Изобретение м.б. использовано в прецизионных генераторах сигналов с частотной модуляцией в радиолокационных и связных системах, в акустоэлектронных фурье-продессорах. Цель изобретения — повышение быстродействия . Устройство содержит опорный генератор 1, делитель частоты 2, блок пaмяtи (БП) 3, делитель частоты с переменным коэффициентом деления (ДПКД) 4, два счетчика 5, 6, блок исключения импульсов 7 и блок кo meнcaции шумов добротности (БКПЩ) 8. Когда уровень напряжения на выходе делителя частоты 2 изменяется, счетчики 5, 6 переходят в счетный режим, счетчик 6 по импульсам с выхода ДПКД 4 формирует код адреса для обращения в БП 3, а счетчик 5 по импульсам , извлекаемым из БП 3, формирует код деления ДПКД 4 K.ent К. Поскольку команда на исключение импульсов при смене адреса из БП 3 поступает не в каждом такте, код деления частоты последовательно соединенных блока исключения импульсов 7 и ДПКД 4 оказывается дробным. Эти ошибки дробности устраняются в БКШД 8, на который из БП 3 поступает многоразрядный код управления. Приведены два примера вьтолнения БКИЩ 8. ,2 ил. о (Л С о to фиг.1
СОЮЗ СОВЕТСКИХ
СОЦИАЛИСТИЧЕСКИХ
РЕСПУБЛИН
Я0„„1210201
ОПИСАНИЕ ИЗОБРЕТЕНИЯ
ГОСУДАРСТВЕННЫЙ КОМИТЕТ СССР
ПО ДЕЛАМ ИЗОБРЕТЕНИЙ И ОТНРЬГГИЙ.(21) 3766329/24-09 (22) 19.06.84 (46) 07.02.86. Бюл ¹ 5 (71) Всесоюзный заочный электротехнический институт связи (72) В.Н. Кочемасов (53) 621.376.3 (088.8) (56) Авторское свидетельство СССР
¹ 113346, кл. G 01 R 23/06, 1958.
Авторское свидетельство СССР
¹ 641628, кл. Н 03 С 3/08, )976. (54)ДАТЧИК СИГНАЛА ОШИБКИ (57)Изобретение м.б. использовано в прецизионных генераторах сигналов с частотной модуляцией в радиолокационных и связных системах, в акустоэлектронных фурье-процессорах.
Цель изобретения — повышение быстродействия. Устройство содержит опорный генератор 1, делитель частоты 2, блок памяти (БП) 3, делитель частоты с переменным коэффициентом деле(51)4 Н 03 D 13/00, Н 03 С 3/02 ния (ДПКД) 4, два счетчика 5, 6, блок исключения импульсов 7 и блок компенсации шумов добротности (БКШД)
8..Когда уровень напряжения на выходе делителя частоты 2 изменяется, счетчики 5, 6 переходят в счетный режим, счетчик 6 по импульсам с выхода ДПКД 4 формирует код адреса для обращения в БП 3, а счетчик 5 по импульсам, извлекаемым из БП 3, формирует код деления ДПКД 4 К =еп1 К1.
Поскольку команда на исключение импульсов при смене адреса из БП 3 поступает не в каждом такте, код деления частоты посяедовательно соединенных блока исключения импульсов
7 и ДПКД 4 оказывается дробным. Эти ошибки дробности устраняются в БКШД
8, на который из БП 3 поступает многоразрядный код управления. Приведены два примера выполнения БКШД 8.
2 ил.
121020 нормированное время; частота сравнения, на которой происходит преобразование ЛЧМ сигнала (на частоте » работа— ср ет входящий в блок 8 компенсации шумов дробности фазовый детектор 9 (14). нт деления К тствии с выражением
Изобретение относится к рациотехнике и может использоваться в прецизионных генераторах сигналов с частотной модуляцией в радиолокационных и связных системах, а также в акустоэлектронных фурье-процессорах.
Целью изобретения является повышение быстродействия.
На фиг, 1 представлена структурная схема предложенного датчика сигнала к ошибки; на фиг . 2 а и 2 о -примеры выполнения блока компенсации шумов дробности.
Датчик сигнала ошибки содержит .опорный генератор 1, делитель 2 частоты, блок 3 памяти, делитель частоты с переменным коэффициентом деления (ДПКД) 4, первый счетчик 5, второй счетчик 6, блок 7 исключения импульсов, блок 8 компенсации шумов дробности.
Блок 8 компенсации шумов дробности согласно фиг 2а содержит фазовый детектор 9, перемножитель 10, цифроаналоговые преобразователи,(ЦАП) 1! и 12 и сумматор 13 и согласно фиг. 2 о — фазовый детектор 14„ перемножитель 15, ЦАП 16 и линию 17 задержки.
Датчик сигнала ошибки работает следующим образом, На вход измерителя сигнала ошиб-. ки поступает сигнал вида
Текущий коэффицие
15 вычисляемьй в соотве
1, =(9(ук1-9(),„„)1/2 en i X4 «.: д 5к,,К -епт м „(и-t)ao,9s,,(r-<), 2О где К = О,!, 2,…, определяет моменты Y появления импульсов на выходе последовательно включенных блока 7 исключения импульсов и ДПКД 4.
25 Значения У, в соответствии с формулой (2) находятся из уравнения Ж! i,<0,5k,, i „=en4(k
Ll(t) (! ь)в (6(И+ 4(t)j, (1) где (t ) — отклонение фазы от требуемого закона ее изменения 9 (t), которое необходимо на выходе датчика сигнала ошибки. В частном случае, когда закон изменения частоты входного сигнала линейный, т ° е.
1(М=2. („U4), где Т„ — начальная частота ЛЧМ сигнала; v = v/Т вЂ” скорость изменения частоты; т — девиация частоты; Т длительность линейно-частотно-модулированного (ЛЧМ) сигнала, требуемая фаза имеет вид
9(=2u(Kg qi05k у }, (2) где Ж = ((.! — начальный коэф1Н= н ср фициент деления
ДПКД 4;
К сА((ТР, ) — код скорости частотной модуляции
ЧМ;
Яс 8(k) — 9!(g с 7 ;,.
Знак равенства соответствует случаю, когда 9Е. К+ О,5 К „К вЂ” елое. г т„ число для любых значений К, При этом с!О импульсы на выходе последовательно включенных блока 7 исключения импульсов и ДПКД 4 следуют через промежутки времени, равные периоду Т = 1/Г
ap ep следования импульсов в выхода опорного генератора 1.
Именно этот случай при К О «»îoòветствует режиму выделения сигнала ошибки, при котором преобразование входного ЛЧМ сигнала на частоту F
-со осуществляется посредством деления частоты ЛЧМ сигнала на целочисленный коэффициент деления К, который от выборки к выборке меняется на целое число единиц (обычно шаг коэффициента деления равен единице). При режиме с целочисленным коэффициентом деления частота сравнения
F < -1 И/Т и сигнал ошибки может выделяться нг чаще, чем один раз эа время Т,р = 1/I, что обуславливает ср> низкое быстродействие .
В предложенном датчике сигнала ошибки коды К» и К могут принимать
Н нецелочисленные значения, в результате чего частота сравнения I» моср жет быть выбрана много большеи, чем
-Я/Т, причем существенно возрастает быстродействие.
Однако, иэ-за того, что коды К» н
К, а следовательно и код К К +
2 н
+ 0 5K „ К нецелочисленны, импульсы на выходе последовательно включенных блока 7 исключения импульсов и ДПКД
4 даже при строгом соблюдении закона изменения фазы (2) неэквидистантны, что является причиной возникновения шумов дробности (систематических ошибок), Присутствие фазовых отклонений (т,) приводит к тому, что импульсы на выходе ДПКД 4 появляются в моменты времени 11„, отличные от „
Подставляя у„ = К вЂ” g/2/2i в равенство
t
1с» где 5 — крутизна дискриминационной характеристики; К =К» К + н
+ 0,5K > К -ent(K»„+0,5К „К );
К =K „+K K — текущий код частоты.
В (3) первое слагаемое пропорционально измеряемым фазовым ошибкам
— (С) во входном сигнале V(t) а второе представляет собой систематическую погрешность измерения, обусловленную дробностью коэффициента деления.
Датчик сигнала ошибки должен формировать на своем выходе напряжение
Когда на выходе делителя 2 частоты присутствует низкии ровень напряжения, на выходе первого счетчика 5 формируется код начальной частоты К», определяющий начальный
N коэффициент деления ДПКД 4. При этом из блока 3 памяти по нулевому адресу извлекаются нулевые управляющие сигналы, которые поступают на управляющий вход блока 7 исключения импульсов и блока 8 компенсации шумов дробности. Когда уровень напряжения на-выходе делителя 2 частоты изменяется, первый и второй счетчики 5 .и 6 переходят в счетный режим, причем второй счетчик 6 по импульсам с выхода ДПКД 4 формирует код
Ф адреса для обращения к блоку 3. памяти, а первый счетчик 5 по импульсам, извлекаемым из блока 3 памяти, формирует код деления ДПКД 4 К еп1К». Поскольку команда на исключение импульсов при смене адреса из блока 3 памяти поступает не в каждом такте, код деления частоты последовательно соединенных блока 7 исключения импульсов и ДПКД 4 ока- зывается дробным. Эти ошибки дробности устраняются в блоке 8, йа который из блока 3 памяти поступает многоразрядный код управления.
В блоке 8 (фиг. 2а) выходное напряжение фазового детектора 9 умножается сначала в перемножителе 10 на преобразованный к аналоговому виду код частоты К», а затем в сумматоре 13 к нему добавляется преобразованный к аналоговому виду код фазы К . Преобразование кодов К» и
К,р осуществляется соответственно в
ЦАП 11 и 12, В блоке 8 компенсации (,фиг. 2 ) ошибки дробности снижаются за счет введения до фазового детектора 14 линии 17 задержки, управляемой кодом К = К /К, извлекаС ю емьм из блока 3 памяти. Постоянная чувствительность к отклонению фазы обеспечивается умножением напряжения с выхода фазового детектора
l4 на преобразованный к аналоговому виду в II 16 код частоты К»
10201 4 ности и сравнение преобразованной импульсной последовательности (с вы. хода ДПКД 4} с эталонной, поступающей от опорного генератора
1210201
Составитель Г. Захарченко
Техред М.Пароцай Корректор С.Иекмар
Редактор P. Цицика
Заказ 530/58 Тираж 818 Подписное
ВНИИПИ Государственного комитета СССР по делам изобретений и открытий
113035, Москва, Ж-35, Раушская наб., д. 4/5
Филиал ППП «Патент», r. Ужгород, ул. Проектная, Формула и з о б р е т е н и я
Датчик сигнала ошибки, содержащий последовательно соединенные опорный генератор и делитель частоты, выход которого соединен с установочным входом первого счетчика, а также делитель частоты с переменным коэффициентом деления, управляющие входы которого соединены с кодовым выходом первого счетчика, о т л ич а ю шийся тем, что, с целью повышения быстродействия, в него введены блок исключения импульсов, выход которого со счетным входом делителя частоты с переменным коэффициентом деления, блок компенса.— ции шумов дробности, вход опорного сигнала которого соединен с выходом опорного генератора, блок памяти, 1 выход первого разряда которого соединен с управляющим входом блока исключения импульсов, выход второго разряда которого соединен со счетным входом первого счетчика, а выходы остальных разрядов — с управляющими входами блока компенсации шумов дробности, и второй счетчик, 10 установочный вход которого соединен с выходом делителя частоты, а кодо— вые выходы — с адресными входами блока памяти, при этом выход дели— теля частоты с переменным коэффици-!
5 ентом деления соединен с информационным входом блока компенсации шумов дробности и со счетным входом второго счетчика, вход блока исключения импульсов является входом, а
20 выход блока компенсации шумов дробности — выходом датчика сигнала ошибки.




СОЮЗ СОВЕТСКИХСОЦИАЛИСТИЧЕСКИХРЕСПУБЛИН ИСАНИЕ БР ГОСУДАРСТВЕННЫЙ КОМИТЕТ СССРПО ДЕЛАМ ИЗОБРЕТЕНИЙ И ОТНРЬПИЙ АВТОРСКОМУ СВИДЕТЕЛ(71) Всесоюзный заочный электротехнический институт связи(56) Авторское свидетельство СССР У 113346, кл. О 01 Б 23/06, 1958.Авторское свидетельство СССР У 641628, кл. Н 03 С 3/08, 1976, (54)ДАТЧИК СИГНАЛА ОШИБКИ (57)Изобретение м.б. использовано в прецизионных генераторах сигналов с частотной модуляцией в радиолокационных и связных системах, в акустоэлектронных фурье-процессорах. Цель изобретения — повышение быстродействия, Устройство содержит опорный генератор 1, делитель частоты 2, блок памяти (БП) 3, делитель частоты с переменным коэффициентом делеЯО 1210201 5114 Н 03 0 13/00, Н 03 С 3/02 ния (ДПКД) 4, два счетчика 5, 6,блок исключения импульсов 7 и блоккомпенсации шумов добротности (БКШД)8 Когда уровень напряжения на выходе делителя частоты 2 изменяется,счетчики 5, 6 переходят в счетныйрежим, счетчик 6 по импульсам с выхода ДПКД 4 формирует код адреса дляобращения в БП 3, а счетчик 5 по импульсам, извлекаемым из БП 3, формирует код деления ДПКД 4 К =епС К 1,Поскольку команда на исключение импульсов при смене адреса из БП 3 поступает не в каждом такте, код деления частоты поспедовательно соединенных блока исключения импульсов7 и ДПКД 4 оказывается дробным. Этиошибки дробности устраняются в БКШД8, на который из БП 3 поступает многоразрядный код управления. Приведены два примера выполнения БКШД 8.2 ил,деляться нг чаще, чем один раз эавремя Т,р = 1/Г , что обуславливаетсрнизкое быстродействие,В предложенном датчике сигналаошибки коды К и К могут приниматьНнецелочисленные значения, в результате чего частота сравнения Р мосржет быть выбрана много большеи, чем-Я/7, причем существенно возрастает быстродействие,Однако, иэ-за того, что коды КнК, а следовательно и код К К +2н+ 0,5 КК нецелочисленны, импульсына выходе последовательно включенныхблока 7 исключения импульсов и ДПКД4 даже при строгом соблюдении законаизменения Фазы (2) неэквидистантны,что является причиной возникновенияшумов дробности (систематических ошибок),Присутствие фазовых отклонений1(т,) приводит к тому, что импульсына выходе ДПКД 4 появляются в моменты времени , отличные отПодставляя у= К — ч/2/2 н в равенство»Г.9 х» 5″ Ик 11 (цх)=2 Я еп (К Коб К 1 с ),решая полученное уравнение относительно у в предположении, что откклонения фазы 4(С) от желаемого закона фазы (2) невелики, получаем6(,х 1 276 ч (3)Кгде Б — крутизна дискриминационнойхарактеристики; К р =К К +1 н+ 0,5 К К -С(К+0,5 К К ); К=Кн+КК — текущий код частоты.В (3) первое слагаемое пропорционально измеряемым фазовым ошибкам .(С) во входном сигнале 0, а второе представляет собой систематическую погрешность измерения, обусловленную дробностью коэффициента деления.Датчик сигнала ошибки должен формировать на своем выходе напряжение(4)В силу того, что характер изменения кодов К и Кр в зависимости от К известен, становится возможным обеспечить переход от (3) к (4), Это осуществляется в блоке 8, в котором производится компенсация шумов дроб 1 О 15 20 25 30 35 40 45 50 55 Когда на выходе делителя 2 частоты присутствует низкий уровень напряжения, на выходе первого счетчика 5 Формируется код начальной частоты К , определяющий начальный коэффициент деления ДПКД 4. При этом из блока 3 памяти по нулевому адресу извлекаются нулевые управляющие сигналы, которые поступают на управляющий вход блока 7 исключения импульсов и блока 8 компенсации шумов дробности. Когда уровень напряжения на.выходе делителя 2 частоты изменяется, первый и второй счетчики 5 .и 6 переходят в счетный режим, причем второй счетчик 6 по импульсам с выхода ДПКД 4 Формирует кодФ адреса для обращения к блоку З.памяти, а первый счетчик 5 по импульсам, извлекаемым из блока 3 памяти, формирует код деления ДПКД 4 Кеп 1 К. Поскольку команда на исключение импульсов при смене адреса из блока 3 памяти поступает не в каждом такте, код деления частоты последовательно соединенных блока 7 исключения импульсов и ДПКД 4 ока- зывается дробным. Эти ошибки дробности устраняются в блоке 8, йа который из блока 3 памяти поступает многоразрядный код управления.В блоке 8 (фиг. 2 а) выходное напряжение фазового детектора 9 умножается сначала в перемножителе 10 на преобразованный к аналоговому виду код частоты К, а затем в сумматоре 13 к нему добавляется преобразованный к аналоговому виду код фазы К, Преобразование кодов К и К,р осуществляется соответственно в ЦАП 11 и 12, В блоке 8 компенсации ,фиг. 2) ошибки дробности снижаются за счет введения до фазового детектора 14 линии 17 задержки, управляемой кодом К, = К /К , извлекаср С фемьм из блока 3 памяти. Постоянная чувствительность к отклонению фазыобеспечивается умножением напряжения с выхода фазового детектора 14 на преобразованный к аналоговому виду в ПП 16 код частоты К 10201 4ности и сравнение преобразованнойимпульсной последовательности (с выхода ДПКД 4) с эталонной, поступающей от опорного генератора 51210201 Формула изобретения Датчик сигнала ошибки, содержащий последовательно соединенные опорный генератор и делитель частоты, выход которого соединен с установочным входом первого счетчика, а также делитель частоты с переменным коэффициентом деления, управляющие входы которого соединены с кодовым выходом первого счетчика, о т л ич а ю щ и й с я тем, что, с целью повышения быстродействия, в него введены блок исключения импульсов, выход которого со счетным входом делителя частоты с переменным коэффициентом деления, блок компенса. — ции шумов дробности, вход опорного сигнала которого соединен с выходом опорного генератора, блок памяти, 1 Составитель Г. ЗахарченкоТехред М,Пароцай Корректор С.Иекмар ктор Р. Цицик ПодписноеСССР го комитетй и открытРаушская 4/5 иал ППП «Патен Ужгород, ул, Проектн з 530/58 Тир ВНИИПИ Государственн по делам изобретен 113035, Москва, Жвыход первого разряда которого соединен с управляющим входом блокаисключения импульсов, выход второгоразряда которого соединен со счетным входом первого счетчика, а выходы остальных разрядов — с управляющими входами блока компенсациишумов дробности, и второй счетчик, 10 установочный вход йоторого соединенс выходом делителя частоты, а кодовые выходы — с адресными входамиблока памяти, при этом выход делителя частоты с переменным коэффици ентом деления соединен с информационным входом блока компенсации шумов дробности и со счетным входомвторого счетчика, вход блока исключения импульсов является входом, а 20 выход блока компенсации шумов дробности — выходом датчика сигнала ошибки.
Смотреть
<a href=»https://patents.su/4-1210201-datchik-signala-oshibki.html» target=»_blank» rel=»follow» title=»База патентов СССР»>Датчик сигнала ошибки</a>
детектор сигнала ошибки
- детектор сигнала ошибки
-
1) Telecommunications: error detector
2) Astronautics: error-signal detector
Универсальный русско-английский словарь.
.
2011.
Смотреть что такое «детектор сигнала ошибки» в других словарях:
-
детектор качества сигнала данных — детектор качества сигнала Устройство, измеряющее значение представляющего параметра сигнала данных и вырабатывающее сигнал, указывающий на возможность ошибки в поступившем сигнале. [ГОСТ 17657 79 ] Тематики передача данных Обобщающие термины… … Справочник технического переводчика
-
детектор ошибки несущей сигнала данных — — [http://www.iks media.ru/glossary/index.html?glossid=2400324] Тематики электросвязь, основные понятия EN data carrier failure detector … Справочник технического переводчика
-
Детектор — 7. Детектор Электрическая цепь, осуществляющая детектирование электрического сигнала Источник: ГОСТ 24375 80: Радиосвязь. Термины и определения оригинал документа 3.3 детектор (detector): Устройство, определяющее величину радиации. Источник … Словарь-справочник терминов нормативно-технической документации
-
Детектор качества сигнала данных — 128. Детектор качества сигнала данных Детектор качества сигнала Е. Data signal quality detector Устройство, измеряющее значение представляющего параметра сигнала данных и вырабатывающее сигнал, указывающий на возможность ошибки в поступившем… … Словарь-справочник терминов нормативно-технической документации
-
Детектор качества сигнала данных — 1. Устройство, измеряющее значение представляющего параметра сигнала данных и вырабатывающее сигнал, указывающий на возможность ошибки в поступившем сигнале Употребляется в документе: ГОСТ 17657 79 Передача данных. Термины и определения … Телекоммуникационный словарь
-
Фазовый детектор — (ФД) в электронике, устройство, сравнивающее фазы двух входных сигналов. Обычно, один из них генерируется генератором сигнала, управляемым напряжением, а второй берется из внешнего источника. ФД имеет два входа, управляющих стоящей за ним схемой… … Википедия
-
ДСО — датчик сигнала ошибки деревообрабатывающее и сельскохозяйственное оборудование детальное соглашение по объекту детектор сигнала ошибки детское спортивное общество диаграмма статической остойчивости (судна) динамическое средство управления… … Словарь сокращений русского языка
-
ДСО — детальное соглашение по объекту ДСО детское соматическое отделение ДСО динамическое средство управления дорстройотдел ДСО дорожно строительный отдел … Словарь сокращений и аббревиатур
-
ГОСТ 17657-79: Передача данных. Термины и определения — Терминология ГОСТ 17657 79: Передача данных. Термины и определения оригинал документа: 78. n кратная ошибка в цифровом сигнале данных n кратная ошибка Е. n fold error Группа из и ошибок в цифровом сигнале данных, при которой ошибочные единичные… … Словарь-справочник терминов нормативно-технической документации
-
Фазовая автоподстройка частоты — (ФАПЧ) система автоматического регулирования, подстраивающая частоту управляемого генератора так, чтобы она была равна частоте опорного сигнала. Регулировка осуществляется благодаря наличию отрицательной обратной связи. Выходной сигнал… … Википедия
-
ФАПЧ — Фазовая автоподстройка частоты (ФАПЧ) система автоматического регулирования, подстраивающая частоту управляемого генератора так, чтобы она была равна частоте опорного сигнала. Регулировка осуществляется благодаря наличию отрицательной обратной… … Википедия
Методы обнаружения и коррекции ошибок в цифровых звуковых сигналах
В цифровых каналах
связи средняя вероятность появления
ошибки составляет 10–5…10–6,
а в отдельных случаях и 10–4,
поэтому влияние ошибок на качество
звукопередачи неизбежно. Это вызывает
необходимость применения помехоустойчивого
кодирования при передаче сигналов ЗВ.
Обнаружение и
коррекция ошибок требуют введения в
сигнал определенной избыточности. Для
этой цели сигнал на выходе АЦП разделяется
на блоки, в которые, кроме основной
информации, связанной с кодированием
отсчетов, включаются дополнительные
символы, необходимые для обнаружения
и исправления ошибок. Перед цифроаналоговым
преобразованием эти блоки подвергаются
дополнительной цифровой обработке, в
процессе которой на этапе обнаружения
определяется наличие ошибок. Для
исправления ошибок необходимо определить
место пораженных символов в блоке, чтобы
заменить их на правильные. Исправление
ошибок — задача гораздо более сложная,
чем их обнаружение.
Помехоустойчивое
кодирование основано на применении
корректирующих кодов, в которые вносится
некоторая избыточность, что приводит
к увеличению требуемой пропускной
способности канала связи. Различают
коды для обнаружения ошибок и коды для
исправления обнаруженных ошибок.
Помехоустойчивые коды могут быть
построены с любым основанием, однако
наиболее простыми и часто используемыми
являются двоичные коды.
Обнаружение ошибок
в корректирующих кодах строится обычно
на том, что для передачи используются
не все кодовые слова кодового списка,
а лишь их некоторая часть (разрешенные);
остальные кодовые слова из этого списка
являются запрещенными. Если переданное
разрешенное кодовое слово вследствие
ошибки преобразуется на приемной стороне
тракта в запрещенное, то такая ошибка
может быть обнаружена. Процедура
исправления ошибок состоит в замене
ошибочно принятой комбинации на
разрешенную, которая принадлежит данному
коду и расстояние до которой оказывается
наименьшим.
Ошибки могут быть
одиночными и сгруппированными в пакеты.
Под пакетами
понимают
появление двух или большего числа ошибок
в пределах одной m-разрядной
кодовой комбинации. Если ошибки,
возникающие при передаче сигналов,
являются статистически независимыми,
то вероятность появления пакета ошибок
кратности q
![]() (1.37)
(1.37)
где
![]() ,
,
— число сочетаний изт
символов по
q.
Для
10-раз-рядных кодовых слов вероятность
появления двойных ошибок при исходной
вероятности рош = 10–5
составляет p1 = 510–9,
а при рош = 10–4
уже составляет р2 = 510–7.
Это соответствует появлению одной
двойной ошибки каждые 2,5…3 мин.
Кроме того, в
цифровых каналах передачи при средней
вероятности появления ошибки рош = 10–4
и выше возникают коррелированные ошибки,
вызванные действием импульсных помех,
несовершенством систем коммутации и
т.д. Поэтому вероятность появления
ошибок большой кратности возрастает.
Особенно велика роль пакетов ошибок в
каналах цифровой магнитной записи и в
системе компакт-диска из-за возможных
повреждений носителя записи. Системы
исправления ошибок должны эффективно
бороться не только с одиночными, но и с
пакетами ошибок, заметность которых
существенно выше. Чем больше кратность
ошибки, тем больше должна быть избыточность,
которую необходимо вносить в сигнал.
Требуемая избыточность тем больше, чем
большее число разрядов кодовой группы
необходимо защищать. С учетом заметности
искажений в системах цифровой передачи
и записи ЗС обычно защищают от ошибок
пять-шесть старших разрядов информационных
символов кодируемых отсчетов, служебные
комбинации, определяющие, например,
номер шкалы квантования при почти
мгновенном компандировании. Ошибки в
младших разрядах, если частота их
появления не слишком велика, достаточно
обнаруживать и затем маскировать,
используя методы интерполяции, о которых
будет сказано ниже.
Выбор способа
обнаружения ошибок, метода их маскирования
и исправления, возможного только при
помехоустойчивом кодировании, зависит
как от среднего значения вероятности
появления ошибки, так и от того, являются
они одиночными или групповыми. Для
тракта студийной аппаратной, а также
трактов звукозаписи и первичного
распределения программ ЗВ эти методы
различны.
Простейшие методы
обнаружения ошибки.
Если цифровые аудиоданные передаются
или считываются, то в приемнике нет
возможности распознать, корректно ли
принимаемое число (например, число 0101)
либо один или несколько символов в
принятом кодовом слове неверны. Для
решения этой проблемы применяют коды.
Самые простые из них — коды
с повторением. Каждый
информационный символ можно, например,
повторить n
раз (обычно n
нечетно и
больше двух), т.е.
-
<—-> 0 0 0 0 0…0,
-
<—-> 1 1 1 1 1…1.
Это (n,1)-код.
Для него минимальное расстояние равно
n,
и в предположении, что большинство
принятых битов совпадает с переданным
информационным битом, может быть
исправлено (n–1)/2
ошибок. Если символы передать только
дважды, а затем обнаружить, что они
различаются, то нет возможности принять
решение о том, какое из двух чисел
является правильным. Каждое число нужно
передать по крайней мере трижды и после
сравнения распознать ошибочное. Такой
метод неэффективен, он приводит к резкому
увеличению требуемой скорости передачи.
Найдены другие, более эффективные
возможности.
Очень простыми
являются коды
с проверкой на четность. К
информационным битам каждого кодового
слова k-й
разрядности
добавляют (к+1)-й
бит так, чтобы полное число единиц (или
нулей) в кодовом слове было четным.
Данный прием в цифровых устройствах
из-за простоты используют очень часто.
При этом дополнительный бит называется
битом проверки
на четность (паритетным
битом). Например, для k = 4
имеем
|
Исходный |
Бит |
||||||||
|
0 |
0 |
0 |
0 |
|
0 |
0 |
0 |
0 |
0 |
|
0 |
0 |
0 |
1 |
|
0 |
0 |
0 |
1 |
1 |
|
0 |
0 |
1 |
0 |
|
0 |
0 |
1 |
0 |
1 |
|
0 |
0 |
1 |
1 |
|
0 |
0 |
1 |
1 |
0 |
и т.д.
Этот код является
(k
+ 1,k)-кодом.
Минимальное расстояние кода равно 2, и,
следовательно, ошибки могут быть
обнаружены, но никакие ошибки не могут
быть исправлены. Если бит передается
неправильно, то распознается появление
ошибки в слове (ибо сумма всех единиц
не будет равна четному числу, если ошибка
одиночная). Однако позицию ошибки в
кодовой комбинации определить невозможно.
Таким образом, данный код не позволяет
исправить ошибки. В силу этого данный
код используется только для обнаружения
одиночных ошибок, но не для их исправления.
Впрочем, можно
распознать позицию единичных (отдельных)
ошибок, если несколько слов предварительно
объединить в матрицу, а контрольные
разряды четности (дополнительные биты
проверки на четность) добавить к
информационным символам кодовых слов
построчно и по столбцам, например:
Правильно
Ошибка в первой строке, третий столбец
(выделена
подчеркиванием)
|
0 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
1 |
0 |
|
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
|
1 |
1 |
0 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
|
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
|
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
||
|
|
(неправильная
четность)
Однако если в таком
блоке одновременно появляется несколько
ошибок, то такой метод не принесет
пользы.
Маскирование
ошибок. Если
средняя вероятность появления ошибки
не превышает рош = 10–5
и источником ошибок является шум в
канале передачи, то расчеты показывают,
что одиночные ошибки появляются в
среднем 2 раза в секунду, а двойные —
примерно 4 раза в сутки. В этих условиях
достаточно учитывать только одиночные
ошибки. Действие последних приводит к
искажению величины отдельных отсчетов
сигнала, и эффективным способом борьбы
с ними является обнаружение ошибочно
принятых кодовых слов с последующим
маскированием искаженных отсчетов. Для
обнаружения обычно используется уже
описанный выше принцип проверки на
четность, причем такой, чтобы число
единиц в кодовом слове было четным. При
приеме после выделения кодовых слов в
каждом из них подсчитывается число
единиц. Нечетное их число будет означать
наличие ошибки в данном кодовом слове.
Вероятность (p0)
того, что при использовании данного
метода ошибка не будет обнаружена,
зависит как от вероятности (рош)
ее появления
в канале, так и от числа разрядов
(символов) т
в кодовом
слове, включая разряд четности. Величину
p0
можно найти
по формуле
![]() ,
,
(1.38)
где
![]() — число сочетанийт
— число сочетанийт
символов по
2. Отсюда видно, что использование длинных
кодовых слов ведет к росту вероятности
необнаруженной ошибки.
Если одиночная
ошибка в кодовом слове обнаружена, то
ее маскирование после этого состоит в
замене искаженного отсчета. Обычные
методы, используемые для этого процесса,
показаны на рис. 1.21.
На рис. 1.21,
а отмечено
ошибочное значение отсчета. Самым плохим
наверняка является его замена на нуль,
т.е. выбрасывание отсчета с ошибочным
значением (рис. 1.21,
б). Лучше,
если ошибочный отсчет будет заменен на
значение предыдущего отсчета (рис.
1.21,
в).
Еще лучше, если его значение будет
получено как интерполяция значений
двух соседних отсчетов, например путем
вычисления среднего значения (рис.
1.21,
г).
Однако все же разность между восстановленным
и истинным значениями отсчета может
быть заметной на слух и намного превысить
шаг квантования.

Рис. 1.21
— Маскирование ошибочных отсчетов:
а
— обнаруженная ошибка в значении отсчета
sn;
б — замена
ошибочного отсчета sn
отсчетом с
нулевым значением; в
— коррекция (экстраполяция нулевого
порядка) через замену ошибочного отсчета
sn
его предыдущим значением sn–1;
г — интерполяция
первого порядка путем вычисления
среднего значения из предыдущего sn–1
и последующего sn+1
отсчетов
Поскольку слух
человека инерционен, то метод маскирования
оказывается эффективным, если число
ошибок не превышает одной-двух в секунду.
Это условие выполняется при вероятности
появления ошибки в канале рош = 10–5.
При т = 6
в этом случае получаем, что вероятность
необнаруженной ошибки р0 = 1510–10,
что примерно соответствует требуемому
значению.
Увеличение рош
до значения
10–4
ведет к резкому росту среднего числа
ошибок в секунду до 20. Метод интерполяции
первого порядка не обеспечивает полного
маскирования ошибок полезным сигналом,
они становятся уже заметными на слух.
Можно считать, что изложенный выше метод
маскирования применим, когда значение
рот
10–5.
Исправление
ошибок. Если
вероятность ошибки превышает рош = 10–5,
то образуются пакеты ошибок и от их
маскирования приходится переходить к
исправлению. Для исправления ошибок
применяют помехоустойчивое кодирование.
При этом наиболее широкое распространение
получили блочные линейные (m,k)-ко-ды.
У таких кодов передаваемая последовательность
символов разделена на блоки, содержащие
одинаковое число символов. Общее число
символов (битов) в кодовом слове равно
m,
из них информационными являются первые
k
символов, а последние r = т – k
символов —
проверочными. Проверочные символы
формируются в результате выполнения
некоторых линейных операций над
информационными символами. В частности,
проверочные символы могут являться
суммой по модулю 2 различных сочетаний
информационных символов. Чем больше
число проверочных символов, тем больше
корректирующие возможности кода.
Особенностью линейного кода является
также то, что сумма (и разность) входящих
в код кодовых слов также является кодовым
словом, принадлежащим этому коду.
Корректирующие
коды характеризуются избыточностью.
Она определяется относительным
увеличением длины блока из-за введения
в него дополнительной проверочной
информации и оценивается выражением
![]() (1.39)
(1.39)
где R
— избыточность
кода.
Наиболее известной
разновидностью блочных линейных (т,
k)-кодов
являются коды Хэмминга. Для каждого т
существует
(2m–1,
2m–1 – m)-код
Хэмминга. Кроме параметров т
и k,
важным
является минимальное расстояние d,
определяющее
меру различия двух наиболее похожих
кодовых слов. Расстоянием d
по Хэммингу
между двумя q-ичными
последовательностями х
и у
длины n
называется число позиций, в которых они
различны. Это расстояние обозначается
d(x,y).
Например,
если х = 10101
и у = 01100,
то имеем d(10101,
01100) = 3. При этом минимальное
расстояние кода равно наименьшему
значению из всех расстояний по Хэммингу
между различными парами кодовых слов
в коде; (п,
k)-код
с минимальным расстоянием d
называется
также (п,
k,
d)—кoдoм.
Из теории
помехоустойчивого кодирования известно,
что если произошло t
ошибок и
расстояние от принятого слова до каждого
другого больше t,
то декодер
исправит эти ошибки, приняв ближайшее
к принятому кодовое слово в качестве
действительного переданного. Это будет
всегда так, если
![]() (1.40)
(1.40)
Например, для
обнаружения одиночной ошибки d = 2.
Это означает, что достаточно информационные
кодовые группы увеличить на один разряд.
Для исправления одиночных ошибок каждую
кодовую группу необходимо увеличить
уже на три разряда. С ростом кратности
ошибок объем требуемой дополнительной
информации резко возрастает. Так, для
числа k
битов
аудиоданных требуется следующее число
контрольных (дополнительных, проверочных)
битов r
в коде Хэмминга, чтобы ошибка могла быть
исправлена:
|
Биты |
1–4 |
5–11 |
12–26 |
27–57 |
58–120 |
|
Контрольные |
3 |
4 |
5 |
6 |
7 |
Контрольные биты
рассчитываются (вычисляются) путем
сложений по модулю 2. В них участвуют
информационные биты аудиоданных по
меньшей мере дважды. Чтобы с большой
вероятностью обнаружить ошибку в потоке
данных, информационные слова и контрольные
слова охватываются совместно в блоки.
Эти блоки затем снова рассматриваются
как отдельные единицы информации и
далее кодируются (блочный код). Иногда
удается исправлять конфигурацию из t
ошибок даже
в том случае, если неравенство (1.40)
не выполняется. Однако если d
< (2t
+ 1), то
исправление любых t
ошибок не
может быть гарантировано, так как оно
зависит от передаваемого слова и
конфигурации из t
ошибок,
возникших внутри блока.
При кодовом
расстоянии d = 3
коды Хэмминга имеют длину т = 2r–1.
При двух проверочных символах r = 2
существует код Хэмминга (3,1); при r = 3
— код (7,4); при r = 4
— код (15,11)
и т.д. Коды, для которых d = 3,
могут исправлять одиночную ошибку. Для
нахождения места этой ошибки необходимо
выполнить r
проверок, представляющих собой операции
суммирования по модулю 2. Технически
это реализуется достаточно просто.
Например, (7,4)-код Хэмминга можно описать
с помощью реализации, приведенной на
рис. 1.22,
а.


Рис. 1.22
— Кодек для простого (7,4)-кода Хэмминга:
а — кодер;
б — декодер
При заданных
четырех информационных битах данных
(i1,
i2,
i3,
i4)
каждое кодовое слово дополняется тремя
проверочными битами, задаваемыми
равенствами
 (1.42)
(1.42)
Знак «+» здесь
означает сложение по модулю 2: 0 + 0 = 0,
0 + 1 = 1, 1 + 0 = 1, 1 + 1 = 0. Шестнадцать
разрешенных кодовых слов (7,4)-кода
Хэмминга имеют вид (i1,i2,
i3,
i4,
r1,
r2,
r3):
|
i1 |
i2 |
i3 |
i4 |
r1 |
r2 |
r3 |
i1 |
i2 |
i3 |
i4 |
r1 |
r2 |
r3 |
|
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
|
|
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
0 |
|
|
0 |
0 |
1 |
0 |
1 |
1 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
|
|
0 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
0 |
0 |
|
|
0 |
1 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
1 |
0 |
|
|
0 |
1 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
0 |
1 |
|
|
0 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
1 |
0 |
0 |
|
|
0 |
1 |
1 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
Пусть при передаче
в принятом слове v = (i‘1,
i‘2,
i‘3,
i‘4,
r‘1,
r‘2,
r‘3).
По изображенному
на рис. 1.22,
б коду
вычисляются биты
 (1.44)
(1.44)
Трехбитовая
последовательность (s1,
s2,
s3)
называется
синдромом.
Она зависит
только от конфигурации ошибок. Всего
имеется восемь возможных синдромов:
один для случая отсутствия ошибки и по
одному для каждой из семи возможных
одиночных ошибок, при этом каждая ошибка
имеет только свой единственный синдром.
Несложно сконструировать цифровую
логику, которая по синдрому локализует
соответствующий ошибочный бит. После
исправления ошибки проверочные символы
опускаются. При наличии двух и более
ошибок код будет ошибаться: он предназначен
для исправления только одной одиночной
ошибки в кодовом слове группы.
При d = 4
коды Хэмминга имеют длину т = 2r–1
и записываются
соответственно как (4,1); (8,4); (16,11) и т.д.
Они получаются из кодов Хэмминга с
минимальным расстоянием d = 3
добавлением к каждому кодовому слову
[см. (1.43)]
одного проверочного символа, равного
сумме по модулю 2 всех остальных символов,
как информационных, так и проверочных
для каждого кодового слова исходного
(7,4)-кода Хэмминга.
При выборе кода
важно определить мощность кода М,
т.е. максимальное
число кодовых слов в двоичном коде
длиной т
(множество
двоичных слов длины m)
при заданном кодовом расстоянии d.
Обычно при
d = 3
![]() (1.45)
(1.45)
Следовательно,
(3, 1)-код Хэмминга состоит всего лишь из
двух кодовых слов. Для увеличения числа
кодовых слов необходимо увеличить длину
кодового слова: для (7,4)-кода Хэмминга
уже имеется 16 кодовых слов. С увеличением
m
растет сложность декодирования. Коды
Хэмминга в силу этой причины целесообразно
использовать для исправления одиночных
независимых ошибок при небольшом числе
возможных информационных символов. В
частности, коды Хэмминга используют
для передачи трехсимвольных комбинаций,
определяющих номер шкалы квантования
при кодировании ЗС с применением почти
мгновенного компандирования.
Достаточно простой
процедурой кодирования и декодирования
обладают линейные циклические коды
(CRC-коды),
где разрешенные кодовые слова формируются
из других разрешенных слов циклическим
сдвигом символов на один шаг вправо.
Цикличность позволяет уменьшить объем
памяти устройств, осуществляющих
кодирование и исправление ошибок, а
возможность записи кодовых слов в виде
степенных полиномов сводит процедуры
кодирования и декодирования к операциям
умножения и деления полиномов, легко
реализуемых технически.
Кодовое слово
Z – (a0,
a1,
a2,…,
an–1),
состоящее из n
символов, определяется полиномом
Y(x) = a0
+ a1x
+ a2x2
+…+ an–1xn–1.
Среди всех полиномов, соответствующих
кодовым словам циклического кода,
имеется ненулевой полином наименьшей
степени. Он называется порождающим,
степень его
r = n – k
(k
— число
информационных символов, n
— число символов в кодовом слове), а
свободный член равен единице. Основная
особенность порождающего полинома
заключается в том, что он полностью
определяет циклический код (все кодовые
слова циклического кода) и является
делителем всех полиномов, соответствующих
кодовым словам циклического кода.
Процесс кодирования
при использовании циклического кода
состоит в следующем. Полином G(x)
степени
(k – 1),
характеризующий k-разрядное
передаваемое информационное кодовое
слово, умножается на хr.
Полученный
полином G(x)xr
степени
k+r–1
делится на
порождающий полином F(x).
В результате
деления образуется остаток q(x)
степени не
более r – 1.
Полином Q(x) =
= xrG(x)
+ q(x),
делящийся
на F(x)
без остатка,
определяет каждое разрешенное кодовое
слово циклического кода. Члены полинома
Q(x)
со степенью
r+1
и выше соответствуют информационным
символам, смещенным на r
разрядов в
результате операции умножения, а остаток
q(x)
от деления
— поверочным символам. Для обнаружения
или исправления ошибок в циклическом
коде обычно используют операцию деления
полинома Q1(x)
принятого
кодового слова на заранее известный
порождающий полином F(x).
Если остаток
от деления не равен нулю, то принятое
кодовое слово считается ошибочным.
Место ошибки определяется детектором
ошибки в результате сравнения остатка
от деления с эталонным полиномом,
хранящимся в памяти. Биты избыточности,
полученные изложенным выше способом,
передаются совместно с первоначальными
битами данных.
Пример.
Последовательность из n = 10
битов можно представить степенным
полиномом, например вида Р(х) = х9
+ х5
+
х2
+
1, который
представляет собой информационное
кодовое слово 1000100101. Разделим теперь
Р(х)
на порождающий
полином, называемый также генераторным
полиномом G(x).
Результатом
деления будут частное Q(x)
и остаток
R(х).
Возьмем в качестве
генераторного полинома G(x) = х5
+ x4
+ + х2
+ 1, представляющий
двоичное число 110101. Перемножим Р(х)
и первый
член полинома G(x),
имеющий
наивысшую степень, а полученный результат
затем разделим на G(x):

Выполним эти
вычисления
|
P(x)x5 |
= |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
|
G(x) |
+ |
1 |
1 |
0 |
1 |
0 |
1 |
|||||||||
|
1 |
0 |
1 |
1 |
1 |
0 |
|||||||||||
|
+ |
1 |
1 |
0 |
1 |
0 |
1 |
||||||||||
|
1 |
1 |
0 |
1 |
1 |
1 |
|||||||||||
|
+ |
1 |
1 |
0 |
1 |
0 |
1 |
||||||||||
|
1 |
0 |
0 |
1 |
0 |
0 |
|||||||||||
|
+ |
1 |
1 |
0 |
1 |
0 |
1 |
||||||||||
|
1 |
0 |
0 |
0 |
1 |
0 |
|||||||||||
|
+ |
1 |
1 |
0 |
1 |
0 |
1 |
||||||||||
|
1 |
0 |
1 |
1 |
1 |
0 |
|||||||||||
|
+ |
1 |
1 |
0 |
1 |
0 |
1 |
||||||||||
|
1 |
1 |
0 |
1 |
1 |
0 |
|||||||||||
|
+ |
1 |
1 |
0 |
1 |
0 |
1 |
||||||||||
|
Остаток |
1 |
1 |
Передаваемое
кодовое слово D(x)
в этом случае
имеет вид
![]()
в примере
соответственно 1 0 0 0 1 0 0 1 0 1 0 0 0 1 1.
Декодирующее устройство делит эти биты
данных на G(x),
и если новый
остаток R‘(x) = 0,
то передача свободна от ошибок (без
ошибок). В противном случае из остатка
можно локализовать ошибку.
В качестве примера
на рис. 1.23
показаны структурные схемы кодирующего
и декодирующего устройств с использованием
циклического кода (29,24). Порождающий
многочлен этого кода имеет вид F1(x) = x5
+ x2
+ 1. Первоначально (рис. 1.23,
а) ключ К
замкнут и на вход схемы последовательно
подаются информационные символы.
Одновременно эти же символы поступают
на выход. Кодер представляет собой здесь
многотактный линейный фильтр Хаффмена,
состоящий из элементов 1 — 5 сдвигового
регистра и двух сумматоров C1
и С2. Данное устройство выполняет деление
полинома x5G(x)
на порождающий
полином F1(x).
После 24-х
тактов работы кодера в его регистре
образуется остаток q(x)
от деления.
На 25-м такте ключ К перебрасывается в
верхнее положение, и символы остатка
(поверочные символы) один за другим
поступают на выход кодера. За пять тактов
на выход поступают пять поверочных
символов и происходит обнуление регистра.
Затем происходит кодирование следующей
группы информационных символов.

Рис. 1.23
— Пример структурных схем кодера (а)
и декодера (б)
с использованием
циклического кода (29,24)
Принятый декодером
(рис. 1.23,
б) входной
сигнал запоминается регистром сдвига
PC
и одновременно через ключ К поступает
на устройство деления УД, подобное тому,
которое имеется в кодере. После поступления
в УД 29-ти символов (блок данного кода)
ключ К перебрасывается в нижнее положение
и поступление входного сигнала на УД
прекращается. Одновременно с выхода УД
сигнал поступает на детектор ошибки.
Если принятое кодовое слово не имеет
ошибок, то на выходе УД имеется нулевой
сигнал, что и фиксирует детектор, разрешая
без коррекции информационным символам
покидать PC
через сумматор С3.
Если принято ошибочное кодовое слово,
то на выходе УД имеется ненулевой сигнал.
В этом случае продолжающийся тактовый
сдвиг разрядов сигнала в регистре УД
приводит к появлению кодового слова,
соответствующего эталонному полиному.
В тот же момент в детекторе формируется
исправляющий сигнал, который соответствует
положению ошибки в информационных
символах, проходящих через сумматор
С3.
Исправляющий символ, поступающий от
детектора ошибок, исправляет ошибочный
информационный символ.
Подклассом
циклических кодов являются широко
распространенные коды
БЧХ (Боуза–Чоудхори–Хоквингема).
Для них справедливо правило: для любых
значений s
и q
< (2s – 1)/2
существует двоичный циклический код
длиной n = 2s – 1,
исправляющий все комбинации из q
или меньшего
числа ошибок и содержащий не более чем
sq
проверочных
символов. Так, код БЧХ (63,44), используемый
в системе спутникового цифрового
радиовещания, позволяет исправить две
или три ошибки, обнаружить и замаскировать
пять или четыре ошибки на каждый кодовый
блок из 63-х символов. При вероятности
ошибки рош = 10–3
это означает появление одной необнаруженной
ошибки в час. Избыточность данного кода
составляет R = (63 – 44)/63 = 0,33
(33 %). Такой же избыточностью обладают и
циклические
коды Рида–Соломона. Двойной
код Рида–Соломона с перемежением
символов (CIRC-код)
как наиболее эффективный при исправлении
ошибок большой кратности нашел применение
в системе компакт-диска и цифровой
магнитной записи.
В последнее время
стали использоваться также сверточные
коды. В них обрабатывается непрерывная
последовательность символов без
разделения ее на независимые блоки.
Поверочные символы в каждой группе из
n0
символов сверточного кода определяются
не только k0
информационными
символами этой группы, но и информационными
символами предшествующих групп. Поэтому
он не является блочным кодом длины n0.
Недостатком сверточных кодов является
возможное размножение ошибок, т.е.
появление нескольких ошибок на выходе
декодера, если одиночные ошибки оказались
не исправленными при декодировании.
Сверточные коды в сочетании с двойным
кодом Рида–Соломона с перемежением
символов предлагается использовать в
системе непосредственного цифрового
радиовещания.
Перемежение
символов.
Этот способ широко применяется для
защиты от пакетов ошибок длиной в сотни
разрядов, например в аппаратуре цифровой
записи сигналов. В принципе имеются три
возможности перемежения: перемежение
разрядов в пределах кодового слова,
соответствующего одному отсчету ЗС,
перемежение между разрядами разных
отсчетов сигнала ЗВ и рассредоточенное
размещение цифрового сигнала в канальных
интервалах цикла цифровой системы
передачи.
Перемежение старших
и младших разрядов в пределах одного
отсчета используется очень часто. При
этом младшие разряды, число которых
обычно равно или составляет более
половины всех разрядов отсчета,
размещаются равномерно между старшими
разрядами (рис. 1.24,
а). Здесь
кодовое слово является 12-сим-вольным,
из которых 11 информационных разрядов
(а1, a2…а11)
и один (b1)
— поверочный, определяемый как сумма
по модулю 2 пяти старших информационных
разрядов (a1,
а2…a5).
Поверочный разряд находится на последней
позиции, а самый младший 11-й разряд —
на первой. В этом случае пакеты ошибок,
состоящие из двух символов, и около 40 %
пакетов ошибок длительностью в три
символа приводят к появлению одиночной
(односимвольной) ошибки на выходе
декодера.
Перемежение
разрядов разных отсчетов сигнала в
принципе позволяет исправлять пакеты
ошибок любой длительности. Ошибки здесь
также преобразуются в одиночные (рис.
1.24,
б). На строке
1 условно записана исходная последовательность
кодовых слов по восемь символов в каждом.
Символы кодовых слов обозначены буквами
от а до
ж с
цифровыми индексами, определяющими
порядковый номер (место) разряда в слове.
Перед передачей или записью порядок
следования символов в последовательности
изменяется, например так, как это показано
в строке 2. Вначале передаются первые
разряды всех кодовых слов, затем вторые,
третьи и т.д. При приеме (воспроизведении)
порядок следования символов
восстанавливается (строка 3 на рис.
1.24,
б). Пусть при
передаче или считывании возник пакет
ошибок в этой последовательности. Места
ошибок обозначены звездочками.

Рис. 1.24
— К перемежению символов при защите от
ошибок:
а — перемежение
разрядов внутри 12-символьного кодового
слова;
б — перемежение
разрядов разных отсчетов; в
— перемежение старших
и младших разрядов
в восьми 10-разрядных отсчетах
В отсутствии
перемежения (строка 1) эти ошибки исказят
подряд символы а7,
a8,
б1,
б2,
б3,
б4,
б5.
Если же пакет
ошибок возник у сигнала, подвергнутого
перемежению (строка 2), то из строки 3
видно, что после операции, обратной
перемежению, пакет ошибок превратился
в совокупность одиночных ошибок, с
которым можно бороться уже описанными
выше способами.
Благодаря перемежению
ошибочно восстановленные отсчеты уже
не следуют друг за другом (рис. 1.25,
б), поэтому
они могут быть скорректированы путем
интерполяции, о которой говорилось уже
выше. При отсутствии перемежения после
считывания в восстановленном сигнале
(рис. 1.25,
а, 4)
появился бы
ряд отсутствующих отсчетов. Рисунок не
требует дополнительного пояснения.
Эффективность
данного метода особенно высока, если
перемежение символов в пределах одного
блока информации дополняется перемежением
самих блоков, как это, например, принято
в цифровых магнитофонах. Однако при
исправлении пакетов ошибок большой
длительности усложняются устройства
перемежения в связи с необходимостью
запоминать большое число отсчетов.
Кроме того, увеличиваются длина цикла
передачи и время задержки сигнала.

Рис. 1.25
— К пояснению принципа перемежения
отсчетов:
а — без
перемежения; б
— с
перемежением; 1
— исходный
аналоговый ЗС; 2
— отсчеты дискретизированного сигнала
(а
— без перемежения; б
—
с перемежением);
3 — пропадание
соседних отсчетов при считывании;
4 — восстановленные
отсчеты (а
— без перемежения,
б — с
перемежением); штриховой линией показаны
потерянные отсчеты при считывании,
их восстановление
возможно путем интерполяции
Размещение цифрового
ЗС в канальных интервалах цикла цифровой
системы передачи обычно производят
емкостью в один октет. Для примера на
рис. 1.24,
в
показано
перемежение восьми 10-разрядных отсчетов.
В первом октете размещены 1-й и 10-й разряды
первых четырех нечетных отсчетов, во
втором октете — 2-й и 9-й разряды тех же
отсчетов и т.д. Затем подобным же образом
перемежаются разряды четырех четных
отсчетов. При разделении отсчетов на
четные и нечетные пакет ошибок
длительностью в восемь символов не
приводит к одновременному искажению
соседних отсчетов. Последнее позволяет
использовать далее интерполяцию нулевого
или первого порядка при коррекции
восстановленных отсчетов.
ГЛАВА 2. Обнаружение и различение сигналов
В литературе задача оценки сообщения, принадлежащего дискретному конечному ансамблю, называется обычно «задачей различения m сигналов». Дискретная модель хорошо подходит для описания сообщений в цифровых системах передачи информации, таких, как цифровая телеметрическая система или система передачи дискретных сообщений. Объем ансамбля определяется выбранным методом приема (посимвольным, пословным и т.д.). Число m при пословном приеме равно числу кодовых комбинаций (команд); при посимвольном приеме – основанию кода. В частности, при посимвольном приеме двоичного кода m=2.
Практически работа любой радиосистемы начинается с обнаружения сигнала, при этом по наблюдаемой реализации смеси требуется определить, имеется ли в смеси сигнал или он отсутствует. Если случай отсутствия сигнала можно отождествить с одним значением сообщения х0, а наличия – с другим х1, то задача обнаружения сведется к задаче различения двух значений сообщения и принципиально ничем не будет отличаться от задачи посимвольного приема двоичной информации. Может встретиться ситуация, например, в системе передачи дискретных сообщений, когда на заданном интервале времени может или передаваться сигнал, соответствующий одному из возможных значений сообщения, или ничего не передаваться. Система обработки в этом случае должна вынести решение о том, имеется ли в наблюдаемой смеси сигнал, и если да, то какой именно. В литературе эта задача называется задачей различения m сигналов с обнаружением. Ясно, что и эта задача приводится к общей задачи различения m + 1 сигналов, если в ансамбль сообщений ввести дополнительный («нулевой») сигнал, соответствующий отсутствию сигнала в смеси.
Таким образом, одной из наиболее важных проблем радиообнаружения является отыскание оптимальных способов выделения сигналов при наличии помех. Оптимальными методами обнаружения называются такие, которые обеспечивают наилучшее выделение сигналов из смеси сигнала с помехой.
В результате процесса обнаружения должно быть выдано решение о наличии или отсутствии сигнала в смеси, действующей на входе обнаружителя.
2.1. Обнаружение сигналов как статистическая задача
Пусть на вход обнаружителя поступает сумма сигнала u(t) и шума n(t), представляющая собой непрерывный случайный процесс, x(t) = au(t) + n(t); u(t) – полностью известный сигнал, т.е. такой сигнал, единственным неизвестным параметром которого является сообщение а. В простейшем случае при обнаружении сообщения а может принимать два значения: а = а0 = 0 или а = а1 = 1.
Рекомендуемые материалы
Когда а0 = 0, сигнал на входе обнаружителя отсутствует, когда а1 = 1, сигнал на входе обнаружителя присутствует. Априорные вероятности присутствия и отсутствия сигнала на входе обнаружителя равны Р(а1) и Р(а0) соответственно.
Обнаружитель анализирует колебание x(t) в течение заранее выбранного (конечного) интервала времени Т и должен на основании анализа воспроизвести сообщение а. Функцию x(t), ограниченную во времени Т, будем называть реализацией колебания.
В настоящее время для решения подобных задач широко применяются методы математической статистики. Основной задачей ее является установление законов распределения случайных величин на основе результатов наблюдения над этими величинами.
В случае обнаружения сигналов реализация колебания x(t) является непрерывной функцией времени (при непрерывном или дискретном сигнале u(t) в смеси) с ограниченным спектром.
Представим x(t) выборочными значениями(x1, …,xn), взятыми в соответствии с теоремой Котельникова с интервалом Δt = 1/F, где F – ширина спектра колебания x(t). При этом, объем выборки определится соотношением:
n = T/ΔT = TF (2.1)
На основании анализа выборки x1, …,xn обнаружитель должен оценить параметр а. Очевидно точность оценки зависит от объема выборки при неограниченном времени наблюдения Т. Однако на практике Т ограниченно, а с увеличением объема выборки при Т = const погрешность оценки не устремляется к нулю. Выборка, у которой n → ∞ при Т = const, называется непрерывной.
Поскольку в задачах обнаружения оценка дискретная (а=0 или1), при конечном объеме выборки можно лишь с некоторыми вероятностями высказать статистические гипотезы. Следовательно, решение задачи обнаружения сводится к проверке двух альтернативных (противоположных) статистических гипотез. Гипотеза H1— сигнал во входной смеси есть и гипотеза H0— сигнала нет.
Решение статистической задачи обнаружения сигнала в шуме имеет следующую последовательность:
¨ Выбор и обоснование критериев оптимальности.
¨ Нахождение математического правила решения задачи оптимального обнаружения.
¨ Реализация правила решения с помощью радиотехнических средств (нахождение структурной схемы обнаружителя).
¨ Исследование характеристик оптимального обнаружителя.
¨ Сравнение оптимального и реального обнаружителей.
2.2. Критерии оптимальности обнаружения. Отношение правдоподобия
Критерием оптимальности называется правило, по которому из всех
возможных обнаружителей можно выбрать наилучший.
Пусть сообщение принимает два значения: а0 = 0 и а1 = 1 с априорными вероятностями Р(а0) и Р(а1) соответственно.
В результате наблюдения выборки x1, …,xn должно быть получено одно из двух взаимоисключающих решений: А1 – сигнал есть, А0 — сигнала нет. Каждая возможная выборка представляется в многомерном пространстве одной точкой. Оптимальный обнаружитель должен разделить пространство выборок на два подпространства Х1 и Х0 (соприкасающихся, но непересекающихся) (рис. 2.1.). Если точка М, соответствующая
k-й выборке (x1, …,xn), попадет в подпространство Х1, — принимается решение А1, в противном случае принимается решение А0.
При решении задачи возможны ошибки двух видов – ложные тревоги (с вероятностью Рл) и пропуски сигналов (с вероятностью Рп). Ложные тревоги имеют место в случае, когда в отсутствии сигнала выборка попадает в пространство Х1. Пропуски сигналов имеют место, если при наличии сигнала на входе обнаружителя выборка попадает в Х0.
Из рис. 2.1. следует, что если подпространство Х1 выбрать равным нулю, то Рл = 0, Рп = 1. Если же выбрать равным нулю подпространство Х0, то Рл = 1, Рп = 0. Таким образом, путем изменения границ подпространств Х1 и Х0 можно получить любое соотношение между вероятностями Рл и Рп. Уменьшая Рл, мы тем самым увеличиваем Рп, и наоборот.
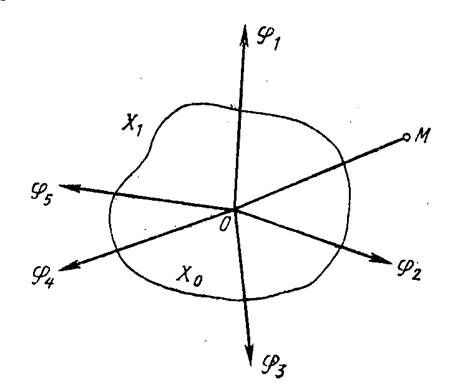
Рис. 2.1. Пространство выборок
Оптимальный обнаружитель должен наилучшим образом по определенному критерию разделить пространство выборок Х на два подпространства: Х1 и Х0. Наиболее распространенными критериями оптимальности обнаружения являются следующие:
1. Критерий минимума среднего риска
 (2.2)
(2.2)
где rл и rп – «весовые» коэффициенты, выбираемые, исходя из значимости каждой ошибки.
Величина  называется средним риском.
называется средним риском.
2. Критерий минимальной «взвешенной» вероятности ошибки
 (2.3)
(2.3)
где a и b – весовые коэффициенты.
3. Критерий минимума вероятности полной ошибки (или критерий
идеального наблюдателя, или критерий Зигерта-Котельникова)
 (2.4)
(2.4)
4. Критерий Неймана – Пирсона

 (2.5)
(2.5)
Величиной Рл задаются, исходя из физической постановки задачи. При этом Рп минимизируют.
Если априорные вероятности Р(а0) и Р(а1) неизвестны, что имеет место во многих случаях, то критерием  пользоваться невозможно. В радиолокации чаще пользуются критерием Неймана – Пирсона.
пользоваться невозможно. В радиолокации чаще пользуются критерием Неймана – Пирсона.
Рассмотрим подробнее критерий минимальной «взвешенной»
вероятности ошибки.
Обозначим отношение  тогда
тогда
 (2.6)
(2.6)
где  (2.7)
(2.7)
 (2.8)
(2.8)
Если при наличии сигнала выборка (х1,…,хn) попадет в область Х1, то имеет место правильное обнаружение. Вероятность правильного обнаружения

 (2.9)
(2.9)
откуда
 (2.10)
(2.10)
Из (2.6), (2.8) и (2.9)
 (2.11)
(2.11)
Следовательно, оптимальный обнаружитель должен обеспечивать максимум интеграла в (2.11)
 (2.12)
(2.12)
Это возможно при положительной подынтегральной разности
 > 0; (2.13)
> 0; (2.13)
т.е.  >
>  . (2.14)
. (2.14)
Таким образом, оптимальный обнаружитель должен вычислять величину
 (2.15)
(2.15)
определяемую отношением функций правдоподобия  и
и  и называемую отношением правдоподобия. Если
и называемую отношением правдоподобия. Если  сравнить с некоторым порогом , то
сравнить с некоторым порогом , то
при > — сигнал есть,
при < — сигнала нет.
Все критерии дают оптимальное решение задачи обнаружения, основанное на вычислении отношения правдоподобия и сравнения его с порогом. Отличаются критерии лишь выбором порога.
Для критерия минимума среднего риска
 (2.16)
(2.16)
Для критерия минимума взвешенной вероятности ошибки
 (2.17)
(2.17)
Для критерия Неймана – Пирсона задается и минимизируется значение Рп.
2.3. Бинарное обнаружение полностью известного сигнала
Положим, что сигнал u(t) известен точно. Сообщение а принимает два значения: а=а0=0 и а=а1=1, с априорными вероятностями Р(а0) и Р(а1) соответственно.
Колебание на входе обнаружителя x(t)=au(t)+n(t), n(t) – нормальный белый шум.
На основании теоремы Котельникова представим колебание x(t) выборкой (х1, …хn) и найдем функцию правдоподобия для выборки в отсутствие сигнала
 (2.18)
(2.18)
Функция правдоподобия для выборки в присутствии сигнала
 (2.19)
(2.19)
В выражениях (2.18) и (2.19) дисперсии равны в силу физической симметрии и определяются соотношением
 (2.20)
(2.20)
где N0 – спектральная мощность шума; F=1/Dt.
Подставим значения s2 в выражения (2.18) и (2.19) и перейдем от суммы к интегралу, устремив  при Т=const. Тогда
при Т=const. Тогда
 (2.21)
(2.21)
 (2.22)
(2.22)
Отношение правдоподобия
 (2.23)
(2.23)
где  — энергия входного сигнала;
— энергия входного сигнала;  — корреляционный интеграл.
— корреляционный интеграл.
Отношение правдоподобия для полностью известного сигнала имеет следующий вид:
 (2.24)
(2.24)
Для вынесения решения необходимо сравнить с порогом ограничения .
Если > — сигнал есть,
Если < — сигнала нет.
Реализовать правило решения (2.24) радиотехническими методами, т.е. построить обнаружитель, который вычислял бы и затем сравнивал с порогом, сложно. Желательно отыскать более простое правило решения.
Поскольку при Е=const зависит только от корреляционного интеграла z(T) и эта зависимость монотонная, то вместо можно установить более простое правило z(T) и сравнивать с порогом z0.
Если z(T) > z0 – сигнал есть,
Если z(T) < z0 — сигнала нет.
Схема оптимального обнаружителя представлена на рис. 2.2 и состоит из перемножителя, интегратора и порогового устройства (ПУ).

Рис. 2.2. Схема оптимального обнаружителя
При вычислении корреляционного интеграла z(T) осуществляются переход от многомерного распределения n выборочных значений напряжения на входе обнаружителя к одномерному распределению напряжения z(T) на его выходе в момент времени Т в результате накопления (суммирования) n выборочных значений в течение длительности выборки Т.
Если входная выборка представляет собой шум n, то zn(T) определяет напряжение шума на выходе коррелятора. Если выборка – смесь сигнала с шумом, то znc(T) можно рассматривать на выходе как аддитивную смесь, поскольку операции суммирования и интегрирования линейные.
Переход от суммы выборочных значений при n→∞ и Т=const к интегралу осуществляется на основании теоремы Котельникова. Напряжение шума на выходе коррелятора
 (2.25)
(2.25)
Напряжение смеси
 (2.26)
(2.26)
Эти напряжения есть максимальные значения отклика коррелятора на шум и смесь соответственно. Превышение порога z0 величиной znc(T) есть правильное обнаружение и вероятность превышения и называется вероятностью правильного обнаружения Р0, а превышение порога z0 величиной zn(T) с вероятностью Рл называется ложной тревогой.
Основными показателями обнаружителя являются рабочие характеристики. Каждая характеристика определяет зависимость Р0, Рл и q2(q2-отношение сигнал/шум). На рис. 2.3 даны качественные характеристики.
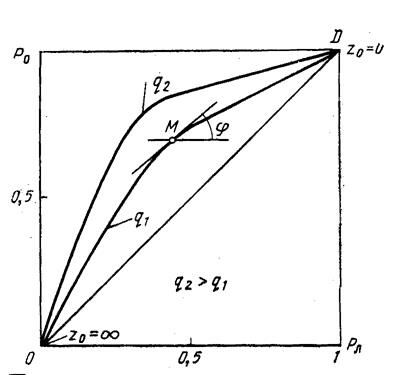
Рис. 2.3. Качественные характеристики обнаружителя.
Из анализа этих характеристик следует:
¨ вероятность правильного обнаружения Р0=0 при вероятности ложной тревоги Рл=0.
¨ чем больше отношение сигнал/шум при заданной вероятности ложной тревоги Рл, тем больше вероятность правильного обнаружения Р0.
¨ Если изменять порог z0 от 0 до ∞, то Р0 и Рл будут изменяться от 1 до 0.
По характеристикам можно определить пороговое отношение
сигнал/шум, которое удовлетворяет заданным вероятностям Р0 и Рл. Найденному значению  и заданной вероятности Рл соответствует точка М. Тангенс угла наклона касательной к рабочей характеристике в точке М определяет необходимую величину порога.
и заданной вероятности Рл соответствует точка М. Тангенс угла наклона касательной к рабочей характеристике в точке М определяет необходимую величину порога.
 . (2.27)
. (2.27)
Для расчета и построения характеристик обнаружения необходимо знать закон распределения отклика коррелятора z(T).
В отсутствии сигнала отклик определяется шумами на входе обнаружителя и может дать ложную тревогу. Величина отклика сравнивается с порогом z0 и вероятностью того, что zn(T) превысит порог z0, называется вероятностью ложной тревоги.
Закон распределения zn(T) будет нормальным с нулевым средним значением. Дисперсия, которая определяет мощность шума на выходе коррелятора:
 . (2.28)
. (2.28)
Сренеквадратичное напряжение шума на выходе коррелятора  Закон распределения отклика коррелятора zn(T) на шум n(t)
Закон распределения отклика коррелятора zn(T) на шум n(t)
 (2.29)
(2.29)
С увеличением порога ограничения z0 вероятность Рл уменьшается. Аналитически вероятность ложной тревоги определяется выражением
 (2.30)
(2.30)
В присутствии на входе обнаружителя отклик коррелятора на смесь сигнала с шумом
 (2.31)
(2.31)
Первый интеграл выражения (2.31) равен Е и определяет амплитуду напряжения на входе коррелятора, которое численно равно энергии входного сигнала и, следовательно, является максимально возможной величиной. Второй интеграл определяет флюктуацию с нулевым средним значением отклика (напряжение шумов) коррелятора.
Случайная величина znс(T) распределена по нормальному закону
 (2.32)
(2.32)
Распределения Wn(z) и Wnc(z) отличаются средними значениями, дисперсии откликов одинаковы.
Вероятность правильного обнаружения вычисляется по формуле
 (2.33)
(2.33)
После преобразований вероятность правильного обнаружения
 (2.34)
(2.34)
Порог ограничения вычисляется в соответствии с выбранным критерием оптимальности.
Зависимость Р0 от q2 при Рл=const называется характеристикой обнаружения. Для различных значений Рл можно построить семейство характеристик обнаружения. Характеристики обнаружения для полностью известного сигнала изображены на рис. 2.4
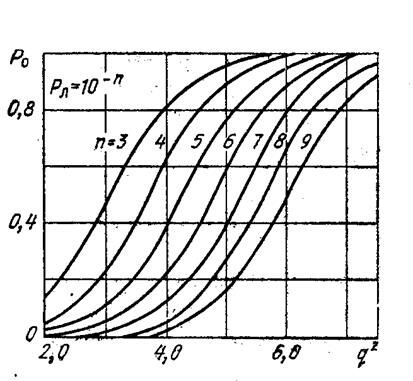
Рис. 2.4. Характеристики обнаружения для полностью известного сигнала
2.4. Обнаружение сигнала со случайной начальной фазой
Рассмотрим задачу обнаружения сигнала, у которой фаза высокочастотного колебания изменяется по случайному закону. Плотность распределения фазы  равномерна в пределах 0….2π. Отношение правдоподобия в этом случае будет еще и функцией фазы β. Энергия сигнала мало зависит от β, поэтому считаем ее постоянной.
равномерна в пределах 0….2π. Отношение правдоподобия в этом случае будет еще и функцией фазы β. Энергия сигнала мало зависит от β, поэтому считаем ее постоянной.
Выражение для корреляционного интеграла через огибающую и фазу запишется в виде:
 (2.35)
(2.35)
где 




 .
.
Отношение правдоподобия для полностью известного сигнала равно:
 (2.36)
(2.36)
которое является случайной функцией β.
Отношение правдоподобия для сигнала со случайной фазой:
 (2.37)
(2.37)
Показатель экспоненты является постоянной величиной, — монотонной функцией Z(T), поэтому оптимальным правилом решения задачи обнаружения сигнала является вычисление корреляционного интеграла Z(T). Затем Z(T) сравнивается с порогом Z0.
Если Z(T) > Z0 – сигнал есть, если Z(T) < Z0 – сигнала нет.
Структурная схема обнаружителя, включающая два квадратурных канала, представлена на рис. 2.5 В каждом канале вычисляется корреляционный интеграл z1 (T) и z2(T) соответственно. В квадратичном детекторе (Кв.Д.) осуществляется операция возведения в квадрат; после вычисления величины  производится сравнение с порогом Z0, который устанавливается в соответствии с выбранным критерием оптимальности.
производится сравнение с порогом Z0, который устанавливается в соответствии с выбранным критерием оптимальности.

Рис. 2.5. Структурная схема обнаружителя
В качестве опорных напряжений на умножителях используются сдвинутые по фазе на π/2 колебания высокой или промежуточной частоты  и
и  В результате отклик Z2 не зависит от случайной фазы сигнала, так как
В результате отклик Z2 не зависит от случайной фазы сигнала, так как 
Вероятность правильного обнаружения равна:
 (2.38)
(2.38)
где  — относительный порог ограничения.
— относительный порог ограничения.
2.5. Бинарное обнаружение сигнала со случайными амплитудой и начальной фазой
Для сигнала  среднеквадритичное значение амплитуды принять равным единице, то выражение для отношения правдоподобия запишется в следующем виде:
среднеквадритичное значение амплитуды принять равным единице, то выражение для отношения правдоподобия запишется в следующем виде:
 (2.39)
(2.39)
Схема оптимального обнаружителя сигнала со случайными амплитудой и начальной фазой не отличается от схемы оптимального обнаружителя сигнала со случайной фазой. По-прежнему оптимальной является квадратурная схема обработки. Изменяется только оптимальный порог, который вычисляется по формуле
 (2.40)
(2.40)
По этой зависимости можно построить характеристики обнаружения
 . (2.41)
. (2.41)
Особенность характеристик обнаружителя со случайными амплитудой и начальной фазой состоит в том, что с ростом q2 вероятность обнаружения увеличивается сначала быстро, после достижения значений q2=0,5…0,6 это увеличение замедляется, а затем становится очень медленным.
Таким образом, характеристики обнаружения для сигнала со случайной начальной фазой сдвигаются в сторону увеличения отношения сигнал/шум, т.е. для обнаружения сигнала требуется большое напряжение его на входе, чем для полностью известного сигнала. Для сигнала со случайной амплитудой и начальной фазой отклик является случайной функцией амплитуды и фазы, поэтому необходимо усреднить отношение правдоподобия и по амплитуде, и по фазе. Характеристики обнаружения сдвигаются еще правее, за исключением участка, где отношение сигнал/шум меньше единицы. Флюктуации амплитуды при q2 < 1 несколько увеличивают вероятность обнаружения.
2.6. Обнаружение сигнала в виде пачки радиоимпульсов
В радиолокации часто применяют сигналы, представляющие собой последовательность из N импульсов, которую для краткости называют пачкой импульсов.
Каждый импульс ui(t) такой пачки полностью характеризуется амплитудой ai, частотой fi, начальной фазой φi, длительностью τi, моментом возникновения ti.
Если зависимость между всеми параметрами импульсов пачки в месте приема полностью известна, то такие импульсы и такая пачка называются когерентными. В противном случае пачка называется некогерентной.
2.6.1. Когерентная пачка импульсов с полностью известными параметрами
Пачка с полностью известными параметрами является частным случаем, полностью известного сигнала и для нее справедливы все расчетные формулы для известного случая. Энергия сигнала u(t):  поэтому для пачки энергия:
поэтому для пачки энергия:  где Еi – энергия i-го импульса.
где Еi – энергия i-го импульса.
Следовательно, все приведенные выше формулы для вероятностей ошибок будут справедливы и для пачки импульсов, если в них понимать под Е энергию всех импульсов пачки, равную сумме энергий всех N импульсов пачки. Если суммарная энергия пачки импульсов такая же, как и у одиночного импульсного сигнала, ошибки обнаружения не изменяются.
Структурная схема обнаружителя для пачки подобна изображенной на рис. 2.2. Однако в этом случае на перемножитель нужно подавать «копию» сигнала в виде пачки радиоимпульсов. Максимальное значение отклика коррелятора будет в момент окончания пачки.
2.6.2. Некогерентная пачка радиоимпульсов с независимыми флюктуациями амплитуды
Сигнал в этом случае запишется так:  Оптимальное правило решения будем искать на основании критерия максимума отношения правдоподобия. Для k-го импульса отношение правдоподобия :
Оптимальное правило решения будем искать на основании критерия максимума отношения правдоподобия. Для k-го импульса отношение правдоподобия :
 (2.42)
(2.42)
При независимых флюктуациях амплитуды импульсов отношение правдоподобия для всего сигнала можно представить в виде произведения отношений правдоподобия для импульсов, тогда:
 (2.43)
(2.43)
После выполнения операции умножения в показателе экспоненты будет сумма откликов на каждый импульс пачки. Поскольку монотонно изменяется с изменением этой суммы, то в этом случае нужно вычислять
 (2.44)
(2.44)
Так же, как и для одиночного импульса, отклик Z(T) будет пропорционален энергии входного сигнала, т.е. энергии пачки импульсов. Результат сравнивают с порогом Z0, выбранным на основании критерия оптимальности. Схема обнаружителя аналогична данной на рис. 2.5. Разница будет состоять в том, что копии сигналов, подаваемых на перемножители, в данном случае представляют собой пачки радиоимпульсов.
2.7. Различение детерминированных сигналов на фоне белого гауссовского шума
Корреляционная функция белого шума со спектральной плотностью N0 равна  После соответствующих преобразований получаем оптимальный аналоговый алгоритм различения сигналов на фоне аддитивного белого гауссовского шума: принимается решение о том, что передан сигнал Sk(t), если
После соответствующих преобразований получаем оптимальный аналоговый алгоритм различения сигналов на фоне аддитивного белого гауссовского шума: принимается решение о том, что передан сигнал Sk(t), если
 (2.45)
(2.45)
где сj определяется по формуле  в которой параметр
в которой параметр  т.е. равен отношению энергии Еj сигнала Sj(t) на интервале наблюдения к спектральной плотности белого шума.
т.е. равен отношению энергии Еj сигнала Sj(t) на интервале наблюдения к спектральной плотности белого шума.
Для ортогональных сигналов : 
2.8. Принцип работы цифровых обнаружителей и различителей сигналов
Оптимальные алгоритмы обнаружения и различения сигналов, как известно, заключаются в накоплении сигнала за длительность входной реализации, сравнении с порогом и измерении параметров сигнала. Реализация алгоритмов в аналоговой форме имеет существенные недостатки:
¨ Аналоговым накопителям свойственно насыщение, в результате которого уменьшается отношение сигнал/шум при накоплении сигналов.
¨ Результаты накопления изменяются в процессе эксплуатации за счет нестабильности элементов динамической памяти.
¨ Нет возможности полной автоматизации процесса обработки сигналов.
¨ Оценка параметров сигналов в процессе обзора сопровождается ошибками, существенно превышающими потенциальные.
Цифровые алгоритмы квазиоптимальны за счет потерь в отношении сигнал/шум при квантовании смеси по амплитуде и дискретизации по времени. Кроме того, реализация алгоритмов в цифровой форме осуществляется на стандартных элементах вычислительной техники, что упрощает конструкции, снижает вес и габариты, увеличивает надежность.
Рис. 2.6. Цифровая схема обнаружения
На рис. 2.6 дана простейшая схема цифровой схемы обнаружения сигналов. Схема включает квантователь по уровню смеси сигнала с шумом (пороговое устройство 1), дискретизатор по времени, выполненный в виде генератора стандартных импульсов (ГСИ), многоканальную схему измерения дальности, включающую регистр сдвига, вентили совпадений (ВС) и накопители сигналов (НУ), распределитель каналов (коммутатор) и анализатор сигналов.
2.9. Дискретизация и квантование непрерывных сигналов
Длительность и период дискретизации выбирают так, чтобы последовательность дискретных значений непрерывного сигнала в течение времени наблюдения позволила восстановить исходный сигнал с заданной точностью.
Вероятность обнаружения смеси Z(t):
 (2.46)
(2.46)
Из этого выражения следует, что с увеличением μ увеличивается вероятность обнаружения сигнала и тем больше, чем меньше исходная вероятность Р01.
Следовательно, увеличение периода квантования приводит к увеличению вероятности обнаружения сигнала, но при этом уменьшается разрешающая способность и точность измерения дальности. Поэтому период квантования Т0 выбирается из условий получения заданной точности измерения при ограниченной сложности измерительного устройства.
Информация в лекции «4 Режущие многогранные пластины» поможет Вам.
Квантование амплитуд сигналов на два уровня означает определение наличия или отсутствия сигнала в дискретном по времени выборочном значении сигнала. На выходе бинарного квантователя появляются 1 и 0 в присутствии сигнала с вероятностью правильного обнаружения
 (2.47)
(2.47)
и пропуска сигнала Рп = 1 – Р0, а в отсутствие сигнала с вероятностью ложной тревоги
 (2.48)
(2.48)
и правильного необнаружения Рн = 1 – Рл. Функции Wnc(Z) и Wn(Z) – распределение смеси сигнала с шумом и шума на выходе детектора огибающей.
После логарифмирования отношения правдоподобия  ) получаем условие оптимального обнаружения квантованной пачки в виде:
) получаем условие оптимального обнаружения квантованной пачки в виде: 