I am using following query to bulk insert from one table to another.
INSERT INTO billitems SELECT * FROM billitems_old;
I want that if insert fails on any row, it must skip that row and proceed. Is there anything that I can include in the above query to skip errors.
asked Nov 21, 2009 at 9:43
![]()
insert ignore into billitems select * from billitems_old;
reference: insert
answered Nov 21, 2009 at 9:47
![]()
shylentshylent
10.1k6 gold badges38 silver badges55 bronze badges
5
From the online documentation:
If you use the IGNORE keyword, errors
that occur while executing the INSERT
statement are treated as warnings
instead.
So try:
INSERT IGNORE INTO billitems SELECT * FROM billitems_old
answered Nov 21, 2009 at 9:48
![]()
AndomarAndomar
233k49 gold badges382 silver badges405 bronze badges
I have to insert a good amount of log records every hour in a table and I would not care about Integrity Errors or Violations that happen in the process.
If I disable autoCommit and do a bulk insert, cursor wont insert anything beyond the row where the transaction failed. Is there a way around this one ?
One hack is to handle this at the application level.
I could implement a n-sized buffer and do bulk inserts. If something failed in that transaction, recursively repeat the insert for buffer_first_half + buffer_second_half
def insert(buffer):
try:
bulk_insert(buffer)
except:
connection.rollback()
marker = len(buffer)/2
insert(buffer[:marker])
insert(buffer[marker:])
But I really hope if it could be achieved using any Postgres’ built-in ?
asked Jan 11, 2014 at 1:46
![]()
meson10meson10
1,93414 silver badges21 bronze badges
5
PostgreSQL doesn’t provide anything built-in for this. You can use SAVEPOINTs, but they’re not much better than individual transactions.
Treat each insert as an individual transaction and work on making those tx’s faster:
SET synchronous_commit = offin your sessionINSERTinto anUNLOGGEDtable, thenINSERT INTO ... SELECTthe results into the real table after checking
Here’s an earlier closely related answer which also links to more information. I haven’t marked this as a duplicate because the other one is specific to upsert-like data loading, you’re interested in more general error handling.
![]()
answered Jan 11, 2014 at 3:10
![]()
Craig RingerCraig Ringer
308k77 gold badges690 silver badges779 bronze badges
2
In the first part of reviewing the basics of bulk insert, we looked at importing entire files, specifying delimiters for rows and columns, and bypassing error messages. Sometimes we’ll want to skip first and ending lines, log errors and bad records for review after inserting data, and work with data types directly without first importing using a varchar and converting to the data type later. In this part, we look at these techniques using T-SQL’s native bulk insert.
Skipping Lines and Working With Data Types
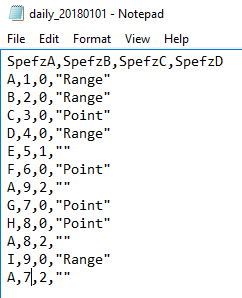
With many imports, the first row of data in the file will specify the columns of the file. We do not necessarily have to keep the column names when we use bulk insert to insert the data, but we should be careful about inserting data into a specific format, if we also insert the first row that doesn’t match that format. For an example of this, in the below code that creates the table and the below image of the file, we see that the first line of data from the file has values like SpefzA, SpefzB, SpefzC, SpefzD which don’t match the table’s data type (except in 2 cases). We also see that other values in the file don’t match those data either – for instance, the 0 or 1 of SpefzC looks like a bit and not a varchar. The file’s first line in this case tells us about the data in the 2nd row through the end of the file, so when we insert the data from the file, we’ll want to skip the first row.
|
CREATE TABLE etlImport5( VarcharSpefzTen VARCHAR(10), IntSpefz INT, BitSpefz BIT, VarcharSpefzMax VARCHAR(MAX) ) |
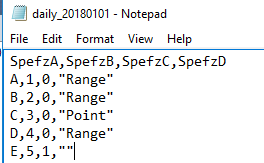
The first line in our file we want to exclude as it won’t match the above format of our table.
In the below bulk insert, we specify the file, comma as the column terminator (called FIELDTERMINATOR), and a new line character as the row terminator. We also add another option – the first row we specify as 2 (the default is the start of the file – row 1). This will skip the first line that we see in the above image and start where the A,1,0,”Range” line is. After our insert, we check our table with a select and see the data without the first row from the file.
|
BULK INSERT etlImport5 FROM ‘C:\ETL\Files\Read\Bulk\daily_20180101.txt’ WITH ( FIELDTERMINATOR = ‘,’, ROWTERMINATOR = ‘\n’, FIRSTROW = 2 ) SELECT * FROM etlImport5 |
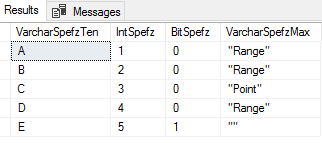
Our bulk insert skipped the first line, which was only specifying the columns in the file.
In some cases, files have first rows simply specify what we’ll find in the file and we can skip this row by starting on row 2 (or if there are several rows to skip, we can start on the row 3, 4, etc). In rarer cases, we may come across files that have an ending line that doesn’t match the format at all. Sometimes these have a sentence with a statement about the end of the file, or in some cases, they may have a line that says something to the effect of “File created at 2018-01-01 at 12 AM.” Since these don’t match the file format at all, they would normally throw an error, but like we can specify the first row of a file, we can specify the last row of a file.
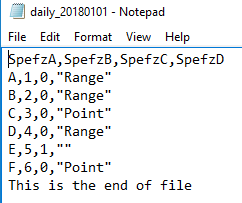
We add two lines – one that matches the format and the last line that is a sentence.
In our file, we’ll add two lines – one of the lines matches our current format with three commas separating data types that match our created table. The last line is a sentence with no delimiters and that doesn’t match our format. In the below code, well empty our table by truncating it and try to bulk insert our updated file without specifying and ending row and seeing the error. After that, we’ll bulk insert the file, but this time specifying that row 7 is the last row of data we want to insert (the bad row is on row 8).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
TRUNCATE TABLE etlImport5 — Fails on last line BULK INSERT etlImport5 FROM ‘C:\ETL\Files\Read\Bulk\daily_20180101.txt’ WITH ( FIELDTERMINATOR = ‘,’, ROWTERMINATOR = ‘\n’, FIRSTROW = 2 ) — Passes BULK INSERT etlImport5 FROM ‘C:\ETL\Files\Read\Bulk\daily_20180101.txt’ WITH ( FIELDTERMINATOR = ‘,’, ROWTERMINATOR = ‘\n’, FIRSTROW = 2, LASTROW = 7 ) SELECT * FROM etlImport5 |

Our first bulk insert fails because the ending line doesn’t match our format.
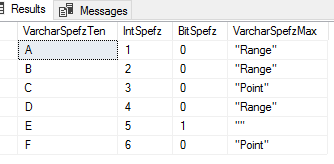
When we specify the last line of 7, which is the last line that matches our file’s format, the bulk insert passes.
While we won’t see ending lines like the above ending line above this, it’s useful to know that bulk insert can insert a range of data in a file, making leaving out an ending line number easy.
As we looked at in the first part of this series, sometimes we will have data that don’t match our table’s format, even if the number of delimiters is present and we can specify a maximum error amount to allow the insert to continue happening, even if some lines don’t get added to our table. This might be easy when it’s one or two lines, but if we have a large file and we want to see a log of all the errors? In our example file, we’ll add some bad data to our file along with good data and test logging these erroneous rows of data.
We add three lines of bad data that we’ll be logging to review.
|
TRUNCATE TABLE etlImport5 BULK INSERT etlImport5 FROM ‘C:\ETL\Files\Read\Bulk\daily_20180101.txt’ WITH ( FIELDTERMINATOR = ‘,’, ROWTERMINATOR = ‘\n’, FIRSTROW = 2, MAXERRORS = 100, ERRORFILE = ‘C:\ETL\Files\Read\Bulk\daily_20180101_log’ ) SELECT * FROM etlImport5 |

We see the three error messages from the three bad rows of data.
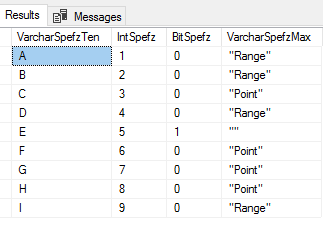
We still have the correct data inserted even with the errors.
Because we’ve allowed up to 100 errors and we only experienced 3 errors, bulk insert continued to insert data and we see the 9 rows of good data, even with the error message about the 3 bad records. We also specified an error file and when we look at our file location, we see two additionally created files – daily_20180101_log and daily_20180101_log.Error. The below images show these files in the directory and their contents (I opened these files in Notepad).
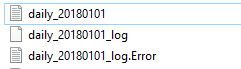
Two error files appear after bulk insert passes with three errors.
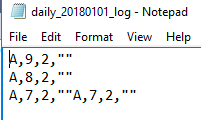
We see the error records with the latter one appearing due to end of file reasons.
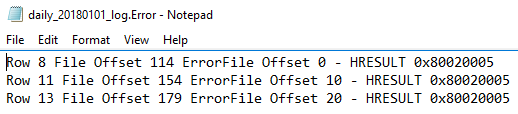
We see the three error row numbers that were experienced during the bulk insert with details.
The general log file shows us the erroneous rows with the latter erroneous row appearing due to end of file reasons (if you add a row with the data J,10,0,”Range” and retest, you’ll only get three error rows because the last row of data is legitimate)The .Error file specifies the erroneous rows of data, in this example rows 8, 11 and 13 and gives us the type of problem with these rows of data as they relate to the table – HRESULT 0x80020005 – which indicates a type mismatch. When we review the file and table, we see that the type expected was a bit, but these values are a 2 and a bit can only be a 1 or 0. From a debugging perspective, this can save us a lot of time, as our data context may allow us to bypass some erroneous rows that we can quickly review along with seeing where they occurred in the file. It is worth noting here that in order to use the error file, the user executing this will need write ability to the file location, or another file location.
More important than understanding how to allow and log errors is recognizing when these are appropriate for our data context. As an example, if we’re testing a data set for validity, use or other purposes, we want the data even if it has some errors as we’re in the process of testing it. This is also true for other business use-cases where we may accept some bad data, if most of the data can be validated (for instance, manual data entry is error-prone, so with data types like this, we will expect a percent of data to be erroneous). On the other hand, there may be contexts where one or two erroneous rows will invalidate a data set and, in these situations, we can use the default option of zero maximum errors (no need to specify the parameter) and avoid logging them.
Summary
We’ve reviewed using bulk insert’s first and last row feature, which can be helpful when we have delimited files that have headers which map out the data, but which we don’t want to import due to being incompatible with our data structure. We’ve also seen how we can use error file parameter along with maximum errors to quickly review what failed with the bulk insert as well as where these failures exist in our file. Finally, we reviewed some thoughts about where the best context for this may be.
Table of contents
- Author
- Recent Posts

Tim manages hundreds of SQL Server and MongoDB instances, and focuses primarily on designing the appropriate architecture for the business model.
He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users’ Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
I get a CSV file with a several million records every few days. I need to insert them into our database. What I do is quite straightforward:
BULK INSERT dbo.activity
FROM 'C:\tmp\activity.csv'
WITH (
FIRSTROW = 2,
FIELDTERMINATOR = '|',
ROWTERMINATOR = '0x0a',
BATCHSIZE = 1000,
MAXERRORS = 2
)
GO
This works well. However, it may be the case that I get some duplicated records. When I run the import I, as expected, get the error:
Violation of PRIMARY KEY constraint 'PK__id__790FF7A****'. Cannot insert duplicate key in object 'dbo.activity'. The duplicate key value is (1234)
This gets quite cumbersome when instead of one duplicated record I have hundreds. Is there any way to tell BULK INSERT to ignore (or log) those errors and carry on with the good records? I am thinking about something like:
BEGIN TRY:
BULK INSERT dbo.activity
FROM 'C:\tmp\activity.csv'
WITH (options....)
END TRY
BEGIN CATCH:
SELECT
ERROR_NUMBER() AS ErrorNumber
,ERROR_MESSAGE() AS ErrorMessage;
-- I know this line wrong. It is just what I would like to do
CONTINUE;
END CATCH
Thanks!
October 27, 2010 at 1:10 am
#230375
HI — I have a table in below format.
create table family(id int, name varchar(100))
go
I have a text file(‘C:\family.txt’) with below data which.
1Husband
2Wife0
hikid
Column delimiter is ‘Tab’. My requirement is to insert the file data ignoring the error row and insert it to error file. I ran below command
BULK INSERT family
from ‘C:\family.txt’
with(ERRORFILE = ‘c:\error.txt’,MAXERRORS = 0 )
However, It has given below error without inserting valid 2 records to table
.Net SqlClient Data Provider: Msg 4864, Level 16, State 1, Line 1
Bulk load data conversion error (type mismatch or invalid character for the specified codepage) for row 3, column 1 (id).
.Net SqlClient Data Provider: Msg 7399, Level 16, State 1, Line 1
The OLE DB provider «BULK» for linked server «(null)» reported an error. The provider did not give any information about the error.
.Net SqlClient Data Provider: Msg 7330, Level 16, State 2, Line 1
Cannot fetch a row from OLE DB provider «BULK» for linked server «(null)».
Is there any way that I can insert valid records even there are invalid records exist in a file.
thanks
erajendar
spaghettidba
SSC Guru
Points: 105732
You specified MAXERRORS = 0, so you don’t allow errors during import.
BOL states:
MAXERRORS = max_errors
Specifies the maximum number of syntax errors allowed in the data before the bulk-import operation is canceled. Each row that cannot be imported by the bulk-import operation is ignored and counted as one error. If max_errors is not specified, the default is 10.
Raise your MAXERRORS and everything should work fine.
— Gianluca Sartori