Понятие исключений и ошибок
Любой, даже самый опытный программист, в ходе разработки программ допускает различного рода ошибки, приводящие к тому, что программа либо не работает вообще,
либо работает, но выполняет вовсе не то, что задумывалось. Причинами ошибок могут быть как неправильное использование синтаксиса и пунктуации языка
(синтаксические ошибки), так и неверное понимание логики программы (семантические ошибки, которые в Python принято называть
исключениями). При этом, если первый тип ошибок легко обнаружить с помощью интерпретатора, то на устранение логических ошибок
порой может потребоваться не один час, поскольку такие ошибки обнаруживаются уже непосредственно в ходе использования программы, проявляясь либо в виде сбоев
в ее работе, либо в получении совершенно непредвиденных результатов (см. пример №1).
Код
Результат
 pythonCodes
pythonCodes
# Синтаксические ошибки обнаружить легко.
# Имя переменной начали с цифры.
# SyntaxError: invalid decimal literal
# 35_days = 35
# Строка должна содержать запись целого числа.
# ValueError: invalid literal for int() with base 10: 'три'
# num = int('три')
# Числа и строки складывать нельзя.
# TypeError: unsupported operand type(s) for +: 'int' and 'str'
# res = 5 + 'один'
# Логические ошибки всплывут потом.
# На первый взгляд все верно, и программа даже будет
# работать, но только до тех пор, пока пользователь
# не введет ноль или неприводимое к числу значение.
a = int(input('Введите число: '))
print(10/a)Введите число: 0
ZeroDivisionError: division by zero
Пример №1. Синтаксические и логические ошибки в Python.
В примере мы показали лишь несколько видов исключений. На самом деле их намного больше. И очень важно знать о них, а также иметь инструменты для их обнаружения и
обработки. Именно поэтому в стандартной библиотеке Python присутствует внушительный набор готовых классов, представляющих различные
виды исключений и синтаксических ошибок. Все они перечислены в разделе Built-in exceptions,
где также представлена и подробная иерархия имеющихся классов исключений. Что касается обработки ошибок, то для этого Python
предоставляет ряд специальных инструкций, которые мы и будем рассматривать в данном параграфе.
Инструкция try/except/else/finally
Пожалуй, основной «рабочей лошадкой» по обработке исключений в Python является составная инструкция
try/except/else/finally, которая имеет следующий общий формат:
# Сначала выполняется основной блок инструкций.
try:
<Основные инструкции>
# Запускается, если в блоке try возникло исключение Exception_1.
except Exception_1:
<Инструкции обработки исключения>
# Запускается, если возникло любое из перечисленных исключений.
except (Exception_2, Exception_3):
<Инструкции обработки исключений>
# Работаем с экземпляром Exception_4, как с err.
except Exception_4 as err:
<Инструкции обработки исключения>
# Запускается для всех видов исключений.
except:
<Инструкции обработки исключений>
# Запускается, если в блоке try не возникло исключений.
else:
<Дополнительные инструкции>
# Запускается в любом случае.
finally:
<Финальные инструкции>
Первыми выполняются инструкции основного блока try. При обнаружении в нем ошибок, интерпретатор пытается найти соответствующий
возникшему исключению блок except и, в случае наличия такового, выполняет его инструкции. После того как исключение будет
обработано, оно уничтожается, а программа пытается продолжить работу в штатном режиме. Если же среди имеющихся блоков except
соответствия найдено не будет, исключение переадресуется инструкции try, стоящей
выше в программе, или на верхний уровень процесса, что скорее всего вынудит интерпретатор аварийно завершить работу программы и вывести сообщение об ошибке по
умолчанию. В случае отсутствия ошибок в блоке try интерпретатор пропускает все блоки except и
начинает выполнять инструкции необязательного блока else, который разрешается использовать только при наличии хотя бы одного блока
except. При этом стоит помнить, что при наличии ошибок в блоке try инструкции данного блока
выполняться не будут. Что касается необязательного блока finally, то он используется для каких-либо завершающих операций, например,
закрытия файлов или открытых соединений с сервером. Его инструкции выполняются всегда, вне зависимости от того, возникли исключения в каком-либо блоке, включая блок
else, или нет (см. пример №2).
Код
Результат
pythonCodes
try:
# Здесь исключения могут возбудиться из-за
# ввода нечислового значения или нуля.
a = int(input('Введите число: '))
print('10/{} = {}'.format(a, 10/a))
# Если введено не целое число.
except ValueError:
print('Введите целое число!')
# Если введен ноль.
except ZeroDivisionError:
print('На ноль делить нельзя!')
# Выполнится только при отсутствии ошибок.
else:
print('Операция прошла успешно!')
# Выполняется в любом случае.
finally:
print('Для завершения нажмите «Enter»!')
# Чтобы окно консоли не закрылось.
input()Введите число: 0
На ноль делить нельзя!
Для завершения нажмите «Enter»!
-------------------------------
Введите число: один
Введите целое число!
Для завершения нажмите «Enter»!
-------------------------------
Введите число: 20
10/20 = 0.5
Операция прошла успешно!
Для завершения нажмите «Enter»!
Пример №2. Инструкция try/except/else/finally в Python (часть 1).
Стоит заметить, что в отличие от блоков except блок finally не останавливает распространение
исключений до вышестоящей инструкции try или до обработчика исключений по умолчанию, т.е. в случае возникновения ошибок
инструкции, следующие за блоком finally в программе, выполняться не будут (см. пример №3).
Код
Результат
pythonCodes
# Внешняя инструкция try.
try:
# Внутреняя инструкция try.
try:
# Здесь исключения могут появиться из-за
# ввода нечислового значения или нуля.
a = int(input('Введите число: '))
print('10/{} = {}'.format(a, 10/a))
# Выполняется в любом случае.
finally:
print('Внутренний блок finally.')
# Выполняется при отсутствии ошибок
# во внутреннем блоке try.
print('Все ОК! Ошибок нет!')
# Если введено не целое число или ноль.
except (ValueError, ZeroDivisionError):
print('Неверный ввод!')
# Выполнится только при отсутствии ошибок.
else:
print('Операция прошла успешно!')
# Выполняется в любом случае.
finally:
print('Внешний блок finally.')
# Чтобы окно консоли не закрылось.
input() Введите число: 7
10/7 = 1.4285714285714286
Внутренний блок finally.
Все ОК! Ошибок нет!
Операция прошла успешно!
Внешний блок finally.
------------------------
Введите число: 0
Внутренний блок finally.
Неверный ввод!
Внешний блок finally.
Пример №3. Инструкция try/except/else/finally в Python (часть 2).
Если необходимо перехватывать сразу все возможные исключения, разрешается использовать инструкцию except без указания классов исключений.
Эта особенность может быть весьма удобна при разработке своих собственных обработчиков ошибок. Однако при использовании такого варианта могут перехватываться нежелательные
системные исключения, не связанные с работой создаваемого программного кода, а также случайно может прерываться распространение исключений, предназначенных для других
обработчиков. Данная проблема была частично решена в Python 3.0 за счет введения альтернативы в виде суперкласса
Exception, представляющего все прикладные исключения, но игнорирующего исключения, связанные с завершением программы (см. пример
№4).
Код
Результат
pythonCodes
# Основной блок try.
try:
# Здесь исключения могут возбудиться из-за
# ввода нечислового значения или нуля.
a = int(input('Введите число: '))
print('10/{} = {}'.format(a, 10/a))
# Выводим строковое представление исключения.
except Exception as err:
print(err)
# Выполнится только при отсутствии ошибок.
else:
print('Операция прошла успешно!')
# Выполняется в любом случае.
finally:
# Чтобы окно консоли не закрылось.
input() Введите число: one
invalid literal for int() with base 10: 'one'
------------------------
Введите число: 0
division by zero
------------------------
Введите число: 10
10/10 = 1.0
Операция прошла успешно!
Пример №4. Инструкция try/except/else/finally в Python (часть 3).
В конце добавим, что помимо основного варианта использования try/except/else/finally инструкция
try может быть использована и в варианте try/finally, т.е. без блоков обработки исключений
except. Как не трудно догадаться, основной задачей такого варианта использования инструкции является выполнение заключительных
операций после выполнения кода основного блока.
Инструкция raise
В примерах выше мы полагались на то, что интерпретатор автоматически определит появление ошибок во время выполнения программного кода. Однако в
Python присутствует возможность и явного возбуждения исключений с помощью инструкции
raise. Все что от нас требуется, это указать через пробел имя класса или экземпляра
возбуждаемого исключения. Также разрешается использовать пустую инструкцию, тогда будет повторно возбуждено самое последнее исключение
(см. пример №5).
Код
Результат
pythonCodes
try:
# Возбудим исключение IndexError принудительно.
# Экземпляр исключения создается автоматически.
raise IndexError
# Обработаем его.
except IndexError:
print('Перехватили IndexError!')
try:
# Все тоже самое, но здесь создаем экземпляр сами.
raise IndexError()
# Обработаем его.
except IndexError:
print('Перехватили IndexError!')
# Вложенная инструкция try.
try:
# Возбудили последнее исключение еще раз.
raise
# Обработаем его.
except IndexError:
print('Перехватили IndexError!')Перехватили IndexError!
Перехватили IndexError!
Перехватили IndexError!
Пример №5. Инструкция raise в Python (часть 1).
Инструкция raise может использоваться для явного возбуждения не только встроенных исключений, но и созданных пользователем.
Пользовательские исключения представляют собой самые обычные классы, наследуемые от классов встроенных исключений, чаще всего от класса
Exception (см. пример №6).
Код
Результат
pythonCodes
# Создаем свой класс исключений, который
# наследуется от встроенного Exception.
class OnlyAlpha(Exception):
# Переопределим строковое представление.
def __str__(self):
return 'Разрешены только буквы!'
# Определим функцию проверки строки на
# наличие сторонних небуквенных символов.
def check_for_alpha(s):
# Если присутствуют не только буквы.
if not s.isalpha():
# Возбуждаем экземпляр своего исключения.
raise OnlyAlpha()
# Проверим, как все работает.
try:
# Просим ввести строку.
s = input('Введите имя: ')
# Проверяем ввод.
check_for_alpha(s)
# Обрабатываем польз. исключение.
except OnlyAlpha as err:
# Строковое представление экз.
print(err)
print('Попробуйте еще раз!')
# Если все прошло гладко.
else:
# Выводим введенное имя.
print('Привет, {}!'.format(s))
# В любом случае дополняем сообщением.
finally:
print('Имя – это ваш ник и логин!')Введите имя: okpython
Привет, okpython!
Имя – это ваш ник и логин!
--------------------------
Введите имя: okpython.net
Разрешены только буквы!
Попробуйте еще раз!
Имя – это ваш ник и логин!
Пример №6. Инструкция raise в Python (часть 2).
Стоит добавить, что инструкция raise может использоваться и в формате raise/from, который используется
значительно реже, поэтому здесь мы его рассматривать не будем. Однако не поленитесь и самостоятельно посетите подраздел
«The raise statement» раздела «Simple statements» официального
справочника языка, где хотя бы бегло ознакомьтесь и с этим вариантом инструкции.
Инструкция assert
Инструкция assert представляет собой компактный условный вариант инструкции raise,
предназначенный в основном для возбуждения исключений на этапе отладки программы. В общем виде ее можно представить в формате
assert condition[, message], где condition – это условие, при невыполнении которого
(возвращается False) будет возбуждено встроенное исключение AssertionError, а также при необходимости
выведено необязательное сообщение message (см. пример №7).
Код
Результат
pythonCodes
# Допустим мы пишем функцию для расчета среднего
# значения чисел переданного ей списка.
def avg(li):
len_li = len(li)
# Список не должен быть пустым.
assert len_li != 0, 'Список пуст!'
# Возвращаем среднее значение.
return round(sum(li)/len_li, 3)
try:
# Запускаем функцию.
res = avg([])
# Отлавливаем исключение для обработки.
except AssertionError as my_err:
print(my_err)
# Результат выводим, если все в порядке.
else:
print('Среднее значение: {}'.format(res)) Список пуст!
Пример №7. Инструкция assert в Python.
Важно не забывать, что инструкция assert главным образом предназначена для проверки соблюдения ограничений, накладываемых самим
программистом, а не для перехвата настоящих ошибок, которые интерпретатор Python в состоянии обработать самостоятельно во время
выполнения программы. Поэтому как правило инструкцию assert не используют для выявления таких проблем, как выход индекса за
допустимые пределы, несоответствие типов или деление на ноль.
Краткие итоги параграфа
-
Основной инструкцией для обработки исключений в Python является составная инструкция try/except/else/finally.
Если в инструкциях обязательного блока try возникают ошибки, интерпретатор пытается перехватить и обработать их с помощью блоков
except. В случае отсутствия соответствий исключение передается инструкции try, стоящей выше в программе,
или на верхний уровень процесса. Необязательный блок else выполняется только при отсутствии ошибок, а необязательный блок
finally выполняется всегда. При этом в отличие от блоков except блок
finally не останавливает распространение исключений до вышестоящей инструкции try или до обработчика
исключений по умолчанию, поэтому в случае возникновения ошибок инструкции, следующие за блоком finally в программе, выполняться не будут. -
В стандартной библиотеке Python присутствует внушительный набор готовых классов, представляющих различные виды исключений и синтаксических
ошибок. Все они перечислены в разделе Built-in exceptions, где также представлена и подробная
иерархия имеющихся классов исключений. -
Важно помнить, что при использовании блока except без указания класса перехватываемого исключения интерпретатор будет пытаться перехватить
все имеющиеся виды встроенных исключений. Однако нужно быть осторожным при использовании такого варианта инструкции воизбежание перехвата нежелательных системных исключений,
не связанных с работой создаваемого программного кода. -
Для явного возбуждения исключений в Python предназначена инструкция raise, которой необходимо через
пробел передавать имя класса или экземпляра возбуждаемого исключения. Данная инструкция может использоваться для явного возбуждения не только встроенных исключений, но
и созданных пользователем. Пользовательские исключения представляют собой самые обычные классы, наследуемые от классов встроенных исключений, чаще всего от класса
Exception. -
Для возбуждения исключений на этапе отладки программы предназначена инструкция assert condition[, message], где
condition – это условие, при невыполнении которого (возвращается False) будет возбуждено
встроенное исключение AssertionError, а также при необходимости выведено необязательное сообщение message.
Использовать инструкцию следует главным образом для проверки соблюдения ограничений, накладываемых самим программистом, а не для перехвата настоящих ошибок, которые могут
быть спокойно перехвачены интерпретатором Python.
Вопросы и задания для самоконтроля
1. В каком случае выполняется код блока else составной инструкции
try/except/else/finally?
Показать решение.
Ответ. Инструкции необязательного блока else выполняются только при отсутствии
исключений в коде основного блока try.
2. Что произойдет с программой в случае возбуждения исключения, если в ней не предусмотреть его обработку?
Показать решение.
Ответ. В таком случае исключение будет передано обработчику предоставляемому интерпретатором по умолчанию.
Этот обработчик выведет сообщение об ошибке и завершит программу.
3. Перечислите верные форматы использования инструкции try:
try/except/else, try/else, try/finally,
try/except/finally, try/else/finally.
Показать решение.
Ответ. Блок else может использоваться только при наличии хотя бы одного блока
except, следовательно варианты try/else и try/else/finally
недопустимы.
4. В каком случае выполняется код блока finally?
Показать решение.
Ответ. Необязательный блок finally выполняется всегда. При этом в отличие от
блоков except блок finally не останавливает распространение исключений до вышестоящей
инструкции try или до обработчика исключений по умолчанию, поэтому в случае возникновения ошибок инструкции, следующие за
блоком finally в программе, выполняться не будут.
5. Присутствуют ли в коде условия ошибки? Проверьте свой ответ, запустив код на исполнение.
Показать решение.
Условие
pythonCodes
try:
a = 5; b = 0
n = a/b
exept Exeption as err:
print('Ошибка: «{}».'.format(err))
else:
print('a/b = {}'.format(n))
finally:
print('Обработка завершена!')
Решение
Результат
pythonCodes
try:
a = 5; b = 0
n = a/b
# Правильно писать except и Exception.
except Exception as err:
print('Ошибка: «{}».'.format(err))
else:
print('a/b = {}'.format(n))
finally:
print('Обработка завершена!')Ошибка: «division by zero».
Обработка завершена!
6. Имеется ли в Python возможность создавать и возбуждать исключения вручную?
Показать решение.
Ответ. Да, имеется. Для явного возбуждения исключений в Python предназначена
инструкция raise, которой необходимо через пробел передавать имя класса или экземпляра возбуждаемого исключения. Данная
инструкция может использоваться для явного возбуждения не только встроенных исключений, но и созданных пользователем. Пользовательские исключения представляют
собой самые обычные классы, наследуемые от классов встроенных исключений, чаще всего от класса Exception.
7. Для чего служит инструкция assert?
Показать решение.
Ответ. Для возбуждения исключений на этапе отладки программы предназначена инструкция
assert condition[, message], где condition – это условие, при невыполнении
которого (возвращается False) будет возбуждено встроенное исключение AssertionError,
а также при необходимости выведено необязательное сообщение message. Использовать инструкцию следует главным образом
для проверки соблюдения ограничений, накладываемых самим программистом, а не для перехвата настоящих ошибок, которые могут быть спокойно перехвачены
интерпретатором Python.
8. Дополнительные упражнения и задачи по теме расположены в разделе
«Обработка исключений»
нашего сборника задач и упражнений по языку программирования Python.
Быстрый переход к другим страницам
Цель функционального тестирования — обнаружение несоответствий между реальным поведением реализованных функций и ожидаемым поведением в соответствии со спецификацией и исходными требованиями. Функциональные тесты должны охватывать все реализованные функции с учетом наиболее вероятных типов ошибок. Тестовые сценарии, объединяющие отдельные тесты, ориентированы на проверку качества решения функциональных задач.
Функциональные тесты создаются по внешним спецификациям функций, проектной информации и по тексту на ЯП, относятся к функциональным его характеристикам и применяются на этапе комплексного тестирования и испытаний для определения полноты реализации функциональных задач и их соответствия исходным требованиям.
В задачи функционального тестирования входят:
· идентификация множества функциональных требований;
· идентификация внешних функций и построение последовательностей функций в соответствии с их использованием в ПС;- идентификация множества входных данных каждой функции и определение областей их изменения;
· построение тестовых наборов и сценариев тестирования функций;
· выявление и представление всех функциональных требований с помощью тестовых наборов и проведение тестирования ошибок в программе и при взаимодействии со средой.
Тесты, создаваемые по проектной информации, связаны со структурами данных, алгоритмами, интерфейсами между отдельными компонентами и применяются для тестирования компонентов и их интерфейсов. Основная цель — обеспечение полноты и согласованности реализованных функций и интерфейсов между ними.
Комбинированный метод «черного ящика» и «прозрачного ящика» основан на разбиении входной области функции на подобласти обнаружения ошибок. Подобласть содержит однородные элементы, которые все обрабатываются корректно либо некорректно. Для тестирования подобласти производится выполнение программы на одном из элементов этой области.
Предпосылки функционального тестирования:
· корректное оформление требований и ограничений к качеству ПО;
· корректное описание модели функционирования ПО в среде эксплуатации у заказчика;
· адекватность модели ПО заданному классу.
Под инфраструктурой процесса тестирования понимается:
· выделение объектов тестирования;
· проведение классификации ошибок для рассматриваемого класса тестируемых программ;
· подготовка тестов, их выполнение и поиск разного рода ошибок и отказов в компонентах и в системе в целом;
· служба проведения и управление процессом тестирования;
· анализ результатов тестирования.
Объекты тестирования — компоненты, группы компонентов, подсистемы и система. Для каждого из них формируется стратегия проведения тестирования. Если объект тестирования относится к «белому ящику» или «черному ящику», состав компонентов которого неизвестный, то тестирование проводится посредством ввода внего входных тестовых данных для получения выходных данных. Стратегическая цель тестирования состоит в том, чтобы убедиться, что каждый рассматриваемый входной набор данных соответствует ожидаемым выходным выходных данным. При таком подходе к тестированию не требуется знания внутренней структуры и логики объекта тестирования.
Проектировщик тестов должен заглянуть внутрь «черного ящика» и исследовать детали процессов обработки данных, вопросы обеспечения защиты и восстановления данных, а также интерфейсы с другими программами и системами. Это способствует подготовке тестовых данных для проведения тестирования.
Для некоторых типов объектов группа тестирования не может сгенерировать представительное множество тестовых наборов, которые демонстрировали бы функциональную правильность работы компоненты при всех возможных наборах тестов.
Поэтому предпочтительным является метод «белого ящика», при котором можно использовать структуру объекта для организации тестирования по различным ветвям. Например, можно выполнить тестовые наборы, которые проходят через все операторы или все контрольные точки компонента для того, чтобы убедиться в правильности их работы.
Международный стандарт ANSI/IEEE-729-83 разделяет все ошибки в разработке программ на следующие типы.
Ошибка (error) — состояние программы, при котором выдаются неправильные результаты, причиной которых являются изъяны (flaw) в операторах программы или в технологическом процессе ее разработки, что приводит к неправильной интерпретации исходной информации, следовательно, и к неверному решению.
Дефект (fault) в программе — следствие ошибок разработчика на любом из этапов разработки, которая может содержаться в исходных или проектных спецификациях, текстах кодов программ, эксплуатационной документация и т.п. В процессе выполнения программы может быть обнаружен дефект или сбой.
Отказ (failure) — это отклонение программы от функционирования или невозможность программы выполнять функции, определенные требованиями и ограничениями, что рассматривается как событие, способствующее переходу программы в неработоспособное состояние из-за ошибок, скрытых в ней дефектов или сбоев в среде функционирования. Отказ может быть результатом следующих причин:
· ошибочная спецификация или пропущенное требование, означающее, что спецификация точно не отражает того, что предполагал пользователь;
· спецификация может содержать требование, которое невозможно выполнить на данной аппаратуре и программном обеспечении;
· проект программы может содержать ошибки (например, база данных спроектирована без средств защиты от несанкционированного доступа пользователя, а требуется защита);
· программа может быть неправильной, т.е. она выполняет несвойственный алгоритм или он реализован не полностью.
Таким образом, отказы, как правило, являются результатами одной или более ошибок в программе, а также наличия разного рода дефектов.
Ошибки на этапах процесса тестирования. Приведенные типы ошибок распределяются по этапам ЖЦ и им соответствуют такие источники их возникновения:
· непреднамеренное отклонение разработчиков от рабочих стандартов или планов реализации;
· спецификации функциональных и интерфейсных требований выполнены без соблюдения стандартов разработки, что приводит к нарушению функционирования программ;
· организации процесса разработки — несовершенная или недостаточное управление руководителем проекта ресурсами (человеческими, техническими, программными и т.д.) и вопросами тестирования и интеграции элементов проекта.
Рассмотрим процесс тестирования, исходя из рекомендаций стандарта ISO/IEC 12207, и приведем типы ошибок, которые обнаруживаются на каждом процессе ЖЦ.
Процесс разработки требований. При определении исходной концепции системы и исходных требований к системе возникают ошибки аналитиков при спецификации верхнего уровня системы и построении концептуальной модели предметной области.
Характерными ошибками этого процесса являются:
· неадекватность спецификации требований конечным пользователям;- некорректность спецификации взаимодействия ПО со средой функционирования или с пользователями;
· несоответствие требований заказчика к отдельным и общим свойствам ПО;
· некорректность описания функциональных характеристик;
· необеспеченность инструментальными средствами всех аспектов реализации требований заказчика и др.
Процесс проектирования. Ошибки при проектировании компонентов могут возникать при описании алгоритмов, логики управления, структур данных, интерфейсов, логики моделирования потоков данных, форматов ввода-вывода и др. В основе этих ошибок лежат дефекты спецификаций аналитиков и недоработки проектировщиков. К ним относятся ошибки, связанные:
· с определением интерфейса пользователя со средой;
· с описанием функций (неадекватность целей и задач компонентов, которые обнаруживаются при проверке комплекса компонентов);
· с определением процесса обработки информации и взаимодействия между процессами (результат некорректного определения взаимосвязей компонентов и процессов);
· с некорректным заданием данных и их структур при описании отдельных компонентов и ПС в целом;
· с некорректным описанием алгоритмов модулей;
· с определением условий возникновения возможных ошибок в программе;
· с нарушением принятых для проекта стандартов и технологий.
Этап кодирования. На данном этапе возникают ошибки, которые являются результатом дефектов проектирования, ошибок программистов и менеджеров в процессе разработки и отладки системы. Причиной ошибок являются:
· бесконтрольность значений входных параметров, индексов массивов, параметров циклов, выходных результатов, деления на 0 и др.;
· неправильная обработка нерегулярных ситуаций при анализе кодов возврата от вызываемых подпрограмм, функций и др.;
· нарушение стандартов кодирования (плохие комментарии, нерациональное выделение модулей и компонент и др.);
· использование одного имени для обозначения разных объектов или разных имен одного объекта, плохая мнемоника имен;- несогласованное внесение изменений в программу разными разработчиками и др.
Процесс тестирования. На этом процессе ошибки допускаются программистами и тестировщиками при выполнении технологии сборки и тестирования, выбора тестовых наборов и сценариев тестирования и др. Отказы в программном обеспечении, вызванные такого рода ошибками, должны выявляться, устраняться и не отражаться на статистике ошибок компонент и программного обеспечения в целом.
Процесс сопровождения. На процессе сопровождения обнаруживаются ошибки, причиной которых являются недоработки и дефекты эксплуатационной документации, недостаточные показатели модифицируемости и удобочитаемости, а также некомпетентность лиц, ответственных за сопровождение и/или усовершенствование ПО. В зависимости от сущности вносимых изменений на этом этапе могут возникать практически любые ошибки, аналогичные ранее перечисленным ошибкам на предыдущих этапах.
Все ошибки, которые возникают в программах, принято подразделять на следующие классы:
· логические и функциональные ошибки;
· ошибки вычислений и времени выполнения;
· ошибки ввода-вывода и манипулирования данными;
· ошибки интерфейсов;
· ошибки объема данных и др.
Логические ошибки являются причиной нарушения логики алгоритма, внутренней несогласованности переменных и операторов, а также правил программирования. Функциональные ошибки — следствие неправильно определенных функций, нарушения порядка их применения или отсутствия полноты их реализации и т.д.
Ошибки вычислений возникают по причине неточности исходных данных и реализованных формул, погрешностей методов, неправильного применения операций вычислений или операндов. Ошибки времени выполнения связаны с не обеспечением требуемой скорости обработки запросов или времени восстановления программы.
Ошибки ввода-вывода и манипулирования данными являются следствием некачественной подготовки данных для выполнения программы, сбоев при занесении их в базы данных или при выборке из нее.
Ошибки интерфейса относятся к ошибкам взаимосвязи отдельных элементов друг с другом, что проявляется при передаче данных между ними, а также при взаимодействии со средой функционирования.
Ошибки объема относятся к данным и являются следствием того, что реализованные методы доступа и размеры баз данных не удовлетворяют реальным объемам информации системы или интенсивности их обработки.
Приведенные основные классы ошибок свойственны разным типам компонентов ПО и проявляются они в программах по разному. Так, при работе с БД возникают ошибки представления и манипулирования данными, логические ошибки в задании прикладных процедур обработки данных и др. В программах вычислительного характера преобладают ошибки вычислений, а в программах управления и обработки — логические и функциональные ошибки. В ПО, которое состоит из множества разноплановых программ, реализующих разные функции, могут содержаться ошибки разных типов. Ошибки интерфейсов и нарушение объема характерны для любого типа систем.
Анализ типов ошибок в программах является необходимым условием создания планов тестирования и методов тестирования для обеспечения правильности ПО.
На современном этапе развития средств поддержки разработки ПО (CASE-технологии, объектно-ориентированные методы и средства проектирования моделей и программ) проводится такое проектирование, при котором ПО защищается от наиболее типичных ошибок и тем самым предотвращается появление программных дефектов.
Связь ошибки с отказом. Наличие ошибки в программе, как правило, приводит к отказу ПО при его функционировании. Для анализа причинно-следственных связей «ошибка отказ» выполняются следующие действия:
· идентификация изъянов в технологиях проектирования и программирования;
· взаимосвязь изъянов процесса проектирования и допускаемых человеком ошибок;
· классификация отказов, изъянов и возможных ошибок, а также дефектов на каждом этапе разработки;- сопоставление ошибок человека, допускаемых на определенном процессе разработки, и дефектов в объекте, как следствий ошибок спецификации проекта, моделей программ;
· проверка и защита от ошибок на всех этапах ЖЦ, а также обнаружение дефектов на каждом этапе разработки;
· сопоставление дефектов и отказов в ПО для разработки системы взаимосвязей и методики локализации, сбора и анализа информации об отказах и дефектах;
· разработка подходов к процессам документирования и испытания ПО.
Конечная цель причинно-следственных связей «ошибка отказ» заключается в определении методов и средств тестирования и обнаружения ошибок определенных классов, а также критериев завершения тестирования на множестве наборов данных; в определении путей совершенствования организации процесса разработки, тестирования и сопровождения ПО.
Приведем следующую классификацию типов отказов:
· аппаратный, при котором общесистемное ПО не работоспособно;
· информационный, вызванный ошибками во входных данных и передаче данных по каналам связи, а также при сбое устройств ввода (следствие аппаратных отказов);
· эргономический, вызванный ошибками оператора при его взаимодействии с машиной (этот отказ — вторичный отказ, может привести к информационному или функциональному отказам);
· программный, при наличии ошибок в компонентах и др.
Некоторые ошибки могут быть следствием недоработок при определении требований, проекта, генерации выходного кода или документации. С другой стороны, они порождаются в процессе разработки программы или при разработке интерфейсов отдельных элементов программы (нарушение порядка параметров, меньше или больше параметров и т.п.).
Источники ошибок. Ошибки могут быть порождены в процессе разработки проекта, компонентов, кода и документации. Как правило, они обнаруживаются при выполнении или сопровождении программного обеспечения в самых неожиданных и разных ее точках.
Некоторые ошибки в программе могут быть следствием недоработок при определении требований, проекта, генерации кода или документации. С другой стороны, ошибки порождаются в процессе разработки программы или интерфейсов ее элементов (например, при нарушении порядка задания параметров связи — меньше или больше, чем требуется и т.п.).
Причиной появления ошибок — непонимание требований заказчика; неточная спецификация требований в документах проекта и др. Это приводит к тому, что реализуются некоторые функции системы, которые будут работать не так, как предлагает
заказчик. В связи с этим проводится совместное обсуждение заказчиком и разработчиком некоторых деталей требований для их уточнения.
Команда разработчиков системы может также изменить синтаксис и семантику описания системы. Однако некоторые ошибки могут быть не обнаружены (например, неправильно заданы индексы или значения переменных этих операторов).
Аннотация: Контроль по четности, CRC, алгоритм Хэмминга. Введение в коды Рида-Соломона: принципы, архитектура и реализация. Метод коррекции ошибок FEC (Forward Error Correction).
Каналы передачи данных ненадежны (шумы, наводки и т.д.), да и само оборудование обработки информации работает со сбоями. По этой причине важную роль приобретают механизмы детектирования ошибок. Ведь если ошибка обнаружена, можно осуществить повторную передачу данных и решить проблему. Если исходный код по своей длине равен полученному коду, обнаружить ошибку передачи не предоставляется возможным. Можно, конечно, передать код дважды и сравнить, но это уже двойная избыточность.
Простейшим способом обнаружения ошибок является контроль по четности. Обычно контролируется передача блока данных ( М бит). Этому блоку ставится в соответствие кодовое слово длиной N бит, причем N>M. Избыточность кода характеризуется величиной 1-M/N. Вероятность обнаружения ошибки определяется отношением M/N (чем меньше это отношение, тем выше вероятность обнаружения ошибки, но и выше избыточность).
При передаче информации она кодируется таким образом, чтобы с одной стороны характеризовать ее минимальным числом символов, а с другой – минимизировать вероятность ошибки при декодировании получателем. Для выбора типа кодирования важную роль играет так называемое расстояние Хэмминга.
Пусть А и Б — две двоичные кодовые последовательности равной длины. Расстояние Хэмминга между двумя этими кодовыми последовательностями равно числу символов, которыми они отличаются. Например, расстояние Хэмминга между кодами 00111 и 10101 равно 2.
Можно показать, что для детектирования ошибок в n битах схема кодирования требует применения кодовых слов с расстоянием Хэмминга не менее N + 1. Можно также показать, что для исправления ошибок в N битах необходима схема кодирования с расстоянием Хэмминга между кодами не менее 2N + 1. Таким образом, конструируя код, мы пытаемся обеспечить расстояние Хэмминга между возможными кодовыми последовательностями большее, чем оно может возникнуть из-за ошибок.
Широко распространены коды с одиночным битом четности. В этих кодах к каждым М бит добавляется 1 бит, значение которого определяется четностью (или нечетностью) суммы этих М бит. Так, например, для двухбитовых кодов 00, 01, 10, 11 кодами с контролем четности будут 000, 011, 101 и 110. Если в процессе передачи один бит будет передан неверно, четность кода из М+1 бита изменится.
Предположим, что частота ошибок ( BER – Bit Error Rate) равна р = 10-4. В этом случае вероятность передачи 8 бит с ошибкой составит 1 – (1 – p)8 = 7,9 х 10-4. Добавление бита четности позволяет детектировать любую ошибку в одном из переданных битах. Здесь вероятность ошибки в одном из 9 битов равна 9p(1 – p)8. Вероятность же реализации необнаруженной ошибки составит 1 – (1 – p)9 – 9p(1 – p)8 = 3,6 x 10-7. Таким образом, добавление бита четности уменьшает вероятность необнаруженной ошибки почти в 1000 раз. Использование одного бита четности типично для асинхронного метода передачи. В синхронных каналах чаще используется вычисление и передача битов четности как
для строк, так и для столбцов передаваемого массива данных. Такая схема позволяет не только регистрировать, но и исправлять ошибки в одном из битов переданного блока.
Контроль по четности достаточно эффективен для выявления одиночных и множественных ошибок в условиях, когда они являются независимыми. При возникновении ошибок в кластерах бит метод контроля четности неэффективен, и тогда предпочтительнее метод вычисления циклических сумм ( CRC — Cyclic Redundancy Check). В этом методе передаваемый кадр делится на специально подобранный образующий полином. Дополнение остатка от деления и является контрольной суммой.
В Ethernet вычисление CRC производится аппаратно. На
рис.
4.1 показан пример реализации аппаратного расчета CRC для образующего полинома R(x) = 1 + x2 + x3 + x5 + x7. В этой схеме входной код приходит слева.
Рис.
4.1.
Схема реализации расчета CRC
Эффективность CRC для обнаружения ошибок на многие порядки выше простого контроля четности. В настоящее время стандартизовано несколько типов образующих полиномов. Для оценочных целей можно считать, что вероятность невыявления ошибки в случае использования CRC, если ошибка на самом деле имеет место, равна (1/2)r, где r — степень образующего полинома.
| CRC -12 | x12 + x11 + x3 + x2 + x1 + 1 |
| CRC -16 | x16 + x15 + x2 + 1 |
| CRC -CCITT | x16 + x12 + x5 + 1 |
4.1. Алгоритмы коррекции ошибок
Исправлять ошибки труднее, чем их детектировать или предотвращать. Процедура коррекции ошибок предполагает два совмещеных процесса: обнаружение ошибки и определение места (идентификации сообщения и позиции в сообщении). После решения этих двух задач исправление тривиально — надо инвертировать значение ошибочного бита. В наземных каналах связи, где вероятность ошибки невелика, обычно используется метод детектирования ошибок и повторной пересылки фрагмента, содержащего дефект. Для спутниковых каналов с типичными для них большими задержками системы коррекции ошибок становятся привлекательными. Здесь используют коды Хэмминга или коды свертки.
Код Хэмминга представляет собой блочный код, который позволяет выявить и исправить ошибочно переданный бит в пределах переданного блока. Обычно код Хэмминга характеризуется двумя целыми числами, например, (11,7), используемыми при передаче 7-битных ASCII-кодов. Такая запись говорит, что при передаче 7-битного кода используется 4 контрольных бита (7 + 4 = 11). При этом предполагается, что имела место ошибка в одном бите и что ошибка в двух или более битах существенно менее вероятна. С учетом этого исправление ошибки осуществляется с определенной вероятностью. Например, пусть возможны следующие правильные коды (все они, кроме первого и последнего, отстоят друг от друга на расстояние Хэмминга 4):
00000000
11110000
00001111
11111111
При получении кода 00000111 нетрудно предположить, что правильное значение полученного кода равно 00001111. Другие коды отстоят от полученного на большее расстояние Хэмминга.
Рассмотрим пример передачи кода буквы s = 0x073 = 1110011 с использованием кода Хэмминга (11,7). Таблица 4.2.
| Позиция бита | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Значение бита | 1 | 1 | 1 | * | 0 | 0 | 1 | * | 1 | * | * |
Символами * помечены четыре позиции, где должны размещаться контрольные биты. Эти позиции определяются целой степенью 2 (1, 2, 4, 8 и т.д.). Контрольная сумма формируется путем выполнения операции XoR (исключающее ИЛИ) над кодами позиций ненулевых битов. В данном случае это 11, 10, 9, 5 и 3. Вычислим контрольную сумму:
| 11= | 1011 |
| 10= | 1010 |
| 09= | 1001 |
| 05= | 0101 |
| 03= | 0011 |
 |
1110 |
Таким образом, приемник получит код
| Позиция бита | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Значение бита | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 |
Просуммируем снова коды позиций ненулевых битов и получим нуль;
| 11= | 1011 |
| 10= | 1010 |
| 09= | 1001 |
| 08= | 1000 |
| 05= | 0101 |
| 04= | 0100 |
| 03= | 0011 |
| 02= | 0010 |
|
0000 |
Ну а теперь рассмотрим два случая ошибок в одном из битов посылки, например в бите 7 (1 вместо 0) и в бите 5 (0 вместо 1). Просуммируем коды позиций ненулевых битов еще раз:
|
|
В обоих случаях контрольная сумма равна позиции бита, переданного с ошибкой. Теперь для исправления ошибки достаточно инвертировать бит, номер которого указан в контрольной сумме. Понятно, что если ошибка произойдет при передаче более чем одного бита, код Хэмминга при данной избыточности окажется бесполезен.
В общем случае код имеет N = M + C бит и предполагается, что не более чем один бит в коде может иметь ошибку. Тогда возможно N+1 состояние кода (правильное состояние и n ошибочных). Пусть М = 4, а N = 7, тогда слово-сообщение будет иметь вид: M4, M3, M2, C3, M1, C2, C1. Теперь попытаемся вычислить значения С1, С2, С3. Для этого используются уравнения, где все операции представляют собой сложение по модулю 2:
С1 = М1 + М2 + М4 С2 = М1 + М3 + М4 С3 = М2 + М3 + М4
Для определения того, доставлено ли сообщение без ошибок, вычисляем следующие выражения (сложение по модулю 2):
С11 = С1 + М4 + М2 + М1 С12 = С2 + М4 + М3 + М1 С13 = С3 + М4 + М3 + М2
Результат вычисления интерпретируется следующим образом:
| C11 | C12 | C13 | Значение |
|---|---|---|---|
| 1 | 2 | 4 | Позиция бит |
| 0 | 0 | 0 | Ошибок нет |
| 0 | 0 | 1 | Бит С3 неверен |
| 0 | 1 | 0 | Бит С2 неверен |
| 0 | 1 | 1 | Бит M3 неверен |
| 1 | 0 | 0 | Бит С1 неверен |
| 1 | 0 | 1 | Бит M2 неверен |
| 1 | 1 | 0 | Бит M1 неверен |
| 1 | 1 | 1 | Бит M4 неверен |
Описанная схема легко переносится на любое число n и М.
Число возможных кодовых комбинаций М помехоустойчивого кода делится на n классов, где N — число разрешенных кодов. Разделение на классы осуществляется так, чтобы в каждый класс вошел один разрешенный код и ближайшие к нему (по расстоянию Хэмминга ) запрещенные коды. В процессе приема данных определяется, к какому классу принадлежит пришедший код. Если код принят с ошибкой, он заменяется ближайшим разрешенным кодом. При этом предполагается, что кратность ошибки не более qm.
В теории кодирования существуют следующие оценки максимального числа N n -разрядных кодов с расстоянием D.
| d=1 | n=2n |
| d=2 | n=2n-1 |
| d=3 | N 2n/(1 + n) |
| d = 2q + 1 | (для кода Хэмминга это неравенство превращается в равенство) |
В случае кода Хэмминга первые k разрядов используются в качестве информационных, причем
K = n – log(n + 1), откуда следует (логарифм по основанию 2), что k может принимать значения 0, 1, 4, 11, 26, 57 и т.д., это и определяет соответствующие коды Хэмминга (3,1); (7,4); (15,11); (31,26); (63,57) и т.д.
Обобщением кодов Хэмминга являются циклические коды BCH (Bose-Chadhuri-hocquenghem). Эти коды имеют широкий выбор длин и возможностей исправления ошибок.
Одной из старейших схем коррекции ошибок является двух-и трехмерная позиционная схема (
рис.
4.2). Для каждого байта вычисляется бит четности (бит <Ч>, направление Х). Для каждого столбца также вычисляется бит четности (направление Y. Производится вычисление битов четности для комбинаций битов с координатами (X,Y) (направление Z, слои с 1 до N ). Если при транспортировке будет искажен один бит, он может быть найден и исправлен по неверным битам четности X и Y. Если же произошло две ошибки в одной из плоскостей, битов четности данной плоскости недостаточно. Здесь поможет плоскость битов четности N+1.
Таким образом, на 512 передаваемых байтов данных пересылается около 200 бит четности.
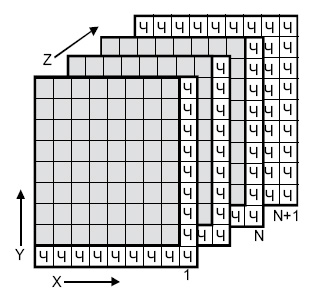
Рис.
4.2.
Позиционная схема коррекции ошибок

In information theory and coding theory with applications in computer science and telecommunication, error detection and correction (EDAC) or error control are techniques that enable reliable delivery of digital data over unreliable communication channels. Many communication channels are subject to channel noise, and thus errors may be introduced during transmission from the source to a receiver. Error detection techniques allow detecting such errors, while error correction enables reconstruction of the original data in many cases.
Definitions[edit]
Error detection is the detection of errors caused by noise or other impairments during transmission from the transmitter to the receiver.
Error correction is the detection of errors and reconstruction of the original, error-free data.
History[edit]
In classical antiquity, copyists of the Hebrew Bible were paid for their work according to the number of stichs (lines of verse). As the prose books of the Bible were hardly ever written in stichs, the copyists, in order to estimate the amount of work, had to count the letters.[1] This also helped ensure accuracy in the transmission of the text with the production of subsequent copies.[2][3] Between the 7th and 10th centuries CE a group of Jewish scribes formalized and expanded this to create the Numerical Masorah to ensure accurate reproduction of the sacred text. It included counts of the number of words in a line, section, book and groups of books, noting the middle stich of a book, word use statistics, and commentary.[1] Standards became such that a deviation in even a single letter in a Torah scroll was considered unacceptable.[4] The effectiveness of their error correction method was verified by the accuracy of copying through the centuries demonstrated by discovery of the Dead Sea Scrolls in 1947–1956, dating from c. 150 BCE-75 CE.[5]
The modern development of error correction codes is credited to Richard Hamming in 1947.[6] A description of Hamming’s code appeared in Claude Shannon’s A Mathematical Theory of Communication[7] and was quickly generalized by Marcel J. E. Golay.[8]
Principles[edit]
All error-detection and correction schemes add some redundancy (i.e., some extra data) to a message, which receivers can use to check consistency of the delivered message and to recover data that has been determined to be corrupted. Error detection and correction schemes can be either systematic or non-systematic. In a systematic scheme, the transmitter sends the original (error-free) data and attaches a fixed number of check bits (or parity data), which are derived from the data bits by some encoding algorithm. If error detection is required, a receiver can simply apply the same algorithm to the received data bits and compare its output with the received check bits; if the values do not match, an error has occurred at some point during the transmission. If error correction is required, a receiver can apply the decoding algorithm to the received data bits and the received check bits to recover the original error-free data. In a system that uses a non-systematic code, the original message is transformed into an encoded message carrying the same information and that has at least as many bits as the original message.
Good error control performance requires the scheme to be selected based on the characteristics of the communication channel. Common channel models include memoryless models where errors occur randomly and with a certain probability, and dynamic models where errors occur primarily in bursts. Consequently, error-detecting and correcting codes can be generally distinguished between random-error-detecting/correcting and burst-error-detecting/correcting. Some codes can also be suitable for a mixture of random errors and burst errors.
If the channel characteristics cannot be determined, or are highly variable, an error-detection scheme may be combined with a system for retransmissions of erroneous data. This is known as automatic repeat request (ARQ), and is most notably used in the Internet. An alternate approach for error control is hybrid automatic repeat request (HARQ), which is a combination of ARQ and error-correction coding.
Types of error correction[edit]
There are three major types of error correction:[9]
Automatic repeat request[edit]
Automatic repeat request (ARQ) is an error control method for data transmission that makes use of error-detection codes, acknowledgment and/or negative acknowledgment messages, and timeouts to achieve reliable data transmission. An acknowledgment is a message sent by the receiver to indicate that it has correctly received a data frame.
Usually, when the transmitter does not receive the acknowledgment before the timeout occurs (i.e., within a reasonable amount of time after sending the data frame), it retransmits the frame until it is either correctly received or the error persists beyond a predetermined number of retransmissions.
Three types of ARQ protocols are Stop-and-wait ARQ, Go-Back-N ARQ, and Selective Repeat ARQ.
ARQ is appropriate if the communication channel has varying or unknown capacity, such as is the case on the Internet. However, ARQ requires the availability of a back channel, results in possibly increased latency due to retransmissions, and requires the maintenance of buffers and timers for retransmissions, which in the case of network congestion can put a strain on the server and overall network capacity.[10]
For example, ARQ is used on shortwave radio data links in the form of ARQ-E, or combined with multiplexing as ARQ-M.
Forward error correction[edit]
Forward error correction (FEC) is a process of adding redundant data such as an error-correcting code (ECC) to a message so that it can be recovered by a receiver even when a number of errors (up to the capability of the code being used) are introduced, either during the process of transmission or on storage. Since the receiver does not have to ask the sender for retransmission of the data, a backchannel is not required in forward error correction. Error-correcting codes are used in lower-layer communication such as cellular network, high-speed fiber-optic communication and Wi-Fi,[11][12] as well as for reliable storage in media such as flash memory, hard disk and RAM.[13]
Error-correcting codes are usually distinguished between convolutional codes and block codes:
- Convolutional codes are processed on a bit-by-bit basis. They are particularly suitable for implementation in hardware, and the Viterbi decoder allows optimal decoding.
- Block codes are processed on a block-by-block basis. Early examples of block codes are repetition codes, Hamming codes and multidimensional parity-check codes. They were followed by a number of efficient codes, Reed–Solomon codes being the most notable due to their current widespread use. Turbo codes and low-density parity-check codes (LDPC) are relatively new constructions that can provide almost optimal efficiency.
Shannon’s theorem is an important theorem in forward error correction, and describes the maximum information rate at which reliable communication is possible over a channel that has a certain error probability or signal-to-noise ratio (SNR). This strict upper limit is expressed in terms of the channel capacity. More specifically, the theorem says that there exist codes such that with increasing encoding length the probability of error on a discrete memoryless channel can be made arbitrarily small, provided that the code rate is smaller than the channel capacity. The code rate is defined as the fraction k/n of k source symbols and n encoded symbols.
The actual maximum code rate allowed depends on the error-correcting code used, and may be lower. This is because Shannon’s proof was only of existential nature, and did not show how to construct codes that are both optimal and have efficient encoding and decoding algorithms.
Hybrid schemes[edit]
Hybrid ARQ is a combination of ARQ and forward error correction. There are two basic approaches:[10]
- Messages are always transmitted with FEC parity data (and error-detection redundancy). A receiver decodes a message using the parity information and requests retransmission using ARQ only if the parity data was not sufficient for successful decoding (identified through a failed integrity check).
- Messages are transmitted without parity data (only with error-detection information). If a receiver detects an error, it requests FEC information from the transmitter using ARQ and uses it to reconstruct the original message.
The latter approach is particularly attractive on an erasure channel when using a rateless erasure code.
Types of error detection[edit]
Error detection is most commonly realized using a suitable hash function (or specifically, a checksum, cyclic redundancy check or other algorithm). A hash function adds a fixed-length tag to a message, which enables receivers to verify the delivered message by recomputing the tag and comparing it with the one provided.
There exists a vast variety of different hash function designs. However, some are of particularly widespread use because of either their simplicity or their suitability for detecting certain kinds of errors (e.g., the cyclic redundancy check’s performance in detecting burst errors).
Minimum distance coding[edit]
A random-error-correcting code based on minimum distance coding can provide a strict guarantee on the number of detectable errors, but it may not protect against a preimage attack.
Repetition codes[edit]
A repetition code is a coding scheme that repeats the bits across a channel to achieve error-free communication. Given a stream of data to be transmitted, the data are divided into blocks of bits. Each block is transmitted some predetermined number of times. For example, to send the bit pattern 1011, the four-bit block can be repeated three times, thus producing 1011 1011 1011. If this twelve-bit pattern was received as 1010 1011 1011 – where the first block is unlike the other two – an error has occurred.
A repetition code is very inefficient and can be susceptible to problems if the error occurs in exactly the same place for each group (e.g., 1010 1010 1010 in the previous example would be detected as correct). The advantage of repetition codes is that they are extremely simple, and are in fact used in some transmissions of numbers stations.[14][15]
Parity bit[edit]
A parity bit is a bit that is added to a group of source bits to ensure that the number of set bits (i.e., bits with value 1) in the outcome is even or odd. It is a very simple scheme that can be used to detect single or any other odd number (i.e., three, five, etc.) of errors in the output. An even number of flipped bits will make the parity bit appear correct even though the data is erroneous.
Parity bits added to each word sent are called transverse redundancy checks, while those added at the end of a stream of words are called longitudinal redundancy checks. For example, if each of a series of m-bit words has a parity bit added, showing whether there were an odd or even number of ones in that word, any word with a single error in it will be detected. It will not be known where in the word the error is, however. If, in addition, after each stream of n words a parity sum is sent, each bit of which shows whether there were an odd or even number of ones at that bit-position sent in the most recent group, the exact position of the error can be determined and the error corrected. This method is only guaranteed to be effective, however, if there are no more than 1 error in every group of n words. With more error correction bits, more errors can be detected and in some cases corrected.
There are also other bit-grouping techniques.
Checksum[edit]
A checksum of a message is a modular arithmetic sum of message code words of a fixed word length (e.g., byte values). The sum may be negated by means of a ones’-complement operation prior to transmission to detect unintentional all-zero messages.
Checksum schemes include parity bits, check digits, and longitudinal redundancy checks. Some checksum schemes, such as the Damm algorithm, the Luhn algorithm, and the Verhoeff algorithm, are specifically designed to detect errors commonly introduced by humans in writing down or remembering identification numbers.
Cyclic redundancy check[edit]
A cyclic redundancy check (CRC) is a non-secure hash function designed to detect accidental changes to digital data in computer networks. It is not suitable for detecting maliciously introduced errors. It is characterized by specification of a generator polynomial, which is used as the divisor in a polynomial long division over a finite field, taking the input data as the dividend. The remainder becomes the result.
A CRC has properties that make it well suited for detecting burst errors. CRCs are particularly easy to implement in hardware and are therefore commonly used in computer networks and storage devices such as hard disk drives.
The parity bit can be seen as a special-case 1-bit CRC.
Cryptographic hash function[edit]
The output of a cryptographic hash function, also known as a message digest, can provide strong assurances about data integrity, whether changes of the data are accidental (e.g., due to transmission errors) or maliciously introduced. Any modification to the data will likely be detected through a mismatching hash value. Furthermore, given some hash value, it is typically infeasible to find some input data (other than the one given) that will yield the same hash value. If an attacker can change not only the message but also the hash value, then a keyed hash or message authentication code (MAC) can be used for additional security. Without knowing the key, it is not possible for the attacker to easily or conveniently calculate the correct keyed hash value for a modified message.
Error correction code[edit]
Any error-correcting code can be used for error detection. A code with minimum Hamming distance, d, can detect up to d − 1 errors in a code word. Using minimum-distance-based error-correcting codes for error detection can be suitable if a strict limit on the minimum number of errors to be detected is desired.
Codes with minimum Hamming distance d = 2 are degenerate cases of error-correcting codes and can be used to detect single errors. The parity bit is an example of a single-error-detecting code.
Applications[edit]
Applications that require low latency (such as telephone conversations) cannot use automatic repeat request (ARQ); they must use forward error correction (FEC). By the time an ARQ system discovers an error and re-transmits it, the re-sent data will arrive too late to be usable.
Applications where the transmitter immediately forgets the information as soon as it is sent (such as most television cameras) cannot use ARQ; they must use FEC because when an error occurs, the original data is no longer available.
Applications that use ARQ must have a return channel; applications having no return channel cannot use ARQ.
Applications that require extremely low error rates (such as digital money transfers) must use ARQ due to the possibility of uncorrectable errors with FEC.
Reliability and inspection engineering also make use of the theory of error-correcting codes.[16]
Internet[edit]
In a typical TCP/IP stack, error control is performed at multiple levels:
- Each Ethernet frame uses CRC-32 error detection. Frames with detected errors are discarded by the receiver hardware.
- The IPv4 header contains a checksum protecting the contents of the header. Packets with incorrect checksums are dropped within the network or at the receiver.
- The checksum was omitted from the IPv6 header in order to minimize processing costs in network routing and because current link layer technology is assumed to provide sufficient error detection (see also RFC 3819).
- UDP has an optional checksum covering the payload and addressing information in the UDP and IP headers. Packets with incorrect checksums are discarded by the network stack. The checksum is optional under IPv4, and required under IPv6. When omitted, it is assumed the data-link layer provides the desired level of error protection.
- TCP provides a checksum for protecting the payload and addressing information in the TCP and IP headers. Packets with incorrect checksums are discarded by the network stack and eventually get retransmitted using ARQ, either explicitly (such as through three-way handshake) or implicitly due to a timeout.
Deep-space telecommunications[edit]
The development of error-correction codes was tightly coupled with the history of deep-space missions due to the extreme dilution of signal power over interplanetary distances, and the limited power availability aboard space probes. Whereas early missions sent their data uncoded, starting in 1968, digital error correction was implemented in the form of (sub-optimally decoded) convolutional codes and Reed–Muller codes.[17] The Reed–Muller code was well suited to the noise the spacecraft was subject to (approximately matching a bell curve), and was implemented for the Mariner spacecraft and used on missions between 1969 and 1977.
The Voyager 1 and Voyager 2 missions, which started in 1977, were designed to deliver color imaging and scientific information from Jupiter and Saturn.[18] This resulted in increased coding requirements, and thus, the spacecraft were supported by (optimally Viterbi-decoded) convolutional codes that could be concatenated with an outer Golay (24,12,8) code. The Voyager 2 craft additionally supported an implementation of a Reed–Solomon code. The concatenated Reed–Solomon–Viterbi (RSV) code allowed for very powerful error correction, and enabled the spacecraft’s extended journey to Uranus and Neptune. After ECC system upgrades in 1989, both crafts used V2 RSV coding.
The Consultative Committee for Space Data Systems currently recommends usage of error correction codes with performance similar to the Voyager 2 RSV code as a minimum. Concatenated codes are increasingly falling out of favor with space missions, and are replaced by more powerful codes such as Turbo codes or LDPC codes.
The different kinds of deep space and orbital missions that are conducted suggest that trying to find a one-size-fits-all error correction system will be an ongoing problem. For missions close to Earth, the nature of the noise in the communication channel is different from that which a spacecraft on an interplanetary mission experiences. Additionally, as a spacecraft increases its distance from Earth, the problem of correcting for noise becomes more difficult.
Satellite broadcasting[edit]
The demand for satellite transponder bandwidth continues to grow, fueled by the desire to deliver television (including new channels and high-definition television) and IP data. Transponder availability and bandwidth constraints have limited this growth. Transponder capacity is determined by the selected modulation scheme and the proportion of capacity consumed by FEC.
Data storage[edit]
Error detection and correction codes are often used to improve the reliability of data storage media.[19] A parity track capable of detecting single-bit errors was present on the first magnetic tape data storage in 1951. The optimal rectangular code used in group coded recording tapes not only detects but also corrects single-bit errors. Some file formats, particularly archive formats, include a checksum (most often CRC32) to detect corruption and truncation and can employ redundancy or parity files to recover portions of corrupted data. Reed-Solomon codes are used in compact discs to correct errors caused by scratches.
Modern hard drives use Reed–Solomon codes to detect and correct minor errors in sector reads, and to recover corrupted data from failing sectors and store that data in the spare sectors.[20] RAID systems use a variety of error correction techniques to recover data when a hard drive completely fails. Filesystems such as ZFS or Btrfs, as well as some RAID implementations, support data scrubbing and resilvering, which allows bad blocks to be detected and (hopefully) recovered before they are used.[21] The recovered data may be re-written to exactly the same physical location, to spare blocks elsewhere on the same piece of hardware, or the data may be rewritten onto replacement hardware.
Error-correcting memory[edit]
Dynamic random-access memory (DRAM) may provide stronger protection against soft errors by relying on error-correcting codes. Such error-correcting memory, known as ECC or EDAC-protected memory, is particularly desirable for mission-critical applications, such as scientific computing, financial, medical, etc. as well as extraterrestrial applications due to the increased radiation in space.
Error-correcting memory controllers traditionally use Hamming codes, although some use triple modular redundancy. Interleaving allows distributing the effect of a single cosmic ray potentially upsetting multiple physically neighboring bits across multiple words by associating neighboring bits to different words. As long as a single-event upset (SEU) does not exceed the error threshold (e.g., a single error) in any particular word between accesses, it can be corrected (e.g., by a single-bit error-correcting code), and the illusion of an error-free memory system may be maintained.[22]
In addition to hardware providing features required for ECC memory to operate, operating systems usually contain related reporting facilities that are used to provide notifications when soft errors are transparently recovered. One example is the Linux kernel’s EDAC subsystem (previously known as Bluesmoke), which collects the data from error-checking-enabled components inside a computer system; besides collecting and reporting back the events related to ECC memory, it also supports other checksumming errors, including those detected on the PCI bus.[23][24][25] A few systems[specify] also support memory scrubbing to catch and correct errors early before they become unrecoverable.
See also[edit]
- Berger code
- Burst error-correcting code
- ECC memory, a type of computer data storage
- Link adaptation
- List of algorithms § Error detection and correction
- List of hash functions
References[edit]
- ^ a b «Masorah». Jewish Encyclopedia.
- ^ Pratico, Gary D.; Pelt, Miles V. Van (2009). Basics of Biblical Hebrew Grammar: Second Edition. Zondervan. ISBN 978-0-310-55882-8.
- ^ Mounce, William D. (2007). Greek for the Rest of Us: Using Greek Tools Without Mastering Biblical Languages. Zondervan. p. 289. ISBN 978-0-310-28289-1.
- ^ Mishneh Torah, Tefillin, Mezuzah, and Sefer Torah, 1:2. Example English translation: Eliyahu Touger. The Rambam’s Mishneh Torah. Moznaim Publishing Corporation.
- ^ Brian M. Fagan (5 December 1996). «Dead Sea Scrolls». The Oxford Companion to Archaeology. Oxford University Press. ISBN 0195076184.
- ^ Thompson, Thomas M. (1983), From Error-Correcting Codes through Sphere Packings to Simple Groups, The Carus Mathematical Monographs (#21), The Mathematical Association of America, p. vii, ISBN 0-88385-023-0
- ^ Shannon, C.E. (1948), «A Mathematical Theory of Communication», Bell System Technical Journal, 27 (3): 379–423, doi:10.1002/j.1538-7305.1948.tb01338.x, hdl:10338.dmlcz/101429, PMID 9230594
- ^ Golay, Marcel J. E. (1949), «Notes on Digital Coding», Proc.I.R.E. (I.E.E.E.), 37: 657
- ^ Gupta, Vikas; Verma, Chanderkant (November 2012). «Error Detection and Correction: An Introduction». International Journal of Advanced Research in Computer Science and Software Engineering. 2 (11). S2CID 17499858.
- ^ a b A. J. McAuley, Reliable Broadband Communication Using a Burst Erasure Correcting Code, ACM SIGCOMM, 1990.
- ^ Shah, Pradeep M.; Vyavahare, Prakash D.; Jain, Anjana (September 2015). «Modern error correcting codes for 4G and beyond: Turbo codes and LDPC codes». 2015 Radio and Antenna Days of the Indian Ocean (RADIO). pp. 1–2. doi:10.1109/RADIO.2015.7323369. ISBN 978-9-9903-7339-4. S2CID 28885076. Retrieved 22 May 2022.
- ^ «IEEE SA — IEEE 802.11ac-2013». IEEE Standards Association.
- ^ «Transition to Advanced Format 4K Sector Hard Drives | Seagate US». Seagate.com. Retrieved 22 May 2022.
- ^ Frank van Gerwen. «Numbers (and other mysterious) stations». Archived from the original on 12 July 2017. Retrieved 12 March 2012.
- ^ Gary Cutlack (25 August 2010). «Mysterious Russian ‘Numbers Station’ Changes Broadcast After 20 Years». Gizmodo. Archived from the original on 5 July 2017. Retrieved 12 March 2012.
- ^ Ben-Gal I.; Herer Y.; Raz T. (2003). «Self-correcting inspection procedure under inspection errors» (PDF). IIE Transactions. IIE Transactions on Quality and Reliability, 34(6), pp. 529-540. Archived from the original (PDF) on 2013-10-13. Retrieved 2014-01-10.
- ^ K. Andrews et al., The Development of Turbo and LDPC Codes for Deep-Space Applications, Proceedings of the IEEE, Vol. 95, No. 11, Nov. 2007.
- ^ Huffman, William Cary; Pless, Vera S. (2003). Fundamentals of Error-Correcting Codes. Cambridge University Press. ISBN 978-0-521-78280-7.
- ^ Kurtas, Erozan M.; Vasic, Bane (2018-10-03). Advanced Error Control Techniques for Data Storage Systems. CRC Press. ISBN 978-1-4200-3649-7.[permanent dead link]
- ^ Scott A. Moulton. «My Hard Drive Died». Archived from the original on 2008-02-02.
- ^ Qiao, Zhi; Fu, Song; Chen, Hsing-Bung; Settlemyer, Bradley (2019). «Building Reliable High-Performance Storage Systems: An Empirical and Analytical Study». 2019 IEEE International Conference on Cluster Computing (CLUSTER). pp. 1–10. doi:10.1109/CLUSTER.2019.8891006. ISBN 978-1-7281-4734-5. S2CID 207951690.
- ^ «Using StrongArm SA-1110 in the On-Board Computer of Nanosatellite». Tsinghua Space Center, Tsinghua University, Beijing. Archived from the original on 2011-10-02. Retrieved 2009-02-16.
- ^ Jeff Layton. «Error Detection and Correction». Linux Magazine. Retrieved 2014-08-12.
- ^ «EDAC Project». bluesmoke.sourceforge.net. Retrieved 2014-08-12.
- ^ «Documentation/edac.txt». Linux kernel documentation. kernel.org. 2014-06-16. Archived from the original on 2009-09-05. Retrieved 2014-08-12.
Further reading[edit]
- Shu Lin; Daniel J. Costello, Jr. (1983). Error Control Coding: Fundamentals and Applications. Prentice Hall. ISBN 0-13-283796-X.
- SoftECC: A System for Software Memory Integrity Checking
- A Tunable, Software-based DRAM Error Detection and Correction Library for HPC
- Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing
External links[edit]
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay, contains chapters on elementary error-correcting codes; on the theoretical limits of error-correction; and on the latest state-of-the-art error-correcting codes, including low-density parity-check codes, turbo codes, and fountain codes.
- ECC Page — implementations of popular ECC encoding and decoding routines
Обнаруже́ние оши́бок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи.
Для обнаружения ошибок используют коды обнаружения ошибок, для исправления — корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды).
Содержание
- 1 Способы борьбы с ошибками
- 2 Коды обнаружения и исправления ошибок
- 2.1 Блоковые коды
- 2.1.1 Линейные коды общего вида
- 2.1.1.1 Минимальное расстояние и корректирующая способность
- 2.1.1.2 Коды Хемминга
- 2.1.1.3 Общий метод декодирования линейных кодов
- 2.1.2 Линейные циклические коды
- 2.1.2.1 Порождающий (генераторный) полином
- 2.1.2.2 Коды CRC
- 2.1.2.3 Коды БЧХ
- 2.1.2.4 Коды коррекции ошибок Рида — Соломона
- 2.1.3 Преимущества и недостатки блоковых кодов
- 2.1.1 Линейные коды общего вида
- 2.2 Свёрточные коды
- 2.2.1 Преимущества и недостатки свёрточных кодов
- 2.3 Каскадное кодирование. Итеративное декодирование
- 2.4 Сетевое кодирование
- 2.5 Оценка эффективности кодов
- 2.5.1 Граница Хемминга и совершенные коды
- 2.5.2 Энергетический выигрыш
- 2.6 Применение кодов, исправляющих ошибки
- 2.1 Блоковые коды
- 3 Автоматический запрос повторной передачи
- 3.1 Запрос ARQ с остановками (stop-and-wait ARQ)
- 3.2 Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)
- 3.3 Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)
- 4 См. также
- 5 Литература
- 6 Ссылки
Способы борьбы с ошибками[править | править код]
В процессе хранения данных и передачи информации по сетям связи неизбежно возникают ошибки. Контроль целостности данных и исправление ошибок — важные задачи на многих уровнях работы с информацией (в частности, физическом, канальном, транспортном уровнях сетевой модели OSI).
В системах связи возможны несколько стратегий борьбы с ошибками:
- обнаружение ошибок в блоках данных и автоматический запрос повторной передачи повреждённых блоков — этот подход применяется, в основном, на канальном и транспортном уровнях;
- обнаружение ошибок в блоках данных и отбрасывание повреждённых блоков — такой подход иногда применяется в системах потокового мультимедиа, где важна задержка передачи и нет времени на повторную передачу;
- исправление ошибок (англ. forward error correction) применяется на физическом уровне.
Коды обнаружения и исправления ошибок[править | править код]
Корректирующие коды — коды, служащие для обнаружения или исправления ошибок, возникающих при передаче информации под влиянием помех, а также при её хранении.
Для этого при записи (передаче) в полезные данные добавляют специальным образом структурированную избыточную информацию (контрольное число), а при чтении (приёме) её используют для того, чтобы обнаружить или исправить ошибки. Естественно, что число ошибок, которое можно исправить, ограничено и зависит от конкретного применяемого кода.
С кодами, исправляющими ошибки, тесно связаны коды обнаружения ошибок. В отличие от первых, последние могут только установить факт наличия ошибки в переданных данных, но не исправить её.
В действительности используемые коды обнаружения ошибок принадлежат к тем же классам кодов, что и коды, исправляющие ошибки. Фактически любой код, исправляющий ошибки, может быть также использован для обнаружения ошибок (при этом он будет способен обнаружить большее число ошибок, чем был способен исправить).
По способу работы с данными коды, исправляющие ошибки, делятся на блоковые, делящие информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности, и свёрточные, работающие с данными как с непрерывным потоком.
Блоковые коды[править | править код]
Пусть кодируемая информация делится на фрагменты длиной  бит, которые преобразуются в кодовые слова длиной
бит, которые преобразуются в кодовые слова длиной  бит. Тогда соответствующий блоковый код обычно обозначают
бит. Тогда соответствующий блоковый код обычно обозначают  . При этом число
. При этом число  называется скоростью кода.
называется скоростью кода.
Если исходные бит код оставляет неизменными, и добавляет  проверочных, такой код называется систематическим, иначе — несистематическим.
проверочных, такой код называется систематическим, иначе — несистематическим.
Задать блоковый код можно по-разному, в том числе таблицей, где каждой совокупности из информационных бит сопоставляется бит кодового слова. Однако хороший код должен удовлетворять как минимум следующим критериям:
- способность исправлять как можно большее число ошибок,
- как можно меньшая избыточность,
- простота кодирования и декодирования.
Нетрудно видеть, что приведённые требования противоречат друг другу. Именно поэтому существует большое количество кодов, каждый из которых пригоден для своего круга задач.
Практически все используемые коды являются линейными. Это связано с тем, что нелинейные коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость кодирования и декодирования.
Линейные коды общего вида[править | править код]
Линейный блоковый код — такой код, что множество его кодовых слов образует -мерное линейное подпространство (назовём его  ) в -мерном линейном пространстве, изоморфное пространству -битных векторов.
) в -мерном линейном пространстве, изоморфное пространству -битных векторов.
Это значит, что операция кодирования соответствует умножению исходного -битного вектора на невырожденную матрицу  , называемую порождающей матрицей.
, называемую порождающей матрицей.
Пусть  — ортогональное подпространство по отношению к , а
— ортогональное подпространство по отношению к , а  — матрица, задающая базис этого подпространства. Тогда для любого вектора
— матрица, задающая базис этого подпространства. Тогда для любого вектора  справедливо:
справедливо:

Минимальное расстояние и корректирующая способность[править | править код]
Расстоянием Хемминга (метрикой Хемминга) между двумя кодовыми словами  и
и  называется количество отличных бит на соответствующих позициях:
называется количество отличных бит на соответствующих позициях:
 .
.

Минимальное расстояние Хемминга  является важной характеристикой линейного блокового кода. Она показывает, насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
является важной характеристикой линейного блокового кода. Она показывает, насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
- .

Корректирующая способность определяет, сколько ошибок передачи кода (типа  ) можно гарантированно исправить. То есть вокруг каждого кодового слова
) можно гарантированно исправить. То есть вокруг каждого кодового слова  имеем
имеем  -окрестность
-окрестность  , которая состоит из всех возможных вариантов передачи кодового слова с числом ошибок () не более . Никакие две окрестности двух любых кодовых слов не пересекаются друг с другом, так как расстояние между кодовыми словами (то есть центрами этих окрестностей) всегда больше двух их радиусов
, которая состоит из всех возможных вариантов передачи кодового слова с числом ошибок () не более . Никакие две окрестности двух любых кодовых слов не пересекаются друг с другом, так как расстояние между кодовыми словами (то есть центрами этих окрестностей) всегда больше двух их радиусов  .
.
Таким образом, получив искажённую кодовую комбинацию из , декодер принимает решение, что исходной была кодовая комбинация , исправляя тем самым не более ошибок.
Поясним на примере. Предположим, что есть два кодовых слова и  , расстояние Хемминга между ними равно 3. Если было передано слово , и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к любому другому, и, в частности, к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ), то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение, что передавалось слово .
, расстояние Хемминга между ними равно 3. Если было передано слово , и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к любому другому, и, в частности, к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ), то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение, что передавалось слово .
Коды Хемминга[править | править код]
Коды Хемминга — простейшие линейные коды с минимальным расстоянием 3, то есть способные исправить одну ошибку. Код Хемминга может быть представлен в таком виде, что синдром
- , где — принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.


Общий метод декодирования линейных кодов[править | править код]
Любой код (в том числе нелинейный) можно декодировать с помощью обычной таблицы, где каждому значению принятого слова  соответствует наиболее вероятное переданное слово
соответствует наиболее вероятное переданное слово  . Однако данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
. Однако данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
Для линейных кодов этот метод можно существенно упростить. При этом для каждого принятого вектора вычисляется синдром  . Поскольку
. Поскольку  , где
, где  — кодовое слово, а
— кодовое слово, а  — вектор ошибки, то
— вектор ошибки, то  . Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
. Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
Линейные циклические коды[править | править код]
Несмотря на то, что декодирование линейных кодов значительно проще декодирования большинства нелинейных, для большинства кодов этот процесс всё ещё достаточно сложен. Циклические коды, кроме более простого декодирования, обладают и другими важными свойствами.
Циклическим кодом является линейный код, обладающий следующим свойством: если является кодовым словом, то его циклическая перестановка также является кодовым словом.
Слова циклического кода удобно представлять в виде многочленов. Например, кодовое слово  представляется в виде полинома
представляется в виде полинома  . При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на
. При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на  по модулю
по модулю  .
.
В дальнейшем, если не указано иное, мы будем считать, что циклический код является двоичным, то есть  могут принимать значения 0 или 1.
могут принимать значения 0 или 1.
Порождающий (генераторный) полином[править | править код]
Можно показать, что все кодовые слова конкретного циклического кода кратны определённому порождающему полиному  . Порождающий полином является делителем .
. Порождающий полином является делителем .
С помощью порождающего полинома осуществляется кодирование циклическим кодом. В частности:
Коды CRC[править | править код]
Коды CRC (англ. cyclic redundancy check — циклическая избыточная проверка) являются систематическими кодами, предназначенными не для исправления ошибок, а для их обнаружения. Они используют способ систематического кодирования, изложенный выше: «контрольная сумма» вычисляется путём деления  на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
Таким образом, вид полинома задаёт конкретный код CRC. Примеры наиболее популярных полиномов:
| Название кода | Степень | Полином |
|---|---|---|
| CRC-12 | 12 | 
|
| CRC-16 | 16 | 
|
| CRC-CCITT | 16 | 
|
| CRC-32 | 32 | 
|
Коды БЧХ[править | править код]
Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических кодов. Их отличительное свойство — возможность построения кода БЧХ с минимальным расстоянием не меньше заданного. Это важно, потому что, вообще говоря, определение минимального расстояния кода есть очень сложная задача.
Коды коррекции ошибок Рида — Соломона[править | править код]
Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида-Соломона, работающие с байтами (октетами).
Математически коды Рида — Соломона являются кодами БЧХ.
Преимущества и недостатки блоковых кодов[править | править код]
Хотя блоковые коды, как правило, хорошо справляются с редкими, но большими пачками ошибок, их эффективность при частых, но небольших ошибках (например, в канале с АБГШ), менее высока.
Свёрточные коды[править | править код]

Свёрточный кодер ( )
)
Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней как со сплошным потоком данных.
Свёрточные коды, как правило, порождаются дискретной линейной инвариантной во времени системой. Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень простая операция, чего нельзя сказать о декодировании.
Кодирование свёрточным кодом производится с помощью регистра сдвига, отводы от которого суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше.
Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби, который пытается восстановить переданную последовательность согласно критерию максимального правдоподобия.
Преимущества и недостатки свёрточных кодов[править | править код]
Свёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет ошибок.
Каскадное кодирование. Итеративное декодирование[править | править код]
Преимущества разных способов кодирования можно объединить, применив каскадное кодирование. При этом информация сначала кодируется одним кодом, а затем другим, в результате получается код-произведение.
Например, популярной является следующая конструкция: данные кодируются кодом Рида-Соломона, затем перемежаются (при этом символы, расположенные близко, помещаются далеко друг от друга) и кодируются свёрточным кодом. На приёмнике сначала декодируется свёрточный код, затем осуществляется обратное перемежение (при этом пачки ошибок на выходе свёрточного декодера попадают в разные кодовые слова кода Рида — Соломона), и затем осуществляется декодирование кода Рида — Соломона.
Некоторые коды-произведения специально сконструированы для итеративного декодирования, при котором декодирование осуществляется в несколько проходов, каждый из которых использует информацию от предыдущего. Это позволяет добиться большой эффективности, однако декодирование требует больших ресурсов. К таким кодам относят турбо-коды и LDPC-коды (коды Галлагера).
Сетевое кодирование[править | править код]
Оценка эффективности кодов[править | править код]
Эффективность кодов определяется количеством ошибок, которые тот может исправить, количеством избыточной информации, добавление которой требуется, а также сложностью реализации кодирования и декодирования (как аппаратной, так и в виде программы для ЭВМ).
Граница Хемминга и совершенные коды[править | править код]
Пусть имеется двоичный блоковый  код с корректирующей способностью . Тогда справедливо неравенство (называемое границей Хемминга):
код с корректирующей способностью . Тогда справедливо неравенство (называемое границей Хемминга):

Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным кодам относятся, например, коды Хемминга. Часто применяемые на практике коды с большой корректирующей способностью (такие, как коды Рида — Соломона) не являются совершенными.
Энергетический выигрыш[править | править код]
При передаче информации по каналу связи вероятность ошибки зависит от отношения сигнал/шум на входе демодулятора, таким образом, при постоянном уровне шума решающее значение имеет мощность передатчика. В системах спутниковой и мобильной, а также других типов связи остро стоит вопрос экономии энергии. Кроме того, в определённых системах связи (например, телефонной) неограниченно повышать мощность сигнала не дают технические ограничения.
Поскольку помехоустойчивое кодирование позволяет исправлять ошибки, при его применении мощность передатчика можно снизить, оставляя скорость передачи информации неизменной. Энергетический выигрыш определяется как разница отношений с/ш при наличии и отсутствии кодирования.
Применение кодов, исправляющих ошибки[править | править код]
Коды, исправляющие ошибки, применяются:
- в системах цифровой связи, в том числе: спутниковой, радиорелейной, сотовой, передаче данных по телефонным каналам.
- в системах хранения информации, в том числе магнитных и оптических.
Коды, обнаруживающие ошибки, применяются в сетевых протоколах различных уровней.
Автоматический запрос повторной передачи[править | править код]
Системы с автоматическим запросом повторной передачи (ARQ — Automatic Repeat reQuest) основаны на технологии обнаружения ошибок. Распространены следующие методы автоматического запроса:
Запрос ARQ с остановками (stop-and-wait ARQ)[править | править код]
Идея этого метода заключается в том, что передатчик ожидает от приемника подтверждения успешного приема предыдущего блока данных перед тем, как начать передачу следующего. В случае, если блок данных был принят с ошибкой, приемник передает отрицательное подтверждение (negative acknowledgement, NAK), и передатчик повторяет передачу блока. Данный метод подходит для полудуплексного канала связи. Его недостатком является низкая скорость из-за высоких накладных расходов на ожидание.
Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)[править | править код]
Для этого метода необходим полнодуплексный канал. Передача данных от передатчика к приемнику производится одновременно. В случае ошибки передача возобновляется, начиная с ошибочного блока (то есть передается ошибочный блок и все последующие).
Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)[править | править код]
При этом подходе осуществляется передача только ошибочно принятых блоков данных.
См. также[править | править код]
- Цифровая связь
- Код ответа (Код причины завершения)
- Линейный код
- Циклический код
- Код Боуза — Чоудхури — Хоквингема
- Код Рида — Соломона
- LDPC
- Свёрточный код
- Турбо-код
Литература[править | править код]
- Блейхут Р. Теория и практика кодов, контролирующих ошибки = Theory and Practice of Error Control Codes. — М.: Мир, 1986. — 576 с.
- Мак-Вильямс Ф. Дж., Слоэн Н. Дж. А. Теория кодов, исправляющих ошибки. М.: Радио и связь, 1979.
- Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение / пер. с англ. В. Б. Афанасьева. — М.: Техносфера, 2006. — 320 с. — (Мир связи). — 2000 экз. — ISBN 5-94836-035-0.
Ссылки[править | править код]
- Помехоустойчивое кодирование (11 ноября 2001). — реферат по проблеме кодирования сообщений с исправлением ошибок. Проверено 25 декабря 2006. Архивировано 25 августа 2011 года.
- Коды Рида-Соломона. Простой пример. Просто, доступно, на конкретных числах. Для начинающих.