В этой статье я поделюсь методикой измерения точности прогноза продаж, которая применяется во многих западных компаниях и позволяет достаточно объективно оценить качество прогнозирования. В частности, данные показатели используются компанией Reckitt Benckiser, в которой я имел честь работать почти 6 лет.
Очевидно, что повышение точности прогнозирования и уменьшение ошибки прогноза улучшают многие бизнес-показатели цепи поставок, начиная от сервиса клиентов и уровня запасов, заканчивая более стабильной работой производства и более предсказуемой закупочной деятельностью. Это особенно актуально в условиях кризиса, когда эффективность становится, пожалуй, основным конкурентным преимуществом.
Именно поэтому описанные ниже показатели можно использовать как KPI функции Demand Planning так и KPI сотрудников, которые отвечают за подготовку прогноза продаж.
Так что же такое MAD, Bias и MAPE?
Bias (англ. – смещение) демонстрирует на сколько и в какую сторону прогноз продаж отклоняется от фактической потребности. Этот индикатор показывает, был ли прогноз оптимистичным или пессимистичным. То есть, отрицательное значение Bias говорит о том, что прогноз был завышен (реальная потребность оказалась ниже), и, наоборот, положительное значение о том, что прогноз был занижен. Цифровое значение показателя определяет величину отклонения (смещения).
MAD (Mean Absolute Deviation) – среднее абсолютное отклонение
MAD = ∑ |Et| / n, где:
|Et| — ошибка прогноза продаж за определенный период времени t
n – количество периодов оценки
Это показатель можно также выразить в процентах:
MAPE (Mean Absolute Percentage Error)
MARE = ∑ |Et| / At /n * 100% , где:
|Et| — ошибка прогноза продаж за период времени t
n – количество периодов оценки
At – фактическая потребность за период времени t
Пример расчета MAD:
|
Месяц |
Фактические продажи |
Прогноз |
Абсолютная ошибка |
|
1 |
310 |
290 |
20 |
|
2 |
300 |
310 |
10 |
|
3 |
290 |
300 |
10 |
|
4 |
260 |
280 |
20 |
|
5 |
275 |
280 |
5 |
|
65 |
MAD = 65/5 = 13
Пример расчета MAD, BIAS и MAPE.
|
Период |
Факт |
Прогноз |
Е |
|E| |
|E| / A |
|
1 |
4650 |
4800 |
-150 |
150 |
0,0323 |
|
2 |
4900 |
4700 |
200 |
200 |
0,0408 |
|
3 |
5100 |
5000 |
100 |
100 |
0,0196 |
|
4 |
4200 |
5000 |
-800 |
800 |
0,1905 |
|
5 |
4500 |
4400 |
100 |
100 |
0,0222 |
|
6 |
3900 |
4200 |
-300 |
300 |
0,0769 |
|
7 |
3300 |
3800 |
-500 |
500 |
0,1515 |
|
8 |
3600 |
3600 |
0 |
0 |
0,0000 |
|
9 |
3900 |
3800 |
100 |
100 |
0,0256 |
|
10 |
4100 |
4000 |
100 |
100 |
0,0244 |
|
42150 |
43300 |
-1150 |
2350 |
0,5839 |
|
|
BIAS = |
-115 |
||||
|
MAD = |
235 |
||||
|
MAPE = |
5,84% |
||||
Эти показатели можно использовать также и по группе SKU, чтобы оценить точность прогноза продаж группы за период времени. В таком случае, мы берем один период времени, например, месяц и считаем MAD и BIAS для каждого SKU:
|
SKU |
Факт |
Прогноз |
Е |
|E| |
|E| / A |
|
SKU 1 |
3000 |
3200 |
-200 |
200 |
0,0667 |
|
SKU 2 |
2900 |
3000 |
-100 |
100 |
0,0345 |
|
SKU 3 |
3400 |
3000 |
400 |
400 |
0,1176 |
|
SKU 4 |
3600 |
3400 |
200 |
200 |
0,0556 |
|
SKU 5 |
3500 |
3500 |
0 |
0 |
0,0000 |
|
300 |
900 |
0,2744 |
|||
|
BIAS = |
60 |
||||
|
MAD = |
180 |
||||
|
MAPE = |
5,49% |
||||
Еще одним наглядным показателем для измерения точности прогноза является непосредственно Forecast Accuracy, который показывает, насколько, собственно, прогноз оказался точным:
FA = (1 – |E|/A)*100%
|
SKU |
Продажи |
Прогноз |
Е |
|E| |
|E| / A |
FA |
|
SKU 1 |
3000 |
3200 |
-200 |
200 |
0,067 |
93,3% |
|
SKU 2 |
2900 |
3000 |
-100 |
100 |
0,034 |
96,6% |
|
SKU 3 |
3400 |
3000 |
400 |
400 |
0,118 |
88,2% |
|
SKU 4 |
3600 |
3400 |
200 |
200 |
0,056 |
94,4% |
|
SKU 5 |
3500 |
3500 |
0 |
0 |
0,000 |
100,0% |
|
16400 |
900 |
0,055 |
94,5% |
Показатели точности измерения прогноза продаж MAD, BIAS, MAPE и FA необходимо измерять на регулярной основе и рассматривать в рамках S&OP (Sales and Operations) процесса.
Измерение и обсуждение описанных выше показателей позволяет значительно улучшить уровень коммуникации между продажами и производством. Рекомендую всем, кто этого ещё не сделал, брать на вооружение.
Тарас Пархомчук.
18 Янв Ошибка прогнозирования: как рассчитать и применять.
Posted at 11:37h
in Статьи
Основной задачей при управлении запасами является определение объема пополнения, то есть, сколько необходимо заказать поставщику. При расчете этого объема используется несколько параметров — сколько будет продано в будущем, за какое время происходит пополнение, какие остатки у нас на складе и какое количество уже заказано у поставщика. То, насколько правильно мы определим эти параметры, будет влиять на то, будет ли достаточно товара на складе или его будет слишком много. Но наибольшее влияние на эффективность управления запасами влияет то, насколько точен будет прогноз. Многие считают, что это вообще основной вопрос в управлении запасами. Действительно, точность прогнозирования очень важный параметр. Поэтому важно понимать, как его оценивать. Это важно и для выявления причин дефицитов или неликвидов, и при выборе программных продуктов для прогнозирования продаж и управления запасами.
В данной статье я представила несколько формул для расчета точности прогноза и ошибки прогнозирования. Кроме этого, вы сможете скачать файлы с примерами расчетов этого показателя.
Статистические методы
Для оценки прогноза продаж используются статистические оценки Оценка ошибки прогнозирования временного ряда. Самый простой показатель – отклонение факта от прогноза в количественном выражении.
В практике рассчитывают ошибку прогнозирования по каждой отдельной позиции, а также рассчитывают среднюю ошибку прогнозирования. Следующие распространенные показатели ошибки относятся именно к показателям средних ошибок прогнозирования.
К ним относятся:
MAPE – средняя абсолютная ошибка в процентах

где Z(t) – фактическое значение временного ряда, а  – прогнозное.
– прогнозное.
Данная оценка применяется для временных рядов, фактические значения которых значительно больше 1. Например, оценки ошибки прогнозирования энергопотребления почти во всех статьях приводятся как значения MAPE.
Если же фактические значения временного ряда близки к 0, то в знаменателе окажется очень маленькое число, что сделает значение MAPE близким к бесконечности – это не совсем корректно. Например, фактическая цена РСВ = 0.01 руб/МВт.ч, a прогнозная = 10 руб/МВт.ч, тогда MAPE = (0.01 – 10)/0.01 = 999%, хотя в действительности мы не так уж сильно ошиблись, всего на 10 руб/МВт.ч. Для рядов, содержащих значения близкие к нулю, применяют следующую оценку ошибки прогноза.
MAE – средняя абсолютная ошибка
 .
.
Для оценки ошибки прогнозирования цен РСВ и индикатора БР корректнее использовать MAE.
После того, как получены значения для MAPE и/или MAE, то в работах обычно пишут: «Прогнозирование временного ряда энергопотребления с часовым разрешение проводилось на интервале с 01.01.2001 до 31.12.2001 (общее количество отсчетов N ~ 8500). Для данного прогноза значение MAPE = 1.5%». При этом, просматривая статьи, можно сложить общее впечатление об ошибки прогнозирования энергопотребления, для которого MAPE обычно колеблется от 1 до 5%; или ошибки прогнозирования цен на электроэнергию, для которого MAPE колеблется от 5 до 15% в зависимости от периода и рынка. Получив значение MAPE для собственного прогноза, вы можете оценить, насколько здорово у вас получается прогнозировать.
Кроме указанных методов иногда используют другие оценки ошибки, менее популярные, но также применимые. Подробнее об этих оценках ошибки прогноза читайте указанные статьи в Википедии.
ME – средняя ошибка

Встречается еще другое название этого показателя — Bias (англ. – смещение) демонстрирует величину отклонения, а также — в какую сторону прогноз продаж отклоняется от фактической потребности. Этот индикатор показывает, был ли прогноз оптимистичным или пессимистичным. То есть, отрицательное значение Bias говорит о том, что прогноз был завышен (реальная потребность оказалась ниже), и, наоборот, положительное значение о том, что прогноз был занижен. Цифровое значение показателя определяет величину отклонения (смещения).
MSE – среднеквадратичная ошибка
 .
.
RMSE – квадратный корень из среднеквадратичной ошибки
 .
.
.
SD – стандартное отклонение
 где ME – есть средняя ошибка, определенная по формуле выше.
где ME – есть средняя ошибка, определенная по формуле выше.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме ниже.
Связь точности и ошибки прогнозирования
В начале этого обсуждения разберемся с определениями.
Ошибка прогноза — апостериорная величина отклонения прогноза от действительного состояния объекта. Если говорить о прогнозе продаж, то это показатель отклонения фактических продаж от прогноза.
Точность прогнозирования есть понятие прямо противоположное ошибке прогнозирования. Если ошибка прогнозирования велика, то точность мала и наоборот, если ошибка прогнозирования мала, то точность велика. По сути дела оценка ошибки прогноза MAPE есть обратная величина для точности прогнозирования — зависимость здесь простая.
Точность прогноза в % = 100% – MAPE, встречается еще название этого показателя Forecast Accuracy. Вы практически не найдете материалов о прогнозировании, в которых приведены оценки именно точности прогноза, хотя с точки зрения здравого маркетинга корректней говорить именно о высокой точности. В рекламных статьях всегда будет написано о высокой точности. Показатель точности прогноза выражается в процентах:
- Если точность прогноза равна 100%, то выбранная модель описывает фактические значения на 100%, т.е. очень точно. Нужно сразу оговориться, что такого показателя никогда не будет, основное свойство прогноза в том, что он всегда ошибочен.
- Если 0% или отрицательное число, то совсем не описывает, и данной модели доверять не стоит.
Выбрать подходящую модель прогноза можно с помощью расчета показателя точность прогноза. Модель прогноза, у которой показатель точность прогноза будет ближе к 100%, с большей вероятностью сделает более точный прогноз. Такую модель можно назвать оптимальной для выбранного временного ряда. Говоря о высокой точности, мы говорим о низкой ошибки прогноза и в этой области недопонимания быть не должно. Не имеет значения, что именно вы будете отслеживать, но важно, чтобы вы сравнивали модели прогнозирования или целевые показатели по одному показателю – ошибка прогноза или точность прогнозирования.
Ранее я использовала оценку MAPE, до тех пор пока не встретила формулу, которую рекомендует Валерий Разгуляев.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме ниже.
Оценка ошибки прогноза – формула Валерия Разгуляева (сайт http://upravlenie-zapasami.ru/)
Одной из самых используемых формул оценки ошибки прогнозирования является следующая формула:
Однако у этой формулы есть серьезное ограничение — как оценить ошибку, если факт равен нулю? Возможный ответ, что в таком случае Ошибка прогноза = 100% – который означает, что мы полностью ошиблись. Однако простой пример показывает, что такой ответ — не верен:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
4 |
0 |
100% |
|
№2 |
4 |
1 |
300% |
|
№3 |
1 |
4 |
75% |
Оказывается, что в варианте развития событий №2, когда мы лучше угадали спрос, чем в варианте №1, ошибка по данной формуле оказалась – больше. То есть ошиблась уже сама формула. Есть и другая проблема, если мы посмотрим на варианты №2 и №3, то увидим, что имеем дело с зеркальной ситуацией в прогнозе и факте, а ошибка при этом отличается – в разы!.. То есть при такой оценке ошибки прогноза нам лучше его заведомо делать менее точным, занижая показатель – тогда ошибка будет меньше!.. Хотя понятно, что чем точнее будет прогноз – тем лучше будет и закупка. Поэтому для расчёта ошибки Валерий Разгуляев рекомендует использовать следующую формулу:

где: P – это прогноз, а S – факт за тот же месяц. В таком случае для тех же примеров ошибка рассчитается иначе:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
4 |
0 |
100% |
|
№2 |
4 |
1 |
75% |
|
№3 |
1 |
4 |
75% |
Как мы видим, в варианте №1 ошибка становится равной 100%, причём это уже – не наше предположение, а чистый расчёт, который можно доверить машине. Зеркальные же варианты №2 и №3 – имеют и одинаковую ошибку, причём эта ошибка меньше ошибки самого плохого варианта №1. Единственная ситуация, когда данная формула не сможет дать однозначный ответ – это равенство знаменателя нулю. Но максимум из прогноза и факта равен нулю, только когда они оба равны нулю. В таком случае получается, что мы спрогнозировали отсутствие спроса, и его, действительно, не было – то есть ошибка тоже равна нулю – мы сделали совершенно точное предсказание.
Визуальный метод – графический
Визуальный метод состоит в том, что мы на график выводим значение прогнозной модели и факта продаж по тем моделям, которые хотим сравнить. Далее сравниваем визуально, насколько прогнозная модель близка к фактическим продажам. Давайте рассмотрим на примере. В таблице представлены две прогнозные модели, а также фактические продажи по этому товару за тот же период. Для наглядности мы также рассчитали ошибку прогнозирования по обеим моделям.

По графикам очевидно, что модель 2 описывает лучше продажи этого товара. Оценка ошибки прогнозирования тоже это показывает – 65% и 31% ошибка прогнозирования по модели 1 и модели 2 соответственно.


Недостатком данного метода является то, что небольшую разницу между моделями сложно выявить — разницу в несколько процентов сложно оценить по диаграмме. Однако эти несколько процентов могут существенно улучшить качество прогнозирования и планирования пополнения запасов в целом.
Использование формул ошибки прогнозирования на практике
Практический аспект оценки ошибки прогнозирования я вывела отдельным пунктом. Это связано с тем, что все статистические методы расчета показателя ошибки прогнозирования рассчитывают то, насколько мы ошиблись в прогнозе в количественных показателях. Давайте теперь обсудим, насколько такой показатель будет полезен в вопросах управления запасами. Дело в том, что основная цель управления запасами — обеспечить продажи, спрос наших клиентов. И, в конечном счете, максимизировать доход и прибыль компании. А эти показатели оцениваются как раз в стоимостном выражении. Таким образом, нам важно при оценке ошибки прогнозирования понимать какой вклад каждая позиция внесла в объем продаж в стоимостном выражении. Когда мы оцениваем ошибку прогнозирования в количественном выражении мы предполагаем, что каждый товар имеет одинаковый вес в общем объеме продаж, но на самом деле это не так – есть очень дорогие товары, есть товары, которые продаются в большом количестве, наша группа А, а есть не очень дорогие товары, есть товары которые вносят небольшой вклад в объем продаж. Другими словами большая ошибка прогнозирования по товарам группы А будет нам «стоить» дороже, чем низкая ошибка прогнозирования по товарам группы С, например. Для того, чтобы наша оценка ошибки прогнозирования была корректной, релевантной целям управления запасами, нам необходимо оценивать ошибку прогнозирования по всем товарам или по отдельной группе не по средними показателями, а средневзвешенными с учетом прогноза и факта в стоимостном выражении.
Пример расчета такой оценки Вы сможете увидеть в файле Excel.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме ниже.
При этом нужно помнить, что для оценки ошибки прогнозирования по отдельным позициям мы рассчитываем по количеству, но вот если нам важно понять в целом ошибку прогнозирования по компании, например, для оценки модели, которую используем, то нам нужно рассчитывать не среднюю оценку по всем товарам, а средневзвешенную с учетом стоимостной оценки. Оценку можно брать по ценам себестоимости или ценам продажи, это не играет большой роли, главное, эти же цены (тип цен) использовать при всех расчетах.
Для чего используется ошибка прогнозирования
В первую очередь, оценка ошибки прогнозирования нам необходима для оценки того, насколько мы ошибаемся при планировании продаж, а значит при планировании поставок товаров. Если мы все время прогнозируем продажи значительно больше, чем потом фактически продаем, то вероятнее всего у нас будет излишки товаров, и это невыгодно компании. В случае, когда мы ошибаемся в обратную сторону – прогнозируем продажи меньше чем фактические продажи, с большой вероятностью у нас будут дефициты и компания не дополучит прибыль. В этом случае ошибка прогнозирования служит индикатором качества планирования и качества управления запасами.
Индикатором того, что повышение эффективности возможно за счет улучшения качества прогнозирования. За счет чего можно улучшить качество прогнозирования мы не будем здесь рассматривать, но одним из вариантов является поиск другой модели прогнозирования, изменения параметров расчета, но вот насколько новая модель будет лучше, как раз поможет показатель ошибки прогнозирования или точности прогноза. Сравнение этих показателей по нескольким моделям поможет определить ту модель, которая дает лучше результат.
В идеальном случае, мы можем так подбирать модель для каждой отдельной позиции. В этом случае мы будем рассчитывать прогноз по разным товарам по разным моделям, по тем, которые дают наилучший вариант именно для конкретного товара.
Также этот показатель можно использовать при выборе автоматизированного инструмента для прогнозирования спроса и управления запасами. Вы можете сделать тестовые расчеты прогноза в предлагаемой программе и сравнить ошибку прогнозирования полученного прогноза с той, которая есть у вашей существующей модели. Если у предлагаемого инструмента ошибка прогнозирования меньше. Значит, этот инструмент можно рассматривать для применения в компании. Кроме этого, показатель точности прогноза или ошибки прогнозирования можно использовать как KPI сотрудников, которые отвечают за подготовку прогноза продаж или менеджеров по закупкам, в том случае, если они рассчитывают прогноз будущих продаж при расчете заказа.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме ниже.
Если вы хотите повысить эффективность управления запасами и увеличить оборачиваемость товарных запасов, предлагаю изучить мастер-класс «Как увеличить оборачиваемость товарных запасов».
Копирование статьи возможно только вместе с этим текстом, с обязательным указанием автора, и ссылки на первоисточник: https://uppravuk.net/

Bias и Variance – это две основные ошибки прогноза, которые чаще всего возникают во время модели машинного обучения. Машинное обучение решает многочисленные проблемы, которые нас беспокоят. С помощью машинного обучения мы можем выполнять действия, которые раньше нам не удавалось выполнить.
Поскольку машинное обучение решает большинство проблем, мы сталкиваемся с различными проблемами. Эти прогнозы могут быть угрожающими и будут влиять на результат режима. Вот почему мы должны понимать и решать эти предсказания.
Чтобы спроектировать модель машинного обучения, нам необходимо передать все важные данные, чтобы модель могла делать прогнозы и самостоятельно разрабатывать новые данные. Варианты сделают подходящую модель отличной от заданных вами параметров. Разбираться с вариациями и Байасами неудобно, так как вы не можете запустить свою модель или продемонстрировать навыки модели, если только результаты не будут точными.
Обучение под наблюдением
Комбинация между Bias и Variance применима только при контролируемом машинном обучении. Самое главное, вы используете эти прогнозы в прогнозном моделировании. Этот компромисс прерывает ошибку прогнозирования, так что вы можете проанализировать, как работает ваш алгоритм.
Каждая модель машинного обучения включает в себя алгоритм, который вы тренируете с помощью соответствующих данных. Алгоритм повторяет ту же самую модель и расширяет возможности модели, создавая новые данные на основе тренировочных данных.
Существуют различные алгоритмы, которые Вы можете выбрать для своих моделей машинного обучения. Некоторые из этих алгоритмов:
– Нейронные сети
– Деревья принятия решений
– SVM
– Линейная регрессия
Все вышеперечисленные алгоритмы отличаются друг от друга. Стиль работы алгоритма и то, как они обрабатывают данные, отличаются друг от друга. Количество Вариантов и Байаса создает наиболее важное различие между этими алгоритмами.
Итоговая модель
После того, как вы определились с алгоритмом и параметрами, которые вы используете для вашего проекта, вы готовите окончательную модель, вставляя данные. Вы предоставляете много данных для модели машинного обучения. Теперь Вам необходимо обучить эти наборы данных и продолжать тестирование до тех пор, пока Вы не начнете находить какие-то результаты. Модель поможет сгенерировать прогноз на основе предыдущих данных и разработать новые данные.
Типы ошибок прогнозирования
Алгоритм модели машинного обучения будет включать в себя эти три вида ошибок прогнозирования:
– Вариант
– Bias
– Неснижаемая ошибка
Что такое Биас?
Разница между количеством целевого значения и прогнозом модели называется Bias. Вы можете изменить Bias проекта, изменив алгоритм или модель. Когда предположения, которые вы используете в модели, просты, вы испытаете Bias.
Вы можете получить среднее значение прогноза, повторив процесс построения модели и проведя процесс выборки. Вы можете извлечь данные повторной выборки из модели, так как она использует набор данных для обучения и генерирует точные результаты. Вы можете выполнить повторную выборку с помощью различных методов, таких как бутстраппинг и K-складка.
При повторной выборке данных вы влияете на Bias. Вы обнаружите высокий уровень Bias, измеряя разницу между истинными значениями данных выборки и средним значением прогноза. Если модель является Bias, то вы столкнетесь с моделью недооценки. Каждая модель включает в себя некоторое смещение.
Вы найдете высокий уровень Bias в линейном алгоритме. Вот почему эти алгоритмы ускоряют процесс машинного обучения. Вы также найдете Bias в анализе линейной регрессии из-за реальной проблемы, с которой простая модель не может справиться. Низкий Бай в нелинейном алгоритме. Простая модель имеет больше Байаса.
Что такое Вариант?
С помощью Variance вы можете найти количество целевой функции, которое необходимо скорректировать, если алгоритм использует различные обучающие наборы. Для простоты можно сказать, что дисперсия помогает понять разницу между случайными переменными и ожидаемыми значениями. Дисперсия не поможет Вам найти общую точность, но Вы можете найти нерегулярность модели при использовании различных прогнозов из различных обучающих наборов данных.
Дисперсия может привести к переупорядочиванию. В этом случае даже небольшая вариация вызовет огромные проблемы в наборе данных. При наличии модели с высокой вариативностью наборы данных будут генерировать случайный шум, а не целевую функцию. Ваша модель должна иметь возможность понимать разницу между переменными и входными данными результата.
Однако, когда модель имеет низкую Variance, прогноз модели о данных выборки близок. При ошибке дисперсии прогноз целевой функции будет сильно меняться.
Если алгоритм имеет низкую Variance, то в модели будет происходить логистическая регрессия, линейная регрессия и линейный дискриминантный анализ. С другой стороны, при высокой Variance, вы будете испытывать k-близких соседей, деревья принятия решений и поддержку векторных машин.
Неустранимая ошибка
Нельзя уменьшить невосполнимую ошибку или шум. Это случайные данные, которые модель использует для составления нового прогноза. Эти данные можно рассматривать как неполный набор функций, некорректную задачу или присущую ей случайность.
Почему Бизнес и Варианты существенны.
Алгоритм машинного обучения, который вы используете для вашего проекта, будет использовать эти статистические или математические модели. С помощью этих вычислений он может привести к двум типам ошибок:
Reducible Error (Сокращаемая ошибка) – Вы можете минимизировать и контролировать эту ошибку для повышения точности и эффективности результатов.
Несокращаемая ошибка – Эти ошибки естественны, и вы не можете устранить эти неопределенности.
Вы можете уменьшить Биоизменения и вариации, так как это сводимые к минимуму ошибки. Чтобы уменьшить эти ошибки, необходимо выбрать модель, обладающую подходящей гибкостью и сложностью. Кроме того, вы можете использовать подходящие данные для обучения модели и уменьшить эти ошибки. Это поможет вам добиться точности модели.
Заключение
Биоразнообразие и вариативность являются основными элементами машинного обучения, которые вы должны изучить и понять. Вы должны использовать эти компоненты в контролируемом машинном обучении. При обучении работе с машинами под наблюдением алгоритм учится на основе набора учебных данных и генерирует новые идеи и данные. Вам необходимо поддерживать баланс между Bias и Variance, помогая вам разработать модель обучения работе с машиной, которая дает точные результаты.
Независимо от того, какой алгоритм вы используете для разработки модели, вы изначально найдете Variance и Bias. Когда вы изменяете один компонент, это влияет на другой. Таким образом, вы не сможете свести оба компонента к нулю. Если вы это сделаете, то это вызовет другие проблемы. Вот почему вам нужно использовать смещение против дисперсии. Чтобы спроектировать безошибочную модель, необходимо сделать обе эти компоненты заметными
I spent some time discussing MAPE and WMAPE in prior posts. In this post, I will discuss Forecast BIAS. Forecast BIAS can be loosely described as a tendency to either
Forecast BIAS is described as a tendency to either
- over-forecast (meaning, more often than not, the forecast is more than the actual), or
- under-forecast (meaning, more often than not, the forecast is less than the actual).
Now there are many reasons why such bias exists, including systemic ones. In this blog, I will not focus on those reasons. Instead, I will talk about how to measure these biases so that one can identify if they exist in their data.

A quick word on improving the forecast accuracy in the presence of bias. Once bias has been identified, correcting the forecast error is generally quite simple. It can be achieved by adjusting the forecast in question by the appropriate amount in the appropriate direction, i.e., increase it in the case of under-forecast bias, and decrease it in the case of over-forecast bias.
Rick Glover on LinkedIn described his calculation of BIAS this way: Calculate the BIAS at the lowest level (for example, by product, by location) as follows:
- BIAS = Historical Forecast Units (Two months frozen) minus Actual Demand Units.
- If the forecast is greater than actual demand than the bias is positive (indicates over-forecast). The inverse, of course, results in a negative bias (indicates under-forecast).
- On an aggregate level, per group or category, the +/- are netted out revealing the overall bias.
The other common metric used to measure forecast accuracy is the tracking signal. On LinkedIn, I asked John Ballantyne how he calculates this metric. Here was his response (I have paraphrased it some):
- The “Tracking Signal” quantifies “Bias” in a forecast. No product can be planned from a badly biased forecast. Tracking Signal is the gateway test for evaluating forecast accuracy. The tracking signal in each period is calculated as follows:

- Once this is calculated, for each period, the numbers are added to calculate the overall tracking signal. A forecast history totally void of bias will return a value of zero, with 12 observations, the worst possible result would return either +12 (under-forecast) or -12 (over-forecast). Generally speaking, such a forecast history returning a value greater than 4.5 or less than negative 4.5 would be considered out of control.
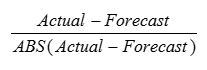
At Arkieva, we use the Normalized Forecast Metric to measure the bias. The formula is very simple.

As can be seen, this metric will stay between -1 and 1, with 0 indicating the absence of bias. Consistent negative values indicate a tendency to under-forecast whereas consistent positive values indicate a tendency to over-forecast. Over a 12 period window, if the added values are more than 2, we consider the forecast to be biased towards over-forecast. Likewise, if the added values are less than -2, we consider the forecast to be biased towards under-forecast.
A forecasting process with a bias will eventually get off-rails unless steps are taken to correct the course from time to time. A better course of action is to measure and then correct for the bias routinely. This is irrespective of which formula one decides to use.
Good supply chain planners are very aware of these biases and use techniques such as triangulation to prevent them. Eliminating bias can be a good and simple step in the long journey to an excellent supply chain.
Like this blog? Follow us on LinkedIn or Twitter, and we will send you notifications on all future blogs.

As COO of Arkieva, Sujit manages the day-to-day operations at Arkieva such as software implementations and customer relationships. He is a recognized subject matter expert in forecasting, S&OP and inventory optimization. Sujit received a Bachelor of Technology degree in Civil Engineering from the Indian Institute of Technology, Kanpur and an M.S. in Transportation Engineering from the University of Massachusetts. Throughout the day don’t be surprised if you find him practicing his cricket technique before a meeting.
Методы оценки качества прогноза
Время на прочтение
3 мин
Количество просмотров 30K
Часто при составлении любого прогноза — забывают про способы оценки его результатов. Потому как часто бывает, прогноз есть, а сравнение его с фактом отсутствует. Еще больше ошибок случается, когда существуют две (или больше) модели и не всегда очевидно — какая из них лучше, точнее. Как правило одной цифрой (R2) сложно обойтись. Как если бы вам сказали — этот парень ходит в синей футболке. И вам сразу все стало про него ясно )
В статьях о методах прогнозирования при оценке полученной модели я постоянно использовал такие аббревиатуры или обозначения.
- R2
- MSE
- MAPE
- MAD
- Bias
Попробую объяснить, что я имел в виду.
Остатки
Итак, по порядку. Основная величина, через которую оценивается точность прогноза это остатки (иногда: ошибки, error, e). В общем виде это разность между спрогнозированными значениями и исходными данными (либо фактическими значениями). Естественно, что чем больше остатки тем сильнее мы ошиблись. Для вычисления сравнительных коэффициентов остатки преобразуют: либо берут по модулю, либо возводят в квадрат (см. таблицу, колонки 4,5,6). В сыром виде почти не используют, так как сумма отрицательных и положительных остатков может свести суммарную ошибку в ноль. А это глупо, сами понимаете.
Суровые MSE и R2
Когда нам требуется подогнать кривую под наши данные, то точность этой подгонки будет оцениваться программой по среднеквадратической ошибке (mean squared error, MSE). Рассчитывается по незамысловатой формуле
![]()
где n-количество наблюдений.
Соотвественно, программа, рассчитывая кривую подгонки, стремится минимизировать этот коэффициент. Квадраты остатков в числителе взяты именно по той причине, чтобы плюсы и минусы не взаимоуничтожились. Физического смысла MSE не имеет, но чем ближе к нулю, тем модель лучше.
Вторая абстрактная величина это R2 — коэффициент детерминации. Характеризует степень сходства исходных данных и предсказанных. В отличии от MSE не зависит от единиц измерения данных, поэтому поддается сравнению. Рассчитывается коэффициент по следующей формуле:
![]()
где Var(Y) — дисперсия исходных данных.
Безусловно коэффициент детерминации — важный критерий выбора модели. И если модель плохо коррелирует с исходными данными, она вряд ли будет иметь высокую предсказательную силу.

MAPE и MAD для сравнения моделей
Статистические методы оценки моделей вроде MSE и R2, к сожалению, трудно интерпретировать, поэтому светлые головы придумали облегченные, но удобные для сравнения коэффициенты.
Среднее абсолютное отклонение (mean absolute deviation, MAD) определяется как частное от суммы остатков по модулю к числу наблюдений. То есть, средний остаток по модулю. Удобно? Вроде да, а вроде и не очень. В моем примере MAD=43. Выраженный в абсолютных единицах MAD показывает насколько единиц в среднем будет ошибаться прогноз.
MAPE призван придать модели еще более наглядный смысл. Расшифровывается выражение как средняя абсолютная ошибка в процентах (mean percentage absolute error, MAPE).
![]()
где Y — значение исходного ряда.
Выражается MAPE в процентах, и в моем случае означает, что в модель может ошибаться в среднем на 16%. Что, согласитесь, вполне допустимо.
Наконец, последняя абсолютно синтетическая величина — это Bias, или просто смещение. Дело в том, что в реальном мире отклонения в одну сторону зачастую гораздо болезненнее, чем в другую. К примеру, при условно неограниченных складских помещениях, важнее учитывать скачки реального спроса вверх от спрогнозированных значений. Поэтому случаи, где остатки положительные относятся к общему числу наблюдений. В моем случае 44% спрогнозированных значений оказались ниже исходных. И можно пожертвовать другими критериями оценки, чтобы минимизировать этот Bias.
Можете попробовать это сами в ![]() Excel и
Excel и ![]() Numbers
Numbers
Интересно узнать — какие методы оценки качества прогнозирования вы используете в своей работе?
Подробности на блоге