It depends on the situation. For example, if you work in the medical field and you want to check if the patient has a critical disease like cancer, the false-negative would be terrible. Because if you pass on the sick patient, the patient might die. In this case, you want to reduce the false-negative as much as possible.
One issue is that if you reduce the false positive, the false-negative tends to increase. They work in the opposite way. In many cases, people want a balanced approach reducing two errors at the same time to a reasonable level. And they calculate the scores like F1 which considers both aspects at the same time.
The hypothesis you make is the null hypothesis. In this case, no difference in the designs. And positive means there is a difference against the null hypothesis, and negative is for no difference with a given significance level. Usually, the null hypothesis is set as indistinguishability as it’s the simpler hypothesis to test.
As Alexis mentioned in a comment, the hypothesis test doesn’t prove or disprove null-hypothesis with certainty. The negation of the null hypothesis doesn’t mean that the situation stated by the null hypothesis is impossible. The hypothesis test is about the probabilistic statement.

Размер выборки и искусство баланса между возможными ошибками.
Перед исследователем, планирующим изучение проблемы с использованием статистических методов так или иначе встает вопрос о необходимости расчета размера выборки для контроля между ошибкой первого и второго рода (о них читайте далее). Не стоит скрывать, что для большинства обсервационных исследований с клиническими данными достаточность объема выборки – достаточно болезненный вопрос, правильный ответ на который могут дать не многие. Мало кто понимает, что вопрос размеры выборки – дело не одной формулы, а достаточно сложная тема, требующая понимания собственных исследовательских задач, понимая, имеющихся данных в распоряжении исследователя, а также чувствительность и специфичность самих статистических критериев, имеющихся в распоряжении биометрики. Предлагаем читателю разобраться с этим важным вопросом.
В наиболее общих чертах стоит отметить, что ответ на вопрос о достаточности данных в исследуемой выборке зависит от четырех характеристик исследования: величины различия и частоте исходов между группами, р (ошибки первого рода альфа), и тип данных. Эти характеристики должен учитывать исследователь, планирующий эксперимент, а также читатель, решающий, следует ли доверять публикации.
Величина эффекта
Размер выборки зависит от того, какова же ожидаемая величина различий, которые предстоит выявить. В принципе можно искать различия любой величины и, конечно, исследователь надеется, что сможет обнаружить даже самые небольшие различия. Однако при прочих равных условиях для выявления малых различий требуется большее число пациентов. Поэтому лучше ставить вопрос таким образом:
Какое число больных достаточно, чтобы выявить наименьший клинически значимый эффект?
В случае если нас интересуют только очень большие различия между экспериментальной группой и группой сравнения (т.е. очень сильный лечебный эффект), то допустимо меньшее число пациентов.
Ошибка первого рода (Альфа-ошибка)
Размер выборки зависит также от риска альфа-ошибки (вывода об эффективности лечения, которое на самом деле неэффективно). Приемлемая величина такого риска выбирается произвольно — от 1 до 0. Если исследователь готов к последствиям высокой вероятности ложного вывода об эффективности метода, то он может взять небольшое число пациентов. Если же он стремится сделать риск ошибочного вывода достаточно малым, то потребуется увеличить число больных. Как обсуждалось выше, обычно ра устанавливается на уровне 0,05 (1 из 20), а иногда 0,01 (1 из 100).
Ошибка второго рода (Бета-ошибка)
Другой фактор, определяющий размер выборки, — это выбранный риск бета-ошибки, который тоже произволен. Вероятность бета-ошибки часто устанавливается на уровне 0,20, т.е. допускается 20% вероятность не выявить существующие в действительности различия. Общепринятые допустимые величины бета- ошибок гораздо больше, чем альфа-ошибок, т.е. мы относимся более требовательно к утверждениям об эффективности лечения. Если говорят, что лечение эффективно, оно должно быть эффективным в действительности.
Тип данных и их однородность
Статистическая мощность исследования определяется еще и типом данных. Когда исходы выражены качественными при- знаками и описываются частотой событий, статистическая мощность исследования зависит от этой частоты. Чем больше число событий, тем выше статистическая мощность исследования для данного числа испытуемых. Например, исследование 100 больных, 50 из которых умерли, имеет примерно такую же чувствительность (мощность), что и исследование 1000 больных, из которых умерли те же 50 пациентов.
Если исход выражается непрерывной количественной переменной (например, артериальное давление или уровень холестерина в сыворотке), то мощность исследования определяется степенью различий пациентов внутри каждой группы (дисперсией). Чем больше различия между пациентами по изучаемым характеристикам, тем меньше уверенности в том, что наблюдаемая разница (или ее отсутствие) между группами обусловлена истинными различиями в эффективности методов лечения. Другими словами, чем больше различия между пациентами внутри групп, тем ниже статистическая мощность исследования.
При планировании исследования автор выбирает такие величины клинической значимости лечебного эффекта, уровни ошибок, которые сам считает приемлемыми. Он может спланировать исследование таким образом, чтобы сделать его мощность максимальной для данного размера выборки, например путем отбора больных с высокой вероятностью развития исходов или с одинаковыми характеристиками (разумеется, в пределах поставленной задачи). Однако, получив данные и имея конкретную научную задачу, исследователь уже не может повлиять на статистическую мощность исследования, поскольку она определяется характеристиками полученных данных.
Взаимосвязь характеристик исследования
Обсуждавшиеся выше взаимоотношения носят характер взаимного компромисса. В принципе для любого числа включенных в исследование пациентов существует определенный баланс между ошибками первого и второго рода. При прочих равных условиях, чем больше допускаемая величина ошибки одного рода, тем меньше должен быть риск ошибки другого рода. При этом по сути своей ни одна из них не «хуже» другой. Последствия принятия ошибочной информации за истинную зависят от клинической ситуации. Если имеется острая необходимость в более эффективном методе лечения (например, болезнь очень опасна и нет эффективного альтернативного метода лечения) и предлагаемое лечение не опасно, то разумнее предпочесть относительно высокий риск вывода о том, что вмешательство эффективно, когда в действительности это не так (большая альфа-ошибка), минимизируя вероятность отвергнуть эффективный метод (бета-ошибка мала). С другой стороны, если болезнь менее серьезна и существуют альтернативные методы лечения либо новый метод лечения более дорог или опасен, следует минимизировать риск применения нового вмешательства, которое может быть неэффективным (альфа-ошибка мала), даже за счет относительно высокой вероятности упустить действительно эффективное лечения (большая бета-ошибка). Конечно, можно уменьшить обе ошибки — если число исследуемых больных велико, частота исходов высока, изучаемый показатель внутри групп варьирует мало, а предполагаемый лечебный эффект значителен.
Пример 1. Согласно наблюдениям серий случаем, нестероидный противовоспалительный препарат Сулипдак эффективен при полипах толстой кишки. Это предположение было промерено в рандомизированном испытании на 22 больных с семейным аденоматозным полппозом, 11 из которых получали сулипдак, а другие 11 плацебо. Через 9 мес у получавших сулипдак среднее число полипов было на 44% меньше, чем у получавших плацебо; различие статистически значимое (p<0,05). Поскольку лечебный эффект значителен, а на каждого пациента приходилось большое количество полипов (у некоторых более 100), для доказательства того, что лечебный эффект неслучаен, достаточно небольшого числа больных.
Пример 2. Исследование 2, было спланировано таким образом, чтобы при включении 41 000 пациентов оно с вероятностью 90% обеспечивало бы обнаружение снижения летальности в экспериментальной группе на 15% или частоты летальных исходов на 1% по сравнению с контрольной группой, в зависимости от того, какой из этих показателей будет больше. При этом допустимый уровень 0,05, а предполагаемая летальность в контрольной группе не ниже 8%. Здесь необходим большой объем выборки, так как доля больных с неблагоприятным исходом (смерть) относительно мала, величина лечебного эффекта невелика (15%) и авторы хотели иметь относительно высокую вероятность обнаружить эффект терапии, если он все-таки присутствует (90%).
Проиллюстрируем также, как задачу расчета объема выборки на примере использования статистического пакета Stata. Для этого воспользуемся командной строкой. Для определения мощности и размера выборки существует команда sampsi.
Предположим, что для сравнения средних мы решили применить t-Критерий Стьюдента для парных выборок. Стандартное отклонение исследуемого показателя одинаково в обеих группах и составляет 20 мм рт. ст. Сами группы также равны по размеру. Тогда следует записать следующую команду:
sampsi 150 135, sd1(20) sd2(20) p(0.8) a(0.05)
Здесь 150 и 135 – это средние величины артериального давления, выраженные в мм рт ст. sd1() и sd2() – стандартные отклонения, p() и a() – целевые мощность (ошибка второго рода) и уровень значимости (ошибка первого рода) соответственно.
В результате работы команды мы выясним, что для решения поставленной задачи необходимо набрать группы по 28 человек.
Необходимо всегда иметь в виду, что приведённые в примере значения мощности и уровня значимости могут изменяться в зависимости от особенностей исследования. Однако любое повышение мощности будет даваться довольно дорого. Так, если в нашем примере увеличить целевую мощность до 90%, то при сохранении всех прочих параметров размер выборки придётся увеличить до 38 испытуемых в каждой группе, что скажется на стоимости планируемой работы.
Вместо заключения
Для получения ответов на большинство возникающих в наше время вопросов относительно эффективности того или иного вмешательства требуется изучение результатов лечения очень большого числа больных. Вместе с тем эффективность таких действенных вмешательств, как введение инсулина при диабетическом кетоацидозе или хирургической операции при аппендиците, можно установить при анализе данных небольшого числа больных. Однако подобные методы лечения появляются редко и многие из них уже хорошо изучены. Теперь нам приходится рассматривать патологию с хроническим течением и с множественными взаимодействующими этиологическими факторами; эффективность предлагаемых новых методов лечения таких заболеваний, в общем, невелика. В подобной ситуации необходимо обращать особое внимание на то, достаточна ли численность больных в клиническом испытании для того, чтобы отличить истинный лечебный эффект от случайного результата.
Автор сайта: Кирилл Мильчаков
Источник:
Флетчер Р., Флетчер С., Вагнер Э. Клиническая эпидемиология: Основы доказательной медицины/ М.: Медиа Сфера, 1998. — 352 с.
Если Вам понравилась статья и оказалась полезной, Вы можете поделиться ею с коллегами и друзьями в социальных сетях:
Основной
опасностью при организации экспериментальных
эпидемио-логических
исследований является возможность
получения искаженных
результатов, т. е. получения ложноположительных
или ложноотрицательных результатов
вследствие недоучета возможных ошибок.
Такие ошибки могут быть систематическими
или случайными.
Систематической
ошибкой
(смещением)
исследования
называют неслучайное (тенденциозное)
искажение (отклонение от истинного
в сторону увеличения или уменьшения)
результатов исследования.
Причинами
систематической ошибки могут быть
нарушения правил:
-
отбора контингентов
в опытные и контрольные группы; -
определения
необходимой численности контингентов
в опытной и контрольной группах; -
обеспечения
достоверности и объективности оценки
полученных
результатов; -
исключения
предвзятости при обнародовании
результатов исследования.
4. Причины появления случайной ошибки в эпидемиологических исследованиях.
Случайной
называют ошибку,
имеющую одинаковую вероятность
увеличения или уменьшения показателей
и обусловленную случайными
различиями опытной и контрольной групп.
Случайную ошибку
невозможно предусмотреть и предупредить,
но можно уменьшить
ее влияние на результаты опыта, обеспечив
правильное планирование
и осуществление исследования и оценку
его результатов.
Для
оценки роли случайности используют
статистические приемы,
направленные на:
а)
проверку гипотезы об отсутствии истинных
различий между показателями в группах
(«нулевая
гипотеза»);
б)
определение диапазона значений,
находящиеся в котором полученные
результаты можно признать достоверными
(«доверительный
интервал»,
«доверительные
границы»).
В
первом случае с помощью статистических
методов стараются выявить
так называемые альфа-ошибку и бета-ошибку.
Альфа-ошибка
имеет место, когда
разница показателей в опытной и
контрольной группе, в действительности
отсутствующая, признается существенной.
Бета-ошибка
возникает,
когда разница показателей, в
действительности имеющая место,
признается несущественной.
Для
оценки существенности разницы показателей
(или статистической значимости различий)
предложено множество статистических
критериев: Хи-квадрат
(между относительными частотами при
большом числе наблюдений), критерий
Манна-Уитни (между
двумя
медианами), критерий
Стьюдента
(между двумя средними), критерий
Фишера
(между двумя и более средними) и др.
Метод
доверительных интервалов
(границ) заключается в определении
диапазона, в пределах которого с
определенной вероятностью
находится истинная величина полученного
в опыте показателя. Так, 95 % доверительного
интервала означает, что истинное значение
искомой величины с вероятностью 95 %
лежит в пределах этого интервала.
Величина доверительного интервала
характеризует степень достоверности
(убедительности, доказательности)
полученных результатов, их соответствия
действительной величине. Чем уже
доверительный интервал, тем ближе
полученная в опыте величина измеряемого
эффекта к истинной величине.
Среди
причин ошибок при эпидемиологическом
обследовании очага
следует прежде всего назвать недостоверность
или
неполноту
сбора фактических данных, в
результате чего сам фундамент
эпидемиологического
диагноза оказывается несостоятельным.
Причиной
неполноты сбора фактических данных
может явиться
отсутствие методичности, последовательности
и всесторонности в сборе
эпидемиологически значимых данных,
обусловленное либо пробелами
в подготовке эпидемиолога, т. е.
недостаточным владением
эпидемиологическим методом исследования,
либо субъективизмом
его при определении направления сбора
эпидемиологической
информации.
Опрос
больного и окружающих его лиц, являясь
одним из важнейших
приемов эпидемиологического обследования,
может однако служить
источником диагностических ошибок в
случаях, если он
проводится формально, нецеленаправленно,
поспешно. Недостоверность
собранных в очаге данных может быть
обусловлена непониманием опрашиваемым
сущности предлагаемых ему вопросов, а
иногда и связанным
с разными причинами сознательным
желанием ввести
в заблуждение. Недостоверность данных
об эпидемиологической
ситуации на определенной территории
за какой-либо период времени
может быть связана с неполнотой
регистрации заболеваний,
обусловленной как состоянием их
выявления, диагностики и учета, так и
особенностями самой нозологической
формы болезни (манифестность,
исходы и др.), либо сочетанием этих
обстоятельств.
Сведения,
полученные при изучении документов,
как и все другие,
нуждаются в критической оценке. Это,
например, относится к диагнозам
заболеваний, предшествовавших тому, по
поводу которого проводится обследование
(так, нередки случаи, когда заболевания,
диагностировавшиеся как грипп, пневмония,
ОРВИ, при тщательном
ретроспективном исследовании оказывались
брюшным тифом).
Иногда приходится сталкиваться с
фиктивными данными, например,
когда документы свидетельствуют о том,
что ребенок привит против данной
инфекции, тогда как в действительности
он привит не был. Подобные же «приписки»
могут касаться привитости
животных против сибирской язвы и т. п.
Вопрос
о полноте и достоверности решается и в
отношении данных,
характеризующих динамику природных и
социальных факторов,
без которых не может осуществляться
эпидемиологическая диагностика.
Ошибки
в группировке и анализе
собранных
данных часто возникают
при обработке их по срокам заболеваний,
когда материал группируется
не по датам начала заболеваний, а по
датам их регистрации.
Между тем, от момента начала заболевания
до момента его регистрации
иногда проходит значительный промежуток
времени, подчас
исчисляющийся не часами, сутками, но и
неделями, что связано с
несвоевременным обращением заболевших
за медицинской помощью,
и диагностическими ошибками при первичном
обращении. В подобном случае кривая,
изображенная на основании группировки
случаев
заболеваний по срокам регистрации,
будет искажать истинную динамику
заболеваемости, что может привести к
ошибочным выводам.
Другая
ошибка в оценке заболеваемости во
времени может быть основана на недооценке
вариабельности инкубационного периода
и неточности в определении больными
времени начала заболевания, либо
недоучете возможной недостоверности
выводов, связанных с небольшим объемом
наблюдений. Такая ошибка может быть
вызвана анализом динамики заболеваемости
по дням, тогда как группировка ее по
пятидневкам дает гораздо более
показательную картину.
Иногда
эпидемиолог может быть введен в
заблуждение в результате использования
в анализе абсолютных или экстенсивных
показателей вместо интенсивных. Такая
ошибка чаще всего возникает при
анализе заболеваемости в различных
группах населения, когда упускается из
виду возможность влияния на показатели
различий в численности этих групп.
Так, обнаружив, что наибольший удельный
вес среди заболевших приходится на
работников какого-либо предприятия,
эпидемиолог перенесет поиск источника
либо факторов
передачи возбудителя на это предприятие.
Когда поиски окажутся
безрезультатными и тем или иным путем
выяснится, что вспышка
в действительности никак не связана с
данным предприятием,
станет очевидным, что степень пораженности
рабочих была не
выше, чем других групп населения, а
большее число заболеваний их,
так же как и больший удельный вес,
обусловлены преобладанием
численности работающих на данном
предприятии среди всего населения.
В подобных случаях анализ стандартизованных
показателей нивелирует различия в
показателях заболеваемости в разных
группах
населения.
Подобные
ошибки могут возникать и при сравнении
абсолютных
чисел или экстенсивных показателей
заболеваемости в разных микрорайонах
населенного пункта, в разных возрастных
группах, среди
посещающих и не посещающих дошкольные
учреждения и т.д.
И в этих случаях только анализ
стандартизованных показателей
способен выявить реальную ситуацию.
К
ошибочным выводам может привести и
анализ средних показателей
заболеваемости в населенном пункте без
учета разброса заболеваний
по его территории или концентрации ее
в каком-нибудь микрорайоне.
САМОСТОЯТЕЛЬНАЯ
РАБОТА
1. Рассчитать и
дать оценку случайной ошибки с помощью
нулевой гипотезы и доверительного
интервала.
2. Изучить и выявить
ошибки при сборе группировке и анализе
собранных данных.
КОНТРОЛЬНЫЕ
ВОПРОСЫ ПО ТЕМЕ
-
Эпидемиологический
эксперимент. -
Виды
экспериментального исследования. -
Естественный
эксперимент. -
Неконтролируемый
эпидемиологический опыт. -
Контролируемый
эпидемиологический опыт. -
Физическое
и биологическое моделирование
эпидемического процесса. -
Эпизоотологический
эксперимент. -
Математическая
эпидемиологическая модель, цель и виды. -
Цель
описательной математической модели. -
Цель
вероятностной математической модели. -
Виды
потенциальных ошибок. -
Причины
систематических ошибок. -
Случайная
ошибка и систематические приемы для
оценки случайной ошибки. -
Нулевая
гипотеза, значение α-ошибки и β-ошибки.
Статистические критерии: Хи – квадрат,
критерий Манна-Уитни, критерий Стьюдента,
критерий Фишера. -
Доверительный
интервал, его значение и границы. -
Причины
ошибки при сборе фактических данных. -
Причины
ошибки в группировке и анализе собранных
данных.
Соседние файлы в папке МР по эпид
- #
- #
- #
- #
14.03.2016489.47 Кб81кэ.doc
- #
- #
- #
- #
- #
- #
- #
В 1 — е и 2 — й типа ошибка , также называемый альфа-ошибку (альфа-ошибкой) и бета-ошибки (бета-ошибка) (или α- / β- риска ), обозначают статистически неправильное решение. Они относятся к методу математической статистики, так называемой проверке гипотез . При проверке гипотезы возникает ошибка типа I, если нулевая гипотеза отклоняется, когда она действительно верна (на основе случайного увеличения или уменьшения числа положительных результатов). Напротив, ошибка типа 2 означает, что тест неправильно не отклоняет нулевую гипотезу, хотя альтернативная гипотеза верна. Ошибки 1 — го и 2 — го типа часто упоминается в статистическом контроле качества (см инспекционных много ) в качестве производителя риска и потребительского риска. При управлении технологическим процессом с помощью карт контроля качества для этого используются термины « слепая сигнализация» и « пропущенная сигнализация» . Ошибки типа 1 и 2 также известны как частотные концепции . Тем не менее, ошибки типа 1 и типа 2 всегда являются условными вероятностями . Понятие ошибок типа 1 и 2 было введено Нейманом и Пирсоном .
Таблица решений
| реальность | |||
|---|---|---|---|
| H 0 верно | H 1 верно | ||
| Решение теста … |
… для H 0 | Правильное решение (специфичность) ( справа отрицательное ) Вероятность: 1 — α |
Ошибка 2-го типа ( ложноотрицательный ) Вероятность: β |
| … для H 1 |
Ошибка типа 1 ( ложное срабатывание ) Вероятность: α |
Правильное решение Вероятность: 1-β ( правильный положительный результат ) ( избирательность теста , чувствительность) |
Формальное представительство
Статистический тест — это проблема решения, которая включает неизвестный параметр, который должен находиться в определенном пространстве параметров . Пространство параметров можно разбить на два непересекающихся подмножества и . Проблема решения теперь состоит в том, чтобы решить, лежит ли оно в или . Определите нулевую гипотезу и альтернативную гипотезу . Поскольку и не пересекаются, только одна из двух гипотез может быть верной. Поскольку гипотетический тест всегда требует решения, существует вероятность того, что вы примете неверное решение. Будь и . После определения диапазона отклонения и статистики испытаний можно определить вероятность отклонения для каждого из них . Пусть , где отклоняется, если статистика теста попадает в критический диапазон ( ). Функцию также называют функцией качества . Обычно существует другая вероятность отклонения нулевой гипотезы , даже если она верна (это называется ошибкой типа I). При проверке гипотез обычно процедуры тестирования разрабатываются только таким образом, чтобы эта вероятность ограничивалась константой, называемой уровнем значимости теста. То есть уровень значимости — это наибольшее значение для каждого значения, которое соответствует действительности . В отличие от ошибки 1-го типа, ошибка 2-го типа не контролируется заданным пределом . Это я. A. Невозможно минимизировать обе вероятности ошибки одновременно. Следовательно, среди всех тестов значимости (тестов, проверяющих наличие ошибки типа I) ищется тот, который минимизирует вероятность ошибки . Другими словами: если уровень значимости или ошибка типа 1 был определен априори , то человек заинтересован в максимальном увеличении степени различения всех соответствующих альтернатив. Селективность теста равно 1 минус вероятность сделать ошибку типа 2, т.е. ЧАС. . Вероятность ошибки типа 2 не считается предопределенной, а скорее зависит от параметра, присутствующего в генеральной совокупности. Таким образом, следующее относится к вероятности совершения ошибки типа 1 или типа 2.



















-
 и .
и .


В случае «простых» гипотез (таких как, например, vs. ), только знак равенства применяется к вероятности совершения ошибки типа 1. ЧАС. . В общем, уменьшение увеличивает вероятность ошибок 2-го типа и наоборот. Также можно определить путем сложных расчетов .



Ошибка типа 1
При проверке гипотезы возникает ошибка типа I, если нулевая гипотеза отклоняется, когда она действительно верна (на основе ложных срабатываний ).
Исходная гипотеза (нулевая гипотеза) — это предположение, что тестовая ситуация находится в «нормальном состоянии». Если это «нормальное состояние» не распознается, хотя оно действительно существует, возникает ошибка типа 1. Примеры ошибок типа 1:
- пациент считается больным, хотя на самом деле он здоров (нулевая гипотеза: пациент здоров ),
- обвиняемый признан виновным, хотя на самом деле он невиновен (нулевая гипотеза: обвиняемый невиновен ),
- человеку не предоставлен доступ, хотя у него есть разрешение на доступ (нулевая гипотеза: у человека есть разрешение на доступ )
Уровень значимости или вероятности ошибки максимальной вероятность , определяется перед гипотезой теста, что нулевая гипотеза будет отвергнута на основании результатов испытаний , даже если нулевая гипотеза верна. Как правило, выбирается уровень значимости 5% (значительный) или 1% (очень значимый).
Другое возможное неправильное решение, а именно отклонение альтернативной гипотезы, даже если она верна, называется ошибкой типа II.

Примеры
- Перед тестером стоит урна, в которую он не может заглянуть. Внутри есть красные и зеленые шары. Для тестирования из урны можно вынуть только один шар.
Альтернативная гипотеза: «В урне больше красных шаров, чем зеленых».
Чтобы иметь возможность судить о содержимом урны, тестер несколько раз удаляет шарики из урны для целей тестирования. Если затем он приходит к выводу, что альтернативная гипотеза может быть верной, т. Е. Он считает, что в урне больше красных, чем зеленых шаров, хотя в действительности нулевая гипотеза верна, а именно, что столько же красных, сколько зеленых или зеленых шаров. меньше красных, чем Если в урне есть зеленые шары, он совершает ошибку 1-го типа. - Мы хотим проверить, увеличивает ли новый метод обучения успеваемость учащихся. Для этого мы сравниваем группу студентов, обучавшихся по новому методу обучения, с выборкой студентов, которые обучались по старому методу.
Альтернативная гипотеза: «Студенты, которые обучались по новому методу обучения, имеют более высокую успеваемость, чем студенты, которые обучались по старому методу».
Предполагая, что в нашем исследовании, выборка студентов, которые обучались в соответствии с новым методом обучения, на самом деле показывает лучший результат обучения на. Возможно, эта разница возникла случайно или по другим причинам. Таким образом, если на самом деле между двумя популяциями нет никакой разницы, и мы ошибочно отвергаем нулевую гипотезу — то есть считаем несомненным, что новый метод улучшает обучение, — тогда мы совершаем ошибку типа I. Это, конечно, может иметь фатальные последствия, если мы z. Например, перевод всего обучения на новый метод обучения с большими затратами и усилиями, хотя на самом деле это совсем не дает лучших результатов. - Фильтр спама для входящей электронной почты : фильтр должен распознавать, является ли электронное письмо спамом или нет.
Нулевая гипотеза: это обычная электронная почта, а не спам.
Альтернативная гипотеза: это спам.
Если электронное письмо классифицируется как спам, но на самом деле это не спам, т.е. сообщение ошибочно классифицируется как спам, мы говорим об ошибке первого типа (ложное срабатывание).
Ошибка 2-го типа
В отличие от ошибки 1-го типа ошибка 2-го типа означает, что тест неверно подтверждает нулевую гипотезу, даже если альтернативная гипотеза верна.
Трудности определения ошибки Art
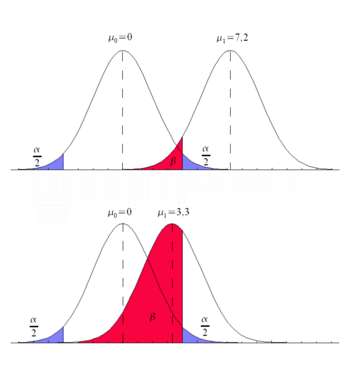
Ошибка 1-го типа синим цветом, ошибка 2-го типа красным. Представление возможных значений вероятности ошибки 2-го типа (красный) на примере теста значимости с использованием ожидаемого значения μ. Поскольку ошибка типа 2 зависит от положения параметра нецентральности (здесь ), но при условии альтернативной гипотезы i. d. Обычно неизвестно, вероятность ошибки типа 2, в отличие от ошибки типа 1 (синий цвет), не может быть определена заранее.
В отличие от риска 1-го типа ошибочного отклонения данной нулевой гипотезы, хотя он действительно применяется, риск 2-го типа, то есть вероятность ошибки 2-го типа, обычно не может быть определен заранее. Причиной этого является способ, которым устанавливаются гипотезы статистических тестов: в то время как нулевая гипотеза всегда представляет собой конкретное утверждение, такое как «среднее значение» , альтернативная гипотеза состоит в том, что она в основном охватывает все другие возможности, так что i. d. Обычно только довольно неопределенного или глобального характера (например : «среднее значение »).


График справа иллюстрирует эту зависимость вероятности ошибки 2-го типа ; (красный) от неизвестного среднего значения , если «уровень значимости», т.е. ЧАС. максимальный риск первого вида ; (синий) в обоих случаях выбрано одно и то же значение. Как можно видеть, существует также парадоксальная ситуация, когда вероятность ошибки второго типа тем больше, чем ближе истинное значение к значению, утвержденному нулевой гипотезой , вплоть до того, что для риска второй тип ; предельное значение ; принимает. Другими словами, чем меньше отклонение фактического значения от заявленного значения , тем парадоксальным образом выше вероятность ошибки, если кто-то продолжает верить заявленному значению на основании результата теста (хотя разница между двумя значениями может быть практически неактуальными из-за своей незначительности больше пьес). Как показывает это противоречие, рассмотрение проблемы ошибок 2-го типа чисто формально-логическим образом может легко стать основанием для неправильных решений. В биометрических и медицинских статистических приложениях вероятность принятия решения для H 0, если H 0 верна, называется специфичностью . Вероятность принятия решения для H 1, если H 1 верна, называется чувствительностью . Желательно, чтобы метод тестирования обладал высокой чувствительностью и высокой специфичностью и, следовательно, малой вероятностью ошибок первого и второго типа.





Примеры
- В управлении проектами « Шесть сигм »: ошибка типа 1: в конце проекта вы замечаете, что аспекты были упущены во время первоначального планирования («сделано слишком мало»). Ошибка 2-го типа здесь будет заключаться в том, что весь проект был посвящен вещам, которые в конечном итоге оказываются излишними или несущественными для успеха проекта («сделано слишком много»).
- Перед тестером стоит урна, в которую он не может заглянуть. Внутри есть красные и зеленые шары. Для тестирования из урны можно вынуть только один шар.
Альтернативная гипотеза : «В урне больше красных шаров, чем зеленых».
Чтобы иметь возможность сделать суждение о содержимом урны, тестер несколько раз извлекает из урны шары для целей тестирования. Нулевая гипотеза в нашем примере, что есть либо как много красных шаров как зеленые шарики или более зеленые шарики , чем красные шары в урне (противоположность альтернативной гипотезы ). Если на основе своей выборки тестировщик приходит к выводу, что нулевая гипотеза верна или альтернативная гипотеза неверна, хотя на самом деле альтернативная гипотеза верна, то он делает ошибку 2-го типа. - Мы хотели бы исследовать влияние диеты на умственное развитие детей в детских домах. Для этого мы сравниваем две группы детей в отношении их результатов в когнитивных тестах: одна группа детей питается по общепринятому плану, другая получает особенно здоровую диету. Мы подозреваем, что здоровая диета положительно влияет на когнитивные способности. .
Альтернативная гипотеза: «Дети, которые питаются особенно здоровой диетой, обладают лучшими когнитивными способностями, чем дети, которых кормят обычным способом».
Если мы теперь сравним когнитивные характеристики наших двух выборок, мы не обнаружим разницы в когнитивных способностях. В результате мы считаем альтернативную гипотезу ложной и подтверждаем нулевую гипотезу. Однако, если на самом деле здоровое, питающееся население работает лучше, тогда мы делаем ошибку типа 2.
Но мы не обнаружили разницы в нашей выборке, не так ли? Однако это равенство может быть также связано со случайным разбросом результатов измерений или с неблагоприятным составом наших образцов.
Совершение ошибки типа 2 обычно менее «плохо», чем ошибка типа 1. Однако это зависит индивидуально от предмета исследования. В нашем примере ошибка типа II имеет очень негативные последствия: хотя здоровая диета улучшает работоспособность, мы решаем придерживаться традиционной диеты. Ошибка первого рода, то есть введение здорового питания для всех детей, хоть и не приводит к улучшению работоспособности, но имела бы здесь меньше негативных последствий.
Противоположное обозначение
В некоторых источниках для обозначения ошибки 2-го типа и серьезности теста используются совершенно противоположные обозначения. Здесь вероятность совершения ошибки 2-го типа обозначается значением 1-β, тогда как сила или мощность теста обозначается β.
Агностические тесты
В мае 2018 года Виктор Кострато , Рафаэль Избицки и Рафаэль Басси предложили метод, с помощью которого можно управлять ошибками как 1-го, так и 2-го типа. Они называют такую процедуру «проверкой агностика». В дополнение к ошибкам 1-го и 2-го типа в независимых тестах определяется еще одна так называемая ошибка 3-го типа. Это происходит, когда результат теста не поддерживает ни нулевую гипотезу ( ), ни альтернативную гипотезу ( ) , а скорее его результат остается агностическим.
Смотри тоже
- Функция качества или рабочая характеристика
- Проверить силу
- Накопление альфа-ошибок
- p-значение
веб ссылки
- Интерактивная иллюстрация
Индивидуальные доказательства
- ↑ a b Денес Сукс, Джон Иоаннидис : Когда проверка значимости нулевой гипотезы непригодна для исследования: переоценка. В: Границы нейробиологии человека , том 11, 2017 г., стр. 390, doi: 10.3389 / fnhum.2017.00390 , PMID 28824397 , PMC 5540883 (полный текст) (обзор).
- ↑ Филип Сиббертсен и Хартмут отдыхают: Статистика: Введение для экономистов и социологов. , С. 379.
- ↑ Ежи Нейман и Эгон Пирсон : Об использовании и интерпретации определенных критериев испытаний для целей статистического вывода: Часть I . В: Биометрика , Том 20А, № 1/2 (июль 1928 г.). Издательство Оксфордского университета. Страницы 175-240.
- ^ Людвиг Фармейр , художник Риты, Ирис Пигеот , Герхард Тутц : Статистика. Путь к анализу данных. 8., перераб. и дополнительное издание. Springer Spectrum, Берлин / Гейдельберг, 2016 г., ISBN 978-3-662-50371-3 , стр. 385.
- ↑ Байер, Хакель: Расчет вероятностей и математическая статистика , стр. 154
- ↑ Примечание : и бета (и альфа) представляют собой условные вероятности.
- ↑ Джордж Джадж, Р. Картер Хилл, В. Гриффитс, Гельмут Люткеполь , Т.С. Ли. Введение в теорию и практику эконометрики. 2-е издание. John Wiley & Sons, Нью-Йорк / Чичестер / Брисбен / Торонто / Сингапур 1988, ISBN 0-471-62414-4 , стр. 96 и далее.
- ↑ Джеффри Марк Вулдридж : Вводная эконометрика: современный подход. 4-е издание. Nelson Education, 2015, с. 779.
- ↑ Джордж Джадж, Р. Картер Хилл, В. Гриффитс, Гельмут Люткеполь , Т.С. Ли. Введение в теорию и практику эконометрики. 2-е издание. John Wiley & Sons, Нью-Йорк / Чичестер / Брисбен / Торонто / Сингапур 1988, ISBN 0-471-62414-4 , стр. 96 и далее.
- ↑ Джеймс Л. Джонсон: вероятность и статистика для компьютерных наук. С. 340 и сл.
- ↑ Эрвин Крейсциг: Статистические методы и их приложения . 7-е издание. Göttingen 1998, p. 209 ff.
- ↑ Виктор Коскрато, Рафаэль Избицки, звезда Рафаэля Басси: Агностические тесты могут контролировать ошибки типа I и типа II одновременно . Май 11, 2018, Arxiv : 1805,04620 .
5.3. Ошибки первого и второго рода
Ошибка первого рода состоит в том, что гипотеза ![]() будет отвергнута, хотя на самом деле она правильная. Вероятность
будет отвергнута, хотя на самом деле она правильная. Вероятность
допустить такую ошибку называют уровнем значимости и обозначают буквой ![]() («альфа»).
(«альфа»).
Ошибка второго рода состоит в том, что гипотеза ![]() будет принята, но на самом деле она неправильная. Вероятность
будет принята, но на самом деле она неправильная. Вероятность
совершить эту ошибку обозначают буквой ![]() («бета»). Значение
(«бета»). Значение ![]() называют мощностью критерия – это вероятность отвержения неправильной
называют мощностью критерия – это вероятность отвержения неправильной
гипотезы.
В практических задачах, как правило, задают уровень значимости, наиболее часто выбирают значения ![]() .
.
И тут возникает мысль, что чем меньше «альфа», тем вроде бы лучше. Но это только вроде: при уменьшении
вероятности ![]() —
—
отвергнуть правильную гипотезу растёт вероятность ![]() — принять неверную гипотезу (при прочих равных условиях).
— принять неверную гипотезу (при прочих равных условиях).
Поэтому перед исследователем стоит задача грамотно подобрать соотношение вероятностей ![]() и
и ![]() , при этом учитывается тяжесть последствий, которые
, при этом учитывается тяжесть последствий, которые
повлекут за собой та и другая ошибки.
Понятие ошибок 1-го и 2-го рода используется не только в статистике, и для лучшего понимания я приведу пару
нестатистических примеров.
Петя зарегистрировался в почтовике. По умолчанию, ![]() – он считается добропорядочным пользователем. Так считает антиспам
– он считается добропорядочным пользователем. Так считает антиспам
фильтр. И вот Петя отправляет письмо. В большинстве случаев всё произойдёт, как должно произойти – нормальное письмо дойдёт до
адресата (правильное принятие нулевой гипотезы), а спамное – попадёт в спам (правильное отвержение). Однако фильтр может
совершить ошибку двух типов:
1) с вероятностью ![]() ошибочно отклонить нулевую гипотезу (счесть нормальное письмо
ошибочно отклонить нулевую гипотезу (счесть нормальное письмо
за спам и Петю за спаммера) или
2) с вероятностью ![]() ошибочно принять нулевую гипотезу (хотя Петя редиска).
ошибочно принять нулевую гипотезу (хотя Петя редиска).
Какая ошибка более «тяжелая»? Петино письмо может быть ОЧЕНЬ важным для адресата, и поэтому при настройке фильтра
целесообразно уменьшить уровень значимости ![]() , «пожертвовав» вероятностью
, «пожертвовав» вероятностью ![]() (увеличив её). В результате в основной ящик будут попадать все
(увеличив её). В результате в основной ящик будут попадать все
«подозрительные» письма, в том числе особо талантливых спаммеров. …Такое и почитать даже можно, ведь сделано с любовью
Существует примеры, где наоборот – более тяжкие последствия влечёт ошибка 2-го рода, и вероятность ![]() следует увеличить (в пользу уменьшения
следует увеличить (в пользу уменьшения
вероятности ![]() ). Не хотел я
). Не хотел я
приводить подобные примеры, и даже отшутился на сайте, но по какой-то мистике через пару месяцев сам столкнулся с непростой
дилеммой. Видимо, таки, надо рассказать:
У человека появилась серьёзная болячка. В медицинской практике её принято лечить (основное «нулевое» решение). Лечение
достаточно эффективно, однако не гарантирует результата и более того опасно (иногда приводит к серьёзному пожизненному
увечью). С другой стороны, если не лечить, то возможны осложнения и долговременные функциональные нарушения.
Вопрос: что делать? И ответ не так-то прост – в разных ситуациях разные люди могут принять разные
решения (упаси вас).
Если болезнь не особо «мешает жить», то более тяжёлые последствия повлечёт ошибка 2-го рода – когда человек соглашается
на лечение, но получает фатальный результат (принимает, как оказалось, неверное «нулевое» решение). Если же…, нет, пожалуй,
достаточно, возвращаемся к теме:
 5.4. Процесс проверки статистической гипотезы
5.4. Процесс проверки статистической гипотезы
 5.2. Нулевая и альтернативная гипотезы
5.2. Нулевая и альтернативная гипотезы
| Оглавление |
Ошибки I и II рода при проверке гипотез, мощность
Общий обзор
Принятие неправильного решения
Мощность и связанные факторы
Проверка множественных гипотез
Общий обзор
Большинство проверяемых гипотез сравнивают между собой группы объектов, которые испытывают влияние различных факторов.
Например, можно сравнить эффективность двух видов лечения, чтобы сократить 5-летнюю смертность от рака молочной железы. Для данного исхода (например, смерть) сравнение, представляющее интерес (например, различные показатели смертности через 5 лет), называют эффектом или, если уместно, эффектом лечения.
Нулевую гипотезу выражают как отсутствие эффекта (например 5-летняя смертность от рака молочной железы одинаковая в двух группах, получающих разное лечение); двусторонняя альтернативная гипотеза будет означать, что различие эффектов не равно нулю.
Критериальная проверка гипотезы дает возможность определить, достаточно ли аргументов, чтобы отвергнуть нулевую гипотезу. Можно принять только одно из двух решений:
- отвергнуть нулевую гипотезу и принять альтернативную гипотезу
- остаться в рамках нулевой гипотезы
Важно: В литературе достаточно часто встречается понятие «принять нулевую гипотезу». Хотелось бы внести ясность, что со статистической точки зрения принять нулевую гипотезу невозможно, т.к. нулевая гипотеза представляет собой достаточно строгое утверждение (например, средние значения в сравниваемых группах равны ![]() ).
).
Поэтому фразу о принятии нулевой гипотезы следует понимать как то, что мы просто остаемся в рамках гипотезы.
Принятие неправильного решения
Возможно неправильное решение, когда отвергают/не отвергают нулевую гипотезу, потому что есть только выборочная информация.
| Верная гипотеза | |||
|---|---|---|---|
| H0 | H1 | ||
| Результат
применения критерия |
H0 | H0 верно принята | H0 неверно принята
(Ошибка второго рода) |
| H1 | H0 неверно отвергнута
(Ошибка первого рода) |
H0 верно отвергнута |
Ошибка 1-го рода: нулевую гипотезу отвергают, когда она истинна, и делают вывод, что имеется эффект, когда в действительности его нет. Максимальный шанс (вероятность) допустить ошибку 1-го рода обозначается α (альфа). Это уровень значимости критерия; нулевую гипотезу отвергают, если наше значение p ниже уровня значимости, т. е., если p < α.
Следует принять решение относительно значения а прежде, чем будут собраны данные; обычно назначают условное значение 0,05, хотя можно выбрать более ограничивающее значение, например 0,01.
Шанс допустить ошибку 1-го рода никогда не превысит выбранного уровня значимости, скажем α = 0,05, так как нулевую гипотезу отвергают только тогда, когда p< 0,05. Если обнаружено, что p > 0,05, то нулевую гипотезу не отвергнут и, следовательно, не допустят ошибки 1-го рода.
Ошибка 2-го рода: не отвергают нулевую гипотезу, когда она ложна, и делают вывод, что нет эффекта, тогда как в действительности он существует. Шанс возникновения ошибки 2-го рода обозначается β (бета); а величина (1-β) называется мощностью критерия.
Следовательно, мощность — это вероятность отклонения нулевой гипотезы, когда она ложна, т.е. это шанс (обычно выраженный в процентах) обнаружить реальный эффект лечения в выборке данного объема как статистически значимый.
В идеале хотелось бы, чтобы мощность критерия составляла 100%; однако это невозможно, так как всегда остается шанс, хотя и незначительный, допустить ошибку 2-го рода.
К счастью, известно, какие факторы влияют на мощность и, таким образом, можно контролировать мощность критерия, рассматривая их.
Мощность и связанные факторы
Планируя исследование, необходимо знать мощность предложенного критерия. Очевидно, можно начинать исследование, если есть «хороший» шанс обнаружить уместный эффект, если таковой существует (под «хорошим» мы подразумеваем, что мощность должна быть по крайней мере 70-80%).
Этически безответственно начинать исследование, у которого, скажем, только 40% вероятности обнаружить реальный эффект лечения; это бесполезная трата времени и денежных средств.
Ряд факторов имеют прямое отношение к мощности критерия.
Объем выборки: мощность критерия увеличивается по мере увеличения объема выборки. Это означает, что у большей выборки больше возможностей, чем у незначительной, обнаружить важный эффект, если он существует.
Когда объем выборки небольшой, у критерия может быть недостаточно мощности, чтобы обнаружить отдельный эффект. Эти методы также можно использовать для оценки мощности критерия для точно установленного объема выборки.
Вариабельность наблюдений: мощность увеличивается по мере того, как вариабельность наблюдений уменьшается.
Интересующий исследователя эффект: мощность критерия больше для более высоких эффектов. Критерий проверки гипотез имеет больше шансов обнаружить значительный реальный эффект, чем незначительный.
Уровень значимости: мощность будет больше, если уровень значимости выше (это эквивалентно увеличению допущения ошибки 1-го рода, α, а допущение ошибки 2-го рода, β, уменьшается).
Таким образом, вероятнее всего, исследователь обнаружит реальный эффект, если на стадии планирования решит, что будет рассматривать значение р как значимое, если оно скорее будет меньше 0,05, чем меньше 0,01.
Обратите внимание, что проверка ДИ для интересующего эффекта указывает на то, была ли мощность адекватной. Большой доверительный интервал следует из небольшой выборки и/или набора данных с существенной вариабельностью и указывает на недостаточную мощность.
Проверка множественных гипотез
Часто нужно выполнить критериальную проверку значимости множественных гипотез на наборе данных с многими переменными или существует более двух видов лечения.
Ошибка 1-го рода драматически увеличивается по мере увеличения числа сравнений, что приводит к ложным выводам относительно гипотез. Следовательно, следует проверить только небольшое число гипотез, выбранных для достижения первоначальной цели исследования и точно установленных априорно.
Можно использовать какую-нибудь форму апостериорного уточнения значения р, принимая во внимание число выполненных проверок гипотез.
Например, при подходе Бонферрони (его часто считают довольно консервативным) умножают каждое значение р на число выполненных проверок; тогда любые решения относительно значимости будут основываться на этом уточненном значении р.
Связанные определения:
p-уровень
Альтернативная гипотеза, альтернатива
Альфа-уровень
Бета-уровень
Гипотеза
Двусторонний критерий
Критерий для проверки гипотезы
Критическая область проверки гипотезы
Мощность
Мощность исследования
Мощность статистического критерия
Нулевая гипотеза
Односторонний критерий
Ошибка I рода
Ошибка II рода
Статистика критерия
Эквивалентные статистические критерии
В начало
Содержание портала
5.3. Ошибки первого и второго рода
Ошибка первого рода состоит в том, что гипотеза ![]() будет отвергнута, хотя на самом деле она правильная. Вероятность
будет отвергнута, хотя на самом деле она правильная. Вероятность
допустить такую ошибку называют уровнем значимости и обозначают буквой ![]() («альфа»).
(«альфа»).
Ошибка второго рода состоит в том, что гипотеза ![]() будет принята, но на самом деле она неправильная. Вероятность
будет принята, но на самом деле она неправильная. Вероятность
совершить эту ошибку обозначают буквой ![]() («бета»). Значение
(«бета»). Значение ![]() называют мощностью критерия – это вероятность отвержения неправильной
называют мощностью критерия – это вероятность отвержения неправильной
гипотезы.
В практических задачах, как правило, задают уровень значимости, наиболее часто выбирают значения ![]() .
.
И тут возникает мысль, что чем меньше «альфа», тем вроде бы лучше. Но это только вроде: при уменьшении
вероятности ![]() —
—
отвергнуть правильную гипотезу растёт вероятность ![]() — принять неверную гипотезу (при прочих равных условиях).
— принять неверную гипотезу (при прочих равных условиях).
Поэтому перед исследователем стоит задача грамотно подобрать соотношение вероятностей ![]() и
и ![]() , при этом учитывается тяжесть последствий, которые
, при этом учитывается тяжесть последствий, которые
повлекут за собой та и другая ошибки.
Понятие ошибок 1-го и 2-го рода используется не только в статистике, и для лучшего понимания я приведу пару
нестатистических примеров.
Петя зарегистрировался в почтовике. По умолчанию, ![]() – он считается добропорядочным пользователем. Так считает антиспам
– он считается добропорядочным пользователем. Так считает антиспам
фильтр. И вот Петя отправляет письмо. В большинстве случаев всё произойдёт, как должно произойти – нормальное письмо дойдёт до
адресата (правильное принятие нулевой гипотезы), а спамное – попадёт в спам (правильное отвержение). Однако фильтр может
совершить ошибку двух типов:
1) с вероятностью ![]() ошибочно отклонить нулевую гипотезу (счесть нормальное письмо
ошибочно отклонить нулевую гипотезу (счесть нормальное письмо
за спам и Петю за спаммера) или
2) с вероятностью ![]() ошибочно принять нулевую гипотезу (хотя Петя редиска).
ошибочно принять нулевую гипотезу (хотя Петя редиска).
Какая ошибка более «тяжелая»? Петино письмо может быть ОЧЕНЬ важным для адресата, и поэтому при настройке фильтра
целесообразно уменьшить уровень значимости ![]() , «пожертвовав» вероятностью
, «пожертвовав» вероятностью ![]() (увеличив её). В результате в основной ящик будут попадать все
(увеличив её). В результате в основной ящик будут попадать все
«подозрительные» письма, в том числе особо талантливых спаммеров. …Такое и почитать даже можно, ведь сделано с любовью
Существует примеры, где наоборот – более тяжкие последствия влечёт ошибка 2-го рода, и вероятность ![]() следует увеличить (в пользу уменьшения
следует увеличить (в пользу уменьшения
вероятности ![]() ). Не хотел я
). Не хотел я
приводить подобные примеры, и даже отшутился на сайте, но по какой-то мистике через пару месяцев сам столкнулся с непростой
дилеммой. Видимо, таки, надо рассказать:
У человека появилась серьёзная болячка. В медицинской практике её принято лечить (основное «нулевое» решение). Лечение
достаточно эффективно, однако не гарантирует результата и более того опасно (иногда приводит к серьёзному пожизненному
увечью). С другой стороны, если не лечить, то возможны осложнения и долговременные функциональные нарушения.
Вопрос: что делать? И ответ не так-то прост – в разных ситуациях разные люди могут принять разные
решения (упаси вас).
Если болезнь не особо «мешает жить», то более тяжёлые последствия повлечёт ошибка 2-го рода – когда человек соглашается
на лечение, но получает фатальный результат (принимает, как оказалось, неверное «нулевое» решение). Если же…, нет, пожалуй,
достаточно, возвращаемся к теме:
5.4. Процесс проверки статистической гипотезы
5.2. Нулевая и альтернативная гипотезы
| Оглавление |
Ошибки, встроенные в систему: их роль в статистике
В прошлой статье я указал, как распространена проблема неправильного использования t-критерия в научных публикациях (и это возможно сделать только благодаря их открытости, а какой трэш творится при его использовании во всяких курсовых, отчетах, обучающих задачах и т.д. — неизвестно). Чтобы обсудить это, я рассказал об основах дисперсионного анализа и задаваемом самим исследователем уровне значимости α. Но для полного понимания всей картины статистического анализа необходимо подчеркнуть ряд важных вещей. И самая основная из них — понятие ошибки.
Ошибка и некорректное применение: в чем разница?
В любой физической системе содержится какая-либо ошибка, неточность. В самой разнообразной форме: так называемый допуск — отличие в размерах разных однотипных изделий; нелинейная характеристика — когда прибор или метод измеряют что-то по строго известному закону в определенных пределах, а дальше становятся неприменимыми; дискретность — когда мы чисто технически не можем обеспечить плавность выходной характеристики.
И в то же время существует чисто человеческая ошибка — некорректное использование устройств, приборов, математических законов. Между ошибкой, присущей системе, и ошибкой применения этой системы есть принципиальная разница. Важно различать и не путать между собой эти два понятия, называемые одним и тем же словом «ошибка». Я в данной статье предпочитаю использовать слово «ошибка» для обозначения свойства системы, а «некорректное применение» — для ошибочного ее использования.
То есть, ошибка линейки равна допуску оборудования, наносящего штрихи на ее полотно. А ошибкой в смысле некорректного применения было бы использовать ее при измерении деталей наручных часов. Ошибка безмена написана на нем и составляет что-то около 50 граммов, а неправильным использованием безмена было бы взвешивание на нем мешка в 25 кг, который растягивает пружину из области закона Гука в область пластических деформаций. Ошибка атомно-силового микроскопа происходит из его дискретности — нельзя «пощупать» его зондом предметы мельче, чем диаметром в один атом. Но способов неправильно использовать его или неправильно интерпретировать данные существует множество. И так далее.
Так, а что же за ошибка имеет место в статистических методах? А этой ошибкой как раз и является пресловутый уровень значимости α.
Ошибки первого и второго рода
Ошибкой в математическом аппарате статистики является сама ее Байесовская вероятностная сущность. В прошлой статье я уже упоминал, на чем стоят статистические методы: определение уровня значимости α как наибольшей допустимой вероятности неправомерно отвергнуть нулевую гипотезу, и самостоятельное задание исследователем этой величины перед исследователем.
Вы уже видите эту условность? На самом деле, в критериальных методах нету привычной математической строгости. Математика здесь оперирует вероятностными характеристиками.
И тут наступает еще один момент, где возможна неправильная трактовка одного слова в разном контексте. Необходимо различать само понятие вероятности и фактическую реализацию события, выражающуюся в распределении вероятности. Например, перед началом любого нашего эксперимента мы не знаем, какую именно величину мы получим в результате. Есть два возможных исхода: загадав некоторое значение результата, мы либо действительно его получим, либо не получим. Логично, что вероятность и того, и другого события равна 1/2. Но показанная в предыдущей статье Гауссова кривая показывает распределение вероятности того, что мы правильно угадаем совпадение.
Наглядно можно проиллюстрировать это примером. Пусть мы 600 раз бросаем два игральных кубика — обычный и шулерский. Получим следующие результаты:

До эксперимента для обоих кубиков выпадение любой грани будет равновероятно — 1/6. Однако после эксперимента проявляется сущность шулерского кубика, и мы можем сказать, что плотность вероятности выпадения на нем шестерки — 90%.
Другой пример, который знают химики, физики и все, кто интересуется квантовыми эффектами — атомные орбитали. Теоретически электрон может быть «размазан» в пространстве и находиться практически где угодно. Но на практике есть области, где он будет находиться в 90 и более процентах случаев. Эти области пространства, образованные поверхностью с плотностью вероятности нахождения там электрона 90%, и есть классические атомные орбитали, в виде сфер, гантелей и т.д.
Так вот, самостоятельно задавая уровень значимости, мы заведомо соглашаемся на описанную в его названии ошибку. Из-за этого ни один результат нельзя считать «стопроцентно достоверным» — всегда наши статистические выводы будут содержать некоторую вероятность сбоя.
Ошибка, формулируемая определением уровня значимости α, называется ошибкой первого рода. Ее можно определить, как «ложная тревога», или, более корректно, ложноположительный результат. В самом деле, что означают слова «ошибочно отвергнуть нулевую гипотезу»? Это значит, по ошибке принять наблюдаемые данные за значимые различия двух групп. Поставить ложный диагноз о наличии болезни, поспешить явить миру новое открытие, которого на самом деле нет — вот примеры ошибок первого рода.
Но ведь тогда должны быть и ложноотрицательные результаты? Совершенно верно, и они называются ошибками второго рода. Примеры — не поставленный вовремя диагноз или же разочарование в результате исследования, хотя на самом деле в нем есть важные данные. Ошибки второго рода обозначаются буквой, как ни странно, β. Но само это понятие не так важно для статистики, как число 1-β. Число 1-β называется мощностью критерия, и как нетрудно догадаться, оно характеризует способность критерия не упустить значимое событие.
Однако содержание в статистических методах ошибок первого и второго рода не является только лишь их ограничением. Само понятие этих ошибок может использоваться непосредственным образом в статистическом анализе. Как?
ROC-анализ
ROC-анализ (от receiver operating characteristic, рабочая характеристика приёмника) — это метод количественного определения применимости некоторого признака к бинарной классификации объектов. Говоря проще, мы можем придумать некоторый способ, как отличить больных людей от здоровых, кошек от собак, черное от белого, а затем проверить правомерность такого способа. Давайте снова обратимся к примеру.
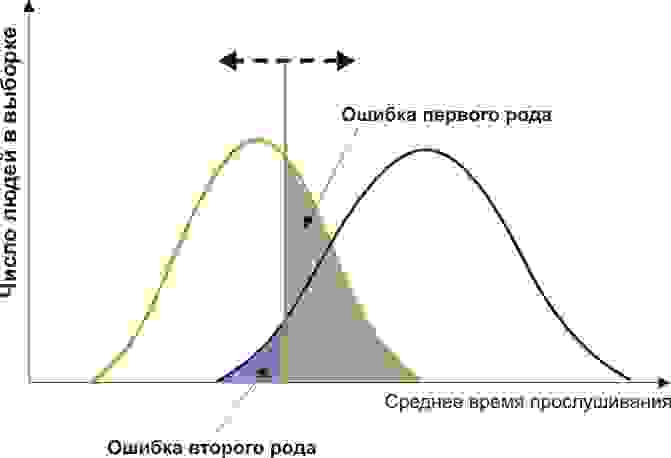
Пусть вы — подающий надежды криминалист, и разрабатываете новый способ скрытно и однозначно определять, является ли человек преступником. Вы придумали количественный признак: оценивать преступные наклонности людей по частоте прослушивания ими Михаила Круга. Но будет ли давать адекватные результаты ваш признак? Давайте разбираться.
Вам понадобится две группы людей для валидации вашего критерия: обычные граждане и преступники. Положим, действительно, среднегодовое время прослушивания ими Михаила Круга различается (см. рисунок):

Здесь мы видим, что по количественному признаку времени прослушивания наши выборки пересекаются. Кто-то слушает Круга спонтанно по радио, не совершая преступлений, а кто-то нарушает закон, слушая другую музыку или даже будучи глухим. Какие у нас есть граничные условия? ROC-анализ вводит понятия селективности (чувствительности) и специфичности. Чувствительность определяется как способность выявлять все-все интересующие нас точки (в данном примере — преступников), а специфичность — не захватывать ничего ложноположительного (не ставить под подозрение простых обывателей). Мы можем задать некоторую критическую количественную черту, отделяющую одних от других (оранжевая), в пределах от максимальной чувствительности (зеленая) до максимальной специфичности (красная).
Посмотрим на следующую схему:
Смещая значение нашего признака, мы меняем соотношения ложноположительного и ложноотрицательного результатов (площади под кривыми). Точно так же мы можем дать определения Чувствительность = Полож. рез-т/(Полож. рез-т + ложноотриц. рез-т) и Специфичность = Отриц. рез-т/(Отриц. рез-т + ложноположит. рез-т).
Но главное, мы можем оценить соотношение положительных результатов к ложноположительным на всем отрезке значений нашего количественного признака, что и есть наша искомая ROC-кривая (см. рисунок):
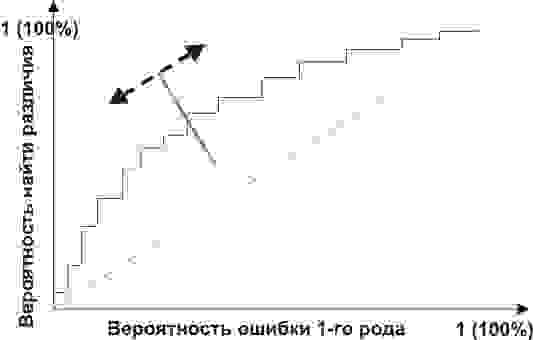
А как нам понять из этого графика, насколько хорош наш признак? Очень просто, посчитать площадь под кривой (AUC, area under curve). Пунктирная линия (0,0; 1,1) означает полное совпадение двух выборок и совершенно бессмысленный критерий (площадь под кривой равна 0,5 от всего квадрата). А вот выпуклость ROC кривой как раз и говорит о совершенстве критерия. Если же нам удастся найти такой критерий, что выборки вообще не будут пересекаться, то площадь под кривой займет весь график. В целом же признак считается хорошим, позволяющим надежно отделить одну выборку от другой, если AUC > 0,75-0,8.
С помощью такого анализа вы можете решать самые разные задачи. Решив, что слишком много домохозяек оказались под подозрением из-за Михаила Круга, а кроме того упущены опасные рецидивисты, слушающие Ноггано, вы можете отвергнуть этот критерий и разработать другой.
Возникнув, как способ обработки радиосигналов и идентификации «свой-чужой» после атаки на Перл-Харбор (отсюда и пошло такое странное название про характеристику приемника), ROC-анализ нашел широкое применение в биомедицинской статистике для анализа, валидации, создания и характеристики панелей биомаркеров и т.д. Он гибок в использовании, если оно основано на грамотной логике. Например, вы можете разработать показания для медицинской диспансеризации пенсионеров-сердечников, применив высокоспецифичный критерий, повысив эффективность выявления болезней сердца и не перегружая врачей лишними пациентами. А во время опасной эпидемии ранее неизвестного вируса вы наоборот, можете придумать высокоселективный критерий, чтобы от вакцинации в прямом смысле не ускользнул ни один чих.
С ошибками обоих родов и их наглядностью в описании валидируемых критериев мы познакомились. Теперь же, двигаясь от этих логических основ, можно разрушить ряд ложных стереотипных описаний результатов. Некоторые неправильные формулировки захватывают наши умы, часто путаясь своими схожими словами и понятиями, а также из-за очень малого внимания, уделяемого неверной интерпретации. Об этом, пожалуй, нужно будет написать отдельно.
Размер выборки и искусство баланса между возможными ошибками.
Перед исследователем, планирующим изучение проблемы с использованием статистических методов так или иначе встает вопрос о необходимости расчета размера выборки для контроля между ошибкой первого и второго рода (о них читайте далее). Не стоит скрывать, что для большинства обсервационных исследований с клиническими данными достаточность объема выборки – достаточно болезненный вопрос, правильный ответ на который могут дать не многие. Мало кто понимает, что вопрос размеры выборки – дело не одной формулы, а достаточно сложная тема, требующая понимания собственных исследовательских задач, понимая, имеющихся данных в распоряжении исследователя, а также чувствительность и специфичность самих статистических критериев, имеющихся в распоряжении биометрики. Предлагаем читателю разобраться с этим важным вопросом.
В наиболее общих чертах стоит отметить, что ответ на вопрос о достаточности данных в исследуемой выборке зависит от четырех характеристик исследования: величины различия и частоте исходов между группами, р (ошибки первого рода альфа), и тип данных. Эти характеристики должен учитывать исследователь, планирующий эксперимент, а также читатель, решающий, следует ли доверять публикации.
Величина эффекта
Размер выборки зависит от того, какова же ожидаемая величина различий, которые предстоит выявить. В принципе можно искать различия любой величины и, конечно, исследователь надеется, что сможет обнаружить даже самые небольшие различия. Однако при прочих равных условиях для выявления малых различий требуется большее число пациентов. Поэтому лучше ставить вопрос таким образом:
Какое число больных достаточно, чтобы выявить наименьший клинически значимый эффект?
В случае если нас интересуют только очень большие различия между экспериментальной группой и группой сравнения (т.е. очень сильный лечебный эффект), то допустимо меньшее число пациентов.
Ошибка первого рода (Альфа-ошибка)
Размер выборки зависит также от риска альфа-ошибки (вывода об эффективности лечения, которое на самом деле неэффективно). Приемлемая величина такого риска выбирается произвольно — от 1 до 0. Если исследователь готов к последствиям высокой вероятности ложного вывода об эффективности метода, то он может взять небольшое число пациентов. Если же он стремится сделать риск ошибочного вывода достаточно малым, то потребуется увеличить число больных. Как обсуждалось выше, обычно ра устанавливается на уровне 0,05 (1 из 20), а иногда 0,01 (1 из 100).
Ошибка второго рода (Бета-ошибка)
Другой фактор, определяющий размер выборки, — это выбранный риск бета-ошибки, который тоже произволен. Вероятность бета-ошибки часто устанавливается на уровне 0,20, т.е. допускается 20% вероятность не выявить существующие в действительности различия. Общепринятые допустимые величины бета- ошибок гораздо больше, чем альфа-ошибок, т.е. мы относимся более требовательно к утверждениям об эффективности лечения. Если говорят, что лечение эффективно, оно должно быть эффективным в действительности.
Тип данных и их однородность
Статистическая мощность исследования определяется еще и типом данных. Когда исходы выражены качественными при- знаками и описываются частотой событий, статистическая мощность исследования зависит от этой частоты. Чем больше число событий, тем выше статистическая мощность исследования для данного числа испытуемых. Например, исследование 100 больных, 50 из которых умерли, имеет примерно такую же чувствительность (мощность), что и исследование 1000 больных, из которых умерли те же 50 пациентов.
Если исход выражается непрерывной количественной переменной (например, артериальное давление или уровень холестерина в сыворотке), то мощность исследования определяется степенью различий пациентов внутри каждой группы (дисперсией). Чем больше различия между пациентами по изучаемым характеристикам, тем меньше уверенности в том, что наблюдаемая разница (или ее отсутствие) между группами обусловлена истинными различиями в эффективности методов лечения. Другими словами, чем больше различия между пациентами внутри групп, тем ниже статистическая мощность исследования.
При планировании исследования автор выбирает такие величины клинической значимости лечебного эффекта, уровни ошибок, которые сам считает приемлемыми. Он может спланировать исследование таким образом, чтобы сделать его мощность максимальной для данного размера выборки, например путем отбора больных с высокой вероятностью развития исходов или с одинаковыми характеристиками (разумеется, в пределах поставленной задачи). Однако, получив данные и имея конкретную научную задачу, исследователь уже не может повлиять на статистическую мощность исследования, поскольку она определяется характеристиками полученных данных.
Взаимосвязь характеристик исследования
Обсуждавшиеся выше взаимоотношения носят характер взаимного компромисса. В принципе для любого числа включенных в исследование пациентов существует определенный баланс между ошибками первого и второго рода. При прочих равных условиях, чем больше допускаемая величина ошибки одного рода, тем меньше должен быть риск ошибки другого рода. При этом по сути своей ни одна из них не «хуже» другой. Последствия принятия ошибочной информации за истинную зависят от клинической ситуации. Если имеется острая необходимость в более эффективном методе лечения (например, болезнь очень опасна и нет эффективного альтернативного метода лечения) и предлагаемое лечение не опасно, то разумнее предпочесть относительно высокий риск вывода о том, что вмешательство эффективно, когда в действительности это не так (большая альфа-ошибка), минимизируя вероятность отвергнуть эффективный метод (бета-ошибка мала). С другой стороны, если болезнь менее серьезна и существуют альтернативные методы лечения либо новый метод лечения более дорог или опасен, следует минимизировать риск применения нового вмешательства, которое может быть неэффективным (альфа-ошибка мала), даже за счет относительно высокой вероятности упустить действительно эффективное лечения (большая бета-ошибка). Конечно, можно уменьшить обе ошибки — если число исследуемых больных велико, частота исходов высока, изучаемый показатель внутри групп варьирует мало, а предполагаемый лечебный эффект значителен.
Пример 1. Согласно наблюдениям серий случаем, нестероидный противовоспалительный препарат Сулипдак эффективен при полипах толстой кишки. Это предположение было промерено в рандомизированном испытании на 22 больных с семейным аденоматозным полппозом, 11 из которых получали сулипдак, а другие 11 плацебо. Через 9 мес у получавших сулипдак среднее число полипов было на 44% меньше, чем у получавших плацебо; различие статистически значимое (p<0,05). Поскольку лечебный эффект значителен, а на каждого пациента приходилось большое количество полипов (у некоторых более 100), для доказательства того, что лечебный эффект неслучаен, достаточно небольшого числа больных.
Пример 2. Исследование 2, было спланировано таким образом, чтобы при включении 41 000 пациентов оно с вероятностью 90% обеспечивало бы обнаружение снижения летальности в экспериментальной группе на 15% или частоты летальных исходов на 1% по сравнению с контрольной группой, в зависимости от того, какой из этих показателей будет больше. При этом допустимый уровень 0,05, а предполагаемая летальность в контрольной группе не ниже 8%. Здесь необходим большой объем выборки, так как доля больных с неблагоприятным исходом (смерть) относительно мала, величина лечебного эффекта невелика (15%) и авторы хотели иметь относительно высокую вероятность обнаружить эффект терапии, если он все-таки присутствует (90%).
Проиллюстрируем также, как задачу расчета объема выборки на примере использования статистического пакета Stata. Для этого воспользуемся командной строкой. Для определения мощности и размера выборки существует команда sampsi.
Предположим, что для сравнения средних мы решили применить t-Критерий Стьюдента для парных выборок. Стандартное отклонение исследуемого показателя одинаково в обеих группах и составляет 20 мм рт. ст. Сами группы также равны по размеру. Тогда следует записать следующую команду:
sampsi 150 135, sd1(20) sd2(20) p(0.8) a(0.05)
Здесь 150 и 135 – это средние величины артериального давления, выраженные в мм рт ст. sd1() и sd2() – стандартные отклонения, p() и a() – целевые мощность (ошибка второго рода) и уровень значимости (ошибка первого рода) соответственно.
В результате работы команды мы выясним, что для решения поставленной задачи необходимо набрать группы по 28 человек.
Необходимо всегда иметь в виду, что приведённые в примере значения мощности и уровня значимости могут изменяться в зависимости от особенностей исследования. Однако любое повышение мощности будет даваться довольно дорого. Так, если в нашем примере увеличить целевую мощность до 90%, то при сохранении всех прочих параметров размер выборки придётся увеличить до 38 испытуемых в каждой группе, что скажется на стоимости планируемой работы.
Вместо заключения
Для получения ответов на большинство возникающих в наше время вопросов относительно эффективности того или иного вмешательства требуется изучение результатов лечения очень большого числа больных. Вместе с тем эффективность таких действенных вмешательств, как введение инсулина при диабетическом кетоацидозе или хирургической операции при аппендиците, можно установить при анализе данных небольшого числа больных. Однако подобные методы лечения появляются редко и многие из них уже хорошо изучены. Теперь нам приходится рассматривать патологию с хроническим течением и с множественными взаимодействующими этиологическими факторами; эффективность предлагаемых новых методов лечения таких заболеваний, в общем, невелика. В подобной ситуации необходимо обращать особое внимание на то, достаточна ли численность больных в клиническом испытании для того, чтобы отличить истинный лечебный эффект от случайного результата.
Автор сайта: Кирилл Мильчаков
Источник:
Флетчер Р., Флетчер С., Вагнер Э. Клиническая эпидемиология: Основы доказательной медицины/ М.: Медиа Сфера, 1998. — 352 с.
Если Вам понравилась статья и оказалась полезной, Вы можете поделиться ею с коллегами и друзьями в социальных сетях:
Сегодня новая статья в рубрике #чтопочитать , где поговорим о статистике, науке о данных и на простом примере разберем A/B тестирование (проверку статистических гипотез).
Замаскированная проверка гипотез
Если вы уже имели дело со статистикой, вы возможно задавались вопросом: «Разве A/B тестирование не тоже самое, что проверка статистических гипотез?». Так и есть! Поэтому давайте узнаем побольше об A/B тестировании, разобрав на простом примере принцип работы проверки статистических гипотез.
Представьте, что наш клиент — владелец очень успешного приложения для работы с личными финансами. Он обратился к нам со следующей проблемой:
Тони, новый дизайн нашего приложения должен помочь пользователям сэкономить больше денег. Но приводит ли он к этому на самом деле? Пожалуйста помоги нам определить это, чтобы мы могли принять решение о внедрении этого дизайна.
Наша цель — определить, экономят ли пользователи лучше благодаря новому дизайну приложения. Для начала, нам надо узнать, имеем ли мы необходимое нам количество данных, поэтому мы задаем вопрос: «Какие потенциально полезные данные вы уже собрали?»
Оказывается, наш клиент уже провел эксперимент и собрал некоторые данные:
-
Шесть месяцев назад, наш клиент выбрал 1000 новых пользователей и разделил их на две группы: 500 в контрольной группе и 500 в экспериментальной группе.
- Контрольной группе был предоставлен текущий дизайн приложения.
- В то же время, экспериментальной группе был предоставлен новый дизайн.
- Все пользователи начали с 0% экономии.
- 1000 пользователей составляют лишь маленькую часть всего количества пользователей данного приложения.
Через шесть месяцев, наш клиент фиксирует процент экономии всех 1000 пользователей. Процент экономии (дословно «норма сбережений») представляет собой процент, который конкретный пользователь экономит от расчетного чека за каждый месяц. Наш клиент узнает следующую информацию:
- В контрольной группе среднее значение процента экономии составило 12% со стандартным (среднеквадратическим) отклонением в 5%.
- В экспериментальной группе среднее значение процента экономии составило 13% со стандартным (среднеквадратическим) отклонением в 5%.
Результаты нашего эксперимента на гистограмме выглядят следующим образом:
Создается впечатление, что по окончании шести месяцев представители экспериментальной группы имели более высокий процент экономии, чем представители контрольной группы. Можем ли мы просто построить данную гистограмму, показать её клиенту и считать работу законченной?
Нет, потому что мы не можем быть уверены в том, что данный рост экономии был вызван новым дизайном. Возможно, нам просто не повезло при выборе пользователей для эксперимента, и все люди с желанием экономить больше попали в экспериментальную группу.
Для решения этой проблемы нам необходимо задать следующий вопрос:
Какова вероятность того, что данный результат мы получили только из-за случайного стечения обстоятельств?
Суть проверки статистических гипотез (и А/В тестирования) как раз и заключается в ответе на данный вопрос.
Нулевая гипотеза
Давайте представим альтернативную ситуацию, в которой новый дизайн не помог пользователям экономить лучше. Даже в таком случае, несмотря на то что новый дизайн получился бесполезным, мы все еще можем наблюдать рост процента экономии при проведении нашего эксперимента.
Как такое могло произойти? Это может произойти из-за того, что мы используем выборку. Приведу пример: если я случайном образом выберу 100 людей из десяти тысячной толпы и вычислю их средний рост, результат составит, например, 170 см. Но проведя данный эксперимент еще несколько раз, результат будет 177 см, 168 см и так далее.
Так как мы вычисляем статистику используя выборки, а не всё целое, средние значения каждой выборки будут различаться.
Зная, что использование выборок приводит к вариациям, мы можем переформулировать предыдущий вопрос:
В случае если новый дизайн на самом деле никак не влияет на экономию пользователей, какова вероятность того, что мы обнаружим настолько же высокий рост экономии, как и при случайном стечении обстоятельств?
Формально говоря, мы формулируем нулевую гипотезу следующим образом: рост процента экономии контрольной группы равен росту процента экономии экспериментальной группы.
Теперь наша работа заключается в проверке данной нулевой гипотезы. Мы можем сделать это проведя мысленный эксперимент.
Многочисленное проведение эксперимента
Представьте, что мы можем проводить наш эксперимент снова и снова. При этом, мы все еще рассматриваем ситуацию, в которой новый дизайн никак не влияет на экономию пользователей. Что мы будем наблюдать?
Для тех, кому интересно, вот как мы это представляем:
-
Для каждой группы генерируем 500 нормально распределенных случайных величин с такими же статистическими характеристиками, как и у контрольной группы (среднее значение = 12%, среднеквадратическое отклонение = 5%). Теперь у нас есть контрольная группа и экспериментальная группа (средние значения одинаковы, так как мы рассматриваем ситуацию, в которой новый дизайн не имеет никакого эффекта). Технически, правильнее было бы использовать распределение Пуассона, но мы используем нормальное распределение для простоты примера.
- Вычисляем разность средних значений процентов экономии двух групп (например, мы можем вычесть из среднего значения процента экономии контрольной группы среднее значение процента экономии экспериментальной группы).
- Проделываем данные шаги 10 000 раз.
- Строим гистограмму, показывающую разности средних значений экономии двух групп.
В итоге, мы получаем гистограмму, приведенную ниже. Данная гистограмма показывает, насколько сильно среднее значение процента экономии между группами различается из-за случайного стечения обстоятельств (обусловленное использованием выборки).
Красная вертикальная линия показывает тот результат, который получил наш клиент при проведении эксперимента (1%). Для нас важен процент количества значений справа от красной линии — он показывает вероятность того, что при проведении эксперимента мы получим разность, равную 1% или выше (мы используем односторонний критерий, потому что он легче для понимания).
В данном случае это значение очень маленькое — из 10 000 экспериментов только в 9 мы получили разность процентов экономии групп, равную 1% или выше.
Это означает, что результат, который наш клиент получил при проведении эксперимента, по случайному стечению обстоятельств может быть получен с вероятностью лишь 0.09%!
Данная вероятность, 0.09%, является нашим p-значением. «Каким значением? Хватит забрасывать меня какими-то случайными терминами!» — вы можете подумать. И правда, когда дело доходит до проверки статистических гипотез, приходится использовать много различных терминов, и, мы, пожалуй, оставим их разъяснение Википедии.
Наша задача, как и всегда, состоит в построении интуитивного понимания того, как работают эти инструменты статистики и для чего они пользуются, поэтому по возможности мы постараемся избегать использования терминологии в пользу простоты объяснении. Однако, p-значение является крайне необходимым термином, с которым вы еще не раз встретитесь в мире науки о данных, поэтому его мы должны обсудить. P-значение (в нашем случае 0.09%) представляет собой:
Вероятность получения, наблюдаемого нами результата, в случае если нулевая гипотеза правильна.
Соответственно, мы можем использовать p-значение для проверки справедливости нулевой гипотеза. Основываясь на определении, кажется, что мы хотим, чтобы это значение было минимальным, так как, чем меньше p-значение, тем менее вероятно то, что результат нашего эксперимента был случайным. Но на практике, мы введем уровень значимости для p-значения (называемый «альфа»), и, в случае если p-значение меньше альфа, мы отвергаем нулевую гипотезу и делаем вывод, что полученный результат и эффект реальны (статистически значимы).
Теперь давайте рассмотрим способ быстрого вычисления p-значения.
Центральная предельная теорема
Время поговорить об одной из фундаментальных концепций статистики. Центральная предельная теорема утверждает, что при сложении независимых случайных величин, их сумма стремится к нормальному распределению по мере сложения всё большего количества величин. Центральная предельная теорема работает даже в случае, если случайные величины не имеют нормального распределения.
Другими словами, если мы вычислим средние значения набора выборок (подразумевая, что все наши наблюдения независимы друг от друга, как, например, друг от друга не зависят броски монетки), распределение всех этих выборок будет близко к нормальному.
Взгляните на гистограмму, которую мы построили ранее. Выглядит как нормальное распределение, не так ли? Мы можем проверить нормальность с помощью КК (квантиль-квантиль) графика, который сравнивает квантиль нашего распределения с другим квантилем (в нашем случае, с нормальным распределением). Если наше распределение нормальное, то КК график будет близок к красной линии, находящейся под углом в 45°. И именно так и получается, здорово!
Значит, когда мы проводили наш эксперимент снова и снова, это был пример работы центральной предельной теоремы!
Так почему же это так важно?
Помните, как мы проверяли нашу нулевую гипотезу, проводя 10 000 экспериментов? Звучит очень утомительно, не так ли? На практике, это и утомительно, и дорого. Но благодаря центральной предельной теореме мы можем это избежать!
Теперь мы знаем, что распределение наших повторяющихся экспериментов будет нормальным, и мы можем использовать это знание для определения того, как распределяться наши 10 000 экспериментов без их проведения!
Давайте обобщим пройденное:
- Мы знаем, что разность средних значений процента экономий экспериментальной группы и контрольной группы составляет 1%, и мы хотим узнать, является ли эта разность оправданной.
- Важно помнить, что мы провели эксперимент лишь на маленькой части от всего количества пользователей приложения. Если мы проведем эксперимент заново, результат немного изменится.
- Так как нас волнует возможность того, что новый дизайн не имеет никакого эффекта на экономию, мы формулируем нулевую гипотезу: разность средних значений экономии двух групп — 0%.
- Согласно центральной предельной теореме, при повторном проведении данного эксперимента, его результаты будут нормально распределены.
- Из основных формул статистики, мы также знаем, что дисперсия разности двух независимых случайных величин равна сумме дисперсий данных величин:
Завершающие шаги
Здорово! Теперь у нас есть всё, что нам требуется для проверки гипотезы. Давайте завершим работу для нашего клиента.
- Перед тем как взглянуть на имеющиеся данные, нам надо выбрать уровень значимости, называемый альфа (если полученное p-значение меньше альфа, мы отвергаем нулевую гипотезу и делаем вывод, что новый дизайн привел к росту экономии). Значение альфа соответствует вероятности допущения ошибки первого рода — отвержения правильной нулевой гипотезы. Обычно специалисты используют значение 0.05, поэтому его мы и используем.
- Далее нам надо вычислить тестовую статистику. Тестовая статистика является числовым эквивалентом вышеприведенной гистограммы и обозначает среднеквадратическое отклонение нашего наблюдаемого значения (1%) от значения нулевой гипотезы (в нашем случае 0%). Вычислить мы её можем по формуле:
- Стандартная ошибка — это среднеквадратическое отклонение разности средне арифметических значений экономии экспериментальной группы и экономии контрольной группы. На графике выше, стандартная ошибка обозначена шириной синей гистограммы. Помните, что дисперсия разности двух случайных величин равна сумме дисперсий данных величин (а среднеквадратическое отклонение — это квадратный корень дисперсии). Зная это, мы с легкостью можем вычислить стандартную ошибку:
-
Среднеквадратическое отклонение равно 5% как для контрольной группы, так и для экспериментальной группы, поэтому наша выборочная дисперсия равна 0.0025. N — это количество наблюдений в каждой группе, поэтому N равно 500. Подставляем числа в формулу и получаем стандартную ошибку, равную 0.316%.
- В формуле тестовой статистики наблюдаемое значение — 1%, а значение гипотезы — 0% (так как наша нулевая гипотеза, предполагает, что эффекта нет). Подставляя данные значения вместе со значением стандартной ошибки в формулу тестовой статистики, мы получаем результат 3,16.
- Это значение довольно велико. Мы можем использовать приведенный ниже Python код для вычисления p-значения (для двустороннего критерия). Получится p-значение, равное 0.0016. Важно понимать, что мы используем двусторонний критерий, потому что мы не можем заранее быть уверенными в том, что новый дизайн или лучше текущего, или не имеет эффекта — новый дизайн может также иметь негативное влияние, и двусторонний критерий учитывает такую возможность.
from scipy.stats import norm
#Двусторонний критерий
print(‘The p-value is: ‘ + str(round((1 — norm.cdf(3.16))*2,4)))
-
P-значение (0.0016) меньше альфа (0.05), поэтому мы отвергаем нулевую гипотезу и говорим клиенту, что новый дизайн на самом деле помогает пользователям лучше экономить. Ура, победа!
Но обратите еще внимание на то, что p-значение, которое мы вычислили аналитически (0.0016), отличается от значения 0.0009, которое мы получили ранее. Связано это с тем, что наша симуляция была односторонней (односторонний тест более легок для понимания и визуализации). Мы можем удвоить данное значение для получения 0.0018, примерно равного настоящему 0.0016.
Подведем итоги
В реальной жизни A/B тестирование не настолько легко как в нашем выдуманном примере. Скорее всего, наш клиент не будет обладать готовыми данными, и нам придется самим искать нужные данные. Приведу несколько трудных моментов, с которыми вы можете встретиться при A/B тестировании:
- Сколько данных вам нужно? Сбор данных требует много времени и денег. Плохо проведенный эксперимент может даже негативно повлиять на пользовательский опыт. Но недостаточное количество информации приведет к тому, что результаты вашей работы будут не очень надежными. Поэтому вам придется соблюдать баланс между преимуществами большего количества данных и возрастающими затратами на их сбор.
- Что хуже — отвержение правильной нулевой гипотезы (ошибка первого рода) или принятие неправильной нулевой гипотезы (ошибка второго рода)? В нашем примере ошибка первого рода означала принятие нового дизайна, в то время как он не имеет никакого эффекта. Ошибка второго рода означала отказ от нового дизайна, хотя он помог бы людям экономить лучше. Мы находим подходящий баланс между вероятностями ошибки первого рода и ошибки второго рода выбирая уровень значимости (альфа). Более высокое значение альфа увеличит риск ошибки первого рода, меньшее значение увеличит риск ошибки второго рода.
This article is about erroneous outcomes of statistical tests. For closely related concepts in binary classification and testing generally, see false positives and false negatives.
In statistical hypothesis testing, a type I error is the mistaken rejection of an actually true null hypothesis (also known as a «false positive» finding or conclusion; example: «an innocent person is convicted»), while a type II error is the failure to reject a null hypothesis that is actually false (also known as a «false negative» finding or conclusion; example: «a guilty person is not convicted»).[1] Much of statistical theory revolves around the minimization of one or both of these errors, though the complete elimination of either is a statistical impossibility if the outcome is not determined by a known, observable causal process.
By selecting a low threshold (cut-off) value and modifying the alpha (α) level, the quality of the hypothesis test can be increased.[2] The knowledge of type I errors and type II errors is widely used in medical science, biometrics and computer science.[clarification needed]
Intuitively, type I errors can be thought of as errors of commission, i.e. the researcher unluckily concludes that something is the fact. For instance, consider a study where researchers compare a drug with a placebo. If the patients who are given the drug get better than the patients given the placebo by chance, it may appear that the drug is effective, but in fact the conclusion is incorrect.
In reverse, type II errors are errors of omission. In the example above, if the patients who got the drug did not get better at a higher rate than the ones who got the placebo, but this was a random fluke, that would be a type II error. The consequence of a type II error depends on the size and direction of the missed determination and the circumstances. An expensive cure for one in a million patients may be inconsequential even if it truly is a cure.
Definition[edit]
Statistical background[edit]
In statistical test theory, the notion of a statistical error is an integral part of hypothesis testing. The test goes about choosing about two competing propositions called null hypothesis, denoted by H0 and alternative hypothesis, denoted by H1. This is conceptually similar to the judgement in a court trial. The null hypothesis corresponds to the position of the defendant: just as he is presumed to be innocent until proven guilty, so is the null hypothesis presumed to be true until the data provide convincing evidence against it. The alternative hypothesis corresponds to the position against the defendant. Specifically, the null hypothesis also involves the absence of a difference or the absence of an association. Thus, the null hypothesis can never be that there is a difference or an association.
If the result of the test corresponds with reality, then a correct decision has been made. However, if the result of the test does not correspond with reality, then an error has occurred. There are two situations in which the decision is wrong. The null hypothesis may be true, whereas we reject H0. On the other hand, the alternative hypothesis H1 may be true, whereas we do not reject H0. Two types of error are distinguished: type I error and type II error.[3]
Type I error[edit]
The first kind of error is the mistaken rejection of a null hypothesis as the result of a test procedure. This kind of error is called a type I error (false positive) and is sometimes called an error of the first kind. In terms of the courtroom example, a type I error corresponds to convicting an innocent defendant.
Type II error[edit]
The second kind of error is the mistaken failure to reject the null hypothesis as the result of a test procedure. This sort of error is called a type II error (false negative) and is also referred to as an error of the second kind. In terms of the courtroom example, a type II error corresponds to acquitting a criminal.[4]
Crossover error rate[edit]
The crossover error rate (CER) is the point at which type I errors and type II errors are equal. A system with a lower CER value provides more accuracy than a system with a higher CER value.
False positive and false negative[edit]
In terms of false positives and false negatives, a positive result corresponds to rejecting the null hypothesis, while a negative result corresponds to failing to reject the null hypothesis; «false» means the conclusion drawn is incorrect. Thus, a type I error is equivalent to a false positive, and a type II error is equivalent to a false negative.
Table of error types[edit]
Tabularised relations between truth/falseness of the null hypothesis and outcomes of the test:[5]
| Table of error types | Null hypothesis (H0) is |
||
|---|---|---|---|
| True | False | ||
| Decision about null hypothesis (H0) |
Don’t reject |
Correct inference (true negative) (probability = 1−α) |
Type II error (false negative) (probability = β) |
| Reject | Type I error (false positive) (probability = α) |
Correct inference (true positive) (probability = 1−β) |
Error rate[edit]

The results obtained from negative sample (left curve) overlap with the results obtained from positive samples (right curve). By moving the result cutoff value (vertical bar), the rate of false positives (FP) can be decreased, at the cost of raising the number of false negatives (FN), or vice versa (TP = True Positives, TPR = True Positive Rate, FPR = False Positive Rate, TN = True Negatives).
A perfect test would have zero false positives and zero false negatives. However, statistical methods are probabilistic, and it cannot be known for certain whether statistical conclusions are correct. Whenever there is uncertainty, there is the possibility of making an error. Considering this nature of statistics science, all statistical hypothesis tests have a probability of making type I and type II errors.[6]
- The type I error rate is the probability of rejecting the null hypothesis given that it is true. The test is designed to keep the type I error rate below a prespecified bound called the significance level, usually denoted by the Greek letter α (alpha) and is also called the alpha level. Usually, the significance level is set to 0.05 (5%), implying that it is acceptable to have a 5% probability of incorrectly rejecting the true null hypothesis.[7]
- The rate of the type II error is denoted by the Greek letter β (beta) and related to the power of a test, which equals 1−β.[8]
These two types of error rates are traded off against each other: for any given sample set, the effort to reduce one type of error generally results in increasing the other type of error.[9]
The quality of hypothesis test[edit]
The same idea can be expressed in terms of the rate of correct results and therefore used to minimize error rates and improve the quality of hypothesis test. To reduce the probability of committing a type I error, making the alpha value more stringent is quite simple and efficient. To decrease the probability of committing a type II error, which is closely associated with analyses’ power, either increasing the test’s sample size or relaxing the alpha level could increase the analyses’ power.[10] A test statistic is robust if the type I error rate is controlled.
Varying different threshold (cut-off) value could also be used to make the test either more specific or more sensitive, which in turn elevates the test quality. For example, imagine a medical test, in which an experimenter might measure the concentration of a certain protein in the blood sample. The experimenter could adjust the threshold (black vertical line in the figure) and people would be diagnosed as having diseases if any number is detected above this certain threshold. According to the image, changing the threshold would result in changes in false positives and false negatives, corresponding to movement on the curve.[11]
Example[edit]
Since in a real experiment it is impossible to avoid all type I and type II errors, it is important to consider the amount of risk one is willing to take to falsely reject H0 or accept H0. The solution to this question would be to report the p-value or significance level α of the statistic. For example, if the p-value of a test statistic result is estimated at 0.0596, then there is a probability of 5.96% that we falsely reject H0. Or, if we say, the statistic is performed at level α, like 0.05, then we allow to falsely reject H0 at 5%. A significance level α of 0.05 is relatively common, but there is no general rule that fits all scenarios.
Vehicle speed measuring[edit]
The speed limit of a freeway in the United States is 120 kilometers per hour. A device is set to measure the speed of passing vehicles. Suppose that the device will conduct three measurements of the speed of a passing vehicle, recording as a random sample X1, X2, X3. The traffic police will or will not fine the drivers depending on the average speed  . That is to say, the test statistic
. That is to say, the test statistic

In addition, we suppose that the measurements X1, X2, X3 are modeled as normal distribution N(μ,4). Then, T should follow N(μ,4/3) and the parameter μ represents the true speed of passing vehicle. In this experiment, the null hypothesis H0 and the alternative hypothesis H1 should be
H0: μ=120 against H1: μ1>120.
If we perform the statistic level at α=0.05, then a critical value c should be calculated to solve

According to change-of-units rule for the normal distribution. Referring to Z-table, we can get

Here, the critical region. That is to say, if the recorded speed of a vehicle is greater than critical value 121.9, the driver will be fined. However, there are still 5% of the drivers are falsely fined since the recorded average speed is greater than 121.9 but the true speed does not pass 120, which we say, a type I error.
The type II error corresponds to the case that the true speed of a vehicle is over 120 kilometers per hour but the driver is not fined. For example, if the true speed of a vehicle μ=125, the probability that the driver is not fined can be calculated as

which means, if the true speed of a vehicle is 125, the driver has the probability of 0.36% to avoid the fine when the statistic is performed at level 125 since the recorded average speed is lower than 121.9. If the true speed is closer to 121.9 than 125, then the probability of avoiding the fine will also be higher.
The tradeoffs between type I error and type II error should also be considered. That is, in this case, if the traffic police do not want to falsely fine innocent drivers, the level α can be set to a smaller value, like 0.01. However, if that is the case, more drivers whose true speed is over 120 kilometers per hour, like 125, would be more likely to avoid the fine.
Etymology[edit]
In 1928, Jerzy Neyman (1894–1981) and Egon Pearson (1895–1980), both eminent statisticians, discussed the problems associated with «deciding whether or not a particular sample may be judged as likely to have been randomly drawn from a certain population»:[12] and, as Florence Nightingale David remarked, «it is necessary to remember the adjective ‘random’ [in the term ‘random sample’] should apply to the method of drawing the sample and not to the sample itself».[13]
They identified «two sources of error», namely:
- (a) the error of rejecting a hypothesis that should have not been rejected, and
- (b) the error of failing to reject a hypothesis that should have been rejected.
In 1930, they elaborated on these two sources of error, remarking that:
…in testing hypotheses two considerations must be kept in view, we must be able to reduce the chance of rejecting a true hypothesis to as low a value as desired; the test must be so devised that it will reject the hypothesis tested when it is likely to be false.
In 1933, they observed that these «problems are rarely presented in such a form that we can discriminate with certainty between the true and false hypothesis» . They also noted that, in deciding whether to fail to reject, or reject a particular hypothesis amongst a «set of alternative hypotheses», H1, H2…, it was easy to make an error:
…[and] these errors will be of two kinds:
- (I) we reject H0 [i.e., the hypothesis to be tested] when it is true,[14]
- (II) we fail to reject H0 when some alternative hypothesis HA or H1 is true. (There are various notations for the alternative).
In all of the papers co-written by Neyman and Pearson the expression H0 always signifies «the hypothesis to be tested».
In the same paper they call these two sources of error, errors of type I and errors of type II respectively.[15]
[edit]
Null hypothesis[edit]
It is standard practice for statisticians to conduct tests in order to determine whether or not a «speculative hypothesis» concerning the observed phenomena of the world (or its inhabitants) can be supported. The results of such testing determine whether a particular set of results agrees reasonably (or does not agree) with the speculated hypothesis.
On the basis that it is always assumed, by statistical convention, that the speculated hypothesis is wrong, and the so-called «null hypothesis» that the observed phenomena simply occur by chance (and that, as a consequence, the speculated agent has no effect) – the test will determine whether this hypothesis is right or wrong. This is why the hypothesis under test is often called the null hypothesis (most likely, coined by Fisher (1935, p. 19)), because it is this hypothesis that is to be either nullified or not nullified by the test. When the null hypothesis is nullified, it is possible to conclude that data support the «alternative hypothesis» (which is the original speculated one).
The consistent application by statisticians of Neyman and Pearson’s convention of representing «the hypothesis to be tested» (or «the hypothesis to be nullified») with the expression H0 has led to circumstances where many understand the term «the null hypothesis» as meaning «the nil hypothesis» – a statement that the results in question have arisen through chance. This is not necessarily the case – the key restriction, as per Fisher (1966), is that «the null hypothesis must be exact, that is free from vagueness and ambiguity, because it must supply the basis of the ‘problem of distribution,’ of which the test of significance is the solution.»[16] As a consequence of this, in experimental science the null hypothesis is generally a statement that a particular treatment has no effect; in observational science, it is that there is no difference between the value of a particular measured variable, and that of an experimental prediction.[citation needed]
Statistical significance[edit]
If the probability of obtaining a result as extreme as the one obtained, supposing that the null hypothesis were true, is lower than a pre-specified cut-off probability (for example, 5%), then the result is said to be statistically significant and the null hypothesis is rejected.
British statistician Sir Ronald Aylmer Fisher (1890–1962) stressed that the «null hypothesis»:
… is never proved or established, but is possibly disproved, in the course of experimentation. Every experiment may be said to exist only in order to give the facts a chance of disproving the null hypothesis.
— Fisher, 1935, p.19
Application domains[edit]
Medicine[edit]
In the practice of medicine, the differences between the applications of screening and testing are considerable.
Medical screening[edit]
Screening involves relatively cheap tests that are given to large populations, none of whom manifest any clinical indication of disease (e.g., Pap smears).
Testing involves far more expensive, often invasive, procedures that are given only to those who manifest some clinical indication of disease, and are most often applied to confirm a suspected diagnosis.
For example, most states in the USA require newborns to be screened for phenylketonuria and hypothyroidism, among other congenital disorders.
Hypothesis: «The newborns have phenylketonuria and hypothyroidism»
Null Hypothesis (H0): «The newborns do not have phenylketonuria and hypothyroidism»,
Type I error (false positive): The true fact is that the newborns do not have phenylketonuria and hypothyroidism but we consider they have the disorders according to the data.
Type II error (false negative): The true fact is that the newborns have phenylketonuria and hypothyroidism but we consider they do not have the disorders according to the data.
Although they display a high rate of false positives, the screening tests are considered valuable because they greatly increase the likelihood of detecting these disorders at a far earlier stage.
The simple blood tests used to screen possible blood donors for HIV and hepatitis have a significant rate of false positives; however, physicians use much more expensive and far more precise tests to determine whether a person is actually infected with either of these viruses.
Perhaps the most widely discussed false positives in medical screening come from the breast cancer screening procedure mammography. The US rate of false positive mammograms is up to 15%, the highest in world. One consequence of the high false positive rate in the US is that, in any 10-year period, half of the American women screened receive a false positive mammogram. False positive mammograms are costly, with over $100 million spent annually in the U.S. on follow-up testing and treatment. They also cause women unneeded anxiety. As a result of the high false positive rate in the US, as many as 90–95% of women who get a positive mammogram do not have the condition. The lowest rate in the world is in the Netherlands, 1%. The lowest rates are generally in Northern Europe where mammography films are read twice and a high threshold for additional testing is set (the high threshold decreases the power of the test).
The ideal population screening test would be cheap, easy to administer, and produce zero false-negatives, if possible. Such tests usually produce more false-positives, which can subsequently be sorted out by more sophisticated (and expensive) testing.
Medical testing[edit]
False negatives and false positives are significant issues in medical testing.
Hypothesis: «The patients have the specific disease».
Null hypothesis (H0): «The patients do not have the specific disease».
Type I error (false positive): «The true fact is that the patients do not have a specific disease but the physicians judges the patients was ill according to the test reports».
False positives can also produce serious and counter-intuitive problems when the condition being searched for is rare, as in screening. If a test has a false positive rate of one in ten thousand, but only one in a million samples (or people) is a true positive, most of the positives detected by that test will be false. The probability that an observed positive result is a false positive may be calculated using Bayes’ theorem.
Type II error (false negative): «The true fact is that the disease is actually present but the test reports provide a falsely reassuring message to patients and physicians that the disease is absent».
False negatives produce serious and counter-intuitive problems, especially when the condition being searched for is common. If a test with a false negative rate of only 10% is used to test a population with a true occurrence rate of 70%, many of the negatives detected by the test will be false.
This sometimes leads to inappropriate or inadequate treatment of both the patient and their disease. A common example is relying on cardiac stress tests to detect coronary atherosclerosis, even though cardiac stress tests are known to only detect limitations of coronary artery blood flow due to advanced stenosis.
Biometrics[edit]
Biometric matching, such as for fingerprint recognition, facial recognition or iris recognition, is susceptible to type I and type II errors.
Hypothesis: «The input does not identify someone in the searched list of people»
Null hypothesis: «The input does identify someone in the searched list of people»
Type I error (false reject rate): «The true fact is that the person is someone in the searched list but the system concludes that the person is not according to the data».
Type II error (false match rate): «The true fact is that the person is not someone in the searched list but the system concludes that the person is someone whom we are looking for according to the data».
The probability of type I errors is called the «false reject rate» (FRR) or false non-match rate (FNMR), while the probability of type II errors is called the «false accept rate» (FAR) or false match rate (FMR).
If the system is designed to rarely match suspects then the probability of type II errors can be called the «false alarm rate». On the other hand, if the system is used for validation (and acceptance is the norm) then the FAR is a measure of system security, while the FRR measures user inconvenience level.
Security screening[edit]
False positives are routinely found every day in airport security screening, which are ultimately visual inspection systems. The installed security alarms are intended to prevent weapons being brought onto aircraft; yet they are often set to such high sensitivity that they alarm many times a day for minor items, such as keys, belt buckles, loose change, mobile phones, and tacks in shoes.
Here, the null hypothesis is that the item is not a weapon, while the alternative hypothesis is that the item is a weapon.
A type I error (false positive): «The true fact is that the item is not a weapon but the system still alarms».
Type II error (false negative) «The true fact is that the item is a weapon but the system keeps silent at this time».
The ratio of false positives (identifying an innocent traveler as a terrorist) to true positives (detecting a would-be terrorist) is, therefore, very high; and because almost every alarm is a false positive, the positive predictive value of these screening tests is very low.
The relative cost of false results determines the likelihood that test creators allow these events to occur. As the cost of a false negative in this scenario is extremely high (not detecting a bomb being brought onto a plane could result in hundreds of deaths) whilst the cost of a false positive is relatively low (a reasonably simple further inspection) the most appropriate test is one with a low statistical specificity but high statistical sensitivity (one that allows a high rate of false positives in return for minimal false negatives).
Computers[edit]
The notions of false positives and false negatives have a wide currency in the realm of computers and computer applications, including computer security, spam filtering, Malware, Optical character recognition and many others.
For example, in the case of spam filtering the hypothesis here is that the message is a spam.
Thus, null hypothesis: «The message is not a spam».
Type I error (false positive): «Spam filtering or spam blocking techniques wrongly classify a legitimate email message as spam and, as a result, interferes with its delivery».
While most anti-spam tactics can block or filter a high percentage of unwanted emails, doing so without creating significant false-positive results is a much more demanding task.
Type II error (false negative): «Spam email is not detected as spam, but is classified as non-spam». A low number of false negatives is an indicator of the efficiency of spam filtering.
See also[edit]
- Binary classification
- Detection theory
- Egon Pearson
- Ethics in mathematics
- False positive paradox
- False discovery rate
- Family-wise error rate
- Information retrieval performance measures
- Neyman–Pearson lemma
- Null hypothesis
- Probability of a hypothesis for Bayesian inference
- Precision and recall
- Prosecutor’s fallacy
- Prozone phenomenon
- Receiver operating characteristic
- Sensitivity and specificity
- Statisticians’ and engineers’ cross-reference of statistical terms
- Testing hypotheses suggested by the data
- Type III error
References[edit]
- ^ «Type I Error and Type II Error». explorable.com. Retrieved 14 December 2019.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Sheskin, David (2004). Handbook of Parametric and Nonparametric Statistical Procedures. CRC Press. p. 54. ISBN 1584884401.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Lindenmayer, David. (2005). Practical conservation biology. Burgman, Mark A. Collingwood, Vic.: CSIRO Pub. ISBN 0-643-09310-9. OCLC 65216357.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Moroi, K.; Sato, T. (15 August 1975). «Comparison between procaine and isocarboxazid metabolism in vitro by a liver microsomal amidase-esterase». Biochemical Pharmacology. 24 (16): 1517–1521. doi:10.1016/0006-2952(75)90029-5. ISSN 1873-2968. PMID 8.
- ^ NEYMAN, J.; PEARSON, E. S. (1928). «On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference Part I». Biometrika. 20A (1–2): 175–240. doi:10.1093/biomet/20a.1-2.175. ISSN 0006-3444.
- ^ C.I.K.F. (July 1951). «Probability Theory for Statistical Methods. By F. N. David. [Pp. ix + 230. Cambridge University Press. 1949. Price 155.]». Journal of the Staple Inn Actuarial Society. 10 (3): 243–244. doi:10.1017/s0020269x00004564. ISSN 0020-269X.
- ^ Note that the subscript in the expression H0 is a zero (indicating null), and is not an «O» (indicating original).
- ^ Neyman, J.; Pearson, E. S. (30 October 1933). «The testing of statistical hypotheses in relation to probabilities a priori». Mathematical Proceedings of the Cambridge Philosophical Society. 29 (4): 492–510. Bibcode:1933PCPS…29..492N. doi:10.1017/s030500410001152x. ISSN 0305-0041. S2CID 119855116.
- ^ Fisher, R.A. (1966). The design of experiments. 8th edition. Hafner:Edinburgh.
Bibliography[edit]
- Betz, M.A. & Gabriel, K.R., «Type IV Errors and Analysis of Simple Effects», Journal of Educational Statistics, Vol.3, No.2, (Summer 1978), pp. 121–144.
- David, F.N., «A Power Function for Tests of Randomness in a Sequence of Alternatives», Biometrika, Vol.34, Nos.3/4, (December 1947), pp. 335–339.
- Fisher, R.A., The Design of Experiments, Oliver & Boyd (Edinburgh), 1935.
- Gambrill, W., «False Positives on Newborns’ Disease Tests Worry Parents», Health Day, (5 June 2006). [1] Archived 17 May 2018 at the Wayback Machine
- Kaiser, H.F., «Directional Statistical Decisions», Psychological Review, Vol.67, No.3, (May 1960), pp. 160–167.
- Kimball, A.W., «Errors of the Third Kind in Statistical Consulting», Journal of the American Statistical Association, Vol.52, No.278, (June 1957), pp. 133–142.
- Lubin, A., «The Interpretation of Significant Interaction», Educational and Psychological Measurement, Vol.21, No.4, (Winter 1961), pp. 807–817.
- Marascuilo, L.A. & Levin, J.R., «Appropriate Post Hoc Comparisons for Interaction and nested Hypotheses in Analysis of Variance Designs: The Elimination of Type-IV Errors», American Educational Research Journal, Vol.7., No.3, (May 1970), pp. 397–421.
- Mitroff, I.I. & Featheringham, T.R., «On Systemic Problem Solving and the Error of the Third Kind», Behavioral Science, Vol.19, No.6, (November 1974), pp. 383–393.
- Mosteller, F., «A k-Sample Slippage Test for an Extreme Population», The Annals of Mathematical Statistics, Vol.19, No.1, (March 1948), pp. 58–65.
- Moulton, R.T., «Network Security», Datamation, Vol.29, No.7, (July 1983), pp. 121–127.
- Raiffa, H., Decision Analysis: Introductory Lectures on Choices Under Uncertainty, Addison–Wesley, (Reading), 1968.
External links[edit]
- Bias and Confounding – presentation by Nigel Paneth, Graduate School of Public Health, University of Pittsburgh
This article is about erroneous outcomes of statistical tests. For closely related concepts in binary classification and testing generally, see false positives and false negatives.
In statistical hypothesis testing, a type I error is the mistaken rejection of an actually true null hypothesis (also known as a «false positive» finding or conclusion; example: «an innocent person is convicted»), while a type II error is the failure to reject a null hypothesis that is actually false (also known as a «false negative» finding or conclusion; example: «a guilty person is not convicted»).[1] Much of statistical theory revolves around the minimization of one or both of these errors, though the complete elimination of either is a statistical impossibility if the outcome is not determined by a known, observable causal process.
By selecting a low threshold (cut-off) value and modifying the alpha (α) level, the quality of the hypothesis test can be increased.[2] The knowledge of type I errors and type II errors is widely used in medical science, biometrics and computer science.[clarification needed]
Intuitively, type I errors can be thought of as errors of commission, i.e. the researcher unluckily concludes that something is the fact. For instance, consider a study where researchers compare a drug with a placebo. If the patients who are given the drug get better than the patients given the placebo by chance, it may appear that the drug is effective, but in fact the conclusion is incorrect.
In reverse, type II errors are errors of omission. In the example above, if the patients who got the drug did not get better at a higher rate than the ones who got the placebo, but this was a random fluke, that would be a type II error. The consequence of a type II error depends on the size and direction of the missed determination and the circumstances. An expensive cure for one in a million patients may be inconsequential even if it truly is a cure.
Definition[edit]
Statistical background[edit]
In statistical test theory, the notion of a statistical error is an integral part of hypothesis testing. The test goes about choosing about two competing propositions called null hypothesis, denoted by H0 and alternative hypothesis, denoted by H1. This is conceptually similar to the judgement in a court trial. The null hypothesis corresponds to the position of the defendant: just as he is presumed to be innocent until proven guilty, so is the null hypothesis presumed to be true until the data provide convincing evidence against it. The alternative hypothesis corresponds to the position against the defendant. Specifically, the null hypothesis also involves the absence of a difference or the absence of an association. Thus, the null hypothesis can never be that there is a difference or an association.
If the result of the test corresponds with reality, then a correct decision has been made. However, if the result of the test does not correspond with reality, then an error has occurred. There are two situations in which the decision is wrong. The null hypothesis may be true, whereas we reject H0. On the other hand, the alternative hypothesis H1 may be true, whereas we do not reject H0. Two types of error are distinguished: type I error and type II error.[3]
Type I error[edit]
The first kind of error is the mistaken rejection of a null hypothesis as the result of a test procedure. This kind of error is called a type I error (false positive) and is sometimes called an error of the first kind. In terms of the courtroom example, a type I error corresponds to convicting an innocent defendant.
Type II error[edit]
The second kind of error is the mistaken failure to reject the null hypothesis as the result of a test procedure. This sort of error is called a type II error (false negative) and is also referred to as an error of the second kind. In terms of the courtroom example, a type II error corresponds to acquitting a criminal.[4]
Crossover error rate[edit]
The crossover error rate (CER) is the point at which type I errors and type II errors are equal. A system with a lower CER value provides more accuracy than a system with a higher CER value.
False positive and false negative[edit]
In terms of false positives and false negatives, a positive result corresponds to rejecting the null hypothesis, while a negative result corresponds to failing to reject the null hypothesis; «false» means the conclusion drawn is incorrect. Thus, a type I error is equivalent to a false positive, and a type II error is equivalent to a false negative.
Table of error types[edit]
Tabularised relations between truth/falseness of the null hypothesis and outcomes of the test:[5]
| Table of error types | Null hypothesis (H0) is |
||
|---|---|---|---|
| True | False | ||
| Decision about null hypothesis (H0) |
Don’t reject |
Correct inference (true negative) (probability = 1−α) |
Type II error (false negative) (probability = β) |
| Reject | Type I error (false positive) (probability = α) |
Correct inference (true positive) (probability = 1−β) |
Error rate[edit]
The results obtained from negative sample (left curve) overlap with the results obtained from positive samples (right curve). By moving the result cutoff value (vertical bar), the rate of false positives (FP) can be decreased, at the cost of raising the number of false negatives (FN), or vice versa (TP = True Positives, TPR = True Positive Rate, FPR = False Positive Rate, TN = True Negatives).
A perfect test would have zero false positives and zero false negatives. However, statistical methods are probabilistic, and it cannot be known for certain whether statistical conclusions are correct. Whenever there is uncertainty, there is the possibility of making an error. Considering this nature of statistics science, all statistical hypothesis tests have a probability of making type I and type II errors.[6]
- The type I error rate is the probability of rejecting the null hypothesis given that it is true. The test is designed to keep the type I error rate below a prespecified bound called the significance level, usually denoted by the Greek letter α (alpha) and is also called the alpha level. Usually, the significance level is set to 0.05 (5%), implying that it is acceptable to have a 5% probability of incorrectly rejecting the true null hypothesis.[7]
- The rate of the type II error is denoted by the Greek letter β (beta) and related to the power of a test, which equals 1−β.[8]
These two types of error rates are traded off against each other: for any given sample set, the effort to reduce one type of error generally results in increasing the other type of error.[9]
The quality of hypothesis test[edit]
The same idea can be expressed in terms of the rate of correct results and therefore used to minimize error rates and improve the quality of hypothesis test. To reduce the probability of committing a type I error, making the alpha value more stringent is quite simple and efficient. To decrease the probability of committing a type II error, which is closely associated with analyses’ power, either increasing the test’s sample size or relaxing the alpha level could increase the analyses’ power.[10] A test statistic is robust if the type I error rate is controlled.
Varying different threshold (cut-off) value could also be used to make the test either more specific or more sensitive, which in turn elevates the test quality. For example, imagine a medical test, in which an experimenter might measure the concentration of a certain protein in the blood sample. The experimenter could adjust the threshold (black vertical line in the figure) and people would be diagnosed as having diseases if any number is detected above this certain threshold. According to the image, changing the threshold would result in changes in false positives and false negatives, corresponding to movement on the curve.[11]
Example[edit]
Since in a real experiment it is impossible to avoid all type I and type II errors, it is important to consider the amount of risk one is willing to take to falsely reject H0 or accept H0. The solution to this question would be to report the p-value or significance level α of the statistic. For example, if the p-value of a test statistic result is estimated at 0.0596, then there is a probability of 5.96% that we falsely reject H0. Or, if we say, the statistic is performed at level α, like 0.05, then we allow to falsely reject H0 at 5%. A significance level α of 0.05 is relatively common, but there is no general rule that fits all scenarios.
Vehicle speed measuring[edit]
The speed limit of a freeway in the United States is 120 kilometers per hour. A device is set to measure the speed of passing vehicles. Suppose that the device will conduct three measurements of the speed of a passing vehicle, recording as a random sample X1, X2, X3. The traffic police will or will not fine the drivers depending on the average speed . That is to say, the test statistic
In addition, we suppose that the measurements X1, X2, X3 are modeled as normal distribution N(μ,4). Then, T should follow N(μ,4/3) and the parameter μ represents the true speed of passing vehicle. In this experiment, the null hypothesis H0 and the alternative hypothesis H1 should be
H0: μ=120 against H1: μ1>120.
If we perform the statistic level at α=0.05, then a critical value c should be calculated to solve
According to change-of-units rule for the normal distribution. Referring to Z-table, we can get
Here, the critical region. That is to say, if the recorded speed of a vehicle is greater than critical value 121.9, the driver will be fined. However, there are still 5% of the drivers are falsely fined since the recorded average speed is greater than 121.9 but the true speed does not pass 120, which we say, a type I error.
The type II error corresponds to the case that the true speed of a vehicle is over 120 kilometers per hour but the driver is not fined. For example, if the true speed of a vehicle μ=125, the probability that the driver is not fined can be calculated as
which means, if the true speed of a vehicle is 125, the driver has the probability of 0.36% to avoid the fine when the statistic is performed at level 125 since the recorded average speed is lower than 121.9. If the true speed is closer to 121.9 than 125, then the probability of avoiding the fine will also be higher.
The tradeoffs between type I error and type II error should also be considered. That is, in this case, if the traffic police do not want to falsely fine innocent drivers, the level α can be set to a smaller value, like 0.01. However, if that is the case, more drivers whose true speed is over 120 kilometers per hour, like 125, would be more likely to avoid the fine.
Etymology[edit]
In 1928, Jerzy Neyman (1894–1981) and Egon Pearson (1895–1980), both eminent statisticians, discussed the problems associated with «deciding whether or not a particular sample may be judged as likely to have been randomly drawn from a certain population»:[12] and, as Florence Nightingale David remarked, «it is necessary to remember the adjective ‘random’ [in the term ‘random sample’] should apply to the method of drawing the sample and not to the sample itself».[13]
They identified «two sources of error», namely:
- (a) the error of rejecting a hypothesis that should have not been rejected, and
- (b) the error of failing to reject a hypothesis that should have been rejected.
In 1930, they elaborated on these two sources of error, remarking that:
…in testing hypotheses two considerations must be kept in view, we must be able to reduce the chance of rejecting a true hypothesis to as low a value as desired; the test must be so devised that it will reject the hypothesis tested when it is likely to be false.
In 1933, they observed that these «problems are rarely presented in such a form that we can discriminate with certainty between the true and false hypothesis» . They also noted that, in deciding whether to fail to reject, or reject a particular hypothesis amongst a «set of alternative hypotheses», H1, H2…, it was easy to make an error:
…[and] these errors will be of two kinds:
- (I) we reject H0 [i.e., the hypothesis to be tested] when it is true,[14]
- (II) we fail to reject H0 when some alternative hypothesis HA or H1 is true. (There are various notations for the alternative).
In all of the papers co-written by Neyman and Pearson the expression H0 always signifies «the hypothesis to be tested».
In the same paper they call these two sources of error, errors of type I and errors of type II respectively.[15]
[edit]
Null hypothesis[edit]
It is standard practice for statisticians to conduct tests in order to determine whether or not a «speculative hypothesis» concerning the observed phenomena of the world (or its inhabitants) can be supported. The results of such testing determine whether a particular set of results agrees reasonably (or does not agree) with the speculated hypothesis.
On the basis that it is always assumed, by statistical convention, that the speculated hypothesis is wrong, and the so-called «null hypothesis» that the observed phenomena simply occur by chance (and that, as a consequence, the speculated agent has no effect) – the test will determine whether this hypothesis is right or wrong. This is why the hypothesis under test is often called the null hypothesis (most likely, coined by Fisher (1935, p. 19)), because it is this hypothesis that is to be either nullified or not nullified by the test. When the null hypothesis is nullified, it is possible to conclude that data support the «alternative hypothesis» (which is the original speculated one).
The consistent application by statisticians of Neyman and Pearson’s convention of representing «the hypothesis to be tested» (or «the hypothesis to be nullified») with the expression H0 has led to circumstances where many understand the term «the null hypothesis» as meaning «the nil hypothesis» – a statement that the results in question have arisen through chance. This is not necessarily the case – the key restriction, as per Fisher (1966), is that «the null hypothesis must be exact, that is free from vagueness and ambiguity, because it must supply the basis of the ‘problem of distribution,’ of which the test of significance is the solution.»[16] As a consequence of this, in experimental science the null hypothesis is generally a statement that a particular treatment has no effect; in observational science, it is that there is no difference between the value of a particular measured variable, and that of an experimental prediction.[citation needed]
Statistical significance[edit]
If the probability of obtaining a result as extreme as the one obtained, supposing that the null hypothesis were true, is lower than a pre-specified cut-off probability (for example, 5%), then the result is said to be statistically significant and the null hypothesis is rejected.
British statistician Sir Ronald Aylmer Fisher (1890–1962) stressed that the «null hypothesis»:
… is never proved or established, but is possibly disproved, in the course of experimentation. Every experiment may be said to exist only in order to give the facts a chance of disproving the null hypothesis.
— Fisher, 1935, p.19
Application domains[edit]
Medicine[edit]
In the practice of medicine, the differences between the applications of screening and testing are considerable.
Medical screening[edit]
Screening involves relatively cheap tests that are given to large populations, none of whom manifest any clinical indication of disease (e.g., Pap smears).
Testing involves far more expensive, often invasive, procedures that are given only to those who manifest some clinical indication of disease, and are most often applied to confirm a suspected diagnosis.
For example, most states in the USA require newborns to be screened for phenylketonuria and hypothyroidism, among other congenital disorders.
Hypothesis: «The newborns have phenylketonuria and hypothyroidism»
Null Hypothesis (H0): «The newborns do not have phenylketonuria and hypothyroidism»,
Type I error (false positive): The true fact is that the newborns do not have phenylketonuria and hypothyroidism but we consider they have the disorders according to the data.
Type II error (false negative): The true fact is that the newborns have phenylketonuria and hypothyroidism but we consider they do not have the disorders according to the data.
Although they display a high rate of false positives, the screening tests are considered valuable because they greatly increase the likelihood of detecting these disorders at a far earlier stage.
The simple blood tests used to screen possible blood donors for HIV and hepatitis have a significant rate of false positives; however, physicians use much more expensive and far more precise tests to determine whether a person is actually infected with either of these viruses.
Perhaps the most widely discussed false positives in medical screening come from the breast cancer screening procedure mammography. The US rate of false positive mammograms is up to 15%, the highest in world. One consequence of the high false positive rate in the US is that, in any 10-year period, half of the American women screened receive a false positive mammogram. False positive mammograms are costly, with over $100 million spent annually in the U.S. on follow-up testing and treatment. They also cause women unneeded anxiety. As a result of the high false positive rate in the US, as many as 90–95% of women who get a positive mammogram do not have the condition. The lowest rate in the world is in the Netherlands, 1%. The lowest rates are generally in Northern Europe where mammography films are read twice and a high threshold for additional testing is set (the high threshold decreases the power of the test).
The ideal population screening test would be cheap, easy to administer, and produce zero false-negatives, if possible. Such tests usually produce more false-positives, which can subsequently be sorted out by more sophisticated (and expensive) testing.
Medical testing[edit]
False negatives and false positives are significant issues in medical testing.
Hypothesis: «The patients have the specific disease».
Null hypothesis (H0): «The patients do not have the specific disease».
Type I error (false positive): «The true fact is that the patients do not have a specific disease but the physicians judges the patients was ill according to the test reports».
False positives can also produce serious and counter-intuitive problems when the condition being searched for is rare, as in screening. If a test has a false positive rate of one in ten thousand, but only one in a million samples (or people) is a true positive, most of the positives detected by that test will be false. The probability that an observed positive result is a false positive may be calculated using Bayes’ theorem.
Type II error (false negative): «The true fact is that the disease is actually present but the test reports provide a falsely reassuring message to patients and physicians that the disease is absent».
False negatives produce serious and counter-intuitive problems, especially when the condition being searched for is common. If a test with a false negative rate of only 10% is used to test a population with a true occurrence rate of 70%, many of the negatives detected by the test will be false.
This sometimes leads to inappropriate or inadequate treatment of both the patient and their disease. A common example is relying on cardiac stress tests to detect coronary atherosclerosis, even though cardiac stress tests are known to only detect limitations of coronary artery blood flow due to advanced stenosis.
Biometrics[edit]
Biometric matching, such as for fingerprint recognition, facial recognition or iris recognition, is susceptible to type I and type II errors.
Hypothesis: «The input does not identify someone in the searched list of people»
Null hypothesis: «The input does identify someone in the searched list of people»
Type I error (false reject rate): «The true fact is that the person is someone in the searched list but the system concludes that the person is not according to the data».
Type II error (false match rate): «The true fact is that the person is not someone in the searched list but the system concludes that the person is someone whom we are looking for according to the data».
The probability of type I errors is called the «false reject rate» (FRR) or false non-match rate (FNMR), while the probability of type II errors is called the «false accept rate» (FAR) or false match rate (FMR).
If the system is designed to rarely match suspects then the probability of type II errors can be called the «false alarm rate». On the other hand, if the system is used for validation (and acceptance is the norm) then the FAR is a measure of system security, while the FRR measures user inconvenience level.
Security screening[edit]
False positives are routinely found every day in airport security screening, which are ultimately visual inspection systems. The installed security alarms are intended to prevent weapons being brought onto aircraft; yet they are often set to such high sensitivity that they alarm many times a day for minor items, such as keys, belt buckles, loose change, mobile phones, and tacks in shoes.
Here, the null hypothesis is that the item is not a weapon, while the alternative hypothesis is that the item is a weapon.
A type I error (false positive): «The true fact is that the item is not a weapon but the system still alarms».
Type II error (false negative) «The true fact is that the item is a weapon but the system keeps silent at this time».
The ratio of false positives (identifying an innocent traveler as a terrorist) to true positives (detecting a would-be terrorist) is, therefore, very high; and because almost every alarm is a false positive, the positive predictive value of these screening tests is very low.
The relative cost of false results determines the likelihood that test creators allow these events to occur. As the cost of a false negative in this scenario is extremely high (not detecting a bomb being brought onto a plane could result in hundreds of deaths) whilst the cost of a false positive is relatively low (a reasonably simple further inspection) the most appropriate test is one with a low statistical specificity but high statistical sensitivity (one that allows a high rate of false positives in return for minimal false negatives).
Computers[edit]
The notions of false positives and false negatives have a wide currency in the realm of computers and computer applications, including computer security, spam filtering, Malware, Optical character recognition and many others.
For example, in the case of spam filtering the hypothesis here is that the message is a spam.
Thus, null hypothesis: «The message is not a spam».
Type I error (false positive): «Spam filtering or spam blocking techniques wrongly classify a legitimate email message as spam and, as a result, interferes with its delivery».
While most anti-spam tactics can block or filter a high percentage of unwanted emails, doing so without creating significant false-positive results is a much more demanding task.
Type II error (false negative): «Spam email is not detected as spam, but is classified as non-spam». A low number of false negatives is an indicator of the efficiency of spam filtering.
See also[edit]
- Binary classification
- Detection theory
- Egon Pearson
- Ethics in mathematics
- False positive paradox
- False discovery rate
- Family-wise error rate
- Information retrieval performance measures
- Neyman–Pearson lemma
- Null hypothesis
- Probability of a hypothesis for Bayesian inference
- Precision and recall
- Prosecutor’s fallacy
- Prozone phenomenon
- Receiver operating characteristic
- Sensitivity and specificity
- Statisticians’ and engineers’ cross-reference of statistical terms
- Testing hypotheses suggested by the data
- Type III error
References[edit]
- ^ «Type I Error and Type II Error». explorable.com. Retrieved 14 December 2019.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Sheskin, David (2004). Handbook of Parametric and Nonparametric Statistical Procedures. CRC Press. p. 54. ISBN 1584884401.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Lindenmayer, David. (2005). Practical conservation biology. Burgman, Mark A. Collingwood, Vic.: CSIRO Pub. ISBN 0-643-09310-9. OCLC 65216357.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Moroi, K.; Sato, T. (15 August 1975). «Comparison between procaine and isocarboxazid metabolism in vitro by a liver microsomal amidase-esterase». Biochemical Pharmacology. 24 (16): 1517–1521. doi:10.1016/0006-2952(75)90029-5. ISSN 1873-2968. PMID 8.
- ^ NEYMAN, J.; PEARSON, E. S. (1928). «On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference Part I». Biometrika. 20A (1–2): 175–240. doi:10.1093/biomet/20a.1-2.175. ISSN 0006-3444.
- ^ C.I.K.F. (July 1951). «Probability Theory for Statistical Methods. By F. N. David. [Pp. ix + 230. Cambridge University Press. 1949. Price 155.]». Journal of the Staple Inn Actuarial Society. 10 (3): 243–244. doi:10.1017/s0020269x00004564. ISSN 0020-269X.
- ^ Note that the subscript in the expression H0 is a zero (indicating null), and is not an «O» (indicating original).
- ^ Neyman, J.; Pearson, E. S. (30 October 1933). «The testing of statistical hypotheses in relation to probabilities a priori». Mathematical Proceedings of the Cambridge Philosophical Society. 29 (4): 492–510. Bibcode:1933PCPS…29..492N. doi:10.1017/s030500410001152x. ISSN 0305-0041. S2CID 119855116.
- ^ Fisher, R.A. (1966). The design of experiments. 8th edition. Hafner:Edinburgh.
Bibliography[edit]
- Betz, M.A. & Gabriel, K.R., «Type IV Errors and Analysis of Simple Effects», Journal of Educational Statistics, Vol.3, No.2, (Summer 1978), pp. 121–144.
- David, F.N., «A Power Function for Tests of Randomness in a Sequence of Alternatives», Biometrika, Vol.34, Nos.3/4, (December 1947), pp. 335–339.
- Fisher, R.A., The Design of Experiments, Oliver & Boyd (Edinburgh), 1935.
- Gambrill, W., «False Positives on Newborns’ Disease Tests Worry Parents», Health Day, (5 June 2006). [1] Archived 17 May 2018 at the Wayback Machine
- Kaiser, H.F., «Directional Statistical Decisions», Psychological Review, Vol.67, No.3, (May 1960), pp. 160–167.
- Kimball, A.W., «Errors of the Third Kind in Statistical Consulting», Journal of the American Statistical Association, Vol.52, No.278, (June 1957), pp. 133–142.
- Lubin, A., «The Interpretation of Significant Interaction», Educational and Psychological Measurement, Vol.21, No.4, (Winter 1961), pp. 807–817.
- Marascuilo, L.A. & Levin, J.R., «Appropriate Post Hoc Comparisons for Interaction and nested Hypotheses in Analysis of Variance Designs: The Elimination of Type-IV Errors», American Educational Research Journal, Vol.7., No.3, (May 1970), pp. 397–421.
- Mitroff, I.I. & Featheringham, T.R., «On Systemic Problem Solving and the Error of the Third Kind», Behavioral Science, Vol.19, No.6, (November 1974), pp. 383–393.
- Mosteller, F., «A k-Sample Slippage Test for an Extreme Population», The Annals of Mathematical Statistics, Vol.19, No.1, (March 1948), pp. 58–65.
- Moulton, R.T., «Network Security», Datamation, Vol.29, No.7, (July 1983), pp. 121–127.
- Raiffa, H., Decision Analysis: Introductory Lectures on Choices Under Uncertainty, Addison–Wesley, (Reading), 1968.
External links[edit]
- Bias and Confounding – presentation by Nigel Paneth, Graduate School of Public Health, University of Pittsburgh
Ошибки первого и второго рода
Выдвинутая гипотеза
может быть правильной или неправильной,
поэтому возникает необходимость её
проверки. Поскольку проверку производят
статистическими методами, её называют
статистической. В итоге статистической
проверки гипотезы в двух случаях может
быть принято неправильное решение, т.
е. могут быть допущены ошибки двух родов.
Ошибка первого
рода состоит в том, что будет отвергнута
правильная гипотеза.
Ошибка второго
рода состоит в том, что будет принята
неправильная гипотеза.
Подчеркнём, что
последствия этих ошибок могут оказаться
весьма различными. Например, если
отвергнуто правильное решение «продолжать
строительство жилого дома», то эта
ошибка первого рода повлечёт материальный
ущерб: если же принято неправильное
решение «продолжать строительство»,
несмотря на опасность обвала стройки,
то эта ошибка второго рода может повлечь
гибель людей. Можно привести примеры,
когда ошибка первого рода влечёт более
тяжёлые последствия, чем ошибка второго
рода.
Замечание 1.
Правильное решение может быть принято
также в двух случаях:
-
гипотеза принимается,
причём и в действительности она
правильная; -
гипотеза отвергается,
причём и в действительности она неверна.
Замечание 2.
Вероятность совершить ошибку первого
рода принято обозначать через
![]() ;
;
её называют уровнем значимости. Наиболее
часто уровень значимости принимают
равным 0,05 или 0,01. Если, например, принят
уровень значимости, равный 0,05, то это
означает, что в пяти случаях из ста
имеется риск допустить ошибку первого
рода (отвергнуть правильную гипотезу).
Статистический
критерий проверки нулевой гипотезы.
Наблюдаемое значение критерия
Для проверки
нулевой гипотезы используют специально
подобранную случайную величину, точное
или приближённое распределение которой
известно. Обозначим эту величину в целях
общности через
![]() .
.
Статистическим
критерием
(или просто критерием) называют случайную
величину
![]() ,
,
которая служит для проверки нулевой
гипотезы.
Например, если
проверяют гипотезу о равенстве дисперсий
двух нормальных генеральных совокупностей,
то в качестве критерия
![]() принимают отношение исправленных
принимают отношение исправленных
выборочных дисперсий: .
.
Эта величина
случайная, потому что в различных опытах
дисперсии принимают различные, наперёд
неизвестные значения, и распределена
по закону Фишера – Снедекора.
Для проверки
гипотезы по данным выборок вычисляют
частные значения входящих в критерий
величин и таким образом получают частное
(наблюдаемое) значение критерия.
Наблюдаемым
значением
![]() называют значение критерия, вычисленное
называют значение критерия, вычисленное
по выборкам. Например, если по двум
выборкам найдены исправленные выборочные
дисперсии![]() и
и![]() ,
,
то наблюдаемое значение критерия .
.
Критическая
область. Область принятия гипотезы.
Критические точки
После выбора
определённого критерия множество всех
его возможных значений разбивают на
два непересекающихся подмножества:
одно из них содержит значения критерия,
при которых нулевая гипотеза отвергается,
а другая – при которых она принимается.
Критической
областью называют совокупность значений
критерия, при которых нулевую гипотезу
отвергают.
Областью принятия
гипотезы (областью допустимых значений)
называют совокупность значений критерия,
при которых гипотезу принимают.
Основной принцип
проверки статистических гипотез можно
сформулировать так: если наблюдаемое
значение критерия принадлежит критической
области – гипотезу отвергают, если
наблюдаемое значение критерия принадлежит
области принятия гипотезы – гипотезу
принимают.
Поскольку критерий
![]() — одномерная случайная величина, все её
— одномерная случайная величина, все её
возможные значения принадлежат некоторому
интервалу. Поэтому критическая область
и область принятия гипотезы также
являются интервалами и, следовательно,
существуют точки, которые их разделяют.
Критическими
точками (границами)
![]() называют точки, отделяющие критическую
называют точки, отделяющие критическую
область от области принятия гипотезы.
Различают
одностороннюю (правостороннюю или
левостороннюю) и двустороннюю критические
области.
Правосторонней
называют критическую область, определяемую
неравенством
![]() >
>![]() ,
,
где![]() — положительное число.
— положительное число.
Левосторонней
называют критическую область, определяемую
неравенством
![]() <
<![]() ,
,
где![]() — отрицательное число.
— отрицательное число.
Односторонней
называют правостороннюю или левостороннюю
критическую область.
Двусторонней
называют критическую область, определяемую
неравенствами
![]() где
где![]() .
.
В частности, если
критические точки симметричны относительно
нуля, двусторонняя критическая область
определяется неравенствами ( в
предположении, что
![]() >0):
>0):
![]() ,
,
или равносильным неравенством
![]() .
.
Отыскание
правосторонней критической области
Как найти критическую
область? Обоснованный ответ на этот
вопрос требует привлечения довольно
сложной теории. Ограничимся её элементами.
Для определённости начнём с нахождения
правосторонней критической области,
которая определяется неравенством
![]() >
>![]() ,
,
где![]() >0.
>0.
Видим, что для отыскания правосторонней
критической области достаточно найти
критическую точку. Следовательно,
возникает новый вопрос: как её найти?
Для её нахождения
задаются достаточной малой вероятностью
– уровнем значимости
![]() .
.
Затем ищут критическую точку![]() ,
,
исходя из требования, чтобы при условии
справедливости нулевой гипотезы
вероятность того, критерий![]() примет значение, большее
примет значение, большее![]() ,
,
была равна принятому уровню значимости:
Р(![]() >
>![]() )=
)=![]() .
.
Для каждого критерия
имеются соответствующие таблицы, по
которым и находят критическую точку,
удовлетворяющую этому требованию.
Замечание 1.
Когда
критическая точка уже найдена, вычисляют
по данным выборок наблюдаемое значение
критерия и, если окажется, что
![]() >
>![]() ,
,
то нулевую гипотезу отвергают; если же![]() <
<![]() ,
,
то нет оснований, чтобы отвергнуть
нулевую гипотезу.
Пояснение. Почему
правосторонняя критическая область
была определена, исходя из требования,
чтобы при справедливости нулевой
гипотезы выполнялось соотношение
Р(![]() >
>![]() )=
)=![]() ?
?
(*)
Поскольку вероятность
события
![]() >
>![]() мала (
мала (![]() — малая вероятность), такое событие при
— малая вероятность), такое событие при
справедливости нулевой гипотезы, в силу
принципа практической невозможности
маловероятных событий, в единичном
испытании не должно наступить. Если всё
же оно произошло, т.е. наблюдаемое
значение критерия оказалось больше![]() ,
,
то это можно объяснить тем, что нулевая
гипотеза ложна и, следовательно, должна
быть отвергнута. Таким образом, требование
(*) определяет такие значения критерия,
при которых нулевая гипотеза отвергается,
а они и составляют правостороннюю
критическую область.
Замечание 2.
Наблюдаемое значение критерия может
оказаться большим
![]() не потому, что нулевая гипотеза ложна,
не потому, что нулевая гипотеза ложна,
а по другим причинам (малый объём выборки,
недостатки методики эксперимента и
др.). В этом случае, отвергнув правильную
нулевую гипотезу, совершают ошибку
первого рода. Вероятность этой ошибки
равна уровню значимости![]() .
.
Итак, пользуясь требованием (*), мы с
вероятностью![]() рискуем совершить ошибку первого рода.
рискуем совершить ошибку первого рода.
Замечание 3. Пусть
нулевая гипотеза принята; ошибочно
думать, что тем самым она доказана.
Действительно, известно, что один пример,
подтверждающий справедливость некоторого
общего утверждения, ещё не доказывает
его. Поэтому более правильно говорить,
«данные наблюдений согласуются с нулевой
гипотезой и, следовательно, не дают
оснований её отвергнуть».
На практике для
большей уверенности принятия гипотезы
её проверяют другими способами или
повторяют эксперимент, увеличив объём
выборки.
Отвергают гипотезу
более категорично, чем принимают.
Действительно, известно, что достаточно
привести один пример, противоречащий
некоторому общему утверждению, чтобы
это утверждение отвергнуть. Если
оказалось, что наблюдаемое значение
критерия принадлежит критической
области, то этот факт и служит примером,
противоречащим нулевой гипотезе, что
позволяет её отклонить.
Отыскание
левосторонней и двусторонней критических
областей***
Отыскание
левосторонней и двусторонней критических
областей сводится (так же, как и для
правосторонней) к нахождению соответствующих
критических точек. Левосторонняя
критическая область определяется
неравенством
![]() <
<![]() (
(![]() <0).
<0).
Критическую точку находят, исходя из
требования, чтобы при справедливости
нулевой гипотезы вероятность того, что
критерий примет значение, меньшее![]() ,
,
была равна принятому уровню значимости:
Р(![]() <
<![]() )=
)=![]() .
.
Двусторонняя
критическая область определяется
неравенствами
![]() Критические
Критические
точки находят, исходя из требования,
чтобы при справедливости нулевой
гипотезы сумма вероятностей того, что
критерий примет значение, меньшее![]() или большее
или большее![]() ,
,
была равна принятому уровню значимости:
![]() .
.
(*)
Ясно, что критические
точки могут быть выбраны бесчисленным
множеством способов. Если же распределение
критерия симметрично относительно нуля
и имеются основания (например, для
увеличения мощности) выбрать симметричные
относительно нуля точки (-
![]() )и
)и![]() (
(![]() >0),
>0),
то
![]() Учитывая (*), получим
Учитывая (*), получим
![]() .
.
Это соотношение
и служит для отыскания критических
точек двусторонней критической области.
Критические точки находят по соответствующим
таблицам.
Дополнительные
сведения о выборе критической области.
Мощность критерия
Мы строили
критическую область, исходя из требования,
чтобы вероятность попадания в неё
критерия была равна
![]() при условии, что нулевая гипотеза
при условии, что нулевая гипотеза
справедлива. Оказывается целесообразным
ввести в рассмотрение вероятность
попадания критерия в критическую область
при условии, что нулевая гипотеза неверна
и, следовательно, справедлива конкурирующая.
Мощностью критерия
называют вероятность попадания критерия
в критическую область при условии, что
справедлива конкурирующая гипотеза.
Другими словами, мощность критерия есть
вероятность того, что нулевая гипотеза
будет отвергнута, если верна конкурирующая
гипотеза.
Пусть для проверки
гипотезы принят определённый уровень
значимости и выборка имеет фиксированный
объём. Остаётся произвол в выборе
критической области. Покажем, что её
целесообразно построить так, чтобы
мощность критерия была максимальной.
Предварительно убедимся, что если
вероятность ошибки второго рода (принять
неправильную гипотезу) равна
![]() ,
,
то мощность равна 1-![]() .
.
Действительно, если![]() — вероятность ошибки второго рода, т.е.
— вероятность ошибки второго рода, т.е.
события «принята нулевая гипотеза,
причём справедливо конкурирующая», то
мощность критерия равна 1 —![]() .
.
Пусть мощность 1
—
![]() возрастает; следовательно, уменьшается
возрастает; следовательно, уменьшается
вероятность![]() совершить ошибку второго рода. Таким
совершить ошибку второго рода. Таким
образом, чем мощность больше, тем
вероятность ошибки второго рода меньше.
Итак, если уровень
значимости уже выбран, то критическую
область следует строить так, чтобы
мощность критерия была максимальной.
Выполнение этого требования должно
обеспечить минимальную ошибку второго
рода, что, конечно, желательно.
Замечание 1.
Поскольку вероятность события «ошибка
второго рода допущена» равна
![]() ,
,
то вероятность противоположного события
«ошибка второго рода не допущена» равна
1 —![]() ,
,
т.е. мощности критерия. Отсюда следует,
что мощность критерия есть вероятность
того, что не будет допущена ошибка
второго рода.
Замечание 2. Ясно,
что чем меньше вероятности ошибок
первого и второго рода, тем критическая
область «лучше». Однако при заданном
объёме выборки уменьшить одновременно
![]() и
и![]() невозможно; если уменьшить
невозможно; если уменьшить![]() ,
,
то![]() будет возрастать. Например, если принять
будет возрастать. Например, если принять![]() =0,
=0,
то будут приниматься все гипотезы, в
том числе и неправильные, т.е. возрастает
вероятность![]() ошибки второго рода.
ошибки второго рода.
Как же выбрать
![]() наиболее целесообразно? Ответ на этот
наиболее целесообразно? Ответ на этот
вопрос зависит от «тяжести последствий»
ошибок для каждой конкретной задачи.
Например, если ошибка первого рода
повлечёт большие потери, а второго рода
– малые, то следует принять возможно
меньшее![]() .
.
Если
![]() уже выбрано, то, пользуясь теоремой Ю.
уже выбрано, то, пользуясь теоремой Ю.
Неймана и Э.Пирсона, можно построить
критическую область, для которой![]() будет минимальным и, следовательно,
будет минимальным и, следовательно,
мощность критерия максимальной.
Замечание 3.
Единственный способ одновременного
уменьшения вероятностей ошибок первого
и второго рода состоит в увеличении
объёма выборок.
Соседние файлы в папке Лекции 2 семестр
- #
- #
- #
- #
Ошибки, встроенные в систему: их роль в статистике
Время на прочтение
6 мин
Количество просмотров 12K
В прошлой статье я указал, как распространена проблема неправильного использования t-критерия в научных публикациях (и это возможно сделать только благодаря их открытости, а какой трэш творится при его использовании во всяких курсовых, отчетах, обучающих задачах и т.д. — неизвестно). Чтобы обсудить это, я рассказал об основах дисперсионного анализа и задаваемом самим исследователем уровне значимости α. Но для полного понимания всей картины статистического анализа необходимо подчеркнуть ряд важных вещей. И самая основная из них — понятие ошибки.
Ошибка и некорректное применение: в чем разница?
В любой физической системе содержится какая-либо ошибка, неточность. В самой разнообразной форме: так называемый допуск — отличие в размерах разных однотипных изделий; нелинейная характеристика — когда прибор или метод измеряют что-то по строго известному закону в определенных пределах, а дальше становятся неприменимыми; дискретность — когда мы чисто технически не можем обеспечить плавность выходной характеристики.
И в то же время существует чисто человеческая ошибка — некорректное использование устройств, приборов, математических законов. Между ошибкой, присущей системе, и ошибкой применения этой системы есть принципиальная разница. Важно различать и не путать между собой эти два понятия, называемые одним и тем же словом «ошибка». Я в данной статье предпочитаю использовать слово «ошибка» для обозначения свойства системы, а «некорректное применение» — для ошибочного ее использования.
То есть, ошибка линейки равна допуску оборудования, наносящего штрихи на ее полотно. А ошибкой в смысле некорректного применения было бы использовать ее при измерении деталей наручных часов. Ошибка безмена написана на нем и составляет что-то около 50 граммов, а неправильным использованием безмена было бы взвешивание на нем мешка в 25 кг, который растягивает пружину из области закона Гука в область пластических деформаций. Ошибка атомно-силового микроскопа происходит из его дискретности — нельзя «пощупать» его зондом предметы мельче, чем диаметром в один атом. Но способов неправильно использовать его или неправильно интерпретировать данные существует множество. И так далее.
Так, а что же за ошибка имеет место в статистических методах? А этой ошибкой как раз и является пресловутый уровень значимости α.
Ошибки первого и второго рода
Ошибкой в математическом аппарате статистики является сама ее Байесовская вероятностная сущность. В прошлой статье я уже упоминал, на чем стоят статистические методы: определение уровня значимости α как наибольшей допустимой вероятности неправомерно отвергнуть нулевую гипотезу, и самостоятельное задание исследователем этой величины перед исследователем.
Вы уже видите эту условность? На самом деле, в критериальных методах нету привычной математической строгости. Математика здесь оперирует вероятностными характеристиками.
И тут наступает еще один момент, где возможна неправильная трактовка одного слова в разном контексте. Необходимо различать само понятие вероятности и фактическую реализацию события, выражающуюся в распределении вероятности. Например, перед началом любого нашего эксперимента мы не знаем, какую именно величину мы получим в результате. Есть два возможных исхода: загадав некоторое значение результата, мы либо действительно его получим, либо не получим. Логично, что вероятность и того, и другого события равна 1/2. Но показанная в предыдущей статье Гауссова кривая показывает распределение вероятности того, что мы правильно угадаем совпадение.
Наглядно можно проиллюстрировать это примером. Пусть мы 600 раз бросаем два игральных кубика — обычный и шулерский. Получим следующие результаты:
До эксперимента для обоих кубиков выпадение любой грани будет равновероятно — 1/6. Однако после эксперимента проявляется сущность шулерского кубика, и мы можем сказать, что плотность вероятности выпадения на нем шестерки — 90%.
Другой пример, который знают химики, физики и все, кто интересуется квантовыми эффектами — атомные орбитали. Теоретически электрон может быть «размазан» в пространстве и находиться практически где угодно. Но на практике есть области, где он будет находиться в 90 и более процентах случаев. Эти области пространства, образованные поверхностью с плотностью вероятности нахождения там электрона 90%, и есть классические атомные орбитали, в виде сфер, гантелей и т.д.
Так вот, самостоятельно задавая уровень значимости, мы заведомо соглашаемся на описанную в его названии ошибку. Из-за этого ни один результат нельзя считать «стопроцентно достоверным» — всегда наши статистические выводы будут содержать некоторую вероятность сбоя.
Ошибка, формулируемая определением уровня значимости α, называется ошибкой первого рода. Ее можно определить, как «ложная тревога», или, более корректно, ложноположительный результат. В самом деле, что означают слова «ошибочно отвергнуть нулевую гипотезу»? Это значит, по ошибке принять наблюдаемые данные за значимые различия двух групп. Поставить ложный диагноз о наличии болезни, поспешить явить миру новое открытие, которого на самом деле нет — вот примеры ошибок первого рода.
Но ведь тогда должны быть и ложноотрицательные результаты? Совершенно верно, и они называются ошибками второго рода. Примеры — не поставленный вовремя диагноз или же разочарование в результате исследования, хотя на самом деле в нем есть важные данные. Ошибки второго рода обозначаются буквой, как ни странно, β. Но само это понятие не так важно для статистики, как число 1-β. Число 1-β называется мощностью критерия, и как нетрудно догадаться, оно характеризует способность критерия не упустить значимое событие.
Однако содержание в статистических методах ошибок первого и второго рода не является только лишь их ограничением. Само понятие этих ошибок может использоваться непосредственным образом в статистическом анализе. Как?
ROC-анализ
ROC-анализ (от receiver operating characteristic, рабочая характеристика приёмника) — это метод количественного определения применимости некоторого признака к бинарной классификации объектов. Говоря проще, мы можем придумать некоторый способ, как отличить больных людей от здоровых, кошек от собак, черное от белого, а затем проверить правомерность такого способа. Давайте снова обратимся к примеру.
Пусть вы — подающий надежды криминалист, и разрабатываете новый способ скрытно и однозначно определять, является ли человек преступником. Вы придумали количественный признак: оценивать преступные наклонности людей по частоте прослушивания ими Михаила Круга. Но будет ли давать адекватные результаты ваш признак? Давайте разбираться.
Вам понадобится две группы людей для валидации вашего критерия: обычные граждане и преступники. Положим, действительно, среднегодовое время прослушивания ими Михаила Круга различается (см. рисунок):
Здесь мы видим, что по количественному признаку времени прослушивания наши выборки пересекаются. Кто-то слушает Круга спонтанно по радио, не совершая преступлений, а кто-то нарушает закон, слушая другую музыку или даже будучи глухим. Какие у нас есть граничные условия? ROC-анализ вводит понятия селективности (чувствительности) и специфичности. Чувствительность определяется как способность выявлять все-все интересующие нас точки (в данном примере — преступников), а специфичность — не захватывать ничего ложноположительного (не ставить под подозрение простых обывателей). Мы можем задать некоторую критическую количественную черту, отделяющую одних от других (оранжевая), в пределах от максимальной чувствительности (зеленая) до максимальной специфичности (красная).
Посмотрим на следующую схему:
Смещая значение нашего признака, мы меняем соотношения ложноположительного и ложноотрицательного результатов (площади под кривыми). Точно так же мы можем дать определения Чувствительность = Полож. рез-т/(Полож. рез-т + ложноотриц. рез-т) и Специфичность = Отриц. рез-т/(Отриц. рез-т + ложноположит. рез-т).
Но главное, мы можем оценить соотношение положительных результатов к ложноположительным на всем отрезке значений нашего количественного признака, что и есть наша искомая ROC-кривая (см. рисунок):
А как нам понять из этого графика, насколько хорош наш признак? Очень просто, посчитать площадь под кривой (AUC, area under curve). Пунктирная линия (0,0; 1,1) означает полное совпадение двух выборок и совершенно бессмысленный критерий (площадь под кривой равна 0,5 от всего квадрата). А вот выпуклость ROC кривой как раз и говорит о совершенстве критерия. Если же нам удастся найти такой критерий, что выборки вообще не будут пересекаться, то площадь под кривой займет весь график. В целом же признак считается хорошим, позволяющим надежно отделить одну выборку от другой, если AUC > 0,75-0,8.
С помощью такого анализа вы можете решать самые разные задачи. Решив, что слишком много домохозяек оказались под подозрением из-за Михаила Круга, а кроме того упущены опасные рецидивисты, слушающие Ноггано, вы можете отвергнуть этот критерий и разработать другой.
Возникнув, как способ обработки радиосигналов и идентификации «свой-чужой» после атаки на Перл-Харбор (отсюда и пошло такое странное название про характеристику приемника), ROC-анализ нашел широкое применение в биомедицинской статистике для анализа, валидации, создания и характеристики панелей биомаркеров и т.д. Он гибок в использовании, если оно основано на грамотной логике. Например, вы можете разработать показания для медицинской диспансеризации пенсионеров-сердечников, применив высокоспецифичный критерий, повысив эффективность выявления болезней сердца и не перегружая врачей лишними пациентами. А во время опасной эпидемии ранее неизвестного вируса вы наоборот, можете придумать высокоселективный критерий, чтобы от вакцинации в прямом смысле не ускользнул ни один чих.
С ошибками обоих родов и их наглядностью в описании валидируемых критериев мы познакомились. Теперь же, двигаясь от этих логических основ, можно разрушить ряд ложных стереотипных описаний результатов. Некоторые неправильные формулировки захватывают наши умы, часто путаясь своими схожими словами и понятиями, а также из-за очень малого внимания, уделяемого неверной интерпретации. Об этом, пожалуй, нужно будет написать отдельно.
Размер выборки и искусство баланса между возможными ошибками.
Перед исследователем, планирующим изучение проблемы с использованием статистических методов так или иначе встает вопрос о необходимости расчета размера выборки для контроля между ошибкой первого и второго рода (о них читайте далее). Не стоит скрывать, что для большинства обсервационных исследований с клиническими данными достаточность объема выборки – достаточно болезненный вопрос, правильный ответ на который могут дать не многие. Мало кто понимает, что вопрос размеры выборки – дело не одной формулы, а достаточно сложная тема, требующая понимания собственных исследовательских задач, понимая, имеющихся данных в распоряжении исследователя, а также чувствительность и специфичность самих статистических критериев, имеющихся в распоряжении биометрики. Предлагаем читателю разобраться с этим важным вопросом.
В наиболее общих чертах стоит отметить, что ответ на вопрос о достаточности данных в исследуемой выборке зависит от четырех характеристик исследования: величины различия и частоте исходов между группами, р (ошибки первого рода альфа), и тип данных. Эти характеристики должен учитывать исследователь, планирующий эксперимент, а также читатель, решающий, следует ли доверять публикации.
Величина эффекта
Размер выборки зависит от того, какова же ожидаемая величина различий, которые предстоит выявить. В принципе можно искать различия любой величины и, конечно, исследователь надеется, что сможет обнаружить даже самые небольшие различия. Однако при прочих равных условиях для выявления малых различий требуется большее число пациентов. Поэтому лучше ставить вопрос таким образом:
Какое число больных достаточно, чтобы выявить наименьший клинически значимый эффект?
В случае если нас интересуют только очень большие различия между экспериментальной группой и группой сравнения (т.е. очень сильный лечебный эффект), то допустимо меньшее число пациентов.
Ошибка первого рода (Альфа-ошибка)
Размер выборки зависит также от риска альфа-ошибки (вывода об эффективности лечения, которое на самом деле неэффективно). Приемлемая величина такого риска выбирается произвольно — от 1 до 0. Если исследователь готов к последствиям высокой вероятности ложного вывода об эффективности метода, то он может взять небольшое число пациентов. Если же он стремится сделать риск ошибочного вывода достаточно малым, то потребуется увеличить число больных. Как обсуждалось выше, обычно ра устанавливается на уровне 0,05 (1 из 20), а иногда 0,01 (1 из 100).
Ошибка второго рода (Бета-ошибка)
Другой фактор, определяющий размер выборки, — это выбранный риск бета-ошибки, который тоже произволен. Вероятность бета-ошибки часто устанавливается на уровне 0,20, т.е. допускается 20% вероятность не выявить существующие в действительности различия. Общепринятые допустимые величины бета- ошибок гораздо больше, чем альфа-ошибок, т.е. мы относимся более требовательно к утверждениям об эффективности лечения. Если говорят, что лечение эффективно, оно должно быть эффективным в действительности.
Тип данных и их однородность
Статистическая мощность исследования определяется еще и типом данных. Когда исходы выражены качественными при- знаками и описываются частотой событий, статистическая мощность исследования зависит от этой частоты. Чем больше число событий, тем выше статистическая мощность исследования для данного числа испытуемых. Например, исследование 100 больных, 50 из которых умерли, имеет примерно такую же чувствительность (мощность), что и исследование 1000 больных, из которых умерли те же 50 пациентов.
Если исход выражается непрерывной количественной переменной (например, артериальное давление или уровень холестерина в сыворотке), то мощность исследования определяется степенью различий пациентов внутри каждой группы (дисперсией). Чем больше различия между пациентами по изучаемым характеристикам, тем меньше уверенности в том, что наблюдаемая разница (или ее отсутствие) между группами обусловлена истинными различиями в эффективности методов лечения. Другими словами, чем больше различия между пациентами внутри групп, тем ниже статистическая мощность исследования.
При планировании исследования автор выбирает такие величины клинической значимости лечебного эффекта, уровни ошибок, которые сам считает приемлемыми. Он может спланировать исследование таким образом, чтобы сделать его мощность максимальной для данного размера выборки, например путем отбора больных с высокой вероятностью развития исходов или с одинаковыми характеристиками (разумеется, в пределах поставленной задачи). Однако, получив данные и имея конкретную научную задачу, исследователь уже не может повлиять на статистическую мощность исследования, поскольку она определяется характеристиками полученных данных.
Взаимосвязь характеристик исследования
Обсуждавшиеся выше взаимоотношения носят характер взаимного компромисса. В принципе для любого числа включенных в исследование пациентов существует определенный баланс между ошибками первого и второго рода. При прочих равных условиях, чем больше допускаемая величина ошибки одного рода, тем меньше должен быть риск ошибки другого рода. При этом по сути своей ни одна из них не «хуже» другой. Последствия принятия ошибочной информации за истинную зависят от клинической ситуации. Если имеется острая необходимость в более эффективном методе лечения (например, болезнь очень опасна и нет эффективного альтернативного метода лечения) и предлагаемое лечение не опасно, то разумнее предпочесть относительно высокий риск вывода о том, что вмешательство эффективно, когда в действительности это не так (большая альфа-ошибка), минимизируя вероятность отвергнуть эффективный метод (бета-ошибка мала). С другой стороны, если болезнь менее серьезна и существуют альтернативные методы лечения либо новый метод лечения более дорог или опасен, следует минимизировать риск применения нового вмешательства, которое может быть неэффективным (альфа-ошибка мала), даже за счет относительно высокой вероятности упустить действительно эффективное лечения (большая бета-ошибка). Конечно, можно уменьшить обе ошибки — если число исследуемых больных велико, частота исходов высока, изучаемый показатель внутри групп варьирует мало, а предполагаемый лечебный эффект значителен.
Пример 1. Согласно наблюдениям серий случаем, нестероидный противовоспалительный препарат Сулипдак эффективен при полипах толстой кишки. Это предположение было промерено в рандомизированном испытании на 22 больных с семейным аденоматозным полппозом, 11 из которых получали сулипдак, а другие 11 плацебо. Через 9 мес у получавших сулипдак среднее число полипов было на 44% меньше, чем у получавших плацебо; различие статистически значимое (p<0,05). Поскольку лечебный эффект значителен, а на каждого пациента приходилось большое количество полипов (у некоторых более 100), для доказательства того, что лечебный эффект неслучаен, достаточно небольшого числа больных.
Пример 2. Исследование 2, было спланировано таким образом, чтобы при включении 41 000 пациентов оно с вероятностью 90% обеспечивало бы обнаружение снижения летальности в экспериментальной группе на 15% или частоты летальных исходов на 1% по сравнению с контрольной группой, в зависимости от того, какой из этих показателей будет больше. При этом допустимый уровень 0,05, а предполагаемая летальность в контрольной группе не ниже 8%. Здесь необходим большой объем выборки, так как доля больных с неблагоприятным исходом (смерть) относительно мала, величина лечебного эффекта невелика (15%) и авторы хотели иметь относительно высокую вероятность обнаружить эффект терапии, если он все-таки присутствует (90%).
Проиллюстрируем также, как задачу расчета объема выборки на примере использования статистического пакета Stata. Для этого воспользуемся командной строкой. Для определения мощности и размера выборки существует команда sampsi.
Предположим, что для сравнения средних мы решили применить t-Критерий Стьюдента для парных выборок. Стандартное отклонение исследуемого показателя одинаково в обеих группах и составляет 20 мм рт. ст. Сами группы также равны по размеру. Тогда следует записать следующую команду:
sampsi 150 135, sd1(20) sd2(20) p(0.8) a(0.05)
Здесь 150 и 135 – это средние величины артериального давления, выраженные в мм рт ст. sd1() и sd2() – стандартные отклонения, p() и a() – целевые мощность (ошибка второго рода) и уровень значимости (ошибка первого рода) соответственно.
В результате работы команды мы выясним, что для решения поставленной задачи необходимо набрать группы по 28 человек.
Необходимо всегда иметь в виду, что приведённые в примере значения мощности и уровня значимости могут изменяться в зависимости от особенностей исследования. Однако любое повышение мощности будет даваться довольно дорого. Так, если в нашем примере увеличить целевую мощность до 90%, то при сохранении всех прочих параметров размер выборки придётся увеличить до 38 испытуемых в каждой группе, что скажется на стоимости планируемой работы.
Вместо заключения
Для получения ответов на большинство возникающих в наше время вопросов относительно эффективности того или иного вмешательства требуется изучение результатов лечения очень большого числа больных. Вместе с тем эффективность таких действенных вмешательств, как введение инсулина при диабетическом кетоацидозе или хирургической операции при аппендиците, можно установить при анализе данных небольшого числа больных. Однако подобные методы лечения появляются редко и многие из них уже хорошо изучены. Теперь нам приходится рассматривать патологию с хроническим течением и с множественными взаимодействующими этиологическими факторами; эффективность предлагаемых новых методов лечения таких заболеваний, в общем, невелика. В подобной ситуации необходимо обращать особое внимание на то, достаточна ли численность больных в клиническом испытании для того, чтобы отличить истинный лечебный эффект от случайного результата.
Автор сайта: Кирилл Мильчаков
Источник:
Флетчер Р., Флетчер С., Вагнер Э. Клиническая эпидемиология: Основы доказательной медицины/ М.: Медиа Сфера, 1998. — 352 с.
Если Вам понравилась статья и оказалась полезной, Вы можете поделиться ею с коллегами и друзьями в социальных сетях:
Сегодня новая статья в рубрике #чтопочитать , где поговорим о статистике, науке о данных и на простом примере разберем A/B тестирование (проверку статистических гипотез).
Замаскированная проверка гипотез
Если вы уже имели дело со статистикой, вы возможно задавались вопросом: «Разве A/B тестирование не тоже самое, что проверка статистических гипотез?». Так и есть! Поэтому давайте узнаем побольше об A/B тестировании, разобрав на простом примере принцип работы проверки статистических гипотез.
Представьте, что наш клиент — владелец очень успешного приложения для работы с личными финансами. Он обратился к нам со следующей проблемой:
Тони, новый дизайн нашего приложения должен помочь пользователям сэкономить больше денег. Но приводит ли он к этому на самом деле? Пожалуйста помоги нам определить это, чтобы мы могли принять решение о внедрении этого дизайна.
Наша цель — определить, экономят ли пользователи лучше благодаря новому дизайну приложения. Для начала, нам надо узнать, имеем ли мы необходимое нам количество данных, поэтому мы задаем вопрос: «Какие потенциально полезные данные вы уже собрали?»
Оказывается, наш клиент уже провел эксперимент и собрал некоторые данные:
-
Шесть месяцев назад, наш клиент выбрал 1000 новых пользователей и разделил их на две группы: 500 в контрольной группе и 500 в экспериментальной группе.
- Контрольной группе был предоставлен текущий дизайн приложения.
- В то же время, экспериментальной группе был предоставлен новый дизайн.
- Все пользователи начали с 0% экономии.
- 1000 пользователей составляют лишь маленькую часть всего количества пользователей данного приложения.
Через шесть месяцев, наш клиент фиксирует процент экономии всех 1000 пользователей. Процент экономии (дословно «норма сбережений») представляет собой процент, который конкретный пользователь экономит от расчетного чека за каждый месяц. Наш клиент узнает следующую информацию:
- В контрольной группе среднее значение процента экономии составило 12% со стандартным (среднеквадратическим) отклонением в 5%.
- В экспериментальной группе среднее значение процента экономии составило 13% со стандартным (среднеквадратическим) отклонением в 5%.
Результаты нашего эксперимента на гистограмме выглядят следующим образом:
Создается впечатление, что по окончании шести месяцев представители экспериментальной группы имели более высокий процент экономии, чем представители контрольной группы. Можем ли мы просто построить данную гистограмму, показать её клиенту и считать работу законченной?
Нет, потому что мы не можем быть уверены в том, что данный рост экономии был вызван новым дизайном. Возможно, нам просто не повезло при выборе пользователей для эксперимента, и все люди с желанием экономить больше попали в экспериментальную группу.
Для решения этой проблемы нам необходимо задать следующий вопрос:
Какова вероятность того, что данный результат мы получили только из-за случайного стечения обстоятельств?
Суть проверки статистических гипотез (и А/В тестирования) как раз и заключается в ответе на данный вопрос.
Нулевая гипотеза
Давайте представим альтернативную ситуацию, в которой новый дизайн не помог пользователям экономить лучше. Даже в таком случае, несмотря на то что новый дизайн получился бесполезным, мы все еще можем наблюдать рост процента экономии при проведении нашего эксперимента.
Как такое могло произойти? Это может произойти из-за того, что мы используем выборку. Приведу пример: если я случайном образом выберу 100 людей из десяти тысячной толпы и вычислю их средний рост, результат составит, например, 170 см. Но проведя данный эксперимент еще несколько раз, результат будет 177 см, 168 см и так далее.
Так как мы вычисляем статистику используя выборки, а не всё целое, средние значения каждой выборки будут различаться.
Зная, что использование выборок приводит к вариациям, мы можем переформулировать предыдущий вопрос:
В случае если новый дизайн на самом деле никак не влияет на экономию пользователей, какова вероятность того, что мы обнаружим настолько же высокий рост экономии, как и при случайном стечении обстоятельств?
Формально говоря, мы формулируем нулевую гипотезу следующим образом: рост процента экономии контрольной группы равен росту процента экономии экспериментальной группы.
Теперь наша работа заключается в проверке данной нулевой гипотезы. Мы можем сделать это проведя мысленный эксперимент.
Многочисленное проведение эксперимента
Представьте, что мы можем проводить наш эксперимент снова и снова. При этом, мы все еще рассматриваем ситуацию, в которой новый дизайн никак не влияет на экономию пользователей. Что мы будем наблюдать?
Для тех, кому интересно, вот как мы это представляем:
-
Для каждой группы генерируем 500 нормально распределенных случайных величин с такими же статистическими характеристиками, как и у контрольной группы (среднее значение = 12%, среднеквадратическое отклонение = 5%). Теперь у нас есть контрольная группа и экспериментальная группа (средние значения одинаковы, так как мы рассматриваем ситуацию, в которой новый дизайн не имеет никакого эффекта). Технически, правильнее было бы использовать распределение Пуассона, но мы используем нормальное распределение для простоты примера.
- Вычисляем разность средних значений процентов экономии двух групп (например, мы можем вычесть из среднего значения процента экономии контрольной группы среднее значение процента экономии экспериментальной группы).
- Проделываем данные шаги 10 000 раз.
- Строим гистограмму, показывающую разности средних значений экономии двух групп.
В итоге, мы получаем гистограмму, приведенную ниже. Данная гистограмма показывает, насколько сильно среднее значение процента экономии между группами различается из-за случайного стечения обстоятельств (обусловленное использованием выборки).
Красная вертикальная линия показывает тот результат, который получил наш клиент при проведении эксперимента (1%). Для нас важен процент количества значений справа от красной линии — он показывает вероятность того, что при проведении эксперимента мы получим разность, равную 1% или выше (мы используем односторонний критерий, потому что он легче для понимания).
В данном случае это значение очень маленькое — из 10 000 экспериментов только в 9 мы получили разность процентов экономии групп, равную 1% или выше.
Это означает, что результат, который наш клиент получил при проведении эксперимента, по случайному стечению обстоятельств может быть получен с вероятностью лишь 0.09%!
Данная вероятность, 0.09%, является нашим p-значением. «Каким значением? Хватит забрасывать меня какими-то случайными терминами!» — вы можете подумать. И правда, когда дело доходит до проверки статистических гипотез, приходится использовать много различных терминов, и, мы, пожалуй, оставим их разъяснение Википедии.
Наша задача, как и всегда, состоит в построении интуитивного понимания того, как работают эти инструменты статистики и для чего они пользуются, поэтому по возможности мы постараемся избегать использования терминологии в пользу простоты объяснении. Однако, p-значение является крайне необходимым термином, с которым вы еще не раз встретитесь в мире науки о данных, поэтому его мы должны обсудить. P-значение (в нашем случае 0.09%) представляет собой:
Вероятность получения, наблюдаемого нами результата, в случае если нулевая гипотеза правильна.
Соответственно, мы можем использовать p-значение для проверки справедливости нулевой гипотеза. Основываясь на определении, кажется, что мы хотим, чтобы это значение было минимальным, так как, чем меньше p-значение, тем менее вероятно то, что результат нашего эксперимента был случайным. Но на практике, мы введем уровень значимости для p-значения (называемый «альфа»), и, в случае если p-значение меньше альфа, мы отвергаем нулевую гипотезу и делаем вывод, что полученный результат и эффект реальны (статистически значимы).
Теперь давайте рассмотрим способ быстрого вычисления p-значения.
Центральная предельная теорема
Время поговорить об одной из фундаментальных концепций статистики. Центральная предельная теорема утверждает, что при сложении независимых случайных величин, их сумма стремится к нормальному распределению по мере сложения всё большего количества величин. Центральная предельная теорема работает даже в случае, если случайные величины не имеют нормального распределения.
Другими словами, если мы вычислим средние значения набора выборок (подразумевая, что все наши наблюдения независимы друг от друга, как, например, друг от друга не зависят броски монетки), распределение всех этих выборок будет близко к нормальному.
Взгляните на гистограмму, которую мы построили ранее. Выглядит как нормальное распределение, не так ли? Мы можем проверить нормальность с помощью КК (квантиль-квантиль) графика, который сравнивает квантиль нашего распределения с другим квантилем (в нашем случае, с нормальным распределением). Если наше распределение нормальное, то КК график будет близок к красной линии, находящейся под углом в 45°. И именно так и получается, здорово!
Значит, когда мы проводили наш эксперимент снова и снова, это был пример работы центральной предельной теоремы!
Так почему же это так важно?
Помните, как мы проверяли нашу нулевую гипотезу, проводя 10 000 экспериментов? Звучит очень утомительно, не так ли? На практике, это и утомительно, и дорого. Но благодаря центральной предельной теореме мы можем это избежать!
Теперь мы знаем, что распределение наших повторяющихся экспериментов будет нормальным, и мы можем использовать это знание для определения того, как распределяться наши 10 000 экспериментов без их проведения!
Давайте обобщим пройденное:
- Мы знаем, что разность средних значений процента экономий экспериментальной группы и контрольной группы составляет 1%, и мы хотим узнать, является ли эта разность оправданной.
- Важно помнить, что мы провели эксперимент лишь на маленькой части от всего количества пользователей приложения. Если мы проведем эксперимент заново, результат немного изменится.
- Так как нас волнует возможность того, что новый дизайн не имеет никакого эффекта на экономию, мы формулируем нулевую гипотезу: разность средних значений экономии двух групп — 0%.
- Согласно центральной предельной теореме, при повторном проведении данного эксперимента, его результаты будут нормально распределены.
- Из основных формул статистики, мы также знаем, что дисперсия разности двух независимых случайных величин равна сумме дисперсий данных величин:
Завершающие шаги
Здорово! Теперь у нас есть всё, что нам требуется для проверки гипотезы. Давайте завершим работу для нашего клиента.
- Перед тем как взглянуть на имеющиеся данные, нам надо выбрать уровень значимости, называемый альфа (если полученное p-значение меньше альфа, мы отвергаем нулевую гипотезу и делаем вывод, что новый дизайн привел к росту экономии). Значение альфа соответствует вероятности допущения ошибки первого рода — отвержения правильной нулевой гипотезы. Обычно специалисты используют значение 0.05, поэтому его мы и используем.
- Далее нам надо вычислить тестовую статистику. Тестовая статистика является числовым эквивалентом вышеприведенной гистограммы и обозначает среднеквадратическое отклонение нашего наблюдаемого значения (1%) от значения нулевой гипотезы (в нашем случае 0%). Вычислить мы её можем по формуле:
- Стандартная ошибка — это среднеквадратическое отклонение разности средне арифметических значений экономии экспериментальной группы и экономии контрольной группы. На графике выше, стандартная ошибка обозначена шириной синей гистограммы. Помните, что дисперсия разности двух случайных величин равна сумме дисперсий данных величин (а среднеквадратическое отклонение — это квадратный корень дисперсии). Зная это, мы с легкостью можем вычислить стандартную ошибку:
-
Среднеквадратическое отклонение равно 5% как для контрольной группы, так и для экспериментальной группы, поэтому наша выборочная дисперсия равна 0.0025. N — это количество наблюдений в каждой группе, поэтому N равно 500. Подставляем числа в формулу и получаем стандартную ошибку, равную 0.316%.
- В формуле тестовой статистики наблюдаемое значение — 1%, а значение гипотезы — 0% (так как наша нулевая гипотеза, предполагает, что эффекта нет). Подставляя данные значения вместе со значением стандартной ошибки в формулу тестовой статистики, мы получаем результат 3,16.
- Это значение довольно велико. Мы можем использовать приведенный ниже Python код для вычисления p-значения (для двустороннего критерия). Получится p-значение, равное 0.0016. Важно понимать, что мы используем двусторонний критерий, потому что мы не можем заранее быть уверенными в том, что новый дизайн или лучше текущего, или не имеет эффекта — новый дизайн может также иметь негативное влияние, и двусторонний критерий учитывает такую возможность.
from scipy.stats import norm
#Двусторонний критерий
print(‘The p-value is: ‘ + str(round((1 — norm.cdf(3.16))*2,4)))
-
P-значение (0.0016) меньше альфа (0.05), поэтому мы отвергаем нулевую гипотезу и говорим клиенту, что новый дизайн на самом деле помогает пользователям лучше экономить. Ура, победа!
Но обратите еще внимание на то, что p-значение, которое мы вычислили аналитически (0.0016), отличается от значения 0.0009, которое мы получили ранее. Связано это с тем, что наша симуляция была односторонней (односторонний тест более легок для понимания и визуализации). Мы можем удвоить данное значение для получения 0.0018, примерно равного настоящему 0.0016.
Подведем итоги
В реальной жизни A/B тестирование не настолько легко как в нашем выдуманном примере. Скорее всего, наш клиент не будет обладать готовыми данными, и нам придется самим искать нужные данные. Приведу несколько трудных моментов, с которыми вы можете встретиться при A/B тестировании:
- Сколько данных вам нужно? Сбор данных требует много времени и денег. Плохо проведенный эксперимент может даже негативно повлиять на пользовательский опыт. Но недостаточное количество информации приведет к тому, что результаты вашей работы будут не очень надежными. Поэтому вам придется соблюдать баланс между преимуществами большего количества данных и возрастающими затратами на их сбор.
- Что хуже — отвержение правильной нулевой гипотезы (ошибка первого рода) или принятие неправильной нулевой гипотезы (ошибка второго рода)? В нашем примере ошибка первого рода означала принятие нового дизайна, в то время как он не имеет никакого эффекта. Ошибка второго рода означала отказ от нового дизайна, хотя он помог бы людям экономить лучше. Мы находим подходящий баланс между вероятностями ошибки первого рода и ошибки второго рода выбирая уровень значимости (альфа). Более высокое значение альфа увеличит риск ошибки первого рода, меньшее значение увеличит риск ошибки второго рода.