Mean absolute error is the measure of error between the observed and the expected values in a given data set.
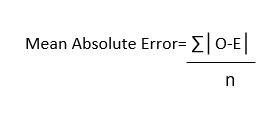
Where,
- O stands for Observed values,
- E stands for Expected values,
- n stands for total no. of observations.
Now let us understand it with the help of an example.
Example:
Follow the below steps to calculate MAE in Excel:
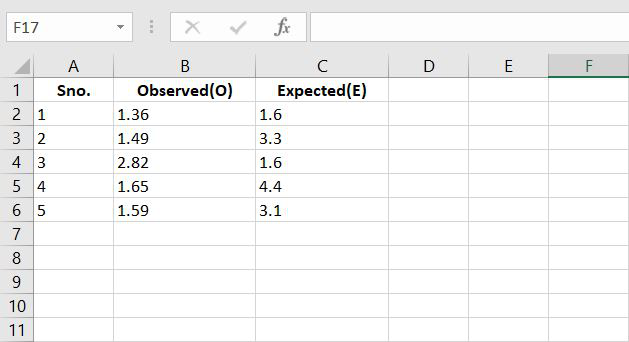
Step 1: Suppose we have the following data:
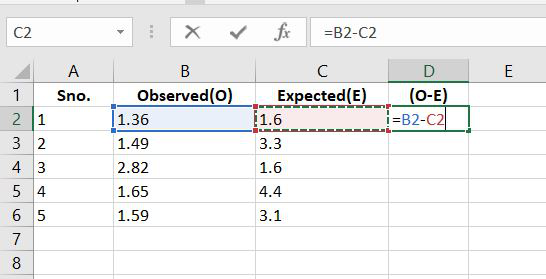
Step 2: According to formulae, let’s calculate the difference between the observed and the expected values.
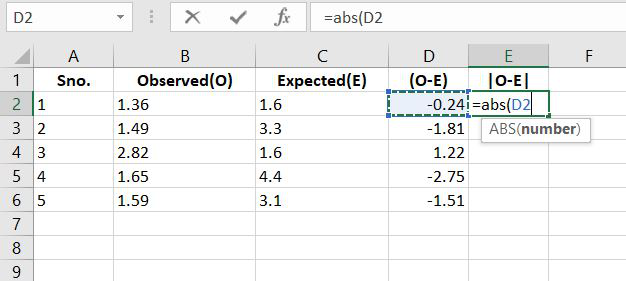
Step 3: Now let’s calculate the absolute values.
Step 4: Now we know from the data that n= no of observations and in this the value of n=5. And also the let’s calculate the total sum of |O-E|.
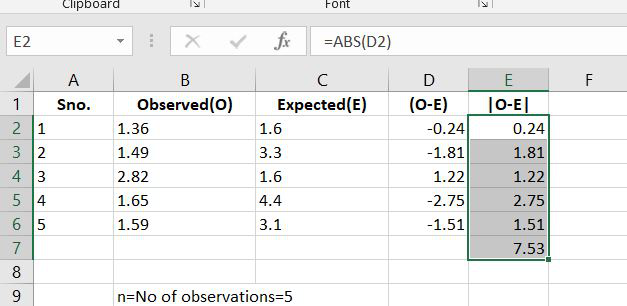
Step 5: Now we have the value of Sum of |O-E| and the value of n. Now according to formulae, the Mean Absolute Error is calculated as:
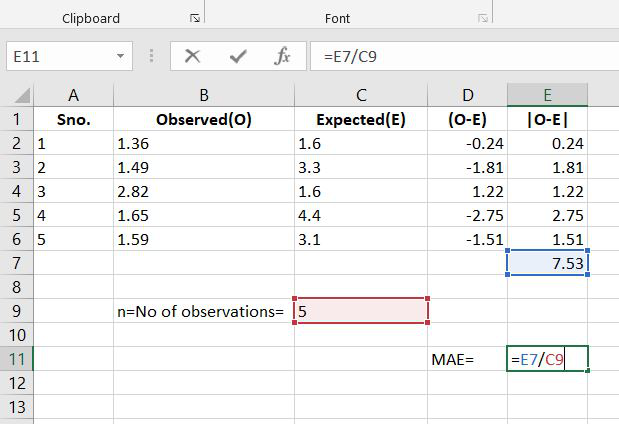
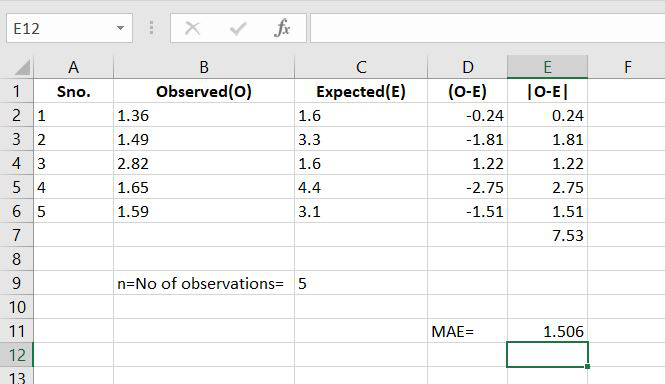
Step 6: So the value of MAE is:
Last Updated :
29 Jun, 2021
Like Article
Save Article
читать 1 мин
В статистике средняя абсолютная ошибка (MAE) — это способ измерения точности данной модели. Он рассчитывается как:
MAE = (1/n) * Σ|y i – x i |
куда:
- Σ: греческий символ, означающий «сумма».
- y i : Наблюдаемое значение для i -го наблюдения
- x i : Прогнозируемое значение для i -го наблюдения
- n: общее количество наблюдений
В следующем пошаговом примере показано, как рассчитать среднюю абсолютную ошибку в Excel.
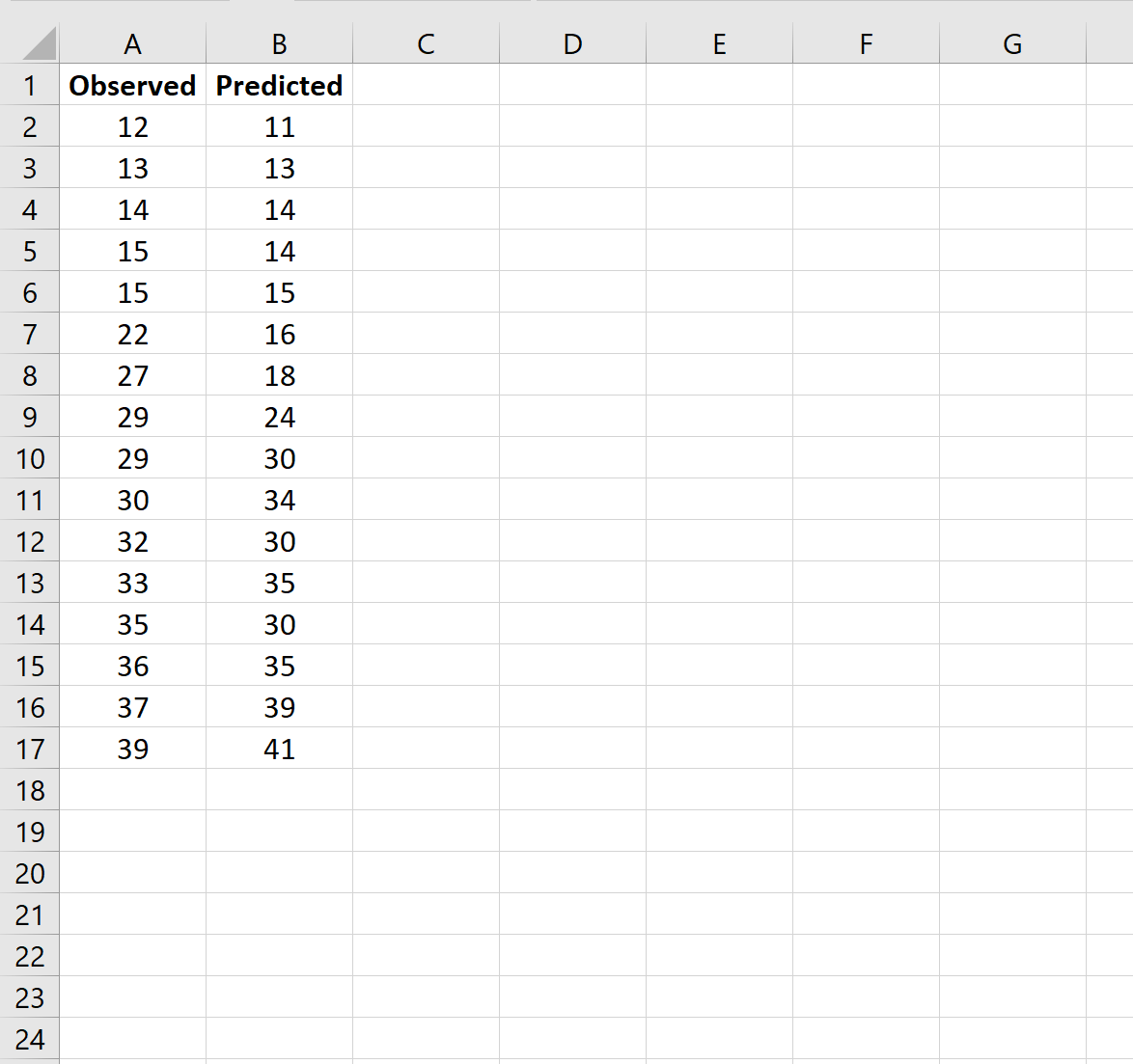
Шаг 1: введите данные
Во-первых, давайте введем список наблюдаемых и прогнозируемых значений в два отдельных столбца:
Примечание. Используйте это руководство , если вам нужно научиться использовать модель регрессии для расчета прогнозируемых значений.
Шаг 2: Рассчитайте абсолютные разницы
Далее мы будем использовать следующую формулу для расчета абсолютных различий между наблюдаемыми и прогнозируемыми значениями:
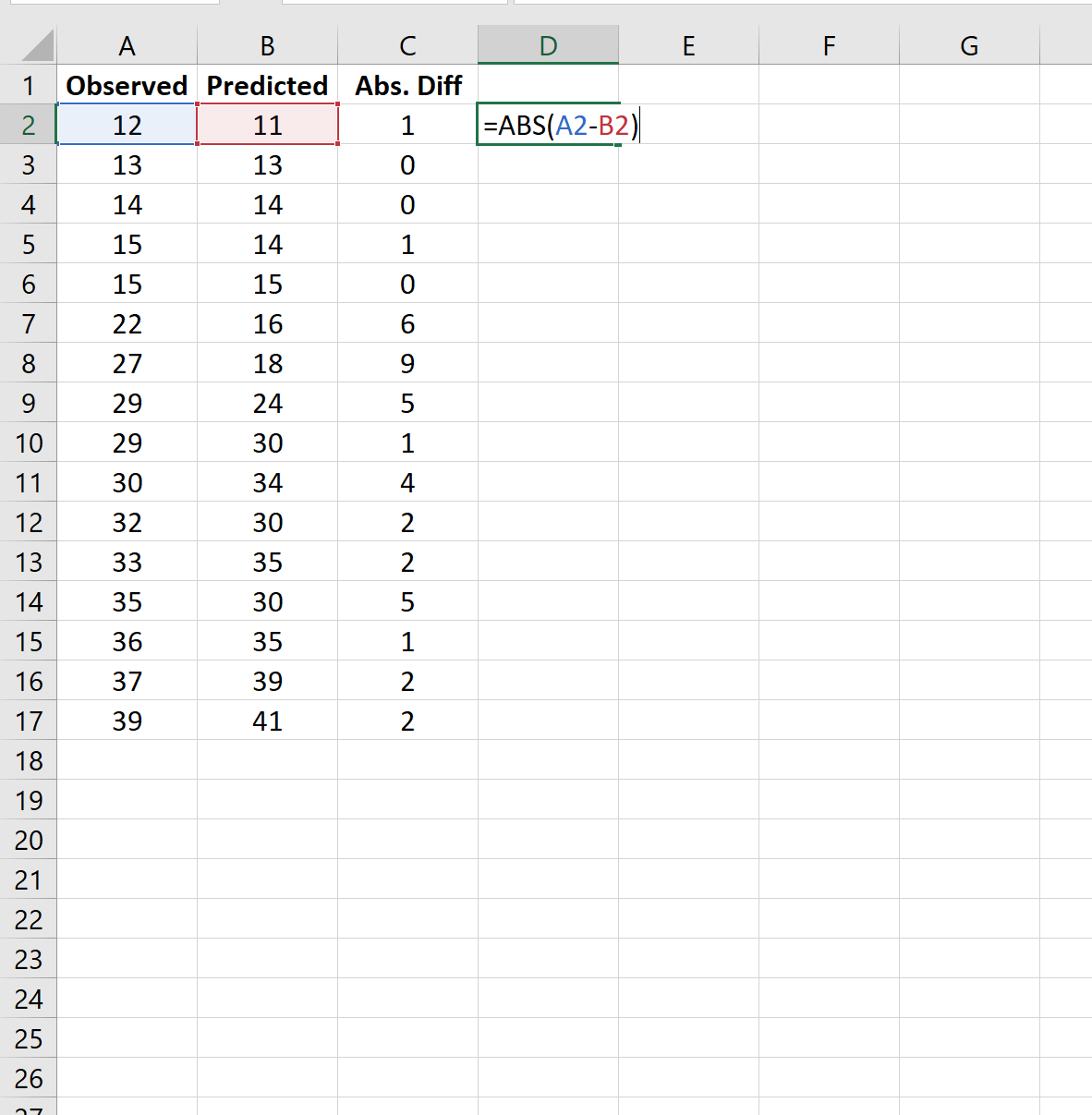
Шаг 3: Рассчитайте MAE
Далее мы будем использовать следующую формулу для расчета средней абсолютной ошибки:
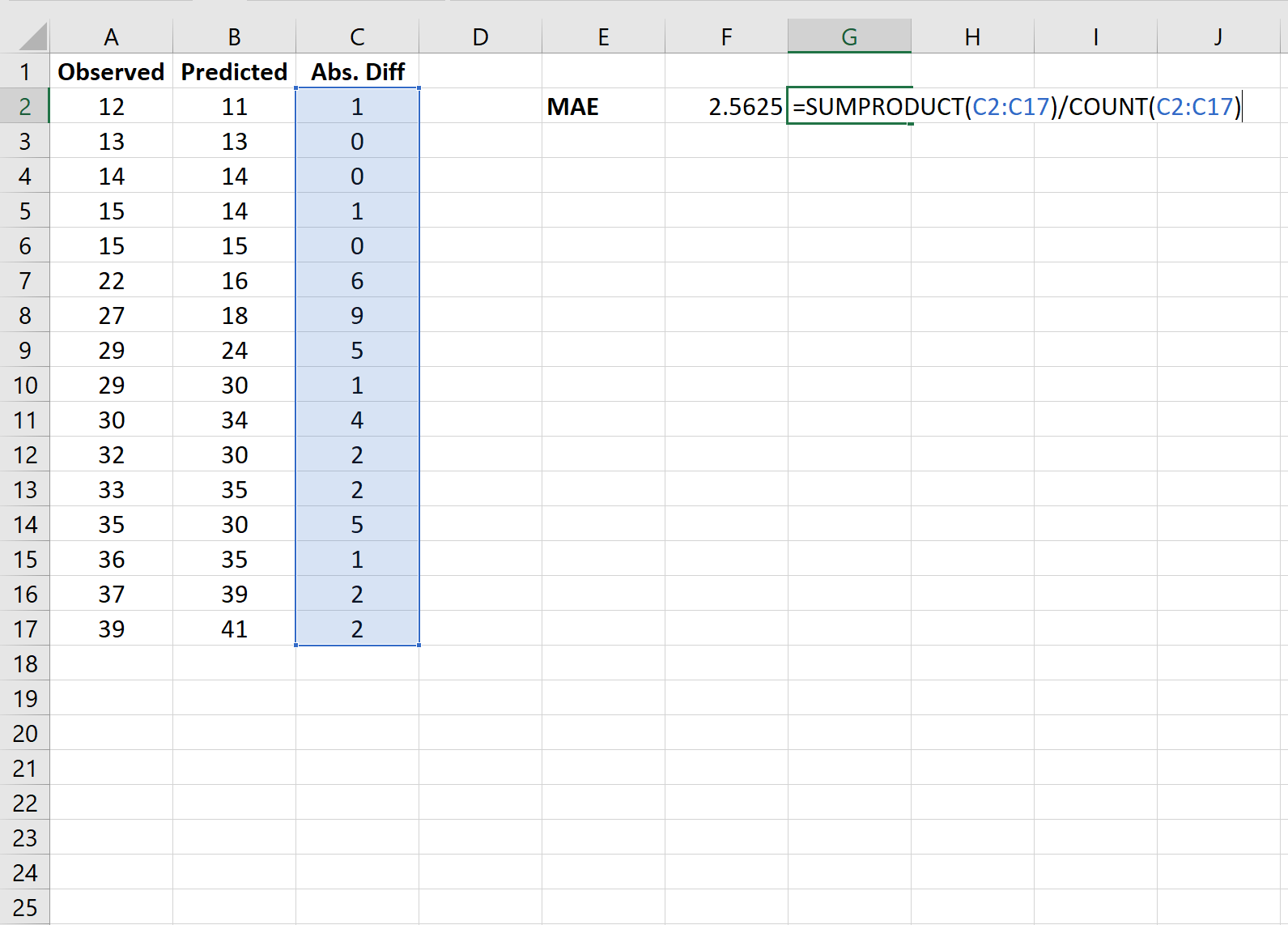
Средняя абсолютная ошибка (MAE) оказывается равной 2,5625 .
Это говорит нам о том, что средняя абсолютная разница между наблюдаемыми значениями и предсказанными значениями составляет 2,5625.
Как правило, чем ниже значение MAE, тем лучше модель соответствует набору данных. При сравнении двух разных моделей мы можем сравнить MAE каждой модели, чтобы узнать, какая из них лучше подходит для набора данных.
Бонус: не стесняйтесь использовать этот Калькулятор средней абсолютной ошибки для автоматического расчета MAE для списка наблюдаемых и прогнозируемых значений.
Дополнительные ресурсы
Как рассчитать MAPE в Excel
Как рассчитать SMAPE в Excel
Написано
![]()
Замечательно! Вы успешно подписались.
Добро пожаловать обратно! Вы успешно вошли
Вы успешно подписались на кодкамп.
Срок действия вашей ссылки истек.
Ура! Проверьте свою электронную почту на наличие волшебной ссылки для входа.
Успех! Ваша платежная информация обновлена.
Ваша платежная информация не была обновлена.
С использованием встроенных функций
Excel расчет доверительного
интервала проводится следующим образом.
1) Рассчитывается среднее значение
=СРЗНАЧ(число1; число2;
…)
число1, число2,
… — аргументы, для которых вычисляется
среднее.
2) Рассчитывается стандартное отклонение
=СТАНДОТКЛОНП(число1; число2;
…)
число1, число2,
… — аргументы, для которых вычисляется
стандартное отклонение.
3) Рассчитывается абсолютная погрешность
=ДОВЕРИТ(альфа ;станд_откл;размер)
альфа —
уровень значимости используемый для
вычисления уровня надежности.
(![]() ,
,
т.е.
![]()
означает надежности![]() );
);
станд_откл
— стандартное отклонение, предполагается
известным;
размер — размер выборки.
Лабораторная работа
1
Тема: Обработка прямых
измерений в Excel (2 часа ).
Задание:
Обработать заданный набор экспериментальных
данных методом Стьюдента, построить
экспериментальные кривые методом
наименьших квадратов.
|
Пример |
Используемуе |
|
|
|

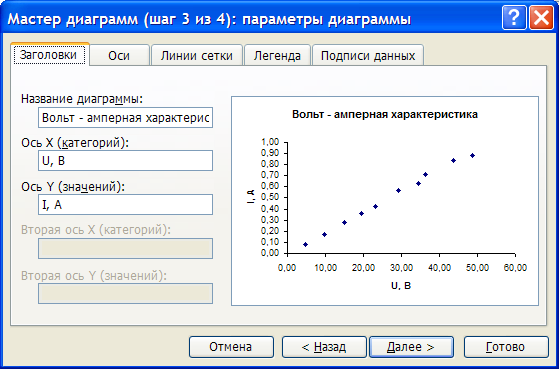
Для построения графика используем
мастер диаграмм.




Расчет
погрешности при косвенных измерениях
При измерении
величины косвенным методом предполагается,
что известна математическая модель
![]()
связывающая искомую
величину
![]()
с величинами
![]() ,
,
измеряемыми непосредственно. Далее
предполагается, выполнена обработка
всех прямых измерений, т. е. определены
доверительные интервалы для величин
![]() :
:
![]()
Погрешность величины у
определяется по формуле:

где
![]() .
.
Расчет косвенной
погрешности в Maple
Рассмотрим расчет погрешности на примере
функции одной переменной
![]() ,
,
где
![]()

Таким образом, найден доверительный
интервал величины
![]() .
.
В случае, если определяемая в косвенном
измерении величина, является функцией
нескольких переменных, рекомендуем:
-
вычисление погрешности оформить в виде
процедуры
>dy:=proc(y, dx) ……код
процедуры
…… end proc
Код процедуры учащийся должен составить
самостоятельно на основе примера,
рассмотренного выше.
-
параметр dx считать массивом из N
переменных -
для определения списка аргументов и
их количества величины y
можно использовать операторы op() и
nops():

-
Лабораторная работа 2 Тема: Обработка косвенных измерений в Maple (4 часа).
Задание:
Написать программу нахождения погрешности
косвенного измерения в среде Maple.
Выполнение задания
1. Ввести выборку значений измеряемых
величин в матричном виде
2. Определить размерность выборки
3. Задать уровень значимости и определить
степень доверия:
4. Вычислить среднее значение выборки
измеряемой величины:
a) с помощью операций
суммирования
б) с помощью встроенных функций
5. Вычислить значения среднеквадратичного
отклонения.
а) с помощью операций суммирования
,
в) с помощью встроенных функций
6. Вычислить доверительный интервал:
а) Задать коэффициент Стьюдента для
данных размерности выборки и степени
доверия:
.
б) Вычислить абсолютную случайную
погрешность
.
в) Вычислить верхнюю и нижнюю границы
доверительного интервала.
.
7. Учесть приборные погрешности:
а) Задать приборные погрешности
.
б) Вычислить абсолютную случайную
погрешность с учетом приборных
погрешностей
.
8. Представить результат:
а) Абсолютная погрешность:
,
б) Относительная погрешность:
,
в) Верхняя и нижняя границы доверительного
интервала.
.
Примечание. Вычисления провести:
а) в обычном виде,
(См. Дов_инт_01)
б) с помощью операций суммирования,
(См. Дов_инт_02)
в) с помощью встроенных функций.
(См. Дов_инт_03)
2. Вычисление косвенных погрешностей
Выполнение задания
1. Провести аналитические вычисления:
а) Ввести выражение для исследуемой
функции:
,
б) Получить выражение для среднего
значения величины исследуемой функции:
,
в) Получить выражение косвенной
погрешности исследуемой функции в общем
виде и для значения :
,
,
1. Провести численные вычисления:
а) Ввести численные значения постоянных,
б) Ввести средние значения и доверительные
интервалы переменных,
в) Вычислить относительные погрешности
переменных,
г) Вычислить среднее значение исследуемой
функции:
,
г) Вычислить косвенную погрешность
(абсолютную погрешность) исследуемой
функции
,
г) Вычислить относительную погрешность
исследуемой функции
,
в) Вычислить верхнюю и нижнюю границы
доверительного интервала исследуемой
функции:
.
(См. Косв_погр).
3. Построение графиков. Полиномиальная
регрессия
Выполнение задания
1. Ввод выборок значений величин :
2. Вычислить верхнюю и нижнюю границы
доверительного величины Y:
.
3. Полиномиальная регрессия:
а) Задать степень полинома k:
б) Задать число точек данных:
.
в) Задать регрессионную зависимость:
.
г) Определить коэффициенты уравнения
регрессии
:
,
.
4. Построить графики:
а) точечных график данных,
б) кривую регрессии,
в) доверительные интервалы величины Y.
(См. Постр_граф).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

Mean Absolute Error (MAE) measures how far predicted values are away from observed values.
It’s a bit different from Root Mean Square Error (RMSE). Overall, it’s just a couple of simple steps and applying formulas in Excel. MAE performs the following 2 computations:
- MAE sums the absolute value of the residual
- Divides by the number of observations.
Let’s go over an example of how to calculate MAE in Excel. To complete this tutorial, you will need a set of observed and predicted values. Also, we assume you already have Microsoft Excel installed.
Mean Absolute Error (MAE) is a statistical measure that quantifies the average magnitude of the errors between predicted and actual values to help understand the accuracy of a predictive model.
Step 1. Enter headers in the first row of Excel
In A1, type “observed value”. In B2, type “predicted value”. In C3, type “difference”. These are just headers to help identify which values belong to predicted or observed.
Step 2. Place values in columns
If you have 10 observations, place these observed values in cells A2 to A11. In addition, you will type in predicted values from B2 to B11. But you can enter as many values as you’d like in these columns and adjust the following steps accordingly.
Step 3. Find the difference between observed and predicted values
In columns C2 to C11, subtract the observed value and predicted value. C2 will use this formula:
=A2-B2You will have to copy and paste this formula all the way down to the last row.
Step 4. Calculate the mean absolute error (MAE)
In cell D2, we can calculate MAE by using the formula below:
=SUMPRODUCT(ABS(C2:C11))/COUNT(C2:C11)After entering this code in Excel, cell D2 is the Mean Absolute Error value.
Learn more tips and tricks with Microsoft Excel

How to use MAE in GIS?
MAE quantifies the difference between forecasted and observed values. For example, you could compare satellite-derived soil moisture values and compare them to what was collected in the field.
In this case, the satellite-derived soil moisture values are the forecasted values. Finally, the network of stations on the ground measuring the true soil moisture values are the observed values.
We often use MAE to see how correct models are like digital elevation models.
- FORECASTED VALUE: Satellite-derived soil moisture value
- OBSERVED VALUE: Ground station network soil moisture measurement
As described above, here is the MAE Formula:
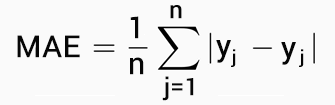
С использованием встроенных функций Excel расчет доверительного интервала проводится следующим образом.
1) Рассчитывается среднее значение
=СРЗНАЧ(число1; число2; . )
число1, число2, . — аргументы, для которых вычисляется среднее.
2) Рассчитывается стандартное отклонение
=СТАНДОТКЛОНП(число1; число2; . )
число1, число2, . — аргументы, для которых вычисляется стандартное отклонение.
3) Рассчитывается абсолютная погрешность
=ДОВЕРИТ(альфа ;станд_откл;размер)
альфа — уровень значимости используемый для вычисления уровня надежности.
( , т.е. означает надежности );
станд_откл — стандартное отклонение, предполагается известным;
размер — размер выборки.
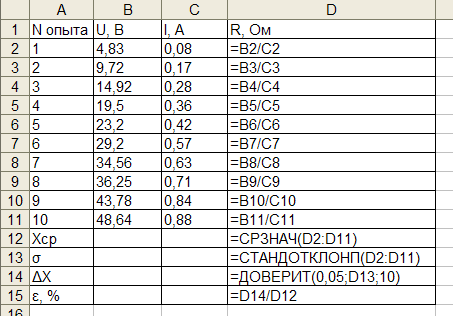
Задание: Обработать заданный набор экспериментальных данных методом Стьюдента, построить экспериментальные кривые методом наименьших квадратов.
Предположим, в ходе эксперимента по измерению электросопротивления были получены следующие данные:

Используя для определения сопротивления закон Ома произведем обработку данной серии экспериментальных данных.
| Используемуе формулы |
 |
| Результат расчета |
 |
Для построения графика используем мастер диаграмм.
Полученные экспериментальные данные следует аппроксимировать. Для выполнения этой процедуры в Excel предусмотрен мастер, добавляющий линию тренда, производящий аппроксимацию и сглаживание.
В меню «Диаграмма» выберите пункт «Добавить линию тренда…».

В результате, должен получиться следующий график.
Задание 1.
Просчитать погрешность измерений и построить график ее распределения.
| Задание 1 | Задание 2 | Задание 3 |
| № опыта | № опыта | № опыта |
| 10,3 | 15,55 | 25,65 |
| 10,277 | 15,527 | 25,627 |
| 10,325 | 15,575 | 25,675 |
| 10,285 | 15,535 | 25,635 |
| 10,297 | 15,547 | 25,647 |
| 10,31 | 15,56 | 25,66 |
| 10,35 | 15,6 | 25,7 |
| 10,35 | 15,6 | 25,7 |
| 10,29 | 15,54 | 25,64 |
| 10,38 | 15,63 | 25,73 |
| Задание 4 | Задание 5 | Задание 6 |
| № опыта | №опыта | № опыта |
| 27,65 | 23,65 | 17,3 |
| 27,627 | 23,627 | 17,277 |
| 27,675 | 23,675 | 17,325 |
| 27,635 | 23,635 | 17,285 |
| 27,647 | 23,647 | 17,297 |
| 27,66 | 23,66 | 17,31 |
| 27,7 | 23,7 | 17,35 |
| 27,7 | 23,7 | 17,35 |
| 27,64 | 23,64 | 17,29 |
| 27,73 | 23,73 | 17,38 |
| Задание 7 | Задание 8 | Задание 9 |
| № опыта | № опыта | № опыта |
| 10,3 | 13,55 | 12,65 |
| 10,277 | 13,527 | 12,627 |
| 10,325 | 13,575 | 12,675 |
| 10,285 | 13,535 | 12,635 |
| 10,297 | 13,547 | 12,647 |
| 10,31 | 13,56 | 12,66 |
| 10,35 | 13,6 | 12,7 |
| 10,35 | 13,6 | 12,7 |
| 10,29 | 13,54 | 12,64 |
| 10,38 | 13,63 | 12,73 |
| Задание 10 | Задание 11 | Задание 12 |
| № опыта | №опыта | № опыта |
| 26,65 | 24,65 | 18,3 |
| 26,627 | 24,627 | 18,277 |
| 26,675 | 24,675 | 18,325 |
| 26,635 | 24,635 | 18,285 |
| 26,647 | 24,647 | 18,297 |
| 26,66 | 24,66 | 18,31 |
| 26,7 | 24,7 | 18,35 |
| 26,7 | 24,7 | 18,35 |
| 26,64 | 24,64 | 18,29 |
| 26,73 | 24,73 | 18,38 |
| Задание 13 | Задание 14 | Задание 15 |
| № опыта | № опыта | № опыта |
| 10,3 | 15,55 | 25,65 |
| 10,277 | 15,527 | 25,627 |
| 10,325 | 15,575 | 25,675 |
| 10,285 | 15,535 | 25,635 |
| 10,297 | 15,547 | 25,647 |
| 10,31 | 15,56 | 25,66 |
| 10,35 | 15,6 | 25,7 |
| 10,35 | 15,6 | 25,7 |
| 10,29 | 15,54 | 25,64 |
| 10,38 | 15,63 | 25,73 |
| Задание 16 | Задание 17 | Задание 18 |
| № опыта | №опыта | № опыта |
| 27,65 | 23,65 | 17,3 |
| 27,627 | 23,627 | 17,277 |
| 27,675 | 23,675 | 17,325 |
| 27,635 | 23,635 | 17,285 |
| 27,647 | 23,647 | 17,297 |
| 27,66 | 23,66 | 17,31 |
| 27,7 | 23,7 | 17,35 |
| 27,7 | 23,7 | 17,35 |
| 27,64 | 23,64 | 17,29 |
| 27,73 | 23,73 | 17,38 |
Задание 2.
Определить является ли 3-е измерение промахом.
Формула погрешности
- Формула погрешности
Формула погрешности (оглавление)
- Формула погрешности
- Примеры формулы допустимой погрешности (с шаблоном Excel)
- Калькулятор формулы ошибки поля
Формула погрешности
В статистике мы рассчитываем доверительный интервал, чтобы увидеть, куда упадет значение данных выборочной статистики. Диапазон значений, которые находятся ниже и выше выборочной статистики в доверительном интервале, называется границей ошибки. Другими словами, это в основном степень ошибки в статистике выборки. Чем выше погрешность, тем меньше будет достоверность результатов, поскольку степень отклонения в этих результатах очень высока. Как следует из названия, погрешность — это диапазон значений выше и ниже фактических результатов. Например, если мы получаем ответ в опросе, в котором 70% людей ответили «хорошо», а допустимая погрешность составляет 5%, это означает, что в целом от 65% до 75% населения считают, что ответ «хороший»,
Margin of Error = Z * S / √n
- Z — Z счет
- S — стандартное отклонение населения
- n — Размер выборки
Другая формула для расчета погрешности:
Margin of Error = Z * √((p * (1 – p)) / n)
- p — доля образца (доля образца, которая является успешной)
Теперь, чтобы найти желаемую оценку z, вам нужно знать доверительный интервал выборки, потому что оценка Z зависит от этого. Ниже приведена таблица, чтобы увидеть отношение доверительного интервала и z балла:
| Доверительный интервал | Z — Оценка |
| 80% | 1, 28 |
| 85% | 1, 44 |
| 90% | 1, 65 |
| 95% | 1, 96 |
| 99% | 2, 58 |
Как только вы знаете доверительный интервал, вы можете использовать соответствующее значение z и рассчитать предел погрешности оттуда.
Примеры формулы допустимой погрешности (с шаблоном Excel)
Давайте рассмотрим пример, чтобы лучше понять расчёт Margin of Error.
Вы можете скачать этот шаблон Margin of Error здесь — Шаблон Margin of Error
Формула погрешности — пример № 1
Допустим, мы проводим опрос, чтобы увидеть, каков балл, который получают студенты университетов. Мы выбрали 500 учеников случайным образом и задали их оценку. Среднее значение составляет 2, 4 из 4, а стандартное отклонение составляет, скажем, 30%. Предположим, что доверительный интервал составляет 99%. Рассчитайте погрешность.
Решение:
Погрешность рассчитывается по формуле, приведенной ниже
Граница ошибки = Z * S / √n
- Погрешность = 2, 58 * 30% / √ (500)
- Погрешность = 3, 46%
Это означает, что с вероятностью 99% средний балл учащихся составляет 2, 4 плюс или минус 3, 46%.
Формула погрешности — пример № 2
Допустим, вы запускаете новый продукт для здоровья на рынке, но вы не знаете, какой вкус понравится людям. Вы путаетесь между ароматом банана и ванили и решили провести опрос. Для вас это 500 000 человек, что является вашим целевым рынком, и из этого вы решили спросить мнение 1000 человек, и это будет образец. Предположим, что доверительный интервал составляет 90%. Рассчитайте погрешность.
Решение:
Как только опрос закончен, вы узнали, что банану понравился 470 человек, а 530 попросили аромат ванили.
Погрешность рассчитывается по формуле, приведенной ниже
Граница ошибки = Z * √ ((p * (1 — p)) / n)
- Погрешность = 1, 65 * √ ((0, 47 * (1 — 0, 47)) / 1000)
- Погрешность = 2, 60%
Таким образом, мы можем сказать, что с 90% уверенностью, что 47% всех людей любили банановый аромат плюс или минус 2, 60%.
объяснение
Как обсуждалось выше, предел погрешности помогает нам понять, подходит ли размер выборки для вашего опроса или нет. В случае, если погрешность слишком велика, возможно, размер нашей выборки слишком мал, и нам нужно его увеличить, чтобы результаты выборки более точно соответствовали результатам совокупности.
Существуют некоторые сценарии, в которых предел погрешности не будет иметь большого значения и не поможет нам в отслеживании ошибки:
- Если вопросы опроса не разработаны и не помогают получить требуемый ответ
- Если люди, отвечающие на опрос, имеют некоторую предвзятость в отношении продукта, для которого проводится опрос, то и результат будет не очень точным
- Если выбранная выборка является надлежащим представителем населения, в этом случае также результаты будут далеко.
Кроме того, одно большое предположение здесь состоит в том, что население обычно распределено. Таким образом, если размер выборки слишком мал и распределение населения не является нормальным, z-оценка не может быть рассчитана, и мы не сможем найти предел погрешности.
Актуальность и использование формулы ошибки
Всякий раз, когда мы используем выборочные данные, чтобы найти какой-то релевантный ответ для набора населения, возникает некоторая неопределенность и вероятность того, что результат может отличаться от фактического результата. Допустимая погрешность скажет нам, что каков уровень отклонения, это образец выборки. Нам необходимо минимизировать погрешность, чтобы результаты наших выборок отражали реальную историю данных о населении. Поэтому, чем ниже погрешность, тем лучше будут результаты. Запас погрешности дополняет и дополняет имеющуюся у нас статистическую информацию. Например, если опрос показал, что 48% людей предпочитают проводить время дома в выходные дни, мы не можем быть настолько точными, и в этой информации отсутствуют некоторые элементы. Когда мы ввели здесь предел погрешности, скажем, 5%, то результат будет интерпретирован как 43-53% людей, которым понравилась идея быть дома в выходные дни, что имеет полный смысл.
Калькулятор формулы ошибки поля
Вы можете использовать следующий калькулятор Margin of Error
Рекомендуемые статьи
Это было руководство по формуле ошибки. Здесь мы обсудим, как рассчитать погрешность, а также на практических примерах. Мы также предоставляем калькулятор Margin of Error с загружаемым шаблоном Excel. Вы также можете посмотреть следующие статьи, чтобы узнать больше —
- Руководство по формуле амортизации прямой линии
- Примеры формулы удвоения времени
- Как рассчитать амортизацию?
- Формула для центральной предельной теоремы
- Альтман Z Оценка | Определение | Примеры
- Формула амортизации | Примеры с шаблоном Excel