В некоторых образах Cisco ASA при сохранении конфигурации командой wr mem выводится сообщение об успешном сохранении, но после перезапуска устройства конфигурация отсутствует.
Проблема может быть в отсутствии файла startup-config в flash: памяти.
Посмотреть содержимое flash:
ciscoasa# sh flash:
—#— —length— ——date/time—— path
12 1359344 Jan 05 2012 12:57:48 asa842-vmlinuz
12289 1024 Aug 04 2016 06:00:25 coredumpinfo
12290 59 Aug 04 2016 06:00:25 coredumpinfo/coredump.cfg
8193 1024 Aug 04 2016 06:00:24 log
11 12288 May 06 2012 00:06:46 lost+found
15 0 Aug 04 2016 06:06:10 nat_ident_migrate
28673 7168 May 06 2012 14:05:00 grub
28765 1804 May 06 2012 00:11:38 grub/lsmmap.mod
28809 41732 May 06 2012 00:11:39 grub/regexp.mod
28879 25962 May 06 2012 00:11:40 grub/core.img
28755 4584 May 06 2012 00:11:38 grub/keylayouts.mod
…………………………………………………………………………………………
28774 3884 May 06 2012 00:11:38 grub/minix.mod
14 196 Aug 04 2016 06:00:25 upgrade_startup_errors_201608040601.log
13 23529673 Jan 05 2012 13:05:38 asa842-initrd.gz
154350592 bytes total (121769984 bytes free)
Как видно, файла startup-config во flash: памяти нет.
Скопировать running-config в startup-config
ciscoasa# copy running-config startup-config
Source filename [running-config]?
Cryptochecksum: 6424e418 1c94709d 8247c8fd 6e607241
1988 bytes copied in 0.150 secs
Скопировать startup-config в flash:
ciscoasa# copy startup-config flash:
Destination filename [startup-config]?
Copy in progress…C
1988 bytes copied in 0.0 secs
Посмотреть содержимое flash: на предмет наличия startup-config
ciscoasa# sh flash:
—#— —length— ——date/time—— path
12 1359344 Jan 05 2012 12:57:48 asa842-vmlinuz
12289 1024 Aug 04 2016 06:00:25 coredumpinfo
12290 59 Aug 04 2016 06:00:25 coredumpinfo/coredump.cfg
8193 1024 Aug 04 2016 06:00:24 log
11 12288 May 06 2012 00:06:46 lost+found
15 0 Aug 04 2016 06:06:10 nat_ident_migrate
28673 7168 May 06 2012 14:05:00 grub
28765 1804 May 06 2012 00:11:38 grub/lsmmap.mod
28809 41732 May 06 2012 00:11:39 grub/regexp.mod
28879 25962 May 06 2012 00:11:40 grub/core.img
28755 4584 May 06 2012 00:11:38 grub/keylayouts.mod
…………………………………………………………………………………………
28774 3884 May 06 2012 00:11:38 grub/minix.mod
16 1988 Aug 04 2016 06:14:01 startup-config
14 196 Aug 04 2016 06:00:25 upgrade_startup_errors_201608040601.log
13 23529673 Jan 05 2012 13:05:38 asa842-initrd.gz
154350592 bytes total (121767936 bytes free)
Теперь можно сохранять конфигурацию ASA командой wr mem
ciscoasa# wr mem
Building configuration…
Cryptochecksum: 6424e418 1c94709d 8247c8fd 6e607241
1988 bytes copied in 0.150 secs
[OK]
Troubleshooting the Software Configuration
This chapter describes how to identify and resolve software problems related to the Cisco IOS software on the switch. Depending
on the nature of the problem, you can use the command-line interface (CLI), Device Manager, or Network Assistant to identify
and solve problems.
Additional troubleshooting information, such as LED descriptions, is provided in the hardware installation guide.
Information About Troubleshooting the Software Configuration
Software Failure on a Switch
Switch software can be corrupted during an upgrade by downloading the incorrect file to the switch, and by deleting the image
file. In all of these cases, the switch does not pass the power-on self-test (POST), and there is no connectivity.Follow the steps described in the Recovering from a Software Failure section to recover from a software failure.
Lost or Forgotten Password on a Device
The default configuration for the device allows an end user with physical access to the device to recover from a lost password by interrupting the boot process during power-on and by entering a new password. These recovery
procedures require that you have physical access to the device.
 Note |
On these devices, a system administrator can disable some of the functionality of this feature by allowing an end user to reset a password |
Note |
You cannot recover encryption password key, when Cisco WLC configuration is copied from one Cisco WLC to another (in case |
Follow the steps described in the section Recovering from a Lost or Forgotten Password to recover from a lost or forgotten password.
Power over Ethernet Ports
A Power over Ethernet (PoE) switch port automatically supplies power to one of these connected devices if the switch detects
that there is no power on the circuit:
-
a Cisco pre-standard powered device (such as a Cisco IP Phone or a Cisco Aironet Access Point)
-
an IEEE 802.3af-compliant powered device
-
an IEEE 802.3at-compliant powered device
A powered device can receive redundant power when it is connected to a PoE switch port and to an AC power source. The device
does not receive redundant power when it is only connected to the PoE port.
After the switch detects a powered device, the switch determines the device power requirements and then grants or denies power
to the device. The switch can also detect the real-time power consumption of the device by monitoring and policing the power
usage.
For more information, see the «Configuring PoE» chapter in the Interface and Hardware Component Configuration Guide (Catalyst 9300 Switches).
Refere the section Scenarios to Troubleshoot Power over Ethernet (PoE) for various PoE troubleshooting scenarios.
Disabled Port Caused by Power Loss
If a powered device (such as a Cisco IP Phone 7910) that is connected to a PoE Device port and powered by an AC power source loses power from the AC power source, the device might enter an error-disabled state.
To recover from an error-disabled state, enter the shutdown interface configuration command, and then enter the no shutdown interface command. You can also configure automatic recovery on the Device to recover from the error-disabled state.
On a Device, the errdisable recovery cause loopback and the errdisable recovery interval
seconds global configuration commands automatically take the interface out of the error-disabled state after the specified period
of time.
Disabled Port Caused by False Link-Up
If a Cisco powered device is connected to a port and you configure the port by using the power inline never
interface configuration command, a false link-up can occur, placing the port into an error-disabled state. To take the port
out of the error-disabled state, enter the shutdown and the no shutdown interface configuration commands.
You should not connect a Cisco powered device to a port that has been configured with the power inline never command.
Ping
The Device supports IP ping, which you can use to test connectivity to remote hosts. Ping sends an echo request packet to an address
and waits for a reply. Ping returns one of these responses:
-
Normal response—The normal response (hostname is alive) occurs in 1 to 10 seconds, depending on network traffic.
-
Destination does not respond—If the host does not respond, a no-answer message is returned.
-
Unknown host—If the host does not exist, an unknown host message is returned.
-
Destination unreachable—If the default gateway cannot reach the specified network, a destination-unreachable message is returned.
-
Network or host unreachable—If there is no entry in the route table for the host or network, a network or host unreachable message is returned.
Refere the section Executing Ping to understand how ping works.
Layer 2 Traceroute
The Layer 2 traceroute feature allows the switch to identify the physical path that a packet takes from a source device to
a destination device. Layer 2 traceroute supports only unicast source and destination MAC addresses. Traceroute finds the
path by using the MAC address tables of the Device in the path. When the Device detects a device in the path that does not support Layer 2 traceroute, the Device continues to send Layer 2 trace queries and lets them time out.
The Device can only identify the path from the source device to the destination device. It cannot identify the path that a packet takes
from source host to the source device or from the destination device to the destination host.
Layer 2 Traceroute Guidelines
-
Cisco Discovery Protocol (CDP) must be enabled on all the devices in the network. For Layer 2 traceroute to function properly,
do not disable CDP.If any devices in the physical path are transparent to CDP, the switch cannot identify the path through these devices.
-
A device is reachable from another device when you can test connectivity by using the ping privileged EXEC command. All devices in the physical path must be reachable from each other.
-
The maximum number of hops identified in the path is ten.
-
You can enter the traceroute mac or the traceroute mac ip privileged EXEC command on a device that is not in the physical path from the source device to the destination device. All
devices in the path must be reachable from this switch. -
The traceroute mac command output shows the Layer 2 path only when the specified source and destination MAC addresses belong to the same VLAN.
If you specify source and destination MAC addresses that belong to different VLANs, the Layer 2 path is not identified, and
an error message appears. -
If you specify a multicast source or destination MAC address, the path is not identified, and an error message appears.
-
If the source or destination MAC address belongs to multiple VLANs, you must specify the VLAN to which both the source and
destination MAC addresses belong. If the VLAN is not specified, the path is not identified, and an error message appears. -
The traceroute mac ip command output shows the Layer 2 path when the specified source and destination IP addresses belong to the same subnet. When
you specify the IP addresses, the device uses the Address Resolution Protocol (ARP) to associate the IP addresses with the
corresponding MAC addresses and the VLAN IDs.-
If an ARP entry exists for the specified IP address, the device uses the associated MAC address and identifies the physical
path. -
If an ARP entry does not exist, the device sends an ARP query and tries to resolve the IP address. If the IP address is not
resolved, the path is not identified, and an error message appears.
-
-
When multiple devices are attached to one port through hubs (for example, multiple CDP neighbors are detected on a port),
the Layer 2 traceroute feature is not supported. When more than one CDP neighbor is detected on a port, the Layer 2 path is
not identified, and an error message appears. -
This feature is not supported in Token Ring VLANs.
-
Layer 2 traceroute opens a listening socket on the User Datagram Protocol (UDP) port 2228 that can be accessed remotely with
any IPv4 address, and does not require any authentication. This UDP socket allows to read VLAN information, links, presence
of particular MAC addresses, and CDP neighbor information, from the device. This information can be used to eventually build
a complete picture of the Layer 2 network topology. -
Layer 2 traceroute is enabled by default and can be disabled by running the no l2 traceroute command in global configuration mode. To re-enable Layer 2 traceroute, use the l2 traceroute command in global configuration mode.
IP Traceroute
You can use IP traceroute to identify the path that packets take through the network on a hop-by-hop basis. The command output
displays all network layer (Layer 3) devices, such as routers, that the traffic passes through on the way to the destination.
Your Device can participate as the source or destination of the traceroute privileged EXEC command and might or might not appear as a hop in the traceroute command output. If the Device is the destination of the traceroute, it is displayed as the final destination in the traceroute output. Intermediate Device do not show up in the traceroute output if they are only bridging the packet from one port to another within the same VLAN.
However, if the intermediate Device is a multilayer Device that is routing a particular packet, this Device shows up as a hop in the traceroute output.
The traceroute privileged EXEC command uses the Time To Live (TTL) field in the IP header to cause routers and servers to generate specific
return messages. Traceroute starts by sending a User Datagram Protocol (UDP) datagram to the destination host with the TTL
field set to 1. If a router finds a TTL value of 1 or 0, it drops the datagram and sends an Internet Control Message Protocol
(ICMP) time-to-live-exceeded message to the sender. Traceroute finds the address of the first hop by examining the source
address field of the ICMP time-to-live-exceeded message.
To identify the next hop, traceroute sends a UDP packet with a TTL value of 2. The first router decrements the TTL field by
1 and sends the datagram to the next router. The second router sees a TTL value of 1, discards the datagram, and returns the
time-to-live-exceeded message to the source. This process continues until the TTL is incremented to a value large enough for
the datagram to reach the destination host (or until the maximum TTL is reached).
To learn when a datagram reaches its destination, traceroute sets the UDP destination port number in the datagram to a very
large value that the destination host is unlikely to be using. When a host receives a datagram destined to itself containing
a destination port number that is unused locally, it sends an ICMP port-unreachable error to the source. Because all errors except port-unreachable errors come from intermediate hops, the receipt of a port-unreachable
error means that this message was sent by the destination port.
Go to Example: Performing a Traceroute to an IP Host to see an example of IP traceroute process.
Debug Commands
 Caution |
Because debugging output is assigned high priority in the CPU process, it can render the system unusable. For this reason, |
All debug commands are entered in privileged EXEC mode, and most debug commands take no arguments.
System Report
System reports or crashinfo files save information that helps Cisco technical support representatives to debug problems that
caused the Cisco IOS image to fail (crash). It is necessary to quickly and reliably collect critical crash information with
high fidelity and integrity. Further, it is necessary to collect this information and bundle it in a way that it can be associated
or identified with a specific crash occurrence.
System reports are generated in these situations:
-
In case of a switch failure—A system report is generated on the member that failed; reports are not generated on other members
in the stack. -
In case of a switchover—System reports are generated only on high availability (HA) member switches. reports are not generated
for non-HA members.
The system does not generate reports in case of a reload.
During a process crash, the following is collected locally from the switch:
-
Full process core
-
Tracelogs
-
IOS syslogs (not guaranteed in case of non-active crashes)
-
System process information
-
Bootup logs
-
Reload logs
-
Certain types of /proc information
This information is stored in separate files which are then archived and compressed into one bundle. This makes it convenient
to get a crash snapshot in one place, and can be then moved off the box for analysis. This report is generated before the
switch goes down to rommon/bootloader.
Except for the full core and tracelogs, everything else is a text file.
Use the request platform software process core fed active command to generate the core dump.
h2-macallan1# request platform software process core fed active
Process : fed main event (28155) encountered fatal signal 6
Process : fed main event stack :
SUCCESS: Core file generated.
h2-macallan1#dir bootflash:core
Directory of bootflash:/core/
178483 -rw- 1 May 23 2017 06:05:17 +00:00 .callhome
194710 drwx 4096 Aug 16 2017 19:42:33 +00:00 modules
178494 -rw- 10829893 Aug 23 2017 09:46:23 +00:00 h2-macallan1_RP_0_fed_28155_20170823-094616-UTC.core.gzCrashinfo Files
By default the system report file will be generated and saved into the /crashinfo directory. Ifit cannot be saved to the crashinfo
partition for lack of space, then it will be saved to the /flash directory.
To display the files, enter the dir crashinfo: command. The following is sample output of a crashinfo directory:
Switch#dir crashinfo:
Directory of crashinfo:/
23665 drwx 86016 Jun 9 2017 07:47:51 -07:00 tracelogs
11 -rw- 0 May 26 2017 15:32:44 -07:00 koops.dat
12 -rw- 4782675 May 29 2017 15:47:16 -07:00 system-report_1_20170529-154715-PDT.tar.gz
1651507200 bytes total (1519386624 bytes free)
System reports are located in the crashinfo directory in the following format:
system-report_[switch number]_[date]-[timestamp]-UTC.gzAfter a switch crashes, check for a system report file. The name of the most recently generated system report file is stored
in the last_systemreport file under the crashinfo directory. The system report and crashinfo files assist TAC while troubleshooting
the issue.
The system report generated can be further copied using TFTP, HTTP and few other options.
Switch#copy crashinfo: ?
crashinfo: Copy to crashinfo: file system
flash: Copy to flash: file system
ftp: Copy to ftp: file system
http: Copy to http: file system
https: Copy to https: file system
null: Copy to null: file system
nvram: Copy to nvram: file system
rcp: Copy to rcp: file system
running-config Update (merge with) current system configuration
scp: Copy to scp: file system
startup-config Copy to startup configuration
syslog: Copy to syslog: file system
system: Copy to system: file system
tftp: Copy to tftp: file system
tmpsys: Copy to tmpsys: file systemThe general syntax for copying onto TFTP server is as follows:
Switch#copy crashinfo: tftp:
Source filename [system-report_1_20150909-092728-UTC.gz]?
Address or name of remote host []? 1.1.1.1
Destination filename [system-report_1_20150909-092728-UTC.gz]?The tracelogs from all members in the stack can be collected by issuing a trace archive command. This command provides time period options. The command syntax is as
follows:
Switch#request platform software trace archive ?
last Archive trace files of last x days
target Location and name for the archive fileThe tracelogs stored in crashinfo: or flash: directory from within the last 3650 days can be collected.
Switch# request platform software trace archive last ?
<1-3650> Number of days (1-3650)
Switch#request platform software trace archive last 3650 days target ?
crashinfo: Archive file name and location
flash: Archive file name and locationNote |
It is important to clear the system reports or trace archives from flash or crashinfo directory once they are copied out, |
Onboard Failure Logging on the Switch
You can use the onboard failure logging (OBFL) feature to collect information about the Device. The information includes uptime, temperature, and voltage information and helps Cisco technical support representatives
to troubleshoot Device problems. We recommend that you keep OBFL enabled and do not erase the data stored in the flash memory.
By default, OBFL is enabled. It collects information about the Device and small form-factor pluggable (SFP) modules. The Device stores this information in the flash memory:
-
CLI commands—Record of the OBFL CLI commands that are entered on a standalone Device or a switch stack member.
-
Environment data—Unique device identifier (UDI) information for a standalone Device
or a switch stack member and for all the connected FRU devices: the product identification (PID), the version identification (VID), and the serial
number. -
Message—Record of the hardware-related system messages generated by a standalone Device
or a switch stack member. -
Power over Ethernet (PoE)—Record of the power consumption of PoE ports on a standalone Device
or a switch stack member. -
Temperature—Temperature of a standalone Device
or a switch stack member. -
Uptime data—Time when a standalone Device
or a switch stack member starts, the reason the Device restarts, and the length of time the Device has been running since it last restarted. -
Voltage—System voltages of a standalone Device
or a switch stack member.
You should manually set the system clock or configure it by using Network Time Protocol (NTP).
When the Device is running, you can retrieve the OBFL data by using the show logging onboard privileged EXEC commands. If the Device fails, contact your Cisco technical support representative to find out how to retrieve the data.
When an OBFL-enabled Device is restarted, there is a 10-minute delay before logging of new data begins.
Fan Failures
By default, the feature is disabled. When more than one of the fans fails in a field-replaceable unit (FRU) or in a power
supply, the device does not shut down, and this error message appears:
Multiple fan(FRU/PS) failure detected. System may get overheated. Change fan quickly.
The Device might overheat and shut down.
To enable the fan failures feature, enter the system env fan-fail-action shut privileged EXEC command. If more than one fan in the Device fails, the Device automatically shuts down, and this error message appears:
Faulty (FRU/PS) fans detected, shutting down system!
After the first fan shuts down, if the Device detects a second fan failure, the Device waits for 20 seconds before it shuts down.
To restart the Device, it must be power cycled.
For more information on Fan failures, refer Cisco Catalyst 9400 Series Switches Hardware Installaion Guide
Possible Symptoms of High CPU Utilization
Excessive CPU utilization might result in these symptoms, but the symptoms might also result from other causes, some of which
are the following:
-
Spanning tree topology changes
-
EtherChannel links brought down due to loss of communication
-
Failure to respond to management requests (ICMP ping, SNMP timeouts, slow Telnet or SSH sessions)
-
UDLD flapping
-
IP SLAs failures because of SLAs responses beyond an acceptable threshold
-
DHCP or IEEE 802.1x failures if the switch does not forward or respond to requests
How to Troubleshoot the Software Configuration
Recovering from a Software Failure
Before you begin
This recovery procedure requires that you have physical access to the switch.
This procedure uses boot loader commands and TFTP to recover from a corrupted or incorrect image file.
Procedure
| Step 1 |
From your PC, download the software image file (image.bin ) from Cisco.com. |
| Step 2 |
Load the software image to your TFTP server. |
| Step 3 |
Connect your PC to the switch Ethernet management port. |
| Step 4 |
Unplug the switch power cord. |
| Step 5 |
Press the Mode button, and at the same time, reconnect the power cord to the switch. |
| Step 6 |
From the bootloader prompt, ensure that you can ping your TFTP server.
Example: |
| Step 7 |
Verify that you have a recovery image in your recovery partition (sda9:). This recovery image is required for recovery using the emergency-install feature. Example: |
| Step 8 |
From the bootloader prompt, initiate the emergency-install feature WARNING: The emergency install command will erase your entire boot flash! Example:Alternatively, you can copy the image from TFTP to local flash through Telnet or Management port and then boot the device |
Recovering from a Lost or Forgotten Password
The default configuration for the switch allows an end user with physical access to the switch to recover from a lost password
by interrupting the boot process during power-on and by entering a new password. These recovery procedures require that you
have physical access to the switch.
Note |
On these switches, a system administrator can disable some of the functionality of this feature by allowing an end user to |
Procedure
| Step 1 |
Connect a terminal or PC to the switch.
|
| Step 2 |
Set the line speed on the emulation software to 9600 baud. |
| Step 3 |
Power off the standalone switch or the entire switch stack. |
| Step 4 |
Reconnect the power cord to the switch or the active switch. The following console messages are displayed during the reload: Proceed to the Procedure with Password Recovery Enabled section, and follow the steps. |
| Step 5 |
After recovering the password, reload the switch or the active switch. On a switch: On the active switch: |
| Step 6 |
Power on the remaining switches in the stack. |
Procedure with Password Recovery Enabled
Procedure
| Step 1 |
Ignore the startup configuration with the following command: |
| Step 2 |
Boot the switch with the packages.conf file from flash. |
| Step 3 |
Terminate the initial configuration dialog by answering No. |
| Step 4 |
At the switch prompt, enter privileged EXEC mode. |
| Step 5 |
Copy the startup configuration to running configuration. Press Return in response to the confirmation prompts. The configuration file is now reloaded, and you can change the password. |
| Step 6 |
Enter global configuration mode and change the enable password. |
| Step 7 |
Write the running configuration to the startup configuration file. |
| Step 8 |
Confirm that manual boot mode is enabled. |
| Step 9 |
Reload the device. |
| Step 10 |
Set the SWITCH_IGNORE_STARTUP_CFG parameter to 0. |
| Step 11 |
Boot the device with the packages.conf file from flash. |
| Step 12 |
After the device boots up, disable manual boot on the device. |
Procedure with Password Recovery Disabled
If the password-recovery mechanism is disabled, this message appears:
The password-recovery mechanism has been triggered, but
is currently disabled. Access to the boot loader prompt
through the password-recovery mechanism is disallowed at
this point. However, if you agree to let the system be
reset back to the default system configuration, access
to the boot loader prompt can still be allowed.
Would you like to reset the system back to the default configuration (y/n)?
Caution |
Returning the device to the default configuration results in the loss of all existing configurations. We recommend that you |
-
If you enter n (no), the normal boot process continues as if the Mode button had not been pressed; you cannot access the boot loader prompt, and you cannot enter a new password. You see the message:
Press Enter to continue........ -
If you enter y (yes), the configuration file in flash memory and the VLAN database file are deleted. When the default configuration loads,
you can reset the password.
Procedure
| Step 1 |
Choose to continue with password recovery and delete the existing configuration: |
||
| Step 2 |
Display the contents of flash memory: |
||
| Step 3 |
Boot up the system: You are prompted to start the setup program. To continue with password recovery, enter N at the prompt: |
||
| Step 4 |
At the device prompt, enter privileged EXEC mode: |
||
| Step 5 |
Enter global configuration mode: |
||
| Step 6 |
Change the password: The secret password can be from 1 to 25 alphanumeric characters, can start with a number, is case sensitive, and allows spaces |
||
| Step 7 |
Return to privileged EXEC mode:
|
||
| Step 8 |
Write the running configuration to the startup configuration file: The new password is now in the startup configuration. |
||
| Step 9 |
You must now reconfigure the device. If the system administrator has the backup device and VLAN configuration files available, |
Preventing Switch Stack Problems
- Make sure that the Device that you add to or remove from the switch stack are powered off. For all powering considerations in switch stacks, see the
“Switch Installation” chapter in the hardware installation guide. -
Press the Mode button on a stack member until the Stack mode LED is on. The last two port LEDs on the Device should be green. Depending on the Device model, the last two ports are either 10/100/1000 ports or small form-factor pluggable (SFP) module. If one or both of the
last two port LEDs are not green, the stack is not operating at full bandwidth. - We recommend using only one CLI session when managing the switch stack. Be careful when using multiple CLI sessions to the
active switch . Commands that you enter in one session are not displayed in the other sessions. Therefore, it is possible that you might
not be able to identify the session from which you entered a command. - Manually assigning stack member numbers according to the placement of the Device in the stack can make it easier to remotely troubleshoot the switch stack. However, you need to remember that the Device have manually assigned numbers if you add, remove, or rearrange Device later. Use the switch current-stack-member-number renumber new-stack-member-number global configuration command to manually assign a stack member number.
If you replace a stack member with an identical model, the new Device functions with the exact same configuration as the replaced Device. This is also assuming the new Device is using the same member number as the replaced Device.
Removing powered-on stack members causes the switch stack to divide (partition) into two or more switch stacks, each with
the same configuration. If you want the switch stacks to remain separate, change the IP address or addresses of the newly
created switch stacks. To recover from a partitioned switch stack, follow these steps:
-
Power off the newly created switch stacks.
-
Reconnect them to the original switch stack through their StackWise Plus ports.
-
Power on the Device.
For the commands that you can use to monitor the switch stack and its members, see the Displaying Switch Stack Information section.
Preventing Autonegotiation Mismatches
The IEEE 802.3ab autonegotiation protocol manages the device settings for speed (10 Mb/s, 100 Mb/s, and 1000 Mb/s, excluding
SFP module ports) and duplex (half or full). There are situations when this protocol can incorrectly align these settings,
reducing performance. A mismatch occurs under these circumstances:
-
A manually set speed or duplex parameter is different from the manually set speed or duplex parameter on the connected port.
-
A port is set to autonegotiate, and the connected port is set to full duplex with no autonegotiation.
To maximize the device performance and ensure a link, follow one of these guidelines when changing the settings for duplex
and speed:
-
Let both ports autonegotiate both speed and duplex.
-
Manually set the speed and duplex parameters for the ports on both ends of the connection.
Note |
If a remote device does not autonegotiate, configure the duplex settings on the two ports to match. The speed parameter can |
Troubleshooting SFP Module Security and Identification
Cisco small form-factor pluggable (SFP) modules have a serial EEPROM that contains the module serial number, the vendor name
and ID, a unique security code, and cyclic redundancy check (CRC). When an SFP module is inserted in the Device, the Device software reads the EEPROM to verify the serial number, vendor name and vendor ID, and recompute the security code and CRC.
If the serial number, the vendor name or vendor ID, the security code, or CRC is invalid, the software generates a security
error message and places the interface in an error-disabled state.
Note |
The security error message references the GBIC_SECURITY facility. The Device supports SFP modules and does not support GBIC modules. Although the error message text refers to GBIC interfaces and modules, |
If you are using a non-Cisco SFP module, remove the SFP module from the Device, and replace it with a Cisco module. After inserting a Cisco SFP module, use the errdisable recovery cause gbic-invalid global configuration command to verify the port status, and enter a time interval for recovering from the error-disabled
state. After the elapsed interval, the Device brings the interface out of the error-disabled state and retries the operation. For more information about the errdisable recovery command, see the command reference for this release.
If the module is identified as a Cisco SFP module, but the system is unable to read vendor-data information to verify its
accuracy, an SFP module error message is generated. In this case, you should remove and reinsert the SFP module. If it continues
to fail, the SFP module might be defective.
Monitoring SFP Module Status
You can check the physical or operational status of an SFP module by using the show interfaces transceiver privileged EXEC command. This command shows the operational status, such as the temperature and the current for an SFP
module on a specific interface and the alarm status. You can also use the command to check the speed and the duplex settings
on an SFP module. For more information, see the show interfaces transceiver command in the command reference for this release.
Executing Ping
If you attempt to ping a host in a different IP subnetwork, you must define a static route to the network or have IP routing
configured to route between those subnets.
IP routing is disabled by default on all Device.
Note |
Though other protocol keywords are available with the ping command, they are not supported in this release. |
Use this command to ping another device on the network from the Device:
|
Command |
Purpose |
|---|---|
|
ping ip |
Pings a remote host through IP or by supplying the hostname or network address. |
Monitoring Temperature
The Device monitors the temperature conditions and uses the temperature information to control the fans.
Use the show env temperature status
privileged EXEC command to display the temperature value, state, and thresholds. The temperature value is the temperature
in the Device (not the external temperature).You can configure only the yellow threshold level (in Celsius) by using the system env temperature threshold yellow
value global configuration command to set the difference between the yellow and red thresholds. You cannot configure the green
or red thresholds. For more information, see the command reference for this release.
Monitoring the Physical Path
You can monitor the physical path that a packet takes from a source device to a destination device by using one of these privileged
EXEC commands:
| Command | Purpose |
|---|---|
|
tracetroute mac [interface |
Displays the Layer 2 path taken by the packets from the specified source MAC address to the specified destination MAC address. |
|
tracetroute mac ip {source-ip-address | source-hostname}{destination-ip-address | destination-hostname} [detail] |
Displays the Layer 2 path taken by the packets from the specified source IP address or hostname to the specified destination |
Executing IP Traceroute
Note |
Though other protocol keywords are available with the traceroute privileged EXEC command, they are not supported in this release. |
|
Command |
Purpose |
|---|---|
|
traceroute ip |
Traces the path that packets take through the network. |
Redirecting Debug and Error Message Output
By default, the network server sends the output from debug commands and system error messages to the console. If you use this default, you can use a virtual terminal connection to
monitor debug output instead of connecting to the console port or the Ethernet management port.
Possible destinations include the console, virtual terminals, internal buffer, and UNIX hosts running a syslog server. The
syslog format is compatible with 4.3 Berkeley Standard Distribution (BSD) UNIX and its derivatives.
Note |
Be aware that the debugging destination you use affects system overhead. When you log messages to the console, very high overhead For more information about system message logging, see Configuring System Message Logging. |
Using the show platform forward Command
The output from the show platform forward privileged EXEC command provides some useful information about the forwarding results if a packet entering an interface is
sent through the system. Depending upon the parameters entered about the packet, the output provides lookup table results
and port maps used to calculate forwarding destinations, bitmaps, and egress information.
Most of the information in the output from the command is useful mainly for technical support personnel, who have access to
detailed information about the Device application-specific integrated circuits (ASICs). However, packet forwarding information can also be helpful in troubleshooting.
Using the show debug command
The show debug command is entered in privileged EXEC mode. This command displays all debug options available on the switch.
To view all conditional debug options run the command show debug condition The commands can be listed by selecting either a condition identifier <1-1000> or all conditions.
To disable debugging, use the no debug all command.
Caution |
Because debugging output is assigned high priority in the CPU process, it can render the system unusable. For this reason, |
Configuring OBFL
Caution |
We recommend that you do not disable OBFL and that you do not remove the data stored in the flash memory. |
-
To enable OBFL, use the hw-switch switch [switch-number] logging onboard [message ] global configuration command. On switches, the range for switch-number is from 1 to 9.
-
To copy the OBFL data to the local network or a specific file system, use the copy logging onboard switch
switch-number url url-destination privileged EXEC command. -
To disable OBFL, use the no hw-switch switch [switch-number] logging onboard [message] global configuration command.
-
To clear all the OBFL data in the flash memory except for the uptime and CLI command information, use the clear logging onboard switch switch-number privileged EXEC command.
To clear all the OBFL data in the flash memory except for the uptime, use the clear logging onboard RP active {application } privileged EXEC command.
Verifying Troubleshooting of the Software Configuration
Displaying OBFL Information
|
Command |
Purpose |
|---|---|
|
show onboard switch |
Displays the OBFL CLI commands that were entered on a standalone switch or the specified stack members. |
|
show onboard switch |
Displays the UDI information for a standalone switch or the specified stack members and for all the connected FRU devices: |
|
show onboard switch |
Displays the hardware-related messages generated by a standalone switch or the specified stack members. |
|
show onboard switch |
Displays the counter information on a standalone switch or the specified stack members. |
|
show onboard switch |
Displays the temperature of a standalone switch or the specified switch stack members. |
|
show onboard switch |
Displays the time when a standalone switch or the specified stack members start, the reason the standalone switch or specified |
|
show onboard switch |
Displays the system voltages of a standalone switch or the specified stack members. |
|
show onboard switch |
Displays the status of a standalone switch or the specified stack members. |
Example: Verifying the Problem and Cause for High CPU Utilization
To determine if high CPU utilization is a problem, enter the show processes cpu sorted privileged EXEC command. Note the underlined information in the first line of the output example.
Device# show processes cpu sorted
CPU utilization for five seconds: 8%/0%; one minute: 7%; five minutes: 8%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
309 42289103 752750 56180 1.75% 1.20% 1.22% 0 RIP Timers
140 8820183 4942081 1784 0.63% 0.37% 0.30% 0 HRPC qos request
100 3427318 16150534 212 0.47% 0.14% 0.11% 0 HRPC pm-counters
192 3093252 14081112 219 0.31% 0.14% 0.11% 0 Spanning Tree
143 8 37 216 0.15% 0.01% 0.00% 0 Exec
...
<output truncated>
This example shows normal CPU utilization. The output shows that utilization for the last 5 seconds is 8%/0%, which has this
meaning:
-
The total CPU utilization is 8 percent, including both time running Cisco IOS processes and time spent handling interrupts.
-
The time spent handling interrupts is zero percent.
|
Type of Problem |
Cause |
Corrective Action |
|---|---|---|
|
Interrupt percentage value is almost as high as total CPU utilization value. |
The CPU is receiving too many packets from the network. |
Determine the source of the network packet. Stop the flow, or change the switch configuration. |
|
Total CPU utilization is greater than 50% with minimal time spent on interrupts. |
One or more Cisco IOS process is consuming too much CPU time. This is usually triggered by an event that activated the process. |
Identify the unusual event, and troubleshoot the root cause. |
Scenarios for Troubleshooting the Software Configuration
Scenarios to Troubleshoot Power over Ethernet (PoE)
|
Symptom or Problem |
Possible Cause and Solution |
||||
|---|---|---|---|---|---|
|
Only one port does not have PoE. Trouble is on only one switch port. PoE and non-PoE devices do not work on this port, but do on other ports. |
Verify that the powered device works on another PoE port. Use the show run , or show interface status user EXEC commands to verify that the port is not shut down or error-disabled.
Verify that power inline never is not configured on that interface or port. Verify that the Ethernet cable from the powered device to the switch port is good: Connect a known good non-PoE Ethernet device
Verify that the total cable length from the switch front panel to the powered device is not more than 100 meters. Disconnect the Ethernet cable from the switch port. Use a short Ethernet cable to connect a known good Ethernet device directly If a powered device does not power on when connected with a patch cord to the switch port, compare the total number of connected |
||||
|
No PoE on all ports or a group of ports. Trouble is on all switch ports. Nonpowered Ethernet devices cannot establish an Ethernet link on any port, and PoE devices |
If there is a continuous, intermittent, or reoccurring alarm related to power, replace the power supply if possible it is If the problem is on a consecutive group of ports but not all ports, the power supply is probably not defective, and the problem Use the show log privileged EXEC command to review alarms or system messages that previously reported PoE conditions or status changes. If there are no alarms, use the show interface status command to verify that the ports are not shut down or error-disabled. If ports are error-disabled, use the shut and no shut interface configuration commands to reenable the ports. Use the show env power and show power inline privileged EXEC commands to review the PoE status and power budget (available PoE). Review the running configuration to verify that power inline never is not configured on the ports. Connect a nonpowered Ethernet device directly to a switch port. Use only a short patch cord. Do not use the existing distribution Disconnect all but one of the Ethernet cables from switch ports. Using a short patch cord, connect a powered device to only Use the show power inline privileged EXEC command to verify that the powered device can receive power when the port is not shut down. Alternatively, If a powered device can power on when only one powered device is connected to the switch, enter the shut and no shut interface configuration commands on the remaining ports, and then reconnect the Ethernet cables one at a time to the switch If there is still no PoE at any port, a fuse might be open in the PoE section of the power supply. This normally produces |
||||
|
Cisco pre-standard powered device disconnects or resets. After working normally, a Cisco phone or wireless access point intermittently reloads or disconnects from PoE. |
Verify all electrical connections from the switch to the powered device. Any unreliable connection results in power interruptions Verify that the cable length is not more than 100 meters from the switch port to the powered device. Notice what changes in the electrical environment at the switch location or what happens at the powered device when the disconnect Notice whether any error messages appear at the same time a disconnect occurs. Use the show log privileged EXEC command to review error messages. Verify that an IP phone is not losing access to the Call Manager immediately before the reload occurs. (It might be a network Replace the powered device with a non-PoE device, and verify that the device works correctly. If a non-PoE device has link |
||||
|
IEEE 802.3af-compliant or IEEE 802.3at-compliant powered devices do not work on Cisco PoE switch. A non-Cisco powered device is connected to a Cisco PoE switch, but never powers on or powers on and then quickly powers off. |
Use the show power inline command to verify that the switch power budget (available PoE) is not depleted before or after the powered device is connected. Use the show interface status command to verify that the switch detects the connected powered device. Use the show log command to review system messages that reported an overcurrent condition on the port. Identify the symptom precisely: Does |
Configuration Examples for Troubleshooting Software
Example: Pinging an IP Host
This example shows how to ping an IP host:
Device# ping 172.20.52.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echoes to 172.20.52.3, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/2/4 ms
Device#
|
Character |
Description |
|---|---|
|
! |
Each exclamation point means receipt of a reply. |
|
. |
Each period means the network server timed out while waiting for a reply. |
|
U |
A destination unreachable error PDU was received. |
|
C |
A congestion experienced packet was received. |
|
I |
User interrupted test. |
|
? |
Unknown packet type. |
|
& |
Packet lifetime exceeded. |
To end a ping session, enter the escape sequence (Ctrl-^ X by default). Simultaneously press and release the Ctrl, Shift, and 6 keys and then press the X key.
Example: Performing a Traceroute to an IP Host
This example shows how to perform a traceroute to an IP host:
Device# traceroute ip 192.0.2.10
Type escape sequence to abort.
Tracing the route to 192.0.2.10
1 192.0.2.1 0 msec 0 msec 4 msec
2 192.0.2.203 12 msec 8 msec 0 msec
3 192.0.2.100 4 msec 0 msec 0 msec
4 192.0.2.10 0 msec 4 msec 0 msec
The display shows the hop count, the IP address of the router, and the round-trip time in milliseconds for each of the three
probes that are sent.
|
Character |
Description |
|---|---|
|
* |
The probe timed out. |
|
? |
Unknown packet type. |
|
A |
Administratively unreachable. Usually, this output means that an access list is blocking traffic. |
|
H |
Host unreachable. |
|
N |
Network unreachable. |
|
P |
Protocol unreachable. |
|
Q |
Source quench. |
|
U |
Port unreachable. |
To end a trace in progress, enter the escape sequence (Ctrl-^ X by default). Simultaneously press and release the Ctrl, Shift, and 6 keys and then press the X key.
Feature History and Information for Troubleshooting Software Configuration
|
Release |
Modification |
|---|---|
|
Cisco IOS XE Everest 16.5.1a |
This feature was introduced. |
Copy startup config running config – одна из самых часто используемых команд в сетевых устройствах. Она позволяет копировать текущую конфигурацию (running config) в постоянную конфигурацию (startup config) устройства. Однако, иногда возникают ситуации, когда данная команда не работает. В этой статье мы рассмотрим несколько возможных причин и способов исправления этой проблемы.
Одной из самых распространенных причин неработоспособности команды Copy startup config running config является недостаток привилегий доступа. У некоторых пользователей не хватает прав на выполнение этой команды. В таком случае, следует убедиться, что пользователь имеет достаточные привилегии для выполнения данной операции.
Еще одной возможной причиной может быть конфигурационный файл, который защищен от записи. Если файл startup config защищен от записи, то команда Copy startup config running config не будет работать. В таком случае, следует проверить права доступа к файлу и изменить их, если необходимо.
Также, стоит учесть, что команда Copy startup config running config может быть недоступна для выполнения в определенных режимах работы устройства. Некоторые устройства требуют переключения в специальный режим для выполнения данной команды. В таком случае, необходимо узнать требования и особенности работы устройства и корректно настроить его для выполнения данной операции.
Содержание
- Причины неработоспособности команды Copy startup config running config
- Ошибки в синтаксисе команды
- Отсутствие прав доступа
Причины неработоспособности команды Copy startup config running config
Команда Copy startup config running config используется для копирования настройки запуска (startup config) на текущую конфигурацию (running config) на сетевых устройствах. Однако, в некоторых случаях эта команда может не работать по нескольким причинам.
Первая причина может заключаться в ограничениях доступа. Если пользователь, запускающий команду Copy startup config running config, не имеет необходимых прав доступа, то команда может не выполняться. В таком случае, необходимо проверить права доступа пользователя и убедиться, что он имеет достаточные привилегии для выполнения данной команды.
Вторая причина связана с наличием ошибок в конфигурации запуска. Если файл запуска (startup config) содержит ошибки или некорректные настройки, то команда Copy startup config running config может не работать. В таком случае, необходимо внимательно просмотреть содержимое файла запуска и исправить все ошибки перед копированием на текущую конфигурацию.
Третья причина может быть связана с техническими проблемами. Некорректное функционирование оборудования или программного обеспечения, такое как неисправности в сетевом соединении или ошибки в операционной системе, могут привести к неработоспособности команды Copy startup config running config. В таких случаях, необходимо провести дополнительную диагностику и исправить технические проблемы, прежде чем повторно выполнить команду.
И наконец, причиной не работоспособности команды также может быть неправильное использование самой команды. Некорректный синтаксис, опечатки или неправильно указанные параметры могут предотвратить правильное выполнение команды. В таком случае, необходимо внимательно проверить правильность написания команды и убедиться, что все необходимые параметры указаны верно.
| Причины неработоспособности |
|---|
| Ограничения доступа |
| Ошибки в конфигурации запуска |
| Технические проблемы |
| Неправильное использование команды |
Ошибки в синтаксисе команды
Команда Copy startup config running config может не работать из-за ошибок в синтаксисе. Вот некоторые распространенные ошибки, которые могут возникнуть:
- Неправильный порядок ключевых слов: команда должна быть записана в следующем порядке: «copy startup-config running-config».
- Отсутствие пробелов или наличие лишних пробелов: важно правильно разделить каждое ключевое слово пробелами.
- Ошибки в написании ключевых слов: ключевые слова должны быть написаны без опечаток и в правильном регистре.
Если вы обнаружите ошибку в синтаксисе команды, попробуйте исправить ее в соответствии с приведенными выше рекомендациями и повторите команду. Если ошибка не исчезает, возможно, вам потребуется проверить, правильно ли настроены операционная система или оборудование.
Отсутствие прав доступа
Перед выполнением данной команды необходимо убедиться, что пользователь имеет достаточные привилегии для чтения конфигурации. Если пользователь не обладает правами администратора или не имеет доступа к файлам конфигурации, то выполнение данной команды будет невозможно.
Чтобы исправить эту проблему, необходимо либо получить необходимые права доступа, либо обратиться к администратору сети или администратору устройства с просьбой предоставить доступ.
Также возможно, что файлы конфигурации на устройстве защищены от записи или чтения другими пользователями или группами. В данном случае, пользователь должен быть добавлен в соответствующую группу или быть назначенным владельцем этих файлов.
Sorry, you have been blocked
This website is using a security service to protect itself from online attacks. The action you just performed triggered the security solution. There are several actions that could trigger this block including submitting a certain word or phrase, a SQL command or malformed data.
What can I do to resolve this?
You can email the site owner to let them know you were blocked. Please include what you were doing when this page came up and the Cloudflare Ray ID found at the bottom of this page.
Cloudflare Ray ID: 71a8e243c86f9013 • Your IP : 82.102.23.104 • Performance & security by Cloudflare
Настройка исходных параметров маршрутизатора. Лабораторная работа 10 4 по курсу Введение в сетевые технологии
А,б,в 
Подключил PCA к R1

Шаг 2. Войдите в привилегированный режим и проверьте текущую конфигурацию.

Вошел привилегированный режим, и ввёл команду show running-config.
Вопросы:
Как называется узел маршрутизатора?
Сколько у маршрутизатора интерфейсов Fast Ethernet?
Сколько у маршрутизатора интерфейсов Gigabit Ethernet?
Сколько у маршрутизатора последовательных интерфейсов?
Каков диапазон значений, отображаемых в vty-линиях?

Почему маршрутизатор отвечает сообщением startup-config is not present (startup-config отсутствует)?
Потому что еще не загрузил в конфиг данные.
Часть 2. Настройка и проверка начальной конфигурации маршрутизатора
Шаг 1. Настройте начальные параметры на маршрутизаторе R1.

Настроил имя хоста и баннер мотд.
В) 
Настроил пароли для режима exec с шифрованием и без, для консольного режима.
Шаг 2: Проверьте начальные параметры на R1.
Б) 
В) 
Нажал enter появилось данное сообщение.
Зачем на всех маршрутизаторах должен быть баннер с сообщением текущего дня (MOTD)?
Он используется для юридического уведомления, на всех подключенных девайсах.
Если вам не предлагается ввести пароль до того, как вы получите приглашение пользователя EXEC, какую команду консоли вы забыли настроить?
Команды enable password и enable secret.
Г) 
Ввел пароли для доступа к режиму EXEC
Почему пароль enable secret позволяет перейти в привилегированный режим EXEC, а пароль enable password больше не действителен?
Команда enable password менее безопасна, чем enable secret, поэтому enable password не востребован.
Если установить на маршрутизаторе другие пароли, они будут храниться в файле конфигурации в открытом или зашифрованном виде? Объясните.
Если установить enable secret, он хранится в зашифрованном виде, а для других паролей необходимо задать команду service password-encryption, и тогда они будут храниться в зашифрованном виде.
Часть 3: Сохранение выполняемого файла конфигурации
Шаг 1: Сохранение файла конфигурации в NVRAM.
а) 
Сделал резервное копирование данных из running-config в startup-config.
Какую команду нужно ввести, чтобы сохранить конфигурацию в NVRAM?
После настройки коммутатора рекомендуется сохранять его текущую конфигурацию. Информация помещается в энергонезависимую память и хранится там столько, сколько нужно. При необходимости все настройки могу быть восстановлены или сброшены.
copy running-config startup-config – команда для сохранения конфигурации
copy startup-config running-config – команда для загрузки конфигурации
Пример выполнения команды:
Switch#copy running-config startup-config Building configuration. [OK] Switch#
В данном примере текущая конфигурация коммутатора была сохранена в энергонезависимую память.
Команда «Show»
Show(англ. — показывать) – одна из наиболее важных команд, использующихся при настройке коммутаторов. Она применяется для просмотра информации любого рода и применяется практически во всех контекстах. Эта команда имеет больше всех параметров.
Здесь будут рассмотрены только те параметры, которые требуются в рамках данного курса. Другие параметры студент может изучить самостоятельно.
Параметр «running-config» команды «Show»
Для просмотра текущей работающей конфигурации коммутатора используется данная команда.
Пример выполнения команды:
Switch#show running-config ! version 12.1 ! hostname Switch …
На экран выводится текущие настройки коммутатора.
Параметр «startup-config» команды «Show»
Для просмотра сохраненной конфигурации используется данная команда.
Пример выполнения команды:
Switch #show startup-config startup-config is not present Switch #
Если энергонезависим память не содержит информации, тогда коммутатор выдаст сообщение о том, что конфигурация не была сохранена.
KB ID 0000987
Problem
I love GNS3, it is a brilliant piece of software, I use it for bench testing and proof of concept work. Yes is can be a bit clunky sometimes, but it’s FREE! I had a project open with about four ASA’s on it, and it would not save the config on just one of them.
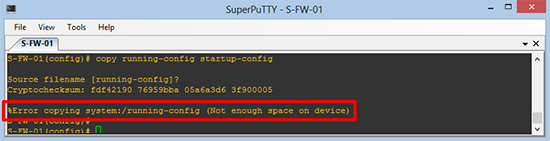
HostName(config)# copy running-config startup-config
Source filename [running-config]?
Cryptochecksum: fdf42190 76959bba 05a6a3d6 3f900005
%Error copying system:/running-config (Not enough space on device)
HostName(config)#
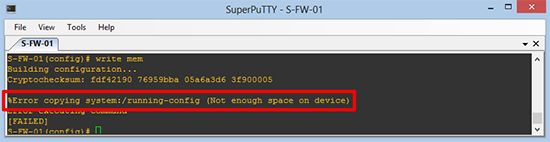
HostName(config)# write mem
Building configuration...
Cryptochecksum: fdf42190 76959bba 05a6a3d6 3f900005
%Error copying system:/running-config (Not enough space on device)
Error executing command
[FAILED]
HostName(config)#
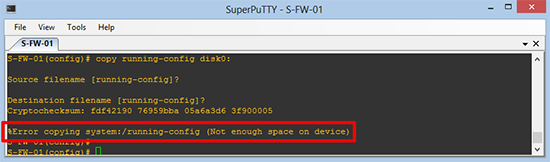
HostName(config)# copy running-config disk0:
Source filename [running-config]?
Destination filename [running-config]?
Cryptochecksum: fdf42190 76959bba 05a6a3d6 3f900005
%Error copying system:/running-config (Not enough space on device)
HostName(config)#
Solution
At first I simply deleted the ASA and added a new one, which annoyingly did the same. Then I read a post that said, do the following;
1. Open the configuration for the affected ASA.
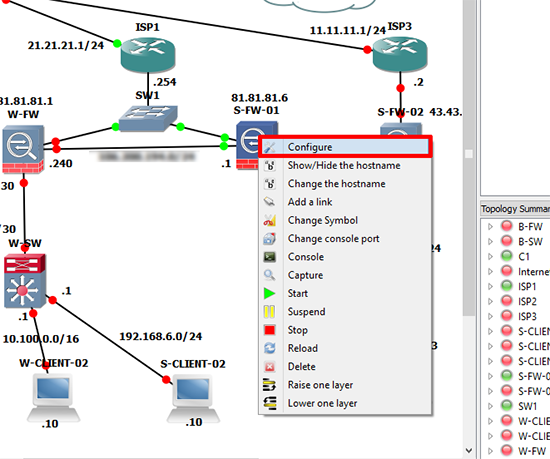
2. Change the NIC Model to pcnet > Apply > OK > Stop the firewall > Start the Firewall.
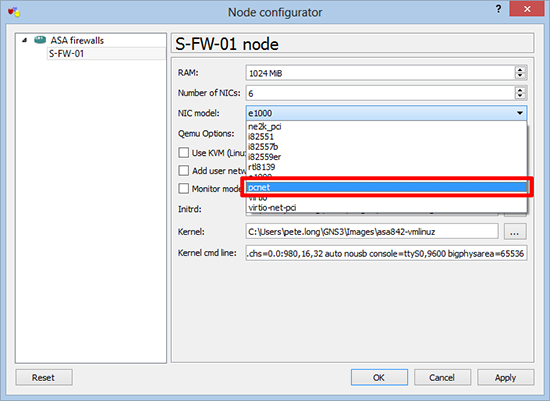
HOWEVER, in my case the problem persisted, I eventually fixed it by formatting the virtual ASA’s flash drive.
3. Execute the following command;
HostName# format flash Format operation may take a while. Continue? [confirm] Format operation will destroy all data in "flash:". Continue? [confirm]{Enter} Initializing partition - hda: hda1 done! mkdosfs 2.11 (12 Mar 2005) System tables written to disk Format of disk0 complete HostName#
4. Power off, then power on the firewall, problem fixed.
Related Articles, References, Credits, or External Links
NA