В
соответствии с четвёртой предпосылкой
МНК требуется, чтобы дисперсия остатков
была гомоскедастичной.
Это значит, что для каждого значения
фактора
![]() остатки
остатки![]() имеют одинаковую дисперсию
имеют одинаковую дисперсию![]() .
.
Если это условие применения МНК не
соблюдается, то имеет местогетероскедастичность.
В
качестве примера реальной гетероскедастичности
можно привести то, что люди с большим
доходом не только тратят в среднем
больше, чем люди с меньшим доходом, но
и разброс в их потреблении также больше,
поскольку они имеют больше простора
для распределения дохода.
Наличие
гетероскедастичности можно наглядно
видеть из поля корреляции (- графический
метод
обнаружения гетероскедастичности).
|
(а) – дисперсия |
(б) – дисперсия |
(в)
– максимальная |



Наличие
гомоскедастичности или гетероскедастичности
можно видеть и по рассмотренному выше
графику зависимости остатков
![]() от теоретических значений результативного
от теоретических значений результативного
признака![]() .
.
|
(а‘) Гетероскедастичность: |
(б‘)
Гетероскедастичность, |
(в‘)
Гетероскедастичность, |
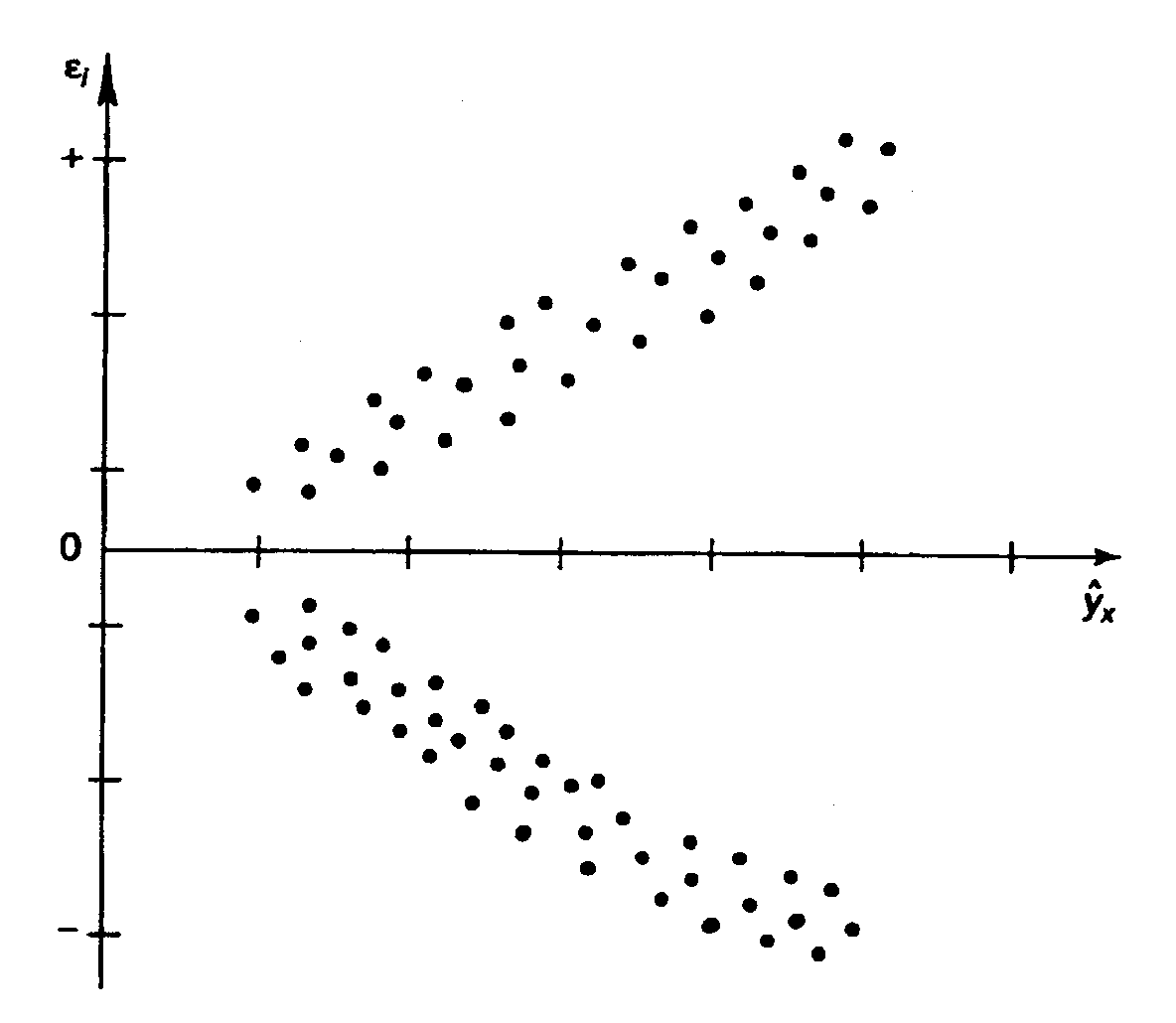
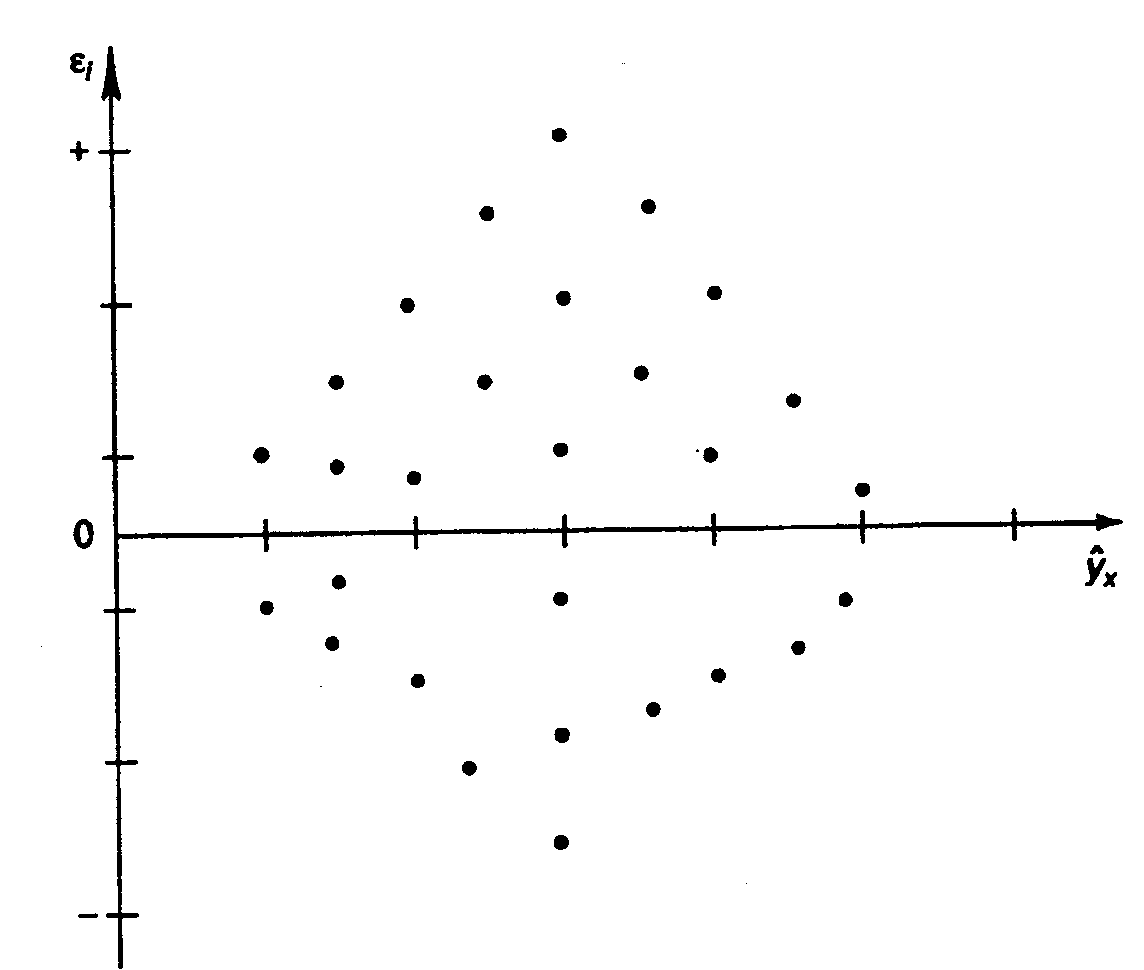

Для
множественной регрессии данный вид
графиков является наиболее приемлемым
визуальным способом изучения гомо- и
гетероскедастичности.
При
нарушении гомоскедастичности имеем
неравенства:
![]() ,
,
где![]() — постоянная дисперсия ошибки при
— постоянная дисперсия ошибки при
соблюдении предпосылки. Т.е. можно
записать, что дисперсия ошибки при![]() наблюдении пропорциональна постоянной
наблюдении пропорциональна постоянной
дисперсии:![]()
![]() .
.
![]() —
—
коэффициент
пропорциональности.
Он меняется при переходе от одного
значения фактора
![]() к другому.
к другому.
Задача
состоит в том, чтобы определить величину
![]() и внести поправку в исходные переменные.
и внести поправку в исходные переменные.
При этом используютобобщённый
МНК, который
эквивалентен обычному МНК, применённому
к преобразованным данным.
Чтобы
убедиться в обоснованности использования
обобщённого МНК проводят эмпирическое
подтверждение наличия гетероскедастичности.
При
малом объёме выборки, что наиболее
характерно для эмпирических исследований,
для оценки гетероскедастичности может
использоваться метод Гольдфельда-Квандта
(в 1965 г. они рассмотрели модель парной
линейной регрессии, в которой дисперсия
ошибок пропорциональна квадрату
фактора).
Пусть
рассматривается модель, в которой
дисперсия
![]() пропорциональна квадрату фактора:
пропорциональна квадрату фактора:
![]() ,
,
![]() .
.
А также остатки имеют нормальное
распределение и отсутствует автокорреляция
остатков.
Параметрический
тест (критерий) Гольдфельда – Квандта:
1.
Все n
наблюдений в выборке упорядочиваются
по величине x.
2.
Вся упорядоченная выборка разбивается
на три подвыборки (объёмом k,
С, k.)
![]() .
.
Исключаются из
рассмотрения С
центральных наблюдений. (По рекомендациям
специалистов, объём исключаемых данных
С
должен быть примерно равен четверти
общего объёма выборки n,
в частности, при
n =20, С=4;
при n
=30, С
= 8; при n
=60, С=16).
3.
Оцениваются отдельные регрессии для
первой подвыборки (k
первых наблюдений) и для последней
подвыборки (k
последних наблюдений).
4.
Определяются остаточные суммы квадратов
![]() для первой и второй
для первой и второй![]() групп.
групп.
Если предположение о пропорциональности
дисперсий отклонений значениямx
верно, то
![]() .
.
5.
Выдвигается нулевая гипотеза
![]() которая
которая
предполагает отсутствие гетероскедастичности.
Для проверки этой
гипотезы рассчитывается отношение
![]() ,
,
которое имеет распределение Фишера с![]() степеней свободы (здесьm
степеней свободы (здесьm
– число объясняющих переменных).
Если
![]() ,
,
то гипотеза об отсутствии гетероскедастичности
отклоняется при уровне значимостиα.
Этот же тест может
быть использован и при предположении
об обратной пропорциональности между
дисперсией и значениями объясняющей
переменной
![]() .
.
В этом случае статистика Фишера принимает
вид:
![]() .
.
При
установлении гетероскедастичности
возникает необходимость преобразования
модели с целью устранения данного
недостатка. Вид преобразования зависит
от того, известны или нет дисперсии
отклонений
![]() .
.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
В
соответствии с четвёртой предпосылкой
МНК требуется, чтобы дисперсия остатков
была гомоскедастичной.
Это значит, что для каждого значения
фактора
![]() остатки
остатки![]() имеют одинаковую дисперсию
имеют одинаковую дисперсию![]() .
.
Если это условие применения МНК не
соблюдается, то имеет местогетероскедастичность.
В
качестве примера реальной гетероскедастичности
можно привести то, что люди с большим
доходом не только тратят в среднем
больше, чем люди с меньшим доходом, но
и разброс в их потреблении также больше,
поскольку они имеют больше простора
для распределения дохода.
Наличие
гетероскедастичности можно наглядно
видеть из поля корреляции (- графический
метод
обнаружения гетероскедастичности).
|
(а) – дисперсия |
(б) – дисперсия |
(в)
– максимальная |
Наличие
гомоскедастичности или гетероскедастичности
можно видеть и по рассмотренному выше
графику зависимости остатков
![]() от теоретических значений результативного
от теоретических значений результативного
признака![]() .
.
|
(а‘) Гетероскедастичность: |
(б‘)
Гетероскедастичность, |
(в‘)
Гетероскедастичность, |
Для
множественной регрессии данный вид
графиков является наиболее приемлемым
визуальным способом изучения гомо- и
гетероскедастичности.
При
нарушении гомоскедастичности имеем
неравенства:
![]() ,
,
где![]() — постоянная дисперсия ошибки при
— постоянная дисперсия ошибки при
соблюдении предпосылки. Т.е. можно
записать, что дисперсия ошибки при![]() наблюдении пропорциональна постоянной
наблюдении пропорциональна постоянной
дисперсии:![]()
![]() .
.
![]() —
—
коэффициент
пропорциональности.
Он меняется при переходе от одного
значения фактора
![]() к другому.
к другому.
Задача
состоит в том, чтобы определить величину
![]() и внести поправку в исходные переменные.
и внести поправку в исходные переменные.
При этом используютобобщённый
МНК, который
эквивалентен обычному МНК, применённому
к преобразованным данным.
Чтобы
убедиться в обоснованности использования
обобщённого МНК проводят эмпирическое
подтверждение наличия гетероскедастичности.
При
малом объёме выборки, что наиболее
характерно для эмпирических исследований,
для оценки гетероскедастичности может
использоваться метод Гольдфельда-Квандта
(в 1965 г. они рассмотрели модель парной
линейной регрессии, в которой дисперсия
ошибок пропорциональна квадрату
фактора).
Пусть
рассматривается модель, в которой
дисперсия
![]() пропорциональна квадрату фактора:
пропорциональна квадрату фактора:
![]() ,
,
![]() .
.
А также остатки имеют нормальное
распределение и отсутствует автокорреляция
остатков.
Параметрический
тест (критерий) Гольдфельда – Квандта:
1.
Все n
наблюдений в выборке упорядочиваются
по величине x.
2.
Вся упорядоченная выборка разбивается
на три подвыборки (объёмом k,
С, k.)
![]() .
.
Исключаются из
рассмотрения С
центральных наблюдений. (По рекомендациям
специалистов, объём исключаемых данных
С
должен быть примерно равен четверти
общего объёма выборки n,
в частности, при
n =20, С=4;
при n
=30, С
= 8; при n
=60, С=16).
3.
Оцениваются отдельные регрессии для
первой подвыборки (k
первых наблюдений) и для последней
подвыборки (k
последних наблюдений).
4.
Определяются остаточные суммы квадратов
![]() для первой и второй
для первой и второй![]() групп.
групп.
Если предположение о пропорциональности
дисперсий отклонений значениямx
верно, то
![]() .
.
5.
Выдвигается нулевая гипотеза
![]() которая
которая
предполагает отсутствие гетероскедастичности.
Для проверки этой
гипотезы рассчитывается отношение
![]() ,
,
которое имеет распределение Фишера с![]() степеней свободы (здесьm
степеней свободы (здесьm
– число объясняющих переменных).
Если
![]() ,
,
то гипотеза об отсутствии гетероскедастичности
отклоняется при уровне значимостиα.
Этот же тест может
быть использован и при предположении
об обратной пропорциональности между
дисперсией и значениями объясняющей
переменной
![]() .
.
В этом случае статистика Фишера принимает
вид:
![]() .
.
При
установлении гетероскедастичности
возникает необходимость преобразования
модели с целью устранения данного
недостатка. Вид преобразования зависит
от того, известны или нет дисперсии
отклонений
![]() .
.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Правильные ответы выделены зелёным цветом.
Все ответы: Даны основы эконометрики и статистического анализа одномерных временных рядов.
Дисциплина эконометрика содержит следующие разделы
(1) моделирование данных, неупорядоченных во времени, теория временных рядов
(2) теория вероятностей и математическая статистика
(3) моделирование экономических процессов и прогнозирование ситуаций
(4) верны все вышеперечисленные варианты
Соответствие, максимальное приближение теоретических моделей к реальным производственно-экономическим процессам предполагает
(1) системность прогнозов
(2) адекватность поведения
(3) альтернативность прогнозирования
(4) все перечисленное
Сглаживание ряда называется центрированным при условии
(1) k = l + 3
(2) k = l
(3) k = l + 2
(4) k = l + 1
Для устранения трудностей построения уравнения регрессии при наличии коррелированности факторов и ошибок модели используют
(1) метод скользящей средней
(2) метод наименьших квадратов
(3) метод сглаживания
(4) метод инструментальных переменных
Построение моделей структуры средних позволяет
(1) проверить гипотезу о том, что матрица ковариации имеет определенный вид
(2) проверить корреляцию между факторами
(3) исследовать структуру средних одновременно с анализом дисперсий и ковариаций
(4) проанализировать корреляционную матрицу общих факторов
К критериям селекции относятся…
(1) критерий Шварца (SBC) и информационный критерий Акайке
(2) критерий Фишера и информационный критерий Акайке
(3) критерий Стьюдента
(4) критерий Стьюдента и информационный критерий Акайке
Стохастическая переменная с постоянной дисперсией называется
(1) основной
(2) гомоскедастической
(3) гетероскедастической
(4) явной
Тенденция к отрицанию гипотезы H0 возрастает по мере
(1) наличия связанных между собой нестационарных временных рядах
(2) увеличения объема выборки
(3) ошибочного обнаружения связей
(4) уменьшения объема выборки
Если при сборе данных об урожайности сельскохозяйственных структур результаты работы в отчетах занижаются, завышаются в зависимости от экономической политики или оцениваются «на глазок», то это объясняется
(1) неправильным выбором вида зависимости в уравнении
(2) отражением уравнением регрессии связи между агрегированными переменными
(3) невключением объясняющих переменных
(4) ошибками измерения
Матрица C = (XTX)-1, обратная матрице XTX, называется
(1) матрицей дисперсий-ковариаций или транспонированной матрицей случайного вектора Х
(2) транспонированной матрицей случайного вектора Х или ковариационной матрицей
(3) матрицей дисперсий-ковариаций или ковариационной матрицей
Каковы последствия гетероскедастичности в случая использования МНК для построения модели?
(1) результаты, основанные на анализе дисперсии коэффициентов, в случае гетероскедастичности применимы полностью
(2) результаты, основанные на анализе дисперсии коэффициентов, в случае гетероскедастичности неприменимы
(3) результаты, основанные на анализе дисперсии коэффициентов, в случае гетероскедастичности применимы в некоторых случаях
Впервые термин «эконометрия» ввел П. Цьемпа в
(1) 1980
(2) 1900
(3) 1910
(4) 1950
Величина Dx(t) характеризует
(1) квадрат колебаний значений процесса вокруг
(2) средний размах значений процесса
(3) размах квадрата колебаний значений процесса вокруг
(4) средний размах квадрата колебаний значений процесса вокруг mx(t)
Простейшим асимметричным фильтром является
(1) взвешенная средняя
(2) дисперсия
(3) скользящая средняя
(4) среднее квадратичное отклонение
Мультипликатор Кейнса характеризуется следующим высказыванием
(1) при увеличении объема инвестиций It на единицу совокупный выпуск возрастает на It единиц
(2) при уменьшении объема инвестиций It на единицу совокупный выпуск возрастает на 1/1-b единиц
(3) при увеличении объема инвестиций It на единицу совокупный выпуск возрастает на 1/1-b единиц
(4) при уменьшении объема инвестиций It на единицу совокупный выпуск возрастает на It единиц
Процесс структурного моделирования включает в себя следующие этапы
(1) все перечисленные этапы
(2) исследователь (пользователь) описывает (обычно с помощью диаграммы путей) модель, представляющую его понимание зависимостей между переменными
(3) программа проверяет, насколько хорошо полученные дисперсии и ковариации отвечают данной модели
(4) программа с помощью специальных внутренних методов определяет, какие значения дисперсий и ковариаций переменных получаются в текущей модели на основании входных данных
Для оценки так называемых моделей авторегрессии интегрированного скользящего среднего (АРИСС-моделей) применяют
(1) критерий Фишера
(2) критерий Стьюдента
(3) методологию Бокса — Дженкинса
(4) критерии Вальда — Вольфовица
В выражении для определения превышения доходности yt = mt + et, параметром mt обозначают
(1) ожидаемое превышение доходности от держания долгосрочных ценных бумаг
(2) непредсказуемые колебания показателей доходности долговременных рискованных ценных бумаг
(3) премию за риск, побуждающую избегающих риска агентов держать долгосрочные ценные бумаги
(4) белый шум
В случае если ряд содержит единичные корни и интегрирует с порядком d, он принадлежит классу
(1) I(d — b)
(2) I(d)
(3) CI(1,1)
(4) I(d + b)
Если регрессия значима, то
(1) Fнабл < Fкрит
(2) Fнабл > Fкрит
(3) Fнабл = Fкрит
К методам устранения мультиколлинеарности относятся
(1) все перечисленное верно
(2) методы, уменьшающие дисперсии оценок коэффициентов
(3) метод главных компонент
(4) метод гребневой регрессии (ридж-регрессии)
Обобщенная линейная модель множественной регрессии, теорема Айткена и обобщенный метод наименьших квадратов характерны для
(1) обоих методов устранения гетероскедастичности
(2) первого метода устранения гетероскедастичности
(3) второго метода устранения гетероскедастичности
Целью эконометрики как науки является
(1) разработка методов прогнозирования
(2) эмпирический анализ экономических законов
(3) разработка методик проведения социально-экономических исследований
(4) верны все вышеперечисленные варианты
Функция P(t) считается полностью определенной, если известны…
(1) все перечисленное
(2) частоты w = 2Пи/T
(3) период Т
(4) коэффициенты ряда Фурье
При сглаживании с помощью скользящей средней нет возможности получить сглаженные значения для
(1) свободного члена а полинома
(2) k первых и k последних членов ряда X(t)
(3) нечетных членов временного ряда
(4) k первых членов ряда X(t)
Число уравнений приведенной системы совпадает
(1) с числом экзогенных переменных
(2) с числом приведенных переменных
(3) с числом эндогенных переменных модели
(4) с числом составляющих переменных
Диаграммы путей используются для
(1) простого и изоморфного представления системы линейных уравнений
(2) составления сетевых графиков
(3) прогнозирования
(4) отражения причинных связей в наборе переменных
При q = 0 уравнение авторегрессии называется
(1) СС(q)-модель
(2) АРСС(p, q)-модель
(3) АРИСС(p, s, q)-моделью
(4) AP(q)-модель
Для определения превышения дохода от держания шестимесячной облигации (без учета квадратичных членов) можно использовать выражение
(1) yt = -0,0241 + 0,687ht + et
(2) yt = 2Rt — rt + 1 — rt
(3) yt = mt + et
(4) yt = 2Rt — rt
Следствием ложных корреляций являются
(1) образование новых стационарных переменных
(2) ложные связи между переменными
(3) образование детерминированных переменных времени
Значимость уравнения регрессии осуществляется по
(1) коэффициенту детерминации
(2) F-критерию Фишера
(3) по дисперсии
(4) все перечисленное
Предельными значениями коэффициента корреляции являются
(1) от 0 до +1
(2) от -1 до 0
(3) от -1 до + 1
Первый подход к решению проблемы гетероскедастичности
(1) предполагает такое преобразование данных, чтобы для них модель приобретала со временем свойство гетероскедастичности
(2) предполагает такое преобразование данных, чтобы для них модель уже обладала свойством гетероскедастичности
(3) состоит в построении моделей, учитывающих гетероскедастичность ошибок наблюдений
Исследование моделей по независимым неупорядоченным наблюдениям включает следующие этапы
(1) выявление тренда, лагов
(2) выделение зависимых и независимых переменных согласно некоторой экономической гипотезе
(3) проверка остатков на гетероскедастичность
(4) выявление циклической компоненты
Предварительную оценку случайности поведения остатков проводят на основе
(1) все перечисленное
(2) критерия поворотных точек
(3) критерия Пирсена
(4) критерия Стъюдента
Для уменьшения амплитуды колебаний у сглаженного ряда Y(t) необходимо
(1) увеличивать ширину интервала сглаживания m и проводить процедуру сглаживания повторно
(2) увеличивать ширину интервала сглаживания m либо проводить процедуру сглаживания повторно
(3) уменьшать ширину интервала сглаживания m
(4) все перечисленное не верно
Экзогенные переменные никогда не коррелируют
(1) с эндогенными переменными
(2) с ошибками модели
(3) с предопределенными переменными
(4) c лаговыми переменными
Явные переменные на путевых диаграммах указываются
(1) внутри овалов
(2) над стрелками
(3) внутри прямоугольников
(4) над дугами
Одним из априорных предположений при применении параметрических тестов для проверки стационарности является
(1) предположение о Пуассоновском законе распределения
(2) предположение о наличии корреляционных связей
(3) предположение о нормальном законе распределения значений временного ряда
(4) все перечисленное не верно
В выражении ln(yt) = a0 + a1ln(xt — 1) + et параметр et = ln et означает
(1) переменная уровня доходности
(2) белый шум
(3) слагаемое ошибок
(4) все перечисленное не верно
В процессе случайного блуждания используются переменные
(1) коррелированные нестационарные переменные
(2) некоррелированные нестационарные переменные
(3) стационарные переменные
(4) детерминированные переменные
Проверка значимости коэффициентов уравнения регрессии производится по
(1) критерию Фишера
(2) коэффициенту корреляции
(3) критерию Стьюдента
(4) коэффициенту детерминации
Если случайная величина является нормированной нормально распределенной величиной, то выполняется условие
(1) дисперсия равна нулю
(2) дисперсия равна единице
(3) все перечисленное
Устранение гетероскедастичности путем применения обобщенного метода наименьших квадратов (ОМНК) требует знания
(1) матрицы случайных ошибок
(2) матрицы ковариаций ошибок наблюдений
(3) матрицы систематических ошибок
(4) все перечисленное
Первой книгой, которую можно назвать эконометрической, была книга ученого
(1) Ф. Гальтона
(2) Дж. Э. Юла
(3) Г. Хукера
(4) Г. Мура
Уравнение кривой можно свести к многочлену посредством
(1) все перечисленное
(2) логарифмирования
(3) дифференцирования
(4) интегрирования
Сглаженный ряд короче исходного на величину
(1) k + l + 1
(2) k + 1
(3) 2k + 1
(4) k — l + 1
Коэффициент структурного уравнения системы называется идентифицируемым, если выполняются условия…
(1) существует не одна формула, связывающая этот коэффициент с коэффициентами приведенной формы
(2) коэффициент однозначно определяется с помощью косвенного метода наименьших квадратов
(3) коэффициент неоднозначно определяется с помощью косвенного метода наименьших квадратов
(4) все перечисленное
Путевые диаграммы наглядно показывают
(1) какие переменные являются значимыми
(2) какие переменные не вызывают изменения в других переменных
(3) какие переменные являются основными
(4) какие переменные вызывают изменения в других переменных
Для проверки условия стационарности ряда последовательность разбивается
(1) на два участка
(2) на три участка
(3) на четыре участка
(4) не разбивается
Коррелируют между собой следующие тренды
(1) нестационарные
(2) временные
(3) стационарные
(4) постоянные
Максимальное значение коэффициента детерминации равно
Для случая парной регрессии справедливым является выражение
(1) Qобщ = Qост — Qрегр
(2) Qобщ = Qост/Qрегр
(3) Qобщ = Qост + Qрегр
(4) все выражения
Ранг неслучайной (детерминированной) матрицы X предполагается равным
(1) p + 3 < n
(2) p + 2 < n
(3) p + 5 < n
(4) p + 1 < n
Начальным этапом применения теории эконометрики является
(1) прогнозирование экономической политики
(2) тестирование гипотез
(3) разработка теоретической модели экономической теории
(4) оценка модели
К приемам, позволяющим подобрать соответствующую (адекватную) действительности форму кривой, относятся…
(1) все перечисленное верно
(2) вычисление последовательных разностей
(3) визуальный
К экзогенным переменным относятся…
(1) все перечисленное
(2) денежная масса
(3) процентная ставка
(4) временной тренд
Третьим этапом структурного моделирования является следующий
(1) программа сообщает пользователю полученные результаты статистических испытаний, а также выводит оценки параметров и стандартные ошибки для численных коэффициентов в линейных уравнениях и одновременно выдает большое количество дополнительной диагностической информации
(2) программа проверяет, насколько хорошо полученные дисперсии и ковариации отвечают данной модели
(3) программа с помощью специальных внутренних методов определяет, какие значения дисперсий и ковариаций переменных получаются в текущей модели на основании входных данных
(4) исследователь (пользователь) описывает (обычно с помощью диаграммы путей) модель, представляющую его понимание зависимостей между переменными
К условиям стационарности модели относятся…
(1) однородное решение не должно быть равно нулю
(2) однородное решение должно быть равно нулю и характеристический корень а1 должен быть по абсолютной величине меньше 1
(3) однородное решение должно быть равно нулю и характеристический корень а1 не должен быть по абсолютной величине меньше 1
(4) однородное решение не должно быть равно нулю и характеристический корень а1 должен быть по абсолютной величине меньше 1
В динамическую модель могут входить следующие переменные
(1) детерминированные переменные
(2) зависимые переменные Y
(3) зависимые переменные X
(4) стационарные переменные
Коэффициент детерминации характеризует
(1) все перечисленное
(2) показатель сложности уравнения
(3) показатель качества построенного уравнения регрессии
(4) показатель выбора вида кривой
Для cov(bi, bj) справедливо следующее равенство
(1) cov(bi, bj) = M{(bi — M(bi))(bj — M(bj))} = M{(bi * bi)(bj * bj)}
(2) cov(bi, bj) = M{(bi — M(bi))(bj — M(bj))} = M{(bi + bi)(bj + bj)}
(3) cov(bi, bj) = M{(bi — M(bi))(bj — M(bj))} = M{(bi/bi)(bj/bj)}
(4) cov(bi, bj) = M{(bi — M(bi))(bj — M(bj))} = M{(bi — bi)(bj — bj)}
Существуют следующие подходы к решению проблемы гетероскедастичности…
(1) все перечисленное
(2) применение обобщенного метода наименьших квадратов
(3) применение взвешенного метода наименьших квадратов
(4) преобразование данных
Эконометрика как отрасль науки возникла на стыке
(1) четырех дисциплин
(2) двух дисциплин
(3) трех дисциплин
(4) пяти дисциплин
Ряды имеют «долговременную память» если убывание коэффициента корреляции носит…
(1) степенной или линейный характер
(2) экспоненциальный или линейный характер
(3) экспоненциальный или степенной характер
(4) все перечисленное не верно
В кейнсианской модели переменная It называется
(1) составляющими переменными
(2) экзогенной переменной
(3) приведенными переменными
(4) экзогенными переменными
Четвертым этапом структурного моделирования является следующий
(1) программа с помощью специальных внутренних методов определяет, какие значения дисперсий и ковариаций переменных получаются в текущей модели на основании входных данных
(2) программа сообщает пользователю полученные результаты статистических испытаний, а также выводит оценки параметров и стандартные ошибки для численных коэффициентов в линейных уравнениях и одновременно выдает большое количество дополнительной диагностической информации
(3) программа проверяет, насколько хорошо полученные дисперсии и ковариации отвечают данной модели
Гипотеза о постоянстве математического ожидания временного ряда принимается в случае
(1) все перечисленное
(2) Tнабл < Tтабл(a, n1 + n2 — 2)
(3) Tнабл = Tтабл(a, n1 + n2 — 2)
(4) Tнабл > Tтабл(a, n1 + n2 — 2)
Временной тренд может быть исключен из результирующей переменной путем
(1) построения регрессии этой переменной по времени
(2) путем введения времени в качестве одной из переменных-регрессоров
(3) перехода к остаткам, свободных от тренда
Перечислите основные причины отклонений от прямой регрессии
(1) верны все перечисленные варианты
(2) отражение уравнением регрессии связи между агрегированными переменными
(3) неправильный выбор вида зависимости в уравнении
(4) ошибки измерения
Система нормальных МНК-уравнений позволяет
(1) осуществлять прогнозную оценку процесса выраженного уравнением регрессии
(2) оценивать оптимальное значение функци
(3) все перечисленное
(4) оценивать коэффициенты b0, b1, b2, …, bk уравнения регрессии
Тесты для определения наличия гетероскедастичности основаны на
(1) предположении о наличии значимых факторов в моделях
(2) предположении о наличии связи между дисперсиями остатков моделей и объясняющими переменными
(3) предположении о наличии значимых коэффициентов регрессии
(4) предположении об отсутствии связи между дисперсиями остатков моделей
Основными характеристиками случайного процесса являются…
(1) все перечисленное
(2) автокорреляционная функция
(3) дисперсия
(4) математическое ожидание
Одной из причин корреляции между факторами и ошибками уравнения регрессии является
(1) неправильный выбор факторов
(2) неправильный выбор вида уравнения регрессии
(3) неправильное измерение объясняющих переменных
(4) в модель подставляются не истинные, а искаженные наблюдения
Основными задачами, для решения которых используются структурные уравнения, являются…
(1) все перечисленное верно
(2) подтверждающий факторный анализ
(3) причинное моделирование, или анализ путей
(4) факторный анализ второго порядка
Гипотеза о постоянстве дисперсии проверяется
(1) по критерию Вальда — Вольфовица
(2) по параметрическим тестам
(3) все перечисленное
(4) по критерию Фишера
Большие значения, близкие к 1, величины (1 — а1) модели корректировки ошибок (МКО) свидетельствуют о том, что
(1) МКО обладает иммунитетом к ложной регрессии
(2) экономические факторы сильно изменяют результат
(3) контроль и достижение долговременной стабилизации происходят медленно
Впервые термин «регрессия» ввел
(1) Дж. Э. Юл
(2) Г. Хукер
(3) Ф. Гальтон
(4) Р. Фриш
Критерий Шварца и критерий Акайке применяют
(1) все перечисленное
(2) если точная спецификация модели неизвестна
(3) если точная спецификация модели не существует
(4) если точная спецификация модели известна
Какие вопросы решают при исследовании моделей?
(1) все перечисленное
(2) как решать проблему гетероскедастичности
(3) какие следствия для оценок, получаемых по методу наименьших квадратов, влечет гетероскедастичность
(4) как правильно провести диагностику существования гетероскедастичности
При построении прогнозных моделей могут использоваться следующие методы…
(1) все перечисленное верно
(2) метод минимизации суммы модулей
(3) регрессионные методы
(4) методы распознавания образов
Нулевая гипотеза при использовании теста Чоу состоит в предположении
(1) все перечисленное
(2) о неравенстве истинных соответствующих параметров регрессии для всех моделей
(3) о равенстве истинных соответствующих параметров регрессии для всех моделей
В случае включения в модель нескольких качественных факторов необходимо выполнение следующих условий…
(1) чтобы в информационной матрице X скалярные произведения столбцов, отвечающих за качественные переменные, были равны нулю
(2) включаемые факторы не были линейно независимы
(3) в информационной матрице X скалярные произведения столбцов, отвечающих за качественные переменные, были равны единице
(4) все перечисленное верно
Для математического ожидания матрицы, элементами которой являются центрированные случайные величины, должно соблюдаться условие
(1) M(XiXj) < cov(Xi,Xj)
(2) M(XiXj) > cov(Xi,Xj)
(3) M(XiXj) = cov(Xi,Xj)
Укажите дисциплины, использующие математические методы применительно к экономике
(1) информатика
(2) многомерный статистический анализ данных, математические методы в экономике
(3) естествознание
(4) социология
К основным принципам разработки прогнозов относится
(1) многозадачность, устойчивость
(2) надежность, массовость, дискретность
(3) системность, адекватность, альтернативность
(4) все перечисленное
Число значений исходного ряда, одновременно участвующих в сглаживании, называется
(1) граничными значениями интервала сглаживания
(2) диапазоном интервала сглаживания
(3) шириной интервала сглаживания
(4) длиной интервала сглаживания
Ошибка наблюдения в модели случае, когда подставляются не истинные, а искаженные наблюдения, состоит
(1) из одного слагаемого
(2) из трех слагаемых
(3) из двух слагаемых
(4) из четырех слагаемых
Моделирование ковариационной структуры позволяет
(1) проанализировать корреляционную матрицу общих факторов
(2) проверить корреляцию между факторами
(3) проверить гипотезу о равенстве дисперсий у всех переменных
(4) проверить гипотезу о том, что матрица ковариации имеет определенный вид
По обучающей выборке определяются следующие числовые характеристики временного ряда
(1) модифицированную последовательность ковариаций
(2) автоковариации и автокорреляционные функции
(3) параметры скользящего среднего
(4) все перечисленное
Ключевым моментом в ОАРУГ-моделях являются
(1) АКФ квадраты остатков, позволяющие идентифицировать порядок ОАРУГ-процесса
(2) АКФ и ЧАКФ остатки
(3) возмущения {yt}-последовательности, образующие АРСС-процесс
(4) возмущения {yt}-последовательности, образующие ОАРУГ-процесс
Результативным признаком в регрессионном анализе называют
(1) фактором
(2) независимую переменную
(3) зависимую переменную
Для установления значимости факторов в шаговой регрессии используют следующие методы
(1) все перечисленное верно
(2) метод включения факторов
(3) метод исключения факторов
(4) комбинированный метод
В обобщенной линейной модели множественной регрессии дисперсии и ковариации ошибок наблюдений
(1) не произвольные
(2) всегда постоянны
(3) могут быть произвольными
Эконометрика как отрасль науки возникла на стыке следующих дисциплин
(1) политологии, социологии, психологии
(2) экономической теории, методов математического анализа, математической статистики
(3) информатики, теории анализа, естествознания
(4) математической статистики, информатики
С увеличением запаздывания объем выборки, по которой вычисляется коэффициент корреляции
(1) остается без изменения
(2) увеличивается
(3) уменьшается
Асимметричные фильтры используются для
(1) сглаживания временных рядов
(2) прогнозирования временных рядов
(3) усреднения временных рядов
(4) все перечисленное
Если система уравнений помимо экзогенных и эндогенных переменных содержит еще и значения эндогенных переменных, полученные в предыдущие периоды времени, то такие значения называют
(1) составляющим переменными
(2) лаговыми переменными
(3) приведенными переменными
(4) экзогенными переменными
Если набор чисел X связан с другим набором чисел Y зависимостью Y = 4X, то дисперсия Y должна быть
(1) в 32 раза больше, чем дисперсия X
(2) в 16 раз больше, чем дисперсия X
(3) в 64 раза больше, чем дисперсия X
(4) в 4 раза больше, чем дисперсия X
Для проверки постоянства математического ожидания используют
(1) тест Сиджела — Тьюки
(2) критерий Фишера
(3) тест Манна — Уитни
(4) критерий Стьюдента
Модель, одновременно оценивающую среднее и дисперсию ряда, предложил
(1) Р. Фриш
(2) Р. Энгл
(3) Л. Клейн
(4) В. Джакоб
Для определения числа степеней свободы для суммы квадратов используют выражение
(1) n — 4
(2) n — 5
(3) n — 3
(4) n — 2
К методам смягчения мультиколлинеарности относятся
(1) отбор из множества объясняющих переменных тех переменных, которые имеют наиболее низкие взаимные коэффициенты корреляции
(2) радикальное увеличение числа опытов
(3) уменьшение дисперсии остатков путем введения упущенной в первоначальной модели важной переменной
(4) все перечисленное
В чем заключается второй подход к решению проблемы гетероскедастичности?
(1) в таком преобразовании данных, чтобы для них модель уже обладала свойством гетероскедастичности
(2) в построении моделей, учитывающих гетероскедастичность ошибок наблюдений
(3) в таком преобразовании данных, чтобы для них модель не обладала свойством гетероскедастичности
(4) все перечисленное
Выявление трендов, лагов, циклической компоненты определяются при проведении исследований
(1) моделей прогнозирования
(2) моделей по независимым неупорядоченным наблюдениям
(3) моделей временных рядов
Задачей гармонического анализа является определение основных гармонических колебаний, входящих в
(1) непериодическую составляющую q(t)
(2) периодическую составляющую ряда P(t)
(3) погрешность ряда e(t)
(4) все перечисленное
В случае если сглаживание происходит на основе уравнения параболы, составляется система m уравнений
(1) m = 2k + 2
(2) m = 2k — 1
(3) m = 2k + 1
(4) m = 2k — 2
Коэффициент b в упрощенной кейнсианской модели формирования доходов в закрытой экономике без государственного вмешательства называют
(1) ликвидными средствами
(2) скрытыми затратами
(3) неликвидными средствами
(4) склонностью к потреблению
Латентными переменными называются
(1) явные переменные
(2) значимые переменные
(3) скрытые переменные, которые нельзя непосредственно измерить
(4) незначимые переменные
Сериальный критерий стационарности применяется для
(1) проверки стационарности коэффициентов модели
(2) проверки стационарности временного ряда
(3) проверки стационарности переменных
Превышение доходности yt от держания рискованных ценных бумаг над государственными облигациями, рассчитанными на погашение в течение одного периода времени, принятого за единицу, определяется выражениием
(1) Mt — 1yt = mt
(2) yt = 2Rt — rt + 1 — rt
(3) yt = mt + et
(4) yt = -0,0241 + 0,687ht + et
Для оценки параметров a, b уравнения регрессии применяют метод
(1) метод правдоподобия
(2) наименьших квадратов (МНК)
(3) метод корректировки ошибок
Показателем статистической связи между двумя переменными является
(1) частный коэффициент ковариации
(2) частный коэффициент детерминации
(3) частный коэффициент корреляции
Сколько существует основных подходов к решению проблемы гетероскедастичности?
(1) два
(2) один
(3) три
(4) четыре
За вклад в развитие эконометрической науки присуждены Нобелевские премии следующим ученым
(1) К. Гауссу, П. Лапласу
(2) Дж. Боксу, Г. Дженкинсу
(3) Р. Фришу, Я. Тинбергену
(4) Р. Фришу, К. Гауссу
Выравнивание считается удовлетворительным, если остатки e(t) образуют стационарный процесс
(1) с математическим ожиданием m e(t) = M[e(t)] = бесконечность
(2) с математическим ожиданием m e(t) = M[e(t)] = 1
(3) с нулевым математическим ожиданием m e(t) = M[e(t)] = 0
Для удобства сопоставления сглаженного и исходного рядов ширину интервала сглаживания чаще выбирают исходя из условия
(1) m = 2k + 3
(2) m = 2k + 2
(3) m = 2k + 4
(4) m = 2k + 1
Необходимое условие идентификации формулируется следующим образом: коэффициенты уравнения идентифицируемы
(1) при k + 1 > r
(2) при k + 1 < r
(3) при k + 1 = r
Однозначное отображение, сохраняющее структуру модели, называется
(1) гетероморфизмом
(2) стереоморфизмом
(3) изоморфизмом
(4) все перечисленное
Для АР(1)-модели частные автокорреляционные функции между yt и yt — 2 равны
(1) единице
(2) бесконечности
(3) нулю
(4) равны между собой
Одним из методов прогнозирования дисперсии является
(1) введение последовательных значений xt
(2) введение независимой переменной
(3) линеаризация модели
Уровень надежности равный 0,95 характеризует
(1) 5%-ный уровень надежности прогноза
(2) 95%-ный уровень надежности прогноза
Если случайная величина является нормированной нормально распределенной величиной, то выполняется условие
(1) математическое ожидание равно 1
(2) математическое ожидание равно 0
Для проверки ошибок модели на гомоскедастичность используют
(1) тест Голдфелда — Квандта
(2) метод Гаусса — Маркова
(3) критерий Спирмена
(4) все перечисленное не верно
Закон, в котором выяснялись закономерности спроса на основе соотношений между урожаем зерновых и ценами на зерно, носит название
(1) закон Л. Клейна
(2) закон Г. Люсака
(3) закон Р. Фриша
(4) закон Кинга
Корреляционным полем временного ряда X(t) называется
(1) множество точек M(X(t)) на плоскости (t, OX)
(2) множество точек Dx(t) на плоскости (t, OX)
(3) множество точек (t, X(t)) на плоскости (t, OX)
(4) множество точек (Dx, X(t)) на плоскости (t, OX)
Как обычно называют сглаживание временного ряда?
(1) оператором
(2) фильтром
(3) фильтрованием
(4) все перечисленное верно
Возможность нескольких вариантов расчета структурных коэффициентов кейнсианской модели называется
(1) неидентифицируемостью
(2) идентифицируемостью
(3) сверхидентифицируемостью
(4) все перечисленное не верно
Каждая связь диаграммы путей включает в себя
(1) все перечисленное
(2) две переменные
(3) не менее пяти переменных
(4) четыре переменные
Возможность получения оценок по одной реализации процесса называется
(1) стохастичность
(2) стационарность
(3) автокорреляция
(4) эргодичность
Коэффициент детерминации определяется выражением
(1) D(Y) = D(Y1 + e) = D(Y1) + D(e) + 2cov(Y1,e)
(2) R2 = D(Y1)/D(Y)
(3) D(Y) = D(a + bx) + D(e)
При хорошем качестве построенной модели средняя относительная ошибка аппроксимации составляет
(1) 24–29%
(2) 14-19%
(3) 34–39%
(4) 4–9%
Согласно теореме Гаусса — Маркова случайные возмущения…
(1) коррелированы друг с другом
(2) не коррелированы друг с другом,имеют постоянную дисперсию
(3) имеют дисперсии равные единице
(4) все перечисленное
Одним из первых количественных законов стал закон
(1) закон Дж. Кларка
(2) закон Л. Клейна
(3) закон Кинга
(4) закон Р. Фриша
Процесс выделения тренда (выравнивание ряда) включает следующие этапы…
(1) определение числовых значений параметров кривой
(2) выбор типа кривой, соответствующей характеру изменения ряда
(3) оценка качества подобранной модели тренда
(4) все перечисленное верно
В кейнсианской модели переменные Yt и Сt называются
(1) приведенной переменной
(2) экзогенной переменной
(3) составляющей переменной
(4) эндогенными переменными
Вторым этапом структурного моделирования является следующий
(1) программа проверяет, насколько хорошо полученные дисперсии и ковариации отвечают данной модели
(2) исследователь (пользователь) описывает (обычно с помощью диаграммы путей) модель, представляющую его понимание зависимостей между переменными
(3) программа сообщает пользователю полученные результаты статистических испытаний, а также выводит оценки параметров и стандартные ошибки для численных коэффициентов в линейных уравнениях и одновременно выдает большое количество дополнительной диагностической информации
(4) программа с помощью специальных внутренних методов определяет, какие значения дисперсий и ковариаций переменных получаются в текущей модели на основании входных данных
Автоковариации предельных значений yt
(1) конечны и не зависят от времени
(2) конечны и зависят от времени
(3) бесконечные
(4) бесконечные и не зависят от времени
Укажите все ограничения на поведение случайного слагаемого e в условиях Гаусса — Маркова, выполнение которых предполагается при использовании для оценки коэффициентов модели метода наименьших квадратов
(1) все перечисленное верно
(2) для всех i = 1, 2, 3, …, n случайные ошибки ei распределены по нормальному закону, а x = (x1, x2, … xn) — фиксированный вектор
(3) ошибки модели ei при разных наблюдениях независимы
(4) нулевое математическое ожидание, М(ei) = 0, i = 1, 2, …, n
При оценке математических ожиданий справедливо следующее
(1) My = M(Xb + e) = M(Xb) + M(e) = -M(Xb) = -Xb
(2) My = M(Xb + e) = M(Xb) + M(e) = M(Xb) = Xb
(3) My = M(Xb + e) = M(Xb)/M(e) = M(Xb) = Xb
(4) My = M(Xb + e) = M(Xb) — M(e) = M(Xb) = Xb
Тест ранговой корреляции Спирмена не требует предположения о
(1) нормальности распределения коэффициента корреляции
(2) нормальности распределения регрессоров
(3) нормальности распределения регрессионных остатков
(4) все перечисленное неверно
Впервые термин «эконометрия» ввел
(1) Л. Клейн
(2) Р. Фриш
(3) П. Цьемпа
(4) В. Джакоб
Коррелограмма показывает убывание положительных rl при возрастании l в случаях…
(1) ряд имеет относительно небольшие колебания вокруг тренда
(2) если ряд имеет тренд
(3) существует явная зависимость между прошлым и будущим ряда
(4) все перечисленное верно
В кейнсианской модели переменная It формируется под воздействием…
(1) внешних факторов и политической надстройки
(2) внутренних факторов и политической надстройки
(3) внутренних факторов
(4) все перечисленное
Подтверждающий факторный анализ используется…
(1) для анализа корреляционной матрицы общих факторов
(2) проверки гипотезы о равенстве дисперсий у всех переменных
(3) все перечисленное
(4) для проверки определенных гипотез о структуре факторных нагрузок
Гипотеза о постоянстве дисперсии принимается при условии
(1) Fрасч > Fтабл(a, n1 — 1, n2 — 1), (a — уровень значимости)
(2) Fрасч = Fтабл(a, n1 — 1, n2 — 1), (a — уровень значимости)
(3) Fрасч < Fтабл(a, n1 — 1, n2 — 1), (a — уровень значимости)
(4) во всех случаях
Простейшая регрессионная модель имеет вид
(1) Y = a2 + bx2
(2) Y = a + bx + e
(3) Y = a — bx
(4) Y =(a/bx) + e
при использовании метода наименьших квадратов (МНК) минимизируется
(1) произведение остатков модели
(2) разность квадратов остатков модели
(3) сумма квадратов остатков модели
(4) произведение квадратов остатков модели
Для определения наличия гетероскедастичности применяют
(1) наблюдения
(2) эксперименты
(3) тесты
(4) расчеты
Анализ временных рядов проводится
(1) методами распознавания образов
(2) методами теории случайных процессов
(3) методами кластерного анализа
(4) методом наименьших квадратов
К причинам возникновения в экономических моделях зависимости между объясняющими переменными Xiu и случайными ошибками eu относится и такая
(1) один из факторов может влиять на поведение объясняющей переменной
(2) один из факторов может одновременно влиять на поведение случайной ошибки и объясняющей переменной
(3) один из факторов может влиять на поведение случайной ошибки
(4) один из факторов не может одновременно влиять на поведение случайной ошибки и объясняющей переменной
Техника моделирования структурными уравнениями основывается на…
(1) все перечисленное верно
(2) факторном анализе
(3) множественной регрессии
(4) многомерном анализе
При априорном предположении о нормальном законе распределения значений временного ряда применяют
(1) критерий Фишера
(2) методологию Бокса — Дженкинса
(3) критерий Стьюдента
(4) параметрические тесты проверки стационарности
Зависимую переменную в регрессионном анализе называют
(1) регрессором
(2) предиктором
(3) результативным признаком
Включение несущественной переменной в модель оказывает следующие последствия
(1) вызывает рост стандартных ошибок коэффициентов
(2) оценки становятся статистически незначимыми
(3) не приводит к смещению оценок коэффициентов
(4) все перечисленное верно
Предположение о том, что ошибки ei наблюдений имеют разные дисперсии, называется
(1) гомоскедастичностью наблюдений
(2) регрессией наблюдений
(3) гетероскедастичностью
(4) ковариацией наблюдений
Основным содержанием ПЭП является…
(1) выявления объективных условий, факторов и тенденций развития
(2) количественный анализ реальных экономических процессов
(3) качественный анализ реальных экономических процессов
(4) все перечисленное верно
При использовании Теста Чоу строятся следующие регрессионные модели
(1) по всей выборке наблюдений
(2) по наблюдениям после происшедших изменений в структуре связей
(3) по наблюдениям, проведенным до изменений
(4) все перечисленное верно
Фиктивные переменные позволяют
(1) строить модели для исследования будущих структурных изменений
(2) строить модели для исследования случайных изменений
(3) все перечисленное
(4) строить модели для исследования структурных изменений
Стандартная процедура регрессионного анализа, выполняемого на основе метода наименьших квадратов, требует выполнения условий
(1) Стьюдента
(2) Гаусса — Маркова
(3) Фишера
(4) Гаусса
Для чего используются эконометрические методы
(1) верны все перечисленные варианты
(2) для прогнозирования в финансах
(3) для прогнозирования в банковском деле
(4) для прогнозирования в бизнесе
Коррелограммой называют
(1) значения M(X(t)), нанесенные на плоскость с осями i и r и соединенные ломаной
(2) все перечисленное
(3) значения Dx(t), нанесенные на плоскость с осями i и r и соединенные прямой
(4) значения ri, нанесенные на плоскость с осями i и r и соединенные ломаной
Причинные модели могут включать
(1) эндогенные переменные
(2) явные переменные и латентные переменные
(3) экзогенные переменные и латентные переменные
(4) явные переменные и эндогенные переменные
В случае, когда в модель не включена существенная переменная, наблюдаются следующие последствия
(1) коэффициенты при оставшихся переменных становятся смещенными
(2) стандартные ошибки коэффициентов и t-статистики некорректны
(3) исчезает возможность правильной оценки и интерпретации уравнений
(4) все перечисленное
Укажите случайную составляющую выражения Y(t) = q(t) + P(t) + e(t)
(1) P(t) — периодическая составляющая
(2) q(t) — непериодическая составляющая
(3) e(t) — погрешность ряда
(4) все перечисленное верно
Сглаживание является центрированным и симметричным при условии
(1) а — r = ar + 1
(2) а — r = a/r
(3) а — r = ar — 1
(4) а — r = ar
Латентные переменные указываются
(1) над стрелками
(2) внутри прямоугольников
(3) над дугами
(4) внутри овалов или окружностей
При значениях k близких к объему выборки N можно получить следующее значение Rвыб в квадрате
(1) близкое к нулю
(2) близкое к единице
(3) все перечисленное
Временной ряд — это
(1) значения величины X(t), расположенные в определенной последовательности
(2) последовательности значений случайной величины X
(3) последовательность значений случайной величины X(t)
(4) последовательности значений случайной величины t
Техника моделирования структурными уравнениями в пакете STATISTICA имеет аббревиатуру
(1) PATH
(2) SEPA
(3) SEPATH
(4) ATH
Теорема Гаусса — Маркова предполагает
(1) все перечисленное верно
(2) нулевую корреляцию между e и Хi
(3) некоррелированность случайного члена и регрессоров
Предположение о том, что ошибки ei наблюдений имеют одинаковые дисперсии, называется
(1) регрессией наблюдений
(2) гомоскедастичностью наблюдений
(3) ковариацией наблюдений
(4) гетероскедастичностью наблюдений
Для уменьшения амплитуды колебаний у сглаженного ряда Y(t) необходимо
(1) уменьшать ширину интервала сглаживания m
(2) увеличивать ширину интервала сглаживания m
(3) сокращать количество определяющих переменных
(4) увеличивать количество определяющих переменных
Структурные модели с линейными зависимостями являются
(1) прогнозными
(2) точными
(3) приближенными
Для проверки стационарности временного ряда применяют
(1) критерий Фишера
(2) сериальный критерий стационарности
(3) тест Сиджела — Тьюки
(4) тест Манна — Уитни
Проверка значимости коэффициентов уравнения регрессии производится по
(1) критерию Уитни
(2) критерию Стьюдента
(3) коэффициенту корреляции
(4) коэффициенту детерминации
Нулевая гипотеза о незначимости уравнения регрессии отвергается и принимается гипотеза о значимости уравнения регрессии, если
(1) Fнабл =Fкрит(a, nрегр, nост)
(2) Fнабл < Fкрит(a, nрегр, nост)
(3) во всех случаях
(4) Fнабл > Fкрит(a, nрегр, nост)
Коэффициент a в выражении Y(t) = Y(t — 1) + a(X(t) — Y(t — 1) является
(1) коэффициентом поправки на систематические ошибки
(2) коэффициентом поправки на «новизну»
(3) коэффициентом поправки на неучтенные факторы
(4) все перечисленное не верно
Всегда ли построенные зависимости отражают реальные связи между переменными?
(1) всегда отражают
(2) отражают причинные связи в наборе переменных, но не предполагают реального наличия таких связей
(3) отражают только в линейных моделях регрессии
(4) отражают причинные связи в наборе переменных, и предполагают реальное наличие таких связей
Под мультиколлинеарностью понимается
(1) низкая степень коррелированности объясняющих переменных
(2) высокая степень не коррелированности объясняющих переменных
(3) высокая степень коррелированности объясняющих переменных
(4) низкая степень не коррелированности объясняющих переменных
Ширина интервала для сглаживания ряда рассчитывается по формуле
(1) k + l — 1
(2) k — l — 1
(3) k + l + 2
(4) k + l + 1
Коэффициенты уравнений, входящие в структурную систему уравнений, можно разделить на две группы…
(1) подлежащие определению и заранее известные из исходных теоретических предположений о модели
(2) экзогенные и предопределенные
(3) подлежащие определению и экзогенные
(4) подлежащие определению и предопределенные
Диаграммы путей представляют собой
(1) ломаные линии
(2) блок-схемы и содержат переменные, связанные линиями, которые отображают причинные связи
(3) блок схемы
(4) ломаные линии, которые отображают причинные связи
Показателями качества построенной модели являются
(1) математическое ожидание
(2) дисперсия
(3) средняя относительная ошибка аппроксимации
(4) коэффициент корреляции
Структурный параметр называется неидентифицируемым, если
(1) если существует несколько формул расчета этого коэффициента через коэффициенты приведенной формы модели
(2) не существует формула расчета этого коэффициента через коэффициенты приведенной формы модели
(3) существует формула расчета этого коэффициента через коэффициенты приведенной формы модели
Путевая диаграмма содержит следующие элементы…
(1) все перечисленное
(2) дисперсию независимых переменных
(3) независимые переменные
(4) линейные уравнения
Первым этапом структурного моделирования является следующий
(1) программа с помощью специальных внутренних методов определяет, какие значения дисперсий и ковариаций переменных получаются в текущей модели на основании входных данных
(2) программа проверяет, насколько хорошо полученные дисперсии и ковариации отвечают данной модели
(3) исследователь (пользователь) описывает (обычно с помощью диаграммы путей) модель, представляющую его понимание зависимостей между переменными
(4) программа сообщает пользователю полученные результаты статистических испытаний, а также выводит оценки параметров и стандартные ошибки для численных коэффициентов в линейных уравнениях и одновременно выдает большое количество дополнительной диагностической информации
Какие условия отрицательно сказываются на объясняющих свойствах модели?
(1) все перечисленное верно
(2) избыточное присутствие незначимой объясняющей переменной
(3) отсутствие значимой переменной
Для чего применяется Тест Чоу?
(1) проверки нулевой гипотезы в задаче выявления мультиколлинеарности
(2) проверки структурных изменений модели
(3) проверки значимости коэффициентов регрессионной модели
(4) расчета коэффициента корреляции
В моделях с бинарными переменными переменные принимают следующие значения
(1) 0 и -1
(2) 0 и 1
(3) -1 и 1
Если случайные величины Xi не только центрированы, но и нормированы, выполняются следующие условия
(1) M(Xi) = 1 D(Xi) = 1
(2) M(Xi) = 1 D(Xi) = 0
(3) M(Xi) = 0, D(Xi) = 0
(4) M(Xi) = 0, D(Xi) = 1
При расчетах первое сглаженное значение Y(k + 1) вычисляется по формуле
(1) Y(k + 1) = (X(1) + X(2) + … + X(m))/2m
(2) Y(k + 1) = (X(1) + X(2) + … + X(m)) * m
(3) Y(k + 1) = (X(1) + X(2) + … + X(m)) — m
(4) Y(k + 1) = (X(1) + X(2) + … + X(m))/m
Одним из основных условий для главных компонент z1 и z2 является
(1) компоненты коррелируют между собой
(2) компоненты имеют сильную корреляцию между собой
(3) компоненты не коррелируют между собой
(4) компоненты имеют слабую корреляцию между собой
Процесс сглаживания ряда называют
(1) отбором
(2) фильтрованием
(3) упрощением
(4) сглаживанием
В случае если объясняющие переменные модели могут принимать любые значения в некотором интервале данных, их называют
(1) качественными переменными
(2) категорийными переменными
(3) количественными переменными
(4) бинарными переменными
Для центрированных случайных величин выполняется следующее условие
(1) М(Xi) = 1
(2) М(Xi) = -1
(3) М(Xi) = 0
(4) М(Xi) =стремится к 1
Дисперсия сглаженного по квадратичному полиному ряда Y(t) при увеличении числа m уравнений
(1) остается без изменения
(2) увеличивается
(3) уменьшается
Одним из распространенных способов выявления тренда является
(1) все перечисленное
(2) сглаживание временного ряда
(3) разложение рада на множители
(4) логарифмирование ряда
Дисперсия сглаженного ряда
(1) больше дисперсии исходного ряда
(2) меньше дисперсии исходного ряда
(3) остается неизменной
В сглаженном временном ряде Y(t) процедуру сглаживания начинают
(1) с последнего члена ряда
(2) с первого члена ряда
(3) с максимального члена ряда
(4) со второго члена ряда
Главная / Экономика /
Введение в эконометрику / Тест 9
Упражнение 1:
Номер 1
Каковы последствия гетероскедастичности в случая использования МНК для построения модели?
Ответ:
(1) результаты, основанные на анализе дисперсии коэффициентов, в случае гетероскедастичности применимы полностью
(2) результаты, основанные на анализе дисперсии коэффициентов, в случае гетероскедастичности неприменимы
(3) результаты, основанные на анализе дисперсии коэффициентов, в случае гетероскедастичности применимы в некоторых случаях
Номер 2
В обобщенной линейной модели множественной регрессии дисперсии и ковариации ошибок наблюдений
Ответ:
(1) не произвольные
(2) всегда постоянны
(3) могут быть произвольными

Упражнение 2:
Номер 1
Обобщенная линейная модель множественной регрессии, теорема Айткена и обобщенный метод наименьших квадратов характерны для
Ответ:
(1) обоих методов устранения гетероскедастичности
(2) первого метода устранения гетероскедастичности
(3) второго метода устранения гетероскедастичности
Номер 2
В чем заключается второй подход к решению проблемы гетероскедастичности?
Ответ:
(1) в таком преобразовании данных, чтобы для них модель уже обладала свойством гетероскедастичности
(2) в построении моделей, учитывающих гетероскедастичность ошибок наблюдений
(3) в таком преобразовании данных, чтобы для них модель не обладала свойством гетероскедастичности
(4) все перечисленное
Упражнение 3:
Номер 1
Первый подход к решению проблемы гетероскедастичности
Ответ:
(1) предполагает такое преобразование данных, чтобы для них модель приобретала со временем свойство гетероскедастичности
(2) предполагает такое преобразование данных, чтобы для них модель уже обладала свойством гетероскедастичности
(3) состоит в построении моделей, учитывающих гетероскедастичность ошибок наблюдений
Номер 2
Сколько существует основных подходов к решению проблемы гетероскедастичности?
Ответ:
(1) два
(2) один
(3) три
(4) четыре
Упражнение 4:
Номер 1
Устранение гетероскедастичности путем применения обобщенного метода наименьших квадратов (ОМНК) требует знания
Ответ:
(1) матрицы случайных ошибок
(2) матрицы ковариаций ошибок наблюдений
(3) матрицы систематических ошибок
(4) все перечисленное
Номер 2
Для проверки ошибок модели на гомоскедастичность используют
Ответ:
(1) тест Голдфелда — Квандта
(2) метод Гаусса — Маркова
(3) критерий Спирмена
(4) все перечисленное не верно
Упражнение 5:
Номер 1
Ранг неслучайной (детерминированной) матрицы X предполагается равным
Ответ:
(1) p + 3 < n
(2) p + 2 < n
(3) p + 5 < n
(4) p + 1 < n
Номер 2
Согласно теореме Гаусса — Маркова случайные возмущения…
Ответ:
(1) коррелированы друг с другом
(2) не коррелированы друг с другом,имеют постоянную дисперсию
(3) имеют дисперсии равные единице
(4) все перечисленное
Упражнение 6:
Номер 1
Существуют следующие подходы к решению проблемы гетероскедастичности…
Ответ:
(1) все перечисленное
(2) применение обобщенного метода наименьших квадратов
(3) применение взвешенного метода наименьших квадратов
(4) преобразование данных
Номер 2
Тест ранговой корреляции Спирмена не требует предположения о
Ответ:
(1) нормальности распределения коэффициента корреляции
(2) нормальности распределения регрессоров
(3) нормальности распределения регрессионных остатков
(4) все перечисленное неверно
Упражнение 7:
Номер 1
Тесты для определения наличия гетероскедастичности основаны на
Ответ:
(1) предположении о наличии значимых факторов в моделях
(2) предположении о наличии связи между дисперсиями остатков моделей и объясняющими переменными
(3) предположении о наличии значимых коэффициентов регрессии
(4) предположении об отсутствии связи между дисперсиями остатков моделей
Номер 2
Для определения наличия гетероскедастичности применяют
Ответ:
(1) наблюдения
(2) эксперименты
(3) тесты
(4) расчеты
Упражнение 8:
Номер 1
Какие вопросы решают при исследовании моделей?
Ответ:
(1) все перечисленное
(2) как решать проблему гетероскедастичности
(3) какие следствия для оценок, получаемых по методу наименьших квадратов, влечет гетероскедастичность
(4) как правильно провести диагностику существования гетероскедастичности
Номер 2
Предположение о том, что ошибки ei наблюдений имеют разные дисперсии, называется
Ответ:
(1) гомоскедастичностью наблюдений
(2) регрессией наблюдений
(3) гетероскедастичностью
(4) ковариацией наблюдений
Номер 3
Предположение о том, что ошибки ei наблюдений имеют одинаковые дисперсии, называется
Ответ:
(1) регрессией наблюдений
(2) гомоскедастичностью наблюдений
(3) ковариацией наблюдений
(4) гетероскедастичностью наблюдений
Главная /
Введение в эконометрику /
Для проверки ошибок модели на гомоскедастичность используют
Для проверки ошибок модели на гомоскедастичность используют
вопрос
Правильный ответ:
тест Голдфелда — Квандта
метод Гаусса — Маркова
критерий Спирмена
все перечисленное не верно
Сложность курса: Введение в эконометрику
78
Оценить вопрос
Очень сложно
Сложно
Средне
Легко
Очень легко
Спасибо за оценку!
Комментарии:
Аноним
Я преподаватель! Незамедлительно заблокируйте сайт vtone.ru с ответами intuit. Не ломайте образование
22 сен 2019
Аноним
Зачёт всё. Лечу в бар отмечать зачёт интуит
03 май 2018
Оставить комментарий
Другие ответы на вопросы из темы экономика интуит.
-
#
Ряды имеют «долговременную память» если убывание коэффициента корреляции носит…
-
#
Если система уравнений помимо экзогенных и эндогенных переменных содержит еще и значения эндогенных переменных, полученные в предыдущие периоды времени, то такие значения называют
-
#
Техника моделирования структурными уравнениями основывается на…
-
#
Перечислите основные причины отклонений от прямой регрессии
-
#
В чем заключается второй подход к решению проблемы гетероскедастичности?
Тенденция к отрицанию гипотезы H0 возрастает по мере

Процесс выделения тренда (выравнивание ряда) включает следующие этапы…
Корреляционным полем временного ряда X(t) называется
Ряды имеют «долговременную память» если убывание коэффициента корреляции носит…
В обобщенной линейной модели множественной регрессии дисперсии и ковариации ошибок наблюдений
Основными характеристиками случайного процесса являются…
Если случайные величины Xi не только центрированы, но и нормированы, выполняются следующие условия
Для чего применяется Тест Чоу?
Целью эконометрики как науки является
При построении прогнозных моделей могут использоваться следующие методы…
Устранение гетероскедастичности путем применения обобщенного метода наименьших квадратов (ОМНК) требует знания
Большие значения, близкие к 1, величины (1 — а1) модели корректировки ошибок (МКО) свидетельствуют о том, что
Для оценки параметров a, b уравнения регрессии применяют метод
Показателями качества построенной модели являются
Превышение доходности yt от держания рискованных ценных бумаг над государственными облигациями, рассчитанными на погашение в течение одного периода времени, принятого за единицу, определяется выражениием
При сглаживании с помощью скользящей средней нет возможности получить сглаженные значения для
Для устранения трудностей построения уравнения регрессии при наличии коррелированности факторов и ошибок модели используют
К экзогенным переменным относятся…
Временной тренд может быть исключен из результирующей переменной путем
Зависимую переменную в регрессионном анализе называют
Четвертым этапом структурного моделирования является следующий
Гипотеза о постоянстве дисперсии проверяется
Задачей гармонического анализа является определение основных гармонических колебаний, входящих в
Автоковариации предельных значений yt
Эконометрика как отрасль науки возникла на стыке следующих дисциплин
В случае если ряд содержит единичные корни и интегрирует с порядком d, он принадлежит классу
Коррелируют между собой следующие тренды
В процессе случайного блуждания используются переменные
Критерий Шварца и критерий Акайке применяют
Выравнивание считается удовлетворительным, если остатки e(t) образуют стационарный процесс
Укажите дисциплины, использующие математические методы применительно к экономике
Исследование моделей по независимым неупорядоченным наблюдениям включает следующие этапы
Первой книгой, которую можно назвать эконометрической, была книга ученого
Начальным этапом применения теории эконометрики является
Эконометрика как отрасль науки возникла на стыке
Проверка значимости коэффициентов уравнения регрессии производится по
Для определения числа степеней свободы для суммы квадратов используют выражение
Проверка значимости коэффициентов уравнения регрессии производится по
Максимальное значение коэффициента детерминации равно
Укажите все ограничения на поведение случайного слагаемого e в условиях Гаусса — Маркова, выполнение которых предполагается при использовании для оценки коэффициентов модели метода наименьших квадратов
Перечислите основные причины отклонений от прямой регрессии
Одним из основных условий для главных компонент z1 и z2 является
Под мультиколлинеарностью понимается
Показателем статистической связи между двумя переменными является
Если случайная величина является нормированной нормально распределенной величиной, то выполняется условие
При оценке математических ожиданий справедливо следующее
В случае, когда в модель не включена существенная переменная, наблюдаются следующие последствия
Нулевая гипотеза при использовании теста Чоу состоит в предположении
Фиктивные переменные позволяют
Стандартная процедура регрессионного анализа, выполняемого на основе метода наименьших квадратов, требует выполнения условий
Каковы последствия гетероскедастичности в случая использования МНК для построения модели?
Обобщенная линейная модель множественной регрессии, теорема Айткена и обобщенный метод наименьших квадратов характерны для
Сколько существует основных подходов к решению проблемы гетероскедастичности?
Согласно теореме Гаусса — Маркова случайные возмущения…
Существуют следующие подходы к решению проблемы гетероскедастичности…
Тесты для определения наличия гетероскедастичности основаны на
Предположение о том, что ошибки ei наблюдений имеют разные дисперсии, называется
К основным принципам разработки прогнозов относится
Величина Dx(t) характеризует
К приемам, позволяющим подобрать соответствующую (адекватную) действительности форму кривой, относятся…
Коррелограммой называют
Временной ряд — это
Основным содержанием ПЭП является…
При расчетах первое сглаженное значение Y(k + 1) вычисляется по формуле
Коэффициент a в выражении Y(t) = Y(t — 1) + a(X(t) — Y(t — 1) является
Для удобства сопоставления сглаженного и исходного рядов ширину интервала сглаживания чаще выбирают исходя из условия
Сглаженный ряд короче исходного на величину
Ошибка наблюдения в модели случае, когда подставляются не истинные, а искаженные наблюдения, состоит
Мультипликатор Кейнса характеризуется следующим высказыванием
Число уравнений приведенной системы совпадает
Необходимое условие идентификации формулируется следующим образом: коэффициенты уравнения идентифицируемы
Возможность нескольких вариантов расчета структурных коэффициентов кейнсианской модели называется
В кейнсианской модели переменные Yt и Сt называются
В кейнсианской модели переменная It формируется под воздействием…
Одной из причин корреляции между факторами и ошибками уравнения регрессии является
Структурные модели с линейными зависимостями являются
Всегда ли построенные зависимости отражают реальные связи между переменными?
Латентными переменными называются
Однозначное отображение, сохраняющее структуру модели, называется
Каждая связь диаграммы путей включает в себя
Первым этапом структурного моделирования является следующий
Техника моделирования структурными уравнениями в пакете STATISTICA имеет аббревиатуру
К критериям селекции относятся…
Для оценки так называемых моделей авторегрессии интегрированного скользящего среднего (АРИСС-моделей) применяют
При q = 0 уравнение авторегрессии называется
Для АР(1)-модели частные автокорреляционные функции между yt и yt — 2 равны
Возможность получения оценок по одной реализации процесса называется
К условиям стационарности модели относятся…
Гипотеза о постоянстве математического ожидания временного ряда принимается в случае
При априорном предположении о нормальном законе распределения значений временного ряда применяют
Стохастическая переменная с постоянной дисперсией называется
Модель, одновременно оценивающую среднее и дисперсию ряда, предложил
Одним из методов прогнозирования дисперсии является
Следствием ложных корреляций являются
В динамическую модель могут входить следующие переменные
Подтверждающий факторный анализ используется…
Выявление трендов, лагов, циклической компоненты определяются при проведении исследований
Впервые термин «эконометрия» ввел П. Цьемпа в
Сглаживание ряда называется центрированным при условии
С увеличением запаздывания объем выборки, по которой вычисляется коэффициент корреляции
Для чего используются эконометрические методы
Система нормальных МНК-уравнений позволяет
Впервые термин «регрессия» ввел
Для случая парной регрессии справедливым является выражение
К методам смягчения мультиколлинеарности относятся
Сглаживание является центрированным и симметричным при условии
Функция P(t) считается полностью определенной, если известны…
Дисциплина эконометрика содержит следующие разделы
Если при сборе данных об урожайности сельскохозяйственных структур результаты работы в отчетах занижаются, завышаются в зависимости от экономической политики или оцениваются «на глазок», то это объясняется
В кейнсианской модели переменная It называется
Коэффициент структурного уравнения системы называется идентифицируемым, если выполняются условия…
В чем заключается второй подход к решению проблемы гетероскедастичности?
Построение моделей структуры средних позволяет
Коэффициент b в упрощенной кейнсианской модели формирования доходов в закрытой экономике без государственного вмешательства называют
Для проверки постоянства математического ожидания используют
Предположение о том, что ошибки ei наблюдений имеют одинаковые дисперсии, называется
За вклад в развитие эконометрической науки присуждены Нобелевские премии следующим ученым
Одним из первых количественных законов стал закон
Коэффициент детерминации определяется выражением
Коэффициент детерминации характеризует
Матрица C = (XTX)-1, обратная матрице XTX, называется
К методам устранения мультиколлинеарности относятся
Предельными значениями коэффициента корреляции являются
Если случайная величина является нормированной нормально распределенной величиной, то выполняется условие
Для cov(bi, bj) справедливо следующее равенство
Теорема Гаусса — Маркова предполагает
При использовании Теста Чоу строятся следующие регрессионные модели
Для проверки ошибок модели на гомоскедастичность используют
Ранг неслучайной (детерминированной) матрицы X предполагается равным
Тест ранговой корреляции Спирмена не требует предположения о
Для определения наличия гетероскедастичности применяют
Какие вопросы решают при исследовании моделей?
Предварительную оценку случайности поведения остатков проводят на основе
Анализ временных рядов проводится
Для уменьшения амплитуды колебаний у сглаженного ряда Y(t) необходимо
Асимметричные фильтры используются для
Как обычно называют сглаживание временного ряда?
Если система уравнений помимо экзогенных и эндогенных переменных содержит еще и значения эндогенных переменных, полученные в предыдущие периоды времени, то такие значения называют
Экзогенные переменные никогда не коррелируют
Моделирование ковариационной структуры позволяет
Если набор чисел X связан с другим набором чисел Y зависимостью Y = 4X, то дисперсия Y должна быть
Путевая диаграмма содержит следующие элементы…
Путевые диаграммы наглядно показывают
Третьим этапом структурного моделирования является следующий
Техника моделирования структурными уравнениями основывается на…
Для проверки стационарности временного ряда применяют
Для проверки условия стационарности ряда последовательность разбивается
Гипотеза о постоянстве дисперсии принимается при условии
Для определения превышения дохода от держания шестимесячной облигации (без учета квадратичных членов) можно использовать выражение
В выражении ln(yt) = a0 + a1ln(xt — 1) + et параметр et = ln et означает
Впервые термин «эконометрия» ввел
Одним из априорных предположений при применении параметрических тестов для проверки стационарности является
Ключевым моментом в ОАРУГ-моделях являются
Уровень надежности равный 0,95 характеризует
Соответствие, максимальное приближение теоретических моделей к реальным производственно-экономическим процессам предполагает
Дисперсия сглаженного ряда
Укажите случайную составляющую выражения Y(t) = q(t) + P(t) + e(t)
Первый подход к решению проблемы гетероскедастичности
Простейшим асимметричным фильтром является
В случае включения в модель нескольких качественных факторов необходимо выполнение следующих условий…
При хорошем качестве построенной модели средняя относительная ошибка аппроксимации составляет
Закон, в котором выяснялись закономерности спроса на основе соотношений между урожаем зерновых и ценами на зерно, носит название
Результативным признаком в регрессионном анализе называют
Если регрессия значима, то
Простейшая регрессионная модель имеет вид
При значениях k близких к объему выборки N можно получить следующее значение Rвыб в квадрате
Какие условия отрицательно сказываются на объясняющих свойствах модели?
В случае если объясняющие переменные модели могут принимать любые значения в некотором интервале данных, их называют
Для математического ожидания матрицы, элементами которой являются центрированные случайные величины, должно соблюдаться условие
Одним из распространенных способов выявления тренда является
Коэффициенты уравнений, входящие в структурную систему уравнений, можно разделить на две группы…
К причинам возникновения в экономических моделях зависимости между объясняющими переменными Xiu и случайными ошибками eu относится и такая
Явные переменные на путевых диаграммах указываются
Диаграммы путей представляют собой
Основными задачами, для решения которых используются структурные уравнения, являются…
Сериальный критерий стационарности применяется для
В выражении для определения превышения доходности yt = mt + et, параметром mt обозначают
Для уменьшения амплитуды колебаний у сглаженного ряда Y(t) необходимо
Структурный параметр называется неидентифицируемым, если
Уравнение кривой можно свести к многочлену посредством
Для установления значимости факторов в шаговой регрессии используют следующие методы
при использовании метода наименьших квадратов (МНК) минимизируется
Для центрированных случайных величин выполняется следующее условие
В случае если сглаживание происходит на основе уравнения параболы, составляется система m уравнений
Латентные переменные указываются
По обучающей выборке определяются следующие числовые характеристики временного ряда
Диаграммы путей используются для
Значимость уравнения регрессии осуществляется по
Нулевая гипотеза о незначимости уравнения регрессии отвергается и принимается гипотеза о значимости уравнения регрессии, если
Число значений исходного ряда, одновременно участвующих в сглаживании, называется
Вторым этапом структурного моделирования является следующий
В моделях с бинарными переменными переменные принимают следующие значения
Процесс сглаживания ряда называют
Включение несущественной переменной в модель оказывает следующие последствия
Коррелограмма показывает убывание положительных rl при возрастании l в случаях…
Дисперсия сглаженного по квадратичному полиному ряда Y(t) при увеличении числа m уравнений
В сглаженном временном ряде Y(t) процедуру сглаживания начинают
Процесс структурного моделирования включает в себя следующие этапы
Причинные модели могут включать
Время на прочтение
20 мин
Количество просмотров 4.5K
Мы школа онлайн-образования, которая уже три года делает курсы по Data Science и разработке. Одна из наших целей — собрать коммьюнити классных специалистов и делиться крутыми и неочевидными знаниями. Так был рождён Симулятор ML — место, в котором начинающие и опытные специалисты решают задачи разной сложности, разрабатывают проекты в командах, осваивают новые инструменты, развивают продуктовое мышление и постоянно растут в профессии.
А, как это свойственно коммьюнити, горящему идеей, студенты и авторы хотят делиться своими инсайтами и открытиями, которые дадут свежий взгляд на устоявшиеся практики. Сегодня хотим поделиться статьей автора Симулятора ML Богдана Печёнкина о том, как лучше использовать анализ ошибок для разработки ML систем.
Введение
Всем привет! Меня зовут Богдан Печёнкин. Я Senior ML Engineer в компании BrandsGoDigital и больше всего известен как автор Симулятора ML.
Мой первый пост на Хабре посвящался 10 первым ошибкам в карьере ML-инженера, что тесно связано с сегодняшней темой. Анализируя свои и чужие ошибки, Я пришёл к выводу, что один из самых недооценённых этапов в построении ML систем — это, как ни странно, анализ ошибок. Он даёт глубокое понимание не только наших моделей, но и данных и метрик, с которыми мы работаем. Сегодня Я хочу поделиться с вами тем, почему анализ ошибок так важен, каким образом его проводить и как он может помочь вам в дизайне и разработке более надёжных и эффективных ML продуктов.
Данная статья написана по мотивам главы «Error Analysis» из книги «Machine Learning System Design with end-2-end examples», которую Я писал вместе с Валерой Бабушкиным и Арсением Кравченко, авторами книги.
Certainly, coming up with new ideas is important.
But even more important, to understand the results.
— Ilya Sutskever, сооснователь OpenAI
Что такое анализ ошибок?
Каждая модель машинного обучения несовершенна и имеет свои границы применимости: на одних данных она работает лучше, на других хуже, а где-то — совсем плохо.
All models are wrong, but some are useful.
– George Box, британский статистик
Определяя, как ведёт себя текущая модель в каждом отдельном кейсе, «в какую сторону» ошибается, мы получаем неоценимые подсказки, какие новые признаки нам нужны, какие преобразования целевой переменной попробовать, каких данных нам не хватает и так далее. Таким образом, анализ ошибок — это важнейший этап построения модели перед проведением A/B экспериментов, её тестированием в боевых условиях.
Но почему нам мало обычной кросс-валидации?
Когда мы считаем метрику на отложенной выборке, мы, по сути, агрегируем ошибки со всех объектов в одно число. Если у нас кросс-валидация вместо отложенной выборки и несколько метрик вместо одной, мы всё ещё агрегируем разного рода ошибки со всех объектов в некую «среднюю температуру по больнице».
Например, считаем MAE, WAPE, wQL в регрессии, или LogLoss в классификации.
Aгрегированная метрика не показывает, как ошибка распределяется по разным объектам, какое у неё распределение, а тем более — что нужно поменять в собранной ML системе, чтобы скорректировать ошибку (какие у метрики «драйверы роста»?).
Метрики сообщают нам, что стало либо «хуже», либо «лучше», но подсказок, что делать дальше, из-за чего результат именно такой и что надо менять в ML системе, они не дадут.
Анализ ошибок — процесс прямо противоположный подсчёту метрики: агрегированную метрику мы разбиваем на компоненты — и анализируем их в совокупности. Это даёт нам полную картину: где и как система проявляет себя и какие встречаются паттерны в разных сегментах объектов отложенной выборки.

Мне нравится проводить параллель с алгоритмом back-propagation: мы пробрасываем градиент ошибки от самых последних слоёв нейросети к самым первым, соответствующим образом обновляя каждый компонент сети. Анализ ошибок — это ровно такое же «взятие градиента метрики», но на этот раз для всего ML пайлпайна.

План рассказа
-
Введение в остатки и псевдоостатки
-
Определение понятий «остатков» и «псевдоостатков» в контексте регрессии и классификации.
-
Визуальный и статистический анализ остатков
-
Методы визуализации распределения остатков.
-
Применение статистических тестов для оценки смещения, гетероскедастичности и нормальности остатков.
-
Что такое fairness и его роль при принятии решения о деплое модели.
-
Анализ кейсов работы модели
-
Разбор наилучших, наихудших и крайних сценариев работы модели.
-
Моделирование ошибок с помощью Adversarial Validation
-
Анализ ошибок в нестандартных задачах машинного обучения
-
Как проводится анализ ошибок в других областях машинного обучения, отличных от стандартных регрессии и классификации.
Остатки и псевдоостатки
Остатки (residuals)
Что формально мы имеем в виду, говоря «ошибки»? Введём понятие «остатков».
Остатки регрессии представляют собой разницу между фактическим значением целевой переменной и предсказанным значением:
residuals = y_true – y_pred
Остаток — это буквально «то, что осталось недопредсказанным», часть значения таргета, которую модель не смогла объяснить с учётом имеющихся признаков.

Псевдоостатки в классификации
Что может служить остатками в бинарной классификации? Да, мы можем также смотреть на разницу между предсказанной вероятностью (скажем, 0.42) и метками класса 0 и 1. Мы уже упорядочим объекты по размеру их ошибки, но будет ли это самым информативным способом их анализа? Более естественно оперировать слагаемыми LogLoss, поскольку так мы учитываем ещё и вклад каждой ошибки в общую метрику, её вес.
Если агрегированный лосс представляется как:
∑ y log(p) + (1−y) log(1−p)
То слагаемые (y log(p) + (1−y) log(1−p)) представляют собой псевдоостатки. Так мы не просто считаем недопредсказанную часть целевой переменной, но ещё и «взвешиваем» объекты пропорционально их влиянию на метрику.

Псевдоостатки в общем случае
Если задуматься, большинство метрик, которые мы используем в машинном обучении (и абсолютно все лоссы) — представляют собой усреднение ошибок по каждому объекту, посчитанных тем или иным образом (вспомните, какие есть исключения из правила?).
-
Mean Squared Error (MSE):
∑ (y_true — y_pred)2 → sign(y_true – y_pred) * (y_true – y_pred)2 -
Mean Absolute Error (MAE):
∑ |y_true — y_pred| → y_true – y_pred
-
Mean Absolute Percentage Error (MAPE):
∑ |y_true — y_pred| / y_true → 1 – y_pred / y_true
Часто возникает путаница между остатками и псевдоостатками, особенно у начинающих специалистов на первых собеседованиях, когда разговор заходит о том, на что обучаются деревья в градиентном бустинге и почему он, собственно, градиентный.
Правильный ответ: каждое дерево ансамбля обучается на градиент функции потерь, или, иначе говоря, на градиент псевдоостатков.
Визуализация остатков
Распределение остатков
Допустим, мы рассчитали остатки. Основываясь на них, какие выводы мы можем сделать? (Примечание: здесь и далее будем использовать термины «остатки», «псевдоостатки» и «ошибки» как взаимозаменяемые).
Для начала мы анализируем их в совокупности — смотрим на их распределение. Распределение остатков позволяет нам «проверить на прочность» наши базовые предположения (assumptions) относительно данных, модели и других компонентов системы.
К примеру, вот наш коллега обучил модель прогноза спроса, визуализировал распределение остатков.
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure()
sns.histplot(residuals, kde=True)
plt.title('Distribution of Residuals')
plt.xlabel('Residuals')
plt.ylabel('Frequency')
plt.show()И увидел один из графиков ниже:

Какие выводы сделал бы наш коллега, посмотрев на эти три картинки?
-
Остатки распределены практически нормально (как мы и хотели):
✓ assumptions are met! -
Распределение нормальное, но с большим хвостом влево (недопредсказания):
✗ assumptions are not met! -
Распределение не нормальное и имеет две моды:
✗ assumptions are not met!
Какие шаги по улучшению модели он бы предпринял дальше?
-
В первом случае, наш коллега, вероятно, оставил бы модель без изменений, однако для полной уверенности перешёл бы к статистическим тестам и проверке скедастичности.
-
Здесь наш коллега возможно бы использовал логарифмирование таргета перед квантильной регрессией, чтобы минимизировать влияние больших значений.
-
В этом случае, возможно, стоит перейти к более сложным методам, таким как бустинг, чтобы уловить пропущенные моделью паттерны.
Обычно мы предполагаем, что остатки, если они в точности не подчиняются нормальному распределению, как минимум должны быть унимодальными и с центром вокруг нуля (не иметь выраженного сдвига: перепредсказания или недопредсказания). Кроме того, мы стремимся избегать ситуаций, когда остатки имеют сильно вытянутые хвосты, что обычно указывает на наличие существенных выбросов.
Ясно, что мы не хотим проверять эти свойства каждый раз вручную, изучая графики распределений глазами. Автоматизировать проверку остатков помогут статистические тесты, которые можно запускать после каждого запуска обучающего пайплайна. Так, в случае возникновения проблем (например, отвалился источник данных, либо новая версия модели оказалась выраженно хуже предыдущей).
Статистические гипотезы
Свойства распределения можно формулировать в виде статистических гипотез. Так, чтобы оценить наличие или отсутствие смещения (bias), мы сравниваем среднее у распределения остатков с нулём, используя t-тест для одной выборки. Тест учтёт их разброс и отвергнет гипотезу о несмещённости остатков, только если наблюдаемое смещение выходит за рамки погрешности.
Подобным образом, мы можем оценить нормальность распределения, используя критерий Колмогорова-Смирнова. Очевидно, здесь глаз человека даже менее надёжен, чем стат. тест, сравнивающий «отклонение» от нормального распределения численно.
На выходе статистического критерия мы получаем p-value — вероятность встретить наблюдаемое значение статистики или более экстремальное при условии, что нулевая гипотеза верна.
-
В случае смещения нулевая гипотеза: остатки не имеют смещения.
-
В случае нормальности нулевая гипотеза: остатки распределены нормально.
Для принятия решения мы руководствуемся уровнем значимости α (например, 5%) или, иначе, уровнем ошибки I рода. Уровень значимости сообщает, начиная с какой степени «невероятности» нулевой гипотезы мы её отвергнем.
Гетероскедастичность
Ещё два свойства распределения, которые мы можем оценивать, — гомоскедастичность и гетероскедастичность. Гомоскедастичность (homo + scedasticity) — буквально «одинаковый разброс». Соответственно, гетероскедастичность (hetero + scedasticity) — «разный разброс».
")
кейсы 2-3: гетероскедастичное (с разным паттерном)
О чём речь в случае остатков? Мы хотим знать, насколько сильно дисперсия остатков варьируется для разных значений целевой переменной. Наблюдаем ли мы, что на малых значениях остатки маленькие, а с ростом таргета они растут (или наоборот)? Наблюдаем ли мы, что на малых и больших значениях таргета (на краях) остатки имеют больший разброс, чем в середине (в основной массе распределения таргетов)? Или остатки везде однородные?
Обратите внимание, что скедастичность остатков (и псевдоостатков) может кардинально отличаться при переходе от одной метрики к другой (например, от разностей таргетов и предиктов — к квадратам разностей), поскольку каждая метрика по-своему взвешивает разные ошибки в зависимости от их знака и величины.
Для гомоскедастичности существует несколько статистических тестов:
-
Bartlett’s test
-
Levene’s test
-
Fligner-Killeen’s test
Все они доступны в пакете scipy.stats. Это семейство тестов называют ANOVA-тестами (ANalysis Of VAriance). Каждый них принимает на вход набор подвыборок и оценивает, насколько валидно предположение, что каждая из подвыборок имеет одну и ту же дисперсию.
Для нас подвыборками будут служить бины из остатков, разбитых по мере увеличения таргета. Например, бьём таргет на 5 бинов по пороговым квантилям: 0.2, 0.4, 0.6, 0.8.

Diagnostic Plots
Diagnostic Plots представляют собой ещё один метод для анализа распределения остатков в дополнение к статистическим тестам. Это набор специфических визуализаций остатков и предсказаний целевой переменной в разных разрезах.
Чаще всего эти визуализации используются в линейных моделях для проверки их основных предположений: несмещённости, нормальности и гомоскедастичности.
1. Residuals vs. Fitted
На этом графике мы визуализируем остатки против предсказанных значений целевой переменной. Он позволяет понять характер смещения: распределено ли оно равномерно по всем предсказаниям (тогда наблюдаем прямую линию, см. левый график внизу), либо имеет значимую неравномерность (например, на втором графике ниже — остатки на очень больших и очень маленьких прогнозах резко отрицательные).
")
2. Normal Q-Q Plot
Q-Q Plot — это способ визуализации отклонения от заданного распределения. Для его отрисовки мы визуализируем, какие теоретические квантили были бы у нашей выборки (остатков), будь она взята из предполагаемого распределения, и какие квантили на самом деле, поэтому график называется Q-Q (Quantile-Quantile) Plot.
Чем больше реальные значения отклоняются от прямой линии, тем менее вероятно, что выборка взята из этого распределения. Частным случаем служит Normal Q-Q Plot, где мы сравниваем выборку с нормальным распределением (ещё один способ оценить, распределены ли остатки нормально — и, если нет, в каких конкретно значениях).
")
3. Scale-Location Plot
Scale-Location Plot помогает в оценке скедастичности распределения (гетероскедастичности либо гомоскедастичности, с которыми мы уже успели познакомиться). Для его отрисовки мы берём предсказания против корня модуля стандартизированных остатков.
Если распределение одинаково для всех предсказаний (иметь одного масштаба отклонение), то остатки считаются гомоскедастичными относительно предсказанного значения. Если мы видим растущий или убывающий тренд, другую неоднородность — значит, присутствует гетероскедастичность.
")
4. Cook’s Distance Plot
Cook’s Distance является мерой влияния каждого отдельного наблюдения на модель в целом. Она помогает выявить наиболее влиятельные объекты в данных, что может быть полезно при проверке модели на наличие аномалий или выбросов, которые могут сильно искажать её предсказания.
Для построения Cook’s Distance Plot визуализируются предсказанные значения против расстояния Кука. В каждой точке графика расстояние Кука представляет собой сумму отклонений предсказаний, полученных при удалении данного наблюдения, к предсказаниям, полученным на всем наборе данных.
Таким образом, если какие-то наблюдения имеют высокое значение расстояния Кука, это означает, что удаление этих точек может значительно изменить модель, поэтому они могут считаться влиятельными.
")
Diagnostic Plots
Эти четыре типа графиков часто используются вместе для полного визуального анализа остатков и проверки предположений модели. Они помогают понять, хорошо ли модель работает, есть ли какие-либо систематические ошибки, а также позволяют определить возможные проблемы с распределением остатков и наличием выбросов.

Существуют готовые пакеты отрисовки всех четырёх графиков. Например, в языке программирования R они входят в стандартную библиотеку и доступны вызовом функции plot на уже обученной линейной модели.
Fairness
Когда мы улучшаем модель, мы не хотим, чтобы метрика росла на одних сегментах пользователей и падала на других (даже если в среднем она оказывается выше). Бенефиты от прироста метрики легко могут быть перечёркнуты негативным User Experience «пострадавшей» группы пользователей — и за счёт совсем других метрик.
Чтобы этого избежать, мы должны смотреть не только на то, выросла ли метрика или упала, но и на то, как она размазана по всем объектам (например, по всем пользователям или по всем товарам). Для этого вводят концепт Fairness (в переводе с английского, «справедливость»).
Идеализированный пример:
Два ML инженера разрабатывали улучшение бейзлайн-модели. Оба из них получили сокращение MAE (Mean Absolute Error) на 20%. Как их рассудить? Чью модель выкатывать на A/B тест? Первая модель дала небольшой равномерный прирост для всех объектов. Вторая модель сильно сократила ошибку на половине объектов и немного увеличила на другой половиние.

Как мы видим из примера, одного и того же улучшения метрики можно добиться разными способами. Мы предпочтём скорее, чтобы метрика везде выросла понемногу, нежели чтобы где-то она сильно выроста, а где-то просела. Поэтому даже если суммарная метрика выросла, этого ещё не достаточно, чтобы принять решение, что новая модель лучше и её нужно катить в прод!
Аналогично можно представить, что неравномерный прирост (unfair uplift) был получен по ключевой онлайн-метрике и во время A/B теста (эксперимента на реальных пользователях), что также может послужить сигналом, что данную модель не стоит раскатывать на остальном трафике.
Gini Index
В экономике для количественной оценки «справедливости» распределения часто используют Gini-индекс, особенно при анализе распределения доходов населения определённой страны.
Gini-индекс варьируется от 0 до 1, где 0 обозначает идеальное равенство (т. е. все значения равны), а 1 обозначает максимальное неравенство (одно значение максимально, все остальные минимальны). Чем выше индекс Gini, тем более несправедливым считается распределение.

То же касается и распределения ошибок. Встретить случай, когда малое число объектов вносит львиную долю вклада в ошибку, для нас нежелательно. Почти во всех случаях для нас предпочтительнее «размазать» ошибку по разным объектам (или, скажем, для некой группы особых объектов построить отдельную модель), чем встретить явный перекос.
Достичь полностью равномерного распределения ошибок невозможно, и к этому нет смысла стремиться как к самоцели, так же как и к равномерному распределению доходов. Однако, кроме точности предсказания, оценивать, что Gini Index не снижаеся более чем на X%, — это полезно. Здесь нам главное избегать вырожденных случаев.
Кроме того, мы можем добавить и более простые эвристики, которые в лоб считают, на какой доле объектов мы увеличили качество, на какой просадили (по разнице знаков остатков).
Best Case / Worse Case / Corner Case
Изучив остатки в их совокупности и проанализировав их верхнеуровневые свойства, мы спускаемся на один уровень ниже. А именно начинаем искать в них паттерны. Так мы понимаем, «в какую сторону» нужно корректировать модель или остальные компоненты пайплайна обучения, когда что-то сломалось.
Best Case & Worst Case
Зная остатки, можно проанализировать поведение модели в лучших и худших сценариях. Для этого мы выводим топ-20, топ-50, топ-100 объектов по величине остатков и ищем в них общие паттерны.
-
Например, если мы прогнозируем число заказов в приложении доставки и видим, что наша модель систематически недооценивает спрос на веганскую и вегетарианскую еду, а также на блюда, которые попадали под промоакции. Мы пришли к выводу, что в качестве признаков нужно добавить «тип кухни» и, кроме того, подключить источник данных, содержащий «промо календарь».
-
Другой случай: мы попробовали построить модель прогноза на Трансформерах, распределение её остатков принципиально отличается от текущей модели в проде. Метрика лучше. Мы хотим с нуля проанализировать, на каких блюдах и на каких пользователях прогноз спроса точнее всего. Где пролегает текущая «граница применимости» текущей модели, чтобы раскатить её в первую очередь на той части данных, где она чувствует себя лучше всего. Для этого мы выводим топ-1000, топ-5000, топ-10,000 объектов с наименьшей ошибкой.
Одним из наилучших методов является автоматическое сохранение объектов с наибольшими ошибками (debug samples) в качестве артефактов при каждом запуске обучения. Благодаря этому мы сможем быстро и легко заметить общие паттерны (сходу получаем багаж идей для улучшения пайплайна) и в будущем проследить, как менялся характер ошибки по мере выкатки новых улучшений и добавления новых признаков.

Corner Case Analysis
В то время как анализ лучших и худших случаев направлен на выявление общих паттернов на основе остатков, corner case analysis фокусируется на том, какие остатки характерны для объектов с конкретными особенностями.

-
Так, если у остатков разный разброс на разных по масштабу таргетах (например, мы предсказываем выручку и наибольший вклад делают ошибки в предсказании наименьших значений выручки, близких к нулю), тогда нам стоит вывести группу объектов с наименьшими таргетами, посмотреть на их остатки.
-
Аналогично, нам может быть любопытно, какие ошибки в районах или ресторанах, которые недавно подключены к нашему сервису (так называемся «проблема холодного старта»: например, как заполнять пропуски в товарах, для которых нет достаточной истории продаж?).
-
Или какие ошибки на пользователях из определённого сегмента, например, присоединившиеся в наш сервис после того, как увидели рекламу на маркетплейсе KarpovExpress; или какие ошибки предсказания у самых популярных ресторанов и блюд. Во всех этих случаях нам нужно отфильтровать нужную подвыборку данных и проанализировать её остатки в изоляции.

Случай из жизни: когда мы строили сервис динамического ценообразования в одном крупном маркетплейсе, то столкнулись с забавной проблемой, которую удалось оперативно решить благодаря анализу ошибок.
Наша система работала по следующему принципу: ML-модель учится предсказывать спрос для товаро-дня с учётом множества факторов, среди которых есть факторы цены и их производные (скидки, наценки, разницы с ценами конкурентов и т.д.). Для дальнейшего использования модели, мы подставляли разные цены (досчитывая зависимые от цены факторы) и оценивали спрос для каждого прайс-поинта.
Например, -10%, -9%, -8%, …, +9%, +10% от последней наценки.
Чтобы понять, делает ли обученная модель осмысленные предсказания, мы смотрим на графики кривой эластичности по каждому товару. Если не вдаваться в детали, эластичность – это и есть зависимость спроса от цены, которую мы получаем подставляя цены и делая прогноз для новой точки.

Ожидаемое поведение: чем выше цена, тем ниже спрос, и наоборот. Эластичные товары имеют “более крутую” кривую: малейшее увеличение цены ведёт к сильному спаду спроса, и наоборот. Неэластичные имеют более “плоскую” зависимость: мы можем наглеть в цене, а спрос – не сильно упадёт (значит, заработаем больше денег).
 – аналог товарооборота (выручки) для e-commerce. Для нашего сервиса он играет роль «спроса».")
Однако, начав анализ первых графиков эластичности, мы обнаружили вот какую картину:

Как вы понимаете, это вообще вышло за рамки нашего ожидания. Из-за чего так произошло? Есть ли у вас догадки?
Дело в том, что в качестве модели прогноза у нас был CatBoost и обучался он на большом числе товаров. Как мы знаем, градиентный бустинг (начиная с LightGBM) делает квантизацию всех признаков перед обучением (разбивая на бины +- одинаковых размеров), таким образом, с десятков уникальных значений по каждому признаку мы переходим, например, к 256 или 512 значениям. Это обеспечивает ускорение обучения за счёт потери части сигнала в признаках.

Таким образом, даже несмотря на то, что цена и признаки на основе цены выходили в топ по важности, тем не менее, модель была физически «нечувствительна» к малым вариациям цены, на которых мы затем её хотели применять.
Решение: повысить гранулярность квантизации (скажем, до 4096 или 8192). В результате мы получили графики с уже осмысленным «гладким» возрастанием спроса по мере уменьшением цены.
Моделируем ошибку
Но вернёмся к worst-case анализу.
Допустим, мы выделили группу объектов, на которых модель показала наихудшие результаты. Как нам это знание использовать для определения «градиента» ML системы, поиска наискорейшего шага её улучшения? Смотреть на ошибки, конечно, можно и вручную, особенно когда признаков мало, а объектов выделено немного. Но что если того и того становится слишком много?
Наверняка, есть пути автоматизировать и этот процесс, ведь мы инженеры…
И такой приём действительно есть: Что, если использовать одну модель машинного обучения для предсказания ошибок другой модели машинного обучения?

Adversarial Validation
Adversarial Validation — приём, который мы сегодня применим для выделения паттернов в ошибках. Он происходит от соревнований по машинному обучению на Kaggle. В соревнованиях участники стремятся улучшить качество своих моделей, используя наиболее умные и сложные методы. Часто они сталкиваются с проблемой, когда их модели хорошо работают на обучающем наборе данных, но плохо на отложенной выборке (тестовом наборе данных, целевые переменные, для которых надо предсказать).
Почему так происходит?
-
Первая возможная причина: модели могут переобучаться на обучающем наборе данных (особенно если не предусмотреть надёжную валидацию, на основе которой мы не просто смотрим, подросла ли метрика или нет, но и учитываем чувствительность выбранной схемы.
-
Вторая возможная причина: и от этого куда труднее спастись — тестовый набор данных может существенно отличаться от обучающего набора данных. Именно это называется «расхождением распределений».

Чтобы оценить, насколько два распределения похожи или не похожи (и в каких признаках именно), мы можем обучить отдельную модель-классификатор. Все объекты обучающей выборки примут класс 0, а все объекты тестовой — класс 1.
Если разница между выборками несущественна (например, ROC-AUC ≈ 0.5), это означает, что распределения обучающего и тестового набора данных схожи.
Если между выборками большая разница (например, ROC-AUC > 0.6), тогда выборки уже различимы, мы можем из обучающей выборки выделить самые похожие на тест объекты и использовать их как отложенную валидационную выборку.
Именно это и называется Adversarial Validation.
Граница применимости модели
Если задуматься, этот подход можно применить к любым двум выборкам, чтобы выявить между ними отличия. Более того, поняв, что две группы объектов различимы, мы можем заглянуть в Feature Importance модели (а выбор подходящей модели для анализа ошибок — отдельный разговор) и узнать, в каких именно признаках различие между выборками себя выдаёт.
Как Adversarial Validation «завести» для анализа ошибок? Какие две выборки у нас есть?
-
Отбираем топ ошибок модели (например, топ-1000 или топ-10%). Это наши worst-cases.
-
Присваиваем им класс 1, а всем остальным («здоровым») объектам — класс 0.
Наши выборки: «хорошо прогнозируемые» и «плохо прогнозируемые». -
Строим вспомогательную модель-классификатор, которая пытается предсказать, является ли объект «плохо прогнозируемым». Эта модель будет использовать признаки объектов (возможно даже куда больший набор, чем тот, на основе которого мы обучаем основную модель), чтобы понять, чем так отличаются «плохие объекты».
-
Если модель классифицирует «хорошо прогнозируемые» и «плохо прогнозируемые» объекты с достаточной точностью (ROC-AUC > 0.6), то это говорит о том, что ошибка модели зависит от значений некоторых признаков.
-
Анализируем важность признаков в этой модели (например, по SHAP-values), чтобы определить, какие признаки сильнее всего влияют на ошибки основной модели.
Это подскажет, паттерны в каких признаках сейчас основная модель не понимает чаще всего. Это направляет вектор нашего поиска новых признаков (и их трансформаций), обогащения датасета и, возможно, модификацией loss-функции или процесса предобработки целевых переменных.
Анализ ошибок за пределами регрессии и классификации
Анализ ошибок не ограничивается простыми задачами классификации или регрессии и столь же активно используется в других областях машинного обучения. Давайте посмотрим шире не то, что может играть роль остатков в других доменах.
1. Сегментация изображений (Image Segmentation). В области компьютерного зрения задача сегментации изображений заключается в выделении определенных областей или объектов на изображении, соответствующих определённым классам. «Остатками» здесь является разница предсказанной маски сегментации (контура объекта) и истинной. С помощью наложения масок или использование цветовых карт, мы можем быстро определить области изображения, где модель допускает ошибки (например, плохо отделяет мелкие детали, волосы или ошибочно выделяет зеркальное отражение).
, ошибочно не выделенные регионы изображения, — и False Positives (FP), ошибочно выделенные.")
С другой стороны, мы можем оперировать не пикселями, а самими картинками: просматривать топ-N изображений с самой большой ошибкой после обучения и анализировать, есть ли в них какой-либо паттерн. Так, например, модель может некорректно работать на картинках с тёмным освещением, с зеркалами, с большим количеством объектов или на специфическом фоне. Обнаруженные закономерности подсказывают, каких данных (на какие паттерны) нужно добавить в выборку больше, либо как нужно модифицировать loss-функцию (чтобы модель была внимательнее на границах масок сегментации).
2. Генерация звука (Voice Cloning). В задачах генерации аудио, таких как генерация голоса или Text-to-Speech (TTS), важным элементом анализа ошибок является использование Attention Plots. Они показывают, на какие части исходного текста модель обращала особое внимание при генерации каждого отдельного звука. Это позволяет выявить неправильные соответствия и улучшить качество генерации.
Кроме того, существует подход Guided Attention, который дополнительно штрафует модель за отклонение от линейного отображения позиции символа в позицию звука. Как мы помним, анализ ошибок служит в том числе и для проверки на прочность наших предположений о модели (model assumptions).

3. Рекомендательные и поисковые движки. Ещё пример — рекомендательные системы. Вместо предсказанной одной цифры, как в классификации и регрессии, мы имеем рейтинг объектов, которые мы порекомендовали бы пользователю. Существует несколько метрик, сравнивающих гипотетическую выдачу и то, что пользователь реально кликал/покупал/смотрел.
Одна из таких метрик — NDCG. Несмотря на отличный от регрессии и классификации формат «предсказаний», эта метрика усредняет качество рекомендации по всем объектам. Значит, ничего не мешает посмотреть на best/worst/corner кейсы по аналогии с регрессией и классификацией: узнать, какие запросы наша система «понимает» хуже всего; как ведёт себя на пользователях с длинной и короткой историей запросов (или просмотров); нет ли очевидных проблем, например, зацикливания на том, что пользователь уже покупал или смотрел?
Вывод
Как мы увидели, анализ ошибок играет ключевую роль в процессе создания и оптимизации ML системы. Это не просто этап «для галочки» перед деплоем, который можно пропустить. Напротив, анализ ошибок стоит в самом начале итеративного цикла улучшения и усложнения модели.
Когда мы создали baseline с минимальным датасетом, анализ ошибок позволяет нам определить её сильные и слабые стороны, а также выявить моменты, которые требуют оптимизации (что далеко не всегда требует сразу заводить бустинги или BERTы). Этот анализ даёт нам понимание о том, какие улучшения модели следует внести в следующем цикле. Так, на каждой итерации, мы заменяем модель на более сложную, добавляем новые факторы в датасет, анализируем ошибки и сравниваем их с ошибками предыдущей версии.
Этот цикл дотошного анализа текущих результатов для определения вектора следующего наискорейшего шага в улучшении ML системы – и, непосредственно, внесения изменений в пайплайн — вот, из чего состоит реальная работа ML инженера на практике.
Анализ ошибок — это лишь часть задач инженера по машинному обучению. Кроме анализа ошибок в повседневной работе мы разрабатываем метрики, собираем датасеты, обучаем сами модели, деплоим и тестируем ML-сервисы, проводим A/B-тесты и много чего ещё, порой выходящего за рамки теоретического понимания, как работают модели машинного обучения.
Главная /
Введение в эконометрику /
Для проверки ошибок модели на гомоскедастичность используют
Для проверки ошибок модели на гомоскедастичность используют
вопрос
Правильный ответ:
тест Голдфелда — Квандта
метод Гаусса — Маркова
критерий Спирмена
все перечисленное не верно
Сложность вопроса
60
Сложность курса: Введение в эконометрику
78
Оценить вопрос
Очень сложно
Сложно
Средне
Легко
Очень легко
Спасибо за оценку!
Комментарии:
Аноним
Я преподаватель! Незамедлительно заблокируйте сайт vtone.ru с ответами intuit. Не ломайте образование
22 сен 2019
Аноним
Зачёт всё. Лечу в бар отмечать зачёт интуит
03 май 2018
Оставить комментарий
Другие ответы на вопросы из темы экономика интуит.
-
#
Ряды имеют «долговременную память» если убывание коэффициента корреляции носит…
-
#
Если система уравнений помимо экзогенных и эндогенных переменных содержит еще и значения эндогенных переменных, полученные в предыдущие периоды времени, то такие значения называют
-
#
Техника моделирования структурными уравнениями основывается на…
-
#
Перечислите основные причины отклонений от прямой регрессии
-
#
В чем заключается второй подход к решению проблемы гетероскедастичности?
Правильные ответы выделены зелёным цветом.
Все ответы: Даны основы эконометрики и статистического анализа одномерных временных рядов.
Дисциплина эконометрика содержит следующие разделы
(1) моделирование данных, неупорядоченных во времени, теория временных рядов
(2) теория вероятностей и математическая статистика
(3) моделирование экономических процессов и прогнозирование ситуаций
(4) верны все вышеперечисленные варианты
Соответствие, максимальное приближение теоретических моделей к реальным производственно-экономическим процессам предполагает
(1) системность прогнозов
(2) адекватность поведения
(3) альтернативность прогнозирования
(4) все перечисленное
Сглаживание ряда называется центрированным при условии
(1) k = l + 3
(2) k = l
(3) k = l + 2
(4) k = l + 1
Для устранения трудностей построения уравнения регрессии при наличии коррелированности факторов и ошибок модели используют
(1) метод скользящей средней
(2) метод наименьших квадратов
(3) метод сглаживания
(4) метод инструментальных переменных
Построение моделей структуры средних позволяет
(1) проверить гипотезу о том, что матрица ковариации имеет определенный вид
(2) проверить корреляцию между факторами
(3) исследовать структуру средних одновременно с анализом дисперсий и ковариаций
(4) проанализировать корреляционную матрицу общих факторов
К критериям селекции относятся…
(1) критерий Шварца (SBC) и информационный критерий Акайке
(2) критерий Фишера и информационный критерий Акайке
(3) критерий Стьюдента
(4) критерий Стьюдента и информационный критерий Акайке
Стохастическая переменная с постоянной дисперсией называется
(1) основной
(2) гомоскедастической
(3) гетероскедастической
(4) явной
Тенденция к отрицанию гипотезы H0 возрастает по мере
(1) наличия связанных между собой нестационарных временных рядах
(2) увеличения объема выборки
(3) ошибочного обнаружения связей
(4) уменьшения объема выборки
Если при сборе данных об урожайности сельскохозяйственных структур результаты работы в отчетах занижаются, завышаются в зависимости от экономической политики или оцениваются «на глазок», то это объясняется
(1) неправильным выбором вида зависимости в уравнении
(2) отражением уравнением регрессии связи между агрегированными переменными
(3) невключением объясняющих переменных
(4) ошибками измерения
Матрица C = (XTX)-1, обратная матрице XTX, называется
(1) матрицей дисперсий-ковариаций или транспонированной матрицей случайного вектора Х
(2) транспонированной матрицей случайного вектора Х или ковариационной матрицей
(3) матрицей дисперсий-ковариаций или ковариационной матрицей
Каковы последствия гетероскедастичности в случая использования МНК для построения модели?
(1) результаты, основанные на анализе дисперсии коэффициентов, в случае гетероскедастичности применимы полностью
(2) результаты, основанные на анализе дисперсии коэффициентов, в случае гетероскедастичности неприменимы
(3) результаты, основанные на анализе дисперсии коэффициентов, в случае гетероскедастичности применимы в некоторых случаях
Впервые термин «эконометрия» ввел П. Цьемпа в
(1) 1980
(2) 1900
(3) 1910
(4) 1950
Величина Dx(t) характеризует
(1) квадрат колебаний значений процесса вокруг
(2) средний размах значений процесса
(3) размах квадрата колебаний значений процесса вокруг
(4) средний размах квадрата колебаний значений процесса вокруг mx(t)
Простейшим асимметричным фильтром является
(1) взвешенная средняя
(2) дисперсия
(3) скользящая средняя
(4) среднее квадратичное отклонение
Мультипликатор Кейнса характеризуется следующим высказыванием
(1) при увеличении объема инвестиций It на единицу совокупный выпуск возрастает на It единиц
(2) при уменьшении объема инвестиций It на единицу совокупный выпуск возрастает на 1/1-b единиц
(3) при увеличении объема инвестиций It на единицу совокупный выпуск возрастает на 1/1-b единиц
(4) при уменьшении объема инвестиций It на единицу совокупный выпуск возрастает на It единиц
Процесс структурного моделирования включает в себя следующие этапы
(1) все перечисленные этапы
(2) исследователь (пользователь) описывает (обычно с помощью диаграммы путей) модель, представляющую его понимание зависимостей между переменными
(3) программа проверяет, насколько хорошо полученные дисперсии и ковариации отвечают данной модели
(4) программа с помощью специальных внутренних методов определяет, какие значения дисперсий и ковариаций переменных получаются в текущей модели на основании входных данных
Для оценки так называемых моделей авторегрессии интегрированного скользящего среднего (АРИСС-моделей) применяют
(1) критерий Фишера
(2) критерий Стьюдента
(3) методологию Бокса — Дженкинса
(4) критерии Вальда — Вольфовица
В выражении для определения превышения доходности yt = mt + et, параметром mt обозначают
(1) ожидаемое превышение доходности от держания долгосрочных ценных бумаг
(2) непредсказуемые колебания показателей доходности долговременных рискованных ценных бумаг
(3) премию за риск, побуждающую избегающих риска агентов держать долгосрочные ценные бумаги
(4) белый шум
В случае если ряд содержит единичные корни и интегрирует с порядком d, он принадлежит классу
(1) I(d — b)
(2) I(d)
(3) CI(1,1)
(4) I(d + b)
Если регрессия значима, то
(1) Fнабл < Fкрит
(2) Fнабл > Fкрит
(3) Fнабл = Fкрит
К методам устранения мультиколлинеарности относятся
(1) все перечисленное верно
(2) методы, уменьшающие дисперсии оценок коэффициентов
(3) метод главных компонент
(4) метод гребневой регрессии (ридж-регрессии)
Обобщенная линейная модель множественной регрессии, теорема Айткена и обобщенный метод наименьших квадратов характерны для
(1) обоих методов устранения гетероскедастичности
(2) первого метода устранения гетероскедастичности
(3) второго метода устранения гетероскедастичности
Целью эконометрики как науки является
(1) разработка методов прогнозирования
(2) эмпирический анализ экономических законов
(3) разработка методик проведения социально-экономических исследований
(4) верны все вышеперечисленные варианты
Функция P(t) считается полностью определенной, если известны…
(1) все перечисленное
(2) частоты w = 2Пи/T
(3) период Т
(4) коэффициенты ряда Фурье
При сглаживании с помощью скользящей средней нет возможности получить сглаженные значения для
(1) свободного члена а полинома
(2) k первых и k последних членов ряда X(t)
(3) нечетных членов временного ряда
(4) k первых членов ряда X(t)
Число уравнений приведенной системы совпадает
(1) с числом экзогенных переменных
(2) с числом приведенных переменных
(3) с числом эндогенных переменных модели
(4) с числом составляющих переменных
Диаграммы путей используются для
(1) простого и изоморфного представления системы линейных уравнений
(2) составления сетевых графиков
(3) прогнозирования
(4) отражения причинных связей в наборе переменных
При q = 0 уравнение авторегрессии называется
(1) СС(q)-модель
(2) АРСС(p, q)-модель
(3) АРИСС(p, s, q)-моделью
(4) AP(q)-модель
Для определения превышения дохода от держания шестимесячной облигации (без учета квадратичных членов) можно использовать выражение
(1) yt = -0,0241 + 0,687ht + et
(2) yt = 2Rt — rt + 1 — rt
(3) yt = mt + et
(4) yt = 2Rt — rt
Следствием ложных корреляций являются
(1) образование новых стационарных переменных
(2) ложные связи между переменными
(3) образование детерминированных переменных времени
Значимость уравнения регрессии осуществляется по
(1) коэффициенту детерминации
(2) F-критерию Фишера
(3) по дисперсии
(4) все перечисленное
Предельными значениями коэффициента корреляции являются
(1) от 0 до +1
(2) от -1 до 0
(3) от -1 до + 1
Первый подход к решению проблемы гетероскедастичности
(1) предполагает такое преобразование данных, чтобы для них модель приобретала со временем свойство гетероскедастичности
(2) предполагает такое преобразование данных, чтобы для них модель уже обладала свойством гетероскедастичности
(3) состоит в построении моделей, учитывающих гетероскедастичность ошибок наблюдений
Исследование моделей по независимым неупорядоченным наблюдениям включает следующие этапы
(1) выявление тренда, лагов
(2) выделение зависимых и независимых переменных согласно некоторой экономической гипотезе
(3) проверка остатков на гетероскедастичность
(4) выявление циклической компоненты
Предварительную оценку случайности поведения остатков проводят на основе
(1) все перечисленное
(2) критерия поворотных точек
(3) критерия Пирсена
(4) критерия Стъюдента
Для уменьшения амплитуды колебаний у сглаженного ряда Y(t) необходимо
(1) увеличивать ширину интервала сглаживания m и проводить процедуру сглаживания повторно
(2) увеличивать ширину интервала сглаживания m либо проводить процедуру сглаживания повторно
(3) уменьшать ширину интервала сглаживания m
(4) все перечисленное не верно
Экзогенные переменные никогда не коррелируют
(1) с эндогенными переменными
(2) с ошибками модели
(3) с предопределенными переменными
(4) c лаговыми переменными
Явные переменные на путевых диаграммах указываются
(1) внутри овалов
(2) над стрелками
(3) внутри прямоугольников
(4) над дугами
Одним из априорных предположений при применении параметрических тестов для проверки стационарности является
(1) предположение о Пуассоновском законе распределения
(2) предположение о наличии корреляционных связей
(3) предположение о нормальном законе распределения значений временного ряда
(4) все перечисленное не верно
В выражении ln(yt) = a0 + a1ln(xt — 1) + et параметр et = ln et означает
(1) переменная уровня доходности
(2) белый шум
(3) слагаемое ошибок
(4) все перечисленное не верно
В процессе случайного блуждания используются переменные
(1) коррелированные нестационарные переменные
(2) некоррелированные нестационарные переменные
(3) стационарные переменные
(4) детерминированные переменные
Проверка значимости коэффициентов уравнения регрессии производится по
(1) критерию Фишера
(2) коэффициенту корреляции
(3) критерию Стьюдента
(4) коэффициенту детерминации
Если случайная величина является нормированной нормально распределенной величиной, то выполняется условие
(1) дисперсия равна нулю
(2) дисперсия равна единице
(3) все перечисленное
Устранение гетероскедастичности путем применения обобщенного метода наименьших квадратов (ОМНК) требует знания
(1) матрицы случайных ошибок
(2) матрицы ковариаций ошибок наблюдений
(3) матрицы систематических ошибок
(4) все перечисленное
Первой книгой, которую можно назвать эконометрической, была книга ученого
(1) Ф. Гальтона
(2) Дж. Э. Юла
(3) Г. Хукера
(4) Г. Мура
Уравнение кривой можно свести к многочлену посредством
(1) все перечисленное
(2) логарифмирования
(3) дифференцирования
(4) интегрирования
Сглаженный ряд короче исходного на величину
(1) k + l + 1
(2) k + 1
(3) 2k + 1
(4) k — l + 1
Коэффициент структурного уравнения системы называется идентифицируемым, если выполняются условия…
(1) существует не одна формула, связывающая этот коэффициент с коэффициентами приведенной формы
(2) коэффициент однозначно определяется с помощью косвенного метода наименьших квадратов
(3) коэффициент неоднозначно определяется с помощью косвенного метода наименьших квадратов
(4) все перечисленное
Путевые диаграммы наглядно показывают
(1) какие переменные являются значимыми
(2) какие переменные не вызывают изменения в других переменных
(3) какие переменные являются основными
(4) какие переменные вызывают изменения в других переменных
Для проверки условия стационарности ряда последовательность разбивается
(1) на два участка
(2) на три участка
(3) на четыре участка
(4) не разбивается
Коррелируют между собой следующие тренды
(1) нестационарные
(2) временные
(3) стационарные
(4) постоянные
Максимальное значение коэффициента детерминации равно
Для случая парной регрессии справедливым является выражение
(1) Qобщ = Qост — Qрегр
(2) Qобщ = Qост/Qрегр
(3) Qобщ = Qост + Qрегр
(4) все выражения
Ранг неслучайной (детерминированной) матрицы X предполагается равным
(1) p + 3 < n
(2) p + 2 < n
(3) p + 5 < n
(4) p + 1 < n
Начальным этапом применения теории эконометрики является
(1) прогнозирование экономической политики
(2) тестирование гипотез
(3) разработка теоретической модели экономической теории
(4) оценка модели
К приемам, позволяющим подобрать соответствующую (адекватную) действительности форму кривой, относятся…
(1) все перечисленное верно
(2) вычисление последовательных разностей
(3) визуальный
К экзогенным переменным относятся…
(1) все перечисленное
(2) денежная масса
(3) процентная ставка
(4) временной тренд
Третьим этапом структурного моделирования является следующий
(1) программа сообщает пользователю полученные результаты статистических испытаний, а также выводит оценки параметров и стандартные ошибки для численных коэффициентов в линейных уравнениях и одновременно выдает большое количество дополнительной диагностической информации
(2) программа проверяет, насколько хорошо полученные дисперсии и ковариации отвечают данной модели
(3) программа с помощью специальных внутренних методов определяет, какие значения дисперсий и ковариаций переменных получаются в текущей модели на основании входных данных
(4) исследователь (пользователь) описывает (обычно с помощью диаграммы путей) модель, представляющую его понимание зависимостей между переменными
К условиям стационарности модели относятся…
(1) однородное решение не должно быть равно нулю
(2) однородное решение должно быть равно нулю и характеристический корень а1 должен быть по абсолютной величине меньше 1
(3) однородное решение должно быть равно нулю и характеристический корень а1 не должен быть по абсолютной величине меньше 1
(4) однородное решение не должно быть равно нулю и характеристический корень а1 должен быть по абсолютной величине меньше 1
В динамическую модель могут входить следующие переменные
(1) детерминированные переменные
(2) зависимые переменные Y
(3) зависимые переменные X
(4) стационарные переменные
Коэффициент детерминации характеризует
(1) все перечисленное
(2) показатель сложности уравнения
(3) показатель качества построенного уравнения регрессии
(4) показатель выбора вида кривой
Для cov(bi, bj) справедливо следующее равенство
(1) cov(bi, bj) = M{(bi — M(bi))(bj — M(bj))} = M{(bi * bi)(bj * bj)}
(2) cov(bi, bj) = M{(bi — M(bi))(bj — M(bj))} = M{(bi + bi)(bj + bj)}
(3) cov(bi, bj) = M{(bi — M(bi))(bj — M(bj))} = M{(bi/bi)(bj/bj)}
(4) cov(bi, bj) = M{(bi — M(bi))(bj — M(bj))} = M{(bi — bi)(bj — bj)}
Существуют следующие подходы к решению проблемы гетероскедастичности…
(1) все перечисленное
(2) применение обобщенного метода наименьших квадратов
(3) применение взвешенного метода наименьших квадратов
(4) преобразование данных
Эконометрика как отрасль науки возникла на стыке
(1) четырех дисциплин
(2) двух дисциплин
(3) трех дисциплин
(4) пяти дисциплин
Ряды имеют «долговременную память» если убывание коэффициента корреляции носит…
(1) степенной или линейный характер
(2) экспоненциальный или линейный характер
(3) экспоненциальный или степенной характер
(4) все перечисленное не верно
В кейнсианской модели переменная It называется
(1) составляющими переменными
(2) экзогенной переменной
(3) приведенными переменными
(4) экзогенными переменными
Четвертым этапом структурного моделирования является следующий
(1) программа с помощью специальных внутренних методов определяет, какие значения дисперсий и ковариаций переменных получаются в текущей модели на основании входных данных
(2) программа сообщает пользователю полученные результаты статистических испытаний, а также выводит оценки параметров и стандартные ошибки для численных коэффициентов в линейных уравнениях и одновременно выдает большое количество дополнительной диагностической информации
(3) программа проверяет, насколько хорошо полученные дисперсии и ковариации отвечают данной модели
Гипотеза о постоянстве математического ожидания временного ряда принимается в случае
(1) все перечисленное
(2) Tнабл < Tтабл(a, n1 + n2 — 2)
(3) Tнабл = Tтабл(a, n1 + n2 — 2)
(4) Tнабл > Tтабл(a, n1 + n2 — 2)
Временной тренд может быть исключен из результирующей переменной путем
(1) построения регрессии этой переменной по времени
(2) путем введения времени в качестве одной из переменных-регрессоров
(3) перехода к остаткам, свободных от тренда
Перечислите основные причины отклонений от прямой регрессии
(1) верны все перечисленные варианты
(2) отражение уравнением регрессии связи между агрегированными переменными
(3) неправильный выбор вида зависимости в уравнении
(4) ошибки измерения
Система нормальных МНК-уравнений позволяет
(1) осуществлять прогнозную оценку процесса выраженного уравнением регрессии
(2) оценивать оптимальное значение функци
(3) все перечисленное
(4) оценивать коэффициенты b0, b1, b2, …, bk уравнения регрессии
Тесты для определения наличия гетероскедастичности основаны на
(1) предположении о наличии значимых факторов в моделях
(2) предположении о наличии связи между дисперсиями остатков моделей и объясняющими переменными
(3) предположении о наличии значимых коэффициентов регрессии
(4) предположении об отсутствии связи между дисперсиями остатков моделей
Основными характеристиками случайного процесса являются…
(1) все перечисленное
(2) автокорреляционная функция
(3) дисперсия
(4) математическое ожидание
Одной из причин корреляции между факторами и ошибками уравнения регрессии является
(1) неправильный выбор факторов
(2) неправильный выбор вида уравнения регрессии
(3) неправильное измерение объясняющих переменных
(4) в модель подставляются не истинные, а искаженные наблюдения
Основными задачами, для решения которых используются структурные уравнения, являются…
(1) все перечисленное верно
(2) подтверждающий факторный анализ
(3) причинное моделирование, или анализ путей
(4) факторный анализ второго порядка
Гипотеза о постоянстве дисперсии проверяется
(1) по критерию Вальда — Вольфовица
(2) по параметрическим тестам
(3) все перечисленное
(4) по критерию Фишера
Большие значения, близкие к 1, величины (1 — а1) модели корректировки ошибок (МКО) свидетельствуют о том, что
(1) МКО обладает иммунитетом к ложной регрессии
(2) экономические факторы сильно изменяют результат
(3) контроль и достижение долговременной стабилизации происходят медленно
Впервые термин «регрессия» ввел
(1) Дж. Э. Юл
(2) Г. Хукер
(3) Ф. Гальтон
(4) Р. Фриш
Критерий Шварца и критерий Акайке применяют
(1) все перечисленное
(2) если точная спецификация модели неизвестна
(3) если точная спецификация модели не существует
(4) если точная спецификация модели известна
Какие вопросы решают при исследовании моделей?
(1) все перечисленное
(2) как решать проблему гетероскедастичности
(3) какие следствия для оценок, получаемых по методу наименьших квадратов, влечет гетероскедастичность
(4) как правильно провести диагностику существования гетероскедастичности
При построении прогнозных моделей могут использоваться следующие методы…
(1) все перечисленное верно
(2) метод минимизации суммы модулей
(3) регрессионные методы
(4) методы распознавания образов
Нулевая гипотеза при использовании теста Чоу состоит в предположении
(1) все перечисленное
(2) о неравенстве истинных соответствующих параметров регрессии для всех моделей
(3) о равенстве истинных соответствующих параметров регрессии для всех моделей
В случае включения в модель нескольких качественных факторов необходимо выполнение следующих условий…
(1) чтобы в информационной матрице X скалярные произведения столбцов, отвечающих за качественные переменные, были равны нулю
(2) включаемые факторы не были линейно независимы
(3) в информационной матрице X скалярные произведения столбцов, отвечающих за качественные переменные, были равны единице
(4) все перечисленное верно
Для математического ожидания матрицы, элементами которой являются центрированные случайные величины, должно соблюдаться условие
(1) M(XiXj) < cov(Xi,Xj)
(2) M(XiXj) > cov(Xi,Xj)
(3) M(XiXj) = cov(Xi,Xj)
Укажите дисциплины, использующие математические методы применительно к экономике
(1) информатика
(2) многомерный статистический анализ данных, математические методы в экономике
(3) естествознание
(4) социология
К основным принципам разработки прогнозов относится
(1) многозадачность, устойчивость
(2) надежность, массовость, дискретность
(3) системность, адекватность, альтернативность
(4) все перечисленное
Число значений исходного ряда, одновременно участвующих в сглаживании, называется
(1) граничными значениями интервала сглаживания
(2) диапазоном интервала сглаживания
(3) шириной интервала сглаживания
(4) длиной интервала сглаживания
Ошибка наблюдения в модели случае, когда подставляются не истинные, а искаженные наблюдения, состоит
(1) из одного слагаемого
(2) из трех слагаемых
(3) из двух слагаемых
(4) из четырех слагаемых
Моделирование ковариационной структуры позволяет
(1) проанализировать корреляционную матрицу общих факторов
(2) проверить корреляцию между факторами
(3) проверить гипотезу о равенстве дисперсий у всех переменных
(4) проверить гипотезу о том, что матрица ковариации имеет определенный вид
По обучающей выборке определяются следующие числовые характеристики временного ряда
(1) модифицированную последовательность ковариаций
(2) автоковариации и автокорреляционные функции
(3) параметры скользящего среднего
(4) все перечисленное
Ключевым моментом в ОАРУГ-моделях являются
(1) АКФ квадраты остатков, позволяющие идентифицировать порядок ОАРУГ-процесса
(2) АКФ и ЧАКФ остатки
(3) возмущения {yt}-последовательности, образующие АРСС-процесс
(4) возмущения {yt}-последовательности, образующие ОАРУГ-процесс
Результативным признаком в регрессионном анализе называют
(1) фактором
(2) независимую переменную
(3) зависимую переменную
Для установления значимости факторов в шаговой регрессии используют следующие методы
(1) все перечисленное верно
(2) метод включения факторов
(3) метод исключения факторов
(4) комбинированный метод
В обобщенной линейной модели множественной регрессии дисперсии и ковариации ошибок наблюдений
(1) не произвольные
(2) всегда постоянны
(3) могут быть произвольными
Эконометрика как отрасль науки возникла на стыке следующих дисциплин
(1) политологии, социологии, психологии
(2) экономической теории, методов математического анализа, математической статистики
(3) информатики, теории анализа, естествознания
(4) математической статистики, информатики
С увеличением запаздывания объем выборки, по которой вычисляется коэффициент корреляции
(1) остается без изменения
(2) увеличивается
(3) уменьшается
Асимметричные фильтры используются для
(1) сглаживания временных рядов
(2) прогнозирования временных рядов
(3) усреднения временных рядов
(4) все перечисленное
Если система уравнений помимо экзогенных и эндогенных переменных содержит еще и значения эндогенных переменных, полученные в предыдущие периоды времени, то такие значения называют
(1) составляющим переменными
(2) лаговыми переменными
(3) приведенными переменными
(4) экзогенными переменными
Если набор чисел X связан с другим набором чисел Y зависимостью Y = 4X, то дисперсия Y должна быть
(1) в 32 раза больше, чем дисперсия X
(2) в 16 раз больше, чем дисперсия X
(3) в 64 раза больше, чем дисперсия X
(4) в 4 раза больше, чем дисперсия X
Для проверки постоянства математического ожидания используют
(1) тест Сиджела — Тьюки
(2) критерий Фишера
(3) тест Манна — Уитни
(4) критерий Стьюдента
Модель, одновременно оценивающую среднее и дисперсию ряда, предложил
(1) Р. Фриш
(2) Р. Энгл
(3) Л. Клейн
(4) В. Джакоб
Для определения числа степеней свободы для суммы квадратов используют выражение
(1) n — 4
(2) n — 5
(3) n — 3
(4) n — 2
К методам смягчения мультиколлинеарности относятся
(1) отбор из множества объясняющих переменных тех переменных, которые имеют наиболее низкие взаимные коэффициенты корреляции
(2) радикальное увеличение числа опытов
(3) уменьшение дисперсии остатков путем введения упущенной в первоначальной модели важной переменной
(4) все перечисленное
В чем заключается второй подход к решению проблемы гетероскедастичности?
(1) в таком преобразовании данных, чтобы для них модель уже обладала свойством гетероскедастичности
(2) в построении моделей, учитывающих гетероскедастичность ошибок наблюдений
(3) в таком преобразовании данных, чтобы для них модель не обладала свойством гетероскедастичности
(4) все перечисленное
Выявление трендов, лагов, циклической компоненты определяются при проведении исследований
(1) моделей прогнозирования
(2) моделей по независимым неупорядоченным наблюдениям
(3) моделей временных рядов
Задачей гармонического анализа является определение основных гармонических колебаний, входящих в
(1) непериодическую составляющую q(t)
(2) периодическую составляющую ряда P(t)
(3) погрешность ряда e(t)
(4) все перечисленное
В случае если сглаживание происходит на основе уравнения параболы, составляется система m уравнений
(1) m = 2k + 2
(2) m = 2k — 1
(3) m = 2k + 1
(4) m = 2k — 2
Коэффициент b в упрощенной кейнсианской модели формирования доходов в закрытой экономике без государственного вмешательства называют
(1) ликвидными средствами
(2) скрытыми затратами
(3) неликвидными средствами
(4) склонностью к потреблению
Латентными переменными называются
(1) явные переменные
(2) значимые переменные
(3) скрытые переменные, которые нельзя непосредственно измерить
(4) незначимые переменные
Сериальный критерий стационарности применяется для
(1) проверки стационарности коэффициентов модели
(2) проверки стационарности временного ряда
(3) проверки стационарности переменных
Превышение доходности yt от держания рискованных ценных бумаг над государственными облигациями, рассчитанными на погашение в течение одного периода времени, принятого за единицу, определяется выражениием
(1) Mt — 1yt = mt
(2) yt = 2Rt — rt + 1 — rt
(3) yt = mt + et
(4) yt = -0,0241 + 0,687ht + et
Для оценки параметров a, b уравнения регрессии применяют метод
(1) метод правдоподобия
(2) наименьших квадратов (МНК)
(3) метод корректировки ошибок
Показателем статистической связи между двумя переменными является
(1) частный коэффициент ковариации
(2) частный коэффициент детерминации
(3) частный коэффициент корреляции
Сколько существует основных подходов к решению проблемы гетероскедастичности?
(1) два
(2) один
(3) три
(4) четыре
За вклад в развитие эконометрической науки присуждены Нобелевские премии следующим ученым
(1) К. Гауссу, П. Лапласу
(2) Дж. Боксу, Г. Дженкинсу
(3) Р. Фришу, Я. Тинбергену
(4) Р. Фришу, К. Гауссу
Выравнивание считается удовлетворительным, если остатки e(t) образуют стационарный процесс
(1) с математическим ожиданием m e(t) = M[e(t)] = бесконечность
(2) с математическим ожиданием m e(t) = M[e(t)] = 1
(3) с нулевым математическим ожиданием m e(t) = M[e(t)] = 0
Для удобства сопоставления сглаженного и исходного рядов ширину интервала сглаживания чаще выбирают исходя из условия
(1) m = 2k + 3
(2) m = 2k + 2
(3) m = 2k + 4
(4) m = 2k + 1
Необходимое условие идентификации формулируется следующим образом: коэффициенты уравнения идентифицируемы
(1) при k + 1 > r
(2) при k + 1 < r
(3) при k + 1 = r
Однозначное отображение, сохраняющее структуру модели, называется
(1) гетероморфизмом
(2) стереоморфизмом
(3) изоморфизмом
(4) все перечисленное
Для АР(1)-модели частные автокорреляционные функции между yt и yt — 2 равны
(1) единице
(2) бесконечности
(3) нулю
(4) равны между собой
Одним из методов прогнозирования дисперсии является
(1) введение последовательных значений xt
(2) введение независимой переменной
(3) линеаризация модели
Уровень надежности равный 0,95 характеризует
(1) 5%-ный уровень надежности прогноза
(2) 95%-ный уровень надежности прогноза
Если случайная величина является нормированной нормально распределенной величиной, то выполняется условие
(1) математическое ожидание равно 1
(2) математическое ожидание равно 0
Для проверки ошибок модели на гомоскедастичность используют
(1) тест Голдфелда — Квандта
(2) метод Гаусса — Маркова
(3) критерий Спирмена
(4) все перечисленное не верно
Закон, в котором выяснялись закономерности спроса на основе соотношений между урожаем зерновых и ценами на зерно, носит название
(1) закон Л. Клейна
(2) закон Г. Люсака
(3) закон Р. Фриша
(4) закон Кинга
Корреляционным полем временного ряда X(t) называется
(1) множество точек M(X(t)) на плоскости (t, OX)
(2) множество точек Dx(t) на плоскости (t, OX)
(3) множество точек (t, X(t)) на плоскости (t, OX)
(4) множество точек (Dx, X(t)) на плоскости (t, OX)
Как обычно называют сглаживание временного ряда?
(1) оператором
(2) фильтром
(3) фильтрованием
(4) все перечисленное верно
Возможность нескольких вариантов расчета структурных коэффициентов кейнсианской модели называется
(1) неидентифицируемостью
(2) идентифицируемостью
(3) сверхидентифицируемостью
(4) все перечисленное не верно
Каждая связь диаграммы путей включает в себя
(1) все перечисленное
(2) две переменные
(3) не менее пяти переменных
(4) четыре переменные
Возможность получения оценок по одной реализации процесса называется
(1) стохастичность
(2) стационарность
(3) автокорреляция
(4) эргодичность
Коэффициент детерминации определяется выражением
(1) D(Y) = D(Y1 + e) = D(Y1) + D(e) + 2cov(Y1,e)
(2) R2 = D(Y1)/D(Y)
(3) D(Y) = D(a + bx) + D(e)
При хорошем качестве построенной модели средняя относительная ошибка аппроксимации составляет
(1) 24–29%
(2) 14-19%
(3) 34–39%
(4) 4–9%
Согласно теореме Гаусса — Маркова случайные возмущения…
(1) коррелированы друг с другом
(2) не коррелированы друг с другом,имеют постоянную дисперсию
(3) имеют дисперсии равные единице
(4) все перечисленное
Одним из первых количественных законов стал закон
(1) закон Дж. Кларка
(2) закон Л. Клейна
(3) закон Кинга
(4) закон Р. Фриша
Процесс выделения тренда (выравнивание ряда) включает следующие этапы…
(1) определение числовых значений параметров кривой
(2) выбор типа кривой, соответствующей характеру изменения ряда
(3) оценка качества подобранной модели тренда
(4) все перечисленное верно
В кейнсианской модели переменные Yt и Сt называются
(1) приведенной переменной
(2) экзогенной переменной
(3) составляющей переменной
(4) эндогенными переменными
Вторым этапом структурного моделирования является следующий
(1) программа проверяет, насколько хорошо полученные дисперсии и ковариации отвечают данной модели
(2) исследователь (пользователь) описывает (обычно с помощью диаграммы путей) модель, представляющую его понимание зависимостей между переменными
(3) программа сообщает пользователю полученные результаты статистических испытаний, а также выводит оценки параметров и стандартные ошибки для численных коэффициентов в линейных уравнениях и одновременно выдает большое количество дополнительной диагностической информации
(4) программа с помощью специальных внутренних методов определяет, какие значения дисперсий и ковариаций переменных получаются в текущей модели на основании входных данных
Автоковариации предельных значений yt
(1) конечны и не зависят от времени
(2) конечны и зависят от времени
(3) бесконечные
(4) бесконечные и не зависят от времени
Укажите все ограничения на поведение случайного слагаемого e в условиях Гаусса — Маркова, выполнение которых предполагается при использовании для оценки коэффициентов модели метода наименьших квадратов
(1) все перечисленное верно
(2) для всех i = 1, 2, 3, …, n случайные ошибки ei распределены по нормальному закону, а x = (x1, x2, … xn) — фиксированный вектор
(3) ошибки модели ei при разных наблюдениях независимы
(4) нулевое математическое ожидание, М(ei) = 0, i = 1, 2, …, n
При оценке математических ожиданий справедливо следующее
(1) My = M(Xb + e) = M(Xb) + M(e) = -M(Xb) = -Xb
(2) My = M(Xb + e) = M(Xb) + M(e) = M(Xb) = Xb
(3) My = M(Xb + e) = M(Xb)/M(e) = M(Xb) = Xb
(4) My = M(Xb + e) = M(Xb) — M(e) = M(Xb) = Xb
Тест ранговой корреляции Спирмена не требует предположения о
(1) нормальности распределения коэффициента корреляции
(2) нормальности распределения регрессоров
(3) нормальности распределения регрессионных остатков
(4) все перечисленное неверно
Впервые термин «эконометрия» ввел
(1) Л. Клейн
(2) Р. Фриш
(3) П. Цьемпа
(4) В. Джакоб
Коррелограмма показывает убывание положительных rl при возрастании l в случаях…
(1) ряд имеет относительно небольшие колебания вокруг тренда
(2) если ряд имеет тренд
(3) существует явная зависимость между прошлым и будущим ряда
(4) все перечисленное верно
В кейнсианской модели переменная It формируется под воздействием…
(1) внешних факторов и политической надстройки
(2) внутренних факторов и политической надстройки
(3) внутренних факторов
(4) все перечисленное
Подтверждающий факторный анализ используется…
(1) для анализа корреляционной матрицы общих факторов
(2) проверки гипотезы о равенстве дисперсий у всех переменных
(3) все перечисленное
(4) для проверки определенных гипотез о структуре факторных нагрузок
Гипотеза о постоянстве дисперсии принимается при условии
(1) Fрасч > Fтабл(a, n1 — 1, n2 — 1), (a — уровень значимости)
(2) Fрасч = Fтабл(a, n1 — 1, n2 — 1), (a — уровень значимости)
(3) Fрасч < Fтабл(a, n1 — 1, n2 — 1), (a — уровень значимости)
(4) во всех случаях
Простейшая регрессионная модель имеет вид
(1) Y = a2 + bx2
(2) Y = a + bx + e
(3) Y = a — bx
(4) Y =(a/bx) + e
при использовании метода наименьших квадратов (МНК) минимизируется
(1) произведение остатков модели
(2) разность квадратов остатков модели
(3) сумма квадратов остатков модели
(4) произведение квадратов остатков модели
Для определения наличия гетероскедастичности применяют
(1) наблюдения
(2) эксперименты
(3) тесты
(4) расчеты
Анализ временных рядов проводится
(1) методами распознавания образов
(2) методами теории случайных процессов
(3) методами кластерного анализа
(4) методом наименьших квадратов
К причинам возникновения в экономических моделях зависимости между объясняющими переменными Xiu и случайными ошибками eu относится и такая
(1) один из факторов может влиять на поведение объясняющей переменной
(2) один из факторов может одновременно влиять на поведение случайной ошибки и объясняющей переменной
(3) один из факторов может влиять на поведение случайной ошибки
(4) один из факторов не может одновременно влиять на поведение случайной ошибки и объясняющей переменной
Техника моделирования структурными уравнениями основывается на…
(1) все перечисленное верно
(2) факторном анализе
(3) множественной регрессии
(4) многомерном анализе
При априорном предположении о нормальном законе распределения значений временного ряда применяют
(1) критерий Фишера
(2) методологию Бокса — Дженкинса
(3) критерий Стьюдента
(4) параметрические тесты проверки стационарности
Зависимую переменную в регрессионном анализе называют
(1) регрессором
(2) предиктором
(3) результативным признаком
Включение несущественной переменной в модель оказывает следующие последствия
(1) вызывает рост стандартных ошибок коэффициентов
(2) оценки становятся статистически незначимыми
(3) не приводит к смещению оценок коэффициентов
(4) все перечисленное верно
Предположение о том, что ошибки ei наблюдений имеют разные дисперсии, называется
(1) гомоскедастичностью наблюдений
(2) регрессией наблюдений
(3) гетероскедастичностью
(4) ковариацией наблюдений
Основным содержанием ПЭП является…
(1) выявления объективных условий, факторов и тенденций развития
(2) количественный анализ реальных экономических процессов
(3) качественный анализ реальных экономических процессов
(4) все перечисленное верно
При использовании Теста Чоу строятся следующие регрессионные модели
(1) по всей выборке наблюдений
(2) по наблюдениям после происшедших изменений в структуре связей
(3) по наблюдениям, проведенным до изменений
(4) все перечисленное верно
Фиктивные переменные позволяют
(1) строить модели для исследования будущих структурных изменений
(2) строить модели для исследования случайных изменений
(3) все перечисленное
(4) строить модели для исследования структурных изменений
Стандартная процедура регрессионного анализа, выполняемого на основе метода наименьших квадратов, требует выполнения условий
(1) Стьюдента
(2) Гаусса — Маркова
(3) Фишера
(4) Гаусса
Для чего используются эконометрические методы
(1) верны все перечисленные варианты
(2) для прогнозирования в финансах
(3) для прогнозирования в банковском деле
(4) для прогнозирования в бизнесе
Коррелограммой называют
(1) значения M(X(t)), нанесенные на плоскость с осями i и r и соединенные ломаной
(2) все перечисленное
(3) значения Dx(t), нанесенные на плоскость с осями i и r и соединенные прямой
(4) значения ri, нанесенные на плоскость с осями i и r и соединенные ломаной
Причинные модели могут включать
(1) эндогенные переменные
(2) явные переменные и латентные переменные
(3) экзогенные переменные и латентные переменные
(4) явные переменные и эндогенные переменные
В случае, когда в модель не включена существенная переменная, наблюдаются следующие последствия
(1) коэффициенты при оставшихся переменных становятся смещенными
(2) стандартные ошибки коэффициентов и t-статистики некорректны
(3) исчезает возможность правильной оценки и интерпретации уравнений
(4) все перечисленное
Укажите случайную составляющую выражения Y(t) = q(t) + P(t) + e(t)
(1) P(t) — периодическая составляющая
(2) q(t) — непериодическая составляющая
(3) e(t) — погрешность ряда
(4) все перечисленное верно
Сглаживание является центрированным и симметричным при условии
(1) а — r = ar + 1
(2) а — r = a/r
(3) а — r = ar — 1
(4) а — r = ar
Латентные переменные указываются
(1) над стрелками
(2) внутри прямоугольников
(3) над дугами
(4) внутри овалов или окружностей
При значениях k близких к объему выборки N можно получить следующее значение Rвыб в квадрате
(1) близкое к нулю
(2) близкое к единице
(3) все перечисленное
Временной ряд — это
(1) значения величины X(t), расположенные в определенной последовательности
(2) последовательности значений случайной величины X
(3) последовательность значений случайной величины X(t)
(4) последовательности значений случайной величины t
Техника моделирования структурными уравнениями в пакете STATISTICA имеет аббревиатуру
(1) PATH
(2) SEPA
(3) SEPATH
(4) ATH
Теорема Гаусса — Маркова предполагает
(1) все перечисленное верно
(2) нулевую корреляцию между e и Хi
(3) некоррелированность случайного члена и регрессоров
Предположение о том, что ошибки ei наблюдений имеют одинаковые дисперсии, называется
(1) регрессией наблюдений
(2) гомоскедастичностью наблюдений
(3) ковариацией наблюдений
(4) гетероскедастичностью наблюдений
Для уменьшения амплитуды колебаний у сглаженного ряда Y(t) необходимо
(1) уменьшать ширину интервала сглаживания m
(2) увеличивать ширину интервала сглаживания m
(3) сокращать количество определяющих переменных
(4) увеличивать количество определяющих переменных
Структурные модели с линейными зависимостями являются
(1) прогнозными
(2) точными
(3) приближенными
Для проверки стационарности временного ряда применяют
(1) критерий Фишера
(2) сериальный критерий стационарности
(3) тест Сиджела — Тьюки
(4) тест Манна — Уитни
Проверка значимости коэффициентов уравнения регрессии производится по
(1) критерию Уитни
(2) критерию Стьюдента
(3) коэффициенту корреляции
(4) коэффициенту детерминации
Нулевая гипотеза о незначимости уравнения регрессии отвергается и принимается гипотеза о значимости уравнения регрессии, если
(1) Fнабл =Fкрит(a, nрегр, nост)
(2) Fнабл < Fкрит(a, nрегр, nост)
(3) во всех случаях
(4) Fнабл > Fкрит(a, nрегр, nост)
Коэффициент a в выражении Y(t) = Y(t — 1) + a(X(t) — Y(t — 1) является
(1) коэффициентом поправки на систематические ошибки
(2) коэффициентом поправки на «новизну»
(3) коэффициентом поправки на неучтенные факторы
(4) все перечисленное не верно
Всегда ли построенные зависимости отражают реальные связи между переменными?
(1) всегда отражают
(2) отражают причинные связи в наборе переменных, но не предполагают реального наличия таких связей
(3) отражают только в линейных моделях регрессии
(4) отражают причинные связи в наборе переменных, и предполагают реальное наличие таких связей
Под мультиколлинеарностью понимается
(1) низкая степень коррелированности объясняющих переменных
(2) высокая степень не коррелированности объясняющих переменных
(3) высокая степень коррелированности объясняющих переменных
(4) низкая степень не коррелированности объясняющих переменных
Ширина интервала для сглаживания ряда рассчитывается по формуле
(1) k + l — 1
(2) k — l — 1
(3) k + l + 2
(4) k + l + 1
Коэффициенты уравнений, входящие в структурную систему уравнений, можно разделить на две группы…
(1) подлежащие определению и заранее известные из исходных теоретических предположений о модели
(2) экзогенные и предопределенные
(3) подлежащие определению и экзогенные
(4) подлежащие определению и предопределенные
Диаграммы путей представляют собой
(1) ломаные линии
(2) блок-схемы и содержат переменные, связанные линиями, которые отображают причинные связи
(3) блок схемы
(4) ломаные линии, которые отображают причинные связи
Показателями качества построенной модели являются
(1) математическое ожидание
(2) дисперсия
(3) средняя относительная ошибка аппроксимации
(4) коэффициент корреляции
Структурный параметр называется неидентифицируемым, если
(1) если существует несколько формул расчета этого коэффициента через коэффициенты приведенной формы модели
(2) не существует формула расчета этого коэффициента через коэффициенты приведенной формы модели
(3) существует формула расчета этого коэффициента через коэффициенты приведенной формы модели
Путевая диаграмма содержит следующие элементы…
(1) все перечисленное
(2) дисперсию независимых переменных
(3) независимые переменные
(4) линейные уравнения
Первым этапом структурного моделирования является следующий
(1) программа с помощью специальных внутренних методов определяет, какие значения дисперсий и ковариаций переменных получаются в текущей модели на основании входных данных
(2) программа проверяет, насколько хорошо полученные дисперсии и ковариации отвечают данной модели
(3) исследователь (пользователь) описывает (обычно с помощью диаграммы путей) модель, представляющую его понимание зависимостей между переменными
(4) программа сообщает пользователю полученные результаты статистических испытаний, а также выводит оценки параметров и стандартные ошибки для численных коэффициентов в линейных уравнениях и одновременно выдает большое количество дополнительной диагностической информации
Какие условия отрицательно сказываются на объясняющих свойствах модели?
(1) все перечисленное верно
(2) избыточное присутствие незначимой объясняющей переменной
(3) отсутствие значимой переменной
Для чего применяется Тест Чоу?
(1) проверки нулевой гипотезы в задаче выявления мультиколлинеарности
(2) проверки структурных изменений модели
(3) проверки значимости коэффициентов регрессионной модели
(4) расчета коэффициента корреляции
В моделях с бинарными переменными переменные принимают следующие значения
(1) 0 и -1
(2) 0 и 1
(3) -1 и 1
Если случайные величины Xi не только центрированы, но и нормированы, выполняются следующие условия
(1) M(Xi) = 1 D(Xi) = 1
(2) M(Xi) = 1 D(Xi) = 0
(3) M(Xi) = 0, D(Xi) = 0
(4) M(Xi) = 0, D(Xi) = 1
При расчетах первое сглаженное значение Y(k + 1) вычисляется по формуле
(1) Y(k + 1) = (X(1) + X(2) + … + X(m))/2m
(2) Y(k + 1) = (X(1) + X(2) + … + X(m)) * m
(3) Y(k + 1) = (X(1) + X(2) + … + X(m)) — m
(4) Y(k + 1) = (X(1) + X(2) + … + X(m))/m
Одним из основных условий для главных компонент z1 и z2 является
(1) компоненты коррелируют между собой
(2) компоненты имеют сильную корреляцию между собой
(3) компоненты не коррелируют между собой
(4) компоненты имеют слабую корреляцию между собой
Процесс сглаживания ряда называют
(1) отбором
(2) фильтрованием
(3) упрощением
(4) сглаживанием
В случае если объясняющие переменные модели могут принимать любые значения в некотором интервале данных, их называют
(1) качественными переменными
(2) категорийными переменными
(3) количественными переменными
(4) бинарными переменными
Для центрированных случайных величин выполняется следующее условие
(1) М(Xi) = 1
(2) М(Xi) = -1
(3) М(Xi) = 0
(4) М(Xi) =стремится к 1
Дисперсия сглаженного по квадратичному полиному ряда Y(t) при увеличении числа m уравнений
(1) остается без изменения
(2) увеличивается
(3) уменьшается
Одним из распространенных способов выявления тренда является
(1) все перечисленное
(2) сглаживание временного ряда
(3) разложение рада на множители
(4) логарифмирование ряда
Дисперсия сглаженного ряда
(1) больше дисперсии исходного ряда
(2) меньше дисперсии исходного ряда
(3) остается неизменной
В сглаженном временном ряде Y(t) процедуру сглаживания начинают
(1) с последнего члена ряда
(2) с первого члена ряда
(3) с максимального члена ряда
(4) со второго члена ряда