 спецификация
спецификация
уравнения ошибочная
 -спецификация
-спецификация
уравнения ошибочная
…, которая
характеризует результат функционирования
анализируемой аналитической системы
наз-ся Эндогенной
ARIMA
(0, C, 1) является: моделью
скользящей средней
DS-процесс
это … процесс имеющий статестический
тренд и приводной …
F-статистика
Фишера используется: определения
статистической значимости модели в
целом.
F-тест
применяется для…выбора лучшей модели
RESET-тест
применяется для…. ошибки линейной
спецификации регрессии
ti —
расчетное значение критерия Стьюдента
для коэффициента В,. Критическое значение
критерия Стьюдента t,5=1.96 для уровня
значимости 0,05 и числа степеней свобод»
более 200…если t1=2.5. то коэффициент S1
значим с уровнем доверия 0.95 . если t1=
-2,5, то коэффициент S1 значим с уровнем
доверия 0.95
TS-процесс
— это… процесс, приводимый к стационарному
путем выделения тренда
t-статистика
Стьюдента используется: для определения
статистической значимости коэффициентов
регрессионного уравнения;
Автокореляция
в остатках –это…кореляция зависимости
между состакомрегриссионного во времени
Автокорреляция
остатков бывает следующих видов:
отрицательная положительная
Автокорреляция
ошибок – это линейная связь между
более чем двумя объясняющими переменными
Автокорреляция
ошибок- это — корреляция ошибок
регрессии для разных наблюдений
Авторегрессионными
моделями порядка p являются
модели вида:

Была
исследована зависимость рентабельности
предприятия (у) от оборачиваемости
оборотных активов (х), фондоотдачи [к)
и производительности труда [/) за 24
квартала. По выборочным данным построены
несколько типов зависимостей и рассчитаны
значения F-статистики для них. Какая из
представленных регрессий является
значимой, если критическое значение
F-статистики равно 3.1 при уровне значимости
5%?ОТВЕТ: 3 1)у=4.12+0.15 F=2,9 2) у-0.75.x
F=l.7 3) у=е^****
F=4.6 4) y=ln F =3,09
В каких
случаях значение коэффициента
детерминации R² может выйти за
пределы[0;1]? —если в уравнении регрессии
отсутствует константа β0
В командной
строке EViews введена следующая
последовательность команд: genr y=3+4*@rnd
genr z=@var(y)
Что появится в рабочем файле после
выполнения этих команд? — будет
создан ряд У , значения которого будут
распределены по равномерному закону
распределения на интервалеот 3 до 7.
Затем будет создан ряд Z, значения
которого будут равны дисперсии ряда У
В
оцениваемо» модели у = хВ +Zу +е присутствуют
несущественные независимые переменные
у. тогда оценка & . полученная в данной
регрессии…дисперсия оценки
увеличивается от включения в модель
несущественных переменных, несмещенная
В
оцениваемой модели y=XB+е отсутствует
часть существенных независимых
переменных тогда оценка B полученная
в данной регрессии в общем случае…смешанная
В
оцениваемой модели у=ХВ+е отсутствует
часть существенных независимых
переменных, тогда оценка В^, полученная
в данной регрессии, в общем случае
смещенная
В результате
оценки параметров регрессии y = β0
+ β1x + ε были получены следующие
результаты: 4,7 β 10,4; β 1 0 = = ˆ ˆ .
Доверительный интервал для 1 βˆ
на 10%ном уровне значимости составил
(4,3; 5,1). Что показывает полученный
доверительный интервал на указанном
уровне значимости? истинное значение
коэффициента β1 находится
в указанном интервале с
вероятностью 90 %;
В результате
оценки параметров регрессии у=α+βх+
ɛ были получены следующие результаты:
ᾶ= 10, ᵬ=4,7. Доверительный интервал для
ᵬ с уровнем доверия 95% составил [3,9;5,5].
Что показывает полученный доверительный
интервал с указанным уровнем доверия?
— истинное значение коэффициента β
находится в указанном интервале с
вероятностью 0,95
В результате
оценки параметров регрессии у=α+βх+
ɛ были получены следующие результаты:
ᾶ= 10, 4, ᵬ=4,7. Доверительный интервал для
ᵬ с уровнем доверия 90% составил [4.3;5,1].
Что показывает полученный доверительный
интервал с указанным уровнем доверия?
— истинное значение коэффициента В
находится в указанном интервале с
вероятностью 0,90
В системе
одновременных уравнений значения
экзогенных переменных… формируются
вне системы и не должны коррелировать
с остатками
В системе
рекурсивных эконометрических уравнений…
матрица коэффициентов при эндогенных
переменных треугольная
В
стационарном временном ряду трендовая
компонента: отсутствует
В чем
суть гетероскедастичности?- дисперсии
случайных отклонений изменяются
В
эконометрической модели линейного
уравнения регрессии у=a+b1x1+b2x2…+bkxk+
ɛ коэффициетом регрессии, характеризующим
среднее изменение зависимой переменной
при изменении независимой переменной
на 1 единицу измерения, является…-bj
В
экономической модели линейного уравнения
регрессии у=a+b1x1+b2x2…+bkxk+
ɛ параметром является…— a,bj
Величина
коэффициента апатичности показывает
… на сколько процентов изменится в
среденем результат при изменении
фактора на 1%
Величина
коэффициента множественное линейной
регрессии при объясняющей переменной
показывает…среднее изменения
результата при изменения фактора на
одну единицу.
Выберите
верные утверждения о производственной
функции Кобба-Дугласа- записывается
степенным уравнением, является нелинейной
зависимостью
Выберите
ответ, который наиболее точно описывает
сущность эконометрики. Эконометрика
– это наука, которая, используя методы
экономической теории, математической
статистики и математического
моделирования, позволяет: количественно
оценивать качественные экономические
закономерности;
Выберите
показатели качества уравнения регрессии
в цепом?1. R^2.2 Скорректированный R^2.
Значения 1-статистик. 4. Значение
F-статистики. Ответ :2,4
Выбирите
показатели качества уравнения регрессии
в целом ? R^2
,скорректированный R^2 , значения F
статистики.
Выражение
вида
 —
—
суммой квадратов отклонений, объясненных
регрессией
Гетероскедастичность
— это:- зависимость дисперсии случайных
ошибок от номера наблюдения
Гомоскедастичность
– это: независимость дисперсии
случайных ошибок от номера наблюдения;
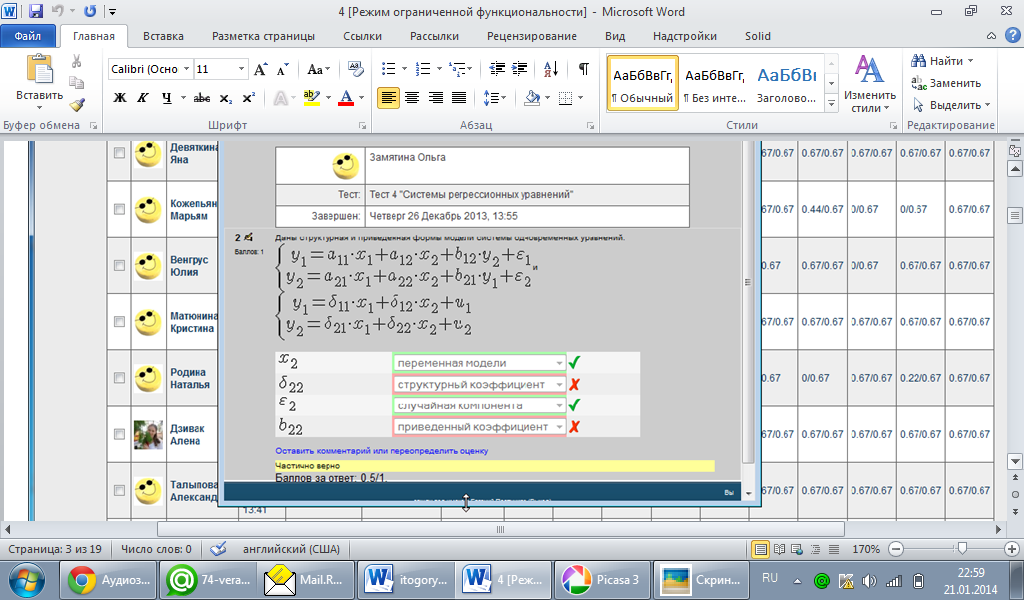
Дана
приведенная форма системы одновременных
уравнений:

эндогенная переменная системы
Дана
приведенная форма системы одновременных
уравнений…Wt-эндогенная переменная
система , Сt-эксанное переменная системы
Дана
система одновременных эконометрических
уравнений :
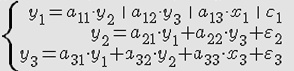
Данная система является : неидентифицируемой
Дана
система одновременных эконометрических
уравнений. Определите, является ли она
идентифицируемой , неидентифицируемой
или сверхидентифицируемой: идентифицируемой
Дана
система одновременных эконометрических
уравнений:

Данная система является: сверхидентифицируемой
Даны
структурная и приведенная формы модели
системы одновременных уравнений:
переменная модели , случайная компонента
Для
выбора лучше модели применяется…РЕ-тест,
J-тест
Для выбора
лучшей спецификации модели применяется:
PE-тест, J-тест
Для
выявления ошибки линейной спецификации
регрессии применяется- RESET-тест
Для
гиперболического уравнена
y=B0+B1/X1+..+BN/XN+e
коэффициент B1 имеет
следующий экономический смысл… Нет
простой интерпретации коэффициента
Для
гиперболической зависимости

коэффициент имеет следующую
интерпретацию:–нет простой интерпретации
данного коэффициента регрессии
Для двух
случайных величин x и y было
получено значение парного коэффициента
корреляции rxy = –0,9. Какой вывод
можно сделать о тесноте линейной
зависимости между x и y? связь
тесная и отрицательная;
Для двух
случайных величин х и у было получено
значение парного коэффициента корреляции
r=0,9. Какой вывод можно сделать о тесноте
линейной связи между х и у?- связь
тесная и прямая
Для
изучения зависимости спроса и предложения
на товары повседневного спроса от цены
и дохода строится: система одновременных
уравнений
Для
какого типа данных в окне создания
рабочего файла EViews необходимо указать
только размер выборки (число
наблюдений)?…Пространственные данные
Для
логарифмического уравнения
y=B0+B1*Ln..коэффициент В имеет следующий
экономический смысл…Для увеличения
У на единицу необходимо увеличить Х1
примерно на {100/В1) %
Для
нелинейной регрессионной модели
зависимости рассчитано значение индекса
детерминации R^2= 0,9. Тогда значение
индекса корреляции составит…Корень
квадратный из 0,9
Для
обнаружения автокорреляции в остатках
используется: статистика Дарбина-Уотсона
Для оценки
качества подбора эконометрической
модели линейного уравнения регрессии
рассчитывают значение коэффициента
детерминации. При этом известны следующие
дисперсии зависимой переменной
Для оценки
параметров регрессионной модели с
гетероскедастичными остатками
используется ___________ метод наименьших
квадратов.- обобщенный
Для оценки
параметров регрессионной модели с
коррелированными остатками используется____
метод наименьших квадратов- обобщенный
Для
построения эконометрической модели
линейного уравнения множественной
регрессии используется таблица
статистических данных.
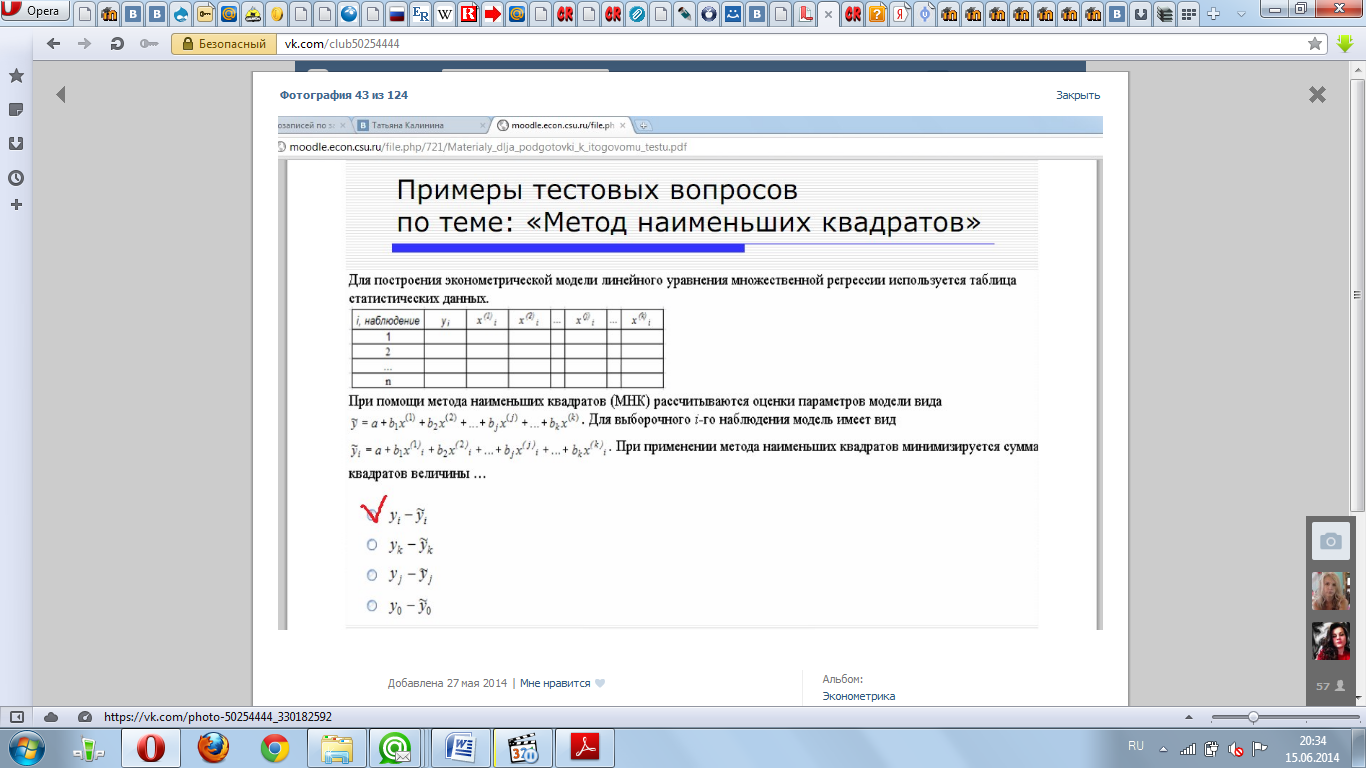
Для
проверки гипотез равенства коэффициентов
какому-либо значению или соотношения
коэффициентов между собой применяется…Тест
Вальда
Для
производной функции Кобба-Дугласа
Q=B0*K^B1*L^B2?
Известно, что B1+b2<1. Выберите верные
утверждения:-отдача от увеличения
масштаба уменьшается, В2-коэффициент
эластичности выпуска по труду,
В1-коэффициент эластичности выпуска
по капиталу
Для
производной функции Кобба-Дугласа
Q=B0*K^B1*L^B2?
Известно, что B1+b2<1. Выберите верные
утверждения- отдача от увеличения
масштаба уменьшается; коэффициент В2
показывает ,на сколько процентов в
среднем изменится объем выпуска ,если
затраты труда увеличить на 1 %
Для
производственной функции Кобба-Дугласа
Q=B0*KB1*LB2 известно что B1 и B2= 1 тогда
увеличения затрат труда и капитала в
несколько раз приведёт к …увеличению
выпуска производства в такой же число
раз.
Для
производственной функции Кобба-Дугласа
отдача от
увеличения масштаба убывает; в2
коэффициент эластичности выпуска по
труду; в1 коэффициент эластичности
выпуска по капиталу
Для
регрессионной модели вида y=a+bx+ɛ
построена на координатной плоскости
совокупность точек с координатами
(у,х), данное графическое отображение
зависимости называется:- полем
корреляции
Для
регрессионной модели вида показателем
тесноты связи является коэффициент
множественной корреляции
Для
регрессионной модели зависимости
потребления материала на единицу
продукции от объема выпуска построено
нелинейное уравнение Объёмом
выпуска продукции объяснено 90,4% дисперсии
потребления материалов на единицу
продукции
Для
регрессионной модели известны следующие
величины дисперсий:
Для указанных дисперсий справедливо
равенство…-
![]()
Для
регрессионной модели несмещенность
оценки параметра означает, что ее
выборочное математическое ожидание
равно…- оцениваемому параметру,
рассчитанному по генеральной совокупности
Для
регрессионной модели парной линейной
модели рассчитано значение коэффициента
детерминации R²=0,831 На дисперсию
зависимой переменной, объясненную
построенным уравнением приходится______________
общей дисперсии зависимой переменной-
16,9%
Для
регрессионной модели парной линейной
регрессии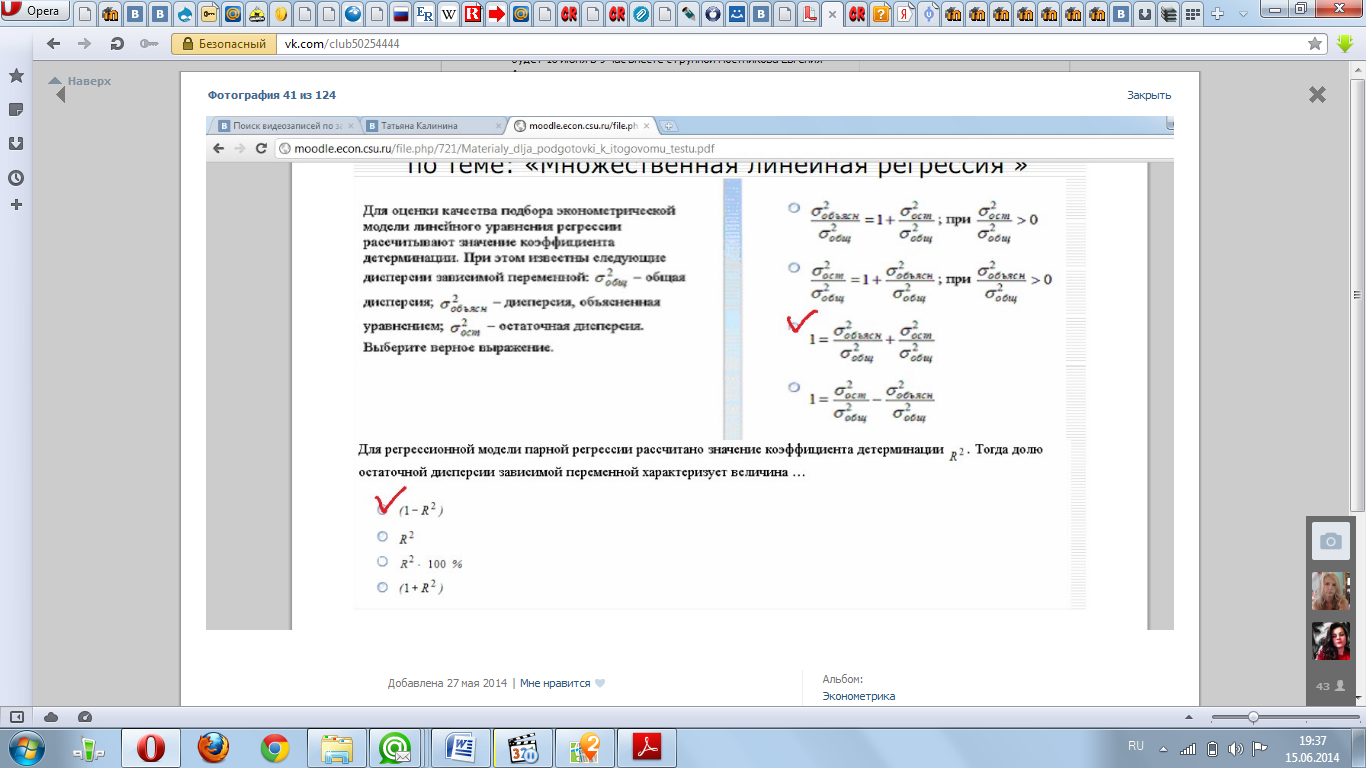
Для совокупности из n
единиц наблюдений рассчитывают
общую дисперсию на одну степень свободы,
при этом величину дисперсии относят к
значению…n-1
Для совокупности из n единиц наблюдений
построена модель линейного уравнения
множественной регрессии с количеством
параметров при независимых переменных,
равным k. Тогда при расчете остаточной
дисперсии на одну степень свободы
величину дисперсии относят к значению…n—k-1
Для
стационарных временных рядов Y1
, Y2, Yt,
Yn, Y
(t=1, … , n)
автоковариация зависит только от
величины: лага
Для
степенной зависимости: При
При
увеличении переменной х1 на 1% переменная
у в среднем увел-ся на 81%
Для
эконометрической модели линейного
уравнения множественной регрессии
вида

Для
экспоненциальной зависимости у=…
коэффициент В1 имеет следующую
интерпретацию:— при увеличении
переменной х1 на единицу переменная у
в среднем увеличится примерно на
(100В1)%; при увеличении переменной х1 на
единицу переменная у в среднем увеличится
в ехр(В1) раз
Долю
объясненной с помощью регрессии
дисперсии в общей дисперсии зависимой
переменной характеризует коэффициент
детерминации
Ежегодные
денные об уровне инфляции за последний
15 лет во всех странах Европы относятся
к…панельным данным
Ежеквартальные
данные по инфляции за 15 лет в РФ относят
к Временным рядам
Если
коэффициент β1 уравнения регрессии
ˆyt = βˆ 0 + βˆ
1x1t + βˆ 2 x2t статистически
значим, то: β1 ≠ 0;
Если
параметр эконометрической модели не
является статистически значимым,
то его значение признается…-равным
0
Если
параметр эконометрической модели не
является статистически значимым
, то соответствующая независимая
переменная на определенном уровне
доверия…- не оказывает влияния на
моделируемый показатель (зависимую
переменную)
Если
параметр эконометрической модели
ЯВЛЯЕТСЯ статистически значимым,
то его значение признается…-отличным
от 0
Зависимость
объема выпускаемой продукции Q от объема
трудовых L и материальных затрат
дописываемая функцией…Q=B0*K^B1*L^B2 ,где
В0 ,В1 и В2- параметры регрессии
….производственной функцией
Кобба-Дугласа
Замещающая
переменная – это… переменная,
коррелирующая с отсутствующей переменной
уравнения регрессии, выполняя функции
этой отсутствующей переменной
Значение
коэффициента множественной корреляции
рассчитывается по формуле R=корень
квадратный из R^2…. Тогда
значение коэффициента множественной
корреляции будет находиться в интервале…
[0;1]
Изменение
объема продаж молока объясняется
переменными 93%
Имеется
матрица парных коэффициентов корреляции.
Мультиколлинеэрность наблюдается
между величинами: ОТВЕТ X1 и X2
Информационные
критики (AIC) и(SBIC
) принимаются для …сравнивая модели
по качеству подгонки …
Исследуется
влияние качества определенного вида
продукции и сервисного обслуживания
ее покупателей на стоимость этой
продукции. Предполагается следующий
вид зависимости: у = β1 ⋅
x1 + β2 ⋅
22 x + ε. В данном уравнении β1,
β2 называются:коэффициентами
регрессии;
Исследуется
влияние качества определенного вида
продукции и сервисного обслуживания
ее покупателей на стоимость этой
продукции. Предполагается следующий
вид зависимости: у = β1 ⋅
x1 + β2 ⋅
22 x + ε. В данном уравнении ε
называется: ошибкой регрессии.
Исследуется
зависимость выпуска продукции Y от
затрат на труд L и капитал K на
основе имеющихся статистических данных
для 40 металлургических предприятий
уральского экономического региона.
Экономическая теория рекомендует
следующий вид модели: ln Yt = ln А + α ln
Кt + β ln Lt + εt, t = 1…40. Что
представляют собой коэффициенты α, β?
коэффициенты эластичности;
Исследуется
зависимость объема продаж от цены
одного галлона и расходов на рекламу

Исследуется
зависимость урожайности зерновых
культур y (ц/га) от ряда факторов x1,
x2, x3, x4, x5. В результате моделирования
были получены большие стандартные
ошибки и малая значимость оценок, в то
время как модель в целом оказалась
значима. Также некоторые коэффициенты
имели неправильные с экономической
точки зрения знаки. Эти признаки
указывают на возможное наличие:
мультиколлинеарности;
Исследуется
регрессия y = β0 + β1×1 + β2×2 +
β3×3 + ε. Известно, что 4,3 + 10×1 –
3,5×2 = x3. В этом случае говорят о наличии:
мультиколлинеарности;
Исследуется
регрессия y=B0+B1X1+B2X2+B3X3+e известно, что
D(e) =/= o^2 В этом случае говорят о
наличии…мультиколлинеарности
Исследуется
регрессия у= β₀+ β ₁х₁+ β₂х₂+ β₃х₃+
ɛ. Известно, что 4,3-10х₁/3.5х₂=х₃. В
этом случае говорят о наличии:—
гетероскедаститчности
Исследуется
регрессия у= β₀+ β ₁х₁+ β₂х₂+ β₃х₃+
ɛ. Известно, что дисперсия ошибок
регрессии D(ɛt)=q^2
для любого t. В этом случае
говорят о наличии —гомоскедастичности
Как влияет
исключение переменной из уравнения
множественной регрессии на значение
F-критерия и коэффициент детерминации?-
F-критерий может
как уменьшиться, так и увеличиться, R2
уменьшится
Как
называется вид графика, по которому
визуально можно сделать предположение
о законе распределения исследуемых
величин?…Гистограмма
Как
проявляется гетероскедастичность на
графике остатков? Разброс остатков
увеличивается или уменьшается с ростом
номера наблюдений
Как
проявляется гомоскедастичность на
графике остатков?… Разброс остатков
не изменяется с ростом наблюдений
Какая
характеристика определяет среднее
значение случайной величины?…Математическое
ожидание
Какие
виды уравнений в системах одновременных
уравнений с точки зрения идентифицируемости
параметров Вы знаете: неидентифицируемые
уравнения , точно идентифицируемые
уравнения , сверхидентифицируемые
уравнения
Каким
будет объём продаж, если цена одного
галлона молока составит 2 доллара 6
Какими
свойствами обладают оценки, полученные
при решении уравнения парной линейной
регрессии у=α+β+ɛ методом наименьших
квадратов, если выполнены условия
Гаусса-Маркова и случайные остатки ɛ
имеют нормальное распределение:-
состоятельностью, несмещенностью,
эффективностью
Какими
свойствами обладают оценки, полученные
при решении уравнения парной линейной
регрессии у-=а,—&-1; методом наименьших
квадратов, если выполнены условия
Гаусса-Маркова и случайные остатки е
имеют нормальное распределение…
Состоятельностью, несмещенностью и
эффективностью
Какими
свойствами обладают оценки, полученные
при решении уравнения парной линейной
регрессии Yt= axt+B+et
методом наименьших квадратов, если
выполнены условия Гаусса-Маркова и
случайные остатки е имеют нормальное
распределение:Состоятельностью,
несмещенностью и эффективностью
Каковы
показатели качества уравнения регрессии
в целом:- значения F-статистики для
уравнения регрессии -скорректированный
коэффициент детерминации
Какое
из уравнении является
показательным?…y=B0*B1^x1..
Какое
из уравнении является экспоненциальным?…y=e^***
Какой
вывод можно сделать по результату
проведения теста Рамсея?

спецификация уравнения ошибочная
Корреляция
ошибок – это: корреляция ошибок для
разных наблюдений.
Когда
целесообразно добавление новой
объясняющей переменной в модель при
росте скорректированного коэффициента
детерминации после ее включения
Коллинеарность
факторов эконометрической модели
y=a+b1x1+b2x2+…+bkxk+ɛ проверяется
на основе матрицы парных коэффициентов
линейной…КОРРЕЛЯЦИИ
Оценка
а^ значения параметра а модели У= aX + B
+ е является эффективной, если 1.
математическое а^ ожидание равно а
2.a^=a3. a^ обладает наименьшей дисперсией
по сравнению с другими оценками
4.a^->a… ОТВЕТ : . a^ обладает наименьшей
дисперсией по сравнению с другими
оценками
Оценка
альфа значения параметра альфа является
несмещенной, если: Мат ожидание альфа
равно альфа
Оценка
альфа со скоб значения параметра альфа
является состоятельной, если: а^->а
при стремлении числа наблюдений к
бесконечности
Оценка
параметров модели – это Сбор необх
стат информации
Оценки
параметров идентифицируемой системы
независимых (внешне не связанных)
эконометрических уравнений могут быть
найдены с помощью…обычного МНК
Параметр
экономической модели не является
статистически значимым, то соответствующая
независимая переменная на определенном
уровне доверия не
оказывает влияния на моделируемый
показатель
Парный
коэффициент линейной корреляции rxy
между случайными переменными x и
y показывает: уровень линейной
зависимости между x и y.
Если rxy > 0, то
x и y связаны
положительной линейной зависимостью.
Если rxy < 0, то x
и y связаны отрицательной
зависимостью;
Переменные
задаваемые извне автономно от модели
называются …экзогенными
Переменные,
которые хар-т результат функцион-я
экспонируемой эконометрической системы,
наз Лаговой
По
графику можно сделать вывод о том, что
представленный на рисунке ряд : ряд
не является стационарным
По типу
функциональной зависимости между
переменными эконометрической модели
различают___ уравнения регрессии-линейные
и нелинейные
Под
верификацией модели понимается:- оценка
качества модели
Под
спецификацией модели понимается…
выбор регрессорое и вида модели
Покажите
на рисунке отклонение фактического
значения от расчетного:
Последствием
гетероскедастичности является то, что
Дисперсии оценок коэф регрессии
остаются несмещенной
Последствием
гетероскедастичности является то, что:
стандартные ошибки коэффициентов
становятся заниженными, а вычисленные
t-статистики – завышенными;
Последствия
включения в уравнение регрессии
несущественных переменных:-Оценки
параметров будут несмещенными,
эффективность оценок снизится
Последствия
мультиколлинеарности:- оценки
становятся очень чувствительными к
изменению отдельных наблюдений, оценки
коэффициентов остаются несмещенными
Последствия
невключения в уравнение регрессии
существенной переменной в общем случае:-
оценки параметров будут смещенными
Построено
несколько типов зависимостей и рассчитаны
значения F-статистики для них. Какая из
представленных регрессий является
значимой, если ____________критическое
значение F-статистики равно 2,56 при
уровне значимости 5 %? y=583⋅k
−0,29 ⋅r
−8,6 ⋅s0,69
, F = 2,75;
Предположения
теоремы Гаусса-Маркова включают в себя
ошибки регрессии
должны быть независимы друг от друга;
дисперсия ошибок регрессии постоянна
для всех наблюдений
Представленная
на рисунке модель будет описываться
уравнением:
При
вводе в командной строке Eviews
команды « plot X
Y » появятся: один график,
на котором будут изображены и значения
ряда X, и значения
ряда Y
При
возникновении мультиколлинеарности:
стандартные ошибки коэффициентов
увеличиваются, вычисленные t-статистики
становятся заниженными;
При
выполнении команды «genr
Z+@cor(X,Y)
в ивьюс будет создана переменная Z,
в которую будет записано Значение
коэф-та кореляции между рядами
При
выполнении команды «plot
X Z» в EViews
,будет построен график, на котором:- по
оси абсцисс будут расположены значения
ряда Z, а по оси ординат- ряда Х.
При
выполнении команды «scat
X Z» в ивьюс
будет построен график Зависимости
ряда Z на разных
плоскостях
При
выполнении команды agenr Z=@cor{X.Y)o в Eviews
будет создана переменная Z. в которую
будет записано….значение коэффициента
корреляции между рядами X и Y.
При
выполнении предпосылок метода наименьших
квадратов оценки параметров регрессионной
модели, рассчитанные с помощью МНК,
обладают свойствами…
— состоятельности, несмещенности
и эффективности
При
добавлении в линейной регрессионной
модели новых регрессоров, коэф детерм
R2 Увеличивается
При
добавлении в линейной регрессионной
модели новых регрессоров коэф-т
детерминации R2^ Уменьшается
При
изучении зависимости зарплаты в
Казахстане от возраста и пола была
получена следующая регрессия…W*1500+735’AGE
*1746’S где W-зарплата (тенге/месяц) AGE —
возраст (лет).Какойвывод можно сделать
о зависимости зарплаты от пола?…мужчины
получают в среднем зарплату больше
женщин на 1746 тенге/месяц
При
изучении зависимости зарплаты в
Казахстане от возраста и пола была
получена следующая регрессия
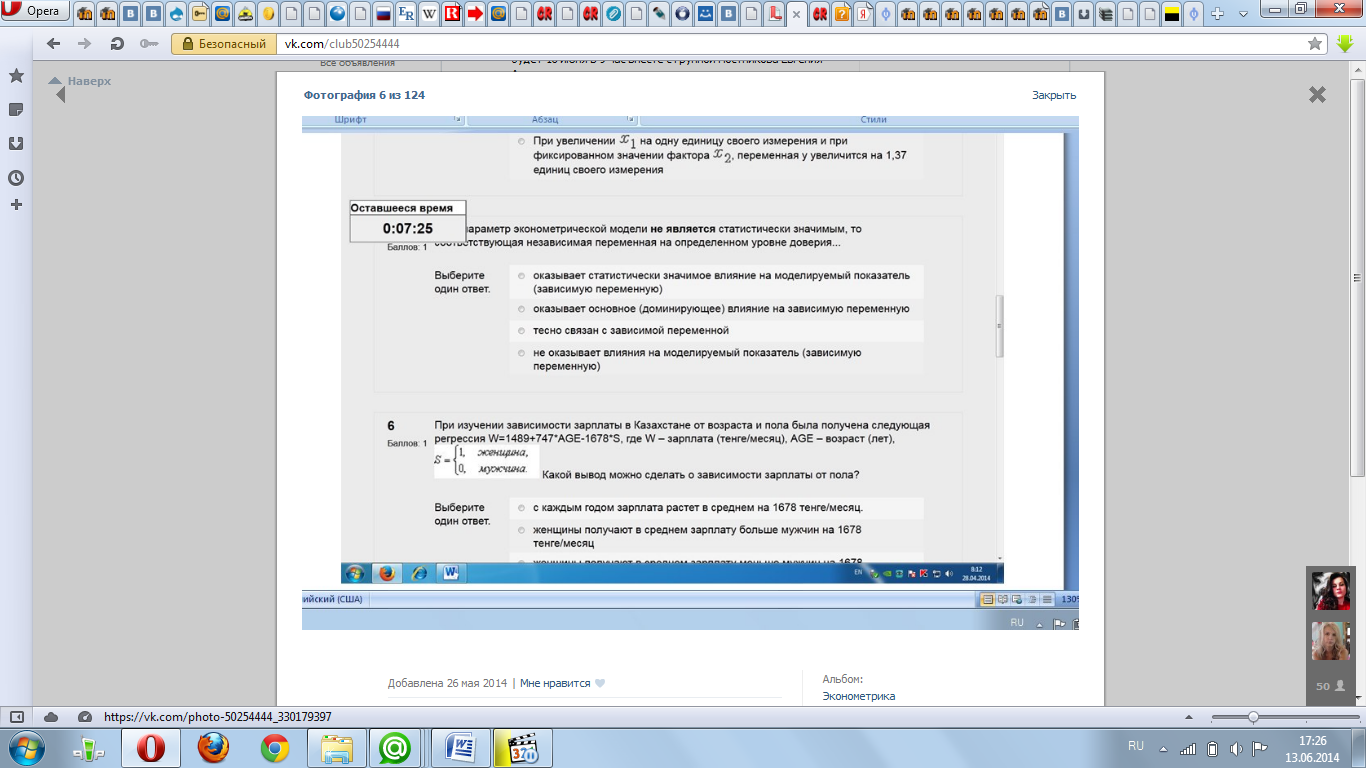 —Женщины
—Женщины
получают в среднем зарплату меньше чем
мужчины на 1678
При
изучении зависимости издержек
производства y (тыс. р.) от основных
производственных фондов x (тыс. р.)
была построена модель: y = 10 + 0,75x. Это
означает, что: 4) при увеличении основных
производственных фондов на 1 тыс.
р. издержки производства в среднем
увеличиваются на 750 р.
При
изучении зависимости издержек
производства y (тыс. р.) от основных
производственных фондов x (тыс. р.)
была построена модель: y = α + βx + ε.
В результате исследования были
получены следующие оценки параметров
регрессии: 0,45 β 7,5; α = = ˆ ˆ .
Доверительный интервал для βˆ на
5%-ном уровне значимости составил
(0,42; 0,48). Какой вывод можно сделать
о точности полученной оценки коэффициента
β? оценка β получена
с достаточно высокой точностью;
При
изучении зависимости издержек
производства y (тыс. р.) от основных
производственных фондов x (тыс. р.)
была построена модель: y = β0 +
β1x + ε . В результате исследования
были получены следующие оценки параметров
регрессии: 10,5 β 7,5; β 1 0 = = ˆ ˆ .
Доверительный интервал для 1 βˆ
на 5%-ном уровне значимости составил
[9,4; 11,6]. Какой вывод можно сделать о
точности полученной оценки коэффициента
β? оценка β
получена с достаточно высокой
точностью;
При
изучении зависимости издержек
производства y (тыс.руб)
от основных производственных фондов
x (тыс.руб) была построена
модель: y=10+0,75x . Это
означает, что: при увеличении основных
производственных фондов на 1 тыс.руб.
издержки производства в среднем
увеличиваются на 750 руб.
При
изучении зависимости издержек
производства у (тыс. руб.) от основных
производственных фондов х (тыс. руб.)
была построена модель: у=а+Bх+£ в результате
исследования были получены следующие
оценки параметров регрессии: a = 7.5B=0.45
.доверительныйинтервал для B на 5%-м
уровне значимости составил [0,42; 0,48].
Какой вывод можно сделать о точности
полученной оценки коэффициентаB?1)
оценка B получена с достаточно высокой
точностью;
При
изучении зависимости издержек
производства у (тыс.руб.) от инвестиций
в совершенствование технологий х
(тыс.руб.)была построена модель у=10-0,15х.
Это означает, что:- при увеличении
инвестиций в совершенствование
технологий на 1 тыс.руб. издержки
производства в среднем снижаются на
150 руб.
При
изучении зависимости между показ безраб
и инфл в Болгарии х=2,1 Не можем, поскольку
абсол значение т-статистики для
показателя безраб меньше крит
При
изучении зависимости между показателями
безработицы (x) и инфляции (y) в
Болгарии была построена модель и
получены оценки коэффициентов для этой
модели: y = 4,23 –2,41x. Расчетное значение
t-статистики для показателя безработицы
x получилось равным 2,1. Можем ли мы
принять гипотезу о значимости показателя
безработицы в модели с уровнем значимости
0,05, если критическое значение t-статистики,
найденное из таблиц распределения
Стьюдента, равно –2,57? не можем,
поскольку абсолютное значение
t-статистики для показателя
безработицы меньше критического
значения;
При
изучении зависимости между показателями
Безработицы (х ) и инфляции ( у ) в Болгарии
была построена модель и получены оценки
коэффициентов для этой модели:
у=4.23-2,41х. Расчетное значение t-статистики
для показателя безработицы х получилось
равным: 2,1. Можем ли мы принять гипотезу
о значимости показателя безработицы
в модели с уровнем значимости 0,06, если
критическое значение t-статистики,
наиденное из таблиц распределения
Стьюдента, равно 2,57?…Не можем, поскольку
абсолютное значение t-статистики для
показателя безработицы меньше
критического значения
При
изучении зависимости между показателями
безработицы (х ) и инфляции (у ) в Чехии
была построена модель и получены оценки
коэффициентов для этой модели: у=3,
22*1,75х. Расчетное значение t-стетистики
для показателя безработицы х получилось
равным: 1.65, Можем ли мы принять гипотезу
о значимости показателя безработицы
в модели с уровнем значимости 0.1. если
критическое значение t-статистики,
наиденное из таблиц распределения
Стьюдента.равно 1.75?…Не можем* поскольку
абсолютное значение t-статистики для
показателя безработицы меньше
критического значения
При
изучении зависимости между показателями
безработицы {х) и инфляции {у ) в Швеции
была построена модель и получены оценки
коэффициентов для этой модели:
у=2,4б-0.б9х. Расчетное значение t-статистики
для показателя безработицы х получилось
равным: 5.2. Можем пи мы принять гипотезу
о значимости показателя безработицы
в модели с уровнем значимости 0,05. если
критическое значение t-статистики,
найденное из таблиц распределения
Стьюдента, равно 2.57?…Можем, поскольку
абсолютное значение t-статистики для
показателя безработицы больше
критического значения t-статистики
При
изучении зависимости между показателями
безработицы и инфляции в Швеции Можем,
поскольку абсол значение т-статистики
для показателя безраб больше крит
При
исследовании выбора обнаружено
«аномальное» значения фактора Y для
одного наблюдения. При каких условиях
корректно будет провести исключение
соответствующего наблюден из выбора
… В случае если «аномальное» значение
Y соответствует действительности, но
это отличие невозможно объяснить в
рамках проводимого исследования
При
исследовании зависимости сумм» активов
банка (у) от собственного капитала {к),
привлеченных ресурсов [г) и объема
вложений в государственные ценные
бумаги (s) было построено несколько
типов зависимостей и рассчитаны значения
F-статистики для них. Какая из представленных
регрессий является значимой, если
критическое значение F-статистики равно
2,56 при уровне значимости 5%?…у=583*К…
При
исследовании зависимости суммы активов
банка (y) от собственного капитала
(k), привлеченных ресурсов (r) и
объема вложений в государственные
ценные бумаги (s) было
При
исследовании зависимости суммы активов
банка (у) от собственного капитала (к).
у=у85-0,46к-19r+0,48s,
F=4,75
При
исследовании зависимости суммы активов
банка (у) от собственного капитала [If),
привлеченных ресурсов [г) и объема
вложений в государственные ценные
бумаги Is) было построено несколько
типов зависимостей и рассчитаны значения
F-статистики для них. Какая из представленных
регрессий является значимой, если
критическое значение F-статистики равно
3,74 при уровне значимости 1%?ОТВЕТ : 4
1)F=2.67 2) F=2.75 3). F=3.6S 4) у=е^*** F=4.75
При
исследовании зависимости суммы активов
банка (у) от собственного капитала(к),
привлеченных ресурсов (r) и объема
вложений в гос цен бумаги (s) было
построено несколько типов зависимостей
и рассчитаны значения F-статистики для
них. Какая из представленных регрессий
является значимой, если критическое
значение F-статистики равно 2,56 при
уровне значимости 5%- у=583к^-029 *r^-8,6
*s^0,69, F=2,75
При
отсутствии свободного члена регрессии
В0 в уравнении… нарушается предпосылка
теоремы Гаусса-Маркова: E(£i)=0
При оценке
качества уравнения регрессии был
рассчитан коэффициент детерминации
R^2=0.91. Это означает, что…- построенная
модель достаточно хорошо подогнана к
выборочным данным
При оценке
качества уравнения регрессии был
рассчитан коэффициент детерминации
R^2=0.18. Это означает, что…-построенная
модель довольно плохо подогнана к
выборочным данным
При
оценке модели вида y=
a0+a1yt-1+a2
yt-2
+ εt необходимо
написать в командной строке: Is
y с ar(1)
ar(2)
При
переходе к линейному виду для …
зависимости вводится замена Х=лп(х),
У=лн(у) Логарифмический
При
переходе к линейному виду для____
зависимости зависимая переменная
преобразуется по формуле Y=ln(y) —
степенной, экспоненциальной
При
переходе обратно от построенного
вспомогательного линейного уравнения
у=в0+в1х к нелинейному виду, для парной
степенной зависимости в0=ев0,
в1=в1
При
переходе обратно от построенного
вспомогательного линейного уравнения
Y=B0-B1X к нелинейному виду, для парной
гиперболической зависимости Y=B0+B1 1/X
надо найти искомое значение коэффициентов
по формуле:B0=BOB1=B1
При
переходе обратно от построенного
линейного уравнения
![]()
к нелинейному виду, для парной степенной
зависимости![]()
надо найти значение коэффициентов по
формуле
![]()
При
перходе к линейному виду для______зависимости
замена X=ln(x),Y=ln(y)— степенной
При
построении какого уравнения в EVews
вводится команда Is у с 1/х1 1/х2 1/хЗ…
Гиперболического
При
построении какого уравнения в EViews
вводится команда Is
log(y)
c x1
x2 x3
— Экспоненциального
При
построении какого уравнения в EViews
вводится команда Is log( у) с log(x1) lоg(х2)
lоg(хЗ)…
степенного
При
построении уравнения множественной
регрессии проверку тесноты связи между
независимыми переменными (объясняющими
переменными, регрессорами, факторами)
модели осуществляют на основе…-матрицы
парных коэффициентов линейной корреляции
При
проведении RESET-теста в EViews линейная
спецификация регрессии является
ошибочной с уровнем доверия 0.9, если
Р-знаиение = Prob. F…меньше 0.1
При
проведении RESET-теста в EViews линейная
спецификация регрессии является
ошибочной с уровнем доверия 0.95. если
Р-значение = Prob. F….меньше 0.05
Применение
обычного МНК непосредственно к системе
одновременных уравнений в структурной
форме приводит в общем случае к…
смещенным и несостоятельным оценкам
коэффициентов
Примера
фиктивны переменных в эконометрической
модели зависимости 1м2 жилья являются
площадь жилья;
величина прожиточного минимума в
регионе
Примерами
фиктивных переменных в эконометрической
модели зависимости стоимости 1м^2 жилья
НЕ ЯВЛЯЮТСЯ… — площадь жилья; величина
прожиточного минимума в регионе
Проверка
наличия коллинеарных факторов в
эконометрической модели х1
и х2
Процесс
![]()
является: нестационарным , случайным
блужданием , авторегрессионным процессом
1-го порядка
Процесс
![]()
является: процессом белого шума ,
стационарным
Процесс
![]()
является: процессом скользящего
среднего 1-го порядка , стационарным
Процесс
ARMA (p,q)
называется : авторегрессионным
процессом скользящего среднего
Пусть
в уравнении Н эндогенных переменных и
D экзогенных переменных, которые в этом
уравнение (в его структурной форме)
отсутствуют Тогда в случае, если 0=3.
н-2. уравнение является:…сверхидентифицируемым
Пусть
качественный признак принимает 4
значения, сколько фиктивных переменных
надо ввести в уравнение 3
Пусть
оцененное уравнение регрессии имеет
вид: у=-2,3+0,4х1-3,7х2+1,2х3. Что можно
сказать об интерпретации значения
коэффициента при переменной х1?—
при увеличении переменной х1 на единицу
ее измерения при неизменных значениях
других переменных у увеличится в среднем
на 0,4 единиц своего измерения.
Рассматривается
зависимость объема выпускаемой продукции
Q от объема трудовых L и материальных
затрат К. Результатом оценки параметров
производственной функции Кобба-Дугласа
стала модель Q=12.8*K^0.4*L^0,3. Это означает,
что…средние издержки, рассчитанные
на единицу продукции, растут по мере
расширения масштабов производства
Расширенный
тест Дики Фуллера показывает, что : ряд
не является стационарным относительно
первой разности , ряд на разностей
исходного ряда содержит единичный
корень
Расширенный
тест Дики-Фуллера показывает, что : ряд
содержит единичный корень , ряд не
является стационарным
Расширенный
тест Дики-Фуллера показывает, что: ряд
не является стационарным , ряд не
является стационарным относительно
линейного тренда
Регрессионная
модель вида y=a+bx1+c(x2^2)+ɛ является
нелинейной относительно…- переменной
Х2
Связь
между объёмом продаж и переменными
«Цена одного галлона» и «Расходы на
рекламу» являются тесной
Слабая
стационарность временного ряда
означает…самый большой
Среднегодовые
цены на бензин во всех субъектах
Российской Федерации за 2011 год относятся
… к пространственным данным .
Стандартное
нормальное распределение имеет параметры
математическое ожидание=0, дисперсия=1
Стационарность
временного ряда означает отсутствие
…тренда
Степенная
зависимость записана уравнением-
![]()
Стоится
эконометрическая модель уравнения
множественной регрессии для зависимости
у от пяти факторов у=f(x1,x2,x3,x4)+E
Строгая
стационарность временного ряда означает:
независимость распределений уровней
ряда от сдвига по времени
Структура
сдвига временного ряда …характерезует
разные внезапные ….
Суть
коэффициента детерминации состоит в
следующем:- коэффициент определяет
долю общего разброса значений,
объясненного уравнением регрессии
Сформулируйте
необходимое условие идентифицируемости
структурного уравнения (порядковое)….число
отсутствующих экзогенных переменных
в уравнении больше числа эндогенных
переменных входящих в уравнение без
единицы
Сформулируйте
необходимое условие идентифицируемости
структурного уравнения (порядковое):…
число отсутствующих экзогенных
переменных в уравнении равно числу
эндогенных переменных, входящих ответ.
уравнение, плюс единица
Тест
Вэльдэ применяется для… проверки
гипотез равенства коэффициентов
какому-либо значению или соотношения
коэффициентов между собой
Тест Чоу
применяется для выявления структурных
сдвигов
Тип данных
«Alpha» в ивьюс соответствует
ряду, содержащему Текстовую информацию
Удаление
из выборки наблюдений, значения факторов
для которых существенно больше или
меньше средних по выборке позволяет
добиться…однородности выборки
Укажите
тест, который используется для выявления
гетероскедастичности? Уайта
Укажите
тест, который не используется для
выявления гетероскедастичности-
Дарбина-Уотсона
Уравнение
множественной регрессии имеет вид
у=-27,16+1,37 х₁-0,29 х₂. Параметр при
переменной х2 означает следующее:-
при увеличении х2 на единицу своего
измерения и при фиксированном значении
фактора х1, переменная у уменьшится на
0,29 единиц своего измерения
Уравнение
множественной регрессии имеет вид:
у=-27,16+1,37 х₁-0,29 х₂. Параметр а₁=1.37
означает следующее:-при увеличении
х₁ на одну единицу своего измерения и
при фиксированном значении фактора
х₂, переменная у увеличится на 1,37 единиц
своего измерения
Уравнение
регрессии называется значимым в целом,
если- есть достаточно высокая
вероятность того, что существует хотя
бы один коэффициент, отличный от нуля
Уравнение
регрессии называется незначимым в
целом, если- есть достаточно высокая
вероятность того, что все коэффициенты
равны 0
Установите
соответствие 1)команда для созд ряда
Х, 2) ком для созд графика ряда Х, 3) ком
для созд группы гр1 и рядов Х и У, 4) ком
для созд гр зависимости А. скат Х У, Б.
Сериес Х, В. Груп, Д. лайн 1-Б, 2-Д, 3-В,
4-А
Фиктивные
переменные заменяют ….качественные
переменные
Фиктивные
переменные эконометрической модели…-
используются в случае совокупностей
данных; отражают качественные признаки
исследуемого объекта наблюдения
Фиктивными
переменными в уравнении множественной
регресси являются… качественные
переменные, преобразованные в
количественные
Фильтрацию
данных (удаление сильно отличающихся
наблюдений) можно проводить, если…определена
причина такого отклонения
Функционал
метода наименьших квадратов для случая
парной линейной регрессии выглядит
следующим образом: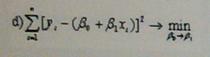
Функционал
метода наименьших квадратов для случая
парной регрессии выглядит следующим
образом:
![]()
Циклические
колебание могут связаны с…сезонность
некоторых видов …
Чем на
ваш взгляд более оправдано использование
скорректированного коэффициента
детерминации R^2adj,
чем R^2 для сравнения двух 1) Попыткой
устранить эффект, связанный с увеличением
значения R2 при добавлении регрессоров.
Чем, на
ваш взгляд, более оправдано использование
скорректированного коэффициента
детерминации R2 adj, чем R2 100
для сравнения двух линейных регрессионных
моделей, одна из которых отличается от
другой добавленными новыми регрессорами?
попыткой устранить эффект, связанный
с увеличением значения R2 при
добавлении регрессоров;
Что бы
оценить модель ARIMA (1.1.0)в командной
строке рабочего окна Eviews необходимо
ввести …isd(y) car(1)
Что не
является целью исследований
эконометрических явлений и процессов?
Разработка теоретико-экон моделей,
поиск зависимостей между признаками…
Что
обозначает команда genr X=2+9*nrnd?… Создание
ряда чисел X, имеющего нормальное
распределение с математическим ожиданием
2 и дисперсией 81
Что
обозначает команда genr Y=10-t-20*rnd?… Создание
ряда чисел Y. представляющего собой
равномерно распределенные на интервале
(10;30) случайные числа
Что
означает «правильно специфицированное
уравнение регрессии» правильная
функциональная зависимость
Что
означает команда genr
Y=10+20*rnd?
Создание ряда чисел У, представляющего
собой равномерно распред-е на интервале
(10;20) случ
Эконометрика
— это… наука, которая дает количественное
выражение взаимосвязей экономических
явлений и процессов
Эконометрическое
моделирование зависимости по неоднородной
совокупности данных может осуществляться
на основе…-разделения неоднородной
совокупности данных на однородные;
использования фиктивных переменных
Экспоненциальная
зависимость записана уравнением
у=ув0+в1*х1+….+вн*хн+Е
Экспоненциальная
зависимость записана уравнением…
![]()
 Выберите
Выберите
верные утверждения — коэфф Z значим,
а С не значим на уровне значимости 0,05
Эндогенные
переменные в системах одновременных
уравнений в общем случае… коррелируют
со случайными ошибками уравнений
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
ТВЕРСКОЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
КАФЕДРА «БУХГАЛТЕРСКИЙ УЧЕТ, АНАЛИЗ И АУДИТ»
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Тверь 2009
________________________________________________________________________________
Раздел 4. Спецификация переменных
в уравнениях регрессии
Тематические вопросы: Эконометрические модели: общая характеристика,
различия статистического и эконометрического подхода к моделированию.
Спецификация
переменных
в
уравнениях
регрессии.
Ошибки
спецификации. Обобщенная линейная модель множественной регрессии.
Обобщенный
метод
наименьших
квадратов.
Проблема
гетероскедастичности.
Автокорреляция.
Анализ
линейной
модели
множественной регрессии при гетероскедастичности и автокорреляции.
Фиктивные переменные: общий случай. Множественные совокупности
фиктивных переменных. Фиктивные переменные для коэффициентов
наклона. Тест Чоу. Моделирование: влияние отсутствия переменной,
которая должна быть включена; влияние включения в модель переменной,
которая не должна быть включена. Замещающие переменные.
Минимум содержания в соответствии с ГОС: линейные регрессионные
модели с гетероскедастичными и автокоррелированными остатками;
регрессионные модели с переменной структурой (фиктивные переменные).
4.1.Выбор формы модели регрессии: проблемы спецификации, основные
регрессионные модели………………………………………………………………..2
4.2.Ошибки спецификации: виды, обнаружение, корректировка……………5
4.3.Проблема автокорреляции остатков в моделях регрессии………………..6
4.4.Проблема гетероскедастичности остатков
в моделях регрессии………………………………………………………………….12
4.5.Обобщенный метод наименьших квадратов………………………………..18
4.6.Фиктивные переменные в регрессионных моделях……………………….18
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
4.1.Выбор формы модели регрессии: проблемы спецификации,
основные регрессионные модели
Многообразие и сложность экономических процессов предопределяет
многообразие моделей, используемых для эконометрического анализа. С
другой стороны, это существенно усложняет процесс нахождения
максимально адекватной формулы зависимости. Для случая парной
регрессии подбор модели обычно осуществляется по виду расположения
наблюдаемых точек на корреляционном поле. Однако нередки ситуации,
когда расположение точек приблизительно соответствует нескольким
функциям и необходимо из них выявить наилучшую. Например,
криволинейные зависимости могут аппроксимироваться полиномиальной,
показательной, степенной, логарифмической функциями. Еще более
неоднозначна ситуация для множествен-нои регрессии, так как наглядное
представление статистических данных в этом случае невозможно.
◊Эконометрическая модель – экономико-математическая модель,
параметры которой оцениваются с помощью методов математической
статистики; выступает в качестве средства анализа и прогнозирования
конкретных экономических процессов как на макро-, так и на
микроэкономическом
уровне
на
основе
реальной
статистической
информации. ◊Экономико-статистическая модель – вид экономикоматематической модели; описывает зависимости, носящие вероятностный
(стохастический) характер и возникающие под воздействием множества
причин и следствий в массовых, повторяющихся явлениях; предназначена
прежде всего для выявления тенденций и закономерностей, которые были
в прошлом, чтобы с их помощью оценивать будущее
Стандартная схема эконометрического исследования
осуществлении ряда последовательных процедур:
состоит
в
•
Подбор
начальной
модели:
осуществляется
на
экономической теории, предыдущих знаний об
исследования, опыта исследователя и его интуиции.
•
Оценка
параметров
статистических данных.
•
Осуществление тестов проверки качества модели (обычно
используются t-статистики для коэффициентов регрессии, Fстатистика для коэффициента детерминации и ряд других
тестов).
•
При наличии хотя бы одного неудовлетворительного ответа по
какому-либо тесту модель совершенствуется с целью устранения
выявленного недостатка.
•
При положительных ответах по всем проведенным тестам модель
считается качественной. Она используется для анализа и
модели
2
на
основе
основе
объекте
имеющихся
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
прогноза объясняемой переменной.
Основные проблемы спецификации модели регрессии:
•
Качественная модель является подгонкой спецификации модели
под имеющийся набор данных. Поэтому вполне реальна картина,
когда исследователи, обладающие разными наборами данных,
строят разные модели для объяснения одной и той же
переменной.
•
Использование
модели
для
прогнозирования
значений
объясняемой переменной. Иногда хорошие с точки зрения
диагностических тестов модели обладают весьма низкими
прогнозными качествами.
Признаки «хорошей» модели:
•
Скупость (простота): модель должна быть максимально простой,
т.е. из двух моделей, приблизительно одинаково отражающих
реальность, предпочтение
отдается
модели,
содержащей
меньшее число объясняющих переменных.
•
Единственность: для любого набора статистических данных
определяемые коэффициенты регрессии должны вычисляться
однозначно.
•
Максимальное соответствие: уравнение тем лучше, чем большую
часть разброса зависимой переменной оно может объяснить, т.е.
с максимально возможным скорректированным коэффициентом
детерминации.
•
Согласованность с теорией: модель обязательно должна
опираться на теоретический фундамент, т.к. в противном случае
результат использования регрессионного уравнения может быть
неадекватным.
•
Прогнозные
качества:
модель
может
быть
признана
качественной, если: полученные на ее основе прогнозы
подтверждаются реальностью; модель имеет малое значение
относительной ошибки прогноза ( V = S y ) при отсутствии
автокорреляции остатков.
Основные регрессионные модели:
◊Коэффициент эластичности переменной Y по переменной Х (Э) как
относительное изменение Y вследствие единичного относительного
изменения X, часто на практике, как процентное изменение Y для
однопроцентного изменения X.
3
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
Функционал
ьная форма
Уравнение
Линейная
модель
Y = β 0+ β 1 X 1 + β 2 X 2 +
Двойная
логарифм
ическая
модель
ln Y = β 0 + β 1 ln X 1 +
Логлинейная
модель
ln Y = β 0 + β 1 X 1 +
Линейнологарифм
ическая
модель
Y = β 0 + β 1 ln X 1 +
Обратная
модель
Степенная
модель
+ … + β m X m + ε
+ β 2 ln X 2 + … +
+ β m ln X m + ε
+ β 2 X 2 + … +
+ β mXm + ε
+ β 2 ln X 2 + … +
+ β m ln X m + ε
Y = β0 + β1
1
+
X1
+ β2
1
+ … +
X2
+ βm
1
+ ε
Xm
Интерпретация
коэффициента (ов) регрессии
предельный
эффект
независимого
фактора,
т.е.
прирост зависимой переменной
при изменении независимого
фактора на единицу
процентное
изменение
зависимой
переменной
вследствие
единичного
относительного прироста (напр.,
однопроцентного) независимого
фактора
темп
прироста
зависимой
переменной по объясняющей
переменной, т.е. процентное
изменение
зависимой
переменной
при
изменении
независимого
фактора
на
единицу (при интерпретации
коэффициент следует умножать
на 100%)
изменение
зависимой
переменной
вследствие
единичного
относительного
прироста
(напр.,
однопроцентного) независимого
фактора (при интерпретации
коэффициент следует делить на
100%)
скорость
асимптотического
приближения
зависимой
переменной
к
некоторому
пределу
(напр.,
β0 )
при
увеличении
объясняющей
переменной
Y = β 0 + β 1 X + β 2 X 2 + аналогично
+ … + β m X m + ε
(после
линейной
X = X1, X 2 = X 2 ,
…, X m = X m
Показател
ьная
модель
Y = β 0aβ X eε
модели
замены:
Э= β
X
Y
Э= β ,
эластичность
постоянна
Э = βX,
эластичность
растет
с
ростом Y
Э= β
1
,
Y
эластичность
убывает
с
ростом Y
1
Э = β−
XY
аналогично
линейной
модели
)
аналогично
лог-линейной
модели
(после
логарифмирования)
4
Коэффициент
эластичности,
Э
аналогично
лог-линейной
модели
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
4.2.Ошибки спецификации: виды, обнаружение, корректировка
◊Ошибка спецификации как неправильный выбор функциональной
формы или набора объясняющих переменных в регрессионной модели.
Основные типы ошибок спецификации:
•
Отбрасывание значимой переменной: в результате оценки,
полученные с помощью МНК по уравнению, являются
смещенными и несостоятельными, следовательно, интервальные
оценки и результаты проверки соответствующих гипотез будут
ненадежными.
•
Добавление незначимой переменной: в результате оценки
коэффициентов, найденные с помощью МНК для модели,
остаются, как правило, несмещенными и состоятельными; однако
их точность уменьшится, увеличивая при этом стандартные
ошибки, т.е. оценки становятся неэффективными, что отразится
на их устойчивости; увеличение дисперсии оценок может
привести
к
ошибочным
результатам
проверки
гипотез
относительно значений коэффициентов регрессии, расширению
интервальных оценок.
•
Выбор неправильной функциональной формы: в результате
оценки коэффициентов, найденные с помощью МНК для модели,
как
правило,
являются
смещенными,
либо
ухудшаются
статистические свойства оценок коэффициентов регрессии и
других показателей качества уравнения; прогнозные качества
модели в этом случае очень низки.
•
Проблемы в использовании переменных: невозможно получение
данных по переменной, невозможно измерить количественно
переменную; такие ситуации характерны для переменных
социально-экономического
характера
(напр.,
качество
образования).
Обнаружение и корректировка ошибок спецификации:
Примеры обнаружения ошибок
спецификации
Примерная корректировка ошибок
спецификации
Если в уравнении регрессии В дальнейшем эту переменную
имеется одна несущественная следует
исключить
из
переменная, то она обнаружит рассмотрения
себя по низкой t-статистике
Если в уравнении несколько
статистически
незначимых
объясняющих
переменных,
обнаруженных по низкой tстатистике
Следует
построить
другое
уравнение
регрессии
без
незначимых
переменных
и
провести анализ качества с
помощью F-статистики.
5
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
Проверить
наличие
мультиколлинеарности
и
провести
соответствующие
меры.
Невозможность
получения Подбор
переменной
данных (количественных) по заместителя:
◊Замещающие
переменной.
переменные
переменные,
которые
вводятся
в
эконометрические
модели
вместо
тех
переменных,
которые
не
поддаются
измерению.
Замещающая
переменная
должна
коррелировать с переменной,
которую она замещает.
Существует ряд тестов обнаружения ошибок спецификации, среди
которых можно выделить:
•
Тест Рамсея RESET
•
Тест (критерий) максимального правдоподобия
•
Тест Валда
•
Тест множителя Лагранжа
•
Тест Хаусмана
•
Box-Сох преобразование
Суть данных тестов состоит либо в осуществлении преобразований
случайных отклонений, либо масштаба зависимой переменной с тем,
чтобы можно было сравнить начальное и преобразованное уравнения
регрессии на основе известного критерия. Подробное описание данных
тестов выходит за рамки данного курса и может быть найдено в
дополнительной литературе.
4.3.Проблема автокорреляции остатков в моделях регрессии
Автокорреляция остатков в моделях регрессии как нарушение важной
предпосылки построения качественной регрессионной модели по МНК
(одного из условий Гаусса-Маркова): «Случайные отклонения являются
независимыми друг от друга: cov(εi,εj)=0, i‡j, cov(εi,εj)=σ2, i=j».
◊Автокорреляция
(последовательная
корреляция)
остатков
определяется
как
корреляция
между
остатками
(отклонениями),
6
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
упорядоченными во времени (временные ряды) или в пространстве
(перекрестные данные): cov(εt-1,εt)<>0.
Автокорреляция остатков (отклонений) обычно встречается в
регрессионном анализе при использовании данных временных рядов. При
использовании
перекрестных
данных
наличие
автокорреляции
(пространственной корреляции) крайне редко. В экономических задачах
значительно
чаще
встречается
так
называемая
положительная
автокорреляция (cov(εt-1,εt) > 0), чем отрицательная автокорреляция
(cov(εt-1,εt)< 0).
Примечание:
Порядок автокорреляции определяется периодом (p) прошлых
значений случайного члена εt-p, относительно периода (t) значения
случайного члена εt , между которыми обнаружена корреляция: cov(εtНапример, автокорреляция первого порядка формализуется
p,εt)<>0.
следующим образом: εt=ρεt-1+ ut, где ρ – коэффициент автокорреляции
первого порядка (-1;1).
Основные причины, вызывающие появление автокорреляции:
•
Ошибки спецификации: неучет в модели какой-либо важной
объясняющей переменной либо неправильный выбор формы
зависимости обычно приводит к системным отклонениям точек
наблюдений от линии регрессии, что может привести к
автокорреляции.
•
Инерция:
многие
экономические
показатели
(например,
инфляция, безработица, ВНП и т.п.) обладают определенной
цикличностью,
связанной
с
волнообразностью
деловой
активности.
•
Эффект паутины: во многих сферах экономики экономические
показатели реагируют на изменение экономических условий с
запаздыванием (временным лагом), в связи с чем неадекватно
предполагать случайность отклонений друг от друга.
7
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
• Сглаживание данных: зачастую данные по некоторому
продолжительному временному периоду получают усреднением
данных по составляющим его подынтервалам, что может
привести к определенному сглаживанию колебаний, которые
имелись внутри рассматриваемого периода.
Последствия автокорреляции:
•
Истинная автокорреляция не приводит к смещению оценок
коэффициентов регрессии. Оценки параметров, оставаясь
линейными и несмещенными, перестают быть эффективными.
Следовательно, они перестают обладать свойствами наилучших
линейных несмещенных оценок (BLUE-оценок).
•
Дисперсии оценок являются смещенными. Зачастую дисперсии,
вычисляемые
по
стандартным
формулам,
являются
заниженными, что приводит к увеличению t-статистик. Это
может привести к признанию статистически значимыми
объясняющие
переменные,
которые
в
действительности
таковыми могут и не являться.
•
Оценка дисперсии регрессии S2 является смещенной оценкой
истинного значения, во многих случаях заниженной, что
вызывает
занижение
оценок
стандартных
ошибок
коэффициентов.
•
В силу вышесказанного выводы по t- и F-статистикам,
определяющим
значимость
коэффициентов
регрессии
и
коэффициента детерминации, возможно, будут неверными.
Вследствие этого ухудшаются прогнозные качества модели.
Методы обнаружения автокорреляции:
•
Графический метод: 1) последовательно-временные графики,
увязывающие отклонения с моментами их получения, т.е. по оси
абсцисс обычно откладываются либо момент получения
статистических данных, либо порядковый номер наблюдения, а по
оси ординат отклонения (оценки отклонений); 2) наложение на
график реальных колебаний зависимой переменной графика
колебаний
переменной
по
уравнению
регрессии
и
сопоставление: если эти графики пересекаются редко, то можно
предположить наличие положительной автокорреляции остатков,
и др. варианты.
•
Метод рядов: последовательно определяются знаки отклонений,
причем ряд определяется как непрерывная последовательность
одинаковых знаков, количество знаков в ряду называется
длиной
ряда.
Визуальное
распределение
знаков
свидетельствует о характере связей между отклонениями. Если
рядов слишком мало по сравнению с количеством наблюдений, то
8
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
вполне вероятна положительная автокорреляция. Если же рядов
слишком много, то вероятна отрицательная автокорреляция. Для
более
детального
анализа
имеются
формализованные
процедуры.
•
Критерий Дарбина-Уотсона: суть состоит в вычислении
статистики Дарбина-Уотсона (в случае неприменимости –
статистики Дарбина) и на основе ее величины осуществлении
выводов об автокорреляции.
◊Статистика Дарбина-Уотсона предназначена для обнаружения
автокорреляции первого порядка, основана на изучении остатков
уравнения регрессии:
T
DW =
∑ (e
t=2
− et − 1 )
t
T
∑
2
≈ 2(1 − ret ,et − 1 ) ,
2
t
e
t=1
где T – число наблюдений (обычно временных периодов), et – остатки
уравнения регрессии, ret ,et − 1 – выборочный коэффициент автокорреляции
T
первого порядка:
ret ,et − 1 =
∑
t=1
T
∑
t=1
et et − 1
2
t
e
T
∑
t=1
.
2
t−1
e
Ограничения использования статистики Дарбина-Уотсона:
•
Критерий DW применяется лишь для тех моделей, которые
содержат свободный член.
•
Предполагается, что случайные отклонения определяются по
следующей
итерационной
схеме:
εt=ρ εt-1+ ut, называемой авторегрессионной схемой первого
порядка AR(1), где ut — случайный член.
•
Статистические
данные
должны
иметь
одинаковую
периодичность (т. е. не должно быть пропусков в наблюдениях).
•
Критерий Дарбина-Уотсона не применим для регрессионных
моделей, содержащих в составе объясняющих переменных
зависимую переменную с временным лагом в один период, т. е.
для так называемых авторегрессионных моделей вида:
y t = β 0 + β 1 x t1 + … + β m x tm + γ y t − 1 + ε t .
9
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
Общая схема использования статистики Дарбина-Уотсона:
•
По
построенному
эмпирическому
уравнению
регрессии
ˆt = b0 + b1 x t1 + … + bm x tm определяются значения отклонений
y
ˆt для каждого наблюдения t=1,2…T.
et = y t − y
•
Рассчитывается статистика DW:
T
DW =
∑ (e
t=2
t
− et − 1 )
T
∑
t=1
•
2
et2
По таблице критических точек Дарбина-Уотсона определяются
границы приемлемости (dl,du) и осуществляются выводы по
правилу:
dl < DW < du
вывод о наличии автокорреляции
не определен
du < DW < 4 — du
автокорреляция отсутствует
4 — du < DW < 4 — dl
вывод о наличии автокорреляции
не определен
4 — dl < DW < 4
существует
автокорреляция
отрицательная
Или применяется грубое правило: «автокорреляция остатков
отсутствует, если 1,5 < DW < 2,5».
◊Статистика Дарбина используется для обнаружения автокорреляции
в авторегрессионных моделях вида y t = β 0 + β 1 x t1 + … + β m x tm + γ y t − 1 + ε t :
h = ρˆ
n
n
≈
(
1
−
,
5
DW
)
1 − nSy2t − 1
1 − nSy2t − 1
,
2
где ρˆ — оценка автокорреляции первого порядка, Syt − 1 — выборочная
дисперсия коэффициента при лаговой переменной yt-1 , n -число
наблюдений. При большом объеме выборки n и ρ=0 статистика h имеет
стандартизированное нормальное распределение (h~N(0,1)).
Ограничения использования статистики Дарбина: только одна лаговая
переменная, только автокорреляция первого порядка, невозможность
2
вычисления при nS yt − 1 = 1 .
10
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
Общая схема использования статистики Дарбина:
•
По
построенному
эмпирическому
уравнению
регрессии
y t = β 0 + β 1 x t1 + … + β m x tm + γ y t − 1 + ε t определяются значения для
расчета h-статистики.
•
Рассчитывается h-статистика:
h = (1 − 0,5DW )
•
n
1 − nSy2t − 1
По
таблицам
критических
точек
стандартизированного
нормального распределения (функции Лапласа) по заданному
уровню значимости α определяется критическая точка uα/2 из
условия Ф(uα/2) = (1-α)/2 и сравнивается h с uα/2: если h < uα/2, то
делается вывод об отсутствии автокорреляции, в противном
случае – гипотеза об отсутствии автокорреляции должна быть
отклонена.
Устранение автокорреляции:
•
При установлении автокорреляции необходимо в первую
очередь проанализировать правильность спецификации модели.
Если после ряда возможных усовершенствований регрессии
(уточнения состава объясняющих переменных либо изменения
формы зависимости) автокорреляция по-прежнему имеет место,
то, возможно, это связано с внутренними свойствами ряда
отклонений.
•
В случае, если наличие автокорреляции связано с внутренними
свойствами
ряда
отклонений,
возможны
определенные
преобразования, устраняющие автокорреляцию. Среди них
выделяется авторегрессионная схема первого порядка AR(1),
которая, в принципе, может быть обобщена в AR(p), p = 2, 3, …
•
Для
применения
указанных
схем
необходимо
оценить
коэффициент корреляции между отклонениями. Это может быть
сделано различными методами: на основе статистики ДарбинаУотсона, Кохрана-Оркатта, Хилдрета-Лу и др.
•
В случае наличия среди объясняющих переменных лаговой
зависимой переменной наличие автокорреляции устанавливается
с помощью h-статистики Дарбина. А для ее устранения в этом
случае предпочтителен метод Хилдрета-Лу.
11
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
Авторегрессионная схема первого порядка AR(1):
•
Оценивается регрессия Y = b0 + b1 X + e и находятся остатки et ,
тогда наблюдениям t и (t-1) соответствуют формулам:
y t = b0 + b1 x t + et , y t − 1 = b0 + b1 x t − 1 + et − 1 .
•
По остаткам, подверженным воздействию авторегрессии первого
порядка
εt=ρ εt-1+ ut,
находится
оценка
коэффициента
автокорреляции первого порядка: напр., на основе статистики
Дарбина-Уотсона ρˆ ≈ ret , et − 1 = 1 − 0,5DW .
•
Оценка автокорреляции используется для пересчета данных для
*
*
*
уравнения регрессии: y t = b0 + b1 x t + v t ,
y t* = y t − ρˆy t − 1 ,
x t* = x t − ρˆx t − 1 ,
b0* = b0 (1 − ρˆ) ,
где
v t = et − ρˆet − 1 ; причем для первого наблюдения выборки обычно
используется
y1* =
•
поправка
Прайса-Винстена:
x1* =
1 − ρˆ2 ⋅ x1 ,
1 − ρˆ2 ⋅ y1 .
Цикл повторяется (процесс останавливается, как только
обеспечивается
достаточная
сходимость,
т.е.
результаты
перестают существенно улучшаться).
4.4.Проблема гетероскедастичности остатков
в моделях регрессии
Гетероскедастичность остатков в моделях регрессии как нарушение
важной предпосылки построения качественной регрессионной модели по
МНК (одного из условий Гаусса-Маркова): «Дисперсия случайных
отклонений εi
постоянна для всех наблюдений: D(εi)=D(εj)=σ2».
Выполнимость данной предпосылки называется гомоскедастичностъю
(постоянством
дисперсии
отклонений).
Невыполнимость
данной
предпосылки
называется
гетероскедастичностъю
(непостоянством
дисперсий отклонений).
◊Гетероскедастичность остатков определяется как различные
вероятностные распределения случайных отклонений при различных
наблюдениях, что основывается на априорной причине, вызывающей
большую ошибку (отклонение) при одних наблюдениях и меньшую — при
других.
Проблема гетероскедастичности в большей степени характерна для
перекрестных данных и довольно редко встречается при рассмотрении
временных рядов.
12
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
Виды гетероскедастичности:
•
истинная (вызывается непостоянством дисперсии случайного
члена, ее зависимостью от различных факторов),
•
ложная (вызывается ошибочной спецификацией модели).
Последствия гетероскедастичности:
•
Истинная гетероскедастичность не приводит к смещению оценок
коэффициентов регрессии. Оценки коэффициентов по-прежнему
остаются несмещенными и линейными.
•
Оценки не будут эффективными (т.е. они не будут иметь наименьшую
дисперсию по сравнению с другими оценками данного параметра).
Они не будут даже асимптотически эффективными. Увеличение
дисперсии оценок снижает вероятность получения максимально
точных оценок.
•
Дисперсии
оценок
будут
рассчитываться
со
смещением.
Смещенность появляется вследствие того, что необъясненная
уравнением регрессии дисперсия, которая используется при
вычислении оценок дисперсий всех коэффициентов, не является
более несмещенной. Как правило, гетероскедастичность увеличивает
дисперсию распределения оценок коэффициентов.
•
Гетероскедастичность
вызывает
тенденцию
к
недооценке
стандартных ошибок коэффициентов. Вполне вероятно, что
стандартные
ошибки
коэффициентов
будут
занижены,
а
следовательно, t-статистики будут завышены. Это может привести к
признанию статистически значимыми коэффициентов, таковыми на
самом деле не являющимися.
•
Вследствие вышесказанного все выводы, получаемые на основе
соответствующих t- и F-статистик, а также интервальные оценки
будут ненадежными. Следовательно, статистические выводы,
получаемые при стандартных проверках качества оценок, могут
быть ошибочными и приводить к неверным заключениям по
построенной модели.
Обнаружение гетероскедастичности. В ряде случаев на базе знаний
характера данных появление проблемы гетероскедастичности можно
предвидеть и попытаться устранить этот недостаток еще на этапе
спецификации. Однако значительно чаще эту проблему приходится решать
после построения уравнения регрессии. В последнем случае наиболее
популярные и наглядные методы: графический анализ отклонений, тест
ранговой корреляции Спирмена, тест Парка, тест Глейзера, тест
Голдфелда-Квандта.
Графический анализ остатков: в этом случае по оси абсцисс
откладывается объясняющая переменная X (либо линейная комбинация
13
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
объясняющих переменных Ŷ, в случае множественной регрессии), а по оси
ординат либо отклонения (остатки) et, либо их квадраты e2t; на основе
визуального анализа формируются суждения: напр., если наблюдаются
некоторые систематические изменения в соотношениях между значениями
переменной и квадратами отклонений, то можно с большой вероятностью
предполагать наличие гетероскедастичности остатков.
Тест ранговой корреляции Спирмена: при использовании данного
теста
предполагается,
что
дисперсия
отклонения
будет
либо
увеличиваться, либо уменьшаться с увеличением значения X; поэтому для
регрессии, построенной по МНК, абсолютные величины отклонений
(остатков) и значения переменной X будут коррелированны.
Схема теста ранговой корреляции Спирмена (проверка осуществляется
по каждой объясняющей переменной отдельно):
•
Выборка упорядочивается по фактору X, при этом определяются
ранги (порядковый номер) pXi, i=1,…,n.
•
Оценивается уравнение регрессии и вычисляются остатки ei, i=1,
…,n.
•
Выборка упорядочивается по величине остатков ei, при этом
определяются ранги (порядковый номер) pei, i=1,…,n.
•
Рассчитывается коэффициент ранговой корреляции Спирмена
между рангами фактора и остатков:
n
rx , e = 1 − 6
•
∑
d
i=1
2
n(n − 1)
= 1− 6
∑
i=1
( p Xi − pei )2
rx , e n − 2
1 − rx2, e
.
2
n(n − 1)
Рассчитывается
t-статистика,
имеющая
Стьюдента с числом степеней свободы (n-2):
t =
•
n
2
i
распределение
.
Формируется суждение по правилу: если наблюдаемое значение
t α / 2, n − 2
t-статистики
превышает
критическое
значение
(определяемое по таблице критических точек распределения
Стьюдента), то необходимо отклонить гипотезу о равенстве нулю
коэффициента корреляции, а следовательно, и об отсутствии
гетероскедастичности. В противном случае гипотеза об
отсутствии гетероскедастичности принимается.
Тест
Парка:
дополняет
графический
метод
некоторыми
формальными зависимостями; может приводить к необоснованным
14
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
выводам, поэтому дополняется другими тестами; включает следующие
этапы:
•
Строится уравнение регрессии y i = b0 + b1 x i + ei .
•
ˆi )2 .
Для каждого наблюдения определяются ln ei2 = ln(y i − y
•
ln ei2 = α + β ln x i + υ i ;
Строится
регрессия:
в
случае
множественной регрессии зависимость строится для каждой
объясняющей переменной.
•
Проверяется
статистическая
значимость коэффициента
β
β
уравнения на основе t-статистики t =
. Если коэффициент
Sβ
статистически
значим,
то
это
означает
гетероскедастичности в статистических данных.
наличие
Тест Глейзера: по своей сути аналогичен тесту Парка и дополняет
его анализом других (возможно, более подходящих) зависимостей между
k
дисперсиями отклонений И значениями переменной: ei = α + β x i + υ i , где
k=…,-1,-0.5,0.5,1,… Так же, как и в тесте Парка, в тесте Глейзера для
отклонений υ i может нарушаться условие гомоскедастичности. Однако во
многих случаях предложенные модели являются достаточно хорошими для
определения гетероскедастичности.
Тест Голдфелда-Квандта: предполагается, что СКО отклонения
пропорционально значению переменной X в i-наблюдении, отклонение
имеют нормальное распределение и отсутствует автокорреляция остатков в
i-наблюдении; состоит в следующем:
•
Все n наблюдений упорядочиваются по величине X.
•
Вся упорядоченная выборка после этого разбивается на три
подвыборки размерностей k, (n – 2k), k соответственно. Для
парной регрессии предлагаются следующие пропорции: n=30 и
k=11, n=60 и k=22; для множественной регрессии k>(m+1).
•
Оцениваются отдельные регрессии для первой подвыборки (k
первых наблюдений) и для третьей подвыборки (k последних
наблюдений). Если предположение о пропорциональности
дисперсий отклонений значениям X верно, то дисперсия
регрессии по первой подвыборке S1 =
k
∑
ei2 будет существенно
i=1
меньше
S3 =
•
дисперсии
n
∑
регрессии
по
третьей
подвыборке
ei2 .
i = n− k + 1
Для сравнения соответствующих дисперсий строится следующая
F-статистика:
15
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
S3
S
(k − m − 1)
F =
= 3,
S1
S1
(k − m − 1)
где (k-m-1) — число степеней свободы соответствующих выборочных дисперсий (m- количество объясняющих переменных в
уравнении
регрессии).
При
сделанных
предположениях
относительно случайных отклонений построенная F-статистика
имеет распределение Фишера с числами степеней свободы v1=
v2 = k-m-1.
•
S3
> Fα , k − m − 1, k − m − 1 , то
S1
гетероскедастичности отклоняется
значимости α.
Если
F =
гипотеза
при
об
отсутствии
выбранном
уровне
Для множественной регрессии данный тест обычно проводится для той
объясняющей переменной, которая в наибольшей степени связана с СКО
отклонения. Если нет уверенности относительно выбора переменной, то
данный тест может осуществляться для каждой из объясняющих
переменных. Этот же тест может быть использован при предположении об
обратной пропорциональности между СКО отклонения и значениями
объясняющей переменной; при этом статистика Фишера примет вид: F =
S1/S3.
Устранение проблемы гетероскедастичности. В случае установления
наличия гетероскедастичности ее корректировка представляет довольно
серьезную проблему. Одним из возможных решений является метод
взвешенных наименьших квадратов (при этом необходима определенная
информация либо обоснованные предположения о величинах дисперсий
отклонений). На практике имеет смысл попробовать несколько методов
определения
гетероскедастичности и способов ее корректировки
(преобразований, стабилизирующих дисперсию). Во многих случаях
дисперсии отклонений зависят не от включенных в уравнение регрессии
объясняющих переменных, а от тех, которые не включены в модель, но
играют существенную роль в исследуемой зависимости, в этом случае они
должны быть включены в модель. В ряде случаев для устранения
гетероскедастичности необходимо изменить
спецификацию
модели
(например,
линейную
на
лог-линейную,
мультипликативную
на
аддитивную и т. п.).
Метод взвешенных наименьших квадратов (ВНК): применяется при
2
известных для каждого наблюдения значениях дисперсии отклонения σ i ;
в этом случае можно устранить гетероскедастичность, разделив каждое
наблюдаемое значение на соответствующее ему значение дисперсии.
16
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
Схема метода взвешенных наименьших квадратов:
•
•
•
Каждую из пар наблюдений (хi, yi) делят на известную величину
СКО отклонения σ i в i-наблюдении. Тем самым наблюдениям с
наименьшими дисперсиями придаются наибольшие «веса», а с
максимальными
дисперсиями –
наименьшие
«веса»;
так,
наблюдения с меньшими дисперсиями отклонений будут более
значимыми
при
оценке
коэффициентов
регрессии,
чем
наблюдения с большими дисперсиями, что увеличивает
вероятность получения более точных оценок.
1 xi yi
строится
,
,
По МНК для преобразованных значений
σ
σ
σ
i
i
i
уравнение регрессии без свободного члена с гарантированными
y i* = y i
y i* = β 0 z i + β 1 x i* + υ i , где
качествами оценок:
σi,
z = 1 , υi = εi
x i* = x i
σi
σi , i
σi.
После определения по МНК оценок коэффициентов β0 и β1 для
преобразованного
уравнения
возвращаются
к
исходному
уравнению регрессии y i = β 0 + β 1 x i + ε i .
Для применения ВНК необходимо знать фактические значения дисперсий
отклонений. На практике такие значения известны крайне редко.
Следовательно, чтобы применить ВНК, необходимо сделать реалистические
2
предположения о значениях σ i :
•
дисперсии
отклонений
пропорциональны
значениям
2
2
2
объясняющей переменной: σ i = σ x i , где σ — коэффициент
пропорциональности, тогда уравнение преобразуется по схеме
1
x
y
, i , i . Если в уравнении регрессии присутствует
x
xi
x i
i
несколько
объясняющих
переменных,
можно
поступить
1
x
y
, i , i , где ŷ — исходное
следующим образом:
y
ˆi
ˆi
y
y
ˆi
уравнение
множественной
регрессии
как
комбинация
объясняющих переменных.
•
дисперсии отклонений пропорциональны квадрату значений
σ i2 = σ 2 x i2 ,
объясняющей
переменной:
тогда
уравнение
1 xi y i
,
,
преобразуется по схеме
xi xi xi
17
.
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
4.5.Обобщенный метод наименьших квадратов
Невозможность или нецелесообразность использования традиционного
МНК по причине проявляющихся в той или иной степени проблем
автокорреляции или гетероскедастичности обуславливает использование
обобщенного метода наименьших квадратов (ОМНК), при котором
корректируется модель, изменяются ее спецификации, преобразуются
исходные данные для обеспечения несмещенности, эффективности и
состоятельности оценок коэффициентов регрессии.
Обобщенный МНК в чистом виде практически не применяется:
•
Подход к реализации ОМНК в виде авторегрессионных
преобразований является целесообразным при наличии проблем
автокорреляции остатков.
•
Подход к реализации ОМНК в виде взвешенного МНК является
достаточно
практичным
при
наличии
проблем
гетероскедастичности;
иногда
его
называют
доступный
обобщенный МНК.
Суть обобщенного МНК: Пусть ковариационная матрица ошибок имеет
T
следующий вид: E (ε ε ) = λ W , где W-известная матрица (симметричная и
положительно определенная), представленная в виде W = АT А , матрица А
– квадратная невырожденная матрица (напр., разложение Холецкого).
Коэффициенты β в этом случае можно оценить по формуле:
βˆ = ( X T W − 1 X )− 1 X TW − 1Y . Обобщенный МНК эквивалентен следующей
~
~
~
~
вспомогательной регрессии: Y = Xβ + ~
ε , где Y = ( A − 1 )T Y , X = ( A − 1 )T X ,
~
ε = ( A − 1 )T ε . Геометрически задача состоит в том, чтобы найти такой
~
~ , чтобы расстояние было минимальным: Y − Y
→ min .
вектор Y
При этом следует учитывать, что коэффициент детерминации не может
служить удовлетворительной мерой качества подгонки при использовании
ОМНК. На практике достаточную общность имеет критерий стандартных
отклонений (стандартных ошибок) регрессии.
4.6.Фиктивные переменные в регрессионных моделях
◊Фиктивная переменная формализует в регрессионных моделях
влияние качественного фактора, отражая два противоположных состояния
фактора: «фактор действует» — «фактор не действует». Как правило,
фиктивная переменная выражается в двоичной форме:
0, фактор не действует
D =
.
1, фактор действует
Регрессионные модели, содержащие лишь качественные объясняющие
переменные, называются ANOVA-моделями (моделями дисперсионного
18
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
анализа): Y = β 0 + γ D + ε , где γ
указывает величину, на которую
отличаются средние значения зависимой переменной Y при отсутствии или
наличии
фактора,
выраженного
переменной
D:
M(Y | D = 0) = β 0 , M(Y | D = 1) = β 0 + γ .
Модели, в которых объясняющие переменные носят как количественный,
так и качественный характер, называются ANCOVA-моделями (моделями
ковариационного анализа):
•
Правило
формализации
качественного
фактора:
«Если
качественная переменная имеет k альтернативных значений, то
при моделировании используются только (k-1) фиктивных
переменных»; если не следовать данному правилу, то при
моделировании исследователь попадает в ситуацию совершенной
мультиколлинеарности или так называемую ловушку фиктивной
переменной.
•
Значение фиктивной переменной, для которого принимается D=0,
называется базовым или сравнительным. Выбор базового значения
обычно диктуется целями исследования, но может быть и произвольным.
•
При наличии у фиктивной переменной двух альтернатив:
Y = β 0 + β 1X + γ D + ε ,
M(Y | x , D = 0) = β 0 + β 1 x ,
M(Y | x, D = 1) = (β 0 + γ ) + β 1 x ; где коэффициент γ называется
дифференциальным коэффициентом свободного члена, т. к. он
показывает, на какую величину отличается свободный член модели
при значении фиктивной переменной, равном единице, от
свободного члена модели при базовом значении фиктивной
переменной.
•
При наличии у фиктивной переменной более двух альтернатив:
Y = β 0 + β 1 X + γ 1D1 + γ 2 D2 + ε , M(Y | x, D1 = 0, D2 = 0) = β 0 + β 1 x ,
M(Y | x , D1 = 1, D2 = 0) = (β 0 + γ 1 ) + β 1 x ,
M(Y | x , D1 = 1, D2 = 1) = (β 0 + γ 1 + γ 2 ) + β 1 x ,
где
коэффициент
γ 1 , γ 2 — дифференциальные коэффициенты свободного члена.
•
Модель регрессии с одной количественной и двумя качественными
Y = β 0 + β 1 X + γ 1D1 + γ 2 D2 + ε ,
переменными:
M(Y | x, D1 = 0, D2 = 0) = β 0 + β 1 x ,
M(Y | x, D1 = 0, D2 = 1) = (β 0 + γ 2 ) + β 1 x ,
M(Y | x , D1 = 1, D2 = 0) = (β 0 + γ 1 ) + β 1 x ,
M(Y | x , D1 = 1, D2 = 1) = (β 0 + γ 1 + γ 2 ) + β 1 x ,
где
коэффициент
γ 1 , γ 2 — дифференциальные коэффициенты свободного члена.
19
Конспект лекций по дисциплине «Эконометрика» для студентов специальности
«Бухгалтерский учет, анализ и аудит»
Составитель: Коновалова А.С.
Раздел 4. Спецификация переменных в уравнениях регрессии
________________________________________________________________________________
• Модель регрессии, где изменение качественного фактора может
привести как к изменению свободного члена уравнения, так и
Y = β 0 + β 1 X + γ 1D1 + γ 2 D1 X + ε ,
наклона
прямой
регрессии:
M(Y | x, D1 = 0) = β 0 + β 1 x , M(Y | x, D1 = 1) = (β 0 + γ 1 ) + (β 1 + γ 2 )x
, где γ 1 — дифференциальный коэффициент свободного члена, γ 2 дифференциальный угловой коэффициентом соответственно.
Представленные выше схемы могут быть распространены на ситуации с
произвольным числом количественных и качественных факторов.
Модели, в которых фиктивная зависимая переменная:
•
Y = β 0 + β 1X + ε ,
Линейные
вероятностные
модели
(LPM):
M(Y | x ) = P (Y = 1 | x ) = β 0 + β 1 x , применимость МНК к которым
имеет определенные ограничения: случайные отклонения в данных
моделях не являются нормальными случайными величинами, а
скорее всего, имеют биноминальное распределение; случайные
отклонения не обладают свойством постоянства дисперсии
(гомоскедастичности); нарушается неравенство 0 ≤ P(Y =1| х) ≤ 1;
применение модели проблематично с содержательной точки зрения;
так непосредственное использование МНК в модели LPM приводит к
серьезным
погрешностям
и
необоснованным
выводам.
Использование
обыкновенного
МНК
в
данном
случае
нецелесообразно.
•
Logit модель для преодоления недостатков модели LPM: такие
модели, в которых не нарушается неравенство 0 ≤ P(Y=1|х) ≤ 1, и
зависимость между P(Y=1|х) и х не имеет линейный характер
pi
= z i = β 0 + β 1 x i , где
(закон убывающей эффективности): ln
1 − pi
условная
pi = M(Y = 1 | x i ) =
вероятность
1
.
1+ e
Использование
обыкновенного
МНК
в
данном
случае
нецелесообразно в силу проблемы гетероскедастичности. Поэтому
при расчетах коэффициентов обычно используется взвешенный
МНК, устраняющий указанный недостаток.
20
− ( β 0 + β 1xi )
Все курсы > Оптимизация > Занятие 4 (часть 1)
Прежде чем обратиться к теме множественной линейной регрессии, давайте вспомним, что было сделано до сих пор. Возможно, будет полезно посмотреть эти уроки, чтобы освежить знания.
- В рамках вводного курса мы узнали про моделирование взаимосвязи переменных и минимизацию ошибки при обучении алгоритма, а также научились строить несложные модели линейной регрессии с помощью библиотеки sklearn.
- При изучении объектно-ориентированного программирования мы создали класс простой линейной регрессии. Сегодня эти знания пригодятся при создании классов более сложных моделей.
- Также рекомендую вспомнить умножение векторов и матриц.
- Кроме того, в рамках текущего курса по оптимизации мы познакомились с понятием производной и методом градиентного спуска, а также построили модель простой линейной регрессии (использовав метод наименьших квадратов и градиент).
- Наконец, на прошлом занятии мы вновь поговорили про взаимосвязь переменных.
В рамках сегодняшнего занятия мы с нуля построим несколько алгоритмов множественной линейной регрессии.
Регрессионный анализ
Прежде чем обратиться к практике, обсудим некоторые теоретические вопросы регрессионного анализа.
Генеральная совокупность и выборка
Как мы уже знаем, множество всех имеющихся наблюдений принято считать генеральной совокупностью (population). И эти наблюдения, если в них есть взаимосвязи, можно теоретически аппроксимировать, например, линией регрессии. При этом важно понимать, что это некоторая идеальная модель, которую мы никогда не сможем построить.
Единственное, что мы можем сделать, взять выборку (sample) и на ней построить нашу модель, предполагая, что если выборка достаточно велика, она сможет достоверно описать генсовокупность.

Отклонение прогнозного значения от фактического для «идеальной» линии принято называть ошибкой (error или true error).
$$ \varepsilon = y-\hat{y} $$
Отклонение прогноза от факта для выборочной модели (которую мы и строим) называют остатками (residuals или residual error).
$$ \varepsilon = y-f(x) $$
В этом смысле среднеквадратическую ошибку (mean squared error, MSE) корректнее называть средними квадратичными остатками (mean squared residuals).
На практике ошибку и остатки нередко используют как взаимозаменяемые термины.
Уравнение множественной линейной регрессии
Посмотрим на уравнение множественной линейной регрессии.
$$ y = \theta_0 + \theta_1x_1 + \theta_2x_2 + … + \theta_jx_j + \varepsilon $$
В отличие от простой линейной регрессии в данном случае у нас несколько признаков x (независимых переменных) и несколько коэффициентов $ \theta $ («тета»).
Интерпретация результатов модели
Коэффициент $ \theta_0 $ задает некоторый базовый уровень (baseline) при условии, что остальные коэффициенты равны нулю и зачастую не имеет смысла с точки зрения интерпретации модели (нужен лишь для того, что поднять линию на нужный уровень).
Параметры $ \theta_1, \theta_2, …, \theta_n $ показывают изменение зависимой переменной при условии «неподвижности» остальных коэффициентов. Например, каждая дополнительная комната может увеличивать цену дома в 1.3 раза.
Переменная $ \varepsilon $ (ошибка) представляет собой отклонение фактических данных от прогнозных. В этой переменной могут быть заложены две составляющие. Во-первых, она может включать вариативность целевой переменной, описанную другими (не включенными в нашу модель) признаками. Во-вторых, «улавливать» случайный шум, случайные колебания.
Категориальные признаки
Модель линейной регрессии может включать категориальные признаки. Продолжая пример с квартирой, предположим, что мы строим модель, в которой цена зависит от того, находится ли квартира в центре города или в спальном районе.
Перед этим переменную необходимо закодировать, создав, например, через Label Encoder признак «центр», который примет значение 1, если квартира в центре, и 0, если она находится в спальном районе.
В модели, представленной выше, если квартира находится в центре (переменная «центр» равна единице), ее стоимость составит 10,1 миллиона рублей, если на окраине (переменная «центр» равна нулю) — лишь восемь.
Для категориального признака с множеством классов можно использовать one-hot encoding, если между классами признака отсутствует иерархия,
или, например, ordinal encoding в случае наличия иерархии классов в признаке

Выбросы в линейной регрессии
Как и коэффициент корреляции Пирсона, модель линейной регрессии чувствительна к выбросам (outliers), то есть наблюдениям, серьезно выпадающим из общей совокупности. Сравните рисунки ниже.

При наличии выброса (слева), линия регрессии имеет наклон и может использоваться для построения прогноза. Удалив это наблюдение (справа), линия регрессии становится горизонтальной и построение прогноза теряет смысл.
При этом различают два типа выбросов:
- горизонтальные выбросы или влиятельные точки (leverage points) — они сильно отклоняются от среднего по оси x; и
- вертикальные выбросы или просто выбросы (influential points) — отклоняются от среднего по оси y
Ключевое отличие заключается в том, что вертикальные выбросы влияют на наклон модели (изменяют ее коэффициенты), а горизонтальные — нет.
Сравним два графика.

На левом графике черная точка (leverage point) сильно отличается от остальных наблюдений, но наклон прямой линии регрессии с ее появлением не изменился. На правом графике, напротив, появление выброса (influential point) существенно изменяет наклон прямой.
На практике нас конечно больше интересуют influential points, потому что именно они существенно влияют на качество модели.
Если в простой линейной регрессии мы можем оценить leverage и influence наблюдения графически⧉, в многомерной модели это сделать сложнее. Можно использовать график остатков (об этом ниже) или применить один из уже известных нам методов выявления выбросов.
Про выявление leverage и infuential points можно почитать здесь⧉.
Допущения модели регрессии
Применение алгоритма линейной регрессии предполагает несколько допущений (assumptions) или условий, при выполнении которых мы можем говорить о качественно построенной модели.
1. Правильный выбор модели
Вначале важно убедиться, что данные можно аппроксимировать с помощью линейной модели (correct model specification).
Оценить распределение данных можно через график остатков (residuals plot), где по оси x отложен прогноз модели, а на оси y — сами остатки.

В отличие от простой линейной регрессии мы не используем точечную диаграмму X vs. y, потому что хотим оценить зависимость целевой переменной от всех признаков сразу.
Остатки модели относительно ее прогнозных значений должны быть распределены случайным образом без систематической составляющей (residuals do not follow a pattern).
- Если вы попробовали применить линейную модель с коэффициентами первой степени ($x_n^1$) и выявили некоторый паттерн в данных, можно попробовать полиномиальную или какую-либо еще функцию (об этом ниже).
- Кроме того, количественные признаки можно попробовать преобразовать таким образом, чтобы их можно было аппроксимировать прямой линией.
- Если ни то, ни другое не помогло, вероятно данные не стоит моделировать линейной регрессией.
Также замечу, что график остатков показывает выбросы в данных.

2. Нормальность распределения остатков
Среднее значение остатков должно быть равно нулю. Если это не так, и среднее значение меньше нуля (скажем –5), то это значит, что модель регулярно недооценивает (underestimates) фактические значения. В противном случае, если среднее больше нуля, переоценивает (overestimated).

Кроме того, предполагается, что остатки следуют нормальному распределению.
$$ \varepsilon \sim N(0, \sigma) $$
Проверить нормальность остатков можно визуально с помощью гистограммы или рассмотренных ранее критериев нормальности распределения.
Если остатки не распределены нормально, мы не сможем провести статистические тесты на значимость коэффициентов или построить доверительные интервалы. Иначе говоря, мы не сможем сделать статистически значимый вывод о надежности нашей модели.
Причинами могут быть (1) выбросы в данных или (2) неверный выбор модели. Решением может быть, соответственно, исследование выбросов, выбор новой модели и преобразование как признаков, так и целевой переменной.
3. Гомоскедастичность остатков
Гомоскедастичность (homoscedasticity) или одинаковая изменчивость остатков предполагают, что дисперсия остатков не изменяется для различных наблюдений. Противоположное и нежелательное явление называется гетероскедастичностью (heteroscedasticity) или разной изменчивостью.

Гетероскедастичность остатков показывает, что модель ошибается сильнее при более высоких или более низких значениях признаков. Как следствие, если для разных прогнозов у нас разная погрешность, модель нельзя назвать надежной (robust).
Как правило, гетероскедастичность бывает изначально заложена в данные. Ее можно попробовать исправить через преобразование целевой переменной (например, логарифмирование)
4. Отсутствие мультиколлинеарности
Еще одним важным допущением является отсутствие мультиколлинеарности. Мультиколлинеарность (multicollinearity) — это корреляция между зависимыми переменными. Например, если мы предсказываем стоимость жилья по квадратным метрам и количеству комнат, то метры и комнаты логичным образом также будут коррелировать между собой.
Почему плохо, если такая корреляция существует? Базовое предположение линейной регрессии — каждый коэффициент $\theta$ оказывает влияние на конечный результат при условии, что остальные коэффициенты постоянны. При мультиколлинеарности на целевую переменную оказывают эффект сразу несколько признаков, и мы не можем с точностью интерпретировать каждый из них.
Также говорят о том, что нужно стремиться к экономной (parsimonious) модели то есть такой модели, которая при наименьшем количестве признаков в наибольшей степени объясняет поведение целевой переменной.
Variance inflation factor
Расчет коэффициента
Variance inflation factor (VIF) или коэффициент увеличения дисперсии позволяет выявить корреляцию между признаками модели.
Принцип расчета VIF заключается в том, чтобы поочередно делать каждый из признаков целевой переменной и строить модель линейной регрессии на основе оставшихся независимых переменных. Например, если у нас есть три признака $x_1, x_2, x_3$, мы поочередно построим три модели линейной регрессии: $x_1 \sim x_2 + x_3, x_2 \sim x_1 + x_3$ и $x_3 \sim x_1 + x_3$.
Обратите внимание на новый для нас формат записи целевой и зависимых переменных модели через символ $\sim$.
Затем для каждой модели (то есть для каждого признака $x_1, x_2, x_3$) мы рассчитаем коэффициент детерминации $R^2$. Если он велик, значит данный признак можно объяснить с помощью других независимых переменных и имеется мультиколлинеарность. Если $R^2$ мал, то нельзя и мультиколлинеарность отсутствует.
Теперь рассчитаем VIF на основе $R^2$:
$$ VIF = \frac{1}{1-R^2} $$
При таком способе расчета большой (близкий к единице) $R^2$ уменьшит знаменатель и существенно увеличит VIF, при небольшом коэффициенте детерминации коэффициент увеличения дисперсии наоборот уменьшится.
Замечу, что $1-R^2$ принято называть tolerance.
Другие способы выявления мультиколлинеарности
Для выявления корреляции между независимыми переменными можно использовать точечные диаграммы или корреляционные матрицы. При этом важно понимать, что в данном случае мы выявляем зависимость лишь между двумя признаками. Корреляцию множества признаков выявляет только коэффициент увеличения дисперсии.
Интерпретация VIF
VIF находится в диапазон от единицы до плюс бесконечности. Как правило, при интерпретации показателей variance inflation factor придерживаются следующих принципов:
- VIF = 1, между признаками отсутствует корреляция
- 1 < VIF $\leq$ 5 — умеренная корреляция
- 5 < VIF $\leq$ 10 — высокая корреляция
- Более 10 — очень высокая
После расчета VIF можно по одному удалять признаки с наибольшей корреляцией и смотреть как изменится этот показатель для оставшихся независимых переменных.
5. Отсутствие автокорреляции остатков
На занятии по временным рядам (time series), мы сказали, что автокорреляция (autocorrelation) — это корреляция между значениями одной и той же переменной в разные моменты времени.
Применительно к модели линейной регрессии автокорреляция целевой переменной (для простой линейной регрессии) и автокорреляция остатков, residuals autocorrelation (для модели множественной регрессии) означает, что результат или прогноз зависят не от признаков, а от самой этой целевой переменной. В такой ситуации признаки теряют свою значимость и применение модели регрессии становится нецелесообразным.
Причины автокорреляции остатков
Существует несколько возможных причин:
- Прогнозирование целевой переменной с высокой автокорреляцией (например, если мы моделируем цену акций с помощью других переменных, то можем ожидать высокую автокорреляцию остатков, поскольку цена акций как правило сильно зависит от времени)
- Удаление значимых признаков
- Другие причины
Автокорреляция первого порядка
Дадим формальное определение автокорреляции первого порядка (first order correlation), то есть автокорреляции с лагом 1.
$$ \varepsilon_t = p\varepsilon_{t-1} + u_t $$
где $u_t$ — некоррелированная при различных t одинаково распределенная случайная величина (independent and identically distributed (i.i.d.) random variable), а $p$ — коэффициент автокорреляции, который находится в диапазоне $-1 < p < 1$. Чем он ближе к нулю, тем меньше зависимость остатка $\varepsilon_t$ от остатка предыдущего периода $\varepsilon_{t-1}$.
Такое уравнение также называется схемой Маркова первого порядка (Markov first-order scheme).
Обратите внимание, что для модели автокорреляции первого порядка коэффициент автокорреляции $p$ совпадает с коэффициентом авторегрессии AR(1) $\varphi$.
$$ y_t = c + \varphi \cdot y_{t-1} $$
Разумеется, мы можем построить модель автокорреляции, например, третьего порядка.
$$ \varepsilon_t = p_1\varepsilon_{t-1} + p_2\varepsilon_{t-2} + p_3\varepsilon_{t-3} + u_t $$
Выявление автокорреляции остатков
Для выявления автокорреляции остатков можно использовать график последовательности и график остатков с лагом 1, график автокорреляционной функции или критерий Дарбина-Уотсона.
График последовательности и график остатков с лагом 1
На графике последовательности (sequence plot) по оси x откладывается время (или порядковый номер наблюдения), а по оси y — остатки модели. Кроме того, на графике остатков с лагом 1 (lag-1 plot) остатки (ось y) можно сравнить с этими же значениями, взятыми с лагом 1 (ось x).
Рассмотрим вариант положительной автокорреляции (positive autocorrelation) на графиках остатков типа (а) и (б).
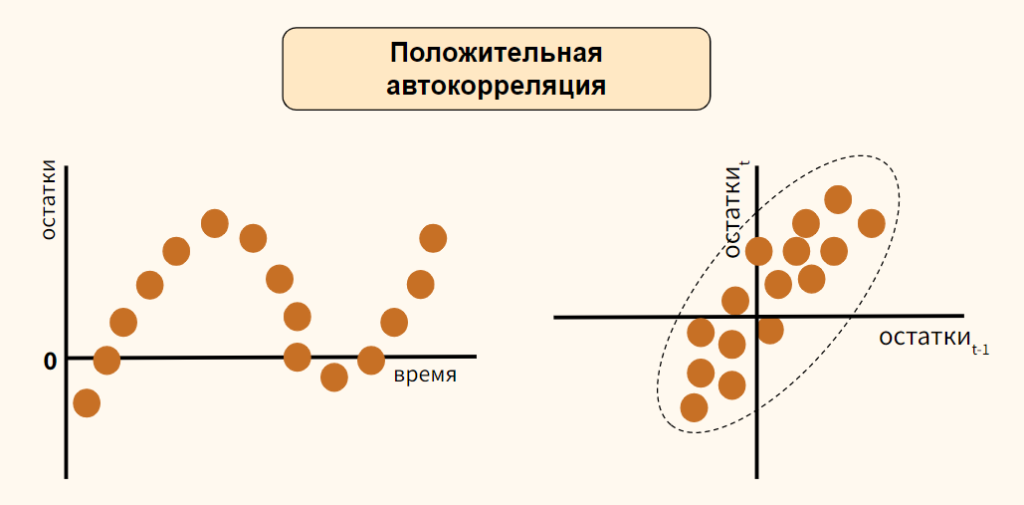
Как вы видите, при положительной автокорреляции в большинстве случаев, если одно наблюдение демонстрирует рост по отношению к предыдущему значению, то и последующее будет демонстрировать рост, и наоборот.
Теперь обратимся к отрицательной автокорреляции (negative autocorrelation).
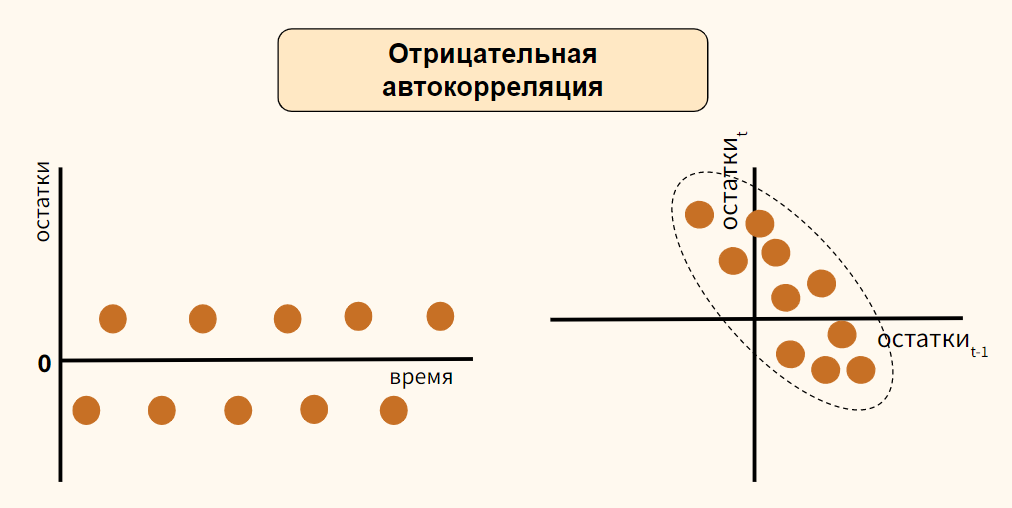
Здесь наоборот, если одно наблюдение демонстрирует рост показателя по отношению к предыдущему значению, то последующее наблюдение будет наоборот снижением. Опять же справедливо и обратное утверждение.
В случае отсутствия автокорреляции мы не должны увидеть на графиках какого-либо паттерна.

График автокорреляционной функции
Еще один способ выявить автокорреляцию — построить график автокорреляционной функции (autocorrelation function, ACF).

Напомню, такой график показывает автокорреляцию данных с этими же данными, взятыми с первым, вторым и последующими лагами.
Критерий Дарбина-Уотсона
Количественным выражением автокорреляции является критерий Дарбина-Уотсона (Durbin-Watson test). Этот критерий выявляет только автокорреляцию первого порядка.
- Нулевая гипотеза утверждает, что такая автокорреляция отсутствует ($p=0$),
- Альтернативная гипотеза соответственно утверждает, что присутствует
- Положительная ($p \approx -1$) или
- Отрицательная ($p \approx 1$) автокорреляция
Значение теста находится в диапазоне от 0 до 4.
- При показателе близком к двум можно говорить об отсутствии автокорреляции
- Приближение к четырем говорит о положительной автокорреляции
- К нулю, об отрицательной
Как избавиться от автокорреляции
Автокорреляцию можно преодолеть, добавив значимый признак в модель, выбрав иной тип модели (например, полиномиальную регрессию) или в целом перейдя к моделированию и прогнозированию временного ряда.
Рассмотрение этих методов находится за рамками сегодняшнего занятия. Перейдем к практике.
АКТУАЛЬНОСТЬ ТЕМЫ
Общие положения
Про регрессионный анализ вообще, и его применение в DataScience написано очень много. Есть множество учебников, монографий, справочников и статей по прикладной статистике, огромное количество информации в интернете, примеров расчетов. Можно найти множество кейсов, реализованных с использованием средств Python. Казалось бы — что тут еще можно добавить?
Однако, как всегда, есть нюансы:
1. Регрессионный анализ — это прежде всего процесс, набор действий исследователя по определенному алгоритму: «подготовка исходных данных — построение модели — анализ модели — прогнозирование с помощью модели». Это ключевая особенность. Не представляет особой сложности сформировать DataFrame исходных данных и построить модель, запустить процедуру из библиотеки statsmodels. Однако подготовка исходных данных и последующий анализ модели требуют гораздо больших затрат человеко-часов специалиста и строк программного кода, чем, собственно, построение модели. На этих этапах часто приходится возвращаться назад, корректировать модель или исходные данные. Этому, к сожалению, во многих источниках, не удаляется достойного внимания, а иногда — и совсем не уделяется внимания, что приводит к превратному представлению о регрессионном анализе.
2. Далеко не во всех источниках уделяется должное внимание интерпретации промежуточных и финальных результатов. Специалист должен уметь интерпретировать каждую цифру, полученную в ходе работы над моделью.
3. Далеко не все процедуры на этапах подготовки исходных данных или анализа модели в источниках разобраны подробно. Например, про проверку значимости коэффициента детерминации найти информацию не представляет труда, а вот про проверку адекватности модели, построение доверительных интервалов регрессии или про специфические процедуры (например, тест Уайта на гетероскедастичность) информации гораздо меньше.
4. Своеобразная сложность может возникнуть с проверкой статистических гипотез: для отечественной литературы по прикладной статистике больше характерно проверять гипотезы путем сравнения расчетного значения критерия с табличным, а в иностранных источниках чаще определяется расчетный уровень значимости и сравнивается с заданным (чаще всего 0.05 = 1-0.95). В разных источниках информации реализованы разные подходы. Инструменты python (прежде всего библиотеки scipy и statsmodels) также в основном оперируют с расчетным уровнем значимости.
5. Ну и, наконец, нельзя не отметить, что техническая документация библиотеки statsmodels составлена, на мой взгляд, далеко не идеально: информация излагается путано, изобилует повторами и пропусками, описание классов, функций и свойств выполнено фрагментарно и количество примеров расчетов — явно недостаточно.
Поэтому я решил написать ряд обзоров по регрессионному анализу средствами Python, в которых акцент будет сделан на практических примерах, алгоритме действий исследователя, интерпретации всех полученных результатов, конкретных методических рекомендациях. Буду стараться по возможности избегать теории (хотя совсем без нее получится) — все-таки предполагается, что специалист DataScience должен знать теорию вероятностей и математическую статистику, хотя бы в рамках курса высшей математики для технического или экономического вуза.
В данном статье остановимся на самои простом, классическом, стереотипном случае — простой линейной регрессии (simple linear regression), или как ее еще принято называть — парной линейной регрессионной модели (ПЛРМ) — в ситуации, когда исследователя не подстерегают никакие подводные камни и каверзы — исходные данные подчиняются нормальному закону, в выборке отсутствуют аномальные значения, отсутствует ложная корреляция. Более сложные случаи рассмотрим в дальнейшем.
Для построение регрессионной модели будем пользоваться библиотекой statsmodels.
В данной статье мы рассмотрим по возможности полный набор статистических процедур. Некоторые из них (например, дескриптивная статистика или дисперсионный анализ регрессионной модели) могут показаться избыточными. Все так, но эти процедуры улучшают наше представление о процессе и об исходных данных, поэтому в разбор я их включил, а каждый исследователь сам вправе для себя определить, потребуются ему эти процедуры или нет.
Краткий обзор источников
Источников информации по корреляционному и регрессионному анализу огромное количество, в них можно просто утонуть. Поэтому позволю себе просто порекомендовать ряд источников, на мой взгляд, наиболее полезных:
-
Кобзарь А.И. Прикладная математическая статистика. Для инженеров и научных работников. — М.: ФИЗМАТЛИТ, 2006. — 816 с.
-
Львовский Е.Н. Статистические методы построения эмпирических формул. — М.: Высшая школа, 1988. — 239 с.
-
Фёрстер Э., Рёнц Б. Методы корреляционного и регрессионного анализа / пер с нем. — М.: Финансы и статистика, 1983. — 302 с.
-
Афифи А., Эйзен С. Статистический анализ. Подход с использованием ЭВМ / пер с англ. — М.: Мир, 1982. — 488 с.
-
Дрейпер Н., Смит Г. Прикладной регрессионный анализ. Книга 1 / пер.с англ. — М.: Финансы и статистика, 1986. — 366 с.
-
Айвазян С.А. и др. Прикладная статистика: Исследование зависимостей. — М.: Финансы и статистика, 1985. — 487 с.
-
Прикладная статистика. Основы эконометрики: В 2 т. 2-е изд., испр. — Т.2: Айвазян С.А. Основы эконометрики. — М.: ЮНИТИ-ДАНА, 2001. — 432 с.
-
Магнус Я.Р. и др. Эконометрика. Начальный курс — М.: Дело, 2004. — 576 с.
-
Носко В.П. Эконометрика. Книга 1. — М.: Издательский дом «Дело» РАНХиГС, 2011. — 672 с.
-
Брюс П. Практическая статистика для специалистов Data Science / пер. с англ. — СПб.: БХВ-Петербург, 2018. — 304 с.
-
Уатт Дж. и др. Машинное обучение: основы, алгоритмы и практика применения / пер. с англ. — СПб.: БХВ-Петербург, 2022. — 640 с.
Прежде всего следует упомянуть справочник Кобзаря А.И. [1] — это безусловно выдающийся труд. Ничего подобного даже близко не издавалось. Всем рекомендую иметь под рукой.
Есть очень хорошее практическое пособие [2] — для начинающих и практиков.>
Добротная работа немецких авторов [3]. Все разобрано подробно, обстоятельно, с примерами — очень хорошая книга. Примеры приведены из области экономики.
Еще одна добротная работа — [4], с примерами медико-биологического характера.
Работа [5] считается одним из наиболее полных изложений прикладного регрессионного анализа.
Более сложные работы — [6] (классика жанра), [7], [8], [9] — выдержаны на достаточно высоком математическом уровне, примеры из экономической области.
Свежие работы [10] (с примерами на языке R) и [11] (с примерами на python).
Cтатьи
Статей про регрессионный анализ в DataScience очень много, обращаю внимание на некоторые весьма полезные из них.
Серия статей «Python, корреляция и регрессия», охватывающая весь процесс регрессионного анализа:
-
первичная обработка данных, визуализация и корреляционный анализ;
-
регрессия;
-
теория матриц в регрессионном анализе, проверка адекватности, мультиколлинеарность;
-
прогнозирование с помощью регрессионных моделей.
Очень хороший обзор «Интерпретация summary из statsmodels для линейной регрессии». В этой статье даны очень полезные ссылки:
-
Statistical Models
-
Interpreting Linear Regression Through statsmodels .summary()
Статья «Регрессионные модели в Python».
Основные предпосылки (гипотезы) регрессионного анализа
Очень кратко — об этом написано тысячи страниц в учебниках — но все же вспомним некоторые основы теории.
Проверка исходных предпосылок является очень важным моментом при статистическом анализе регрессионной модели. Если мы рассматриваем классическую линейную регрессионную модель вида:
![]()
то основными предпосылками при использовании обычного метода наименьших квадратов (МНК) для оценки ее параметров являются:
-
Среднее значение (математическое ожидание) случайной составляющей равно нулю:
![]()
-
Дисперсия случайной составляющей является постоянной:
![]()
В случае нарушения данного условия мы сталкиваемся с явлением гетероскедастичности.
-
Значения случайной составляющей статистически независимы (некоррелированы) между собой:
![]()
В случае нарушения данного условия мы сталкиваемся с явлением автокорреляции.
-
Условие существования обратной матрицы
![]()
что эквивалентно одному из двух следующих условий:

то есть число наблюдений должно превышать число параметров.
-
Значения случайной составляющей некоррелированы со значениями независимых переменных:
![]()
-
Случайная составляющая имеет нормальный закон распределения (с математическим ожиданием равным нулю — следует из условия 1):
![]()
Более подробно — см.: [3, с.90], [4, с.147], [5, с.122], [6, с.208], [7, с.49], [8, с.68], [9, с.88].
Кроме гетероскедастичности и автокорреляции возможно возникновение и других статистических аномалий — мультиколлинеарности, ложной корреляции и т.д.
Доказано, что оценки параметров, полученные с помощью МНК, обладают наилучшими свойствами (несмещенность, состоятельность, эффективность) при соблюдении ряда условий:
-
выполнение приведенных выше исходных предпосылок регрессионного анализа;
-
число наблюдений на одну независимую переменную должно быть не менее 5-6;
-
должны отсутствовать аномальные значения (выбросы).
Кроме обычного МНК существуют и другие его разновидности (взвешенный МНК, обобщенный МНК), которые применяются при наличии статистических аномалий. Кроме МНК применяются и другие методы оценки параметров моделей. В этом обзоре мы эти вопросы рассматривать не будем.
Алгоритм проведения регрессионного анализа
Алгоритм действий исследователя при построении регрессионной модели (полевые работы мы, по понятным причинам, не рассматриваем — считаем, что исходные данные уже получены):
-
Подготовительный этап — постановка целей и задач исследования.
-
Первичная обработка исходных данных — об этом много написано в учебниках и пособиях по DataScience, сюда могут относится:
-
выявление нерелевантных признаков (признаков, которые не несут полезной информации), нетипичных данных (выбросов), неинформативных признаков (имеющих большое количество одинаковых значений) и работа с ними (удаление/преобразование);
-
выделение категориальных признаков;
-
работа с пропущенными значениями;
-
преобразование признаков-дат в формат datetime и т.д.
-
Визуализация исходных данных — предварительный графический анализ.
-
Дескриптивная (описательная) статистика — расчет выборочных характеристик и предварительные выводы о свойствах исходных данных.
-
Исследование закона распределения исходных данных и, при необходимости, преобразование исходных данных к нормальному закону распределения.
-
Выявление статистически аномальных значений (выбросов), принятие решения об их исключении.
Этапы 4, 5 и 6 могут быть при необходимости объединены.
-
Корреляционный анализ — исследование корреляционных связей между исходными данными; это разведка перед проведением регрессионного анализа.
-
Построение регрессионной модели:
-
выбор моделей;
-
выбор методов;
-
оценка параметров модели.
-
Статистический анализ регрессионной модели:
-
оценка ошибок аппроксимации (error metrics);
-
анализ остатков (проверка нормальности распределения остатков и гипотезы о равенстве нулю среднего значения остатков);
-
проверка адекватности модели;
-
проверка значимости коэффициента детерминации;
-
проверка значимости коэффициентов регрессии;
-
проверка мультиколлинеарности (для множественных регрессионных моделей; вообще мультиколлинеарные переменные выявляются еще на стадии корреляционного анализа);
-
проверка автокорреляции;
-
проверка гетероскедастичности.
Этапы 8 и 9 могут быть при необходимости повторяться несколько раз.
-
Сравнительный анализ нескольких регрессионных моделей, выбор наилучшей (при необходимости).
-
Прогнозирование с помощью регрессионной модели и оценка качества прогноза.
-
Выводы и рекомендации.
Само собой, этот алгоритм не есть истина в последней инстанции — в зависимости от особенностей исходных данных и вида модели могут возникать дополнительные задачи.
Применение пользовательских функций
Далее в обзоре мной будут использованы несколько пользовательских функций для решения разнообразных задач. Все эти функции созданы для облегчения работы и уменьшения размера программного кода. Данные функции загружается из пользовательского модуля my_module__stat.py, который доступен в моем репозитории на GitHub. Лично мне так удобнее работать, хотя каждый исследователь сам формирует себе инструменты по душе — особенно в части визуализации. Желающие могут пользоваться этими функциями, либо создать свои.
Итак, вот перечень данных функций:
-
graph_scatterplot_sns — функция позволяет построить точечную диаграмму средствами seaborn и сохранить график в виде png-файла;
-
graph_hist_boxplot_probplot_XY_sns — функция позволяет визуализировать исходные данные для простой линейной регрессии путем одновременного построения гистограммы, коробчатой диаграммы и вероятностного графика (для переменных X и Y) средствами seaborn и сохранить график в виде png-файла; имеется возможность выбирать, какие графики строить (h — hist, b — boxplot, p — probplot);
-
descriptive_characteristics — функция возвращает в виде DataFrame набор статистических характеристики выборки, их ошибок и доверительных интервалов;
-
detecting_outliers_mad_test — функция выполняет проверку наличия аномальных значений (выбросов) по критерию наибольшего абсолютного отклонения (более подробно — см.[1, с.547]);
-
norm_distr_check — проверка нормальности распределения исходных данных с использованием набора из нескольких статистических тестов;
-
corr_coef_check — функция выполняет расчет коэффициента линейной корреляции Пирсона, проверку его значимости и расчет доверительных интервалов; об этой функции я писал в своей статье.
-
graph_regression_plot_sns — — функция позволяет построить график регрессионной модели.
Ряд пользовательских функций мы создаем в процессе данного обзора (они тоже включены в пользовательский модуль my_module__stat.py):
-
regression_error_metrics — расчет ошибок аппроксимации регрессионной модели;
-
ANOVA_table_regression_model — вывод таблицы дисперсионного анализа регрессионной модели;
-
regression_model_adequacy_check — проверка адекватности регрессионной модели по критерию Фишера;
-
determination_coef_check — проверка значимости коэффициента детерминации по критерию Фишера;
-
regression_coef_check — проверка значимости коэффициентов регрессии по критеирю Стьюдента;
-
Goldfeld_Quandt_test, Breush_Pagan_test, White_test — проверка гетероскедастичности с использование тестов Голдфелда-Квандта, Бриша-Пэгана и Уайта соответственно;
-
regression_pair_predict — функция для прогнозирования с помощью парной регрессионной модели: рассчитывает прогнозируемое значение переменной Y по заданной модели, а также доверительные интервалы среднего и индивидуального значения для полученного прогнозируемого значения Y;
-
graph_regression_pair_predict_plot_sns — прогнозирование: построение графика регрессионной модели (с доверительными интервалами) и вывод расчетной таблицы с данными для заданной области значений X.
ПОСТАНОВКА ЗАДАЧИ
В качестве примера рассмотрим практическую задачу из области экспертизы промышленной безопасности — калибровку ультразвукового прибора для определения прочности бетона.
Итак, суть задачи: при обследовании несущих конструкций зданий и сооружений эксперт определяет прочность бетона с использованием ультразвукового прибора «ПУЛЬСАР-2.1», для которого необходимо предварительно построить градуировочную зависимость. Заключается это в следующем — производятся замеры с фиксацией следующих показателей:
-
X — показания ультразвукового прибора «ПУЛЬСАР-2.1» (м/с)
-
Y — результаты замера прочности бетона (методом отрыва со скалыванием) склерометром ИПС-МГ4.03.
Предполагается, что между показателями X и Y имеется линейная регрессионная зависимость, которая позволит прогнозировать прочность бетона на основании измерений, проведенных прибором «ПУЛЬСАР-2.1».
Были выполнены замеры фактической прочности бетона конструкций для бетонов одного вида с одним типом крупного заполнителя, с единой технологией производства. Для построения были выбраны 14 участков (не менее 12), включая участки, в которых значение косвенного показателя максимальное, минимальное и имеет промежуточные значения.
Настройка заголовков отчета:
# Общий заголовок проекта
Task_Project = 'Калибровка ультразвукового прибора "ПУЛЬСАР-2.1" \nдля определения прочности бетона'
# Заголовок, фиксирующий момент времени
AsOfTheDate = ""
# Заголовок раздела проекта
Task_Theme = ""
# Общий заголовок проекта для графиков
Title_String = f"{Task_Project}\n{AsOfTheDate}"
# Наименования переменных
Variable_Name_X = "Скорость УЗК (м/с)"
Variable_Name_Y = "Прочность бетона (МПа)"
# Константы
INCH = 25.4 # мм/дюйм
DecPlace = 5 # number of decimal places - число знаков после запятой
# Доверительная вероятность и уровень значимости:
p_level = 0.95
a_level = 1 - p_level Подключение модулей и библиотек:
# Стандартные модули и библиотеки
import os # загрузка модуля для работы с операционной системой
import sys
import platform
print('{:<35}{:^0}'.format("Текущая версия Python: ", platform.python_version()), '\n')
import math
from math import * # подключаем все содержимое модуля math, используем без псевдонимов
import numpy as np
#print ("Текущая версия модуля numpy: ", np.__version__)
print('{:<35}{:^0}'.format("Текущая версия модуля numpy: ", np.__version__))
from numpy import nan
import scipy as sci
print('{:<35}{:^0}'.format("Текущая версия модуля scipy: ", sci.__version__))
import scipy.stats as sps
import pandas as pd
print('{:<35}{:^0}'.format("Текущая версия модуля pandas: ", pd.__version__))
import matplotlib as mpl
print('{:<35}{:^0}'.format("Текущая версия модуля matplotlib: ", mpl.__version__))
import matplotlib.pyplot as plt
import seaborn as sns
print('{:<35}{:^0}'.format("Текущая версия модуля seaborn: ", sns.__version__))
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.graphics.api as smg
import statsmodels.stats.api as sms
from statsmodels.compat import lzip
print('{:<35}{:^0}'.format("Текущая версия модуля statsmodels: ", sm.__version__))
import statistics as stat # module 'statistics' has no attribute '__version__'
import sympy as sym
print('{:<35}{:^0}'.format("Текущая версия модуля sympy: ", sym.__version__))
# Настройки numpy
np.set_printoptions(precision = 4, floatmode='fixed')
# Настройки Pandas
pd.set_option('display.max_colwidth', None) # текст в ячейке отражался полностью вне зависимости от длины
pd.set_option('display.float_format', lambda x: '%.4f' % x)
# Настройки seaborn
sns.set_style("darkgrid")
sns.set_context(context='paper', font_scale=1, rc=None) # 'paper', 'notebook', 'talk', 'poster', None
# Настройки Mathplotlib
f_size = 8 # пользовательская переменная для задания базового размера шрифта
plt.rcParams['figure.titlesize'] = f_size + 12 # шрифт заголовка
plt.rcParams['axes.titlesize'] = f_size + 10 # шрифт заголовка
plt.rcParams['axes.labelsize'] = f_size + 6 # шрифт подписей осей
plt.rcParams['xtick.labelsize'] = f_size + 4 # шрифт подписей меток
plt.rcParams['ytick.labelsize'] = f_size + 4
plt.rcParams['legend.fontsize'] = f_size + 6 # шрифт легенды
# Пользовательские модули и библиотеки
Text1 = os.getcwd() # вывод пути к текущему каталогу
#print(f"Текущий каталог: {Text1}")
sys.path.insert(1, "D:\REPOSITORY\MyModulePython")
from my_module__stat import *ФОРМИРОВАНИЕ ИСХОДНЫХ ДАННЫХ
Показания ультразвукового прибора «ПУЛЬСАР-2.1» (м/с):
X = np.array([
4416, 4211, 4113, 4110, 4122,
4427, 4535, 4311, 4511, 4475,
3980, 4490, 4007, 4426
])Результаты замера прочности бетона (методом отрыва со скалыванием) прибором ИПС-МГ4.03:
Y = np.array([
34.2, 35.1, 31.5, 30.8, 30.0,
34.0, 35.4, 35.8, 38.0, 37.7,
30.0, 37.8, 31.0, 35.2
])Запишем данные в DataFrame:
calibrarion_df = pd.DataFrame({
'X': X,
'Y': Y})
display(calibrarion_df)
calibrarion_df.info()Сохраняем данные в csv-файл:
calibrarion_df.to_csv(
path_or_buf='data/calibrarion_df.csv',
mode='w+',
sep=';')Cоздаем копию исходной таблицы для работы:
dataset_df = calibrarion_df.copy()ВИЗУАЛИЗАЦИЯ ДАННЫХ
Границы значений переменных (при построении графиков):
(Xmin_graph, Xmax_graph) = (3800, 4800)
(Ymin_graph, Ymax_graph) = (25, 45)# Пользовательская функция
graph_scatterplot_sns(
X, Y,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=Ymin_graph, Ymax=Ymax_graph,
color='orange',
title_figure=Task_Project,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
s=100,
file_name='graph/scatterplot_XY_sns.png')
Существует универсальный набор графиков — гистограмма, коробчатая диаграмма, вероятностный график — которые позволяют исследователю сделать предварительные выводы о свойствах исходных данных.
Так как объем выборки невелик (n=14), строить гистограммы распределения переменных X и Y не имеет смысла, поэтому ограничимся построением коробчатых диаграмм и вероятностных графиков:
# Пользовательская функция
graph_hist_boxplot_probplot_XY_sns(
data_X=X, data_Y=Y,
data_X_min=Xmin_graph, data_X_max=Xmax_graph,
data_Y_min=Ymin_graph, data_Y_max=Ymax_graph,
graph_inclusion='bp', # выбираем для построения виды графиков: b - boxplot, p - probplot)
data_X_label=Variable_Name_X,
data_Y_label=Variable_Name_Y,
title_figure=Task_Project,
file_name='graph/hist_boxplot_probplot_XY_sns.png') 
Для сравнения характера распределений переменных X и Y возможно также построить совмещенную коробчатую диаграмму по стандартизованным данным:
# стандартизуем исходные данные
standardize_df = lambda X: ((X - np.mean(X))/np.std(X))
dataset_df_standardize = dataset_df.copy()
dataset_df_standardize = dataset_df_standardize.apply(standardize_df)
display(dataset_df_standardize)
# построим график
fig, axes = plt.subplots(figsize=(210/INCH, 297/INCH/2))
axes.set_title("Распределение стандартизованных переменных X и Y", fontsize = 16)
sns.boxplot(
data=dataset_df_standardize,
orient='h',
width=0.5,
ax=axes)
plt.show()
Графический анализ позволяет сделать следующие выводы:
-
Отсутствие выбросов на коробчатых диаграммах свидетельствует об однородности распределения переменных.
-
Смещение медианы вправо на коробчатых диаграммах свидетельствует о левосторонней асимметрии распределения.
ДЕСКРИПТИВНАЯ (ОПИСАТЕЛЬНАЯ СТАТИСТИКА)
Собственно говоря, данный этап требуется проводить далеко не всегда, однако с помощью статистических характеристик выборки мы тоже можем сделать полезные выводы.
Описательная статистика исходных данных средствами библиотеки Pandas — самый простой вариант:
dataset_df.describe()
Описательная статистика исходных данных средствами библиотеки statsmodels — более развернутый вариант, с большим количеством показателей:
from statsmodels.stats.descriptivestats import Description
result = Description(
dataset_df,
stats=["nobs", "missing", "mean", "std_err", "ci", "ci", "std", "iqr", "mad", "coef_var", "range", "max", "min", "skew", "kurtosis", "mode",
"median", "percentiles", "distinct", "top", "freq"],
alpha=a_level,
use_t=True)
display(result.summary())
Описательная статистика исходных данных с помощью пользовательской функции descriptive_characteristics:
# Пользовательская функция
descriptive_characteristics(X)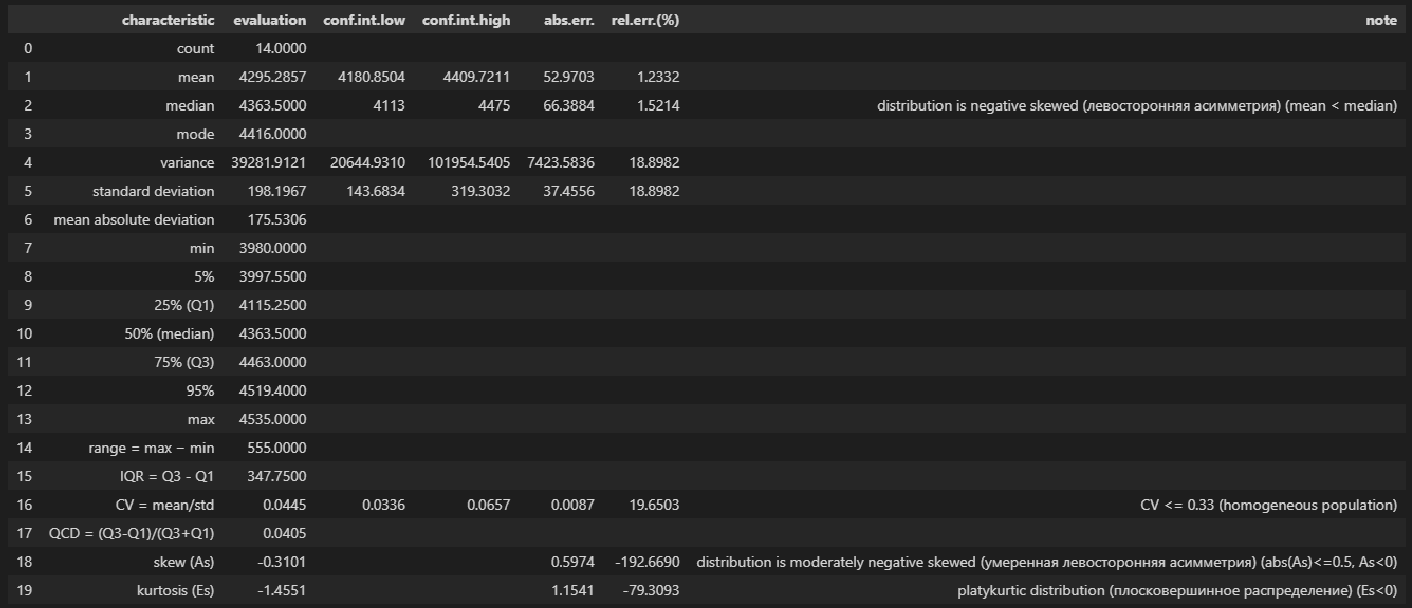
Выводы:
-
Сравнение показателей среднего арифметического (mean) и медианы (median) свидетельствует о левосторонней асимметрии (т.к.mean < median).
-
Значение коэффициента вариации CV = 0.0445 и доверительный интервал для него 0.0336 ≤ CV ≤ 0.0657 свидетельствует об однородности исходных данных (т.к. CV ≤ 0.33).
-
Значение показателя асимметрии skew (As) = -0.3101 свидетельствует об умеренной левосторонней асимметрии распределении (т.к. |As| ≤ 0.5, As < 0).
-
Значение показателя эксцесса kurtosis (Es) = -1.4551 свидетельствует о плосковершинном распределении (platykurtic distribution) (т.к. Es < 0).
# Пользовательская функция
descriptive_characteristics(Y)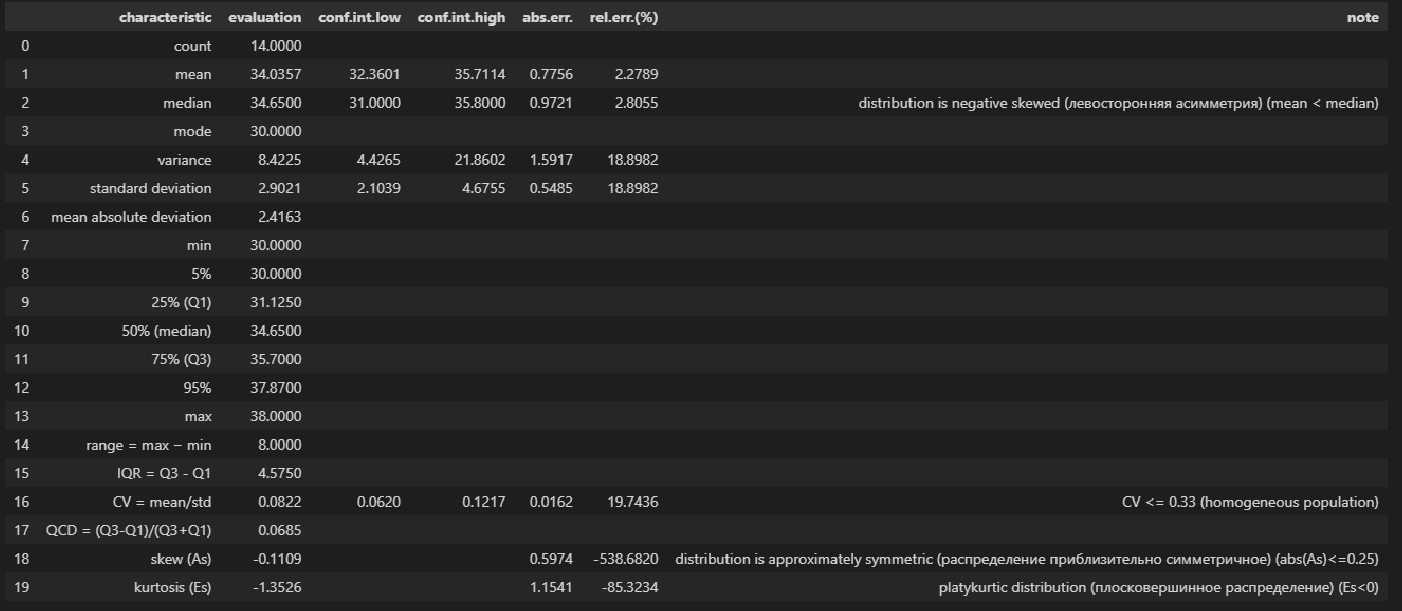
Выводы:
-
Сравнение показателей среднего арифметического (mean) и медианы (median) свидетельствует о левосторонней асимметрии (т.к.mean < median).
-
Значение коэффициента вариации CV = 0.0822 и доверительный интервал для него 0.06202 ≤ CV ≤ 0.1217 свидетельствует об однородности исходных данных (т.к. CV ≤ 0.33).
-
Значение показателя асимметрии skew (As) = -0.1109 свидетельствует о приблизительно симметричном распределении (т.к. |As| ≤ 0.25).
-
Значение показателя эксцесса kurtosis (Es) = -1.3526 свидетельствует о плосковершинном распределении (platykurtic distribution) (т.к. Es < 0).
ПРОВЕРКА НОРМАЛЬНОСТИ РАСПРЕДЕЛЕНИЯ
Для проверки нормальности распределения использована пользовательская функция norm_distr_check, которая объединяет в себе набор стандартных статистических тестов проверки нормальности. Все тесты относятся к стандартному инструментарию Pyton (библиотека scipy, модуль stats), за исключением теста Эппса-Палли (Epps-Pulley test); о том, как реализовать этот тест средствами Pyton я писал в своей статье https://habr.com/ru/post/685582/.
Примечание: для использования функции norm_distr_check в каталог с ipynb-файлом необходимо поместить папку table c файлом Tep_table.csv, который содержит табличные значения статистики критерия Эппса-Палли.
# пользовательская функция
norm_distr_check(X)
# Пользовательская функция
norm_distr_check (Y)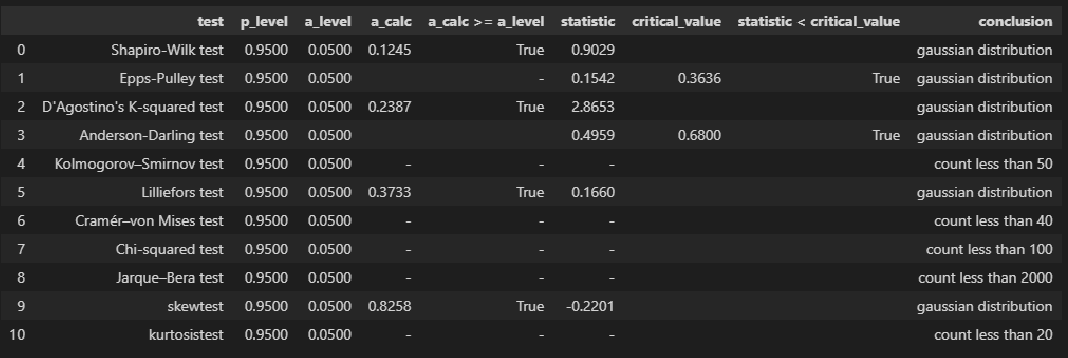
Вывод: большинство статистических тестов позволяют принять гипотезу о нормальности распределения переменных X и Y.
ПРОВЕРКА АНОМАЛЬНЫХ ЗНАЧЕНИЙ (ВЫБРОСОВ)
Статистическую проверку аномальных значений (выбросов) не стоит путать с проверкой выбросов, которая проводится на этапе первичной обработки результатов наблюдений. Последняя проводится с целью отсеять явные ошибочные данные (например, в результате неправильно поставленной запятой величина показателя может увеличиться/уменьшиться на порядок); здесь же мы говорим о статистической проверке данных, которые уже прошли этап первичной обработки.
Имеется довольно много критериев для проверки аномальных значений (подробнее см.[1]); вообще данная процедура довольно неоднозначная:
-
критерии зависят от вида распределения;
-
мало данных о сравнительной мощности этих критериев;
-
даже в случае принятии гипотезы о нормальном распределении в выборке могут быть обнаружены аномальные значения и пр.
Кроме существует дилемма: если какие-то значения в выборке признаны выбросами — стоит или не стоит исследователю исключать их? Ведь каждое значение несет в себе информацию, причем иногда весьма ценную, а сильно отклоняющиеся от основного массива данные (которые не являются выбросами в смысле первичной обработки, но являются статистическим значимыми аномальными значениями) могут кардинально изменить статистический вывод.
В общем, о задаче выявления аномальных значений (выбросов) можно написать отдельно, а пока, в данном разборе, ограничимся проверкой аномальных значений по критерию наибольшего максимального отклонения (см.[1, с.547]) с помощью пользовательской функции detecting_outliers_mad_test. Данные функция возвращает DataFrame, которые включает список аномальных значений со следующими признаками:
-
value — проверяемое значение из выборки;
-
mad_calc и mad_table — расчетное и табличное значение статистики критерия;
-
outlier_conclusion — вывод (выброс или нет).
Обращаю внимание, что критерий наибольшего максимального отклонения можно использовать только для нормально распределенных данных.
# пользовательская функция
print("Проверка наличия выбросов переменной X:\n")
result = detecting_outliers_mad_test(X)
mask = (result['outlier_conclusion'] == 'outlier')
display(result[mask])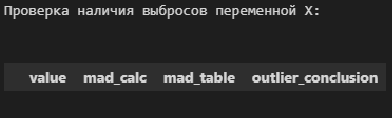
# пользовательская функция
print("Проверка наличия выбросов переменной Y:\n")
result = detecting_outliers_mad_test(Y)
mask = (result['outlier_conclusion'] == 'outlier')
display(result[mask])
Вывод: в случае обеих переменных X и Y список пуст, следовательно, аномальных значений (выбросов) не выявлено.
КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
Корреляционный анализ — это разведка перед построением регрессионной модели.
Выполним расчет коэффициента линейной корреляции Пирсона, проверку его значимости и построение доверительных интервалов с помощью пользовательской функции corr_coef_check (про эту функцию более подробно написано в моей статье https://habr.com/ru/post/683442/):
# пользовательская функция
display(corr_coef_check(X, Y, scale='Evans'))
Выводы:
-
Значение коэффициента корреляции coef_value = 0.8900 свидетельствует о весьма сильной корреляционной связи (по шкале Эванса).
-
Коэффициент корреляции значим по критерию Стьюдента: t_calc ≥ t_table, a_calc ≤ a_level.
-
Доверительный интервал для коэффициента корреляции: 0.6621 ≤ coef_value ≤ 0.9625.
РЕГРЕССИОННЫЙ АНАЛИЗ
Предварительная визуализация
python позволяет выполнить предварительную визуализацию, например, с помощью функции jointplot библиотеки seaborn:
fig = plt.figure(figsize=(297/INCH, 210/INCH))
axes = sns.jointplot(
x=X, y=Y,
kind='reg',
ci=95)
plt.show()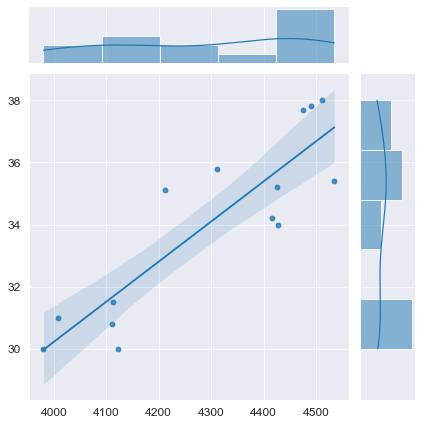
Построение модели
Выполним оценку параметров и анализ простой линейной регрессии (simple linear regression), используя библиотеку statsmodels (https://www.statsmodels.org/) и входящий в нее модуль линейной регрессии Linear Regression (https://www.statsmodels.org/stable/regression.html).
Данный модуль включает в себя классы, реализующие различные методы оценки параметров моделей линейной регрессии, в том числе:
-
класс OLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.OLS.html#statsmodels.regression.linear_model.OLS) — Ordinary Least Squares (обычный метод наименьших квадратов).
-
класс WLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.WLS.html#statsmodels.regression.linear_model.WLS) — Weighted Least Squares (метод взвешенных наименьших квадратов) (https://en.wikipedia.org/wiki/Weighted_least_squares), применяется, если имеет место гетероскедастичность данных (https://ru.wikipedia.org/wiki/Гетероскедастичность).
-
класс GLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.GLS.html#statsmodels.regression.linear_model.GLS) — Generalized Least Squares (обобщенный метод наименьших квадратов) (https://en.wikipedia.org/wiki/Generalized_least_squares), применяется, если существует определенная степень корреляции между остатками в модели регрессии.
-
класс GLSAR (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.GLSAR.html#statsmodels.regression.linear_model.GLSAR) — Generalized Least Squares with AR covariance structure (обобщенный метод наименьших квадратов, ковариационная структура с автокорреляцией — экспериментальный метод)
-
класс RecurciveLS (https://www.statsmodels.org/stable/examples/notebooks/generated/recursive_ls.html) — Recursive least squares (рекурсивный метод наименьших квадратов) (https://en.wikipedia.org/wiki/Recursive_least_squares_filter)
-
классы RollingOLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.rolling.RollingOLS.html#statsmodels.regression.rolling.RollingOLS) и RollingWLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.rolling.RollingWLS.html#statsmodels.regression.rolling.RollingWLS) — скользящая регрессия (https://www.statsmodels.org/stable/examples/notebooks/generated/rolling_ls.html, https://help.fsight.ru/ru/mergedProjects/lib/01_regression_models/rolling_regression.htm)
и т.д.
Так как исходные данные подчиняются нормальному закону распределения и аномальные значения (выбросы) отсутствуют, воспользуемся для оценки параметров обычным методом наименьших квадратов (класс OLS):
model_linear_ols = smf.ols(formula='Y ~ X', data=dataset_df)
result_linear_ols = model_linear_ols.fit()
print(result_linear_ols.summary())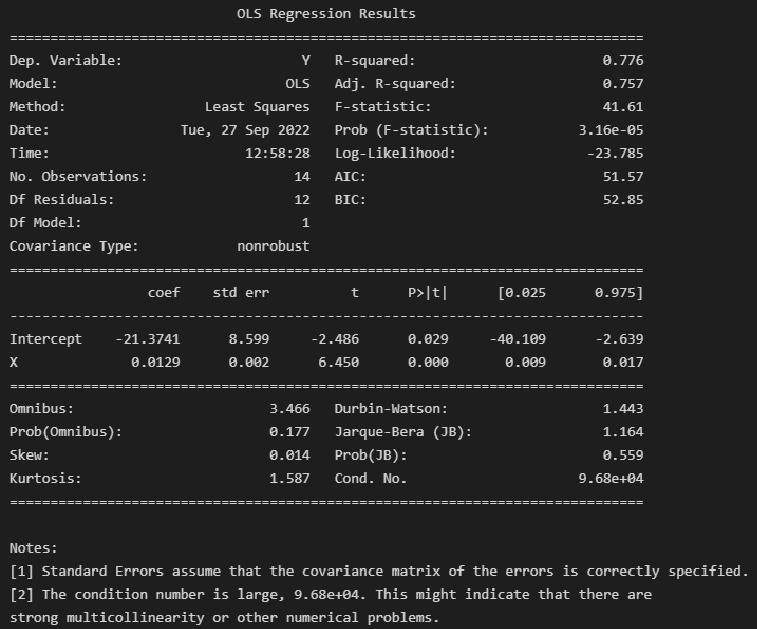
Альтернативная форма выдачи результатов:
print(result_linear_ols.summary2())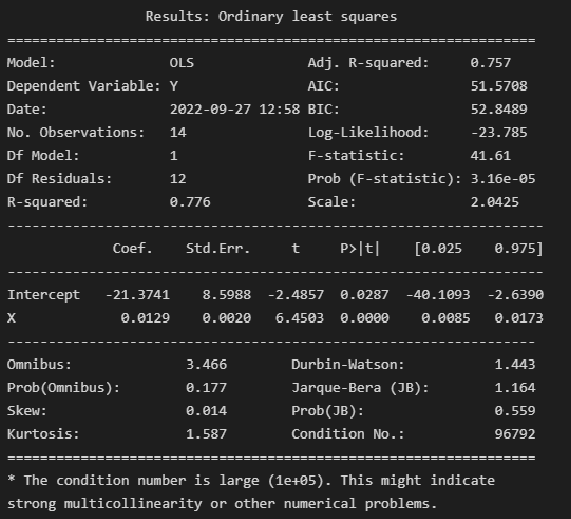
Результаты построения модели мы получаем как класс statsmodels.regression.linear_model.RegressionResults (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.html#statsmodels.regression.linear_model.RegressionResults).
Экспресс-выводы, которые мы можем сразу сделать из результатов построения модели:
-
Коэффициенты регрессии модели Y = b0 + b1∙X:
-
Intercept = b0 = -21.3741
-
b1 = 0.0129
-
-
Коэффициент детерминации R-squared = 0.776, его скорректированная оценка Adj. R-squared = 0.757 — это означает, что регрессионная модуль объясняет 75.75% вариации переменной Y.
-
Проверка значимости коэффициента детерминации:
-
расчетное значение статистики критерия Фишера: F-statistic = 41.61
-
расчетный уровень значимости Prob (F-statistic) = 3.16e-05
-
так как значение Prob (F-statistic) < 0.05, то нулевая гипотеза R-squared = 0 НЕ ПРИНИМАЕТСЯ, т.е. коэффициент детерминации ЗНАЧИМ
-
-
Проверка значимости коэффициентов регрессии:
-
расчетный уровень значимости P>|t| не превышает 0.05 — это означает, что оба коэффициента регрессии значимы
-
об этом же свидетельствует то, что доверительный интервал для обоих коэффициентов регрессии ([0.025; 0.975]) не включает в себя точку 0
Также в таблице результатов содержится прочая информация по коэффициентам регрессии: стандартная ошибка Std.Err. расчетное значение статистики критерия Стьюдента t для проверки гипотезы о значимости.
-
-
Анализ остатков модели:
-
Тест Omnibus — про этот тест подробно написано в https://en.wikipedia.org/wiki/Omnibus_test, https://medium.com/swlh/interpreting-linear-regression-through-statsmodels-summary-4796d359035a, http://work.thaslwanter.at/Stats/html/statsModels.html.
Расчетное значение статистики критерия Omnibus = 3.466 — по сути расчетное значение F-критерия (см. https://en.wikipedia.org/wiki/Omnibus_test).
Prob(Omnibus) = 0.177 — показывает вероятность нормального распределения остатков (значение 1 указывает на совершенно нормальное распределение).
Учитывая, что в дальнейшем мы проверим нормальность распределения остатков по совокупности различных тестов, в том числе с достаточно высокой мощностью, и все тесты позволят принять гипотезу о нормальном распределении — в данном случае к тесту Omnibus возникают вопросы. С этим тестом нужно разбираться отдельно.
-
Skew = 0.014 и Kurtosis = 1.587 — показатели асимметрии и эксцесса остатков свидетельствуют, что распределение остатков практически симметричное, островершинное.
-
проверка нормальности распределения остатков по критерию Харке-Бера: расчетное значение статистики критерия Jarque-Bera (JB) = 1.164 и расчетный уровень значимости Prob(JB) = 0.559. К данным результатам также возникают вопросы, особенно, если учесть, что критерий Харке-Бера является асимптотическим, расчетное значение имеет распределение хи-квадрат, поэтому данный критерий рекомендуют применять только для больших выборок (см. https://en.wikipedia.org/wiki/Jarque–Bera_test). Проверку нормальности распределения остатков модели лучше проводить с использованием набора стандартных статистических тестов python (см. далее).
-
-
Проверка автокорреляции по критерию Дарбина-Уотсона: Durbin-Watson = 1.443.
Мы не будем здесь разбирать данный критерий, так как явление автокорреляции больше характерно для данных, выражаемых в виде временных рядов. Однако, для грубой оценки считается, что при расчетном значении статистики криетрия Дарбина=Уотсона а интервале [1; 2] автокорреляция отсутствует (см.https://en.wikipedia.org/wiki/Durbin–Watson_statistic).
Более подробно про критерий Дарбина-Уотсона — см. [1, с.659].
Прочая информация, которую можно извлечь из результатов построения модели:
-
Covariance Type — тип ковариации, подробнее см. https://habr.com/ru/post/681218/, https://towardsdatascience.com/simple-explanation-of-statsmodel-linear-regression-model-summary-35961919868b#:~:text=Covariance type is typically nonrobust,with respect to each other.
-
Scale — масштабный коэффициент для ковариационной матрицы (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.scale.html#statsmodels.regression.linear_model.RegressionResults.scale), равен величине Mean squared error (MSE) (cреднеквадратической ошибке), об подробнее см. далее, в разделе про ошибки аппроксимации моделей.
-
Показатели сравнения качества различных моделей:
-
Log-Likelihood — логарифмическая функция правдоподобия, подробнее см. https://en.wikipedia.org/wiki/Likelihood_function#Log-likelihood, https://habr.com/ru/post/433804/
-
AIC — информационный критерий Акаике (Akaike information criterion), подробнее см. https://en.wikipedia.org/wiki/Akaike_information_criterion
-
BIC — информационный критерий Байеса (Bayesian information criterion), подробнее см. https://en.wikipedia.org/wiki/Bayesian_information_criterion
В данной статье мы эти показатели рассматривать не будем, так как задача выбора одной модели из нескольких перед нами не стоит.
-
-
Число обусловленности Cond. No = 96792 используется для проверки мультиколлинеарности (считается, что мультиколлинеарность есть, если значение Cond. No > 30) (см. http://work.thaslwanter.at/Stats/html/statsModels.html). В нашем случае парной регрессионной модели о мультиколлинеарности речь не идет.
Далее будем извлекать данные из стандартного набора выдачи результатов и анализировать их более подробно. Последующие этапы вовсе не обязательно проводить в полном объеме при решении задач, но здесь мы рассмотрим их подробно.
Параметры и уравнение регрессионной модели
Извлечем параметры полученной модели — как свойство params модели:
print('Параметры модели: \n', result_linear_ols.params, type(result_linear_ols.params))
Имея параметры модели, можем формализовать уравнение модели Y = b0 + b1*X:
b0 = result_linear_ols.params['Intercept']
b1 = result_linear_ols.params['X']
Y_calc = lambda x: b0 + b1*xГрафик регрессионной модели
Для построения графиков регрессионных моделей можно воспользоваться стандартными возможностями библиотек statsmodels, seaborn, либо создать пользовательскую функцию — на усмотрение исследователя:
1. Построение графиков регрессионных моделей с использованием библиотеки statsmodels
С помощью функции statsmodels.graphics.plot_fit (https://www.statsmodels.org/stable/generated/statsmodels.graphics.regressionplots.plot_fit.html#statsmodels.graphics.regressionplots.plot_fit) — отображается график Y and Fitted vs.X (фактические и расчетные значения Y с доверительным интервалом для каждого значения Y):
fig, ax = plt.subplots(figsize=(297/INCH, 210/INCH))
fig = sm.graphics.plot_fit(
result_linear_ols, 'X',
vlines=True, # это параметр отвечает за отображение доверительных интервалов для Y
ax=ax)
ax.set_ylabel(Variable_Name_Y)
ax.set_xlabel(Variable_Name_X)
ax.set_title(Task_Project)
plt.show()
С помощью функции statsmodels.graphics.plot_regress_exog (https://www.statsmodels.org/stable/generated/statsmodels.graphics.regressionplots.plot_regress_exog.html#statsmodels.graphics.regressionplots.plot_regress_exog) — отображается область 2х2, которая содержит:
-
предыдущий график Y and Fitted vs.X;
-
график остатков Residuals versus X;
-
график Partial regression plot — график частичной регрессии, пытается показать эффект добавления другой переменной в модель, которая уже имеет одну или несколько независимых переменных (более подробно см. https://en.wikipedia.org/wiki/Partial_regression_plot);
-
график CCPR Plot (Component-Component plus Residual Plot) — еще один способ оценить влияние одной независимой переменной на переменную отклика, принимая во внимание влияние других независимых переменных (более подробно — см. https://towardsdatascience.com/calculating-price-elasticity-of-demand-statistical-modeling-with-python-6adb2fa7824d, https://www.kirenz.com/post/2021-11-14-linear-regression-diagnostics-in-python/linear-regression-diagnostics-in-python/).
fig = plt.figure(figsize=(297/INCH, 210/INCH))
sm.graphics.plot_regress_exog(result_linear_ols, 'X', fig=fig)
plt.show()
2. Построение графиков регрессионных моделей с использованием библиотеки seaborn
Воспользуемся модулем regplot библиотеки seaborn (https://seaborn.pydata.org/generated/seaborn.regplot.html). Данный модуль позволяет визуализировать различные виды регрессии:
-
линейную
-
полиномиальную
-
логистическую
-
взвешенную локальную регрессию (LOWESS — Locally Weighted Scatterplot Smoothing) (см. http://www.machinelearning.ru/wiki/index.php?title=Алгоритм_LOWESS, https://www.statsmodels.org/stable/generated/statsmodels.nonparametric.smoothers_lowess.lowess.html)
Более подробно про модуль regplot можно прочитать в статье: https://pyprog.pro/sns/sns_8_regression_models.html.
Есть более совершенный модуль lmplot (https://seaborn.pydata.org/generated/seaborn.lmplot.html), который объединяет в себе regplot и FacetGrid, но мы его здесь рассматривать не будем.
# создание рисунка (Figure) и области рисования (Axes)
fig = plt.figure(figsize=(297/INCH, 420/INCH/1.5))
ax1 = plt.subplot(2,1,1)
ax2 = plt.subplot(2,1,2)
# заголовок рисунка (Figure)
title_figure = Task_Project
fig.suptitle(title_figure, fontsize = 18)
# заголовок области рисования (Axes)
title_axes_1 = 'Линейная регрессионная модель'
ax1.set_title(title_axes_1, fontsize = 16)
# график регрессионной модели
order_mod = 1 # порядок модели
#label_legend_regr_model = 'фактические данные'
sns.regplot(
#data=dataset_df,
x=X, y=Y,
#x_estimator=np.mean,
order=order_mod,
logistic=False,
lowess=False,
robust=False,
logx=False,
ci=95,
scatter_kws={'s': 30, 'color': 'red'},
line_kws={'color': 'blue'},
#label=label_legend_regr_model,
ax=ax1)
ax1.set_ylabel(Variable_Name_Y)
ax1.legend()
# график остатков
title_axes_2 = 'График остатков'
ax2.set_title(title_axes_2, fontsize = 16)
sns.residplot(
#data=dataset_df,
x=X, y=Y,
order=order_mod,
lowess=False,
robust=False,
scatter_kws={'s': 30, 'color': 'darkorange'},
ax=ax2)
ax2.set_xlabel(Variable_Name_X)
plt.show()
3. Построение графиков регрессионных моделей с помощью пользовательской функции
# Пользовательская функция
graph_regression_plot_sns(
X, Y,
regression_model=Y_calc,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=Ymin_graph, Ymax=Ymax_graph,
title_figure=Task_Project,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X',
s=80,
file_name='graph/regression_plot_lin.png')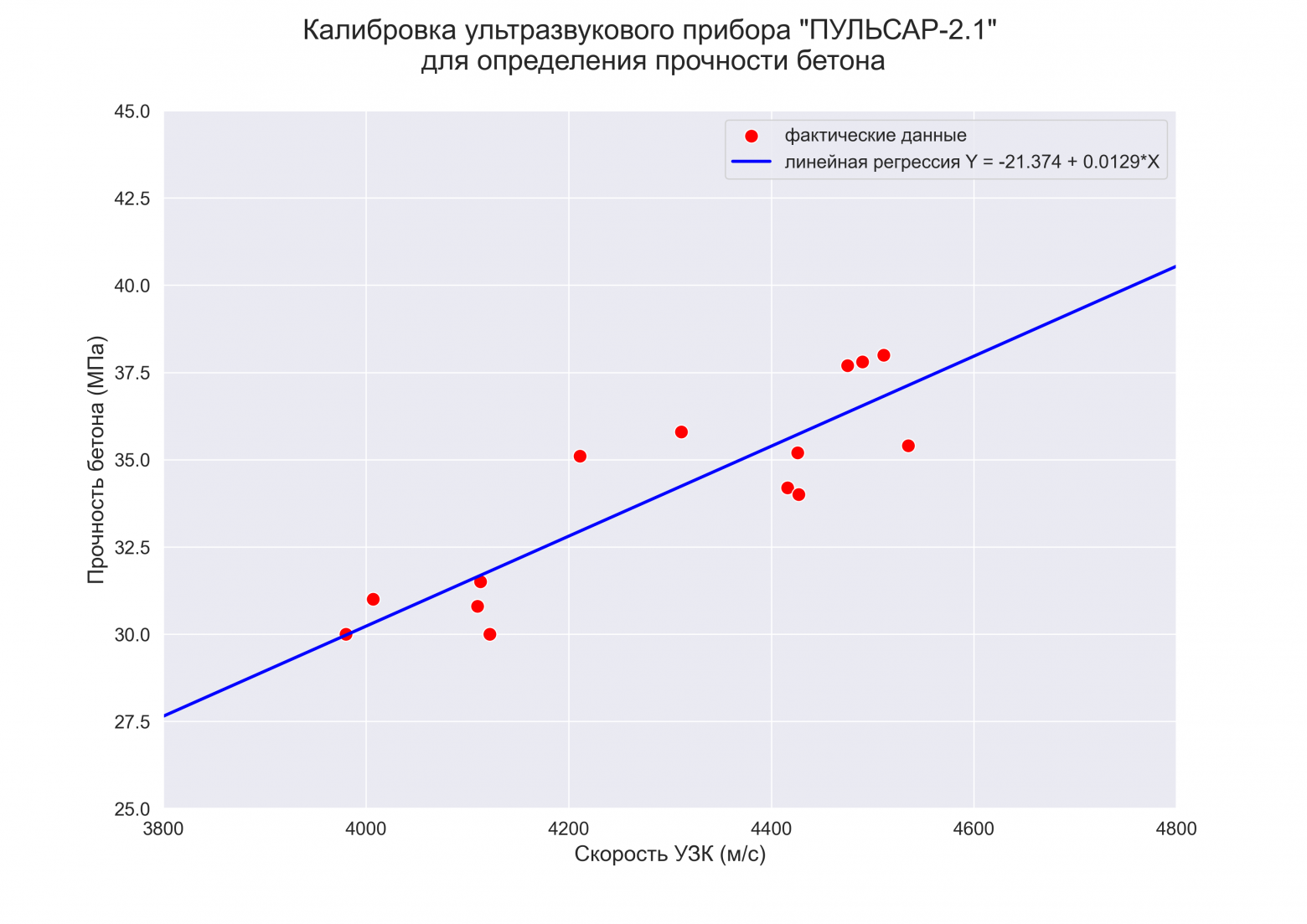
Статистический анализ регрессионной модели
1. Расчет ошибки аппроксимации (Error Metrics)
Ошибки аппроксимации (Error Metrics) позволяют получить общее представление о качестве модели, а также позволяют сравнивать между собой различные модели.
Создадим пользовательскую функцию, которая рассчитывает основные ошибки аппроксимации для заданной модели:
-
Mean squared error (MSE) или Mean squared deviation (MSD) — среднеквадратическая ошибка (https://en.wikipedia.org/wiki/Mean_squared_error):

-
Root mean square error (RMSE) или Root mean square deviation (RMSD) — квадратный корень из MSE (https://en.wikipedia.org/wiki/Root-mean-square_deviation):
![]()
-
Mean absolute error (MAE) — средняя абсолютная ошибка (https://en.wikipedia.org/wiki/Mean_absolute_error):

-
Mean squared prediction error (MSPE) — среднеквадратическая ошибка прогноза (среднеквадратическая ошибка в процентах) (https://en.wikipedia.org/wiki/Mean_squared_prediction_error):
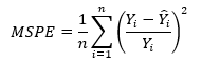
-
Mean absolute percentage error (MAPE) — средняя абсолютная ошибка в процентах (https://en.wikipedia.org/wiki/Mean_absolute_percentage_error):

Про выбор метрики см. также https://machinelearningmastery.ru/how-to-select-the-right-evaluation-metric-for-machine-learning-models-part-2-regression-metrics-d4a1a9ba3d74/.
# Пользовательская функция
def regression_error_metrics(model, model_name=''):
model_fit = model.fit()
Ycalc = model_fit.predict()
n_fit = model_fit.nobs
Y = model.endog
MSE = (1/n_fit) * np.sum((Y-Ycalc)**2)
RMSE = sqrt(MSE)
MAE = (1/n_fit) * np.sum(abs(Y-Ycalc))
MSPE = (1/n_fit) * np.sum(((Y-Ycalc)/Y)**2)
MAPE = (1/n_fit) * np.sum(abs((Y-Ycalc)/Y))
model_error_metrics = {
'MSE': MSE,
'RMSE': RMSE,
'MAE': MAE,
'MSPE': MSPE,
'MAPE': MAPE}
result = pd.DataFrame({
'MSE': MSE,
'RMSE': RMSE,
'MAE': MAE,
'MSPE': "{:.3%}".format(MSPE),
'MAPE': "{:.3%}".format(MAPE)},
index=[model_name])
return model_error_metrics, result
(model_error_metrics, result) = regression_error_metrics(model_linear_ols, model_name='linear_ols')
display(result)
В литературе по прикладной статистике нет единого мнения о допустимом размере относительных ошибок аппроксимации: в одних источниках допустимой считается ошибка 5-7%, в других она может быть увеличена до 8-10%, и даже до 15%.
Вывод: модель хорошо аппроксимирует фактические данные (относительная ошибка аппроксимации MAPE = 3.405% < 10%).
2. Дисперсионный анализ регрессионной модели (ДАРМ)
ДАРМ не входит в стандартную форму выдачи результатов Regression Results, однако я решил написать здесь о нем по двум причинам:
-
Именно анализ дисперсии регрессионной модели, разложение этой дисперсии на составляющие дает фундаментальное представление о сути регрессии, а термины, используемые при ДАРМ, применяются на последующих этапах анализа.
-
С терминами ДАРМ в литературе по прикладной статистике имеется некоторая путаница, в разных источниках они могут именоваться по-разному (см., например, [8, с.52]), поэтому, чтобы двигаться дальше, необходимо определиться с понятиями.
При ДАРМ общую вариацию результативного признака (Y) принято разделять на две составляющие — вариация, обусловленная регрессией и вариация, обусловленная отклонениями от регрессии (остаток), при этом в разных источниках эти термины могут именоваться и обозначаться по-разному, например:
-
Вариация, обусловленная регрессией — может называться Explained sum of squares (ESS), Sum of Squared Regression (SSR) (https://en.wikipedia.org/wiki/Explained_sum_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684), Sum of squared deviations (SSD).
-
Вариация, обусловленная отклонениями от регрессии (остаток) — может называться Residual sum of squares (RSS), Sum of squared residuals (SSR), Squared estimate of errors, Sum of Squared Error (SSE) (https://en.wikipedia.org/wiki/Residual_sum_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684); в отчественной практике также применяется термин остаточная дисперсия.
-
Общая (полная) вариация — может называться Total sum of squares (TSS), Sum of Squared Total (SST) (https://en.wikipedia.org/wiki/Partition_of_sums_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684).
Как видим, путаница знатная:
-
в разных источниках под SSR могут подразумеваться различные показатели;
-
легко перепутать показатели ESS и SSE;
-
в библиотеке statsmodel также есть смешение терминов: для показателя Explained sum of squares используется свойство ess, а для показателя Sum of squared (whitened) residuals — свойство ssr.
Мы будем пользоваться системой обозначений, принятой в большинстве источников — SSR (Sum of Squared Regression), SSE (Sum of Squared Error), SST (Sum of Squared Total). Стандартная таблица ДАРМ в этом случае имеет вид:

Примечания:
-
Здесь приведена таблица ДАРМ для множественной линейной регрессионной модели (МЛРМ), в нашем случае при ПЛРМ мы имеем частный случай p=1.
-
Показатели Fcalc-ad и Fcalc-det — расчетные значения статистики критерия Фишера при проверке адекватности модели и значимости коэффициента детерминации (об этом — см.далее).
Более подробно про дисперсионный анализ регрессионной модели — см.[4, глава 3].
Класс statsmodels.regression.linear_model.RegressionResults позволяет нам получить данные для ANOVA (см. https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.html#statsmodels.regression.linear_model.RegressionResults) как свойства класса:
-
Сумма квадратов, обусловленная регрессией / SSR (Sum of Squared Regression) — свойство ess.
-
Сумма квадратов, обусловленная отклонением от регрессии / SSE (Sum of Squared Error) — свойство ssr.
-
Общая (полная) сумма квадратов / SST (Sum of Squared Total) — свойство centered_tss.
-
Кол-во наблюдений / Number of observations — свойство nobs.
-
Число степеней свободы модели / Model degrees of freedom — равно числу переменных модели (за исключением константы, если она присутствует — свойство df_model.
-
Среднеквадратичная ошибка модели / Mean squared error the model — сумма квадратов, объясненная регрессией, деленная на число степеней свободы регрессии — свойство mse_model.
-
Среднеквадратичная ошибка остатков / Mean squared error of the residuals — сумма квадратов остатков, деленная на остаточные степени свободы — свойство mse_resid.
-
Общая среднеквадратичная ошибка / Total mean squared error — общая сумма квадратов, деленная на количество наблюдений — свойство mse_total.
Также имеется модуль statsmodels.stats.anova.anova_lm, который позволяет получить результаты ДАРМ (нескольких типов — 1, 2, 3):
# тип 1
print('The type of Anova test: 1')
display(sm.stats.anova_lm(result_linear_ols, typ=1))
# тип 2
print('The type of Anova test: 2')
display(sm.stats.anova_lm(result_linear_ols, typ=2))
# тип 3
print('The type of Anova test: 3')
display(sm.stats.anova_lm(result_linear_ols, typ=3))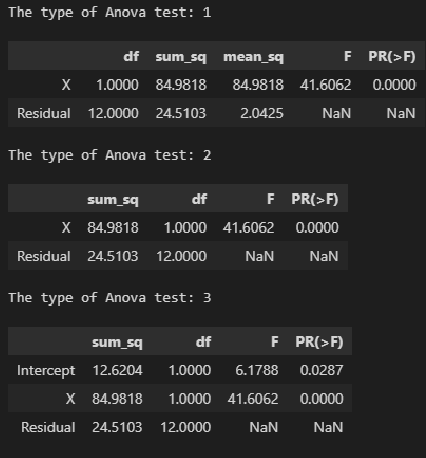
На мой взгляд, форма таблица результатов statsmodels.stats.anova.anova_lm не вполне удобна, поэтому сформируем ее самостоятельно, для чего создадим пользовательскую функцию ANOVA_table_regression_model:
# Пользовательская функция
def ANOVA_table_regression_model(model_fit):
n = int(model_fit.nobs)
p = int(model_fit.df_model)
SSR = model_fit.ess
SSE = model_fit.ssr
SST = model_fit.centered_tss
result = pd.DataFrame({
'sources_of_variation': ('regression (SSR)', 'deviation from regression (SSE)', 'total (SST)'),
'sum_of_squares': (SSR, SSE, SST),
'degrees_of_freedom': (p, n-p-1, n-1)})
result['squared_error'] = result['sum_of_squares'] / result['degrees_of_freedom']
R2 = 1 - result.loc[1, 'sum_of_squares'] / result.loc[2, 'sum_of_squares']
F_calc_adequacy = result.loc[2, 'squared_error'] / result.loc[1, 'squared_error']
F_calc_determ_check = result.loc[0, 'squared_error'] / result.loc[1, 'squared_error']
result['F-ratio'] = (F_calc_determ_check, F_calc_adequacy, '')
return result
result = ANOVA_table_regression_model(result_linear_ols)
display(result)
print(f"R2 = 1 - SSE/SST = {1 - result.loc[1, 'sum_of_squares'] / result.loc[2, 'sum_of_squares']}")
print(f"F_calc_adequacy = MST / MSE = {result.loc[2, 'squared_error'] / result.loc[1, 'squared_error']}")
print(f"F_calc_determ_check = MSR / MSE = {result.loc[0, 'squared_error'] / result.loc[1, 'squared_error']}")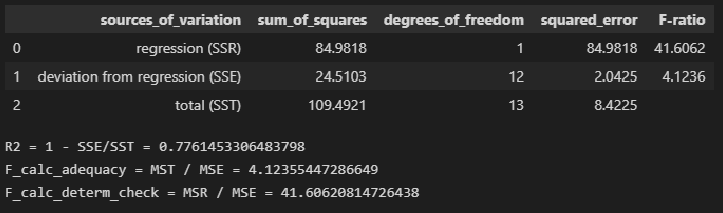
ДАРМ позволяет визуализировать вариацию:
fig, axes = plt.subplots(figsize=(210/INCH, 297/INCH/1.5))
axes.pie(
(result.loc[0, 'sum_of_squares'], result.loc[1, 'sum_of_squares']),
labels=(result.loc[0, 'sources_of_variation'], result.loc[1, 'sources_of_variation']),
autopct='%.1f%%',
startangle=60)
plt.show()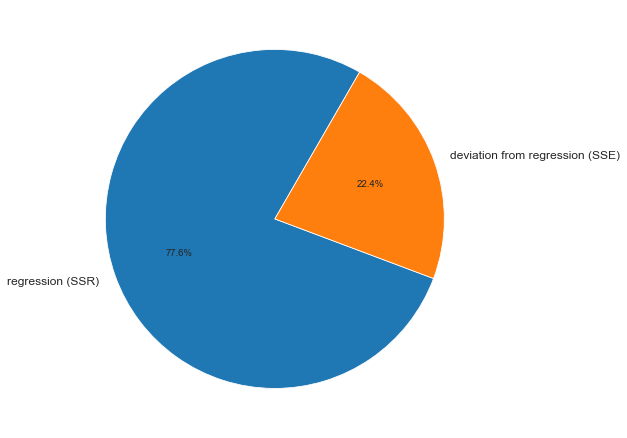
На основании данных ДАРМ мы рассчитали ряд показателей (R2, Fcalc-ad и Fcalc-det), которые будут использоваться в дальнейшем.
3. Анализ остатков (проверка нормальности распределения остатков и гипотезы о равенстве нулю среднего значения остатков)
Проверка нормальности распределения остатков — один их важнейших этапов анализа регрессионной модели. Требование нормальности распределения остатков не требуется для отыскания параметров модели, но необходимо в дальнейшем для проверки статистических гипотез с использованием критериев Фишера и Стьюдента (проверка адекватности модели, значимости коэффициента детерминации, значимости коэффициентов регрессии) и построения доверительных интервалов [5, с.122].
Остатки регрессионной модели:
print('Остатки регрессионной модели:\n', result_linear_ols.resid, type(result_linear_ols.resid))
res_Y = np.array(result_linear_ols.resid)statsmodels может выдавать различные преобразованные виды остатков (см. https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.resid_pearson.html, https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.wresid.html).
График остатков:
# Пользовательская функция
graph_scatterplot_sns(
X, res_Y,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=-3.0, Ymax=3.0,
color='red',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=18,
x_label=Variable_Name_X,
y_label='ΔY = Y - Ycalc',
s=75,
file_name='graph/residuals_plot_sns.png')
Проверка нормальности распределения остатков:
# Пользовательская функция
graph_hist_boxplot_probplot_sns(
data=res_Y,
data_min=-2.5, data_max=2.5,
graph_inclusion='bp',
data_label='ΔY = Y - Ycalc',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=16,
file_name='graph/residuals_hist_boxplot_probplot_sns.png') 
norm_distr_check(res_Y)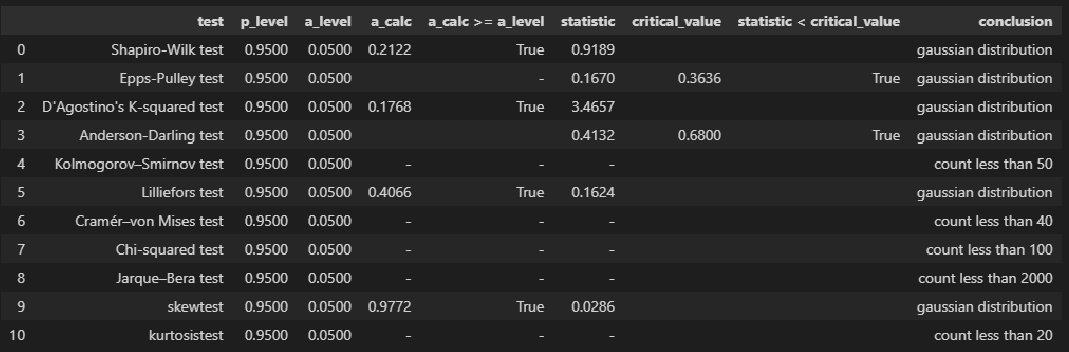
Вывод: большинство статистических тестов позволяют принять гипотезу о нормальности распределения остатков.
Проверка гипотезы о равенстве нулю среднего значения остатков — так как остатки имеют нормальное распределение, воспользуемся критерием Стьюдента (функция scipy.stats.ttest_1samp, https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ttest_ind.html):
sps.ttest_1samp(res_Y, popmean=0)![]()
Вывод: так как расчетный уровень значимости превышает заданный (0.05), то нулевая гипотеза о равенстве нулю остатков ПРИНИМАЕТСЯ.
4. Проверка адекватности модели
Суть проверки адекватности регрессионной модели заключается в сравнении полной дисперсии MST и остаточной дисперсии MSE — проверяется гипотеза о равенстве этих дисперсий по критерию Фишера. Если дисперсии различаются значимо, то модель считается адекватной. Более подробно про проверку адекватности регрессионной — см.[1, с.658], [2, с.49], [4, с.154].
Для проверки адекватности регрессионной модели создадим пользовательскую функцию regression_model_adequacy_check:
def regression_model_adequacy_check(
model_fit,
p_level: float=0.95,
model_name=''):
n = int(model_fit.nobs)
p = int(model_fit.df_model) # Число степеней свободы регрессии, равно числу переменных модели (за исключением константы, если она присутствует)
SST = model_fit.centered_tss # SST (Sum of Squared Total)
dfT = n-1
MST = SST / dfT
SSE = model_fit.ssr # SSE (Sum of Squared Error)
dfE = n - p - 1
MSE = SSE / dfE
F_calc = MST / MSE
F_table = sci.stats.f.ppf(p_level, dfT, dfE, loc=0, scale=1)
a_calc = 1 - sci.stats.f.cdf(F_calc, dfT, dfE, loc=0, scale=1)
conclusion_model_adequacy_check = 'adequacy' if F_calc >= F_table else 'adequacy'
# формируем результат
result = pd.DataFrame({
'SST': (SST),
'SSE': (SSE),
'dfT': (dfT),
'dfE': (dfE),
'MST': (MST),
'MSE': (MSE),
'p_level': (p_level),
'a_level': (a_level),
'F_calc': (F_calc),
'F_table': (F_table),
'F_calc >= F_table': (F_calc >= F_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'adequacy_check': (conclusion_model_adequacy_check),
},
index=[model_name]
)
return result
regression_model_adequacy_check(result_linear_ols, p_level=0.95, model_name='linear_ols')
Вывод: модель является АДЕКВАТНОЙ.
5. Коэффициент детерминации и проверка его значимости
Различают несколько видов коэффициента детерминации:
-
Собственно обычный коэффициент детерминации:

Его значение может быть получено как свойство rsquared модели.
-
Скорректированный (adjusted) коэффициент детерминации — используется для того, чтобы была возможность сравнивать модели с разным числом признаков так, чтобы число регрессоров (признаков) не влияло на статистику R2, при его расчете используются несмещённые оценки дисперсий:


Его значение может быть получено как свойство rsquared_adj модели.
-
Обобщённый (extended) коэффициент детерминации — используется для сравнения моделей регрессии со свободным членом и без него, а также для сравнения между собой регрессий, построенных с помощью различных методов: МНК, обобщённого метода наименьших квадратов (ОМНК), условного метода наименьших квадратов (УМНК), обобщённо-условного метода наименьших квадратов (ОУМНК). В данном разборе ПЛРМ рассматривать этот коэффициент мы не будем.
Более подробно с теорией вопроса можно ознакомиться, например: http://www.machinelearning.ru/wiki/index.php?title=Коэффициент_детерминации), а также в [7].
Значения коэффициента детерминации и скорректированного коэффициента детерминации, извлеченные с помощью свойств rsquared и rsquared_adj модели.
print('R2 =', result_linear_ols.rsquared)
print('R2_adj =', result_linear_ols.rsquared_adj)
Значимость коэффициента детерминации можно проверить по критерию Фишера [3, с.201-203; 8, с.83].
Расчетное значение статистики критерия Фишера может быть получено с помощью свойства fvalue модели:
print(f"result_linear_ols.fvalue = {result_linear_ols.fvalue}")![]()
Расчетный уровень значимости при проверке гипотезы по критерию Фишера может быть получено с помощью свойства f_pvalue модели:
print(f"result_linear_ols.f_pvalue = {result_linear_ols.f_pvalue}")![]()
Можно рассчитать уровень значимости самостоятельно (так сказать, для лучшего понимания и общей демонстрации возможностей) — для этого воспользуемся библиотекой scipy, модулем распределения Фишера scipy.stats.f, свойством cdf (функция распределения):
df1 = int(result_linear_ols.df_model)
df2 = int(result_linear_ols.nobs - result_linear_ols.df_model - 1)
F_calc = result_linear_ols.fvalue
a_calc = 1 - sci.stats.f.cdf(F_calc, df1, df2, loc=0, scale=1)
print(a_calc)![]()
Как видим, результаты совпадают.
Табличное значение статистики критерия Фишера получить с помощью Regression Results нельзя. Рассчитаем его самостоятельно — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.f, свойством ppf (процентные точки):
F_table = sci.stats.f.ppf(p_level, df1, df2, loc=0, scale=1)
print(F_table)![]()
Для удобства создадим пользовательскую функцию determination_coef_check для проверки значимости коэффициента детерминации, которая объединяет все вышеперечисленные расчеты:
# Пользовательская функция
def determination_coef_check(
model_fit,
p_level: float=0.95):
a_level = 1 - p_level
R2 = model_fit.rsquared
R2_adj = model_fit.rsquared_adj
n = model_fit.nobs # объем выборки
p = model_fit.df_model # Model degrees of freedom. The number of regressors p. Does not include the constant if one is present.
F_calc = R2 / (1 - R2) * (n-p-1)/p
df1 = int(p)
df2 = int(n-p-1)
F_table = sci.stats.f.ppf(p_level, df1, df2, loc=0, scale=1)
a_calc = 1 - sci.stats.f.cdf(F_calc, df1, df2, loc=0, scale=1)
conclusion_determ_coef_sign = 'significance' if F_calc >= F_table else 'not significance'
# формируем результат
result = pd.DataFrame({
'notation': ('R2'),
'coef_value (R)': (sqrt(R2)),
'coef_value_squared (R2)': (R2),
'p_level': (p_level),
'a_level': (a_level),
'F_calc': (F_calc),
'df1': (df1),
'df2': (df2),
'F_table': (F_table),
'F_calc >= F_table': (F_calc >= F_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'significance_check': (conclusion_determ_coef_sign),
'conf_int_low': (''),
'conf_int_high': ('')
},
index=['Coef. of determination'])
return result
determination_coef_check(
result_linear_ols,
p_level=0.95)
Вывод: коэффициент детерминации ЗНАЧИМ.
6. Коэффициенты регрессии и проверка их значимости
Ранее мы уже извлекли коэффициенты регрессии как параметры модели b0 и b1 (как свойство params модели). Также можно получить их значения, как свойство bse модели:
print(b0, b1)
print(result_linear_ols.bse, type(result_linear_ols.bse))
Значимость коэффициентов регрессии можно проверить по критерию Стьюдента [3, с.203-212; 8, с.78].
Расчетные значения статистики критерия Стьюдента могут быть получены с помощью свойства tvalues модели:
print(f"result_linear_ols.tvalues = \n{result_linear_ols.tvalues}")
Расчетные значения уровня значимости при проверке гипотезы по критерию Стьюдента могут быть получены с помощью свойства pvalues модели:
print(f"result_linear_ols.pvalues = \n{result_linear_ols.pvalues}")
Доверительные интервалы для коэффициентов регрессии могут быть получены с помощью свойства conf_int модели:
print(result_linear_ols.conf_int(), '\n')
Можно рассчитать уровень значимости самостоятельно (как ранее для критерия Фишера — для лучшего понимания и общей демонстрации возможностей) — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.t, свойством cdf (функция распределения):
t_calc = result_linear_ols.tvalues
df = int(result_linear_ols.nobs - result_linear_ols.df_model - 1)
a_calc = 2*(1-sci.stats.t.cdf(abs(t_calc), df, loc=0, scale=1))
print(a_calc)![]()
Как видим, результаты совпадают.
Табличные значения статистики критерия Стьюдента получить с помощью Regression Results нельзя. Рассчитаем их самостоятельно — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.t, свойством ppf (процентные точки):
t_table = sci.stats.t.ppf((1 + p_level)/2 , df)
print(t_table)![]()
Для удобства создадим пользовательскую функцию regression_coef_check для проверки значимости коэффициентов регрессии, которая объединяет все вышеперечисленные расчеты:
def regression_coef_check(
model_fit,
notation_coef: list='',
p_level: float=0.95):
a_level = 1 - p_level
# параметры модели (коэффициенты регрессии)
model_params = model_fit.params
# стандартные ошибки коэффициентов регрессии
model_bse = model_fit.bse
# проверка гипотезы о значимости регрессии
t_calc = abs(model_params) / model_bse
n = model_fit.nobs # объем выборки
p = model_fit.df_model # Model degrees of freedom. The number of regressors p. Does not include the constant if one is present.
df = int(n - p - 1)
t_table = sci.stats.t.ppf((1 + p_level)/2 , df)
a_calc = 2*(1-sci.stats.t.cdf(t_calc, df, loc=0, scale=1))
conclusion_ = ['significance' if elem else 'not significance' for elem in (t_calc >= t_table).values]
# доверительный интервал коэффициента регрессии
conf_int_low = model_params - t_table*model_bse
conf_int_high = model_params + t_table*model_bse
# формируем результат
result = pd.DataFrame({
'notation': (notation_coef),
'coef_value': (model_params),
'std_err': (model_bse),
'p_level': (p_level),
'a_level': (a_level),
't_calc': (t_calc),
'df': (df),
't_table': (t_table),
't_calc >= t_table': (t_calc >= t_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'significance_check': (conclusion_),
'conf_int_low': (conf_int_low),
'conf_int_high': (conf_int_high),
})
return result
regression_coef_check(
result_linear_ols,
notation_coef=['b0', 'b1'],
p_level=0.95)
Вывод: коэффициенты регрессии b0 и b1 ЗНАЧИМЫ.
7. Проверка гетероскедастичности
Для проверка гетероскедастичности statsmodels предлагает нам следующие инструменты:
-
тест Голдфелда-Квандта (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_goldfeldquandt.html#statsmodels.stats.diagnostic.het_goldfeldquandt) — теорию см. [8, с.178], также https://ru.wikipedia.org/wiki/Тест_Голдфелда_—_Куандта.
-
тест Бриша-Пэгана (Breush-Pagan test) (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_breuschpagan.html#statsmodels.stats.diagnostic.het_breuschpagan) — теорию см.[8, с.179], также https://en.wikipedia.org/wiki/Breusch–Pagan_test.
-
тест Уайта (White test) (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_white.html#statsmodels.stats.diagnostic.het_white) — теорию см.[8, с.177], а также https://ru.wikipedia.org/wiki/Тест_Уайта.
Тест Голдфелда-Квандта (Goldfeld–Quandt test)
# тест Голдфелда-Квандта (Goldfeld–Quandt test)
test = sms.het_goldfeldquandt(result_linear_ols.resid, result_linear_ols.model.exog)
test_result = lzip(['F_calc', 'p_calc'], test) # распаковка результатов теста
# расчетное значение статистики F-критерия
F_calc_tuple = test_result[0]
F_calc = F_calc_tuple[1]
print(f"Расчетное значение статистики F-критерия: F_calc = {round(F_calc, DecPlace)}")
# расчетный уровень значимости
p_calc_tuple = test_result[1]
p_calc = p_calc_tuple[1]
print(f"Расчетное значение доверительной вероятности: p_calc = {round(p_calc, DecPlace)}")
#a_calc = 1 - p_value
#print(f"Расчетное значение уровня значимости: a_calc = 1 - p_value = {round(a_calc, DecPlace)}")
# вывод
if p_calc < a_level:
conclusion_GQ_test = f"Так как p_calc = {round(p_calc, DecPlace)} < a_level = {round(a_level, DecPlace)}" + \
", то дисперсии в подвыборках отличаются значимо, т.е. гипотеза о наличии гетероскедастичности ПРИНИМАЕТСЯ"
else:
conclusion_GQ_test = f"Так как p_calc = {round(p_calc, DecPlace)} >= a_level = {round(a_level, DecPlace)}" + \
", то дисперсии в подвыборках отличаются незначимо, т.е. гипотеза о наличии гетероскедастичности ОТВЕРГАЕТСЯ"
print(conclusion_GQ_test)
Для удобства создадим пользовательскую функцию Goldfeld_Quandt_test:
def Goldfeld_Quandt_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_goldfeldquandt(model_fit.resid, model_fit.model.exog)
test_result = lzip(['F_statistic', 'p_calc'], test) # распаковка результатов теста
# расчетное значение статистики F-критерия
F_calc_tuple = test_result[0]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости
p_calc_tuple = test_result[1]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('Goldfeld–Quandt test'),
'p_level': (p_level),
'a_level': (a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
Goldfeld_Quandt_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Тест Бриша-Пэгана (Breush-Pagan test)
# тест Бриша-Пэгана (Breush-Pagan test)
name = ["Lagrange multiplier statistic", "p-value", "f-value", "f p-value"]
test = sms.het_breuschpagan(result_linear_ols.resid, result_linear_ols.model.exog)
lzip(name, test)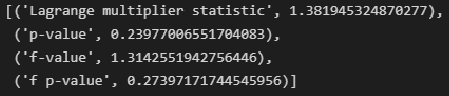
Для удобства создадим пользовательскую функцию Breush_Pagan_test:
def Breush_Pagan_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_breuschpagan(model_fit.resid, model_fit.model.exog)
name = ['Lagrange_multiplier_statistic', 'p_calc_LM', 'F_statistic', 'p_calc']
test_result = lzip(name, test) # распаковка результатов теста
# расчетное значение статистики теста множителей Лагранжа
LM_calc_tuple = test_result[0]
Lagrange_multiplier_statistic = LM_calc_tuple[1]
# расчетный уровень значимости статистики теста множителей Лагранжа
p_calc_LM_tuple = test_result[1]
p_calc_LM = p_calc_LM_tuple[1]
# расчетное значение F-статистики гипотезы о том, что дисперсия ошибки не зависит от x
F_calc_tuple = test_result[2]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости F-статистики
p_calc_tuple = test_result[3]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('Breush-Pagan test'),
'p_level': (p_level),
'a_level': (a_level),
'Lagrange_multiplier_statistic': (Lagrange_multiplier_statistic),
'p_calc_LM': (p_calc_LM),
'p_calc_LM < a_level': (p_calc_LM < a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
Breush_Pagan_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Тест Уайта (White test)
# тест Уайта (White test)
name = ["Lagrange multiplier statistic", "p-value", "f-value", "f p-value"]
test = sms.het_white(result_linear_ols.resid, result_linear_ols.model.exog)
lzip(name, test)
Для удобства создадим пользовательскую функцию White_test:
def White_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_white(model_fit.resid, model_fit.model.exog)
name = ['Lagrange_multiplier_statistic', 'p_calc_LM', 'F_statistic', 'p_calc']
test_result = lzip(name, test) # распаковка результатов теста
# расчетное значение статистики теста множителей Лагранжа
LM_calc_tuple = test_result[0]
Lagrange_multiplier_statistic = LM_calc_tuple[1]
# расчетный уровень значимости статистики теста множителей Лагранжа
p_calc_LM_tuple = test_result[1]
p_calc_LM = p_calc_LM_tuple[1]
# расчетное значение F-статистики гипотезы о том, что дисперсия ошибки не зависит от x
F_calc_tuple = test_result[2]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости F-статистики
p_calc_tuple = test_result[3]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('White test'),
'p_level': (p_level),
'a_level': (a_level),
'Lagrange_multiplier_statistic': (Lagrange_multiplier_statistic),
'p_calc_LM': (p_calc_LM),
'p_calc_LM < a_level': (p_calc_LM < a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
White_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Объединим результаты всех тестов гетероскедастичность в один DataFrame:
Goldfeld_Quandt_test_df = Goldfeld_Quandt_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Breush_Pagan_test_df = Breush_Pagan_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
White_test_df = White_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
heteroscedasticity_tests_df = pd.concat([Breush_Pagan_test_df, White_test_df, Goldfeld_Quandt_test_df])
display(heteroscedasticity_tests_df)
Выводы
Итак, мы провели статистический анализ регрессионной модели и установили:
-
исходные данные имеют нормальное распределение;
-
между переменными имеется весьма сильная корреляционная связь;
-
регрессионная модель хорошо аппроксимирует фактические данные;
-
остатки модели имеют нормальное распределение;
-
регрессионная модель адекватна по критерию Фишера;
-
коэффициент детерминации значим по критеию Фишера;
-
коэффициенты регрессии значимы по критерию Стьюдента;
-
гетероскедастичность отсутствует.
Применительно к рассматриваемой задаче выполнять проверку автокорреляции не имеет особого смысла из-за особенностей исходных данных (результаты замеров прочности бетона на разных участках здания).
Про статистический анализ регрессионных моделей с помощью statsmodels— см. еще https://www.statsmodels.org/stable/examples/notebooks/generated/regression_diagnostics.html.
Доверительные интервалы регрессионной модели
Для регрессионных моделей определяют доверительные интервалы двух видов [3, с.184-192; 4, с.172; 8, с.205-209]:
-
Доверительный интервал средних значений переменной Y.
-
Доверительный интервал индивидуальных значений переменной Y.
При этом размер доверительного интервала для индивидуальных значений больше, чем для средних значений.
Доверительные интервалы регрессионных моделей (ДИРМ) могут быть найдены разными способами:
-
непосредственно путем расчетов по формулам (см., например, https://habr.com/ru/post/558158/);
-
с использованием инструментария библиотеки statsmodels (см., например, https://www.stackfinder.ru/questions/17559408/confidence-and-prediction-intervals-with-statsmodels).
Разбререм более подробно способ с использованием библиотеки statsmodels. Прежде всего, с помощью свойства summary_table класса statsmodels.stats.outliers_influence.OLSInfluence (https://www.statsmodels.org/stable/generated/statsmodels.stats.outliers_influence.OLSInfluence.html?highlight=olsinfluence) мы можем получить таблицу данных, содержащую необходимую нам информацию:
-
Dep Var Population — фактические значения переменной Y;
-
Predicted Value — предсказанные значения переменной Y по по регрессионной модели;
-
Std Error Mean Predict — среднеквадратическая ошибка предсказанного среднего;
-
Mean ci 95% low и Mean ci 95% upp — границы доверительного интервала средних значений переменной Y;
-
Predict ci 95% low и Predict ci 95% upp — границы доверительного интервала индивидуальных значений переменной Y;
-
Residual — остатки регрессионной модели;
-
Std Error Residual — среднеквадратическая ошибка остатков;
-
Student Residual — стьюдентизированные остатки (подробнее см. http://statistica.ru/glossary/general/studentizirovannie-ostatki/);
-
Cook’s D — Расстояние Кука (Cook’s distance) — оценивает эффект от удаления одного (рассматриваемого) наблюдения; наблюдение считается выбросом, если Di > 4/n (более подробно — см.https://translated.turbopages.org/proxy_u/en-ru.ru.f584ceb5-63296427-aded8f31-74722d776562/https/en.wikipedia.org/wiki/Cook’s_distance, http://www.machinelearning.ru/wiki/index.php?title=Расстояние_Кука).
from statsmodels.stats.outliers_influence import summary_table
st, data, ss2 = summary_table(result_linear_ols, alpha=0.05)
print(st, '\n', type(st))
В нашем случае критическое значение расстояния Кука равно:
print(f'D_crit = 4/n = {4/result_linear_ols.nobs}')![]()
то есть выбросов, смещающих оценки коэффициентов регрессии, не наблюдается.
Мы получили данные как класс statsmodels.iolib.table.SimpleTable. Свойство data преобразует данные в список. Далее для удобства работы преобразуем данные в DataFrame:
st_data_df = pd.DataFrame(st.data)Будем использовать данный DataFrame в дальнейшем, несколько преобразуем его:
-
изменим наименование столбцов (с цифр на названия показателей из таблицы summary_table)
-
удалим строки с текстовыми значениями
-
изменим индекс
-
добавим новый столбец — значения переменной X
-
отсортируем по возрастанию значений переменной X (это необходимо, чтобы графики границ доверительных интервалов выглядели как линии)
st_df = st_data_df.copy()
# изменим наименования столбцов
str = st_df.iloc[0,0:] + ' ' + st_df.iloc[1,0:]
st_df = st_df.rename(str, axis='columns')
# удалим строки 0, 1
st_df = st_df.drop([0,1])
# изменим индекс
st_df = st_df.set_index(np.arange(0, result_linear_ols.nobs))
# добавим новый столбец - значения переменной X
st_df.insert(1, 'X', X)
# отсортируем по возрастанию значений переменной X
st_df = st_df.sort_values(by='X')
display(st_df)
С помощью полученных данных мы можем построить график регрессионной модели с доверительными интервалами:
# создание рисунка (Figure) и области рисования (Axes)
fig, axes = plt.subplots(figsize=(297/INCH, 210/INCH))
# заголовок рисунка (Figure)
title_figure = Task_Project
fig.suptitle(title_figure, fontsize = 16)
# заголовок области рисования (Axes)
title_axes = 'Линейная регрессионная модель'
axes.set_title(title_axes, fontsize = 14)
# фактические данные
sns.scatterplot(
x=st_df['X'], y=st_df['Dep Var Population'],
label='фактические данные',
s=50,
color='red',
ax=axes)
# график регрессионной модели
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X'
sns.lineplot(
x=st_df['X'], y=st_df['Predicted Value'],
label=label_legend_regr_model,
color='blue',
ax=axes)
# доверительный интервал средних значений переменной Y
Mean_ci_low = st_df['Mean ci 95% low']
plt.plot(
st_df['X'], Mean_ci_low,
color='magenta', linestyle='--', linewidth=1,
label='доверительный интервал средних значений Y')
Mean_ci_upp = st_df['Mean ci 95% upp']
plt.plot(
st_df['X'], Mean_ci_upp,
color='magenta', linestyle='--', linewidth=1)
# доверительный интервал индивидуальных значений переменной Y
Predict_ci_low = st_df['Predict ci 95% low']
plt.plot(
st_df['X'], Predict_ci_low,
color='orange', linestyle='-.', linewidth=2,
label='доверительный интервал индивидуальных значений Y')
Predict_ci_upp = st_df['Predict ci 95% upp']
plt.plot(
st_df['X'], Predict_ci_upp,
color='orange', linestyle='-.', linewidth=2)
axes.set_xlabel(Variable_Name_X)
axes.set_ylabel(Variable_Name_Y)
axes.legend(prop={'size': 12})
plt.show()
Однако, мы получили данные о границах доверительных интервалов регрессионной модели только в пределах области фактических значений переменной X. Как быть, если мы хотим распространить прогноз за пределы этой области?
Прогнозирование
Под прогнозированием мы в данном случае будем понимать определение значений переменной Y и доверительных интервалов для ее средних и индивидуальных значений при заданном X. По сути, нам предстоит построить аналог рассмотренной выше таблицы summary_table, только с другими значениями X, причем эти значения могут выходить за пределы тех значений, которые использовались нами для построения регрессии.
Методика расчета доверительных интервалов регрессионных моделей разобрана в статье «Python, корреляция и регрессия: часть 4» (https://habr.com/ru/post/558158/), всем рекомендую ознакомиться.
Найти прогнозные значения Y не представляет труда, так как ранее мы уже формализовали модель в виде лямбда-функции, а вот для построения доверительных интервалов придется выполнить расчеты по формулам. Для этого создадим пользовательскую функцию regression_pair_predict, которая в случае парной регрессии (pair regression) для заданного значения X возвращает:
-
прогнозируемое по регрессионной модели значение y_calc
-
доверительный интервал [y_calc_mean_ci_low, y_calc_mean_ci_upp] средних значений переменной Y
-
доверительный интервал [y_calc_predict_ci_low, y_calc_predict_ci_upp] индивидуальных значений переменной Y
Алгоритм расчета доверительных интервалов для множественной регрессии (multiple regression) отличается и в данном обзоре не рассматривается (рассмотрим в дальнейшем).
Про прогнозирование с помощью регрессионных моделей — см.также:
-
https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.predict.html?highlight=predict#statsmodels.regression.linear_model.RegressionResults.predict
-
How to Make Predictions Using Regression Model in Statsmodels
-
https://www.statsmodels.org/stable/examples/notebooks/generated/predict.html
def regression_pair_predict(
x_in,
model_fit,
regression_model,
p_level: float=0.95):
a_level = 1 - p_level
X = pd.DataFrame(model_fit.model.exog)[1].values # найти лучшее решение
Y = model_fit.model.endog
# вспомогательные величины
n = int(result_linear_ols.nobs)
SSE = model_fit.ssr # SSE (Sum of Squared Error)
dfE = n - p - 1
MSE = SSE / dfE # остаточная дисперсия
Xmean = np.mean(X)
SST_X = np.sum([(X[i] - Xmean)**2 for i in range(0, n)])
t_table = sci.stats.t.ppf((1 + p_level)/2 , dfE)
S2_y_calc_mean = MSE * (1/n + (x_in - Xmean)**2 / SST_X)
S2_y_calc_predict = MSE * (1 + 1/n + (x_in - Xmean)**2 / SST_X)
# прогнозируемое значение переменной Y
y_calc=regression_model(x_in)
# доверительный интервал средних значений переменной Y
y_calc_mean_ci_low = y_calc - t_table*sqrt(S2_y_calc_mean)
y_calc_mean_ci_upp = y_calc + t_table*sqrt(S2_y_calc_mean)
# доверительный интервал индивидуальных значений переменной Y
y_calc_predict_ci_low = y_calc - t_table*sqrt(S2_y_calc_predict)
y_calc_predict_ci_upp = y_calc + t_table*sqrt(S2_y_calc_predict)
result = y_calc, y_calc_mean_ci_low, y_calc_mean_ci_upp, y_calc_predict_ci_low, y_calc_predict_ci_upp
return resultСравним результаты расчета доверительных интервалов разными способами — с использованием функции regression_pair_predict и средствами statsmodels, для этого сформируем DaraFrame с новыми данными:
regression_pair_predict_df = pd.DataFrame(
[regression_pair_predict(elem, result_linear_ols, regression_model=Y_calc) for elem in st_df['X'].values],
columns=['y_calc', 'y_calc_mean_ci_low', 'y_calc_mean_ci_upp', 'y_calc_predict_ci_low', 'y_calc_predict_ci_upp'])
regression_pair_predict_df.insert(0, 'X', st_df['X'].values)
display(regression_pair_predict_df)
Видим, что результаты расчетов идентичны, следовательно мы можем использовать функцию regression_pair_predict для прогнозирования.
def graph_regression_pair_predict_plot_sns(
model_fit,
regression_model_in,
Xmin=None, Xmax=None, Nx=10,
Ymin_graph=None, Ymax_graph=None,
title_figure=None, title_figure_fontsize=18,
title_axes=None, title_axes_fontsize=16,
x_label=None,
y_label=None,
label_fontsize=14, tick_fontsize=12,
label_legend_regr_model='', label_legend_fontsize=12,
s=50, linewidth_regr_model=2,
graph_size=(297/INCH, 210/INCH),
result_output=True,
file_name=None):
# фактические данные
X = pd.DataFrame(model_fit.model.exog)[1].values # найти лучшее решение
Y = model_fit.model.endog
X = np.array(X)
Y = np.array(Y)
# границы
if not(Xmin) and not(Xmax):
Xmin=min(X)
Xmax=max(X)
Xmin_graph=min(X)*0.99
Xmax_graph=max(X)*1.01
else:
Xmin_graph=Xmin
Xmax_graph=Xmax
if not(Ymin_graph) and not(Ymax_graph):
Ymin_graph=min(Y)*0.99
Ymax_graph=max(Y)*1.01
# формируем DataFrame данных
Xcalc = np.linspace(Xmin, Xmax, num=Nx)
Ycalc = regression_model_in(Xcalc)
result_df = pd.DataFrame(
[regression_pair_predict(elem, model_fit, regression_model=regression_model_in) for elem in Xcalc],
columns=['y_calc', 'y_calc_mean_ci_low', 'y_calc_mean_ci_upp', 'y_calc_predict_ci_low', 'y_calc_predict_ci_upp'])
result_df.insert(0, 'x_calc', Xcalc)
# заголовки графика
fig, axes = plt.subplots(figsize=graph_size)
fig.suptitle(title_figure, fontsize = title_figure_fontsize)
axes.set_title(title_axes, fontsize = title_axes_fontsize)
# фактические данные
sns.scatterplot(
x=X, y=Y,
label='фактические данные',
s=s,
color='red',
ax=axes)
# график регрессионной модели
sns.lineplot(
x=Xcalc, y=Ycalc,
color='blue',
linewidth=linewidth_regr_model,
legend=True,
label=label_legend_regr_model,
ax=axes)
# доверительный интервал средних значений переменной Y
Mean_ci_low = result_df['y_calc_mean_ci_low']
plt.plot(
result_df['x_calc'], Mean_ci_low,
color='magenta', linestyle='--', linewidth=1,
label='доверительный интервал средних значений Y')
Mean_ci_upp = result_df['y_calc_mean_ci_upp']
plt.plot(
result_df['x_calc'], Mean_ci_upp,
color='magenta', linestyle='--', linewidth=1)
# доверительный интервал индивидуальных значений переменной Y
Predict_ci_low = result_df['y_calc_predict_ci_low']
plt.plot(
result_df['x_calc'], Predict_ci_low,
color='orange', linestyle='-.', linewidth=2,
label='доверительный интервал индивидуальных значений Y')
Predict_ci_upp = result_df['y_calc_predict_ci_upp']
plt.plot(
result_df['x_calc'], Predict_ci_upp,
color='orange', linestyle='-.', linewidth=2)
axes.set_xlim(Xmin_graph, Xmax_graph)
axes.set_ylim(Ymin_graph, Ymax_graph)
axes.set_xlabel(x_label, fontsize = label_fontsize)
axes.set_ylabel(y_label, fontsize = label_fontsize)
axes.tick_params(labelsize = tick_fontsize)
#axes.tick_params(labelsize = tick_fontsize)
axes.legend(prop={'size': label_legend_fontsize})
plt.show()
if file_name:
fig.savefig(file_name, orientation = "portrait", dpi = 300)
if result_output:
return result_df
else:
return
graph_regression_pair_predict_plot_sns(
model_fit=result_linear_ols,
regression_model_in=Y_calc,
Xmin=Xmin_graph-300, Xmax=Xmax_graph+200, Nx=25,
Ymin_graph=Ymin_graph-5, Ymax_graph=Ymax_graph+5,
title_figure=Task_Project, title_figure_fontsize=16,
title_axes='Линейная регрессионная модель', title_axes_fontsize=14,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X',
s=50,
result_output=True,
file_name='graph/regression_plot_lin.png')

Выводы и рекомендации
Исследована зависимость показаний ультразвукового прибора «ПУЛЬСАР-2.1» (X) и результатов замера прочности бетона (методом отрыва со скалыванием) склерометром ИПС-МГ4.03 (Y).
Между переменными имеется весьма сильная линейная корреляционная связь. Получена регрессионная модель:
Y = b0 + b1∙X = -21.3741 + 0.0129∙X
Модель хорошо аппроксимирует фактические данные, является адекватной, значимой и может использоваться для предсказания прочности бетона.
Также построен график прогноза с доверительными интервалами.
ИТОГИ
Итак, мы рассмотрели все этапы регрессионного анализа в случае простой линейной регрессии (simple linear regression) с использованием библиотеки statsmodels на конкретном практическом примере; подробно остановились на статистическом анализа модели с проверкой гипотез; также предложен ряд пользовательских функций, облегчающих работу исследователя и уменьшающих размер программного кода.
Конечно, мы разобрали далеко не все вопросы анализа регрессионных моделей и возможности библиотеки statsmodels применительно к simple linear regression, в частности статистики влияния (Influence Statistics), инструмент Leverage, анализ стьюдентизированных остатков и пр. — это темы для отдельных обзоров.
Исходный код находится в моем репозитории на GitHub.
Надеюсь, данный обзор поможет специалистам DataScience в работе.
Спецификация эконометрической модели: способы и диагностика отбора экзогенных переменных. Тесты Рамсея и Амемья.
Спецификация модели множественной линейной регрессии включает проверку:
1. правильного выбора экзогенных переменных.
2. корректного выбора формы зависимости мду эндо- и экзогенной переменными.
Для решения 1 задачи различают пропущенные и избыточные экзогенные переменные
Пропущенные переменные – существенные факторы, которые не были включены в эконометрическую модель по ошибке. Опасность наличия пропущенных переменных заключается в смещении оценок параметров при включенных переменных. Признак, по которому определяют пропущенную переменную: Знак “+” у произведения оценки параметра при подозреваемой пропущенной переменной и коэффициента корреляции этой переменной с другими переменными, включенными в модель.

Выбранная модель с пропуском переменной 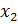 :
:
 , где
, где 
Тогда, применяя МНК для оценки усеченной модели получаем формулу смещения оценки 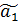 ^
^

Экзогенную переменную относят к избыточным, если она по ошибке включена в эконометрическую модель. Включение избыточной переменной оказывает влияние на уменьшение точности (увеличение дисперсии) оценок параметров модели, что, в свою очередь, вызывает уменьшение t-статистик и коэффициента детерминации.

Если  – избыточная, то коэффициент корреляции
– избыточная, то коэффициент корреляции  , тогда
, тогда 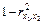 будет уменьшаться, а в соответствии с формулой
будет уменьшаться, а в соответствии с формулой  будет возрастать.
будет возрастать.
Замещающие переменные – обычно бывает полезно вместо пропущенной переменной, которую трудно измерить, использовать некоторый её заменитель.
4 основных качественных правила спецификации экономической модели:
1. Опираясь на эконометрическую теорию, следует ответить на вопрос: «Является ли переменная существенной в модели зависимости с эндогенной переменной?».
2. Осуществить проверку значимого отличия от нуля t-статистик.
3. Осуществить проверку, насколько значимо изменяется коэффициент детерминации при добавлении некоторой переменной в модель.
4. Существенно ли изменяются оценки других переменных после добавления новой переменной в модель.
Кроме отмеченных правил спецификации модели, наиболее из-вестны два следующих количественных критерия спецификации:
Критерий Рамсея (Ramsey):
RESET-тест Рамсея — это обобщенный тест на наличие следующих ошибок спецификации модели линейной регрессии:
- наличие пропущенных переменных. Регрессия содержит не все объясняющие переменные;
- неверная функциональная форма. Некоторые или все переменные должны быть преобразованы с помощью логарифмической, степенной, обратной или какой-либо другой функции;
- корреляция между фактором Х и случайной составляющей модели, которая может быть вызвана ошибками измерения факторов, рассмотрением систем уравнений или другими причинами.
Тест Рамсея позволяет проверить, стоит ли начинать поиск дополнительной переменной для включения в уравнение
1. Оценивается уравнение регрессии
2. Вычисляются степени оценок зависимой переменной
3. Оценивается уравнение регрессии с этими степенями
4. Проводится оценка улучшения по F-критерию
Ошибки такого рода приводят к смещению среднего остатков регрессионной модели.
1. Оценивают зависимость в соответствии с выбранной моделью по МНК:

2. Анализируют вид функциональной зависимости остатков  и её номинальное приближение включают в модель.
и её номинальное приближение включают в модель.
3. Например, с учетом 2) вычисляют величины 
 , конструируют новую модель:
, конструируют новую модель:
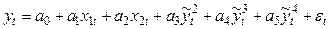
и применяют для ее оценивания по МНК.
4) Сравнивают качество модели по отношению к модели с помощью F-критерия:
Если  где M – число дополнительных переменных, включенных в модель (M=3), k – число экзогенных переменных в
где M – число дополнительных переменных, включенных в модель (M=3), k – число экзогенных переменных в  то модель плохо специфицирована.
то модель плохо специфицирована.
Недостаток: он указывает только на наличие ошибочной спец-ции модели, но не выявляет, сколько и какого рода переменную нужно добавить в модель.
Критерий Амемья (Amemiya):
Решающей функцией F-критерия служит:

Модель, для которой значение AF меньше, является лучше специфицированной.
Этот критерий минимизирует число экзогенных переменных.
F-тест качества спецификации парной линейной регрессионной модели
F-тест — оценивание качества уравнения регрессии — состоит в проверке гипотезы Н0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fвыч и критического (табличного) Fкрит значений F-критерия Фишера. Fвыч определяется из соотношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы.
Коэффициент детерминации является случайной величиной (так как вычисляется по выборочным данным), и для оценки его статистической
значимости, в соответствии со стандартной процедурой, следовало бы
сравнить его вычисленное значение с табличным (критическим). Однако
таблиц распределения коэффициента детерминации не существует, поэтому для проверки статистической гипотезы о значимости R 2 используется косвенный метод: вычисляется некоторая вспомогательная статистика с известным распределением; проверяется гипотеза ее статистической значимости; устанавливается взаимосвязь между вспомогательной статисткой и коэффициентом детерминации; на основании этой взаимосвязи делается вывод о статистической значимости коэффициента детерминации. Для составления вспомогательной статистики рассмотрим две случайные величины U и V. Статистика U имеет распределение х 2 (хи-квадрат)
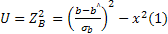 (1)
(1)
так как случайная величина 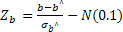 , как было показано выше, имеет стандартное нормальное распределение, а ее квадрат можно рассматривать как сумму квадратов стандартных нормальных величин, включающую только одно слагаемое.
, как было показано выше, имеет стандартное нормальное распределение, а ее квадрат можно рассматривать как сумму квадратов стандартных нормальных величин, включающую только одно слагаемое.
В качестве второй вспомогательной статистики, имеющей распределение х 2 с параметром, равным числу степеней свободы n — 2, используется статистика вида:
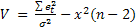 (2)
(2)
Статистика F, как легко проверить, совпадает с квадратом f-статистики для параметра b:
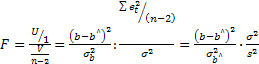 =
= 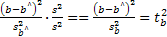
и имеет распределение Фишера с параметрами v1=1,v2=n-2 (n— объем выборки):
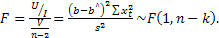 (3)
(3)
Для проверки гипотезы Н0:b = 0 статистика (3) принимает вид:
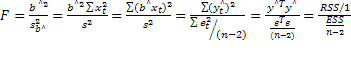 .
.
Связь между статистиками F и R 2 для случая парной регрессии
(k=2) имеет вид:
F= 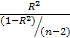 (4)
(4)
Справедливость (4) проверяется непосредственно:
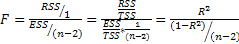 (5)
(5)
Таким образом, как следует из формулы (5), F = 0 в том случае, если R 2 =0. Поэтому, проверяя значимость F статистики (сравнивая ее вычисленное по выборочным данным значение с табличным), мы можем проверить статистическую значимость коэффициента детерминации. ЕслиFвыч
Дата добавления: 2015-01-10 ; просмотров: 5107 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
F-тест качества спецификации множественной регрессионной модели
Цель этой статьи — рассказать о роли степеней свободы в статистическом анализе, вывести формулу F-теста для отбора модели при множественной регрессии.
1. Роль степеней свободы (degree of freedom) в статистике
Имея выборочную совокупность, мы можем лишь оценивать числовые характеристики совокупности, параметры выбранной модели. Так не имеет смысла говорить о среднеквадратическом отклонении при наличии лишь одного наблюдения. Представим линейную регрессионную модель в виде:
Сколько нужно наблюдений, чтобы построить линейную регрессионную модель? В случае двух наблюдений можем получить идеальную модель (рис.1), однако есть в этом недостаток. Причина в том, что сумма квадратов ошибки (MSE) равна нулю и не можем оценить оценить неопределенность коэффициентов . Например не можем построить доверительный интервал для коэффициента наклона по формуле:
А значит не можем сказать ничего о целесообразности использования коэффициента в данной регрессионной модели. Необходимо по крайней мере 3 точки. А что же, если все три точки могут поместиться на одну линию? Такое может быть. Но при большом количестве наблюдений маловероятна идеальная линейная зависимость между зависимой и независимыми переменными (рис. 1).
 Рисунок 1 — простая линейная регрессия
Рисунок 1 — простая линейная регрессия
Количество степеней свободы — количество значений, используемых при расчете статистической характеристики, которые могут свободно изменяться. С помощью количества степеней свободы оцениваются коэффициенты модели и стандартные ошибки. Так, если имеется n наблюдений и нужно вычислить дисперсию выборки, то имеем n-1 степеней свободы.
Мы не знаем среднее генеральной совокупности, поэтому оцениваем его средним значением по выборке. Это стоит нам одну степень свободы.
Представим теперь что имеется 4 выборочных совокупностей (рис.3).
 Рисунок 3
Рисунок 3
Каждая выборочная совокупность имеет свое среднее значение, определяемое по формуле . И каждое выборочное среднее может быть оценено . Для оценки мы используем 2 параметра , а значит теряем 2 степени свободы (нужно знать 2 точки). То есть количество степеней свобод Заметим, что при 2 наблюдениях получаем 0 степеней свободы, а значит не можем оценить коэффициенты модели и стандартные ошибки.
Таким образом сумма квадратов ошибок имеет (SSE, SSE — standard error of estimate) вид:
Стоит упомянуть, что в знаменателе стоит n-2, а не n-1 в связи с тем, что среднее значение оценивается по формуле . Квадратные корень формулы (4) — ошибка стандартного отклонения.
В общем случае количество степеней свободы для линейной регрессии рассчитывается по формуле:
где n — число наблюдений, k — число независимых переменных.
2. Анализ дисперсии, F-тест
При выполнении основных предположений линейной регрессии имеет место формула:
где ,
,
В случае, если имеем модель по формуле (1), то из предыдущего раздела знаем, что количество степеней свободы у SSTO равно n-1. Количество степеней свободы у SSE равно n-2. Таким образом количество степеней свободы у SSR равно 1. Только в таком случае получаем равенство .
Масштабируем SSE и SSR с учетом их степеней свободы:
Получены хи-квадрат распределения. F-статистика вычисляется по формуле:
Формула (9) используется при проверке нулевой гипотезы при альтернативной гипотезе в случае линейной регрессионной модели вида (1).
3. Выбор линейной регрессионной модели
Известно, что с увеличением количества предикторов (независимых переменных в регрессионной модели) исправленный коэффициент детерминации увеличивается. Однако с ростом количества используемых предикторов растет стоимость модели (под стоимостью подразумевается количество данных которые нужно собрать). Однако возникает вопрос: “Какие предикторы разумно использовать в регрессионной модели?”. Критерий Фишера или по-другому F-тест позволяет ответить на данный вопрос.
Определим “полную” модель: (10)
Определим “укороченную” модель: (11)
Вычисляем сумму квадратов ошибок для каждой модели:
(12)
(13)
Определяем количество степеней свобод
(14)
Нулевая гипотеза — “укороченная” модель мало отличается от “полной (удлиненной) модели”. Поэтому выбираем “укороченную” модель. Альтернативная гипотеза — “полная (удлиненная)” модель объясняет значимо большую долю дисперсии в данных по сравнению с “укороченной” моделью.
Коэффициент детерминации из формулы (6):
Из формулы (15) выразим SSE(F):
SSTO одинаково как для “укороченной”, так и для “длинной” модели. Тогда (14) примет вид:
Поделим числитель и знаменатель (14a) на SSTO, после чего прибавим и вычтем единицу в числителе.
Используя формулу (15) в конечном счете получим F-статистику, выраженную через коэффициенты детерминации.
3 Проверка значимости линейной регрессии
Данный тест очень важен в регрессионном анализе и по существу является частным случаем проверки ограничений. Рассмотрим ситуацию. У линейной регрессионной модели всего k параметров (Сейчас среди этих k параметров также учитываем ).Рассмотрим нулевую гипотеза — об одновременном равенстве нулю всех коэффициентов при предикторах регрессионной модели (то есть всего ограничений k-1). Тогда “короткая модель” имеет вид . Следовательно. Используя формулу (14.в), получим
Заключение
Показан смысл числа степеней свободы в статистическом анализе. Выведена формула F-теста в простом случае(9). Представлены шаги выбора лучшей модели. Выведена формула F-критерия Фишера и его запись через коэффициенты детерминации.
Можно посчитать F-статистику самому, а можно передать две обученные модели функции aov, реализующей ANOVA в RStudio. Для автоматического отбора лучшего набора предикторов удобна функция step.
Надеюсь вам было интересно, спасибо за внимание.
При выводе формул очень помогли некоторые главы из курса по статистике STAT 501
http://helpiks.org/2-3401.html
http://habr.com/ru/post/592677/