From Wikipedia, the free encyclopedia
For broader coverage of this topic, see Approximation.
«Absolute error» redirects here. Not to be confused with Absolute deviation.

 (blue) with its linear approximation
(blue) with its linear approximation  (red) at a = 0. The approximation error is the gap between the curves, and it increases for x values further from 0.
(red) at a = 0. The approximation error is the gap between the curves, and it increases for x values further from 0.The approximation error in a data value is the discrepancy between an exact value and some approximation to it. This error can be expressed as an absolute error (the numerical amount of the discrepancy) or as a relative error (the absolute error divided by the data value).
An approximation error can occur for a variety of reasons, among them a computing machine precision or measurement error (e.g. the length of a piece of paper is 4.53 cm but the ruler only allows you to estimate it to the nearest 0.1 cm, so you measure it as 4.5 cm).
In the mathematical field of numerical analysis, the numerical stability of an algorithm indicates the extent to which errors in the input of the algorithm will lead to large errors of the output; numerically stable algorithms to not yield a significant error in output when the input is malformed and vice versa. [1]
Formal definition[edit]
Given some value v and its approximation vapprox, the absolute error is
 [2][3]
[2][3]

where the vertical bars denote the absolute value.
If  the relative error is
the relative error is

and the percent error (an expression of the relative error) is [3]

An error bound is an upper limit on the relative or absolute size of an approximation error.[4]
Generalizations[edit]
|
This section needs expansion. You can help by adding to it. (April 2023) |
These definitions can be extended to the case when  and
and  are n-dimensional vectors, by replacing the absolute value with an n-norm.[5]
are n-dimensional vectors, by replacing the absolute value with an n-norm.[5]
Examples[edit]

- v
- t
- e
As an example, if the exact value is 50 and the approximation is 49.9, then the absolute error is 0.1 and the relative error is 0.1/50 = 0.002 = 0.2%. As a practical example, when measuring a 6 mL beaker, the value read was 5 mL. The correct reading being 6 mL, this means the percent error in that particular situation is, rounded, 16.7%.
The relative error is often used to compare approximations of numbers of widely differing size; for example, approximating the number 1,000 with an absolute error of 3 is, in most applications, much worse than approximating the number 1,000,000 with an absolute error of 3; in the first case the relative error is 0.003 while in the second it is only 0.000003.
There are two features of relative error that should be kept in mind. First, relative error is undefined when the true value is zero as it appears in the denominator (see below). Second, relative error only makes sense when measured on a ratio scale, (i.e. a scale which has a true meaningful zero), otherwise it is sensitive to the measurement units. For example, when an absolute error in a temperature measurement given in Celsius scale is 1 °C, and the true value is 2 °C, the relative error is 0.5. But if the exact same approximation is made with the Kelvin scale, a 1 K absolute error with the same true value of 275.15 K = 2 °C gives a relative error of 3.63×10−3.
Instruments[edit]
In most indicating instruments, the accuracy is guaranteed to a certain percentage of full-scale reading. The limits of these deviations from the specified values are known as limiting errors or guarantee errors.[6]
See also[edit]
- Accepted and experimental value
- Condition number
- Errors and residuals in statistics
- Experimental uncertainty analysis
- Machine epsilon
- Measurement error
- Measurement uncertainty
- Propagation of uncertainty
- Quantization error
- Relative difference
- Round-off error
- Uncertainty
References[edit]
- ^ Weisstein, Eric W. «Numerical Stability». mathworld.wolfram.com. Retrieved 2023-06-11.
- ^ Weisstein, Eric W. «Absolute Error». mathworld.wolfram.com. Retrieved 2023-06-11.
- ^ a b «Absolute and Relative Error | Calculus II». courses.lumenlearning.com. Retrieved 2023-06-11.
- ^ «Approximation and Error Bounds». www.math.wpi.edu. Retrieved 2023-06-11.
- ^ Golub, Gene; Charles F. Van Loan (1996). Matrix Computations – Third Edition. Baltimore: The Johns Hopkins University Press. p. 53. ISBN 0-8018-5413-X.
- ^ Helfrick, Albert D. (2005) Modern Electronic Instrumentation and Measurement Techniques. p. 16. ISBN 81-297-0731-4
External links[edit]
- Weisstein, Eric W. «Percentage error». MathWorld.
Средняя ошибка аппроксимации.
Фактические
значения результативного признака
![]() отличаются от теоретических, рассчитанных
отличаются от теоретических, рассчитанных
по уравнению регрессии![]() .
.
Величина отклонений![]() по каждому наблюдению представляет
по каждому наблюдению представляет
собойошибку
аппроксимации.
Их число соответствует объему
совокупности
(k).
В отдельных случаях ошибка аппроксимации
может оказаться равной нулю. Для сравнения
используются величины отклонений,
выраженные в процентах к фактическим
значениям.
Отклонения
![]() можно рассматривать какабсолютную
можно рассматривать какабсолютную
ошибку
аппроксимации, а ![]() −как
−как
относительную
ошибку
аппроксимации.
Чтобы
иметь общее суждение о качестве модели
из относительных отклонений по каждому
наблюдению, определяют среднюю ошибку
аппроксимации как среднюю арифметическую
простую:
![]() .
.
Ошибка
аппроксимации в пределах 5 – 7%
свидетельствует о хорошем подборе
модели к исходным данным. Допустимый
предел
значений
А
− не более 8− 10% (допускается 8− 15%).
Возможно
и иное определение средней ошибки
аппроксимации:
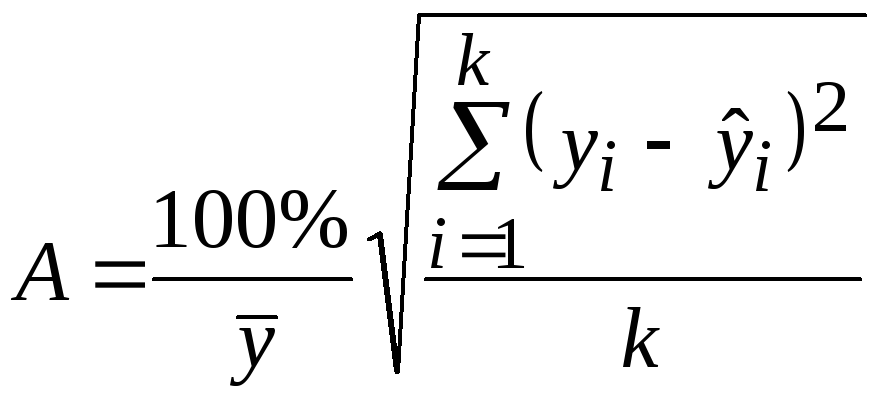 .
.
В
стандартных программах чаще используется
первая формула.
12
Оценка этой формы связи по коэффициенту множественной корреляции и средней ошибке аппроксимации показывает, что адекватность данной модели не подтверждается. Действительно, хотя значение коэффициента достаточно высокое (0,92), средняя ошибка аппроксимации составляет более 10% (I = 14,5%). Поэтому данная форма должна быть исключена из перебора известных уравнений регрессии. [c.29]
Анализ полученной формы связи по той же причине, что и в первом случае, позволяет сделать вывод о непригодности и этой модели. Коэффициент множественной корреляции хотя и имеет более высокое значение, чем в линейной зависимости (0,93), но по величине средней ошибки аппроксимации (б = 12,4%) это уравнение регрессии подлежит исключению из дальнейшего перебора. [c.29]
Последняя модель себестоимости добычи нефти, как показывает оценка ее по известным критериям, удовлетворяет условиям адекватности. Коэффициент множественной корреляции R составляет 0,98, что свидетельствует о том, что колеблемость исследуемого показателя более чем на 96 % определяется факторами, включенными в эту модель. При оценке по f-критерию (t R = 30,5) можно утверждать, что с вероятностью 0,99 факторы, включенные в модель, имеют существенную связь с исследуемым показателем (t a n = 2,58). Средняя ошибка аппроксимации составляет всего лишь 2,9 %, а F-критерий, характеризующий уровень остаточной дисперсии, превышает критическое (табличное) значение в четыре раза. К этому следует добавить, что полученная модель себестоимости добычи нефти представляет собой достаточно простую форму связи, легко решается и поддается экономической интерпретации. [c.30]
Оценка полученной модели по статистическим характеристикам показывает, что колеблемость затрат исследуемой подсистемы на 85 % обусловлена колеблемостью факторов, включенных в модель, коэффициент множественной корреляции высокий (/ = 0,92) и существенный (f = = 39,8), модель является адекватной, средняя ошибка аппроксимации (ё = 5,7%) меньше 10%. [c.39]
Чем продолжительнее период, по данным которого построены модели, тем меньше темп роста ошибки аппроксимации при прочих равных условиях. Следовательно, чем короче период упреждения, тем короче следует брать и период анализа, и, наоборот, при долгосрочном планировании необходимо использовать максимально возможную продолжитель- [c.64]
Статистический анализ показывает, что уравнение значимо Рф = 5,054 при /»табл = 3,01, корреляционное отношение равно 0,9959, ее»стандартная ошибка равна 0,0015. Среднее квадратическое отклонение расчетной себестоимости от фактической равно 0,018. Средняя ошибка аппроксимации 1,1%. [c.90]
Средняя ошибка аппроксимации [c.94]
Средняя ошибка аппроксимации……,……. [c.95]
В случаях, когда трудно обосновать форму зависимости, решение задачи можно провести по разным моделям и сравнить полученные результаты. Адекватность разных моделей фактическим зависимостям проверяется по критерию Фишера, показателю средней ошибки аппроксимации и величине множественного коэффициента детерминации, о которых речь пойдет несколько позже (см. 7.4). [c.144]
Эти сведения вводятся в ПЭВМ и рассчитываются матрицы парных и частных коэффициентов корреляции, уравнение множественной регрессии, а также показатели, с помощью которых оценивается надежность коэффициентов корреляции и уравнения связи критерий Стьюдента, критерий Фишера, средняя ошибка аппроксимации, множественные коэффициенты корреляции и детерминации. [c.145]
Для того чтобы убедиться в надежности уравнения связи и правомерности его использования для практической цели, необходимо дать статистическую оценку надежности показателей связи. Для этого используются критерий Фишера (F-отношение), средняя ошибка аппроксимации ( ), коэффициенты множественной корреляции (/ ) и детерминации (D). [c.151]
Для статистической оценки точности уравнения связи используется также средняя ошибка аппроксимации [c.152]
Чем меньше теоретическая линия регрессии (рассчитанная по уравнению) отклоняется от фактической (эмпиричной), тем меньше средняя ошибка аппроксимации. В нашем примере она составляет 0,0364, или 3,64 %. Учитывая, что в экономических расчетах допускается погрешность 5-8 %, можно сделать вывод, что исследуемое уравнение связи довольно точно описывает изучаемые зависимости. [c.152]
После построения уравнения регрессии необходимо сделать проверку его значимости с помощью специальных критериев установить, не является ли полученная зависимость, выраженная уравнением регрессии, случайной, т.е. можно ли ее использовать в прогнозных целях и для факторного анализа. В статистике разработаны методики строгой проверки значимости коэффициентов регрессии с помощью дисперсионного анализа и расчета специальных критериев (например, F-критерия). Нестрогая проверка может быть выполнена путем расчета среднего относительного линейного отклонения (ё), называемого средней ошибкой аппроксимации [c.123]
Модель считается адекватной, т.е. пригодной для практического использования, если средняя ошибка аппроксимации не превосходит 15%. [c.123]
Подобное обоснование является приблизительным и нуждается в дальнейшем уточнении с помощью ошибки аппроксимации. [c.50]
Наибольшее значение ошибки аппроксимации свидетельствует о том, что оцениваемая модель дает наиболее адекватное описание формы взаимосвязи. Причем ошибка аппроксимации не должна превышать 0,2, или 20%. [c.52]
Подставляя последовательно значения времени /, получим теоретические уровни товарооборота. Ошибка аппроксимации для прямолинейной формы тренда составит [c.184]
Далее рассчитывается ошибка аппроксимации для функции тренда в виде параболы второго порядка по формуле [c.187]
Для повышения надежности прогноза потребности в нефтепродуктах по управлению в целом и определения границ его достоверности на всех этапах прогнозирования предусматривается проведение верификации. При верификации принимаются в расчет не все частные прогнозы, а только те из них, которые удовлетворяют требованиям статистической надежности, дают наименьшую ошибку аппроксимации, подтверждаются проверкой ретроспективным методом и дают результаты, близкие к фактическим значениям за последний год ретроспективного периода. Для облегчения проведения расчетов по алгоритму (рис. 7) на каждом этапе прогнозирования (кратко-, средне- и долгосрочный прогнозы) составляются подсобные таблицы по форме 010107 (табл. 6). [c.63]
Очевидно, что ошибки аппроксимации носят непериодический характер. В противном случае нужно было бы повторить всю процедуру, используя в качестве исходной выборки эти ошибки, и повторять ее до тех пор, пока не будут выделены все значимые гармоники. [c.137]
Оценку качества построенной модели даст коэффициент (индекс) детерминации, а также средняя ошибка аппроксимации. [c.6]
Средняя ошибка аппроксимации — среднее отклонение расчетных значений от фактических [c.6]
Подставляя в данное уравнение фактические значения х, получаем теоретические значения результата ух. По ним рассчитаем показатели тесноты связи — индекс корреляции рху и среднюю ошибку аппроксимации 7, [c.13]
А = 8,0%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах. Показательная функция чуть хуже, чем степенная, она описывает изучаемую зависимость. [c.15]
Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации. [c.16]
Это означает, что 52% вариации заработной латы (у) объясняется вариацией фактора х — среднедушевого прожиточного минимума. Качество модели определяет средняя ошибка аппроксимации [c.18]
Оцените качество модели, определив ошибку аппроксимации, индекс корреляции и F-критерий Фишера. [c.32]
Оцените качество модели. Для этого а) определите ошибку аппроксимации t б) найдите показатель тесноты связи прибыли с исследуемым в мо- [c.33]
Оцените с помощью средней ошибки аппроксимации качество уравнений. [c.38]
Оцените качество уравнений с помощью средней ошибки аппроксимации. [c.42]
Оцените качество уравнения через среднюю ошибку аппроксимации. [c.92]
Оцените качество каждого тренда через среднюю ошибку аппроксимации, линейный коэффициент автокорреляции отклонений. [c.166]
СРЕДНЯЯ ОШИБКА АППРОКСИМАЦИИ [c.87]
Параметры моделей и выбор формы связи, определяющие уровень затрат в зависимости от значений отобранных факторов, вычисляются по методике, изложенной в работе [51]. Затем исследуется характер изменения случайных отклонений (ошибки аппроксимации) по каждому НГДУ отдельно. Если обнаружится определенная закономерность их изменений, то вычисляется функция их изменения во времени, и далее плановый [c.68]
Такого рода характеристика явлений, влияющих на уровень и динамику валютного курса, является непременным этапом, предшествующим самостоятельному статистическому анализу факторов на основе конкретного цифрового материала. Дальнейший анализ выглядит чаще как моделирование взаимосвязей и оценка тесноты взаимозависимости (корреляционно-регрессионный анализ). Напомним, что выбор функции осуществляется исходя из показателей значимости уравнения и ошибок аппроксимации. Это относительная ошибка аппроксимации, средняя квадратическая ошибка аппроксимации (6ОСТ) (чем они меньше, тем лучше уравнение) и коэффициент множественной детерминации (R2) или коэффициент множественной корреляции (R) (чем ближе он к 1, тем более вероятность, что уравнение регрессии носит совершенно случайный характер). Для проверки значимости используют F-критерий с распределением Фишера. [c.670]