You should be able to reproduce this error condition on demand by:
1. Opening a database connection (in your client application)
2. Unplugging the network cable
3. Plugging network cable back in (wait until the network connection is restored)
4. Using the previously opened connection to query the database
As far as I can tell from experience, client side ADO code is not able to consistently determine if an underlying network connection is actually valid or not. Checking if the database connection is open (in the client code) returns true. However, performing any operations on that connection results in a General network error.
The connection pool appears to be able to determine when a connection goes ‘bad’ so it never returns a bad connection to the application. It simply opens a new connection instead.
So, if a database connection is kept alive for a long time (used or unused) by the application, the underlying TCP/IP connectivity can get broken.
The bottom line is that database connections should be closed and returned back to the connection pool when not in use.
Edit
Also, depending on the number of clients connecting to the db, not using the connection pool can cause another issue. You may hit the maximum number of sockets open on the server side. This is from memory. Once a connection is closed on the client side, the connection on the server goes into a TIME_WAIT state. By default, the server socket takes about 4 minutes to close, so it is not available to other clients during that time. The bottom line is that there is a limited number of available sockets on the server. Keeping too many connections open can create a problem.
One project I worked on easily hit this socket limit with around 120 users. A new ‘feature’ was added that absolutely hammered the server, and after a few hours of using the app, things would suddenly slow to a crawl for everyone. SQL server was not closing enough sockets in time for new connection requests. Although there are 65K sockets altogether, only the first 5000 are made available to the ADO (this is a default registry setting thing, so can be changed).
The number of sockets in TIME_WAIT state would slowly build up until the OS would not allocate any more. So clients had to wait until server side sockets closed and a new connection could then be created.
considering the oldest version of sql 2008, when try to access application I receive the following error:
[DBNETLIB][ConnectionWrite (send()).]General network error. Check your network documentation
constructor TDBRowset.OpenQuery
function Rowset_OpenQuery
constructor TFrRowset.FrsOpen
function TdmMain.IsTempDB
procedure TMainForm.CheckMenuAccessRights
function TMainForm.DoCommand
procedure TMainForm.mSetPlanGroupsClick
SQL | TDBRowset.OpenQuery()
SQL | Msg: 11, Level: 16, State: 1, Line: 0
SQL | [DBNETLIB][ConnectionWrite (send()).]General network error. Check your network documentation
SQL | Error: -2147467259, Minor Error: 11, SQL State: 08S01
Please help, thanks all for your kindly assistance.
I Have SQL Express installed on 17 ships. Each ship has a VB6 Client application using OLEDB to connect to the database on local machine. Other workstations on network also connect — we think without error. The error above is thrown on 4 of the 17 ships. The workstations acting as the file server are supposed to be identical (Windows XP).
We have been assured that all poer save settings on LAN Card and motherboard have been disabled.
If I google on this error, I get over 100 hits going back several years ! Ideas to fix have included turning off connection pooling and using TCPIP instead of Named Pipes on client workstation where database server and application are running.
Any other ideas on what could cause this, or why 13 machines are OK, but 4 are not ? Thanks.
Michael Meierruth
SSChampion
Points: 10051
Have been getting this error sporadically for years on a large SS2K site. Fortunately, it does not happen that often. But, in my case, it is mostly associated with something that goes through ADO+ODBC using TCP/IP. For a long time our software was blamed on it until I wrote a simple VB script routine that runs in a loop and remains permanently connected and executes a simple ‘select 0’ every mìnute. When an error occured it would get logged and then attempt to re-establish the connection.
The ADO Err stack always had two errors with the second one always being ‘General network error’. The first error would vary including your ‘ConnectionWrite(Send())’.
Now the problem was squarely in Microsoft’s terrrory. This problem was never solved. We checked the hardware, routers, service packs — you name it. We even ran the script on the database server itself and it would happen there as well.
Irish
Hall of Fame
Points: 3958
By far this is the most frustrating issue that I have been dealing with lately!! ![]()
We have a number of Services that connect to a SQL 2005 Database via OLEDB/ADO. We are seeing these «General Network» Errors all the time recently. We have checked hardware, software, Database Settings you name it. Nothing seems to be able to shake this.
The network admins are insulted that we even suggest that there might be a problem with the network, but what else can we say? They of course have not suggested any better solution.
Michael, you said that it’s squarely in Mico$oft’s territory now? Did you open an incident on this? Where is it now?
Regards, Irish
Mark Story
SSC-Addicted
Points: 406
Thanks for the comments. I think opening up an incident with Microsoft is best idea here. Too bad, SQL Express is a really nice product — but if it can’t be made reliable…that certainly is an issue…
Michael Meierruth
SSChampion
Points: 10051
At the time an incident was opened but I think the client I worked for at the time then dropped it. The problem still occurs today but apparently with a frequency sufficiently low to be ignored by everyone.
Mark Story
SSC-Addicted
Points: 406
We are sending technician to one ship that has it bad and reinstall SQL Express 2005, make sure the most recent version is installed. Customer will loom to replace the workstation (XP) that holds the database.
Sugesh Kumar
One Orange Chip
Points: 27311
Mark Story
SSC-Addicted
Points: 406
Unfortnately thr service pack is for SQL Server 2000, while the database engine is SQL Express 2005.
We sent technician to ship; uninstalled/reinstalled. Looked ok until he left ship, then original problem resumes.
One note of interest, he had some trouble with .NET Framework 2.0 and had to reinstall that. So maybe «Assembly Hell» replaces «DLL Hell» ?![]()
In any event, still no solution. During SQL installation the message was displayed that computer does not meet requirements…but those messages have been ignored up til now because no details are given and most computers work fine.
Irish
Hall of Fame
Points: 3958
We are still working on this one. From what we have been able to discern, it appears to be the combination of SQL 2005 SP2 and 2003 SP2. The investigation is on-going. Thus far the Microsoft representation we have gotten has been unimpressive.
Regards, Irish
Mike Sheen
SSC Veteran
Points: 235
I’m seeing this on SQL 2005, SQL 2000 — on both Windows XP and Windows Server 2003.
I can reproduce the problem reliably, but using our rather large ERP software (that we develop). I’m working on a small test app which will also reproduce the problem, such that I can raise a support issue with Microsoft. Being in software, I understand the importance of giving them something they can use to reliably reproduce the problem.
It seems to be (for us, anyway), when an ADO (OLEDB) connection is busy waiting for the server (in our case a long running stored procedure to return results to a Crystal Report), a second, separate OLEDB connection attempts to fire some queries against the same server. In my tests these queries are merely SELECT statements — which surprised me — given the error message returned was a ConnectionWrite send() error — nothing’s trying to write, so I suspect ConnectionWrite is referring to not a SQL Write (ie UPDATE / INSERT / DELETE), but a network connection to the SQL Server (think socket comms).
I thought it may have been related to connection pooling (as this was the only way I could see how one ADO connection could be affecting another), so I made sure the second connection to use different SQL credentials — this should make the two connections forced into separate pools — as the connection string is what is used to pool connections together. Anyway — the problem still occurs with connection pooling out of the equation.
Like I mentioned earlier, we use two ADO connections in our software — one for reporting, one for the application — and usually the reporting ADO connection has different SQL credentials anyway (for security purposes). Now the Reporting connection is in fact used by Crystal Reports 11 — I’m *assuming* it’s creating an OLEDB connection — as I’ve coded it to use the SQL OLEDB data provider. What other connection options Crystal decides to set is at present a complete mystery to me (In my experience Crystal can do bizarre things). First I’ll try to reproduce the problem with Crystal out of the equation.
I also tried the SynAttackProtect registry hack (http://support.microsoft.com/default.aspx?scid=kb;en-us;899599) — this also had no effect.
We’re a certified MS partner, and a certified MS ISV. If I can reproduce the problem reliable with a simple application I can provide to MS, I’ll do my all to make sure we see a solution… and I’ll be sure to post my progress with this issue here ![]()
Mike Sheen
SSC Veteran
Points: 235
Ok, I’ve made some discoveries.
It doesn’t seem to be a SQL or OLEDB problem. It certainly seems to be (in my case, anyway) related to Crystal Reports.
I found the problem only occurs when a query is issued on one connection whilst a Crystal Application Object (CRAXDT Version 11) is waiting for a stored procedure based report to being returning results. The Crystal Application object must be in the same application domain as the application issuing the query which fails.
Changing the network protocol used by SQL to be named pipes instead of TCP/IP seemed to improve things — I no longer got the DBNETLIB error, but the Crystal Report Application threw errors when it’s report finished (could be related, but with Crystal it’s hard to know).
This problem seems to be only reproducible when you are able to execute a query concurrently to the Crystal Application object awaiting stored procedure results — I would have said «ie: multi-threaded applications», but our application is not multi-threaded — it’s written in VB6 — but still we somehow are able to fire queries through our application despite the Crystal Application object awaiting results. Perhaps Crystal creates a new thread and runs in that ?
Mike Sheen
SSC Veteran
Points: 235
More discoveries.
I see this behaviour on SQL 2000 SP4, but not SQL 2000 with no SP’s.
In my situation, SQL 2000 with no SP seems to cause my application to be «less threaded» — ie: any Reports running waiting for stored procs causes the whole application to «block» and wait — ie: nothing else within the application can be run.
However, SP4 of SQL 2000 and the behaviour changes — no longer is my application «blocked» — I can load other reports, navigate menu’s, etc — and thus cause other queries to run and the DBNETLIB error occurs.
Mike Sheen
SSC Veteran
Points: 235
October 26, 2007 at 4:37 pm
#745932
An email from a reader of this forum has prompted me to post my conclusions.
Firstly, to re-cap on how we got the errors — they only occurred when Crystal Reports 11 was busy running a query, and we attempted to issue a SQL query (using OLEDB) on a different connection, but a connection within the same application.
We never found a solution to this problem. We did however, discover how we were able to issue a query when our application should have been blocked and waiting for Crystal to finish (our app is in VB6 and thus single threaded).
We use the Catalyst Socket Control for some of our functionality, and that control being in the app caused it to behave in a multi-threaded fashion ‘sometimes’. It seems that control gives the UI a degree of multi-threadedness (for want of a better term), and allowed the user to open forms, etc whilst waiting for a report and thus causing the subsequent errors.
From memory I believe we upgraded the control to the latest version, and the behaviour returned to what we had before — the UI does not respond whilst Crystal reports is running, and therefore no errors.
MikeySQL
Newbie
Points: 9
Irish
Hall of Fame
Points: 3958
December 6, 2007 at 10:26 am
#757765
What we found was related to a security feature added in Windows 2003 Service Pack 2. It is something called TCP Chimney. It all cropped up after applying SP 2. Removing the Service Pack did not resolve the issue. What we found out later is that the feature was there with SP1, but was not enabled by default as it was in SP2. Removing SP2 did not revert the setting back. We eneded up making a change in the Registry to resolve this.
Here’s more information:
http://www.microsoft.com/whdc/device/network/TCP_Chimney.mspx
http://msexchangeteam.com/archive/2007/07/18/446400.aspx
We issued the command «Netsh int ip set chimney DISABLED» and that made the issue go away for us.
Regards, Irish
Общая сетевая ошибка после ночи бездействия
Обновлено
Вопрос:
В течение некоторого времени у нашего флагманского приложения были загадочные ошибки. Сообщение об ошибке является общим
[DBNETLIB] [ConnectionWrite (send()).] Общая сетевая ошибка. Проверьте свою сетевую документацию.
Это надежно воспроизводится, оставив приложение открытым на ночь и возобновив работу утром. Поскольку это серверное приложение для бэкэнд, это обычный сценарий.
Самое смешное – мы перенесли с SQL Server 7 на 2000 по 2008 год, и проблема присутствует на всех из них. Но то, что кажется важным, – это ОС, на которой мы запускаем приложение. На WinXP он отлично работает, на Vista/7 он терпит неудачу. Таким образом, проблема находится на стороне клиента.
Результаты Google в сообщении об ошибке охватывают очень широкий спектр различных причин (так как это очень общая ошибка), и ни один из найденных там сценариев не похож на наш.
Итак, может быть, кто-то здесь узнает, в чем проблема в нашем случае?
Ответ №1
Вы должны иметь возможность воспроизвести это условие ошибки по запросу:
1. Открытие соединения с базой данных (в вашем клиентском приложении)
2. Отсоединение сетевого кабеля
3. Повторное подключение сетевого кабеля (подождите, пока сетевое соединение будет восстановлено)
4. Используя ранее открытое соединение для запроса базы данных
Насколько я могу судить по опыту, код ADO на стороне клиента не может последовательно определить, действительно ли базовое сетевое соединение действительно или нет. Проверка открытия соединения с базой данных (в клиентском коде) возвращает значение true. Однако выполнение любых операций над этим соединением приводит к General network error.
Пул соединений, по-видимому, может определить, когда соединение “плохо”, поэтому оно никогда не возвращает плохое соединение с приложением. Вместо этого он просто открывает новое соединение.
Таким образом, если соединение с базой данных поддерживается в течение длительного времени (используется или не используется) приложением, базовая связь TCP/IP может быть нарушена.
Суть в том, что соединения с базой данных должны быть закрыты и возвращены обратно в пул соединений, когда они не используются.
Изменить
Кроме того, в зависимости от количества клиентов, подключающихся к db, использование пула соединений может вызвать другую проблему. Вы можете поразить максимальное количество сокетов, открытых на стороне сервера. Это из памяти. Когда соединение закрывается на стороне клиента, соединение на сервере переходит в состояние TIME_WAIT. По умолчанию серверный сокет занимает около 4 минут, поэтому он недоступен для других клиентов за это время. Суть в том, что на сервере имеется ограниченное количество доступных сокетов. Сохранение слишком большого количества подключений может создать проблему.
Один проект, над которым я работал, легко попал в этот сокет с примерно 120 пользователями. Добавлена новая “функция”, которая абсолютно забила сервер, и через несколько часов после использования приложения внезапно замедлится сканирование для всех. SQL-сервер не закрывал достаточно сокетов вовремя для новых запросов на подключение. Несмотря на то что есть 65K сокетов, только первые 5000 доступны для ADO (это стандартная настройка реестра, поэтому ее можно изменить).
Количество сокетов в состоянии TIME_WAIT будет медленно наращиваться до тех пор, пока ОС не будет выделять больше. Таким образом, клиентам приходилось ждать, пока сокеты на стороне сервера не будут закрыты, и тогда может быть создано новое соединение.
Ответ №2

В большинстве случаев истинная причина периодически возникающей проблемы с подключением клиентского компьютера к удаленному серверу базы данных MS SQL Server связана с сетевым уровнем модели OSI. Собирая данные трассировки сети и анализируя их, мы можем сузить зону поиска и определить точную причину того, почему не удалось установить соединение или было внезапно разорвано существующее соединение.
Для большей наглядности предоставляемой информации в рамках данной статьи, мы дополнили ее пошаговыми иллюстрациями практического решения проблемы из реальной жизни. Проблема в предлагаемом нами кейсе заключалась в том, что клиент с определенной периодичностью получал сообщение GNE (General Network error, «Общая ошибка сети») от приложения, которое пыталось подключиться удаленно к серверу Microsoft SQL Server. Ниже приведен пример такого сообщения об ошибке:
«OleDB Error Microsoft OLE DB Provider for SQL Server [0x80004005][11] : [DBNETLIB][ConnectionWrite (send()).]General network error. Check your network documentation».
После проведения некоторых стандартных начальных процедур по поиску неисправностей (таких как проверка, не была ли отключена функция разгрузки TCP chimney, или не было ли превышено значение установленного максимального количества соединений и т.д.) были в одно и то же время собраны сетевые трассировки, как с сервера приложений, так и с MS SQL server. Когда вы собираете трассировки сети, всегда соблюдайте следующие два правила:
- Используйте данные, полученные с помощью утилиты «ipconfig», запущенную с ключом «/all», со всех задействованных серверов.
- Ориентируйтесь на сообщения об ошибке с установленной временной меткой (timestamp). Если по какой-то причине сообщения об ошибке с временной меткой вам недоступны, попросите клиента сделать запись точного времени возникновения проблемы и отправить ее вам.
Далее мы детально, шаг за шагом рассмотрим, как были проанализированы собранные трассировки сети. Вы можете использовать подобные методы для анализа трассировок, собранных вами для решения периодически возникающих проблем с подключением к серверу SQL.
Для захвата и анализа трассировок вы можете использовать Wireshark, либо любой другой инструментарий с подобной функциональностью. В данном примере был использован Wireshark, поскольку трассировки, отправленные клиентом, не могли быть открыты другим инструментарием (это было связано с расширением полученных файлов).
IP-адреса и точное время возникновение проблемы
Для начала стоит проверить информацию, полученную с помощью утилиты ipconfig, чтобы узнать необходимые нам IP-адреса. В рассматриваемом примере они следующие:
«SQL server:
IP Address. . . . . . . . . . . . : 10.10.100.131
App server:
IP Address. . . . . . . . . . . . : 10.10.100.59»
Теперь из сообщения об ошибке выясним, когда именно возникла проблема. Наше сообщение об ошибке выглядит так:
«02/24/2010 09:28:08 DataBase Warning OleDB Error Microsoft OLE DB Provider for SQL Server [0x80004005][11] : [DBNETLIB][ConnectionWrite (send()).]General network error. Check your network documentation».
Таким образом, проблема произошла 24.02.2010 в 09:28:08.
Почему так важно точное время события? Зачастую, при сборе трассировок сети для решения периодически возникающих сетевых проблем вы получите внушительное количество файлов трассировки с каждого сервера, так как вам может понадобиться осуществлять захват сетевых трассировок в течение довольно продолжительного периода времени, и это может привести к генерации большого количества файлов трассировки, хранящих информацию о всей цепочке событий, произошедших за это время. В рассматриваемом нами примере клиент отправил более 60 файлов трассировки размером 25 МБ каждый для сервера приложений, а также было получено 6 подобных файлов для сервера Microsoft SQL Server. Когда у вас слишком много данных для анализа, информация о точном времени возникновения проблемы становится бесценной.
Анализ трассировок сервера приложений
Начнем наш анализ с файлов трассировки, полученных от сервера приложений. С помощью временной метки мы можем определить, какой файл трассировки необходимо проанализировать первым. Первое, что необходимо сделать, когда мы имеем дело с периодически возникающими проблемами сетевого соединения, это проверить данные трассировки сети на наличие каких-либо сбросов соединения (сообщений по протоколу TCP с установленным флагом RST, означающим «RESET»). Кроме того, из журнала ошибок сервера SQL можно узнать, какой порт прослушивает SQL-сервер. В рассматриваемом нами примере это был порт 1433. Таким образом, мы начинаем свой анализ со следующего фильтра:
«tcp.port eq 1433 && tcp.flags.reset==1»
С помощью данного фильтра можно получить список всех сообщений «RESET», относящихся к данному SQL-серверу (конечно же, сразу стоит удостовериться, что сервер приложений подключается только к проблемному SQL-серверу, и не происходит других подключений еще к какому-то другому SQL-серверу, который также прослушивает порт 1433). В рассматриваемом нами примере с помощью этого фильтра было обнаружено около 20 сообщений по протоколу TCP с флагом RST:
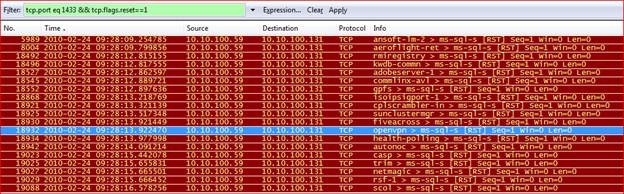
Следующим нашим шагом будет проверка полного взаимодействия в течение состоявшегося TCP-соединения, частью которого является сообщение о сбросе соединения. Для того чтобы увидеть сетевое взаимодействие, включающее в себя фрейм с флагом RST, следуйте следующему шаблону действий:
«Выберите фрейм с флагом RST —> кликните правой кнопкой мыши —> Conversation Filter («Фильтр взаимодействия») —> TCP».
В результате вы получите все фреймы для текущего взаимодействия. В ходе выполнения аналогичной проверки для рассматриваемого нами примера было найдено всего два фрейма:

Теперь, если вы работаете с несколькими файлами трассировки, формирующих непрерывную цепочку событий, а не с одним файлом, вам следует проанализировать и другие файлы трассировки, которые содержат информацию о событиях непосредственно до и после обнаруженного вами события, чтобы найти и другие фреймы этого сетевого взаимодействия, если таковые существуют. Нам необходимо восстановить полную картину событий и узнать, что происходило до того, как сообщение о сбросе соединения было отправлено. Эта информация поможем нам узнать первопричину отправки сообщения с флагом RST. Чтобы сделать это, скопируйте фильтр для данного взаимодействия из текущего файла трассировки. Для нашего примера он следующий:
«(ip.addr eq 10.10.100.59 and ip.addr eq 10.10.100.131) and (tcp.port eq 1194 and tcp.port eq 1433)»
Затем следует открыть файл трассировки, собранный на сервере приложений непосредственно перед текущим файлом трассировки, и, используя вышеупомянутый фильтр, найти фреймы, которые являются частью одного и того же сетевого взаимодействия.
Если вы не нашли проблему, а только наблюдаете нормальный траффик (наподобие пакетов «keep-alive»), откройте файл трассировки, предшествующий этому, и проанализируйте его, используя тот же фильтр. Продолжайте делать это, пока не увидите какую-то проблему или не дойдете до начала разговора (трехстороннего рукопожатия TCP для установления соединения).
В нашем примере было много траффика «keep-alive». Microsoft SQL Server (10.10.100.131) и сервер приложений (10.10.100.59) отправляли туда и обратно пакеты «TCP Keep-Alive» и «TCP Keep-Alive ACK». Но в конце сетевого взаимодействия сервер приложений (10.10.100.59) отправил пять пакетов «TCP Keep-Alive» на сервер SQL, но не получил никакого ответа от сервера SQL, как вы можете убедиться ниже:
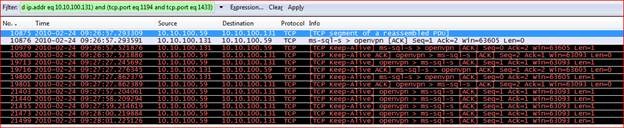
Проверка всех предыдущих файлов трассировки, содержащих исследуемое взаимодействие, других проблем не выявила. Затем был проверен файл трассировки, следующий за изначальным файлом трассировки (в котором было обнаружено сообщение с флагом RST), но он не содержал фреймов для текущего соединения. Таким образом, данное сетевое взаимодействие закончилось после этого сообщения с сигналом о разрыве соединения.
Анализ трассировок сервера Microsoft SQL Server
Теперь приступаем к проверке файлов трассировки, которые были получены от сервера SQL. Еще раз использовав временную метку возникновения ошибки, мы можем определиться с файлом трассировки, с которого нам нужно начать.
Данный материал доступен только зарегистрированным пользователям!
Войдите или зарегистрируйтесь бесплатно, чтобы получить доступ!
Регистрация займёт несколько секунд.
См. также: