Как отмечалось в п.2.1, по ограниченным
данным выборки объема n можно
построить модель лишь с некоторой
точностью. её параметры a и b
являются оценками истинных значений α
и β, которые определяются генеральной
совокупностью объема N >> n.
Последней приписываются вероятностные
свойства с применением аксиом теории
вероятности, определений случайной
величины, вероятности, плотности
вероятности, оператора усреднения и
т.д. В рамках свойств генеральной
совокупности объема N рассматривается
спецификация модели линейной
регрессии
![]()
,
в
которой α, β, xi –
детерминированные (фиксированные или
известные) величины, а значения показателя
yi и ошибки модели i
– случайные величины (СВ) с
заданным распределением (например,
плотности вероятности). Часто yi,
i считаются
нормальными СВ (НСВ), тогда модель
называют нормальной.
Ограниченные данные выборки объема n
<< N позволяют вместо точной
модели (2.1) с параметрами α и β
построить приближенную модель (2.2)
![]()
.
Здесь еі – остатки
регрессии, вероятностные свойства
которых считаются аналогичными ошибкам
i , а
a, b – некоторые оценки (приближенные
значения) параметров модели.
Мы
будем оценивать дисперсии и
среднеквадратичные ошибки (СКО) для
оценок параметров модели и величины :
![]()
;
![]()
;
![]()
,
где M[X], D[X] – математическое
ожидание и дисперсия случайной величины
Х.
Для непрерывной случайной величины Х
с плотностью вероятности р(х)
они определяются как
![]()
,
![]()
.
Следовательно, для точного определения
того или иного параметра случайной
величины достаточно знать (или задать)
её распределение плотности вероятности.
2.4.1. Основные условия (гипотезы) анализа ошибок
Поскольку в корреляционно-регрессионном
анализе мы опираемся на методы
математической статистики и теории
вероятности, любые оценки ошибок
моделирования являются корректными
лишь при выполнении исходно принятых
условий (гипотез) в отношении величин
и переменных, входящих в модель. Примем
следующие гипотезы:
1. В спецификации модели (2.1) фактор х
и параметры модели α, β – детерминированные
величины, а показатель уi
и ошибки моделирования i
– случайные величины.
2. Ошибки моделирования имеют нулевое
среднее значение и некоррелированны:
![]()
Невыполнение второго условия называют
автокорреляцией ошибок модели.
3. Дисперсия ошибок моделирования i
показателя не зависят от номера i
(гомоскедастичность):
![]()
Невыполнение этого условия называют
гетероскедастичностью.
Дополнительным условием, которое может
не выполняться в ряде случаев, является
свойство нормальной модели:
4. Ошибки i
являются нормальными СВ:
N(0,
2) c нулевым
математическим ожиданием mε
= 0 и дисперсией 2.
2.4.2. Ошибки оценок параметров модели
Покажем сначала, что оценки МНК параметров
линейной модели являются несмещенными,
т.е. математические ожидания оценок
совпадают с истинными значениями
параметров:
M[b] = β, M[a] = α.
Действительно, согласно (2.12) и (2.7) имеем:

. (2.27)
С учетом (2.1), детерминированности vi
и условия
M[i]
= 0 гипотезы 2 получим в результате
усреднения оценки b в рамках
генеральной совокупности
![]()
.
Здесь использовано одно из свойств для
коэффициентов vi

(2.28)
которые
следуют из (2.27).
Аналогично, для параметра a с учетом
(2.6) и несмещенности b получим
![]()
.
Таким
образом, обе оценки МНК параметров
линейной модели являются несмещенными,
то есть сходятся при неограниченном
увеличении объема выборки к точным
значениям параметров α и β. Поэтому при
определении их дисперсий усредняются
квадраты разностей оценок и истинных
значений параметров.
Определим дисперсию коэффициента
регрессии. Известными свойствами
дисперсии СВ Х, умножаемой или
складываемой с константой с, являются:
![]()
. (2.29)
Тогда
с использованием (2.27) – (2.29)

.(2.30)
Здесь принято во внимание, что дисперсии
D[yi] =D[i],
так как показатель и ошибка модели
как случайные величины отличаются на
детерминированное слагаемое a+ bxi.
Дисперсию
постоянной составляющей модели определим
как
![]()
. (2.31)
Так как
![]()
. (2.32)
и
![]()
, (2.33)
то с
учетом (2.32), (2.33) дисперсия (2.31) становится
равной

. (2.34)
Более
сложным является определение оценки
дисперсии ошибок модели. Опуская вывод,
приведем окончательную формулу для
несмещенной оценки дисперсии ошибок
моделирования
![]()
, (2.35)
выраженную
через остатки регрессии (2.2).
Выражения (2.30), (2.34) дают точные значения
дисперсий оценок параметров модели,
однако практически воспользоваться
ими нельзя, так как точное значение
дисперсии ошибок 2
неизвестно (оно определяется из
генеральной совокупности, а не из
выборки). На основе выборочных данных
можно лишь оценить с помощью (2.35) эту
дисперсию. Поэтому на практике в формулы
(2.31), (2.35) вместо 2
подставляют её оценку (2.35) и получают
оценки дисперсий параметров b и a:

, (2.36)

. (2.37)
Эти
оценки используют лишь выборочные
данные. СКО этих оценок равны положительным
значениям квадратного корня из дисперсий.
В
лияние
СКО оценок параметров на точность модели
отражается на рис.2.5, а, б. Сдвиг
постоянной составляющей в пределах а
а
не является существенным при моделировании,
так как он не изменяется при всех
значениях фактора х и его можно
легко скорректировать. Более существенные
последствия имеет ошибка в определении
коэффициента регрессии b. Как видно
из рис.2.5, б, ошибки в прогнозах
показателя у* становятся тем
больше, чем больше отклонение от среднего
значения фактора х. Стандартное отклонение
у* b
имеет место при
![]()
.
В общем случае граничная ошибка регрессии
(с доверительной вероятностью 68%)
пропорциональна величине
![]()
.
Иначе говоря, чем больше отличается
значение фактора х при прогнозе от
среднего, тем больше можно ошибиться в
результате прогнозирования. Ясно также,
что СКО b
уменьшается с ростом объема выборки n,
так как растет число положительных
слагаемых в знаменателе (2.36).

а б
Рис.2.5
Пример 2.2. Оценим
СКО и доверительные интервалы оценок
параметров модели примера 2.1 для малой
выборки объема n
= 5, приняв доверительную вероятность Р
= 0,954.
Оценка дисперсии
ошибок модели согласно (2.36) и расчетов,
приведенных в таблице 2.1, равна
![]()
.
Тогда СКО оценок
b
= 0,588 a
= – 0,529 параметров модели в соответствии
с (2.37), (2.38) равны
![]()
.
Ошибки оказались
сравнительно большими в связи с малым
объемом выборки (n
= 5). Найденные значения СКО являются
точечными ошибками оценок параметров.
Определим далее доверительные интервалы
этих оценок. Для нормальной модели
граничная ошибка равна
Δ = tσ,
где
параметр доверия t
= 1 при доверительной вероятности Р
= 0,68,
t = 2
при Р
= 0,954,
t =
3 при Р
= 0,997.
В нашем примере
t = 2
(Р
= 0,954), Δb
= 0,256, Δa
= 1,678,
тогда
доверительные интервалы для истинных
значений параметров
и α с границами b
Δb,
a
Δa
определяются как
[0,332; 0,844],
α
[ – 2,207; 1,149].
Это значит, что
при доверительной вероятности 95,4%
коэффициент регрессии
b (и,
соответственно, наклон прямой линии
модели) может измениться более чем в
2,5 раза, а девиация (отклонение) постоянной
составляющей а
близка к
1,7 у.е. Очевидно, подобные ошибки малой
выборки неприемлемы для практических
целей, поэтому реальные объемы выборки
должны составлять десятки, сотни и более
элементов.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

In statistics, the standard deviation is a measure of the amount of variation or dispersion of a set of values.[1] A low standard deviation indicates that the values tend to be close to the mean (also called the expected value) of the set, while a high standard deviation indicates that the values are spread out over a wider range.
Standard deviation may be abbreviated SD, and is most commonly represented in mathematical texts and equations by the lower case Greek letter σ (sigma), for the population standard deviation, or the Latin letter s, for the sample standard deviation.
The standard deviation of a random variable, sample, statistical population, data set, or probability distribution is the square root of its variance. It is algebraically simpler, though in practice less robust, than the average absolute deviation.[2][3] A useful property of the standard deviation is that, unlike the variance, it is expressed in the same unit as the data.
The standard deviation of a population or sample and the standard error of a statistic (e.g., of the sample mean) are quite different, but related. The sample mean’s standard error is the standard deviation of the set of means that would be found by drawing an infinite number of repeated samples from the population and computing a mean for each sample. The mean’s standard error turns out to equal the population standard deviation divided by the square root of the sample size, and is estimated by using the sample standard deviation divided by the square root of the sample size. For example, a poll’s standard error (what is reported as the margin of error of the poll), is the expected standard deviation of the estimated mean if the same poll were to be conducted multiple times. Thus, the standard error estimates the standard deviation of an estimate, which itself measures how much the estimate depends on the particular sample that was taken from the population.
In science, it is common to report both the standard deviation of the data (as a summary statistic) and the standard error of the estimate (as a measure of potential error in the findings). By convention, only effects more than two standard errors away from a null expectation are considered «statistically significant», a safeguard against spurious conclusion that is really due to random sampling error.
When only a sample of data from a population is available, the term standard deviation of the sample or sample standard deviation can refer to either the above-mentioned quantity as applied to those data, or to a modified quantity that is an unbiased estimate of the population standard deviation (the standard deviation of the entire population).
Basic examples[edit]
Population standard deviation of grades of eight students[edit]
Suppose that the entire population of interest is eight students in a particular class. For a finite set of numbers, the population standard deviation is found by taking the square root of the average of the squared deviations of the values subtracted from their average value. The marks of a class of eight students (that is, a statistical population) are the following eight values:

These eight data points have the mean (average) of 5:

First, calculate the deviations of each data point from the mean, and square the result of each:

The variance is the mean of these values:

and the population standard deviation is equal to the square root of the variance:

This formula is valid only if the eight values with which we began form the complete population. If the values instead were a random sample drawn from some large parent population (for example, they were 8 students randomly and independently chosen from a class of 2 million), then one divides by 7 (which is n − 1) instead of 8 (which is n) in the denominator of the last formula, and the result is  In that case, the result of the original formula would be called the sample standard deviation and denoted by s instead of
In that case, the result of the original formula would be called the sample standard deviation and denoted by s instead of  Dividing by n − 1 rather than by n gives an unbiased estimate of the variance of the larger parent population. This is known as Bessel’s correction.[4][5] Roughly, the reason for it is that the formula for the sample variance relies on computing differences of observations from the sample mean, and the sample mean itself was constructed to be as close as possible to the observations, so just dividing by n would underestimate the variability.
Dividing by n − 1 rather than by n gives an unbiased estimate of the variance of the larger parent population. This is known as Bessel’s correction.[4][5] Roughly, the reason for it is that the formula for the sample variance relies on computing differences of observations from the sample mean, and the sample mean itself was constructed to be as close as possible to the observations, so just dividing by n would underestimate the variability.
Standard deviation of average height for adult men[edit]
If the population of interest is approximately normally distributed, the standard deviation provides information on the proportion of observations above or below certain values. For example, the average height for adult men in the United States is about 70 inches, with a standard deviation of around 3 inches. This means that most men (about 68%, assuming a normal distribution) have a height within 3 inches of the mean (67–73 inches) – one standard deviation – and almost all men (about 95%) have a height within 6 inches of the mean (64–76 inches) – two standard deviations. If the standard deviation were zero, then all men would be exactly 70 inches tall. If the standard deviation were 20 inches, then men would have much more variable heights, with a typical range of about 50–90 inches. Three standard deviations account for 99.73% of the sample population being studied, assuming the distribution is normal or bell-shaped (see the 68–95–99.7 rule, or the empirical rule, for more information).
Definition of population values[edit]
Let μ be the expected value (the average) of random variable X with density f(x):
![{\displaystyle \mu \equiv \operatorname {E} [X]=\int _{-\infty }^{+\infty }xf(x)\,\mathrm {d} x}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fb2a61843da0d05619c0dd691dbf3fe315b395ad)
The standard deviation σ of X is defined as
![{\displaystyle \sigma \equiv {\sqrt {\operatorname {E} \left[(X-\mu )^{2}\right]}}={\sqrt {\int _{-\infty }^{+\infty }(x-\mu )^{2}f(x)\,\mathrm {d} x}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e3a1cfef8ad100fbcae387d9581763f0b389bbc3)
which can be shown to equal ![{\textstyle {\sqrt {\operatorname {E} \left[X^{2}\right]-(\operatorname {E} [X])^{2}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e2dd8d466c3ecb05713377fefcb7e7f787b29ce7)
Using words, the standard deviation is the square root of the variance of X.
The standard deviation of a probability distribution is the same as that of a random variable having that distribution.
Not all random variables have a standard deviation. If the distribution has fat tails going out to infinity, the standard deviation might not exist, because the integral might not converge. The normal distribution has tails going out to infinity, but its mean and standard deviation do exist, because the tails diminish quickly enough. The Pareto distribution with parameter ![{\displaystyle \alpha \in (1,2]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/782b1d598278b0238ee817c658744e8a7ed3a06e) has a mean, but not a standard deviation (loosely speaking, the standard deviation is infinite). The Cauchy distribution has neither a mean nor a standard deviation.
has a mean, but not a standard deviation (loosely speaking, the standard deviation is infinite). The Cauchy distribution has neither a mean nor a standard deviation.
Discrete random variable[edit]
In the case where X takes random values from a finite data set x1, x2, …, xN, with each value having the same probability, the standard deviation is
![{\displaystyle \sigma ={\sqrt {{\frac {1}{N}}\left[(x_{1}-\mu )^{2}+(x_{2}-\mu )^{2}+\cdots +(x_{N}-\mu )^{2}\right]}},{\text{ where }}\mu ={\frac {1}{N}}(x_{1}+\cdots +x_{N}),}](https://wikimedia.org/api/rest_v1/media/math/render/svg/827beb1be760eed3cb07b20d29f01d326f728071)
or, by using summation notation,

If, instead of having equal probabilities, the values have different probabilities, let x1 have probability p1, x2 have probability p2, …, xN have probability pN. In this case, the standard deviation will be

Continuous random variable[edit]
The standard deviation of a continuous real-valued random variable X with probability density function p(x) is

and where the integrals are definite integrals taken for x ranging over the set of possible values of the random variable X.
In the case of a parametric family of distributions, the standard deviation can be expressed in terms of the parameters. For example, in the case of the log-normal distribution with parameters μ and σ2, the standard deviation is

Estimation[edit]
One can find the standard deviation of an entire population in cases (such as standardized testing) where every member of a population is sampled. In cases where that cannot be done, the standard deviation σ is estimated by examining a random sample taken from the population and computing a statistic of the sample, which is used as an estimate of the population standard deviation. Such a statistic is called an estimator, and the estimator (or the value of the estimator, namely the estimate) is called a sample standard deviation, and is denoted by s (possibly with modifiers).
Unlike in the case of estimating the population mean, for which the sample mean is a simple estimator with many desirable properties (unbiased, efficient, maximum likelihood), there is no single estimator for the standard deviation with all these properties, and unbiased estimation of standard deviation is a very technically involved problem. Most often, the standard deviation is estimated using the corrected sample standard deviation (using N − 1), defined below, and this is often referred to as the «sample standard deviation», without qualifiers. However, other estimators are better in other respects: the uncorrected estimator (using N) yields lower mean squared error, while using N − 1.5 (for the normal distribution) almost completely eliminates bias.
Uncorrected sample standard deviation[edit]
The formula for the population standard deviation (of a finite population) can be applied to the sample, using the size of the sample as the size of the population (though the actual population size from which the sample is drawn may be much larger). This estimator, denoted by sN, is known as the uncorrected sample standard deviation, or sometimes the standard deviation of the sample (considered as the entire population), and is defined as follows:[6]

where  are the observed values of the sample items, and
are the observed values of the sample items, and  is the mean value of these observations, while the denominator N stands for the size of the sample: this is the square root of the sample variance, which is the average of the squared deviations about the sample mean.
is the mean value of these observations, while the denominator N stands for the size of the sample: this is the square root of the sample variance, which is the average of the squared deviations about the sample mean.
This is a consistent estimator (it converges in probability to the population value as the number of samples goes to infinity), and is the maximum-likelihood estimate when the population is normally distributed.[7] However, this is a biased estimator, as the estimates are generally too low. The bias decreases as sample size grows, dropping off as 1/N, and thus is most significant for small or moderate sample sizes; for  the bias is below 1%. Thus for very large sample sizes, the uncorrected sample standard deviation is generally acceptable. This estimator also has a uniformly smaller mean squared error than the corrected sample standard deviation.
the bias is below 1%. Thus for very large sample sizes, the uncorrected sample standard deviation is generally acceptable. This estimator also has a uniformly smaller mean squared error than the corrected sample standard deviation.
Corrected sample standard deviation[edit]
If the biased sample variance (the second central moment of the sample, which is a downward-biased estimate of the population variance) is used to compute an estimate of the population’s standard deviation, the result is

Here taking the square root introduces further downward bias, by Jensen’s inequality, due to the square root’s being a concave function. The bias in the variance is easily corrected, but the bias from the square root is more difficult to correct, and depends on the distribution in question.
An unbiased estimator for the variance is given by applying Bessel’s correction, using N − 1 instead of N to yield the unbiased sample variance, denoted s2:

This estimator is unbiased if the variance exists and the sample values are drawn independently with replacement. N − 1 corresponds to the number of degrees of freedom in the vector of deviations from the mean, 
Taking square roots reintroduces bias (because the square root is a nonlinear function which does not commute with the expectation, i.e. often ![{\textstyle E[{\sqrt {X}}]\neq {\sqrt {E[X]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3dbf273b716d2bdaac95f31a6890ded4645d8709) ), yielding the corrected sample standard deviation, denoted by s:
), yielding the corrected sample standard deviation, denoted by s:

As explained above, while s2 is an unbiased estimator for the population variance, s is still a biased estimator for the population standard deviation, though markedly less biased than the uncorrected sample standard deviation. This estimator is commonly used and generally known simply as the «sample standard deviation». The bias may still be large for small samples (N less than 10). As sample size increases, the amount of bias decreases. We obtain more information and the difference between  and
and  becomes smaller.
becomes smaller.
Unbiased sample standard deviation[edit]
For unbiased estimation of standard deviation, there is no formula that works across all distributions, unlike for mean and variance. Instead, s is used as a basis, and is scaled by a correction factor to produce an unbiased estimate. For the normal distribution, an unbiased estimator is given by s/c4, where the correction factor (which depends on N) is given in terms of the Gamma function, and equals:

This arises because the sampling distribution of the sample standard deviation follows a (scaled) chi distribution, and the correction factor is the mean of the chi distribution.
An approximation can be given by replacing N − 1 with N − 1.5, yielding:

The error in this approximation decays quadratically (as 1/N2), and it is suited for all but the smallest samples or highest precision: for N = 3 the bias is equal to 1.3%, and for N = 9 the bias is already less than 0.1%.
A more accurate approximation is to replace N − 1.5 above with N − 1.5 + 1/8(N − 1).[8]
For other distributions, the correct formula depends on the distribution, but a rule of thumb is to use the further refinement of the approximation:

where γ2 denotes the population excess kurtosis. The excess kurtosis may be either known beforehand for certain distributions, or estimated from the data.[9]
Confidence interval of a sampled standard deviation[edit]
The standard deviation we obtain by sampling a distribution is itself not absolutely accurate, both for mathematical reasons (explained here by the confidence interval) and for practical reasons of measurement (measurement error). The mathematical effect can be described by the confidence interval or CI.
To show how a larger sample will make the confidence interval narrower, consider the following examples:
A small population of N = 2 has only one degree of freedom for estimating the standard deviation. The result is that a 95% CI of the SD runs from 0.45 × SD to 31.9 × SD; the factors here are as follows:

where  is the p-th quantile of the chi-square distribution with k degrees of freedom, and 1 − α is the confidence level. This is equivalent to the following:
is the p-th quantile of the chi-square distribution with k degrees of freedom, and 1 − α is the confidence level. This is equivalent to the following:

With k = 1, q0.025 = 0.000982 and q0.975 = 5.024. The reciprocals of the square roots of these two numbers give us the factors 0.45 and 31.9 given above.
A larger population of N = 10 has 9 degrees of freedom for estimating the standard deviation. The same computations as above give us in this case a 95% CI running from 0.69 × SD to 1.83 × SD. So even with a sample population of 10, the actual SD can still be almost a factor 2 higher than the sampled SD. For a sample population N = 100, this is down to 0.88 × SD to 1.16 × SD. To be more certain that the sampled SD is close to the actual SD we need to sample a large number of points.
These same formulae can be used to obtain confidence intervals on the variance of residuals from a least squares fit under standard normal theory, where k is now the number of degrees of freedom for error.
Bounds on standard deviation[edit]
For a set of N > 4 data spanning a range of values R, an upper bound on the standard deviation s is given by s = 0.6R.[10]
An estimate of the standard deviation for N > 100 data taken to be approximately normal follows from the heuristic that 95% of the area under the normal curve lies roughly two standard deviations to either side of the mean, so that, with 95% probability the total range of values R represents four standard deviations so that s ≈ R/4. This so-called range rule is useful in sample size estimation, as the range of possible values is easier to estimate than the standard deviation. Other divisors K(N) of the range such that s ≈ R/K(N) are available for other values of N and for non-normal distributions.[11]
Identities and mathematical properties[edit]
The standard deviation is invariant under changes in location, and scales directly with the scale of the random variable. Thus, for a constant c and random variables X and Y:

The standard deviation of the sum of two random variables can be related to their individual standard deviations and the covariance between them:

where  and
and  stand for variance and covariance, respectively.
stand for variance and covariance, respectively.
The calculation of the sum of squared deviations can be related to moments calculated directly from the data. In the following formula, the letter E is interpreted to mean expected value, i.e., mean.
![{\displaystyle \sigma (X)={\sqrt {\operatorname {E} \left[(X-\operatorname {E} [X])^{2}\right]}}={\sqrt {\operatorname {E} \left[X^{2}\right]-(\operatorname {E} [X])^{2}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d3ab12089bd2027790ef060ff7cc2ec05ae2021f)
The sample standard deviation can be computed as:
![{\displaystyle s(X)={\sqrt {\frac {N}{N-1}}}{\sqrt {\operatorname {E} \left[(X-\operatorname {E} [X])^{2}\right]}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/702e9da21c721697e6e81932bf8b7443028f7d6d)
For a finite population with equal probabilities at all points, we have

which means that the standard deviation is equal to the square root of the difference between the average of the squares of the values and the square of the average value.
See computational formula for the variance for proof, and for an analogous result for the sample standard deviation.
Interpretation and application[edit]

A large standard deviation indicates that the data points can spread far from the mean and a small standard deviation indicates that they are clustered closely around the mean.
For example, each of the three populations {0, 0, 14, 14}, {0, 6, 8, 14} and {6, 6, 8, 8} has a mean of 7. Their standard deviations are 7, 5, and 1, respectively. The third population has a much smaller standard deviation than the other two because its values are all close to 7. These standard deviations have the same units as the data points themselves. If, for instance, the data set {0, 6, 8, 14} represents the ages of a population of four siblings in years, the standard deviation is 5 years. As another example, the population {1000, 1006, 1008, 1014} may represent the distances traveled by four athletes, measured in meters. It has a mean of 1007 meters, and a standard deviation of 5 meters.
Standard deviation may serve as a measure of uncertainty. In physical science, for example, the reported standard deviation of a group of repeated measurements gives the precision of those measurements. When deciding whether measurements agree with a theoretical prediction, the standard deviation of those measurements is of crucial importance: if the mean of the measurements is too far away from the prediction (with the distance measured in standard deviations), then the theory being tested probably needs to be revised. This makes sense since they fall outside the range of values that could reasonably be expected to occur, if the prediction were correct and the standard deviation appropriately quantified. See prediction interval.
While the standard deviation does measure how far typical values tend to be from the mean, other measures are available. An example is the mean absolute deviation, which might be considered a more direct measure of average distance, compared to the root mean square distance inherent in the standard deviation.
Application examples[edit]
The practical value of understanding the standard deviation of a set of values is in appreciating how much variation there is from the average (mean).
Experiment, industrial and hypothesis testing[edit]
Standard deviation is often used to compare real-world data against a model to test the model.
For example, in industrial applications the weight of products coming off a production line may need to comply with a legally required value. By weighing some fraction of the products an average weight can be found, which will always be slightly different from the long-term average. By using standard deviations, a minimum and maximum value can be calculated that the averaged weight will be within some very high percentage of the time (99.9% or more). If it falls outside the range then the production process may need to be corrected. Statistical tests such as these are particularly important when the testing is relatively expensive. For example, if the product needs to be opened and drained and weighed, or if the product was otherwise used up by the test.
In experimental science, a theoretical model of reality is used. Particle physics conventionally uses a standard of «5 sigma» for the declaration of a discovery. A five-sigma level translates to one chance in 3.5 million that a random fluctuation would yield the result. This level of certainty was required in order to assert that a particle consistent with the Higgs boson had been discovered in two independent experiments at CERN,[12] also leading to the declaration of the first observation of gravitational waves.[13]
Weather[edit]
As a simple example, consider the average daily maximum temperatures for two cities, one inland and one on the coast. It is helpful to understand that the range of daily maximum temperatures for cities near the coast is smaller than for cities inland. Thus, while these two cities may each have the same average maximum temperature, the standard deviation of the daily maximum temperature for the coastal city will be less than that of the inland city as, on any particular day, the actual maximum temperature is more likely to be farther from the average maximum temperature for the inland city than for the coastal one.
Finance[edit]
In finance, standard deviation is often used as a measure of the risk associated with price-fluctuations of a given asset (stocks, bonds, property, etc.), or the risk of a portfolio of assets[14] (actively managed mutual funds, index mutual funds, or ETFs). Risk is an important factor in determining how to efficiently manage a portfolio of investments because it determines the variation in returns on the asset and/or portfolio and gives investors a mathematical basis for investment decisions (known as mean-variance optimization). The fundamental concept of risk is that as it increases, the expected return on an investment should increase as well, an increase known as the risk premium. In other words, investors should expect a higher return on an investment when that investment carries a higher level of risk or uncertainty. When evaluating investments, investors should estimate both the expected return and the uncertainty of future returns. Standard deviation provides a quantified estimate of the uncertainty of future returns.
For example, assume an investor had to choose between two stocks. Stock A over the past 20 years had an average return of 10 percent, with a standard deviation of 20 percentage points (pp) and Stock B, over the same period, had average returns of 12 percent but a higher standard deviation of 30 pp. On the basis of risk and return, an investor may decide that Stock A is the safer choice, because Stock B’s additional two percentage points of return is not worth the additional 10 pp standard deviation (greater risk or uncertainty of the expected return). Stock B is likely to fall short of the initial investment (but also to exceed the initial investment) more often than Stock A under the same circumstances, and is estimated to return only two percent more on average. In this example, Stock A is expected to earn about 10 percent, plus or minus 20 pp (a range of 30 percent to −10 percent), about two-thirds of the future year returns. When considering more extreme possible returns or outcomes in future, an investor should expect results of as much as 10 percent plus or minus 60 pp, or a range from 70 percent to −50 percent, which includes outcomes for three standard deviations from the average return (about 99.7 percent of probable returns).
Calculating the average (or arithmetic mean) of the return of a security over a given period will generate the expected return of the asset. For each period, subtracting the expected return from the actual return results in the difference from the mean. Squaring the difference in each period and taking the average gives the overall variance of the return of the asset. The larger the variance, the greater risk the security carries. Finding the square root of this variance will give the standard deviation of the investment tool in question.
Financial time series are known to be non-stationary series, whereas the statistical calculations above, such as standard deviation, apply only to stationary series. To apply the above statistical tools to non-stationary series, the series first must be transformed to a stationary series, enabling use of statistical tools that now have a valid basis from which to work.
Geometric interpretation[edit]
To gain some geometric insights and clarification, we will start with a population of three values, x1, x2, x3. This defines a point P = (x1, x2, x3) in R3. Consider the line L = {(r, r, r) : r ∈ R}. This is the «main diagonal» going through the origin. If our three given values were all equal, then the standard deviation would be zero and P would lie on L. So it is not unreasonable to assume that the standard deviation is related to the distance of P to L. That is indeed the case. To move orthogonally from L to the point P, one begins at the point:

whose coordinates are the mean of the values we started out with.
|
Derivation of |
|---|
|
The line L is to be orthogonal to the vector from M to P. Therefore:
|




\cdot (x_{1}-\ell ,x_{2}-\ell ,x_{3}-\ell )&=0\\[4pt]r(x_{1}-\ell +x_{2}-\ell +x_{3}-\ell )&=0\\[4pt]r\left(\sum _{i}x_{i}-3\ell \right)&=0\\[4pt]\sum _{i}x_{i}-3\ell &=0\\[4pt]{\frac {1}{3}}\sum _{i}x_{i}&=\ell \\[4pt]{\bar {x}}&=\ell \end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/51526a39caa45834866ae2dc4bb3ed262ba7fbe0)
A little algebra shows that the distance between P and M (which is the same as the orthogonal distance between P and the line L)  is equal to the standard deviation of the vector (x1, x2, x3), multiplied by the square root of the number of dimensions of the vector (3 in this case).
is equal to the standard deviation of the vector (x1, x2, x3), multiplied by the square root of the number of dimensions of the vector (3 in this case).
Chebyshev’s inequality[edit]
An observation is rarely more than a few standard deviations away from the mean. Chebyshev’s inequality ensures that, for all distributions for which the standard deviation is defined, the amount of data within a number of standard deviations of the mean is at least as much as given in the following table.
| Distance from mean | Minimum population |
|---|---|
 |
50% |
 |
75% |
 |
89% |
 |
94% |
 |
96% |
 |
97% |
 |
 [15] [15]
|
 |

|
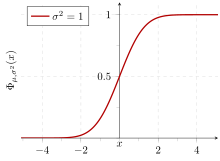
Rules for normally distributed data[edit]
The central limit theorem states that the distribution of an average of many independent, identically distributed random variables tends toward the famous bell-shaped normal distribution with a probability density function of

where μ is the expected value of the random variables, σ equals their distribution’s standard deviation divided by n1⁄2, and n is the number of random variables. The standard deviation therefore is simply a scaling variable that adjusts how broad the curve will be, though it also appears in the normalizing constant.
If a data distribution is approximately normal, then the proportion of data values within z standard deviations of the mean is defined by:

where  is the error function. The proportion that is less than or equal to a number, x, is given by the cumulative distribution function:[16]
is the error function. The proportion that is less than or equal to a number, x, is given by the cumulative distribution function:[16]
![{\displaystyle {\text{Proportion}}\leq x={\frac {1}{2}}\left[1+\operatorname {erf} \left({\frac {x-\mu }{\sigma {\sqrt {2}}}}\right)\right]={\frac {1}{2}}\left[1+\operatorname {erf} \left({\frac {z}{\sqrt {2}}}\right)\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/19a6aad42f0352f855f10ad517460517ae848e4f)
If a data distribution is approximately normal then about 68 percent of the data values are within one standard deviation of the mean (mathematically, μ ± σ, where μ is the arithmetic mean), about 95 percent are within two standard deviations (μ ± 2σ), and about 99.7 percent lie within three standard deviations (μ ± 3σ). This is known as the 68–95–99.7 rule, or the empirical rule.
For various values of z, the percentage of values expected to lie in and outside the symmetric interval, CI = (−zσ, zσ), are as follows:
| Confidence interval |
Proportion within | Proportion without | |
|---|---|---|---|
| Percentage | Percentage | Fraction | |
| 0.318639σ | 25% | 75% | 3 / 4 |
| 0.674490σ | 50% | 50% | 1 / 2 |
| 0.977925σ | 66.6667% | 33.3333% | 1 / 3 |
| 0.994458σ | 68% | 32% | 1 / 3.125 |
| 1σ | 68.2689492% | 31.7310508% | 1 / 3.1514872 |
| 1.281552σ | 80% | 20% | 1 / 5 |
| 1.644854σ | 90% | 10% | 1 / 10 |
| 1.959964σ | 95% | 5% | 1 / 20 |
| 2σ | 95.4499736% | 4.5500264% | 1 / 21.977895 |
| 2.575829σ | 99% | 1% | 1 / 100 |
| 3σ | 99.7300204% | 0.2699796% | 1 / 370.398 |
| 3.290527σ | 99.9% | 0.1% | 1 / 1000 |
| 3.890592σ | 99.99% | 0.01% | 1 / 10000 |
| 4σ | 99.993666% | 0.006334% | 1 / 15787 |
| 4.417173σ | 99.999% | 0.001% | 1 / 100000 |
| 4.5σ | 99.9993204653751% | 0.0006795346249% | 1 / 147159.5358 6.8 / 1000000 |
| 4.891638σ | 99.9999% | 0.0001% | 1 / 1000000 |
| 5σ | 99.9999426697% | 0.0000573303% | 1 / 1744278 |
| 5.326724σ | 99.99999% | 0.00001% | 1 / 10000000 |
| 5.730729σ | 99.999999% | 0.000001% | 1 / 100000000 |
| 6σ | 99.9999998027% | 0.0000001973% | 1 / 506797346 |
| 6.109410σ | 99.9999999% | 0.0000001% | 1 / 1000000000 |
| 6.466951σ | 99.99999999% | 0.00000001% | 1 / 10000000000 |
| 6.806502σ | 99.999999999% | 0.000000001% | 1 / 100000000000 |
| 7σ | 99.9999999997440% | 0.000000000256% | 1 / 390682215445 |
Relationship between standard deviation and mean[edit]
The mean and the standard deviation of a set of data are descriptive statistics usually reported together. In a certain sense, the standard deviation is a «natural» measure of statistical dispersion if the center of the data is measured about the mean. This is because the standard deviation from the mean is smaller than from any other point. The precise statement is the following: suppose x1, …, xn are real numbers and define the function:

Using calculus or by completing the square, it is possible to show that σ(r) has a unique minimum at the mean:

Variability can also be measured by the coefficient of variation, which is the ratio of the standard deviation to the mean. It is a dimensionless number.
Standard deviation of the mean[edit]
Often, we want some information about the precision of the mean we obtained. We can obtain this by determining the standard deviation of the sampled mean. Assuming statistical independence of the values in the sample, the standard deviation of the mean is related to the standard deviation of the distribution by:

where N is the number of observations in the sample used to estimate the mean. This can easily be proven with (see basic properties of the variance):

(Statistical independence is assumed.)

hence

Resulting in:

In order to estimate the standard deviation of the mean σmean it is necessary to know the standard deviation of the entire population σ beforehand. However, in most applications this parameter is unknown. For example, if a series of 10 measurements of a previously unknown quantity is performed in a laboratory, it is possible to calculate the resulting sample mean and sample standard deviation, but it is impossible to calculate the standard deviation of the mean. However, one can estimate the standard deviation of the entire population from the sample, and thus obtain an estimate for the standard error of the mean.
Rapid calculation methods[edit]
The following two formulas can represent a running (repeatedly updated) standard deviation. A set of two power sums s1 and s2 are computed over a set of N values of x, denoted as x1, …, xN:

Given the results of these running summations, the values N, s1, s2 can be used at any time to compute the current value of the running standard deviation:

Where N, as mentioned above, is the size of the set of values (or can also be regarded as s0).
Similarly for sample standard deviation,

In a computer implementation, as the two sj sums become large, we need to consider round-off error, arithmetic overflow, and arithmetic underflow. The method below calculates the running sums method with reduced rounding errors.[17] This is a «one pass» algorithm for calculating variance of n samples without the need to store prior data during the calculation. Applying this method to a time series will result in successive values of standard deviation corresponding to n data points as n grows larger with each new sample, rather than a constant-width sliding window calculation.
For k = 1, …, n:

where A is the mean value.

Note: Q1 = 0 since k − 1 = 0 or x1 = A1.
Sample variance:

Population variance:

Weighted calculation[edit]
When the values xi are weighted with unequal weights wi, the power sums s0, s1, s2 are each computed as:

And the standard deviation equations remain unchanged. s0 is now the sum of the weights and not the number of samples N.
The incremental method with reduced rounding errors can also be applied, with some additional complexity.
A running sum of weights must be computed for each k from 1 to n:

and places where 1/σ is used above must be replaced by wi/Wn:

In the final division,

and

or

where n is the total number of elements, and n′ is the number of elements with non-zero weights.
The above formulas become equal to the simpler formulas given above if weights are taken as equal to one.
History[edit]
The term standard deviation was first used in writing by Karl Pearson in 1894, following his use of it in lectures.[18][19] This was as a replacement for earlier alternative names for the same idea: for example, Gauss used mean error.[20]
Standard deviation index[edit]
The standard deviation index (SDI) is used in external quality assessments, particularly for medical laboratories. It is calculated as:[21]

Higher dimensions[edit]
In two dimensions, the standard deviation can be illustrated with the standard deviation ellipse (see Multivariate normal distribution § Geometric interpretation).
See also[edit]
- 68–95–99.7 rule
- Accuracy and precision
- Algorithms for calculating variance
- Chebyshev’s inequality An inequality on location and scale parameters
- Coefficient of variation
- Cumulant
- Deviation (statistics)
- Distance correlation Distance standard deviation
- Error bar
- Geometric standard deviation
- Mahalanobis distance generalizing number of standard deviations to the mean
- Mean absolute error
- Pooled variance
- Propagation of uncertainty
- Percentile
- Raw data
- Reduced chi-squared statistic
- Robust standard deviation
- Root mean square
- Sample size
- Samuelson’s inequality
- Six Sigma
- Standard error
- Standard score
- Yamartino method for calculating standard deviation of wind direction
References[edit]
- ^ Bland, J.M.; Altman, D.G. (1996). «Statistics notes: measurement error». BMJ. 312 (7047): 1654. doi:10.1136/bmj.312.7047.1654. PMC 2351401. PMID 8664723.
- ^ Gauss, Carl Friedrich (1816). «Bestimmung der Genauigkeit der Beobachtungen». Zeitschrift für Astronomie und Verwandte Wissenschaften. 1: 187–197.
- ^ Walker, Helen (1931). Studies in the History of the Statistical Method. Baltimore, MD: Williams & Wilkins Co. pp. 24–25.
- ^ Weisstein, Eric W. «Bessel’s Correction». MathWorld.
- ^ «Standard Deviation Formulas». www.mathsisfun.com. Retrieved 21 August 2020.
- ^ Weisstein, Eric W. «Standard Deviation». mathworld.wolfram.com. Retrieved 21 August 2020.
- ^ «Consistent estimator». www.statlect.com. Retrieved 10 October 2022.
- ^ Gurland, John; Tripathi, Ram C. (1971), «A Simple Approximation for Unbiased Estimation of the Standard Deviation», The American Statistician, 25 (4): 30–32, doi:10.2307/2682923, JSTOR 2682923
- ^ «Standard Deviation Calculator». PureCalculators. 11 July 2021. Retrieved 14 September 2021.
- ^ Shiffler, Ronald E.; Harsha, Phillip D. (1980). «Upper and Lower Bounds for the Sample Standard Deviation». Teaching Statistics. 2 (3): 84–86. doi:10.1111/j.1467-9639.1980.tb00398.x.
- ^ Browne, Richard H. (2001). «Using the Sample Range as a Basis for Calculating Sample Size in Power Calculations». The American Statistician. 55 (4): 293–298. doi:10.1198/000313001753272420. JSTOR 2685690. S2CID 122328846.
- ^ «CERN experiments observe particle consistent with long-sought Higgs boson | CERN press office». Press.web.cern.ch. 4 July 2012. Archived from the original on 25 March 2016. Retrieved 30 May 2015.
- ^ LIGO Scientific Collaboration, Virgo Collaboration (2016), «Observation of Gravitational Waves from a Binary Black Hole Merger», Physical Review Letters, 116 (6): 061102, arXiv:1602.03837, Bibcode:2016PhRvL.116f1102A, doi:10.1103/PhysRevLett.116.061102, PMID 26918975, S2CID 124959784
- ^ «What is Standard Deviation». Pristine. Retrieved 29 October 2011.
- ^ Ghahramani, Saeed (2000). Fundamentals of Probability (2nd ed.). New Jersey: Prentice Hall. p. 438. ISBN 9780130113290.
- ^ Eric W. Weisstein. «Distribution Function». MathWorld. Wolfram. Retrieved 30 September 2014.
- ^ Welford, B. P. (August 1962). «Note on a Method for Calculating Corrected Sums of Squares and Products». Technometrics. 4 (3): 419–420. CiteSeerX 10.1.1.302.7503. doi:10.1080/00401706.1962.10490022.
- ^ Dodge, Yadolah (2003). The Oxford Dictionary of Statistical Terms. Oxford University Press. ISBN 978-0-19-920613-1.
- ^ Pearson, Karl (1894). «On the dissection of asymmetrical frequency curves». Philosophical Transactions of the Royal Society A. 185: 71–110. Bibcode:1894RSPTA.185…71P. doi:10.1098/rsta.1894.0003.
- ^ Miller, Jeff. «Earliest Known Uses of Some of the Words of Mathematics».
- ^ Harr, Robert R. (2012). Medical laboratory science review. Philadelphia: F. A. Davis Co. p. 236. ISBN 978-0-8036-3796-2. OCLC 818846942.
External links[edit]
- «Quadratic deviation», Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- «Standard Deviation Calculator»
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Дисперсия
Дисперсия случайной величины – это один из основных показателей в статистике. Он отражает меру разброса данных вокруг средней арифметической.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики. Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра.
Формула дисперсии в теории вероятностей имеет вид:
![]()
То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое. Расчет дисперсии производят по формуле:
![]()
где
s2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
Простыми словами дисперсия – это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Теперь вы знаете, как найти дисперсию.
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.

В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
D(A) = 0
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
D(AX) = А2 D(X)
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
D(A + X) = D(X)
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
D(X+Y) = D(X) + D(Y)
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
D(X-Y) = D(X) + D(Y)
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:
![]()
На практике формула стандартного отклонения следующая:
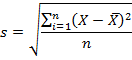
Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
 отклонение в Excel")
Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:
![]()
По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. В реальности, если коэффициент вариации превышает 33%, то специально ничего делать по этому поводу не нужно. Это информация для общего представления. В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
=СТАНДОТКЛОН.В()/СРЗНАЧ()
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:

Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.

Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
Поделиться в социальных сетях:

Статистические данные
Слово статистика образовано от латинского status, которое обозначает состояние. От этого корня произошли слова stato (государство), statistica (сумма знаний о государстве). Математическая статистика — наука, которая изучает методы сбора и обработки информации, представленной в численном виде. Эта информация появляется как результат экспериментов. Во многом математическая статистика опирается на теорию вероятностей, которая позволяет оценить точность и надёжность заключений, сделанных на основании изучения ограниченных статистических данных.
Метод не исследует сущность процессов, а формулирует и описывает их количественную сторону. Термином генеральная совокупность обозначается общность всех объектов, относительно которых необходимо сделать выводы при изучении научной проблемы. Выборочная совокупность или выборка — множество объектов, отобранных из генеральной совокупности для исследования. Основные цели математической статистики:

- указание способов сбора и систематизации статистических данных;
- определение закона распределения случайной величины;
- поиск неопределённых параметров;
- проверка подлинности выдвинутых гипотез.
Главный метод математической статистики — выборочный метод, состоящий в исследовании представительной выборочной совокупности для получения достоверной характеристики генеральной. Отбор объектов в выборку производится случайно, а исследуемое свойство должно обладать статистической устойчивостью, то есть иметь высокую частоту повторений при многократных испытаниях.
Выборочный метод сокращает время и трудоёмкость исследований, так как изучение всей совокупности оказывается более тяжёлым или невозможным. Математическая статистика выявляет закономерности массовых явлений и предсказывает появление внешних влияний.
Размах вариации
Вариация — это различия значений признака у единиц исследуемой совокупности. Она образуется из-за того, что индивидуальные значения формируются при различных условиях. Выборка должна быть представительной, чтобы по результатам её исследований можно было сделать правильные выводы о характеристиках всей совокупности.
Количественная репрезентативность достигается при использовании достаточного числа наблюдений в выборке, которое может обеспечить получение достоверных результатов. Качественная репрезентативность заключается в одинаковой структуре выборочной и генеральной совокупностей по признакам, имеющим влияние на получение конечного результата. К абсолютным показателям вариации относятся:
- размах, R;
- среднее линейное отклонение, a;
- среднеквадратичное отклонение, σ (сигма);
- дисперсия, D.

Размах вариации показывает абсолютную разницу между максимумом и минимумом значений признака:
R = x max — x min, где x — значения признака.
Основным недостатком показателя R можно назвать то обстоятельство, что колебания значений признака могут вызываться случайными причинами и искажать характерный для исследуемой совокупности размах.
Показатели отклонения
Существуют показатели вариации, учитывающие все значения величин, а не только наибольшие или наименьшие. Одним из них можно назвать среднее линейное отклонение — показатель, характеризующий меру разброса значений. Сначала требуется определить точку отсчёта разброса. Как правило, ею становится среднее арифметическое значение, входящее в исследование величин. Потом необходимо измерить, отклонение от среднего для каждого значения. Все отклонения вычисляются по модулю и определяется среднее значение уже среди них. Формула для расчёта отклонения:
a = Σ n i=1 (x — x̅) / n, где:
- a — среднее линейное отклонение;
- n — количество значений в исследуемой совокупности;
- x — анализируемый показатель;
- x̅ — среднее значение показателя.

СКО характеризует разброс значений относительно среднего математического ожидания. Оно измеряется в единицах измерения само́й величины. Существует правило, согласно которому для нормально распределённых данных диапазон разброса 997 значений из 1 тыс. составляет три сигмы от средней арифметической, [x̅ — 3σ; x̅ + 3σ].
Коэффициент вариации
Квадратичное отклонение — это абсолютная оценка меры разброса. Для того чтобы сравнить величину разброса с самими значениями величины, необходимо применить относительный показатель — коэффициент вариации:
V = σ / x̅, где σ — стандартное отклонение из выборки, x̅ — среднее арифметическое.
Коэффициент вариации измеряется в процентах. Показатель полезен для сравнивания однородности разных процессов.

Математическое ожидание — среднее значение случайной величины. Для дискретной выборки оно определяется по формуле:
M (X)= Σ ni=1 xi ⋅ pi, где xi — случайные значения, pi — их вероятность.
Дисперсией называется среднее значение квадрата отклонения случайной величины от её математического ожидания:
D (X) = M (X2) — (M (X))2
Для дискретной случайной величины формула приобретает вид:
D (X) = Σ ni=1 xi2 ⋅ pi — M (X)2.
Среднеквадратическое отклонение или стандартный разброс — это корень квадратный из дисперсии, формула которого имеет вид:
σ(X) = √ D (X).
Дисперсия и стандартный разброс — взаимозависимые характеристики. Стандартная ошибка среднего — величина, которая характеризует квадратическое отклонение выборочного среднего, рассчитанного по выборке размера из генеральной совокупности. Величина ошибки SDx̅ зависит от дисперсии генеральной совокупности и объёма выборки и рассчитывается по формуле:
SDx̅ = σ / √ n, где σ — величина стандартного разброса генеральной совокупности, а n — объём выборки.

Статистическая закономерность — это количественная форма проявления причинной связи. Она возникает как результат воздействия большого числа причин, действующих либо постоянно, либо только временами. Существует ряд статистических критериев, которые позволяют сравнивать экспериментально полученное распределение с нормальным, полученным в теории. Погрешность измерения — отклонение измеренного значения величины от действительного, являющиеся характеристикой точности измерения. Вместе с полученным результатом должна указываться погрешность измерений.
Пример расчёта
Пример расчёта по формулам для среднеквадратичного отклонения и дисперсии при решении следующей задачи по теории вероятностей: для выполнения ремонтных работ рабочему необходима краска определённого цвета. В городе имеется четыре строительных магазина, в каждом из которых эта краска может находиться в продаже с вероятностью 0,41. Записать закон распределения количества посещаемых магазинов. Рассчитать дисперсию и среднеквадратичное отклонение случайной величины. Обход заканчивается после того, как необходимая краска будет куплена или после посещения всех четырёх магазинов.

x = 1 — краска куплена в первом магазине.
p (1) = 0,41.
x = 2 — краски не нашлось в первом магазине, но она была во втором.
p (2) = (1 — 0,41) · 0,41 = 0,59 · 0,41 = 0,242.
x = 3 — краски не нашлось в двух первых магазинах, но она была в третьем.
p (3) = (1 — 0,41)2 · 0,41 = 0,592 · 0,41 = 0,143.
x = 4 — краски не было в первых трёх магазинах, рабочий зашёл в четвёртый магазин, купил краску или просто закончил обход.
p (4) = 0,593 · 0,41 + 0,594 = 0,205.
Закон распределения:
| xi | 1 | 2 | 3 | 4 |
| p (X) | 0,41 | 0,242 | 0,143 | 0.205 |
Математическое ожидание: M (X) = 1 · 0,41 + 2 · 0.242 + 3 · 0,143 + 4 · 0,205 = 2,143.
Дисперсия: D (X) = Σ ni=1 xi2 ⋅ pi — M (X)2 = 12 · 0,41 + 22 · 0,242 + 32 · 0,143 + 42 · 0,205 — 2,1432 = 1,353.
Стандартное отклонение: σ(X) = √ D (X) = √1,353 = 1,163.
Ответ: Дисперсия 1,353; квадратическое отклонение 1,163.
Для вычисления среднеквадратичного отклонения в онлайн-калькуляторе достаточно внести в таблицу значения случайной величины xi и их количество.
Среднеквадратичное отклонение применяется для определения погрешности при проведении последовательных измерений. Эта характеристика играет важную роль для сравнения изучаемого процесса с теоретически предсказанным. Если СКО велико, то полученные результаты или метод их получения нужно проверить.
Стандартное отклонение (англ. Standard Deviation) — простыми словами это мера того, насколько разбросан набор данных.
Вычисляя его, можно узнать, являются ли числа близкими к среднему значению или далеки от него. Если точки данных находятся далеко от среднего значения, то в наборе данных имеется большое отклонение; таким образом, чем больше разброс данных, тем выше стандартное отклонение.
Стандартное отклонение обозначается буквой σ (греческая буква сигма).
Стандартное отклонение также называется:
- среднеквадратическое отклонение,
- среднее квадратическое отклонение,
- среднеквадратичное отклонение,
- квадратичное отклонение,
- стандартный разброс.
Использование и интерпретация величины среднеквадратического отклонения
Стандартное отклонение используется:
- в финансах в качестве меры волатильности,
- в социологии в опросах общественного мнения — оно помогает в расчёте погрешности.
Пример:
Рассмотрим два малых предприятия, у нас есть данные о запасе какого-то товара на их складах.
| День 1 | День 2 | День 3 | День 4 | |
|---|---|---|---|---|
| Пред.А | 19 | 21 | 19 | 21 |
| Пред.Б | 15 | 26 | 15 | 24 |
В обеих компаниях среднее количество товара составляет 20 единиц:
- А -> (19 + 21 + 19+ 21) / 4 = 20
- Б -> (15 + 26 + 15+ 24) / 4 = 20
Однако, глядя на цифры, можно заметить:
- в компании A количество товара всех четырёх дней очень близко находится к этому среднему значению 20 (колеблется лишь между 19 ед. и 21 ед.),
- в компании Б существует большая разница со средним количеством товара (колеблется между 15 ед. и 26 ед.).
Если рассчитать стандартное отклонение каждой компании, оно покажет, что
- стандартное отклонение компании A = 1,
- стандартное отклонение компании Б ≈ 5.
Стандартное отклонение показывает эту волатильность данных — то, с каким размахом они меняются; т.е. как сильно этот запас товара на складах компаний колеблется (поднимается и опускается).
Расчет среднеквадратичного (стандартного) отклонения
Формулы вычисления стандартного отклонения

σ — стандартное отклонение,
xi — величина отдельного значения выборки,
μ — среднее арифметическое выборки,
n — размер выборки.
Эта формула применяется, когда анализируются все значения выборки.

S — стандартное отклонение,
n — размер выборки,
xi — величина отдельного значения выборки,
xср — среднее арифметическое выборки.
Эта формула применяется, когда присутствует очень большой размер выборки, поэтому на анализ обычно берётся только её часть.
Единственная разница с предыдущей формулой: “n — 1” вместо “n”, и обозначение «xср» вместо «μ».
Разница между формулами S и σ («n» и «n–1»)
Состоит в том, что мы анализируем — всю выборку или только её часть:
- только её часть – используется формула S (с «n–1»),
- полностью все данные – используется формула σ (с «n»).
Как рассчитать стандартное отклонение?
Пример 1 (с σ)
Рассмотрим данные о запасе какого-то товара на складах Предприятия Б.
| День 1 | День 2 | День 3 | День 4 | |
| Пред.Б | 15 | 26 | 15 | 24 |
Если значений выборки немного (небольшое n, здесь он равен 4) и анализируются все значения, то применяется эта формула:

Применяем эти шаги:
1. Найти среднее арифметическое выборки:
μ = (15 + 26 + 15+ 24) / 4 = 20
2. От каждого значения выборки отнять среднее арифметическое:
x1 — μ = 15 — 20 = -5
x2 — μ = 26 — 20 = 6
x3 — μ = 15 — 20 = -5
x4 — μ = 24 — 20 = 4
3. Каждую полученную разницу возвести в квадрат:
(x1 — μ)² = (-5)² = 25
(x2 — μ)² = 6² = 36
(x3 — μ)² = (-5)² = 25
(x4 — μ)² = 4² = 16
4. Сделать сумму полученных значений:
Σ (xi — μ)² = 25 + 36+ 25+ 16 = 102
5. Поделить на размер выборки (т.е. на n):
(Σ (xi — μ)²)/n = 102 / 4 = 25,5
6. Найти квадратный корень:
√((Σ (xi — μ)²)/n) = √ 25,5 ≈ 5,0498
Пример 2 (с S)
Задача усложняется, когда существуют сотни, тысячи или даже миллионы данных. В этом случае берётся только часть этих данных и анализируется методом выборки.
У Андрея 20 яблонь, но он посчитал яблоки только на 6 из них.
Популяция — это все 20 яблонь, а выборка — 6 яблонь, это деревья, которые Андрей посчитал.
| Яблоня 1 | Яблоня 2 | Яблоня 3 | Яблоня 4 | Яблоня 5 | Яблоня 6 |
| 9 | 2 | 5 | 4 | 12 | 7 |
Так как мы используем только выборку в качестве оценки всей популяции, то нужно применить эту формулу:

Математически она отличается от предыдущей формулы только тем, что от n нужно будет вычесть 1. Формально нужно будет также вместо μ (среднее арифметическое) написать X ср.
Применяем практически те же шаги:
1. Найти среднее арифметическое выборки:
Xср = (9 + 2 + 5 + 4 + 12 + 7) / 6 = 39 / 6 = 6,5
2. От каждого значения выборки отнять среднее арифметическое:
X1 – Xср = 9 – 6,5 = 2,5
X2 – Xср = 2 – 6,5 = –4,5
X3 – Xср = 5 – 6,5 = –1,5
X4 – Xср = 4 – 6,5 = –2,5
X5 – Xср = 12 – 6,5 = 5,5
X6 – Xср = 7 – 6,5 = 0,5
3. Каждую полученную разницу возвести в квадрат:
(X1 – Xср)² = (2,5)² = 6,25
(X2 – Xср)² = (–4,5)² = 20,25
(X3 – Xср)² = (–1,5)² = 2,25
(X4 – Xср)² = (–2,5)² = 6,25
(X5 – Xср)² = 5,5² = 30,25
(X6 – Xср)² = 0,5² = 0,25
4. Сделать сумму полученных значений:
Σ (Xi – Xср)² = 6,25 + 20,25+ 2,25+ 6,25 + 30,25 + 0,25 = 65,5
5. Поделить на размер выборки, вычитав перед этим 1 (т.е. на n–1):
(Σ (Xi – Xср)²)/(n-1) = 65,5 / (6 – 1) = 13,1
6. Найти квадратный корень:
S = √((Σ (Xi – Xср)²)/(n–1)) = √ 13,1 ≈ 3,6193
Дисперсия и стандартное отклонение
Стандартное отклонение равно квадратному корню из дисперсии (S = √D). То есть, если у вас уже есть стандартное отклонение и нужно рассчитать дисперсию, нужно лишь возвести стандартное отклонение в квадрат (S² = D).
Дисперсия — в статистике это «среднее квадратов отклонений от среднего». Чтобы её вычислить нужно:
- Вычесть среднее значение из каждого числа
- Возвести каждый результат в квадрат (так получатся квадраты разностей)
- Найти среднее значение квадратов разностей.
Ещё расчёт дисперсии можно сделать по этой формуле:

S² — выборочная дисперсия,
Xi — величина отдельного значения выборки,
Xср (может появляться как X̅) — среднее арифметическое выборки,
n — размер выборки.
Правило трёх сигм
Это правило гласит: вероятность того, что случайная величина отклонится от своего математического ожидания более чем на три стандартных отклонения (на три сигмы), почти равна нулю.

Глядя на рисунок нормального распределения случайной величины, можно понять, что в пределах:
- одного среднеквадратического отклонения заключаются 68,26% значений (Xср ± 1σ или μ ± 1σ),
- двух стандартных отклонений — 95,44% (Xср ± 2σ или μ ± 2σ),
- трёх стандартных отклонений — 99,72% (Xср ± 3σ или μ ± 3σ).
Это означает, что за пределами остаются лишь 0,28% — это вероятность того, что случайная величина примет значение, которое отклоняется от среднего более чем на 3 сигмы.
Стандартное отклонение в excel
Вычисление стандартного отклонения с «n – 1» в знаменателе (случай выборки из генеральной совокупности):
1. Занесите все данные в документ Excel.

2. Выберите поле, в котором вы хотите отобразить результат.
3. Введите в этом поле «=СТАНДОТКЛОНА(«
4. Выделите поля, где находятся данные, потом закройте скобки.

5. Нажмите Ввод (Enter).

В случае если данные представляют всю генеральную совокупность (n в знаменателе), то нужно использовать функцию СТАНДОТКЛОНПА.


Коэффициент вариации
Коэффициент вариации — отношение стандартного отклонения к среднему значению, т.е. Cv = (S/μ) × 100% или V = (σ/X̅) × 100%.
Стандартное отклонение делится на среднее и умножается на 100%.
Можно классифицировать вариабельность выборки по коэффициенту вариации:
- при <10% выборка слабо вариабельна,
- при 10% – 20 % — средне вариабельна,
- при >20 % — выборка сильно вариабельна.
Узнайте также про:
- Корреляции,
- Метод Крамера,
- Метод наименьших квадратов,
- Теорию вероятностей
- Интегралы.