В этом видео я покажу как сделать с нуля нейросеть для распознавания графических образов Fashion MNIST. Расскажу о том как сделать многослойный перцептрон и запрограммировать метод обратного распространения ошибки. Писать проект буду в одной из последних версий Delphi XE10.
Проект на Boosty: 🤍boosty.to/techniciannotes
Еще поддержать меня можно тут: 🤍🤍donationalerts.com/r/tech…
Группа в ВК: 🤍vk.com/public196473848
музыка в видео:
––––––––––––––––––––––––––––––
Track: Back to 1981 — Iaio [Audio Library Release]
Music provided by Audio Library Plus
Watch: 🤍youtu.be/3MVRIfyWlnA
Free Download / Stream: 🤍alplus.io/back-1981
––––––––––––––––––––––––––––––

tad edi
2023-07-18 08:34:33
Очень хорошее понятное объяснение. Скачал проект, повторил, всё ок! Но потом решил поменять функцию активации с сигмоида на ReLU, но обучение не происходит, и точность остаётся в районе 10%. Вот функции ReLU и DifReLU(для производной), которые я использовал:
function ReLU(x: Single): Single;
begin
if x > 0 then Result := x else Result := 0;
end;
function DifReLU(x: Single): Single;
begin
if x > 0 then Result := 1 else Result := 0;
end;
Тогда я попробовал еще другую функцию активации, говорят крутую:
function Swish(X: Single): Single;
begin
Result := X / (1 + Exp(-X));
end;
function DifSwish(X: Single): Single;//для производной
begin
Result := Swish(X)+ (Swish(X) * (1 — Swish(X)));
end;
Но появилась ошибка floating point overflow. Видимо где-то надо делать какие-то ограничения, но где — не могу понять.

Кошкин Кошкин
2023-02-19 07:06:27
а почему на nmgCCC0sB-s&t=0m22s 0:22 картинки летают в каком то 3Д мире?? тут какой то смысл заложен или шо

Levka Live
2023-02-18 12:18:06
Приветствую! Очень интересный контент ты создаешь, узкое и нелегкое направление. Можно ли с тобой связаться, чтобы задать пару вопросов. Имеется конкретная задача с определенными данными, интересует, сможет ли машинное обучение справиться с ней или сделать неплохой результат. Информация нужна для проработки темы на конференцию (нефтяная промышленность)

Deus Ex Machina
2023-02-09 08:52:06
правильно ли я понимаю, что эта нейросеть будет угадывать только среди этого набора графических ассетов? что если уже обученной нейросети начать скармливать изображения модифицированные но без искажения облика. Где-то штанины или рукава слегка укоротить, где-то дырки добавить или крестики площадью 1-3 кв пкс или цвет. Можно ли этот алгоритм из видео применить на массиве ключевых слов на разных языках, чтобы приводить их к английскому слову, например, для АИ ассистента?

Парамонов Александр
2023-01-03 12:28:52
Давно хотел разобраться в этом вопросе. Супер!! Благодарю за видео.

Иван Роналин
2022-11-28 15:31:11
Почаще бы ролики

XBSZIDOS SHOW
2022-11-11 05:23:59
ничего не понятно

Илья Ефремов
2022-08-09 15:13:00
Повторил, вроде все работает. Но чтобы разобраться как оно работает, решил упростить сеть до 1*1. И сделать элемент НЕ. То есть если на входе 0 то на входе 1, и наоборот. Инициализировал массив для тренировки нулями и единицами, а в ответах, соответственно наоборот. И вот такой упрощённый вариант не работает. Могли бы вы привести рабочий пример? Примеры разные в сети есть(2ине, 3или и тп) а вот самого поостого (1 вход и 1 НЕ выход)не могу найти.

Ришат Мутафин
2022-07-08 21:29:16
А можешь обучить на конкретных примерах? Мне для задач надо.

Еще можно сделать функции записи и чтения нейросетей в файл

Priyatham
2022-02-13 23:09:08
I want to learn them. Seems so cool.. But can’t understand the russian language. Could you please make them in english?

Nikolay DD
2022-01-17 00:27:59
Класс! Очень качественный урок и лично мне нужный.

GavnaCraft Project
2022-01-15 08:35:24
Like For «Magic»

kotsya1
2021-12-21 03:58:47
есть небольшой вопрос по поводу применимости нейросети при анализе совершенных сделок ботом на криптобирже. с нейросетями ни разу не имел дела, но разрозненная информация в сети наталкивает на мысль, что они могут немного упростить задачу в поиске верных настроек бота. из логов удалось получить огромную тучу разных параметров по сделкам. пока не могу понять, что и как использовать. можно ли как-то с Вами связаться? может натолкнёте на здравую мысль…. если возможно 

Сергей Воронин
2021-12-20 09:32:59
Как расписать четыре строчки на питоне в дофига на дельфи…для понимания как работает из нутри полезно но не больше. Тем более пуловер он правильно отгадал а всеравно красный. Те надо еще учить и сколько надо нажать лерн чтобы не переучить

🙏

Armag Play
2021-12-18 15:40:07
Спасибо за интересный материал и подробные объяснения!

Jiaofeng X
2021-12-18 13:29:46
👍
|
7 / 7 / 0 Регистрация: 13.09.2009 Сообщений: 263 |
|
|
1 |
|
Нейронные сети «Многослойный персептрон и алгоритм обратного распространения ошибки»08.11.2010, 18:27. Показов 7180. Ответов 5
Помогите, пожалуйста!
0 |

|
Programming Эксперт 94731 / 64177 / 26122 Регистрация: 12.04.2006 Сообщений: 116,782 |
08.11.2010, 18:27 |
|
Ответы с готовыми решениями: многослойный персептрон Избавиться от ошибки при нажатии на кнопку «Вперед» или «Назад» в браузере
Из слов «Работа», «крест», «тон» составить фразу «Кто не работает, тот не ест» и определить ее длину 5 |
") В каждом слове текста замените «а» на букву «е», если «а» стоит на четном месте, и заменить букву «б» на сочетание «ак»,
В каждом слове текста замените «а» на букву «е», если «а» стоит на четном месте, и заменить букву «б» на сочетание «ак»,|
7 / 7 / 0 Регистрация: 13.09.2009 Сообщений: 263 |
|
|
08.11.2010, 21:22 [ТС] |
3 |
|
спасибо, посмотрю
0 |
")
|
0 / 0 / 0 Регистрация: 26.03.2021 Сообщений: 12 |
|
|
30.03.2021, 22:39 |
4 |
|
ОшибкаВыхода1=ЖелаемоеЗначение1-Выход1 Я делал так, если три слоя:
0 |
|
D1973 |
|
31.03.2021, 05:25
|
|
Не по теме: ТС обязательно бы прислушался к Вашему совету, если бы Вы 11 лет назад это написали…
0 |
|
0 / 0 / 0 Регистрация: 26.03.2021 Сообщений: 12 |
|
|
04.04.2021, 21:40 |
6 |
|
Сначала распространяем ошибки от выходных нейронов к началу (влево),
0 |
|
IT_Exp Эксперт 87844 / 49110 / 22898 Регистрация: 17.06.2006 Сообщений: 92,604 |
04.04.2021, 21:40 |
|
Помогаю со студенческими работами здесь На форме располагаются компоненты: редактор Edit; линейка ScrollBar; радионабор с опциями «Цветы», «Деревья», «Рыбы», «Звери»
Алгоритм обратного распространения ошибки. Нейронные сети Нейронные сети. Алгоритм обратного распространения Искать еще темы с ответами Или воспользуйтесь поиском по форуму: 6 |
Статья опубликована в выпуске журнала № 1 за 2010 год.
Аннотация:В работе проведено моделирование динамики стоимости ценных бумаг с помощью аппарата нейронных сетей. На основе построенной модели многослойного персептрона и алгоритма обучения методом обратного распространения ошибки в среде Borland Delphi 7.0 разработан программный продукт, позволяющий моделировать и использовать обученную нейронную сеть для прогнозирования котировок ценных бумаг на фондовом рынке.
Abstract:This paper deals with the application of a well-known neural network technique, multi-layer back-propagation neural network in financial data forecasting. A modified neural network forecasting model is presented. The software application developed according this model in Borland Delphi 7.0 allows to realize pre-processing data analysis and MICEX stock series forecasting.
Размер шрифта:
Шрифт:
Целью настоящей статьи являются построение нейросетевой модели для прогнозирования временных рядов финансовых данных на базе многослойного персептрона, обученного по алгоритму обратного распространения ошибки, а также формализация полной схемы применения данной модели для анализа и прогнозирования временных рядов на примере котировок акций российских эмитентов на ММВБ.
Актуальность исследования объясняется важностью получения качественных прогнозов основных финансовых индикаторов в условиях рыночной экономики, а также успешным опытом применения нейронных сетей в задачах прогнозирования.
В соответствии с целью работы решаются следующие задачи:
— обоснование применения моделей на основе нейронных сетей в задаче прогнозирования временных рядов;
— описание методики предварительной обработки временного ряда и формирования примеров для обучения нейронной сети;
— описание архитектуры и моделирование нейронной сети для прогнозирования временных рядов;
— описание и программная реализация алгоритма обучения нейронной сети на основе процедуры обратного распространения ошибки;
— построение прогноза будущих значений временного ряда.
Предлагаемая методика прогнозирования состоит из четырех основных этапов:
1) предварительный анализ временного ряда;
2) построение нейросетевой модели;
3) обучение нейронной сети по модифицированному алгоритму обратного распространения ошибки;
4) прогнозирование с помощью обученной нейросетевой модели.
Для решения задачи прогнозирования временного ряда zk, где k=0,1,…, находят применение нелинейные модели вида  , где
, где  – некоторая нелинейная функция;
– некоторая нелинейная функция; 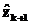 – прогнозируемое значение ряда;
– прогнозируемое значение ряда; 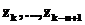 – наблюдаемые значения (предыстория ряда); n – порядок модели.
– наблюдаемые значения (предыстория ряда); n – порядок модели.
Эффективность нейросетевого подхода при прогнозировании временного ряда, основанного на данной модели, обосновывается теоремой об универсальной аппроксимации, которая утверждает, что многослойного персептрона с одним скрытым слоем достаточно для построения равномерной аппроксимации с точностью e для любого обучающего множества, представленного набором входов 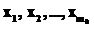 и желаемых откликов
и желаемых откликов 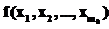 . Тем не менее, из теоремы не следует, что один скрытый слой является оптимальным относительно времени обучения, простоты реализации, а также качества обобщения [1].
. Тем не менее, из теоремы не следует, что один скрытый слой является оптимальным относительно времени обучения, простоты реализации, а также качества обобщения [1].
Для моделирования динамики временного ряда в работе использована полносвязная нейронная сеть, в которой каждый нейрон слоя l связан со всеми нейронами предыдущего слоя l-1; 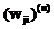 – синаптический вес, связывающий выход нейрона i со входом нейрона j на итерации n;
– синаптический вес, связывающий выход нейрона i со входом нейрона j на итерации n; 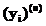 – функциональный сигнал, генерируемый на выходе нейрона i на итерации n. Пусть на нейрон j поступает поток сигналов от нейронов, расположенных в предыдущем слое, тогда индуцированное локальное поле
– функциональный сигнал, генерируемый на выходе нейрона i на итерации n. Пусть на нейрон j поступает поток сигналов от нейронов, расположенных в предыдущем слое, тогда индуцированное локальное поле  , полученное на входе функции активации, связанной с данным нейроном, вычисляется по формуле
, полученное на входе функции активации, связанной с данным нейроном, вычисляется по формуле
 , (1)
, (1)
где m – общее число входов (за исключением порога) нейрона j. Синаптический вес wj0 (соответствующий фиксированному входу y0=1) равен порогу bj, применяемому к нейрону j. Функциональный сигнал 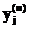 на выходе нейрона j на итерации n равен
на выходе нейрона j на итерации n равен
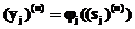 , (2)
, (2)
где jj – функция активации j-го нейрона. Функция активации – непрерывно дифференцируемая нелинейная функция. В качестве функции активации в работе используется функция гиперболического тангенса:
 , (a, b)>0, (3)
, (a, b)>0, (3)
где a и b – константы.
Нейронная сеть указанной структуры обучается по алгоритму обратного распространения ошибки в последовательном режиме, в котором корректировка весовых коэффициентов проводится после подачи каждого примера обучения вида  , где x(n) – входной вектор, поступающий на вход сети; d(n) – желаемый отклик; N – общее число примеров.
, где x(n) – входной вектор, поступающий на вход сети; d(n) – желаемый отклик; N – общее число примеров.
Изменение синаптических весов нейронов скрытых и выходного слоев сети, l=1,…,L, выполняется в соответствии с обобщенным дельта-правилом
 (4)
(4)
где  h – параметр скорости обучения; a – постоянная момента;
h – параметр скорости обучения; a – постоянная момента;  – сигнал ошибки выходного нейрона j на итерации n (соответствующий n-му примеру обучения) [1].
– сигнал ошибки выходного нейрона j на итерации n (соответствующий n-му примеру обучения) [1].
Цель обучения – минимизация суммарной среднеквадратической ошибки на всем обучающем множестве
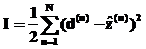 , (5)
, (5)
где d(n) – целевое значение для примера n; 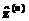 – прогнозное значение.
– прогнозное значение.
Для извлечения прибыли от инвестиций на фондовом рынке важно получить точный прогноз направления тренда. Для повышения качества прогноза в целевой функционал I вводится штрафной коэффициент g, таким образом, целевой функционал будет вычисляться по формуле
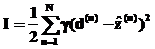 , (6)
, (6)
где 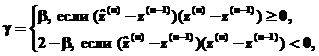 bÎ(0,1).
bÎ(0,1).
Для практической реализации алгоритма обратного распространения ошибки будем полагать, что сходимость алгоритма достигнута, если значение целевой функции I(w)0 – заранее заданный вещественный параметр, называемый точностью обучения [2].
Исходные данные для прогнозирования представляют собой табулированный текстовый файл, который содержит ежедневные котировки акций ОАО «Ростелеком» по цене закрытия. Файл содержит 248 записей, что соответствует временному интервалу в один календарный год [3].
Для улучшения качества прогноза исходный временной ряд подвергается предварительной обработке. На первом этапе предобработки данных использован метод сглаживания скользящим средним. Пусть zk, k=1,2,…N, – временной ряд длины N, тогда временной ряд 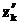 ,
,
 (7)
(7)
называется сглаженным временным рядом относительно zk, параметр p – период скольжения. Для сближения исходного и сглаженного рядов и сохранения тенденции исходного ряда в работе проведено сглаживание по трем членам временного ряда, то есть период сглаживания p=3 [4].
С целью получения качественного прогноза и сокращения времени обучения нейронной сети для анализа данных не следует выбирать сами котировки, которые обозначим zn (сглаженное значение котировки акции во время n=0,1,2,…). Действительно значимыми для предсказаний являются изменения котировок Dzn=zn–zn–1. Поэтому в качестве исходных данных логично выбирать наиболее статистически независимые величины, например, изменения котировок Dzn или логарифм относительного приращения 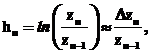
 , ведущие себя более однородно, что особенно важно для длительных временных рядов, когда уже заметно влияние инфляции. Величины hn интерпретируются как «возврат», «отдача», «логарифмическая прибыль» [5].
, ведущие себя более однородно, что особенно важно для длительных временных рядов, когда уже заметно влияние инфляции. Величины hn интерпретируются как «возврат», «отдача», «логарифмическая прибыль» [5].
В данной работе в качестве исходных данных для прогнозирования используется логарифм относительного приращения сглаженных котировок.
Сформированный на этапе предварительной обработки набор исходных данных делится на два множества – обучающее и тестовое. Обучающие данные подаются сети для обучения, а тестовые – для расчета ошибки сети. Исследуемый в работе временной ряд состоит из 248 элементов, из которых первые 223 составляют обучающее множество, а последние 25 – тестовое.
Из элементов обучающего множества по методу скользящего окна формируются примеры для обучения нейронной сети. Этот метод подразумевает использование окон Wi и W0 с фиксированными размерами pi и p0. Для описываемой в работе модели размерность выходного слоя нейронной сети совпадает с размерностью выходного окна p0=1. Размерность входного слоя совпадает с размерностью входного окна pi=5, что соответствует продолжительности торговой недели на фондовой бирже. Таким образом, обучающее множество в данной работе состоит из 218 примеров.
 После завершения обучения нейронной сети на примерах из обучающего множества проверяется качество прогноза на элементах тестового множества. Для этого вычисляется ошибка прогнозирования нейронной сети по формуле
После завершения обучения нейронной сети на примерах из обучающего множества проверяется качество прогноза на элементах тестового множества. Для этого вычисляется ошибка прогнозирования нейронной сети по формуле 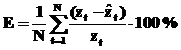 , где N=25 – размерность тестового множества;
, где N=25 – размерность тестового множества; 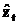 – прогнозируемое значение для t-го тестового значения zt.
– прогнозируемое значение для t-го тестового значения zt.
Выбор оптимальной архитектуры нейронной сети и параметров скорости обучения h и момента a не имеет математического решения и производится опытным путем.
Проведенный численный эксперимент показал, что оптимальные значения параметров скорости обучения и момента для рассматриваемого временного ряда hопт, aоптÎ(0,1; 0,5). Когда параметр момента a=0, оптимальное значение параметра скорости обучения hопт®1. Также отметим, что конечная среднеквадратическая ошибка мало отличается для разных кривых, а это означает, что поверхность ошибок в рассматриваемой задаче достаточно гладкая.
Согласно результатам проведенных исследований, оптимальная нейронная сеть для рассматриваемой задачи содержит два скрытых слоя. Входной слой состоит из 5 нейронов; на первом скрытом слое находится 10 нейронов, на втором – 15, а выходной слой содержит 1 нейрон.
Значения основных параметров нейросетевой модели приведены в таблице.
|
Название параметра |
Значение параметра |
|
Диапазон начальных значений весовых коэффициентов |
|
|
Коэффициент скорости обучения h |
0,5 |
|
Момент a |
0,1 |
|
Точность обучения e |
0,005 |
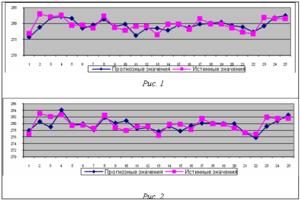
Для нейронной сети, обученной по алгоритму обратного распространения ошибки с целевым функционалом (5) средняя ошибка прогнозирования на тестовом множестве E=0,4487 %, точность прогноза направления тренда составила 52 %. Результаты прогнозирования для нейронной сети данной архитектуры приведены на рисунке 1.
Для нейронной сети, обученной по алгоритму обратного распространения ошибки с целевым функционалом (6), где параметр b=0,5, средняя ошибка прогнозирования на тестовом множестве E=0,4106 %, точность прогноза направления тренда составила 76 %. Результаты прогнозирования для нейронной сети данной архитектуры приведены на рисунке 2.
Результаты применения построенной в работе нейросетевой модели для прогнозирования динамики временного ряда котировок акций компании «Ростелеком» показывают, что нейронные сети могут служить эффективным инструментом для прогнозирования временных рядов финансовых данных. Для всех рассмотренных в работе комбинаций значений параметров нейросетевой модели ошибка прогноза не превышает 0,5 %, что соответствует прогнозу высокого качества.
Предложенная в работе модификация целевого функционала для алгоритма обратного распространения введением в него штрафного коэффициента позволила добиться существенного повышения качества прогноза в направлении тренда, что будет способствовать извлечению прибыли от сделок на фондовом рынке.
Программный продукт, реализованный на базе описанной нейросетевой модели, с успехом применяется в ОАО «ГУТА-БАНК» (г. Тверь) для принятия инвестиционных решений на фондовом рынке.
Литература
1. Хайкин С. Нейронные сети: полный курс; пер. с англ. М.: Издат. дом «Вильямс», 2006. 1104 с.
2. Luo Z. On the convergence of the LMS algorithm with adaptive learning rate for linear feedforward networks. Neural Computation. 1991, vol. 3, pp. 226–245.
3. Рынок акций, котировки акций, рынок ценных бумаг, акции, брокеры и брокерское обслуживание в России. URL: http://stocks.investfunds.ru (дата обращения: 06.07.2009).
4. Kramer A.H. and A. Sangiovanni-Vincentelli. Efficient parallel learning algorithms for neural networks, Advances in neural Information Processing Systems. San Mateo, CA: Morgan Kaufmann. 1989, vol. 1, pp. 40–48.
5. Ширяев А.Н. Основы стохастической финансовой математики. Т. 1. Факты. Модели. М.: ФАЗИС, 1998. 512 с.
I have an artificial neural network which plays Tic-Tac-Toe — but it is not complete yet.
What I have yet:
- the reward array «R[t]» with integer values for every timestep or move «t» (1=player A wins, 0=draw, -1=player B wins)
- The input values are correctly propagated through the network.
- the formula for adjusting the weights:

What is missing:
- the TD learning: I still need a procedure which «backpropagates» the network’s errors using the TD(λ) algorithm.
But I don’t really understand this algorithm.
My approach so far …
The trace decay parameter λ should be «0.1» as distal states should not get that much of the reward.
The learning rate is «0.5» in both layers (input and hidden).
It’s a case of delayed reward: The reward remains «0» until the game ends. Then the reward becomes «1» for the first player’s win, «-1» for the second player’s win or «0» in case of a draw.
My questions:
- How and when do you calculate the net’s error (TD error)?
- How can you implement the «backpropagation» of the error?
- How are the weights adjusted using TD(λ)?
Thank you so much in advance 
asked Jan 30, 2011 at 20:59
![]()
cawcaw
31k62 gold badges181 silver badges291 bronze badges
If you’re serious about making this work, then understanding TD-lambda would be very helpful. Sutton and Barto’s book, «Reinforcement Learning» is available for free in HTML format and covers this algorithm in detail. Basically, what TD-lambda does is create a mapping between a game state and the expected reward at the game’s end. As games are played, states that are more likely to lead to winning states tend to get higher expected reward values.
For a simple game like tic-tac-toe, you’re better off starting with a tabular mapping (just track an expected reward value for every possible game state). Then once you’ve got that working, you can try using a NN for the mapping instead. But I would suggest trying a separate, simpler NN project first…
answered Jan 30, 2011 at 22:56
![]()
darkcanuckdarkcanuck
2791 silver badge2 bronze badges
1
I have been confused about this too, but I believe this is the way it works:
Starting from the end node, you check R, (output received) and E, (output expected). If E = R, it’s fine, and you have no changes to make.
If E != R, you see how far off it was, based on thresholds and whatnot, and then shift the weights or threshold up or down a bit. Then, based on the new weights, you go back in, and guess whether or not it was too high, or too low, and repeat, with a weaker effect.
I’ve never really tried this algorithm, but that’s basically the version of the idea as I understand it.
answered Jan 31, 2011 at 1:24
![]()
TaslemGuyTaslemGuy
5945 silver badges13 bronze badges
1
As far as I remember you do the training with a known result set — so you calculate the output for a known input and subtract your known output value from that — that is the error.
Then you use the error to correct the net — for a single layer NN adjusted with the delta rule I know that an epsilon of 0.5 is too high — something like 0.1 is better — slower but better. With backpropagation it is a bit more advanced — but as far as I remember the math equation description of a NN is complex and hard to understand — it is not that complicated.
take a look at
http://www.codeproject.com/KB/recipes/BP.aspx
or google for «backpropagation c» — it is probably easier to understand in code.
answered Feb 8, 2011 at 21:14
![]()
2
← →
Tirael ©
(2007-01-17 01:25)
[0]
вот читаю я сабжи про них и воспринимаю как сказку… в итоге возник вопрос — сказка ли это или чтото реальное? хотелось бы взглянуть на простенький пример, а не на теорию — есль ли они в свобожном доступе? (не важно что, пусть хоть 2+2 складывает, но «интеллектуально»)
![]()
![]()
← →
ors_archangel ©
(2007-01-17 02:51)
[1]
Они действительно обучаются, но очень долго. Я бы не стал говорить о интеллектуальности, сети могут лишь находить закономерности, или, например, ассоциативно запоминать. Вот очень очень простой пример сети прямого расспространения, которая может решить задачу XOR, обучение — обратное распространение ошибки.type
TSigmoidFunc = function(x: double): double;
// Сигмоидальная сжимающая функция
function DefSigmoid(x: double): double;
begin
result := 1 / (1 + exp(-x));
end;
type
TNeuron = object
w: array of double;
thess: double;
y: double;
end;
TNeuNet = class
private
input,hidden,output: integer;
neuron: array of array of TNeuron;
protected
function CalcErr: double;
public
sigmoid: TSigmoidFunc;
indata: array of double;
outdata: array of double;
trainout: array of double;
t: double;
constructor Create(input,hidden,output: integer);
procedure Calc;
procedure Train;
procedure BackPropagation;
end;
{ TNeuNet }
constructor TNeuNet.Create(input, hidden, output: integer);
var
i,j: int;
begin
inherited Create;
self.input := input;
self.hidden := hidden;
self.output := output;
setlength(neuron, 3);
setlength(neuron[0], input);
setlength(neuron[1], hidden);
setlength(neuron[2], output);
for i := 0 to hidden-1 do with neuron[1][i] do begin
thess := random;
setlength(w, input);
for j := 0 to input-1 do w[j] := random; // 0..1
end;
for i := 0 to output-1 do with neuron[2][i] do begin
thess := random;
setlength(w, hidden);
for j := 0 to hidden-1 do w[j] := random;
end;
setlength(indata, input);
setlength(outdata, output);
setlength(trainout, output);
sigmoid := DefSigmoid;
t := 0.1;
end;
procedure TNeuNet.Calc;
var
i,h,n: int;
begin
for i := 0 to input-1 do neuron[0][i].y := indata[i];
// each layer (exluse input)
for h := 1 to high(neuron) do begin
// each inner neuron
for n := 0 to high(neuron[h]) do begin
neuron[h][n].y := neuron[h][n].thess;
for i := 0 to high(neuron[h-1]) do
neuron[h][n].y := neuron[h][n].y + neuron[h][n].w[i] * neuron[h-1][i].y;
neuron[h][n].y := Sigmoid(neuron[h][n].y);
end;
end;
for i := 0 to output-1 do outdata[i] := neuron[high(neuron)][i].y;
end;
procedure TNeuNet.Train;
begin
Calc;
BackPropagation;
end;
function TNeuNet.CalcErr: double;
var
i: int;
begin
result := 0;
for i := 0 to output-1 do
result := result + sqr(outdata[i]-trainout[i]);
end;
procedure TNeuNet.BackPropagation;
var
delta: array of array of double;
d,y: double;
i,j: int;
begin
setlength(delta, 2);
setlength(delta[0], hidden);
setlength(delta[1], output);
for i := 0 to output-1 do begin
d := trainout[i];
y := outdata[i];
delta[1,i] := y*(1-y)*(d-y);
end;
for j := 0 to hidden-1 do begin
y := neuron[1,j].y;
delta[0,j] := y*(1-y)*(neuron[2,0].w[j]*delta[1,0]);
end;
for i := 0 to hidden-1 do with neuron[1][i] do begin
thess := thess + t*delta[0,i];
for j := 0 to input-1 do w[j] := w[j] + indata[j]*t*delta[0,i];
end;
for i := 0 to output-1 do with neuron[2][i] do begin
thess := thess + t*delta[1,i];
for j := 0 to hidden-1 do w[j] := w[j] + neuron[1][j].y*t*delta[1,i];
end;
end;
procedure TForm1.FormCreate(Sender: TObject);
begin
nn := TNeuNet.Create(2,3,1);
end;
procedure TForm1.Button2Click(Sender: TObject);
begin
nn.indata[0] := Str2Float(Edit1.Text);
nn.indata[1] := Str2Float(Edit2.Text);
nn.Calc;
Edit3.Text := Float2Str(nn.outdata[0]);
nn.indata[0] := Str2Float(Edit4.Text);
nn.indata[1] := Str2Float(Edit5.Text);
nn.Calc;
Edit6.Text := Float2Str(nn.outdata[0]);
nn.indata[0] := Str2Float(Edit7.Text);
nn.indata[1] := Str2Float(Edit8.Text);
nn.Calc;
Edit9.Text := Float2Str(nn.outdata[0]);
nn.indata[0] := Str2Float(Edit10.Text);
nn.indata[1] := Str2Float(Edit11.Text);
nn.Calc;
Edit12.Text := Float2Str(nn.outdata[0]);
end;
procedure TForm1.Button1Click(Sender: TObject);
const
e = 0.01;
var
err: double;
trained: boolean;
begin
repeat
trained := true;
nn.indata[0] := Str2Float(Edit1.Text);
nn.indata[1] := Str2Float(Edit2.Text);
nn.trainout[0] := Str2Float(Edit3.Text);
nn.Train;
err := nn.CalcErr;
if err > e then trained := false;
nn.indata[0] := Str2Float(Edit4.Text);
nn.indata[1] := Str2Float(Edit5.Text);
nn.trainout[0] := Str2Float(Edit6.Text);
nn.Train;
err := nn.CalcErr;
if err > e then trained := false;
nn.indata[0] := Str2Float(Edit7.Text);
nn.indata[1] := Str2Float(Edit8.Text);
nn.trainout[0] := Str2Float(Edit9.Text);
nn.Train;
err := nn.CalcErr;
if err > e then trained := false;
nn.indata[0] := Str2Float(Edit10.Text);
nn.indata[1] := Str2Float(Edit11.Text);
nn.trainout[0] := Str2Float(Edit12.Text);
nn.Train;
err := nn.CalcErr;
if err > e then trained := false;
until trained;
end;
![]()
![]()
← →
kaZaNoVa ©
(2007-01-17 02:54)
[2]
ors_archangel © (17.01.07 2:51) [1]
то есть по сути они основаны на рандоме?
![]()
![]()
← →
ors_archangel ©
(2007-01-17 02:55)
[3]
> thess := thess + t*delta[0,i]; for j := 0 to input-
> 1 do w[j] := w[j] + indata[j]*t*delta[0,i];
Тут вообще-то delt»у нужно взвешивать:
wdelta := 0;
for i := 0 to output-1 do
wdelta := wdelta + neuron[2,i].w[j]*delta[1,i];
Но и так сработало. Это был мой первый эксперемент
![]()
![]()
← →
ors_archangel ©
(2007-01-17 02:57)
[4]
> kaZaNoVa © (17.01.07 02:54) [2]
> основаны на рандоме?
Да нет, они основаны на очень простых вещах, что-то типа покоординатного спуска, только более точный — по антиградиенту, бывают ещё варианты, учитывающие вторые производные. Рандом — ни коим образом — только для инициализации: в начале сеть ничего не знает — выдаёт случайные данные, если всё обнулить, в среднем будет дольше обучаться
![]()
![]()
← →
Tirael ©
(2007-01-17 03:41)
[5]
а терь в 2-словах плиз описание работы )
![]()
![]()
← →
Ne-Ld
(2007-01-17 03:49)
[6]
Как я понимаю ни какой особенно глубокой математической основы за ними нет, и этим все сказано. Полуэмпиризм.
Нечеткая логика которую там пытаются использовать просто переформулированная теория меры — то то я сначала думал что это все что то подозрительно на обычный теорвер смахивает. (Думкин, и кто тут еще Математики — объясните мне глупому где я заблуждаюсь — что где недоучил — недопонял почему одну и ту же вешь разными именами называют? =) И почему они *так* похожи? )
Та литература которая доступна на русском языке — болтовня и примеры «на пальцах» толком и теорем там нет. Англоязычную литературу я еще не смотрел.
Сам с радостью выслушаю объяснения старших товарищей.
![]()
![]()
← →
Ne-Ld
(2007-01-17 03:52)
[7]
[offtopic]Ах, да коли уж Математики начнут рассказывать а чем обычный теорвер от теории меры отличается то? Цепями маркова что -ли? Где там «магия» начинается?
![]()
![]()
← →
ors_archangel ©
(2007-01-17 04:14)
[8]
Вообще, есть много типов (топологий, архитектур) нейронных сетей. Самая популярная (имхо, самая универсальная пока что) — сеть прямого распространения. Для эффективной работы сеть должна иметь два или более слоёв, т.е. хотя бы один скрытый слой. Каждый слой содержит нейроны, функция которых есть вычисление значения сигмоида от взвешенной по весам суммы входных значений — координат входного вектора, т.е. нейрон вычисляет сигмоид от скалярного произведения входного вектора и вектора весов, который для каждого нейрона свой. Сигмоид — это нелинейная функция, имеющая S-образный график: она имеет производную —> 0 при x —> ±inf, и максимальную производную при x = 0, или при x = b, зависит от реализации, сигмоидальная функция называется сжимающей, она призвана создавать нелинейные зависимости и препятствовать чрезмерному увеличению значений. Описание работы нейронной сети прямого распространения в друх словах: единтсвенная её функция — выполнение отображения входного вектора в выходной, наборы векторов могут быть произвольные, но естественно, выходной вектор должен зависеть от входного, иначе сеть не сможет обучиться. Некоторые архитектуры могут самообучаться, но чаще применяется обучение с учителем (т.е. на примерах): изначально, как я уже писал, сеть ничего не знает, но после удачного обучения сеть может делать отображение с заданной точностью. Т.е. например, мы хотим чтобы сеть складывала числа, для этого её сначала нужно обучить на показательных примерах, т.е. чтобы они учитывали все закономерности, которые нам нужно, чтобы сеть воспроизводила, набор примеров должен быть сбалансированным. Классический алгоритм обучения с учителем — это алгоритм обратного распространения ошибки — это итерационный алгоритм минимизации многомерной функции методом градиентного спуска, вычисляющий для этого частные производные функции ошибки по весам нейросети для каждого нейрона. Многомерная функция — это функция ошибки сети, которая показывает точность вычислений нейроссети, это может быть, например, средняя квадратная разность координат выходного и целевого векторов. Функция ошибки является n-мерной, где n — число весов сети. Веса, собственно, задают сеть в выбранной архитектуре. Поэтому задача обучаения — это задача вычисления значений этих весов. Фишка алгоритма обучения обратным распространением ошибки состоит в том, что он позволяет быстро вычислять частные производные функции ошибки в данной точке, причём не только для выходнго слоя, что довольно просто, но и для скрытого. Далее веса модифицируются в соответствии с тем, как они влияют на значение ошибки. Общий алгоритм обучения — это цикл вычислений ошибки сети и модификация весов, цикл заканчивается в лучшем случае если ошибка сети стала меньше заданной.
С уважением, Ваш младший товарищ.
Ne-Ld, а что такое теорвер? Первый раз слышу, это к чему относится?
![]()
![]()
← →
Gero ©
(2007-01-17 04:27)
[9]
> [8] ors_archangel © (17.01.07 04:14)
> Ne-Ld, а что такое теорвер?
Видимо, имеется ввиду тервер.
![]()
![]()
← →
Ne-Ld
(2007-01-18 00:28)
[10]
ors_archangel ©
1. Спасибо за развернутый ответ.
2. Прошу прощения за сленг.=) (он в разных ВУЗах разный немного =) )
теорвер — Теория вероятностей и\или стохастических процессов, Математическая статистика — короче много названий =), разные люди называют по разному, но суть от этого не меняетя.(да, я понимаю, что отличия есть, но это сейчас не существенно )
Начинается с аксиоматики Колмогорова и пошло поехало…
3.Меня несмотря на все что то манят нейросети. Подскажите книжку какую стоящую… А вот! Видел сегодня в книжном магазине толстый талмуд по сабжу, автора к сожалению забыл, но толщина меня потрясла =). Бегло просмотрел — вроде бы ничего так написано. Вот сейчас думаю покупать или нет? 900рублей все таки(я просто надеюсь что Вы ее знаете — сейчас она почти в каждом магазине есть и толщиной своей выделяется неслабо). М… завтра надо будет зайти автора посмотреть еще разок…
![]()
![]()
← →
Думкин ©
(2007-01-18 08:26)
[11]
> Ne-Ld (18.01.07 00:28) [10]
Я в нейросетях ни бум-бум, не иньтерисовался и не сталкивался. Тут скорее поможет Alex2 — он вроде в теме, да и почти доктор.
![]()
![]()
← →
Jeer ©
(2007-01-18 10:49)
[12]
Рекомендую посмотреть:
http://www.basegroup.ru/neural/
http://www.basegroup.ru/neural/fastneuralnet.htm
![]()
![]()
← →
ors_archangel ©
(2007-01-18 14:12)
[13]
> Ne-Ld (18.01.07 00:28) [10]
Не Саймон Хайкин «Нейронные сети»?
![]()
![]()
← →
@!!ex ©
(2007-01-18 14:21)
[14]
Общие познания в плане нейросетей немного устарели.
Сейчас сети обычно изначально строятся под конкретную задачу.
Плюс метод обучения — трассировка(был представлен в 2002 году) — позволяет добиться очень быстрого обучения.
Случайностью в нейросетях и не пахнет. Как раз наоборот, нейросеть способна выявлять закономерности и по ним строить предположения о тех ситуациях, которые ей не были заданы в процессе обучения.
Сеть изначально забивается случайными значениями, а если забивать 0(что вроде бы логично) сеть в большинстве случаев вообще не сможет обучиться.
Нейросеть — это ОЧЕНЬ сложная функция. И с математической точки зрения сами принцыпы весьма сложны, поэтому сеть обычно описывают просто.
Математика, что может быть проще 2+2? А если начать рассуждать о группах, полях и т.д?
НЕйросети — способны очень сложные задачи одного вида и не спообны решать задачи простые, но другого вида.
Ничего особенно чудесного в них нету, просто очень мощная вещь и все.
![]()
![]()
← →
ancara ©
(2007-01-18 17:03)
[15]
там автор просил простенький пример, у меня тут лежит дема, сейчас ее выложит к сожалению не могу, gprs, но думаю гугл найдет, называется
Artificial Neuronal Network Trial Version
(c) Copyright 2001 by logiware gmbh
это вообще пакет компонентов для делфи там есть скомпилированный пример работы нейронной сети — распознавание символов, очень все наглядно в картинках показано.
![]()
![]()
← →
ancara ©
(2007-01-18 17:04)
[16]
скачать триал можно тут: http://www.logiware.de/ann/
![]()
![]()
← →
ors_archangel ©
(2007-01-19 05:46)
[17]
> @!!ex © (18.01.07 14:21) [14]
Ух-ты! не может быть, наконец-то что-то придумали :)))))))))
Можешь дать хттп на алгоритм (трассировки), если не сложно, пожалуйста.
(По инету нашёл много всякой всячины, но самое похожее — 1998 года, наверно не то, называется «Subspace Tracking and NN Learning by a NIC», и там жестокая математика)
![]()
![]()
← →
@!!ex ©
(2007-01-19 08:22)
[18]
> ors_archangel © (19.01.07 05:46) [17]
Боюсь не помогу…
ВСе познания о трассировке и построению сетей из бумажных книг.
Даже названия не смогу сказать, поскольку книги эти сейчас не у меня.
Позже. Заберу, скажу.
![]()
![]()
← →
Ne-Ld
(2007-01-21 21:34)
[19]
> ors_archangel © (18.01.07 14:12) [13]
>
>
> > Ne-Ld (18.01.07 00:28) [10]
>
> Не Саймон Хайкин «Нейронные сети»?
Она самая. Примерно как она? Уж если скажем так, не денег то хоть места на полке она стоит? =) (я понимаю что вся ответственность при покупке за мной…)
![]()
![]()
← →
Loginov Dmitry ©
(2007-01-21 22:07)
[20]
Могу Осовского рекомендовать почитать.
Что касается личного мнения о применимости данного аппарата, то считаю все это весьма наукоемким всемирным обманом. И в большинстве случаев НС не стоят потраченного на них времени. Можно использовать НС, но только если она уже кем-то разработана, обучена и успешно решает возложенную на нее задачу. Имхо все.
![]()
![]()
← →
Ne-Ld
(2007-01-22 14:55)
[21]
>Loginov Dmitry © (21.01.07 22:07) [20]
Благодарю за совет.
![]()
![]()
← →
KygECHuK ©
(2007-01-22 16:02)
[22]
[8] To ORS Respect !!!!. Только вирусов больше не пиши ;-)). При встрече перетрём сабж. если только математические методы сдаш :)).
![]()
![]()
← →
Jeer ©
(2007-01-22 16:46)
[23]
> то считаю все это весьма наукоемким всемирным обманом.
И, разумеется, за исключением TMatrix :)))
![]()
![]()
← →
Loginov Dmitry ©
(2007-01-22 18:43)
[24]
> И, разумеется, за исключением TMatrix
Я еще не писал нейросети на нем!
![]()
![]()
← →
Jeer ©
(2007-01-22 18:52)
[25]
> Loginov Dmitry © (22.01.07 18:43) [24]
> Я еще не писал нейросети на нем!
Вот когда напишешь — будет всемирный адман в квадрате:))
Ладно, не бери в голову — я уже тебе говорил как-то: это учебный (для тебя) проект.
Всего лишь не надо из него пытаться создать видимость чрезвычайно полезного другим.
Другие пользуются другими возможностями — более адекватными решаемым реальным практическим задачам.
![]()
![]()
← →
Loginov Dmitry ©
(2007-01-23 07:40)
[26]
Интересно, у кого из нас больше голова об этом болит :))
![]()
![]()
← →
Ne-Ld
(2007-01-23 14:10)
[27]
Что можно использовать для поиска скрытых закономерностей, тогда, коли нейросети отпали (видимо)? В какую сторону рыть, что читать etc?
![]()
![]()
← →
Jeer ©
(2007-01-23 14:22)
[28]
— авторегрессии
— МГУА
— метод «Гусеница»
— вейвлет/фурье
![]()
![]()
← →
Ne-Ld
(2007-01-23 15:16)
[29]
2Jeer ©
О! Уже кое что есть! Спасибо — пойду покурю =).
![]()
![]()