on the part of many individuals).
Given the time and effort that is required to collect various types of speech errors, it is perhaps not surprising that diaries and other collections of errors become almost proprietary, and are made available to other researchers only after the primary researcher has thoroughly examined them. This practice may result in a delay ranging from years to decades before other investigators can examine the collections, assuming that the collections are even released at all instead of being lost due to the retirement or death of the primary researcher.
If a diary or other collection of errors is made available to other researchers, there are a number of issues related to the long-term curation of those data that must be considered. For example, as described at this URL, http://www.mpi.nl/resources/data/fromkins-speech-error-database/fromkins-speech-error-database-background, the speech error database compiled (originally on paper notecards) by Vicki Fromkin was converted some years later to a computer-readable format. However, that software format was no longer receiving technical support, which meant an invaluable resource could have easily been lost. Fortunately, Anne Cutler, Caroline Henton, Peter Ladefoged, Sieb Nooteboom, Carson Schutze, and Stefanie Shattuck-Hufnagel, with financial support from the Max Planck Society, arranged to have the database converted to XML format. The conversion process was carried out by Hansje Braam under the supervision of Sieb Nooteboom, and the resulting searchable database is available via the webpage for the Max Planck Institute for Psycholinguistics1. Although the Fromkin database of speech errors has a happy ending, there is an unknown number of other diaries and collections of errors that have not been preserved in this way, and have been lost to future researchers.
Data curation refers to the preservation of what has already been collected, but a related concern with diaries and other collections of errors is their continued growth. Typically diaries and collections of errors commence on a certain date, and then end on a certain date (i.e., the predetermined end of the study, or the retirement/death of the researcher). Such temporal constraints impose limits on the ultimate size of and hinder continued growth of the collection, which is counter-productive to statistical analysis where there is the desire for large sample sizes to satisfy various statistical assumptions.
A final concern about previous diaries and other collections of errors that we will discuss (although there are surely others) is that they have typically focused on a specific population, such as native speakers of a particular language who were free of any speech, language, or hearing disorders. Excluding individuals with speech, language, or hearing disorders (e.g., people who stutter, or people who are hard of hearing), individuals with cognitive impairments or diseases such as Alzheimer’s disease, non-native speakers of a given language, etc. makes sense from a methodological point of view in that a more homogenous sample reduces extraneous sources of variability that may obscure small, but theoretically important differences. Bowing to these methodological concerns, however, results in some unintended consequences. For example, the investigation of speech errors in each of the populations mentioned above (as well as cross-linguistic errors, and a number of other areas) is woefully underrepresented, thereby limiting our understanding of many aspects of language processing.
To address some of the issues discussed above (and a few others that we describe further below), we developed a method for individuals to document the observation of three common types of naturally occurring speech errors (made by themselves or by others)—slips of the ear, slips of the tongue, and ToT states—and for those individual errors to accumulate, be archived, and made available for dissemination. Slips of the ear (also known as mondegreens) refers to errors in which the speaker produces a word or phrase correctly, but the listener mis-hears what is said (Bond, 1999). In contrast, slips of the tongue include errors in which the speaker intends to say one thing, but instead produces something else (this includes the type of error known as a malapropism). Slips of the tongue include (but are not limited to) substituting one word or sound for another, exchanging sounds in adjacent words, or blending two or more words together. Finally, the tip of the tongue state refers to instances in which a speaker tries to retrieve a known word from the lexicon, but is unable to do so. The speaker may be able to retrieve some information about the word, such as its meaning (e.g., “the thing you use in a submarine to look above the water”), the first letter or sound of the word, or other words that sound like the target word (e.g., microscope, telescope), but not the intended word (e.g., periscope).
There are a variety of other language-related errors, e.g., slips of the pen: errors made when writing; slips of the key: errors made when typing; slips of the finger: errors made in signed languages, slips of the dot: errors made while using Braille (Wells-Jensen et al., 2007), etc., but the tool that we have developed, at present, focuses just on slips of the ear, slips of the tongue, and ToT states. Should the present database prove to be a success, it is possible that it could be expanded in the future to also include these other types of errors. In addition, slips of the tongue and other types of speech errors can be further categorized and sub-classified. We did not want to impose upon other researchers a particular theoretical perspective, so the present tool simply provides a way to amass the errors; researchers who download the archives are responsible for sorting, classifying, and “cleaning” the collected errors according to the criteria that they develop.
In addition to bringing three types of speech errors together in one resource, the present tool addresses a number of the issues described above. For example, instead of an individual researcher documenting the naturally occurring errors that he or she observes, or a small sample of participants keeping a diary for a specified period of time, the work of documenting various types of naturally occurring speech errors is distributed among all of the users of the on-line tool. “Crowd-sourcing” the documentation of naturally occurring speech errors in this way distributes the effort across a larger number of individuals (instead of being the burden of a single investigator) and also reduces the amount of time required to obtain a large sample of errors suitable for statistical analysis. Indeed, Dufau et al. (2011) used a smartphone application to collect data from over 4000 participants located around the world in a 4-month period. Other demonstrations of the speed, efficiency, and power of this approach include De Deyne et al. (2012), and Keuleers et al. (2015), among others.
With regards to the limited availability of diaries and collections of errors to other researchers, the documented errors amassed by the present tool will be available to anyone who creates an account on the website. One does not need to contribute to the site in order to access the errors that have been collected by others. Instead, we hope that users will be familiar with the problems associated with “free-riders” and the “tragedy of the commons,” and will contribute any errors that they observe if they download and analyze the errors that have been collected by others.
The on-line resource of speech errors described here also addresses the problem of previous diaries being limited in size and duration of the collection period. Because a large number of individuals can contribute to the error database, there is the potential for a very large number of errors to be amassed even if each person only contributes a small number of errors. Furthermore, the data are stored in a plain text format, making them accessible for potentially a long time (i.e., the concern about support for a particular software format disappearing is reduced). Moreover, there is great potential for the collection to grow over a very long period of time (and perhaps continue to grow after the developers have retired from the field and died). The continued growth of and the long duration that errors could be contributed opens the possibility for longitudinal analysis of errors on a large number of individuals (cf., the three children studied in Jaeger, 2005).
In addition to documenting the naturally occurring speech error, the present tool enables contributors to include other relevant information such as the presence of a regional dialect, a different native language, a speech, language or hearing disorder, etc. Including this information in the collection of errors offers more researchers the opportunity to analyze naturally occurring speech errors in a number of populations that are less often examined in mainstream psycholinguistic research, thereby greatly expanding our understanding of various language processes.
Finally, a number of on-line tools have been created for language scientists by language scientists (e.g., Vitevitch and Luce, 2004; Storkel and Hoover, 2010; Vitevitch et al., 2012). We certainly hope that the present tool will prove useful to language scientists in a variety of fields. Indeed, this resource offers researchers an easy and quick way to test a hypothesis before investing time and effort into designing and running a full-blown experiment, as well as a means to replicate with ecologically valid data the results they obtain from laboratory-based experiments (e.g., Vitevitch, 2002; Vitevitch et al., 2014a).
However, we also hope that the present tool will serve a broader, educational purpose as well. For example, a common homework assignment in Advanced Placement (AP) Psychology classes taught in high schools across the United States, and in Psychology of Language or Psycholinguistics classes taught in colleges and universities around the world is to document a speech error of some sort. Instead of depositing these assignments in the literal or electronic trashcan at the end of the semester, these individual class assignments could be amassed with the present tool (thereby increasing the size of the collection). Furthermore, the errors collected to date could serve as raw data that students in such classes could use to obtain practice in categorizing the errors and in performing statistical analyses.
The educational aspect of the present tool could also extend beyond the academic context by encouraging language enthusiasts and citizen-scientists to contribute to language research, and further educating the general public about language research. We hope that the widespread use of the on-line tool by language researchers (e.g., Linguists, Speech Pathologists, Audiologist, Psychologists, Engineers, etc.), instructors of college-level and AP classes, as well as by citizen scientists and language enthusiasts will be facilitated by making this on-line tool available for free. The next section contains more technical details about the on-line tool, as well as additional information about the type of information that is collected.
Details about the Speech Error Diary (SpEDi)
The Pew Research Center reported that as of April, 2015: 64% of American adults have a smartphone, and 53% of American adults own a tablet computer (Pew Research Center Internet Project Survey, 2015). In order to capitalize on the ubiquity of these mobile devices we set out to develop a way to document naturally occurring speech errors that could be implemented on these ever-present devices. Because operating systems vary across devices, it would be financially prohibitive to create, maintain, and continually update an application that users could download to a wide variety of devices to document speech errors.
Instead, we developed a website that would prompt users through a number of questions to document various types of speech errors. Because the speech error diary is web-based the user does not have to download specialized software to their device (risking infection by a computer virus, etc.), nor do we have to continually update the software to keep it functional with the release of a new mobile operating system or update. To facilitate easy access to the questions a browser shortcut can be made to take the user to the automatic login page (or to automatically login the user) on any device with a web browser including tablets, mobile/smart phones, laptops, desktops, etc. This shortcut icon can be placed on the home (or other) screen of a mobile device, thereby giving the appearance that the SpEDi is a native app, while still capitalizing on the advantages of a web-based application. For instructions on how to add shortcuts to websites on various smartphone and tablet devices see: http://www.howtogeek.com/196087/how-to-add-websites-to-the-home-screen-on-any-smartphone-or-tablet/
Below we use screen shots to help us describe how to proceed through the on-line speech error diary. As shown in panel (a) of Figure 1, the URL http://spedi.ku.edu takes the user to a webpage from which new users can register, and previously registered users can log in. New users are asked, see panel (b) of Figure 1, to generate a username and password and to provide their e-mail and minimal demographic information that will automatically populate the record for any speech error they document in themselves (if the registered user witnesses a speech error made by someone else, then the registered user will be prompted for demographic information about the speaker who made the error).
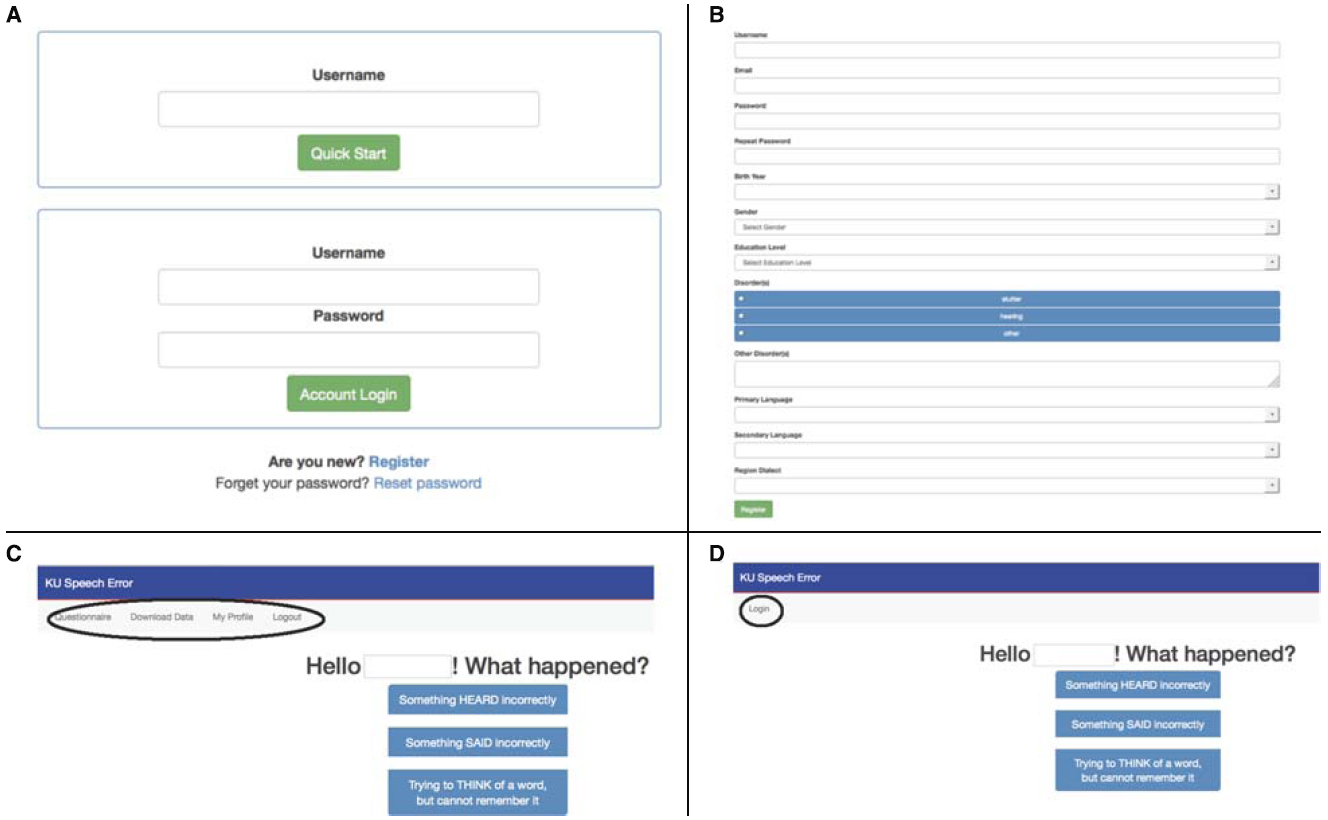
Figure 1. (A) The initial login page of the on-line speech error diary. (B) Information requested from new users registering with the site. (C) After entering the username and password using the “Account Login” option, the registered user will see the prompts that assist in documenting various types of speech errors (in the center of the screen; also accessible with the “Questionnaire” option) as well as options to “Download Data” (i.e., the errors amassed to date), to edit or update the user profile (i.e., “My Profile”), or to “Logout.” (D) Using the “Quick Start” option a registered user will be taken directly to the speech error prompts. Notice the slight difference in the upper left hand portion of the page when using the “Quick Start” option compared to when the “Account Login” option is used (see Figure 1C).
For previously registered users there are two login options. Referring back to Figure 1A, there is the “Quick Start” option, and the “Account Login” option. For the “Quick Start” option only the registered username needs to be entered, enabling the user to proceed directly to the prompts to document the observed speech error (described in more detail below). For the “Account Login” option, both the username and password must be entered. Upon doing so the user sees, as shown in Figure 1C, the first prompts to document various types of speech errors, and, importantly, also sees (in the upper left hand portion of the page) options to download the collection of errors amassed to date; the database can only be accessed by registered users through the “Account Login” option.
The “Quick Start” option was designed to quickly take registered users to the error prompts, thereby facilitating the documentation of the speech error. By comparing Figures 1C,D the reader will notice a slight difference in the upper left hand portion of the page when the “Quick Start” option is used. Most importantly, the errors amassed to date cannot be downloaded when a registered user enters the site via the “Quick Start” option, otherwise the prompts for documenting the speech error are the same, and described below. Again, to facilitate easy access to the initial page of the speech error diary, a user can use the preferred web browser to create a shortcut to the “Quick Start” page, and place the shortcut on their desktop/tablet-top/phone-top.
Something HEARD Incorrectly
When a slip of the ear occurs, that is the user hears something incorrectly or when the user witnesses someone else mishearing something that was said correctly, the button for “Something HEARD incorrectly” should be pressed. This leads the user to the screen displayed in Figure 2A, which prompts the user to enter in the words or phrase that was (incorrectly) heard, and then the words or phrases that were actually (correctly) spoken. The user is also asked to indicate if they were the person who misheard the words or phrases, or if they witnessed the mishearing; perhaps the user was the person who spoke correctly but their interlocutor misheard what was said, or the user was a third-party in a group where the slip of the ear occurred.

Figure 2. (A) The first screen for the “Something HEARD incorrectly” prompt. (B) The second screen of the “Something HEARD incorrectly” prompt and the “Something SAID incorrectly” prompt, soliciting the user for demographic information about the individual who made the error that was documented on the first screen. (C) The third screen of the “Something HEARD incorrectly” prompt and the “Something SAID incorrectly” prompt, soliciting the user for demographic information about the individual who made the error that was documented on the first screen. (D) The fourth screen of the “Something HEARD incorrectly” prompt and the “Something SAID incorrectly” prompt, soliciting the user for demographic information about the individual who made the error that was documented on the first screen.
Once the error has been documented the user is then prompted for: an estimate of the age of the speaker on the second of four screens (see Figure 2B), and information about the gender and education level of the speaker on the third of four screens (see Figure 2C). On the final screen of prompts (see Figure 2D) the user is asked: “Where are they from?” which is intended to unobtrusively obtain information related to regional dialects (we thank Zinny Bond for suggesting this approach), for information related to speech, language, or hearing disorders, as well as options for any other type of cognitive or neurological disorder that might have contributed in some way to the error. There is also a prompt for “Additional notes” where a user might document that an alcoholic beverage had been consumed shortly before the error was made, that the error occurred in a noisy environment, or document any other facts that might be of interest. The user is not required to enter information on the screens depicted in Figures 2B–D, but at least some of this information would be useful for others analyzing the collection of errors in the future.
Something SAID Incorrectly
When a slip of the tongue occurs, that is the user says something incorrectly or when the user witnesses someone else saying something incorrectly, the button for “Something SAID incorrectly” should be pressed. This leads the user to the screen displayed in Figure 3, which prompts the user to enter in the words or phrase that were incorrectly spoken (“What was actually said?”), and then the words or phrases that were intended (or that the speaker spontaneously uttered as a correction, “What was supposed to have been said?”). The user is also asked to indicate if they were the person who misspoke the words or phrases, or if they witnessed someone else making the error. Once the error has been documented the user is prompted for the same demographic information that appeared for the “Something SAID incorrectly” prompt (see again Figures 2B–D).
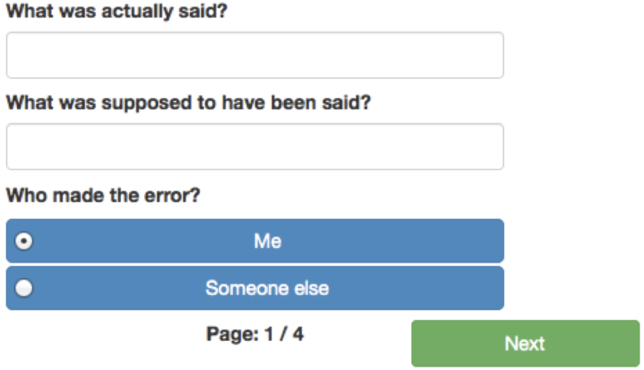
Figure 3. The first screen for the “Something SAID incorrectly” prompt.
Trying to THINK of a Word, but Cannot Remember it
In a ToT state a person tries to recall a word or name of a person, place, book or movie, but cannot. Often the individual will be able to retrieve some information about the word or name, such as the first letter or sound of the word or name, the number of syllables in the word or name, and sometimes words or names that sound similar to the target word or name. Brown and McNeill (1966) developed a method to elicit ToT states in the laboratory by giving participants a definition and asking them to provide the best-fitting word; this approach has been used successfully by a number of researchers to examine a variety of questions (Harley and Bown, 1998; James and Burke, 2000; Vitevitch and Sommers, 2003). ToT states have also been documented in diary studies, in which participants recorded details about each occurrence of a ToT state (Burke et al., 1991). To maintain some continuity with previous diary studies we adapted the prompts used in Burke et al. (1991; available at http://www.lcs.pomona.edu/cogaging/materials/research/TOT%20diary.pdf) for the present on-line error diary.
The first screen for the ToT prompt asks the user to indicate which type of word cannot be recalled (Figure 4A). The second screen asks for a subjective rating on a 7-point scale “How certain are you that this is a word you know?” (Figure 4B). On the second and subsequent screens, users are free to enter as much or as little information as they recall (or wish to enter) before advancing to the next screen. The third screen asks for a subjective rating on a 7-point scale “How certain are you that you will be able to recall this word?” (Figure 4C). The fourth screen asks the user if they can recall any characteristics about the word they are trying to recall, such as the number of syllables, the first sound it starts with, etc.; multiple options can be checked here (Figure 4D). On the fifth screen the user is asked to provide any additional information they can think of about the word they are trying to recall (Figure 4E).
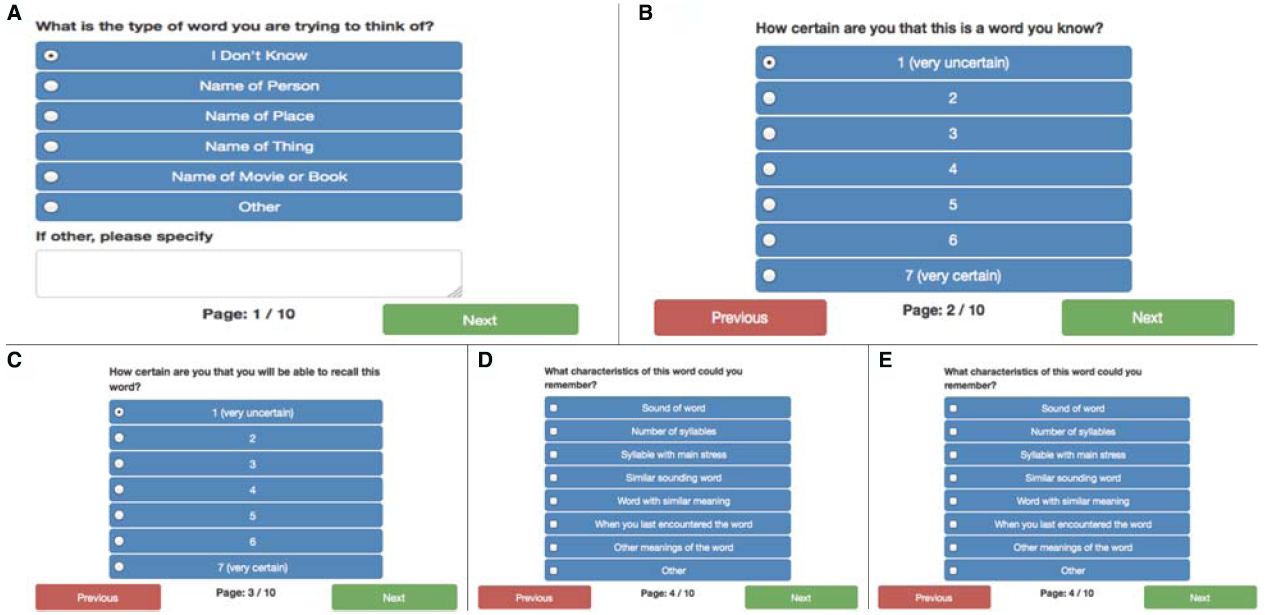
Figure 4. (A) The first screen for the ToT prompt asking for information about the type of word that cannot be recalled. (B) The second screen for the ToT prompt asking for information about the type of word that cannot be recalled. (C) The third screen for the ToT prompt asking for information about the type of word that cannot be recalled. (D) The fourth screen for the ToT prompt asking for information about the type of word that cannot be recalled (E) The fifth screen for the ToT prompt asking for information about the type of word that cannot be recalled.
On the sixth screen (Figure 5A) the user is asked to enter any interlopers, or similar sounding words that come to mind instead of the target word. The seventh screen (Figure 5B) asks the user which strategies they may have employed to recall the name or word, such as asking a friend or consulting the Internet. Other strategies that a user might employ are asked about on the eighth page (Figure 5C). On the ninth screen, the user is asked how they were finally able to recall the work (if the ToT state was successfully resolved). They are also asked to estimate the amount of time that elapsed between the initial attempt to retrieve the word or name and the resolution of the ToT state (Figure 5D). Once the ToT has been resolved, the final screen (Figure 5E) asks the user for the word or name that produced the initial ToT state.

Figure 5. (A) The sixth screen for the ToT prompt asking for information about the type of word that cannot be recalled. (B) The seventh screen for the ToT prompt asking for information about the type of word that cannot be recalled. (C) The eighth screen for the ToT prompt asking for information about the type of word that cannot be recalled. (D) The ninth screen for the ToT prompt asking for information about the type of word that cannot be recalled. (E) The final screen for the ToT prompt asking for information about the type of word that cannot be recalled.
Downloading the Data
All the information entered at the prompts for the on-line speech error diary (see Figures 2A and 5E) is saved in a comma-separated values (CSV) text file. This text file can be downloaded after a registered user enters his or her account name and password using the “Account Login” option. Recall that the “Quick Start” option was designed to quickly take registered users to the error prompts to facilitate the documentation of the speech error; the collected errors cannot be accessed using the “Quick Start” option.
The information provided in the data file is raw and not processed in any way. Researchers are encouraged to use available spreadsheet software, word-processing software, or custom written scripts or software to facilitate initial and subsequent processing of the raw data. We did not implement any type of search or sort functions on the website because we did not wish to impose a particular theoretical perspective on other users who may wish to analyze the data from a novel or alternative theoretical perspective. Although the raw nature of the data requires a bit of work on the part of a researcher to analyze it, the raw nature of the data ensures the longevity of the amassed data as theoretical perspectives come and go over time.
Limitations of the SpEDi
The present on-line speech error diary is limited by the same issues, biases and concerns that limit all forms of naturalistic observation, including speech error collections and diaries (see another limitation of error collections described in Vitevitch et al., 2016). Despite these common limitations, we believe there is still much scientific and educational value to the present on-line speech error diary.
By “crowd-sourcing” the collection of various types of speech errors, we have potentially accelerated the pace of amassing a large enough number of errors to subject them to statistical analysis. The “crowd-sourcing” of error collection does, however, open the process to contributors who may lack even basic training in Linguistics and other language-related sciences. This means that subtle speech production errors, such as producing a phonetic feature not found in one’s native language, may go unnoticed or undocumented, or be documented incorrectly. Although this aspect of the on-line speech error diary may introduce or increase variability in the responses, we hope that the data processing carried out by researchers (to remove outliers, etc.) and the large number of errors amassed over time will provide the necessary statistical stability to enable researchers to observe novel and interesting patterns in the data.
Another limitation of the SpEDi is that the prompts for information are in English, which may limit the use of the error diary to English-speaking individuals. We recognize that tools like Google Translate can be used to translate the prompts on the webpages; unfortunately we cannot verify the accuracy of such translations. The use of English in the prompts is somewhat symptomatic of a larger issue in psycholinguistic research, namely, most of the research is in and about English (Vitevitch et al., 2014b). There is undoubtedly much insight into the mechanisms involved in various aspects of language processing that can be gained from studying languages other than English or by studying the use of more than one language at a time. Fortunately, the error diary allows users to enter information using any character that can be produced by a keyboard, enabling users of logographic, syllabic, and alphabetic orthographies to submit (at least certain types of) speech errors if their keyboard is set to their font of choice. This also opens up the possibility that linguistically-sophisticated users could employ characters from the International Phonetic Alphabet (IPA) to document more fine-grained errors with phonological transcription.
Finally, SpEDi only allows one to document three types of speech errors: slips of the tongue/malapropisms, slips of the ear, and ToT states. There are other types of language-related errors—such as slips of the key and slips of the finger—that language-users make, but the current form of SpEDi does not offer prompts for users to document these other types of language-related errors. There are also other types of motor or performance errors that humans make—such as reaching into a kitchen drawer to retrieve a knife, but instead one erroneously retrieves a spoon—that the current form of SpEDi does not offer prompts for users to document. Broader insight into cognition might be obtained if such motor/performance errors were considered alongside speech errors. Perhaps some of the limitations of SpEDi can be addressed by raising financial support through crowd-funding efforts to support later stages of development of SpEDi. Despite these limitations we believe the on-line speech error diary will prove to be a useful tool for language-related research and for scientific outreach efforts.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We wish to thank Zinny Bond, Debbie Burke, Susan Kemper, and Thomas Dellecave for helpful discussions and suggestions regarding language diaries and error collections, and for explaining issues related to implementation. This project was supported in part by funding from the Behavioral Science General Research Fund from the University of Kansas.
Footnotes
- ^ http://www.mpi.nl/dbmpi/cgi-bin/sedb/sperco_form4.pl
References
Baars, B. J. (1992). “A dozen competing-plans techniques for inducing predictable slips in speech and action,” in Experimental Slips and Human Error: Exploring the Architecture of Volition, ed. B. J. Baars (New York, NY: Plenum Press), 129–150.
Google Scholar
Bond, Z. S. (1999). Slips of the Ear: Errors in the Perception of Casual Conversation. New York: Academic Press.
Google Scholar
Brown, R., and McNeill, D. (1966). The “tip of the tongue” phenomenon. J. Verb. Learn. Verb. Behav. 5, 325–337. doi: 10.1016/S0022-5371(66)80040-3
CrossRef Full Text | Google Scholar
Burke, D. M., MacKay, D. G., Worthley, J. S., and Wade, E. (1991). On the tip of the tongue: what causes word finding failures in young and older adults? J. Mem. Lang. 30, 542–579. doi: 10.1016/0749-596X(91)90026-G
CrossRef Full Text | Google Scholar
De Deyne, S., Navarro, D., and Storms, G. (2012). Better explanations of lexical and semantic cognition using networks derived from continued rather than single word associations. Behav. Res. Methods 45, 480–498. doi: 10.3758/s13428-012-0260-7
PubMed Abstract | CrossRef Full Text | Google Scholar
Dell, G. S. (1988). The retrieval of phonological forms in production: tests of predictions from a connectionist model. J. Mem. Lang. 27, 124–142. doi: 10.1016/0749-596X(88)90070-8
CrossRef Full Text | Google Scholar
Dufau, S., Duñabeitia, J. A., Moret-Tatay, C., McGonigal, A., Peeters, D., and Alario, F.-X, et al. (2011). Smart phone, smart science: how the use of smartphones can revolutionize research in cognitive science. PLoS ONE 6:e24974. doi: 10.1371/journal.pone.0024974
PubMed Abstract | CrossRef Full Text | Google Scholar
Fay, D., and Cutler, A. (1977). Malapropisms and the structure of the mental lexicon. Linguist. Inq. 8, 505–520.
Google Scholar
Gaskell, M. G., and Marslen-Wilson, W. D. (1997). Integrating form and meaning: a distributed model of speech perception. Lang. Cogn. Proc. 12, 613–656. doi: 10.1080/016909697386646
CrossRef Full Text | Google Scholar
Harley, T. A., and Bown, H. E. (1998). What causes a tip-of-the-tongue state? Evidence for lexical neighbourhood effects in speech production. Br. J. Psychol. 89, 151–174. doi: 10.1111/j.2044-8295.1998.tb02677.x
CrossRef Full Text | Google Scholar
Jaeger, J. J. (2005). Kids’ Slips: What Young Children’s Slips of the Tongue Reveal About Language Development. Mahwah, NJ: Lawrence Erlbaum.
Google Scholar
James, L. E., and Burke, D. M. (2000). Phonological priming effects on word retrieval and tip-of-the-tongue experiences in young and older adults. J. Exp. Psychol. 26, 1378–1391. doi: 10.1037/0278-7393.26.6.1378
PubMed Abstract | CrossRef Full Text | Google Scholar
Keuleers, E., Stevens, M., Mandera, P., and Brysbaert, M. (2015). Word knowledge in the crowd: measuring vocabulary size and word prevalence in a massive online experiment. Q. J. Exp. Psychol. 68, 1665–1692. doi: 10.1080/17470218.2015.1022560
PubMed Abstract | CrossRef Full Text | Google Scholar
Lambert, B. L., Dickey, L. W., Fisher, W. M., Gibbons, R. D., Lin, S. J., Luce, P. A., et al. (2010). Listen carefully: the risk of error in spoken medication orders. Soc. Sci. Med. 70, 1599–1608. doi: 10.1016/j.socscimed.2010.01.042
PubMed Abstract | CrossRef Full Text | Google Scholar
Levelt, W. J. M. (2013). A History of Psycholinguistics: The Pre-chomskyan Era. Oxford: Oxford University Press.
Google Scholar
Luce, P. A., Goldinger, S. D., Auer, E. T. Jr., and Vitevitch, M. S. (2000). Phonetic priming, neighborhood activation, and PARSYN. Percept. Psychophys. 62, 615–625. doi: 10.3758/BF03212113
PubMed Abstract | CrossRef Full Text | Google Scholar
Meringer, M., and Meyer, C. (1895). Versprechen und Verlesen: Eine Psychologisch-linguistische Studie. Stuttgart: G. J. Göschen’sche Verlagshandung, eds A. Cutler and D. A. Fay (Amsterdam: J. Benjamins).
Google Scholar
Norris, D. (1994). Shortlist: a connectionist model of continuous speech recognition. Cognition 52, 189–234. doi: 10.1016/0010-0277(94)90043-4
CrossRef Full Text | Google Scholar
Oppenheim, G. M., Dell, G. S., and Schwartz, M. F. (2010). The dark side of incremental learning: a model of cumulative semantic interference during lexical access in speech production. Cognition 114, 227–252. doi: 10.1016/j.cognition.2009.09.007
PubMed Abstract | CrossRef Full Text | Google Scholar
Stemberger, J. P. (1985). “The reliability and replicability of naturalistic speech error data: a comparison with experimentally induced errors,” in Experimental Slips and Human Error: Exploring the Architecture of Volition, ed. B. J. Baars (New York: Plenum Press), 195–215.
Google Scholar
Storkel, H. L., and Hoover, J. R. (2010). An on-line calculator to compute phonotactic probability and neighborhood density based on child corpora of spoken American English. Behav. Res. Methods 42, 497–506. doi: 10.3758/BRM.42.2.497
PubMed Abstract | CrossRef Full Text | Google Scholar
Vitevitch, M. S. (2002). Naturalistic and experimental analyses of word frequency and neighborhood density effects in slips of the ear. Lang. Speech 45, 407–434. doi: 10.1177/00238309020450040501
PubMed Abstract | CrossRef Full Text | Google Scholar
Vitevitch, M. S., Chan, K. Y., and Goldstein, R. (2014b). “Using English as a ‘model language’ to understand language processing,” in Motor Speech Disorders A Cross-Language Perspective, eds N. Miller and A. Lowit (Bristol: Multilingual Matters), 58–73.
Google Scholar
Vitevitch, M. S., Goldstein, R., and Johnson, E. (2016). “Path-length and the misperception of speech: insights from Network Science and Psycholinguistics,” in Towards a Theoretical Framework for Analyzing Complex Linguistic Networks, eds A. Mehler, A. Lücking, S. Banisch, P. Blanchard, and B. Frank-Job (Berlin: Understanding Complex Systems, Springer), 29–45. doi: 10.1007/978-3-662-47238-5
CrossRef Full Text | Google Scholar
Vitevitch, M. S., and Luce, P. A. (2004). A web-based interface to calculate phonotactic probability for words and nonwords in English. Behav. Res. Methods Instrum. Comput. 36, 481–487. doi: 10.3758/BF03195594
PubMed Abstract | CrossRef Full Text | Google Scholar
Vitevitch, M. S., and Sommers, M. S. (2003). The facilitative influence of phonological similarity and neighborhood frequency in speech production in younger and older adults. Mem. Cogn. 31, 491–504. doi: 10.3758/BF03196091
PubMed Abstract | CrossRef Full Text | Google Scholar
Vitevitch, M. S., Stamer, M. K., and Kieweg, D. (2012). The Beginning Spanish Lexicon: a web-based interface to calculate phonological similarity among Spanish words in adults learning Spanish as a foreign language. Second Lang. Res. 28, 103–112. doi: 10.1177/0267658311432199
PubMed Abstract | CrossRef Full Text | Google Scholar
Wells-Jensen, S., Schwartz, A., and Gosche, B. (2007). A cognitive approach to Brailling errors. J. Vis. Impair. Blind. 101, 416–428.
Google Scholar
Wijnen, F. (1992). Incidental word and sound errors in young speakers. J. Mem. Lang. 31, 734–755. doi: 10.1016/0749-596X(92)90037-X
CrossRef Full Text | Google Scholar
Речь – это канал развития интеллекта,
чем раньше будет усвоен язык,
тем легче и полнее будут усваиваться знания.
Николай Иванович Жинкин,
советский лингвист и психолог
Речь мыслится нами как абстрактная категория, недоступная для непосредственного восприятия. А между тем это – важнейший показатель культуры человека, его интеллекта и мышления, способ познания сложных связей природы, вещей, общества и передачи этой информации путём коммуникации.
Очевидно, что и обучаясь, и уже пользуясь чем-либо, мы в силу неумения или незнания совершаем ошибки. И речь, как и другие виды деятельности человека (в которых язык – важная составляющая часть), в данном отношении не является исключением. Ошибки делают все люди, как в письменной, так и в устной речи. Более того, понятие культуры речи, как представление о «речевом идеале», неразрывно связано с понятием речевой ошибки. По сути это – части одного процесса, а, значит, стремясь к совершенству, мы должны уметь распознавать речевые ошибки и искоренять их.
Что такое ошибки в языке? Зачем говорить грамотно?
Сто лет назад человек считался грамотным, если он умел писать и читать на родном языке. Сейчас грамотным называют того, кто не только читает и говорит, но и пишет в соответствии с правилами языка, которые нам дают филологи и система образования. В устаревшем смысле мы все грамотные. Но далеко не все из нас всегда правильно ставят знаки препинания или пишут трудные слова.
Виды речевых ошибок
Сначала разберёмся с тем, что такое речевые ошибки. Речевые ошибки – это любые случаи отклонения от действующих языковых норм. Без их знания человек может нормально жить, работать и настраивать коммуникацию с другими. Но вот эффективность совершаемых действий в определённых случаях может страдать. В связи с этим возникает риск быть недопонятым или понятым превратно. А в ситуациях, когда от этого зависит наш личный успех, подобное недопустимо.
Автором приведённой ниже классификации речевых ошибок является доктор филологических наук Ю. В. Фоменко. Его деление, по нашему мнению, наиболее простое, лишённое академической вычурности и, как следствие, понятное даже тем, кто не имеет специального образования.
Виды речевых ошибок:
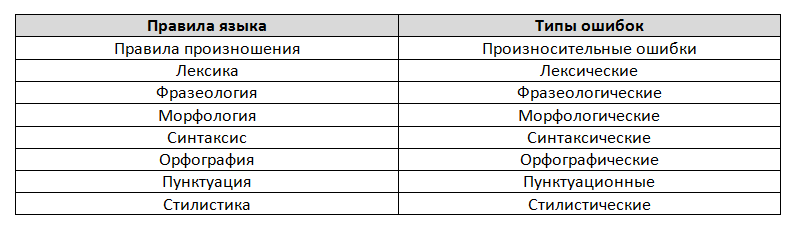
Примеры и причины возникновения речевых ошибок
С. Н. Цейтлин пишет: «В качестве фактора, способствующего возникновению речевых ошибок, выступает сложность механизма порождения речи». Давайте рассмотрим частные случаи, опираясь на предложенную выше классификацию видов речевых ошибок.
Произносительные ошибки
Произносительные или орфоэпические ошибки возникают в результате нарушения правил орфоэпии. Другими словами, причина кроется в неправильном произношении звуков, звукосочетаний, отдельных грамматических конструкций и заимствованных слов. К ним также относятся акцентологические ошибки – нарушение норм ударения. Примеры:
Произношение: «конечно» (а не «конешно»), «пошти» («почти»), «плотит» («платит»), «прецендент» («прецедент»), «иликтрический» («электрический»), «колидор» («коридор»), «лаболатория» («лаборатория»), «тыща» («тысяча»), «щас» («сейчас»).
Неправильное ударение: «зво́нит», «диа́лог», «до́говор», «ката́лог», «путепро́вод», «а́лкоголь», «свекла́», «феноме́н», «шо́фер», «э́ксперт».
Лексические ошибки
Лексические ошибки – нарушение правил лексики, прежде всего – употребление слов в несвойственных им значениях, искажение морфемной формы слов и правил смыслового согласования. Они бывают нескольких видов.
Употребление слова в несвойственном ему значении. Это самая распространённая лексическая речевая ошибка. В рамках этого типа выделяют три подтипа:
- Смешение слов, близких по значению: «Он обратно прочитал книжку».
- Смешение слов, близких по звучанию: экскаватор – эскалатор, колос – колосс, индианка – индейка, одинарный – ординарный.
- Смешение слов, близких по значению и звучанию: абонент – абонемент, адресат – адресант, дипломат – дипломант, сытый – сытный, невежа – невежда. «Касса для командировочных» (нужно – командированных).
Словосочинительство. Примеры ошибок: грузинец, героичество, подпольцы, мотовщик.
Нарушение правил смыслового согласования слов. Смысловое согласование – это взаимное приспособление слов по линии их вещественных значений. Например, нельзя сказать: «Я поднимаю этот тост», поскольку «поднимать» значит «перемещать», что не согласовывается с пожеланием. «Через приоткрытую настежь дверь», – речевая ошибка, потому что дверь не может быть и приоткрыта (открыта немного), и настежь (широко распахнута) одновременно.
Сюда же относятся плеоназмы и тавтологии. Плеоназм – словосочетание, в котором значение одного компонента целиком входит в значение другого. Примеры: «май месяц», «маршрут движения», «адрес местожительства», «огромный мегаполис», «успеть вовремя». Тавтология – словосочетание, члены которого имеют один корень: «Задали задание», «Организатором выступила одна общественная организация», «Желаю долгого творческого долголетия».
Фразеологические ошибки
Фразеологические ошибки возникают, когда искажается форма фразеологизмов или они употребляются в несвойственном им значении. Ю. В. Фоменко выделяет 7 разновидностей:
- Изменение лексического состава фразеологизма: «Пока суть да дело» вместо «Пока суд да дело»;
- Усечение фразеологизма: «Ему было впору биться об стенку» (фразеологизм: «биться головой об стенку»);
- Расширение лексического состава фразеологизма: «Вы обратились не по правильному адресу» (фразеологизм: обратиться по адресу);
- Искажение грамматической формы фразеологизма: «Терпеть не могу сидеть сложив руки». Правильно: «сложа»;
- Контаминация (объединение) фразеологизмов: «Нельзя же все делать сложа рукава» (объединение фразеологизмов «спустя рукава» и «сложа руки»);
- Сочетание плеоназма и фразеологизма: «Случайная шальная пуля»;
- Употребление фразеологизма в несвойственном значении: «Сегодня мы будем говорить о фильме от корки до корки».
Морфологические ошибки
Морфологические ошибки – неправильное образование форм слова. Примеры таких речевых ошибок: «плацкарт», «туфель», «полотенцев», «дешевше», «в полуторастах километрах».
Синтаксические ошибки
Синтаксические ошибки связаны с нарушением правил синтаксиса – конструирования предложений, правил сочетания слов. Их разновидностей очень много, поэтому приведём лишь некоторые примеры.
- Неправильное согласование: «В шкафу стоят много книг»;
- Неправильное управление: «Оплачивайте за проезд»;
- Синтаксическая двузначность: «Чтение Маяковского произвело сильное впечатление» (читал Маяковский или читали произведения Маяковского?);
- Смещение конструкции: «Первое, о чём я вас прошу, – это о внимании». Правильно: «Первое, о чём я вас прошу, – это внимание»;
- Лишнее соотносительное слово в главном предложении: «Мы смотрели на те звёзды, которые усеяли всё небо».
Орфографические ошибки
Этот вид ошибок возникает из-за незнания правил написания, переноса, сокращения слов. Характерен для письменной речи. Например: «сабака лаяла», «сидеть на стули», «приехать на вогзал», «русск. язык», «грамм. ошибка».
Пунктуационные ошибки
Пунктуационные ошибки – неправильное употребление знаков препинания при письме.
Стилистические ошибки
Этой теме мы посвятили отдельный материал.
Пути исправления и предупреждения речевых ошибок
Как предупредить речевые ошибки? Работа над своей речью должна включать:
- Чтение художественной литературы.
- Посещение театров, музеев, выставок.
- Общение с образованными людьми.
- Постоянная работа над совершенствованием культуры речи.
Онлайн-курс «Русский язык»
Речевые ошибки – одна из самых проблемных тем, которой уделяется мало внимания в школе. Тем русского языка, в которых люди чаще всего допускают ошибки, не так уж много — примерно 20. Именно данным темам мы решили посвятить курс «Русский язык». На занятиях вы получите возможность отработать навык грамотного письма по специальной системе многократных распределенных повторений материала через простые упражнения и специальные техники запоминания.
Подробнее Купить сейчас
Источники
- Беззубов А. Н. Введение в литературное редактирование. – Санкт-Петербург, 1997.
- Савко И. Э. Основные речевые и грамматические ошибки
- Сергеева Н. М. Ошибки речевые, грамматические, этические, фактологические…
- Фоменко Ю. В. Типы речевых ошибок. – Новосибирск: НГПУ, 1994.
- Цейтлин С. Н. Речевые ошибки и их предупреждение. – М.: Просвещение, 1982.
Отзывы и комментарии
А теперь вы можете потренироваться и найти речевые ошибки в данной статье или поделиться другими известными вам примерами. Кроме того, обратите внимание на наш курс по развитию грамотности.
Содержание
- 1 Что такое речевая ошибка
- 1.1 Лексико-стилистические ошибки
- 1.2 Морфолого-стилистические ошибки
- 1.3 Синтаксисо-стилистические ошибки
- 2 Причины речевых ошибок
- 3 Как избежать ошибок в речи
- 4 Так ли важно соблюдать культуру речи
Речевые ошибки случаются у каждого, если не во взрослом, то в детском возрасте. Возникают они, когда не соблюдаются лексические, либо стилистические языковые нормы.
Это отдельная категория наряду с грамматическими, этическими, орфографическими, логическими, фактическими, пунктуационными ошибками русского языка.
О том, какие бывают речевые ошибки, как их не допускать в своей речи, мы и поговорим.
Что такое речевая ошибка
Речевая ошибка — это неправильное употребление слов. В отличие, например, от грамматической, ее можно увидеть только в контексте.
Ошибки делают нашу речь неточной, некрасивой и даже непонятной.
Это может быть неправильное применение синонимов, антонимов, омонимов, неудачное употребление выразительных средств, неуместное использование диалектизмов, жаргонизмов, а также плеоназм (наличие в высказывании слов, имеющих одно и то же значение) и тавтология (повторение одинаковых или однокоренных слов).
Для наглядности классификация речевых ошибок по видам, с примерами и исправлениями, представлена в таблице:

Вот еще показательные примеры предложений с речевыми ошибками:
- Ему захотелось заглянуть на небо (неразличение оттенков значения слова, вносимых приставкой или суффиксом, правильно-взглянуть).
- Мы назначили встречу после дождичка в четверг (искажение образного значения фразеологизма в неудачно сформулированном контексте).
- Прозвучал не грустный, но и не минорный мотив (неверное построение антитезы и выбор антонимов).
- В этом пространстве располагался офис (ошибочный выбор синонима, правильно-помещение).
- Этот писатель написал много замечательных рассказов (тавтология — повторение близких по смыслу слов).
- Дождь шел всю ночь. Дождь даже не собирался заканчиваться (неоправданные повторения слова).
- Когда я вышел на улицу, то встретил своих друзей. Когда мы поболтали, я пошел в школу (однообразие в составлении предложений).
Если умные взрослые способны контролировать свою речь, то у детей это процесс иного рода. Богатый русский язык дает широкий простор для неуемной детской фантазии и творчества.
Детское словотворчество, результат которого хоть и не соответствует языковым нормам, но в полной мере раскрывает, по словам К. И. Чуковского, творческую силу ребенка, его поразительную чуткость к языку.
Особенно часто речевые ошибки можно встретить у младших школьников. Окунаясь с головой в процесс познания, они допускают их, не задумываясь, на ходу исправляют, совершают новые и так постигают все премудрости родного языка.
Самые распространенные у них ошибки в речи — это:
- неправильное склонение по падежам (исполнение мечт);
- неверное употребление слов во множественном или единственном числе (одна качель);
- произвольное словообразование (дватый вместо второй);
- неточное использование предлогов (ходили в концерт).

В целом, допускаемые учащимися речевые ошибки можно подразделить на типы: лексико — стилистические, морфолого — стилистические, синтаксисо — стилистические.
Лексико-стилистические ошибки
К ним относятся повторения слов, употребление их в неточном значении, использование просторечий. Например:
- Ежик смешно пыхтел. Витя налил ежику молока. В комнату забежала собака, и ежик свернулся клубком.
- Мама одела плащ и пошла на работу.
- Полкан плелся взади.
Морфолого-стилистические ошибки
В этой группе — неправильно образованные слова. Например:
- он хотит;
- это ихний;
- работают малярщики;
- идут трудящие;
- крыша текет;
- много делов.
Синтаксисо-стилистические ошибки
Эти ошибки встречаются в словосочетаниях и предложениях из-за перестановки слов, несогласованности между словами, неправильных границ, неверного употребления местоимения. Например:
- Только под ногами шелестела листва.
- Вся компания дружно встретили Новый Год.
- Когда ребята пришли к реке. Там было много народу.
- Папа, когда пришел домой, он был очень уставшим.
Причины речевых ошибок
Почему мы совершаем ошибки в своей речи?

Причинами речевых ошибок принято считать:
- влияние среды;
- низкий уровень речевых навыков;
- индивидуальные особенности речи.
Речь окружающих оказывает влияние и на нашу речь. Это может быть диалектная, просторечная лексика (одежа, скипятить, послабже), а также не всегда соответствующая нормам литературного языка речь средств массовой информации.
Неправильное употребление лексических средств выразительности, непонимание значения употребляемых слов, склонение несклоняемых существительных и неверное согласование с ними прилагательных, ошибки типа “масло масляное”, несочетаемые слова — все это говорит о невысоком уровне речевых навыков.
Индивидуальные особенности речи, связанные с отклонением от норм литературного словоупотребления, могут выражаться в неуместном повторении какого-либо слова или выражения, склонности к использованию иностранных слов в разговоре, постоянном проглатывании слов в предложениях.
Как избежать ошибок в речи
Чтобы ваша речь не резала слух окружающим, попробуйте следующее:
- Изучите разные виды речевых ошибок и постарайтесь от них избавиться.
- Если у вас есть сомнение в правильности того или иного высказывания, лучше переформулируйте его.
- Если вам предстоит речь перед аудиторией, уточните все сомнительные моменты с помощью словарей, толкового, орфоэпического, сочетаемости слов русского языка, антонимов, синонимов, омонимов, иностранных слов и др.
- Больше читайте художественную литературу.
- Общайтесь с образованными людьми, культуре речи которых можно поучиться.

А самое главное — не оставайтесь равнодушными к качеству своей речи, меняйтесь, стремитесь к лучшему.
Так ли важно соблюдать культуру речи
Небрежная речь, изобилующая ошибками, как и неряшливость в одежде, производит неблагоприятное впечатление. Согласитесь, что человеку с такими качествами, трудно избегать помех в общении, выстраивать гармоничные отношения с окружающими.
И, напротив, овладение культурой речи позволяет повысить уровень любой сферы жизни, будь то карьера, семья или саморазвитие. Через речь проявляются культивируемые человеком ценности: нравственные, научные, философские.
Услышав, как человек говорит, можно сразу понять, с кем имеешь дело. Уважение к себе и к окружающим — это тоже о культуре речи.
Как говорит! Хотите слышать такое в свой адрес? Работайте над ошибками. 🙂
- Новость
- 2019
- мая
- 25
- Топ-10 речевых ошибок, которые мы допускаем, по версии филолога ЮУрГУ
25 мая в России отмечается День филолога – праздник всех, кто «любит слово». Современные филологи работают во многих областях лингвистики и литературы, вносят большой вклад в сферу образования и исследований языковых изменений. Особое значение праздник имеет для кафедры русского языка и литературы Института социально-гуманитарных наук ЮУрГУ.
Коллектив кафедры уделяет пристальное внимание современным изменениям в русском языке. Проследить эти изменения можно по наиболее распространенным ошибкам, которые допускаются в устной и письменной речи. Доцент кафедры, кандидат филологических наук Денис Пелихов рассказывает, какие ошибки филологи считают недопустимыми, а к каким можно относиться более спокойно.
«С ошибками в речи нам приходится сталкиваться, к сожалению, очень часто. Воспринимаю я эти ошибки по-разному: чаще всего они, конечно, раздражают, иногда вызывают интерес и желание порассуждать о причинах их появления. Всё зависит от ситуации, от того, где эти ошибки встречаются – в устной речи или на письме, кто их допускает, каков характер этих ошибок, степень грубости и т. д. Если это ошибка в журнальной статье, научной монографии или художественном произведении, то, конечно, такая небрежность в обращении с языком не может не вызывать негодование. Если ошибки встречаются в устной речи, то здесь следует быть более снисходительными: мы должны понимать, что устная речь чаще всего спонтанна, ей свойственны оговорки, использование дискурсивных слов, которые называют еще словами-паразитами, и некоторые другие особенности».
Почему люди допускают ошибки
Именно специфику живого общения филолог называет главной причиной возникновения ошибок в устной речи, которая требует быстрой реакции на реплики собеседника, умение слушать другого человека и корректировать своё речевое поведение в ходе диалога. Всё это приводит к оговоркам, которые говорящий может не замечать, поскольку сосредоточивает своё внимание на дальнейшем построении фразы.
Но есть причины и внутреннего, сугубо языкового характера, отмечает Денис Александрович. Например, ошибки в постановке ударения вызваны объективными трудностями.
«Как все мы знаем, русское ударение разноместно и подвижно, то есть оно может падать на любой слог в слове и перемещаться с одной морфемы на другую при словоизменении и словообразовании. Сравните: голова́ – го́ловы – голо́вушка. И порой внешне похожие слова ведут себя абсолютно по-разному. Например, в формах слова стол ударение при изменении по падежам перемещается на окончание – стола́, столу́, столо́м, столы́, столо́в, стола́ми, на стола́х. В слове стул, отличающемся от предыдущего всего только одним звуком, мы наблюдаем обратную картину: во всех формах этого слова ударение будет оставаться на корне — сту́ла, сту́лу, сту́лом, сту́лья, сту́льями, на сту́льях. Эту разницу в постановке ударения на современном этапе развития языка объяснить невозможно, поэтому остаётся лишь запоминать, как правильно произносится то или иное слово».
Речевые ошибки, то есть ошибки, связанные с употреблением слов и устойчивых выражений, часто вызваны таким явлением, как метонимия, когда два предмета или явления настолько тесно связаны друг с другом, что свойство одного из них переносится на другое. Отсюда возникают ошибки наподобие выражений «дорогая цена» вместо «высокая цена». Товары по высоким ценам часто называют дорогими, происходит этот перенос, и прилагательное дорогой начинает относиться уже непосредственно к слову цена.
«Можно назвать ещё несколько причин появления в речи ошибок — влияние других языков, диалектных особенностей и профессионального жаргона. О каждой такой причине можно говорить очень долго. Остановлюсь только на последней. Жаргон обслуживает сферу профессионального общения и объединяет людей одних интересов, одного круга. В каждом таком кругу формируется свой набор слов, свойственный той или иной профессии, зачастую также и свои особенности образования слов и их произношения».
Филолог приводит в пример песню В. Высоцкого, в которой характеристика персонажей – моряков – даётся через особенности их речи:
Мы говорим не «што́рмы», а «шторма́» –
Слова выходят ко́ротки и смачны:
«Ветра́» – не «ве́тры» – сводят нас с ума,
Из палуб выкорчевывая мачты…
Таким образом, между нормой и ошибкой могут существовать еще несколько вариантов, которые не являются нормативными, но которые нельзя считать и в полной мере ошибочными. Какое же речевое поведение выбрать в этой ситуации?
«Оптимальным решением, на мой взгляд, может быть владение двумя или более нормами и умение переключаться с одного стилистического регистра на другой. К примеру, если я судмедэксперт и в моей сфере принято говорить слово а́лкоголь с ударением на первый слог, то в общении с коллегами я буду использовать именно этот, жаргонный вариант произношения. В другой же ситуации я выберу общеупотребительную литературную норму с ударением на последнем слоге – алкого́ль», – объясняет доцент кафедры русского языка и литературы.
ТОП-10 наиболее частых ошибок
Филолог ЮУрГУ составил список из десяти самых грубых ошибок, которые встречаются как в устной, так и в письменной речи:
- Неуместное использование местоимения «то» при придаточном изъяснительном: «я думаю то, что…» вместо правильного «я думаю, что…».
- «До скольки́» вместо «до ско́льких», «ко скольки́» вместо «ко ско́льким», и даже «со сколькью́» вместо «со ско́лькими». Это местоименное числительное склоняется как прилагательное, и это надо просто запомнить.
- Неправильное употребление предлога «по» во временно́м значении: «по прилёту» вместо правильного «по прилёте», «по приходу» вместо «по приходе», «по окончанию» вместо «по окончании» и т. п.
- Неправильное использование этикетного междометия «пожалуйста». Это слово призвано смягчить просьбу, поэтому использоваться оно может только в сочетании с глаголом в повелительном наклонении. К примеру, можно услышать фразу «Можно, пожалуйста, у вас отпроситься?» вместо правильного «Отпустите меня, пожалуйста!». Первый вариант так же ошибочен, как выражения «Который, пожалуйста, час?» или «Что это, пожалуйста, такое?».
- Смешение паронимов «одеть» и «надеть». Запоминанию сочетаемости этих слов может помочь фраза: «одеть Надежду, надеть одежду».
- Неумение склонять названия населённых пунктов, оканчивающихся на «-о»: «в Кемерово» вместо правильного «в Кемерове», «из Домодедово» вместо «из Домодедова», «битва под Бородино» вместо «битва под Бородином». Такие названия традиционно склонялись по модели слов среднего рода. Запомнить это правило помогут строки из известного стихотворения М. Ю. Лермонтова: «Недаром помнит вся Россия про день Бородина».
- Неумение склонять числительные: «двухста рублей» вместо правильного «двухсот рублей», «трёхста рублями» вместо «тремястами рублями», «тысячей рублей» вместо «тысячью рублями» и т. д.
- Незнание личных окончаний некоторых глаголов. Чаще всего страдают, по моим наблюдениям, глаголы бороться и клеить. Первый из них относится к первому спряжению, а второй — ко второму. Незнание этого правила, а также закон аналогии приводит к частым ошибкам, которые я вижу в интернете: «борятся» и «борящийся» вместо правильных форм «борются» и «борющийся», а также «клеют» и «клеющий» вместо правильных «клеят» и «клеящий».
- Образование гибрида «вообщем», восходящего к двум словам – «вообще» и «в общем».
- Ну и напоследок еще один гибрид – на этот раз фразеологический. Это выражение «имеет место быть», которое появилось в результате контаминации, то есть объединения, двух выражений: «имеет место» со значением «есть, наличествует» и устаревшего «имеет быть» со значением «должно состояться, произойти».
Эти и другие ошибки находят отражение в интернет-мемах, которые активно применяется в межличностной коммуникации в социальных сетях и мессенджерах. Филолог ЮУрГУ использует это относительно новое языковое явление при обучении студентов:
«Существуют интернет-мемы, которые построены на ошибках. Они, как правило, забавны, но подчас за ними стоит и нечто большее. Некоторые из них призваны, как мне кажется, высмеять неграмотность. А ещё мне представляется, что это может стать и хорошим методическим инструментом. Так, например, я сам порой делаю такие мемы – подбираю к смешным картинкам подписи из тех ошибок, что допускают обучающиеся. Молодежи такие вещи нравятся в силу их внешней несерьёзности, а самое главное, они подспудно позволяют запомнить трудные случаи написания слов».
Станут ли эти ошибки нормой?
При частом повторении неправильная форма может перестать восприниматься как таковая. Из перечисленных ошибок вариантом нормы уже считается отсутствие склонения у имён собственных, оканчивающихся на «-о». Как предполагают лингвисты, эта норма стала входить в речевую практику для того, чтобы избежать неточностей при обозначении созвучных населённых пунктов. К примеру, названия городов Пушкино Московской области и Пушкин Ленинградской области во всех косвенных падежах, кроме винительного, приобретут одинаковые окончания: Пушкина, Пушкину, Пушкином, о Пушкине. И именно требования коммуникации привели к изменению этой нормы и появлению нового, равноправного варианта.
К изменениям нормы нередко приводит и закон аналогии. Так, прежнее ударение в слове гу́ба на основе, сохранившееся только в выражении «гу́ба не дура» было вытеснено новым ударением на окончании – губа́ – под влиянием таких слов, как рука́ или нога́, также обозначающих части тела.
Денис Александрович отмечает, что не всякая ошибка может закрепиться в качестве новой, или – как говорят лингвисты – младшей, нормы. Чтобы это произошло, новая норма не должна нарушать общих принципов построения слов, законов словоизменения. Но как же можно бороться с неграмотностью?
«Боюсь, ответ на этот вопрос будет самым банальным: читать классическую и современную русскую литературу, которая была и остаётся одним из важнейших источников языковых норм. Чтение не только развивает словарный запас, но и позволяет запомнить написание многих слов, орфография которых не поддаётся проверке на современном этапе развития языка. Кроме того, нужно следить за своей речью и в случае затруднений обращаться к словарям и вообще воспитывать в себе привычку пользоваться справочниками и научной литературой, в которой отражены самые разные нормативные критерии устройства и функционирования языка», – советует филолог.

Справочно:
Кафедра русского языка и литературы была образована в Южно-Уральском государственном университете в 2000 году, первый выпуск специалистов-филологов состоялся в 2006 году. Сейчас кафедра готовит выпускников по всем ступеням высшего образования: бакалавриат, магистратура, аспирантура. Филолог – выпускник ЮУрГУ – может реализовать себя в любой сфере деятельности, предполагающей работу с текстами. Подробнее узнать об особенностях обучения филологов можно на сайте кафедры.
Вы нашли ошибку в тексте:
Просто нажмите кнопку «Сообщить об ошибке» — этого достаточно. Также вы можете добавить комментарий.
Слово — важнейшая единица языка, самая многообразная и объемная. Именно слово отражает все изменения, происходящие в жизни общества. Слово не только называет предмет или явление, но и выполняет эмоционально- экспрессивную функцию.
И, выбирая слова, мы должны обращать внимание на их значение, стилистическую окраску, употребительность, сочетаемость с другими словами. Так как нарушение хоть одного из этих критериев может привести к речевой ошибке.
Основные причины речевых ошибок:
Непонимание значения слова.
Лексическая сочетаемость.
Употребление синонимов.
Употребление омонимов.
Употребление многозначных слов.
Многословие.
Лексическая неполнота высказывания.
Новые слова.
Устаревшие слова.
Слова иноязычного происхождения.
Диалектизмы.
Разговорные и просторечные слова.
Профессиональные жаргонизмы.
Фразеологизмы.
Клише и штампы.
1. Непонимание значения слова.
1.1. Употребление слова в несвойственном ему значении.
Пример: Костер все больше и больше распалялся, пылал. Ошибка заключается в неверном выборе слова:
Распаляться – 1. Нагреться до очень высокой температуры, раскалиться. 2. (перен.) Прийти в сильное возбуждение, стать охваченным каким-либо сильным чувством.
Разгораться – начинать сильно или хорошо, ровно гореть.
1.2. Употребление знаменательных и служебных слов без учета их семантики.
Пример: Благодаря пожару, вспыхнувшему от костра, сгорел большой участок леса.
В современном русском языке предлог благодаря сохраняет известную смысловую связь с глаголом благодарить и употребляется обычно лишь в тех случаях, когда говорится о причинах, вызывающих желательный результат: благодаря чьей-нибудь помощи, поддержке. Ошибка возникает в связи со смысловым отвлечением предлога от исходного глагола благодарить. В этом предложении предлог благодаря следует заменить на один из следующих: из-за, в результате, вследствие.
1.3. Выбор слов-понятий с различным основанием деления (конкретная и отвлеченная лексика).
Пример: Предлагаем полное излечение алкоголиков и других заболеваний.
Если речь идет о заболеваниях, то слово алкоголики следовало бы заменить на алкоголизм. Алкоголик- тот, кто страдает алкоголизмом. Алкоголизм – болезненное пристрастие к употреблению спиртных напитков.
1.4. Неправильное употребление паронимов.
Пример: Человек ведет праздничную жизнь. У меня сегодня праздное настроение.
Праздный и праздничный – очень похожие слова, однокоренные. Но значение имеют разное: праздничный – прилагательное к праздник (праздничный ужин, праздничное настроение); праздный- не заполненный, не занятый делом, работой (праздная жизнь). Чтобы восстановить смысл высказываний в примере, нужно поменять слова местами.
2. Лексическая сочетаемость. При выборе слова следует учитывать не только значение, которое ему присуще в литературном языке, но и лексическую сочетаемость. Далеко не все слова могут сочетаться друг с другом. Границы лексической сочетаемости определяются семантикой слов, их стилистической принадлежностью, эмоциональной окраской, грамматическими свойствами и т. д.
Пример: Хороший руководитель должен во всем показывать образец своим подчиненным.
Показывать можно пример, но не образец. А образцом можно быть, например, для подражания.
Пример: Их сильная, закаленная в жизненных испытаниях дружба многими была замечена.
Слово дружба сочетается с прилагательным крепкая – крепкая дружба.
Отличать от речевой ошибки следует умышленное объединение, казалось бы, несочетаемых между собой слов: живой труп, обыкновенное чудо… В этом случае перед нами один из видов тропов – оксюморон.
В сложных случаях, когда трудно определить, можно ли употребить вместе те или иные слова, необходимо пользоваться словарем сочетаемости.
3.Употребление синонимов.
Синонимы обогащают язык, делают образной нашу речь. У синонимов может быть разная функционально-стилистическая окраска. Так, слова ошибка, просчет, оплошность, погрешность – стилистически нейтральны, общеупотребительны; проруха, накладка – просторечные; оплошка – разговорное; ляп – профессионально-жаргонное. Употребление одного из синонимов без учета его стилистической окраски может привести к речевой ошибке.
Пример:Совершив оплошку, директор завода сразу же стал ее исправлять.
При использовании синонимов часто не учитывается способность каждого из них в большей или меньшей степени избирательно сочетаться с другими словами.
Различаясь оттенками лексического значения, синонимы могут выражать разную степень проявления признака, действия. Но, даже обозначая одно и то же, взаимозаменяясь в одних случаях, в других синонимы заменяться не могут – это ведет к речевой ошибке.
Пример: Вчера мне было печально.
Синоним грустно сюда вполне подходит: Вчера мне было грустно. Но в двусоставных предложениях эти синонимы взаимозаменяются. Печально я гляжу на наше поколенье….
4. Употребление омонимов.
Благодаря контексту омонимы, как правило, понимаются верно. Но все же в определенных речевых ситуациях омонимы не могут быть поняты однозначно.
Пример: Экипаж находится в отличном состоянии.
Экипаж – это повозка или команда? Само слово экипаж употреблено правильно. Но для раскрытия смысла этого слова необходимо расширить контекст.
Очень часто к двусмысленности приводит употребление в речи (особенно устной) омофонов (одинаково звучащих, но по-разному пишущихся) и омоформ (слов, совпадающих по звучанию и написанию в отдельных формах). Так что, выбирая слова для какой-либо фразы, мы должны обращать внимание и на контекст, который в некоторых речевых ситуациях призван раскрывать смысл слов.
5. Употребление многозначных слов.
Включая в свою речь многозначные слова, мы должны быть очень внимательны, должны следить, понятно ли именно то значение, которое мы хотели раскрыть в этой речевой ситуации. При употреблении многозначных слов (как и при употреблении омонимов) очень важен контекст. Именно благодаря контексту ясно то или иное значение слова. И если контекст отвечает своим требованиям (законченный в смысловом отношении отрезок речи, позволяющий установить значения входящих в него слов или фраз), то каждое слово в предложении понятно. Но бывает и иначе.
Пример: Он уже распелся.
Непонятно: или он начал петь, увлекся; или, пропев некоторое время, начал петь свободно, легко.
6. Многословие.
Встречаются следующие виды многословия:
1. Плеоназм (от греч. pleonasmos – избыток, чрезмерность) – употребление в речи близких по смыслу и потому логически излишних слов.
Пример: Все гости получили памятные сувениры.
Сувенир – подарок на память, поэтому памятные в этом предложении – лишнее слово. Разновидностью плеоназмов являются выражения типа очень огромный, очень малюсенький, очень прекрасный и т. п. Прилагательные, обозначающие признак в его предельно сильном или предельно слабом проявлении, не нуждаются в уточнении степени признака.
2. Использование лишних слов. Лишних не потому, что свойственное им лексическое значение выражено другими словами, а потому, что они просто не нужны в данном тексте.
Пример: Тогда о том, чтобы вы могли улыбнуться, 11 апреля об этом позаботится книжный магазин “Дружба”.
3. Тавтология (от греч. tauto- то же самое logos – слово) – повторение однокоренных слов или одинаковых морфем. Тавтологическими ошибками “пестрят” не только сочинения учащихся, но и газеты и журналы.
Пример: Руководители предприятий настроены на деловой настрой.
4. Расщепление сказуемого. Это замена глагольного сказуемого синонимичным глагольно-именным сочетанием: бороться – вести борьбу, убирать – производить уборку.
Пример: Ученики приняли решение произвести уборку школьного двора.
Может быть, в официально-деловом стиле такие выражения уместны, но в речевой ситуации лучше: Ученики решили убрать школьный двор.
5. Слова-паразиты. Такие слова засоряют речь, особенно устную. Это разнообразные частицы, которыми говорящий заполняет вынужденные паузы, не оправданные содержанием и структурой высказывания: вот, ну, это и т. п.; словечки типа: знаете ли, так сказать, фактически, вообще, честно говоря и т. п. Но эта речевая ошибка, встречающаяся сплошь и рядом в устной речи, иногда просачивается и на страницы печатных изданий.
Пример: В небольших дешевых кафе, ну, куда ходят люди из своего квартала, обычно нет свободных мест.
7.Лексическая неполнота высказывания.
Эта ошибка по смыслу противоположна многословию. Неполнота высказывания заключается в пропуске необходимого в предложении слова.
Пример: Достоинство Куприна в том, что ничего лишнего.
У Куприна, может, и нет ничего лишнего, но в этом предложении не хватает (и даже не одного) слова. Или: “… не допускать на страницы печати и телевидения высказывания, способные разжечь межнациональную вражду”. Так получается – “страница телевидения”.
При выборе слова необходимо учитывать не только его семантику, лексическую, стилистическую и логическую сочетаемость, но и сферу распространения. Употребление слов, имеющих ограниченную сферу распространения (лексические новообразования, устаревшие слова, слова иноязычного происхождения, профессионализмы, жаргонизмы, диалектизмы), всегда должно быть мотивировано условиями контекста.
8.Новые слова.
Неудачно образованные неологизмы являются речевыми ошибками.
Пример: А в прошлом году на ямочный ремонт после весенней распутицы было потрачено 23 тысячи рублей.
И только контекст помогает разобраться: “ямочный ремонт” – это ремонт ям.
Устаревшие слова.
Архаизмы – слова, называющие существующие реалии, но вытесненные по каким-либо причинам из активного употребления синонимичными лексическими единицами, – должны соответствовать стилистике текста, иначе они совершенно неуместны.
Пример: Ныне в университете был день открытых дверей.
Здесь устаревшее слово ныне (сегодня, теперь, в настоящее время) совершенно неуместно.
Среди слов, вышедших из активного употребления, выделяются еще и историзмы. Историзмы – слова, вышедшие из употребления в связи с исчезновением обозначавшихся ими понятий: армяк, камзол, бурса, опричник и т. п. Ошибки в употреблении историзмов часто связаны с незнанием их лексического значения.
Пример:Крестьяне не выдерживают своей тяжелой жизни и идут к главному губернатору города.
Губернатор – начальник какой-нибудь области (например, губернии в царской России, штата в США). Следовательно, главный губернатор – нелепость, к тому же в губернии мог быть только один губернатор, а его помощник назывался вице-губернатором.
10.Слова иноязычного происхождения.
Сейчас многие имеют пристрастие к иностранным словам, даже не зная иногда их точного значения. Иногда контекст не принимает иностранное слово.
Пример: Работа конференции лимитируется из-за отсутствия ведущих специалистов.
Лимитировать – установить лимит чего-нибудь, ограничить. Иностранное слово лимитировать в данном предложении следует заменить словами: идет медленнее, приостановилась и т. п.
11.Диалектизмы.
Диалектизмы – слова или устойчивые сочетания, которые не входят в лексическую систему литературного языка и являются принадлежностью одного или нескольких говоров русского общенационального языка. Диалектизмы оправданны в художественной или публицистической речи для создания речевых характеристик героев. Немотивированное же использование диалектизмов говорит о недостаточном владении нормами литературного языка.
Пример: Пришла ко мне шаберка и просидела целый вечер.
Шаберка – соседка. Употребление диалектизма в данном предложении не оправдано ни стилистикой текста, ни целью высказывания.
12. Разговорные и просторечные слова.
Разговорные слова входят в лексическую систему литературного языка, но употребляются преимущественно в устной речи, главным образом в сфере повседневного общения. Просторечие – слово, грамматическая форма или оборот преимущественно устной речи, употребляемые в литературном языке обычно в целях сниженной, грубоватой характеристики предмета речи, а также простая непринужденная речь, содержащая такие слова, формы и обороты. Разговорная и просторечная лексика, в отличие от диалектной (областной), употребляется в речи всего народа.
Пример: У меня совсем худая куртка.
Худой(разг.) – дырявый, испорченный (худой сапог). Ошибки возникают в тех случаях, когда употребление разговорных и просторечных слов не мотивировано контекстом.
13. Профессиональные жаргонизмы.
Профессионализмы выступают как принятые в определенной профессиональной группе просторечные эквиваленты терминов: опечатка – в речи журналистов ляп; руль – в речи шоферов баранка.
Но немотивированное перенесение профессионализмов в общелитературную речь нежелательно. Такие профессионализмы, как пошить, пошив, заслушать и другие, портят литературную речь.
По ограниченности употребления и характеру экспрессии (шутливая, сниженная и т. п.) профессионализмы сходны с жаргонизмами и являются составной частью жаргонов – своеобразных социальных диалектов, свойственных профессиональным или возрастным группам людей (жаргоны спортсменов, моряков, охотников, студентов, школьников). Жаргонизмы – это обиходно-бытовая лексика и фразеология, наделенная сниженной экспрессией и характеризующая- ся социально ограниченным употреблением.
Пример: Хотел пригласить на праздник гостей, да хибара не позволяет.
Хибара – дом.
14. Фразеологизмы.
Нужно помнить, что фразеологизмы всегда имеют переносное значение. Украшая нашу речь, делая ее более живой, образной, яркой, красивой, фразеологизмы доставляют нам и немало хлопот – при неверном их употреблении появляются речевые ошибки.
1. Ошибки в усвоении значения фразеологизмов.
1) Существует опасность буквального понимания фразеологизмов, которые могут восприниматься как свободные объединения слов.
2) Ошибки могут быть связаны с изменением значения фразеологизма.
Пример: Хлестаков все время мечет бисер перед свиньями, а ему все верят.
Здесь фразеологизм метать бисер перед свиньями, имеющий значение “напрасно говорить о чем-либо или доказывать что-либо тому, кто не способен понять этого”, употреблен неверно – в значении “выдумывать, плести небылицы”.
2. Ошибки в усвоении формы фразеологизма.
1) Грамматическое видоизменение фразеологизма.
Пример: Я привык отдавать себе полные отчеты.
Здесь изменена форма числа. Существует фразеологизм отдавать отчет.
Пример: Он постоянно сидит сложив руки. Фразеологизмы типа сложа руки, сломя голову, очертя голову сохраняют в своем составе старую форму деепричастия совершенного вида с суффиксом -а (-я).
В некоторых фразеологизмах употребляются краткие формы прилагательных, замена их полными формами ошибочна.
2) Лексическое видоизменение фразеологизма.
Пример: Пора уже тебе взяться за свой ум.
Большая часть фразеологизмов является непроницаемой: в состав фразеологизма нельзя ввести дополнительную единицу.
Пример: Ну хоть бейся об стенку!
Пропуск компонента фразеологизма также является речевой ошибкой.
Пример: Все возвращается на спирали своя!..
Есть фразеологизм на круги своя. Замена слова недопустима.
3. Изменение лексической сочетаемости фразеологизма.
Пример: Эти и другие вопросы имеют большую роль в развитии этой, еще молодой науки.
Произошло смешение двух устойчивых оборотов: играет роль и имеет значение. Можно сказать так: вопросы имеют большое значение… или вопросы играют большую роль.
15. Клише и штампы.
Канцеляризмы – слова и выражения, употребление которых закреплено за официально-деловым стилем, но в других стилях речи они неуместны, являются штампами.
Пример: Имеет место отсутствие запасных частей.
Штампы – это избитые выражения с потускневшим лексическим значением и стертой экспрессивностью. Штампами становятся слова, словосочетания и даже целые предложения, которые возникают как новые, стилистически выразительные речевые средства, но в результате слишком частого употребления утрачивают первоначальную образность.
Пример: При голосовании поднялся лес рук.
Разновидностью штампов являются универсальные слова. Это слова, которые употребляются в самых общих и неопределенных значениях: вопрос, задача, поднять, обеспечить и т. д. Обычно универсальные слова сопровождаются трафаретными привесками: работа – повседневная, уровень – высокий, поддержка – горячая. Многочисленны публицистические штампы (труженики полей, город на Волге), литературоведческие (волнующий образ, гневный протест).