When Ansible receives a non-zero return code from a command or a failure from a module, by default it stops executing on that host and continues on other hosts. However, in some circumstances you may want different behavior. Sometimes a non-zero return code indicates success. Sometimes you want a failure on one host to stop execution on all hosts. Ansible provides tools and settings to handle these situations and help you get the behavior, output, and reporting you want.
Ignoring failed commands
By default Ansible stops executing tasks on a host when a task fails on that host. You can use ignore_errors to continue on in spite of the failure.
- name: Do not count this as a failure ansible.builtin.command: /bin/false ignore_errors: true
The ignore_errors directive only works when the task is able to run and returns a value of ‘failed’. It does not make Ansible ignore undefined variable errors, connection failures, execution issues (for example, missing packages), or syntax errors.
Ignoring unreachable host errors
New in version 2.7.
You can ignore a task failure due to the host instance being ‘UNREACHABLE’ with the ignore_unreachable keyword. Ansible ignores the task errors, but continues to execute future tasks against the unreachable host. For example, at the task level:
- name: This executes, fails, and the failure is ignored ansible.builtin.command: /bin/true ignore_unreachable: true - name: This executes, fails, and ends the play for this host ansible.builtin.command: /bin/true
And at the playbook level:
- hosts: all ignore_unreachable: true tasks: - name: This executes, fails, and the failure is ignored ansible.builtin.command: /bin/true - name: This executes, fails, and ends the play for this host ansible.builtin.command: /bin/true ignore_unreachable: false
Resetting unreachable hosts
If Ansible cannot connect to a host, it marks that host as ‘UNREACHABLE’ and removes it from the list of active hosts for the run. You can use meta: clear_host_errors to reactivate all hosts, so subsequent tasks can try to reach them again.
Handlers and failure
Ansible runs handlers at the end of each play. If a task notifies a handler but
another task fails later in the play, by default the handler does not run on that host,
which may leave the host in an unexpected state. For example, a task could update
a configuration file and notify a handler to restart some service. If a
task later in the same play fails, the configuration file might be changed but
the service will not be restarted.
You can change this behavior with the --force-handlers command-line option,
by including force_handlers: True in a play, or by adding force_handlers = True
to ansible.cfg. When handlers are forced, Ansible will run all notified handlers on
all hosts, even hosts with failed tasks. (Note that certain errors could still prevent
the handler from running, such as a host becoming unreachable.)
Defining failure
Ansible lets you define what “failure” means in each task using the failed_when conditional. As with all conditionals in Ansible, lists of multiple failed_when conditions are joined with an implicit and, meaning the task only fails when all conditions are met. If you want to trigger a failure when any of the conditions is met, you must define the conditions in a string with an explicit or operator.
You may check for failure by searching for a word or phrase in the output of a command
- name: Fail task when the command error output prints FAILED ansible.builtin.command: /usr/bin/example-command -x -y -z register: command_result failed_when: "'FAILED' in command_result.stderr"
or based on the return code
- name: Fail task when both files are identical ansible.builtin.raw: diff foo/file1 bar/file2 register: diff_cmd failed_when: diff_cmd.rc == 0 or diff_cmd.rc >= 2
You can also combine multiple conditions for failure. This task will fail if both conditions are true:
- name: Check if a file exists in temp and fail task if it does ansible.builtin.command: ls /tmp/this_should_not_be_here register: result failed_when: - result.rc == 0 - '"No such" not in result.stdout'
If you want the task to fail when only one condition is satisfied, change the failed_when definition to
failed_when: result.rc == 0 or "No such" not in result.stdout
If you have too many conditions to fit neatly into one line, you can split it into a multi-line YAML value with >.
- name: example of many failed_when conditions with OR ansible.builtin.shell: "./myBinary" register: ret failed_when: > ("No such file or directory" in ret.stdout) or (ret.stderr != '') or (ret.rc == 10)
Defining “changed”
Ansible lets you define when a particular task has “changed” a remote node using the changed_when conditional. This lets you determine, based on return codes or output, whether a change should be reported in Ansible statistics and whether a handler should be triggered or not. As with all conditionals in Ansible, lists of multiple changed_when conditions are joined with an implicit and, meaning the task only reports a change when all conditions are met. If you want to report a change when any of the conditions is met, you must define the conditions in a string with an explicit or operator. For example:
tasks: - name: Report 'changed' when the return code is not equal to 2 ansible.builtin.shell: /usr/bin/billybass --mode="take me to the river" register: bass_result changed_when: "bass_result.rc != 2" - name: This will never report 'changed' status ansible.builtin.shell: wall 'beep' changed_when: False
You can also combine multiple conditions to override “changed” result.
- name: Combine multiple conditions to override 'changed' result ansible.builtin.command: /bin/fake_command register: result ignore_errors: True changed_when: - '"ERROR" in result.stderr' - result.rc == 2
Note
Just like when these two conditionals do not require templating delimiters ({{ }}) as they are implied.
See Defining failure for more conditional syntax examples.
Ensuring success for command and shell
The command and shell modules care about return codes, so if you have a command whose successful exit code is not zero, you can do this:
tasks: - name: Run this command and ignore the result ansible.builtin.shell: /usr/bin/somecommand || /bin/true
Aborting a play on all hosts
Sometimes you want a failure on a single host, or failures on a certain percentage of hosts, to abort the entire play on all hosts. You can stop play execution after the first failure happens with any_errors_fatal. For finer-grained control, you can use max_fail_percentage to abort the run after a given percentage of hosts has failed.
Aborting on the first error: any_errors_fatal
If you set any_errors_fatal and a task returns an error, Ansible finishes the fatal task on all hosts in the current batch, then stops executing the play on all hosts. Subsequent tasks and plays are not executed. You can recover from fatal errors by adding a rescue section to the block. You can set any_errors_fatal at the play or block level.
- hosts: somehosts any_errors_fatal: true roles: - myrole - hosts: somehosts tasks: - block: - include_tasks: mytasks.yml any_errors_fatal: true
You can use this feature when all tasks must be 100% successful to continue playbook execution. For example, if you run a service on machines in multiple data centers with load balancers to pass traffic from users to the service, you want all load balancers to be disabled before you stop the service for maintenance. To ensure that any failure in the task that disables the load balancers will stop all other tasks:
--- - hosts: load_balancers_dc_a any_errors_fatal: true tasks: - name: Shut down datacenter 'A' ansible.builtin.command: /usr/bin/disable-dc - hosts: frontends_dc_a tasks: - name: Stop service ansible.builtin.command: /usr/bin/stop-software - name: Update software ansible.builtin.command: /usr/bin/upgrade-software - hosts: load_balancers_dc_a tasks: - name: Start datacenter 'A' ansible.builtin.command: /usr/bin/enable-dc
In this example Ansible starts the software upgrade on the front ends only if all of the load balancers are successfully disabled.
Setting a maximum failure percentage
By default, Ansible continues to execute tasks as long as there are hosts that have not yet failed. In some situations, such as when executing a rolling update, you may want to abort the play when a certain threshold of failures has been reached. To achieve this, you can set a maximum failure percentage on a play:
--- - hosts: webservers max_fail_percentage: 30 serial: 10
The max_fail_percentage setting applies to each batch when you use it with serial. In the example above, if more than 3 of the 10 servers in the first (or any) batch of servers failed, the rest of the play would be aborted.
Note
The percentage set must be exceeded, not equaled. For example, if serial were set to 4 and you wanted the task to abort the play when 2 of the systems failed, set the max_fail_percentage at 49 rather than 50.
Controlling errors in blocks
You can also use blocks to define responses to task errors. This approach is similar to exception handling in many programming languages. See Handling errors with blocks for details and examples.
Обработка ошибок в плейбуках
Когда Ansible получает ненулевой код возврата от команды или сбоя от модуля,по умолчанию он прекращает выполнение на этом хосте и продолжается на других хостах.Тем не менее,в некоторых случаях вам может потребоваться иное поведение.Иногда ненулевой код возврата указывает на успех.Иногда вы хотите,чтобы сбой на одном хосте остановил выполнение на всех хостах.Ansible предоставляет инструменты и настройки,чтобы справиться с этими ситуациями и помочь вам получить поведение,вывод и отчетность вы хотите.
- Игнорирование неудачных команд
- игнорирование недоступных ошибок хоста
- Сброс недоступных хостов
- Дескрипторы и отказ
- Defining failure
- Defining “changed”
- Обеспечение успеха для командования и снаряда
-
Прерывание игры на всех хозяевах
- Прерывание первой ошибки:any_errors_fatal
- Установка максимального процента отказа
- Ошибки управления блоками
Игнорирование неудачных команд
По умолчанию Ansible прекращает выполнение задач на хосте при сбое задачи на этом хосте. Вы можете использовать ignore_errors , чтобы продолжить несмотря на сбой:
- name: Do not count this as a failure ansible.builtin.command: /bin/false ignore_errors: yes
Директива ignore_errors работает только тогда, когда задача может быть запущена и возвращает значение «сбой». Это не заставляет Ansible игнорировать ошибки неопределенных переменных, сбои соединения, проблемы с выполнением (например, отсутствующие пакеты) или синтаксические ошибки.
игнорирование недоступных ошибок хоста
Новинка в версии 2.7.
Вы можете игнорировать сбой задачи из-за того, что экземпляр хоста недоступен с ключевым словом ignore_unreachable . Ansible игнорирует ошибки задачи, но продолжает выполнять будущие задачи на недостижимом хосте. Например, на уровне задачи:
- name: This executes, fails, and the failure is ignored ansible.builtin.command: /bin/true ignore_unreachable: yes - name: This executes, fails, and ends the play for this host ansible.builtin.command: /bin/true
И на игровом уровне:
- hosts: all ignore_unreachable: yes tasks: - name: This executes, fails, and the failure is ignored ansible.builtin.command: /bin/true - name: This executes, fails, and ends the play for this host ansible.builtin.command: /bin/true ignore_unreachable: no
Сброс недоступных хостов
Если Ansible не может подключиться к хосту, он помечает этот хост как «НЕДОСТУПНЫЙ» и удаляет его из списка активных хостов для выполнения. Вы можете использовать meta: clear_host_errors для повторной активации всех хостов, чтобы последующие задачи могли снова попытаться связаться с ними.
Дескрипторы и отказ
Ansible runs handlers at the end of each play. If a task notifies a handler but another task fails later in the play, by default the handler does not run on that host, which may leave the host in an unexpected state. For example, a task could update a configuration file and notify a handler to restart some service. If a task later in the same play fails, the configuration file might be changed but the service will not be restarted.
Вы можете изменить это поведение с --force-handlers опций командной строки, в том числе путем force_handlers: True в пьесе, или путем добавления force_handlers = True в ansible.cfg. Когда обработчики принудительно запущены, Ansible будет запускать все обработчики уведомлений на всех хостах, даже на хостах с неудачными задачами. (Обратите внимание, что некоторые ошибки все еще могут помешать запуску обработчика, например, когда хост становится недоступным.)
Defining failure
Ansible позволяет определить, что означает «сбой» в каждой задаче, используя условие failed_when . Как и все условные операторы в Ansible, списки нескольких условий failed_when объединяются неявным оператором and , что означает, что задача завершается сбоем только при соблюдении всех условий. Если вы хотите инициировать сбой при выполнении любого из условий, вы должны определить условия в строке с явным оператором or .
Проверить на неудачу можно с помощью поиска слова или фразы в выводе команды:
- name: Fail task when the command error output prints FAILED ansible.builtin.command: /usr/bin/example-command -x -y -z register: command_result failed_when: "'FAILED' in command_result.stderr"
или на основании кода возврата:
- name: Fail task when both files are identical ansible.builtin.raw: diff foo/file1 bar/file2 register: diff_cmd failed_when: diff_cmd.rc == 0 or diff_cmd.rc >= 2
Вы также можете комбинировать несколько условий для отказа.Эта задача будет неудачной,если оба условия верны:
- name: Check if a file exists in temp and fail task if it does ansible.builtin.command: ls /tmp/this_should_not_be_here register: result failed_when: - result.rc == 0 - '"No such" not in result.stdout'
Если вы хотите, чтобы задача не выполнялась при выполнении только одного условия, измените определение failed_when на:
failed_when: result.rc == 0 or "No such" not in result.stdout
Если у вас слишком много условий для аккуратного размещения в одной строке, вы можете разделить его на многострочное значение yaml с помощью > :
- name: example of many failed_when conditions with OR ansible.builtin.shell: "./myBinary" register: ret failed_when: > ("No such file or directory" in ret.stdout) or (ret.stderr != '') or (ret.rc == 10)
Defining “changed”
Ansible позволяет вам определить, когда конкретная задача «изменила» удаленный узел, используя условное changed_when . Это позволяет вам определить, на основе кодов возврата или вывода, следует ли сообщать об изменении в статистике Ansible и должен ли запускаться обработчик или нет. Как и все условные операторы в Ansible, списки нескольких условий changed_when объединяются неявным оператором and , что означает, что задача сообщает об изменении только тогда, когда все условия соблюдены. Если вы хотите сообщить об изменении при выполнении любого из условий, вы должны определить условия в строке с явным оператором or .Например:
tasks: - name: Report 'changed' when the return code is not equal to 2 ansible.builtin.shell: /usr/bin/billybass --mode="take me to the river" register: bass_result changed_when: "bass_result.rc != 2" - name: This will never report 'changed' status ansible.builtin.shell: wall 'beep' changed_when: False
Вы также можете объединить несколько условий,чтобы отменить результат «изменено»:
- name: Combine multiple conditions to override 'changed' result ansible.builtin.command: /bin/fake_command register: result ignore_errors: True changed_when: - '"ERROR" in result.stderr' - result.rc == 2
Дополнительные примеры условного синтаксиса см. В разделе Определение ошибки .
Обеспечение успеха для командования и снаряда
В командных и оболочки модулей заботятся о кодах возврата, поэтому если у вас есть команда , чей успешный код завершения не равен нулю, то вы можете сделать это:
tasks: - name: Run this command and ignore the result ansible.builtin.shell: /usr/bin/somecommand || /bin/true
Прерывание игры на всех хозяевах
Иногда требуется, чтобы сбой на одном хосте или сбой на определенном проценте хостов прервали всю игру на всех хостах. Вы можете остановить выполнение воспроизведения после первого сбоя с помощью any_errors_fatal . Для более max_fail_percentage управления вы можете использовать max_fail_percentage, чтобы прервать выполнение после сбоя определенного процента хостов.
Прерывание первой ошибки:any_errors_fatal
Если вы устанавливаете any_errors_fatal и задача возвращает ошибку, Ansible завершает фатальную задачу на всех хостах в текущем пакете, а затем прекращает воспроизведение на всех хостах. Последующие задания и спектакли не выполняются. Вы можете избавиться от фатальных ошибок, добавив в блок раздел восстановления. Вы можете установить any_errors_fatal на уровне игры или блока:
- hosts: somehosts any_errors_fatal: true roles: - myrole - hosts: somehosts tasks: - block: - include_tasks: mytasks.yml any_errors_fatal: true
Вы можете использовать эту функцию,когда все задачи должны быть на 100% успешными,чтобы продолжить выполнение Playbook.Например,если вы запускаете сервис на машинах в нескольких центрах обработки данных с балансировщиками нагрузки для передачи трафика от пользователей к сервису,вы хотите,чтобы все балансировщики нагрузки были отключены до того,как вы остановите сервис на техническое обслуживание.Чтобы гарантировать,что любой сбой в задаче,отключающей работу балансировщиков нагрузки,остановит все остальные задачи:
--- - hosts: load_balancers_dc_a any_errors_fatal: true tasks: - name: Shut down datacenter 'A' ansible.builtin.command: /usr/bin/disable-dc - hosts: frontends_dc_a tasks: - name: Stop service ansible.builtin.command: /usr/bin/stop-software - name: Update software ansible.builtin.command: /usr/bin/upgrade-software - hosts: load_balancers_dc_a tasks: - name: Start datacenter 'A' ansible.builtin.command: /usr/bin/enable-dc
В данном примере Ansible запускает обновление программного обеспечения на передних концах только в том случае,если все балансировщики нагрузки успешно отключены.
Установка максимального процента отказа
По умолчанию,Ansible продолжает выполнять задачи до тех пор,пока есть хосты,которые еще не вышли из строя.В некоторых ситуациях,например,при выполнении скользящего обновления,вы можете прервать воспроизведение,когда достигнут определенный порог неудач.Для этого вы можете установить максимальный процент сбоев при воспроизведении:
--- - hosts: webservers max_fail_percentage: 30 serial: 10
Параметр max_fail_percentage применяется к каждому пакету, когда вы используете его с последовательным интерфейсом . В приведенном выше примере, если более 3 из 10 серверов в первой (или любой) группе серверов вышли из строя, остальная часть игры будет прервана.
Note
Установленный процент должен быть превышен,а не равен.Например,если серийный набор установлен на 4 и вы хотите,чтобы задача прерывала воспроизведение при сбое 2-х систем,установите max_fail_percentage на 49,а не на 50.
Ошибки управления блоками
Вы также можете использовать блоки для определения ответов на ошибки задачи. Этот подход похож на обработку исключений во многих языках программирования. См. Подробности и примеры в разделе Обработка ошибок с помощью блоков .
Ansible
-
Контроль над тем,где выполняются задачи:делегирование и местные действия.
По умолчанию Ansible собирает факты и выполняет все задачи на машинах, которые соответствуют строке hosts из вашего playbook.
-
Настройка удаленной среды
Новое в версии 1.1.
-
Использование фильтров для манипулирования данными
Фильтры позволяют преобразовывать данные JSON в разделенный URL-адрес YAML, извлекать имя хоста, получать хэш строки SHA1, добавлять несколько целых чисел и многое другое.
-
Объединение и выбор данных
Вы можете комбинировать данные из нескольких источников и типов, выбирать значения больших структур, предоставляя точный контроль над комплексом Новое в версии 2.3.
Have you ever gotten to the end of your Ansible Playbook execution and found you needed to:
- Rescue from errors or partial execution of your tasks
- Capture a summary of the results per host for further revision
If you have Ansible Automation Platform (AAP), you can use the techniques I described in How to use workflow job templates in Ansible to handle #1, and you will need something like the set_stats module for #2 (to be able to persist variables between workflow nodes).
In this article, I will cover the block/rescue feature in Ansible. You can incorporate it into your playbooks, whether or not you have AAP. You can then take these playbooks and run then in your AAP instance.
[ Compare Ansible vs. Red Hat Ansible Automation Platform. ]
By learning this new technique, you can use the approach that suits you best.
What is a block?
A block is a logical grouping of tasks within a playbook that can be executed as a single unit. This makes it easy to manage complex playbooks by breaking them down into smaller, more manageable parts.
You can use blocks to apply options to a group of tasks and avoid repeating code, like in this example from the documentation.
tasks:
- name: Install, configure, and start Apache
block:
- name: Install httpd and memcached
ansible.builtin.yum:
name:
- httpd
- memcached
state: present
- name: Apply the foo config template
ansible.builtin.template:
src: templates/src.j2
dest: /etc/foo.conf
- name: Start service bar and enable it
ansible.builtin.service:
name: bar
state: started
enabled: True
when: ansible_facts['distribution'] == 'CentOS'
become: true
become_user: root
ignore_errors: trueNotice that the keywords when, become, become_user, and ignore_errors are all applied to the block.
[ Write your first Ansible Playbook in this hands-on interactive lab. ]
How to use blocks and rescue in Ansible
Blocks and rescue work together to provide error-handling capabilities in Ansible. Use the rescue keyword in association with a block to define a set of tasks that will be executed if an error occurs in the block. You can use the rescue tasks to handle errors, log messages, or take other actions to recover from the error.
Here is a high-level example:
---
- hosts: <hosts>
tasks:
- block:
- <task1>
- <task2>
- <task3>
rescue:
- <rescue_task1>
- <rescue_task2>
- <rescue_task3>
always:
- <always_task>You define tasks under the block keyword, which could be as simple as invoking the ansible.builtin.ping module, or you could have a combination of multiple tasks and including/importing roles.
The associated rescue keyword is where the playbook execution will be sent, for each host, if anything fails along the block.
Finally, the always section executes for all nodes, no matter if they succeed or fail.
Some key ideas from this structure:
- rescue and always are optional features, which I will use for the specific purpose of demonstrating this «recover and summary» logic.
- When your playbook runs against a considerable number of hosts, handling the individual results becomes harder to track. This is how the ideas discussed in this article can help.
For the following example, the inventory file contains:
[nodes]
node1
node2
node3Here is the playbook:
---
- name: Test block/rescue
hosts: nodes
gather_facts: false
tasks:
- name: Main block
block:
- name: Role 1
ansible.builtin.include_role:
name: role1
- name: Role 2
ansible.builtin.include_role:
name: role2
- name: Accumulate success
ansible.builtin.set_fact:
_result:
host: "{{ inventory_hostname }}"
status: "OK"
interfaces: "{{ ansible_facts['interfaces'] }}"
rescue:
- name: Accumulate failure
ansible.builtin.set_fact:
_result:
host: "{{ inventory_hostname }}"
status: "FAIL"
always:
- name: Tasks that will always run after the main block
block:
- name: Collect results
ansible.builtin.set_fact:
_global_result: "{{ (_global_result | default([])) + [hostvars[item]['_result']] }}"
loop: "{{ ansible_play_hosts }}"
- name: Classify results
ansible.builtin.set_fact:
_result_ok: "{{ _global_result | selectattr('status', 'equalto', 'OK') | list }}"
_result_fail: "{{ _global_result | selectattr('status', 'equalto', 'FAIL') | list }}"
- name: Display results OK
ansible.builtin.debug:
msg: "{{ _result_ok }}"
when: (_result_ok | length ) > 0
- name: Display results FAIL
ansible.builtin.debug:
msg: "{{ _result_fail }}"
when: (_result_fail | length ) > 0
delegate_to: localhost
run_once: true
...
Think about this playbook as an illustration of some logic that could be applied to a complex automation in the real world. Yes, you could run simpler actions to recover or issue a notification about the failure, but you want a summary of all results. Then you can use this summary in the always section to automate sending a notification by email or writing the individual results into a database.
Also, the variables starting with _ are my personal naming convention preference… there’s no special meaning in Ansible for that.
- For this example, the roles in the main block don’t do anything special. They represent the actions that you would put in the main block, which could fail at different points. In this simplified example, if a node succeeds, there will be a list of interfaces in the
_resultvariable. Otherwise, the status will be set to FAIL. - For each host the playbook is running on:
- If the actions proceed without errors, the task Accumulate success will execute.
- If the action fails in any of the roles, the flow goes to the rescue block for each host.
- The always section collects the results saved in the variable
_result. Here is a little breakdown of the logic:- Up to this point, each host has a variable in its hostvars structure, either with a success or failed status information.
- In the Collect results task, which runs once and is delegated to localhost, it captures the individual results and adds them to the list
_global_result. - The loop is done using the Ansible magic variable
ansible_play_hosts_all, which is a list of all hosts targeted by this playbook. - Classify results does some filtering to create a list of all OK and failed results. You can use these in notifications, reports, or to send to a database (this example just displays them).
If you run this playbook and no node fails, there is no need for rescue, and the display should show that results are OK in all nodes:
PLAY [Test block/rescue] *******************************************************
TASK [Role 1] ******************************************************************
TASK [role1 : Execution of role 1] *********************************************
ok: [node1] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [node2] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [node3] => {
"changed": false,
"msg": "All assertions passed"
}
TASK [Role 2] ******************************************************************
TASK [role2 : Execution of role 2] *********************************************
ok: [node1]
ok: [node2]
ok: [node3]
TASK [role2 : Show network information] ****************************************
skipping: [node1]
skipping: [node2]
skipping: [node3]
TASK [Accumulate success] ******************************************************
ok: [node1]
ok: [node2]
ok: [node3]
TASK [Collect results] *********************************************************
ok: [node1 -> localhost] => (item=node1)
ok: [node1 -> localhost] => (item=node2)
ok: [node1 -> localhost] => (item=node3)
TASK [Classify results] ********************************************************
ok: [node1 -> localhost]
TASK [Display results OK] ******************************************************
ok: [node1 -> localhost] => {
"msg": [
{
"host": "node1",
"interfaces": [
"lo",
"enp7s0",
"enp1s0"
],
"status": "OK"
},
{
"host": "node2",
"interfaces": [
"lo",
"enp7s0",
"enp1s0"
],
"status": "OK"
},
{
"host": "node3",
"interfaces": [
"enp7s0",
"lo",
"enp1s0"
],
"status": "OK"
}
]
}
TASK [Display results FAIL] ****************************************************
skipping: [node1]
PLAY RECAP *********************************************************************
node1 : ok=6 changed=0 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
node2 : ok=3 changed=0 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
node3 : ok=3 changed=0 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0 If you force a failure in some nodes, they will invoke the rescue section, and the summary will show the ones that succeeded and those that failed:
PLAY [Test block/rescue] *******************************************************
TASK [Role 1] ******************************************************************
TASK [role1 : Execution of role 1] *********************************************
ok: [node1] => {
"changed": false,
"msg": "All assertions passed"
}
fatal: [node2]: FAILED! => {
"assertion": "inventory_hostname in nodes_ok",
"changed": false,
"evaluated_to": false,
"msg": "Assertion failed"
}
fatal: [node3]: FAILED! => {
"assertion": "inventory_hostname in nodes_ok",
"changed": false,
"evaluated_to": false,
"msg": "Assertion failed"
}
TASK [Role 2] ******************************************************************
TASK [role2 : Execution of role 2] *********************************************
ok: [node1]
TASK [role2 : Show network information] ****************************************
skipping: [node1]
TASK [Accumulate success] ******************************************************
ok: [node1]
TASK [Accumulate failure] ******************************************************
ok: [node2]
ok: [node3]
TASK [Collect results] *********************************************************
ok: [node1 -> localhost] => (item=node1)
ok: [node1 -> localhost] => (item=node2)
ok: [node1 -> localhost] => (item=node3)
TASK [Classify results] ********************************************************
ok: [node1 -> localhost]
TASK [Display results OK] ******************************************************
ok: [node1 -> localhost] => {
"msg": [
{
"host": "node1",
"interfaces": [
"enp7s0",
"enp1s0",
"lo"
],
"status": "OK"
}
]
}
TASK [Display results FAIL] ****************************************************
ok: [node1 -> localhost] => {
"msg": [
{
"host": "node2",
"status": "FAIL"
},
{
"host": "node3",
"status": "FAIL"
}
]
}
PLAY RECAP *********************************************************************
node1 : ok=7 changed=0 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
node2 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=1 ignored=0
node3 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=1 ignored=0 Notice that even though there were failures, at the end, the Ansible output counts them as rescued.
[ Get started with automation controller in this hands-on interactive lab. ]
Handle exceptions
I hope this article has given you some ideas about how to handle exceptions in your playbooks.
You can also think about what actions you want in your rescue section, such as displaying a message or performing some «undo» action, depending on what stage it reached before the failure.
Finally, you can execute the always section for each host or, as in my example, one time only.
Topics
- Error Handling In Playbooks
- Ignoring Failed Commands
- Handlers and Failure
- Controlling What Defines Failure
- Overriding The Changed Result
- Aborting the play
Ansible normally has defaults that make sure to check the return codes of commands and modules and
it fails fast – forcing an error to be dealt with unless you decide otherwise.
Sometimes a command that returns 0 isn’t an error. Sometimes a command might not always
need to report that it ‘changed’ the remote system. This section describes how to change
the default behavior of Ansible for certain tasks so output and error handling behavior is
as desired.
Ignoring Failed Commands¶
New in version 0.6.
Generally playbooks will stop executing any more steps on a host that
has a failure. Sometimes, though, you want to continue on. To do so,
write a task that looks like this:
- name: this will not be counted as a failure command: /bin/false ignore_errors: yes
Note that the above system only governs the return value of failure of the particular task,
so if you have an undefined variable used, it will still raise an error that users will need to address.
Neither will this prevent failures on connection nor execution issues, the task must be able to run and
return a value of ‘failed’.
Handlers and Failure¶
New in version 1.9.1.
When a task fails on a host, handlers which were previously notified
will not be run on that host. This can lead to cases where an unrelated failure
can leave a host in an unexpected state. For example, a task could update
a configuration file and notify a handler to restart some service. If a
task later on in the same play fails, the service will not be restarted despite
the configuration change.
You can change this behavior with the --force-handlers command-line option,
or by including force_handlers: True in a play, or force_handlers = True
in ansible.cfg. When handlers are forced, they will run when notified even
if a task fails on that host. (Note that certain errors could still prevent
the handler from running, such as a host becoming unreachable.)
Controlling What Defines Failure¶
New in version 1.4.
Suppose the error code of a command is meaningless and to tell if there
is a failure what really matters is the output of the command, for instance
if the string “FAILED” is in the output.
Ansible in 1.4 and later provides a way to specify this behavior as follows:
- name: this command prints FAILED when it fails command: /usr/bin/example-command -x -y -z register: command_result failed_when: "'FAILED' in command_result.stderr"
In previous version of Ansible, this can be still be accomplished as follows:
- name: this command prints FAILED when it fails command: /usr/bin/example-command -x -y -z register: command_result ignore_errors: True - name: fail the play if the previous command did not succeed fail: msg="the command failed" when: "'FAILED' in command_result.stderr"
Overriding The Changed Result¶
New in version 1.3.
When a shell/command or other module runs it will typically report
“changed” status based on whether it thinks it affected machine state.
Sometimes you will know, based on the return code
or output that it did not make any changes, and wish to override
the “changed” result such that it does not appear in report output or
does not cause handlers to fire:
tasks: - shell: /usr/bin/billybass --mode="take me to the river" register: bass_result changed_when: "bass_result.rc != 2" # this will never report 'changed' status - shell: wall 'beep' changed_when: False
Aborting the play¶
Sometimes it’s desirable to abort the entire play on failure, not just skip remaining tasks for a host.
The any_errors_fatal play option will mark all hosts as failed if any fails, causing an immediate abort:
- hosts: somehosts any_errors_fatal: true roles: - myrole
for finer-grained control max_fail_percentage can be used to abort the run after a given percentage of hosts has failed.

Ansible Error handling – In this lesson, you will learn the different ways of how to handle failures in Ansible tasks by using the ignore_errors, force_handlers, Ansible blocks, Ansible rescue, and Ansible always directives in a playbook.
Contents
- How Can You Handle Error In Ansible
- Specifying Task Failure Conditions
- Managing Changed Status
- Using Ansible Blocks
- Using Ansible Blocks With Rescue and Always Statement
How Can Error Handling Be Done In Ansible
Ansible plays and tasks are executed in the order they are defined in a playbook, and by default, if a task fails, the other tasks will not be executed in that order. However, this behavior can be changed with the use of a keyword called “ignore_errors: true“.
This keyword can be added to a play or a task as the case may be. If it is added to a play, it means that all the errors in the tasks associated to a play will be ignored. More so, if it is added to a task, it means all the errors in the task will be ignored.
Well, we learnt about handlers in one of our previous lessons, what about handlers? Yes, this is also applicable to handlers, handlers error can be handled by the keyword, “force_handlers:yes”.
If a task that is supposed to notify a handler fails, the handlers will not be executed. This behavior can also be changed by using the keyword, “force_handler: yes” .
As usual, let’s understand better with examples.
If we were to install the httpd package and the autofs package using a playbook, the name argument will consist of the “httpd” value and the “autofs” value.
Now, we are going to write a playbook, and we will intentionally make an error by making the name argument of autofs containing “autos“.
1. Create a playbook
[lisa@drdev1 ~]$ vim playbook7.yml- name: Install basic package
hosts: hqdev1.tekneed.com
tasks:
- name: install autofs
yum:
name: autos
state: present
ignore_errors: true
- name: install httpd
yum:
name: httpd
state: present2. Run the playbook
[lisa@drdev1 ~]$ ansible-playbook playbook7.yml
PLAY [Install basic package] ***********************************************************
........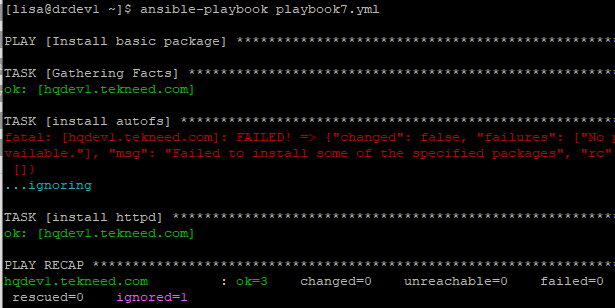
This playbook we run should have resulted in an error or task failure, and the second task shouldn’t have run because the first task failed, but because we used the “ignore_errors” keyword, the task did not fail and the play run.
Also, remember that you can choose to use the “ignore_errors” keyword at a play level or at a task level. In our case, it was used at the task level.
Again, let’s see an example of how we can use the force_handlers keyword to forcefully run a task with handlers.
1. create a playbook
- name: restarting httpd using handlers
hosts: hqdev1.tekneed.com
force_handlers: yes
tasks:
- name: restart httpd
service:
name: httpd
state: restarted
notify: restart httpd
handlers:
- name: restart httpd
service:
name: httpd
state: restartedThe force_handler directive will always force handlers to run whether it is called or not. Note that the keyword can only be used at a play level
2. Run the playbook
[lisa@drdev1 ~]$ ansible-playbook playbook3.yml
PLAY [restarting httpd using handlers] ********************************
......Because the force_handlers directive is set to yes, the handler will always run.
Specifying Task Failure conditions
Ansible may run a task/command successfully, however may be a failure due to the final result a user desires to get. In this sense, one can specify a condition for tasks to fail or in other words, you are at liberty to determine what a failure is.
Let’s see how this can be done by using the “failed_when” directive. The failed_when directive, from its word, simply means the task should fail when a condition is met or not met.
Let’s use the playbook below as an example,
[lisa@drdev1 ~]$ vim playbook5.yml- name: Web page fetcher
hosts: hqdev1.tekneed.com
tasks:
- name: connect to website
uri:
url: https://tekneed.com
return_content: true
register: output
- name: verify content
debug:
msg: "verifying content"
failed_when:
- '"this content" not in output.content'
- '"other content" not in output.content'
This is what this playbook will do. The uri module will interact with the webserver and fetch the page, https://www.tekneed.com.
More so, With the true value for the return_content argument, the body of the response of https://tekneed.com will be returned as content, and output will be captured with the aid of the register directive.
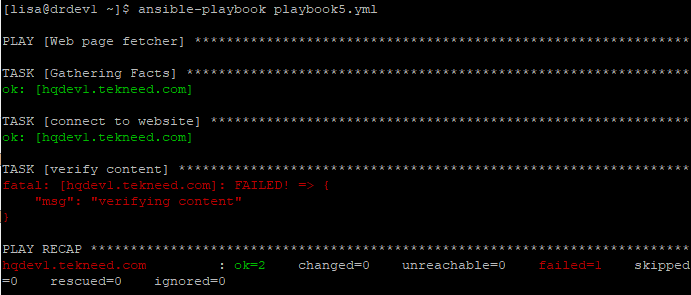
For the second task, the content “verifying content” will be printed by the debug module with the aid of the msg argument, and with the “failed_when” directive, the task will fail when the string, “this content” and “other content” is not in the captured output.
Run the playbook
[lisa@drdev1 ~]$ ansible-playbook playbook5.yml
PLAY [Web page fetcher] ************************************************************
.......
Alternatively, the “fail” module can be used to specify when a task fails. This module can only be very useful if the “when” keyword is used to specify the exact failure condition.
Let’s use the same example we used above, but this time around use the “fail” module and “when” keyword
[lisa@drdev1 ~]$ vim playbook5.yml- name: Web page fetcher
hosts: hqdev1.tekneed.com
tasks:
- name: connect to website
uri:
url: https://tekneed.com
return_content: true
register: output
- name: verify content
fail:
msg: "verifying content"
when:
- '"this content" not in output.content'
- '"other content" not in output.content'Run the playbook
[lisa@drdev1 ~]$ ansible-playbook playbook5.yml
PLAY [Web page fetcher] ************************************************************
.......
Managing Changed Status
Managing a changed status can be useful in avoiding unexpected results while running a playbook. Some tasks may even report a changed status and nothing in the real sense has really changed. It could just be that information was retrieved.
In some cases, you may not want a task to result in a changed status. In this case, one needs to use the “changed_when: false” keyword. The playbook will only report “ok” or “failed” status, and will never report a changed status.
An example of such task can be seen below.
- name: copy in nginx conf
template: src=nginx.conf.j2
dest=/etc/nginx/nginx.conf
- name: validate nginx conf
command: nginx -t
changed_when: falseOne can also specify a condition when a task should change, an example of such task is seen in the playbook below.
- name: Web page fetcher
hosts: hqdev1.tekneed.com
tasks:
- name: connect to website
uri:
url: https://tekneed.com
return_content: true
register: output
- name: verify content
fail:
msg: "verifying content"
changed_when: "'success' in output.stdout"Using Ansible Blocks
Blocks are used to group tasks, specific tasks that are related, and can be very useful with a conditional statement.
If tasks are grouped conditionally, and the conditions is/are true, all the tasks will be executed. You should also know that block is a directive in Ansible and not a module, hence the block directive and the when directive will be at the same indentation level.
Let’s see how blocks can be used with examples.
create a playbook
[lisa@drdev1 ~]$ vim playbook8.yml- name: setting up httpd
hosts: localhost
tasks:
- name: Install start and enable httpd
block:
- name: install httpd
yum:
name: httpd
state: present
- name: start and enable httpd
service:
name: httpd
state: started
enabled: true
when: ansible_distribution == "Red Hat"
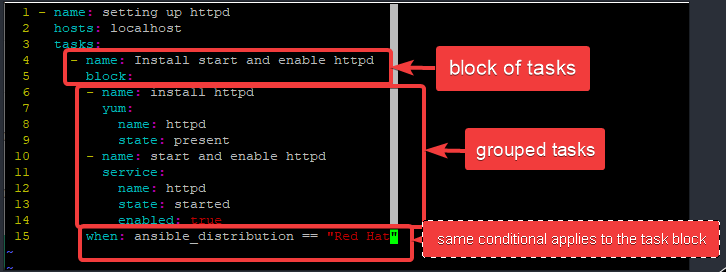
This playbook will group only two tasks in a block(install and enable httpd). The first task name is “install httpd” while the second task name is “start and enable httpd“. These tasks will only execute if the condition is true, which is, the OS ansible will execute against is/are Red Hat.
Run the playbook
[lisa@drdev1 ~]$ ansible-playbook playbook8.yml
PLAY [setting up httpd] ********************************************************
.......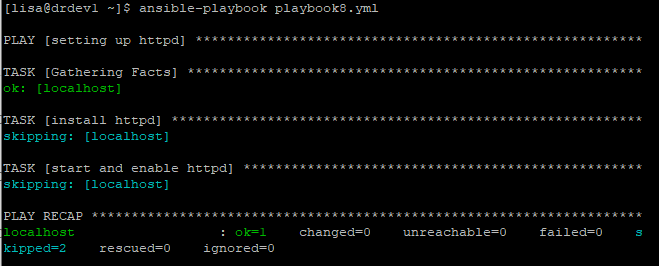
With this kind of playbook, if the condition fails, other tasks will not be executed. Let’s see how we can use block with rescue and always if we don’t want this type of condition.
Using Ansible block With rescue and always Statement
Apart from blocks being used to group different tasks, they can also be used specifically for error handling with the rescue keyword.
It works in a way that; if a task that is defined in a block fails, the tasks defined in the rescue section will be executed. This is also similar to the ignore_errors keyword.
More so, there is also an always section, this section will always run either the task fails or not. This is also similar to the ignore_errors keyword.
Let’s understand better with examples.
create a playbook.
[lisa@drdev1 ~]$ vim playbook9.yml- name: setting up httpd
hosts: localhost
tasks:
- name: Install the latest httpd and restart
block:
- name: install httpd
yum:
name: htt
state: latest
rescue:
- name: restart httpd
service:
name: httpd
state: started
- name: Install autofs
yum:
name: autofs
always:
- name: restart autofs
service:
name: autofs
state: started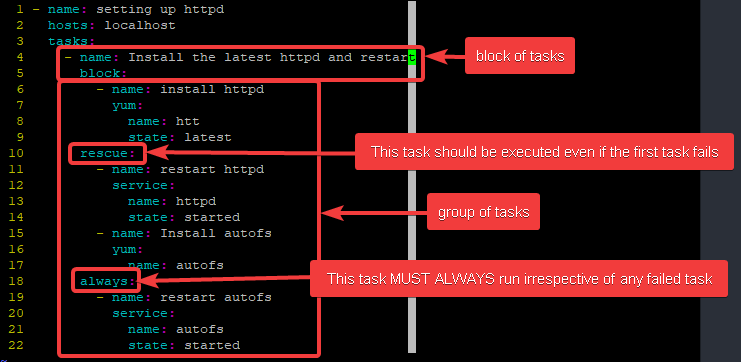
This playbook will group four tasks in a block(install the latest httpd and restart).
The first task in the block section will fail because the name of the package is incorrect. However, the second and third tasks will run because they are in the rescue section. More so, the fourth task will run because it is in the always section.
Note that you can have as many tasks you want in the block section, rescue section or always section
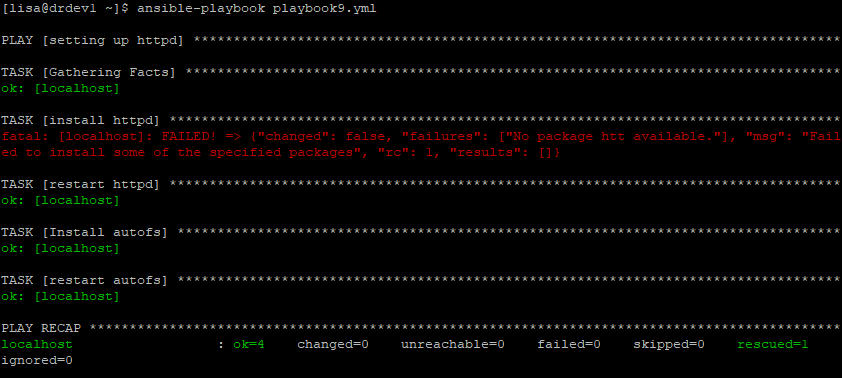
Run the playbook
[lisa@drdev1 ~]$ ansible-playbook playbook9.yml
PLAY [setting up httpd] *********************************************************
......
Class Activity
create a playbook that contains 1 play with tasks using block, always and rescue statements
If you like this article, you can support us by
1. sharing this article.
2. Buying the article writer a coffee (click here to buy a coffee)
3. Donating to push our project to the next level. (click here to donate)
If you need personal training, send an email to info@tekneed.com
Click To Watch Video On Ansible Error Handling
RHCE EX294 Exam Practice Question On Ansible Error Handling
Suggested: Managing Layered Storage With Stratis – Video
Your feedback is welcomed. If you love others, you will share with others