Статья давно не обновлялась, поэтому информация могла устареть.
Содержание
- 1 Как выявить аппаратную проблему с сервером?
- 2 Сервер не отвечает на запросы
- 3 Проверка состояния жестких дисков
- 4 SATA/SAS
- 5 SSD
- 6 Правила подачи запроса в службу поддержки
- 6.1 Информация, необходимая для подачи запроса:
- 6.2 Пример запроса
- 7 Возможности по диагностированию оперативной памяти
- 8 Заключение
Как выявить аппаратную проблему с сервером?
В данной статье мы рассмотрим выявление и диагностирование сбойных винчестеров, возможности для проверки оперативной памяти, так же рассмотрим подачу заявки в службу технической поддержки.
Анализируя запросы в службу поддержки, связанные с аппаратными проблемами на выделенных серверах, можно резюмировать следующее: большинство клиентов просто не умеют правильно идентифицировать проблему, возникшую на сервере, а так же составить четкий запрос специалистам компании.
Помочь клиентам в этом вопросе и будет являться целью данной статьи. Во множестве заявок клиент не указывает всей необходимой информации о сервере, выяснение которой затягивает решение вопросов.
Сервер, являясь электронным прибором, может рано или поздно выйти из строя. Любой современный электронный прибор, и сервер в частности, построен на модульном принципе, что имеет множество преимуществ: взаимозаменяемость, быстрая замена и диагностика без применения специального оборудования. При выходе сервера из эксплуатации, эти преимущества играют огромную роль.
Сервер не отвечает на запросы
Наиболее типичной является ситуация, когда сервер перестает отвечать на запросы. Перед тем, как написать запрос в службу технической поддержки, следует провести следующие диагностические мероприятия:
Для начала необходимо перезагрузить сервер, используя панель управления DCImanager, «Перезагрузить».
Если сервер не загрузился, по прошествии некоторого времени, следует запросить IP-KVM для того, чтобы иметь доступ к консоли сервера и видеть вывод ошибок.
Возможно, идет проверка файловой системы, при худшем раскладе – на консоли ошибки “kernel panic”, ошибки “disk boot failure, insert system disk and press enter”, темный экран. В первом случае вам просто следует подождать, сервер «поднимется». Во втором случае желательно обратиться к техническим специалистам компании.
После загрузки сервера, необходимо проверить состояние винчестеров.
Проверка состояния жестких дисков
В этом поможет технология SMART, встроенная в современные диски. Она позволяет оценить состояние и предсказать выход диска из стоя. Доступ к данным, предоставляемым технологией SMART, осуществляется различными утилитами. В ОС семейства FreeBSD и Linux это – smartctl входящая в пакет утилит smartmontools, адрес официального сайта: http://sourceforge.net/apps/trac/smartmontools/.
Чтобы установить пакет воспользуйтесь командой для вашего дистрибутива ОС:
* для Centos/Redhat: yum install -y smartmontools * для Debian/Ubuntu: apt-get install -y smartmontools * для FreeBSD: make -C /usr/ports/sysutils/smartmontools/ install clean
Проверяем диск так:
# smartctl -a /dev/sda
Имя диска может отличаться и быть одним из следующих:
- /dev/ada0
- /dev/sda
- /dev/sdb
Виртуальный сервер на виртуализации KVM имеет диски /dev/vda
smartctl -a /dev/УСТРОЙСТВО
Например, для FreeBSD команда может выглядеть так:
smartctl -a /dev/ad1
а для Linux так:
smartctl -a /dev/sda
Детальное описание можно посмотреть на официальном сайте проекта smartmontools , описание атрибутов на русском языке на Википедии.
Получив данные SMART с диска, следует обратить внимание на следующие показатели:
SATA/SAS
Reallocated Sectors Count — Показывает количество переназначенных секторов (remaping). Большое число свидетельствует о проблемах с поверхностью дисков. Можно считать ключевым параметром при оценке состояния диска, особенно при постоянном увеличении данного параметра.
Current Pending Sector Count — Текущее количество нестабильных секторов. Поле raw value этого атрибута показывает общее количество секторов, которые накопитель в данный момент считает претендентами на переназначение в резервную область (remap). Если в дальнейшем какой-то из этих секторов будет прочитан успешно, то он исключается из списка претендентов. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить данные и перенести их в резервную область, а сам сектор пометить как переназначенный (remapped). Постоянно ненулевое значение raw value этого атрибута говорит о низком качестве (отдельной зоны) поверхности диска.
Uncorrectable Sector Count — Количество нескорректированных ошибок. Атрибут показывает общее количество ошибок, возникших при чтении/записи сектора и которые не удалось скорректировать. Рост значения в поле raw value этого атрибута указывает на явные дефекты поверхности и/или проблемы в работе механики накопителя.
Рассмотрение остальных параметров имеет менее важное значение и не входит в рамки данной статьи. Более детальное описание есть на ресурсе, указанном выше.
В качестве примера рассмотрим вывод утилиты smartctl
В данном случае наблюдается большое значение параметра “Reallocated Sectors Count” указывающее на возможное наличие сбойных секторов(bad blocks) и “Seek_Error_Rate” – ошибки позиционирования считывающих головок диска. В данном примере диск можно считать сбойным и в ближайшее время, возможен выход его из строя.
Как показывает наш опыт в случае если значения Uncorrectable Sector Count, Current Pending Sector Count, UDMA_CRC_Error_Count больше нуля, то жесткий диск требует срочной замены.
Так же будет полезно провести тест диска:
smartctl --test=short /dev/sda
Следить за процессом и посмотреть результат можно командой:
smartctl -a /dev/sda | grep -A1 "Test_Description"
Если нужной информации не отобразилось, то просмотрите полный вывод команды:
smartctl -a /dev/sda
SSD
Основной показатель здоровья диска:
233 Media_Wearout_Indicator
Media Wearout Indicator — эта переменная напрямую указывает на износ диска. Счётчик имеет ненулевое значение в начале (100), и уменьшается со временем. При достижении некоего определённого производителем порогового значения, диск признается изношенным и переходит в read-only режим.
Если его значение упало ниже 10, значит пора диск менять.
Так же стоит обращать внимание на:
5 Reallocated_Sector_Ct
При оценке состояния жестких дисков очень важно делать проверку не при возникновении проблем, а с достаточной для оперативной реакции периодичностью. Поможет в этом демон мониторинга жестких дисков smatrd. Его настройка не составит больших трудностей, т.к. он очень хорошо документирован на официальном сайте проекта (см. http://smartmontools.sourceforge.net/man/smartd.8.html и http://smartmontools.sourceforge.net/man/smartd.conf.5.html). Процедура не займет много времени, но при этом позволит всегда знать в каком состоянии находятся жесткие диски ваших серверов, а при появлении ошибок позволит вовремя принять меры и предотвратить потерю данных.
Получив и проанализировав показатели SMART, необходимо написать запрос в службу технической поддержки. Правильно составленный запрос облегчает работу специалистов и уменьшает время реакции.
Правила подачи запроса в службу поддержки
Информация, необходимая для подачи запроса:
- Идентификационные данные сбойного диска, при невозможности извлечения, данные о целом диске. Информация будет передана техническим сотрудникам в ДЦ, которые будут заниматься заменой сбойного диска.
- Результат выполнения команды smartctl -a на проблемном жестком диске.
- Данные доступа на сервер, для подтверждения состояния дисков сотрудниками компании.
Сообщения, не содержащие данной информации не могут быть приняты к рассмотрению.
Работа утилиты smartctl. Для определения данных о сбойном диске необходим следующий блок информации:
=== START OF INFORMATION SECTION === Model Family: Seagate Momentus 5400.3 series Device Model: ST9120822AS Serial Number: 5LZ71TKQ Firmware Version: 3.ALC User Capacity: 120 034 123 776 bytes Device is: In smartctl database [for details use: -P show] ATA Version is: 7 ATA Standard is: Exact ATA specification draft version not indicated Local Time is: Mon Oct 15 06:52:24 2012 IRKT SMART support is: Available - device has SMART capability. SMART support is: Enabled
Пример запроса
Рассмотрим небольшой пример переписки воображаемого клиента К с сотрудником технической поддержки С:
К: У меня вышел из строя диск.В приложении файл с результатом работы команды smartctl -a. Можете произвести замену? С: Да, мы можем заменить ваш диск. Для этого нам необходимы данные целого диска(серийный номер) или доступ на сервер. К: Вот номер целого – 000000000, доступ к серверу — root:PASSWORD С: Работы выполнены, диск заменен.
Данный диалог можно сократить до запроса о замене диска и ответа о выполнении работ:
Прошу заменить сбойный диск Serial Number: 5LZ71TKQ, Device Model: ST9120822AS. В приложении файл с результатом работы команды smartctl -a Доступ к серверу — root:PASSWORD
Такой запрос будет выполнен сотрудниками технической поддержки без дополнительных уточняющих вопросов, что сокращает время выполнения заявки и экономит рабочее время сотрудников технической поддержки.
Возможности по диагностированию оперативной памяти
Данная проблема может проявляться неявно и решение проблемы затянется. Примером могут быть случаи с выходом из строя отдельных ячеек памяти. Сбои в работе сервера будут происходить не часто или проявляться как ошибки чтения/записи по адресу памяти без выхода из строя сервера.
Диагностика данной проблемы проводится тестом Memtest, официальный сайт проекта — http://www.memtest.org/. Идея данного теста проста — проверка ячеек памяти чтением/записью значений, от простого к сложному. Запуск теста можно сделать, заказав IP-KVM и подключение образа с Memtes’ом в техподдержке (нужно будет загрузиться с этого образа). При наличии проблем с памятью, вероятнее всего, тест пройден не будет, что будет отображено на экране (в какой ячейке и при записи какого значения произошел сбой).
Примечание: Тестирование идет в цикле и его завершение производится вручную. Нужно, чтобы было проведено минимум 3-4 круга тестирования (определяется значением параметра Pass - между Test и Errors).
После выявления проблемы с памятью пишем запрос в службу технической поддержки. В запросе необходимо приложить снимок экрана с ошибкой. Сообщения, не содержащие данной информации не могут быть приняты к рассмотрению. Если ваш провайдер не предоставляет доступ в панель DCImanager, то вам следует сразу написать обращение в службу поддержки с просьбой провести данный тест. При подтверждении ошибки, память будет заменена.
Заключение
Вместо заключения хотелось бы сказать следующее: проблемы выхода винчестеров из строя — явление прогнозируемое и в этом может помочь сервис мониторинга состояния диска smartd, так же включенный в пакет smartmontools . Его настройка и использование неоднократно рассматривались в интернете и не входит в рамки данной статьи. Использование клиентами этого средства мониторинга может спасти от нежелательной потери данных.
Проблемы оперативной памяти — явление непредсказуемое и спонтанное. Выход её из строя не грозит потерей информации, однако вызывает простои в эксплуатации.
И последнее — желаем вам, чтобы ваши сервера не ломались, а обращений в службу технической поддержки по данной тематике было меньше.
Проведение диагностики
- Настройте на диагностируемом сервере функцию загрузки по сети с помощью iPXE или PXE. Подробнее см. Как изменить способ загрузки сервера?
- Рекомендуем настроить подключение диагностируемого сервера к BMC (Intel AMT) или распределителю питания. Если подключение не будет настроено, то для старта диагностики сервер потребуется перезагрузить вручную.
Запуск диагностики
- Перейдите в Серверы →
 → Провести диагностику.
→ Провести диагностику. -
Выберите Шаблон диагностики:
- Diag6 — рекомендуемый шаблон для диагностики.
- Выберите Режим загрузки сервера. Если сервер поддерживает только один из режимов загрузки по сети, выберите требуемый: PXE или iPXE. Если поддерживаются оба варианта загрузки, рекомендуем использовать режим, заданный шаблоном по умолчанию.
-
Если требуется, включите опцию Настроить BMC и выберите Пул для выдачи IP-адреса BMC.
- Пул можно выбрать независимо от того, настроено ли подключение к BMC.
- При выборе опции DCImanager 6 добавит подключение к BMC, выделит IP-адрес из пула и изменит пароль пользователя, под которым происходит подключение. Остальные пользователи BMC будут отключены.
- Для выделения IP-адреса нужно чтобы на локации была создана физическая сеть.
-
включите опцию Очистить и HDD диски во время диагностики и выберите
Диски будут очищены в любом случае, если в шаблон диагностики добавлен макрос $CLEAR_HDD или $FULL_HDD_CLEAR со значением «YES». Подробнее см. Макросы шаблонов.

![]()
Жёсткие диски, подключённые к RAID-контроллеру, будут определены во время диагностики, только если они объединены в RAID.
Результаты диагностики
В карточке сервера вы можете ознакомиться с информацией, собранной в ходе диагностики. Для этого перейдите в Серверы → меню ![]() → Параметры сервера → Комплектующие.
→ Параметры сервера → Комплектующие.

Интерфейс раздела «Комплектующие»
Чтобы скопировать конфигурацию сервера в буфер обмена, нажмите ![]() .
.
Чтобы ознакомиться с подробной информацией, нажмите Полный отчёт.
Ошибки диагностики
диагностики будет завершена с ошибкой, если в процессе её работы выявлены проблемы:
- работы SSD и HDD дисков;
- работы RAID;
- конфигурации и подключения к BMC;
- выполнения теста производительности оборудования;
- передачи информации, собранной модулем диагностики, на сервер с DCImanager 6.
Информация об ошибках, выявленных в процессе диагностики, отображается во всплывающем сообщении в интерфейсе DCImanager 6. Чтобы ознакомиться с ошибками, перейдите в Серверы → выберите сервер → нажмите подробнее в колонке .
Игнорирование ошибок
Если операция диагностики сервера завершилась с ошибкой, клиент не сможет заказать этот сервер через биллинговую систему. Чтобы такой сервер был доступен для клиента, вы можете проигнорировать ошибки диагностики:
- Перейдите в Серверы → выберите сервер → нажмите подробнее в колонке Статус.
- Включите опцию Проигнорировать все.
- Нажмите кнопку Сохранить и закрыть.
У серверов с проигнорированными ошибками отображается статус игнорируется. Вы можете отфильтровать столбец Статус по факту игнорирования ошибок.
![]()
Если после игнорирования ошибок на сервере были обнаружены дополнительные ошибки, статус игнорирования автоматически снимается.
Чтобы отключить игнорирование ошибок:
- Перейдите в Серверы → выберите сервер → нажмите подробнее в колонке Статус.
- Отключите опцию Проигнорировать все.
- Нажмите кнопку Сохранить и закрыть.
![]()
Для быстрого анализа производительности сервера и диагностики возникающих проблем можно использовать всего несколько удобных команд. Давайте разберемся!
Команда top выводит текущие процессы, которые обрабатываются ядром. Данные обновляются каждые пять секунд (по умолчанию), вывод примерно такой:
top - 10:27:44 up 16 days, 1:26, 4 users, load average: 1.21, 1.02, 0.88
Tasks: 213 total, 1 running, 212 sleeping, 0 stopped, 0 zombie
%Cpu(s): 9.5 us, 1.0 sy, 0.0 ni, 88.9 id, 0.2 wa, 0.0 hi, 0.4 si, 0.0 st
KiB Mem: 12334660 total, 10879760 used, 1454900 free, 793424 buffers
KiB Swap: 3880956 total, 219888 used, 3661068 free. 5070564 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1516 mysql 20 0 4616124 2.348g 9068 S 22.6 20.0 4611:20 mysqld
1083 www-data 20 0 547904 180172 31660 S 4.0 1.5 0:09.86 apache2
1140 www-data 20 0 551436 183332 31884 S 2.0 1.5 0:09.19 apache2
4616 www-data 20 0 550660 181832 31256 S 1.7 1.5 0:05.01 apache2
9454 root 20 0 184564 36136 7692 S 1.3 0.3 0:00.10 searchd
12766 www-data 20 0 125344 9060 4996 S 1.3 0.1 8:36.07 nginx
1324 root 20 0 500164 12396 4740 S 1.0 0.1 248:39.45 fail2ban-server
32218 www-data 20 0 726532 196140 42672 S 1.0 1.6 0:24.08 apache2
1084 www-data 20 0 549856 181352 31916 S 0.7 1.5 0:08.77 apache2
1085 www-data 20 0 554616 181784 31920 S 0.7 1.5 0:08.60 apache2
1088 www-data 20 0 547216 181276 33632 S 0.7 1.5 0:09.98 apache2
9473 root 20 0 175764 31384 7188 S 0.7 0.3 0:00.02 searchd
12767 www-data 20 0 125344 9148 4976 S 0.7 0.1 8:03.92 nginx
23003 www-data 20 0 551536 190008 44260 S 0.7 1.5 0:23.79 apache2
23707 www-data 20 0 559788 196408 43556 S 0.7 1.6 0:22.69 apache2
3 root 20 0 0 0 0 S 0.3 0.0 82:19.68 ksoftirqd/0
7 root 20 0 0 0 0 S 0.3 0.0 82:17.58 rcu_sched
13 root 20 0 0 0 0 S 0.3 0.0 15:40.67 ksoftirqd/1
136 root 20 0 0 0 0 S 0.3 0.0 1:00.08 jbd2/sda1-8
576 root 20 0 102924 4796 4476 S 0.3 0.0 19:00.40 vmtoolsd
712 root 20 0 106512 2860 2476 S 0.3 0.0 22:17.03 monit
806 zabbix 20 0 89660 2944 2656 S 0.3 0.0 46:47.72 zabbix_agentd
808 zabbix 20 0 89764 4172 4000 S 0.3 0.0 10:17.92 zabbix_agentd
810 zabbix 20 0 89636 3920 3784 S 0.3 0.0 1:14.27 zabbix_agentd
1082 www-data 20 0 550740 184372 33492 S 0.3 1.5 0:09.84 apache2
1872 www-data 20 0 550280 183596 32744 S 0.3 1.5 0:08.15 apache2
9419 root 20 0 175764 31628 7468 S 0.3 0.3 0:00.02 searchd
9500 root 20 0 175764 29652 5488 S 0.3 0.2 0:00.13 searchd
9515 root 20 0 172980 29220 7088 S 0.3 0.2 0:00.01 searchd
9527 root 20 0 28400 3108 2540 R 0.3 0.0 0:00.04 top
23000 www-data 20 0 559928 194812 41844 S 0.3 1.6 0:21.81 apache2
25163 www-data 20 0 492344 193688 40772 S 0.3 1.6 0:20.45
Выводится базовая информация о памяти, процессоре и процессах на сервере. Процессорное время делится на следующие типы:
us:— время, затраченное на обработку пользовательских задач;sy:— время, затраченное на работу системы (ядра);id:— время простоя (ожидания);wa:— время, затраченное на ожидание ответа от дисковой подсистемы/сети;hi:— время, затраченное на обработку прерываний (hardware);si:— время, затраченное на обработку прерываний (software);st:— время, использованное платформой виртуализации.
Подробнее узнать о команде top можно нажав кнопку “H”.
С помощью команды vmstat можно увидеть краткосрочный снимок процессора, памяти, процессов и операций ввода/вывода:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 1 220868 1325216 599956 5195496 0 0 51 111 6 3 10 2 88 0 0
Здесь видно следующие колонки:
r:— процессы, ожидающие выделения процессорного времени;b:— процессы, ожидающие ответа диска/сети/пользователя;swpd:— размер используемого свопа;free:— размер свободной памяти;buff:— буферы (страницы памяти, зарезервированные системой для выделения их процессам, когда они затребуют этого);cache:— кэш (данные, которые недавно были использованы системой/процессами и хранящиеся в памяти на случай если вскоре они снова потребуются);si:— количество блоков в секунду, которое система считывает из свопа в память;so:— количество блоков в секунду, которое система перемещает из памяти в своп;bi:— количество блоков в секунду, считанных с диска;bo:— количество блоков в секунду, записанных на диск;in:— прерывания;bo:— переключения контекста;us,sy,id,wa,st: — использование процессора, формат аналогичен формату командыtop.
С помощью команды iostat можно получить отчет об использовании процессора, нагрузке на дисковую и сетевую подсистему. Результат запуска команды без дополнительных параметров выглядит следующим образом:
Linux 3.16.0-4-amd64 (example.com) 06/09/2016 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
9.82 0.00 2.31 0.24 0.00 87.63
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sdb 21.68 199.62 252.49 280941560 355350416
sda 2.63 2.40 187.19 3371168 263445152
dm-0 20.74 159.65 207.13 224689725 291513556
dm-1 3.42 4.51 26.25 6350785 36943492
dm-2 6.48 35.45 19.11 49897297 26887944
dm-3 0.00 0.00 0.00 496 0
dm-4 0.00 0.00 0.00 2901 5424
Данной информации может показаться недостаточно, поэтому лучше использовать следующие ключи:
-d— отображать только использование дисков;-c— отобразить только использование CPU;-j— отобразить имя раздела (ID | LABEL | PATH | UUID);-k— отобразить данные в килобайтах;-m— отобразить данные в мегабайтах;-p— отобразить статистику по указанному блочному устройству;-t— отобразить время выполнения теста;-x— отобразить расширенную статистику.
Информацию об использовании оперативной памяти и свопа можно увидеть с помощью команды free:
total used free shared buffers cached
Mem: 12334660 10892940 1441720 419980 609740 5108228
-/+ buffers/cache: 5174972 7159688
Swap: 3880956 220844 3660112
Вывод показывает общее количество свободной и используемой физической памяти, памяти отведенной для свопа и т.д.
Если при открытии сайта вы получаете ошибку вида ERR_NAME_NOT_RESOLVED или в тексте ошибки есть слово DNS — причиной могут быть проблемы с доменом. Проведите диагностику по инструкции.
Если же сайт работает медленно, или при его открытии возникают ошибки 502/504, ошибки баз данных, некорректно работают скрипты — скорее всего причина в отказе служб или высокой нагрузке на сервере.
В этой статье мы расскажем, как провести диагностику ресурсов сервера и решить некоторых из возможных проблем.
- Диагностика из панели ISPmanager
- Проверяем свободное пространство через ISPmanager
- Проверяем нагрузку через ISPmanager
- Диагностика сервера из консоли
- Проверяем свободное пространство через консоль
- Проверяем нагрузку через консоль
- Останавливаем процесс
- Перезапускаем сервисы (службы)
- Проверяем использование оперативной памяти через консоль
Диагностика из панели ISPmanager
На всех Linux-серверах мы предоставляем панель ISPmanager. С её помощью можно выполнить простую диагностику из любого браузера, без навыков администрирования. Доступ к панели можно получить, используя данные, отправленные на ваш email после активации сервера.
Проверяем свободное пространство через ISPmanager
На главной странице есть блок с информацией о ресурсах сервера:
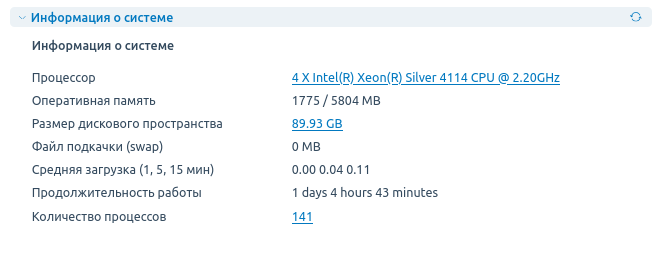
Нажмите на Размер диска — откроется вкладка, где указано, сколько сейчас занято дискового пространства.
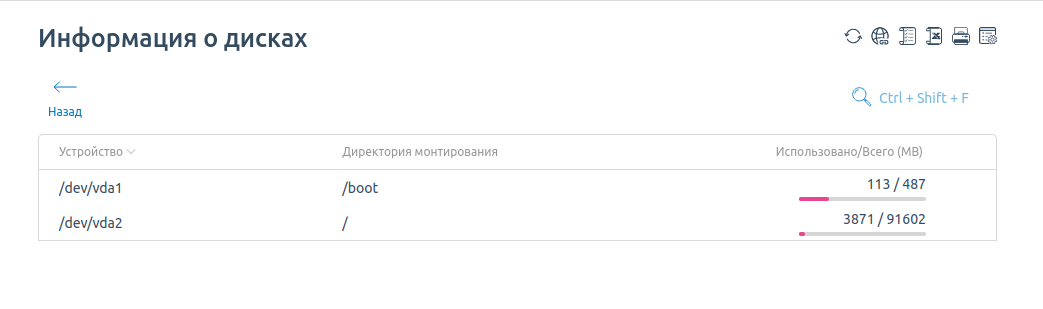
Если диск полон или почти полон — это может быть причиной недоступности сайта. Нужно понять, что занимает это место и можем ли мы его освободить.
Диск могут переполнить, например, резервные копии. Настройками панели можно установить ограничение по объёму или количеству хранимых копий, подробнее в нашей статье.
Если резервные копии не занимают много места или их нет, то стоит проверить содержимое сервера. Поиск по файлам лучше выполнить в командной строке. Так как файловый менеджер в ISPmanager отображает размер файлов, но не каталогов.
Подробнее про диагностику места из консоли можно почитать в соответствующем разделе. ISPmanager имеет встроенную консоль в разделе Администрирование → Shell-клиент, для поиска можете воспользоваться ей.
Проверяем нагрузку через ISPmanager
На главной странице панели справа находится график используемых ресурсов.
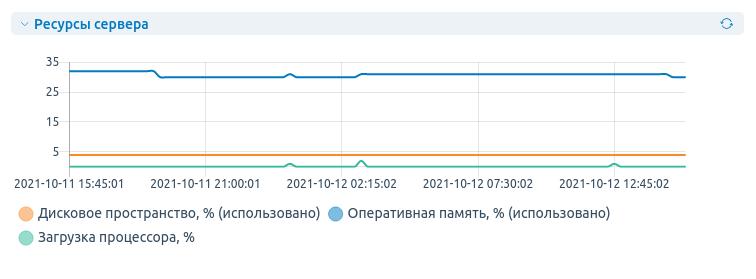
На графике отмечены 10 значений за последние сутки, которые обновляются раз в 2,5 часа (при высокой нагрузке могут не обновляться). Значения помогут отследить, в какой из промежутков времени был скачок нагрузки.
Например, если на вашем сайте есть ошибка баз данных, а на графике был скачок использования оперативной памяти — стоит проверить, не была ли остановлена служба БД. Это происходит, когда заканчивается свободная оперативная память и для запуска новых служб завершаются старые (вне зависимости от их важности).
Для перезапуска перейдите в раздел Мониторинг и журналы → Службы
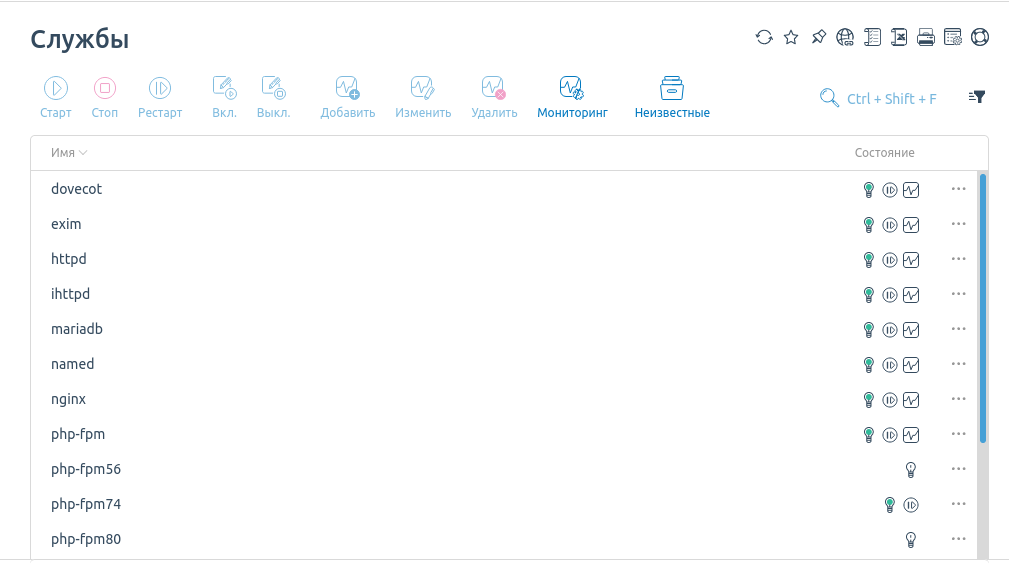
Справа от имени службы индикатор состояния — лампочка. Например, если на сайте ошибка «DB query error» или «Не удалось подключиться к базе данных», то, скорее всего, остановлена служба, отвечающая за работу этих баз данных. На скриншоте это mariadb, у вас может быть mysqld (mysql). Нажмите на службы→ Рестарт После этого проверьте ваш сайт, обновите страницу.
Иногда нажатие не приводит к перезагрузке службы — больше информации о проблеме можно получить, перезапустив службу вручную из консоли. В панели ISPmanager есть SSH-клиент в разделе Администрирование, воспользуйтесь им.
По нажатию справа от графика на число процессов (см. рис 1 «Информация о системе») — откроется список с информацией о том, сколько каждый процесс потребляет ресурсов.
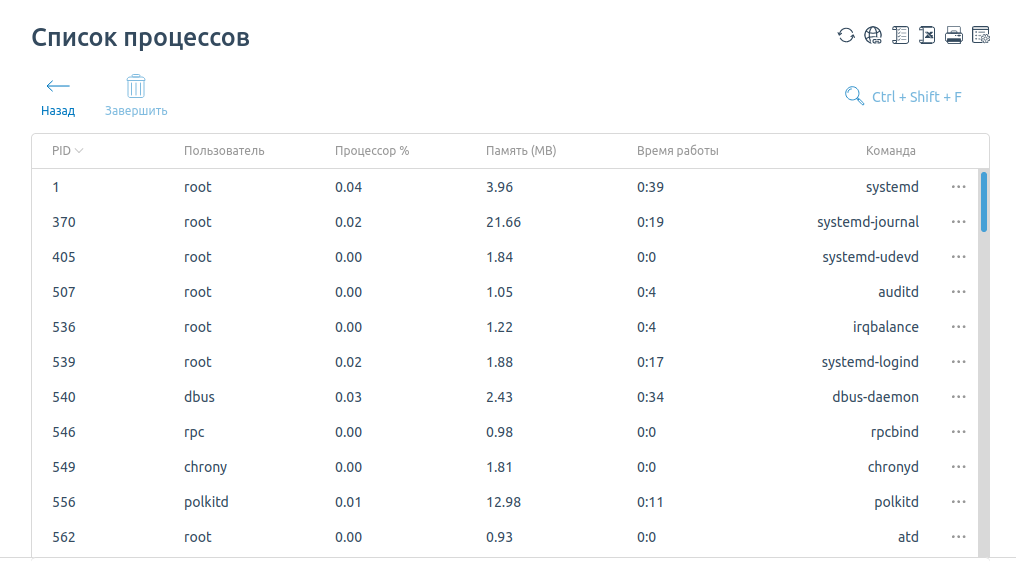
Если вы проверили свободное место и уверены, что его достаточно, а текущая нагрузка невысока — для решения проблемы обратитесь в службу технической поддержки. Опишите, какую проблему и на каком сайте/странице заметили, ваши действия и наблюдения.
Диагностика сервера из консоли
Это инструкция для пользователей, у которых есть опыт работы с командной строкой. Если у вас его нет — обратитесь за помощью к нам, и ваш вопрос рассмотрят технические специалисты.
Бывает так, что ISPmanager недоступен из-за существующей нагрузки или работает медленно. Тогда лучший вариант — подключиться к серверу по SSH и провести диагностику при помощи консольных команд и утилит. Их набор довольно обширен, но для самостоятельного изучения будет достаточно тех, что приведены ниже.
Проверяем свободное пространство через консоль
Зачастую проблемы в недоступности сайта или сервера связаны с банальным переполнением диска.
df — отобразит информацию о занятом на диске месте.
Для более удобного отображения используйте ключ -h, так как сама по себе команда отобразит размер без единиц измерения (Kилобайт, Mегабайт, Гигабайт). Ключ h означает human readable — удобный для прочтения человеком.
df -h
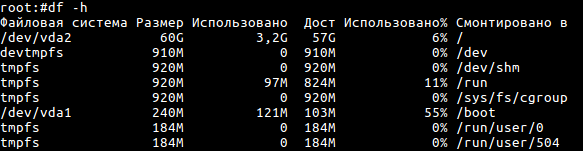
Если на диске не осталось или почти не осталось свободного пространства — нужно выяснить, какие файлы или каталоги занимают много места. В поиске нам поможет du
du -hs /* отобразит информацию обо всех директориях:
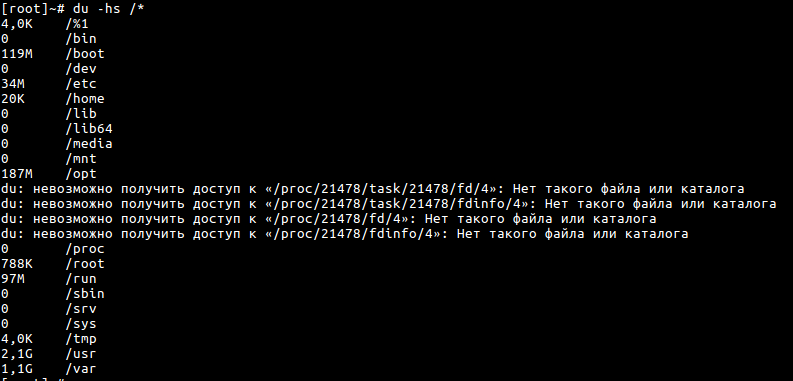
Теперь вы видите, сколько места на диске занимает каждый каталог в корне сервера. Чтобы найти сами файлы, которые заполнили ваш диск, нужно ввести du -hs /имя_каталога/*
Например, du -hs /var/*
И таким же образом двигайтесь дальше, чтобы обнаружить каталог с файлами, которые занимают значительный объём или содержат уже ненужные вам файлы.
Пара советов для упрощения работы с командной строкой:
-
- Используйте стрелки вверх и вниз на клавиатуре для навигации по истории вводимых команд.
- Чтобы быстро написать название каталога используйте клавишу
Tab.
Например, наберитеdu -hs /vaи нажмитеTab— в строке появитсяdu -hs /var/
Это не сработает, если есть несколько каталогов/файлов с одинаковыми наименованиями в начале. Например,du -hs /var/loи нажатиеTabне сработало — нажмите второй раз, и отобразится список каталогов. Всё равно не сработало — была допущена ошибка или такого файла/каталога нет.
Двойное нажатие Tabво время ввода поможет, когда не уверены, правильно ли пишете название каталога, и если не знаете точно, какой каталог следующий.
Если вы и без поиска знаете, какой каталог всегда заполняется, используйте:
du -h /путь/до/каталога/ — команда выведет информацию об объёме всех каталогов по указанному пути, включая вложенные.
Нашли каталог большого объёма? Замечательно! Давайте посмотрим что в нём.
ls — выводит содержимое каталога. Например, ls /usr/local/mgr5 выведет список всего, что есть по указанному пути.
Чтобы привести список файлов в более читаемый вид, используем опцию -lha
ls -lha /usr/local/mgr5
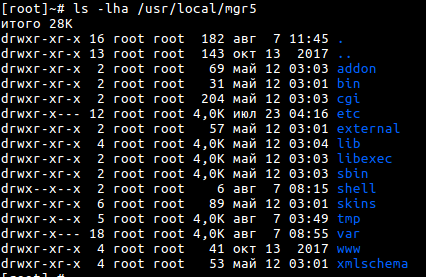
В списке есть уже неактуальный каталог или файл вашего сайта — давайте удалим его: Перейдите в нужный нам каталог — cd /путь/до/каталога, путь нам известен по командам выше.
Для удаления файлов используйте rm
rm /путь/до/файла
Чтобы случайно не удалить нужный файл, лучше перестраховаться и запросить подтверждение. Для этого используйте ключ -i
rm -i /путь/до/файла
Хотите удалить файл — введите y или Y и нажмите Enter. Если ошиблись — сочетание клавиш Ctrl + C, и файл останется на месте.
Для удаления каталога используем ключ -R
rm -Ri /путь/до/каталога
Внимание! Используйте команду rm -Ri /* аккуратно. Существует возможность удалить все файлы на сервере.
Ещё более опасный вариант этой команды — m -Rf /* — ключ f удаляет файлы без подтверждения, символ * указывает, что нужно применить действие на все файлы и каталоги.
Проверяем нагрузку через консоль
Утилита top поможет выявить, связана ли медленная работа сайта с нагрузкой на сервере.
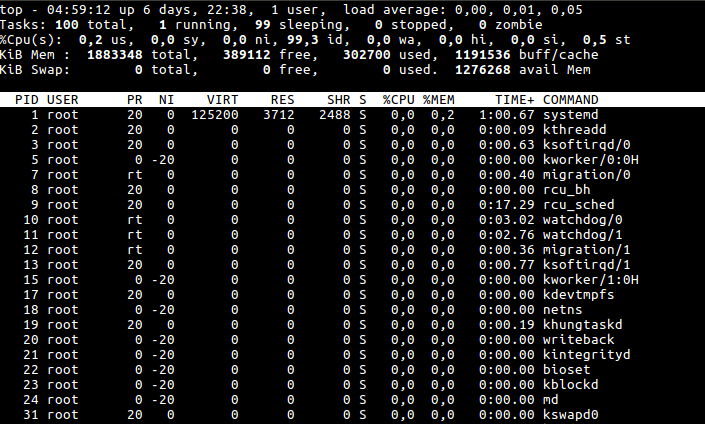
Первое, на что стоит обратить внимание — Load Average — число процессов в очереди на выполнение за последние 1, 5 и 15 минут.
Значения LA должны быть меньше количества ядер вашего сервера. Например, при наличии 2 ядер показатель LA равный или больше 2 свидетельствует о том, что ядра уже загружены на 100%, и процессы вашего сервера не выполняется сразу, а «ждут» когда подойдёт их очередь.
Также стоит обратить внимание на следующие показатели:
- us — время процессора, затраченное на выполнение пользовательских процессов.
- id — время бездействия процессора.
Если значение us намного выше id — процессы пользователя создают нагрузку, в списке они обычно занимают верхние позиции.
- По имени пользователя (столбец USER) можно понять, какой из пользователей запустил процесс.
- В COMMAND отображается информация о команде (процессе), запустившей процесс.
- %CPU — время ЦП, затраченное для выполнения процесса (в процентах).
- PID — идентификационный номер процесса. Может пригодиться для его завершения, если вы уверены, что процесс не должен работать или работает некорректно и нужно его перезапустить.
- wa — время простоя процессора (в процентах), когда он ожидал завершения операций ввода-вывода. Чтобы процесс мог считать нужные ему данные — которых нет в кеше процессора или оперативной памяти — он обращается за ними к диску. Ждёт, пока данные с диска загружаются в оперативную память. И только после этого может начать работать с ними. Если значение wa выше 10-15% — есть проблемы с работой дисковой системы. Возможная причина — высокая нагрузка от базы данных (самих процессов mysql на сервере может быть немного) Они часто обращаются к диску и могут создать «очередь», которая замедляет его работу.
- st (Steal Time) — процессорное время, забранное у виртуальной машины гипервизором для решения других задач. В случае с услугой хостинга виртуальных серверов это работа других контейнеров, расположенных на этом же физическом родительском оборудовании. По факту этот параметр отображает оверселлинг на ноде. Значение ниже 5-10% не повлияют на производительность именно вашего сервера.
Если значения wa и st выше допустимых пределов — обратитесь в службу технической поддержки.
Утилита ps является одной из альтернатив top.
Результатом вывода без дополнительных опций будут только процессы текущего пользователя и терминала. Наиболее удобное сочетание параметров:
ps auxwwf
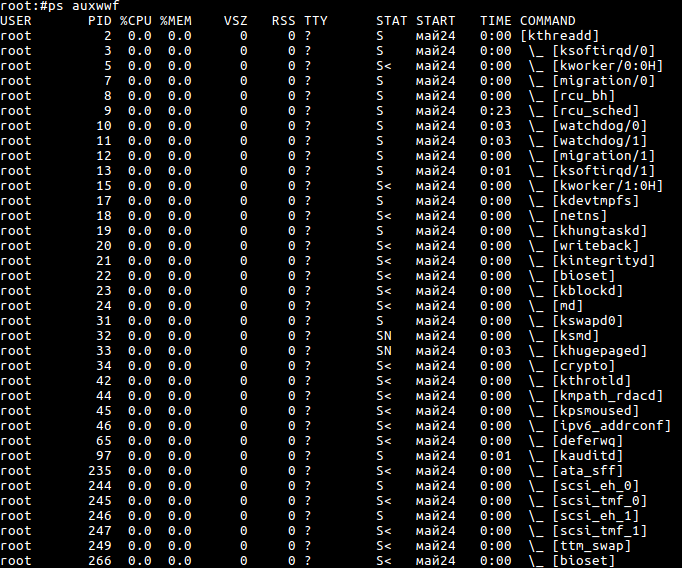
C помощью утилиты ps вы можете найти все процессы одного пользователя или службы. Для поиска всех нужных вам процессов:
ps aux | grep <имя процесса>
или
ps aux | grep <имя пользователя>
Останавливаем процесс
Если процесс использует слишком много ресурсов, и вы уверены, что причина в его некорректной работе — можно остановить процесс по идентификатору (известен нам благодаря top или ps).
kill PID
Также можно завершить процесс по его имени:
killall processname
Не остановился? Тогда остановите процесс принудительно:
kill -9 PID
killall -9 processname
Опция -9 отправляет сигнал процессу о принудительной остановке, не дожидаясь его корректного завершения (подробнее о сигналах можно прочитать в Википедии).
Перезапускаем сервисы (службы)
Если необходимая вам служба не работает/работает неправильно — можно попробовать запустить/перезагрузить её. При условии, что вы уверены — это не приведёт к полной недоступности проекта.
Используйте следующую команду для перезапуска сервиса на любой unix-подобной операционной системе:
service start/restart/stop/status
где — имя сервиса.
Проверяем использование оперативной памяти через консоль
free -mh отобразит значение в Мегабайтах.

- total — общий объём оперативной памяти (ОЗУ)
- used — сколько сейчас используется
- free — свободная память
- buff/cache — закешированная ОЗУ
Более подробную информацию можно получить командой cat /proc/meminfo
Однострачник покажет какие процессы используют память в текущий момент, в Мегабайтах:
ps axo rss,comm,pid \
| awk '{ proc_list[$2]++; proc_list[$2 "," 1] += $1; } \
END { for (proc in proc_list) { printf("%d\t%s\n", \
proc_list[proc "," 1],proc); }}' | sort -n | tail -n 10 | sort -rn \
| awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'p`
Иногда при работе сайта или приложения могут возникать неполадки. Одна из типичных ошибок — это код ответа сервера в формате 5хх. Ошибка вида 5хх говорит о том, что сервер не может корректно обработать запрос и вернуть ответ браузеру.
Среди ошибок сервера чаще всего встречаются:
- 500 Internal Server Error;
- 502 Bad Gateway;
- 504 Gateway Time Out. Также можно встретить варианты “ошибка подключения 504” или “504 Nginx”.
В статье мы расскажем о возможных способах устранения этих ошибок.
- Проверьте доступность сервера из внешней сети
- Запустите службы для работы сайта
- Проанализируйте дисковое пространство
- Проверьте количество inodes
- Назначьте необходимые права для папок с логами
- Проверьте отработку скриптов в коде сайта
- Как включить отображение ошибок через php.ini
- Как включить отображение ошибок через .htaccess
Проверьте доступность сервера из внешней сети
Проверка доступности сервера будет полезна для того, чтобы исключить отказ оборудования. Для проверки доступности используется команда:
ping 123.123.123.123
Вместо 123.123.123.123 укажите IP-адрес сервера. Если сервер доступен, пакеты будут доставлены без потерь:
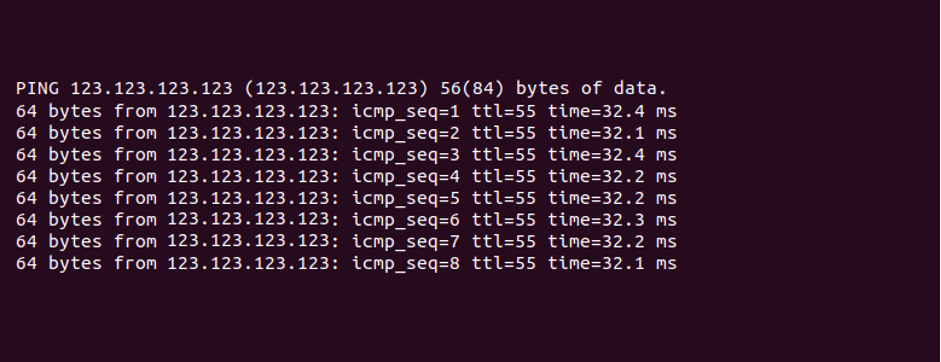
Чтобы остановить выполнение команды, используйте комбинацию клавиш Ctrl + C.
Если обмен пакетами не происходит, сервер недоступен. Чтобы исправить это, необходимо выполнить ряд действий:
- Подключитесь к серверу по SSH.
- Проверьте конфигурацию с помощью команды:
ifconfig
Вывод должен иметь следующий вид:
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 123.123.123.123 netmask 255.255.254.0 broadcast 123.123.123.255
inet6 fe80::3eec:efff:fe1c:c53c prefixlen 64 scopeid 0x20<link>
inet6 2a02:408:7722:1:77:222:40:224 prefixlen 64 scopeid 0x0<global>
ether 3c:ec:ef:1c:c5:3c txqueuelen 1000 (Ethernet)
RX packets 4401360996 bytes 2764801604146 (2.5 TiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 6286642214 bytes 6849482341634 (6.2 TiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0.405: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.4.6.224 netmask 255.255.252.0 broadcast 10.4.7.255
inet6 fe80::3eec:efff:fe1c:c53c prefixlen 64 scopeid 0x20<link>
ether 3c:ec:ef:1c:c5:3c txqueuelen 1000 (Ethernet)
RX packets 319292750 bytes 138957932266 (129.4 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 674925007 bytes 288439583338 (268.6 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0:auto.42c3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 123.123.123.105 netmask 255.255.254.0 broadcast 123.123.123.255
ether 3c:ec:ef:1c:c5:3c txqueuelen 1000 (Ethernet)
eth0:auto.6e27: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 123.123.123.129 netmask 255.255.254.0 broadcast 123.123.123.255
ether 3c:ec:ef:1c:c5:3c txqueuelen 1000 (Ethernet)
eth0:auto.a8c3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 123.123.123.210 netmask 255.255.254.0 broadcast 123.123.123.255
ether 3c:ec:ef:1c:c5:3c txqueuelen 1000 (Ethernet)
eth0:auto.af0a: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 123.123.123.88 netmask 255.255.254.0 broadcast 123.123.123.255
ether 3c:ec:ef:1c:c5:3c txqueuelen 1000 (Ethernet)
eth0:auto.e7ff: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 123.123.123.197 netmask 255.255.254.0 broadcast 123.123.123.255
ether 3c:ec:ef:1c:c5:3c txqueuelen 1000 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 1395489571 bytes 10476506884474 (9.5 TiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1395489571 bytes 10476506884474 (9.5 TiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Если в одном из блоков строка inet пустая, укажите IP-адрес вашего сервера.
Затем сохраните изменения и закройте файл.
Запустите службы для работы сайта
Службы — это программы, которые предназначены для помощи в работе вашего сайта. Чаще всего используется следующее ПО:
- веб-серверы Apache и Nginx,
- СУБД MySQL и ее модификация MariaDB.
При выполнении команд по SSH-соединению нужно использовать специализированные наименования.
|
Служба |
Наименование |
|---|---|
|
Apache |
apache2 или httpd |
|
Nginx |
nginx |
|
MySQL |
mysql или mysqld |
|
MariaDB |
mariadb |
Чтобы проверить работу служб:
- Подключитесь к серверу по SSH.
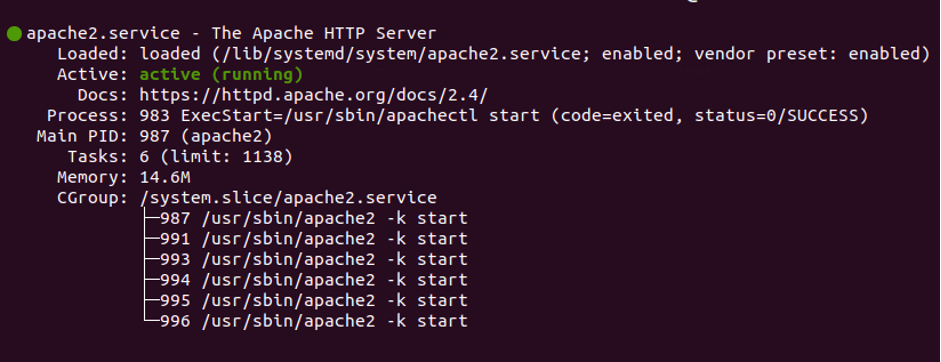
- Проверьте работу службы:
service apache2 status
Вместо apache2 укажите наименование нужной вам службы.
Если в сообщении от службы указан статус Active (running), она запущена и работает:
- Если служба выключена, запустите ее. Для этого выполните команду:
service apache2 start
Вместо apache2 укажите наименование запущенной службы.
Проанализируйте дисковое пространство
Иногда ошибки в работе сайта связаны с тем, что на сервере закончилось место для файлов. Узнать об этом поможет диагностика дискового пространства сервера. Чтобы начать проверку:
- Подключитесь к серверу по SSH.
- Выполните команду:
df -h
На экране отобразится информация об объеме диска и занятом пространстве на нем:
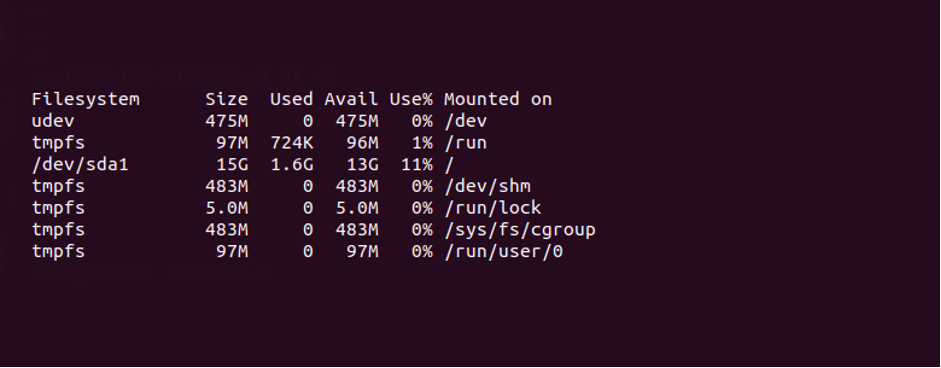
Если диск переполнен, нужно удалить ненужные файлы с сервера или повысить тариф (если речь идет о виртуальном сервере).
Чтобы получить дополнительную информацию о состоянии диска, используйте инструкцию Анализ дискового пространства.
Проверьте количество inodes
Индексные дескрипторы, или inodes, — это идентификатор файла в системах Linux. Каждый файл имеет только один индексный дескриптор.
Проблемы в работе сайта могут возникать, если число inodes превысило рамки тарифа. Чтобы проверить сервер сайта на количество индексных дескрипторов:
- Подключитесь к серверу по SSH(https://help.sweb.ru/entry/84/).
- Выполните команду:
df -hTi
На экране отобразится подробная информация о количестве свободных и занятых inodes:
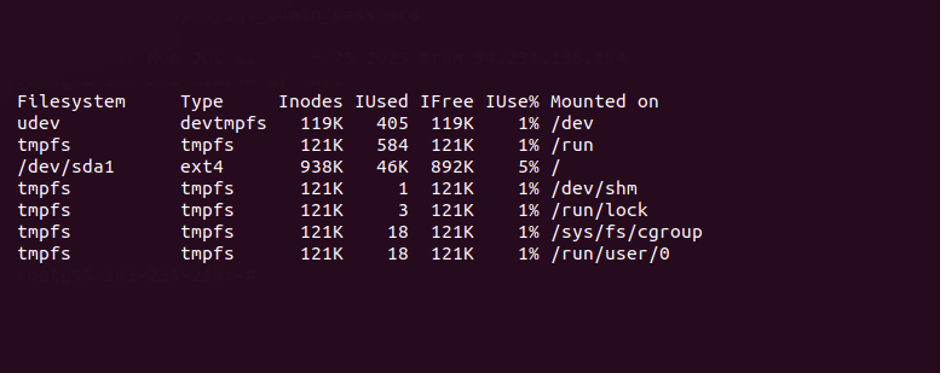
Если количество inodes превышено, его можно изменить по инструкции.
Назначьте необходимые права для папок с логами
Лог — это текстовый файл, в который записывается информация о работе программы. В логах могут быть отражены дата и время запуска службы, а также ошибки в ее работе.
Так как на сервере установлено несколько программ, логи каждой из них записываются в отдельные директории: это помогает избежать путаницы.
Чтобы логи записывались корректно, директории должны иметь права на запись. Чтобы проверить их наличие:
- Подключитесь к серверу по SSH.
- Проверьте наличие прав на запись:
ls -lah /var/log/
Вместо /var/log/ укажите путь к общей директории логов.
На экране отобразится содержимое общей папки и права на каждый объект:
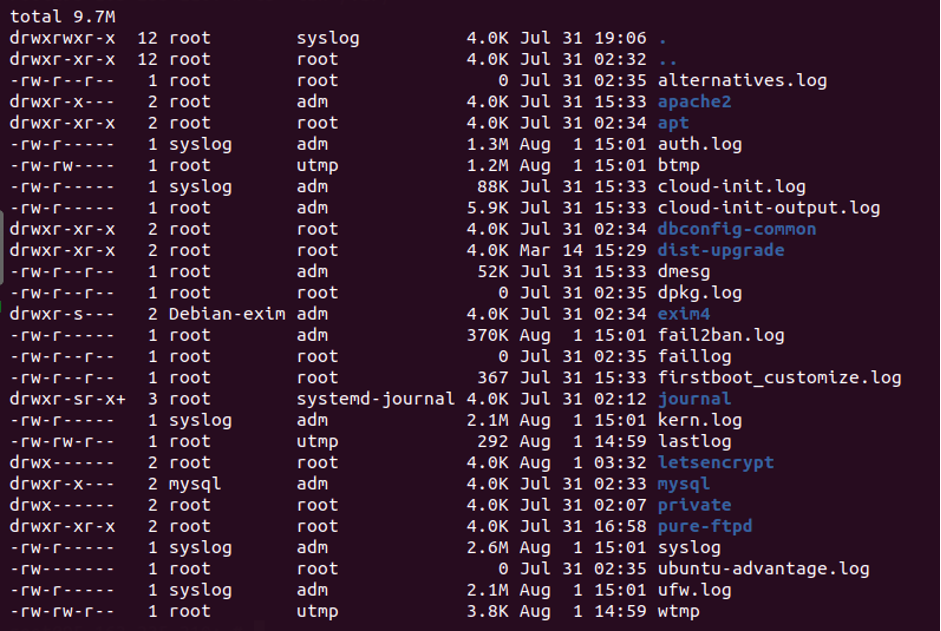
Если у одной из директорий нет прав на запись, выполните следующие действия:
- Подключитесь к серверу по SSH.
- Назначьте права директории с логами:
chmod -R 755 /var/log/apache2/
Вместо /var/log/apache2/ укажите путь к директории, которой нужно назначить новые права.
Проверьте отработку скриптов в коде сайта
Иногда перебои в работе сайта могут быть вызваны скриптами в коде сайта: например, долгой их отработкой или ошибкой в синтаксисе. Чтобы выполнить поиск и устранение ошибок, нужно включить их отображение. Например, для PHP-скриптов существует несколько способов:
- директива в php.ini,
- директива в .htaccess.
О том, как включить отображение ошибок, мы рассказали ниже.
Как включить отображение ошибок через php.ini
- Подключитесь к серверу по SSH.
- Чтобы получить доступ к редактированию файла, выполните команду:
chmod -R 644 /usr/local/php/etc/php.ini
Вместо /usr/local/php/etc/php.ini укажите путь к файлу на вашем сервере.
- Откройте php.ini:
sudo nano /usr/local/php/etc/php.ini
Вместо /usr/local/php/etc/php.ini укажите путь к файлу на вашем сервере.
- Добавьте строку:
display_errors = on
После этого сохраните изменения и закройте файл.
- Верните стандартные права для php.ini:
chmod -R 444 /usr/local/php/etc/php.ini
Вместо /usr/local/php/etc/php.ini укажите путь к файлу на вашем сервере.
Как включить отображение ошибок через .htaccess
- Подключитесь к серверу по SSH.
- Откройте файл .htaccess:
sudo nano /var/www/test.ru/.htaccess
Вместо /var/www/test.ru/.htaccess укажите путь к директории, где размещен файл htaccess для сайта.
- Добавьте строки:
php_flag display_startup_errors on
php_flag display_errors on
После этого сохраните изменения и закройте файл.
Если у вас возникли сложности или сайт по-прежнему недоступен, обратитесь в службу поддержки.