Недостатки алгоритма обратного распространения ошибки
Алгоритм обратного распространения
ошибки осуществляет так называемый
градиентный спуск по поверхности ошибок.
Не углубляясь, это означает следующее:
в данной точке поверхности находится
направление скорейшего спуска, затем
делается прыжок вниз на расстояние,
пропорциональное коэффициенту скорости
обучения и крутизне склона, при этом
учитывается инерция, то есть стремление
сохранить прежнее направление движения.
Можно сказать, что метод ведет себя как
слепой кенгуру – каждый раз прыгает в
направлении, которое кажется ему
наилучшим. На самом деле шаг спуска
вычисляется отдельно для всех обучающих
наблюдений, взятых в случайном порядке,
но в результате получается достаточно
хорошая аппроксимация спуска по
совокупной поверхности ошибок.
Несмотря на достаточную простоту и
применимость в решении большого круга
задач, алгоритм обратного распространения
ошибки имеет ряд серьезных недостатков.
Отдельно стоит отметить неопределенно
долгий процесс обучения. В сложных
задачах для обучения сети могут
потребоваться дни или даже недели, а
иногда она может и вообще не обучиться.
Это может произойти из-за следующих
нижеописанных факторов.
1. Паралич сети
В процессе обучения сети, значения весов
могут в результате коррекции стать
очень большими величинами. Это может
привести к тому, что все или большинство
нейронов будут выдавать на выходе сети
большие значения, где производная
функции активации от них будет очень
мала. Так как посылаемая обратно в
процессе обучения ошибка пропорциональна
этой производной, то процесс обучения
может практически замереть. В теоретическом
отношении эта проблема плохо изучена.
Обычно этого избегают уменьшением
размера шага (скорости обучения), но это
увеличивает время обучения. Различные
эвристики использовались для предохранения
от паралича или для восстановления
после него, но пока что они могут
рассматриваться лишь как экспериментальные.
2. Локальные минимумы
Как говорилось вначале, алгоритм
обратного распространения ошибки
использует разновидность градиентного
спуска, т. е. осуществляет спуск вниз по
поверхности ошибки, непрерывно подстраивая
веса в направлении к минимуму. Поверхность
ошибки сложной сети сильно изрезана и
состоит из холмов, долин, складок и
оврагов в пространстве высокой
размерности. Сеть может попасть в
локальный минимум (неглубокую долину),
когда рядом имеется более глубокий
минимум. В точке локального минимума
все направления ведут вверх, и сеть
неспособна из него выбраться. Статистические
методы обучения могут помочь избежать
этой ловушки, но они медленны.
3. Размер шага
Алгоритм обратного распространения
ошибки имеет доказательство своей
сходимости. Это доказательство
основывается на том, что коррекция весов
предполагается бесконечно малой. Ясно,
что это неосуществимо на практике, так
как ведет к бесконечному времени
обучения. Размер шага должен браться
конечным, и в этом вопросе приходится
опираться только на опыт. Если размер
шага очень мал, то сходимость слишком
медленная, если же очень велик, то может
возникнуть паралич или постоянная
неустойчивость.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Применение алгоритма обратного распространения ошибки — один из известных методов, используемых для глубокого обучения нейронных сетей прямого распространения (такие сети ещё называют многослойными персептронами). Этот метод относят к методу обучения с учителем, поэтому требуется задавать в обучающих примерах целевые значения. В этой статье мы рассмотрим, что собой представляет метод обратного распространения ошибки, как он реализуется, каковы его плюсы и минусы.
Сегодня нейронные сети прямого распространения используются для решения множества сложных задач. Если говорить об обучении нейронных сетей методом обратного распространения, то тут пользуются двумя проходами по всем слоям нейросети: прямым и обратным. При выполнении прямого прохода осуществляется подача входного вектора на входной слой сети, после чего происходит распространение по нейронной сети от слоя к слою. В итоге должна осуществляться генерация набора выходных сигналов — именно он, по сути, является реакцией нейронной сети на этот входной образ. При прямом проходе все синаптические веса нейросети фиксированы. При обратном проходе все синаптические веса настраиваются согласно правил коррекции ошибок, когда фактический выход нейронной сети вычитается из желаемого, что приводит к формированию сигнала ошибки. Такой сигнал в дальнейшем распространяется по сети, причём направление распространения обратно направлению синаптических связей. Именно поэтому соответствующий метод и называют алгоритмом с обратно распространённой ошибкой. Синаптические веса настраивают с целью наибольшего приближения выходного сигнала нейронной сети к желаемому.
Общее описание алгоритма обратного распространения ошибки
К примеру, нам надо обучить нейронную сеть по аналогии с той, что представлена на картинке ниже. Естественно, задачу следует выполнить, применяя алгоритм обратного распространения ошибки:
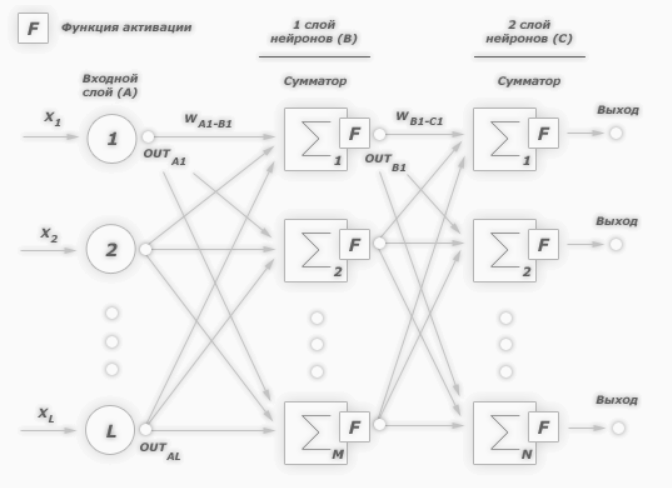

В многослойных персептронах в роли активационной функции обычно применяют сигмоидальную активационную функция, в нашем случае — логистическую. Формула:
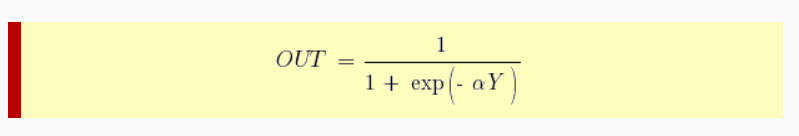
Причём «альфа» здесь означает параметр наклона сигмоидальной функции. Меняя его, мы получаем возможность строить функции с разной крутизной.
Сигмоид может сужать диапазон изменения таким образом, чтобы значение OUT лежало между нулем и единицей. Нейронные многослойные сети характеризуются более высокой представляющей мощностью, если сравнивать их с однослойными, но это утверждение справедливо лишь в случае нелинейности. Нужную нелинейность и обеспечивает сжимающая функция. Но на практике существует много функций, которые можно использовать. Говоря о работе алгоритма обратного распространения ошибки, скажем, что для этого нужно лишь, чтобы функция была везде дифференцируема, а данному требованию как раз и удовлетворяет сигмоид. У него есть и дополнительное преимущество — автоматический контроль усиления. Если речь идёт о слабых сигналах (OUT близко к нулю), то кривая «вход-выход» характеризуется сильным наклоном, дающим большое усиление. При увеличении сигнала усиление падает. В результате большие сигналы будут восприниматься сетью без насыщения, а слабые сигналы будут проходить по сети без чрезмерного ослабления.
Цель обучения сети
Цель обучения нейросети при использовании алгоритма обратного распространения ошибки — это такая подстройка весов нейросети, которая позволит при приложении некоторого множества входов получить требуемое множество выходов нейронов (выходных нейронов). Можно назвать эти множества входов и выходов векторами. В процессе обучения предполагается, что для любого входного вектора существует целевой вектор, парный входному и задающий требуемый выход. Эту пару называют обучающей. Работая с нейросетями, мы обучаем их на многих парах.
Также можно сказать, что алгоритм использует стохастический градиентный спуск и продвигается в многомерном пространстве весов в направлении антиградиента, причём цель — это достижение минимума функции ошибки.
При практическом применении метода обучение продолжают не до максимально точной настройки нейросети на минимум функции ошибки, а пока не будет достигнуто довольно точное его приближение. С одной стороны, это даёт возможность уменьшить количество итераций обучения, с другой — избежать переобучения нейронной сети.
Пошаговая реализация метода обратного распространения ошибки
Необходимо выполнить следующие действия:
1. Инициализировать синаптические веса случайными маленькими значениями.
2. Выбрать из обучающего множества очередную обучающую пару; подать на вход сети входной вектор.
3. Выполнить вычисление выходных значений нейронной сети.
4. Посчитать разность между выходом нейросети и требуемым выходом (речь идёт о целевом векторе обучающей пары).
5. Скорректировать веса сети в целях минимизации ошибки.
6. Повторять для каждого вектора обучающего множества шаги 2-5, пока ошибка обучения нейронной сети на всём множестве не достигнет уровня, который является приемлемым.
Виды обучения сети по методу обратного распространения
Сегодня существует много модификаций алгоритма обратного распространения ошибки. Возможно обучение не «по шагам» (выходная ошибка вычисляется, веса корректируются на каждом примере), а «по эпохам» в offline-режиме (изменения весовых коэффициентов происходит после подачи на вход нейросети всех примеров обучающего множества, а ошибка обучения neural сети усредняется по всем примерам).
Обучение «по эпохам» более устойчиво к выбросам и аномальным значениям целевой переменной благодаря усреднению ошибки по многим примерам. Зато в данном случае увеличивается вероятность «застревания» в локальных минимумах. При обучении «по шагам» такая вероятность меньше, ведь применение отдельных примеров создаёт «шум», «выталкивающий» алгоритм обратного распространения из ям градиентного рельефа.
Преимущества и недостатки метода
К плюсам можно отнести простоту в реализации и устойчивость к выбросам и аномалиям в данных, и это основные преимущества. Но есть и минусы:
• неопределенно долгий процесс обучения;
• вероятность «паралича сети» (при больших значениях рабочая точка функции активации попадает в область насыщения сигмоиды, а производная величина приближается к 0, в результате чего коррекции весов почти не происходят, а процесс обучения «замирает»;
• алгоритм уязвим к попаданию в локальные минимумы функции ошибки.
Значение метода обратного распространения
Появление алгоритма стало знаковым событием и положительно отразилось на развитии нейросетей, ведь он реализует эффективный с точки зрения вычислительных процессов способ обучения многослойного персептрона. В то же самое время, было бы неправильным сказать, что алгоритм предлагает наиболее оптимальное решение всех потенциальных проблем. Зато он действительно развеял пессимизм относительно машинного обучения многослойных машин, который воцарился после публикации в 1969 году работы американского учёного с фамилией Минский.
Источники:
— «Алгоритм обратного распространения ошибки»;
— «Back propagation algorithm».
Недостатки алгоритма обратного распространения ошибки
Алгоритм обратного распространения
ошибки осуществляет так называемый
градиентный спуск по поверхности ошибок.
Не углубляясь, это означает следующее:
в данной точке поверхности находится
направление скорейшего спуска, затем
делается прыжок вниз на расстояние,
пропорциональное коэффициенту скорости
обучения и крутизне склона, при этом
учитывается инерция, то есть стремление
сохранить прежнее направление движения.
Можно сказать, что метод ведет себя как
слепой кенгуру – каждый раз прыгает в
направлении, которое кажется ему
наилучшим. На самом деле шаг спуска
вычисляется отдельно для всех обучающих
наблюдений, взятых в случайном порядке,
но в результате получается достаточно
хорошая аппроксимация спуска по
совокупной поверхности ошибок.
Несмотря на достаточную простоту и
применимость в решении большого круга
задач, алгоритм обратного распространения
ошибки имеет ряд серьезных недостатков.
Отдельно стоит отметить неопределенно
долгий процесс обучения. В сложных
задачах для обучения сети могут
потребоваться дни или даже недели, а
иногда она может и вообще не обучиться.
Это может произойти из-за следующих
нижеописанных факторов.
1. Паралич сети
В процессе обучения сети, значения весов
могут в результате коррекции стать
очень большими величинами. Это может
привести к тому, что все или большинство
нейронов будут выдавать на выходе сети
большие значения, где производная
функции активации от них будет очень
мала. Так как посылаемая обратно в
процессе обучения ошибка пропорциональна
этой производной, то процесс обучения
может практически замереть. В теоретическом
отношении эта проблема плохо изучена.
Обычно этого избегают уменьшением
размера шага (скорости обучения), но это
увеличивает время обучения. Различные
эвристики использовались для предохранения
от паралича или для восстановления
после него, но пока что они могут
рассматриваться лишь как экспериментальные.
2. Локальные минимумы
Как говорилось вначале, алгоритм
обратного распространения ошибки
использует разновидность градиентного
спуска, т. е. осуществляет спуск вниз по
поверхности ошибки, непрерывно подстраивая
веса в направлении к минимуму. Поверхность
ошибки сложной сети сильно изрезана и
состоит из холмов, долин, складок и
оврагов в пространстве высокой
размерности. Сеть может попасть в
локальный минимум (неглубокую долину),
когда рядом имеется более глубокий
минимум. В точке локального минимума
все направления ведут вверх, и сеть
неспособна из него выбраться. Статистические
методы обучения могут помочь избежать
этой ловушки, но они медленны.
3. Размер шага
Алгоритм обратного распространения
ошибки имеет доказательство своей
сходимости. Это доказательство
основывается на том, что коррекция весов
предполагается бесконечно малой. Ясно,
что это неосуществимо на практике, так
как ведет к бесконечному времени
обучения. Размер шага должен браться
конечным, и в этом вопросе приходится
опираться только на опыт. Если размер
шага очень мал, то сходимость слишком
медленная, если же очень велик, то может
возникнуть паралич или постоянная
неустойчивость.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

Недостатки алгоритма обратного распространения ошибки
Имея дело с нейронной сетью, приходится тратить большие усилия на её обучение. Только в этом случае можно рассчитывать, что её работа станет достаточно эффективной. Один из основных методов обучения – метод обратного распространения ошибки.
В этом случае, когда полученное значение не соответствует требуемому, сигнал отправляется по сети обратно, а веса межнейронных связей изменяются до тех пор, пока результат не станет удовлетворительным.
Однако всё так просто лишь в теории. На практике приходится сталкиваться с рядом недостатков такого метода, которые делают обучение сети очень сложным, а порой и невозможным.
1. Длительность
Если сеть большая, а корректировки значительные, то может потребоваться множество циклов прохождения сигнала в прямом и обратном направлении, в каких-то ситуациях – сотни тысяч. В этом случае время корректировки может составить несколько недель, месяцев, лет, а то и вовсе выйти за границы разумных временных отрезков.
Естественно, что если такое происходит, никто обычно не затрачивает годы на корректировку значений нейросети, потому что такие сроки уже говорят о том, что она крайне несовершенна.
2. Паралич сети
Когда сигнал передаётся в обратном направлении, то ему должен быть присвоен какой-то шаг. Если шаг большой, то мы сталкиваемся с тем, что сигнал при каждом прохождении ослабевает. А поскольку сигнал обладает электрической природой, то речь идёт о фактическом затухании электрического импульса. Если импульс становится меньше порога восприятия следующим нейроном, то сигнал, который должен был дойти до конца сети (в данном случае до начала), до него не доходит, и обучение становится невозможным.
3. Локальные минимумы
Если поставить малый шаг, то может возникнуть ситуация, когда система выберет нейрон с минимальным значением, так называемый локальный минимум. Такой нейрон не имеет выходов, и получается, что сеть попала в ловушку, в связи с чем обучение тоже будет прекращено.
Стоит заметить, что таких локальных минимумов в любой нейросети достаточно, им может стать любой нейрон, поэтому всегда есть риск обрыва процесса обучения в любой момент.
4. Время схождения сети.
Другими словами – время, которое нужно, чтобы сигнал снова дошёл до «старта». Если выбрать шаг малым, то этот процесс, опять же, может затянуться на чрезмерно длительное время, особенно если параллельно возникают проблемы, описанные в пункте 1.
5. Отсутствие запоминания.
Одна из самых больших проблем любой нейросети: обучив её избегать ошибок при обработке сигнала А, вы затем корректируете её работу по сигналу Б, и всё вроде бы удаётся. Но затем вы снова пускаете сигнал А и обнаруживаете, что сеть опять ошибается. Причина в том, что сигнал Б её перенастроил на себя, а свой предыдущий «опыт» сеть успешно забыла.
Если предыдущие 4 проблемы более-менее решаемы, то вот эту можно назвать критической. Ни одна искусственная нейросеть не способна учитывать в полной мере весь предыдущий опыт, вся разница только в том, насколько корректировка под новые сигналы сбивают точность для предыдущих. Пока разработчикам не удастся создать что-то, приближенное к человеческому мозгу, такая проблема, скорее всего, останется актуальной.
Хотите своевременно узнавать новости QuantPro ?
Недостатки алгоритма обратного распространения ошибки

Несмотря на многочисленные успешные применения метода обратного распространения ошибки, оно не является универсальным решением. Больше всего неприятностей приносит неопределённо долгий процесс обучения. В сложных задачах для обучения сети могут потребоваться дни или даже недели, она может и вообще не обучиться. Причиной может быть одна из описанных ниже.
Паралич сети
В процессе обучения сети значения весов могут в результате коррекции стать очень большими величинами. Это может привести к тому, что все или большинство нейронов будут функционировать при очень больших значениях OUT, в области, где производная сжимающей функции очень мала. Так как посылаемая обратно в процессе обучения ошибка пропорциональна этой производной, то процесс обучения может практически замереть. В теоретическом отношении эта проблема плохо изучена. Обычно этого избегают уменьшением размера шага η, но это увеличивает время обучения. Различные эвристики использовались для предохранения от паралича или для восстановления после него, но пока что они могут рассматриваться лишь как экспериментальные.
- Эволюция генетических алгоритмов и искусственная селекция
- Эволюция генетических алгоритмов и искусственная селекция
Локальные минимумы
Обратное распространение использует разновидность градиентного спуска, то есть осуществляет спуск вниз по поверхности ошибки, непрерывно подстраивая веса в направлении к минимуму. Поверхность ошибки сложной сети сильно изрезана и состоит из холмов, долин, складок и оврагов в пространстве высокой размерности. Сеть может попасть в локальный минимум (неглубокую долину), когда рядом имеется гораздо более глубокий минимум. В точке локального минимума все направления ведут вверх, и сеть неспособна из него выбраться. Основную трудность при обучении нейронных сетей составляют как раз методы выхода из локальных минимумов: каждый раз выходя из локального минимума снова ищется следующий локальный минимум тем же методом обратного распространения ошибки до тех пор, пока найти из него выход уже не удаётся.
Размер шага
Внимательный разбор доказательства сходимости[3] показывает, что коррекции весов предполагаются бесконечно малыми. Ясно, что это неосуществимо на практике, так как ведёт к бесконечному времени обучения. Размер шага должен браться конечным. Если размер шага фиксирован и очень мал, то сходимость слишком медленная, если же он фиксирован и слишком велик, то может возникнуть паралич или постоянная неустойчивость. Эффективно увеличивать шаг до тех пор, пока не прекратится улучшение оценки в данном направлении антиградиента и уменьшать, если такого улучшения не происходит. П. Д. Вассерман[7] описал адаптивный алгоритм выбора шага, автоматически корректирующий размер шага в процессе обучения. В книге А. Н. Горбаня[8] предложена разветвлённая технология оптимизации обучения.
Следует также отметить возможность переобучения сети, что является скорее результатом ошибочного проектирования её топологии. При слишком большом количестве нейронов теряется свойство сети обобщать информацию. Весь набор образов, предоставленных к обучению, будет выучен сетью, но любые другие образы, даже очень похожие, могут быть классифицированы неверно.
- Отличия «сильного искусственного интеллекта» AGI от «высшего разума» ASI
- Искусственный интеллект — Царь Белой Руси
- Как искусственный интеллект управлял государством Практопия
- Новая американская мечта: искусственный интеллект “Омега”
Популярное за неделю: 26 марта — 2 апреля
Типы личности в соционике: таблица знаменитостей VIP TOP

Чаще всего авто с аукционов Японии покупают NT типы: Аналитик INTJ, Критик INTP, Предприниматель ENTJ и Новатор ENTP. Никогда не используют дистанционный способ покупки: Энтузиасты ESFJ, Хранители ISFJ, Политики ESFP и Посредники ISFP. Портал «TRON в зоне RUбля» имеет честь предложить актуализированный на 2018 год список VIP-TOP представителей различных соционических типов, определяемых согласно тесту Майерс — Бриггс . Типы следуют от меньшего количества к большему. В скобках: количество представителей и упоминаний о конкретном типе личности. Внутри группы VIP-TOPы следуют в порядке убывания количества упоминаний.
Что значат значки на панели авто Японии если горит индикатор

Эксплуатация легковых автомобилей и техобслуживание авто Технический ремонт легкового автомобиля своими руками Если взять «Справочник автомобильных сокращений и аббревиатур» или «Англо — русский словарь автомобильных терминов» , то там легко можно найти множество различных технологических систем, предназначенных для управления автомобилем. Часть их них имеют свои индикаторы, выведенные на панель управления авто. Предупредительные индикаторы Задействован стояночный тормоз, может быть низкий уровень тормозной жидкости, так же не исключена вероятность неисправности тормозной системе. Красный цвет повышенная температура системы охлаждения, синий — пониженная температура. Мигающий указатель — неисправность в электрике системы охлаждения. Упало давление в системе смазки (Oil Pressure) двигателя. Еще может обозначать низкий уровень масла. Датчик уровня масла в двигателе (Engine Oil Sensor). Уровень масла (Oil Level) опустился ниже допустимого значения. Падение напря
Оценки автоаукционов Японии при описании состояния автомобиля

На различных аукционах существуют различные системы оценок. Есть аукционы где оценки отсутствуют вовсе. Покупатель просматривают перед торгами аукционные листы и их на основании предлагают максимальные ставки на автомобиль. Торги длятся до тех пор, пока не останется одна ставка. Автомобиль с пробегом более 100.000 по дорогам Японии автоматически теряет 0,5 балла и стоит заметно дешевле, чем например авто с пробегом 98.000 Шестибальная оценка аукциона USS S Лучшая из возможных оценок. Автомобиль новый или возрастом до 1 года, в отличном состоянии. Не требует никакого ремонта. 6 Отличное состояние, ремонт не нужен (возраст до 3 лет и пробег не более 30 000 км). 5 Возраст автомобиля не имеет четких ограничений, но при очень хорошем состоянии. При минимальном ремонте или даже после тщательной уборки такой автомобиль будет соответствовать оценке <6>. 4.5 Автомобиль так же, как и в оценке <5>, может быть любого возраста, но в очень хорошем состоянии, ремонт н
«Договор присоединения» — информационные услуги по поставке легкового автомобиля из Японии
ИНДИВИДУАЛЬНЫЙ ПРЕДПРИНИМАТЕЛЬ ЯРОВОЙ БОРИС ДМИТРИЕВИЧ ИНН: 253900399729 Договор присоединения Индивидуальный Предприниматель Яровой Борис Дмитриевич, именуемый в дальнейшем «Исполнитель», с одной стороны, и {ContactLastName} {ContactName} {ContactSecondName} именуемый в дальнейшем «Заказчик», с другой стороны, заключили настоящий договор о нижеследующем: 1. ОПРЕДЕЛЕНИЕ ТЕРМИНОВ Для целей данного Договора термины употребляются в следующем значении: 1.1. Договор — настоящий Договор, регулирующий отношения в области предоставления информационных услуг физическим лицам, имеющим намерение приобрести легковой автомобиль на территории Японии и его последующим получением по адресу, указанному Заказчиком. Настоящий Договор не является офертой согласно ст. 435 Гражданского кодекса РФ, а действует в соответствии со ст. 428 Гражданского кодекса РФ путем присоединения Заказчика к настоящему Договору. 1.2. Подрядчик – индивидуальный предприниматель, юридическое или физическое лицо,
«Договор присоединения» — информационные услуги по поставке легкового автомобиля из Южной Кореи
ИНДИВИДУАЛЬНЫЙ ПРЕДПРИНИМАТЕЛЬ ЯРОВОЙ БОРИС ДМИТРИЕВИЧ ИНН: 253900399729 Договор присоединения Индивидуальный Предприниматель Яровой Борис Дмитриевич, именуемый в дальнейшем «Исполнитель», с одной стороны, и {ContactLastName} {ContactName} {ContactSecondName} именуемый в дальнейшем «Заказчик», с другой стороны, заключили настоящий договор о нижеследующем: 1. ОПРЕДЕЛЕНИЕ ТЕРМИНОВ Для целей данного Договора термины употребляются в следующем значении: 1.1. Договор — настоящий Договор, регулирующий отношения в области предоставления информационных услуг физическим лицам, имеющим намерение приобрести легковой автомобиль на территории Республика Корея и его последующим получением по адресу, указанному Заказчиком. Настоящий Договор не является офертой согласно ст. 435 Гражданского кодекса РФ, а действует в соответствии со ст. 428 Гражданского кодекса РФ путем присоединения Заказчика к настоящему Договору. 1.2. Подрядчик – индивидуальный предприниматель, юридическое или физичес
Какие расходники заменить сразу после покупки автомобиля

Эксплуатация легковых автомобилей и техобслуживание авто Технический ремонт легкового автомобиля своими руками Вы купили японский автомобиль , сверив реальные номера двигателя, шасси, кузова с теми, что зафиксированы в «бумажках». Убедились, что подписали именно акт приема-передачи машины, а не дарственную на квартиру. Теперь внимательно обследуйте кузов автомобиля на предмет вмятин, осмотрите его под разными углами — мало ли что пришлось пережить транспортному средству по пути к Вам. Приглядитесь к лакокрасочному покрытию на предмет различных «царапок» и потертостей. Проверьте, ровные ли проемы дверей, не перекошена ли крышка капота и багажника.
Перевод различных наклеек на авто с японского на русский язык

Эксплуатация легковых автомобилей и техобслуживание авто Технический ремонт легкового автомобиля своими руками В Японии делаются много чего, чтобы облегчить человеку жизнь и разгрузить его мозги от ненужного напряжения. Водителям японских легковых автомобилей в этом очень помогают различных автонаклейки и стикеры.
Текст Конституции Республики Китай на русском и китайском языке
![]()
Оригинальный подарок iPhone 14 Pro Max за $244: реплика Китай Товары из Китая оптом уже в России. Хозтовары, бытовая химия Практическое руководство Предпринимателя для работы с Китаем Системы управления организацией: Китай, Япония, Корея, США. Глава I. Основные принципы. 第一章 总纲 Статья 1. Республика является социалистическим государством демократической диктатуры народа, руководимым рабочим классом и основанное на союзе рабочих и крестьян. Социалистический строй является основным строем Республики. Запрещается любым организациям или частным лицам подрывать социалистический строй. 第一条 中华人民共和国是工人阶级领导的、以工农联盟为基础的人民民主专政的社会主义国家。 社会主义制度是中华人民共和国的根本制度。禁止任何组织或者个人破坏社会主义制度。 Статья 2. Вся власть в Республике принадлежит народу. Народ осуществляет государственную власть через собрание народных представителей и местные собрания народных представителей различных ступеней. Народ в соответствии с положениями закона различными путями и в различных формах управляет государст
Купить новый автомобиль 2023 года — поставка из Кореи в Россию

Новые автомобили 2023 года выпуска, предлагаемые к поставке из Республики Кореи. Предложение актуально на апрель 2023 года. Расчет «цена авто под ключ» с учетом региона поставки — Москва, С- Петербург. Время поставки: — 2 месяца. Hyundai Staria 4WD Lounge 9Seater Inspiration. Микроавтобус. Объем двигателя: 2 199, дизель, коробка автомат. Экстерьер: темный хром. Интерьер: черный. Цена: 10 900 000 руб BMW X4M 3.0 competition. SUV, внедорожник. Объем двигателя: 2993, бензин, коробка автомат. Экстерьер: белый. Интерьер: серый. Цена: 13 750 000 руб. BMW X4M 3.0 competition. SUV, внедорожник. Объем двигателя: 2993, бензин, коробка автомат. Экстерьер: белый. Интерьер: оранжевый. Цена: 13 800 000 руб. BMW X7 xDrive 40i M Sports 7Seater. SUV, внедорожник. Объем двигателя: 2998, бензин, коробка автомат. Экстерьер: манхэттен. Интерьер: черный. Цена: 18 450 000 руб. BMW X7 xDrive 40d M Sports 7Seater SUV, внедорожник. Объем двигателя: 2993, дизель, коробка автомат. Экстерьер: черный. Интерь
Как купить автомобиль с левым рулем на авто аукционе Японии

В Японии нет ограничений на левый руль. BMW, AMG, Mercedes Benz, VW, Volvo, Audi, Saab, Hammer, Lamborghini, Ferrari, Porsche, Venturi, Jaguar, Aston Martin, Maserati, McLaren, Bugatti, Bentley, Alfa Romeo — этих машин в «Стране восходящего Солнца» достаточно много. Исключение: автомобили производства Южной Кореи и самой Японии ( Леворульные аналоги Тойота, Хонда, Ниссан, Мазда, Мицубиси ). Уровень обслуживания автомобилей с левым рулем в Японии аналогичен общемировым стандартам. Как и везде, все основные профилактические и диагностические работы осуществляются в специализированных сервисных центрах. Однако есть два фактора, которые отличают автомобили с левым рулем, приобретенные на авто аукционе Японии, от аналогичных покупок с рынка Европы, США или Азии. Во первых — это годовой пробег. На дальние расстояния японцы передвигаться железнодорожным транспортом, да и сама по себе Япония маленькая страна. Средний годовой пробег автомобиля в Японии составляет около 5-10 тыс.
Взгляните на альтернативные алгоритмы обратного распространения ошибки
-Равичандра, исследователь компьютерного зрения, @ Sally Robotics.

С тех пор, как в 1986 году была представлена идея использования обратного распространения для обучения нейронных сетей, обучение с помощью нейронных сетей никогда не оглядывалось назад. Внезапно учебные сети превратились в эффективный процесс, который позволил достичь грандиозных достижений. Он стал отраслевым стандартом, и на нем построено множество фреймворков (Tensorflow, PyTorch), которыми пользуются все. Но постепенно, по мере того как мы пытались тренировать с его помощью все более и более глубокие сети, мы выявили некоторые из его недостатков. В основном это были-
1. Исчезающие градиенты. Сигмоидная и тангенциальная нелинейности имеют тенденцию к насыщению и полностью прекращают обучение. Это происходит, когда выходы нейрона находятся на крайних значениях, в результате чего градиенты равны 0 или близки к 0, то есть исчезают. При использовании ReLU, если нейроны будут ограничены до 0, тогда веса будут иметь нулевые градиенты, что приведет к так называемой проблеме «мертвого ReLU».
2. Взрывающиеся градиенты. В глубоких сетях или RNN градиенты ошибок могут накапливаться во время обновления и приводить к очень большим градиентам. Это, в свою очередь, приводит к большим обновлениям веса сети. В крайнем случае, значения веса могут стать настолько большими, что выйдут за пределы допустимого диапазона, что приведет к появлению значений Nan.
3. В вычислительном отношении дорого: Послойное вычисление градиентов, несомненно, является дорогостоящим в вычислительном отношении процессом. Это заставляет задуматься, есть ли лучший способ оптимизировать функцию потерь.
Хотя они остаются основными недостатками, существуют и другие, такие как выбор гиперпараметров и т. Д., Которые классифицируют скорее как раздражение, чем как недостатки. Итак, что мы тогда с этим сделали? Мы разработали более совершенную сетевую архитектуру, чтобы избежать этих проблем. Архитектура ResNet (https://arxiv.org/abs/1512.03385) — лучший пример, где были созданы пропускаемые соединения, чтобы избежать исчезающих градиентов.

Обратное распространение — ошибочный подход?
Многие известные исследователи, такие как Джеффри Хинтон и Йошуа Бенжио, выразили обеспокоенность по поводу того, что обратное распространение не является идеальным подходом. Нет никаких доказательств того, что наш мозг выполняет обратное распространение, и если это так, как тогда мы можем достичь полного искусственного интеллекта, если мы не моделируем сети по образцу нашего собственного биологического разума? Вопрос о более биологически правдоподобном алгоритме все еще остается, и эта идея дополнительно исследуется в этой статье: https://arxiv.org/abs/1502.04156.
Хинтон больше озабочен существованием другого способа обучения, чем принуждением решений использовать контролируемые данные, то есть обучением без учителя. Он сомневается, что методы, которые он разработал и отстаивал на протяжении многих лет, достигнут первоначальной цели для нейронных сетей, в частности, для автономных обучающихся машин. Несмотря на заметный прогресс последних нескольких лет, мы до сих пор не решили вопрос о том, как человеческий мозг самоорганизуется в отсутствие фиксированной внешней обратной связи с использованием чрезвычайно разреженных данных. Взлом этого может привести к общему алгоритму обучения с учителем и без учителя, а также обучения с подкреплением.
В науке можно говорить вещи, которые кажутся безумными, но в конечном итоге они могут оказаться правильными. Мы можем получить действительно хорошие доказательства, и, в конце концов, сообщество вернется.
— Джеффри Хинтон
Альтернативы
1. Распространение разностной цели
Обратное распространение полагается на бесконечно малые изменения (частные производные) для выполнения присвоения кредита. Это может стать серьезной проблемой, поскольку каждый рассматривает более глубокие и более нелинейные функции, например, крайний случай нелинейности, когда связь между параметрами и стоимостью фактически дискретна. Ссылаясь на это как на мотивацию, этот алгоритм был разработан как альтернатива обратному распространению ошибки. Основная идея состоит в том, чтобы вычислять цели, а не градиенты на каждом слое. В некотором смысле это похоже на обратное распространение, но намного быстрее. Так как же тогда это реализовано? Вот краткий обзор этого —
а. Формулирование целей
б. Назначение правильной цели каждому слою
c. Разница в целевом распространении
d. Обучение автокодировщика с разностным целевым распространением
Хотя это очень абстрактное и высокоуровневое описание метода, я намеренно сохранил его, чтобы углубление в математику и уравнения излишне удлинило статью. Точную математику этого можно найти в этой статье https://arxiv.org/pdf/1412.7525.pdf.

2. Узкое место HSIC (критерий независимости Гильберта-Шмидта)
Подход состоит в том, чтобы обучить сеть, используя аппроксимацию информационного узкого места вместо обратного распространения.

На приведенном выше рисунке представлен обзор того, как проводится обучение с использованием HSIC. Сеть, обученная HSIC, рисунок (a), представляет собой стандартную сеть с прямой связью, обученную с использованием цели HSIC IB, что приводит к скрытым представлениям на последнем уровне, которые можно быстро обучить. На рисунке (b) показана σ-объединенная сеть, где каждая ветвь сети HSIC-net обучается определенному σ.
На следующем этапе будет найдена и развернута замена взаимной информации между скрытыми представлениями и метками. Это одновременно минимизирует взаимную зависимость между скрытыми представлениями и входными данными. Таким образом, каждое скрытое представление из сети, обученной HSIC, может содержать различную информацию, полученную путем оптимизации цели узкого места HSIC в конкретном масштабе. Затем агрегатор суммирует скрытые представления, чтобы сформировать выходное представление. Дополнительную информацию можно найти здесь https://arxiv.org/pdf/1908.01580v1.pdf.
В чем тогда преимущества? Авторы утверждают, что это облегчает параллельную обработку, требует значительно меньше операций и не страдает от исчезающих или взрывающихся градиентов. Более того, это кажется более вероятным с биологической точки зрения, чем обратное распространение. После тестирования сети, обученные HSIC, работали сравнимыми с обратным распространением в наборах данных MNIST и CIFAR-10.
3. Чередующаяся минимизация в режиме онлайн с помощью вспомогательных переменных.
Основным вкладом этой работы является новый онлайновый (стохастический / мини-пакетный) подход с чередующейся минимизацией (AM) для обучения глубоких нейронных сетей вместе с первыми гарантиями теоретической сходимости для AM в стохастических настройках. Это решает проблему оптимизации, разрывая цепочки градиентов с помощью вспомогательных переменных. Эта работа основана на ранее предложенных автономных методах, которые разбивают вложенную цель на более простые для решения локальные подзадачи путем вставки вспомогательных переменных, соответствующих активациям на каждом уровне. Подробнее об этом можно прочитать здесь https://arxiv.org/pdf/1806.09077.pdf.

Итак, что же тогда главный вывод? Мы можем избежать вычисления цепочки градиентов, что означает отсутствие исчезающих градиентов, отсутствие перекрестного распараллеливания и трудности с обработкой недифференцируемых нелинейностей.
4. Разделение нейронных интерфейсов с использованием синтетических градиентов.
Это дает нам возможность позволить нейронным сетям общаться, научиться отправлять сообщения между собой в несвязанной, масштабируемой манере, прокладывая путь нескольким нейронным сетям для связи друг с другом или улучшая долгосрочную временную зависимость повторяющихся сетей.

Правомерным вопросом было бы спросить, сколько вычислительной сложности добавляют эти синтетические градиентные модели — возможно, вам понадобится архитектура синтетической градиентной модели, столь же сложная, как сама сеть. Удивительно, но синтетические градиентные модели могут быть очень простыми. Для сетей с прямой связью было фактически обнаружено, что даже один линейный слой хорошо работает в качестве модели синтетического градиента. Следовательно, его очень легко обучить, и поэтому он быстро создает синтетические градиенты. Подробнее можно прочитать здесь https://arxiv.org/pdf/1608.05343.pdf.

Разработанный исследователями DeepMind, этот метод имеет значительные преимущества благодаря увеличенному временному горизонту, который могут моделировать RNN с поддержкой DNI, а также более быстрой сходимости по сравнению с обратным распространением информации. Синтетические градиенты FTW!
Машины пойдут по пути, отражающему эволюцию человека. В конечном итоге, однако, самоосознающие, самосовершенствующиеся машины будут развиваться, превзойдя человеческие способности контролировать или даже понимать их.
— Рэй Курцвейл
Заключение
Мы обсудили недостатки обратного распространения ошибки, возможные недостатки общего подхода, высказанные известными исследователями, и, наконец, некоторые хорошие альтернативы. В конечном счете, ни один из них нельзя назвать «лучше, чем обратное распространение», потому что все, что они делают, — это достижение конкурентных результатов. Эта неудача может быть объяснена отсутствием проведенных исследований, что заставляет нас ожидать значительного прогресса и развития в ближайшем будущем. Итак, ключевой вывод заключается в следующем: для того, чтобы алгоритм свергнул Backprop, он должен решать проблемы исчезающего и взрывающегося градиента, быть в вычислительном отношении быстрее, быстрее сходиться, предпочтительно уменьшать гиперпараметры и, что наиболее важно, быть биологически правдоподобным. Это гарантирует, что мы продвигаемся в направлении воссоздания человеческого разума, позволяя нам использовать его беспрецедентный потенциал. А пока все, что мы можем сделать, это поэкспериментировать и продолжить исследования!
Ресурсы
Let’s Not Stop At Back-prop! Check Out 5 Alternatives To This Popular Deep Learning Technique
Https://analyticsindiamag.com/is-deep-learning-possible-without-back-propagation/
Https://deepmind.com/blog/article/decoupled-neural-networks-using-synthetic-gradients
Https://www.ibm.com/blogs/research/2019/06/beyond-backprop/
Https://arxiv.org/pdf/1412.7525.pdf
Https://arxiv.org/pdf/1908.01580v1.pdf
Https://arxiv.org/pdf/1806.09077.pdf
Https://arxiv.org/pdf/1608.05343.pdf

OF: Отличная обучающая команда
команда переводчиков deephub.ai
- Нейронные сети
- Что такое обратное распространение?
- Как работает обратное распространение?
- Функция потерь
- Зачем нам нужно обратное распространение?
- Прямая связь
- Типы обратного распространения
- тематическое исследование
В типичном программировании мы вводим данные, выполняем логику обработки и получаем вывод. Что, если выходные данные могут каким-то образом повлиять на логику обработки? Это алгоритм обратного распространения. Это положительно повлияло на предыдущие модули, повысив точность и эффективность.
Рассмотрим подробнее.
Нейронная сеть
Нейронная сеть — это совокупность связанных единиц. Каждое соединение имеет связанный с ним вес. Система помогает создать модель прогнозирования, основанную на массивных наборах данных. Он работает как нервная система человека, помогает понимать изображения, учиться как люди, синтезировать речь и т. Д.
Что такое обратное распространение?
Мы можем определить алгоритм обратного распространения ошибки как алгоритм, который обучает некоторую заданную нейронную сеть прямого распространения для заданного входного шаблона с известной классификацией. Когда каждый сегмент набора образцов отображается в сети, сеть будет смотреть на свой выходной ответ на образец ввода образца. После этого измерьте отклик на выходе и сравните ожидаемый результат со значением ошибки. После этого корректируем вес подключения исходя из измеренного значения погрешности.
Прежде чем углубляться в обратное распространение, мы должны знать, кто ввел эту концепцию и когда. Впервые он появился в 1960-х годах, а 30 лет спустя он был продвинут в известной статье 1986 года Дэвида Раммельхарта, Джеффри Хинтона и Рональда Уильямса. В этой статье они рассказали о различных нейронных сетях. Сегодня обратное распространение распространяется хорошо. Обучение нейронной сети достигается за счет обратного распространения. Таким образом, мы точно настраиваем веса нейронной сети на основе частоты ошибок, полученной в предыдущем прогоне. Правильное использование этого метода может снизить количество ошибок и повысить надежность модели. Используйте обратное распространение, чтобы обучить нейронную сеть правилу цепочки. Проще говоря, каждый раз, когда прямая связь проходит через сеть, алгоритм выполняет обратную передачу в соответствии с весом и отклонением для корректировки параметров модели. Типичные алгоритмы контролируемого обучения пытаются найти функцию, которая сопоставляет входные данные с правильными выходными. Обратное распространение работает с многослойными нейронными сетями, чтобы изучить внутреннее представление сопоставления ввода и вывода.
Как работает обратное распространение? (Как работает обратное распространение?)
Посмотрим, как работает обратное распространение. Он имеет четыре слоя: входной слой, скрытый слой, скрытый слой II и конечный выходной слой.
Таким образом, три основных слоя:
1. Входной слой
2. Скрытый слой
3. Выходной слой
Каждый уровень имеет свой собственный способ работы и реагирования, поэтому мы можем получить желаемые результаты и соотнести эти ситуации с нашей ситуацией. Давайте обсудим другие детали, которые помогут обобщить этот алгоритм.

На этом рисунке показана производительность метода обратного распространения ошибки.
1. Входной слой получает x
2. Используйте вес w для моделирования входных данных.
3. Каждый скрытый слой вычисляет выходные данные, и данные готовы в выходном слое.
4. Разница между фактическим и ожидаемым результатом называется ошибкой.
5. Вернитесь к скрытому слою и отрегулируйте вес, чтобы уменьшить эту ошибку в будущих запусках.
Этот процесс повторяется до тех пор, пока мы не получим желаемый результат. Этап обучения проходит под присмотром. Как только модель станет стабильной, ее можно будет использовать в производстве.
Функция потерь (функция потерь)
Одна или несколько переменных отображаются в действительные числа, и эти действительные числа представляют собой определенное значение, связанное со значением этих переменных. Для обратного распространения функция потерь вычисляет разницу между выходом сети и его возможным выходом.
Зачем нам нужно обратное распространение? (Зачем нам нужно обратное распространение?)
Обратное распространение имеет много преимуществ, некоторые из них перечислены ниже:
• Обратное распространение происходит быстро, просто и легко.
• Нет параметров для настройки
• Никаких предварительных знаний о сети не требуется, поэтому это становится гибким методом
• Этот метод эффективен в большинстве случаев.
• Модель не требует изучения характеристик функции.
Сеть прямого распространения
Сеть с прямой связью также называется MLN, то есть многоуровневой сетью. Это называется прямой связью, потому что данные проходят только через входной узел в NN (нейронной сети), скрывают слой и, наконец, достигают выходного узла. Это простейшая искусственная нейронная сеть.
Типы обратного распространения
Есть два типа сетей обратного распространения.
• Статическое обратное распространение
• Повторяющееся обратное распространение
- Статическое обратное распространение
В этой сети отображение статического ввода генерирует статический вывод. Проблемы статической классификации, такие как оптическое распознавание символов, будут областью, подходящей для статического обратного распространения.
- Рецидивирующее обратное распространение
Обратное распространение повторяется до тех пор, пока не будет достигнут определенный порог. После достижения порога ошибка будет рассчитана и распространена в обратном направлении.
Разница между этими двумя методами в том, что статическое обратное распространение происходит так же быстро, как статическое отображение.
Пример использования
Давайте воспользуемся обратным распространением ошибки в качестве примера. Для этого мы будем использовать данные Iris (набор данных Iris Flower), которые содержат такие характеристики, как длина и ширина чашелистиков и лепестков. С их помощью нам необходимо определить вид растения.
Для этого мы построим многослойную нейронную сеть и будем использовать сигмовидную функцию, потому что это проблема классификации.
Давайте посмотрим на необходимые библиотеки и данные.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
Чтобы игнорировать предупреждение, мы импортируем другую библиотеку под названием warnings.
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
Тогда давайте прочитаем данные.
iris = pd.read_csv("iris.csv")
iris.head()

Теперь отметим классы как 0, 1 и 2.
iris. replace (, , inplace=True)
Теперь мы определим функцию, которая будет выполнять следующие операции.
1. Выполните одно горячее кодирование на выходе.
2. Выполните сигмовидную функцию.
3. Стандартизированные функции
Для однократного кодирования мы определяем следующую функцию.
defto_one_hot(Y):
n_col = np.amax(Y) + 1
binarized = np.zeros((len(Y), n_col))
for i in range(len(Y)):
binarized ] = 1.return binarized
Теперь мы определяем сигмовидную функцию
defsigmoid_func(x):return1/(1+np.exp(-x))
defsigmoid_derivative(x):return sigmoid_func(x)*(1 – sigmoid_func(x))
Теперь мы определим функцию для нормализации.
defnormalize(X, axis=-1, order=2):
l2 = np. atleast_1d (np.linalg.norm(X, order, axis))
l2 = 1return X / np.expand_dims(l2, axis)
Теперь мы нормализуем функции и применим к выходу горячую кодировку.
x = pd.DataFrame(iris, columns=columns)
x = normalize(x.as_matrix())
y = pd.DataFrame(iris, columns=columns)
y = y.as_matrix()
y = y.flatten()
y = to_one_hot(y)
Теперь пора применить обратное распространение. Для этого нам нужно определить веса и скорость обучения. Давай сделаем это. Но перед этим нам нужно разделить данные для обучения и тестирования.
# Разделить данные на данные обучения и проверки (разделить данные на данные обучения и проверки)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.33)
#Weights
w0 = 2*np.random.random((4, 5)) - 1#forinput - 4 inputs, 3 outputs
w1 = 2*np.random.random((5, 3)) - 1#for layer 1 - 5 inputs, 3 outputs
#learning rate
n = 0.1
Мы составим список ошибок и визуализируем, как изменения в обучении уменьшают количество ошибок.
errors = []
Реализуем сети прямого и обратного распространения. Для обратного распространения мы будем использовать алгоритм градиентного спуска.
for i in range (100000):
#Feed forward network
layer0 = X_train
layer1 = sigmoid_func(np.dot(layer0, w0))
layer2 = sigmoid_func(np.dot(layer1, w1))
Back propagation using gradient descent
layer2_error = y_train - layer2
layer2_delta = layer2_error * sigmoid_derivative(layer2)
layer1_error = layer2_delta.dot (w1.T)
layer1_delta = layer1_error * sigmoid_derivative(layer1)
w1 += layer1.T.dot(layer2_delta) * n
w0 += layer0.T.dot(layer1_delta) * n
error = np.mean(np.abs(layer2_error))
errors.append(error)
Степень точности будет собираться и отображаться путем вычитания ошибки из данных обучения.
accuracy_training = (1 - error) * 100
Давайте теперь наглядно посмотрим, как повысить точность за счет уменьшения ошибок. (Визуализация)
plt.plot(errors)
plt.xlabel('Training')
plt.ylabel('Error')
plt.show()

Теперь давайте проверим точность.
print ("Training Accuracy of the model " + str (round(accuracy_training,2)) + "%")
Output: Training Accuracy of the model 99.04%
Наша модель обучения работает хорошо. Теперь посмотрим на точность проверки.
#Validate
layer0 = X_test
layer1 = sigmoid_func(np.dot(layer0, w0))
layer2 = sigmoid_func(np.dot(layer1, w1))
layer2_error = y_test - layer2
error = np.mean(np.abs(layer2_error))
accuracy_validation = (1 - error) * 100print ("Validation Accuracy of the model "+ str(round(accuracy_validation,2)) + "%")
Output: Validation Accuracy 92.86%
Этот спектакль оправдывает ожидания.
Лучшие практики, которым нужно следовать
Вот несколько способов получить хорошую модель:
• Если ограничений очень мало, система может не работать
• Перетренированность, чрезмерная сдержанность приведут к замедлению процесса
• Сосредоточение внимания только на нескольких аспектах может привести к предубеждениям.
Недостатки обратного распространения ошибки
• Исходные данные — ключ к общей производительности
• Шумные данные могут привести к неточным результатам.
• Матричный метод лучше, чем метод мини-партии
Таким образом, нейронная сеть представляет собой набор подключенных модулей с механизмами ввода и вывода, и каждое соединение имеет связанный вес. Обратное распространение ошибок — это «обратное распространение ошибок», которое полезно для обучения нейронных сетей. Это быстро, легко и просто. Обратное распространение очень полезно для глубоких нейронных сетей, которые работают с проектами, подверженными ошибкам, такими как распознавание речи или изображений.
Исходная ссылка:https://imba.deephub.ai/p/1c5b5250659911ea90cd05de3860c663

Знакомимся с методом обратного распространения ошибки
Время на прочтение
6 мин
Количество просмотров 40K
Всем привет! Новогодние праздники подошли к концу, а это значит, что мы вновь готовы делиться с вами полезным материалом. Перевод данной статьи подготовлен в преддверии запуска нового потока по курсу «Алгоритмы для разработчиков».
Поехали!

Метод обратного распространения ошибки – вероятно самая фундаментальная составляющая нейронной сети. Впервые он был описан в 1960-е и почти 30 лет спустя его популяризировали Румельхарт, Хинтон и Уильямс в статье под названием «Learning representations by back-propagating errors».
Метод используется для эффективного обучения нейронной сети с помощью так называемого цепного правила (правила дифференцирования сложной функции). Проще говоря, после каждого прохода по сети обратное распространение выполняет проход в обратную сторону и регулирует параметры модели (веса и смещения).
В этой статья я хотел бы подробно рассмотреть с точки зрения математики процесс обучения и оптимизации простой 4-х слойной нейронной сети. Я считаю, что это поможет читателю понять, как работает обратное распространение, а также осознать его значимость.
Определяем модель нейронной сети
Четырехслойная нейронная сеть состоит из четырех нейронов входного слоя, четырех нейронов на скрытых слоях и 1 нейрона на выходном слое.

Простое изображение четырехслойной нейронной сети.
Входной слой
На рисунке нейроны фиолетового цвета представляют собой входные данные. Они могут быть простыми скалярными величинами или более сложными – векторами или многомерными матрицами.

Уравнение, описывающее входы xi.
Первый набор активаций (а) равен входным значениям. «Активация» — это значение нейрона после применения функции активации. Подробнее смотрите ниже.
Скрытые слои
Конечные значения в скрытых нейронах (на рисунке зеленого цвета) вычисляются с использованием zl – взвешенных входов в слое I и aI активаций в слое L. Для слоев 2 и 3 уравнения будут следующими:
Для l = 2:

Для l = 3:

W2 и W3 – это веса на слоях 2 и 3, а b2 и b3 – смещения на этих слоях.
Активации a2 и a3 вычисляются с помощью функции активации f. Например, эта функция f является нелинейной (как сигмоид, ReLU и гиперболический тангенс) и позволяет сети изучать сложные паттерны в данных. Мы не будем подробно останавливаться на том, как работают функции активации, но, если вам интересно, я настоятельно рекомендую прочитать эту замечательную статью.
Присмотревшись внимательно, вы увидите, что все x, z2, a2, z3, a3, W1, W2, b1 и b2 не имеют нижних индексов, представленных на рисунке четырехслойной нейронной сети. Дело в том, что мы объединили все значения параметров в матрицы, сгруппированные по слоям. Это стандартный способ работы с нейронными сетями, и он довольно комфортный. Однако я пройдусь по уравнениям, чтобы не возникло путаницы.
Давайте возьмем слой 2 и его параметры в качестве примера. Те же самые операции можно применить к любому слою нейронной сети.
W1 – это матрица весов размерности (n, m), где n – это количество выходных нейронов (нейронов на следующем слое), а m – число входных нейронов (нейронов в предыдущем слое). В нашем случае n = 2 и m = 4.

Здесь первое число в нижнем индексе любого из весов соответствует индексу нейрона в следующем слое (в нашем случае – это второй скрытый слой), а второе число соответствует индексу нейрона в предыдущем слое (в нашем случае – это входной слой).
x – входной вектор размерностью (m, 1), где m – число входных нейронов. В нашем случае m = 4.

b1 – это вектор смещения размерности (n, 1), где n – число нейронов на текущем слое. В нашем случае n = 2.

Следуя уравнению для z2 мы можем использовать приведенные выше определения W1, x и b1 для получения уравнения z2:

Теперь внимательно посмотрите на иллюстрацию нейронной сети выше:

Как видите, z2 можно выразить через z12 и z22, где z12 и z22 – суммы произведений каждого входного значения xi на соответствующий вес Wij1.
Это приводит к тому же самому уравнению для z2 и доказывает, что матричные представления z2, a2, z3 и a3 – верны.
Выходной слой
Последняя часть нейронной сети – это выходной слой, который выдает прогнозируемое значение. В нашем простом примере он представлен в виде одного нейрона, окрашенного в синий цвет и рассчитываемого следующим образом:

И снова мы используем матричное представление для упрощения уравнения. Можно использовать вышеприведенные методы, чтобы понять лежащую в их основе логику.
Прямое распространение и оценка
Приведенные выше уравнения формируют прямое распространение по нейронной сети. Вот краткий обзор:

(1) – входной слой
(2) – значение нейрона на первом скрытом слое
(3) – значение активации на первом скрытом слое
(4) – значение нейрона на втором скрытом слое
(5) – значение активации на втором скрытом уровне
(6) – выходной слой
Заключительным шагом в прямом проходе является оценка прогнозируемого выходного значения s относительно ожидаемого выходного значения y.
Выходные данные y являются частью обучающего набора данных (x, y), где x – входные данные (как мы помним из предыдущего раздела).
Оценка между s и y происходит через функцию потерь. Она может быть простой как среднеквадратичная ошибка или более сложной как перекрестная энтропия.
Мы назовем эту функцию потерь С и обозначим ее следующим образом:

Где cost может равняться среднеквадратичной ошибке, перекрестной энтропии или любой другой функции потерь.
Основываясь на значении С, модель «знает», насколько нужно скорректировать ее параметры, чтобы приблизиться к ожидаемому выходному значению y. Это происходит с помощью метода обратного распространения ошибки.
Обратное распространение ошибки и вычисление градиентов
Опираясь на статью 1989 года, метод обратного распространения ошибки:
Постоянно настраивает веса соединений в сети, чтобы минимизировать меру разности между фактическим выходным вектором сети и желаемым выходным вектором.
и
…дает возможность создавать полезные новые функции, что отличает обратное распространение от более ранних и простых методов…
Другими словами, обратное распространение направлено на минимизацию функции потерь путем корректировки весов и смещений сети. Степень корректировки определяется градиентами функции потерь по отношению к этим параметрам.
Возникает один вопрос: Зачем вычислять градиенты?
Чтобы ответить на этот вопрос, нам сначала нужно пересмотреть некоторые понятия вычислений:
Градиентом функции С(x1, x2, …, xm) в точке x называется вектор частных производных С по x.

Производная функции С отражает чувствительность к изменению значения функции (выходного значения) относительно изменения ее аргумента х (входного значения). Другими словами, производная говорит нам в каком направлении движется С.
Градиент показывает, насколько необходимо изменить параметр x (в положительную или отрицательную сторону), чтобы минимизировать С.
Вычисление этих градиентов происходит с помощью метода, называемого цепным правилом.
Для одного веса (wjk)l градиент равен:

(1) Цепное правило
(2) По определению m – количество нейронов на l – 1 слое
(3) Вычисление производной
(4) Окончательное значение
Аналогичный набор уравнений можно применить к (bj)l:

(1) Цепное правило
(2) Вычисление производной
(3) Окончательное значение
Общая часть в обоих уравнениях часто называется «локальным градиентом» и выражается следующим образом:

«Локальный градиент» можно легко определить с помощью правила цепи. Этот процесс я не буду сейчас расписывать.
Градиенты позволяют оптимизировать параметры модели:
Пока не будет достигнут критерий остановки выполняется следующее:
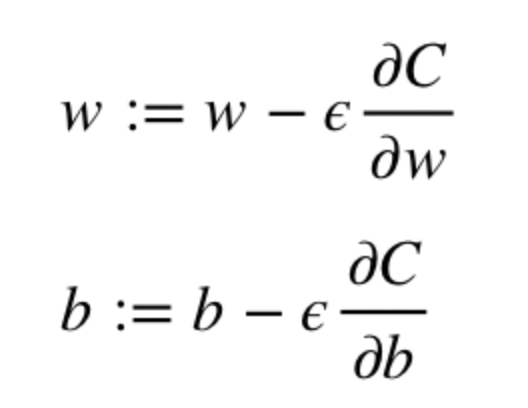
Алгоритм оптимизации весов и смещений (также называемый градиентным спуском)
- Начальные значения w и b выбираются случайным образом.
- Эпсилон (e) – это скорость обучения. Он определяет влияние градиента.
- w и b – матричные представления весов и смещений.
- Производная C по w или b может быть вычислена с использованием частных производных С по отдельным весам или смещениям.
- Условие завершение выполняется, как только функция потерь минимизируется.
Заключительную часть этого раздела я хочу посвятить простому примеру, в котором мы рассчитаем градиент С относительно одного веса (w22)2.
Давайте увеличим масштаб нижней части вышеупомянутой нейронной сети:

Визуальное представление обратного распространения в нейронной сети
Вес (w22)2 соединяет (a2)2 и (z2)2, поэтому вычисление градиента требует применения цепного правила на (z2)3 и (a2)3:

Вычисление конечного значения производной С по (a2)3 требует знания функции С. Поскольку С зависит от (a2)3, вычисление производной должно быть простым.
Я надеюсь, что этот пример сумел пролить немного света на математику, стоящую за вычислением градиентов. Если захотите узнать больше, я настоятельно рекомендую вам посмотреть Стэндфордскую серию статей по NLP, где Ричард Сочер дает 4 замечательных объяснения обратного распространения.
Заключительное замечание
В этой статье я подробно объяснил, как обратное распространение ошибки работает под капотом с помощью математических методов, таких как вычисление градиентов, цепное правило и т.д. Знание механизмов этого алгоритма укрепит ваши знания о нейронных сетях и позволит вам чувствовать себя комфортно при работе с более сложными моделями. Удачи вам в путешествии по глубокому обучению!
На этом все. Приглашаем всех на бесплатный вебинар по теме «Дерево отрезков: просто и быстро».
Алгоритм обратного распространения ошибки и его недостатки
Данный алгоритм является эффективным средством обучения многослойных нейронных сетей и представляет собой следующую последовательность шагов:
1. Задаются шаг обучения a (0<a<1) и желаемая среднеквадратичная ошибка нейронной сети Еm.
2. Инициализируются случайным образом весовые коэффициенты и пороговые значения нейронной сети.
3. Подаются последовательно образы из обучающей выборки на вход нейронной сети и для каждого входного образа выполняются следующие действия:
3.1. Производится фаза прямого распространения входного образа по нейронной сети. При этом вычисляется выходная активность всех нейронов сети

где индекс j характеризует нейроны следующего слоя по отношению к слою i.
3.2. Осуществляется фаза обратного распространения сигнала, в результате которой определяется ошибка gj , j = 1,2,… нейронных элементов для всех слоев сети. При этом для выходного слоя gj = yj — tj, а для скрытого слоя

3.3. Изменяются веса и пороги нейронов для каждого слоя нейронной сети:
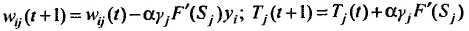
4. Вычисляется суммарная среднеквадратичная ошибка нейронной сети
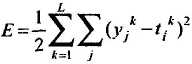
где L – размерность обучающей выборки.
5. Если Е > Еm, то происходит переход к шагу 3 алгоритма. В противном случае алгоритм обратного распространения ошибки заканчивается.
Таким образом, данный алгоритм функционирует до тех пор, пока суммарная среднеквадратичная ошибка сети не станет меньше заданной, т.е. Е £ Еm.
Алгоритм обратного распространения ошибки, основанный на методе градиентного спуска, имеет следующие недостатки:
ü неизвестность выбора числа слоев и количества нейронов в слое;
ü медленная сходимость градиентного метода с постоянным шагом обучения;
ü сложность выбора подходящей скорости обучения a: слишком малое a увеличивает время обучения и приводит к скатыванию нейронной сети в локальный минимум, большое a может привести к пропуску глобального минимума и сделать процесс обучения расходящимся;
ü невозможность определения точек локального и глобального минимумов, так как градиентный метод их не различает;
ü влияние случайной инициализации весовых коэффициентов нейронной сети на поиск минимума функции среднеквадратичной ошибки.
Последний пункт отражает, что при разной инициализации могут получаться различные решения задачи. Это характеризует неустойчивость алгоритма обучения. То, что алгоритм не позволяет в общем случае достичь глобального минимума, не уменьшает его достоинств, так как во многих практических задачах достаточно обучить нейронную сеть до требуемой среднеквадратичной ошибки. Является ли при этом найденный минимум локальным или глобальным, не имеет большого значения.

|
Функция спроса населения на данный товар Функция спроса населения на данный товар: Qd=7-Р. Функция предложения: Qs= -5+2Р,где… |
Аальтернативная стоимость. Кривая производственных возможностей В экономике Буридании есть 100 ед. труда с производительностью 4 м ткани или 2 кг мяса… |
Вычисление основной дактилоскопической формулы Вычислением основной дактоформулы обычно занимается следователь. Для этого все десять пальцев разбиваются на пять пар… |
Расчетные и графические задания Равновесный объем — это объем, определяемый равенством спроса и предложения… |




Нейронные сети обучаются с помощью тех или иных модификаций градиентного спуска, а чтобы применять его, нужно уметь эффективно вычислять градиенты функции потерь по всем обучающим параметрам. Казалось бы, для какого-нибудь запутанного вычислительного графа это может быть очень сложной задачей, но на помощь спешит метод обратного распространения ошибки.
Открытие метода обратного распространения ошибки стало одним из наиболее значимых событий в области искусственного интеллекта. В актуальном виде он был предложен в 1986 году Дэвидом Э. Румельхартом, Джеффри Э. Хинтоном и Рональдом Дж. Вильямсом и независимо и одновременно красноярскими математиками С. И. Барцевым и В. А. Охониным. С тех пор для нахождения градиентов параметров нейронной сети используется метод вычисления производной сложной функции, и оценка градиентов параметров сети стала хоть сложной инженерной задачей, но уже не искусством. Несмотря на простоту используемого математического аппарата, появление этого метода привело к значительному скачку в развитии искусственных нейронных сетей.
Суть метода можно записать одной формулой, тривиально следующей из формулы производной сложной функции: если $f(x) = g_m(g_{m-1}(\ldots (g_1(x)) \ldots))$, то $\frac{\partial f}{\partial x} = \frac{\partial g_m}{\partial g_{m-1}}\frac{\partial g_{m-1}}{\partial g_{m-2}}\ldots \frac{\partial g_2}{\partial g_1}\frac{\partial g_1}{\partial x}$. Уже сейчас мы видим, что градиенты можно вычислять последовательно, в ходе одного обратного прохода, начиная с $\frac{\partial g_m}{\partial g_{m-1}}$ и умножая каждый раз на частные производные предыдущего слоя.
Backpropagation в одномерном случае
В одномерном случае всё выглядит особенно просто. Пусть $w_0$ — переменная, по которой мы хотим продифференцировать, причём сложная функция имеет вид
$$f(w_0) = g_m(g_{m-1}(\ldots g_1(w_0)\ldots)),$$
где все $g_i$ скалярные. Тогда
$$f'(w_0) = g_m'(g_{m-1}(\ldots g_1(w_0)\ldots))\cdot g’_{m-1}(g_{m-2}(\ldots g_1(w_0)\ldots))\cdot\ldots \cdot g’_1(w_0)$$
Суть этой формулы такова. Если мы уже совершили forward pass, то есть уже знаем
$$g_1(w_0), g_2(g_1(w_0)),\ldots,g_{m-1}(\ldots g_1(w_0)\ldots),$$
то мы действуем следующим образом:
-
берём производную $g_m$ в точке $g_{m-1}(\ldots g_1(w_0)\ldots)$;
-
умножаем на производную $g_{m-1}$ в точке $g_{m-2}(\ldots g_1(w_0)\ldots)$;
-
и так далее, пока не дойдём до производной $g_1$ в точке $w_0$.
Проиллюстрируем это на картинке, расписав по шагам дифференцирование по весам $w_i$ функции потерь логистической регрессии на одном объекте (то есть для батча размера 1):

Собирая все множители вместе, получаем:
$$\frac{\partial f}{\partial w_0} = (-y)\cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}\cdot\frac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
$$\frac{\partial f}{\partial w_1} = x_1\cdot(-y)\cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}\cdot\frac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
$$\frac{\partial f}{\partial w_2} = x_2\cdot(-y)\cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}\cdot\frac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
Таким образом, мы видим, что сперва совершается forward pass для вычисления всех промежуточных значений (и да, все промежуточные представления нужно будет хранить в памяти), а потом запускается backward pass, на котором в один проход вычисляются все градиенты.
Почему же нельзя просто пойти и начать везде вычислять производные?
В главе, посвящённой матричным дифференцированиям, мы поднимаем вопрос о том, что вычислять частные производные по отдельности — это зло, лучше пользоваться матричными вычислениями. Но есть и ещё одна причина: даже и с матричной производной в принципе не всегда хочется иметь дело. Рассмотрим простой пример. Допустим, что $X^r$ и $X^{r+1}$ — два последовательных промежуточных представления $N\times M$ и $N\times K$, связанных функцией $X^{r+1} = f^{r+1}(X^r)$. Предположим, что мы как-то посчитали производную $\frac{\partial\mathcal{L}}{\partial X^{r+1}_{ij}}$ функции потерь $\mathcal{L}$, тогда
$$\frac{\partial\mathcal{L}}{\partial X^{r}_{st}} = \sum_{i,j}\frac{\partial f^{r+1}_{ij}}{\partial X^{r}_{st}}\frac{\partial\mathcal{L}}{\partial X^{r+1}_{ij}}$$
И мы видим, что, хотя оба градиента $\frac{\partial\mathcal{L}}{\partial X_{ij}^{r+1}}$ и $\frac{\partial\mathcal{L}}{\partial X_{st}^{r}}$ являются просто матрицами, в ходе вычислений возникает «четырёхмерный кубик» $\frac{\partial f_{ij}^{r+1}}{\partial X_{st}^{r}}$, даже хранить который весьма болезненно: уж больно много памяти он требует ($N^2MK$ по сравнению с безобидными $NM + NK$, требуемыми для хранения градиентов). Поэтому хочется промежуточные производные $\frac{\partial f^{r+1}}{\partial X^{r}}$ рассматривать не как вычисляемые объекты $\frac{\partial f_{ij}^{r+1}}{\partial X_{st}^{r}}$, а как преобразования, которые превращают $\frac{\partial\mathcal{L}}{\partial X_{ij}^{r+1}}$ в $\frac{\partial\mathcal{L}}{\partial X_{st}^{r}}$. Целью следующих глав будет именно это: понять, как преобразуется градиент в ходе error backpropagation при переходе через тот или иной слой.
Вы спросите себя: надо ли мне сейчас пойти и прочитать главу учебника про матричное дифференцирование?
Встречный вопрос. Найдите производную функции по вектору $x$:
$$f(x) = x^TAx,\ A\in Mat_{n}{\mathbb{R}}\text{ — матрица размера }n\times n$$
А как всё поменяется, если $A$ тоже зависит от $x$? Чему равен градиент функции, если $A$ является скаляром? Если вы готовы прямо сейчас взять ручку и бумагу и посчитать всё, то вам, вероятно, не надо читать про матричные дифференцирования. Но мы советуем всё-таки заглянуть в эту главу, если обозначения, которые мы будем дальше использовать, покажутся вам непонятными: единой нотации для матричных дифференцирований человечество пока, увы, не изобрело, и переводить с одной на другую не всегда легко.
Мы же сразу перейдём к интересующей нас вещи: к вычислению градиентов сложных функций.
Градиент сложной функции
Напомним, что формула производной сложной функции выглядит следующим образом:
$$\left[D_{x_0} (\color{#5002A7}{u} \circ \color{#4CB9C0}{v}) \right](h) = \color{#5002A7}{\left[D_{v(x_0)} u \right]} \left( \color{#4CB9C0}{\left[D_{x_0} v\right]} (h)\right)$$
Теперь разберёмся с градиентами. Пусть $f(x) = g(h(x))$ – скалярная функция. Тогда
$$\left[D_{x_0} f \right] (x-x_0) = \langle\nabla_{x_0} f, x-x_0\rangle.$$
С другой стороны,
$$\left[D_{h(x_0)} g \right] \left(\left[D_{x_0}h \right] (x-x_0)\right) = \langle\nabla_{h_{x_0}} g, \left[D_{x_0} h\right] (x-x_0)\rangle = \langle\left[D_{x_0} h\right]^* \nabla_{h(x_0)} g, x-x_0\rangle.$$
То есть $\color{#FFC100}{\nabla_{x_0} f} = \color{#348FEA}{\left[D_{x_0} h \right]}^* \color{#FFC100}{\nabla_{h(x_0)}}g$ — применение сопряжённого к $D_{x_0} h$ линейного отображения к вектору $\nabla_{h(x_0)} g$.
Эта формула — сердце механизма обратного распространения ошибки. Она говорит следующее: если мы каким-то образом получили градиент функции потерь по переменным из некоторого промежуточного представления $X^k$ нейронной сети и при этом знаем, как преобразуется градиент при проходе через слой $f^k$ между $X^{k-1}$ и $X^k$ (то есть как выглядит сопряжённое к дифференциалу слоя между ними отображение), то мы сразу же находим градиент и по переменным из $X^{k-1}$:

Таким образом слой за слоем мы посчитаем градиенты по всем $X^i$ вплоть до самых первых слоёв.
Далее мы разберёмся, как именно преобразуются градиенты при переходе через некоторые распространённые слои.
Градиенты для типичных слоёв
Рассмотрим несколько важных примеров.
Примеры
-
$f(x) = u(v(x))$, где $x$ — вектор, а $v(x)$ – поэлементное применение $v$:
$$v\begin{pmatrix}
x_1 \\
\vdots\\
x_N
\end{pmatrix}
= \begin{pmatrix}
v(x_1)\\
\vdots\\
v(x_N)
\end{pmatrix}$$Тогда, как мы знаем,
$$\left[D_{x_0} f\right] (h) = \langle\nabla_{x_0} f, h\rangle = \left[\nabla_{x_0} f\right]^T h.$$
Следовательно,
$$
\left[D_{v(x_0)} u\right] \left( \left[ D_{x_0} v\right] (h)\right) = \left[\nabla_{v(x_0)} u\right]^T \left(v'(x_0) \odot h\right) =\\
$$$$
= \sum\limits_i \left[\nabla_{v(x_0)} u\right]_i v'(x_{0i})h_i
= \langle\left[\nabla_{v(x_0)} u\right] \odot v'(x_0), h\rangle.
,$$где $\odot$ означает поэлементное перемножение. Окончательно получаем
$$\color{#348FEA}{\nabla_{x_0} f = \left[\nabla_{v(x_0)}u\right] \odot v'(x_0) = v'(x_0) \odot \left[\nabla_{v(x_0)} u\right]}$$
Отметим, что если $x$ и $h(x)$ — это просто векторы, то мы могли бы вычислять всё и по формуле $\frac{\partial f}{\partial x_i} = \sum_j\big(\frac{\partial z_j}{\partial x_i}\big)\cdot\big(\frac{\partial h}{\partial z_j}\big)$. В этом случае матрица $\big(\frac{\partial z_j}{\partial x_i}\big)$ была бы диагональной (так как $z_j$ зависит только от $x_j$: ведь $h$ берётся поэлементно), и матричное умножение приводило бы к тому же результату. Однако если $x$ и $h(x)$ — матрицы, то $\big(\frac{\partial z_j}{\partial x_i}\big)$ представлялась бы уже «четырёхмерным кубиком», и работать с ним было бы ужасно неудобно.
-
$f(X) = g(XW)$, где $X$ и $W$ — матрицы. Как мы знаем,
$$\left[D_{X_0} f \right] (X-X_0) = \text{tr}, \left(\left[\nabla_{X_0} f\right]^T (X-X_0)\right).$$
Тогда
$$
\left[ D_{X_0W} g \right] \left(\left[D_{X_0} \left( \ast W\right)\right] (H)\right) =
\left[ D_{X_0W} g \right] \left(HW\right)=\\
$$ $$
= \text{tr}\, \left( \left[\nabla_{X_0W} g \right]^T \cdot (H) W \right) =\\
$$ $$
=
\text{tr} \, \left(W \left[\nabla_{X_0W} (g) \right]^T \cdot (H)\right) = \text{tr} \, \left( \left[\left[\nabla_{X_0W} g\right] W^T\right]^T (H)\right)
$$Здесь через $\ast W$ мы обозначили отображение $Y \hookrightarrow YW$, а в предпоследнем переходе использовалось следующее свойство следа:
$$
\text{tr} , (A B C) = \text{tr} , (C A B),
$$где $A, B, C$ — произвольные матрицы подходящих размеров (то есть допускающие перемножение в обоих приведённых порядках). Следовательно, получаем
$$\color{#348FEA}{\nabla_{X_0} f = \left[\nabla_{X_0W} (g) \right] \cdot W^T}$$
-
$f(W) = g(XW)$, где $W$ и $X$ — матрицы. Для приращения $H = W — W_0$ имеем
$$
\left[D_{W_0} f \right] (H) = \text{tr} , \left( \left[\nabla_{W_0} f \right]^T (H)\right)
$$Тогда
$$
\left[D_{XW_0} g \right] \left( \left[D_{W_0} \left(X \ast\right) \right] (H)\right) = \left[D_{XW_0} g \right] \left( XH \right) = \
$$ $$
= \text{tr} , \left( \left[\nabla_{XW_0} g \right]^T \cdot X (H)\right) =
\text{tr}, \left(\left[X^T \left[\nabla_{XW_0} g \right] \right]^T (H)\right)
$$Здесь через $X \ast$ обозначено отображение $Y \hookrightarrow XY$. Значит,
$$\color{#348FEA}{\nabla_{X_0} f = X^T \cdot \left[\nabla_{XW_0} (g)\right]}$$
-
$f(X) = g(softmax(X))$, где $X$ — матрица $N\times K$, а $softmax$ — функция, которая вычисляется построчно, причём для каждой строки $x$
$$softmax(x) = \left(\frac{e^{x_1}}{\sum_te^{x_t}},\ldots,\frac{e^{x_K}}{\sum_te^{x_t}}\right)$$
В этом примере нам будет удобно воспользоваться формализмом с частными производными. Сначала вычислим $\frac{\partial s_l}{\partial x_j}$ для одной строки $x$, где через $s_l$ мы для краткости обозначим $softmax(x)_l = \frac{e^{x_l}} {\sum_te^{x_t}}$. Нетрудно проверить, что
$$\frac{\partial s_l}{\partial x_j} = \begin{cases}
s_j(1 — s_j),\ & j = l,\
-s_ls_j,\ & j\ne l
\end{cases}$$Так как softmax вычисляется независимо от каждой строчки, то
$$\frac{\partial s_{rl}}{\partial x_{ij}} = \begin{cases}
s_{ij}(1 — s_{ij}),\ & r=i, j = l,\
-s_{il}s_{ij},\ & r = i, j\ne l,\
0,\ & r\ne i
\end{cases},$$где через $s_{rl}$ мы обозначили для краткости $softmax(X)_{rl}$.
Теперь пусть $\nabla_{rl} = \nabla g = \frac{\partial\mathcal{L}}{\partial s_{rl}}$ (пришедший со следующего слоя, уже известный градиент). Тогда
$$\frac{\partial\mathcal{L}}{\partial x_{ij}} = \sum_{r,l}\frac{\partial s_{rl}}{\partial x_{ij}} \nabla_{rl}$$
Так как $\frac{\partial s_{rl}}{\partial x_{ij}} = 0$ при $r\ne i$, мы можем убрать суммирование по $r$:
$$\ldots = \sum_{l}\frac{\partial s_{il}}{\partial x_{ij}} \nabla_{il} = -s_{i1}s_{ij}\nabla_{i1} — \ldots + s_{ij}(1 — s_{ij})\nabla_{ij}-\ldots — s_{iK}s_{ij}\nabla_{iK} =$$
$$= -s_{ij}\sum_t s_{it}\nabla_{it} + s_{ij}\nabla_{ij}$$
Таким образом, если мы хотим продифференцировать $f$ в какой-то конкретной точке $X_0$, то, смешивая математические обозначения с нотацией Python, мы можем записать:
$$\begin{multline*}
\color{#348FEA}{\nabla_{X_0}f =}\\
\color{#348FEA}{= -softmax(X_0) \odot \text{sum}\left(
softmax(X_0)\odot\nabla_{softmax(X_0)}g, \text{ axis = 1}
\right) +}\\
\color{#348FEA}{softmax(X_0)\odot \nabla_{softmax(X_0)}g}
\end{multline*}
$$
Backpropagation в общем виде
Подытожим предыдущее обсуждение, описав алгоритм error backpropagation (алгоритм обратного распространения ошибки). Допустим, у нас есть текущие значения весов $W^i_0$ и мы хотим совершить шаг SGD по мини-батчу $X$. Мы должны сделать следующее:
- Совершить forward pass, вычислив и запомнив все промежуточные представления $X = X^0, X^1, \ldots, X^m = \widehat{y}$.
- Вычислить все градиенты с помощью backward pass.
- С помощью полученных градиентов совершить шаг SGD.
Проиллюстрируем алгоритм на примере двуслойной нейронной сети со скалярным output’ом. Для простоты опустим свободные члены в линейных слоях.
 Обучаемые параметры – матрицы $U$ и $W$. Как найти градиенты по ним в точке $U_0, W_0$?
Обучаемые параметры – матрицы $U$ и $W$. Как найти градиенты по ним в точке $U_0, W_0$?
$$\nabla_{W_0}\mathcal{L} = \nabla_{W_0}{\left({\vphantom{\frac12}\mathcal{L}\circ h\circ\left[W\mapsto g(XU_0)W\right]}\right)}=$$
$$=g(XU_0)^T\nabla_{g(XU_0)W_0}(\mathcal{L}\circ h) = \underbrace{g(XU_0)^T}_{k\times N}\cdot
\left[\vphantom{\frac12}\underbrace{h’\left(\vphantom{\int_0^1}g(XU_0)W_0\right)}_{N\times 1}\odot
\underbrace{\nabla_{h\left(\vphantom{\int_0^1}g(XU_0)W_0\right)}\mathcal{L}}_{N\times 1}\right]$$
Итого матрица $k\times 1$, как и $W_0$
$$\nabla_{U_0}\mathcal{L} = \nabla_{U_0}\left(\vphantom{\frac12}
\mathcal{L}\circ h\circ\left[Y\mapsto YW_0\right]\circ g\circ\left[ U\mapsto XU\right]
\right)=$$
$$=X^T\cdot\nabla_{XU^0}\left(\vphantom{\frac12}\mathcal{L}\circ h\circ [Y\mapsto YW_0]\circ g\right) =$$
$$=X^T\cdot\left(\vphantom{\frac12}g'(XU_0)\odot
\nabla_{g(XU_0)}\left[\vphantom{\in_0^1}\mathcal{L}\circ h\circ[Y\mapsto YW_0\right]
\right)$$
$$=\ldots = \underset{D\times N}{X^T}\cdot\left(\vphantom{\frac12}
\underbrace{g'(XU_0)}_{N\times K}\odot
\underbrace{\left[\vphantom{\int_0^1}\left(
\underbrace{h’\left(\vphantom{\int_0^1}g(XU_0)W_0\right)}_{N\times1}\odot\underbrace{\nabla_{h(\vphantom{\int_0^1}g\left(XU_0\right)W_0)}\mathcal{L}}_{N\times 1}
\right)\cdot \underbrace{W^T}_{1\times K}\right]}_{N\times K}
\right)$$
Итого $D\times K$, как и $U_0$
Схематически это можно представить следующим образом:

Backpropagation для двуслойной нейронной сети
Подробнее о предыдущих вычисленияхЕсли вы не уследили за вычислениями в предыдущем примере, давайте более подробно разберём его чуть более конкретную версию (для $g = h = \sigma$).
Рассмотрим двуслойную нейронную сеть для классификации. Мы уже встречали ее ранее при рассмотрении линейно неразделимой выборки. Предсказания получаются следующим образом:
$$
\widehat{y} = \sigma(X^1 W^2) = \sigma\Big(\big(\sigma(X^0 W^1 )\big) W^2 \Big).
$$
Пусть $W^1_0$ и $W^2_0$ — текущее приближение матриц весов. Мы хотим совершить шаг по градиенту функции потерь, и для этого мы должны вычислить её градиенты по $W^1$ и $W^2$ в точке $(W^1_0, W^2_0)$.
Прежде всего мы совершаем forward pass, в ходе которого мы должны запомнить все промежуточные представления: $X^1 = X^0 W^1_0$, $X^2 = \sigma(X^0 W^1_0)$, $X^3 = \sigma(X^0 W^1_0) W^2_0$, $X^4 = \sigma(\sigma(X^0 W^1_0) W^2_0) = \widehat{y}$. Они понадобятся нам дальше.
Для полученных предсказаний вычисляется значение функции потерь:
$$
l = \mathcal{L}(y, \widehat{y}) = y \log(\widehat{y}) + (1-y) \log(1-\widehat{y}).
$$
Дальше мы шаг за шагом будем находить производные по переменным из всё более глубоких слоёв.
-
Градиент $\mathcal{L}$ по предсказаниям имеет вид
$$
\nabla_{\widehat{y}}l = \frac{y}{\widehat{y}} — \frac{1 — y}{1 — \widehat{y}} = \frac{y — \widehat{y}}{\widehat{y} (1 — \widehat{y})},
$$где, напомним, $ \widehat{y} = \sigma(X^3) = \sigma\Big(\big(\sigma(X^0 W^1_0 )\big) W^2_0 \Big)$ (обратите внимание на то, что $W^1_0$ и $W^2_0$ тут именно те, из которых мы делаем градиентный шаг).
-
Следующий слой — поэлементное взятие $\sigma$. Как мы помним, при переходе через него градиент поэлементно умножается на производную $\sigma$, в которую подставлено предыдущее промежуточное представление:
$$
\nabla_{X^3}l = \sigma'(X^3)\odot\nabla_{\widehat{y}}l = \sigma(X^3)\left( 1 — \sigma(X^3) \right) \odot \frac{y — \widehat{y}}{\widehat{y} (1 — \widehat{y})} =
$$$$
= \sigma(X^3)\left( 1 — \sigma(X^3) \right) \odot \frac{y — \sigma(X^3)}{\sigma(X^3) (1 — \sigma(X^3))} =
y — \sigma(X^3)
$$ -
Следующий слой — умножение на $W^2_0$. В этот момент мы найдём градиент как по $W^2$, так и по $X^2$. При переходе через умножение на матрицу градиент, как мы помним, умножается с той же стороны на транспонированную матрицу, а значит:
$$
\color{blue}{\nabla_{W^2_0}l} = (X^2)^T\cdot \nabla_{X^3}l = (X^2)^T\cdot(y — \sigma(X^3)) =
$$$$
= \color{blue}{\left( \sigma(X^0W^1_0) \right)^T \cdot (y — \sigma(\sigma(X^0W^1_0)W^2_0))}
$$Аналогичным образом
$$
\nabla_{X^2}l = \nabla_{X^3}l\cdot (W^2_0)^T = (y — \sigma(X^3))\cdot (W^2_0)^T =
$$$$
= (y — \sigma(X^2W_0^2))\cdot (W^2_0)^T
$$ -
Следующий слой — снова взятие $\sigma$.
$$
\nabla_{X^1}l = \sigma'(X^1)\odot\nabla_{X^2}l = \sigma(X^1)\left( 1 — \sigma(X^1) \right) \odot \left( (y — \sigma(X^2W_0^2))\cdot (W^2_0)^T \right) =
$$$$
= \sigma(X^1)\left( 1 — \sigma(X^1) \right) \odot\left( (y — \sigma(\sigma(X^1)W_0^2))\cdot (W^2_0)^T \right)
$$ -
Наконец, последний слой — это умножение $X^0$ на $W^1_0$. Тут мы дифференцируем только по $W^1$:
$$
\color{blue}{\nabla_{W^1_0}l} = (X^0)^T\cdot \nabla_{X^1}l = (X^0)^T\cdot \big( \sigma(X^1) \left( 1 — \sigma(X^1) \right) \odot (y — \sigma(\sigma(X^1)W_0^2))\cdot (W^2_0)^T\big) =
$$$$
= \color{blue}{(X^0)^T\cdot\big(\sigma(X^0W^1_0)\left( 1 — \sigma(X^0W^1_0) \right) \odot (y — \sigma(\sigma(X^0W^1_0)W_0^2))\cdot (W^2_0)^T\big) }
$$
Итоговые формулы для градиентов получились страшноватыми, но они были получены друг из друга итеративно с помощью очень простых операций: матричного и поэлементного умножения, в которые порой подставлялись значения заранее вычисленных промежуточных представлений.
Автоматизация и autograd
Итак, чтобы нейросеть обучалась, достаточно для любого слоя $f^k: X^{k-1}\mapsto X^k$ с параметрами $W^k$ уметь:
- превращать $\nabla_{X^k_0}\mathcal{L}$ в $\nabla_{X^{k-1}_0}\mathcal{L}$ (градиент по выходу в градиент по входу);
- считать градиент по его параметрам $\nabla_{W^k_0}\mathcal{L}$.
При этом слою совершенно не надо знать, что происходит вокруг. То есть слой действительно может быть запрограммирован как отдельная сущность, умеющая внутри себя делать forward pass и backward pass, после чего слои механически, как кубики в конструкторе, собираются в большую сеть, которая сможет работать как одно целое.
Более того, во многих случаях авторы библиотек для глубинного обучения уже о вас позаботились и создали средства для автоматического дифференцирования выражений (autograd). Поэтому, программируя нейросеть, вы почти всегда можете думать только о forward-проходе, прямом преобразовании данных, предоставив библиотеке дифференцировать всё самостоятельно. Это делает код нейросетей весьма понятным и выразительным (да, в реальности он тоже бывает большим и страшным, но сравните на досуге код какой-нибудь разухабистой нейросети и код градиентного бустинга на решающих деревьях и почувствуйте разницу).
Но это лишь начало
Метод обратного распространения ошибки позволяет удобно посчитать градиенты, но дальше с ними что-то надо делать, и старый добрый SGD едва ли справится с обучением современной сетки. Так что же делать? О некоторых приёмах мы расскажем в следующей главе.
Метод обратного распространения ошибки – один из основных подходов в обучении нейронных сетей, который основывается на минимизации ошибки и последующем корректировании весов с использованием градиентного спуска.
О чем статья
Введение
В данной лекции мы рассмотрим метод обратного распространения ошибки, который является одним из основных алгоритмов машинного обучения. Этот метод используется для обучения нейронных сетей и позволяет оптимизировать их веса, чтобы достичь наилучшей производительности. Мы изучим основные понятия, принцип работы метода, алгоритм обратного распространения ошибки, а также рассмотрим пример его применения. Также мы обсудим преимущества и недостатки этого метода. Давайте начнем!
Нужна помощь в написании работы?
![]()
Мы — биржа профессиональных авторов (преподавателей и доцентов вузов). Наша система гарантирует сдачу работы к сроку без плагиата. Правки вносим бесплатно.
Заказать работу
Основные понятия
В машинном обучении и искусственном интеллекте существует понятие нейронных сетей, которые являются моделями, вдохновленными работой человеческого мозга. Нейронные сети состоят из множества искусственных нейронов, которые взаимодействуют друг с другом и обрабатывают информацию.
Одним из ключевых понятий в нейронных сетях является понятие весов. Веса представляют собой числа, которые определяют важность связей между нейронами. Каждая связь имеет свой вес, который может быть положительным или отрицательным.
Другим важным понятием является функция активации. Функция активации определяет, какой будет выходной сигнал нейрона на основе его входных данных и весов. Она может быть линейной или нелинейной.
Нейронные сети также имеют понятие слоев. Слои представляют собой группы нейронов, которые обрабатывают информацию последовательно. Входной слой принимает входные данные, скрытые слои выполняют промежуточные вычисления, а выходной слой предсказывает результат.
Обучение нейронной сети осуществляется с помощью алгоритма обратного распространения ошибки. Этот алгоритм позволяет настраивать веса нейронов на основе разницы между предсказанными и ожидаемыми значениями. Цель обучения – минимизировать ошибку и достичь наилучшей производительности сети.
Принцип работы метода
Метод обратного распространения ошибки является одним из основных алгоритмов обучения нейронных сетей. Он основан на идее, что нейроны в сети могут корректировать свои веса в зависимости от разницы между предсказанными и ожидаемыми значениями.
Процесс обучения нейронной сети с использованием метода обратного распространения ошибки состоит из нескольких шагов:
Инициализация весов
В начале обучения веса нейронов случайным образом инициализируются. Веса определяют, как сильно входные сигналы влияют на активацию нейрона.
Прямое распространение
Входные данные подаются на входной слой нейронной сети. Каждый нейрон в слое вычисляет свою активацию на основе входных данных и текущих весов. Активация передается на следующий слой, где происходят аналогичные вычисления.
Вычисление ошибки
После прямого распространения сеть выдает предсказанные значения. Ошибка вычисляется путем сравнения предсказанных значений с ожидаемыми значениями. Чем больше разница между ними, тем больше ошибка.
Обратное распространение ошибки
Ошибка распространяется обратно через сеть, начиная с выходного слоя. Каждый нейрон в слое вычисляет свою частную производную ошибки по своей активации. Затем эта производная умножается на производную активации нейрона, чтобы получить ошибку для весов нейрона.
Обновление весов
Веса нейронов обновляются на основе вычисленных ошибок. Обновление происходит с использованием градиентного спуска, который позволяет найти оптимальные значения весов, минимизирующие ошибку.
Эти шаги повторяются множество раз, пока сеть не достигнет заданной точности или не пройдет определенное количество эпох обучения.
Алгоритм обратного распространения ошибки
Алгоритм обратного распространения ошибки является основным методом обучения нейронных сетей. Он позволяет оптимизировать веса нейронов, чтобы минимизировать ошибку предсказания сети.
Алгоритм состоит из следующих шагов:
Прямое распространение
В этом шаге входные данные подаются на вход сети, и сигналы проходят через все слои нейронов до выходного слоя. Каждый нейрон вычисляет свою активацию на основе входных данных и текущих весов.
Вычисление ошибки
После прямого распространения сеть выдает предсказание. Затем вычисляется ошибка, которая является разницей между предсказанным значением и ожидаемым значением. Эта ошибка используется для определения, насколько сильно нужно изменить веса нейронов, чтобы улучшить предсказание.
Обратное распространение ошибки
В этом шаге ошибка распространяется обратно через сеть. Ошибка каждого нейрона вычисляется путем умножения ошибки следующего слоя на веса связей между нейронами. Это позволяет определить, насколько каждый нейрон влияет на ошибку предсказания.
Вычисление градиента
После обратного распространения ошибки каждый нейрон вычисляет свою частную производную ошибки по своей активации. Затем эта производная умножается на производную активации нейрона, чтобы получить ошибку для весов нейрона.
Обновление весов
Веса нейронов обновляются на основе вычисленных ошибок. Обновление происходит с использованием градиентного спуска, который позволяет найти оптимальные значения весов, минимизирующие ошибку.
Эти шаги повторяются множество раз, пока сеть не достигнет заданной точности или не пройдет определенное количество эпох обучения.
Пример применения метода
Допустим, у нас есть задача классификации изображений на два класса: кошки и собаки. Мы хотим создать нейронную сеть, которая будет автоматически определять, является ли на изображении кошка или собака.
Для этого мы можем использовать метод обратного распространения ошибки. Сначала мы создаем нейронную сеть с несколькими слоями. Входной слой будет содержать нейроны, соответствующие пикселям изображения. Скрытые слои будут выполнять вычисления для определения признаков изображения, а выходной слой будет содержать два нейрона, соответствующих классам “кошка” и “собака”.
Затем мы обучаем сеть на наборе изображений, предварительно размеченных как “кошка” или “собака”. Для каждого изображения мы подаем его на вход сети и получаем предсказание в виде вероятностей принадлежности к каждому классу.
Далее мы сравниваем предсказание с правильным ответом и вычисляем ошибку. Эта ошибка затем распространяется назад через сеть с помощью метода обратного распространения ошибки. Каждый нейрон вычисляет свою частную производную ошибки по своей активации и обновляет свои веса в соответствии с этой ошибкой.
После множества итераций обучения сеть будет способна давать достаточно точные предсказания для новых изображений. Мы можем использовать эту обученную сеть для классификации новых изображений кошек и собак.
Преимущества метода обратного распространения ошибки:
1. Эффективность: Метод обратного распространения ошибки является одним из самых эффективных методов обучения нейронных сетей. Он позволяет достичь высокой точности предсказаний при обучении на больших объемах данных.
2. Гибкость: Метод обратного распространения ошибки может быть применен к различным типам нейронных сетей, включая многослойные перцептроны, сверточные нейронные сети и рекуррентные нейронные сети. Это делает его универсальным инструментом для обучения различных моделей машинного обучения.
3. Автоматическое обучение: Метод обратного распространения ошибки позволяет нейронной сети автоматически настраивать свои веса и параметры на основе обучающих данных. Это упрощает процесс обучения и позволяет сети адаптироваться к изменяющимся условиям и новым данным.
Недостатки метода обратного распространения ошибки:
1. Зависимость от исходных данных: Метод обратного распространения ошибки требует большого объема размеченных данных для обучения. Если данных недостаточно или они не репрезентативны, то сеть может давать неправильные предсказания или быть неустойчивой.
2. Проблема градиентного затухания: При обратном распространении ошибки градиент может снижаться по мере прохождения через слои сети. Это может привести к затуханию градиента и затруднить обучение глубоких нейронных сетей.
3. Вычислительная сложность: Обратное распространение ошибки требует вычисления градиента для каждого веса в сети. Это может быть вычислительно затратным, особенно для больших сетей с множеством параметров.
4. Переобучение: Метод обратного распространения ошибки может привести к переобучению, когда сеть слишком точно подстраивается под обучающие данные и теряет обобщающую способность. Это может привести к плохим предсказаниям на новых данных.
Таблица сравнения методов обучения нейронных сетей
| Метод | Описание | Преимущества | Недостатки |
|---|---|---|---|
| Метод обратного распространения ошибки | Алгоритм, используемый для обучения нейронных сетей путем минимизации ошибки между предсказанными и ожидаемыми значениями |
|
|
| Генетические алгоритмы | Метод оптимизации, основанный на принципах естественного отбора и генетики |
|
|
| Стохастический градиентный спуск | Метод оптимизации, который обновляет параметры модели на основе градиента функции потерь, вычисленного на случайно выбранных подмножествах данных |
|
|
Заключение
Метод обратного распространения ошибки является одним из основных алгоритмов машинного обучения. Он позволяет обучать нейронные сети, оптимизируя их веса на основе ошибки предсказания. Метод имеет свои преимущества, такие как способность обрабатывать большие объемы данных и высокую точность предсказаний. Однако, он также имеет недостатки, такие как сложность в выборе оптимальных параметров и возможность попадания в локальные минимумы. В целом, метод обратного распространения ошибки является мощным инструментом в области машинного обучения и находит широкое применение в различных задачах.
Взгляните на альтернативные алгоритмы обратного распространения ошибки
-Равичандра, исследователь компьютерного зрения, @ Sally Robotics.
С тех пор, как в 1986 году была представлена идея использования обратного распространения для обучения нейронных сетей, обучение с помощью нейронных сетей никогда не оглядывалось назад. Внезапно учебные сети превратились в эффективный процесс, который позволил достичь грандиозных достижений. Он стал отраслевым стандартом, и на нем построено множество фреймворков (Tensorflow, PyTorch), которыми пользуются все. Но постепенно, по мере того как мы пытались тренировать с его помощью все более и более глубокие сети, мы выявили некоторые из его недостатков. В основном это были-
1. Исчезающие градиенты. Сигмоидная и тангенциальная нелинейности имеют тенденцию к насыщению и полностью прекращают обучение. Это происходит, когда выходы нейрона находятся на крайних значениях, в результате чего градиенты равны 0 или близки к 0, то есть исчезают. При использовании ReLU, если нейроны будут ограничены до 0, тогда веса будут иметь нулевые градиенты, что приведет к так называемой проблеме «мертвого ReLU».
2. Взрывающиеся градиенты. В глубоких сетях или RNN градиенты ошибок могут накапливаться во время обновления и приводить к очень большим градиентам. Это, в свою очередь, приводит к большим обновлениям веса сети. В крайнем случае, значения веса могут стать настолько большими, что выйдут за пределы допустимого диапазона, что приведет к появлению значений Nan.
3. В вычислительном отношении дорого: Послойное вычисление градиентов, несомненно, является дорогостоящим в вычислительном отношении процессом. Это заставляет задуматься, есть ли лучший способ оптимизировать функцию потерь.
Хотя они остаются основными недостатками, существуют и другие, такие как выбор гиперпараметров и т. Д., Которые классифицируют скорее как раздражение, чем как недостатки. Итак, что мы тогда с этим сделали? Мы разработали более совершенную сетевую архитектуру, чтобы избежать этих проблем. Архитектура ResNet (https://arxiv.org/abs/1512.03385) — лучший пример, где были созданы пропускаемые соединения, чтобы избежать исчезающих градиентов.
Обратное распространение — ошибочный подход?
Многие известные исследователи, такие как Джеффри Хинтон и Йошуа Бенжио, выразили обеспокоенность по поводу того, что обратное распространение не является идеальным подходом. Нет никаких доказательств того, что наш мозг выполняет обратное распространение, и если это так, как тогда мы можем достичь полного искусственного интеллекта, если мы не моделируем сети по образцу нашего собственного биологического разума? Вопрос о более биологически правдоподобном алгоритме все еще остается, и эта идея дополнительно исследуется в этой статье: https://arxiv.org/abs/1502.04156.
Хинтон больше озабочен существованием другого способа обучения, чем принуждением решений использовать контролируемые данные, то есть обучением без учителя. Он сомневается, что методы, которые он разработал и отстаивал на протяжении многих лет, достигнут первоначальной цели для нейронных сетей, в частности, для автономных обучающихся машин. Несмотря на заметный прогресс последних нескольких лет, мы до сих пор не решили вопрос о том, как человеческий мозг самоорганизуется в отсутствие фиксированной внешней обратной связи с использованием чрезвычайно разреженных данных. Взлом этого может привести к общему алгоритму обучения с учителем и без учителя, а также обучения с подкреплением.
В науке можно говорить вещи, которые кажутся безумными, но в конечном итоге они могут оказаться правильными. Мы можем получить действительно хорошие доказательства, и, в конце концов, сообщество вернется.
— Джеффри Хинтон
Альтернативы
1. Распространение разностной цели
Обратное распространение полагается на бесконечно малые изменения (частные производные) для выполнения присвоения кредита. Это может стать серьезной проблемой, поскольку каждый рассматривает более глубокие и более нелинейные функции, например, крайний случай нелинейности, когда связь между параметрами и стоимостью фактически дискретна. Ссылаясь на это как на мотивацию, этот алгоритм был разработан как альтернатива обратному распространению ошибки. Основная идея состоит в том, чтобы вычислять цели, а не градиенты на каждом слое. В некотором смысле это похоже на обратное распространение, но намного быстрее. Так как же тогда это реализовано? Вот краткий обзор этого —
а. Формулирование целей
б. Назначение правильной цели каждому слою
c. Разница в целевом распространении
d. Обучение автокодировщика с разностным целевым распространением
Хотя это очень абстрактное и высокоуровневое описание метода, я намеренно сохранил его, чтобы углубление в математику и уравнения излишне удлинило статью. Точную математику этого можно найти в этой статье https://arxiv.org/pdf/1412.7525.pdf.
2. Узкое место HSIC (критерий независимости Гильберта-Шмидта)
Подход состоит в том, чтобы обучить сеть, используя аппроксимацию информационного узкого места вместо обратного распространения.
На приведенном выше рисунке представлен обзор того, как проводится обучение с использованием HSIC. Сеть, обученная HSIC, рисунок (a), представляет собой стандартную сеть с прямой связью, обученную с использованием цели HSIC IB, что приводит к скрытым представлениям на последнем уровне, которые можно быстро обучить. На рисунке (b) показана σ-объединенная сеть, где каждая ветвь сети HSIC-net обучается определенному σ.
На следующем этапе будет найдена и развернута замена взаимной информации между скрытыми представлениями и метками. Это одновременно минимизирует взаимную зависимость между скрытыми представлениями и входными данными. Таким образом, каждое скрытое представление из сети, обученной HSIC, может содержать различную информацию, полученную путем оптимизации цели узкого места HSIC в конкретном масштабе. Затем агрегатор суммирует скрытые представления, чтобы сформировать выходное представление. Дополнительную информацию можно найти здесь https://arxiv.org/pdf/1908.01580v1.pdf.
В чем тогда преимущества? Авторы утверждают, что это облегчает параллельную обработку, требует значительно меньше операций и не страдает от исчезающих или взрывающихся градиентов. Более того, это кажется более вероятным с биологической точки зрения, чем обратное распространение. После тестирования сети, обученные HSIC, работали сравнимыми с обратным распространением в наборах данных MNIST и CIFAR-10.
3. Чередующаяся минимизация в режиме онлайн с помощью вспомогательных переменных.
Основным вкладом этой работы является новый онлайновый (стохастический / мини-пакетный) подход с чередующейся минимизацией (AM) для обучения глубоких нейронных сетей вместе с первыми гарантиями теоретической сходимости для AM в стохастических настройках. Это решает проблему оптимизации, разрывая цепочки градиентов с помощью вспомогательных переменных. Эта работа основана на ранее предложенных автономных методах, которые разбивают вложенную цель на более простые для решения локальные подзадачи путем вставки вспомогательных переменных, соответствующих активациям на каждом уровне. Подробнее об этом можно прочитать здесь https://arxiv.org/pdf/1806.09077.pdf.
Итак, что же тогда главный вывод? Мы можем избежать вычисления цепочки градиентов, что означает отсутствие исчезающих градиентов, отсутствие перекрестного распараллеливания и трудности с обработкой недифференцируемых нелинейностей.
4. Разделение нейронных интерфейсов с использованием синтетических градиентов.
Это дает нам возможность позволить нейронным сетям общаться, научиться отправлять сообщения между собой в несвязанной, масштабируемой манере, прокладывая путь нескольким нейронным сетям для связи друг с другом или улучшая долгосрочную временную зависимость повторяющихся сетей.
Правомерным вопросом было бы спросить, сколько вычислительной сложности добавляют эти синтетические градиентные модели — возможно, вам понадобится архитектура синтетической градиентной модели, столь же сложная, как сама сеть. Удивительно, но синтетические градиентные модели могут быть очень простыми. Для сетей с прямой связью было фактически обнаружено, что даже один линейный слой хорошо работает в качестве модели синтетического градиента. Следовательно, его очень легко обучить, и поэтому он быстро создает синтетические градиенты. Подробнее можно прочитать здесь https://arxiv.org/pdf/1608.05343.pdf.
Разработанный исследователями DeepMind, этот метод имеет значительные преимущества благодаря увеличенному временному горизонту, который могут моделировать RNN с поддержкой DNI, а также более быстрой сходимости по сравнению с обратным распространением информации. Синтетические градиенты FTW!
Машины пойдут по пути, отражающему эволюцию человека. В конечном итоге, однако, самоосознающие, самосовершенствующиеся машины будут развиваться, превзойдя человеческие способности контролировать или даже понимать их.
— Рэй Курцвейл
Заключение
Мы обсудили недостатки обратного распространения ошибки, возможные недостатки общего подхода, высказанные известными исследователями, и, наконец, некоторые хорошие альтернативы. В конечном счете, ни один из них нельзя назвать «лучше, чем обратное распространение», потому что все, что они делают, — это достижение конкурентных результатов. Эта неудача может быть объяснена отсутствием проведенных исследований, что заставляет нас ожидать значительного прогресса и развития в ближайшем будущем. Итак, ключевой вывод заключается в следующем: для того, чтобы алгоритм свергнул Backprop, он должен решать проблемы исчезающего и взрывающегося градиента, быть в вычислительном отношении быстрее, быстрее сходиться, предпочтительно уменьшать гиперпараметры и, что наиболее важно, быть биологически правдоподобным. Это гарантирует, что мы продвигаемся в направлении воссоздания человеческого разума, позволяя нам использовать его беспрецедентный потенциал. А пока все, что мы можем сделать, это поэкспериментировать и продолжить исследования!
Ресурсы
Https://analyticsindiamag.com/lets-not-stop-at-back-prop-check-out-5-alternatives-to-this-popular-deep-learning-technique/
Https://analyticsindiamag.com/is-deep-learning-possible-without-back-propagation/
Https://deepmind.com/blog/article/decoupled-neural-networks-using-synthetic-gradients
Https://www.ibm.com/blogs/research/2019/06/beyond-backprop/
Https://arxiv.org/pdf/1412.7525.pdf
Https://arxiv.org/pdf/1908.01580v1.pdf
Https://arxiv.org/pdf/1806.09077.pdf
Https://arxiv.org/pdf/1608.05343.pdf