Аннотация: Лекция носит факультативный характер. Здесь мы рассматриваем виды допускаемых в программировании ошибок, способы тестирования и отладки программ, инструменты встроенного отладчика.
Цель лекции
Освоить работу с встроенным отладчиком, изучить категории ошибок, способы их обнаружения и устранения.
Тестирование и отладка программы
Чем больше опыта имеет программист, тем меньше ошибок в коде он совершает. Но, хотите верьте, хотите нет, даже самый опытный программист всё же допускает ошибки. И любая современная среда разработки программ должна иметь собственные инструменты для отладки приложений, а также для своевременного обнаружения и исправления возможных ошибок. Программные ошибки на программистском сленге называют багами (англ. bug — жук), а программы отладки кода — дебаггерами (англ. debugger — отладчик). Lazarus, как современная среда разработки приложений, имеет собственный встроенный отладчик, работу с которым мы разберем на этой лекции.
Ошибки, которые может допустить программист, условно делятся на три группы:
- Синтаксические
- Времени выполнения (run-time errors)
- Алгоритмические
Синтаксические ошибки
Синтаксические ошибки легче всего обнаружить и исправить — их обнаруживает компилятор, не давая скомпилировать и запустить программу. Причем компилятор устанавливает курсор на ошибку, или после неё, а в окне сообщений выводит соответствующее сообщение, например, такое:
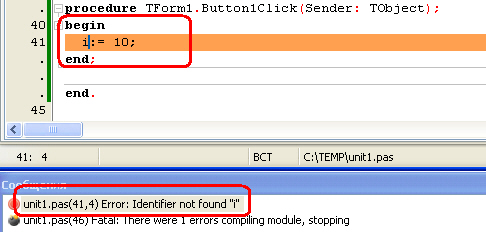
Рис.
27.1.
Найденная компилятором синтаксическая ошибка — нет объявления переменной i
Подобные ошибки могут возникнуть при неправильном написании директивы или имени функции (процедуры); при попытке обратиться к переменной или константе, которую не объявляли (
рис.
27.1); при попытке вызвать функцию (процедуру, переменную, константу) из модуля, который не был подключен в разделе uses; при других аналогичных недосмотрах программиста.
Как уже говорилось, компилятор при нахождении подобной ошибки приостанавливает процесс компиляции, выводит сообщение о найденной ошибке и устанавливает курсор на допущенную ошибку, или после неё. Программисту остается только внести исправления в код программы и выполнить повторную компиляцию.
Ошибки времени выполнения
Ошибки времени выполнения (run-time errors) тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы, или во время тестирования. Если такую программу запустить из среды Lazarus, то она скомпилируется, но при попытке загрузки, или в момент совершения ошибки, приостановит свою работу, выведя на экран соответствующее сообщение. Например, такое:

Рис.
27.2.
Сообщение Lazarus об ошибке времени выполнения
В данном случае программа при загрузке должна была считать в память отсутствующий текстовый файл MyFile.txt. Поскольку программа вызвала ошибку, она не запустилась, но в среде Lazarus процесс отладки продолжается, о чем свидетельствует сообщение в скобках в заголовке главного меню, после названия проекта. Программисту в подобных случаях нужно сбросить отладчик командой меню «Запуск -> Сбросить отладчик«, после чего можно продолжить работу над проектом.
Ошибка времени выполнения может возникнуть не только при загрузке программы, но и во время её работы. Например, если бы попытка чтения несуществующего файла была сделана не при загрузке программы, а при нажатии на кнопку, то программа бы нормально запустилась и работала, пока пользователь не нажмет на эту кнопку.
Если программу запустить из самой Windows, при возникновении этой ошибки появится такое же сообщение. При этом если нажать «OK«, программа даже может запуститься, но корректно работать все равно не будет.
Ошибки времени выполнения бывают не только явными, но и неявными, при которых программа продолжает свою работу, не выводя никаких сообщений, а программист даже не догадывается о наличии ошибки. Примером неявной ошибки может служить так называемая утечка памяти. Утечка памяти возникает в случаях, когда программист забывает освободить выделенную под объект память. Например, мы объявляем переменную типа TStringList, и работаем с ней:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
end;
В данном примере программист допустил типичную для начинающих ошибку — не освободил класс TStringList. Это не приведет к сбою или аварийному завершению программы, но в итоге можно бесполезно израсходовать очень много памяти. Конечно, эта память будет освобождена после выгрузки программы (за этим следит операционная система), но утечка памяти во время выполнения программы тоже может привести к неприятным последствиям, потребляя все больше и больше ресурсов и излишне нагружая процессор. В подобных случаях после работы с объектом программисту нужно не забывать освобождать память:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
MySL.Free; //освободили объект
end;
Однако ошибки времени выполнения могут случиться и во время работы с объектом. Если есть такой риск, программист должен не забывать про возможность обработки исключительных ситуаций. В данном случае вышеприведенный код правильней будет оформить таким образом:
begin
try
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
finally
MySL.Free; //освободили объект, даже если была ошибка
end;
end;
Итак, во избежание ошибок времени выполнения программист должен не забывать делать проверку на правильность ввода пользователем допустимых значений, заключать опасный код в блоки try…finally…end или try…except…end, делать проверку на существование открываемого файла функцией FileExists и вообще соблюдать предусмотрительность во всех слабых местах программы. Не полагайтесь на пользователя, ведь недаром говорят, что если в программе можно допустить ошибку, пользователь эту возможность непременно найдет.
Алгоритмические ошибки
Если вы не допустили ни синтаксических ошибок, ни ошибок времени выполнения, программа скомпилировалась, запустилась и работает нормально, то это еще не означает, что в программе нет ошибок. Убедиться в этом можно только в процессе её тестирования.
Тестирование — процесс проверки работоспособности программы путем ввода в неё различных, даже намеренно ошибочных данных, и последующей контрольной проверке выводимого результата.
Если программа работает правильно с одними наборами исходных данных, и неправильно с другими, то это свидетельствует о наличии алгоритмической ошибки. Алгоритмические ошибки иногда называют логическими, обычно они связаны с неверной реализацией алгоритма программы: вместо «+» ошибочно поставили «-«, вместо «/» — «*», вместо деления значения на 0,01 разделили на 0,001 и т.п. Такие ошибки обычно не обнаруживаются во время компиляции, программа нормально запускается, работает, а при анализе выводимого результата выясняется, что он неверный. При этом компилятор не укажет программисту на ошибку — чтобы найти и устранить её, приходится анализировать код, пошагово «прокручивать» его выполнение, следя за результатом. Такой процесс называется отладкой.
Отладка — процесс поиска и устранения ошибок, чаще алгоритмических. Хотя отладчик позволяет справиться и с ошибками времени выполнения, которые не обнаруживаются явно.
Раздел 1. ОБЩИЕ ПОЛОЖЕНИЯ
Изучаемые темы:
Тема 1.1. Технология программирования Тема 1.2. Базовые понятия алгоритма и алгоритмического языка
Тема 1.3. Основы алгоритмического языка С++ и системы программирования С++Builder
Лабораторные работы — не проводятся Тесты:
Тест 1. Технология программирования Тест 2. Базовые понятия алгоритма и алгоритмического языка
Максимальное число баллов: 8.
Введение
Студенту предстоит освоить:
•основные приёмы алгоритмирования практических задач;
•технологию подготовки задачи к программированию с учётом особенностей её реализации на компьютере;
•составление и отладку программ в среде С++Buider.
Настоящий курс не преследует цель полностью изучить всю систему программирования С++Buider: для этого потребовалось бы изучить 1200 страниц текста и такой курс имел бы объём порядка 700-800 часов. Предполагается изучение сравнительно небольшой части этой мощной системы, порядка 20 % всех средств программирования, но таких, которые составляют базовую основу практической работы . Освоив эти приемы, далее студент самостоятельно без большого труда сможет разобраться и в других способах программирования, обратившись к специальной литературе [1,2,3] и к службе помощи, встроенной в С++Builder (Help) .
Особенность изложения материала курса состоит в том, что средства программирования изучаются «материнским» методом, то есть ставится практическая задача и рассматриваются необходимые для её реализации программные средства. Таким образом, основной путь изучения материала идёт от задачи к программе.
Изложение материала предполагает, что читатель знаком с работой основных устройств компьютера и представляет их технические характеристики, имеет среднее образование и знает элементарные основы с английского языка.
Показатели качества ПО
Как и любое рыночное изделие, программное обеспечение обладает определённым качеством. Однако к настоящему моменту стандарты
качества не разработаны, нормативные документы отсутствуют. Тем не менее, в литературе широко распространены следующие понятия, относящиеся к качеству ПО.
Основные показатели качества
•Функциональность;
•Надежность;
•Дружественность.
Дополнительные показатели качества
•Добротность;
•Переносимость;
•Сопровождаемость;
•Удобство;
•Эффективность.
Функциональность ПО — способность программного продукта выполнять набор функций, определенных в его спецификации, и удовлетворяющих заданным потребностям пользователей. Уровень функциональности характеризуется отношением реализованных функций к требуемым функциям. Если это отношение больше единицы, продукт является функционально избыточным. При отношении меньше единицы продукт функционально недостаточен.
Надежность ПО — способность программного продукта безотказно выполнять определенные спецификацией функции. Надежность характеризуется:
•получением корректных результатов на любых наборах данных (отсутствии алгоритмических ошибок);
•отсутствием аварийных остановов и зависанием машины;
•отсутствием непредвиденных реакций машины при
некорректных манипуляциях пользователя.
Дружественность ПО заключается :
• в способности предоставлять пользователю интуитивно понятный интерфейс на национальном языке;
•в наличии встроенной контекстно-зависимой инструкцией по эксплуатации;
•в выводе на печать и экран документов в принятом на предприятии виде;
•в обеспечении комфортного быстродействия программного продукта.
Добротность ПО – это характеристика программного продукта с точки зрения:
•продуманности и рациональности его организации;
•организации его потоков управления и информационных потоков.
Переносимость (мобильность) ПО —способность программного обеспечения работать на различных аппаратных платформах или под управлением различных операционных систем.
Сопровождаемость программного обеспечения характеристика программного продукта, позволяющая минимизировать усилия по внесению в него изменений как для устранения ошибок, так и для модификации в соответствии с изменяющимися потребностями пользователей.
Удобство (эргономичность) ПО – это характеристики программного продукта, которые позволяют минимизировать усилия пользователей по подготовке исходных данных, по его применению и оценке полученных результатов, а также позволяют вызывать положительные эмоции пользователя.
Эффективность ПО оценивается отношением уровня услуг, предоставляемых программным продуктом пользователю к объему используемых ресурсов.
Стандарты на разработку ПО Действующее законодательство РФ включает государственные
стандарты [12] на проектирование и разработку ПО, определяющие общие принципы технологии программирования.
Тема 1.1. Технология программирования
Алгоритмом называется точное описание процесса преобразования исходных данных в конечный результат. Понятие алгоритма относится к наиболее фундаментальным положениям математики и логики.
Программированием в узком смысле называется запись алгоритма на алгоритмическом языке. Однако по мере развития программирования как индустриальной отрасли и в силу того, что программы становятся рыночными продуктами, термин «программирование» стал использоваться в более широком смысле, подразумевающим все этапы цикла производства программного продукта или, как говорят, «жизненного цикла» программного обеспечения (ПО). Сюда включается и разработка алгоритмов, и проектирование структур данных и программ, и отладка, и т.п. В этом разделе жизненный цикл ПО рассматривается подробно.
Основным общепринятым в профессиональном программировании принципом является «нисходящее проектирование и восходящее программирование». «Нисходящее проектирование» состоит в том, что программист, прежде всего, анализирует общую задачу, производя её декомпозицию. То есть он раскладывает общую задачу на совокупность более мелких подзадач таких, что решение каждой из них становится тривиальным или легко реализуемым. Затем осуществляется отдельное программирование каждой подзадачи, возникают базовые модули. На основе этой библиотеки базовых модулей производится сборка общей программы, то есть осуществляется «восходящее программирование».
Такой метод позволяет избежать повторного программирования типовых участков программы, уменьшается возможность ошибок, увеличивается надёжность программирования и производительность труда программиста.
Современное состояние технологии программирования характеризуется постоянным и широким использованием компьютера на всех этапах работы, что получило название CASE-технологии (Computer-Aided System Engineering).
Под термином CASE-технология подразумевается программный комплекс, автоматизирующий технологический процесс анализа, проектирования, разработки и сопровождения сложных программных систем.
Жизненный цикл программного обеспечения (ПО)
В промышленном программировании принято выделять следующие этапы разработки ПО:
1.Постановка задачи.
2.Разработка технического задания.
3.Декомпозиция.
4.Разработка решающих алгоритмов.
5.Кодирование и отладка.
6.Тестирование.
7.Внедрение.
8.Сопровождение.
9.Ликвидация.
Постановка задачи
На первом этапе производится формализация задачи — такое её описание, при котором в максимальной степени следует избегать общих неконкретных слов и фраз, а представить задачу в виде набора внешних спецификаций.
Спецификация — определение требований к программе. Здесь подробно описывается форма представления входной и выходной информации, формулируются требования к результату, поведение программы в особых случаях (например при вводе неверных данных), разрабатываются проекты диалоговых окон, обеспечивающих взаимодействие пользователя и программы. Исчерпывающим вариантом спецификации является описание форм представления исходных данных и выходных документов, производимых программой.
Разработка технического задания (ТЗ)
Этот этап играет первостепенную роль в проектировании ПО, принципиально разделяя работу профессионала и ремесленника. Проектирование любого объекта состоит в поиске инженерных решений, удовлетворяющих техническому заданию. Если нет ТЗ, то нечего и говорить о проектировании ПО, а можно рассматривать полученный программный продукт как результат свободного творчества, роль и функции которого слабо определены.
Всоответствии с существующими общегосударственными стандартами
[11]содержание и структура ТЗ строго определены в ГОСТ 19.106-78 и их надо неукоснительно соблюдать. Основные положения ГОСТов будут рассмотрены ниже.
Декомпозиция
Суть процесса декомпозиции уже рассматривалась выше в связи с основополагающим принципом нисходящего проектирования. Можно лишь добавить, что непосредственное кодирование программы без анализа составляющих её процедур приводит к дополнительным трудностям, вызванным тем, что программисту придется несколько раз перепрограммировать типовые участки алгоритма. Отсюда и потери времени, и дополнительные ошибки.
Разработка решающих алгоритмов
На этапе разработки алгоритма необходимо определить последовательность действий, которые надо выполнить для получения результата. Если задача может быть решена несколькими способами и, следовательно, возможны различные варианты алгоритма решения, то программист, используя некоторый критерий, например скорость решения алгоритма, выбирает наиболее подходящее решение. Результатом этапа разработки алгоритма является подробное словесное описание алгоритма или построение его блок-схема.
Кодирование и отладка
После того как определены требования к программе и составлен алгоритм решения, алгоритм записывается на выбранном языке программирования. В результате получается исходная программа. Термин кодирование нельзя признать очень удачным для русского языка, однако надо как-то различать программирование в целом со всеми вышеперечисленными этапами от собственно записи программы на языке программирования.
На современных компьютерах, ориентированных на интерактивную работу, кодирование программы фактически неотделимо от её отладки.
Отладка — это процесс поиска и устранения ошибок. Чтобы найти ошибки, надо попытаться скомпилировать и выполнить программу. Компиляция состоит в преобразовании исходного текста программы в машинный язык и выполняется программой-компилятором.
Ошибки в программе разделяют на две группы: синтаксические (ошибки в тексте) и алгоритмические. Синтаксические ошибки — наиболее легко устраняемые, их обнаруживает компилятор, а программисту остается их исправить, что нетрудно сделать, зная синтаксис и грамматику входного языка. Алгоритмические ошибки обнаружить труднее, поскольку они вызваны неправильным алгоритмом и могут быть найдены только по результатам тестирования. Этап отладки можно считать законченным, если программа правильно работает на одном — двух наборах входных данных.
Тестирование
Этап тестирования особенно важен, если Вы предполагаете, что Вашей программой будут пользоваться другие. На этом этапе следует проверить, как ведет себя программа на как можно большем количестве входных наборов данных, в том числе и на заведомо неверных.
Внедрение
Когда программа закончена, производятся её контрольно-сдаточные испытания и внедрение. Сдача программы заказчику подразумевает испытание программы на предмет соответствия выполняемых программой функций тем спецификациям, которые были заявлены в техническом задании. Внедрение предполагает пробную эксплуатацию программного продукта на предприятии — заказчике программы. Очень важно, чтобы с вашим ПО работали другие люди, а не те, которые участвовали в разработке. Это позволяет обнаруживать ошибки в таких вариантах использования, которые не могут прийти в голову разработчикам, а также адаптировать интерфейс и вид документов под нужды заказчика.
Сопровождение
Главной задачей разработчика на этой фазе жизненного цикла ПО является устранение ошибок, не найденных при тестировании и внедрении. Это своего рода гарантийное обслуживание своего изделия. Именно на этом этапе наличие ТЗ на программный продукт играет решающую роль. Суть в том, что заказчик ПО в процессе эксплуатации всегда находит причины быть неудовлетворенным работой программы – например выясняется, что она чего-то не делает или делает не так. Если программа не выполняет функции, указанные в ТЗ, то разработчик, конечно же, должен немедленно устранить эти недостатки. Если же функции в ТЗ не указаны, то разработчик имеет полное право не заниматься вопросами модификации программы или же потребовать заключение нового договора с новым ТЗ.
Однако если ТЗ отсутствует или нечётко составлено, разработчик попадает в полную зависимость от капризов заказчика и формально никогда не закончит работу над системой. Именно поэтому в программистской среде распространён термин « проклятие сопровождения».
Содержание ГОСТ на разработку ПО
ГОСТ 19.102-77 определяет основные стадии разработки ПО таким образом:
1.Техническое задание.
2.Эскизный проект.
3.Технический проект.
4.Рабочий проект.
5.Внедрение.
Как видно, формулировки ГОСТа существенно отличаются от названий этапов жизненного цикла, принятых в литературе по программированию. Однако противоречий на самом деле нет, если соотнести этапы проектирования по ГОСТу с этапами жизненного цикла ПО следующим образом:
|
Стадия |
по |
Этап жизненного |
Результат |
|||||||
|
ГОСТ 19.102-77 |
цикла ПО |
|||||||||
|
1 |
Техническое |
Постановка |
задачи, |
Техническое задание |
||||||
|
задание |
разработка ТЗ |
|||||||||
|
2 |
Эскизный |
Декомпозиция задачи, |
Структура |
данных, |
||||||
|
проект |
определение |
логической |
структуры хранения, |
|||||||
|
и физической структуры |
архитектура ПО |
|||||||||
|
данных |
и |
архитектуры |
||||||||
|
ПО |
||||||||||
|
3 |
Технический |
Кодирование, |
отладка |
ПО, |
выполняющее |
|||||
|
проект |
и |
тестирование. |
все |
функции |
ТЗ, но |
|||||
|
Апробирование |
пока |
не |
являющееся |
|||||||
|
решающих алгоритмов. |
рыночным продуктом |
|||||||||
|
4 |
Рабочий |
Полное |
ПО, являющееся |
|||||||
|
проект |
удовлетворение |
рыночным продуктом |
||||||||
|
требований ТЗ к качеству |
||||||||||
|
ПО. |
||||||||||
|
5 |
Внедрение |
Внедрение, |
Работа |
по |
||||||
|
сопровождение |
внедрению |
и |
||||||||
|
сопровождению |
Вопросы для самопроверки
1.Объясните смысл основных показателей качества программного обеспечения (ПО).
2.Перечислите общепринятые этап жизненного цикла (ПО).
3.При каких обстоятельствах термин «проклятие сопровождения» становится реальностью ?
4.Что самое главное в техническом задании ?
5.Каково взаимоотношение стадий жизненного цикла ПО и этапов проектирования, регламентированных ГОСТ 19.106-78 ?
6.Какими документами по ГОСТ 19.101-77 должен снабжаться программный продукт ?
7.В чем заключается понятие CASE-технологий ?
8.В чём заключается декомпозиция задачи и зачем её проводить?
9.В чем состоит смысл лозунга программистов «проектирование – нисходящее, программированиевосходящее»?
10.В чём заключается принцип модульного программирования?
Тема 1.2. Базовые понятия алгоритма и алгоритмического языка
Если применить принцип декомпозиции к изложению курса «Программирование и основы алгоритмизации», то можно выделить четыре базовых структуры алгоритмов, с помощью которых затем могут быть построены любые конкретные алгоритмы. Если научиться программировать базовые алгоритмы, то и решения сложных задач не будет вызывать затруднений.
Кбазовым алгоритмам относятся такие типы:
1.прямые;
2.разветвляющиеся;
3.циклические;
4.с подпрограммами (процедурами).
Особым образом выделяются алгоритмы с процедурами, но они не являются самостоятельной формой: любой из первых трёх вариантов может быть как с процедурами, так и без них. Для экономии места УМК здесь не будут рассматриваться блок-схемы этих структур, а мы ограничимся только их словесными определениями.
Прямыми алгоритмами называются такие структуры, все составляющие которых выполняются один и только один раз.
Такие алгоритмы подразумевают следующие действия:
1.определение значений исходных данных (чаще всего это ввод с пульта);
2.вычисление результатов;
3.вывод результатов (на экран или/и печать).
Разветвляющимися алгоритмами называются такие структуры, составляющие которых могут выполняться или опускаться.
Эти структуры являются наследниками прямых алгоритмов, сохраняя все их свойства и добавляя к ним ещё одно: выбор того или иного пути расчёта.
Циклическими алгоритмами называются такие структуры, составляющие которых могут выполняться много раз с автоматическим изменением аргументов расчета.
Такие алгоритмы являются наследниками двух первых структур, которые служат телом циклов. Эти участки охватываются управляющими инструкциями, обеспечивающими многократное повторение одинаковых вычислений при изменяющихся значениях аргументов.
Подпрограммой называется типовой участок алгоритма, обеспечивающий многократные вычисления для различных сочетаний аргументов этих вычислений.
Примечание. В общей литературе по программированию часто используется термин процедура как синоним слова подпрограмма. В источниках, посвящённых языку С++ вместо слова подпрограмма используется термин функция.
Алгоритм подпрограммы обычно описывается в начале общей программе относительно абстрактных аргументов, называемых формальными параметрами. Никаких вычислений описание процедуры не вызывает. Реализация вычислений происходят при вызове подпрограммы.
С точки зрения синтаксиса языка, оператор вызова представляет собою имя процедуры, за которым следует список реальных аргументов вычислений, называемых фактическими параметрами. При вызове подпрограммы происходит передача управления к описанию процедуры, все формальные параметры заменяются фактическими, происходят собственно вычисления, а их результаты возвращаются в главную программу в точку вызова. После этого возобновляется обычный ход программы.
Подпрограммы различаются на функции и процедуры. Функция возвращает в точку вызова одно и только одно значение, поэтому её вызов может быть включен в состав вычислительного выражения, например:
W=T*sin(alpha)+ U*cos(alpha);
Здесь sin и cos – стандартные функции (кстати, их алгоритмы описывать не надо, так как они встроены в библиотеки системы программирования).
Процедура возвращает в точку вызова одно, много или ни одного значения, поэтому её вызов не может быть включен в состав вычислительного выражения, а играет роль самостоятельного оператора. Например, вызов процедуры вычерчивания на экране треугольника по координатам трёх его вершин (X1,Y1) ,(X2,Y2) и (X3,Y3) может иметь вид:
Treugolnik(X1,Y1,X2,Y2,X3,Y3);
Такая процедура не возвращает никаких значений в точку вызова, так её результат выводится на экран. Примеры аналогичных процедур рассматриваются в лабораторных работах 5 и 6 и в теме 2.4 «Обработка строк».
Дальнейшее изложение материала посвящено изучению программирования базовых алгоритмов.
Языки программирования и компиляция
Чтобы передать алгоритм компьютеру для его реализации, надо записать этот алгоритм на языке программирования, который с одной стороны понятен человеку, а с другой — его может распознавать компьютер.
Студент должен по литературе ознакомиться с общими данными различных языков программирования.
Классификация языков программирования:
—по области применения :универсальные(язык ассемблера, C++, Pasсal, Ada, Basic ) и специализированные (Java, SQL, HTML, языки СУБД – dBase, Paradox,Oracle);
—по методу реализации : компиляторы (ассемблер, С++, Pascal) и
интерпретаторы (Basic, Java, HTML);
—по уровню: низкого уровня, машинно-зависимые языки (ассемблеры) и высокого уровня, машинно-независимые языки (C++, Pascal, Java).
Компиляция
После составления текста программы на языке высокого уровня, каким является С++, его необходимо преобразовать в машинные коды, то есть в последовательность нулей и единиц. Этот процесс называется компиляцией и выполняется программой компилятором.
Компилятор, схема работы которого приведена на рис. 1, состоит из двух отдельных программ. Первая программа – собственно компилятор, выполняющий последовательно две задачи:
1.Проверяет текст исходной программы на отсутствие синтаксических ошибок.
2.Создаёт (генерирует) объектную программу.
Объектная программаэто записанная в машинном коде программа, эквивалентная исходному алгоритму, но не готовая к выполнению, так как в ней отсутствуют библиотечные подпрограммы. Дело в том, что при написании исходного модуля на языке высокого уровня программист освобождается от многих рутинных действий, таких, как преобразование форматов данных, от написания алгоритмов стандартных функций, например тригонометрических.
На втором этапе работает программакомпоновщик, в задачу которого входит подсоединение к объектному модулю подпрограмм, которые он отыскивает в библиотеке стандартных процедур. В результате строится загрузочный модуль – полностью готовая к выполнению машинная программа.
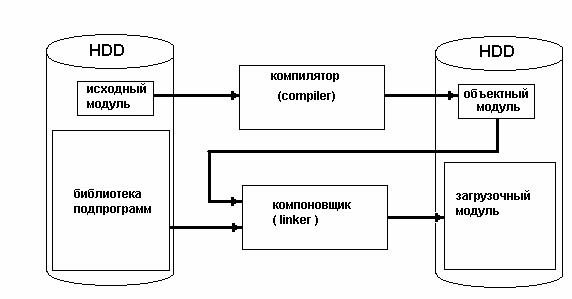
Рис. 1. Схема работы компилятора
Следует отметить, что генерация исполняемой программы происходит только в том случае, если в тексте исходной программы нет синтаксических ошибок.
Генерация машинного кода компилятором свидетельствует лишь о том, что в тексте программы нет синтаксических ошибок. Убедиться, что программа работает правильно можно только в процессе ее тестирования — пробных запусках программы и анализе полученных результатов.
При успешной компиляции возникает три различных файла, в которых хранятся различные модули одной программы. Файлы различаются расширениями их имён:
*.cpp — исходный модуль программы на языке Cи Plus Plus;
*.obj — объектный модуль программы (от слова object) в двоичном коде, не готовый к выполнению, являющийся промежуточным результатом компиляции;
*.exe — загрузочный модуль программы в двоичном коде (от глагола execute), полностью готовый к выполнению.
Записанный на жёсткий диск загрузочный модуль может быть выполнен впоследствии без какой-либо дополнительной подготовки, следовательно, быстро. Кроме того, от пользователя скрывается исходный текст программы, чем охраняются авторские права. Все фирменные программные продукты как, например операционные системы, редакторы изображений и т.п., поставляются в виде загрузочных модулей.
Исходная программа может выполняться и по принципу интерпретации. Суть его в том, что программаинтерпретатор, постоянно находясь в памяти машины, обращается к исходному модулю, вызывает первую команду, превращает её в эквивалентную последовательность машинных команд и тут же её исполняет. Затем происходит аналогичный акт интерпретации второй команды входного языка, а предыдущий фрагмент
теряется. Таким образом, загрузочный модуль не образуется, для последующего выполнения той же программы или даже фрагмента той же программы потребуется снова производить её интерпретацию. Следовательно, процесс выполнения программы по этому принципу очень медленный и требует присутствия исходного модуля, текст которого понятен
|
человеку. Значит, возникает вопрос с охраной авторских прав. |
Однако |
||||
|
пользуясь |
принципом |
интерпретации, |
гораздо |
легче |
находить |
|
алгоритмические ошибки в программе, а |
также |
проще обеспечить |
|||
|
машинную независимость программ. Поэтому |
профессиональные системы |
программирования, как Builder или Delphi, обеспечивают обе возможности.
Объектно-ориентированное программирование
Появление этого метода было вызвано следующими обстоятельствами:
•необходимостью построения больших программ, составление отдельных фрагментов которых можно было бы поручить различным программистам;
•растущими требованиями надежности программирования в смысле уменьшения вероятности совершения ошибок и увеличения легкости их обнаружения;
•приближением внутренней структуры данных к реальным объектам внешнего мира и как следствие упрощение алгоритмов их представления и обработки;
•требованиями организации параллельной обработки различных процессов.
Объектом называется программная конструкция, объединяющая в единое целое данные, методы их обработки и механизм реакции на внешние события.
В языках предшествующих типов, таких как С (без плюса), начальный Pascal или Basic главным объектом программирования было объединение данных. Процедуры их обработки не были связаны с этим объединением, что порождало ошибки, когда к данным применялись неадекватные алгоритмы. С введением объединений типа «объект» этот недостаток был преодолён.
Другая ограниченность предыдущих языков выражалась в концепции управления процедурами, то есть порядком их исполнения. Это были программы, управляемые данными, что означало метод перехода от одной команды или процедуры к другой. Последовательность выполнения команд зависела от двух обстоятельств: во-первых, от порядка написания программных командных строк и, во-вторых, от выполнения некоторых условий, полученных при вычислении. Эти условия зависели от полученных значений, и в зависимости от истинности условия определялось, какую команду надо выполнять следующей; естественная последовательность выполнения команд изменялась.
Кроме того, в языках того времени не были предусмотрены средства реагирования на внешние события, выраженные кодами прерываний, например на окончание работы жесткого диска или движения мыши. Следовательно, было трудно создать программу, управляемую пользователем в режиме диалога, то есть, интерактивную.
Объекты, в отличие от простого объединения данных, предусматривают возможность реагирования на прерывания, поэтому про программу, написанную с учетом реакции на внешние воздействия, говорят, что это программа, управляемая событиями. Программа состоит из блоков, называемых функциями, порядок написания которых не влияет на последовательность их выполнения. Функции выполняются при наступлении того внешнего события, на которое их настроил программист, внутри тела функции команды выполняются в естественном порядке их написания, за исключением условных переходов.
В целом для программирования вводится термин «событийное» программирование, тогда как предыдущая концепция называлась процедурным программированием. Естественно, что событийное программирование унаследовало все особенности процедурного программирования и привнесло ещё и собственную индивидуальную черту – реакцию на прерывания.
Объекты
Как программная конструкция объект характеризуется:
•свойствами,
•методами,
•событиями.
Свойства представлены значениями, являющимися параметрами объекта. Например, если объект – это визуальный компонент типа кнопки на экране, то к простым свойствам можно отнести координаты кнопки, её длину и ширину. Под каждое свойство такого типа отводится поле памяти, соответствующее типу значения свойства (int, float и т.п.). Свойства могут быть и боле сложными, состоящими из группы элементов. Например, визуальный компонент TListBox обладает сложным свойством «список» (Items), который представляет собой специфическую структуру данных, отдалённо напоминающую массив – объединение однородных данных, представленное цепным списком (рис.38). Кстати, в языке C++ такой тип данных не предусмотрен, но в системе C++Builder он существует. Для таких сложных свойств память выделяется особым образом (динамически) и представляет группу связанных полей.
Методы— это функции, обеспечивающие доступ к свойствам объекта и их обработку. Метод жестко связан с объектом или со свойством объекта, поэтому его невозможно применить к «чужому» объекту или свойству. Этим достигается надежность программирования. По своему внутреннему содержанию методы мало чем отличаются от стандартных подпрограмм, встроенных в язык. Методы разработаны создателями системы
программирования, их не надо переделывать, они полностью готовы для использования.
Событие – это предусмотренное разработчиком объекта прерывание в операционной среде, на которое способен реагировать объект. Механизм отклика на прерывание встроен в объект его разработчиком, программисту остается только выбрать подходящее по логике работы программы событие и составить собственную программу, описывающую реакцию объекта на это событие. Такая программа называется обработчиком события (Handler).
Физически под объект отводится область памяти, в которой хранятся все эти характеристики. В системе C++Builder память под объект отводится динамически в момент его создания скрытым программным модулем, называемым конструктором. По окончании работы с объектом память, занимаемая им, освобождается другим скрытым модулем, деструктором. Программисту не надо программировать эти модули, за него эту работу выполняет система.
Динамическое выделение памяти, заключающееся в том, что при построении объекта для него резервируется какая-то область память; позднее
|
после его обработки, эта память освобождается, |
затем вновь отводится уже |
|
под другие объекты. Динамическое выделения |
памяти является очень |
важным принципом работы объектно-ориентированных систем, так как он обеспечивает последовательную загрузку одной и той же области памяти разными задачами, позволяя выполнять программы практически любого объема на машинах с ограниченной физической памятью.
Статическое выделения памяти, состоит в том, что память под объект отводится на этапе инициализации программы и закрепляется за ним на протяжении всего времени выполнения программы. Программа со статическим объектами выполняется несколько быстрее, чем с динамическими, поскольку нет надобности тратить машинное время на перераспределения, однако создаются ограничения на исполнения больших программ.
Классы объектов
Технология программирования уже давно обнаружила явление, сильно влияющее на производительность программиста. При написании новых программ зачастую встречаются алгоритмы, повторяющие или мало отличающиеся от ранее написанных фрагментов старых программ. Естественно, рационально не программировать такие участки вновь, а использовать старые части или их прообразы.
Чтобы это стало возможным, в объектно-ориентированных системах было предложено объединять объекты в семейства или классы, а отношения между классами подчинить принципам инкапсуляции, наследования и полиморфизма.
Под классом объектов понимают формальное (абстрактное) описание объекта, то есть его свойств, методов и событий. Например, для «кнопки» на экране указывается, что этот объект:
• обладает длиной, шириной, цветом (свойства);
•может быть временно спрятан, а затем снова показан на экране (методы);
•способен реагировать на щелчок кнопкой мыши (события).
Описание не порождает объекта, он ещё не существует, есть только сведения о его характеристиках. Когда же произойдет инициализация объекта и конструктор выделит под него память, объект начнет существовать. Боле того, в одной программе может быть несколько объектов одного и того же класса, тогда их называют представителями класса.
Можно провести аналогию между описанием класса объектов и описанием процедуры (функции): описание процедуры тоже не порождает её выполнения, это только лишь описание алгоритма относительно несуществующих параметров, называемых формальными. При вызове процедуры на место формальных параметров будут подставлены реальные аргументы и запущен процесс вычисления.
Если в программе требуется воспроизвести какой-то алгоритм, который раньше уже был оформлен как метод некоторого класса, то достаточно включить этот класс в программу, инициализировать объект и пользоваться нужным методом без повторного программирования. В этом плане реализуется идея библиотеки личных подпрограмм, что является одним из
|
самых мощных инструментов повышения производительности |
труда |
|
программиста. |
Инкапсуляция
Когда объект проинициализирован, с ним можно начинать работать. Его свойствам присваиваются начальные значения, то есть они записываются в поля памяти, отведенные конструктором. Каждое поле имеет свой адрес и этот адрес доступен только в рамках данного объекта. Вне объекта обращение к этому адресу запрещено механизмами защиты доступа. Этим обеспечивается неприкосновенность данных и увеличивается надежность программирования, так как собственные данные не могут быть повреждены за счет некорректного обращения к ним со стороны чужих процедур. Таким же образом недопустимо и обращение к методам объекта со стороны посторонних объектов или функций.
Блокирование доступа к свойствам и методам объекта называется инкапсуляцией; для этого же явления используется термин локализация.
Наследование
На практике часто возникает такая необходимость: надо описать объект, в основном напоминающий уже существующий, но с небольшими отличиями. Чтобы реализовать такую потребность, введён механизм наследования. Если в качестве прообраза объекта взять какой-либо существующий класс и добавить к нему некоторые новые свойства или методы, то новый объект унаследует все черты базового класса, т.е. можно пользоваться всеми свойствами, методами и событиями предшествующего
класса, не повторяя их описаний. В этом плане используются бытовые термины: родительский и дочерний. Вышесказанная мысль может быть выражена такими словами: дочерний класс наследует все характеристики родительского класса без повторного описания.
Принцип наследования избавляет программиста от лишних повторяющихся строк программного текста, хотя проследить всю иерархию свойств дочернего объекта порою довольно сложно.
Полиморфизм
Полиморфизм — это способность представителей различных классов решать подобные по смыслу проблемы разными способами. В рамках языка С++ поведенческие свойства класса определяются набором входящих в него методов. Изменяя алгоритм того или иного метода в дочерних классах, программист может придавать этим потомкам отсутствующие у родителя специфические свойства. Для изменения метода необходимо переопределить (перекрыть) его в потомке, т. е. объявить в потомке одноименный метод и реализовать в нем нужные действия. В результате в объекте-родителе и объекте-потомке будут действовать два одноименных метода, имеющих разную алгоритмическую основу и, следовательно, придающих объектам разные свойства. Это и называется полиморфизмом объектов.
В С++ полиморфизм достигается не только описанным выше механизмом наследования и перекрытия методов родителя, но и их виртуализацией (см. ниже), позволяющей родительским методам обращаться к методам своих потомков.
Вопросы для самопроверки
1.Являются ли правила решения арифметических задач типа «первым действием мы узнаем . . .» алгоритмами?
2.Объясните понятие «синтаксис» языка.
3.Может ли русский (английский) язык служить алгоритмическим языком программирования?
4.Что такое компиляция? Интерпретация?
5.Какой метод реализации языка программирования эффективнее для отладки программ?
6.Какой метод реализации языка программирования эффективнее для обеспечения переносимости программ?
7.Приведите сравнительную характеристику известных языков программирования.
8.Каков смысл понятий «объект» и «объектно-ориентированное программирование»?
9.Является ли достаточным объяснением понятия «структурное программирование» запись текста программы «лесенкой»?
10.Укажите общее и различия между функциями и процедурами.
Тема 1.3. Основные понятия алгоритмического языка С++ и системы программирования Builder
В среде программирования С++Builder для записи программ используется язык программирования С++. Программа на С++ представляет собой последовательность инструкций, которые довольно часто называют операторами. Одна инструкция от другой отделяется точкой с запятой. Каждая инструкция состоит из идентификаторов. Идентификатор может обозначать:
•инструкцию языка (=, if, while, for);
•переменную;
•константу (целое или дробное число, строка символов);
•арифметическую операцию (+, -,*,/)
•логическую операцию (&&(и), ||(или), !(не);
•подпрограмму (процедуру или функцию).
Типы данных, используемые в C++Builder, можно разбить на четыре группы:
1.отсутствие значения (void );
2.скалярные значения (scalar );
3.структурированные данные (aggregate);
4.функции (function).
Объяснения
Отсутствие значения (служебное слово void)
Этот тип используется в описании функций и процедур, не возвращающих в вызывающую программу никакого значения, например для процедур вывода на экран.
Скалярные значения (scalar)
Скалярные значения представлены такими типами данных
|
• |
арифметические |
(arithmetic); |
|
• |
строковые |
(string); |
|
• |
перечислимые |
(enumeration): |
|
• |
указатели |
(pointer). |
Если некоторая переменная описана как скалярная, значит, для её хранения отводится одно поле памяти, как правило, фиксированной длины, и туда может быть записано только одно значение. Так арифметическая переменная Х, описанная как int (целое), может принимать одно из значений целых чиcел (со знаком или без него), например
Х=+14 или Х= -1234 или Х=6543.
Варианты скалярных типов:
|
Арифметические |
значения изображают десятичные числа, |
как целые, так и |
|
дробные: |
||
|
4321 3.1415 |
-0.0003 |
|
|
1.23 E 4 (это экспоненциальная форма, означающая: 1.23 |
умножить на 10 в |
|
|
четвертой степени). |
Строковые значения изображают последовательность любых символов, которые записываются в двойных кавычках, количество символов не ограничивается:
“ABCDEF” ”АБВГДЕ” “A15_бис”
Перечислимые значения аранжируют произвольную группу чисел или слов в фиксированном порядке, так что впоследствии к членам этого ряда можно обращаться по принципу «следующий» или «предыдущий», например:
(январь, февраль, март, апрель, май).
Указатели формально представляют собою целые числа, но используется в качестве значений адресов ячеек памяти, в которых находятся нужные нам операнды.
В данной главе мы рассмотрим наиболее простые типы – арифметический и строковый; остальные будут рассмотрены по мере необходимости их использования (см. также [1,2,3])
Структурированные данные (aggregate)
Структурированные данные представлены такими типами
|
• |
массивы |
(array); |
|
• |
структуры |
(sruct); |
|
• |
объединения |
(union); |
|
• |
классы |
(class). |
Структурированное данное представляют собою иерархическое объединение данных, в конечных ветвях которых находятся данные простого (скалярного) типа. Такие сложные объединения позволяют достаточно точно отобразить взаимоотношение данных в объектах реального мира и сделать процесс программирования более простым, понятным и надёжным. Здесь будут рассматриваться такие данные, как массивы и структуры, а другие типы будут объяснены по мере их появления в программах.
Массивы
|
Определение: совокупность однородных значений, |
организованных в |
|
регулярную структуру |

Описание в программе:
int X[8]; AnsiString Y[3],[8];
Обращение к элементам:
X[3] X[k] Y[2][4] Y[i] [j]
Организация массивов такова, что имеется возможность обращаться к его элементам по индексу (порядковому номеру). Индексы изменяются, начиная с нуля, поэтому X[0] – это первый элемент массива, X[1] – второй и т.д. Если в массиве имеется N элементов, то последний элемент – это X[N-1], а границы изменения индекса – от 0 до N-1. Если в процессе работы оказалось, что индекс вышел за допустимые границы, то система выдаёт сообщение об ошибке
Index out of bounds (индекс вне границ)
и программа завершается аварийно.
Внимание: после идентификатора массива используются только квадратные скобки.
Если записать индекс массива в круглых скобках, например X(3), то компилятор «подумает», что X – это не массив, а функция, ведь при обращении к функции в круглых скобках записываются её аргументы. Поскольку функции с именем X не существует, будет выдана ошибка: «E2314 Call of nonfunction» и компиляция прекратится.
Массивы могут быть:
•одномерными – это ряды чисел или других значений;
•двумерными – они отражают плоские таблицы;
•многомерными.
Примеры
Одномерный массив X из восьми чисел (табл.1):
Таблица 1 Размещение в памяти одномерного массива чисел типа float
|
Индекс |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
Элемент |
36.6, |
37.1 |
37.7 |
37.9 |
38.1 |
37.4 |
37.3 |
37.4 |
|
массива |
||||||||
|
Обращение к элементам массива: |
||||||||
|
X [0]=36.6 |
X[7]=37.4 |
Обратите внимание, что количество элементов 8, но индекс изменяется от 0 до 7, поскольку первый элемент массива имеет индекс 0
Двумерный массив Y из трёх строк и пяти столбцов, элементами массива являются строки символов:

|
Номер столбцов |
|||||||
|
Номера строк |
0 |
1 |
2 |
3 |
4 |
||
|
0 |
ABC |
D |
E |
FGH |
KLM |
||
|
1 |
ABCD |
CD |
EFGH |
MN |
SAS |
||
|
2 |
ABCDF |
CDE |
FG |
K |
ALL |
||
|
Обращение к элементам массива: |
|||||||
|
Y[0][0]=”ABC” |
Y[2][4]=”ALL” |
Размещение в памяти. Память под массивы выделяется одним экстентом, т.е. непрерывным участком памяти, достаточным для размещения всех элементов массива.
Рассмотрим размещение массива X (рис. 2). Значения элементов массива — дробные числа, такие данные описываются как float (плавающий) и для каждого числа выделяется 4 байта памяти. Тогда в целом для массива X , будет выделено 32 байта — 8 (число элементов массива ) полей памяти по 4 байта. Адрес каждого соседнего элемента будет отличаться от адреса предыдущего тоже на 4(табл.2).
Таблица 2 Адреса ячеек для одномерного массива чисел типа float
|
Индекс |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
Адрес |
1000 |
1004 |
1008 |
1012 |
1016 |
1020 |
1024 |
1028 |
|
Элемент |
36.6 |
37.1 |
37.7 |
37.9 |
38.1 |
37.4 |
37.3 |
37.4 |
Поскольку адреса элементов массива идут с регулярными промежутками, их легко вычислять автоматически путём модификации индексного регистра, что и делается в реальности. Следовательно, при последовательном просмотре элементов массива переход от одного элемента к другому производится аппаратным путём и, значит, очень быстро. Это же обстоятельство позволяет не хранить в памяти значений индексов, поскольку они функционально зависят от адресов. Следовательно, массивы экономно расходуют память.
Если же речь идёт о сортировке, включении или исключении элемента из последовательного ряда, то предпочтительнее пользоваться цепными списками, где эти операции выполнятся значительно быстрее (см. раздел
TListBox).
Структуры
Определение: совокупность неоднородных значений
Описание в программе:
<ключевое слово struct > <общее наименование типа>

{ <описание членов структуры>} <имя структурированной переменной>
Обращение к элементам:
<имя структурированной переменной>.<имя члена структуры> <общее наименование типа> — не обязательно
Структуры представляют собою совокупность разнородных типов данных, причём в этом объединении никакая регулярность не соблюдается. Структуры хорошо отражают набор характеристик или свойств реальных объектов и по своей конструкции напоминают анкету, паспорт или формуляр. Как пример приведём структуру для регистрации данных книги, поступающей на хранение в библиотеку:
|
Назначение |
Тип |
Значение |
||||
|
поля |
||||||
|
Автор |
AnsiString |
Б.И.Шамис |
||||
|
Название |
AnsiString |
С++Builder |
для |
|||
|
профессионалов |
||||||
|
Издательство |
AnsiString |
БХВ-Петербург |
||||
|
Место |
AnsiString |
С.Петербург |
||||
|
издания |
||||||
|
Год издания |
int |
2003 |
||||
|
Тираж |
int |
12000 |
||||
|
Цена |
float |
420.50 |
||||
|
Описание в программе будет иметь вид: |
||||||
|
struct |
//ключевое слово |
|||||
|
{ AnsiString |
||||||
|
Avtor, |
//автор |
|||||
|
Naimenovanie, //наименование |
||||||
|
Izdanie |
//издание |
|||||
|
int |
Mesto; |
//место издания |
||||
|
God |
//год |
|||||
|
float |
Tirage; |
//тираж |
||||
|
} |
Price; |
//цена |
||||
|
Formular; |
//имя структурированной переменной |
Примечание. Символ « //» отделяет комментарий от программного текста. Комментарии выводятся на дисплей, но не обрабатываются компилятором, поэтому в них можно использовать русский язык.
Поскольку все элементы структуры разнородны, в памяти они располагаются нерегулярно, и понятие индекса для структур не существует.
Для обращения к элементу структуры используется составная запись
вида:
<имя структурированной переменной>.<имя члена структуры>
|
Например: |
|
|
Formular. Avtor |
//обращение к имени автора |
|
Formular. Price |
//обращение к цене |
Примечание. Обратите внимание на точку, соединяющую имя переменной с именем поля: в большинстве подобных случаев в языке С++ используется знак стрелки –>, так что точка — редкое исключение.
|
(Более |
обширные варианты |
аггрегативных данных, такие как |
|
«объединения» и «классы», будут |
рассматриваться в следующем курсе |
|
|
«Прикладное программирование». |
Базовые типы данных
Программа может оперировать данными различных типов: целыми и дробными числами, символами, строками символов, логическими величинами. Для обозначения типа значения используются предопределенные ключевые слова int, float, char и т.д.
Целый тип
Язык C++ поддерживает много различных целых типов данных, в данном курсе мы ограничимся следующими: char, unsigned char, short, unsigned short, int, unsigned int, описание которых приведено в таблице 3.
|
Таблица 3. Целые типы |
|||
|
Тип |
Перевод |
Диапазон значений |
Формат поля |
|
памяти (байтов) |
|||
|
char |
символ |
от-128 до 127 |
1 |
|
unsigned |
символ |
от 0 до 255 |
1 |
|
char |
без знака |
||
|
short |
короткий |
от-32 768 до 32 767 |
2 |
|
unsigned |
короткий |
от 0 до 65 535 |
2 |
|
short |
без знака |
||
|
int |
целый |
от -2 147 483 648 |
4 |
|
до 2 147 483 647 |
|||
|
unsigned int |
целый |
от 0 до 4 294 967 295 |
4 |
|
без знака |
Вещественный тип
Язык C++ поддерживает 4 вещественных типа, мы ограничимся двумя: float и double. Типы различаются между собой диапазоном допустимых значений, количеством значащих цифр и количеством байтов, необходимых для хранения данных в памяти компьютера (табл. 4).
|
Таблица 4. Вещественные (дробные) типы |
|||
|
Тип |
Диапазон |
Значащие цифры |
Байтов |
|
float |
от 3.4*10−38 |
7-8 |
4 |
|
double |
до 3.4*1038 |
15-16 |
8 |
|
от 1.7*10−308 |
|||
|
до 1.7*10308 |
Символьный тип
Язык C++ поддерживает символьный тип char (символ, печатный знак). Этот тип обладает сложным дуальным свойством : одно и то же значение, записанное в некоторую ячейку памяти, программист может интерпретировать либо как целую величину в диапазоне от 0 до 255, либо как символ алфавита, установленного на данной машине. Например, если переменная sym описана так:
char sym;
и имеет десятичное значение 198 , то эту переменную можно толковать как число 198, либо как символ ‘Ж’ – прописная русская буква.

Основное назначение поля типа char – это кодирование символов алфавита. Для хранения значения типа char в памяти отводится один байт, куда записывается код алфавитного символа в соответствии с системой ANSI
(American National Standard Institute). Поскольку один байт содержит 8
двоичных разрядов, общее количество кодируемых символов равно 28-1=255. Таблица разделяется на две части. Нижняя половина содержит коды от 0 до 127, это базовая таблица кодировки, она остаётся неизменной для любых вариантов таблицы. Особенную роль играют коды от 0 до 31 – это так называемые управляющие символы, которым не ставится в соответствие изображение на экране. Эти коды использовались традиционно для управления внешними устройствами, например дисплеем или принтером
(табл. 5)
|
Таблица 5. Управляющие ANSI-коды |
||||||||
|
Код |
||||||||
|
Код |
Символ |
Код |
Символ |
Символ |
Код |
Символ |
||
|
0 |
NUL (конец |
8 |
BS |
16 |
DEL |
24 |
CAN |
|
|
стека) |
17 |
|||||||
|
1 |
SОН |
9 |
HT(горизон- |
DC1 |
25 |
EM |
||
|
тальная |
||||||||
|
табуляция) |
18 |
|||||||
|
2 |
STX |
10 |
LF(перевод |
DC2 |
26 |
SUB(конец |
||
|
строки) |
19 |
файла) |
||||||
|
3 |
ЕТХ |
11 |
VT(вертикаль- |
DC3 |
27 |
ESC |
||
|
ная табуляция) |
20 |
|||||||
|
4 |
EOT |
12 |
FF |
DC 4 |
28 |
FS |
||
|
5 |
ENQ |
13 |
CR(возврат |
21 |
NAK |
29 |
GS |
|
|
каретки) |
22 |
|||||||
|
6 |
ACK |
14 |
SO |
SYN |
30 |
RS |
||
|
7 |
BEL(сис- |
15 |
SI |
23 |
ETB |
31 |
US |
|
|
темный |
||||||||
|
динамик) |
|
Таблица 6. Базовые ANSI коды |
|||||
|
32 |
64 |
@ |
96 |
` |
|
|
33 |
! |
65 |
A |
97 |
a |
|
34 |
« |
66 |
B |
98 |
b |
|
35 |
# |
67 |
C |
99 |
c |
|
36 |
$ |
68 |
D |
100 |
d |
|
37 |
% |
69 |
E |
101 |
e |
|
38 |
& |
70 |
F |
102 |
f |
|
39 |
‘ |
71 |
G |
103 |
g |
|
40 |
( |
72 |
H |
104 |
h |
|
41 |
) |
73 |
I |
105 |
i |
|
42 |
* |
74 |
J |
106 |
j |
|
43 |
+ |
75 |
K |
107 |
k |
|
44 |
, |
76 |
L |
108 |
l |
|
45 |
— |
77 |
M |
109 |
m |
|
46 |
. |
78 |
N |
110 |
n |
|
47 |
/ |
79 |
O |
111 |
o |
|
48 |
0 |
80 |
P |
112 |
p |
|
49 |
1 |
81 |
Q |
113 |
q |
|
50 |
2 |
82 |
R |
114 |
r |
|
51 |
3 |
83 |
S |
115 |
s |
|
52 |
4 |
84 |
T |
116 |
t |
|
53 |
5 |
85 |
U |
117 |
u |
|
54 |
6 |
86 |
V |
118 |
v |
|
55 |
7 |
87 |
W |
119 |
w |
|
56 |
8 |
88 |
X |
120 |
x |
|
57 |
9 |
89 |
Y |
121 |
y |
|
58 |
: |
90 |
Z |
122 |
z |
|
59 |
; |
91 |
[ |
123 |
{ |
|
60 |
< |
92 |
\ |
124 |
| |
|
61 |
= |
93 |
] |
125 |
} |
|
62 |
> |
94 |
^ |
126 |
~ |
|
63 |
? |
95 |
_ |
127 |
Коды от 32 до 127 изображаются буквами латинского алфавита (табл. 6), а кодам от 128 до 255 соответствуют символы национального алфавита. Символы старшей половины таблицы изменяются в зависимости от кодовой страницы (code page)– условного номера кодировочной таблицы. Так для европейских стран используется страница № 850, а для России — № 866 (табл.7).
Таблица 7.Кириллическая страница № 866 таблицы по стандарту ANSI
|
128 |
Ђ |
160 |
192 |
А |
224 |
а |
|
|
129 |
Ѓ |
161 |
Ў |
193 |
Б |
225 |
б |
|
130 |
‚ |
162 |
ў |
194 |
В |
226 |
в |
|
131 |
ѓ |
163 |
Ј |
195 |
Г |
227 |
г |
|
132 |
„ |
164 |
¤ |
196 |
Д |
228 |
д |
|
133 |
… |
165 |
Ґ |
197 |
Е |
229 |
е |
|
134 |
† |
166 |
¦ |
198 |
Ж |
230 |
ж |
|
135 |
‡ |
167 |
§ |
199 |
З |
231 |
з |
|
136 |
€ |
168 |
Ё |
200 |
И |
232 |
и |
|
137 |
‰ |
169 |
© |
201 |
Й |
233 |
й |
|
138 |
Љ |
170 |
Є |
202 |
К |
234 |
к |
|
139 |
‹ |
171 |
« |
203 |
Л |
235 |
л |
|
140 |
Њ |
172 |
¬ |
204 |
М |
236 |
м |
|
141 |
Ќ |
173 |
— |
205 |
Н |
237 |
н |
|
142 |
Ћ |
174 |
® |
206 |
О |
238 |
о |
|
143 |
Џ |
175 |
Ї |
207 |
П |
239 |
п |
|
144 |
ђ |
176 |
° |
208 |
Р |
240 |
р |
|
145 |
‘ |
177 |
± |
209 |
С |
241 |
с |
|
146 |
’ |
178 |
І |
210 |
Т |
242 |
т |
|
147 |
“ |
179 |
і |
211 |
У |
243 |
у |
|
148 |
” |
180 |
ґ |
212 |
Ф |
244 |
ф |
|
149 |
• |
181 |
µ |
213 |
Х |
245 |
х |
|
150 |
– |
182 |
¶ |
214 |
Ц |
246 |
ц |
|
151 |
— |
183 |
· |
215 |
Ч |
247 |
ч |
|
152 |
184 |
ё |
216 |
Ш |
248 |
ш |
|
|
153 |
™ |
185 |
№ |
217 |
Щ |
249 |
щ |
|
154 |
љ |
186 |
є |
218 |
Ъ |
250 |
ъ |
|
155 |
› |
187 |
» |
219 |
Ы |
251 |
ы |
|
156 |
њ |
188 |
ј |
220 |
Ь |
252 |
ь |
|
157 |
ќ |
189 |
Ѕ |
221 |
Э |
253 |
э |
|
158 |
ћ |
190 |
ѕ |
222 |
Ю |
254 |
ю |
|
159 |
џ |
191 |
ї |
223 |
Я |
255 |
я |
Строковый тип
Язык C++ поддерживает два строковых типа: string и AnsiString. Тип string представляет поле переменной длины, каждый байт которого содержит коды символов, образующих строку. В последнем байте записывается ноль. Например, строка “ABBA” будет выглядеть так
|
65 |
66 |
66 |
65 |
0 |
Здесь код 65 обозначает латинскую заглавную букву A , а 66 – B.
В поле string содержится столько байтов, сколько символов в строке плюс 1. Такой формат часто называют « строки с нулевым окончанием».
Строковые поля этого типа широко применяются в системном программировании для передачи параметров в процедуры, поэтому они удобны для прикладных программ, использующих функции операционной системы, так называемые средства API – Application Program Interface.
Однако для задач обработки строк как, например сравнение строк, определение вхождения одной строки в другую и т.п., строки с нулевым окончанием мало пригодны, поскольку приводят к усложнённым алгоритмам, поэтому в C++ используются строки типа AnsiString,
заимствованные из языка Pascal вместе со всеми процедурами и функциями для их обработки.
Строка “ABBA” в формате AnsiString будет выглядеть так: 4 65 66 66 65
В первом байте поля указывается длина собственно строки в байтах, в остальных содержатся ANSIкоды символов, что и определило название формата. Строковые операции над таким форматом производятся значительно проще, что и предопределило широкое использование таких строк.
Машинное представление данных
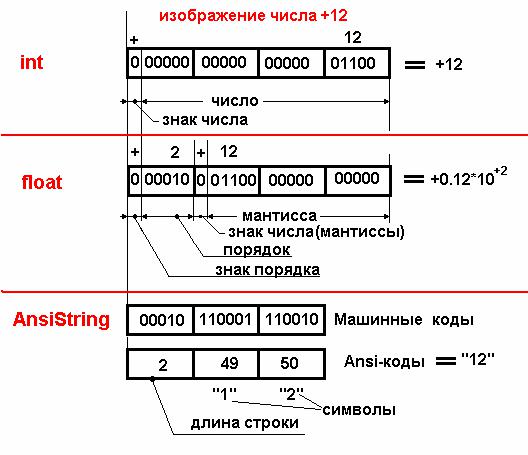
Строковый тип данных используется для ввода данных в память компьютера и для вывода значений на экран или печать. Однако для вычислительных операций строковые данные надо преобразовывать в числовое представление. Чтобы хорошо понять, зачем это делается, студенту следует основательно изучить машинные формы представления данных всех типов, изображенные на рис. 2.
Рис. 2. Машинное представление данных
Из рисунка видно, что нельзя непосредственно в одном операнде обрабатывать данные различных типов. Действительно, операция, например сложения, выполняется поразрядно, но ведь нет никакого смысла непосредственно складывать нулевой разряд целого числа int, выражающего знак числа, c нулевым разрядом строкового типа, изображающего такое же число, но где нулевой разряд выражает длину строки !
Логический тип
Логическая величина может принимать одно из двух значений true (истина) или false (ложь). В языке C++ логические величины относят к типу bool (булевское значение ).
Переменная
Переменная — это область памяти, в которой находятся данные для программы. Когда программа манипулирует с данными, она, фактически, оперирует содержимым ячеек памяти, т. е. переменными.
Чтобы программа могла обратиться к переменной (области памяти), переменная должна иметь имя. Имя переменной придумывает программист.
Вкачестве имени переменной можно использовать последовательность из букв латинского алфавита, цифр и некоторых специальных символов. Первым символом в имени переменной должна быть буква. Пробел в имени переменной использовать нельзя. Использование русских букв приведёт к
синтаксической ошибке.
Следует обратить внимание на то, что компилятор языка C++ различает прописные и строчные буквы в именах переменных, поэтому имена SUMMA, Summa и summa обозначают различные переменные.
Желательно, чтобы имя переменной было логически связано с ее назначением. Например, переменным, предназначенным для хранения коэффициентов и корней квадратного уравнения, которое в общем виде традиционно записывают
ах2 + bх + с = 0,
вполне логично присвоить имена а, b, с, x1 и х2. Другой пример. Если в программе есть переменные, предназначенные для хранения суммы покупки
ивеличины скидки, то этим переменным можно присвоить имена TotalSumm
иDiscount или (на русский манер) ObSumma и Skidka.
Вязыке C++ каждая переменная перед использованием должна быть объявлена. С помощью объявления устанавливается не только факт существования переменной, но и задается ее тип, чем указывается и диапазон допустимых значений.
Вобщем виде инструкция объявления переменной выглядит так:
<наименование типа><пробел><имя переменной><;> Пример
int а; float b; char c; AnsiString s;
Если в программе имеется несколько переменных, относящихся к одному типу, то имена этих переменных можно перечислить в одной строке через запятую, а тип переменных указать перед именем первой переменной, например:
float а,b,с; int x1,x2;
Константы
В языке C++ существуют два вида констант: обычные и именованные. Обычная константа — это целое или дробное число, строка символов
или отдельный символ, логическое значение.
Числовые константы
В тексте программы числовые константы записываются обычным образом, т. е. так же, как числа, например при решении математических задач. При записи дробных чисел для разделения целой и дробных частей используется точка. Если константа отрицательная, то непосредственно перед первой цифрой ставится знак «минус».
Ниже приведены примеры числовых констант: 123 0.0 -543.02
Дробные константы могут изображаться в виде числа с плавающей точкой. Представление в виде числа с плавающей точкой основано на том, что любое число может быть записано в алгебраической форме как произведение числа, меньшего 10, которое называется мантиссой, и степени десятки, именуемой порядком.
В табл. 8 приведены примеры чисел, записанных в обычной форме, в алгебраической форме и форме с плавающей точкой.
Таблица 8. Примеры записи дробных чисел
|
Число |
Алгебраическая форма |
Форма с плавающей |
|
точкой |
||
|
1 000 000 |
1х106 |
1 .0000000000Е+06 |
|
-123.452 |
-1,23456×10 2 |
-1 .2345600000Е+02 |
|
0,0056789 |
5,6789х10 −3 |
5,6789000000Е-03 |
Строковые и символьные константы заключаются в кавычки. Ниже приведены примеры строковых констант:
‘Язык программирования C++’ ‘2.4’ ‘Д’
Здесь следует обратить внимание на константу ‘ 2.4’. Это именно символьная константа, т. е. строка символов, которая изображает число «две целые четыре десятых», а не число 2,4.
Инструкция присваивания
Инструкция присваивания является основной вычислительной инструкцией. Если в программе надо выполнить вычисление, то нужно использовать инструкцию присваивания.
Врезультате выполнения инструкции присваивания значение переменной меняется, ей присваивается значение, то есть в ячейку, отведенную для переменной, записывается вычисленное значение.
Вобщем виде инструкция присваивания выглядит так:
<имя переменной > = <выражение><;> где знак равенства (=) это символ инструкции присваивания.
Пример
Sum =Stimost* Kolich; Skidka = 10;//в процентах
Выражение
Выражение состоит из операндов и знаков операций. Знаки операций находятся между операндами и обозначают действия, которые выполняются над операндами. В качестве операндов выражения можно использовать: переменную, константу, функцию или другое выражение. Обозначения основных операций приведены в табл. 9.
|
Таблица 9. Алгебраические операторы |
||
|
Операция |
Действие |
|
|
+ |
Сложение |
|
|
— |
Вычитание |
|
|
* |
Умножение |
|
|
/ |
Деление |
|
|
% |
Вычисление остатка от целочисленного |
|
|
деления |
||
|
++ |
Увеличение целого на единицу (инкремент) |
|
|
— |
Уменьшение целого на единицу (декремент) |
|
Результат применения операторов +, -, * очевиден.
Операция деления / производится по-разному над целыми и дробными числами. Если переменная записана как float, то результат деления таков же,

как и в простой арифметике. Если переменная имеет тип int, то результатом деления является только целая часть десятичного результата, поэтому
6/3=2 7/3=2 8/3=2 9/3=3
К целым числам применим особый вид деления, называемый «деление по модулю», который попросту определяет остаток от целочисленного деления. Эта операция обозначается символом процента %, но никакого отношения к процентам не имеет! Например:
6%3=0 7%3=1 8%3=2 9%3=0.
Применять целочисленное деление особенно к числовым константам надо с большой осторожностью. Например, требуется определить значение по формуле:
V = 34πR3
Если записать вычисления так: V=3/4*Pi*R*R*R;
то результат всегда будет равен нулю, так как 3/4=0, поскольку в этом контексте компилятор применит целочисленное деление, ибо константы 3 и 4 по умолчанию имеют тип int.
Если же видоизменить запись на
V=0.75*Pi*R*R*R; или V=3.0/4.0*Pi*R*R*R,
то результат будет вычислен правильно, так как 3.0 и 4.0 по умолчанию имеют тип float, и к ним будет применено обычное арифметическое деление
При вычислении значений выражений следует учитывать, что операции имеют разный приоритет. Так у операций *, /, % более высокий приоритет, чем у операций сложения и вычитания + и -.
Приоритет операций влияет на порядок их выполнения. При вычислении значения выражения в первую очередь выполняются операции с более высоким приоритетом. Если приоритет операций в выражении одинаковый, то они выполняются последовательно слева направо.
Для задания нужного порядка выполнения операций в выражении можно использовать скобки, например:
(r1+r2+r3)/(r1*r2*r3).
Выражение, заключенное в скобки, трактуется как один операнд. Это означает, что операции над операндами в скобках будут выполняться в обычном порядке, но раньше, чем операции над операндами, находящимися за скобками. При записи выражений, содержащих скобки, должна соблюдаться парность скобок, т. е. число открывающих скобок должно быть равно числу закрывающих скобок. Нарушение парности скобок — наиболее распространенная ошибка при записи выражений.
Тип выражения
Тип выражения определяется типом операндов, входящих в выражение, и зависит от операций, выполняемых над ними. Например, если оба операнда, над которыми выполняется операция сложения, целые, то, очевидно, что результат тоже является целым. А если хотя бы один из операндов дробный, то тип результата дробный, даже в том случае, если дробная часть значения выражения равна нулю.
Важно уметь определять тип выражения. При определении типа выражения следует иметь в виду, что тип константы определяется ее видом, а тип переменной задается в инструкции объявления. Например, константы 0, 1 и -51 — целого типа (int), а константы 1.0, 0.0 и 3.2Е-05 — вещественного типа (float).
В табл.10 приведены правила определения типа выражения в зависимости от типа операндов и вида оператора.
Таблица 10. Правила определения типа выражения
|
Операция |
Тип операндов |
Тип выражения |
|
|
*, /,+, — |
Хотя бы один из операндов |
float |
|
|
float |
|||
|
*, /, +, — |
Оба операнда int |
int |
|
|
% |
Всегда int |
Всегда int |
|
Выполнение инструкции присваивания
Инструкция присваивания выполняется следующим образом:
1.Сначала вычисляется значение выражения, которое находится справа от символа инструкции присваивания.
2.Затем вычисленное значение приводится к типу переменной, имя которой стоит слева от символа инструкции присваивания, и записывается в ячейку памяти, предназначенную для этой переменной.
Например, в результате выполнения инструкций:
i=0; — значение переменной i становится равным нулю;
а=b+с; — значением переменной а будет число, равное сумме значений переменных b и с;
j =j+1; — значение переменной j увеличивается на единицу.
Инструкция присваивания считается верной, если тип выражения соответствует или может быть приведен к типу переменной, получающей значение. Например, переменной типа float можно присвоить значение выражения, тип которого float или int, а переменной типа int можно присвоить значение выражения как типа int, так и float.
Если слева от знака операции присваивания указана переменная типа int, а выражения справа от знака «=» имеет тип float, то дробное число будет
приведено к целому путём простого отбрасывания дробной части,
округления не производится
Так, например, после выполнения инструкций: int i; float d;
d=1.9; i=d;
переменная i станет равной 1.
Во время компиляции выполняется проверка соответствия типа выражения типу переменной. Если тип выражения не соответствует типу переменной, то компилятор выводит сообщение об ошибке. Например, запись:
i=”ABCD”;
вызовет сообщение
Cannot convert AnsiString to ‘int’
(невозможно преобразовать символьную строку в целое)
и компиляция прекратится.
Стандартные функции
Для выполнения часто встречающихся вычислений и преобразований язык C++ предоставляет программисту ряд стандартных функций.
Значение функции связано с ее именем. Поэтому функцию можно использовать в качестве операнда выражения, например в инструкции присваивания. Так, чтобы вычислить квадратный корень, достаточно записать k=sqrt(n), где sqrt — функция вычисления квадратного корня, n — переменная, содержащая число, квадратный корень которого надо вычислить.
Функция характеризуется типом значения и типом параметров. Тип переменной, которой присваивается значение функции, должен соответствовать типу функции. Точно так же тип фактического параметра функции, т. е. параметра, который указывается при обращении к функции, должен соответствовать типу формального параметра. Если это не так, компилятор выводит сообщение об ошибке.
Математические функции
Математические функции (табл. 11) позволяют выполнять различные вычисления.
|
Таблица 11. Математические функции |
||
|
Функция |
Значение |
|
|
fabs (n) |
Абсолютное значение n |
|
|
sqrt (n) |
Квадратный корень из n |
|
|
sqr (n) |
Квадрат n |
|
|
sin (n) |
Синус n |
|
|
cos (n) |
Косинус n |
|
|
atan (n) |
Арктангенс n |
|
|
eхр(n) |
Экспонента n |
|
|
log(n) |
Натуральный логарифм n |
|
|
random(n) |
Случайное целое число в диапазоне от 0 до n- 1 |
|
Величина угла тригонометрических функций должна быть выражена в радианах. Для преобразования величины угла из градусов в радианы используется формула (а*з.141525б)/180, где а— величина угла в градусах; 3.1415926 — число π. Вместо дробной константы 3.1415926 можно использовать стандартную именованную константу PI. В этом случае выражение пересчета угла из градусов в радианы будет выглядеть так: a*Pi/180.
Функции преобразования
Функции преобразования (табл. 12) наиболее часто используются в инструкциях, обеспечивающих ввод и вывод информации. Например, для того чтобы вывести в поле вывода (компонент Label) диалогового окна значение переменной типа float, необходимо преобразовать число в строку символов, изображающую данное число. Это можно сделать при помощи функции FloatToStr, которая возвращает строковое представление значения выражения, указанного в качестве параметра функции.
Например, инструкция Labei1.Caption = FioatTostr(x) выводит значение переменной х в поле Labei1.

|
Таблица 12. Функции преобразования |
|
|
Функция |
Значение функции |
|
IntToStr (k) |
Строка, являющаяся изображением целого k |
|
FloatToStr (n) |
Строка, являющаяся изображением вещественного n |
|
Строка, являющаяся изображением вещественного n. |
|
|
При вызове функции указывают: f — формат (способ |
|
|
FloatToStrF(n, f , k,m) |
изображения); k — точность (нужное общее |
|
количество цифр); m — количество цифр после |
|
|
десятичной точки |
|
|
StrToInt (s) |
Целое значение, изображением которого является |
|
строка s |
|
|
StrToFloat (s) |
Вещественное значение, изображением которого |
|
является строка s |
|
|
FloatToStr (n) |
Строка, являющаяся изображением вещественного n |
|
floor (n) |
Целая часть вещественной переменной n |
|
ceil (n) |
Ближайшее целое число, превосходящее данное |
Использование функций
Обычно функции используют в качестве операндов выражений. Параметром функции может быть константа, переменная или выражение соответствующего типа. Ниже приведены примеры использования стандартных функций и функций преобразования.
n = floor((x2-x1)/dx); x1= (-b + sqrt(d)) / (2*а); m = random(10);
cena = StrToInt(Edit1.Text); Edit1.Text= IntToStr(456); mes =FloatToStr(xl);.
Стиль программирования
Работая над программой, программист должен хорошо представлять, что программа, которую он разрабатывает, предназначена, с одной стороны, для пользователя, с другой — для самого программиста. Текст программы нужен, прежде всего, самому программисту, а также другим людям, с которыми он совместно работает над проектом. Поэтому для того чтобы работа была эффективной, программа должна быть легко читаемой, ее структура должна соответствовать структуре и алгоритму решаемой задачи. Как этого добиться? Надо следовать правилам хорошего стиля программирования. Стиль программирования — это набор правил, которым следует программист в процессе своей работы. Очевидно, что хороший программист должен следовать правилам хорошего стиля.
Хороший стиль программирования предполагает:
•использование комментариев;
•использование несущих смысловую нагрузку имен переменных, процедур и функций;
•использование отступов;
•использование пустых строк.
Следование правилам хорошего стиля программирования значительно уменьшает вероятность появления ошибок на этапе набора текста, делает программу легко читаемой, что, в свою очередь, облегчает процессы отладки и внесения изменений.
Четкого критерия оценки степени соответствия программы хорошему стилю программирования не существует. Вместе с тем достаточно одного взгляда, чтобы понять, соответствует программа хорошему стилю или нет.
Сводить понятие стиля программирования только к правилам записи текста программы было бы неверно. Стиль, которого придерживается программист, проявляется во время работы программы. Хорошая программа должна быть, прежде всего, надежной и дружественной по отношению к пользователю.
Надежность подразумевает, что программа, не полагаясь на «разумное» поведение пользователя, контролирует исходные данные, проверяет результат выполнения операций, которые по какой-либо причине могут быть не выполнены.
Дружественность предполагает хорошо спроектированные диалоговые окна, наличие справочной системы, разумное и предсказуемое, с точки зрения пользователя, поведение программы.
Начало работы в среде C++Builder
Общие сведения о системе программирования
Термин «система программирования» обозначает группу средств, предназначенных для автоматизации работы программиста с целью облегчения его труда и повышения производительности. Традиционные системы программирования включают:
•язык программирования высокого уровня;
•компилятор (Compilator) – программа преобразования исходного текста программы в объектный код (программа на машинном языке, в которой отсутствуют подпрограммы );
•компоновщик (Linker) – программа, подключающая подпрограммы к объектному модулю;
•отладчик (Debugger) – программа для поиска ошибок в программе пользователя, работающая в режиме интерпретации
•редактор программных текстов;
•вспомогательные программы типа редактора икон и других подобных изображений.
Ктаким системам относятся классические, но устаревшие Turbo Pascal, Turbo C, Turbo Java, предназначенные для работы в системе MS DOS. С их помощью можно получить высококлассные программы, но для этого приходится прилагать большие усилия и затрачивать значительное время.
Система C++Builder позволяет строить 32-разрядные приложения в среде Windows, основанные на широком использовании функций самой операционной системы. В результате получаются эффективные программы, имеющие интерфейс, принятый для Windows-приложений.
Кроме ориентации на использование Windows-функций, система C++Builder обладает следующими неоспоримыми достоинствами:
1.позволяет производить визуальное проектирование интерфейса путем компоновки из готовых модулей;
2.строит заготовки программных текстов (to build — строить);
Визуальное проектирование интерфейса состоит в том, что программист простыми средствами собирает из многообразных стандартных компонентов нужное изображение, которое затем будет воспроизводиться на экране, обеспечивая взаимодействие с человеком. Построение заготовок программных текстов происходит автоматически при создании интерфейса, программисту остается включить в них собственные программные тексты, не заботясь об общей организации программы.
Самым главным средством автоматизации программирования является язык высокого уровня, в данном случае С++, главная особенность которого состоит в том, что он ориентирован на объектную технологию программирования.
Программный проект, файлы проекта, форма
Состав проекта
Система программирования C++Builder предназначена для создания Windows-подобных интерактивных программ, управление которыми осуществляется с пульта путем нажатия кнопок или выбора пунктов меню. Подразумевается, что программа должна иметь хотя бы одно окно, в котором размещаются элементы представления информации и органы управления. Таким образом, программа должна иметь две функционально различные части: одна часть программы обеспечивает визуальное представление информации на экране, а другая часть интерпретирует команды пользователя и выполняет обработку информации. Это существенно различные действия и поэтому они программируются в различных модулях, в совокупности образующих проект – группу функционально связанных файлов.
Программный проект может содержать большое количество файлов, количество которых напрямую связано с числом окон, формируемых программой, и может достигать многих сотен. Никакие ограничения на количество окон не вводятся. В минимальном варианте, когда программа имеет всего одно окно, ещё до компиляции C++Builder построит 6 файлов, принадлежащих одному проекту, в них содержатся исходные тексты программы. Система подразделяет файлы на две категории:
•3 общих файла проекта;
•3 файла для каждого окна.
Таким образом, если программа будет иметь N окон, то число модулей с исходными текстами будет 3*(N+1).
После компиляции число файлов увеличивается за счет образования объектных, загрузочных, вспомогательных и временных файлов.
Файлы проекта
Как только программист создал первое окно проекта и записал его на диск, система C++Builder строит файлы, являющиеся основой будущей программы. По умолчанию C++Builder назначает имена файлам проекта таким образом:
Три общих файла проекта (модули проекта): Project1.dpr
Project1.cpp
Project1.res,
три файла для первого окна ( модули окна) Unit1.dfm
Unit1.cpp
Unit1.h
ещё три файла для модулей второго окна
Unit2.dfm
Unit2.cpp
Unit2.h
и т.д.
Роли файлов, имеющих различные расширения имён, описаны в табл. 13
1.Project1.bpr – файл проекта. Этот файл содержит текст в специальном формате XML. По содержанию этот текст не программа, а набор параметров, определяющих режимы компиляции и компоновки. Файл создаётся автоматически и практически его никогда не надо корректировать.
2.Project1.cpp — главная управляющая программа проекта на языке С++. Она определяет порядок инициализации модулей, составляющих проект. В нем автоматически происходят изменения, когда вы добавляете новый модуль или исключаете старый. Вручную этот файл корректируется в очень редких случаях, при решении таких задач, для которых не предусмотрены специальные компоненты, например для смены заставки программы —
3.Project1.resфайл ресурсов, записанный в стандартном для Windows формате ресурсов. Ресурсами являются иконки, курсоры, картинки,
принадлежащие создаваемой программе. Кодировка файла не является ни текстом, ни программой, однако его можно корректировать при помощи редактора ресурсов, добавляя или изменяя элементы ресурсов.
4. Unit1.cppосновной программный модуль на языке C++. Это главный объект работы программиста, в котором описываются решающие алгоритмы. В соответствии с общей концепцией построения программ на С++ в этом модуле содержатся описания стандартных и индивидуальных функций, заголовки же этих функций находятся в модуле Unit1.h. При аккуратном программировании можно полностью написать программу в пределах модуля Unit1.cpp, не обращаясь ни к каким другим модулям.
5.Unit1.h – часть программы на С++, которая, в основном строится автоматически системой С++Builder. Здесь записываются заголовочные части функций, хранящихся в модуле Unit1.cpp, а также переменные, доступные для других модулей. Обращаться сюда программисту приходится редко.
6.Unit.dfm – текст в кодах ANSI, описывающий графический образ окна, который может быть легко прочитан любым текстовым редактором. По содержанию этот текст является ничем иным, как командами графического модуля операционной системы, который воспроизводит на экране закодированную здесь картинку. Это описание не следует редактировать вручную, поскольку все изменения производятся в нем автоматически при
разработке дизайна интерфейса на стадии проектирования. Любые изменения положения компонента на экране или других его свойств тут же отражаются в изменении текста файла. В этом и заключается одна из сторон реализации визуального программирования.
|
Таблица 13. Основные файлы проекта. |
|
|
<имя проекта>.dpr |
Файл проекта на языке XML |
|
<имя проекта>.cpp |
Файл проекта на языке C++ |
|
<имя проекта>.res |
Файл ресурсов |
|
<имя модуля окна >.cpp |
Модуль окна на С++ |
|
<имя модуля окна >.h |
Заголовочный модуль окна на С++ |
|
<имя модуля окна>.dfm |
Описатель формы (текстовый файл) |
Совет программисту
Фалы с расширениями bpr res cpp h dfm относятся к исходным модулям проекта и представляют наибольшую ценность, поэтому для установки проекта на другую машину достаточно перенести только эти файлы и повторить компиляцию. (Естественно, на этой машине должна быть установлена система C++Builder той же версии).
После компиляции система С++Builder строит ещё несколько файлов, роль которых определяется их расширениями. Они описаны в табл. 14.
1. obj — объектные модули программные. Они являются промежуточной формой представления программы между этапами компиляции и
компоновки. Самостоятельного значения не имеют. Их можно удалять, при следующей компиляции они снова образуются.
2. exe — загрузочный модуль программы. Этот файл необходимо сохранять в текущей директории для последующего исполнения. Однако в случае неполадок его всегда можно получить из исходных модулей путём компиляции.
3. tds – вспомогательный файл , который строит и использует система C++Builder для ускорения компиляции и поиска ошибок при выполнении программы. После компиляции файл не используется, поэтому его можно и нужно удалять, когда проект завершен, поскольку этот файл очень большой: его объём может превосходить суммарный объём всех остальных файлов проекта.
4.~ — временные файлы, являющиеся резервными копиями исходных модулей, которые образуются при их редактировании. В случае необходимости из них можно воспроизвести предыдущую версию файла. После завершения проекта их надо удалять.
|
Таблица 14. Дополнительные файлы проекта |
|
|
<имя проекта>.tds |
Вспомогательный файл компилятора |
|
<имя проекта>.exe |
Загрузочный модуль программы |
|
<имя модуля окна >.obj |
Объектный модуль |
|
<имя проекта>.~ |
Временный файл |
|
<имя модуля окна >.~ |
Временный файл |
Выбор имен файлов и каталогов проекта
Как только программист создал первое окно проекта и записывает его на диск, он должен назначить имена файлам проекта. При этом имеется две возможности:
•согласиться с именами, которые C++Builder назначает по умолчанию;
•выбрать собственные имена.
Для серьёзных практических проектов не следует соглашаться с именами, назначенными по умолчанию, потому что они не несут в себе семантического содержания и при большом количестве модулей программисту трудно ориентироваться, какую роль выполняет модуль, например Unit15 или Unit34. Боле того, при несоблюдении технологии программирования, о которой речь впереди, может оказаться, что некоторый модуль, например Unit12, оказался записанным в другом, не в рабочем каталоге, и программисту непросто будет ответить, от какого проекта «оторвался» этот файл – от Project1 или от Project9?
Назначение индивидуальных имен является более рациональным, поскольку они позволяют избавиться от перечисленных недостатков, хотя это и связано с небольшими дополнительными затратами времени.

Совет программисту
Назначайте собственные имена модулям проекта
При выборе имён для обеспечения совместимости с различными вариантами операционных систем и систем программирования
|
придерживайтесь |
правил, |
представленных в табл. |
15. |
Главным |
|
ограничением является недопустимость русских букв в составе имён. |
||||
|
Дело в том, что в русифицированных версиях Windows |
использование |
русских букв разрешено не только в текстах, но и в названиях файлов и папок. C++Builder, как и другие системы программирования, поддерживает кириллицу только при выводе информации на экран или принтер. Для внутренних программных целей, то есть для имён переменных, файлов и папок, русские буквы не воспринимаются, и их использование будет считаться ошибкой. По той же причине не следует помещать свои проекты в папку «Мои документы», поскольку её русифицированное имя не позволит обращаться к ней программным путём.
Имя не должно включать русских букв, даже если их начертание совпадает с латинскими; в имени недопустимы пробелы. Желательно ограничиться следующими символами.
Таблица 15 Правила выбора имён модулей и каталогов проекта
Латинские буквы Цифры Тире и подчеркивание
Имя должно нести семантическую нагрузку. Чтобы избежать коллизий с зарезервированными английскими словами и аббревиатурами, разумно пользоваться русскими словами, записанными латиницей (в стиле SMSсообщений)
![]()
Создание нового проекта
Создание проекта начинается с создания главного окна, которое будет появляться первым на экране при запуске программы. Последовательность действий такова:
1. Запустите C++Builder и вы увидите следующий экран (рис. 3):
Рис. 3. Первоначальный вид основных инструментальных средств С++Builder
2. Выберите команду File|New Appliation, на экране появится новая область для проектирования дизайна первого окна – так называемая форма (рис. 4)
Рис. 4. Реакция на команду File|New Appliation. Первоначальный вид пустой формы
Форма – это контейнер, в котором вы будете размещать элементы интерфейса, — надписи, окошки ввода — вывода, кнопки, меню. Это происходит на этапе проектирования дизайна интерфейса (design time), когда
в соответствии с идеей визуального программирования вы, пользуясь мышью, перетаскиваете компоненты из их хранилища (палитры компонентов) на форму и размещаете в нужных местах. Компоненты оказываются соединенными с формой и далее представляют единое целое. Параллельно с построением формы происходит формирование файла c расширением имени dfm, в котором в текстовом формате описываются все компоненты с тем, чтобы впоследствии система смогла бы вычертить их на экране. Этот файл называется «Определитель формы» (define form), откуда и произошла аббревиатура dfm.
Одновременно с определителем формы система строит заготовку для написания текста программы, или программного кода. Её окно спрятано за окном формы; чтобы переключиться на окно программы лучше всего пользоваться функциональной клавишей F12. Нажав на эту клавишу, вы получите окно, представленное на рис. 5.
Рис. 5. Окно программного кода для пустой формы
В этом окне и происходит собственно программирование. Общую структуру программы и некоторые модули С++Builder строит автоматически и нам не нужно их корректировать. Это директивы компилятора и функция «конструктор объекта». Эта функция изображается как пустая, на самом деле она содержит множество довольно сложных команд, связанных с инициализацией объекта, но поскольку программист не должен туда вносить никаких исправлений, её текст не афишируется.
Для программирования собственных модулей необходимо выбрать нужный компонент и событие, с которым вы связываете алгоритм его
обработки, открыть заготовку обработчика этого события и написать программный код. Подробно этот процесс рассмотрен ниже.
3. Запишите новый (пустой) проект в избранный вами каталог.
Основы технологии программирования в среде C++Builder
Программируя в среде C++Builder , следует выполнять приведенные ниже рекомендации, тогда Вы не потеряете своих файлов, программирование будет успешным и надёжным. Здесь под надёжностью понимается безошибочное программирование, когда будет легко идентифицировать объект, зоны его действия и т.п. Если игнорировать нижеприведённые советы, то тоже можно получить работоспособную программу, но с гораздо бóльшими усилиями.
|
Совет программисту |
||
|
1. |
Для каждого проекта |
организуйте отдельный каталог, не |
допускайте, чтобы файлы одного проекта «разбегались» бы по разным директориям или чтобы в одном каталоге существовали бы файлы различных проектов.
2. Для файлов проекта не используйте стандартные имена, предлагаемые системой. Назначайте свои семантические имена, придерживаясь правил выбора имён, представленных в табл. 15.
Можно предложить такую стратегию формирования имён файлов, которую рассмотрим на примере. Пусть мы строим программную модель арифметического калькулятора. Назовем каталог проекта «понятным» именем ArCalc, файлы проекта получат наименования pArCalc.dpr, pArCalc.cpp и pArCalc.res, а файлы программного модуля uAtrCalc.cpp, uAtrCalc.hc и uAtrCalc.dfm. Здесь префикс p указывает на принадлежность к группе файлов проекта, а префикс u – к группе программного модуля. При таком наименовании файлов их можно будет разыскать в других директориях, если случайно они окажутся не на месте, в противном случае это почти невозможно.
3. Для наименований компонентов своей программы также не используйте стандартные имена, предлагаемые системой. В первую очередь эта рекомендация относится к таким компонентам, которые часто используются, в частности к кнопкам и окнам ввода/вывода. Например, кнопки по умолчанию получают имена Button1, Button2, Button3 и т.д. С кнопками связываются события, а с событиями – программы (обработчики событий). Системные имена событий носят семантический характер, их легко опознать и запомнить, например щелчок –Click, изменение состояния
– Change . Имя функции, соответствующей событию, С++Builder строит автоматически, соединяя имя компонента и имя события. Тогда для события «щелчок» получим такой ряд наименований Button1Click, Button2Click, Button3Click.
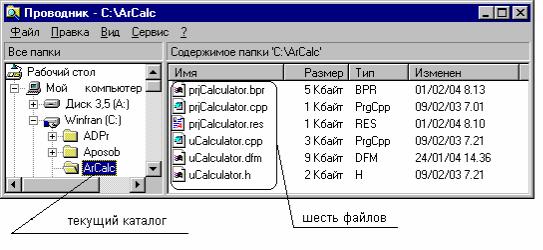
Если же кнопок много, а на практике так и бывает, то запомнить смысл таких функций нелегко, придется часто обращаться к картинке дизайна или писать дополнительные комментарии. Если же дать кнопкам собственные семантические имена, то программирование упрощается. Например, пусть мы имеем три кнопки :
•Button1 служит для закрытия сеанса работы;
•Button2 служит для вычисления среднего значения;
•Button3 служит для сравнения каких-то величин.
Назовем их соответственно btbClose, btbSredn, btbSravnen (где btb –
префикс принадлежности компонента к классу кнопокTButton; этот префикс выбирает программист ). Тогда заголовки функций, построенные системой, примут осмысленный вид:
•btbCloseClick – щелчок по кнопке закрытия;
•btbSrednClick – щелчок по кнопке вычисления среднего;
•btbSravnenClick – щелчок по кнопке сравнения.
4.При организации нового проекта убедитесь с помощью Проводника, что вы записали в выбранную директорию точно 6 файлов при первом же сохранении файлов (подробно о создании нового проекта см ниже ).
Правило «шести файлов»: после первого сохранения пустой формы проекта и до компиляции в целевом каталоге образуется шесть файлов, составляющих исходные модули проекта.
Если же вы видите, что в вашем каталоге не точно шесть файлов, то не продолжайте работу: всё дальнейшее программирование будет ошибочным и приведёт только к напрасным потерям времени. Не разыскивайте потерянные файлы, в них нет ничего ценного, начните всё сначала.
5. Не изменяйте строк программного текста, написанных системой. Если вы стёрли какой-то заголовок функции, а затем в точности вновь напечатали его, внутренние связи программных модулей всё равно будут
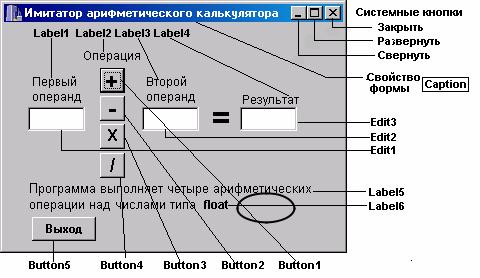
нарушены и в программе появятся трудно устранимые ошибки . Никогда не удаляйте функций, построенных системой.
6. Если потребуется удалить собственную функцию, удалите её тело, оставьте только обрамляющие фигурные скобки, а затем выдайте команду на сохранение или на компиляцию. Система самостоятельно и корректно удалит пустую программу и все внутренние связи.
Правила создания нового проекта
Нижеприведённые рекомендации позволят вам надёжно, то есть безошибочно, создавать новые проекты. Для этого следует придерживаться советов, изложенных в табл. 15 «Правила выбора имён модулей и каталогов проекта», в пунктах «Создания нового проекта» и «Основы технологии программирования в среде C++Builder».
Элементы интерфейса
Рассмотрим вариант простейшей программы : модель калькулятора (рис. 6). Программа предназначена для выполнения четырёх арифметических операций, роль элементов интерфейса понятна из рисунка, на котором приведены наименования используемых компонентов.
Рис. 6. Компоненты арифметического калькулятора
Все показанные на рис. 6 компоненты находятся на вкладке «Стандартные» палитры компонентов. Рассмотрим основные компоненты, используемые для построения простейших интерфейсов.
Вкладка STANDARD
На странице Standard палитры компонентов сосредоточены стандартные для Windows интерфейсные элементы, без которых не обходится практически ни одна программа. Вот наиболее часто используемые компоненты (табл. 16).
|
Таблица 16. Часто используемые компоненты вкладки Stanard |
|
|
MainMenu |
Главное меню программы. Компонент способен создавать и |
|
обслуживать сложные иерархические меню |
|
|
PopupMenu |
Вспомогательное или локальное меню. Это меню появляется |
|
в отдельном окне после нажатия правой кнопки мыши |
|
|
Label |
Метка. Этот компонент используется для размещения в окне |
|
не очень длинных надписей |
|
|
Edit |
Строка ввода. Предназначена для ввода, отображения или |
|
редактирования одной текстовой строки |
|
|
Button |
Командная кнопка. Обработчик события OnClick (щелчок |
|
левой клавишей мышки) этого компонента обычно |
|
|
используется для реализации некоторой команды |
|
|
CheckBox |
Независимый переключатель. Щелчок мышью на этом |
|
компоненте в работающей программе изменяет его |
|
|
логическое свойство Checked |
|
|
RadioButton |
Зависимый переключатель. Позволяет включить или |
|
исключить из обработки один указанный параметр |
|
|
RadioGroup |
Группа зависимых переключателей. Позволяет выбрать один |
|
параметр из группы |
|
|
ListBox |
Список выбора. Содержит список предлагаемых вариантов |
|
(опций) и дает возможность выбрать один из них. Удобен для |
|
|
отображения значений элементов массивов (однако для ввода |
|
|
данных он не приспособлен) |
|
|
Memo |
Многострочный текстовый редактор. Используется для ввода |
|
и/или отображения многострочного текста. Удобен для ввода |
|
|
и вывода значений элементов массивов |
|
|
ComboBox |
Комбинированный список выбора. Представляет собой |
|
комбинацию списка выбора ListBox и текстового редактора |
|
|
Panel |
Панель. Этот компонент служит для объединения нескольких |
|
компонентов, т.е. является «контейнером». Содержит |
|
|
внутреннюю и внешнюю кромки, что позволяет создать |
|
|
эффекты «вдавленности» и «выпуклости» |
В данном курсе рассматриваются не все компоненты, а только те из них, которые используются в примерах: Form, Label, Edit, Button, RadioGroup, ListBox, ComboBox, Panel, причем описание компонентов дается не полностью, а в сокращенном виде. (Полное описание всех компонентов см. [1].)
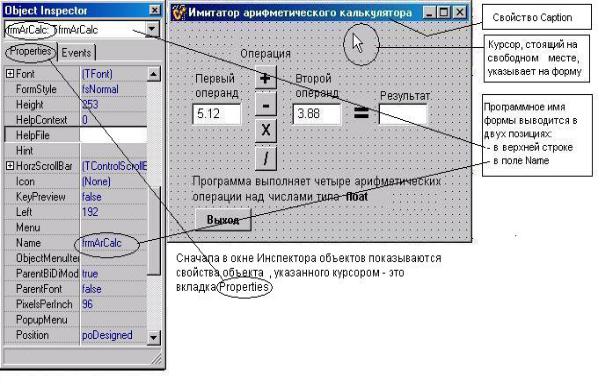
Самым распространенным компонентом является форма — компонент типа TForm. Он не входит ни в одну страницу палитры компонентов, а образуется по команде File|New Application. Рассмотрим его свойства, методы и события.
Форма — компонент TForm
Назначение формы : это контейнер, инкапсулирующий компоненты, составляющие интерфейс программы.
Свойства компонента TForm
Свойства и события компонента указываются Инспектором объектов, когда курсор находится на компоненте, для формы это значит, что курсор должен находится на любом пустом месте формы. Установите курсор и щёлкните левой клавишей. Откроется окно Инспектора объектов, состоящее из двух вкладок – рис. 7. Если окно Инспектора не появилось автоматически, его можно вызвать принудительно клавишей F11, либо командой
View|Object Inspector
Рис. 7. Свойства компонента TForm

На рисунке показаны не все возможные свойства формы, их можно просмотреть в окне Инспектора. Часто используемые свойства представлены в табл. 17.
|
Таблица 17. Часто используемые свойства формы TForm |
|
|
Значение свойства |
|
|
Системное название |
|
|
свойства |
Текст заголовка формы. Допустимы русские буквы |
|
Caption (надпись) |
|
|
Color(цвет) |
Цвет фона формы |
|
Name(имя) |
Программное имя формы, по которому к ней |
|
производится обращение внутри программы. Русские |
|
|
буквы недопустимы |
|
|
Width(ширина) |
Ширина формы в пикселях |
|
Height(высота) |
Высота формы в пикселях |
|
Left(левый) |
Расстояние формы от левого края экрана в пикселях |
|
Top(верх) |
Расстояние формы от верха экрана в пикселях |
|
Visible(видимость) |
Управляет видимостью формы |
|
AutoScrol |
Определяет, будут ли появляться полосы прокрутки, |
|
l(автопрокрутка) |
если форма целиком помещается на экране. |
|
Canvas(холст) |
Рисунок, размещаемый на форме. Его создают |
|
программным путём с помощью графических команд |
Все указанные свойства (кроме Canvas) могут быть как изменены вручную во время проектирования дизайна интерфейса (Design Time), так и программным путем во время выполнения программы (Run Time). Свойство Canvas является сложным и не имеет статического значения, оно представляет поверхность экрана, на которой вычерчиваются линии только программным путем. Для размещения статических изображений используется компонент TImage.
События компонента TForm
События формы представлены на вкладке Events окна Инспектора объектов
(рис. 8).
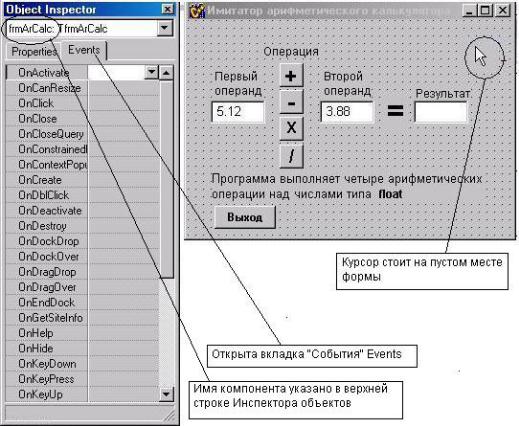
Рис. 8. События компонента TForm
Наиболее часто используются события, представленные в табл. 18. Системные наименования событий содержат предлог On (при) и наступают при тех внешних действиях, которые выражаются английским словом, например, событие OnClick происходит при щелчке мышью по форме.
Системное название события
OnActivate
(при активизации)
OnClick(при щелчке)
OnDblClick (при двойном щелчке)
OnKeyDown (при нажатии клавиши)
OnKeyPress (при нажатии клавиши)
Таблица 18. Часто используемые события формы TForm.
Описание события
Возникает при входе в программный модуль, когда система уже выделила память под динамический объект «форму» и устанавливает начальные значения параметров включённых в неё компонентов Возникает при одинарном щелчке по свободному месту формы Возникает при двойном щелчке по свободному месту формы
Возникает при нажатии клавиатурной клавиши, когда курсор находится на свободном месте формы
То же, что и OnKeyDown. Различие в том, что обработчики соответствующих событий ориентированы на различные переменные, выражающие код символа, полученного от нажатой клавиши. Событие OnKeyPress рассматривает этот код как переменную типа char, тогда как в OnKeyDown используется переменная типа word
Совет программисту
Наиболее естественным и часто используемым событием компонента TForm является OnActivate, которое удобно использовать для общих начальных действий в программе. Например, для инициализации значений глобальных переменных, установления состояния видимости некоторых компонентов или для открытия таблиц (файлов) базы данных:
|
void _fastcall TForm::Form1Activate(TObject *Sender) |
//заголовок |
|
обработчика |
{CommonMessage=»Вам недоступны эти ресурсы»;//глобальная переменная
Panel1->Visible=false; //спрятать панель
Table1->Open(); //jОткрыть таблицу базы данных
}
Пример использования события OnActivate компонента Form1
![]()
Отображения надписей и вывод данных
В любой программе необходимо располагать поясняющие надписи на экране, а также по ходу выполнения программы выводить полученные результаты. Наиболее распространённым приёмом для размещения надписей является компонент TLabel (метка); для вывода данных используются многочисленные варианты , как например метка TLabel, окно ввода-вывода
Tedit, встроенные функции ShowMessage, MessageBox, MessageDlg.
Метка — компонент TLabel.
Ни одна программа не обходится без надписей на экране — меток, взгляните на рис. 9: в таком примитивном интерфейсе использовано 6 меток. Рассмотрим основные характеристики этого компонента.
Назначение метки :
короткие одно- и многострочные надписи на экране
Свойства компонента TLabel
Полный перечень свойств указывается Инспектором объектов, когда курсор находится на компоненте. Установите курсор на изображение метки и откройте окно Инспектора объектоврис. 9.
Рис. 9. Свойства компонента TLabel
Курсор (чёрная стрелка) стоит на метке Label2., поэтому инспектор показывает его свойства.
Обратите внимание: надписи (свойство Caption) выведены в две строки, хотя обычно меткаэто однострочная надпись. Приём состоит в том, что логическое свойство WordWrap установлено в значение true.
Часто используемые свойства метки представлены в табл. 19.
Таблица 19. Часто используемые свойства метки TLabel.
|
Системное |
название |
Описание свойства |
|
свойства |
||
|
Caption (надпись) |
Текст надписи на экране. Допустимы русские |
|
|
буквы |
||
|
Name(имя) |
Программное имя надписи, по которому к ней |
|
|
производится обращение внутри программы. |
||
|
Русские буквы недопустимы |
||
|
Color(цвет) |
Цвет фона надписи |
|
|
Width(ширина) |
Ширина надписи в пикселях |
|
|
Height(высота) |
Высоту надписи в пикселях |
|
|
Left(левый) |
Расстояние надписи от левого края формы в |
|
|
пикселях |
||
|
Top(верх) |
Расстояние надписи от верха формы в пикселях |
|
|
Visible(видимость) |
Управляет видимостью надписи: Visible=true — |
|
|
надпись видна, Visible=false — надпись спрятана |
||
|
WordWrap (Сворачивать |
Управляет размещением надписи в одну строку |
|
|
слова) |
(WordWrap=false) или в несколько строк |
|
|
(WordWrap=true) |
Совет программисту
Иногда метка исчезает с экрана. Найти её можно так: воспользуйтесь маленькой стрелкой в правом верхнем углу окна Инспектора объектов и найдите её имя (Name) в выпадающем списке. Инспектор покажет её свойства. Убедитесь, что её координаты (Left и Top) находятся в пределах формы и метка не спряталась за другим компонентом. Проверьте также её размеры (Heigh и Wodth): они не должны быть нулевыми, так же как и текст надписи (Caption) должен иметь не нулевую длину.
События компонента TLabel
Метка – это надпись, а не орган управления. События же – это прерывания, управляющие ходом программы, поэтому по своему существу они ассоциируются с органами управления — кнопками, ползунками,
стрелками и т.п. Поэтому события метки редко используются для программирования.
Полностью список событий выдаёт Инспектор объектов по методике, изложенной в § 4.2. Следует отметить событие OnClick, возникающее при щелчке мышью по надписи на экране. Конечно, можно построить обработчик этого события и тогда компонент TLabel будет выполнять ту же функцию, что и кнопка, но, однако, зачем это делать, если для обработки щелчка существуют специальные компоненты, например кнопки.
Использование компонента TLabel
Надпись на метке (свойство Caption) по умолчанию располагается в одну строку(см. метки Label1 — Label4 на рис. 9). Однако можно разместить надпись в две и более строк, если указать свойство метки WordWrap=true и изменять размер рамки для надписи вручную мышкой (см. метку Label2 на рис. 9)
Надпись на метке чаще всего заносится в статике при проектировании дизайна (в период Design Time), однако она доступна для изменения и при выполнении программы (в период Run Time). Например, если программа получает некоторый результат в виде целой переменной X, то его можно показать, записав его строковое представление в свойство Caption метки, специально для этого выбранной, допустим, LabelResult. Для этого в том месте программы, где образуется переменная X, нужно поместить команду :
LabelResult->Caption=IntToStr(X);
Примечание. Обратите внимание, что свойство Caption является переменной типа AnsiString, тогда как переменная X имеет тип «целый» (int), поэтому для согласования типов используется функция — преобразователь IntToStr — «ЦелоеВСтроку».
Однако метку можно использовать и как элемент экрана для представления результатов вычислений (см. ниже)
Функция ShowMessage
В системе C++Bulder имеется несколько встроенных функций, предназначенных для вывода результатов и организации диалога с пользователем. Простейшей является функция ShowMessage- «Показать сообщение». Она не требует специального визуального компонента и организует небольшое окно сообщений в центре экрана – рис. 10.
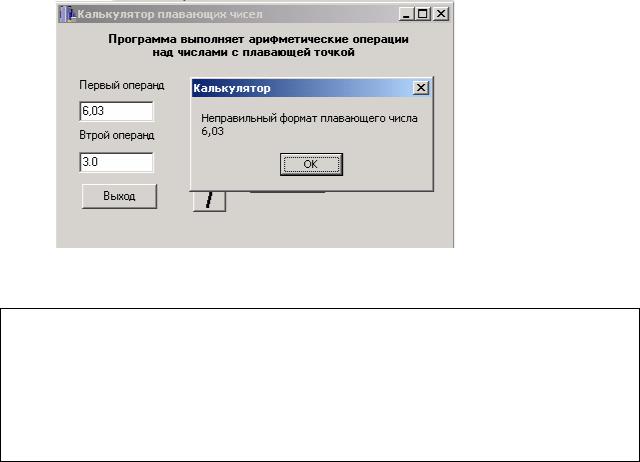
Рис. 10. Результат функции ShowMessage
Назначение: вывод на экран строковых значений без использования визуальных компонентов
Структура функции: ShowMessage(<текст сообщения>);
Пример: ShowMessage(«Неправильный формат плавающего числа»);
Действия системы: в центре экрана строится окно в соответствии с размером надписи.
Объяснение: текст сообщения может быть представлен как строковая константа , т.е. последовательность символов в кавычках (см.пример выше), либо как строковая переменная типа AnsiString, например:
AnsiString s; s=»Конец сеанса»; ShowMessage(s);
Результат этих трех команд будет точно таким же, как на рис.10.
Для записи сообщения в несколько строк надо использовать в выводимой строке специальные управляющие символы (так называемые escape-команды, доставшиеся нам из эпохи текстового программирования вывода на экран). Так для разрыва текущей строки сообщений и перехода на следующую строку экрана можно в любом месте строки вставлять команду «\n» — это не вывод символа «n», а команда дисплея, вызывающая «перевод строки и возврат каретки». Тогда команды

int X=123;
s=»Полученное значение =\n»+IntToStr(X); ShowMessage(s);
Приведут к такому выводу:
Полученное значение = 123
Окно ввода-вывода — компонент TEdit
Назначение окна : ввод или вывод текста в одну строку. Этот компонент является наиболее часто используемым средством для ввода данных с пульта машины. Он позволяет установить начальные значения при запуске программы и изменять, поэтому его часто называют однострочным редактором. Кроме того, можно и выводить внутренние значения переменных в это окно.
Свойства компонента TEdit
Полный состав свойств указывается Инспектором объектов, когда курсор находится на компоненте. Установите курсор на элемент TEdit, откройте окно Инспектора объектов (клавиша F11) и Вы получите перечень свойстврис. 11 (на экране компьютера список свойств выводится в одну колонку).
Рис. 11. Свойства компонент Tedit.
Подробное описание свойств вы найдёте в [1], здесь же описываются только те свойства, которые будут использоваться в последующих примерах
|
Часто используемые свойства компоненты Tedit |
|
|
Свойство |
Значение |
|
Font (тип шрифта) |
Тип шрифта, допустимого в данной версии |
|
Windows |
|
|
Name(имя) |
Программное имя окна, по которому к нему |
|
производится обращение внутри программы |
|
|
ReadOnly (только |
Когда логический параметр ReadOnly=true, |
|
чтение) |
значение в окне можно прочесть, но нельзя |
|
изменить. При ReadOnly=false, значение в окне |
|
|
можно и читать, и изменять |
|
|
Text (текст) |
Основное свойство окна. Это поле памяти |
|
объекта Edit, предназначенное для хранения |
|
|
строкового значения, отображаемого на экране. |
|
|
Visible (видимость) |
Управление видимостью компонента. При |
|
Visible=true окно прорисовывается как в период |
|
|
design-time, так и в run-time. При Visible=false |
|
|
во время конструирования интерфейса (design- |
|
|
time) окно остается видимым, но при |
|
|
выполнении программы (run-time) оно не |
|
|
изображается |
Совет программисту
Поскольку в окне (свойство Edit->Text) изображается строковая переменная, то с пульта могут быть введены любые символы, имеющиеся на клавиатуре. На практике в большинстве случаев по смыслу задачи и для обеспечения надежного ввода данных не следует разрешать ввод произвольных символов. Например, при вводе целого числа (скажем, года рождения) нужно допустить ввод только цифр, а остальные символы не пропускать в окно. В этом плане сам компонент TEdit не позволяет выполнить такую фильтрацию; для этой цели следует воспользоваться компонентом TMaskEdit или построить фильтр по событию OnKeyPress.
События компонента TEdit
Перечень событий представлен на рис. 12.
Рис.12. События компонента TEdit
На рисунке выделены наиболее часто используемые события.
Событие OnChange наступает, когда изменяется содержимое поля Text, т.е. при вводе или удалении любого символа. Событие OnKeyPress происходит, когда курсор стоит на объекте TEdit и нажимается любая клавиша.
Использование компонента TEdit
Компонент используется всюду, где необходимо по ходу программы вводить значения с пульта, он дает простой и понятный интерфейс. Те пользователи, которые знакомы с классическим языком C++, смогут по достоинству оценить простоту и удобство метода ввода с помощью компонента TEdit по сравнению с неуклюжим и трудно программируемым вводом данных в изначальном варианте языка.
Особенности программирования
Главная особенность состоит в том, что основное свойство компонента, в котором хранится значение нужной нам переменной, имеет строковый тип. В тех же случаях, когда надо работать с другими типами данных, например с целыми, или вещественными числами, необходимо выполнять соответствующие преобразования (табл. 12).
Запуск процедур
Для запуска каких-либо действий в Builder-программе можно использовать либо специальные компоненты — кнопку TButton или меню TMainMenu , либо различные события, возникающие при прогонке программы (рис. 8).
Кнопка — компонент TButton
Назначение кнопки: запуск какого-либо действия.

Иллюстрацию смотрите на рис. 6, где с каждой кнопкой связана соответствующая символу арифметическая операция.
Свойства кнопки TButton представлены на рис. 13.
Рис.13. Свойства компонента TButton
На рисунке выделены наиболее часто используемые свойства. Полный перечень свойств указывается Инспектором объектов.
Подробное описание свойств вы найдёте в [1], здесь же описываются только те свойства, которые будут использоваться в последующих примерах
(табл. 20)
Таблица 20. Часто используемые свойства кнопки TButton
|
Системное |
название |
Описание свойства |
||
|
свойства |
||||
|
Caption (надпись) |
Текст надписи на кнопке. Допустимы русские |
|||
|
буквы. Стандартно надпись размещается в одной |
||||
|
строке, при необходимости многострочной |
||||
|
надписи надо |
воспользоваться |
специальными |
||
|
процедурами |
самой Windows |
— прикладным |
||
|
программным интерфейсом API |
||||
|
Enable(способность) |
Если Enable=true, кнопка способна реагировать |
|||
|
на щелчок; при Enable=false, кнопка не |
||||
|
реагирует на щелчок |
||||
|
Font (тип шрифта) |
Можно установить любой шрифт Windows |
|||
|
Name(имя) |
Программное имя кнопки, по которому к ней |
|||
|
производится обращение внутри программы. |
||||
|
Русские буквы недопустимы |
||||
|
Visible(видимость) |
Управляет видимостью кнопки: Visible=true — |
|||
|
кнопка видна, Visible=false — кнопка спрятана |
Совет программисту
По умолчанию кнопки получают имена (свойство Name) типа Button1, Button2, Button3 и т.д. Когда на форме находится две-три кнопки, можно удовлетвориться такими стандартными именами, ибо их роль легко удержать в памяти. Однако более грамотно, особенно при большем количестве кнопок, вручную назначать кнопкам программные имена, отображающие функцию кнопки, тогда гораздо легче и быстрее ориентироваться в программном тексте. Например, для кнопок арифметического калькулятора вполне приемлемыми могут быть такие имена кнопок:
•btbPlus для кнопки «Сложение»;
•btbMinus для кнопки «Вычитание»;
•btbUmn для кнопки «Умножение»;
•btbDel для кнопки «Деление»;
•btbExit для кнопки «Выход».
Обратите внимание на префикс имён — btb — он поможет впоследствии внутри программного текста легко отличать объект «Кнопка» от других объектов, которые, конечно же, будут иметь свои характерные префиксы.
События объекта TButton представлены на рис. 14.
Рис. 14. События компонента TButton
На рисунке выделены наиболее часто используемые события Подробное описание событий вы найдёте в [1]. Основным событием,
естественно, является щелчок по изображению кнопки OnClick. Если же вы хотите связать обработчик кнопки с нажатием клавиши на пульте, следует воспользоваться событиями OnKeyPress или OnKeyDown, которые возникают, когда курсор стоит на кнопке, а на пульте нажимается какая-либо клавиша. Различие двух последних событий состоит только в слегка отличающихся внутренних аргументах процедур, построенных Builder-ом.
Особенности программирования Чтобы запрограммировать обработчик события «Щелчок по кнопке»,
дважды щёлкните по изображению нужной кнопки и Builder создаст заготовку программного модуля. Например, для программы «Арифметический калькулятор», интерфейс которой изображен на рис. 17, заготовка обработчика щелчка (события Click) будет следующей, если кнопка «Сложение» названа btbPlus:
void __fastcall TfrmCalculator::btbPlusClick(TObject *Sender)
{
}
//————————————————————
Обратите внимание, как Builder строит имя процедуры btbPlusClick: оно составлено путем соединение двух строк, первая из которых — это имя объекта btbPlus (значение свойства Name) , вторая — имя события Click.Такой принцип позволяет программисту легко определить, к какому объекту относится та или иная процедура.
Затем вы записываете программный текст для операции сложения, например так:
![]()
//процедура сложения
void __fastcall TfrmCalculator::BtPlusClick(TObject *Sender) {float a,b,c;
AnsiString s;
a=StrToFloat(Edit1->Text);//преобразование строки в число b=StrToFloat(Edit2->Text);
c=a+b; //собственно сложение s=FloatToStr(c);//преобразование числа в строку Edit3->Text=s; //запись результата в компонент Edit3 }//конец процедуры сложения
Рис. 15. Обработчик щелчка по кнопке «Сложение»
Напоминание: никогда самостоятельно не удаляйте программных текстов, созданных Builder-ом (см. пункты 5 и 6 из § 2.4)
Главное меню — компонент TMainMenu
Назначение компонента TMainMenu: запуск какого-либо действия. Иллюстрацией может служить меню любой офисной программы, например: главное меню Проводника (рис. 16).
Рис. 16. Организация меню компонентом TMainMenu
В данном примере меню состоит из Главного меню
Файл Правка Вид Сервис
и нескольких групп выпадающих меню — на рисунке это группа
Отметить
Вырезать
Копировать
Вставить Вставить ярлык Выделить все
Обратить выделенное
Компонент TMainMenu относится к категории не визуальных компонентов — это такие элементы, которые присутствуют на экране во время проектирования (в период design-time), но скрываются при выполнении программы (в период run-time).
Свойства компонента TMainMenu
Подробно свойства компонента см. в [1], здесь мы остановимся только на одном важнейшем свойстве — Items. Это список пунктов выпадающих подменю, каждый из которых в свою очередь может обладать дочерними выпадающими меню.
Создание главного меню
1.Поместите пиктограмму(значок) TMainMenu на форму.
2.Сделайте двойной щелчок по значку — откроется программы Дизайнер меню.
3.В поле Caption укажите наименование первого пункта главного меню (можно на русском).
4.Как только вы подтвердите это наименование клавишей Enter или курсорной клавише, автоматически образуется следующий пункт, которому тоже надо задать наименование.
5Для каждого пункта главного меню аналогично формируются подпункты — строки выпадающего меню.
Особенности программирования
Собственно компонент TMainMenu не располагает никакими событиями, для обработки событий предназначены пункты (Items) меню и подменю, причём, событиё — всего одно, это щелчок (OnClick).
Чтобы запрограммировать соответствующий обработчик, выделите с помощью Инспектора объектов нужный пункт и просто щёлкните по нему — откроется программная заготовка обработчика, в котором записываются нужные команды. В силу очевидной простоты этого приема в данном пособии эти действия не рассматриваются более подробно.
Таким образом, компонент TMainMenu позволяет создать разветвленную систему выпадающих меню любой сложности, количество пунктов и подпунктов не ограничено.
Использование компонентов TButton и TMainMenu.
Кнопки используются для программирования действий пользователя за пультом, это самый естественный способ организации интерфейса, дающий возможность наиболее быстрой работы. Если все возможные функции приложения представлены кнопками, такой интерфейс называют «Кнопочной формой».
Однако если программный продукт обладает большим количеством функций, скажем, более двух десятков, кнопочная форма теряет свои
|
преимущества, да |
и разместить |
на экране десятки |
кнопок не |
всегда |
|
возможно. Тогда |
прибегают к |
другому компоненту |
— «Главное |
Меню» |
(TMainMenu). Главное достоинство этого компонента в том, что на экране он занимает только одну , обычно верхнюю, строку, содержащую несколько видимых пунктов. Остальные пункты спрятаны, и чтобы их увидеть, надо последовательно щелкать по видимым пунктам. Единственным недостатком меню как метода выбора и запуска функций является относительно долгое время, необходимое для поиска нужного спрятанного пункта.
Кроме кнопок (TButton) и меню (TMainMenu) можно запрограммировать событие «Щелчок» практически по любому компоненту и тогда число программируемых функций приложения не будет ничем ограничено. Однако такой метод управление не является корректным с точки зрения инженерной психологии, поскольку он не связан с естественным предназначением компонентов и без специальных подсказок остается невидимым, а следовательно никто им не будет пользоваться. Значит, такой метод не следует рекомендовать Примечание. В ряде случаев удобным может оказаться компонент
TPopMenu — всплывающее или контекстное меню, которое чаще всего вызывается нажатием правой клавиши (см[1]).
Элементы оформления TPanel, TBevel
Управление видимостью компонентов.
Для выделения группы логически связанных компонентов часто используются элементы TPanel (панель)и TBevel (рамка). Внешне оба компонента напоминают друг друга, так как создают рамку на экране, внутрь которой помещают компоненты, объединяемые общим назначение, допустим, управление таблицей базы данных. Существенное отличие заключается в том, что TBevel — это просто декоративная рамка и объединение элементов чисто изобразительное. При перемещении компонента TBevel размещённые в нём компоненты остаются на своих местах. Панель TPanel является контейнером для размещённых на ней элементов, это означает, что действие, производимые над панелью, одновременно влияют и на все внутренние компоненты. Например, при перетаскивании панели по экрану будут перемещены и все её компоненты.
Рисунок 2 – последствия и результаты
проявления некоторых внутренних дефектов.
Системные ошибки в большом (сложном) программном обеспечении определяются, прежде всего неполной информацией о реальных процессах, происходящих в источниках и потребителях информации. На начальных стадиях проектирования программного обеспечения не всегда удается точно сформулировать целевую задачу всей системы и требования к ней. В процессе проектирования целевая функция системы уточняется и выявляются отклонения от уточненных требований, которые могут квалифицироваться как системные ошибки. Некачественное определение требований к программе приводит к созданию программы, которая будет правильно решать неверно сформулированную задачу. В таких случаях, как правило, требуется полное перепрограммирование. Признаком того, что создаваемая для заказчика программа может оказаться не соответствующей его истинным потребностям, служит ощущение неясности задачи. Письменная регистрация требований к программе заставляет заказчика собраться с мыслями и дать достаточно точное определение требований. Всякие устные указания являются заведомо ненадежными и часто приводят к взаимному недопониманию. При автономной и в начале комплексной отладки программного обеспечения доля найденных системных ошибок в нем невелика (примерно 10%), но она существенно возрастает (до 35—40%) на завершающих этапах комплексной отладки. В процессе эксплуатации преобладающими являются системные ошибки (примерно 80% всех ошибок). Ошибки в выборе алгоритма. Часто плохой выбор алгоритма становится очевидным лишь после его опробования. Поэтому все же следует уделять внимание и время выбору алгоритма, с тем, чтобы впоследствии не приходилось переделывать каждую программу. Во избежание выбора некорректных алгоритмов, необходимо хорошо ознакомиться с литературой по своей специальности. К алгоритмическим ошибкам следует отнести, прежде всего, ошибки, обусловленные некорректной постановкой функциональных задач, когда в спецификациях не полностью оговорены все условия, необходимые для получения правильного результата. Эти условия формируются и уточняются в значительной части в процессе тестирования и выявления ошибок в результатах функционирования программ. Также следует отнести ошибки связей модулей и функциональных групп программ. Их можно квалифицировать как ошибки некорректной постановки задачи. Алгоритмические ошибки проявляются в неполном учете диапазонов изменения переменных, в неправильной оценке точности используемых и получаемых величин, в неправильном учете связи между различными переменными, в неадекватном представлении формализованных условий решения задачи в спецификациях или схемах, подлежащих программированию и т.д. Эти обстоятельства являются причиной того, что для исправления каждой алгоритмической ошибки приходится изменять иногда целые ветви программного обеспечения, т.е. пока еще существенно больше операторов, чем при исправлении программных ошибок. Алгоритмические ошибки значительно труднее поддаются обнаружению методами формализованного автоматического контроля. Вот почему необходимо тщательным образом продумывать алгоритм прежде, чем транслировать его в программу. Некоторые программисты проверяют алгоритм следующим образом. Через несколько дней после составления алгоритма они повторно обращаются к описанию задачи и составляют алгоритм заново. Затем сличают оба варианта. Такой шаг на первый взгляд может показаться пустой тратой времени, однако всякая ошибка на уровне алгоритма может в дальнейшем обернуться катастрофой и повлечь основательный пересмотр программы. Технологические ошибки— это ошибки документации и фиксирования программ в памяти ЭВМ. Они составляют 5—10 % от общего числа ошибок, обнаруживаемых при отладке. Большинство технологических ошибок выявляются автоматически формализованными методами (например, транслятором). Программные ошибки. Языки программирования — это искусственные языки, созданные человеком для описания алгоритмов. Все предложения таких языков строятся по строгим синтаксическим правилам, обеспечивающим однозначное их понимание, что позволяет поручать расшифровку алгоритма ЭВМ, построенного по правилам семантики. Синтаксис — это набор правил построения из символов алфавита специальных конструкций, с помощью которых можно составлять различные алгоритмы (программы). Эти правила требуют их неукоснительного соблюдения. В противном случае будет нарушен основной принцип — четкая и строгая однозначность в понимании алгоритма.
Семантика языка — это система правил истолкования построений конструкций. Правила семантики конструкций обычно вполне естественны и понятны, но в некоторых случаях их надо специально оговаривать, комментировать. Таким образом, программы, позволяющие однозначно производить процесс переработки данных, составляются с помощью соединения символов из алфавита в предложения в соответствии с синтаксическими правилами, определяющими язык, с учетом правил семантики. Выделяют синтаксические и семантические ошибки. Под синтаксическими ошибками понимается нарушение правил записи программ на данном языке программирования. Они выявляются самой машиной, точнее транслятором, вовремя перевода записи алгоритма на язык машины. Исправление их осуществляется просто — достаточно сравнить формат исправляемой конструкции с синтаксисом в справочнике и исправить его. Семантические (смысловые) ошибки — это применение операторов, которые не дают нужного эффекта (например, а—вместо, а+в), ошибка в структуре алгоритма, в логической взаимосвязи его частей, в применении алгоритма к тем данным, к которым он неприменим и т.д. Правила семантики не формализуемы. Поэтому поиск и устранение семантической ошибки и составляет основу отладки. Каждая программная ошибка влечет за собой необходимость изменения команд существенно меньше, чем при алгоритмических и системных ошибках. На этапах комплексной отладки программного обеспечения и эксплуатации удельный вес программных ошибок падает и составляет примерно 15 и 30 % соответственно от общего количества ошибок, выявляемых в единицу времени.
Алгоритмическая ошибка
Cтраница 1
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формализованного автоматического контроля, чем предыдущие типы ошибок. К алгоритмическим следует отнести прежде всего ошибки, обусловленные некорректной постановкой функциональных задач, когда в спецификациях не полностью оговорены все условия, необходимые для получения правильного результата. Эти условия формируются и уточняются в значительной части в процессе тестирования и выявления ошибок в результатах функционирования программ. Ошибки, обусловленные неполным учетом всех условий решения задач, являются наиболее частыми в этой группе и составляют до 70 % всех алгоритмических ошибок или около 30 % общего количества ошибок на начальных этапах проектирования.
[1]
Алгоритмические ошибки и ошибки кодирования, связанные с некорректной формулировкой и реализацией алгоритмов программным путем.
[2]
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формального автоматического контроля, чем все предыдущие типы ошибок. Это определяется прежде всего отсутствием для большинства логических управляющих алгоритмов строго формализованной постановки задач, которую можно использовать в качестве эталона для сравнения результатов функционирования разработанных алгоритмов. Разработка управляющих алгоритмов осуществляется обычно при наличии большого количества параметров и в условиях значительной неопределенности самой исходной постановки задачи. Эти условия формируются в значительной части в процессе выявления ошибок по результатам функционирования алгоритмов. Ошибки некорректной постановки задач приводят к сокращению полного перечня маршрутов обработки информации, необходимых для получения всей гаммы числовых и логических решений, или к появлению маршрутов обработки информации, дающих неправильный результат. Таким образом, область получающихся выходных результатов изменяется.
[3]
Алгоритмические ошибки представляют собой ошибки в программной трактовке алгоритма, например недоучет всех вариантов работы алгоритма.
[4]
К алгоритмическим ошибкам следует отнести также ошибки связей модулей и функциональных групп программ.
[5]
К алгоритмическим ошибкам следует отнести также ошибки сопряжения алгоритмических блоков, когда информация, необходимая для функционирования некоторого блока, оказывается неполностью подготовленной блоками, предшествующими по моменту включения. Этот тип ошибок также можно квалифицировать как ошибки некорректной постановки задачи, однако в данном случае некорректность может проявляться при определенной временной последовательности функционирования алгоритмических блоков.
[6]
С алгоритмическими ошибками дело обстоит иначе. Компиляция программы, в которой есть алгоритмическая ошибка, завершается успешно. При пробных запусках программа ведет себя нормально, однако при анализе результата выясняется, что он неверный. Для того чтобы устранить алгоритмическую ошибку, приходится анализировать алгоритм, вручную прокручивать его выполнение.
[8]
Особую часть алгоритмических ошибок составляют просчеты в использовании доступных ресурсов ВС. Одновременная разработка множества модулей различными специалистами затрудняет оптимальное распределение ограниченных ресурсов ЭВМ по всем задачам, так как отсутствуют достоверные данные потребных ресурсов для решения каждой из них. В результате возникает либо недоиспользование, либо ( в подавляющем большинстве случаев) нехватка каких-то ресурсов ЭВМ для решения задач в первоначальном варианте. Наиболее крупные просчеты обычно происходят при оценке времени реализации различных групп программ и при распределении производительности ЭВМ.
[9]
Этот побочный эффект может привести к алгоритмическим ошибкам при работе программы. Для того чтобы избавить программиста от необходимости помнить о таком побочном эффекте, достаточно в начале макрокоманды сохранять, а после выполнения восстанавливать содержимое этих регистров. Для этих целей в СМ ЭВМ обычно используется стек. Необходимо отметить, что в отдельных случаях сохранение регистров не обязательно.
[10]
В предыдущем параграфе был рассмотрен характер формирования алгоритмической ошибки вычислений при отсутствии искажающих воздействий со стороны окружающей среды и вычислительной системы. В реальных условиях на процесс смены состояний АлСУ и ошибку выходных сигналов существенное влияние оказывают искажающие воздействия, которые по отношению к управляющему объекту могут быть как внешними, так и внутренними. Внешние воздействия, источником которых является внешняя ( по отношению к управляющему объекту) среда, связаны с ошибками определения параметров управляемого процесса, отказами и сбоями в работе датчиков информации, каналов связи и преобразующих устройств. Внутренние воздействия, источниками которых являются ЦВМ или комплексы ЦВМ, используемые для реализации алгоритмической системы, обусловлены сбоями, частичными отказами и прерываниями.
[11]
Кроме того, значительные трудности представляет разделение системных и алгоритмических ошибок и выделение доработок, которые не следует квалифицировать как ошибки.
[12]
Однако формула ( 29) позволяет судить о характере формирования алгоритмической ошибки в реальных системах и сделать важный вывод о несостоятельности попыток оценки качества АлСУ всякого рода контрольными просчетами.
[13]
Защита от перегрузки ЭВМ по пропускной способности предполагает обнаружение и снижение влияния последствий алгоритмических ошибок, обусловленных неправильным определением необходимой пропускной способности ЭВМ для работы в реальном времени. Кроме того, перегрузки могут быть следствием неправильного функционирования источников информации и превышения интенсивности потоков сообщений расчетного, нормального, уровня. Последствия обычно сводятся к прекращению решения некоторых функциональных задач, обладающих низким приоритетом.
[14]
В настоящее время структурные методы контроля ориентированы в основном на обнаружение и доказательство отсутствия технологических и некоторых алгоритмических ошибок в записи программ, которые выполняются на этапе программной отладки.
[15]
Страницы:
1
2
3
Аннотация: Лекция носит факультативный характер. Здесь мы рассматриваем виды допускаемых в программировании ошибок, способы тестирования и отладки программ, инструменты встроенного отладчика.
Цель лекции
Освоить работу с встроенным отладчиком, изучить категории ошибок, способы их обнаружения и устранения.
Тестирование и отладка программы
Чем больше опыта имеет программист, тем меньше ошибок в коде он совершает. Но, хотите верьте, хотите нет, даже самый опытный программист всё же допускает ошибки. И любая современная среда разработки программ должна иметь собственные инструменты для отладки приложений, а также для своевременного обнаружения и исправления возможных ошибок. Программные ошибки на программистском сленге называют багами (англ. bug — жук), а программы отладки кода — дебаггерами (англ. debugger — отладчик). Lazarus, как современная среда разработки приложений, имеет собственный встроенный отладчик, работу с которым мы разберем на этой лекции.
Ошибки, которые может допустить программист, условно делятся на три группы:
- Синтаксические
- Времени выполнения (run-time errors)
- Алгоритмические
Синтаксические ошибки
Синтаксические ошибки легче всего обнаружить и исправить — их обнаруживает компилятор, не давая скомпилировать и запустить программу. Причем компилятор устанавливает курсор на ошибку, или после неё, а в окне сообщений выводит соответствующее сообщение, например, такое:
Рис.
27.1.
Найденная компилятором синтаксическая ошибка — нет объявления переменной i
Подобные ошибки могут возникнуть при неправильном написании директивы или имени функции (процедуры); при попытке обратиться к переменной или константе, которую не объявляли (
рис.
27.1); при попытке вызвать функцию (процедуру, переменную, константу) из модуля, который не был подключен в разделе uses; при других аналогичных недосмотрах программиста.
Как уже говорилось, компилятор при нахождении подобной ошибки приостанавливает процесс компиляции, выводит сообщение о найденной ошибке и устанавливает курсор на допущенную ошибку, или после неё. Программисту остается только внести исправления в код программы и выполнить повторную компиляцию.
Ошибки времени выполнения
Ошибки времени выполнения (run-time errors) тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы, или во время тестирования. Если такую программу запустить из среды Lazarus, то она скомпилируется, но при попытке загрузки, или в момент совершения ошибки, приостановит свою работу, выведя на экран соответствующее сообщение. Например, такое:
Рис.
27.2.
Сообщение Lazarus об ошибке времени выполнения
В данном случае программа при загрузке должна была считать в память отсутствующий текстовый файл MyFile.txt. Поскольку программа вызвала ошибку, она не запустилась, но в среде Lazarus процесс отладки продолжается, о чем свидетельствует сообщение в скобках в заголовке главного меню, после названия проекта. Программисту в подобных случаях нужно сбросить отладчик командой меню «Запуск -> Сбросить отладчик«, после чего можно продолжить работу над проектом.
Ошибка времени выполнения может возникнуть не только при загрузке программы, но и во время её работы. Например, если бы попытка чтения несуществующего файла была сделана не при загрузке программы, а при нажатии на кнопку, то программа бы нормально запустилась и работала, пока пользователь не нажмет на эту кнопку.
Если программу запустить из самой Windows, при возникновении этой ошибки появится такое же сообщение. При этом если нажать «OK«, программа даже может запуститься, но корректно работать все равно не будет.
Ошибки времени выполнения бывают не только явными, но и неявными, при которых программа продолжает свою работу, не выводя никаких сообщений, а программист даже не догадывается о наличии ошибки. Примером неявной ошибки может служить так называемая утечка памяти. Утечка памяти возникает в случаях, когда программист забывает освободить выделенную под объект память. Например, мы объявляем переменную типа TStringList, и работаем с ней:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
end;
В данном примере программист допустил типичную для начинающих ошибку — не освободил класс TStringList. Это не приведет к сбою или аварийному завершению программы, но в итоге можно бесполезно израсходовать очень много памяти. Конечно, эта память будет освобождена после выгрузки программы (за этим следит операционная система), но утечка памяти во время выполнения программы тоже может привести к неприятным последствиям, потребляя все больше и больше ресурсов и излишне нагружая процессор. В подобных случаях после работы с объектом программисту нужно не забывать освобождать память:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
MySL.Free; //освободили объект
end;
Однако ошибки времени выполнения могут случиться и во время работы с объектом. Если есть такой риск, программист должен не забывать про возможность обработки исключительных ситуаций. В данном случае вышеприведенный код правильней будет оформить таким образом:
begin
try
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
finally
MySL.Free; //освободили объект, даже если была ошибка
end;
end;
Итак, во избежание ошибок времени выполнения программист должен не забывать делать проверку на правильность ввода пользователем допустимых значений, заключать опасный код в блоки try…finally…end или try…except…end, делать проверку на существование открываемого файла функцией FileExists и вообще соблюдать предусмотрительность во всех слабых местах программы. Не полагайтесь на пользователя, ведь недаром говорят, что если в программе можно допустить ошибку, пользователь эту возможность непременно найдет.
Алгоритмические ошибки
Если вы не допустили ни синтаксических ошибок, ни ошибок времени выполнения, программа скомпилировалась, запустилась и работает нормально, то это еще не означает, что в программе нет ошибок. Убедиться в этом можно только в процессе её тестирования.
Тестирование — процесс проверки работоспособности программы путем ввода в неё различных, даже намеренно ошибочных данных, и последующей контрольной проверке выводимого результата.
Если программа работает правильно с одними наборами исходных данных, и неправильно с другими, то это свидетельствует о наличии алгоритмической ошибки. Алгоритмические ошибки иногда называют логическими, обычно они связаны с неверной реализацией алгоритма программы: вместо «+» ошибочно поставили «-«, вместо «/» — «*», вместо деления значения на 0,01 разделили на 0,001 и т.п. Такие ошибки обычно не обнаруживаются во время компиляции, программа нормально запускается, работает, а при анализе выводимого результата выясняется, что он неверный. При этом компилятор не укажет программисту на ошибку — чтобы найти и устранить её, приходится анализировать код, пошагово «прокручивать» его выполнение, следя за результатом. Такой процесс называется отладкой.
Отладка — процесс поиска и устранения ошибок, чаще алгоритмических. Хотя отладчик позволяет справиться и с ошибками времени выполнения, которые не обнаруживаются явно.
Аннотация: Лекция носит факультативный характер. Здесь мы рассматриваем виды допускаемых в программировании ошибок, способы тестирования и отладки программ, инструменты встроенного отладчика.
Цель лекции
Освоить работу с встроенным отладчиком, изучить категории ошибок, способы их обнаружения и устранения.
Тестирование и отладка программы
Чем больше опыта имеет программист, тем меньше ошибок в коде он совершает. Но, хотите верьте, хотите нет, даже самый опытный программист всё же допускает ошибки. И любая современная среда разработки программ должна иметь собственные инструменты для отладки приложений, а также для своевременного обнаружения и исправления возможных ошибок. Программные ошибки на программистском сленге называют багами (англ. bug — жук), а программы отладки кода — дебаггерами (англ. debugger — отладчик). Lazarus, как современная среда разработки приложений, имеет собственный встроенный отладчик, работу с которым мы разберем на этой лекции.
Ошибки, которые может допустить программист, условно делятся на три группы:
- Синтаксические
- Времени выполнения (run-time errors)
- Алгоритмические
Синтаксические ошибки
Синтаксические ошибки легче всего обнаружить и исправить — их обнаруживает компилятор, не давая скомпилировать и запустить программу. Причем компилятор устанавливает курсор на ошибку, или после неё, а в окне сообщений выводит соответствующее сообщение, например, такое:
Рис.
27.1.
Найденная компилятором синтаксическая ошибка — нет объявления переменной i
Подобные ошибки могут возникнуть при неправильном написании директивы или имени функции (процедуры); при попытке обратиться к переменной или константе, которую не объявляли (
рис.
27.1); при попытке вызвать функцию (процедуру, переменную, константу) из модуля, который не был подключен в разделе uses; при других аналогичных недосмотрах программиста.
Как уже говорилось, компилятор при нахождении подобной ошибки приостанавливает процесс компиляции, выводит сообщение о найденной ошибке и устанавливает курсор на допущенную ошибку, или после неё. Программисту остается только внести исправления в код программы и выполнить повторную компиляцию.
Ошибки времени выполнения
Ошибки времени выполнения (run-time errors) тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы, или во время тестирования. Если такую программу запустить из среды Lazarus, то она скомпилируется, но при попытке загрузки, или в момент совершения ошибки, приостановит свою работу, выведя на экран соответствующее сообщение. Например, такое:
Рис.
27.2.
Сообщение Lazarus об ошибке времени выполнения
В данном случае программа при загрузке должна была считать в память отсутствующий текстовый файл MyFile.txt. Поскольку программа вызвала ошибку, она не запустилась, но в среде Lazarus процесс отладки продолжается, о чем свидетельствует сообщение в скобках в заголовке главного меню, после названия проекта. Программисту в подобных случаях нужно сбросить отладчик командой меню «Запуск -> Сбросить отладчик«, после чего можно продолжить работу над проектом.
Ошибка времени выполнения может возникнуть не только при загрузке программы, но и во время её работы. Например, если бы попытка чтения несуществующего файла была сделана не при загрузке программы, а при нажатии на кнопку, то программа бы нормально запустилась и работала, пока пользователь не нажмет на эту кнопку.
Если программу запустить из самой Windows, при возникновении этой ошибки появится такое же сообщение. При этом если нажать «OK«, программа даже может запуститься, но корректно работать все равно не будет.
Ошибки времени выполнения бывают не только явными, но и неявными, при которых программа продолжает свою работу, не выводя никаких сообщений, а программист даже не догадывается о наличии ошибки. Примером неявной ошибки может служить так называемая утечка памяти. Утечка памяти возникает в случаях, когда программист забывает освободить выделенную под объект память. Например, мы объявляем переменную типа TStringList, и работаем с ней:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
end;
В данном примере программист допустил типичную для начинающих ошибку — не освободил класс TStringList. Это не приведет к сбою или аварийному завершению программы, но в итоге можно бесполезно израсходовать очень много памяти. Конечно, эта память будет освобождена после выгрузки программы (за этим следит операционная система), но утечка памяти во время выполнения программы тоже может привести к неприятным последствиям, потребляя все больше и больше ресурсов и излишне нагружая процессор. В подобных случаях после работы с объектом программисту нужно не забывать освобождать память:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
MySL.Free; //освободили объект
end;
Однако ошибки времени выполнения могут случиться и во время работы с объектом. Если есть такой риск, программист должен не забывать про возможность обработки исключительных ситуаций. В данном случае вышеприведенный код правильней будет оформить таким образом:
begin
try
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
finally
MySL.Free; //освободили объект, даже если была ошибка
end;
end;
Итак, во избежание ошибок времени выполнения программист должен не забывать делать проверку на правильность ввода пользователем допустимых значений, заключать опасный код в блоки try…finally…end или try…except…end, делать проверку на существование открываемого файла функцией FileExists и вообще соблюдать предусмотрительность во всех слабых местах программы. Не полагайтесь на пользователя, ведь недаром говорят, что если в программе можно допустить ошибку, пользователь эту возможность непременно найдет.
Алгоритмические ошибки
Если вы не допустили ни синтаксических ошибок, ни ошибок времени выполнения, программа скомпилировалась, запустилась и работает нормально, то это еще не означает, что в программе нет ошибок. Убедиться в этом можно только в процессе её тестирования.
Тестирование — процесс проверки работоспособности программы путем ввода в неё различных, даже намеренно ошибочных данных, и последующей контрольной проверке выводимого результата.
Если программа работает правильно с одними наборами исходных данных, и неправильно с другими, то это свидетельствует о наличии алгоритмической ошибки. Алгоритмические ошибки иногда называют логическими, обычно они связаны с неверной реализацией алгоритма программы: вместо «+» ошибочно поставили «-«, вместо «/» — «*», вместо деления значения на 0,01 разделили на 0,001 и т.п. Такие ошибки обычно не обнаруживаются во время компиляции, программа нормально запускается, работает, а при анализе выводимого результата выясняется, что он неверный. При этом компилятор не укажет программисту на ошибку — чтобы найти и устранить её, приходится анализировать код, пошагово «прокручивать» его выполнение, следя за результатом. Такой процесс называется отладкой.
Отладка — процесс поиска и устранения ошибок, чаще алгоритмических. Хотя отладчик позволяет справиться и с ошибками времени выполнения, которые не обнаруживаются явно.
Классификация ошибок
Ошибки, которые могут быть в программе,
принято делить на три группы:
-
синтаксические;
-
ошибки времени выполнения;
-
алгоритмические.
Синтаксические ошибки, их также называют
ошибками времени компиляции (Compile-time
error), наиболее легко устранимы. Их
обнаруживает компилятор, а программисту
остается только внести изменения в
текст программы и выполнить повторную
компиляцию.
Ошибки времени выполнения, в Delphi они
называются исключениями (exception), тоже,
как правило, легко устранимы. Они обычно
проявляются уже при первых запусках
программы и во время тестирования.
При возникновении ошибки
в программе, запущенной из Delphi, среда
разработки прерывает работу программы,
о чем свидетельствует заключенное в
скобки слово Stopped в
заголовке главного окна Delphi, и на экране
появляется диалоговое окно, которое
содержит сообщение об ошибке и информацию
о типе (классе) ошибки. На рис. 13.1 приведен
пример сообщения об ошибке, возникающей
при попытке открыть несуществующий
файл.
После возникновения ошибки
программист может либо прервать
выполнение программы, для этого надо
из менюRun выбрать
команду Program
Reset, либо продолжить
ее выполнение, например, по шагам (для
этого из менюRun надо
выбрать команду Step), наблюдая
результат выполнения каждой инструкции.
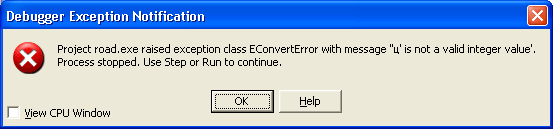
Рис. 13.1. Сообщение
об ошибке при запуске программы из
Delphi
Если программа запущена из
Windows, то при возникновении ошибки на
экране также появляется сообщение об
ошибке, но тип ошибки (исключения) в
сообщении не указывается (рис. 13.2). После
щелчка на кнопке ОКпрограмма,
в которой проявилась ошибка, продолжает
(если сможет) работу.
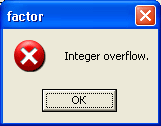
Рис. 13.2. Сообщение
об ошибке при запуске программы из
Windows
С алгоритмическими ошибками дело обстоит
иначе. Компиляция программы, в которой
есть алгоритмическая ошибка, завершается
успешно. При пробных запусках программа
ведет себя нормально, однако при анализе
результата выясняется, что он неверный.
Для того чтобы устранить алгоритмическую
ошибку,» приходится анализировать
алгоритм, вручную «прокручивать»
его выполнение.
Предотвращение и обработка ошибок
Как было сказано выше, в программе во
время ее работы могут возникать ошибки,
причиной которых, как правило, являются
действия пользователя. Например,
пользователь может ввести неверные
данные или, что бывает довольно часто,
удалить нужный программе файл.
Нарушение в работе программы называется
исключением. Обработку исключений
(ошибок) берет на себя автоматически
добавляемый в выполняемую программу
код, который обеспечивает, в том числе,
вывод информационного сообщения. Вместе
с тем Delphi дает возможность программе
самой выполнить обработку исключения.
Инструкция обработки исключения в общем
виде выглядит так:
try
// здесь инструкции, выполнение которых
может вызвать исключение
except //
начало секции обработки исключений
on ТипИсключения1 do Обработка1;
on ТипИсключения2 do Обработка2;
on ТипИсключенияJ do ОбработкаJ;
else
// здесь инструкции обработки остальных
исключений
end;
где:
-
try — ключевое слово, обозначающее, что
далее следуют инструкции, при выполнении
которых возможно возникновение
исключений, и что обработку этих
исключений берет на себя программа; -
except — ключевое слово, обозначающее
начало секции обработки исключений.
Инструкции этой секции будут выполнены,
если в программе возникнет ошибка; -
on — ключевое слово, за которым следует
тип исключения, обработку которого
выполняет инструкция, следующая за do; -
else — ключевое слово, за которым следуют
инструкции, обеспечивающие обработку
исключений, тип которых не указаны в
секции except.
Как было сказано выше, основной
характеристикой исключения является
его тип. В таблице 13.1 перечислены наиболее
часто возникающие исключения и указаны
причины, которые могут привести к их
возникновению.
Таблица 13.1. Типичные
исключения
|
Тип исключения |
Возникает |
||
|
EZeroDivide |
При выполнении операции деления, если |
||
|
EConvertError |
При выполнении преобразования, если |
||
|
Тип исключения |
Возникает |
||
|
EFilerError |
При обращении к файлу. Наиболее частой |
||
Ошибки выполнения:
Определения данных;
Передачи;
Преобразования;
Перезаписи;
Неправильные данные.
Логические;
Неприемлемый подход;
Неверный алгоритм;
Неверная структура данных;
Другие;
Кодирования;
Проектирования;
Некорректная работа с переменными;
Некорректные вычисления;
Ошибки интерфейсов;
Неправильная реализация алгоритма;
Другие.
Накопления погрешностей;
Игнорирование ограничений разрядной
сетки;
Игнорирование способов уменьшения
погрешностей.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Отладка программ
Введение
Успешное завершение процесса компиляции не означает, что в программе нет ошибок. Убедиться, что программа работает правильно, можно только в процессе проверки ее работоспособности, который называется тестирование. Обычно программа редко сразу начинает работать так, как надо, или работает правильно только на некотором ограниченном наборе исходных данных. Это свидетельствует о том, что в программе есть алгоритмические ошибки. Процесс поиска и устранения ошибок называется отладкой
Классификация ошибок
Введение
Ошибки, которые могут быть в программе, принято делить на три группы:
- синтаксические;
- ошибки времени выполнения;
- алгоритмические.
Синтаксические ошибки
Синтаксические ошибки, их также называют ошибками времени компиляции (Compile-time error), наиболее легко устранимы. Их обнаруживает компилятор, а программисту остается внести изменения в текст программы и выполнить повторную компиляцию.
Ошибки времени выполнения
Ошибки времени выполнения, они называются исключениями (Exception), тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы и во время тестирования
При возникновении ошибки в программе, запущенной из ИСР, среда прерывает работу программы и в окне сообщений дает информацию о типе ошибки.
После возникновения ошибки программист может либо прервать выполнение программы, либо продолжить ее выполнение, например, по шагам, наблюдая результат выполнения каждой инструкции.
Если программа запущена из Windows, то при возникновении ошибки на экране также появляется сообщение об ошибке, но тип ошибки (исключения) в сообщении не указывается. После щелчка на кнопке ОК программа, в которой проявилась ошибка, продолжает (если сможет) работу.
Алгоритмические ошибки
С алгоритмическими ошибками дело обстоит иначе. Компиляция программы, в которой есть алгоритмическая ошибка, завершается успешно. При пробных запусках программа ведет себя нормально, однако при анализе результата выясняется, что он неверный. Для того чтобы устранить алгоритмическую ошибку, приходится анализировать алгоритм, вручную “прокручивать” его выполнение.
Предотвращение и обработка ошибок
В программе во время ее работы могут возникать ошибки, причиной которых, как правило, являются действия пользователя. Например, пользователь может ввести неверные данные или, что бывает довольно часто, удалить нужный программе файл. Нарушение в работе программы называется исключением. Обработку исключений (ошибок) берет на себя автоматически добавляемый в выполняемую программу код, который обеспечивает, в том числе, вывод информационного сообщения.
FPC и ИСР предоставляют программисту мощные средства:
- Компилятор с регулируемыми опциями.
Отладчик для поиска и устранения ошибок в программе. Отладчик позволяет выполнять трассировку программы, наблюдать значения переменных, контролировать выводимые программой данные.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Ошибки, которые могут
быть в программе, принято делить на три группы:
- синтаксические;
- ошибки времени выполнения;
- алгоритмические.
Синтаксические ошибки,
их также называют ошибками времени компиляции (Compile-time error), наиболее
легко устранимы. Их обнаруживает компилятор, а программисту остается только
внести изменения в текст программы и выполнить повторную компиляцию.
Ошибки времени выполнения,
в Delphi они называются исключениями (exception), тоже, как правило, легко устранимы.
Они обычно проявляются уже при первых запусках программы и во время тестирования.
При возникновении ошибки
в программе, запущенной из Delphi, среда разработки прерывает работу программы,
о чем свидетельствует заключенное в скобки слово Stopped в заголовке
главного окна Delphi, и на экране появляется диалоговое окно, которое содержит
сообщение об ошибке и информацию о типе (классе) ошибки. На рис. 13.1 приведен
пример сообщения об ошибке, возникающей при попытке открыть несуществующий файл.
После возникновения
ошибки программист может либо прервать выполнение программы, для этого надо
из меню Run выбрать команду Program Reset, либо продолжить ее
выполнение, например, по шагам (для этого из меню
Run надо выбрать команду Step), наблюдая результат выполнения
каждой инструкции.

Рис. 13.1. Сообщение
об ошибке при запуске программы из Delphi
Если программа запущена
из Windows, то при возникновении ошибки на экране также появляется сообщение
об ошибке, но тип ошибки (исключения) в сообщении не указывается (рис. 13.2).
После щелчка на кнопке ОК программа, в которой проявилась ошибка, продолжает
(если сможет) работу.

Рис. 13.2. Сообщение
об ошибке при запуске программы из Windows
С алгоритмическими
ошибками дело обстоит иначе. Компиляция программы, в которой есть алгоритмическая
ошибка, завершается успешно. При пробных запусках программа ведет себя нормально,
однако при анализе результата выясняется, что он неверный. Для того чтобы устранить
алгоритмическую ошибку,» приходится анализировать алгоритм, вручную «прокручивать»
его выполнение.
Improve Article
Save Article
Improve Article
Save Article
Compile-Time Errors: Errors that occur when you violate the rules of writing syntax are known as Compile-Time errors. This compiler error indicates something that must be fixed before the code can be compiled. All these errors are detected by the compiler and thus are known as compile-time errors.
Most frequent Compile-Time errors are:
- Missing Parenthesis (})
- Printing the value of variable without declaring it
- Missing semicolon (terminator)
Below is an example to demonstrate Compile-Time Error:
C++
#include <iostream>
using namespace std;
int main()
{
int x = 10;
int y = 15;
cout << " "<< (x, y)
}
C
#include<stdio.h>
void main()
{
int x = 10;
int y = 15;
printf("%d", (x, y));
}
Error:
error: expected ';' before '}' token
Run-Time Errors: Errors which occur during program execution(run-time) after successful compilation are called run-time errors. One of the most common run-time error is division by zero also known as Division error. These types of error are hard to find as the compiler doesn’t point to the line at which the error occurs.
For more understanding run the example given below.
C++
#include <iostream>
using namespace std;
int main()
{
int n = 9, div = 0;
div = n/0;
cout <<"result = " << div;
}
C
#include<stdio.h>
void main()
{
int n = 9, div = 0;
div = n/0;
printf("result = %d", div);
}
Error:
warning: division by zero [-Wdiv-by-zero]
div = n/0;
In the given example, there is Division by zero error. This is an example of run-time error i.e errors occurring while running the program.
The Differences between Compile-Time and Run-Time Error are:
| Compile-Time Errors | Runtime-Errors |
|---|---|
| These are the syntax errors which are detected by the compiler. | These are the errors which are not detected by the compiler and produce wrong results. |
| They prevent the code from running as it detects some syntax errors. | They prevent the code from complete execution. |
| It includes syntax errors such as missing of semicolon(;), misspelling of keywords and identifiers etc. | It includes errors such as dividing a number by zero, finding square root of a negative number etc. |
Improve Article
Save Article
Improve Article
Save Article
Compile-Time Errors: Errors that occur when you violate the rules of writing syntax are known as Compile-Time errors. This compiler error indicates something that must be fixed before the code can be compiled. All these errors are detected by the compiler and thus are known as compile-time errors.
Most frequent Compile-Time errors are:
- Missing Parenthesis (})
- Printing the value of variable without declaring it
- Missing semicolon (terminator)
Below is an example to demonstrate Compile-Time Error:
C++
#include <iostream>
using namespace std;
int main()
{
int x = 10;
int y = 15;
cout << " "<< (x, y)
}
C
#include<stdio.h>
void main()
{
int x = 10;
int y = 15;
printf("%d", (x, y));
}
Error:
error: expected ';' before '}' token
Run-Time Errors: Errors which occur during program execution(run-time) after successful compilation are called run-time errors. One of the most common run-time error is division by zero also known as Division error. These types of error are hard to find as the compiler doesn’t point to the line at which the error occurs.
For more understanding run the example given below.
C++
#include <iostream>
using namespace std;
int main()
{
int n = 9, div = 0;
div = n/0;
cout <<"result = " << div;
}
C
#include<stdio.h>
void main()
{
int n = 9, div = 0;
div = n/0;
printf("result = %d", div);
}
Error:
warning: division by zero [-Wdiv-by-zero]
div = n/0;
In the given example, there is Division by zero error. This is an example of run-time error i.e errors occurring while running the program.
The Differences between Compile-Time and Run-Time Error are:
| Compile-Time Errors | Runtime-Errors |
|---|---|
| These are the syntax errors which are detected by the compiler. | These are the errors which are not detected by the compiler and produce wrong results. |
| They prevent the code from running as it detects some syntax errors. | They prevent the code from complete execution. |
| It includes syntax errors such as missing of semicolon(;), misspelling of keywords and identifiers etc. | It includes errors such as dividing a number by zero, finding square root of a negative number etc. |
Чтобы разобраться, в чем разница между ошибками времени компиляции и ошибками времени выполнения в Java, разберемся в сути каждого вида.
Ошибки времени компиляции
Это синтаксические ошибки в коде, которые препятствуют его компиляции.
Пример
public class Test{
public static void main(String args[]){
System.out.println("Hello")
}
}
Итог
C:Sample>Javac Test.java
Test.java:3: error: ';' expected
System.out.println("Hello")
Ошибки времени выполнения
Исключение (или исключительное событие) – это проблема, возникающая во время выполнения программы. Когда возникает исключение, нормальный поток программы прерывается, и программа / приложение прерывается ненормально, что не рекомендуется, поэтому эти исключения должны быть обработаны.
Пример
import java.io.File;
import java.io.FileReader;
public class FilenotFound_Demo {
public static void main(String args[]) {
File file = new File("E://file.txt");
FileReader fr = new FileReader(file);
}
}
Итог
C:>javac FilenotFound_Demo.java
FilenotFound_Demo.java:8: error: unreported exception
FileNotFoundException; must be caught or declared to be thrown
FileReader fr = new FileReader(file);
^
1 error
Алгоритмическая ошибка
Cтраница 1
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формализованного автоматического контроля, чем предыдущие типы ошибок. К алгоритмическим следует отнести прежде всего ошибки, обусловленные некорректной постановкой функциональных задач, когда в спецификациях не полностью оговорены все условия, необходимые для получения правильного результата. Эти условия формируются и уточняются в значительной части в процессе тестирования и выявления ошибок в результатах функционирования программ. Ошибки, обусловленные неполным учетом всех условий решения задач, являются наиболее частыми в этой группе и составляют до 70 % всех алгоритмических ошибок или около 30 % общего количества ошибок на начальных этапах проектирования.
[1]
Алгоритмические ошибки и ошибки кодирования, связанные с некорректной формулировкой и реализацией алгоритмов программным путем.
[2]
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формального автоматического контроля, чем все предыдущие типы ошибок. Это определяется прежде всего отсутствием для большинства логических управляющих алгоритмов строго формализованной постановки задач, которую можно использовать в качестве эталона для сравнения результатов функционирования разработанных алгоритмов. Разработка управляющих алгоритмов осуществляется обычно при наличии большого количества параметров и в условиях значительной неопределенности самой исходной постановки задачи. Эти условия формируются в значительной части в процессе выявления ошибок по результатам функционирования алгоритмов. Ошибки некорректной постановки задач приводят к сокращению полного перечня маршрутов обработки информации, необходимых для получения всей гаммы числовых и логических решений, или к появлению маршрутов обработки информации, дающих неправильный результат. Таким образом, область получающихся выходных результатов изменяется.
[3]
Алгоритмические ошибки представляют собой ошибки в программной трактовке алгоритма, например недоучет всех вариантов работы алгоритма.
[4]
К алгоритмическим ошибкам следует отнести также ошибки связей модулей и функциональных групп программ.
[5]
К алгоритмическим ошибкам следует отнести также ошибки сопряжения алгоритмических блоков, когда информация, необходимая для функционирования некоторого блока, оказывается неполностью подготовленной блоками, предшествующими по моменту включения. Этот тип ошибок также можно квалифицировать как ошибки некорректной постановки задачи, однако в данном случае некорректность может проявляться при определенной временной последовательности функционирования алгоритмических блоков.
[6]
С алгоритмическими ошибками дело обстоит иначе. Компиляция программы, в которой есть алгоритмическая ошибка, завершается успешно. При пробных запусках программа ведет себя нормально, однако при анализе результата выясняется, что он неверный. Для того чтобы устранить алгоритмическую ошибку, приходится анализировать алгоритм, вручную прокручивать его выполнение.
[8]
Особую часть алгоритмических ошибок составляют просчеты в использовании доступных ресурсов ВС. Одновременная разработка множества модулей различными специалистами затрудняет оптимальное распределение ограниченных ресурсов ЭВМ по всем задачам, так как отсутствуют достоверные данные потребных ресурсов для решения каждой из них. В результате возникает либо недоиспользование, либо ( в подавляющем большинстве случаев) нехватка каких-то ресурсов ЭВМ для решения задач в первоначальном варианте. Наиболее крупные просчеты обычно происходят при оценке времени реализации различных групп программ и при распределении производительности ЭВМ.
[9]
Этот побочный эффект может привести к алгоритмическим ошибкам при работе программы. Для того чтобы избавить программиста от необходимости помнить о таком побочном эффекте, достаточно в начале макрокоманды сохранять, а после выполнения восстанавливать содержимое этих регистров. Для этих целей в СМ ЭВМ обычно используется стек. Необходимо отметить, что в отдельных случаях сохранение регистров не обязательно.
[10]
В предыдущем параграфе был рассмотрен характер формирования алгоритмической ошибки вычислений при отсутствии искажающих воздействий со стороны окружающей среды и вычислительной системы. В реальных условиях на процесс смены состояний АлСУ и ошибку выходных сигналов существенное влияние оказывают искажающие воздействия, которые по отношению к управляющему объекту могут быть как внешними, так и внутренними. Внешние воздействия, источником которых является внешняя ( по отношению к управляющему объекту) среда, связаны с ошибками определения параметров управляемого процесса, отказами и сбоями в работе датчиков информации, каналов связи и преобразующих устройств. Внутренние воздействия, источниками которых являются ЦВМ или комплексы ЦВМ, используемые для реализации алгоритмической системы, обусловлены сбоями, частичными отказами и прерываниями.
[11]
Кроме того, значительные трудности представляет разделение системных и алгоритмических ошибок и выделение доработок, которые не следует квалифицировать как ошибки.
[12]
Однако формула ( 29) позволяет судить о характере формирования алгоритмической ошибки в реальных системах и сделать важный вывод о несостоятельности попыток оценки качества АлСУ всякого рода контрольными просчетами.
[13]
Защита от перегрузки ЭВМ по пропускной способности предполагает обнаружение и снижение влияния последствий алгоритмических ошибок, обусловленных неправильным определением необходимой пропускной способности ЭВМ для работы в реальном времени. Кроме того, перегрузки могут быть следствием неправильного функционирования источников информации и превышения интенсивности потоков сообщений расчетного, нормального, уровня. Последствия обычно сводятся к прекращению решения некоторых функциональных задач, обладающих низким приоритетом.
[14]
В настоящее время структурные методы контроля ориентированы в основном на обнаружение и доказательство отсутствия технологических и некоторых алгоритмических ошибок в записи программ, которые выполняются на этапе программной отладки.
[15]
Страницы:
1
2
3
Типичные ошибки
в программных комплексах.
Статистические характеристики ошибок
могут служить ориентиром для разработчиков
при распределении усилий на создание
программ. Кроме того, характеристики
ошибок в процессе проектирования
программ помогают:
-
оценивать реальное
состояние проекта и планировать
трудоемкость и длительность до его
завершения; -
рассчитывать
необходимую эффективность средств
оперативной защиты от невыявленных
первичных ошибок; -
оценивать
требующиеся ресурсы ЭВМ по памяти и
производительности с учетом затрат на
устранение ошибок; -
проводить
исследования и осуществлять адекватный
выбор показателей сложности компонент
и КП, а также некоторых других показателей
качества.
Анализ первичных
ошибок в программах производится на
двух уровнях детализации:
-
дифференциально
— с учетом
типов ошибок, сложности и степени
автоматизации их обнаружения, затрат
на корректировку и этапов наиболее
вероятного устранения; -
обобщенно —
по суммарным характеристикам их
обнаружения в зависимости от
продолжительности разработки,
эксплуатации и сопровождения комплекса
программ.
Технологические
ошибки
документации и фиксирования программ
в памяти ЭВМ составляют 5…10 % от общего
числа ошибок, обнаруживаемых при отладке
[12]. Большинство технологических ошибок
выявляется автоматически формализованными
методами.
Программные
ошибки по
количеству и типам в первую очередь
определяются степенью автоматизации
программирования и глубиной формализованного
контроля текстов программ. Количество
программных ошибок зависит от квалификации
разработчиков, от общего объема комплекса
программ, от глубины логического и
информационного взаимодействия модулей
и от ряда других факторов. При разработке
программ на автокодах программные
ошибки можно классифицировать по видам
используемых операций на следующие
группы: ошибки типов операций; ошибки
переменных; ошибки управления и циклов.
В комплексе программ
информационно-справочных систем эти
виды ошибок близки по удельному весу,
однако для автоматизации их обнаружений
применяются различные методы. На
начальных этапах разработки и автономной
отладки модулей программные ошибки
составляют около 1/3 всех ошибок. Ошибки
применения операций на начальных этапах
разработки достигают 14 %, а затем быстро
убь-1вают при повышении квалификации
программистов. Ошибки в переменных
составляют около 13 %, а ошибки управления
и организации циклов—около 10 %. Каждая
программная ошибка влечет за собой
необходимость изменения около шести
команд, что существенно меньше, чем при
алгоритмических и системных ошибках.
На этапах комплексной отладки и
эксплуатации удельный вес программных
ошибок падает и составляет около 15 и 3
% соответственно от общего количества
ошибок, выявляемых в единицу времени.
Алгоритмические
ошибки
значительно труднее поддаются обнаружению
методами формализованного автоматического
контроля, чем предыдущие типы ошибок.
К алгоритмическим следует отнести
прежде всего ошибки, обусловленные
некорректной постановкой функциональных
задач, когда в спецификациях не полностью
оговорены все условия, необходимые для
получения правильного результата. Эти
условия формируются и уточняются в
значительной части в процессе тестирования
и выявления ошибок в результатах
функционирования программ. Ошибки,
обусловленные неполным учетом всех
условий решения задач, являются наиболее
частыми в этой группе и составляют до
70 % всех алгоритмических ошибок или
около 30 % общего количества ошибок на
начальных этапах проектирования.
К алгоритмическим
ошибкам следует отнести также ошибки
связей модулей и функциональных групп
программ. Этот вид ошибок составляет
6…8 % от общего количества, их можно
квалифицировать как ошибки некорректной
постановки задач. Алгоритмические
ошибки проявляются в неполном учете
диапазонов изменения переменных, в
неправильной оценке точности используемых
и получаемых величин, в неправильном
учете связи между различными переменными,
в неадекватном представлении
формализованных условий решения задачи
в спецификациях или схемах, подлежащих
программированию, и т. д. Эти обстоятельства
являются причиной того, что для исправления
каждой алгоритмической ошибки приходится
изменять в среднем около 14 команд, т. е.
существенно больше, чем при программных
ошибках.
Особую часть
алгоритмических ошибок составляют
просчеты в использовании доступных
ресурсов ВС. Одновременная разработка
множества модулей различными специалистами
затрудняет оптимальное распределение
ограниченных ресурсов ЭВМ по всем
задачам, так как отсутствуют достоверные
данные потребных ресурсов для решения
каждой из них. В результате возникает
либо недоиспользование, либо (в подавляющем
большинстве случаев) нехватка каких-то
ресурсов ЭВМ для решения задач в
первоначальном варианте. Наиболее
крупные просчеты обычно происходят при
оценке времени реализации различных
групп программ и при распределении
производительности ЭВМ.
Системные ошибки
в сложных комплексах программ определяются
прежде всего неполной информацией о
реальных процессах, происходящих в
источниках и потребителях информации.
Кроме того, эти процессы зачастую зависят
от самих алгоритмов и поэтому не могут
быть достаточно определены и описаны
заранее без исследования функционирования
комплекса программ во взаимодействии
с внешней средой. На начальных стадиях
проектирования не всегда удается точно
сформулировать целевую задачу всей
системы, а также целевые задачи основных
групп программ, и эти задачи уточняются
в процессе проектирования. В соответствии
с этим уточняются и конкретизируются
технические задания или спецификации
на отдельные программы и выявляются
отклонения от уточненного задания,
которые могут квалифицироваться как
системные ошибки.
При автономной и
в начале комплексной отладки доля
системных ошибок невелика (около 10 %),
но она существенно возрастает (до 35…40
%) на завершающих этапах комплексной
отладки. В процессе эксплуатации
системные ошибки являются преобладающими
(около 80 % от всех ошибок). Следует также
отметить большое количество команд,
корректируемых при исправлении каждой
ошибки (около 25 команд на одну ошибку).
Убывание ошибок
в комплексе программ и интенсивности
их обнаружения не беспредельно. После
отладки в течение некоторого времени
интенсивность обнаружения ошибок при
самом активном тестировании снижается
настолько, что коллектив, ведущий
разработку, попадает в зону
нечувствительности к
ошибкам и отказам. При такой интенсивности
отказов трудно прогнозировать затраты
времени, необходимые для обнаружения
очередной ошибки. Создается представление
о полном отсутствии ошибок, о невозможности
и бесцельности их поиска, поэтому усилия
на отладку сокращаются и интенсивность
обнаружения ошибок еще больше снижается.
Этой предельной интенсивности обнаружения
отказов соответствует наработка на
обнаруженную ошибку, при которой
прекращается улучшение характеристик
комплекса программ на этапах отладки
и испытаний у заказчика.
Отладка программ
Введение
Успешное завершение процесса компиляции не означает, что в программе нет ошибок. Убедиться, что программа работает правильно, можно только в процессе проверки ее работоспособности, который называется тестирование. Обычно программа редко сразу начинает работать так, как надо, или работает правильно только на некотором ограниченном наборе исходных данных. Это свидетельствует о том, что в программе есть алгоритмические ошибки. Процесс поиска и устранения ошибок называется отладкой
Классификация ошибок
Введение
Ошибки, которые могут быть в программе, принято делить на три группы:
- синтаксические;
- ошибки времени выполнения;
- алгоритмические.
Синтаксические ошибки
Синтаксические ошибки, их также называют ошибками времени компиляции (Compile-time error), наиболее легко устранимы. Их обнаруживает компилятор, а программисту остается внести изменения в текст программы и выполнить повторную компиляцию.
Ошибки времени выполнения
Ошибки времени выполнения, они называются исключениями (Exception), тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы и во время тестирования
При возникновении ошибки в программе, запущенной из ИСР, среда прерывает работу программы и в окне сообщений дает информацию о типе ошибки.
После возникновения ошибки программист может либо прервать выполнение программы, либо продолжить ее выполнение, например, по шагам, наблюдая результат выполнения каждой инструкции.
Если программа запущена из Windows, то при возникновении ошибки на экране также появляется сообщение об ошибке, но тип ошибки (исключения) в сообщении не указывается. После щелчка на кнопке ОК программа, в которой проявилась ошибка, продолжает (если сможет) работу.
Алгоритмические ошибки
С алгоритмическими ошибками дело обстоит иначе. Компиляция программы, в которой есть алгоритмическая ошибка, завершается успешно. При пробных запусках программа ведет себя нормально, однако при анализе результата выясняется, что он неверный. Для того чтобы устранить алгоритмическую ошибку, приходится анализировать алгоритм, вручную “прокручивать” его выполнение.
Предотвращение и обработка ошибок
В программе во время ее работы могут возникать ошибки, причиной которых, как правило, являются действия пользователя. Например, пользователь может ввести неверные данные или, что бывает довольно часто, удалить нужный программе файл. Нарушение в работе программы называется исключением. Обработку исключений (ошибок) берет на себя автоматически добавляемый в выполняемую программу код, который обеспечивает, в том числе, вывод информационного сообщения.
FPC и ИСР предоставляют программисту мощные средства:
- Компилятор с регулируемыми опциями.
Отладчик для поиска и устранения ошибок в программе. Отладчик позволяет выполнять трассировку программы, наблюдать значения переменных, контролировать выводимые программой данные.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Справочник /
Термины /
Информатика /
Алгоритмические ошибки
Термин и определение
Алгоритмические ошибки
Опубликовано:
yuliya-aleksandrova-1973
Предмет:
Информатика
👍 Проверено Автор24
ошибки в методе, постановке, сценарии и реализации.
Научные статьи на тему «Алгоритмические ошибки»
1.
Уравнения и передаточные функции одноконтурной САУ
Рассмотрим алгоритмическую схему, которая соответствует схеме типовой одноконтурной системы автоматического…
На входе управляющего устройства с передаточной функцией Wp(p) действует сигнал рассогласования/ошибки…
Алгоритмическая схема системы автоматического управления….
Алгоритмическая схема системы автоматического управления….
Алгоритмы управления в автоматических системах управления
Алгоритмом управления устанавливается связь ошибки
Статья от экспертов
![]()
2.
Алгоритмическая и программная реализация построения оптимальных моделей прогноза
Рассматривается методика отыскания моделей прогноза с минимальными ошибками прогноза. Основу методики составляют полиномиальные модели параметрического прогноза и алгоритмическая схема поиска оптимальных моделей прогноза.
3.
Исполнитель Чертежник в среде КуМир
Исполнитель «Чертежник» в среде КуМир — это программа для формирования рисунков и чертежей, написанная на алгоритмическом…
Исполнитель Чертёжник написан на алгоритмическом языке, то есть в системе, которая имеет обозначения…
У алгоритмического языка есть свой словарный комплект, основанный на словах, употребляемых для отображения…
написано заместится на вектор, то такая запись будет непонятна Чертёжнику, и он выдаст сообщение об ошибке…
Такого типа ошибки в формулировании команды считаются синтаксическими.
Статья от экспертов
![]()
4.
Алгоритмическое исключение многолучевой погрешности из радионавигационных измерений
Предложена и проанализирована алгоритмическая процедура компенсации многолучевой ошибки в дальномерных измерениях приемника радионавигационной системы космического базирования. С помощью компьютерного моделирования выявлены условия сходимости алгоритма и область шумовых погрешностей, в пределах которой его применение имеет смысл.
Повышай знания с онлайн-тренажером от Автор24!
- 📝 Напиши термин
- ✍️ Выбери определение из предложенных или загрузи свое
-
🤝 Тренажер от Автор24 поможет тебе выучить термины, с помощью удобных и приятных
карточек
Отладка программ
Введение
Успешное завершение процесса компиляции не означает, что в программе нет ошибок. Убедиться, что программа работает правильно, можно только в процессе проверки ее работоспособности, который называется тестирование. Обычно программа редко сразу начинает работать так, как надо, или работает правильно только на некотором ограниченном наборе исходных данных. Это свидетельствует о том, что в программе есть алгоритмические ошибки. Процесс поиска и устранения ошибок называется отладкой
Классификация ошибок
Введение
Ошибки, которые могут быть в программе, принято делить на три группы:
- синтаксические;
- ошибки времени выполнения;
- алгоритмические.
Синтаксические ошибки
Синтаксические ошибки, их также называют ошибками времени компиляции (Compile-time error), наиболее легко устранимы. Их обнаруживает компилятор, а программисту остается внести изменения в текст программы и выполнить повторную компиляцию.
Ошибки времени выполнения
Ошибки времени выполнения, они называются исключениями (Exception), тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы и во время тестирования
При возникновении ошибки в программе, запущенной из ИСР, среда прерывает работу программы и в окне сообщений дает информацию о типе ошибки.
После возникновения ошибки программист может либо прервать выполнение программы, либо продолжить ее выполнение, например, по шагам, наблюдая результат выполнения каждой инструкции.
Если программа запущена из Windows, то при возникновении ошибки на экране также появляется сообщение об ошибке, но тип ошибки (исключения) в сообщении не указывается. После щелчка на кнопке ОК программа, в которой проявилась ошибка, продолжает (если сможет) работу.
Алгоритмические ошибки
С алгоритмическими ошибками дело обстоит иначе. Компиляция программы, в которой есть алгоритмическая ошибка, завершается успешно. При пробных запусках программа ведет себя нормально, однако при анализе результата выясняется, что он неверный. Для того чтобы устранить алгоритмическую ошибку, приходится анализировать алгоритм, вручную “прокручивать” его выполнение.
Предотвращение и обработка ошибок
В программе во время ее работы могут возникать ошибки, причиной которых, как правило, являются действия пользователя. Например, пользователь может ввести неверные данные или, что бывает довольно часто, удалить нужный программе файл. Нарушение в работе программы называется исключением. Обработку исключений (ошибок) берет на себя автоматически добавляемый в выполняемую программу код, который обеспечивает, в том числе, вывод информационного сообщения.
FPC и ИСР предоставляют программисту мощные средства:
- Компилятор с регулируемыми опциями.
Отладчик для поиска и устранения ошибок в программе. Отладчик позволяет выполнять трассировку программы, наблюдать значения переменных, контролировать выводимые программой данные.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()