Заметили ошибку в решении суда — ничего страшного, всё можно исправить.
Ошибки бывают разные. В зависимости от того, какая ошибка, закон предусматривает разные пути её исправления.
Неумышленная описка в тексте решения или ошибка в расчётах исправляется просто. Сложнее, если суд ошибся в своих суждениях.
Имеет ли судья право на ошибку
Кто ничего не делает, тот и не ошибается — простое и понятное изречение.
Судья каждый день принимает решения и каждое решение несёт риск ошибки.
Можете возразить — судья представляет власть и не должен ошибаться.
Да, не должен, но иногда ошибается и с этим ничего не поделаешь.
Поэтому закон предусматривает многоэтапную проверку судебных решений — апелляция и кассация, в некоторых случаях надзор.
Вероятность ошибиться в нескольких инстанциях крайне низкая, но не нулевая. Ошибаются даже в Верховном Суде. И с этим то же ничего не поделаешь.
Что такое описка в решении суда
Были времена, когда текст судебного решения печатали на механической машинке, иногда писали от руки.
Нельзя было скопировать кусок текста из одного решение и вставить в другой. Мотивировка решения была скудной, а текст решения умещался на одной странице.
Сегодня тексты набирают на компьютере: быстро, удобно, повышает производительность.
Однако ошибались всегда: в рукописном тексте допускали описку, в печатном — опечатку.
В любом случае, описка или опечатка — это неумышленная случайная ошибка из-за невнимательности при подготовке текста.
Отличие от судебной ошибки
Описку в решении суда нужно отличать от судебной ошибки. Это важно, от этого зависит способ исправления дефекта в судебном решении.
Описка — это результат невнимательности: хотели написать одно, получилось другое.
Судья или помощник торопились при составлении текста решения, потом не проверили его, и вот результат.
Судебная же ошибка всегда осознанна — суд ошибается в суждениях, оценке доказательств, выборе и применении закона.
Описка или опечатка — ошибка в букве, слове, предложении. Судебная ошибка — ошибка в мыслях.
Ошибка в арифметике: явная и неявная
У судей нет времени сидеть с калькулятором, делать или проверять сложные расчёты.
Особо сложные, например проверку бухгалтерского или налогового учёта, судьи поручают экспертам.
Расчёт предоставляют участники процесса. Судья либо соглашается с ним, либо делает свой.
Обсчитаться может каждый. Не нужно забывать, что большинство судей гуманитарии не только по образованию, но и по типу мышления.
Арифметическая ошибка — ошибка в математических расчётах.
Неправильно умножили, не там поставили запятую перед десятичным знаком, сложили не те значения, наконец, просто потеряли ноль.
Явная арифметическая ошибка — очевидная, грубая, которую может определить человек со школьным уровнем знаний в арифметике.
Почти все ошибки явные. Поэтому не нужно забивать голову вопросом: «Явную или неявную арифметическую ошибку допустил судья?»
Способы исправления
Исправление описки или арифметической ошибки в тексте решении суда — это НЕ изменение самого решения
При изменении решения меняется его смысловое содержание. Неважно, полностью или частично.
Суд не вправе изменить своё решение. Это запрещено законом и разрешено только вышестоящему суду.
А вот неумышленную описку и ошибку в расчётах исправляет суд, который её допустил.
Отсюда следующее правило:
- Судья неумышленно в решении допустил описку (опечатку) или ошибся в математических расчётах — подаём заявление об исправлении
- Судья ошибся в суждениях, оценке доказательств, выборе и применении закона (допустил осознанную судебную ошибку) — подаем апелляционную жалобу на решение суда
Когда нужно исправлять решение
«Исправить или оставить как есть» — зависит от конкретной ситуации, от обстоятельств дела.
Важно определить, какие последствия может повлечь такая описка. Лучше, если это сделает юрист.
Немаловажно в какой части решения описка.
Описка в резолютивной части (после «суд решил») — лучше исправить.
В мотивировочной части (где выводы суда) — на усмотрение, опять же в зависимости от возможных последствий.
Арифметические ошибки нужно исправлять, когда обсчёт существенен.
Не нужно тратить силы и время, если судья ошибся на несколько копеек или рублей.
Кстати, исправить описку или ошибку в арифметике можно не только в решении суда, но и в определении, по аналогии.
Кто инициирует, кто исправляет, куда подавать
Исправление описки или арифметической ошибки инициирует тот, кто её обнаружил.
Если заметил судья — исправит по собственной инициативе, если участник процесса — суд на основании его заявления.
Не нужно ждать инициативы от суда — у судей много работы и нет времени на перепроверку своих же решений.
Просто помогите судье — подайте заявление об исправлении, не ждите что это сделает кто-то другой.
Заявление нужно подавать по принципу: кто ошибся, тот и должен исправить — кто должен исправить, тому адресуем и ему же подаём.
Заявление в суд об исправлении описки
Составить самому заявление в суд об исправлении описки не сложно. В Интернете масса образцов, само же заявление — на одну страницу.
Структура заявления проста и состоит из четырёх частей:
- Обозначаем описку
- Мотивируем, почему это описка
- Ссылаемся на статьи 200 и 203.1 ГПК РФ (в арбитраже — статья 179 АПК РФ)
- Просим исправить, предлагая свой вариант
В качестве примера. Разъясняя в мотивировочной части решения права истцу, судья перепутал его ФИО с ФИО ответчика.
Просительная часть заявления об исправлении описки будет выглядеть следующим образом:
— Прошу исправить допущенную в первом предложении последнего абзаца мотивировочной части решения суда описку:
«При таких обстоятельствах, Иванов Иван Иванович вправе требовать установления сервитута в отношении застроенного земельного участка»,
изложив его в следующей редакции:
«При таких обстоятельствах, Петров Пётр Петрович вправе требовать установления сервитута в отношении застроенного земельного участка»
Когда лучше привлечь юриста
Заявление не всегда простенький текст на половину страницы. Иногда его нужно дополнить смысловой нагрузкой.
Суд исказил фамилию участника, неправильно указал отчество, ошибся в дате рождения — всё это легко исправимо и не требует участия юриста.
Другое дело, когда не совсем ясно, почему суд допустил описку и описка ли это вообще.
В этом случае за составлением заявления лучше обратиться к юристу или адвокату, минимум — получить консультацию.
Почему меня не вызвали в суд
Раньше суд рассматривал заявление об исправлении описки в решении только в судебном заседании.
Рассмотрение вопроса об исправлении вне судебного заседания считалось процессуальным нарушением.
Сейчас у судьи два варианта:
- Не проводить заседание, не извещать участников процесса
- Провести заседание, предварительно сообщив участникам время и место проведения
Вариант определяет судья, по своему усмотрению. Сочтёт необходимым — вызовет и проведёт заседание, не сочтёт — рассмотрит не заседая в одиночестве.
Суд отказал в исправлении описки. Что дальше?
Рассмотрев заявление о исправлении, суд выносит определение — либо исправляет, либо отказывает в этом.
Если вопрос рассматривался в судебном заседании с вызовом, обычно копию определения вручают здесь же.
Если суд не проводил заседания, копию высылают в течение трёх дней по почте.
Почтовые отправления — всегда риск. Лучше отследить дело и получить определение в суде.
Судья отказал в исправлении, вы не согласны, позиции разошлись — можно подать частную жалобу
Здесь точно лучше обратиться к юристу.
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)
Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.










Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.
Заметили ошибку в решении суда — ничего страшного, всё можно исправить.
Ошибки бывают разные. В зависимости от того, какая ошибка, закон предусматривает разные пути её исправления.
Неумышленная описка в тексте решения или ошибка в расчётах исправляется просто. Сложнее, если суд ошибся в своих суждениях.
Имеет ли судья право на ошибку
Кто ничего не делает, тот и не ошибается — простое и понятное изречение.
Судья каждый день принимает решения и каждое решение несёт риск ошибки.
Можете возразить — судья представляет власть и не должен ошибаться.
Да, не должен, но иногда ошибается и с этим ничего не поделаешь.
Поэтому закон предусматривает многоэтапную проверку судебных решений — апелляция и кассация, в некоторых случаях надзор.
Вероятность ошибиться в нескольких инстанциях крайне низкая, но не нулевая. Ошибаются даже в Верховном Суде. И с этим то же ничего не поделаешь.
Что такое описка в решении суда
Были времена, когда текст судебного решения печатали на механической машинке, иногда писали от руки.
Нельзя было скопировать кусок текста из одного решение и вставить в другой. Мотивировка решения была скудной, а текст решения умещался на одной странице.
Сегодня тексты набирают на компьютере: быстро, удобно, повышает производительность.
Однако ошибались всегда: в рукописном тексте допускали описку, в печатном — опечатку.
В любом случае, описка или опечатка — это неумышленная случайная ошибка из-за невнимательности при подготовке текста.
Отличие от судебной ошибки
Описку в решении суда нужно отличать от судебной ошибки. Это важно, от этого зависит способ исправления дефекта в судебном решении.
Описка — это результат невнимательности: хотели написать одно, получилось другое.
Судья или помощник торопились при составлении текста решения, потом не проверили его, и вот результат.
Судебная же ошибка всегда осознанна — суд ошибается в суждениях, оценке доказательств, выборе и применении закона.
Описка или опечатка — ошибка в букве, слове, предложении. Судебная ошибка — ошибка в мыслях.
Ошибка в арифметике: явная и неявная
У судей нет времени сидеть с калькулятором, делать или проверять сложные расчёты.
Особо сложные, например проверку бухгалтерского или налогового учёта, судьи поручают экспертам.
Расчёт предоставляют участники процесса. Судья либо соглашается с ним, либо делает свой.
Обсчитаться может каждый. Не нужно забывать, что большинство судей гуманитарии не только по образованию, но и по типу мышления.
Арифметическая ошибка — ошибка в математических расчётах.
Неправильно умножили, не там поставили запятую перед десятичным знаком, сложили не те значения, наконец, просто потеряли ноль.
Явная арифметическая ошибка — очевидная, грубая, которую может определить человек со школьным уровнем знаний в арифметике.
Почти все ошибки явные. Поэтому не нужно забивать голову вопросом: «Явную или неявную арифметическую ошибку допустил судья?»
Способы исправления
Исправление описки или арифметической ошибки в тексте решении суда — это НЕ изменение самого решения
При изменении решения меняется его смысловое содержание. Неважно, полностью или частично.
Суд не вправе изменить своё решение. Это запрещено законом и разрешено только вышестоящему суду.
А вот неумышленную описку и ошибку в расчётах исправляет суд, который её допустил.
Отсюда следующее правило:
- Судья неумышленно в решении допустил описку (опечатку) или ошибся в математических расчётах — подаём заявление об исправлении
- Судья ошибся в суждениях, оценке доказательств, выборе и применении закона (допустил осознанную судебную ошибку) — подаем апелляционную жалобу на решение суда
Когда нужно исправлять решение
«Исправить или оставить как есть» — зависит от конкретной ситуации, от обстоятельств дела.
Важно определить, какие последствия может повлечь такая описка. Лучше, если это сделает юрист.
Немаловажно в какой части решения описка.
Описка в резолютивной части (после «суд решил») — лучше исправить.
В мотивировочной части (где выводы суда) — на усмотрение, опять же в зависимости от возможных последствий.
Арифметические ошибки нужно исправлять, когда обсчёт существенен.
Не нужно тратить силы и время, если судья ошибся на несколько копеек или рублей.
Кстати, исправить описку или ошибку в арифметике можно не только в решении суда, но и в определении, по аналогии.
Кто инициирует, кто исправляет, куда подавать
Исправление описки или арифметической ошибки инициирует тот, кто её обнаружил.
Если заметил судья — исправит по собственной инициативе, если участник процесса — суд на основании его заявления.
Не нужно ждать инициативы от суда — у судей много работы и нет времени на перепроверку своих же решений.
Просто помогите судье — подайте заявление об исправлении, не ждите что это сделает кто-то другой.
Заявление нужно подавать по принципу: кто ошибся, тот и должен исправить — кто должен исправить, тому адресуем и ему же подаём.
Заявление в суд об исправлении описки
Составить самому заявление в суд об исправлении описки не сложно. В Интернете масса образцов, само же заявление — на одну страницу.
Структура заявления проста и состоит из четырёх частей:
- Обозначаем описку
- Мотивируем, почему это описка
- Ссылаемся на статьи 200 и 203.1 ГПК РФ (в арбитраже — статья 179 АПК РФ)
- Просим исправить, предлагая свой вариант
В качестве примера. Разъясняя в мотивировочной части решения права истцу, судья перепутал его ФИО с ФИО ответчика.
Просительная часть заявления об исправлении описки будет выглядеть следующим образом:
— Прошу исправить допущенную в первом предложении последнего абзаца мотивировочной части решения суда описку:
«При таких обстоятельствах, Иванов Иван Иванович вправе требовать установления сервитута в отношении застроенного земельного участка»,
изложив его в следующей редакции:
«При таких обстоятельствах, Петров Пётр Петрович вправе требовать установления сервитута в отношении застроенного земельного участка»
Когда лучше привлечь юриста
Заявление не всегда простенький текст на половину страницы. Иногда его нужно дополнить смысловой нагрузкой.
Суд исказил фамилию участника, неправильно указал отчество, ошибся в дате рождения — всё это легко исправимо и не требует участия юриста.
Другое дело, когда не совсем ясно, почему суд допустил описку и описка ли это вообще.
В этом случае за составлением заявления лучше обратиться к юристу или адвокату, минимум — получить консультацию.
Почему меня не вызвали в суд
Раньше суд рассматривал заявление об исправлении описки в решении только в судебном заседании.
Рассмотрение вопроса об исправлении вне судебного заседания считалось процессуальным нарушением.
Сейчас у судьи два варианта:
- Не проводить заседание, не извещать участников процесса
- Провести заседание, предварительно сообщив участникам время и место проведения
Вариант определяет судья, по своему усмотрению. Сочтёт необходимым — вызовет и проведёт заседание, не сочтёт — рассмотрит не заседая в одиночестве.
Суд отказал в исправлении описки. Что дальше?
Рассмотрев заявление о исправлении, суд выносит определение — либо исправляет, либо отказывает в этом.
Если вопрос рассматривался в судебном заседании с вызовом, обычно копию определения вручают здесь же.
Если суд не проводил заседания, копию высылают в течение трёх дней по почте.
Почтовые отправления — всегда риск. Лучше отследить дело и получить определение в суде.
Судья отказал в исправлении, вы не согласны, позиции разошлись — можно подать частную жалобу
Здесь точно лучше обратиться к юристу.
Представление результатов исследования
В научных публикациях важно представление результатов исследования. Очень часто окончательный результат приводится в следующем виде: M±m, где M – среднее арифметическое, m –ошибка среднего арифметического. Например, 163,7±0,9 см.
Прежде чем разбираться в правилах представления результатов исследования, давайте точно усвоим, что же такое ошибка среднего арифметического.
Ошибка среднего арифметического
Среднее арифметическое, вычисленное на основе выборочных данных (выборочное среднее), как правило, не совпадает с генеральным средним (средним арифметическим генеральной совокупности). Экспериментально проверить это утверждение невозможно, потому что нам неизвестно генеральное среднее. Но если из одной и той же генеральной совокупности брать повторные выборки и вычислять среднее арифметическое, то окажется, что для разных выборок среднее арифметическое будет разным.
Чтобы оценить, насколько выборочное среднее арифметическое отличается от генерального среднего, вычисляется ошибка среднего арифметического или ошибка репрезентативности.
Ошибка среднего арифметического обозначается как m или ![]()
Ошибка среднего арифметического рассчитывается по формуле:
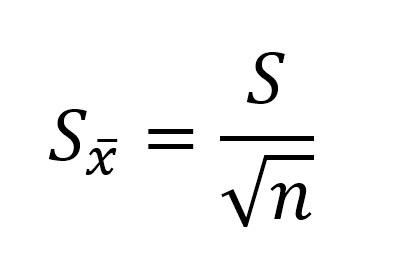
где: S — стандартное отклонение, n – объем выборки; Например, если стандартное отклонение равно S=5 см, объем выборки n=36 человек, то ошибка среднего арифметического равна: m=5/6 = 0,833.
Ошибка среднего арифметического показывает, какая ошибка в среднем допускается, если использовать вместо генерального среднего выборочное среднее.
Так как при небольшом объеме выборки истинное значение генерального среднего не может быть определено сколь угодно точно, поэтому при вычислении выборочного среднего арифметического нет смысла оставлять большое число значащих цифр.
Правила записи результатов исследования
- В записи ошибки среднего арифметического оставляем две значащие цифры, если первые цифры в ошибке «1» или «2».
- В остальных случаях в записи ошибки среднего арифметического оставляем одну значащую цифру.
- В записи среднего арифметического положение последней значащей цифры должно соответствовать положению первой значащей цифры в записи ошибки среднего арифметического.
Представление результатов научных исследований
В своей статье «Осторожно, статистика!», опубликованной в 1989 году В.М. Зациорский указал, какие числовые характеристики должны быть представлены в публикации, чтобы она имела научную ценность. Он писал, что исследователь «…должен назвать: 1) среднюю величину (или другой так называемый показатель положения); 2) среднее квадратическое отклонение (или другой показатель рассеяния) и 3) число испытуемых. Без них его публикация научной ценности иметь не будет “с. 52
В научных публикациях в области физической культуры и спорта очень часто окончательный результат приводится в виде: (М±m) (табл.1).
Таблица 1 — Изменение механических свойств латеральной широкой мышцы бедра под воздействием физической нагрузки (n=34)
| Эффективный модуль
упругости (Е), кПа |
Эффективный модуль
вязкости (V), Па с |
|||
| Этап
эксперимента |
Рассл. | Напряж. | Рассл. | Напряж. |
| До ФН | 7,0±0,3 | 17,1±1,4 | 29,7±1,7 | 46±4 |
| После ФН | 7,7±0,3 | 18,7±1,4 | 30,9±2,0 | 53±6 |
Литература
- Высшая математика и математическая статистика: учебное пособие для вузов / Под общ. ред. Г. И. Попова. – М. Физическая культура, 2007.– 368 с.
- Гласс Дж., Стэнли Дж. Статистические методы в педагогике и психологии. М.: Прогресс. 1976.- 495 с.
- Зациорский В.М. Осторожно — статистика! // Теория и практика физической культуры, 1989.- №2.
- Катранов А.Г. Компьютерная обработка данных экспериментальных исследований: Учебное пособие/ А. Г. Катранов, А. В. Самсонова; СПб ГУФК им. П.Ф. Лесгафта. – СПб.: изд-во СПб ГУФК им. П.Ф. Лесгафта, 2005. – 131 с.
- Основы математической статистики: Учебное пособие для ин-тов физ. культ / Под ред. В.С. Иванова.– М.: Физкультура и спорт, 1990. 176 с.
Условное
обозначение средней арифметической
величины через М (от латинского слова
Media) чаще применяется в медицинских и
педагогических исследованиях. В
математической статистике предпочитают
обозначение через ![]() .
.
Средняя арифметическая величина является
производной, обобщающей количественные
признаки ряда однородных показателей
(совокупности). Выражая одним числом
определенную совокупность, она как бы
ослабляет влияние случайных индивидуальных
отклонений, и акцентирует некую обобщенную
количественную характеристику, наиболее
типичное свойство изучаемого ряда
показателей.
Определяя
значение средней арифметической
величины, следует придерживаться
некоторых правил.
1.
Средняя арифметическая величина может
характеризовать только те признаки
изучаемого объекта, которые присущи
всей совокупности, но в разной
количественной мере (например, уровень
развития быстроты движений характерен
для каждого человека, хотя и в разной
количественной мере). Средняя арифметическая
величина не может характеризовать
количественную меру тех признаков,
которые одной части совокупности
присущи, а другой нет, т. е. она не может
отражать присутствие или отсутствие
того или иного признака (например, умение
или неумение выполнять то или иное
двигательное действие).
2.
Средняя арифметическая величина должна
включать все показатели, полученные в
данном исследовании. Произвольное
исключение даже некоторых из них
неизбежно приведет к искажению конечного
результата.
3.
Средняя арифметическая величина обязана
отражать только однородную совокупность.
Нельзя, например, определять средний
уровень физического развития школьников,
не разделив их предварительно по возрасту
и полу.
4.
Средняя арифметическая величина должна
вычисляться на достаточно большой
совокупности, размеры которой определяются
в каждом конкретном случае отдельно
(см. «Подбор исследуемых»).
5.
Необходимо стремиться к тому, чтобы
средняя арифметическая величина имела
четкие и простые свойства, позволяющие
легко и быстро ее вычислять.
6.
Средняя арифметическая величина должна
обладать достаточной устойчивостью к
действию случайных факторов. Только в
этом случае она будет отражать
действительное состояние изучаемого
явления, а не его случайные изменения.
7.
Точность вычисления средней арифметической
величины должна соответствовать
содержанию изучаемого педагогического
явления. В некоторых случаях нет
необходимости в расчетах с большой
точностью, в других — большая точность
нужна при вычислениях, но совершенно
не нужна в выводах. Например, при расчете
средних величин числа подтягиваний на
перекладине можно пользоваться и сотыми
долями целого, но представлять и выводах,
что исследуемые в среднем подтянулись
7,83 раза, было бы неграмотна, так как
невозможно измерение с подобной
точностью. В этом случае необходимо в
выводах представлять числа, округленные
до целых единиц.
В
простейшем случае этот показатель
вычисляется путем сложения всех
полученных значений (которые называются
вариантами) и деления суммы на число
вариант:
![]()
где
S — знак суммирования;
V
— полученные в исследовании значения
(варианты);
п
— число вариант.
По
этой формуле вычисляется так называемая
простая средняя арифметическая величина.
Применяется она в тех случаях, когда
имеется небольшое число вариант.
При
большом числе вариант прибегают к
вычислению так называемой взвешенной
средней арифметической величины. С этой
целью строят ряд распределения, или
вариационный ряд, который представляет
собой ряд вариант и их частот,
характеризующих какой-нибудь признак
в убывающем или возрастающем порядке.
Например, в нашем случае измерение
точности попадания мячом в цель дало
125 вариант, т. е. в группе I, где применялась
методика обучения «А», одноразово
исследовалось 125 детей с числовым
выражением от 0 (точное попадание в цель)
до 21,5 см (максимальное отклонение от
цели). Каждое числовое выражение
встречалось в исследовании один и более
раз, например «0» встретился 28 раз.
Другими словами, 28 участников эксперимента
точно попали в цель. Этот показатель
называется числом наблюдений или
частотой вариант и условно обозначается
буквой «Р» (число наблюдений составляет
часть числа вариант).
Для
упрощения числовых операций все 125
вариант разбиваются на классы с величиной
интервала 1,9 см. Число классов зависит
от величины колебаний вариант (разности
между максимальной и минимальной
вариантами), наличия вариант для каждого
класса (если, например, для первого
класса — «0 — 1,9» — нет соответствующих
вариант, т.е. ни один исследуемый не имел
точных попаданий или отклонений от цели
в пределах от 0 до 1,9 см, то подобный класс
не вносится в вариационный ряд) и,
наконец, требуемой точности вычисления,
(чем больше классов, тем точность
вычисления выше). Вполне понятно, что
чем больше величина интервала, тем
меньше число классов при одной и той же
величине колебаний вариант.
После
разбивки вариант по классам в каждом
классе определяется срединная варианта
«Vc»,
и для каждой срединной варианты
проставляется число наблюдений. Пример
этих операций, и дальнейший ход вычислений
приведены в следующей таблице:
|
Классы |
Серединные |
Число |
VCP |
VC-M=d |
d2 |
d2P |
|
0 |
1 |
28 |
28 |
-4.6 |
21.16 |
592.48 |
|
2 |
3 |
29 |
87 |
-2.6 |
6.76 |
196.04 |
|
4 |
5 |
22 |
110 |
-0.6 |
0.36 |
7.92 |
|
6 |
7 |
13 |
91 |
1.4 |
1.96 |
25.48 |
|
8 |
9 |
11 |
99 |
3.4 |
11.56 |
127.16 |
|
10 |
11 |
13 |
143 |
5.4 |
29.16 |
379.08 |
|
12 |
13 |
4 |
52 |
7.4 |
54.76 |
219.04 |
|
14 |
15 |
2 |
30 |
9.4 |
88.36 |
176.72 |
|
16 |
17 |
1 |
17 |
11.4 |
130.00 |
130.00 |
|
18 |
19 |
1 |
19 |
13.4 |
179.60 |
179.60 |
|
20 |
21 |
1 |
21 |
15.4 |
237.20 |
237.20 |
|
125 |
697 |
2270.72 |
Очередность
числовых операций:
1)
вычислить сумму числа наблюдений (в
нашем примере она равна 125);
2)
вычислить произведение каждой срединной
варианты на ее частоту (например, 1*28 =
28);
3)
вычислить сумму произведений срединных
вариант на их частоты (в нашем примере
она равна 697);
4)
вычислить взвешенную среднюю арифметическую
величину по формуле:
![]()
Средняя
арифметическая величина позволяет
сравнивать и оценивать группы изучаемых
явлений в целом. Однако для характеристики
группы явлений только этой величины
явно недостаточно, так как размер
колебаний вариант, из которых она
складывается, может быть различным.
Поэтому в характеристику группы явлений
необходимо ввести такой показатель,
который давал бы представление о величине
колебаний вариант около их средней
величины.
Вычисление
средней ошибки среднего арифметического.
Условное обозначение средней ошибки
среднего арифметического — т. Следует
помнить, что под «ошибкой» в статистике
понимается не ошибка исследования, а
мера представительства данной величины,
т. е. мера, которой средняя арифметическая
величина, полученная на выборочной
совокупности (в нашем примере — на 125
детях), отличается от истинной средней
арифметической величины, которая была
бы получена на генеральной совокупности
(в нашем примере это были бы все дети
аналогичного возраста, уровня
подготовленности и т. д.). Например, в
приведенном ранее примере определялась
точность попадания малым мячом в цель
у 125 детей и была получена средняя
арифметическая величина примерно равная
5,6 см. Теперь надо установить, в какой
мере эта величина будет характерна,
если взять для исследования 200, 300, 500 и
больше аналогичных детей. Ответ на этот
вопрос и даст вычисление средней ошибки
среднего арифметического, которое
производится по формуле:
![]()
Для
приведенного примера величина средней
ошибки среднего арифметического будет
равна:
![]()
Следовательно,
M±m = 5,6±0,38. Это означает, что полученная
средняя арифметическая величина (M =
5,6) может иметь в других аналогичных
исследованиях значения от 5,22 (5,6 — 0,38 =
5,22) до 5,98 (5,6+0,38 = 5,98).
Соседние файлы в предмете Ветеринарная генетика
- #
- #
- #
Материал из MachineLearning.
Перейти к: навигация, поиск
Содержание
- 1 Введение
- 1.1 Постановка вопроса. Виды погрешностей
- 2 Виды мер точности
- 3 Предельные погрешности
- 4 Погрешности округлений при представлении чисел в компьютере
- 5 Погрешности арифметических операций
- 6 Погрешности вычисления функций
- 7 Числовые примеры
- 8 Список литературы
- 9 См. также
Введение
Постановка вопроса. Виды погрешностей
Процесс исследования исходного объекта методом математического моделирования и вычислительного эксперимента неизбежно носит приближенный характер, так как на каждом этапе вносятся погрешности. Построение математической модели связано с упрощением исходного явления, недостаточно точным заданием коэффициентов уравнения и других входных данных. По отношению к численному методу, реализующему данную математическую модель, указанные погрешности являются неустранимыми, поскольку они неизбежны в рамках данной модели.
При переходе от математической модели к численному методу возникают погрешности, называемые погрешностями метода. Они связаны с тем, что всякий численный метод воспроизводит исходную математическую модель приближенно. Наиболее типичными погрешностями метода являются погрешность дискретизации и погрешность округления.
При построении численного метода в качестве аналога исходной математической задачи обычно рассматривается её дискретная модель. Разность решений дискретизированной задачи и исходной называется погрешностью дискретизации. Обычно дискретная модель зависит от некоторого параметра (или их множества) дискретизации, при стремлении которого к нулю должна стремиться к нулю и погрешность дискретизации.
Дискретная модель представляет собой систему большого числа алгебраических уравнений. Для её решения используется тот или иной численный алгоритм. Входные данные этой системы, а именно коэффициенты и правые части, задаются в ЭВМ не точно, а с округлением. В процессе работы алгоритма погрешности округления обычно накапливаются, и в результате, решение, полученное на ЭВМ, будет отличаться от точного решения дискретизированной задачи. Результирующая погрешность называется погрешностью округления (вычислительной погрешностью). Величина этой погрешности определяется двумя факторами: точностью представления вещественных чисел в ЭВМ и чувствительностью данного алгоритма к погрешностям округления.
Итак, следует различать погрешности модели, дискретизации и округления. В вопросе преобладания какой-либо погрешности ответ неоднозначен. В общем случае нужно стремиться, чтобы все погрешности имели один и тот же порядок. Например, нецелесообразно пользоваться разностными схемами, имеющими точность 10−6, если коэффициенты исходных уравнений задаются с точностью 10−2.
Виды мер точности
Мерой точности вычислений являются абсолютные и относительные погрешности. Абсолютная погрешность определяется формулой
где – приближение к точному значению .
Относительная погрешность определяется формулой
Относительная погрешность часто выражается в процентах. Абсолютная и относительная погрешности тесно связаны с понятием верных значащих цифр. Значащими цифрами числа называют все цифры в его записи, начиная с первой ненулевой цифры слева. Например, число 0,000129 имеет три значащих цифры. Значащая цифра называется верной, если абсолютная погрешность числа не превышает половины веса разряда, соответствующего этой цифре. Например, , абсолютная погрешность . Записывая число в виде
имеем , следовательно, число имеет две верных значащих цифр (9 и 3).
В общем случае абсолютная погрешность должна удовлетворять следующему неравенству:
где — порядок (вес) старшей цифры, — количество верных значащих цифр.
В рассматриваемом примере .
Относительная погрешность связана с количеством верных цифр приближенного числа соотношением:
где — старшая значащая цифра числа.
Для двоичного представления чисел имеем .
Тот факт, что число является приближенным значением числа с абсолютной погрешностью , записывают в виде
причем числа и записываются с одинаковым количеством знаков после запятой, например, или .
Запись вида
означает, что число является приближенным значение числа с относительной погрешностью .
Так как точное решение задачи как правило неизвестно, то погрешности приходится оценивать через исходные данные и особенности алгоритма. Если оценка может быть вычислена до решения задачи, то она называется априорной. Если оценка вычисляется после получения приближенного решения задачи, то она называется апостериорной.
Очень часто степень точности решения задачи характеризуется некоторыми косвенными вспомогательными величинами. Например точность решения системы алгебраических уравнений
характеризуется невязкой
где — приближенное решение системы.
Причём невязка достаточно сложным образом связана с погрешностью решения , причём если невязка мала, то погрешность может быть значительной.
Предельные погрешности
Пусть искомая величина является функцией параметров — приближенное значение . Тогда предельной абсолютной погрешностью называется величина
Предельной относительной погрешностью называется величина .
Пусть — приближенное значение . Предполагаем, что — непрерывно дифференцируемая функция своих аргументов. Тогда, по формуле Лагранжа,
где .
Отсюда
где .
Можно показать, что при малых эта оценка не может быть существенно улучшена. На практике иногда пользуются грубой (линейной) оценкой
где .
Несложно показать, что:
- — предельная погрешность суммы или разности равна сумме предельных погрешностей.
- — предельная относительная погрешность произведения или частного приближенного равна сумме предельных относительных погрешностей.
Погрешности округлений при представлении чисел в компьютере
Одним из основных источников вычислительных погрешностей является приближенное представление чисел в компьютере, обусловленное конечностью разрядной сетки (см. Международный стандарт представления чисел с плавающей точкой в ЭВМ). Число , не представимое в компьютере, подвергается округлению, т. е. заменяется близким числом , представимым в компьютере точно.
Найдем границу относительной погрешности представления числа с плавающей точкой. Допустим, что применяется простейшее округление – отбрасывание всех разрядов числа, выходящих за пределы разрядной сетки. Система счисления – двоичная. Пусть надо записать число, представляющее бесконечную двоичную дробь
где , — цифры мантиссы.
Пусть под запись мантиссы отводится t двоичных разрядов. Отбрасывая лишние разряды, получим округлённое число
Абсолютная погрешность округления в этом случае равна
Наибольшая погрешность будет в случае , тогда
Т.к. , где — мантисса числа , то всегда . Тогда и относительная погрешность равна . Практически применяют более точные методы округления и погрешность представления чисел равна
( 1 )
т.е. точность представления чисел определяется разрядностью мантиссы .
Тогда приближенно представленное в компьютере число можно записать в виде , где – «машинный эпсилон» – относительная погрешность представления чисел.
Погрешности арифметических операций
При вычислениях с плавающей точкой операция округления может потребоваться после выполнения любой из арифметических операций. Так умножение или деление двух чисел сводится к умножению или делению мантисс. Так как в общем случае количество разрядов мантисс произведений и частных больше допустимой разрядности мантиссы, то требуется округление мантиссы результатов. При сложении или вычитании чисел с плавающей точкой операнды должны быть предварительно приведены к одному порядку, что осуществляется сдвигом вправо мантиссы числа, имеющего меньший порядок, и увеличением в соответствующее число раз порядка этого числа. Сдвиг мантиссы вправо может привести к потере младших разрядов мантиссы, т.е. появляется погрешность округления.
Округленное в системе с плавающей точкой число, соответствующее точному числу , обозначается через (от англ. floating – плавающий). Выполнение каждой арифметической операции вносит относительную погрешность, не большую, чем погрешность представления чисел с плавающей точкой (1). Верна следующая запись:
где — любая из арифметических операций, .
Рассмотрим трансформированные погрешности арифметических операций. Арифметические операции проводятся над приближенными числами, ошибка арифметических операций не учитывается (эту ошибку легко учесть, прибавив ошибку округления соответствующей операции к вычисленной ошибке).
Рассмотрим сложение и вычитание приближенных чисел. Абсолютная погрешность алгебраической суммы нескольких приближенных чисел равна сумме абсолютных погрешностей слагаемых.
Если сумма точных чисел равна
сумма приближенных чисел равна
где — абсолютные погрешности представления чисел.
Тогда абсолютная погрешность суммы равна
Относительная погрешность суммы нескольких чисел равна
( 2 )
где — относительные погрешности представления чисел.
Из (2) следует, что относительная погрешность суммы нескольких чисел одного и того же знака заключена между наименьшей и наибольшей из относительных погрешностей слагаемых:
При сложении чисел разного знака или вычитании чисел одного знака относительная погрешность может быть очень большой (если числа близки между собой). Так как даже при малых величина может быть очень малой. Поэтому вычислительные алгоритмы необходимо строить таким образом, чтобы избегать вычитания близких чисел.
Необходимо отметить, что погрешности вычислений зависят от порядка вычислений. Далее будет рассмотрен пример сложения трех чисел.
( 3 )
При другой последовательности действий погрешность будет другой:
Из (3) видно, что результат выполнения некоторого алгоритма, искаженный погрешностями округлений, совпадает с результатом выполнения того же алгоритма, но с неточными исходными данными. Т.е. можно применять обратный анализ: свести влияние погрешностей округления к возмущению исходных данных. Тогда вместо (3) будет следующая запись:
где
При умножении и делении приближенных чисел складываются и вычитаются их относительные погрешности.
-
-
- ≅
с точностью величин второго порядка малости относительно .
Тогда .
Если , то ≅
При большом числе n арифметических операций можно пользоваться приближенной статистической оценкой погрешности арифметических операций, учитывающей частичную компенсацию погрешностей разных знаков:
где – суммарная погрешность, – погрешность выполнения операций с плавающей точкой, – погрешность представления чисел с плавающей точкой.
Погрешности вычисления функций
Рассмотрим трансформированную погрешность вычисления значений функций.
Абсолютная трансформированная погрешность дифференцируемой функции , вызываемая достаточно малой погрешностью аргумента , оценивается величиной .
Если , то .
Абсолютная погрешность дифференцируемой функции многих аргументов , вызываемая достаточно малыми погрешностями аргументов оценивается величиной:
-
- .
Если , то .
Практически важно определить допустимую погрешность аргументов и допустимую погрешность функции (обратная задача). Эта задача имеет однозначное решение только для функций одной переменной , если дифференцируема и :
-
- .
Для функций многих переменных задача не имеет однозначного решения, необходимо ввести дополнительные ограничения. Например, если функция наиболее критична к погрешности , то:
-
- (погрешностью других аргументов пренебрегаем).
Если вклад погрешностей всех аргументов примерно одинаков, то применяют принцип равных влияний:
Числовые примеры
Специфику машинных вычислений можно пояснить на нескольких элементарных примерах.
ПРИМЕР 1. Вычислить все корни уравнения
Точное решение задачи легко найти:
Если компьютер работает при , то свободный член в исходном уравнении будет округлен до и, с точки зрения представления чисел с плавающей точкой, будет решаться уравнение , т.е. , что, очевидно, неверно. В данном случае малые погрешности в задании свободного члена привели, независимо от метода решения, к погрешности в решении .
ПРИМЕР 2. Решается задача Коши для обыкновенного дифференциального уравнения 2-го порядка:
Общее решение имеет вид:
При заданных начальных данных точное решение задачи: , однако малая погрешность в их задании приведет к появлению члена , который при больших значениях аргумента может существенно исказить решение.
ПРИМЕР 3. Пусть необходимо найти решение обыкновенного дифференциального уравнения:
Его решение: , однако значение известно лишь приближенно: , и на самом деле .
Соответственно, разность будет:
Предположим, что необходимо гарантировать некоторую заданную точность вычислений всюду на отрезке . Тогда должно выполняться условие:
Очевидно, что:
Отсюда можно получить требования к точности задания начальных данных при .
Таким образом, требование к заданию точности начальных данных оказываются в раз выше необходимой точности результата решения задачи. Это требование, скорее всего, окажется нереальным.
Решение оказывается очень чувствительным к заданию начальных данных. Такого рода задачи называются плохо обусловленными.
ПРИМЕР 4. Решением системы линейных алгебраических уравнений (СЛАУ):
является пара чисел .
Изменив правую часть системы на , получим возмущенную систему:
с решением , сильно отличающимся от решения невозмущенной системы. Эта система также плохо обусловлена.
ПРИМЕР 5. Рассмотрим методический пример вычислений на модельном компьютере, обеспечивающем точность . Проанализируем причину происхождения ошибки, например, при вычитании двух чисел, взятых с точностью до третьей цифры после десятичной точки , разность которых составляет .
В памяти машины эти же числа представляются в виде:
-
- , причем и
Тогда:
Относительная ошибка при вычислении разности будет равна:
Очевидно, что , т.е. все значащие цифры могут оказаться неверными.
ПРИМЕР 6. Рассмотрим рекуррентное соотношение
Пусть при выполнении реальных вычислений с конечной длиной мантиссы на -м шаге возникла погрешность округления, и вычисления проводятся с возмущенным значением , тогда вместо получим , т.е. .
Следовательно, если , то в процессе вычислений погрешность, связанная с возникшей ошибкой округления, будет возрастать (алгоритм неустойчив). В случае погрешность не возрастает и численный алгоритм устойчив.
Список литературы
- А.А.Самарский, А.В.Гулин. Численные методы. Москва «Наука», 1989.
- http://www.mgopu.ru/PVU/2.1/nummethods/Chapter1.htm
- http://www.intuit.ru/department/calculate/calcmathbase/1/4.html
См. также
- Практикум ММП ВМК, 4й курс, осень 2008
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
Заметили ошибку в решении суда — ничего страшного, всё можно исправить.
Ошибки бывают разные. В зависимости от того, какая ошибка, закон предусматривает разные пути её исправления.
Неумышленная описка в тексте решения или ошибка в расчётах исправляется просто. Сложнее, если суд ошибся в своих суждениях.
Имеет ли судья право на ошибку
Кто ничего не делает, тот и не ошибается — простое и понятное изречение.
Судья каждый день принимает решения и каждое решение несёт риск ошибки.
Можете возразить — судья представляет власть и не должен ошибаться.
Да, не должен, но иногда ошибается и с этим ничего не поделаешь.
Поэтому закон предусматривает многоэтапную проверку судебных решений — апелляция и кассация, в некоторых случаях надзор.
Вероятность ошибиться в нескольких инстанциях крайне низкая, но не нулевая. Ошибаются даже в Верховном Суде. И с этим то же ничего не поделаешь.
Что такое описка в решении суда
Были времена, когда текст судебного решения печатали на механической машинке, иногда писали от руки.
Нельзя было скопировать кусок текста из одного решение и вставить в другой. Мотивировка решения была скудной, а текст решения умещался на одной странице.
Сегодня тексты набирают на компьютере: быстро, удобно, повышает производительность.
Однако ошибались всегда: в рукописном тексте допускали описку, в печатном — опечатку.
В любом случае, описка или опечатка — это неумышленная случайная ошибка из-за невнимательности при подготовке текста.
Отличие от судебной ошибки
Описку в решении суда нужно отличать от судебной ошибки. Это важно, от этого зависит способ исправления дефекта в судебном решении.
Описка — это результат невнимательности: хотели написать одно, получилось другое.
Судья или помощник торопились при составлении текста решения, потом не проверили его, и вот результат.
Судебная же ошибка всегда осознанна — суд ошибается в суждениях, оценке доказательств, выборе и применении закона.
Описка или опечатка — ошибка в букве, слове, предложении. Судебная ошибка — ошибка в мыслях.
Ошибка в арифметике: явная и неявная
У судей нет времени сидеть с калькулятором, делать или проверять сложные расчёты.
Особо сложные, например проверку бухгалтерского или налогового учёта, судьи поручают экспертам.
Расчёт предоставляют участники процесса. Судья либо соглашается с ним, либо делает свой.
Обсчитаться может каждый. Не нужно забывать, что большинство судей гуманитарии не только по образованию, но и по типу мышления.
Арифметическая ошибка — ошибка в математических расчётах.
Неправильно умножили, не там поставили запятую перед десятичным знаком, сложили не те значения, наконец, просто потеряли ноль.
Явная арифметическая ошибка — очевидная, грубая, которую может определить человек со школьным уровнем знаний в арифметике.
Почти все ошибки явные. Поэтому не нужно забивать голову вопросом: «Явную или неявную арифметическую ошибку допустил судья?»
Способы исправления
Исправление описки или арифметической ошибки в тексте решении суда — это НЕ изменение самого решения
При изменении решения меняется его смысловое содержание. Неважно, полностью или частично.
Суд не вправе изменить своё решение. Это запрещено законом и разрешено только вышестоящему суду.
А вот неумышленную описку и ошибку в расчётах исправляет суд, который её допустил.
Отсюда следующее правило:
- Судья неумышленно в решении допустил описку (опечатку) или ошибся в математических расчётах — подаём заявление об исправлении
- Судья ошибся в суждениях, оценке доказательств, выборе и применении закона (допустил осознанную судебную ошибку) — подаем апелляционную жалобу на решение суда
Когда нужно исправлять решение
«Исправить или оставить как есть» — зависит от конкретной ситуации, от обстоятельств дела.
Важно определить, какие последствия может повлечь такая описка. Лучше, если это сделает юрист.
Немаловажно в какой части решения описка.
Описка в резолютивной части (после «суд решил») — лучше исправить.
В мотивировочной части (где выводы суда) — на усмотрение, опять же в зависимости от возможных последствий.
Арифметические ошибки нужно исправлять, когда обсчёт существенен.
Не нужно тратить силы и время, если судья ошибся на несколько копеек или рублей.
Кстати, исправить описку или ошибку в арифметике можно не только в решении суда, но и в определении, по аналогии.
Кто инициирует, кто исправляет, куда подавать
Исправление описки или арифметической ошибки инициирует тот, кто её обнаружил.
Если заметил судья — исправит по собственной инициативе, если участник процесса — суд на основании его заявления.
Не нужно ждать инициативы от суда — у судей много работы и нет времени на перепроверку своих же решений.
Просто помогите судье — подайте заявление об исправлении, не ждите что это сделает кто-то другой.
Заявление нужно подавать по принципу: кто ошибся, тот и должен исправить — кто должен исправить, тому адресуем и ему же подаём.
Заявление в суд об исправлении описки
Составить самому заявление в суд об исправлении описки не сложно. В Интернете масса образцов, само же заявление — на одну страницу.
Структура заявления проста и состоит из четырёх частей:
- Обозначаем описку
- Мотивируем, почему это описка
- Ссылаемся на статьи 200 и 203.1 ГПК РФ (в арбитраже — статья 179 АПК РФ)
- Просим исправить, предлагая свой вариант
В качестве примера. Разъясняя в мотивировочной части решения права истцу, судья перепутал его ФИО с ФИО ответчика.
Просительная часть заявления об исправлении описки будет выглядеть следующим образом:
— Прошу исправить допущенную в первом предложении последнего абзаца мотивировочной части решения суда описку:
«При таких обстоятельствах, Иванов Иван Иванович вправе требовать установления сервитута в отношении застроенного земельного участка»,
изложив его в следующей редакции:
«При таких обстоятельствах, Петров Пётр Петрович вправе требовать установления сервитута в отношении застроенного земельного участка»
Когда лучше привлечь юриста
Заявление не всегда простенький текст на половину страницы. Иногда его нужно дополнить смысловой нагрузкой.
Суд исказил фамилию участника, неправильно указал отчество, ошибся в дате рождения — всё это легко исправимо и не требует участия юриста.
Другое дело, когда не совсем ясно, почему суд допустил описку и описка ли это вообще.
В этом случае за составлением заявления лучше обратиться к юристу или адвокату, минимум — получить консультацию.
Почему меня не вызвали в суд
Раньше суд рассматривал заявление об исправлении описки в решении только в судебном заседании.
Рассмотрение вопроса об исправлении вне судебного заседания считалось процессуальным нарушением.
Сейчас у судьи два варианта:
- Не проводить заседание, не извещать участников процесса
- Провести заседание, предварительно сообщив участникам время и место проведения
Вариант определяет судья, по своему усмотрению. Сочтёт необходимым — вызовет и проведёт заседание, не сочтёт — рассмотрит не заседая в одиночестве.
Суд отказал в исправлении описки. Что дальше?
Рассмотрев заявление о исправлении, суд выносит определение — либо исправляет, либо отказывает в этом.
Если вопрос рассматривался в судебном заседании с вызовом, обычно копию определения вручают здесь же.
Если суд не проводил заседания, копию высылают в течение трёх дней по почте.
Почтовые отправления — всегда риск. Лучше отследить дело и получить определение в суде.
Судья отказал в исправлении, вы не согласны, позиции разошлись — можно подать частную жалобу
Здесь точно лучше обратиться к юристу.
Арифметическая ошибка
Cтраница 1
Арифметические ошибки при подсчете записей на счетах бухгалтерского учета и итогов в оборотной ведомости также приведут к нарушению трех рассматриваемых равенств.
[1]
Величина абсолютной арифметической ошибки не может полностью характеризовать точность измерения. Так, например, если средняя арифметическая ошибка определения составляет 0 1 %, то при содержании определяемого элемента в пробах в 5 % эта ошибка мала, а при содержании определяемого элемента в 0 5 % велика.
[2]
Во избежание арифметических ошибок рекомендуется вычерчивать схемы расположения полей допусков, разделенных на групповые допуски, и проставлять на схеме соответствующие обозначения.
[3]
При наличии арифметических ошибок задача se может считаться решенной безукоризненно.
[4]
Способом корректуры исправляют арифметические ошибки, описки, записи операций не в тот учетный регистр в момент их совершения и до составления бухгалтерского баланса. Корректурным способом нецелесообразно пользоваться для исправления ошибочно записанных сумм в тех учетных регистрах, в которых уже подсчитаны итоги.
[5]
Данные по определению относительной арифметической ошибки единичного определения представлены в таблице.
[6]
Небольшое несоответствие вызывается частично арифметическими ошибками округления при вычислении коэффициентов в уравнении (12.100) л частично небольшим, но неизбежным наложением.
[7]
Об исправлении описок, арифметических ошибок, а также о разъяснении решения выносится определение в срок не более трех рабочих дней со дня получения заявления. Исправление и разъяснение определения Арбитража производится также в соответствии с настоящим пунктом Правил.
[8]
При этом гарантируется отсутствие арифметических ошибок и ошибок, связанных с неправильной реализацией алгоритма расчета режимов.
[9]
Об исправлении описок, арифметических ошибок, а также о разъяснении решения выносится определение в срок не более трех рабочих дней со дня получения заявления. Исправление и разъяснение определения Арбитража производится также в соответствии с настоящим пунктом Правил.
[10]
В целях уменьшения вероятности арифметических ошибок все расчеты целесообразно осуществлять в единицах СИ, а окончательный ответ выражать, если это удобно, в кратных и дольных единицах.
[11]
Слутский и Бауэр [4] нашли арифметическую ошибку в расчетах авторов работы [3] величины теплоты образования монофторида иода и показали, что следует принимать высшее значение величины энергии диссоциации JF, откуда следует, что монофторид иода является наиболее устойчивым из двухатомных межгалоидных соединений. Это находится в соответствии с возрастанием отношений энергий диссоциации к силовым константам ( 0 57 — 0 63 — 0 79) в ряду GIF — BrF — JF по мере увеличения атомного веса, а также согласуется с увеличением полярности связи в этих соединениях вследствие возрастания разности значений электроотрицательное-тей, входящих в молекулу атомов.
[12]
В счетах-фактурах отражены правильные количества; арифметических ошибок нет.
[13]
Так что извещать налогоплательщика при обнаружении арифметических ошибок необходимо как в случае неполной, так и излишней уплаты налогов.
[15]
Страницы:
1
2
3
4
Полученные
в результате статистического исследования
средние и относительные величины должны
отражать закономерности, характерные
для всей совокупности. Результаты
исследования обычно тем достовернее,
чем больше сделано наблюдений, и наиболее
точными они являются при сплошном
исследовании (т.е. при изучении генеральной
совокупности). Однако должны быть
достаточно надежные и данные, полученные
путем выборочных исследований, т.е. на
относительно небольшом числе наблюдений.
Различие
результатов выборочного исследования
и результатов, которые могут быть
получены на генеральной совокупности,
представляет собой ошибку выборочного
исследования, которую можно точно
определить математическим путем. Метод
ее оценки основан на закономерностях
случайных вариаций, установленных
теорией вероятности.
1.
Оценка достоверности средней
арифметической.
Средняя
арифметическая, полученная при обработке
результатов научно-практических
исследований, под влиянием случайных
явлений может отличаться от средних,
полученных при проведении повторных
исследований. Поэтому, чтобы иметь
представление о возможных пределах
колебаний средней, о том, с какой
вероятностью возможно перенести
результаты исследования с выборочной
совокупности на всю генеральную
совокупность, определяют степень
достоверности средней величины.
Мерой
достоверности средней является средняя
ошибка средней арифметической (ошибка
репрезентативности – m).
Ошибки репрезентативности возникают
в связи с тем, что при выборочным
наблюдении изучается только часть
генеральной совокупности, которая
недостаточно точно ее представляет.
Фактически ошибка репрезентативности
является разностью между средними,
полученными при выборочном статистическом
наблюдении, и средними, которые были бы
получены при сплошном наблюдении (т.е.
при изучении всей генеральной
совокупности).
Средняя
ошибка средней арифметической вычисляется
по формуле:
—
при числе наблюдений больше 30 (n
> 30):
![]()
—
при небольшом числе наблюдений (n
< 30):
![]()
Ошибка
репрезентативности прямо пропорциональна
колеблемости ряда (сигме) и обратно
пропорциональна числу наблюдений.
Следовательно,
чем больше
число наблюдений
(т.е. чем ближе по числу наблюдений
выборочная совокупность к генеральной),
тем меньше
ошибка репрезентативности.
Интервал,
в котором с заданным уровнем вероятности
колеблется истинное значение средней
величины или показателя, называется
доверительным
интервалом,
а его границы – доверительными
границами.
Они используются для определения
размеров средней или показателя в
генеральной совокупности.
Доверительные
границы
средней арифметической и показателя в
генеральной совокупности равны:
M
+
tm
P
+
tm,
где
t
– доверительный коэффициент.
Доверительный
коэффициент (t)
– это число, показывающее, во сколько
раз надо увеличить ошибку средней
величины или показателя, чтобы при
данном числе наблюдений с желаемой
степенью вероятности утверждать, что
они не выйдут за полученные таким образом
пределы.
С
увеличением t
степень вероятности возрастает.
Т.к.
известно, что полученная средняя или
показатель при повторных наблюдениях,
даже при одинаковых условиях, в силу
случайных колебаний будут отличаться
от предыдущего результат, теорией
статистики установлена степень
вероятности, с которой можно ожидать,
что колебания эти не выйдут за определенные
пределы. Так, колебания средней
в интервале M
+
1m
гарантируют ее точность с вероятностью
68.3% (такая
степень вероятности не удовлетворяет
исследователей), в
интервале M
+
2m
– 95.5%
(достаточная степень вероятности) и в
интервале M
+
3m
– 99,7% (большая
степень вероятности).
Для
медико-биологических исследований
принята степень вероятности 95% (t
= 2), что соответствует доверительному
интервалу M
+
2m.
Это
означает, что практически
с полной достоверностью (в 95%) можно
утверждать, что полученный средний
результат (М) отклоняется от истинного
значения не больше, чем на удвоенную (M
+
2m) ошибку.
Конечный
результат любого медико-статистического
исследования выражается средней
арифметической и ее параметрами:
![]()
2.
Оценка достоверности относительных
величин (показателей).
Средняя
ошибка показателя также служит для
определения пределов его случайных
колебаний, т.е. дает представление, в
каких пределах может находиться
показатель в различных выборках в
зависимости от случайных причин. С
увеличением численности выборки ошибка
уменьшается.
Мерой
достоверности показателя является его
средняя ошибка (m),
которая показывает, на сколько результат,
полученный при выборочным исследовании,
отличается от результата, который был
бы получен при изучении всей генеральной
совокупности.
Средняя
ошибка показателя определяется по
формуле:
![]() ,
,
где mp
– ошибка относительного показателя,
р
– показатель,
q
– величина, обратная показателю (100-p,
1000-р и т.д. в зависимости от того, на какое
основание рассчитан показатель);
n
– число наблюдений.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Материал из MachineLearning.
Перейти к: навигация, поиск
Содержание
- 1 Введение
- 1.1 Постановка вопроса. Виды погрешностей
- 2 Виды мер точности
- 3 Предельные погрешности
- 4 Погрешности округлений при представлении чисел в компьютере
- 5 Погрешности арифметических операций
- 6 Погрешности вычисления функций
- 7 Числовые примеры
- 8 Список литературы
- 9 См. также
Введение
Постановка вопроса. Виды погрешностей
Процесс исследования исходного объекта методом математического моделирования и вычислительного эксперимента неизбежно носит приближенный характер, так как на каждом этапе вносятся погрешности. Построение математической модели связано с упрощением исходного явления, недостаточно точным заданием коэффициентов уравнения и других входных данных. По отношению к численному методу, реализующему данную математическую модель, указанные погрешности являются неустранимыми, поскольку они неизбежны в рамках данной модели.
При переходе от математической модели к численному методу возникают погрешности, называемые погрешностями метода. Они связаны с тем, что всякий численный метод воспроизводит исходную математическую модель приближенно. Наиболее типичными погрешностями метода являются погрешность дискретизации и погрешность округления.
При построении численного метода в качестве аналога исходной математической задачи обычно рассматривается её дискретная модель. Разность решений дискретизированной задачи и исходной называется погрешностью дискретизации. Обычно дискретная модель зависит от некоторого параметра (или их множества) дискретизации, при стремлении которого к нулю должна стремиться к нулю и погрешность дискретизации.
Дискретная модель представляет собой систему большого числа алгебраических уравнений. Для её решения используется тот или иной численный алгоритм. Входные данные этой системы, а именно коэффициенты и правые части, задаются в ЭВМ не точно, а с округлением. В процессе работы алгоритма погрешности округления обычно накапливаются, и в результате, решение, полученное на ЭВМ, будет отличаться от точного решения дискретизированной задачи. Результирующая погрешность называется погрешностью округления (вычислительной погрешностью). Величина этой погрешности определяется двумя факторами: точностью представления вещественных чисел в ЭВМ и чувствительностью данного алгоритма к погрешностям округления.
Итак, следует различать погрешности модели, дискретизации и округления. В вопросе преобладания какой-либо погрешности ответ неоднозначен. В общем случае нужно стремиться, чтобы все погрешности имели один и тот же порядок. Например, нецелесообразно пользоваться разностными схемами, имеющими точность 10−6, если коэффициенты исходных уравнений задаются с точностью 10−2.
Виды мер точности
Мерой точности вычислений являются абсолютные и относительные погрешности. Абсолютная погрешность определяется формулой
где – приближение к точному значению .
Относительная погрешность определяется формулой
Относительная погрешность часто выражается в процентах. Абсолютная и относительная погрешности тесно связаны с понятием верных значащих цифр. Значащими цифрами числа называют все цифры в его записи, начиная с первой ненулевой цифры слева. Например, число 0,000129 имеет три значащих цифры. Значащая цифра называется верной, если абсолютная погрешность числа не превышает половины веса разряда, соответствующего этой цифре. Например, , абсолютная погрешность . Записывая число в виде
имеем , следовательно, число имеет две верных значащих цифр (9 и 3).
В общем случае абсолютная погрешность должна удовлетворять следующему неравенству:
где — порядок (вес) старшей цифры, — количество верных значащих цифр.
В рассматриваемом примере .
Относительная погрешность связана с количеством верных цифр приближенного числа соотношением:
где — старшая значащая цифра числа.
Для двоичного представления чисел имеем .
Тот факт, что число является приближенным значением числа с абсолютной погрешностью , записывают в виде
причем числа и записываются с одинаковым количеством знаков после запятой, например, или .
Запись вида
означает, что число является приближенным значение числа с относительной погрешностью .
Так как точное решение задачи как правило неизвестно, то погрешности приходится оценивать через исходные данные и особенности алгоритма. Если оценка может быть вычислена до решения задачи, то она называется априорной. Если оценка вычисляется после получения приближенного решения задачи, то она называется апостериорной.
Очень часто степень точности решения задачи характеризуется некоторыми косвенными вспомогательными величинами. Например точность решения системы алгебраических уравнений
характеризуется невязкой
где — приближенное решение системы.
Причём невязка достаточно сложным образом связана с погрешностью решения , причём если невязка мала, то погрешность может быть значительной.
Предельные погрешности
Пусть искомая величина является функцией параметров — приближенное значение . Тогда предельной абсолютной погрешностью называется величина
Предельной относительной погрешностью называется величина .
Пусть — приближенное значение . Предполагаем, что — непрерывно дифференцируемая функция своих аргументов. Тогда, по формуле Лагранжа,
где .
Отсюда
где .
Можно показать, что при малых эта оценка не может быть существенно улучшена. На практике иногда пользуются грубой (линейной) оценкой
где .
Несложно показать, что:
- — предельная погрешность суммы или разности равна сумме предельных погрешностей.
- — предельная относительная погрешность произведения или частного приближенного равна сумме предельных относительных погрешностей.
Погрешности округлений при представлении чисел в компьютере
Одним из основных источников вычислительных погрешностей является приближенное представление чисел в компьютере, обусловленное конечностью разрядной сетки (см. Международный стандарт представления чисел с плавающей точкой в ЭВМ). Число , не представимое в компьютере, подвергается округлению, т. е. заменяется близким числом , представимым в компьютере точно.
Найдем границу относительной погрешности представления числа с плавающей точкой. Допустим, что применяется простейшее округление – отбрасывание всех разрядов числа, выходящих за пределы разрядной сетки. Система счисления – двоичная. Пусть надо записать число, представляющее бесконечную двоичную дробь
где , — цифры мантиссы.
Пусть под запись мантиссы отводится t двоичных разрядов. Отбрасывая лишние разряды, получим округлённое число
Абсолютная погрешность округления в этом случае равна
Наибольшая погрешность будет в случае , тогда
Т.к. , где — мантисса числа , то всегда . Тогда и относительная погрешность равна . Практически применяют более точные методы округления и погрешность представления чисел равна
( 1 )
т.е. точность представления чисел определяется разрядностью мантиссы .
Тогда приближенно представленное в компьютере число можно записать в виде , где – «машинный эпсилон» – относительная погрешность представления чисел.
Погрешности арифметических операций
При вычислениях с плавающей точкой операция округления может потребоваться после выполнения любой из арифметических операций. Так умножение или деление двух чисел сводится к умножению или делению мантисс. Так как в общем случае количество разрядов мантисс произведений и частных больше допустимой разрядности мантиссы, то требуется округление мантиссы результатов. При сложении или вычитании чисел с плавающей точкой операнды должны быть предварительно приведены к одному порядку, что осуществляется сдвигом вправо мантиссы числа, имеющего меньший порядок, и увеличением в соответствующее число раз порядка этого числа. Сдвиг мантиссы вправо может привести к потере младших разрядов мантиссы, т.е. появляется погрешность округления.
Округленное в системе с плавающей точкой число, соответствующее точному числу , обозначается через (от англ. floating – плавающий). Выполнение каждой арифметической операции вносит относительную погрешность, не большую, чем погрешность представления чисел с плавающей точкой (1). Верна следующая запись:
где — любая из арифметических операций, .
Рассмотрим трансформированные погрешности арифметических операций. Арифметические операции проводятся над приближенными числами, ошибка арифметических операций не учитывается (эту ошибку легко учесть, прибавив ошибку округления соответствующей операции к вычисленной ошибке).
Рассмотрим сложение и вычитание приближенных чисел. Абсолютная погрешность алгебраической суммы нескольких приближенных чисел равна сумме абсолютных погрешностей слагаемых.
Если сумма точных чисел равна
сумма приближенных чисел равна
где — абсолютные погрешности представления чисел.
Тогда абсолютная погрешность суммы равна
Относительная погрешность суммы нескольких чисел равна
( 2 )
где — относительные погрешности представления чисел.
Из (2) следует, что относительная погрешность суммы нескольких чисел одного и того же знака заключена между наименьшей и наибольшей из относительных погрешностей слагаемых:
При сложении чисел разного знака или вычитании чисел одного знака относительная погрешность может быть очень большой (если числа близки между собой). Так как даже при малых величина может быть очень малой. Поэтому вычислительные алгоритмы необходимо строить таким образом, чтобы избегать вычитания близких чисел.
Необходимо отметить, что погрешности вычислений зависят от порядка вычислений. Далее будет рассмотрен пример сложения трех чисел.
( 3 )
При другой последовательности действий погрешность будет другой:
Из (3) видно, что результат выполнения некоторого алгоритма, искаженный погрешностями округлений, совпадает с результатом выполнения того же алгоритма, но с неточными исходными данными. Т.е. можно применять обратный анализ: свести влияние погрешностей округления к возмущению исходных данных. Тогда вместо (3) будет следующая запись:
где
При умножении и делении приближенных чисел складываются и вычитаются их относительные погрешности.
-
-
- ≅
с точностью величин второго порядка малости относительно .
Тогда .
Если , то ≅
При большом числе n арифметических операций можно пользоваться приближенной статистической оценкой погрешности арифметических операций, учитывающей частичную компенсацию погрешностей разных знаков:
где – суммарная погрешность, – погрешность выполнения операций с плавающей точкой, – погрешность представления чисел с плавающей точкой.
Погрешности вычисления функций
Рассмотрим трансформированную погрешность вычисления значений функций.
Абсолютная трансформированная погрешность дифференцируемой функции , вызываемая достаточно малой погрешностью аргумента , оценивается величиной .
Если , то .
Абсолютная погрешность дифференцируемой функции многих аргументов , вызываемая достаточно малыми погрешностями аргументов оценивается величиной:
-
- .
Если , то .
Практически важно определить допустимую погрешность аргументов и допустимую погрешность функции (обратная задача). Эта задача имеет однозначное решение только для функций одной переменной , если дифференцируема и :
-
- .
Для функций многих переменных задача не имеет однозначного решения, необходимо ввести дополнительные ограничения. Например, если функция наиболее критична к погрешности , то:
-
- (погрешностью других аргументов пренебрегаем).
Если вклад погрешностей всех аргументов примерно одинаков, то применяют принцип равных влияний:
Числовые примеры
Специфику машинных вычислений можно пояснить на нескольких элементарных примерах.
ПРИМЕР 1. Вычислить все корни уравнения
Точное решение задачи легко найти:
Если компьютер работает при , то свободный член в исходном уравнении будет округлен до и, с точки зрения представления чисел с плавающей точкой, будет решаться уравнение , т.е. , что, очевидно, неверно. В данном случае малые погрешности в задании свободного члена привели, независимо от метода решения, к погрешности в решении .
ПРИМЕР 2. Решается задача Коши для обыкновенного дифференциального уравнения 2-го порядка:
Общее решение имеет вид:
При заданных начальных данных точное решение задачи: , однако малая погрешность в их задании приведет к появлению члена , который при больших значениях аргумента может существенно исказить решение.
ПРИМЕР 3. Пусть необходимо найти решение обыкновенного дифференциального уравнения:
Его решение: , однако значение известно лишь приближенно: , и на самом деле .
Соответственно, разность будет:
Предположим, что необходимо гарантировать некоторую заданную точность вычислений всюду на отрезке . Тогда должно выполняться условие:
Очевидно, что:
Отсюда можно получить требования к точности задания начальных данных при .
Таким образом, требование к заданию точности начальных данных оказываются в раз выше необходимой точности результата решения задачи. Это требование, скорее всего, окажется нереальным.
Решение оказывается очень чувствительным к заданию начальных данных. Такого рода задачи называются плохо обусловленными.
ПРИМЕР 4. Решением системы линейных алгебраических уравнений (СЛАУ):
является пара чисел .
Изменив правую часть системы на , получим возмущенную систему:
с решением , сильно отличающимся от решения невозмущенной системы. Эта система также плохо обусловлена.
ПРИМЕР 5. Рассмотрим методический пример вычислений на модельном компьютере, обеспечивающем точность . Проанализируем причину происхождения ошибки, например, при вычитании двух чисел, взятых с точностью до третьей цифры после десятичной точки , разность которых составляет .
В памяти машины эти же числа представляются в виде:
-
- , причем и
Тогда:
Относительная ошибка при вычислении разности будет равна:
Очевидно, что , т.е. все значащие цифры могут оказаться неверными.
ПРИМЕР 6. Рассмотрим рекуррентное соотношение
Пусть при выполнении реальных вычислений с конечной длиной мантиссы на -м шаге возникла погрешность округления, и вычисления проводятся с возмущенным значением , тогда вместо получим , т.е. .
Следовательно, если , то в процессе вычислений погрешность, связанная с возникшей ошибкой округления, будет возрастать (алгоритм неустойчив). В случае погрешность не возрастает и численный алгоритм устойчив.
Список литературы
- А.А.Самарский, А.В.Гулин. Численные методы. Москва «Наука», 1989.
- http://www.mgopu.ru/PVU/2.1/nummethods/Chapter1.htm
- http://www.intuit.ru/department/calculate/calcmathbase/1/4.html
См. также
- Практикум ММП ВМК, 4й курс, осень 2008
Заметили ошибку в решении суда — ничего страшного, всё можно исправить.
Ошибки бывают разные. В зависимости от того, какая ошибка, закон предусматривает разные пути её исправления.
Неумышленная описка в тексте решения или ошибка в расчётах исправляется просто. Сложнее, если суд ошибся в своих суждениях.
Имеет ли судья право на ошибку
Кто ничего не делает, тот и не ошибается — простое и понятное изречение.
Судья каждый день принимает решения и каждое решение несёт риск ошибки.
Можете возразить — судья представляет власть и не должен ошибаться.
Да, не должен, но иногда ошибается и с этим ничего не поделаешь.
Поэтому закон предусматривает многоэтапную проверку судебных решений — апелляция и кассация, в некоторых случаях надзор.
Вероятность ошибиться в нескольких инстанциях крайне низкая, но не нулевая. Ошибаются даже в Верховном Суде. И с этим то же ничего не поделаешь.
Что такое описка в решении суда
Были времена, когда текст судебного решения печатали на механической машинке, иногда писали от руки.
Нельзя было скопировать кусок текста из одного решение и вставить в другой. Мотивировка решения была скудной, а текст решения умещался на одной странице.
Сегодня тексты набирают на компьютере: быстро, удобно, повышает производительность.
Однако ошибались всегда: в рукописном тексте допускали описку, в печатном — опечатку.
В любом случае, описка или опечатка — это неумышленная случайная ошибка из-за невнимательности при подготовке текста.
Отличие от судебной ошибки
Описку в решении суда нужно отличать от судебной ошибки. Это важно, от этого зависит способ исправления дефекта в судебном решении.
Описка — это результат невнимательности: хотели написать одно, получилось другое.
Судья или помощник торопились при составлении текста решения, потом не проверили его, и вот результат.
Судебная же ошибка всегда осознанна — суд ошибается в суждениях, оценке доказательств, выборе и применении закона.
Описка или опечатка — ошибка в букве, слове, предложении. Судебная ошибка — ошибка в мыслях.
Ошибка в арифметике: явная и неявная
У судей нет времени сидеть с калькулятором, делать или проверять сложные расчёты.
Особо сложные, например проверку бухгалтерского или налогового учёта, судьи поручают экспертам.
Расчёт предоставляют участники процесса. Судья либо соглашается с ним, либо делает свой.
Обсчитаться может каждый. Не нужно забывать, что большинство судей гуманитарии не только по образованию, но и по типу мышления.
Арифметическая ошибка — ошибка в математических расчётах.
Неправильно умножили, не там поставили запятую перед десятичным знаком, сложили не те значения, наконец, просто потеряли ноль.
Явная арифметическая ошибка — очевидная, грубая, которую может определить человек со школьным уровнем знаний в арифметике.
Почти все ошибки явные. Поэтому не нужно забивать голову вопросом: «Явную или неявную арифметическую ошибку допустил судья?»
Способы исправления
Исправление описки или арифметической ошибки в тексте решении суда — это НЕ изменение самого решения
При изменении решения меняется его смысловое содержание. Неважно, полностью или частично.
Суд не вправе изменить своё решение. Это запрещено законом и разрешено только вышестоящему суду.
А вот неумышленную описку и ошибку в расчётах исправляет суд, который её допустил.
Отсюда следующее правило:
- Судья неумышленно в решении допустил описку (опечатку) или ошибся в математических расчётах — подаём заявление об исправлении
- Судья ошибся в суждениях, оценке доказательств, выборе и применении закона (допустил осознанную судебную ошибку) — подаем апелляционную жалобу на решение суда
Когда нужно исправлять решение
«Исправить или оставить как есть» — зависит от конкретной ситуации, от обстоятельств дела.
Важно определить, какие последствия может повлечь такая описка. Лучше, если это сделает юрист.
Немаловажно в какой части решения описка.
Описка в резолютивной части (после «суд решил») — лучше исправить.
В мотивировочной части (где выводы суда) — на усмотрение, опять же в зависимости от возможных последствий.
Арифметические ошибки нужно исправлять, когда обсчёт существенен.
Не нужно тратить силы и время, если судья ошибся на несколько копеек или рублей.
Кстати, исправить описку или ошибку в арифметике можно не только в решении суда, но и в определении, по аналогии.
Кто инициирует, кто исправляет, куда подавать
Исправление описки или арифметической ошибки инициирует тот, кто её обнаружил.
Если заметил судья — исправит по собственной инициативе, если участник процесса — суд на основании его заявления.
Не нужно ждать инициативы от суда — у судей много работы и нет времени на перепроверку своих же решений.
Просто помогите судье — подайте заявление об исправлении, не ждите что это сделает кто-то другой.
Заявление нужно подавать по принципу: кто ошибся, тот и должен исправить — кто должен исправить, тому адресуем и ему же подаём.
Заявление в суд об исправлении описки
Составить самому заявление в суд об исправлении описки не сложно. В Интернете масса образцов, само же заявление — на одну страницу.
Структура заявления проста и состоит из четырёх частей:
- Обозначаем описку
- Мотивируем, почему это описка
- Ссылаемся на статьи 200 и 203.1 ГПК РФ (в арбитраже — статья 179 АПК РФ)
- Просим исправить, предлагая свой вариант
В качестве примера. Разъясняя в мотивировочной части решения права истцу, судья перепутал его ФИО с ФИО ответчика.
Просительная часть заявления об исправлении описки будет выглядеть следующим образом:
— Прошу исправить допущенную в первом предложении последнего абзаца мотивировочной части решения суда описку:
«При таких обстоятельствах, Иванов Иван Иванович вправе требовать установления сервитута в отношении застроенного земельного участка»,
изложив его в следующей редакции:
«При таких обстоятельствах, Петров Пётр Петрович вправе требовать установления сервитута в отношении застроенного земельного участка»
Когда лучше привлечь юриста
Заявление не всегда простенький текст на половину страницы. Иногда его нужно дополнить смысловой нагрузкой.
Суд исказил фамилию участника, неправильно указал отчество, ошибся в дате рождения — всё это легко исправимо и не требует участия юриста.
Другое дело, когда не совсем ясно, почему суд допустил описку и описка ли это вообще.
В этом случае за составлением заявления лучше обратиться к юристу или адвокату, минимум — получить консультацию.
Почему меня не вызвали в суд
Раньше суд рассматривал заявление об исправлении описки в решении только в судебном заседании.
Рассмотрение вопроса об исправлении вне судебного заседания считалось процессуальным нарушением.
Сейчас у судьи два варианта:
- Не проводить заседание, не извещать участников процесса
- Провести заседание, предварительно сообщив участникам время и место проведения
Вариант определяет судья, по своему усмотрению. Сочтёт необходимым — вызовет и проведёт заседание, не сочтёт — рассмотрит не заседая в одиночестве.
Суд отказал в исправлении описки. Что дальше?
Рассмотрев заявление о исправлении, суд выносит определение — либо исправляет, либо отказывает в этом.
Если вопрос рассматривался в судебном заседании с вызовом, обычно копию определения вручают здесь же.
Если суд не проводил заседания, копию высылают в течение трёх дней по почте.
Почтовые отправления — всегда риск. Лучше отследить дело и получить определение в суде.
Судья отказал в исправлении, вы не согласны, позиции разошлись — можно подать частную жалобу
Здесь точно лучше обратиться к юристу.
Понятие «счетная ошибка» белорусским законодательством не закреплено, из-за чего у бухгалтеров и иных специалистов возникают затруднения в том, что принимать за счетную ошибку, а что нет. Рассмотрим некоторые примеры, на первый взгляд кажущиеся счетной ошибкой, но таковыми не являющиеся.
Справочно: заработная плата, излишне выплаченная работнику нанимателем, в т.ч. при неправильном применении закона, не может быть с него взыскана, за исключением случаев счетной ошибки (часть третья ст. 107 ТК*).
* Трудовой кодекс Республики Беларусь (далее – ТК).
Из сложившейся практики, счетная ошибка – это техническая ошибка, т.е. описка, опечатка, пропуск или повторный ввод данных, арифметическая ошибка при подведении итогов, неточное округление.
К примерам счетных ошибок можно отнести:
1) арифметическую ошибку, допущенную в результате арифметических действий (сложения, деления, умножения, вычитания, округления). Например, при подсчете размера заработной платы произведено неправильное сложение. При сложении 1 030 + 200 получено 1 330, а необходимо 1 230 руб.;
2) механическую ошибку, допущенную при вводе данных на компьютере. Например, при наборе цифр вместо 230 руб. введено 320 руб.;
3) сбой бухгалтерской программы, который привел к появлению счетной ошибки.
Несмотря на кажущуюся первоначально понятность, на практике часто возникают пограничные случаи, вызывающие неправильное понимание счетной ошибки.
Рассмотрим это на примерах.
Пример 1. Неправильное применение норм законодательства при предоставлении трудовых отпусков (не счетная ошибка)
1. Кадровый работник при предоставлении трудового отпуска сотруднику неправильно суммировал основной и дополнительные отпуска. К примеру, специалистом по кадрам ошибочно оформлен трудовой отпуск работнику, работающему по трудовому договору на неопределенный срок, в количестве 30 календарных дней, из которых 24 дня – основной отпуск, 5 дней – дополнительный за ненормированный рабочий день и 1 день – дополнительный отпуск в связи с заключением контракта согласно ст. 261.2 ТК. Дополнительный поощрительный отпуск согласно ст. 261.2 ТК предоставляется только в связи с заключением контракта.
В данном же случае у работника заключен трудовой договор на неопределенный срок. В результате работнику предоставлено трудового отпуска и выплачено отпускных за 30 календарных дней трудового отпуска вместо полагающихся 29.
В данном случае имеет место неправильное применение норм законодательства при предоставлении трудовых отпусков и излишне выплаченные отпускные за 1 день отпуска не могут быть удержаны из заработной платы работника.
Пример 2. Счетная ошибка в связи с неправильным арифметическим сложением
Специалист по кадрам подготовил приказ о предоставлении трудового отпуска, в котором отразил: «предоставить трудовой отпуск продолжительностью 30 календарных дней за рабочий год с 12.11.2021 по 11.11.2022, в том числе 24 дня основного отпуска, 2 календарных дня в связи с заключением контракта и 3 дня дополнительного отпуска в связи с работой во вредных условиях труда».
В данном случае имеет место не неправильное применение норм о суммировании отпуска, а просто арифметическая ошибка, выразившаяся в неправильном сложении основного отпуска с дополнительным. Вместо 29 дней отпуска указано 30 дней в общем. Поэтому такой случай можно признать технической ошибкой и соответственно произвести удержание в порядке ст. 107 ТК.
Пример 3. Начисление лишней зарплаты в результате халатности бухгалтера (не счетная ошибка)
В бухгалтерию передан приказ о наказании, согласно которому работнику объявлен выговор с лишением премиальных за месяц. Однако при начислении заработной платы бухгалтер по зарплате не обратил внимания на данный приказ (он находился под ворохом других бумаг) и начислил работнику премиальные в полном объеме.
Это не счетная ошибка, а халатные действия бухгалтера, который в силу ст. 400 ТК и в порядке ст. 408 ТК может быть привлечен к материальной ответственности за действия, повлекшие причинение материального ущерба нанимателю.
К счетным ошибкам следует относить и технические ошибки.
Пример 4. Техническая ошибка при начислении зарплаты (счетная ошибка)
При зачислении на карт-счет работника причитающаяся ему сумма заработной платы зачислена дважды (зачислена заработная плата его однофамильца и т.п.).
Однако если работнику начислена заработная плата сверху установленного размера, например, начислена премия, которая согласно Положению о премировании не должна быть выплачена, то это уже не счетная ошибка, а неправильное применение норм локальных правовых актов.
Пример 5. Неправильное применение норм об определении среднего заработка (не счетная ошибка)
При расчете среднедневного заработка бухгалтером была включена стоимость подарка ко дню рождения работника в размере 100,00 руб.
Данная выплата относится к выплатам, неучитываемым при исчислении среднего заработка (приложение к Инструкции № 47*). Это нельзя признать счетной ошибкой, так как налицо неправильное применение Инструкции № 47.
* Инструкция о порядке исчисления среднего заработка, утвержденная постановлением Минтруда Республики Беларусь от 10.04.2000 № 47 (далее – Инструкция № 47).
Пример 6. Счетная ошибка в результате сбоя программы
Из-за перепада напряжения случился сбой программы 1С, и в результате произошло изменение ранее набранных цифр.
Так как произошел сбой программы, это счетная ошибка.
Как видим, ситуации могут быть разные. Причем у работника и нанимателя, а иногда у разных работников могут возникнуть разные мнения о том, считать данные действия бухгалтера или иного лица счетной ошибкой или нет. Поэтому желательно при обнаружении счетной ошибки как минимум зафиксировать выявление такой ошибки, т.е. определить факт ее наличия комиссионно – составить акт.
Пример 7. Акт о фиксации счетной ошибки

После оформления акта об обнаружении счетной ошибки необходимо определить, каким образом будет произведено удержание, а также получить согласие работника на удержание.
Данное обстоятельство на практике зачастую упускают, но необходимо обратить внимание, что удержание возможно, если работник не оспаривает основания и размер удержания (п. 1 части второй ст. 107 ТК):
– для возвращения аванса, выданного в счет заработной платы;
– возврата сумм, излишне выплаченных вследствие счетных ошибок;
– погашения неизрасходованного и своевременно не возвращенного аванса, выданного на служебную командировку или перевод в другую местность, на хозяйственные нужды.
Статья 107 ТК не конкретизирует:
– как определить, оспаривает или нет удержание работник. Лучше заручиться письменным согласием. Это может быть, как письменное заявление, так и согласительная надпись на приказе об удержании.
Обратите внимание! Если работник не согласен данный случай считать счетной ошибкой и не согласен с удержанием, то удержание возможно только в судебном порядке;
– в каком виде должно быть получено согласие работника на удержание из его заработной платы излишне выплаченных сумм – устно или письменно. Чтобы в дальнейшем не возникло никаких недоразумений (например, сначала работник дал устное согласие на вычет, а потом стал предъявлять претензии по поводу получения заработной платы в меньшем размере), лучше зафиксировать согласие письменно. Например, в соответствующей записи в уведомлении о счетной ошибке или заявлении работника.
Все это будет свидетельствовать о том, что сотрудник не оспаривает основание и размер удержания. Так, предусмотрено, что лицо, которое без установленных законодательством или сделкой оснований приобрело или сберегло имущество (приобретатель) за счет другого лица (потерпевшего), обязано возвратить последнему неосновательно приобретенное или сбереженное имущество (неосновательное обогащение) (п. 1 ст. 971 ГК*).
* Гражданский кодекс Республики Беларусь (далее – ГК).
Важно! В случае отсутствия счетной ошибки, при совершении ошибки, которая произошла в результате невнимательности, небрежности, ненадлежащего исполнения обязанностей лицом, ответственным за начисление зарплаты в организации, излишне выплаченные в таких случаях суммы взысканию не подлежат.
Обращение нанимателем в суд не имеет никакого смысла, так как добиться возврата денег без доброй воли на то работника не удастся.
Обратите внимание! При отсутствии недобросовестности со стороны получателя и счетной ошибки не подлежат возврату в качестве неосновательного обогащения заработная плата и приравненные к ней платежи (п. 3 ст. 978 ГК). Также нормами трудового законодательства предусмотрено, что заработная плата, излишне выплаченная работнику, может быть взыскана с него только в случае счетной ошибки (часть третья ст. 107 ТК).
В данном случае единственным способом возврата излишне выплаченных сумм работнику является привлечение виновного специалиста к материальной ответственности при наличии условий привлечения к материальной ответственности, изложенных в ст. 400 ТК
Представление результатов исследования
В научных публикациях важно представление результатов исследования. Очень часто окончательный результат приводится в следующем виде: M±m, где M – среднее арифметическое, m –ошибка среднего арифметического. Например, 163,7±0,9 см.
Прежде чем разбираться в правилах представления результатов исследования, давайте точно усвоим, что же такое ошибка среднего арифметического.
Ошибка среднего арифметического
Среднее арифметическое, вычисленное на основе выборочных данных (выборочное среднее), как правило, не совпадает с генеральным средним (средним арифметическим генеральной совокупности). Экспериментально проверить это утверждение невозможно, потому что нам неизвестно генеральное среднее. Но если из одной и той же генеральной совокупности брать повторные выборки и вычислять среднее арифметическое, то окажется, что для разных выборок среднее арифметическое будет разным.
Чтобы оценить, насколько выборочное среднее арифметическое отличается от генерального среднего, вычисляется ошибка среднего арифметического или ошибка репрезентативности.
Ошибка среднего арифметического обозначается как m или ![]()
Ошибка среднего арифметического рассчитывается по формуле:

где: S — стандартное отклонение, n – объем выборки; Например, если стандартное отклонение равно S=5 см, объем выборки n=36 человек, то ошибка среднего арифметического равна: m=5/6 = 0,833.
Ошибка среднего арифметического показывает, какая ошибка в среднем допускается, если использовать вместо генерального среднего выборочное среднее.
Так как при небольшом объеме выборки истинное значение генерального среднего не может быть определено сколь угодно точно, поэтому при вычислении выборочного среднего арифметического нет смысла оставлять большое число значащих цифр.
Правила записи результатов исследования
- В записи ошибки среднего арифметического оставляем две значащие цифры, если первые цифры в ошибке «1» или «2».
- В остальных случаях в записи ошибки среднего арифметического оставляем одну значащую цифру.
- В записи среднего арифметического положение последней значащей цифры должно соответствовать положению первой значащей цифры в записи ошибки среднего арифметического.
Представление результатов научных исследований
В своей статье «Осторожно, статистика!», опубликованной в 1989 году В.М. Зациорский указал, какие числовые характеристики должны быть представлены в публикации, чтобы она имела научную ценность. Он писал, что исследователь «…должен назвать: 1) среднюю величину (или другой так называемый показатель положения); 2) среднее квадратическое отклонение (или другой показатель рассеяния) и 3) число испытуемых. Без них его публикация научной ценности иметь не будет “с. 52
В научных публикациях в области физической культуры и спорта очень часто окончательный результат приводится в виде: (М±m) (табл.1).
Таблица 1 — Изменение механических свойств латеральной широкой мышцы бедра под воздействием физической нагрузки (n=34)
| Эффективный модуль
упругости (Е), кПа |
Эффективный модуль
вязкости (V), Па с |
|||
| Этап
эксперимента |
Рассл. | Напряж. | Рассл. | Напряж. |
| До ФН | 7,0±0,3 | 17,1±1,4 | 29,7±1,7 | 46±4 |
| После ФН | 7,7±0,3 | 18,7±1,4 | 30,9±2,0 | 53±6 |
Литература
- Высшая математика и математическая статистика: учебное пособие для вузов / Под общ. ред. Г. И. Попова. – М. Физическая культура, 2007.– 368 с.
- Гласс Дж., Стэнли Дж. Статистические методы в педагогике и психологии. М.: Прогресс. 1976.- 495 с.
- Зациорский В.М. Осторожно — статистика! // Теория и практика физической культуры, 1989.- №2.
- Катранов А.Г. Компьютерная обработка данных экспериментальных исследований: Учебное пособие/ А. Г. Катранов, А. В. Самсонова; СПб ГУФК им. П.Ф. Лесгафта. – СПб.: изд-во СПб ГУФК им. П.Ф. Лесгафта, 2005. – 131 с.
- Основы математической статистики: Учебное пособие для ин-тов физ. культ / Под ред. В.С. Иванова.– М.: Физкультура и спорт, 1990. 176 с.